SAS-データセットを連結する
複数のSASデータセットを連結して、を使用して単一のデータセットを作成できます。 SETステートメント。連結されたデータセット内の観測値の総数は、元のデータセット内の観測値の数の合計です。観測の順序は連続しています。最初のデータセットからのすべての観測値の後に、2番目のデータセットからのすべての観測値が続きます。
理想的には、すべての結合データセットが同じ変数を持っていますが、変数の数が異なる場合、結果としてすべての変数が表示され、小さいデータセットの値が欠落します。
構文
SASのSETステートメントの基本的な構文は次のとおりです。
SET data-set 1 data-set 2 data-set 3.....;以下は、使用されるパラメーターの説明です-
data-set1,data-set2 次々と書かれたデータセット名です。
例
IT部門用と非IT部門用の2つの異なるデータセットで利用できる組織の従業員データについて考えてみます。すべての従業員の完全な詳細を取得するために、以下に示すSETステートメントを使用して両方のデータセットを連結します。
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
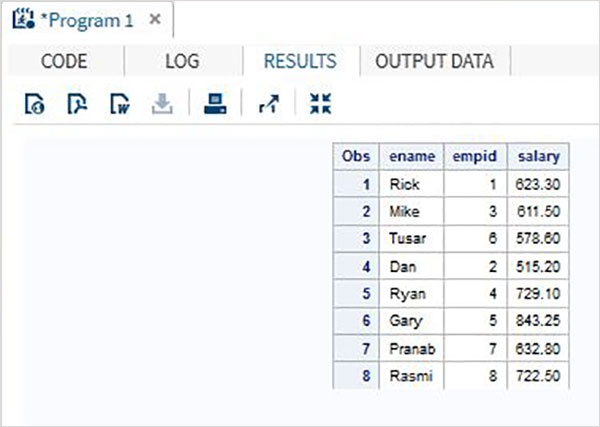
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。
シナリオ
連結のデータセットに多くのバリエーションがある場合、変数の結果は異なる可能性がありますが、連結されたデータセットの観測値の総数は、常に各データセットの観測値の合計になります。このバリエーションに関する多くのシナリオを以下で検討します。
変数の数が異なる
元のデータセットの1つに別の変数よりも多くの変数がある場合でも、データセットは結合されますが、小さいデータセットではそれらの変数が欠落しているように見えます。
例
以下の例では、最初のデータセットにDOJという名前の追加の変数があります。その結果、2番目のデータセットのDOJの値が欠落しているように見えます。
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。

別の変数名
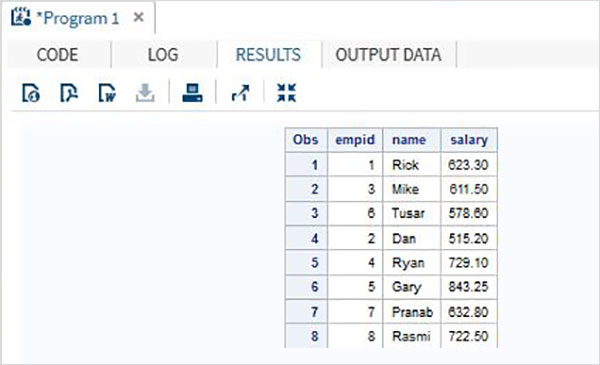
このシナリオでは、データセットには同じ数の変数がありますが、変数名はそれらの間で異なります。その場合、通常の連結では結果セット内のすべての変数が生成され、異なる2つの変数に対して欠落した結果が得られます。元のデータセットの変数名を変更することはできませんが、作成する連結データセットにRENAME関数を適用できます。これにより、通常の連結と同じ結果が得られますが、もちろん、元のデータセットに存在する2つの異なる変数名の代わりに1つの新しい変数名が使用されます。
例
以下の例のデータ・セットでは、ITDEPTの変数名は ename 一方、データセット NON_ITDEPT 変数名があります empname.ただし、これらの変数は両方とも同じタイプ(文字)を表します。適用しますRENAME 以下に示すように、SETステートメントで機能します。
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。
さまざまな可変長
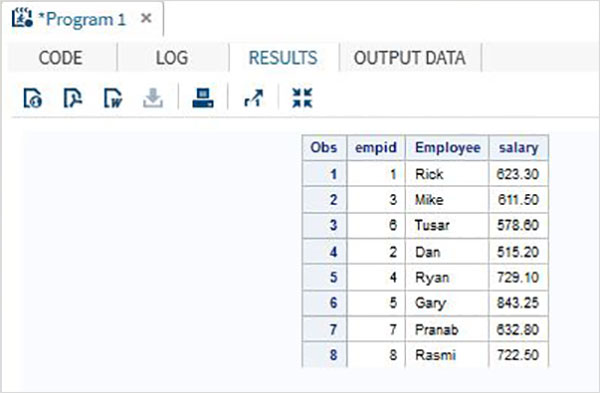
2つのデータセットの変数の長さが連結されたデータセットと異なる場合、長さが短い変数の一部のデータが切り捨てられる値があります。最初のデータセットの長さが短い場合に発生します。これを解決するために、以下に示すように、両方のデータセットに高い長さを適用します。
例
以下の例では、変数 enameは、最初のデータセットでは長さが5、2番目のデータセットでは長さが7です。連結するときは、連結されたデータセットにLENGTHステートメントを適用して、enameの長さを7に設定します。
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。