SAS-クイックガイド
SAS を意味する Statistical Analysis Software。1960年にSASInstituteによって作成されました。1960年1月1日から、SASはデータ管理、ビジネスインテリジェンス、予測分析、記述および規範分析などに使用されました。それ以来、多くの新しい統計手順とコンポーネントがソフトウェアに導入されました。
統計用のJMP(Jump)の導入により、SASは Graphical user InterfaceこれはMacintoshによって導入されました。Jumpは基本的に、シックスシグマ、設計、品質管理、エンジニアリング、科学分析などのアプリケーションに使用されます。
SASはプラットフォームに依存しないため、LinuxまたはWindowsの任意のオペレーティングシステムでSASを実行できます。SASは、SASデータセットに対していくつかの一連の操作を使用して、データ分析用の適切なレポートを作成するSASプログラマーによって駆動されます。
長年にわたり、SASは製品ポートフォリオに多数のソリューションを追加してきました。データガバナンス、データ品質、ビッグデータ分析、テキストマイニング、不正管理、健康科学などのソリューションがあります。SASにはすべてのビジネスドメインに対応するソリューションがあると考えられます。
利用可能な製品のリストを確認するには、SASコンポーネントにアクセスしてください。
SASを使用する理由
SASは基本的に大規模なデータセットで動作します。SASソフトウェアの助けを借りて、次のようなデータに対してさまざまな操作を実行できます。
- データ管理
- 統計分析
- 完璧なグラフィックでレポート形成
- 事業計画
- オペレーションズリサーチとプロジェクト管理
- 品質改善
- アプリケーション開発
- データ抽出
- データ変換
- データの更新と変更
SASのコンポーネントについて言えば、SASでは200を超えるコンポーネントが利用可能です。
| シニア番号 | SASコンポーネントとその使用法 |
|---|---|
| 1 | Base SAS これは、データ管理機能とデータ分析用のプログラミング言語を含むコアコンポーネントです。また、最も広く使用されています。 |
| 2 | SAS/GRAPH グラフやプレゼンテーションを作成して、結果をよりよく理解し、適切な形式で紹介します。 |
| 3 | SAS/STAT 分散分析、回帰、多変量分析、生存分析、心理測定分析、混合モデル分析を使用して統計分析を実行します。 |
| 4 | SAS/OR オペレーションズリサーチ。 |
| 5 | SAS/ETS 計量経済学と時系列分析。 |
| 6 | SAS/IML Cインタラクティブマトリックス言語。 |
| 7 | SAS/AF アプリケーション機能。 |
| 8 | SAS/QC 品質管理。 |
| 9 | SAS/INSIGHT データマイニング。 |
| 10 | SAS/PH 臨床試験分析。 |
| 11 | SAS/Enterprise Miner データマイニング。 |
SASソフトウェアの種類
- WindowsまたはPCSAS
- SAS EG(エンタープライズガイド)
- SAS EM(Enterprise Miner、つまり予測分析用)
- SASの手段
- SAS統計
ほとんどの場合、組織およびトレーニング機関でWindowSASを使用しています。一部の組織はLinuxを使用していますが、グラフィカルユーザーインターフェイスがないため、クエリごとにコードを作成する必要があります。しかし、ウィンドウSASには、プログラマーに非常に役立つ多くのユーティリティがあり、コードの記述時間も短縮されます。
SaSウィンドウには5つの部分があります。
| シニア番号 | SASウィンドウとその使用法 |
|---|---|
| 1 | Log Window ログウィンドウは、SASプログラムの実行を確認できる実行ウィンドウのようなものです。このウィンドウでは、エラーも確認できます。プログラムの実行後、ログウィンドウを毎回確認することが非常に重要です。プログラムの実行について適切に理解できるようにするためです。 |
| 2 | Editor Window
エディタウィンドウは、すべてのコードを記述するSASの部分です。それはメモ帳のようなものです。 |
| 3 | Output Window 出力ウィンドウは、プログラムの出力を確認できる結果ウィンドウです。 |
| 4 | Result Window これは、すべての出力のインデックスのようなものです。SASの1つのセッションで実行したすべてのプログラムがそこに一覧表示され、出力結果をクリックして出力を開くことができます。しかし、これらはSASの1つのセッションでのみ言及されています。ソフトウェアを閉じてから開くと、結果ウィンドウは空になります。 |
| 5 | Explore Window ここにすべてのライブラリがリストされています。ここから、システムのSASでサポートされているファイルを参照することもできます。 |
SASのライブラリ
ライブラリはSASのストレージのようなものです。ライブラリを作成して、同様のプログラムをすべてそのライブラリに保存できます。SASは、複数のライブラリを作成する機能を提供します。SASライブラリの長さはわずか8文字です。
SASで利用できるライブラリには2つのタイプがあります-
| シニア番号 | SASウィンドウとその使用法 |
|---|---|
| 1 | Temporary or Work Library これは、デフォルトでSASのライブラリです。私たちが作成するすべてのプログラムは、他のライブラリを割り当てない限り、この作業ライブラリに保存されます。この作業ライブラリは、エクスプローラウィンドウで確認できます。SASプログラムを作成し、それに永続ライブラリを割り当てていない場合、その後セッションを終了すると、ソフトウェアを再度起動すると、このプログラムは作業ライブラリに含まれなくなります。セッションが行われる限り、Workライブラリにのみ存在するためです。 |
| 2 | Permanent Library これらはSASの永続的なライブラリです。SASユーティリティを使用するか、エディターウィンドウにコードを書き込むことで、新しいSASライブラリを作成できます。これらのライブラリは、SASでプログラムを作成し、これらの永続ライブラリに保存すると、必要な限り利用できるため、永続として名前が付けられます。 |
SAS InstituteInc。が無料でリリースしました SAS University EditionこれはSASプログラミングを学ぶのに十分です。BASE SASプログラミングで学習する必要のあるすべての機能を提供し、他のSASコンポーネントを学習できるようにします。
SAS UniversityEditionをダウンロードしてインストールするプロセスは非常に簡単です。これは、仮想環境で実行する必要がある仮想マシンとして使用できます。SASソフトウェアを実行する前に、仮想化ソフトウェアをPCにインストールしておく必要があります。このチュートリアルでは、VMware。以下は、SAS環境をダウンロード、セットアップ、およびインストールを確認する手順の詳細です。
SAS UniversityEditionをダウンロードする
SAS University EditionURL SAS UniversityEditionからダウンロードできます。ダウンロードを開始する前に、下にスクロールしてシステム要件をお読みください。このURLにアクセスすると、次の画面が表示されます。
仮想化ソフトウェアのセットアップ
同じページを下にスクロールして、インストールstpe-1を見つけます。このステップでは、お客様に適した仮想化ソフトウェアを入手するためのリンクを提供します。これらのソフトウェアのいずれかがシステムにすでにインストールされている場合は、この手順をスキップできます。

クイックスタート仮想化ソフトウェア
仮想化環境にまったく慣れていない場合は、ステップ2で利用できる次のガイドとビデオを参照して、仮想化環境に慣れることができます。すでに慣れている場合は、この手順をスキップできます。

Zipファイルをダウンロードする
手順3では、使用している仮想化環境と互換性のあるSAS UniversityEditionの適切なバージョンを選択できます。unvbasicvapp__9411005__vmx__en__sp0__1.zipのような名前のzipファイルとしてダウンロードされます
zipファイルを解凍します
上記のzipファイルは、解凍して適切なディレクトリに保存する必要があります。この例では、解凍後に次のファイルを表示するVMwarezipファイルを選択しました。
仮想マシンのロード
VMwareプレーヤー(またはワークステーション)を起動し、拡張子.vmxで終わるファイルを開きます。以下の画面が表示されます。vmに割り当てられたメモリやハードディスク容量などの基本設定に注意してください。
仮想マシンの電源をオンにします
クリック Power on this virtual machine緑色の矢印の横にある仮想マシンを起動します。次の画面が表示されます。

以下の画面は、SAS vmがロード状態にあるときに表示されます。その後、実行中のvmは、SAS環境を開くURLの場所に移動するように求めるプロンプトを表示します。
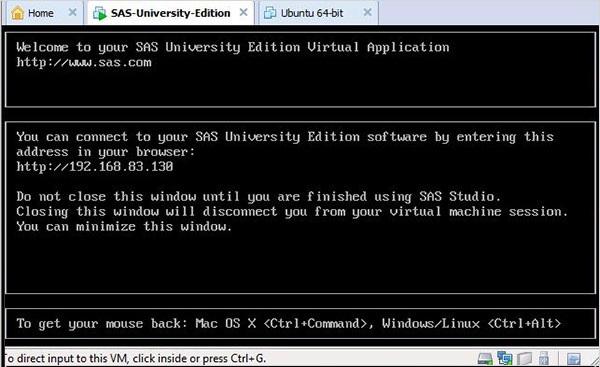
SASスタジオの開始
新しいブラウザタブを開き、上記のURLをロードします(PCごとに異なります)。以下の画面が表示され、SAS環境の準備ができていることが示されます。
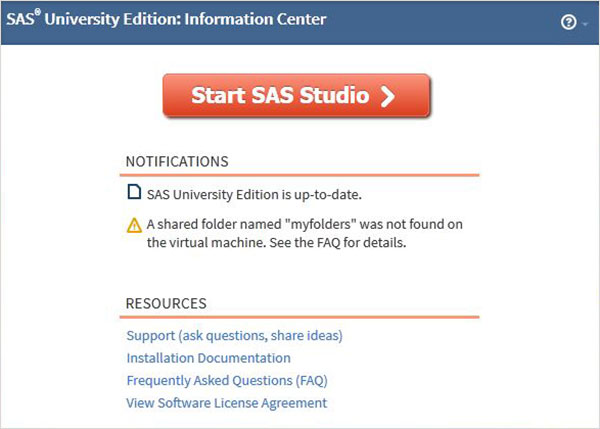
SAS環境
クリックすると Start SAS Studio 以下に示すように、デフォルトでビジュアルプログラマーモードで開くSAS環境を取得します。
ドロップダウンをクリックして、SASプログラマーモードに変更することもできます。
これで、SASプログラムを作成する準備が整いました。
SASプログラムは、次のようなユーザーインターフェイスを使用して作成されます。 SAS Studio。
以下は、さまざまなウィンドウとその使用法の説明です。
SASメインウィンドウ
これは、SAS環境に入るときに表示されるウィンドウです。左側はNavigation Paneさまざまなプログラミング機能をナビゲートするために使用されます。右側はWork Area これは、コードの記述と実行に使用されます。

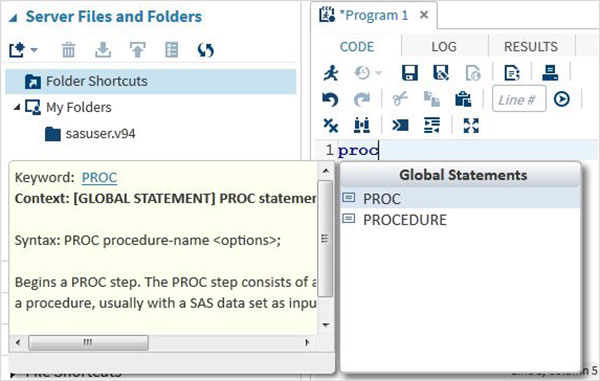
コードオートコンプリート
これは、SASキーワードの正しい構文を取得するのに役立つだけでなく、そのキーワードのドキュメントへのリンクを提供する非常に強力な機能です。
プログラムの実行
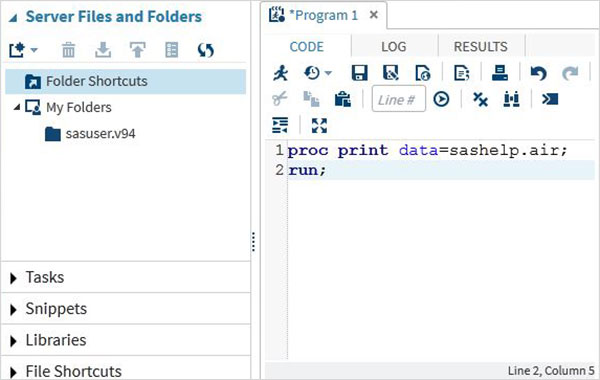
コードの実行は、左から最初のアイコンである実行アイコンまたはF3ボタンを押すことによって実行されます。
プログラムログ
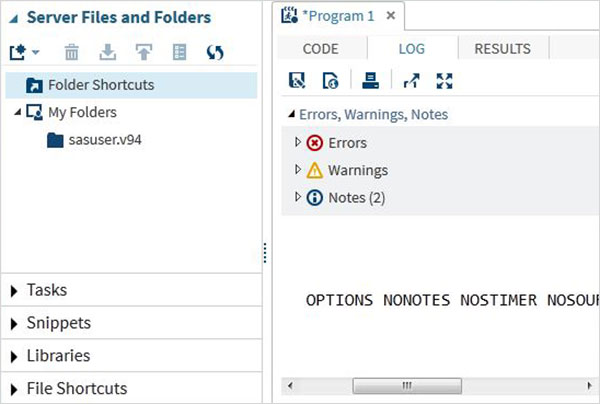
実行されたコードのログは、 Logタブ。プログラムの実行に関するエラー、警告、またはメモについて説明します。これは、コードのトラブルシューティングを行うためのすべての手がかりを得るウィンドウです。
プログラム結果
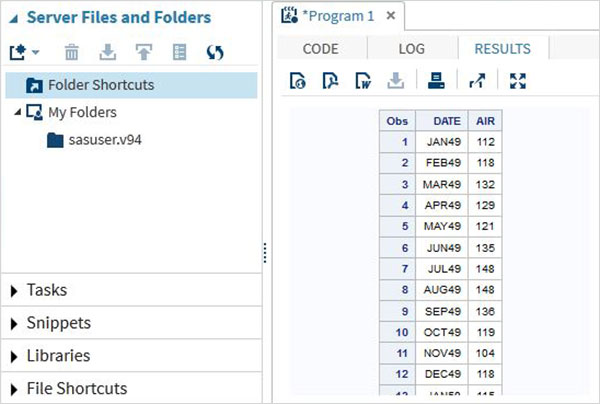
コード実行の結果は、[結果]タブに表示されます。デフォルトでは、それらはhtmlテーブルとしてフォーマットされます。
プログラムタブ
ナビゲーションエリアには、プログラムを作成および管理するための機能が含まれています。また、プログラムで使用するビルド済みの機能も提供します。
サーバーのファイルとフォルダー
このタブでは、追加のプログラムを作成したり、分析するデータをインポートしたり、既存のデータをクエリしたりできます。また、フォルダのショートカットを作成するために使用することもできます。
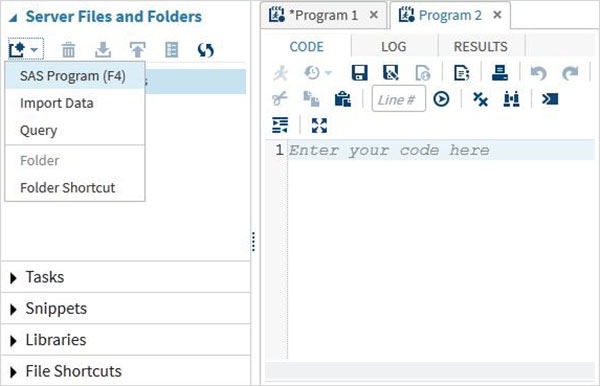
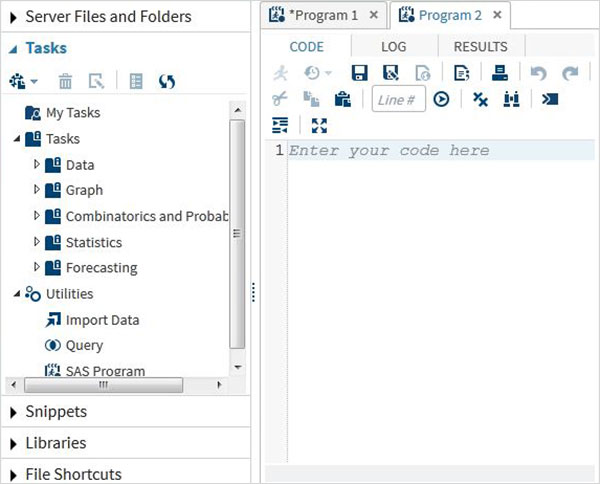
タスク
[タスク]タブには、入力変数のみを指定することにより、組み込みのSASプログラムを使用する機能があります。たとえば、statisticsフォルダーの下に、SASデータセット名と変数名を指定するだけで線形回帰を実行するSASプログラムを見つけることができます。
切れ端
[スニペット]タブには、SASマクロを記述し、既存のデータセットからファイルを生成する機能があります。

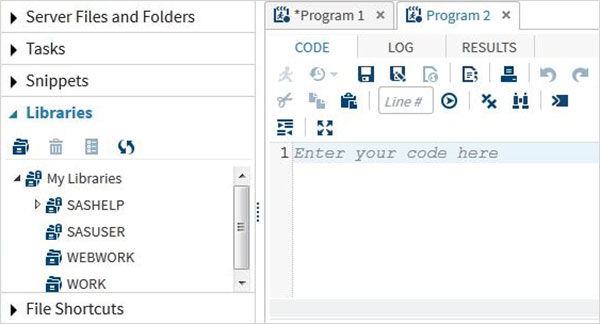
プログラムライブラリ
SASはデータセットをSASライブラリに保存します。一時ライブラリーは単一のセッションでのみ使用可能であり、WORKという名前が付けられています。ただし、永続的なライブラリはいつでも利用できます。
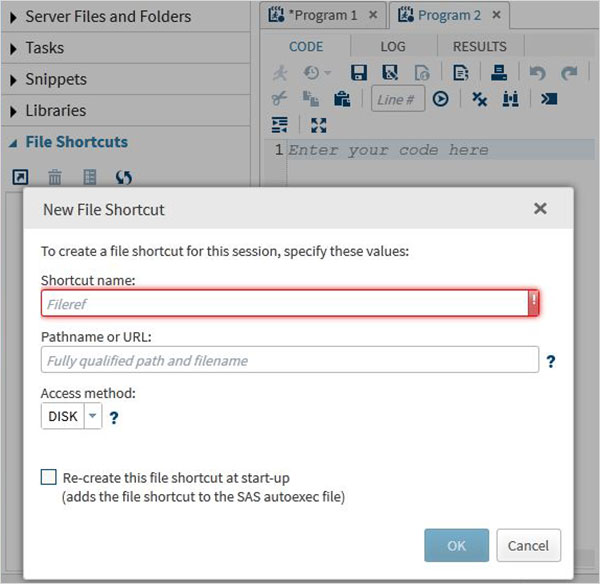
ファイルのショートカット
このタブは、SAS環境の外部に保存されているファイルにアクセスするために使用されます。このようなファイルへのショートカットは、このタブに保存されています。
SASプログラミングでは、最初にデータセットを作成してメモリに読み込み、次にこのデータの分析を行います。これを実現するには、プログラムが作成されるフローを理解する必要があります。
SASプログラム構造
次の図は、SASプログラムを作成するために指定された順序で記述される手順を示しています。
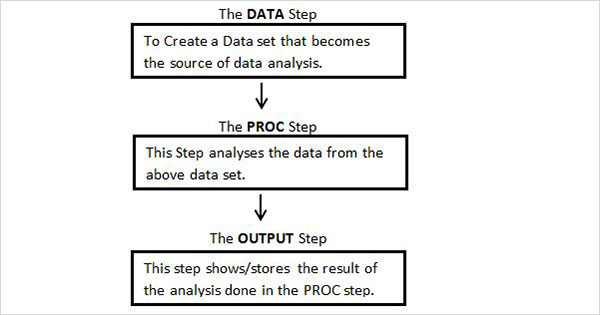
すべてのSASプログラムには、入力データの読み取り、データの分析、および分析の出力の提供を完了するために、これらすべてのステップが必要です。また、RUN そのステップの実行を完了するには、各ステップの最後にあるステートメントが必要です。
データステップ
このステップでは、必要なデータセットをSASメモリにロードし、データセットの変数(列とも呼ばれます)を識別します。また、レコード(観測または対象とも呼ばれます)をキャプチャします。DATAステートメントの構文は次のとおりです。
構文
DATA data_set_name; #Name the data set.
INPUT var1,var2,var3; #Define the variables in this data set.
NEW_VAR; #Create new variables.
LABEL; #Assign labels to variables.
DATALINES; #Enter the data.
RUN;例
以下の例は、データセットに名前を付け、変数を定義し、新しい変数を作成し、データを入力する簡単なケースを示しています。ここで、文字列変数の末尾には$があり、数値には$がありません。
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
comm = SALARY*0.25;
LABEL ID = 'Employee ID' comm = 'COMMISION';
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;PROCステップ
このステップでは、SAS組み込みプロシージャを呼び出してデータを分析します。
構文
PROC procedure_name options; #The name of the proc.
RUN;例
以下の例は、 MEANS データセット内の数値変数の平均値を出力する手順。
PROC MEANS;
RUN;OUTPUTステップ
データセットのデータは、条件付き出力ステートメントで表示できます。
構文
PROC PRINT DATA = data_set;
OPTIONS;
RUN;例
次の例は、出力でwhere句を使用して、データセットから少数のレコードのみを生成する方法を示しています。
PROC PRINT DATA = TEMP;
WHERE SALARY > 700;
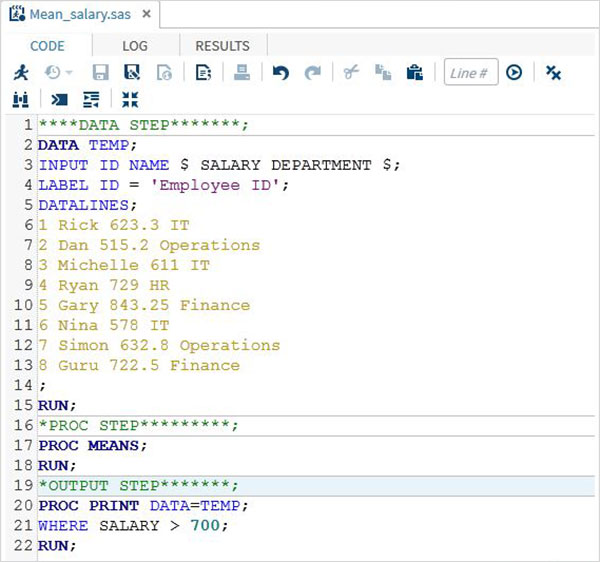
RUN;完全なSASプログラム
以下は、上記の各ステップの完全なコードです。
プログラム出力
RESULTS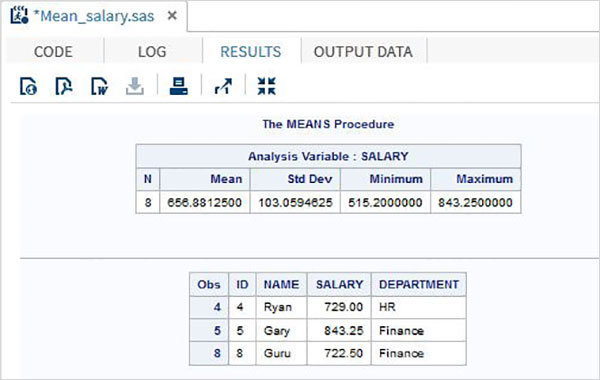
他のプログラミング言語と同様に、SAS言語には、SASプログラムを作成するための独自の構文規則があります。
SASプログラムの3つのコンポーネント(ステートメント、変数、データセット)は、構文に関する以下のルールに従います。
SASステートメント
ステートメントはどこからでも開始でき、どこでも終了できます。最後の行の終わりにあるセミコロンは、ステートメントの終わりを示します。
多くのSASステートメントを同じ行に配置でき、各ステートメントはセミコロンで終わります。
スペースは、SASプログラムステートメントのコンポーネントを区切るために使用できます。
SASキーワードでは、大文字と小文字は区別されません。
すべてのSASプログラムは、RUNステートメントで終了する必要があります。
SAS変数名
SASの変数は、SASデータセットの列を表します。変数名は以下のルールに従います。
最大32文字の長さにすることができます。
空白を含めることはできません。
AからZ(大文字と小文字は区別されません)またはアンダースコア(_)で始まる必要があります。
数字を含めることはできますが、最初の文字として含めることはできません。
変数名では大文字と小文字は区別されません。
例
# Valid Variable Names
REVENUE_YEAR
MaxVal
_Length
# Invalid variable Names
Miles Per Liter #contains Space.
RainfFall% # contains apecial character other than underscore.
90_high # Starts with a number.SASデータセット
DATAステートメントは、新しいSASデータセットの作成を示します。DATAセット作成のルールは以下のとおりです。
DATAステートメントの後の1つの単語は、一時データ・セット名を示します。これは、セッションの終了時にデータセットが消去されることを意味します。
データセット名の前にライブラリ名を付けることができるため、永続的なデータセットになります。これは、セッションが終了した後もデータセットが保持されることを意味します。
SASデータセット名が省略されている場合、SASは、SASによって生成された名前(DATA1、DATA2など)で一時データセットを作成します。
例
# Temporary data sets.
DATA TempData;
DATA abc;
DATA newdat;
# Permanent data sets.
DATA LIBRARY1.DATA1
DATA MYLIB.newdat;SASファイル拡張子
SASプログラム、データファイル、およびプログラムの結果は、さまざまな拡張子でWindowsに保存されます。
*.sas −SASエディタまたは任意のテキストエディタを使用して編集できるSASコードファイルを表します。
*.log −送信されたSASプログラムのエラー、警告、データセットの詳細などの情報を含むSASログファイルを表します。
*.mht / *.html -SAS結果ファイルを表します。
*.sas7bdat -変数名、ラベル、計算結果を含むSASデータセットを含むSASデータファイルを表します。
SASのコメント
SASコードのコメントは、2つの方法で指定されます。以下は、これら2つの形式です。
*メッセージ; コメントを入力
の形でのコメント *message;セミコロンや一致しない引用符を内部に含めることはできません。また、そのようなコメント内のマクロステートメントへの参照があってはなりません。複数行にまたがることができ、任意の長さにすることができます。以下は、単一行コメントの例です。
* This is comment ;以下は複数行コメントの例です-
* This is first line of the comment
* This is second line of the comment;/ *メッセージ* /タイプコメント
の形でのコメント /*message*/より頻繁に使用され、ネストすることはできません。ただし、複数の行にまたがることができ、任意の長さにすることができます。以下は1行コメントの例です-
/* This is comment */以下は複数行コメントの例です-
/* This is first line of the comment
* This is second line of the comment */分析のためにSASプログラムで利用できるデータは、SASデータセットと呼ばれます。DATAステップを使用して作成されます。SASは、次のようなデータソースとしてさまざまなファイルを読み取ることができます。CSV, Excel, Access, SPSS and also raw data。また、使用可能な多くの組み込みデータソースがあります。
データセットは呼び出されます temporary Data Set それらがSASプログラムによって使用され、セッションの実行後に破棄された場合。
しかし、将来の使用のために永続的に保存されている場合は、 permanent Data set。すべての永続的なデータセットは、特定のライブラリに保存されます。
SASデータセットは行と列の形式で保存され、SASデータテーブルとも呼ばれます。以下に、組み込みの永続的なデータセットと外部ソースからの赤の例を示します。
SASビルトインデータセット
これらのデータセットは、インストールされているSASソフトウェアですでに利用可能です。それらは、データ分析用のサンプル式を作成する際に調査および使用できます。これらのデータセットを調べるには、Libraries -> My Libraries -> SASHELP。展開すると、使用可能なすべての組み込みデータセットの名前のリストが表示されます。
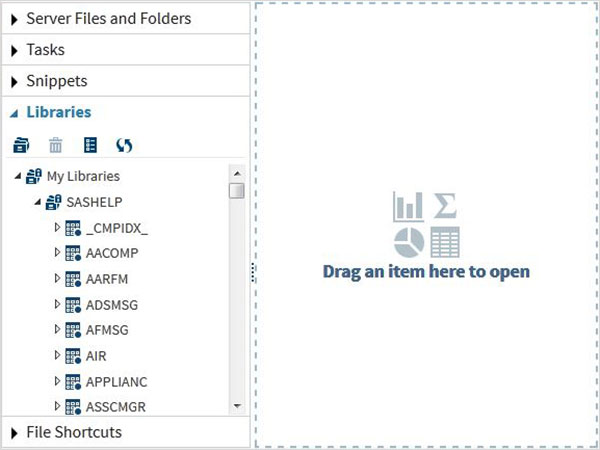
下にスクロールして、という名前のデータセットを見つけましょう CARS。このデータセットをダブルクリックすると、右側のウィンドウペインが開き、さらに詳しく調べることができます。右側のペインの下にある[最大表示]ボタンを使用して、左側のペインを最小化することもできます。
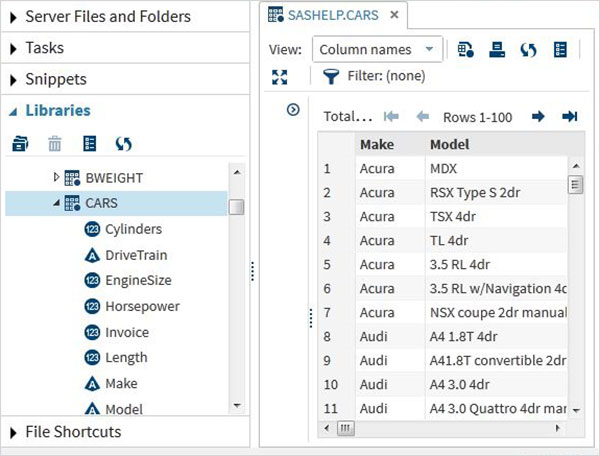
下部のスクロールバーを使用して右にスクロールすると、テーブル内のすべての列とその値を調べることができます。
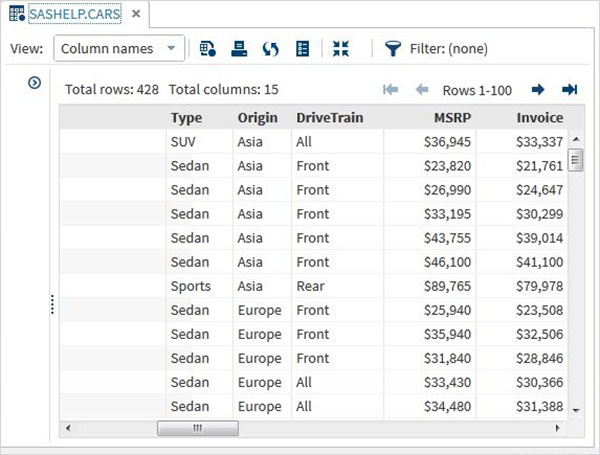
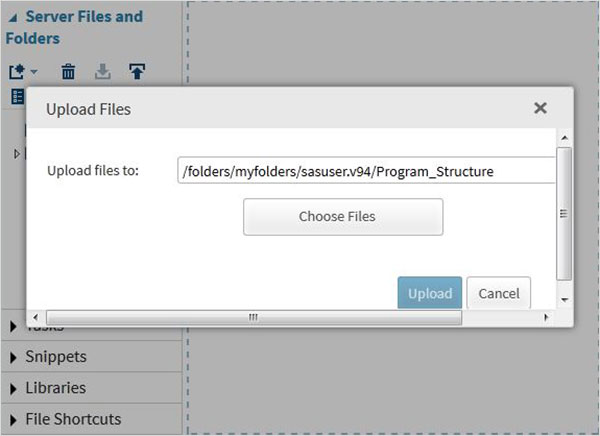
外部データセットのインポート
SAS Studioで利用可能なインポート機能を使用して、独自のファイルをデータセットとしてエクスポートできます。ただし、これらのファイルはSASサーバーフォルダーで使用可能である必要があります。そのため、下のアップロードオプションを使用して、ソースデータファイルをSASフォルダーにアップロードする必要があります。Server Files and Folders。
次に、上記のファイルをインポートして、SASプログラムで使用します。これを行うには、オプションを使用しますTasks -> Utilities -> Import data 以下に示すように。[データのインポート]ボタンをダブルクリックすると、右側のウィンドウが開き、データセットのファイルを選択できます。
次へをクリックします Select Files右ペインのデータインポートプログラムの下にあるボタン。インポートできるファイルの種類は次のとおりです。
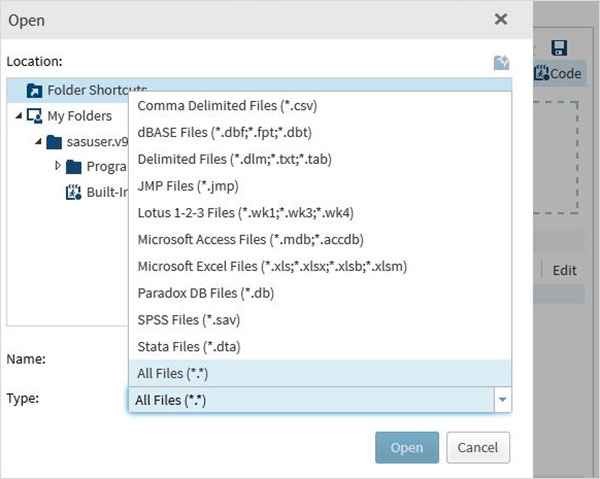
ローカルシステムに保存されている「employee.txt」ファイルを選択し、以下に示すようにファイルをインポートします。
インポートしたデータを表示する
[実行]オプションを使用して生成されたデフォルトのインポートコードを実行することで、インポートされたデータを表示できます
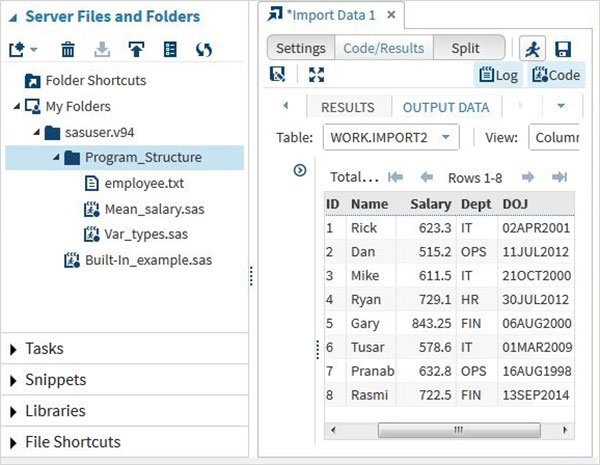
上記と同じアプローチを使用して他のファイルタイプをインポートし、さまざまなSASプログラムで使用できます。
一般に、SASの変数は、分析しているデータテーブルの列名を表します。ただし、プログラミングループのカウンターとして使用するなど、他の目的にも使用できます。現在の章では、SASデータセットの列名としてのSAS変数の使用について説明します。
SAS変数タイプ
SASには以下の3種類の変数があります-
数値変数
これはデフォルトの変数タイプです。これらの変数は数式で使用されます。
構文
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.上記の構文では、INPUTステートメントは数値変数の宣言を示しています。
例
INPUT ID SALARY COMM_PERCENT;文字変数
文字変数は、数式で使用されない値に使用されます。それらはテキストまたは文字列として扱われます。変数名の最後にスペースを入れて$ singを追加すると、変数は文字変数になります。
構文
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.上記の構文では、INPUTステートメントは文字変数の宣言を示しています。
例
INPUT FNAME $ LNAME $ ADDRESS $;日付変数
これらの変数は日付としてのみ扱われ、有効な日付形式である必要があります。変数名の末尾にスペースを入れた日付形式を追加すると、変数は日付変数になります。
構文
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.上記の構文では、INPUTステートメントは日付変数の宣言を示しています。
例
INPUT DOB DATE11. START_DATE MMDDYY10. ;SASプログラムでの変数の使用
上記の変数は、以下の例に示すようにSASプログラムで使用されます。
例
以下のコードは、SASプログラムで3種類の変数がどのように宣言および使用されるかを示しています。
DATA TEMP;
INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ;
FORMAT DOJ DATE9. ;
DATALINES;
1 Rick 623.3 IT 02APR2001
2 Dan 515.2 OPS 11JUL2012
3 Michelle 611 IT 21OCT2000
4 Ryan 729 HR 30JUL2012
5 Gary 843.25 FIN 06AUG2000
6 Tusar 578 IT 01MAR2009
7 Pranab 632.8 OPS 16AUG1998
8 Rasmi 722.5 FIN 13SEP2014
;
PROC PRINT DATA = TEMP;
RUN;上記の例では、すべての文字変数の後に$記号が続き、日付変数の後に日付形式が宣言されています。上記のプログラムの出力は以下のとおりです。
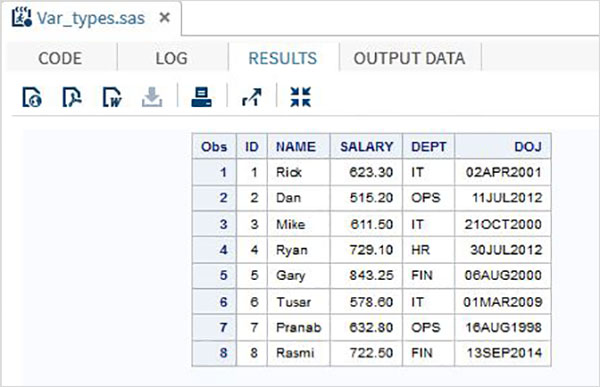
変数の使用
変数は、データの分析に非常に役立ちます。これらは、統計分析が適用される式で使用されます。名前の付いた組み込みデータセットを分析する例を見てみましょう。CARS 下に存在します Libraries → My Libraries → SASHELP。それをダブルクリックして、変数とそのデータ型を調べます。

次に、SAS Studioのタスクオプションを使用して、これらの変数のいくつかの要約統計量を生成できます。に移動Tasks -> Statistics -> Summary Statisticsそれをダブルクリックして、以下のようなウィンドウを開きます。データセットを選択SASHELP.CARS分析変数の下で、MPG_CITY、MPG_Highway、Weightの3つの変数を選択します。Ctrlキーを押しながら、をクリックして変数を選択します。[実行]をクリックします。

上記の手順の後、[結果]タブをクリックします。選択した3つの変数の統計要約が表示されます。最後の列は、分析で使用された観測値(レコード)の数を示します。
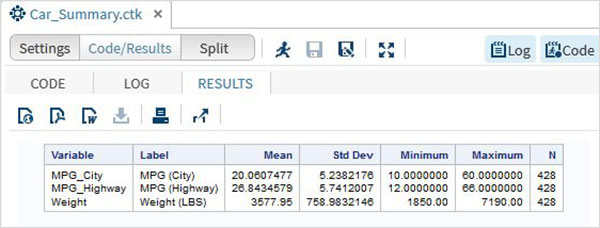
SASの文字列は、一重引用符のペアで囲まれた値です。また、文字列変数は、変数宣言の最後にスペースと$記号を追加することによって宣言されます。SASには、文字列を分析および操作するための多くの強力な機能があります。
文字列変数の宣言
以下に示すように、文字列変数とその値を宣言できます。以下のコードでは、長さ6と5の2つの文字変数を宣言します。LENGTHキーワードは、複数の観測値を作成せずに変数を宣言するために使用されます。
data string_examples;
LENGTH string1 $ 6 String2 $ 5;
/*String variables of length 6 and 5 */
String1 = 'Hello';
String2 = 'World';
Joined_strings = String1 ||String2 ;
run;
proc print data = string_examples noobs;
run;上記のコードを実行すると、変数名とその値を示す出力が得られます。
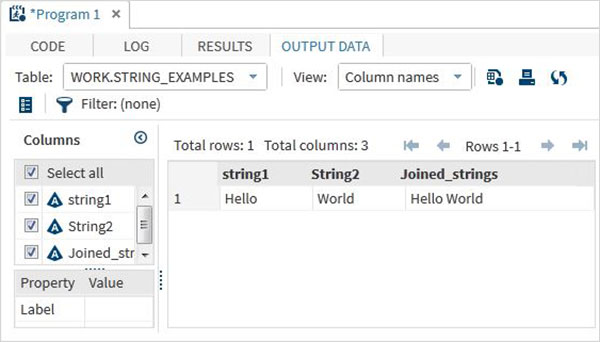
文字列関数
以下は、頻繁に使用されるいくつかのSAS関数の例です。
SUBSTRN
この関数は、開始位置と終了位置を使用して部分文字列を抽出します。終了位置が記載されていない場合は、文字列の最後まですべての文字を抽出します。
構文
SUBSTRN('stringval',p1,p2)以下は、使用されるパラメーターの説明です-
- stringval 文字列変数の値です。
- p1 抽出の開始位置です。
- p2 抽出の最終位置です。
例
data string_examples;
LENGTH string1 $ 6 ;
String1 = 'Hello';
sub_string1 = substrn(String1,2,4) ;
/*Extract from position 2 to 4 */
sub_string2 = substrn(String1,3) ;
/*Extract from position 3 onwards */
run;
proc print data = string_examples noobs;
run;上記のコードを実行すると、substrn関数の結果を示す出力が得られます。

トリム
この関数は、文字列から末尾のスペースを削除します。
構文
TRIMN('stringval')以下は、使用されるパラメーターの説明です-
- stringval 文字列変数の値です。
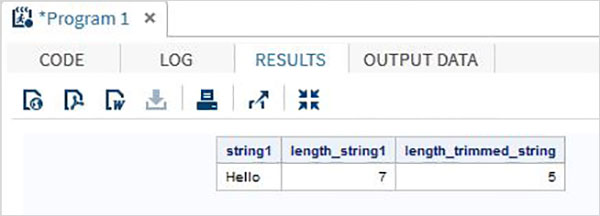
data string_examples;
LENGTH string1 $ 7 ;
String1='Hello ';
length_string1 = lengthc(String1);
length_trimmed_string = lengthc(TRIMN(String1));
run;
proc print data = string_examples noobs;
run;上記のコードを実行すると、TRIMN関数の結果を示す出力が得られます。
SASの配列は、インデックス値を使用して一連の値を格納および取得するために使用されます。インデックスは、予約済みメモリ領域内の場所を表します。
構文
SASでは、配列は次の構文を使用して宣言されます-
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUES上記の構文では-
ARRAY 配列を宣言するSASキーワードです。
ARRAY-NAME は、変数名と同じ規則に従う配列の名前です。
SUBSCRIPT 配列が格納しようとしている値の数です。
($) 配列が文字値を格納する場合にのみ使用されるオプションのパラメーターです。
VARIABLE-LIST 配列値のプレースホルダーである変数のオプションのリストです。
ARRAY-VALUES配列に格納されている実際の値です。ここで宣言することも、ファイルまたはデータラインから読み取ることもできます。
配列宣言の例
配列は、上記の構文を使用してさまざまな方法で宣言できます。以下に例を示します。
# Declare an array of length 5 named AGE with values.
ARRAY AGE[5] (12 18 5 62 44);
# Declare an array of length 5 named COUNTRIES with values starting at index 0.
ARRAY COUNTRIES(0:8) A B C D E F G H I;
# Declare an array of length 5 named QUESTS which contain character values.
ARRAY QUESTS(1:5) $ Q1-Q5;
# Declare an array of required length as per the number of values supplied.
ARRAY ANSWER(*) A1-A100;配列値へのアクセス
配列に格納されている値には、を使用してアクセスできます。 print以下に示す手順。上記のメソッドのいずれかを使用して宣言された後、データはDATALINESステートメントを使用して提供されます。
DATA array_example;
INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5;
mix = a1||'+'||a2;
DATALINES;
yello pink orange green blue
;
RUN;
PROC PRINT DATA = array_example;
RUN;上記のコードを実行すると、次の結果が生成されます-
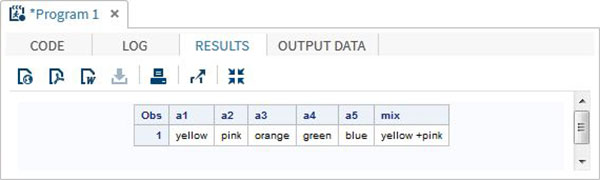
OF演算子の使用
OF演算子は、配列のデータ形式を分析して、配列の行全体に対して計算を実行するときに使用されます。以下の例では、各行に値の合計と平均を適用します。
DATA array_example_OF;
INPUT A1 A2 A3 A4;
ARRAY A(4) A1-A4;
A_SUM = SUM(OF A(*));
A_MEAN = MEAN(OF A(*));
A_MIN = MIN(OF A(*));
DATALINES;
21 4 52 11
96 25 42 6
;
RUN;
PROC PRINT DATA = array_example_OF;
RUN;上記のコードを実行すると、次の結果が生成されます-
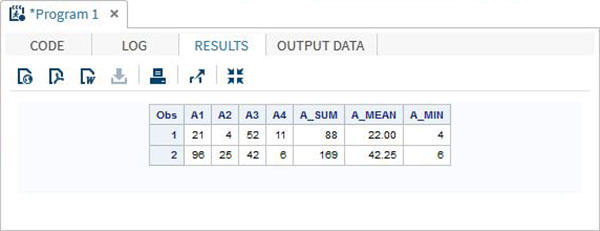
IN演算子の使用
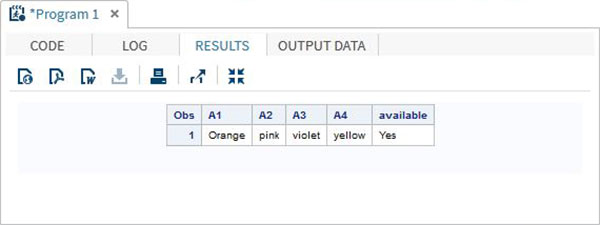
配列の値には、配列の行に値が存在するかどうかを確認するIN演算子を使用してアクセスすることもできます。以下の例では、データ内の「黄色」の色が使用可能かどうかを確認します。この値では大文字と小文字が区別されます。
DATA array_in_example;
INPUT A1 $ A2 $ A3 $ A4 $;
ARRAY COLOURS(4) A1-A4;
IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No';
DATALINES;
Orange pink violet yellow
;
RUN;
PROC PRINT DATA = array_in_example;
RUN;上記のコードを実行すると、次の結果が生成されます-
SASは、さまざまな数値データ形式を処理できます。変数名の最後にこれらの形式を使用して、特定の数値形式をデータに適用します。SASは2種類の数値形式を使用します。と呼ばれる数値データの特定の形式を読み取るための1つinformat もう1つは、数値データを特定の形式で表示するためのものです。 output format。
構文
数値情報の構文は次のとおりです。
Varname Formatnamew.d以下は、使用されるパラメーターの説明です-
Varname 変数の名前です。
Formatname 変数に適用される数値形式の名前の名前です。
w 変数に格納できるデータ列の最大数(小数点以下の桁数と小数点自体を含む)です。
d 小数点の右側の桁数です。
数値形式の読み取り
以下は、SASにデータを読み込むために使用される形式のリストです。
入力数値形式
| フォーマット | 使用する |
|---|---|
| n. | 小数点のない列の最大「n」数。 |
| n.p | 小数点が「p」の列の最大「n」数。 |
| COMMAn.p | コンマまたはドル記号を削除する小数点以下「p」の列の最大「n」数。 |
| COMMAn.p | コンマまたはドル記号を削除する小数点以下「p」の列の最大「n」数。 |
数値形式の表示
データの読み取り中にフォーマットを適用するのと同様に、SASプログラムの出力でデータを表示するために使用されるフォーマットのリストを以下に示します。
出力数値フォーマット
| フォーマット | 使用する |
|---|---|
| n. | 小数点なしで最大「n」桁の桁数を書き込みます。 |
| n.p | 小数点以下「p」の列の最大「np」数を書き込みます。 |
| DOLLARn.p | 小数点以下p桁、先頭のドル記号、および1000番目のコンマを含む最大「n」列の数を書き込みます。 |
注意してください-
小数点以下の桁数がフォーマット指定子より少ない場合は、zeros will be appended 最後に。
小数点以下の桁数がフォーマット指定子より大きい場合、最後の桁は次のようになります。 rounded off。
例
以下の例は、上記のシナリオを示しています。
DATA MYDATA1;
input x 6.; /*maxiiuum width of the data*/
format x 6.3;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA1;
RUN;
DATA MYDATA2;
input x 6.; /*maximum width of the data*/
format x 5.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA2;
RUN;
DATA MYDATA3;
input x 6.; /*maximum width of the data*/
format x DOLLAR10.2;
datalines;
8722
93.2
.1122
15.116
PROC PRINT DATA = MYDATA3;
RUN;上記のコードを実行すると、次の結果が生成されます-
# MYDATA1.
Obs x
1 8722.0 # Display 6 columns with zero appended after decimal.
2 93.200 # Display 6 columns with zero appended after decimal.
3 0.112 # No integers before decimal, so display 3 available digits after decimal.
4 15.116 # Display 6 columns with 3 available digits after decimal.
# MYDATA2
Obs x
1 8722 # Display 5 columns. Only 4 are available.
2 93.20 # Display 5 columns with zero appended after decimal.
3 0.11 # Display 5 columns with 2 places after decimal.
4 15.12 # Display 5 columns with 2 places after decimal.
# MYDATA3
Obs x
1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal.
2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal.
4 $15.12 # Only 2 integers available before decimal and two available after the decimal.SASの演算子は、数式、論理式、または比較式で使用される記号です。これらの記号はSAS言語に組み込まれており、多くの演算子を1つの式に組み合わせて、最終的な出力を得ることができます。
以下は、SASカテゴリのオペレーターのリストです。
- 算術演算子
- 論理演算子
- 比較演算子
- 最小/最大演算子
- 連結演算子
それぞれを一つずつ見ていきます。演算子は常に、SASプログラムによって分析されているデータの一部である変数とともに使用されます。
算術演算子
次の表に、算術演算子の詳細を示します。2つのデータ変数を想定しましょうV1 そして V2値付き 8 そして 4 それぞれ。
| オペレーター | 説明 | 例 |
|---|---|---|
| + | 添加 | V1 + V2 = 12 |
| - | 減算 | V1-V2 = 4 |
| * | 乗算 | V1 * V2 = 32 |
| / | 分割 | V1 / V2 = 2 |
| **** | べき乗 | V1 ** V2 = 4096 |
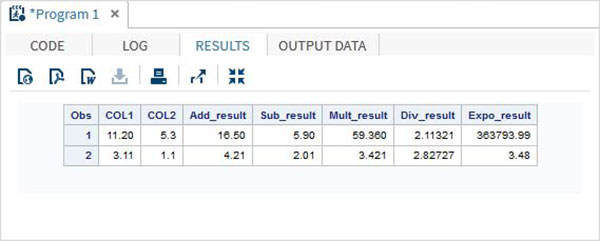
例
DATA MYDATA1;
input @1 COL1 4.2 @7 COL2 3.1;
Add_result = COL1+COL2;
Sub_result = COL1-COL2;
Mult_result = COL1*COL2;
Div_result = COL1/COL2;
Expo_result = COL1**COL2;
datalines;
11.21 5.3
3.11 11
;
PROC PRINT DATA = MYDATA1;
RUN;上記のコードを実行すると、次の出力が得られます。
論理演算子
次の表に、論理演算子の詳細を示します。これらの演算子は、式の真理値を評価します。したがって、論理演算子の結果は常に1または0になります。2つのデータ変数を想定しましょう。V1 そして V2値付き 8 そして 4 それぞれ。
| オペレーター | 説明 | 例 |
|---|---|---|
| & | AND演算子。両方のデータ値がtrueと評価された場合、結果は1になり、それ以外の場合は0になります。 | (V1> 2&V2> 3)は0を与えます。 |
| | | OR演算子。データ値のいずれかがtrueと評価された場合、結果は1になり、それ以外の場合は0になります。 | (V1> 9&V2> 3)は1です。 |
| 〜 | NOT演算子。値がFALSEであるか、欠落している値が1であるか、それ以外の場合は0である式の形式のNOT演算子の結果。 | NOT(V1> 3)は1です。 |
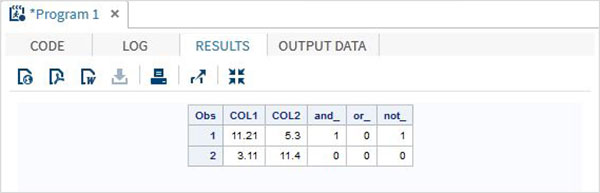
例
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
and_=(COL1 > 10 & COL2 > 5 );
or_ = (COL1 > 12 | COL2 > 15 );
not_ = ~( COL2 > 7 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;上記のコードを実行すると、次の出力が得られます。
比較演算子
次の表に、比較演算子の詳細を示します。これらの演算子は変数の値を比較し、結果はTRUEの場合は1、Falseの場合は0で表される真理値です。2つのデータ変数を想定しましょうV1 そして V2値付き 8 そして 4 それぞれ。
| オペレーター | 説明 | 例 |
|---|---|---|
| = | EQUAL演算子。両方のデータ値が等しい場合、結果は1になり、そうでない場合は0になります。 | (V1 = 8)は1を与えます。 |
| ^ = | NOTEQUAL演算子。両方のデータ値が等しくない場合、結果は1になり、そうでない場合は0になります。 | (V1 ^ = V2)は1を与えます。 |
| < | LESSTHAN演算子。 | (V2 <V2)は1を与えます。 |
| <= | LESSTHANまたはEQUALTO演算子。 | (V2 <= 4)は1を与えます。 |
| >> | 大なり記号演算子。 | (V2> V1)は1を与えます。 |
| > = | 大なり記号または同等の演算子。 | (V2> = V1)は0を与えます。 |
| に | IN演算子。変数の値が指定された値のリスト内の値のいずれかと等しい場合は1を返し、そうでない場合は0を返します。 | (5,7,9,8)のV1は1を与えます。 |
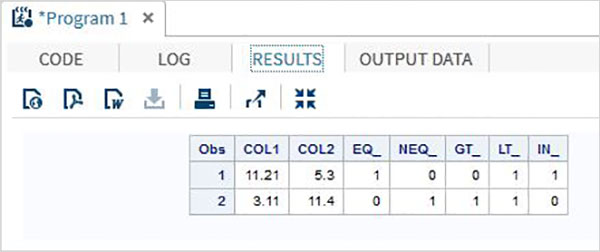
例
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1;
EQ_ = (COL1 = 11.21);
NEQ_= (COL1 ^= 11.21);
GT_ = (COL2 => 8);
LT_ = (COL2 <= 12);
IN_ = COL2 in( 6.2,5.3,12 );
datalines;
11.21 5.3
3.11 11.4
;
PROC PRINT DATA = MYDATA1;
RUN;上記のコードを実行すると、次の出力が得られます。
最小/最大演算子
次の表に、最小/最大演算子の詳細を示します。これらの演算子は、行全体の変数の値を比較し、行の値のリストから最小値または最大値が返されます。
| オペレーター | 説明 | 例 |
|---|---|---|
| MIN | MIN演算子。行の値のリストから最小値を返します。 | MIN(45.2,11.6,15.41)は11.6を与えます |
| MAX | MAXオペレーター。行の値のリストから最大値を返します。 | MAX(45.2,11.6,15.41)は45.2を与えます |
例
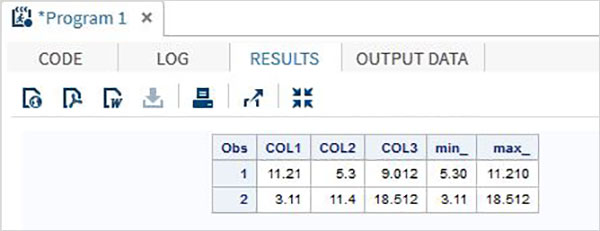
DATA MYDATA1;
input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3;
min_ = MIN(COL1 , COL2 , COL3);
max_ = MAX( COL1, COl2 , COL3);
datalines;
11.21 5.3 29.012
3.11 11.4 18.512
;
PROC PRINT DATA = MYDATA1;
RUN;上記のコードを実行すると、次の出力が得られます。
連結演算子
次の表に、連結演算子の詳細を示します。この演算子は、2つ以上の文字列値を連結します。1文字の値が返されます。
| オペレーター | 説明 | 例 |
|---|---|---|
| || | 連結演算子。2つ以上の値の連結を返します。 | 'こんにちは' || ' World 'はHelloWorldを提供します |
例
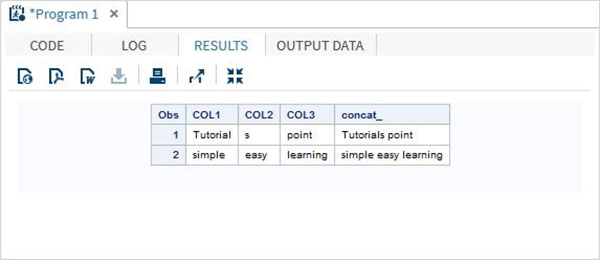
DATA MYDATA1;
input COL1 $ COL2 $ COL3 $;
concat_ = (COL1 || COL2 || COL3);
datalines;
Tutorial s point
simple easy learning
;
PROC PRINT DATA = MYDATA1;
RUN;上記のコードを実行すると、次の出力が得られます。
オペレーターの優先順位
演算子の優先順位は、複雑な式に存在する複数の演算子の評価の順序を示します。次の表は、演算子のグループでの優先順位を示しています。
| グループ | 注文 | 記号 |
|---|---|---|
| グループI | 右から左へ | ** +-最小最大ではありません |
| グループII | 左から右へ | * / |
| グループIII | 左から右へ | +- |
| グループIV | 左から右へ | || |
| グループV | 左から右へ | << = => => |
コードのブロックを数回実行する必要がある場合があります。一般に、ステートメントは順番に実行されます-関数の最初のステートメントが最初に実行され、次に2番目のステートメントが実行されます。ただし、同じステートメントセットを何度も実行する場合は、ループの助けが必要です。
SASでは、ループはDOステートメントを使用して実行されます。とも呼ばれますDO Loop。以下に示すのは、SASでのDOループステートメントの一般的な形式です。
フロー図

SASのDOループのタイプは次のとおりです。
| シニア番号 | ループの種類と説明 |
|---|---|
| 1 | DOインデックス。 ループは、インデックス変数の開始値から停止値まで続きます。 |
| 2 | 一方を行います。 ループは、while条件がfalseになるまで続きます。 |
| 3 | までしてください。 ループは、UNTIL条件がTrueになるまで続きます。 |
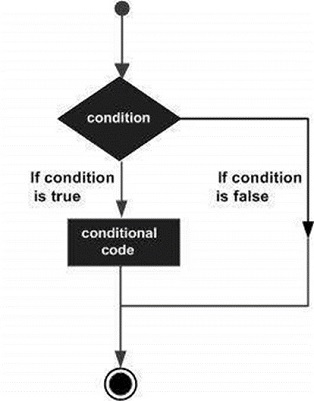
意思決定構造では、プログラマーは、プログラムによって評価またはテストされる1つ以上の条件と、条件が次のように決定された場合に実行される1つまたは複数のステートメントを指定する必要があります。 true、およびオプションで、条件が次のように決定された場合に実行される他のステートメント false。
以下は、ほとんどのプログラミング言語に見られる典型的な意思決定構造の一般的な形式です。
SASは、次のタイプの意思決定ステートメントを提供します。詳細を確認するには、次のリンクをクリックしてください。
| シニア番号 | ステートメントの種類と説明 |
|---|---|
| 1 | IFステートメント。 アン if statement条件で構成されます。条件が真の場合、特定のデータがフェッチされます。 |
| 2 | IF-THEN-ELSEステートメント。 アン if statement その後にelseステートメントが続きます。これは、ブール条件がfalseの場合に実行されます。 |
| 3 | IF-THEN-ELSE-IFステートメント。 アン if statement その後にelseステートメントが続き、その後にIF-THENステートメントの別のペアが続きます。 |
| 4 | IF-THEN-DELETEステートメント。 アン if statement 条件で構成され、trueの場合、観測から特定のデータを削除します。 |
SASには、データの分析と処理に役立つさまざまな組み込み関数があります。これらの関数は、DATAステートメントの一部として使用されます。それらは引数としてデータ変数を取り、別の変数に格納される結果を返します。関数のタイプに応じて、取る引数の数は異なります。ゼロ引数を受け入れる関数もあれば、固定数の変数を受け入れる関数もあります。以下は、SASが提供する機能の種類のリストです。
構文
SASで関数を使用するための一般的な構文は次のとおりです。
FUNCTIONNAME(argument1, argument2...argumentn)ここで、引数は定数、変数、式、または別の関数にすることができます。
機能カテゴリ
SASの機能は、用途に応じて以下のように分類されます。
- Mathematical
- 日時
- Character
- Truncation
- Miscellaneous
数学関数
これらは、変数値にいくつかの数学計算を適用するために使用される関数です。
Examples
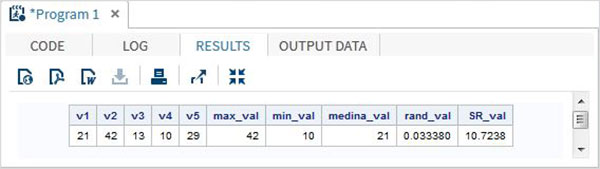
The below SAS program shows the use of some important mathematical functions.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29;
/* Get Maximum value */
max_val = MAX(v1,v2,v3,v4,v5);
/* Get Minimum value */
min_val = MIN (v1,v2,v3,v4,v5);
/* Get Median value */
med_val = MEDIAN (v1,v2,v3,v4,v5);
/* Get a random number */
rand_val = RANUNI(0);
/* Get Square root of sum of the values */
SR_val= SQRT(sum(v1,v2,v3,v4,v5));
proc print data = Math_functions noobs;
run;When the above code is run, we get the following output −
Date and Time Functions
These are the functions used to process date and time values.
Examples
The below SAS program shows the use of date and time functions.
data date_functions;
INPUT @1 date1 date9. @11 date2 date9.;
format date1 date9. date2 date9.;
/* Get the interval between the dates in years*/
Years_ = INTCK('YEAR',date1,date2);
/* Get the interval between the dates in months*/
months_ = INTCK('MONTH',date1,date2);
/* Get the week day from the date*/
weekday_ = WEEKDAY(date1);
/* Get Today's date in SAS date format */
today_ = TODAY();
/* Get current time in SAS time format */
time_ = time();
DATALINES;
21OCT2000 16AUG1998
01MAR2009 11JUL2012
;
proc print data = date_functions noobs;
run;When the above code is run, we get the following output −
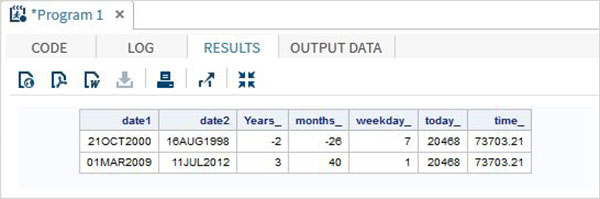
Character Functions
These are the functions used to process character or text values.
Examples
The below SAS program shows the use of character functions.
data character_functions;
/* Convert the string into lower case */
lowcse_ = LOWCASE('HELLO');
/* Convert the string into upper case */
upcase_ = UPCASE('hello');
/* Reverse the string */
reverse_ = REVERSE('Hello');
/* Return the nth word */
nth_letter_ = SCAN('Learn SAS Now',2);
run;
proc print data = character_functions noobs;
run;When the above code is run, we get the following output −
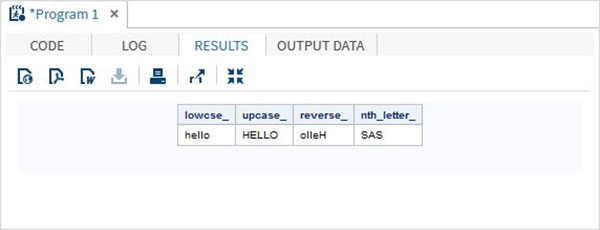
Truncation Functions
These are the functions used to truncate numeric values.
Examples
The below SAS program shows the use of truncation functions.
data trunc_functions;
/* Nearest greatest integer */
ceil_ = CEIL(11.85);
/* Nearest greatest integer */
floor_ = FLOOR(11.85);
/* Integer portion of a number */
int_ = INT(32.41);
/* Round off to nearest value */
round_ = ROUND(5621.78);
run;
proc print data = trunc_functions noobs;
run;上記のコードを実行すると、次の出力が得られます-

その他の機能
ここで、いくつかの例を使用して、SASのその他の機能を理解しましょう。
例
以下のSASプログラムは、その他の機能の使用法を示しています。
data misc_functions;
/* Nearest greatest integer */
state2=zipstate('01040');
/* Amortization calculation */
payment = mort(50000, . , .10/12,30*12);
proc print data = misc_functions noobs;
run;上記のコードを実行すると、次の出力が得られます-

入力メソッドは、生データを読み取るために使用されます。生データは、外部ソースからのものでも、ストリームデータラインからのものでもかまいません。inputステートメントは、各フィールドに割り当てた名前で変数を作成します。したがって、Inputステートメントで変数を作成する必要があります。同じ変数がSASデータセットの出力に表示されます。以下は、SASで使用可能なさまざまな入力方法です。
- リスト入力方法
- 名前付き入力方式
- 列の入力方法
- フォーマットされた入力方法
各入力方法の詳細は以下のとおりです。
リスト入力方法
このメソッドでは、変数はデータ型とともにリストされます。宣言された変数の順序がデータと一致するように、生データは注意深く分析されます。区切り文字(通常はスペース)は、隣接する列の任意のペア間で均一である必要があります。データが欠落していると、結果が間違っているため、出力に問題が発生します。
例
次のコードと出力は、リスト入力方式の使用法を示しています。
DATA TEMP;
INPUT EMPID ENAME $ DEPT $ ;
DATALINES;
1 Rick IT
2 Dan OPS
3 Tusar IT
4 Pranab OPS
5 Rasmi FIN
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
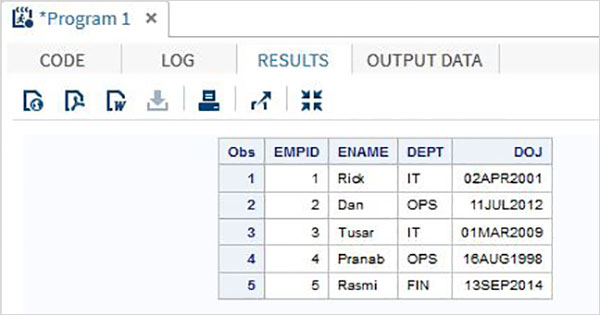
名前付き入力方式
このメソッドでは、変数はデータ型とともにリストされます。生データは、一致するデータの前に変数名が宣言されるように変更されます。区切り文字(通常はスペース)は、隣接する列の任意のペア間で均一である必要があります。
例
次のコードと出力は、名前付き入力方式の使用法を示しています。
DATA TEMP;
INPUT
EMPID= ENAME= $ DEPT= $ ;
DATALINES;
EMPID = 1 ENAME = Rick DEPT = IT
EMPID = 2 ENAME = Dan DEPT = OPS
EMPID = 3 ENAME = Tusar DEPT = IT
EMPID = 4 ENAME = Pranab DEPT = OPS
EMPID = 5 ENAME = Rasmi DEPT = FIN
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
列の入力方法
この方法では、変数は、データの単一列の値を指定する列のデータ型と幅とともにリストされます。たとえば、従業員名に最大9文字が含まれ、各従業員名が10列目から始まる場合、従業員名変数の列幅は10〜19になります。
例
次のコードは、列入力方式の使用法を示しています。
DATA TEMP;
INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16;
DATALINES;
14 Rick IT
241Dan OPS
30 Sanvi IT
410Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の結果が生成されます-
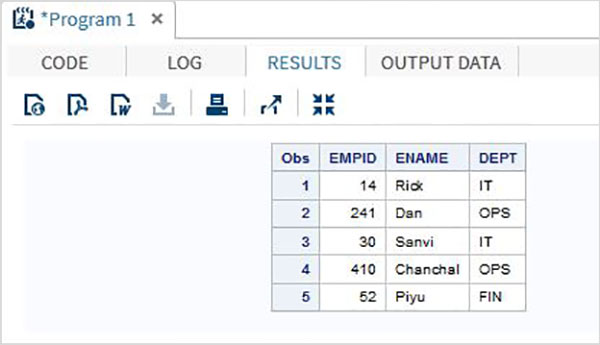
フォーマットされた入力方法
この方法では、変数は、スペースが検出されるまで、固定された開始点から読み取られます。すべての変数には固定の開始点があるため、変数の任意のペア間の列の数が最初の変数の幅になります。文字「@n」は、変数の開始列位置をn番目の列として指定するために使用されます。
例
次のコードは、フォーマットされた入力方式の使用法を示しています。
DATA TEMP;
INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ;
DATALINES;
14 Rick IT
241 Dan OPS
30 Sanvi IT
410 Chanchal OPS
52 Piyu FIN
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の結果が生成されます-
SASには、と呼ばれる強力なプログラミング機能があります Macrosこれにより、コードの繰り返しセクションを回避し、必要に応じて何度も使用することができます。また、同じコードの異なる実行インスタンスに対して異なる値をとることができる動的変数をコード内に作成するのにも役立ちます。マクロは、マクロ変数と同様の方法で複数回再利用されるコードのブロックに対して宣言することもできます。以下の例では、これらの両方を確認します。
マクロ変数
これらは、SASプログラムによって何度も使用される値を保持する変数です。これらはSASプログラムの開始時に宣言され、プログラムの本文の後半で呼び出されます。スコープはグローバルまたはローカルにすることができます。
グローバルマクロ変数
これらは、SAS環境で使用可能な任意のSASプログラムからアクセスできるため、グローバルマクロ変数と呼ばれます。一般に、それらは複数のプログラムによってアクセスされるシステム割り当て変数です。一般的な例はシステム日付です。
例
以下は、システム日付を表すSYSDATEと呼ばれるSAS変数の例です。レポートが生成される毎日、SASレポートのタイトルにシステム日付を印刷するシナリオを考えてみます。タイトルには、値をコーディングせずに現在の日付と曜日が表示されます。SASHELPライブラリで利用可能なCARSと呼ばれる組み込みのSASデータセットを使用します。
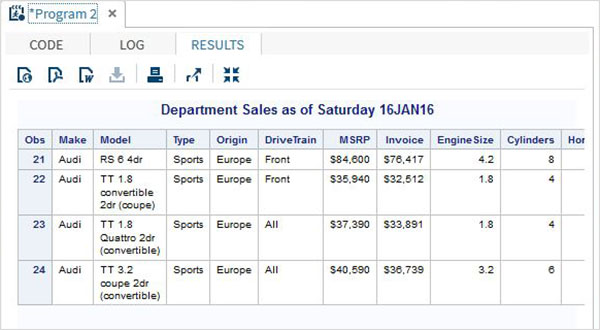
proc print data = sashelp.cars;
where make = 'Audi' and type = 'Sports' ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;上記のコードを実行すると、次の出力が得られます。
ローカルマクロ変数
これらの変数は、プログラムの一部として宣言されているSASプログラムからアクセスできます。これらは通常、データセットのさまざまな観測を処理できる同じSASステートメントslにさまざまな変数を提供するために使用されます。
構文
ローカル変数は、以下の構文でデカールされます。
% LET (Macro Variable Name) = Value;ここで、[値]フィールドは、プログラムの必要に応じて、任意の数値、テキスト、または日付の値を取ることができます。マクロ変数名は、任意の有効なSAS変数です。
例
変数は、SASステートメントで使用されます。 & 変数名の先頭に追加される文字。以下のプログラムは、メーカー「アウディ」とタイプ「スポーツ」のすべての観察結果を取得します。の結果が必要な場合different make、変数の値を変更する必要があります make_nameプログラムの他の部分を変更せずに。持参プログラムの場合、この変数は任意のSASステートメントで何度も参照できます。
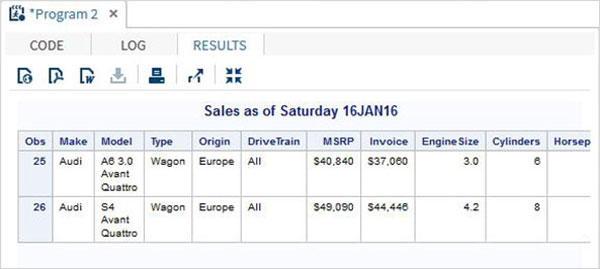
%LET make_name = 'Audi';
%LET type_name = 'Sports';
proc print data = sashelp.cars;
where make = &make_name and type = &type_name ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;上記のコードを実行すると、前のプログラムと同じ出力が得られます。しかし、変更しましょうtype name に 'Wagon'同じプログラムを実行します。以下の結果が得られます。
マクロプログラム
マクロは、名前で参照され、その名前を使用してプログラム内のどこでも使用できるSASステートメントのグループです。%MACROステートメントで始まり、%MENDステートメントで終わります。
構文
ローカル変数は、以下の構文で宣言されています。
# Creating a Macro program.
%MACRO <macro name>(Param1, Param2,….Paramn);
Macro Statements;
%MEND;
# Calling a Macro program.
%MacroName (Value1, Value2,…..Valuen);例
以下のプログラムは、SATstaemnetのグループをという名前のマクロの下でデカールします。 'show_result'; このマクロは、他のSASステートメントによって呼び出されています。
%MACRO show_result(make_ , type_);
proc print data = sashelp.cars;
where make = "&make_" and type = "&type_" ;
TITLE "Sales as of &SYSDAY &SYSDATE";
run;
%MEND;
%show_result(BMW,SUV);上記のコードを実行すると、次の出力が得られます。

一般的に使用されるマクロ
SASには、SASプログラミング言語に組み込まれている多くのMACROステートメントがあります。これらは、明示的に宣言せずに他のSASプログラムによって使用されます。一般的な例は、ある条件が満たされたときにプログラムを終了したり、プログラムログに変数の実行時の値をキャプチャしたりすることです。以下はいくつかの例です。
マクロ%PUT
このマクロステートメントは、テキストまたはマクロ変数情報をSASログに書き込みます。以下の例では、変数「today」の値がプログラムログに書き込まれます。
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;上記のコードを実行すると、次の出力が得られます。

マクロ%RETURN
このマクロを実行すると、特定の条件がtrueと評価されたときに、現在実行中のマクロが正常に終了します。以下の例では、変数の値が"val" 10になると、マクロは終了し、それ以外の場合は続行します。
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;上記のコードを実行すると、次の出力が得られます。

マクロ%END
このマクロ定義には、 %DO %WHILE必要に応じて、%ENDステートメントで終了するループ。以下の例では、testという名前のマクロがユーザー入力を受け取り、この入力値を使用してDOループを実行します。DOループの終わりは%endステートメントを介して達成され、マクロの終わりは%mendステートメントを介して達成されます。
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)上記のコードを実行すると、次の出力が得られます。

IN SASの日付は、数値の特殊なケースです。1960年1月1日以降、毎日特定の数値が割り当てられます。この日付には日付値0が割り当てられ、次の日付には日付値1が割り当てられます。この日付までの前日は、-1、-2などで表されます。このアプローチにより、SASは将来の任意の日付と過去の任意の日付を表すことができます。
SASは、ソースからデータを読み取るときに、読み取ったデータを指定された日付形式に変換します。日付値を格納する変数は、必要な適切な情報で宣言されています。出力日は、出力データ形式を使用して表示されます。
SAS日付情報
以下に示すように、特定の日付情報を使用することにより、ソースデータを適切に読み取ることができます。情報の末尾の数字は、情報を使用して完全に読み取られる日付文字列の最小幅を示します。幅を小さくすると、誤った結果になります。SAS V9には、一般的な日付形式がありますanydtdte15. 任意の日付入力を処理できます。
| 入力日 | 日付幅 | 情報 |
|---|---|---|
| 2014年3月11日 | 10 | mmddyy10。 |
| 2014年3月11日 | 8 | mmddyy8。 |
| 2012年12月11日 | 20 | worddate20。 |
| 2011年3月14日 | 9 | 日付9。 |
| 2011年3月14日 | 11 | 日付11。 |
| 2011年3月14日 | 15 | anydtdte15。 |
例
以下のコードは、さまざまな日付形式の読み取りを示しています。出力値にフォーマットステートメントを適用していないため、すべての出力値は単なる数値であることに注意してください。
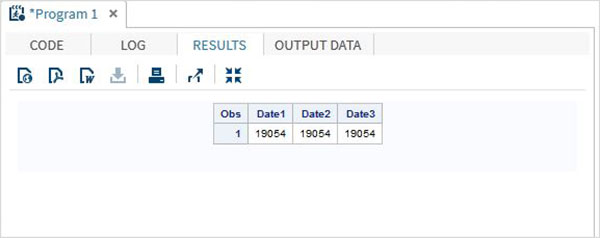
DATA TEMP;
INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ;
DATALINES;
02-mar-2012 3/02/2012 3/02/2012
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
SAS日付出力形式
読み取った後の日付は、表示に応じて別の形式に変換できます。これは、日付タイプのフォーマットステートメントを使用して実現されます。それらはinformatsと同じフォーマットを取ります。
例
以下の例では、日付は1つの形式で読み取られますが、別の形式で表示されます。
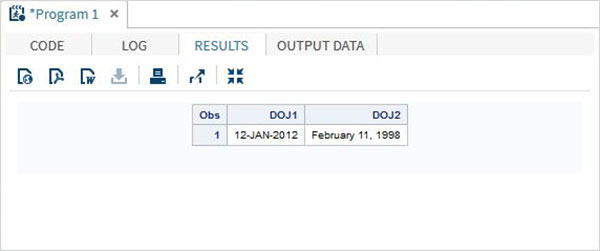
DATA TEMP;
INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.;
format DOJ1 date11. DOJ2 worddate20. ;
DATALINES;
01/12/2012 02/11/1998
;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
SASは、多くのファイル形式を含むさまざまなソースからデータを読み取ることができます。SAS環境で使用されるファイル形式については、以下で説明します。
- ASCII(テキスト)データセット
- 区切られたデータ
- Excelデータ
- 階層データ
ASCII(テキスト)データセットの読み取り
これらは、テキスト形式のデータを含むファイルです。通常、データはスペースで区切られますが、SASが処理できるさまざまなタイプの区切り文字が存在する場合もあります。従業員データを含むASCIIファイルについて考えてみましょう。このファイルは、Infile SASで利用可能なステートメント。
例
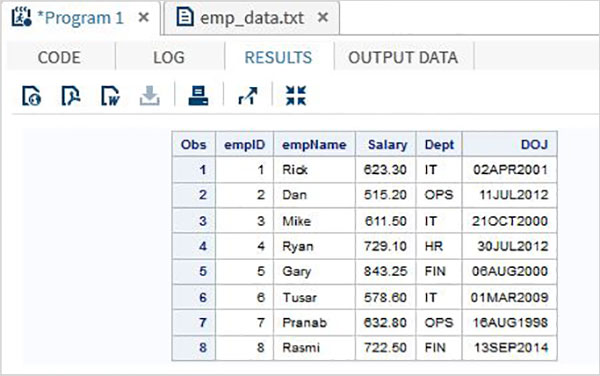
以下の例では、という名前のデータファイルを読み取ります emp_data.txt ローカル環境から。
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt';
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
区切られたデータの読み取り
これらは、列の値がコンマやパイプラインなどの区切り文字で区切られているデータファイルです。この場合、 dlm のオプション infile ステートメント。
例
以下の例では、ローカル環境からemp.csvという名前のデータファイルを読み取ります。
data TEMP;
infile
'/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=",";
input empID empName $ Salary Dept $ DOJ date9. ;
format DOJ date9.;
run;
PROC PRINT DATA = TEMP;
RUN;上記のコードを実行すると、次の出力が得られます。
Excelデータの読み取り
SASは、インポート機能を使用してExcelファイルを直接読み取ることができます。SASデータセットの章にあるように、MSExcelを含むさまざまなファイルタイプを処理できます。ファイルemp.xlsがSAS環境でローカルに使用可能であると想定します。
例
FILENAME REFFILE
"/folders/myfolders/TutorialsPoint/emp.xls"
TERMSTR = CR;
PROC IMPORT DATAFILE = REFFILE
DBMS = XLS
OUT = WORK.IMPORT;
GETNAMES = YES;
RUN;
PROC PRINT DATA = WORK.IMPORT RUN;上記のコードはExcelファイルからデータを読み取り、上記の2つのファイルタイプと同じ出力を提供します。
階層ファイルの読み取り
これらのファイルでは、データは階層形式で存在します。特定の観測に対して、ヘッダーレコードがあり、その下に多くの詳細レコードが記載されています。詳細レコードの数は、観測ごとに異なる可能性があります。以下は、階層ファイルの図です。
以下のファイルには、各部門の各従業員の詳細がリストされています。最初のレコードは部門に言及するヘッダーレコードであり、次のレコードはDTLSで始まるいくつかのレコードが詳細レコードです。
DEPT:IT
DTLS:1:Rick:623
DTLS:3:Mike:611
DTLS:6:Tusar:578
DEPT:OPS
DTLS:7:Pranab:632
DTLS:2:Dan:452
DEPT:HR
DTLS:4:Ryan:487
DTLS:2:Siyona:452例
階層ファイルを読み取るには、以下のコードを使用します。このコードでは、IF句を使用してヘッダーレコードを識別し、doループを使用して詳細レコードを処理します。
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @; if Type = 'DEP' then input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;上記のコードを実行すると、次の出力が得られます。

データセットの読み取りと同様に、SASはさまざまな形式でデータセットを書き込むことができます。SASファイルから通常のテキストファイルにデータを書き込むことができます。これらのファイルは、他のソフトウェアプログラムで読み取ることができます。SASはPROC EXPORT データセットを書き込む。
PROC EXPORT
これは、さまざまな形式のファイルにデータを書き込むためにSASデータセットをエクスポートするために使用されるSAS組み込みプロシージャです。
構文
SASでプロシージャを作成するための基本的な構文は次のとおりです。
PROC EXPORT
DATA = libref.SAS data-set (SAS data-set-options)
OUTFILE = "filename"
DBMS = identifier LABEL(REPLACE);以下は、使用されるパラメーターの説明です-
SAS data-setエクスポートされるデータセット名です。SASは、さまざまなオペレーティングシステムで読み取ることができるファイルを作成することにより、その環境のデータセットを他のアプリケーションと共有できます。組み込みのEXPORT関数を使用して、さまざまな形式のデータセットファイルを出力します。この章では、を使用したSASデータセットの記述について説明します。proc export オプションと一緒に dlm そして dbms。
SAS data-set-options エクスポートする列のサブセットを指定するために使用されます。
filename データが書き込まれるファイルの名前です。
identifier ファイルに書き込まれる区切り文字について言及するために使用されます。
LABEL オプションは、ファイルに書き込まれる変数の名前を示すために使用されます。
例
SASHELPライブラリで利用可能なcarsという名前のSASデータセットを使用します。次のプログラムに示すコードを使用して、スペースで区切られたテキストファイルとしてエクスポートします。
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt'
dbms = dlm;
delimiter = ' ';
run;上記のコードを実行すると、出力がテキストファイルとして表示され、右クリックして次のように内容が表示されます。
CSVファイルの作成
カンマ区切りファイルを作成するには、値「csv」を指定してdlmオプションを使用できます。次のコードは、ファイルcar_data.csvを書き込みます。
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv'
dbms = csv;
run;上記のコードを実行すると、以下の出力が得られます。

タブ区切りファイルの書き込み
タブ区切りファイルを作成するには、 dlm値が「tab」のオプション。次のコードはファイルを書き込みますcar_tab.txt.
proc export data = sashelp.cars
outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt'
dbms = csv;
run;データは、出力配信システムの章で説明するHTMLファイルとして書き込むこともできます。
複数のSASデータセットを連結して、を使用して単一のデータセットを作成できます。 SETステートメント。連結されたデータセット内の観測値の総数は、元のデータセット内の観測値の数の合計です。観測の順序は連続しています。最初のデータセットからのすべての観測値の後に、2番目のデータセットからのすべての観測値が続きます。
理想的には、すべての結合データセットが同じ変数を持っていますが、変数の数が異なる場合、結果としてすべての変数が表示され、小さいデータセットの値が欠落します。
構文
SASのSETステートメントの基本的な構文は次のとおりです。
SET data-set 1 data-set 2 data-set 3.....;以下は、使用されるパラメーターの説明です-
data-set1,data-set2 次々と書かれたデータセット名です。
例
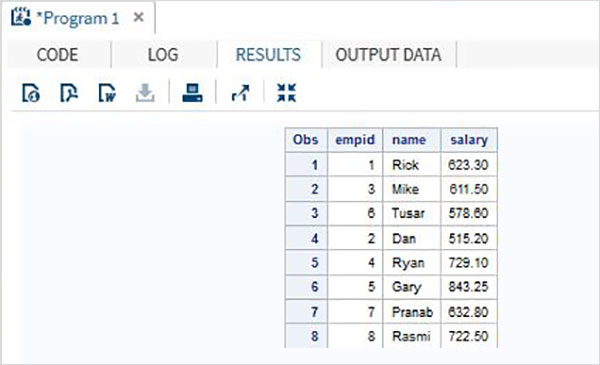
IT部門用と非IT部門用の2つの異なるデータセットで利用できる組織の従業員データについて考えてみます。すべての従業員の完全な詳細を取得するために、以下に示すSETステートメントを使用して両方のデータセットを連結します。
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。
シナリオ
連結のデータセットに多くのバリエーションがある場合、変数の結果は異なる可能性がありますが、連結されたデータセットの観測値の総数は、常に各データセットの観測値の合計になります。このバリエーションに関する多くのシナリオを以下で検討します。
変数の数が異なる
元のデータセットの1つに別の変数よりも多くの変数がある場合でも、データセットは結合されますが、小さいデータセットではそれらの変数が欠落しているように見えます。
例
以下の例では、最初のデータセットにDOJという名前の追加の変数があります。その結果、2番目のデータセットのDOJの値が欠落しているように見えます。
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。

別の変数名
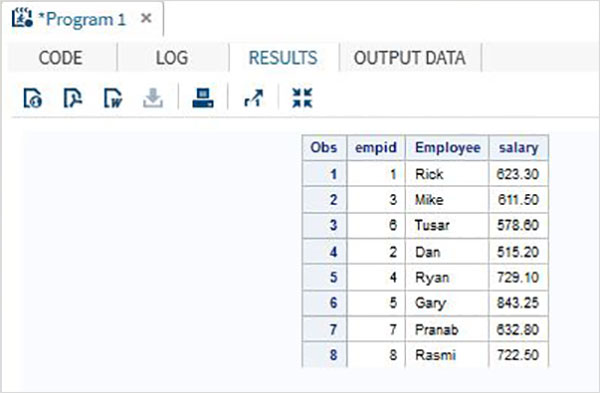
このシナリオでは、データセットには同じ数の変数がありますが、変数名はそれらの間で異なります。その場合、通常の連結では結果セット内のすべての変数が生成され、異なる2つの変数に対して欠落した結果が得られます。元のデータセットの変数名を変更することはできませんが、作成する連結データセットにRENAME関数を適用できます。これにより、通常の連結と同じ結果が得られますが、もちろん、元のデータセットに存在する2つの異なる変数名の代わりに1つの新しい変数名が使用されます。
例
以下の例のデータ・セットでは、ITDEPTの変数名は ename 一方、データセット NON_ITDEPT 変数名があります empname.ただし、これらの変数は両方とも同じタイプ(文字)を表します。適用しますRENAME 以下に示すように、SETステートメントで機能します。
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。
さまざまな可変長
2つのデータセットの変数の長さが連結されたデータセットと異なる場合、長さが短い変数の一部のデータが切り捨てられる値があります。最初のデータセットの長さが短い場合に発生します。これを解決するために、以下に示すように、両方のデータセットに高い長さを適用します。
例
以下の例では、変数 enameは、最初のデータセットでは長さが5、2番目のデータセットでは長さが7です。連結するときは、連結されたデータセットにLENGTHステートメントを適用して、enameの長さを7に設定します。
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;上記のコードを実行すると、次の出力が得られます。
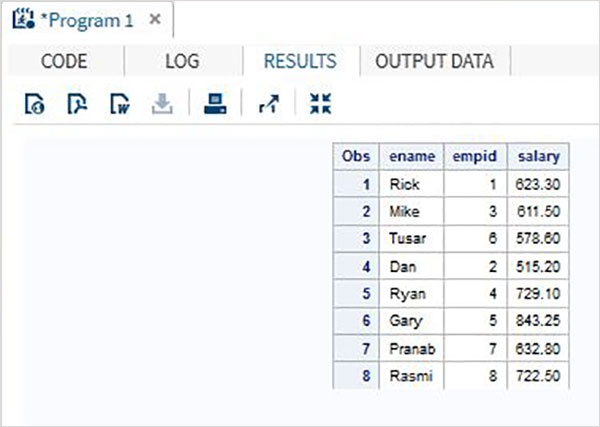
特定の共通変数に基づいて複数のSASデータセットをマージして、単一のデータセットを作成できます。これは、MERGE ステートメントと BYステートメント。マージされたデータセットの観測値の総数は、多くの場合、元のデータセットの観測値の合計よりも少なくなります。これは、両方のデータセットを形成する変数が、共通の変数の値に一致する場合に基づいて1つのレコードとしてマージされるためです。
以下に示すデータセットをマージするための2つの前提条件があります-
- 入力データセットには、マージする共通変数が少なくとも1つ必要です。
- 入力データセットは、マージに使用される共通変数で並べ替える必要があります。
構文
SASのMERGEおよびBYステートメントの基本的な構文は次のとおりです。
MERGE Data-Set 1 Data-Set 2
BY Common Variable以下は、使用されるパラメーターの説明です-
Data-set1,Data-set2 次々に書き込まれるデータセット名です。
Common Variable は、データセットがマージされる一致する値に基づく変数です。
データのマージ
例を使用して、データのマージについて理解しましょう。
例
名前と給与を含む従業員IDを含む2つのSASデータセットと、従業員IDと部門を含む従業員IDを含む2つのSASデータセットについて考えてみます。この場合、各従業員の完全な情報を取得するために、これら2つのデータセットをマージできます。最終的なデータセットには、従業員ごとに1つの観測値が含まれますが、給与変数と部門変数の両方が含まれます。
# Data set 1
ID NAME SALARY
1 Rick 623.3
2 Dan 515.2
3 Mike 611.5
4 Ryan 729.1
5 Gary 843.25
6 Tusar 578.6
7 Pranab 632.8
8 Rasmi 722.5
# Data set 2
ID DEPT
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
# Merged data set
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN上記の結果は、BYステートメントで共通変数(ID)が使用されている次のコードを使用することで実現されます。両方のデータセットの観測値はすでにID列に並べ替えられていることに注意してください。
DATA SALARY;
INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ;
DATALINES;
1 IT
2 OPS
3 IT
4 HR
5 FIN
6 IT
7 OPS
8 FIN
;
RUN;
DATA All_details;
MERGE SALARY DEPT;
BY (empid);
RUN;
PROC PRINT DATA = All_details;
RUN;一致する列に値がありません
共通変数の一部の値がデータセット間で一致しない場合があります。このような場合でも、データセットはマージされますが、結果に欠落した値が表示されます。
例
ID NAME SALARY DEPT
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 . . IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 .
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN一致のみをマージする
結果の欠落値を回避するために、共通変数の値が一致する観測値のみを保持することを検討できます。これは、INステートメント。SASプログラムのマージステートメントを変更する必要があります。
例
以下の例では、 IN= valueは、両方のデータセットからの値が存在する観測値のみを保持します SALARY そして DEPT 一致。
DATA All_details;
MERGE SALARY(IN = a) DEPT(IN = b);
BY (empid);
IF a = 1 and b = 1;
RUN;
PROC PRINT DATA = All_details;
RUN;上記の変更された部分を使用して上記のSASプログラムを実行すると、次の出力が得られます。
1 Rick 623.3 IT
2 Dan 515.2 OPS
4 Ryan 729.1 HR
5 Gary 843.25 FIN
7 Pranab 632.8 OPS
8 Rasmi 722.5 FINSASデータセットのサブセット化とは、より少ない数の変数またはより少ない数の観測値、あるいはその両方を選択することにより、データセットの一部を抽出することを意味します。変数のサブセット化は、KEEP そして DROP ステートメント、観測のサブ設定はを使用して行われます DELETE ステートメント。
また、サブセット化操作の結果のデータは、さらに分析するために使用できる新しいデータセットに保持されます。サブ設定は主に、分析に関係のない変数や観測値を使用せずに、データセットの一部を分析する目的で使用されます。
変数のサブセット化
この方法では、データセット全体からわずかな変数のみを抽出します。
構文
SASで変数をサブセット化するための基本的な構文は次のとおりです。
KEEP var1 var2 ... ;
DROP var1 var2 ... ;以下は、使用されるパラメーターの説明です-
var1 and var2 保持または削除する必要があるデータセットの変数名です。
例
組織の従業員の詳細を含む以下のSASデータセットについて考えてみます。データセットからNameとDepartmentの値のみを取得することに関心がある場合は、以下のコードを使用できます。
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
KEEP ename DEPT;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;上記のコードを実行すると、次の出力が得られます。
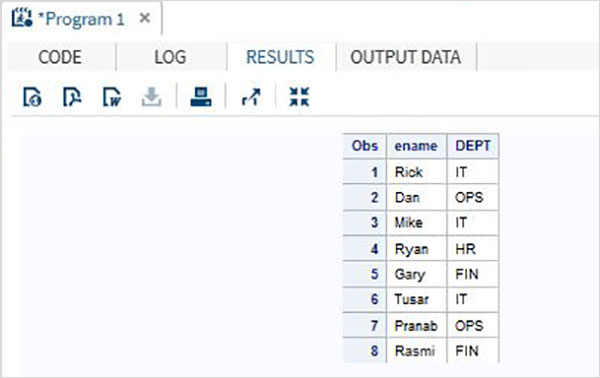
不要な変数を削除しても同じ結果が得られます。以下のコードはこれを示しています。
DATA Employee;
INPUT empid ename $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
DROP empid salary;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;観測値のサブセット化
この方法では、データセット全体からわずかな観測値のみを抽出します。
構文
新しいデータセット用に選択された観測値を追跡するPROCFREQを使用します。
観測値をサブセット化するための構文は次のとおりです。
IF Var Condition THEN DELETE ;以下は、使用されるパラメーターの説明です-
Var は、指定された条件を使用して観測値が削除される値に基づく変数の名前です。
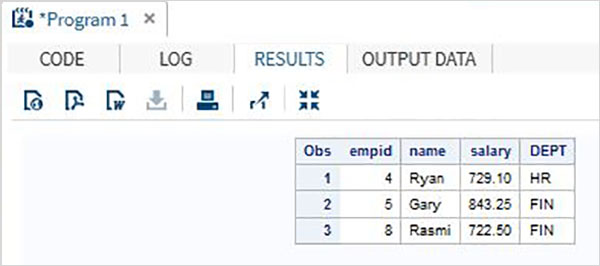
例
組織の従業員の詳細を含む以下のSASデータセットについて考えてみます。給与が700を超える従業員のデータのみを取得することに関心がある場合は、以下のコードを使用します。
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
DATA OnlyDept;
SET Employee;
IF salary < 700 THEN DELETE;
RUN;
PROC PRINT DATA = OnlyDept;
RUN;上記のコードを実行すると、次の出力が得られます。
分析されたデータを、データセットにすでに存在する形式とは異なる形式で表示したい場合があります。たとえば、価格情報を持つ変数にドル記号と小数点以下2桁を追加します。または、テキスト変数をすべて大文字で表示したい場合があります。使用できますFORMAT 組み込みのSASフォーマットを適用し、 PROC FORMATユーザー定義のフォーマットを適用することです。また、単一の形式を複数の変数に適用できます。
構文
組み込みSASフォーマットを適用するための基本的な構文は次のとおりです。
format variable name format name以下は、使用されるパラメーターの説明です-
variable name データセットで使用される変数名です。
format name 変数に適用されるデータ形式です。
例
組織の従業員の詳細を含む以下のSASデータセットについて考えてみましょう。すべての名前を大文字で表示したいと思います。ザ・formatstatement これを達成するために使用されます。
DATA Employee;
INPUT empid name $ salary DEPT $ ;
format name $upcase9. ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
RUN;
PROC PRINT DATA = Employee;
RUN;上記のコードを実行すると、次の出力が得られます。

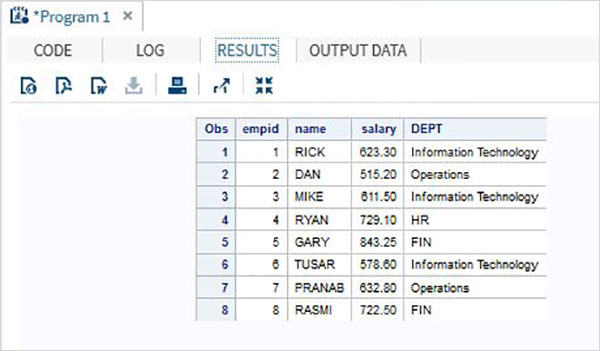
PROCFORMATの使用
使用することもできます PROC FORMATデータをフォーマットします。以下の例では、部門の名前を示す変数DEPTに新しい値を割り当てます。
DATA Employee;
INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; proc format; value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;上記のコードを実行すると、次の出力が得られます。
SASは、SASプログラム内でSQLクエリを使用することにより、一般的なリレーショナルデータベースのほとんどに広範なサポートを提供します。ほとんどANSI SQL構文がサポートされています。手順PROC SQLSQLステートメントを処理するために使用されます。このプロシージャは、SQLクエリの結果を返すだけでなく、SASテーブルと変数を作成することもできます。これらすべてのシナリオの例を以下に説明します。
構文
SASでPROCSQLを使用するための基本的な構文は次のとおりです。
PROC SQL;
SELECT Columns
FROM TABLE
WHERE Columns
GROUP BY Columns
;
QUIT;以下は、使用されるパラメーターの説明です-
SQLクエリは、PROCSQLステートメントの後にQUITステートメントが続く下に記述されます。
以下に、このSASプロシージャをどのように使用できるかを示します。 CRUD SQLでの(作成、読み取り、更新、削除)操作。
SQL作成操作
SQLを使用して、生データから新しいデータセットを作成できます。以下の例では、最初に生データを含むTEMPという名前のデータセットを宣言します。次に、このデータセットの変数からテーブルを作成するSQLクエリを記述します。
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES AS
SELECT * FROM TEMP;
QUIT;
PROC PRINT data = EMPLOYEES;
RUN;上記のコードを実行すると、次の結果が得られます。
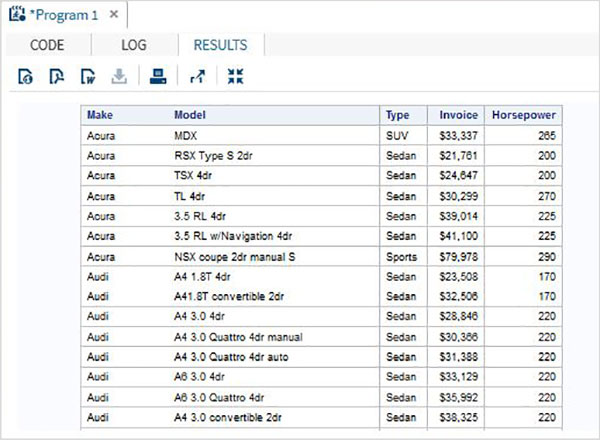
SQL読み取り操作
SQLの読み取り操作には、テーブルからデータを読み取るためのSQLSELECTクエリの記述が含まれます。以下のプログラムでは、ライブラリSASHELPで使用可能なCARSという名前のSASデータセットを照会します。クエリは、データセットのいくつかの列をフェッチします。
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
;
QUIT;上記のコードを実行すると、次の結果が得られます。
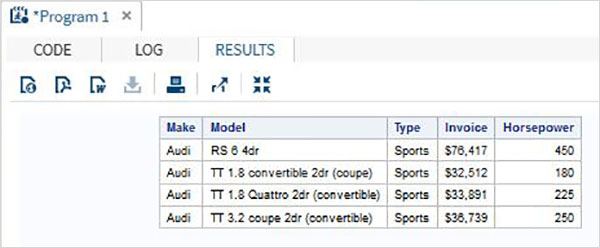
WHERE句を使用したSQLSELECT
以下のプログラムは、CARSデータセットをクエリします。 where句。結果として、makeが「Audi」でタイプが「Sports」の観測値のみが取得されます。
PROC SQL;
SELECT make,model,type,invoice,horsepower
FROM
SASHELP.CARS
Where make = 'Audi'
and Type = 'Sports'
;
QUIT;上記のコードを実行すると、次の結果が得られます。
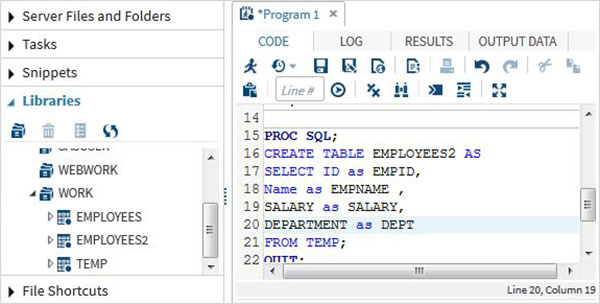
SQLUPDATE操作
SQLUpdateステートメントを使用してSASテーブルを更新できます。以下では、最初にEMPLOYEES2という名前の新しいテーブルを作成し、次にSQLUPDATEステートメントを使用してそれを更新します。
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;上記のコードを実行すると、次の結果が得られます。

SQLDELETE操作
SQLでの削除操作には、SQLDELETEステートメントを使用してテーブルから特定の値を削除することが含まれます。上記の例のデータを引き続き使用し、従業員の給与が900を超える行をテーブルから削除します。
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;上記のコードを実行すると、次の結果が得られます。

SASプログラムからの出力は、次のようなよりユーザーフレンドリーな形式に変換できます。 .html または PDF. これは、 ODSSASで利用可能なステートメント。ODSはoutput delivery system.これは主に、SASプログラムの出力データを、見たり理解したりするのに適した優れたレポートにフォーマットするために使用されます。これは、他のプラットフォームやソフトウェアと出力を共有するのにも役立ちます。また、複数のPROCステートメントの結果を1つのファイルにまとめることもできます。
構文
SASでODSステートメントを使用するための基本的な構文は次のとおりです。
ODS outputtype
PATH path name
FILE = Filename and Path
STYLE = StyleName
;
PROC some proc
;
ODS outputtype CLOSE;以下は、使用されるパラメーターの説明です-
PATHHTML出力の場合に使用されるステートメントを表します。他のタイプの出力では、ファイル名にパスを含めます。
Style SAS環境で使用可能な組み込みスタイルの1つを表します。
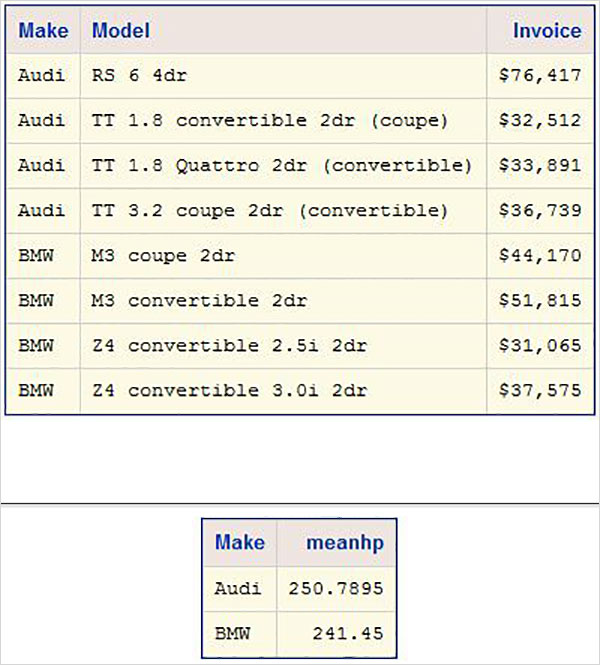
HTML出力の作成
ODS HTMLステートメントを使用してHTML出力を作成します。次の例では、目的のパスにhtmlファイルを作成します。スタイルライブラリで利用可能なスタイルを適用します。上記のパスに出力ファイルが表示され、ダウンロードしてSAS環境とは異なる環境に保存できます。2つのprocSQLステートメントがあり、両方の出力が1つのファイルにキャプチャされていることに注意してください。
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;上記のコードを実行すると、次の結果が得られます。
PDF出力の作成
以下の例では、目的のパスにPDFファイルを作成します。スタイルライブラリで利用可能なスタイルを適用します。上記のパスに出力ファイルが表示され、ダウンロードしてSAS環境とは異なる環境に保存できます。2つのprocSQLステートメントがあり、両方の出力が1つのファイルにキャプチャされていることに注意してください。
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;上記のコードを実行すると、次の結果が得られます。
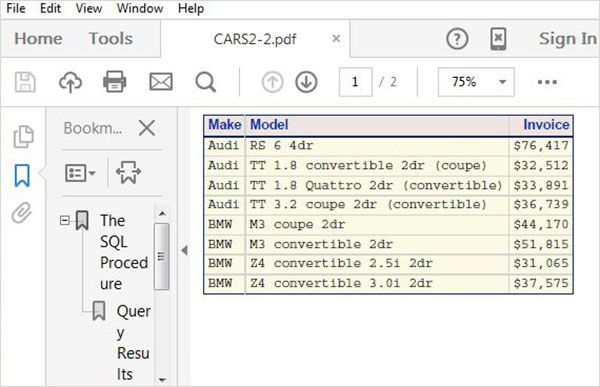
TRF(Word)出力の作成
以下の例では、目的のパスにRTFファイルを作成します。スタイルライブラリで利用可能なスタイルを適用します。上記のパスに出力ファイルが表示され、ダウンロードしてSAS環境とは異なる環境に保存できます。2つのprocSQLステートメントがあり、両方の出力が1つのファイルにキャプチャされていることに注意してください。
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
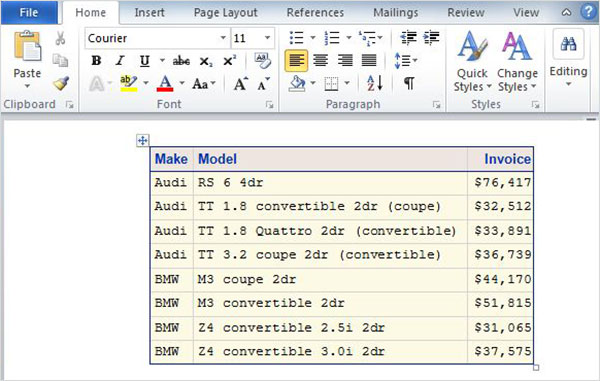
ODS rtf CLOSE;上記のコードを実行すると、次の結果が得られます。
シミュレーションは、統計量を推定するために、多くの異なるランダムサンプルで繰り返し計算を使用する計算手法です。SASを使用すると、実際のシステムで統計的特性を指定した複雑なデータをシミュレートできます。ソフトウェアを使用してシステムのモデルを構築し、実際のシステムの動作をよりよく理解するために使用できるデータを数値で生成します。コンピュータシミュレーションモデルを設計する技術の一部は、モデルによって生成されたデータを使用して効果的な決定を行うことができるように、実際のシステムのどの側面をモデルに含める必要があるかを決定することです。この複雑さのために、SASにはシミュレーション専用のソフトウェアコンポーネントがあります。
SASシミュレーションの作成に使用されるSASソフトウェアコンポーネントは、 SAS Simulation Studio。そのグラフィカルユーザーインターフェイスは、離散イベントシミュレーションモデルの結果を構築、実行、および分析するためのツールのフルセットを提供します。
SASシミュレーションを適用できるさまざまなタイプの統計分布を以下に示します。
- 連続分布からのデータのシミュレーション
- 離散分布からのデータのシミュレーション
- 混合分布からのデータのシミュレーション
- 複雑な分布からのデータのシミュレーション
- 多変量分布からのデータのシミュレーション
- サンプリング分布の近似値
- 回帰推定の評価
ヒストグラムは、さまざまな高さのバーを使用したデータのグラフィック表示です。データセット内のさまざまな数値を多くの範囲にグループ化します。また、連続変数の分布の確率の推定を表します。SASではPROC UNIVARIATE 以下のオプションでヒストグラムを作成するために使用されます。
構文
SASでヒストグラムを作成するための基本的な構文は次のとおりです。
PROC UNIVARAITE DATA = DATASET;
HISTOGRAM variables;
RUN;DATASET 使用されるデータセットの名前です。
variables ヒストグラムをプロットするために使用される値です。
単純なヒストグラム
変数の名前と値をグループ化するために考慮される範囲を指定することにより、単純なヒストグラムが作成されます。
例
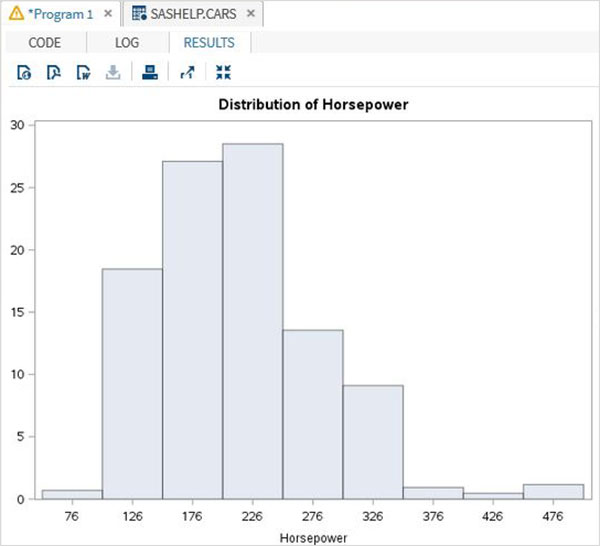
以下の例では、可変馬力の最小値と最大値を考慮し、50の範囲を取ります。したがって、値は50のステップでグループを形成します。
proc univariate data = sashelp.cars;
histogram horsepower
/ midpoints = 176 to 350 by 50;
run;上記のコードを実行すると、次の出力が得られます。
カーブフィッティングのヒストグラム
追加のオプションを使用して、いくつかの分布曲線をヒストグラムに適合させることができます。
例
以下の例では、ESTとして言及されている平均値と標準偏差値を使用して分布曲線を近似します。このオプションは、パラメーターを使用して推定します。
proc univariate data = sashelp.cars noprint;
histogram horsepower
/
normal (
mu = est
sigma = est
color = blue
w = 2.5
)
barlabel = percent
midpoints = 70 to 550 by 50;
run;上記のコードを実行すると、次の出力が得られます。

棒グラフは、変数の値に比例する棒の長さを持つ長方形の棒でデータを表します。SASはこの手順を使用しますPROC SGPLOT棒グラフを作成します。棒グラフには、単純な棒と積み上げ棒の両方を描画できます。棒グラフでは、各棒に異なる色を付けることができます。
構文
SASで棒グラフを作成するための基本的な構文は次のとおりです。
PROC SGPLOT DATA = DATASET;
VBAR variables;
RUN;DATASET −は使用されるデータセットの名前です。
variables −は、ヒストグラムをプロットするために使用される値です。
シンプルな棒グラフ
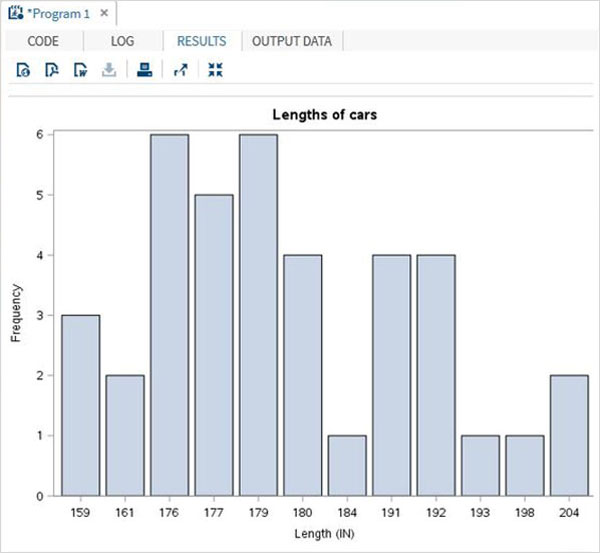
単純な棒グラフは、データセットの変数が棒として表される棒グラフです。
例
以下のスクリプトは、車の長さを棒として表す棒グラフを作成します。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;上記のコードを実行すると、次の出力が得られます。
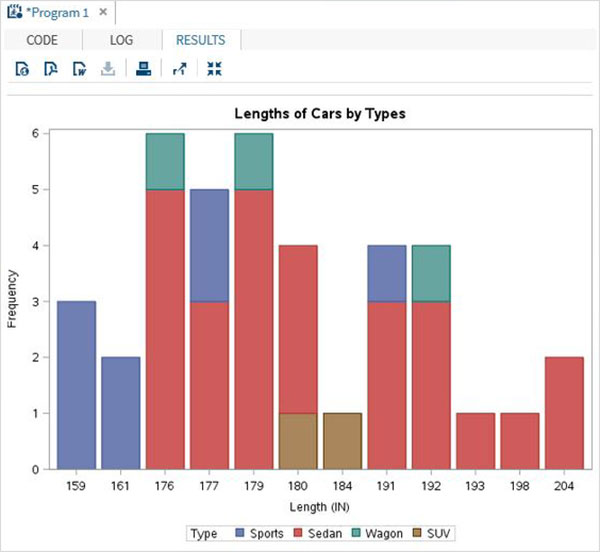
積み上げ棒グラフ
積み上げ棒グラフは、データセットの変数が別の変数に関して計算される棒グラフです。
例
以下のスクリプトは、車のタイプごとに車の長さが計算される積み上げ棒グラフを作成します。groupオプションを使用して、2番目の変数を指定します。
proc SGPLOT data = work.cars1;
vbar length /group = type ;
title 'Lengths of Cars by Types';
run;
quit;上記のコードを実行すると、次の出力が得られます。
クラスター化された棒グラフ
クラスター化された棒グラフは、変数の値がカルチャ全体にどのように分散しているかを示すために作成されます。
例
以下のスクリプトは、車の長さが車種の周りにクラスター化されたクラスター化された棒グラフを作成します。したがって、長さ191の2つの隣接する棒が表示されます。1つは車種「セダン」用で、もう1つは車種「ワゴン」用です。 。
proc SGPLOT data = work.cars1;
vbar length /group = type GROUPDISPLAY = CLUSTER;
title 'Cluster of Cars by Types';
run;
quit;上記のコードを実行すると、次の出力が得られます。

円グラフは、さまざまな色の円のスライスとしての値の表現です。スライスにはラベルが付けられ、各スライスに対応する番号もチャートに表示されます。
SASでは、円グラフは次を使用して作成されます PROC TEMPLATE これは、パーセンテージ、ラベル、色、タイトルなどを制御するためのパラメーターを取ります。
構文
SASで円グラフを作成するための基本的な構文は次のとおりです。
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;variable は、円グラフを作成するための値です。
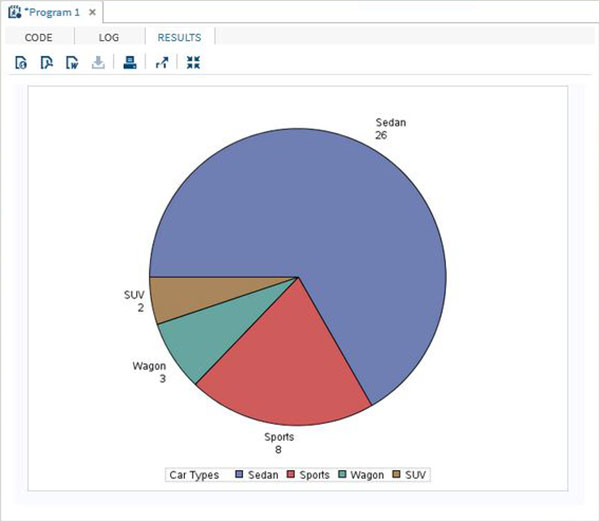
シンプルな円グラフ
この円グラフでは、データセットから単一の変数を取得します。円グラフは、変数の合計値に対する変数のカウントの割合を表すスライスの値を使用して作成されます。
例
以下の例では、各スライスは、車の総数に対する車のタイプの割合を表しています。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;上記のコードを実行すると、次の出力が得られます。
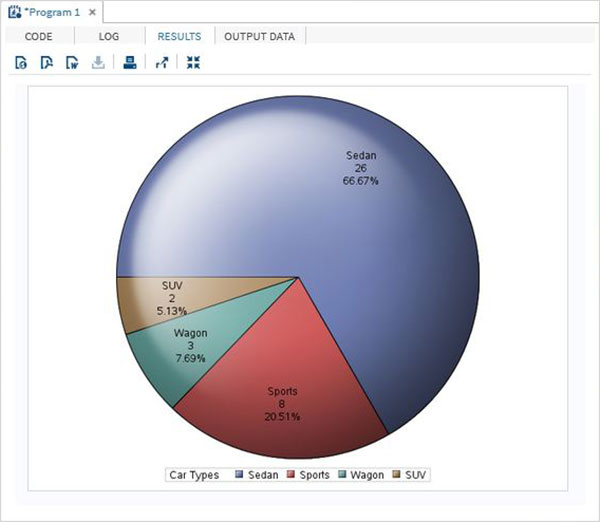
データラベル付きの円グラフ
この円グラフでは、各スライスの小数値とパーセンテージ値の両方を表しています。また、ラベルの場所をチャート内に変更します。チャートの外観のスタイルは、DATASKINオプションを使用して変更されます。SAS環境で利用可能な組み込みスタイルの1つを使用します。
例
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;上記のコードを実行すると、次の出力が得られます。
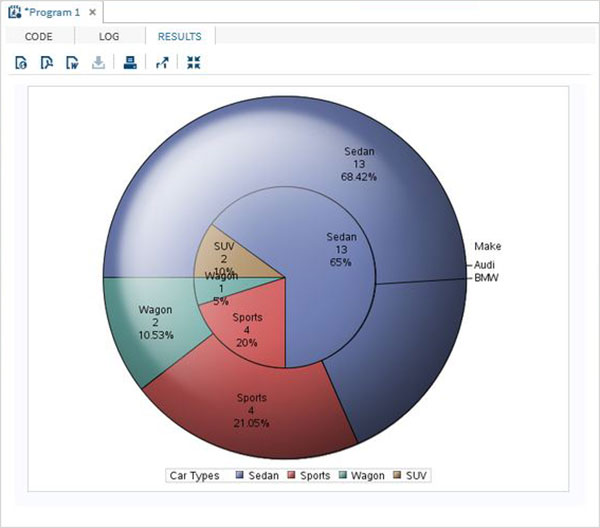
グループ化された円グラフ
この円グラフでは、グラフに表示されている変数の値が、同じデータセットの別の変数に関してグループ化されています。各グループは1つの円になり、グラフには使用可能なグループの数と同じ数の同心円があります。
例
以下の例では、「Make」という名前の変数に関してチャートをグループ化します。利用可能な2つの値(「Audi」と「BMW」)があるため、それぞれが独自の車種のスライスを表す2つの同心円を取得します。
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;上記のコードを実行すると、次の出力が得られます。
散布図は、デカルト平面にプロットされた2つの変数の値を使用するグラフの一種です。これは通常、2つの変数間の関係を見つけるために使用されます。SASではPROC SGSCATTER 散布図を作成します。
最初の例ではCARS1という名前のデータセットを作成し、後続のすべてのデータセットに同じデータセットを使用することに注意してください。このデータセットは、SASセッションが終了するまで作業ライブラリに残ります。
構文
SASで散布図を作成するための基本的な構文は次のとおりです。
PROC sgscatter DATA = DATASET;
PLOT VARIABLE_1 * VARIABLE_2
/ datalabel = VARIABLE group = VARIABLE;
RUN;以下は、使用されるパラメーターの説明です-
DATASET データセットの名前です。
VARIABLE データセットから使用される変数です。
単純な散布図
単純な散布図では、データセットから2つの変数を選択し、3番目の変数に関してそれらをグループ化します。データにラベルを付けることもできます。結果は、2つの変数がどのように分散しているかを示しています。Cartesian plane.
例
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
TITLE 'Scatterplot - Two Variables';
PROC sgscatter DATA = CARS1;
PLOT horsepower*Invoice
/ datalabel = make group = type grid;
title 'Horsepower vs. Invoice for car makers by types';
RUN;上記のコードを実行すると、次の出力が得られます。
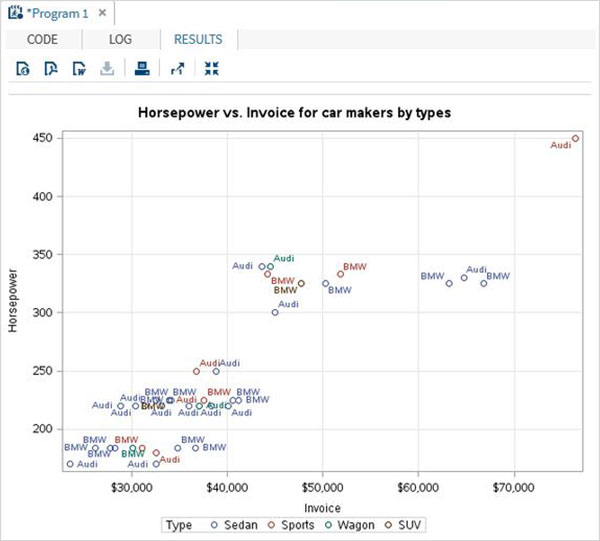
予測による散布図
推定パラメーターを使用して、値の周りに楕円を描くことにより、間の相関の強さを予測できます。以下に示すように、手順で追加のオプションを使用して楕円を描画します。
例
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;上記のコードを実行すると、次の出力が得られます。

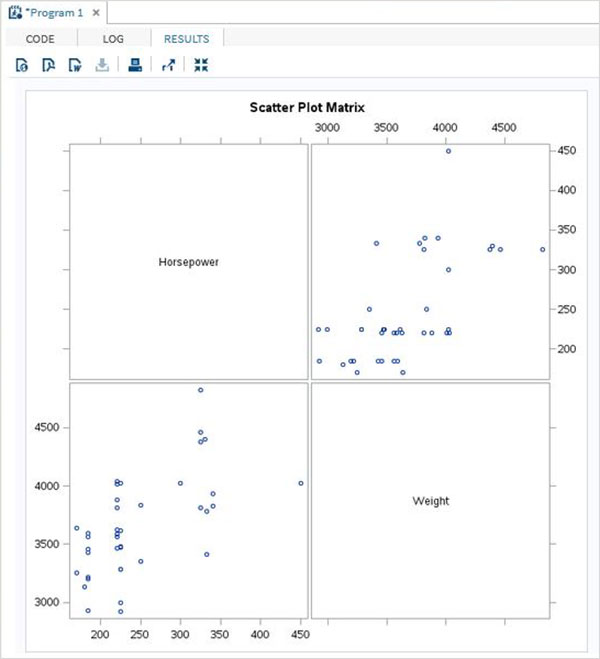
散布行列
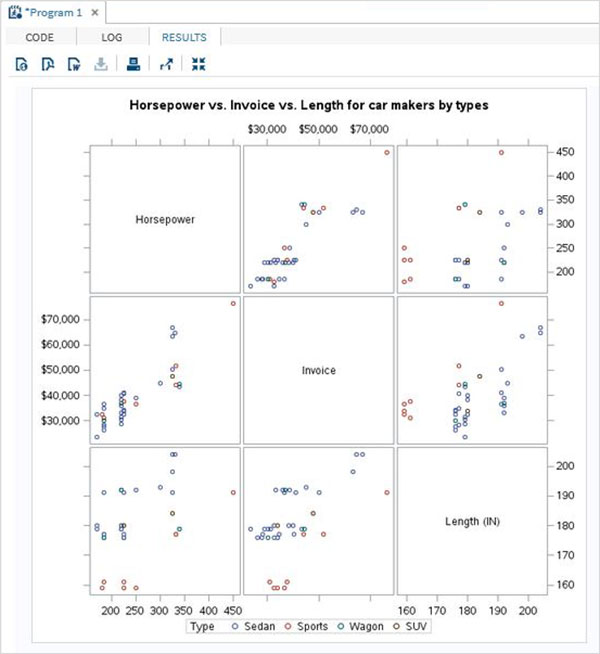
また、3つ以上の変数をペアにグループ化することにより、それらを含む散布図を作成することもできます。以下の例では、3つの変数を検討し、散布図行列を描画します。結果の行列の3つのペアを取得します。
例
PROC sgscatter DATA = CARS1;
matrix horsepower invoice length
/ group = type;
title 'Horsepower vs. Invoice vs. Length for car makers by types';
RUN;上記のコードを実行すると、次の出力が得られます。
箱ひげ図は、四分位数による数値データのグループのグラフィック表現です。箱ひげ図には、ボックス(ひげ)から垂直に伸びる線があり、上下の四分位数の外側の変動を示している場合もあります。ボックスの下部と上部は常に第1四分位数と第3四分位数であり、ボックス内のバンドは常に第2四分位数(中央値)です。SASでは、単純な箱ひげ図がPROC SGPLOT パネル付き箱ひげ図は、 PROC SGPANEL。
最初の例ではCARS1という名前のデータセットを作成し、後続のすべてのデータセットに同じデータセットを使用することに注意してください。このデータセットは、SASセッションが終了するまで作業ライブラリに残ります。
構文
SASで箱ひげ図を作成するための基本的な構文は次のとおりです。
PROC SGPLOT DATA = DATASET;
VBOX VARIABLE / category = VARIABLE;
RUN;
PROC SGPANEL DATA = DATASET;;
PANELBY VARIABLE;
VBOX VARIABLE> / category = VARIABLE;
RUN;DATASET −は使用されるデータセットの名前です。
VARIABLE −は箱ひげ図をプロットするために使用される値です。
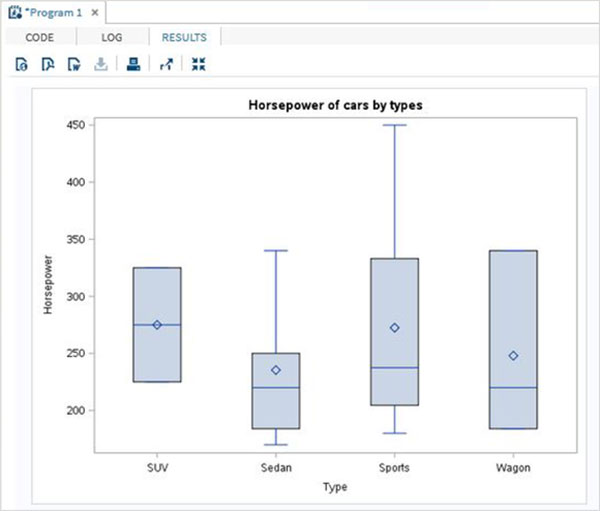
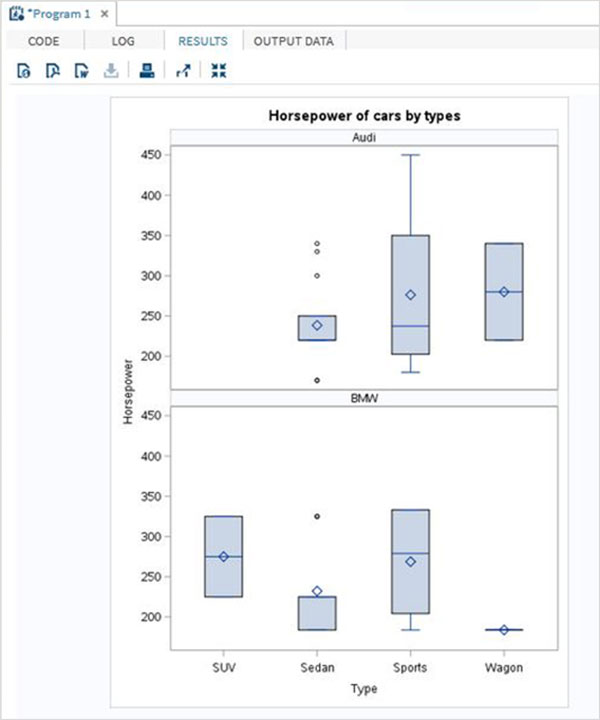
単純な箱ひげ図
単純な箱ひげ図では、データセットから1つの変数を選択し、別の変数を選択してカテゴリを形成します。最初の変数の値は、2番目の変数の個別の値の数と同じ数のグループに分類されます。
例
以下の例では、最初の変数として変数horsepowerを選択し、カテゴリ変数としてtypeを選択します。したがって、各タイプの車の馬力の値の分布の箱ひげ図を取得します。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
PROC SGPLOT DATA = CARS1;
VBOX horsepower
/ category = type;
title 'Horsepower of cars by types';
RUN;上記のコードを実行すると、次の出力が得られます。
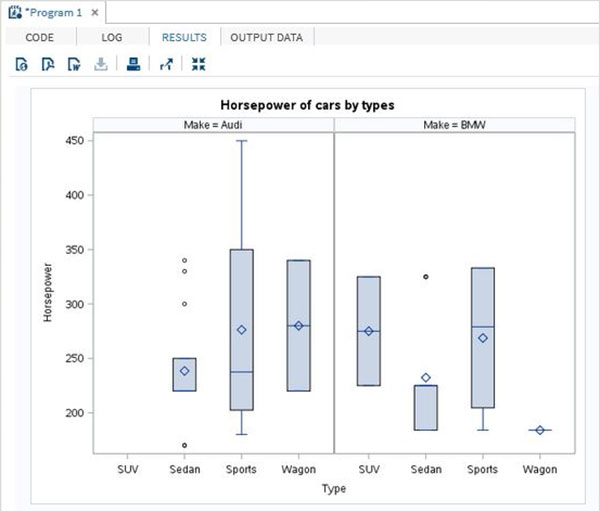
垂直パネルの箱ひげ図
変数の箱ひげ図を多くの垂直パネル(列)に分割できます。各パネルには、すべてのカテゴリ変数の箱ひげ図があります。ただし、箱ひげ図は、グラフを複数のパネルに分割する別の3番目の変数を使用してさらにグループ化されます。
例
以下の例では、変数「make」を使用してグラフをパネリングしています。'make'には2つの異なる値があるため、2つの垂直パネルを取得します。
PROC SGPANEL DATA = CARS1;
PANELBY MAKE;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;上記のコードを実行すると、次の出力が得られます。
水平パネルの箱ひげ図
変数の箱ひげ図を多くの水平パネル(行)に分割できます。各パネルには、すべてのカテゴリ変数の箱ひげ図があります。ただし、箱ひげ図は、グラフを複数のパネルに分割する別の3番目の変数を使用してさらにグループ化されます。以下の例では、変数「make」を使用してグラフをパネリングしています。'make'には2つの異なる値があるため、2つの水平パネルを取得します。
PROC SGPANEL DATA = CARS1;
PANELBY MAKE / columns = 1 novarname;
VBOX horsepower / category = type;
title 'Horsepower of cars by types';
RUN;上記のコードを実行すると、次の出力が得られます。
算術平均は、数値変数の値を合計し、その合計を変数の数で割って得られる値です。平均とも呼ばれます。SASでは、算術平均は次を使用して計算されますPROC MEANS。このSASプロシージャを使用して、データセットのすべての変数または一部の変数の平均を見つけることができます。グループを形成し、そのグループに固有の値の変数の平均を見つけることもできます。
構文
SASで算術平均を計算するための基本的な構文は次のとおりです。
PROC MEANS DATA = DATASET;
CLASS Variables ;
VAR Variables;以下は、使用されるパラメーターの説明です-
DATASET −は使用されるデータセットの名前です。
Variables −はデータセットからの変数の名前です。
データセットの平均
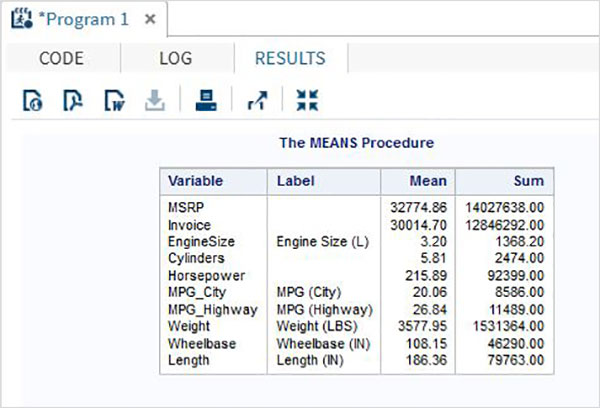
データセット内の各数値変数の平均は、PROCを使用して、変数なしでデータセット名のみを指定して計算されます。
例
以下の例では、CARSという名前のSASデータセット内のすべての数値変数の平均を見つけます。小数点以下の最大桁数を2に指定し、それらの変数の合計も求めます。
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2;
RUN;上記のコードを実行すると、次の出力が得られます。
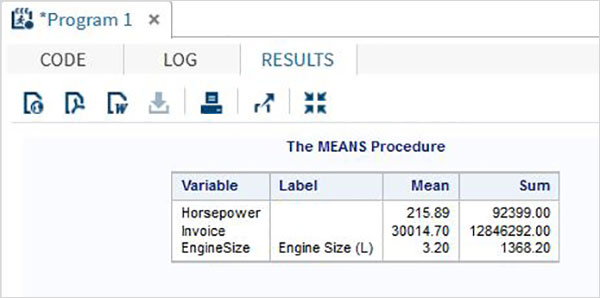
選択変数の平均
に名前を指定することで、いくつかの変数の平均を取得できます。 var オプション。
例
以下では、3つの変数の平均を計算します。
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ;
var horsepower invoice EngineSize;
RUN;上記のコードを実行すると、次の出力が得られます。
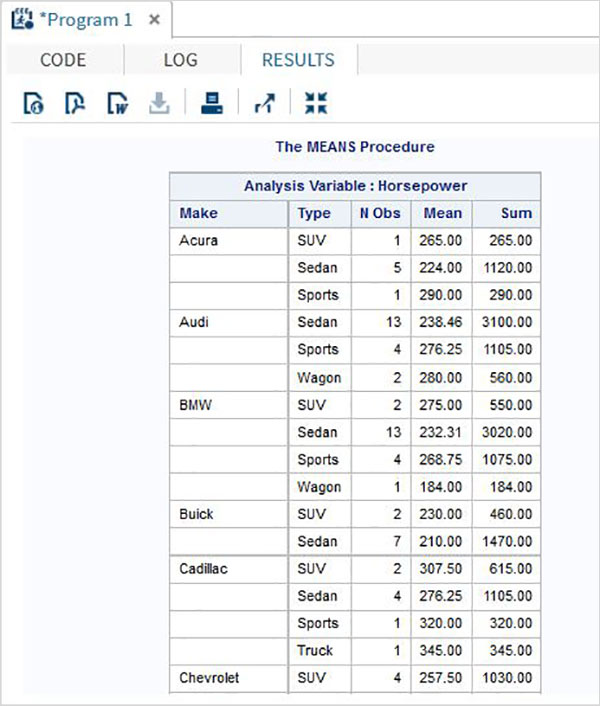
クラス別平均
他のいくつかの変数を使用して数値変数をグループに編成することにより、数値変数の平均を見つけることができます。
例
以下の例では、車の各メーカーの各タイプの可変馬力の平均を求めています。
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2;
class make type;
var horsepower;
RUN;上記のコードを実行すると、次の出力が得られます。
標準偏差(SD)は、データセット内のデータの変動度の尺度です。数学的には、各値がデータセットの平均値に対してどれだけ離れているか、または近いかを測定します。0に近い標準偏差値は、データポイントがデータセットの平均に非常に近い傾向があることを示し、高い標準偏差は、データポイントがより広い範囲の値に分散していることを示します。
SASでは、SD値はPROCMEANおよびPROCSURVEYMEANSを使用して測定されます。
PROCMEANSの使用
を使用してSDを測定するには proc meansPROCステップでSTDオプションを選択します。データセットに存在する各数値変数のSD値を引き出します。
構文
SASで標準偏差を計算するための基本的な構文は次のとおりです。
PROC means DATA = dataset STD;以下は、使用されるパラメーターの説明です-
Dataset −はデータセットの名前です。
例
以下の例では、SASHELPライブラリのCARSデータセットからデータセットCARS1を作成します。PROC平均ステップでSTDオプションを選択します。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;上記のコードを実行すると、次の出力が得られます-
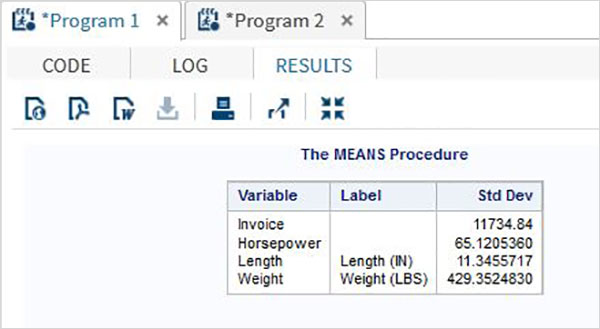
PROCSURVEYMEANSの使用
この手順は、カテゴリ変数のSDの測定などのいくつかの高度な機能とともに、SDの測定にも使用され、分散の推定値を提供します。
構文
PROCSURVEYMEANSを使用するための構文は次のとおりです。
PROC SURVEYMEANS options statistic-keywords ;
BY variables ;
CLASS variables ;
VAR variables ;以下は、使用されるパラメーターの説明です-
BY −観測値のグループを作成するために使用される変数を示します。
CLASS −は、カテゴリ変数に使用される変数を示します。
VAR −SDが計算される変数を示します。
例
以下の例では、 class クラス変数の各値の統計を作成するオプション。
proc surveymeans data = CARS1 STD;
class type;
var type horsepower;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;上記のコードを実行すると、次の出力が得られます-
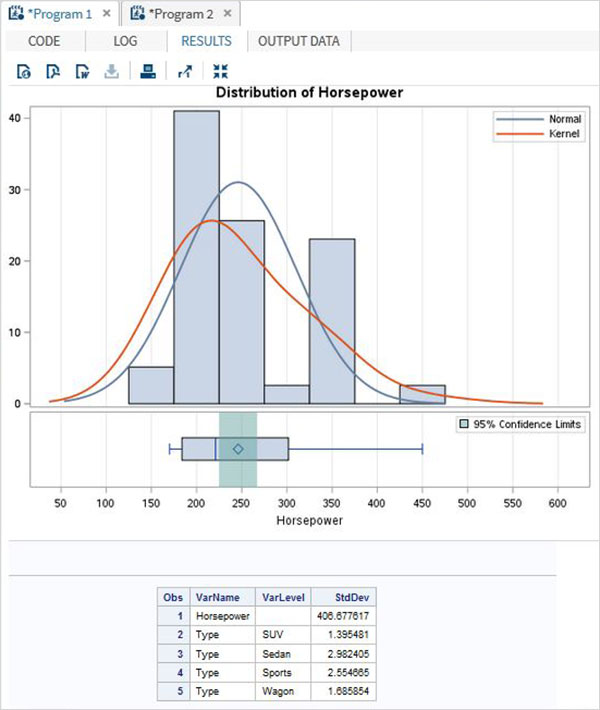
BYオプションの使用
以下のコードは、BYオプションの例を示しています。その中で、結果はBYオプションの値ごとにグループ化されます。
例
proc surveymeans data = CARS1 STD;
var horsepower;
BY make;
ods output statistics = rectangle;
run;
proc print data = rectangle;
run;上記のコードを実行すると、次の出力が得られます-
make = "Audi"の結果

make = "BMW"の結果
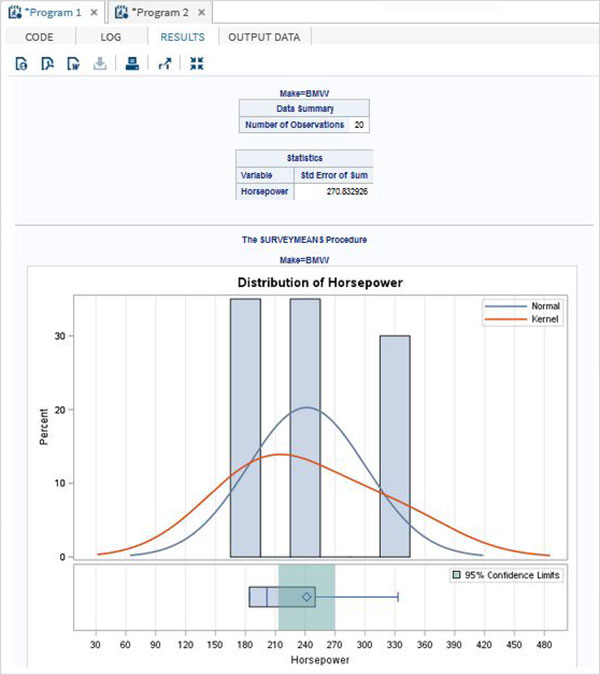
度数分布は、データセット内のデータポイントの度数を示す表です。テーブルの各エントリには、特定のグループまたは間隔内での値の出現頻度またはカウントが含まれています。このようにして、テーブルはサンプル内の値の分布を要約します。
SASはと呼ばれる手順を提供します PROC FREQ データセット内のデータポイントの度数分布を計算します。
構文
SASで度数分布を計算するための基本的な構文は次のとおりです。
PROC FREQ DATA = Dataset ;
TABLES Variable_1 ;
BY Variable_2 ;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
Variables_1 度数分布を計算する必要があるデータセットの変数名です。
Variables_2 度数分布の結果を分類した変数です。
単一の可変度数分布
を使用して、単一変数の度数分布を決定できます。 PROC FREQ.この場合、結果には変数の各値の頻度が表示されます。結果には、パーセンテージ分布、累積度数、累積パーセンテージも表示されます。
例
以下の例では、という名前のデータセットの可変馬力の度数分布を見つけます。 CARS1 ライブラリから作成されます SASHELP.CARS.結果は2つのカテゴリの結果に分けられます。車のメーカーごとに1つ。
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;上記のコードを実行すると、次の結果が得られます。

複数の可変度数分布
考えられるすべての組み合わせにグループ化する複数の変数の度数分布を見つけることができます。
例
以下の例では、車のメーカーの度数分布を計算します。 grouped by car type また、各タイプの車の度数分布 grouped by each make.
proc FREQ data = CARS1 ;
tables make type;
run;上記のコードを実行すると、次の結果が得られます。
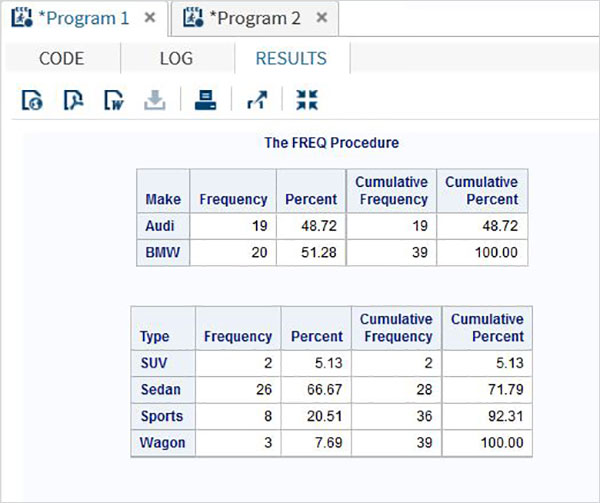
重み付き度数分布
重みオプションを使用すると、変数の重みでバイアスされた度数分布を計算できます。ここで、変数の値は、値のカウントではなく、観測の数として取得されます。
例
以下の例では、馬力に割り当てられた重みを使用して、変数makeおよびtypeの度数分布を計算します。
proc FREQ data = CARS1 ;
tables make type;
weight horsepower;
run;上記のコードを実行すると、次の結果が得られます。
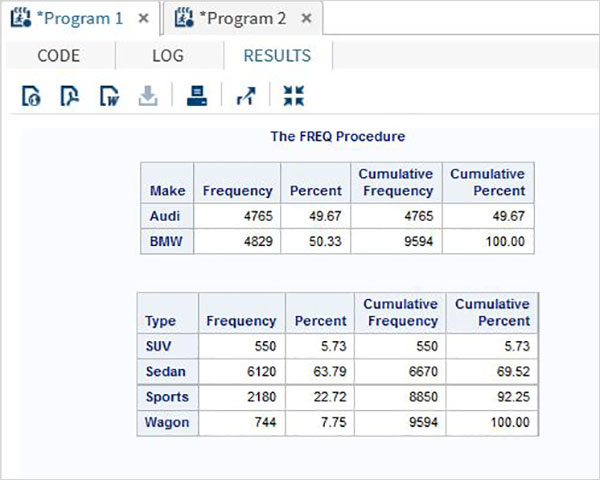
クロス集計では、2つ以上の変数のすべての可能な組み合わせを使用して、分割表とも呼ばれるクロステーブルを作成します。SASでは、を使用して作成されますPROC FREQ 一緒に TABLESオプション。たとえば、各車種カテゴリの各メーカーの各モデルの頻度が必要な場合は、PROCFREQのTABLESオプションを使用する必要があります。
構文
SASでクロス集計を適用するための基本的な構文は次のとおりです。
PROC FREQ DATA = dataset;
TABLES variable_1*Variable_2;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
Variable_1 and Variable_2 度数分布を計算する必要があるデータセットの変数名です。
例
フォームで作成されたデータセットcars1から、各車のブランドで利用可能な車のタイプがいくつあるかを見つける場合を考えてみます。 SASHELP.CARS以下に示すように。この場合、個々の周波数値と、メーカー間およびタイプ間での周波数値の合計が必要です。結果が行と列全体の値を示していることがわかります。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;上記のコードを実行すると、次の結果が得られます。
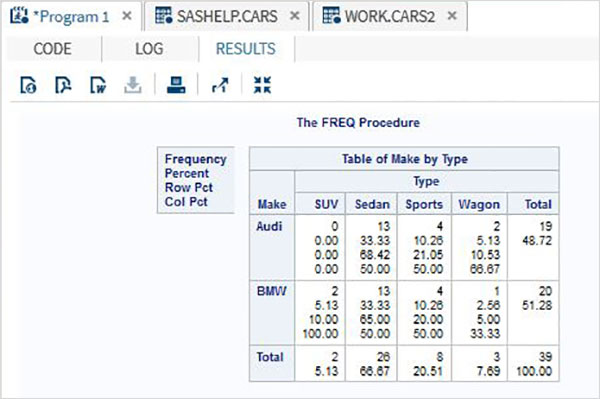
3つの変数のクロス集計
3つの変数がある場合、それらの2つをグループ化し、これら2つの変数のそれぞれを3番目の変数とクロス集計できます。したがって、結果には2つのクロステーブルがあります。
例
以下の例では、車のメーカーに関する各タイプの車と各モデルの車の頻度を示しています。また、nocolおよびnorowオプションを使用して、合計値とパーセンテージ値を回避します。
proc FREQ data = CARS2 ;
tables make * (type model) / nocol norow nopercent;
run;上記のコードを実行すると、次の結果が得られます。
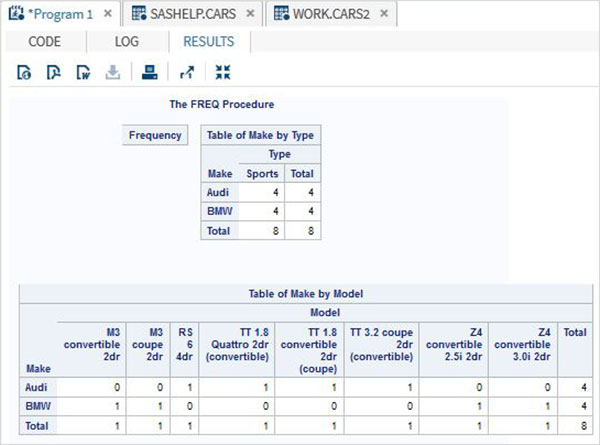
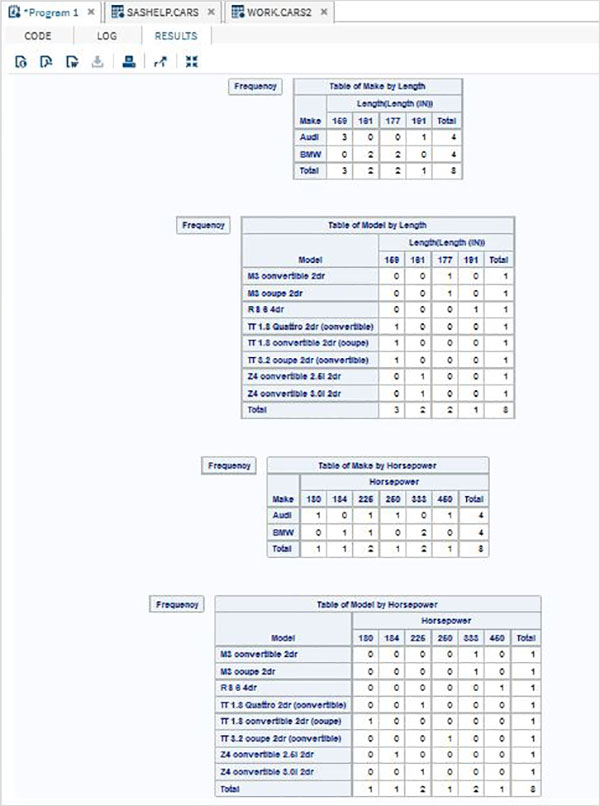
4つの変数のクロス集計
4つの変数を使用すると、ペアの組み合わせの数は4に増加します。グループ1の各変数は、グループ2の各変数とペアになります。
例
以下の例では、各メーカーと各モデルの車の長さの頻度を示しています。同様に、各メーカーおよび各モデルの馬力の頻度。
proc FREQ data = CARS2 ;
tables (make model) * (length horsepower) / nocol norow nopercent;
run;上記のコードを実行すると、次の結果が得られます。
T検定は、平均と平均差を比較することにより、1つのサンプルまたは2つの独立したサンプルの信頼限界を計算するために実行されます。名前の付いたSASプロシージャPROC TTEST は、単一の変数と変数のペアに対してt検定を実行するために使用されます。
構文
SASでPROCTTESTを適用するための基本的な構文は次のとおりです。
PROC TTEST DATA = dataset;
VAR variable;
CLASS Variable;
PAIRED Variable_1 * Variable_2;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
Variable_1 and Variable_2 t検定で使用されるデータセットの変数名です。
例
以下に、95%の信頼限界を持つ可変馬力のt検定推定値を見つける1つのサンプルt検定を示します。
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;上記のコードを実行すると、次の結果が得られます。
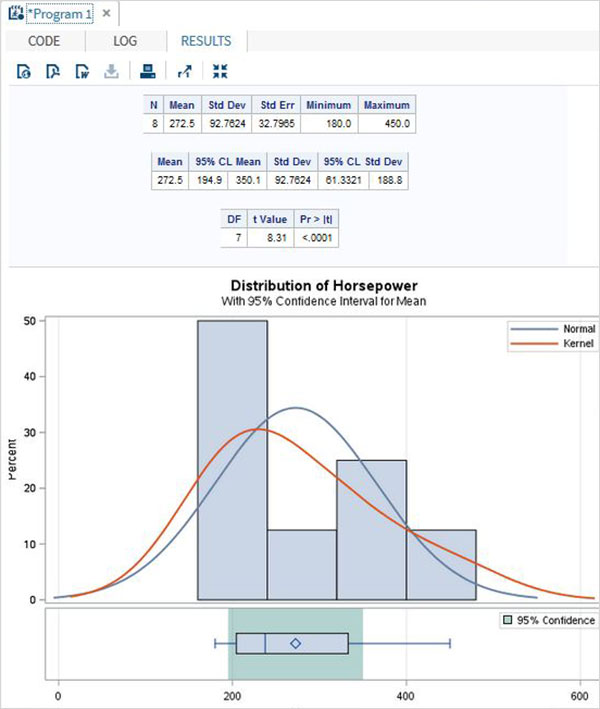
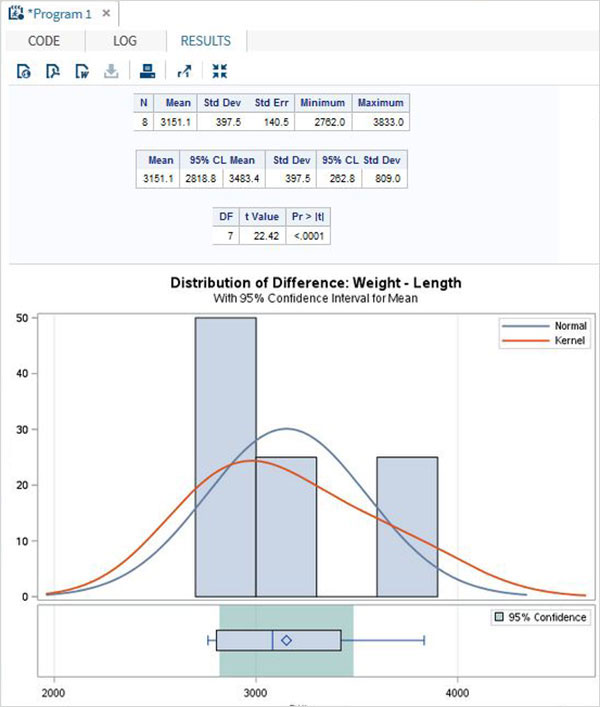
対応のあるT検定
対応のあるT検定は、2つの従属変数が互いに統計的に異なるかどうかをテストするために実行されます。
例
車の長さと重量は相互に依存するため、以下に示すように対応のあるT検定を適用します。
proc ttest data = cars1 ;
paired weight*length;
run;上記のコードを実行すると、次の結果が得られます。
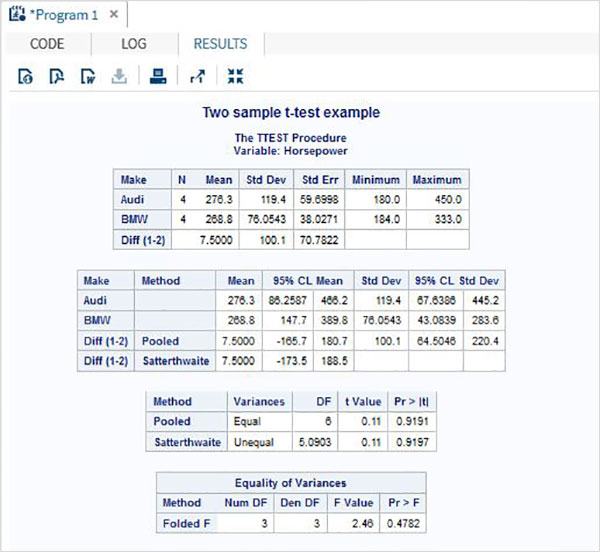
2つのサンプルのt検定
このt検定は、2つのグループ間で同じ変数の平均を比較するように設計されています。
例
私たちの場合、2つの異なる車種(「アウディ」と「BMW」)の可変馬力の平均を比較します。
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0;
title "Two sample t-test example";
class make;
var horsepower;
run;上記のコードを実行すると、次の結果が得られます。
相関分析は、変数間の関係を扱います。相関係数は、2つの変数間の線形関連の尺度です。相関係数の値は常に-1から+1の間です。SASは手順を提供しますPROC CORR データセット内の変数のペア間の相関係数を見つけるため。
構文
SASでPROCCORRを適用するための基本的な構文は次のとおりです。
PROC CORR DATA = dataset options;
VAR variable;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
Options 行列のプロットなどの手順を使用した追加オプションです。
Variable 相関を見つけるために使用されるデータセットの変数名です。
例
データセットで使用可能な変数のペア間の相関係数は、VARステートメントでそれらの名前を使用して取得できます。次の例では、データセットCARS1を使用して、馬力と重量の間の相関係数を示す結果を取得します。
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;上記のコードを実行すると、次の結果が得られます。
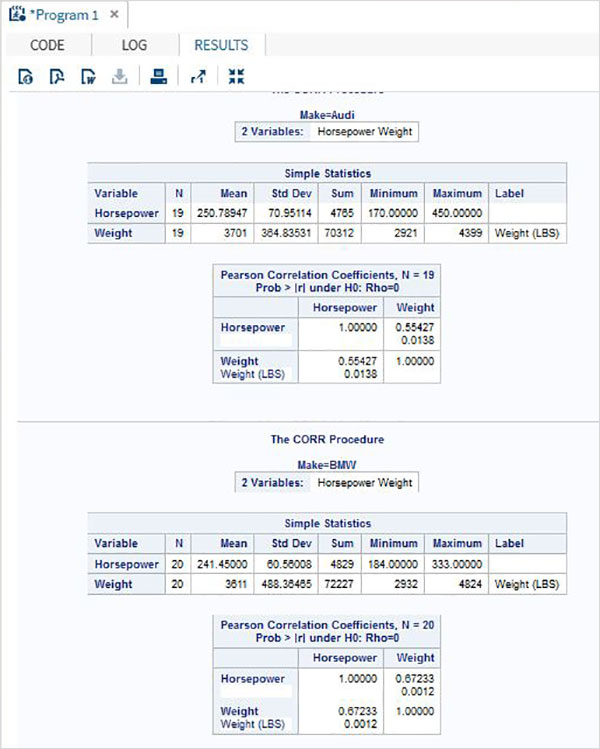
すべての変数間の相関
データセットで使用可能なすべての変数間の相関係数は、データセット名を使用してプロシージャを適用するだけで取得できます。
例
以下の例では、データセットCARS1を使用して、変数の各ペア間の相関係数を示す結果を取得します。
proc corr data = cars1 ;
run;上記のコードを実行すると、次の結果が得られます。
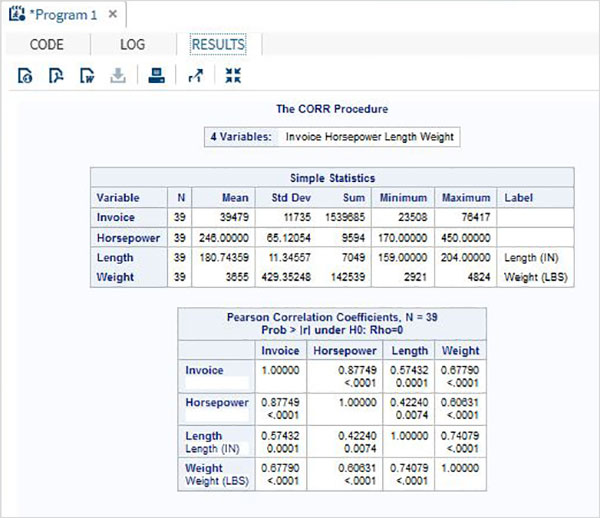
相関行列
で行列をプロットするオプションを選択することにより、変数間の散布図行列を取得できます。 PROC ステートメント。
例
以下の例では、馬力と重量の間の行列を取得します。
proc corr data = cars1 plots = matrix ;
VAR horsepower weight ;
run;上記のコードを実行すると、次の結果が得られます。
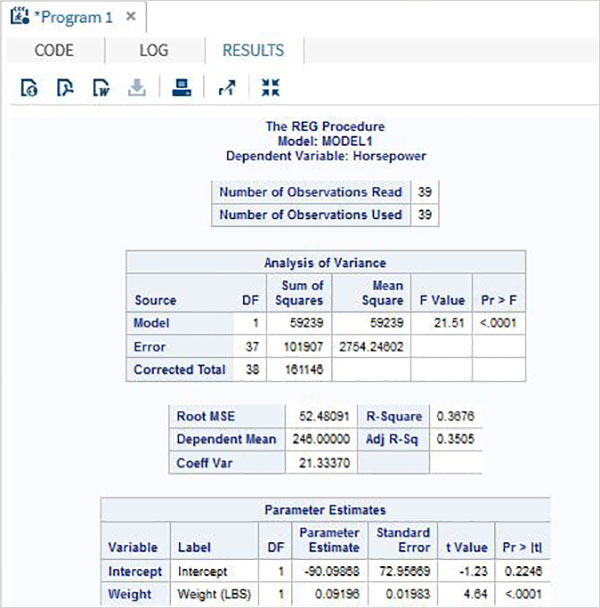
線形回帰は、従属変数と1つ以上の独立変数の間の関係を識別するために使用されます。関係のモデルが提案され、パラメーター値の推定値を使用して、推定された回帰方程式が作成されます。
次に、さまざまなテストを使用して、モデルが満足のいくものであるかどうかを判断します。その場合、推定された回帰方程式を使用して、独立変数の値が与えられた場合の従属変数の値を予測できます。SASでの手順PROC REG 2つの変数間の線形回帰モデルを見つけるために使用されます。
構文
SASでPROCREGを適用するための基本的な構文は次のとおりです。
PROC REG DATA = dataset;
MODEL variable_1 = variable_2;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
variable_1 and variable_2 相関を見つけるために使用されるデータセットの変数名です。
例
次の例は、を使用して2つの変数の馬力と車の重量の間の相関関係を見つけるプロセスを示しています。 PROC REG. 結果には、回帰方程式を形成するために使用できる切片値が表示されます。
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;上記のコードを実行すると、次の結果が得られます。
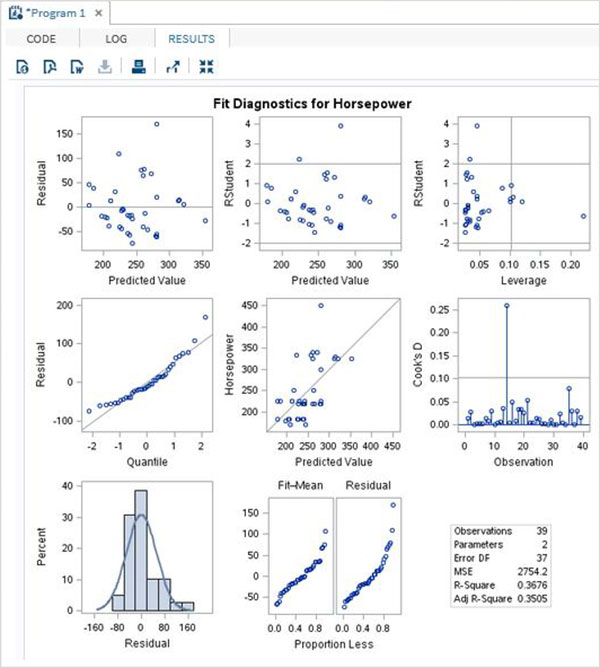
上記のコードは、以下に示すように、モデルのさまざまな推定値のグラフィカルビューも提供します。高度なSASプロシージャであるため、インターセプト値を出力として提供するだけではありません。
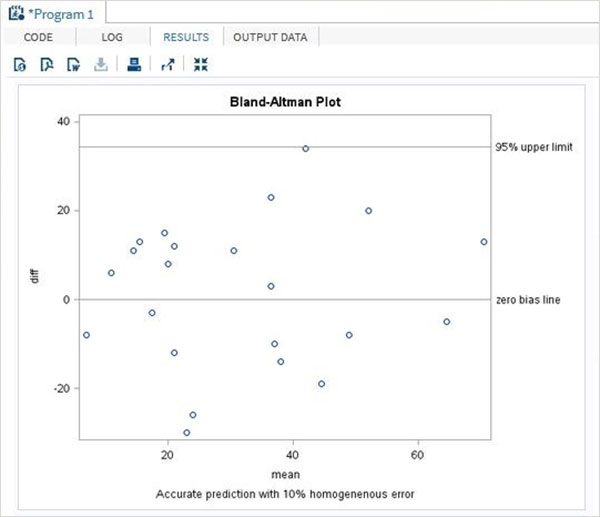
Bland-Altman分析は、同じパラメーターを測定するように設計された2つの方法間の一致または不一致の程度を検証するプロセスです。メソッド間の高い相関関係は、データ分析で十分なサンプルが選択されたことを示しています。SASでは、変数値の平均、上限、下限を計算することにより、ブランド-アルトマンプロットを作成します。次に、PROC SGPLOTを使用して、ブランド-アルトマンプロットを作成します。
構文
SASでPROCSGPLOTを適用するための基本的な構文は次のとおりです。
PROC SGPLOT DATA = dataset;
SCATTER X = variable Y = Variable;
REFLINE value;以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
SCATTER ステートメントは、XおよびYの形式で提供された値の散布図グラフを示します。
REFLINE 水平または垂直の参照線を作成します。
例
以下の例では、newとoldという名前の2つのメソッドによって生成された2つの実験の結果を取り上げます。変数の値の差と、同じ観測値の変数の平均を計算します。また、計算の上限と下限に使用される標準偏差値も計算します。
結果は、散布図としてブランド-アルトマンプロットを示しています。
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;上記のコードを実行すると、次の結果が得られます。
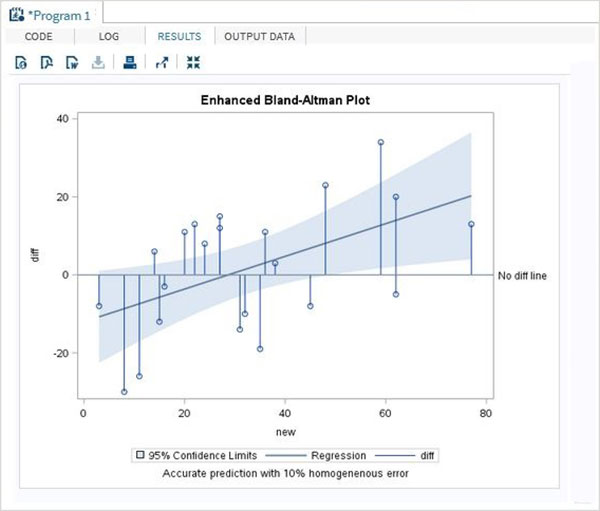
強化されたモデル
上記のプログラムの拡張モデルでは、95%の信頼水準のカーブフィッティングが得られます。
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;上記のコードを実行すると、次の結果が得られます。
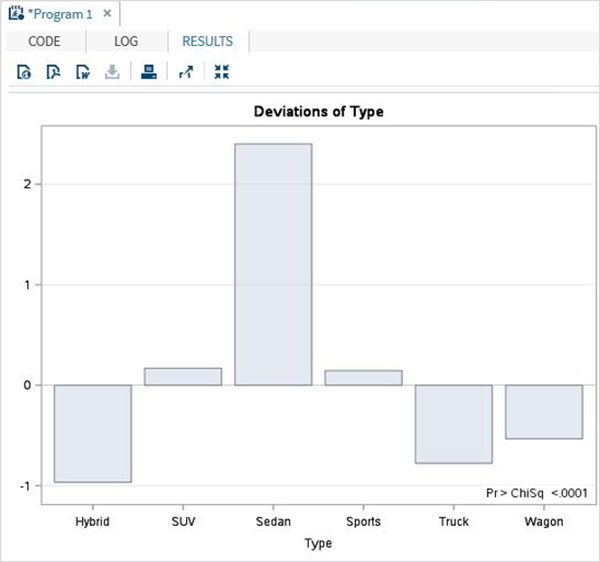
カイ二乗検定は、2つのカテゴリ変数間の関連を調べるために使用されます。変数間の依存度と独立度の両方をテストするために使用できます。SASはPROC FREQ オプションと一緒に chisq カイ二乗検定の結果を決定します。
構文
SASのカイ2乗検定にPROCFREQを適用するための基本的な構文は次のとおりです。
PROC FREQ DATA = dataset;
TABLES variables
/CHISQ TESTP = (percentage values);以下は、使用されるパラメーターの説明です-
Dataset データセットの名前です。
Variables カイ二乗検定で使用されるデータセットの変数名です。
Percentage Values TESTPステートメントでは、変数のレベルのパーセンテージを表します。
例
以下の例では、データセット内のtypeという名前の変数に対するカイ2乗検定を検討します。 SASHELP.CARS. この変数には6つのレベルがあり、テストの設計に従って各レベルにパーセンテージを割り当てます。
proc freq data = sashelp.cars;
tables type
/chisq
testp = (0.20 0.12 0.18 0.10 0.25 0.15);
run;上記のコードを実行すると、次の結果が得られます。

次のスクリーンショットに示すように、変数タイプの偏差を示す棒グラフも取得します。
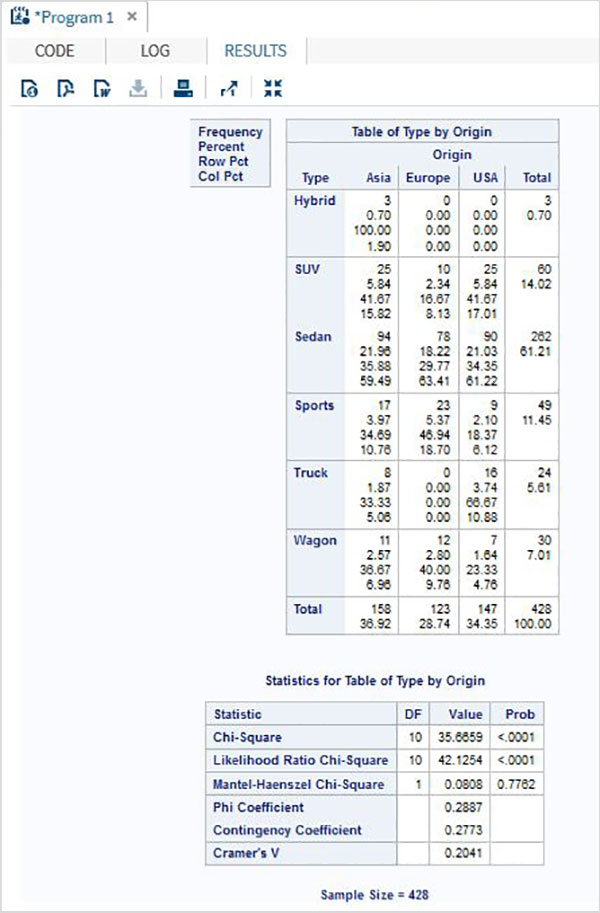
双方向カイ二乗
データセットの2つの変数に検定を適用する場合、双方向カイ2乗検定が使用されます。
例
以下の例では、typeとoriginという名前の2つの変数にカイ2乗検定を適用します。結果は、これら2つの変数のすべての組み合わせの表形式を示しています。
proc freq data = sashelp.cars;
tables type*origin
/chisq
;
run;上記のコードを実行すると、次の結果が得られます。
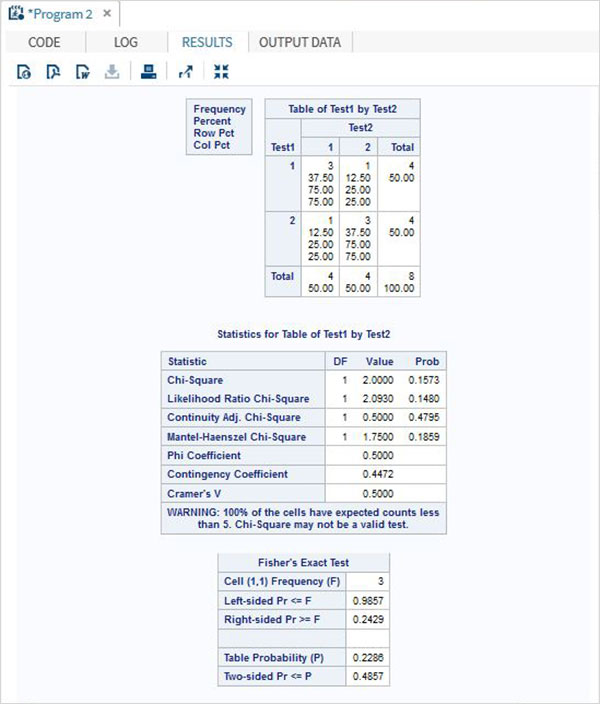
フィッシャーの直接確率検定は、2つのカテゴリ変数間にランダムでない関連があるかどうかを判断するために使用される統計的検定です。SASでは、これは次を使用して実行されます。 PROC FREQ。テーブルオプションを使用して、フィッシャーの直接確率検定の対象となる2つの変数を使用します。
構文
SASでフィッシャーの直接確率検定を適用するための基本的な構文は次のとおりです。
PROC FREQ DATA = dataset ;
TABLES Variable_1*Variable_2 / fisher;以下は、使用されるパラメーターの説明です-
dataset データセットの名前です。
Variable_1*Variable_2 データセットを形成する変数です。
フィッシャーの直接確率検定の適用
フィッシャーの直接確率検定を適用するには、Test1とTest2という名前の2つのカテゴリ変数とその結果を選択します。PROCFREQを使用して、以下に示すテストを適用します。
例
data temp;
input Test1 Test2 Result @@;
datalines;
1 1 3 1 2 1 2 1 1 2 2 3
;
proc freq;
tables Test1*Test2 / fisher;
run;上記のコードを実行すると、次の結果が得られます。
反復測定分析は、ランダムサンプルのすべてのメンバーがさまざまな条件下で測定される場合に使用されます。サンプルが各条件に順番にさらされると、従属変数の測定が繰り返されます。この場合、標準のANOVAを使用することは、反復測定間の相関をモデル化できないため、適切ではありません。
との違いについて明確にする必要があります repeated measures design と simple multivariate design. どちらの場合も、サンプルメンバーは数回、つまり試行で測定されますが、反復測定の設計では、各試行は異なる条件下での同じ特性の測定を表します。
SASでは PROC GLM 反復測定分析を実行するために使用されます。
構文
SASでのPROCGLMの基本的な構文は次のとおりです。
PROC GLM DATA = dataset;
CLASS variable;
MODEL variables = group / NOUNI;
REPEATED TRIAL n;以下は、使用されるパラメーターの説明です-
dataset データセットの名前です。
CLASS 変数に分類変数として使用される変数を与えます。
MODEL データセットから特定の変数を使用して適合するモデルを定義します。
REPEATED 仮説を検定するための各グループの反復測定の数を定義します。
例
以下の例では、2つのグループの人々が薬物の効果のテストを受けています。各人の反応時間は、テストされた4つの薬剤タイプのそれぞれについて記録されます。ここでは、4つの薬剤タイプの効果間の相関の強さを確認するために、各グループの人々に対して5つの試験が行われます。
DATA temp;
INPUT person group $ r1 r2 r3 r4;
CARDS;
1 A 2 1 6 5
2 A 5 4 11 9
3 A 6 14 12 10
4 A 2 4 5 8
5 A 0 5 10 9
6 B 9 11 16 13
7 B 12 4 13 14
8 B 15 9 13 8
9 B 6 8 12 5
10 B 5 7 11 9
;
RUN;
PROC PRINT DATA = temp ;
RUN;
PROC GLM DATA = temp;
CLASS group;
MODEL r1-r4 = group / NOUNI ;
REPEATED trial 5;
RUN;上記のコードを実行すると、次の結果が得られます。
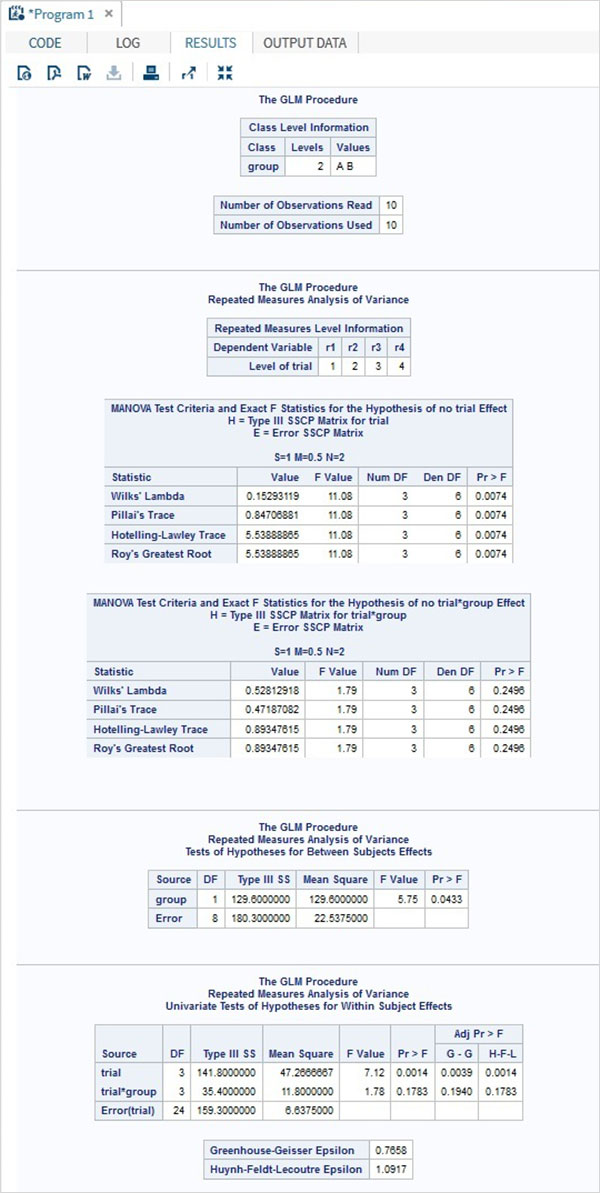
ANOVAはAnalysisofVarianceの略です。SASでは、PROC ANOVA。さまざまな実験計画からのデータの分析を実行します。このプロセスでは、従属変数と呼ばれる連続応答変数が、独立変数と呼ばれる分類変数によって識別される実験条件下で測定されます。応答の変動は分類の影響によるものと想定され、残りの変動はランダムエラーによって説明されます。
構文
SASでPROCANOVAを適用するための基本的な構文は次のとおりです。
PROC ANOVA dataset ;
CLASS Variable;
MODEL Variable1 = variable2 ;
MEANS ;以下は、使用されるパラメーターの説明です-
dataset データセットの名前です。
CLASS 変数に分類変数として使用される変数を与えます。
MODEL データセットの特定の変数を使用してフィットするモデルを定義します。
Variable_1 and Variable_2 分析で使用されるデータセットの変数名です。
MEANS 計算のタイプと平均の比較を定義します。
ANOVAの適用
SASでANOVAを適用する概念を理解しましょう。
例
データセットSASHELP.CARSについて考えてみましょう。ここでは、変数の車種とその馬力の間の依存関係を調べます。車のタイプはカテゴリ値を持つ変数であるため、クラス変数と見なし、モデルでこれらの変数の両方を使用します。
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
RUN;上記のコードを実行すると、次の結果が得られます。

平均によるANOVAの適用
SASでMEANSを使用してANOVAを適用する概念を理解しましょう。
例
トルコのスチューデント化手法を使用してさまざまな車種の平均値を比較するMEANSステートメントを適用することで、モデルを拡張することもできます。車種のカテゴリは、各カテゴリの馬力の平均値と、次のようないくつかの追加値とともに一覧表示されます。誤差平均二乗など。
PROC ANOVA DATA = SASHELPS.CARS;
CLASS type;
MODEL horsepower = type;
MEANS type / tukey lines;
RUN;上記のコードを実行すると、次の結果が得られます。

仮説検定は、統計を使用して、特定の仮説が真である確率を決定することです。仮説検定の通常のプロセスは、以下に示す4つのステップで構成されます。
ステップ1
帰無仮説H0(通常、観測値は純粋な偶然の結果である)と対立仮説H1(通常、観測値が偶然の変動の成分と組み合わされた実際の効果を示す)を定式化します。
ステップ2
帰無仮説の真偽を評価するために使用できる検定統計量を特定します。
ステップ-3
P値を計算します。これは、帰無仮説が真であると仮定して、観測されたものと少なくとも同じ有意な検定統計量が得られる確率です。P値が小さいほど、帰無仮説に対する証拠が強くなります。
ステップ-4
p値を許容可能な有意値alpha(アルファ値と呼ばれることもあります)と比較します。p <= alphaの場合、観測された効果が統計的に有意である場合、帰無仮説は除外され、対立仮説は有効です。
SASプログラミング言語には、以下に示すように、さまざまなタイプの仮説検定を実行する機能があります。
| テスト | 説明 | SAS PROC |
|---|---|---|
| T-Test | t検定は、1つの変数の平均が仮説値と有意に異なるかどうかをテストするために使用されます.2つの独立したグループの平均が有意に異なるかどうか、および従属グループまたはペアのグループの平均が有意に異なるかどうかも判断します。 | PROC TTEST |
| ANOVA | また、独立したカテゴリ変数が1つある場合の平均の比較にも使用されます。区間従属変数の平均が独立カテゴリ変数によって異なるかどうかをテストするときに、一元配置分散分析を使用します。 | PROC ANOVA |
| Chi-Square | カイ二乗適合度を使用して、カテゴリ変数の頻度が偶然に発生する可能性が高いかどうかを評価します。カテゴリ変数の比率が仮説値であるかどうかにかかわらず、カイ2乗検定を使用する必要があります。 | PROC FREQ |
| Linear Regression | 単純な線形回帰は、変数が別の変数をどれだけうまく予測できるかをテストする場合に使用されます。複数の線形回帰を使用すると、複数の変数が対象の変数をどの程度予測できるかをテストできます。複数の線形回帰を使用する場合、予測変数は独立しているとさらに仮定します。 | PROC REG |