Apache Tajo-빠른 가이드
분산 데이터웨어 하우스 시스템
데이터웨어 하우스는 트랜잭션 처리보다는 쿼리 및 분석을 위해 설계된 관계형 데이터베이스입니다. 주제 지향적이고 통합 된 시변 비 휘발성 데이터 모음입니다. 이 데이터는 분석가가 조직에서 정보에 입각 한 결정을 내리는 데 도움이되지만 관계형 데이터 양은 날로 증가합니다.
문제를 극복하기 위해 분산 데이터웨어 하우스 시스템은 OLAP (Online Analytical Processing) 목적으로 여러 데이터 저장소에서 데이터를 공유합니다. 각 데이터웨어 하우스는 하나 이상의 조직에 속할 수 있습니다. 로드 밸런싱 및 확장 성을 수행합니다. 메타 데이터는 복제되고 중앙에서 배포됩니다.
Apache Tajo는 HDFS (Hadoop Distributed File System)를 스토리지 계층으로 사용하고 MapReduce 프레임 워크 대신 자체 쿼리 실행 엔진을 갖는 분산 데이터웨어 하우스 시스템입니다.
Hadoop의 SQL 개요
Hadoop은 분산 환경에서 빅 데이터를 저장하고 처리 할 수있는 오픈 소스 프레임 워크입니다. 매우 빠르고 강력합니다. 그러나 Hadoop은 쿼리 기능이 제한되어 있으므로 Hadoop의 SQL을 사용하여 성능을 더욱 향상시킬 수 있습니다. 이를 통해 사용자는 쉬운 SQL 명령을 통해 Hadoop과 상호 작용할 수 있습니다.
Hadoop 애플리케이션에서 SQL의 몇 가지 예는 Hive, Impala, Drill, Presto, Spark, HAWQ 및 Apache Tajo입니다.
Apache Tajo 란?
Apache Tajo는 관계형 및 분산 데이터 처리 프레임 워크입니다. 짧은 지연 시간과 확장 가능한 임시 쿼리 분석을 위해 설계되었습니다.
Tajo는 표준 SQL 및 다양한 데이터 형식을 지원합니다. 대부분의 Tajo 쿼리는 수정없이 실행할 수 있습니다.
타조가 fault-tolerance 실패한 작업에 대한 다시 시작 메커니즘과 확장 가능한 쿼리 재 작성 엔진을 통해
Tajo는 필요한 것을 수행합니다 ETL (Extract Transform and Load process)HDFS에 저장된 대규모 데이터 세트를 요약하는 작업. Hive / Pig의 대안입니다.
최신 버전의 Tajo는 Java 프로그램 및 Oracle 및 PostGreSQL과 같은 타사 데이터베이스에 대한 연결성이 뛰어납니다.
Apache Tajo의 기능
Apache Tajo에는 다음과 같은 기능이 있습니다.
- 뛰어난 확장 성 및 최적화 된 성능
- 짧은 대기 시간
- 사용자 정의 함수
- 행 / 열 저장 처리 프레임 워크.
- HiveQL 및 Hive MetaStore와의 호환성
- 간단한 데이터 흐름과 쉬운 유지 관리.
Apache Tajo의 이점
Apache Tajo는 다음과 같은 이점을 제공합니다.
- 사용하기 쉬운
- 단순화 된 아키텍처
- 비용 기반 쿼리 최적화
- 벡터화 된 쿼리 실행 계획
- 빠른 배달
- 간단한 I / O 메커니즘과 다양한 유형의 스토리지를 지원합니다.
- 결함 허용
Apache Tajo의 사용 사례
다음은 Apache Tajo의 사용 사례 중 일부입니다-
데이터웨어 하우징 및 분석
한국의 SK 텔레콤 회사는 1.7 테라 바이트에 달하는 데이터에 대해 Tajo를 실행 한 결과 Hive 나 Impala보다 빠른 속도로 쿼리를 완료 할 수 있음을 발견했습니다.
데이터 발견
한국 음악 스트리밍 서비스 멜론은 분석 처리를 위해 타조를 사용합니다. Tajo는 ETL (추출-변환-로드 프로세스) 작업을 Hive보다 1.5 ~ 10 배 빠르게 실행합니다.
로그 분석
한국에 기반을 둔 Bluehole Studio는 판타지 멀티 플레이어 온라인 게임 인 TERA를 개발했습니다. 이 회사는 게임 로그 분석 및 서비스 품질 중단의 주요 원인을 찾기 위해 Tajo를 사용합니다.
저장 및 데이터 형식
Apache Tajo는 다음 데이터 형식을 지원합니다.
- JSON
- 텍스트 파일 (CSV)
- Parquet
- 시퀀스 파일
- AVRO
- 프로토콜 버퍼
- Apache Orc
Tajo는 다음 저장 형식을 지원합니다-
- HDFS
- JDBC
- 아마존 S3
- Apache HBase
- Elasticsearch
다음 그림은 Apache Tajo의 아키텍처를 보여줍니다.

다음 표에서는 각 구성 요소에 대해 자세히 설명합니다.
| S. 아니. | 구성 요소 및 설명 |
|---|---|
| 1 | Client Client 결과를 얻기 위해 SQL 문을 Tajo Master에 제출합니다. |
| 2 | Master 마스터는 주요 데몬입니다. 쿼리 계획을 담당하고 작업자를위한 조정자입니다. |
| 삼 | Catalog server 테이블 및 인덱스 설명을 유지합니다. 마스터 데몬에 포함됩니다. 카탈로그 서버는 Apache Derby를 스토리지 계층으로 사용하고 JDBC 클라이언트를 통해 연결합니다. |
| 4 | Worker 마스터 노드는 작업자 노드에 작업을 할당합니다. TajoWorker는 데이터를 처리합니다. TajoWorker의 수가 증가함에 따라 처리 용량도 선형 적으로 증가합니다. |
| 5 | Query Master Tajo 마스터는 쿼리 마스터에 쿼리를 할당합니다. 쿼리 마스터는 분산 실행 계획을 제어합니다. TaskRunner를 시작하고 TaskRunner에 작업을 예약합니다. Query Master의 주요 역할은 실행중인 작업을 모니터링하고이를 마스터 노드에보고하는 것입니다. |
| 6 | Node Managers 작업자 노드의 리소스를 관리합니다. 노드에 대한 요청 할당을 결정합니다. |
| 7 | TaskRunner 로컬 쿼리 실행 엔진으로 작동합니다. 쿼리 프로세스를 실행하고 모니터링하는 데 사용됩니다. TaskRunner는 한 번에 하나의 작업을 처리합니다. 그것은 다음 세 가지 주요 속성을 가지고 있습니다-
|
| 8 | Query Executor 쿼리를 실행하는 데 사용됩니다. |
| 9 | Storage service 기본 데이터 저장소를 Tajo에 연결합니다. |
워크 플로우
Tajo는 HDFS (Hadoop Distributed File System)를 스토리지 계층으로 사용하며 MapReduce 프레임 워크 대신 자체 쿼리 실행 엔진을 가지고 있습니다. Tajo 클러스터는 하나의 마스터 노드와 클러스터 노드의 여러 작업자로 구성됩니다.
마스터는 주로 쿼리 계획과 작업자의 코디네이터를 담당합니다. 마스터는 쿼리를 작은 작업으로 나누고 작업자에게 할당합니다. 각 작업자에는 물리 연산자의 방향성 비순환 그래프를 실행하는 로컬 쿼리 엔진이 있습니다.
또한 Tajo는 MapReduce보다 유연하게 분산 데이터 흐름을 제어 할 수 있으며 인덱싱 기술을 지원합니다.
Tajo의 웹 기반 인터페이스에는 다음과 같은 기능이 있습니다.
- 제출 된 쿼리를 계획하는 방법을 찾는 옵션
- 쿼리가 노드에 분산되는 방법을 찾는 옵션
- 클러스터 및 노드의 상태를 확인하는 옵션
Apache Tajo를 설치하려면 시스템에 다음 소프트웨어가 있어야합니다.
- Hadoop 버전 2.3 이상
- Java 버전 1.7 이상
- Linux 또는 Mac OS
이제 다음 단계를 계속하여 Tajo를 설치하겠습니다.
Java 설치 확인
컴퓨터에 Java 버전 8이 이미 설치되어 있기를 바랍니다. 이제 확인하여 진행하면됩니다.
확인하려면 다음 명령을 사용하십시오-
$ java -version시스템에 Java가 성공적으로 설치되면 설치된 Java의 현재 버전을 볼 수 있습니다. Java가 설치되어 있지 않은 경우 다음 단계에 따라 시스템에 Java 8을 설치하십시오.
JDK 다운로드
다음 링크를 방문하여 최신 버전의 JDK를 다운로드 한 다음 최신 버전을 다운로드하십시오.
https://www.oracle.com
최신 버전은 JDK 8u 92 그리고 파일은 “jdk-8u92-linux-x64.tar.gz”. 컴퓨터에 파일을 다운로드하십시오. 그런 다음 파일을 추출하고 특정 디렉토리로 이동하십시오. 이제 Java 대안을 설정하십시오. 마지막으로 Java가 컴퓨터에 설치됩니다.
Hadoop 설치 확인
이미 설치했습니다. Hadoop시스템에서. 이제 다음 명령을 사용하여 확인하십시오.
$ hadoop version설정에 문제가 없으면 Hadoop 버전을 볼 수 있습니다. Hadoop이 설치되어 있지 않은 경우 다음 링크를 방문하여 Hadoop을 다운로드하여 설치하십시오.https://www.apache.org
Apache Tajo 설치
Apache Tajo는 로컬 모드와 완전 분산 모드의 두 가지 실행 모드를 제공합니다. Java 및 Hadoop 설치를 확인한 후 다음 단계를 진행하여 컴퓨터에 Tajo 클러스터를 설치합니다. 로컬 모드 Tajo 인스턴스에는 매우 쉬운 구성이 필요합니다.
다음 링크를 방문하여 최신 버전의 Tajo를 다운로드하십시오. https://www.apache.org/dyn/closer.cgi/tajo
이제 파일을 다운로드 할 수 있습니다. “tajo-0.11.3.tar.gz” 당신의 기계에서.
Tar 파일 추출
다음 명령을 사용하여 tar 파일을 추출하십시오.
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3환경 변수 설정
다음에 다음 변경 사항을 추가하십시오. “conf/tajo-env.sh” 파일
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/여기에서 Hadoop 및 Java 경로를 지정해야합니다. “tajo-env.sh”파일. 변경 한 후 파일을 저장하고 터미널을 종료합니다.
Tajo 서버 시작
Tajo 서버를 시작하려면 다음 명령을 실행하십시오.
$ bin/start-tajo.sh다음과 유사한 응답을 받게됩니다.
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002이제 "jps"명령을 입력하여 실행중인 데몬을 확인합니다.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterTajo Shell (Tsql) 시작
Tajo 셸 클라이언트를 시작하려면 다음 명령을 사용하십시오.
$ bin/tsql다음과 같은 출력을 받게됩니다.
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Tajo Shell 종료
Tsql을 종료하려면 다음 명령을 실행하십시오-
default> \q
bye!여기서 기본값은 Tajo의 카탈로그를 나타냅니다.
웹 UI
Tajo 웹 UI를 시작하려면 다음 URL을 입력하십시오- http://localhost:26080/
이제 ExecuteQuery 옵션과 유사한 다음 화면이 표시됩니다.

타조 중지
Tajo 서버를 중지하려면 다음 명령을 사용하십시오.
$ bin/stop-tajo.sh다음과 같은 응답을 받게됩니다.
localhost: stopping worker
stopping masterTajo의 구성은 Hadoop의 구성 시스템을 기반으로합니다. 이 장에서는 Tajo 구성 설정에 대해 자세히 설명합니다.
기본 설정
Tajo는 다음 두 가지 구성 파일을 사용합니다.
- catalog-site.xml-카탈로그 서버에 대한 구성.
- tajo-site.xml-다른 Tajo 모듈에 대한 설정.
분산 모드 구성
분산 모드 설정은 HDFS (Hadoop 분산 파일 시스템)에서 실행됩니다. Tajo 분산 모드 설정을 구성하는 단계를 따르십시오.
tajo-site.xml
이 파일은 @ /path/to/tajo/conf다른 Tajo 모듈에 대한 구성 역할을합니다. 분산 모드에서 Tajo에 액세스하려면 다음 변경 사항을 적용하십시오.“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>마스터 노드 구성
Tajo는 HDFS를 기본 스토리지 유형으로 사용합니다. 구성은 다음과 같으며 다음에 추가해야합니다.“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>카탈로그 구성
카탈로그 서비스를 사용자 정의하려면 $path/to/Tajo/conf/catalogsite.xml.template ...에 $path/to/Tajo/conf/catalog-site.xml 필요에 따라 다음 구성을 추가합니다.
예를 들어 “Hive catalog store” Tajo에 액세스하려면 구성은 다음과 같아야합니다.
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>저장해야하는 경우 MySQL 카탈로그, 다음 변경 사항을 적용하십시오-
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>마찬가지로 구성 파일에 다른 Tajo 지원 카탈로그를 등록 할 수 있습니다.
작업자 구성
기본적으로 TajoWorker는 로컬 파일 시스템에 임시 데이터를 저장합니다. 다음과 같이“tajo-site.xml”파일에 정의되어 있습니다.
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>각 작업자 리소스의 실행 작업 용량을 늘리려면 다음 구성을 선택하십시오.
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Tajo 작업자를 전용 모드에서 실행하려면 다음 구성을 선택하십시오.
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>이 장에서는 Tajo Shell 명령을 자세히 이해합니다.
Tajo 쉘 명령을 실행하려면 다음 명령을 사용하여 Tajo 서버와 Tajo 쉘을 시작해야합니다.
서버 시작
$ bin/start-tajo.sh셸 시작
$ bin/tsql이제 위의 명령을 실행할 준비가되었습니다.
메타 명령
이제 논의하겠습니다 Meta Commands. Tsql 메타 명령은 백 슬래시로 시작합니다.(‘\’).
도움말 명령
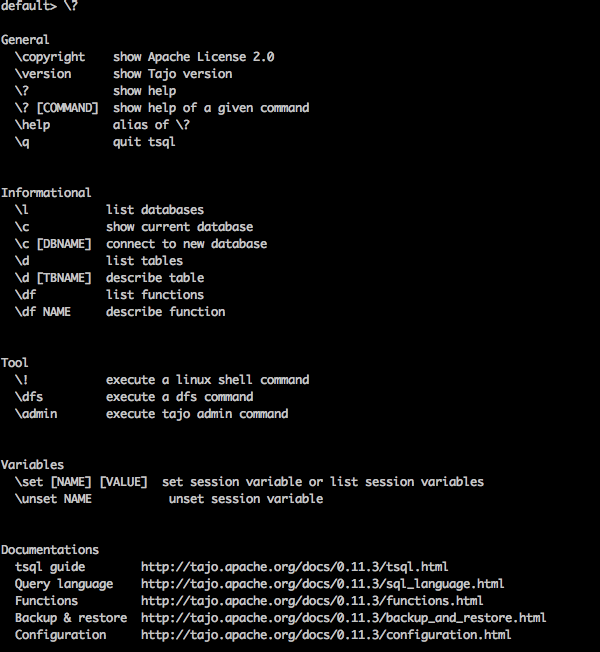
“\?” 명령은 도움말 옵션을 표시하는 데 사용됩니다.
Query
default> \?Result
위 \?명령은 Tajo의 모든 기본 사용 옵션을 나열합니다. 다음과 같은 출력을 받게됩니다.
데이터베이스 나열
Tajo의 모든 데이터베이스를 나열하려면 다음 명령을 사용하십시오.
Query
default> \lResult
다음과 같은 출력을 받게됩니다.
information_schema
default현재 우리는 데이터베이스를 생성하지 않았으므로 두 개의 내장 된 Tajo 데이터베이스를 보여줍니다.
현재 데이터베이스
\c 옵션은 현재 데이터베이스 이름을 표시하는 데 사용됩니다.
Query
default> \cResult
이제 "username"사용자로 "default"데이터베이스에 연결되었습니다.
내장 기능 나열
모든 내장 함수를 나열하려면 다음과 같이 쿼리를 입력하십시오.
Query
default> \dfResult
다음과 같은 출력을 받게됩니다.

기능 설명
\df function name −이 쿼리는 주어진 함수에 대한 완전한 설명을 반환합니다.
Query
default> \df sqrtResult
다음과 같은 출력을 받게됩니다.

터미널 종료
터미널을 종료하려면 다음 쿼리를 입력하십시오.
Query
default> \qResult
다음과 같은 출력을 받게됩니다.
bye!관리 명령
Tajo 쉘은 \admin 모든 관리자 기능을 나열하는 옵션.
Query
default> \adminResult
다음과 같은 출력을 받게됩니다.

클러스터 정보
Tajo에서 클러스터 정보를 표시하려면 다음 쿼리를 사용하십시오.
Query
default> \admin -clusterResult
다음과 같은 출력을 받게됩니다.

마스터보기
다음 쿼리는 현재 마스터 정보를 표시합니다.
Query
default> \admin -showmastersResult
localhost마찬가지로 다른 관리 명령을 시도 할 수 있습니다.
세션 변수
Tajo 클라이언트는 고유 한 세션 ID를 통해 마스터에 연결합니다. 세션은 클라이언트의 연결이 끊어 지거나 만료 될 때까지 활성 상태입니다.
다음 명령은 모든 세션 변수를 나열하는 데 사용됩니다.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'그만큼 \set key val 세션 변수를 설정합니다. key 가치와 함께 val. 예를 들면
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]여기에서 키와 값을 \set명령. 변경 사항을 되돌려 야하는 경우\unset 명령.
Tajo 쉘에서 쿼리를 실행하려면 터미널을 열고 Tajo가 설치된 디렉토리로 이동 한 후 다음 명령을 입력하십시오.
$ bin/tsql이제 다음 프로그램과 같이 응답을 볼 수 있습니다.
default>이제 쿼리를 실행할 수 있습니다. 그렇지 않으면 웹 콘솔 응용 프로그램을 통해 다음 URL로 쿼리를 실행할 수 있습니다.http://localhost:26080/
원시 데이터 유형
Apache Tajo는 다음과 같은 기본 데이터 유형 목록을 지원합니다.
| S. 아니. | 데이터 유형 및 설명 |
|---|---|
| 1 | integer 4 바이트 저장과 함께 정수 값 저장에 사용됩니다. |
| 2 | tinyint 작은 정수 값은 1 바이트입니다. |
| 삼 | smallint 작은 크기의 정수 2 바이트 값을 저장하는 데 사용됩니다. |
| 4 | bigint 큰 범위 정수 값에는 8 바이트 저장 공간이 있습니다. |
| 5 | boolean 참 / 거짓을 반환합니다. |
| 6 | real 실제 가치를 저장하는 데 사용됩니다. 크기는 4 바이트입니다. |
| 7 | float 4 또는 8 바이트 저장 공간이있는 부동 소수점 정밀도 값입니다. |
| 8 | double 8 바이트에 저장된 배정 밀도 값입니다. |
| 9 | char[(n)] 캐릭터 가치. |
| 10 | varchar[(n)] 가변 길이 비 유니 코드 데이터. |
| 11 | number 소수 값. |
| 12 | binary 이진 값. |
| 13 | date 달력 날짜 (년, 월, 일). Example − 날짜 '2016-08-22' |
| 14 | time 시간대가없는 시간 (시, 분, 초, 밀리 초). 이 유형의 값은 세션 시간대에서 구문 분석되고 렌더링됩니다. |
| 15 | timezone 시간대가있는 시간 (시, 분, 초, 밀리 초)입니다. 이 유형의 값은 값의 시간대를 사용하여 렌더링됩니다. Example − TIME '01 : 02 : 03.456 Asia / kolkata ' |
| 16 | timestamp 시간대없이 날짜와 시간을 포함하는 순간. Example − TIMESTAMP '2016-08-22 03 : 04 : 05.321' |
| 17 | text 가변 길이 유니 코드 텍스트. |
Tajo에서는 다음 연산자를 사용하여 원하는 작업을 수행합니다.
| S. 아니. | 연산자 및 설명 |
|---|---|
| 1 | 산술 연산자 Presto는 +, −, *, /, %와 같은 산술 연산자를 지원합니다. |
| 2 | 관계 연산자 <,>, <=,> =, =, <> |
| 삼 | 논리 연산자 AND, OR, NOT |
| 4 | 문자열 연산자 '||' 연산자는 문자열 연결을 수행합니다. |
| 5 | 범위 연산자 범위 연산자는 특정 범위의 값을 테스트하는 데 사용됩니다. Tajo는 BETWEEN, IS NULL, IS NOT NULL 연산자를 지원합니다. |
지금까지 Tajo에서 간단한 기본 쿼리를 실행하는 것을 알고있었습니다. 다음 몇 장에서 다음 SQL 함수에 대해 설명합니다.
- 수학 함수
- 문자열 함수
- DateTime 함수
- JSON 함수
수학 함수는 수학 공식에서 작동합니다. 다음 표는 기능 목록을 자세히 설명합니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | abs (x) x의 절대 값을 반환합니다. |
| 2 | cbrt (x) x의 세제곱근을 반환합니다. |
| 삼 | ceil (x) 가장 가까운 정수로 반올림 된 x 값을 반환합니다. |
| 4 | 층 (x) 가장 가까운 정수로 내림 한 x를 반환합니다. |
| 5 | pi () 파이 값을 반환합니다. 결과는 이중 값으로 반환됩니다. |
| 6 | 라디안 (x) 각도 x를 라디안 단위로 변환합니다. |
| 7 | 도 (x) x의 각도 값을 반환합니다. |
| 8 | pow (x, p) 값 'p'의 거듭 제곱을 x 값으로 반환합니다. |
| 9 | div (x, y) 주어진 두 x, y 정수 값에 대한 나눗셈 결과를 반환합니다. |
| 10 | exp (x) 오일러의 수를 반환합니다. e 숫자의 거듭 제곱으로 올렸습니다. |
| 11 | sqrt (x) x의 제곱근을 반환합니다. |
| 12 | 기호 (x) x의 부호 함수, 즉 −를 반환합니다.
|
| 13 | mod (n, m) n을 m으로 나눈 계수 (나머지)를 반환합니다. |
| 14 | 원형 (x) x에 대해 반올림 된 값을 반환합니다. |
| 15 | cos (x) 코사인 값 (x)을 반환합니다. |
| 16 | asin (x) 역 사인 값 (x)을 반환합니다. |
| 17 | acos (x) 역 코사인 값 (x)을 반환합니다. |
| 18 | atan (x) 역 탄젠트 값 (x)을 반환합니다. |
| 19 | atan2 (y, x) 역 탄젠트 값 (y / x)을 반환합니다. |
데이터 유형 함수
다음 표는 Apache Tajo에서 사용할 수있는 데이터 유형 함수를 나열합니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | to_bin (x) 정수의 이진 표현을 반환합니다. |
| 2 | to_char (int, text) 정수를 문자열로 변환합니다. |
| 삼 | to_hex (x) x 값을 16 진수로 변환합니다. |
다음 표는 Tajo의 문자열 함수를 나열합니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | concat (문자열 1, ..., 문자열 N) 주어진 문자열을 연결합니다. |
| 2 | 길이 (문자열) 주어진 문자열의 길이를 반환합니다. |
| 삼 | 낮은 (문자열) 문자열의 소문자 형식을 반환합니다. |
| 4 | 대문자 (문자열) 주어진 문자열의 대문자 형식을 반환합니다. |
| 5 | ascii (문자열 텍스트) 텍스트 첫 문자의 ASCII 코드를 반환합니다. |
| 6 | bit_length (문자열 텍스트) 문자열의 비트 수를 반환합니다. |
| 7 | char_length (문자열 텍스트) 문자열의 문자 수를 반환합니다. |
| 8 | octet_length (문자열 텍스트) 문자열의 바이트 수를 반환합니다. |
| 9 | digest (입력 텍스트, 메서드 텍스트) 계산 Digest문자열의 해시. 여기서 두 번째 arg 메서드는 해시 메서드를 나타냅니다. |
| 10 | initcap (문자열 텍스트) 각 단어의 첫 글자를 대문자로 변환합니다. |
| 11 | md5 (문자열 텍스트) 계산 MD5 문자열의 해시. |
| 12 | left (문자열 텍스트, 정수 크기) 문자열에서 처음 n 개의 문자를 반환합니다. |
| 13 | right (문자열 텍스트, 정수 크기) 문자열의 마지막 n자를 반환합니다. |
| 14 | 위치 (소스 텍스트, 대상 텍스트, 시작 _ 색인) 지정된 부분 문자열의 위치를 반환합니다. |
| 15 | strposb (소스 텍스트, 대상 텍스트) 지정된 하위 문자열의 이진 위치를 반환합니다. |
| 16 | substr (원본 텍스트, 시작 색인, 길이) 지정된 길이의 하위 문자열을 반환합니다. |
| 17 | trim (문자열 텍스트 [, 문자 텍스트]) 문자열의 시작 / 끝 / 양 끝에서 문자 (기본적으로 공백)를 제거합니다. |
| 18 | split_part (문자열 텍스트, 구분 기호 텍스트, 필드 정수) 구분 기호에서 문자열을 분할하고 주어진 필드를 반환합니다 (하나에서 계산). |
| 19 | regexp_replace (문자열 텍스트, 패턴 텍스트, 대체 텍스트) 주어진 정규식 패턴과 일치하는 부분 문자열을 바꿉니다. |
| 20 | reverse (문자열) 문자열에 대해 역방향 작업이 수행되었습니다. |
Apache Tajo는 다음과 같은 DateTime 함수를 지원합니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | add_days (날짜 날짜 또는 타임 스탬프, int day 주어진 날짜 값으로 더해진 날짜를 반환합니다. |
| 2 | add_months (날짜 날짜 또는 타임 스탬프, int 월) 주어진 월 값으로 더해진 날짜를 반환합니다. |
| 삼 | 현재 _ 날짜 () 오늘 날짜를 반환합니다. |
| 4 | 현재 시간() 오늘의 시간을 반환합니다. |
| 5 | 추출 (날짜 / 시간 소인에서 세기) 주어진 매개 변수에서 세기를 추출합니다. |
| 6 | 추출 (날짜 / 타임 스탬프의 날짜) 주어진 매개 변수에서 일을 추출합니다. |
| 7 | 추출 (날짜 / 타임 스탬프에서 10 년) 주어진 매개 변수에서 10 년을 추출합니다. |
| 8 | 추출 (날짜 다우 날짜 / 타임 스탬프) 주어진 매개 변수에서 요일을 추출합니다. |
| 9 | 추출 (날짜 / 타임 스탬프에서 수행) 주어진 매개 변수에서 일을 추출합니다. |
| 10 | 추출 선택 (타임 스탬프에서 시간) 주어진 매개 변수에서 시간을 추출합니다. |
| 11 | 추출 선택 (타임 스탬프에서 이소 도우) 주어진 매개 변수에서 요일을 추출합니다. 이것은 일요일을 제외하고 다우와 동일합니다. 이는 ISO 8601 요일 번호 지정과 일치합니다. |
| 12 | 추출 선택 (날짜와 동일) 지정된 날짜에서 ISO 연도를 추출합니다. ISO 연도는 그레고리력 연도와 다를 수 있습니다. |
| 13 | 추출 (시간에서 마이크로 초) 주어진 매개 변수에서 마이크로 초를 추출합니다. 분수 부분을 포함한 초 필드에 1000000을 곱한 값입니다. |
| 14 | 추출 (타임 스탬프에서 밀레니엄) 주어진 매개 변수에서 천년을 추출합니다. 천년은 1000 년에 해당합니다. 따라서 3 천년은 2001 년 1 월 1 일에 시작되었습니다. |
| 15 | 추출 (시간에서 밀리 초) 주어진 매개 변수에서 밀리 초를 추출합니다. |
| 16 | 추출 (타임 스탬프에서 분) 주어진 매개 변수에서 분을 추출합니다. |
| 17 | 추출 (타임 스탬프에서 분기) 주어진 매개 변수에서 분기 (1-4)를 추출합니다. |
| 18 | date_part (필드 텍스트, 소스 날짜 또는 타임 스탬프 또는 시간) 텍스트에서 날짜 필드를 추출합니다. |
| 19 | 지금() 현재 타임 스탬프를 반환합니다. |
| 20 | to_char (타임 스탬프, 텍스트 서식) 타임 스탬프를 텍스트로 변환합니다. |
| 21 | to_date (src 텍스트, 서식 텍스트) 텍스트를 날짜로 변환합니다. |
| 22 | to_timestamp (src 텍스트, 형식 텍스트) 텍스트를 타임 스탬프로 변환합니다. |
JSON 함수는 다음 표에 나열되어 있습니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | json_extract_path_text (js on text, json_path 텍스트) 지정된 json 경로를 기반으로 JSON 문자열에서 JSON 문자열을 추출합니다. |
| 2 | json_array_get (json_array 텍스트, 인덱스 int4) 지정된 인덱스의 요소를 JSON 배열로 반환합니다. |
| 삼 | json_array_contains (json_ 배열 텍스트, 값 임의) 주어진 값이 JSON 배열에 있는지 확인합니다. |
| 4 | json_array_length (json_ar ray 텍스트) json 배열의 길이를 반환합니다. |
이 섹션에서는 Tajo DDL 명령에 대해 설명합니다. Tajo에는 이름이 내장 된 데이터베이스가 있습니다.default.
데이터베이스 문 생성
Create DatabaseTajo에서 데이터베이스를 생성하는 데 사용되는 문입니다. 이 명령문의 구문은 다음과 같습니다.
CREATE DATABASE [IF NOT EXISTS] <database_name>질문
default> default> create database if not exists test;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
OKDatabase는 Tajo의 네임 스페이스입니다. 데이터베이스에는 고유 한 이름을 가진 여러 테이블이 포함될 수 있습니다.
현재 데이터베이스 표시
현재 데이터베이스 이름을 확인하려면 다음 명령을 실행하십시오.
질문
default> \c결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
You are now connected to database "default" as user “user1".
default>데이터베이스에 연결
지금까지 "test"라는 데이터베이스를 만들었습니다. 다음 구문은 "test"데이터베이스를 연결하는 데 사용됩니다.
\c <database name>질문
default> \c test결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
You are now connected to database "test" as user “user1”.
test>이제 기본 데이터베이스에서 테스트 데이터베이스로의 프롬프트 변경을 볼 수 있습니다.
데이터베이스 삭제
데이터베이스를 삭제하려면 다음 구문을 사용하십시오.
DROP DATABASE <database-name>질문
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
OK테이블은 하나의 데이터 소스에 대한 논리적보기입니다. 논리적 스키마, 파티션, URL 및 다양한 속성으로 구성됩니다. Tajo 테이블은 HDFS의 디렉토리, 단일 파일, 하나의 HBase 테이블 또는 RDBMS 테이블 일 수 있습니다.
Tajo는 다음 두 가지 유형의 테이블을 지원합니다.
- 외부 테이블
- 내부 테이블
외부 테이블
외부 테이블에는 테이블을 만들 때 위치 속성이 필요합니다. 예를 들어 데이터가 이미 Text / JSON 파일 또는 HBase 테이블로있는 경우 Tajo 외부 테이블로 등록 할 수 있습니다.
다음 쿼리는 외부 테이블 생성의 예입니다.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';여기,
External keyword− 외부 테이블을 생성 할 때 사용합니다. 이렇게하면 지정된 위치에 테이블을 만드는 데 도움이됩니다.
샘플은 테이블 이름을 나타냅니다.
Location− HDFS, Amazon S3, HBase 또는 로컬 파일 시스템을위한 디렉토리입니다. 디렉토리에 대한 위치 속성을 할당하려면 아래 URI 예제를 사용하십시오.
HDFS − hdfs : // localhost : port / path / to / table
Amazon S3 − s3 : // bucket-name / table
local file system − file : /// path / to / table
Openstack Swift − swift : // bucket-name / table
테이블 속성
외부 테이블에는 다음과 같은 속성이 있습니다.
TimeZone − 사용자는 테이블을 읽거나 쓰기위한 시간대를 지정할 수 있습니다.
Compression format− 데이터 크기를 압축하는 데 사용됩니다. 예를 들어, text / json 파일은compression.codec 특성.
내부 테이블
내부 테이블은 Managed Table. 테이블 스페이스라고하는 사전 정의 된 물리적 위치에 생성됩니다.
통사론
create table table1(col1 int,col2 text);기본적으로 Tajo는“conf / tajo-site.xml”에있는“tajo.warehouse.directory”를 사용합니다. 테이블의 새 위치를 지정하려면 테이블 스페이스 구성을 사용할 수 있습니다.
테이블 스페이스
테이블 스페이스는 스토리지 시스템의 위치를 정의하는 데 사용됩니다. 내부 테이블에 대해서만 지원됩니다. 이름으로 테이블 스페이스에 액세스 할 수 있습니다. 각 테이블 스페이스는 다른 스토리지 유형을 사용할 수 있습니다. 테이블 스페이스를 지정하지 않으면 Tajo는 루트 디렉토리의 기본 테이블 스페이스를 사용합니다.
테이블 스페이스 구성
당신은 “conf/tajo-site.xml.template”타조에서. 파일을 복사하고 다음으로 이름을 바꿉니다.“storagesite.json”. 이 파일은 테이블 스페이스에 대한 구성 역할을합니다. Tajo 데이터 형식은 다음 구성을 사용합니다.
HDFS 구성
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase 구성
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}텍스트 파일 구성
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}테이블 스페이스 생성
Tajo의 내부 테이블 레코드는 다른 테이블에서만 액세스 할 수 있습니다. 테이블 스페이스로 구성 할 수 있습니다.
통사론
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]여기,
IF NOT EXISTS − 동일한 테이블이 아직 생성되지 않은 경우 오류를 방지합니다.
TABLESPACE −이 절은 테이블 스페이스 이름을 지정하는 데 사용됩니다.
Storage type − Tajo 데이터는 text, JSON, HBase, Parquet, Sequencefile 및 ORC와 같은 형식을 지원합니다.
AS select statement − 다른 테이블에서 레코드를 선택합니다.
테이블 스페이스 구성
Hadoop 서비스를 시작하고 파일을 엽니 다. “conf/storage-site.json”, 다음 변경 사항을 추가하십시오-
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}여기서 Tajo는 HDFS 위치의 데이터를 참조하고 space1테이블 스페이스 이름입니다. Hadoop 서비스를 시작하지 않으면 테이블 스페이스를 등록 할 수 없습니다.
질문
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;위의 쿼리는 "table1"이라는 테이블을 생성하고 "space1"은 테이블 스페이스 이름을 나타냅니다.
데이터 형식
Tajo는 데이터 형식을 지원합니다. 각 형식을 하나씩 자세히 살펴 보겠습니다.
본문
문자로 구분 된 값의 일반 텍스트 파일은 행과 열로 구성된 테이블 형식 데이터 세트를 나타냅니다. 각 행은 일반 텍스트 행입니다.
테이블 생성
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;여기, “customers.csv” file은 Tajo 설치 디렉토리에있는 쉼표로 구분 된 값 파일을 나타냅니다.
텍스트 형식을 사용하여 내부 테이블을 생성하려면 다음 쿼리를 사용하십시오.
default> create table customer(id int,name text,address text,age int) using text;위 쿼리에서 테이블 스페이스를 할당하지 않았으므로 Tajo의 기본 테이블 스페이스를 사용합니다.
속성
텍스트 파일 형식에는 다음과 같은 속성이 있습니다.
text.delimiter− 이것은 구분 문자입니다. 기본값은 '|'입니다.
compression.codec− 이것은 압축 형식입니다. 기본적으로 비활성화되어 있습니다. 지정된 알고리즘을 사용하여 설정을 변경할 수 있습니다.
timezone − 읽기 또는 쓰기에 사용되는 테이블.
text.error-tolerance.max-num − 최대 허용 오차 수준 수.
text.skip.headerlines − 건너 뛴 헤더 행 수.
text.serde − 이것은 직렬화 속성입니다.
JSON
Apache Tajo는 데이터 쿼리를 위해 JSON 형식을 지원합니다. Tajo는 JSON 객체를 SQL 레코드로 취급합니다. 하나의 개체는 Tajo 테이블의 한 행과 같습니다. 다음과 같이 "array.json"을 고려해 보겠습니다.
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}이 파일을 생성 한 후 Tajo 셸로 전환하고 다음 쿼리를 입력하여 JSON 형식을 사용하여 테이블을 생성합니다.
질문
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;파일 데이터는 테이블 스키마와 일치해야한다는 점을 항상 기억하십시오. 그렇지 않으면 열 이름을 생략하고 열 목록이 필요하지 않은 *를 사용할 수 있습니다.
내부 테이블을 생성하려면 다음 쿼리를 사용하십시오.
default> create table sample (num1 int,num2 text,num3 float) using json;쪽매 세공
Parquet는 열 저장 형식입니다. Tajo는 쉽고 빠르고 효율적인 액세스를 위해 Parquet 형식을 사용합니다.
테이블 생성
다음 쿼리는 테이블 생성의 예입니다-
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Parquet 파일 형식에는 다음과 같은 속성이 있습니다.
parquet.block.size − 메모리에 버퍼링되는 행 그룹의 크기.
parquet.page.size − 페이지 크기는 압축 용입니다.
parquet.compression − 페이지를 압축하는 데 사용되는 압축 알고리즘.
parquet.enable.dictionary − 부울 값은 사전 인코딩을 활성화 / 비활성화하는 것입니다.
RCFile
RCFile은 레코드 컬럼 파일입니다. 이진 키 / 값 쌍으로 구성됩니다.
테이블 생성
다음 쿼리는 테이블 생성의 예입니다-
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile에는 다음과 같은 속성이 있습니다-
rcfile.serde − 커스텀 디시리얼라이저 클래스.
compression.codec − 압축 알고리즘.
rcfile.null − NULL 문자.
SequenceFile
SequenceFile은 키 / 값 쌍으로 구성된 Hadoop의 기본 파일 형식입니다.
테이블 생성
다음 쿼리는 테이블 생성의 예입니다-
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;이 시퀀스 파일은 Hive와 호환됩니다. 이것은 Hive에서 다음과 같이 작성할 수 있습니다.
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar)는 Hive의 열 저장 형식입니다.
테이블 생성
다음 쿼리는 테이블 생성의 예입니다-
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;ORC 형식에는 다음과 같은 속성이 있습니다.
orc.max.merge.distance − ORC 파일을 읽고 거리가 멀어지면 병합합니다.
orc.stripe.size − 이것은 각 스트라이프의 크기입니다.
orc.buffer.size − 기본값은 256KB입니다.
orc.rowindex.stride − 이것은 행 수의 ORC 인덱스 보폭입니다.
이전 장에서 Tajo에서 테이블을 만드는 방법을 이해했습니다. 이 장에서는 Tajo의 SQL 문에 대해 설명합니다.
테이블 문 만들기
테이블 생성으로 이동하기 전에 다음과 같이 Tajo 설치 디렉토리 경로에“students.csv”텍스트 파일을 생성합니다.
students.csv
| 신분증 | 이름 | 주소 | 나이 | 점수 |
|---|---|---|---|---|
| 1 | 아담 | 23 뉴 스트리트 | 21 | 90 |
| 2 | 아밋 | 12 올드 스트리트 | 13 | 95 |
| 3 | 단발 | 10 크로스 스트리트 | 12 | 80 |
| 4 | 데이비드 | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
After the file has been created, move to the terminal and start the Tajo server and shell one by one.
Create Database
Create a new database using the following command −
Query
default> create database sampledb;
OKConnect to the database “sampledb” which is now created.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Then, create a table in “sampledb” as follows −
Query
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Result
The above query will generate the following result.
OKHere, the external table is created. Now, you just have to enter the file location. If you have to assign the table from hdfs then use hdfs instead of file.
Next, the “students.csv” file contains comma separated values. The text.delimiter field is assigned with ‘,’.
You have now created “mytable” successfully in “sampledb”.
Show Table
To show tables in Tajo, use the following query.
Query
sampledb> \d
mytable
sampledb> \d mytableResult
The above query will generate the following result.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4List table
To fetch all the records in the table, type the following query −
Query
sampledb> select * from mytable;Result
The above query will generate the following result.

Insert Table Statement
Tajo uses the following syntax to insert records in table.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo’s insert statement is similar to the INSERT INTO SELECT statement of SQL.
Query
Let’s create a table to overwrite table data of an existing table.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Where 절
Where 절은 테이블에서 레코드를 필터링하는 데 사용됩니다.
질문
sampledb> select * from mytable where id > 5;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
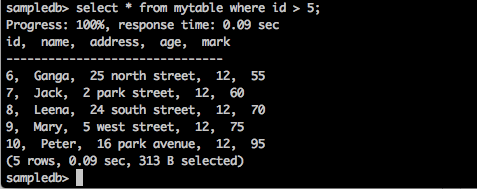
쿼리는 ID가 5보다 큰 학생의 레코드를 반환합니다.
질문
sampledb> select * from mytable where name = ‘Peter’;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12결과는 Peter의 레코드 만 필터링합니다.
고유 조항
테이블 열에 중복 값이 포함될 수 있습니다. DISTINCT 키워드는 고유 한 (다른) 값만 반환하는 데 사용할 수 있습니다.
통사론
SELECT DISTINCT column1,column2 FROM table_name;질문
sampledb> select distinct age from mytable;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12쿼리는 다음과 같은 학생의 고유 한 연령을 반환합니다. mytable.
조항 별 그룹화
GROUP BY 절은 SELECT 문과 공동으로 사용되어 동일한 데이터를 그룹으로 배열합니다.
통사론
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;질문
select age,sum(mark) as sumofmarks from mytable group by age;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
age, sumofmarks
-------------------------------
13, 145
12, 610여기에서 "mytable"열에는 12 세와 13 세라는 두 가지 유형의 연령이 있습니다. 이제 쿼리는 연령별로 레코드를 그룹화하고 해당 학생 연령에 대한 점수 합계를 생성합니다.
조항 있음
HAVING 절을 사용하면 최종 결과에 나타나는 그룹 결과를 필터링하는 조건을 지정할 수 있습니다. WHERE 절은 선택한 열에 조건을 배치하는 반면 HAVING 절은 GROUP BY 절에 의해 생성 된 그룹에 조건을 배치합니다.
통사론
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]질문
sampledb> select age from mytable group by age having sum(mark) > 200;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
age
-------------------------------
12쿼리는 연령별로 레코드를 그룹화하고 조건 결과 sum (mark)> 200 인 경우 연령을 반환합니다.
조항 별 주문
ORDER BY 절은 하나 이상의 열을 기준으로 오름차순 또는 내림차순으로 데이터를 정렬하는 데 사용됩니다. Tajo 데이터베이스는 기본적으로 쿼리 결과를 오름차순으로 정렬합니다.
통사론
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];질문
sampledb> select * from mytable where mark > 60 order by name desc;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.

쿼리는 점수가 60보다 큰 학생의 이름을 내림차순으로 반환합니다.
인덱스 문 생성
CREATE INDEX 문은 테이블에 인덱스를 만드는 데 사용됩니다. 인덱스는 데이터를 빠르게 검색하는 데 사용됩니다. 현재 버전은 HDFS에 저장된 일반 TEXT 형식에 대해서만 인덱스를 지원합니다.
통사론
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }질문
create index student_index on mytable(id);결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
id
———————————————열에 할당 된 인덱스를 보려면 다음 쿼리를 입력하십시오.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )여기서는 Tajo에서 기본적으로 TWO_LEVEL_BIN_TREE 메소드를 사용합니다.
Drop Table 문
Drop Table 문은 데이터베이스에서 테이블을 삭제하는 데 사용됩니다.
통사론
drop table table name;질문
sampledb> drop table mytable;테이블이 테이블에서 삭제되었는지 확인하려면 다음 쿼리를 입력하십시오.
sampledb> \d mytable;결과
위의 쿼리는 다음과 같은 결과를 생성합니다.
ERROR: relation 'mytable' does not exist사용 가능한 Tajo 테이블을 나열하기 위해 "\ d"명령을 사용하여 쿼리를 확인할 수도 있습니다.
이 장에서는 집계 및 창 함수에 대해 자세히 설명합니다.
집계 함수
집계 함수는 입력 값 집합에서 단일 결과를 생성합니다. 다음 표에서는 집계 함수 목록을 자세히 설명합니다.
| S. 아니. | 기능 및 설명 |
|---|---|
| 1 | AVG (exp) 데이터 소스에있는 모든 레코드의 열을 평균합니다. |
| 2 | CORR (식 1, 식 2) 숫자 쌍 집합 간의 상관 계수를 반환합니다. |
| 삼 | 카운트() 행 수를 반환합니다. |
| 4 | MAX (표현식) 선택한 열의 가장 큰 값을 반환합니다. |
| 5 | MIN (표현식) 선택한 열의 가장 작은 값을 반환합니다. |
| 6 | SUM (표현식) 주어진 열의 합계를 반환합니다. |
| 7 | LAST_VALUE (표현식) 주어진 열의 마지막 값을 반환합니다. |
창 기능
Window 함수는 행 집합에서 실행되고 쿼리의 각 행에 대해 단일 값을 반환합니다. 창이라는 용어는 기능에 대한 행 집합의 의미를 갖습니다.
쿼리의 Window 함수는 OVER () 절을 사용하여 창을 정의합니다.
그만큼 OVER() 절에는 다음과 같은 기능이 있습니다.
- 창 파티션을 정의하여 행 그룹을 형성합니다. (PARTITION BY 절)
- 파티션 내에서 행을 정렬합니다. (ORDER BY 절)
다음 표에서는 창 기능에 대해 자세히 설명합니다.
| 함수 | 반환 유형 | 기술 |
|---|---|---|
| 계급() | int | 간격이있는 현재 행의 순위를 반환합니다. |
| row_num () | int | 1부터 계산하여 파티션 내의 현재 행을 반환합니다. |
| 리드 (값 [, 오프셋 정수 [, 기본값 모두]]) | 입력 유형과 동일 | 파티션 내에서 현재 행 뒤의 오프셋 행인 행에서 평가 된 값을 반환합니다. 해당 행이 없으면 기본값이 반환됩니다. |
| lag (값 [, 오프셋 정수 [, 기본값 모두]]) | 입력 유형과 동일 | 파티션 내에서 현재 행 이전의 오프셋 행인 행에서 평가 된 값을 반환합니다. |
| first_value (값) | 입력 유형과 동일 | 입력 행의 첫 번째 값을 반환합니다. |
| last_value (값) | 입력 유형과 동일 | 입력 행의 마지막 값을 반환합니다. |
이 장에서는 다음과 같은 중요한 쿼리에 대해 설명합니다.
- Predicates
- Explain
- Join
계속해서 쿼리를 수행하겠습니다.
술어
술어는 참 / 거짓 값과 UNKNOWN을 평가하는 데 사용되는 표현식입니다. 술어는 WHERE 절과 HAVING 절의 검색 조건 및 부울 값이 필요한 기타 구성에 사용됩니다.
IN 술어
테스트 할 expression의 값이 하위 쿼리 또는 목록의 값과 일치하는지 여부를 확인합니다. 하위 쿼리는 하나의 열과 하나 이상의 행으로 구성된 결과 집합이있는 일반 SELECT 문입니다. 목록의이 열 또는 모든 표현식은 테스트 할 표현식과 동일한 데이터 유형을 가져야합니다.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenue쿼리는 다음에서 레코드를 반환합니다. mytable 학생 ID 2,3 및 4의 경우
Query
select id,name,address from mytable where id not in(2,3,4);Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenue위 쿼리는 다음에서 레코드를 반환합니다. mytable 학생들은 2,3,4에 있지 않습니다.
술어처럼
LIKE 술어는 테스트 할 값으로 참조되는 문자열 값을 계산하기 위해 첫 번째 표현식에 지정된 문자열을 문자열 값 계산을 위해 두 번째 표현식에 정의 된 패턴과 비교합니다.
패턴에는 다음과 같은 와일드 카드 조합이 포함될 수 있습니다.
테스트 할 값에서 단일 문자 대신 사용할 수있는 밑줄 기호 (_)입니다.
테스트 할 값에서 0 개 이상의 문자로 구성된 문자열을 대체하는 백분율 기호 (%).
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95쿼리는 이름이 'A'로 시작하는 학생의 mytable에서 레코드를 반환합니다.
Query
select * from mytable where name like ‘_a%';Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75쿼리는 다음에서 레코드를 반환합니다. mytable 두 번째 문자로 'a'로 시작하는 이름을 가진 학생들의.
검색 조건에서 NULL 값 사용
이제 검색 조건에서 NULL 값을 사용하는 방법을 이해하겠습니다.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)여기서 결과는 참이므로 테이블의 모든 이름을 반환합니다.
Query
이제 NULL 조건으로 쿼리를 확인하겠습니다.
default> select name from mytable where name is null;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)설명
Explain쿼리 실행 계획을 얻는 데 사용됩니다. 명령문의 논리적 및 글로벌 계획 실행을 보여줍니다.
논리적 계획 쿼리
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
위의 쿼리는 다음과 같은 결과를 생성합니다.

쿼리 결과는 주어진 테이블에 대한 논리적 계획 형식을 보여줍니다. 논리 계획은 다음 세 가지 결과를 반환합니다.
- 대상 목록
- 아웃 스키마
- 스키마에서
글로벌 계획 쿼리
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
위의 쿼리는 다음과 같은 결과를 생성합니다.

여기서 글로벌 플랜은 실행 블록 ID, 실행 순서 및 정보를 보여줍니다.
조인
SQL 조인은 둘 이상의 테이블에서 행을 결합하는 데 사용됩니다. 다음은 SQL 조인의 다른 유형입니다-
- 내부 조인
- {왼쪽 | 오른쪽 | 전체} 외부 조인
- 교차 결합
- 셀프 조인
- 자연스러운 결합
조인 작업을 수행하려면 다음 두 테이블을 고려하십시오.
표 1-고객
| 신분증 | 이름 | 주소 | 나이 |
|---|---|---|---|
| 1 | 고객 1 | 23 올드 스트리트 | 21 |
| 2 | 고객 2 | 12 뉴 스트리트 | 23 |
| 3 | 고객 3 | 10 익스프레스 애비뉴 | 22 |
| 4 | 고객 4 | 15 Express Avenue | 22 |
| 5 | 고객 5 | 20 가든 스트리트 | 33 |
| 6 | 고객 6 | 21 노스 스트리트 | 25 |
표 2-customer_order
| 신분증 | 주문 아이디 | Emp ID |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 삼 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
이제 계속해서 위의 두 테이블에서 SQL 조인 작업을 수행하겠습니다.
내부 조인
내부 조인은 두 테이블의 열이 일치하는 경우 두 테이블의 모든 행을 선택합니다.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105쿼리는 두 테이블의 5 개 행과 일치합니다. 따라서 첫 번째 테이블에서 일치하는 행 연령을 반환합니다.
왼쪽 외부 결합
왼쪽 외부 조인은 "오른쪽"테이블에서 일치하는 행이 있는지 여부에 관계없이 "왼쪽"테이블의 모든 행을 유지합니다.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,여기서 왼쪽 외부 조인은 customers (left) 테이블에서 이름 열 행을 반환하고 customer_order (right) 테이블에서 empid 열 일치 행을 반환합니다.
오른쪽 외부 결합
오른쪽 외부 조인은 "왼쪽"테이블에 일치하는 행이 있는지 여부에 관계없이 "오른쪽"테이블의 모든 행을 유지합니다.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105여기에서 Right Outer Join은 customer_order (right) 테이블의 empid 행과 customers 테이블의 행과 일치하는 이름 열을 반환합니다.
전체 외부 결합
완전 외부 조인은 왼쪽 및 오른쪽 테이블의 모든 행을 유지합니다.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.

쿼리는 customers 및 customer_order 테이블 모두에서 일치하는 행과 일치하지 않는 행을 모두 반환합니다.
교차 결합
두 개 이상의 조인 된 테이블에서 레코드 집합의 데카르트 곱을 반환합니다.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
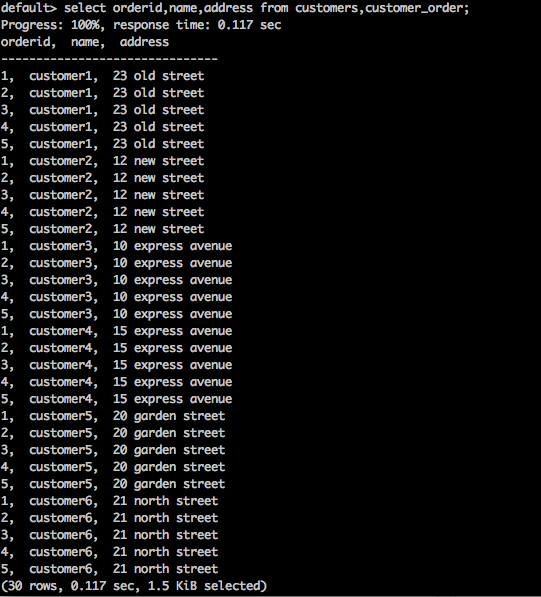
위 쿼리는 테이블의 카티 전 곱을 반환합니다.
자연 조인
Natural Join은 비교 연산자를 사용하지 않습니다. 데카르트 곱이하는 방식을 연결하지 않습니다. 두 관계 사이에 하나 이상의 공통 속성이있는 경우에만 자연 조인을 수행 할 수 있습니다.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.

여기에는 두 테이블 사이에 존재하는 하나의 공통 열 ID가 있습니다. 공통 열을 사용하여Natural Join 두 테이블을 조인합니다.
셀프 조인
SQL SELF JOIN은 테이블이 두 테이블 인 것처럼 테이블을 자신에 조인하는 데 사용되며 SQL 문에서 하나 이상의 테이블 이름을 일시적으로 변경합니다.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
위의 쿼리는 다음과 같은 결과를 생성합니다.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6쿼리는 고객 테이블을 자신에 조인합니다.
Tajo는 다양한 저장 형식을 지원합니다. 스토리지 플러그인 구성을 등록하려면 구성 파일“storage-site.json”에 변경 사항을 추가해야합니다.
storage-site.json
구조는 다음과 같이 정의됩니다-
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}각 스토리지 인스턴스는 URI로 식별됩니다.
PostgreSQL 스토리지 핸들러
Tajo는 PostgreSQL 스토리지 핸들러를 지원합니다. 사용자 쿼리가 PostgreSQL의 데이터베이스 개체에 액세스 할 수 있도록합니다. Tajo의 기본 스토리지 핸들러이므로 쉽게 구성 할 수 있습니다.
구성
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}여기, “database1” 참조 postgreSQL 데이터베이스에 매핑 된 데이터베이스 “sampledb” 타조에서.
Apache Tajo는 HBase 통합을 지원합니다. 이를 통해 Tajo의 HBase 테이블에 액세스 할 수 있습니다. HBase는 Hadoop 파일 시스템 위에 구축 된 분산 열 지향 데이터베이스입니다. Hadoop 파일 시스템의 데이터에 대한 임의의 실시간 읽기 / 쓰기 액세스를 제공하는 Hadoop 에코 시스템의 일부입니다. HBase 통합을 구성하려면 다음 단계가 필요합니다.
환경 변수 설정
“conf / tajo-env.sh”파일에 다음 변경 사항을 추가합니다.
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseHBase 경로를 포함하면 Tajo는 HBase 라이브러리 파일을 클래스 경로로 설정합니다.
외부 테이블 생성
다음 구문을 사용하여 외부 테이블을 만듭니다-
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;HBase 테이블에 액세스하려면 테이블 스페이스 위치를 구성해야합니다.
여기,
Table− hbase 원본 테이블 이름을 설정합니다. 외부 테이블을 만들려면 테이블이 HBase에 있어야합니다.
Columns− 키는 HBase 행 키를 나타냅니다. 열 항목의 수는 Tajo 테이블 열의 수와 같아야합니다.
hbase.zookeeper.quorum − 사육사 쿼럼 주소를 설정합니다.
hbase.zookeeper.property.clientPort − 사육사 클라이언트 포트를 설정합니다.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';여기에서 위치 경로 필드는 사육사 클라이언트 포트 ID를 설정합니다. 포트를 설정하지 않으면 Tajo는 hbase-site.xml 파일의 속성을 참조합니다.
HBase에서 테이블 만들기
다음 쿼리에 표시된대로 "hbase shell"명령을 사용하여 HBase 대화 형 셸을 시작할 수 있습니다.
Query
/bin/hbase shellResult
위의 쿼리는 다음과 같은 결과를 생성합니다.
hbase(main):001:0>HBase를 쿼리하는 단계
HBase를 쿼리하려면 다음 단계를 완료해야합니다.
Step 1 − 다음 명령을 HBase 셸에 파이프하여 "튜토리얼"테이블을 생성합니다.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 − 이제 hbase 셸에서 다음 명령을 실행하여 데이터를 테이블에로드합니다.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 − 이제 Tajo 셸로 돌아가서 다음 명령을 실행하여 테이블의 메타 데이터를 확인합니다. −
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 − 테이블에서 결과를 가져 오려면 다음 쿼리를 사용하세요 −
Query
default> select * from studentsResult
위의 쿼리는 다음 결과를 가져옵니다-
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo는 Apache Hive와 통합하기 위해 HiveCatalogStore를 지원합니다. 이 통합을 통해 Tajo는 Apache Hive의 테이블에 액세스 할 수 있습니다.
환경 변수 설정
“conf / tajo-env.sh”파일에 다음 변경 사항을 추가합니다.
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveHive 경로를 포함하면 Tajo는 Hive 라이브러리 파일을 클래스 경로로 설정합니다.
카탈로그 구성
"conf / catalog-site.xml"파일에 다음 변경 사항을 추가하십시오.
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>HiveCatalogStore가 구성되면 Tajo에서 Hive의 테이블에 액세스 할 수 있습니다.
Swift는 분산되고 일관된 개체 / Blob 저장소입니다. Swift는 간단한 API로 많은 데이터를 저장하고 검색 할 수 있도록 클라우드 스토리지 소프트웨어를 제공합니다. Tajo는 Swift 통합을 지원합니다.
다음은 Swift Integration의 전제 조건입니다-
- Swift
- Hadoop
Core-site.xml
hadoop "core-site.xml"파일에 다음 변경 사항을 추가합니다.
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>이는 Hadoop에서 Swift 객체에 액세스하는 데 사용됩니다. 모든 변경 사항을 적용한 후 Tajo 디렉토리로 이동하여 Swift 환경 변수를 설정하십시오.
conf / tajo-env.h
Tajo 구성 파일을 열고 다음과 같이 환경 변수를 추가하십시오.
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jar이제 Tajo는 Swift를 사용하여 데이터를 쿼리 할 수 있습니다.
테이블 생성
다음과 같이 Tajo에서 Swift 객체에 액세스하기위한 외부 테이블을 생성 해 보겠습니다.
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';테이블이 생성 된 후 SQL 쿼리를 실행할 수 있습니다.
Apache Tajo는 쿼리를 연결하고 실행하기위한 JDBC 인터페이스를 제공합니다. 동일한 JDBC 인터페이스를 사용하여 Java 기반 애플리케이션에서 Tajo를 연결할 수 있습니다. 이제이 섹션에서 JDBC 인터페이스를 사용하여 샘플 Java 애플리케이션에서 Tajo를 연결하고 명령을 실행하는 방법을 이해하겠습니다.
JDBC 드라이버 다운로드
다음 링크를 방문하여 JDBC 드라이버를 다운로드하십시오. http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
이제“tajo-jdbc-0.11.3.jar”파일이 컴퓨터에 다운로드되었습니다.
클래스 경로 설정
프로그램에서 JDBC 드라이버를 사용하려면 다음과 같이 클래스 경로를 설정하십시오.
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHTajo에 연결
Apache Tajo는 JDBC 드라이버를 단일 jar 파일로 제공하며 사용할 수 있습니다. @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
Apache Tajo를 연결하는 연결 문자열은 다음 형식입니다.
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/database여기,
host − TajoMaster의 호스트 이름.
port− 서버가 수신하는 포트 번호. 기본 포트 번호는 26002입니다.
database− 데이터베이스 이름. 기본 데이터베이스 이름은 default입니다.
자바 애플리케이션
이제 Java 애플리케이션을 이해하겠습니다.
코딩
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}다음 명령을 사용하여 응용 프로그램을 컴파일하고 실행할 수 있습니다.
편집
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.java실행
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample결과
위의 명령은 다음 결과를 생성합니다-
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo는 사용자 정의 / 사용자 정의 함수 (UDF)를 지원합니다. 커스텀 함수는 파이썬으로 생성 할 수 있습니다.
커스텀 함수는 데코레이터가있는 평범한 파이썬 함수입니다. “@output_type(<tajo sql datatype>)” 다음과 같이-
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;UDF가있는 Python 스크립트는 아래 구성을 추가하여 등록 할 수 있습니다. “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>스크립트가 등록되면 클러스터를 다시 시작하면 다음과 같이 SQL 쿼리에서 UDF를 바로 사용할 수 있습니다.
select sum_py(10, 10) as pyfn;Apache Tajo는 사용자 정의 집계 함수도 지원하지만 사용자 정의 창 함수는 지원하지 않습니다.