Apache Tajo-SQL 쿼리
이 장에서는 다음과 같은 중요한 쿼리에 대해 설명합니다.
- Predicates
- Explain
- Join
계속해서 쿼리를 수행하겠습니다.
술어
술어는 참 / 거짓 값과 UNKNOWN을 평가하는 데 사용되는 표현식입니다. 술어는 WHERE 절과 HAVING 절의 검색 조건 및 부울 값이 필요한 기타 구성에 사용됩니다.
IN 술어
테스트 할 expression의 값이 하위 쿼리 또는 목록의 값과 일치하는지 여부를 확인합니다. 하위 쿼리는 하나의 열과 하나 이상의 행으로 구성된 결과 집합이있는 일반 SELECT 문입니다. 목록의이 열 또는 모든 표현식은 테스트 할 표현식과 동일한 데이터 유형을 가져야합니다.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
위의 쿼리는 다음 결과를 생성합니다.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenue쿼리는 다음에서 레코드를 반환합니다. mytable 학생 ID 2,3 및 4의 경우
Query
select id,name,address from mytable where id not in(2,3,4);Result
위의 쿼리는 다음 결과를 생성합니다.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenue위의 쿼리는 mytable 학생들은 2,3,4에 있지 않습니다.
술어처럼
LIKE 술어는 테스트 할 값으로 참조되는 문자열 값을 계산하기 위해 첫 번째 표현식에 지정된 문자열을 문자열 값을 계산하기 위해 두 번째 표현식에 정의 된 패턴과 비교합니다.
패턴에는 다음과 같은 와일드 카드 조합이 포함될 수 있습니다.
테스트 할 값에서 단일 문자 대신 사용할 수있는 밑줄 기호 (_).
테스트 할 값에서 0 개 이상의 문자로 구성된 문자열을 대체하는 백분율 기호 (%).
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
위의 쿼리는 다음 결과를 생성합니다.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95쿼리는 이름이 'A'로 시작하는 학생의 mytable에서 레코드를 반환합니다.
Query
select * from mytable where name like ‘_a%';Result
위의 쿼리는 다음 결과를 생성합니다.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75쿼리는 다음에서 레코드를 반환합니다. mytable 두 번째 문자로 'a'로 시작하는 이름을 가진 학생들의.
검색 조건에서 NULL 값 사용
이제 검색 조건에서 NULL 값을 사용하는 방법을 이해하겠습니다.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
위의 쿼리는 다음 결과를 생성합니다.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)여기서 결과는 참이므로 테이블의 모든 이름을 반환합니다.
Query
이제 NULL 조건으로 쿼리를 확인하겠습니다.
default> select name from mytable where name is null;Result
위의 쿼리는 다음 결과를 생성합니다.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)설명
Explain쿼리 실행 계획을 얻는 데 사용됩니다. 명령문의 논리적 및 글로벌 계획 실행을 보여줍니다.
논리적 계획 쿼리
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
위의 쿼리는 다음 결과를 생성합니다.

쿼리 결과는 주어진 테이블에 대한 논리적 계획 형식을 보여줍니다. 논리 계획은 다음 세 가지 결과를 반환합니다.
- 대상 목록
- 아웃 스키마
- 스키마에서
글로벌 계획 쿼리
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
위의 쿼리는 다음 결과를 생성합니다.

여기서 글로벌 플랜은 실행 블록 ID, 실행 순서 및 정보를 보여줍니다.
조인
SQL 조인은 둘 이상의 테이블에서 행을 결합하는 데 사용됩니다. 다음은 SQL 조인의 다른 유형입니다-
- 내부 조인
- {왼쪽 | 오른쪽 | 전체} 외부 조인
- 교차 결합
- 셀프 조인
- 자연스러운 결합
조인 작업을 수행하려면 다음 두 테이블을 고려하십시오.
표 1-고객
| 신분증 | 이름 | 주소 | 나이 |
|---|---|---|---|
| 1 | 고객 1 | 23 올드 스트리트 | 21 |
| 2 | 고객 2 | 12 뉴 스트리트 | 23 |
| 3 | 고객 3 | 10 익스프레스 애비뉴 | 22 |
| 4 | 고객 4 | 15 Express Avenue | 22 |
| 5 | 고객 5 | 20 가든 스트리트 | 33 |
| 6 | 고객 6 | 21 노스 스트리트 | 25 |
표 2-customer_order
| 신분증 | 주문 아이디 | Emp ID |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 삼 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
이제 계속해서 위의 두 테이블에서 SQL 조인 작업을 수행하겠습니다.
내부 조인
내부 조인은 두 테이블의 열이 일치하는 경우 두 테이블의 모든 행을 선택합니다.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음 결과를 생성합니다.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105쿼리는 두 테이블의 5 개 행과 일치합니다. 따라서 첫 번째 테이블에서 일치하는 행 수명을 반환합니다.
왼쪽 외부 결합
왼쪽 외부 조인은 "오른쪽"테이블과 일치하는 행이 있는지 여부에 관계없이 "왼쪽"테이블의 모든 행을 유지합니다.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음 결과를 생성합니다.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,여기서 왼쪽 외부 조인은 customers (left) 테이블에서 이름 열 행을 반환하고 customer_order (right) 테이블에서 empid 열 일치 행을 반환합니다.
오른쪽 외부 결합
오른쪽 외부 조인은 "왼쪽"테이블에 일치하는 행이 있는지 여부에 관계없이 "오른쪽"테이블의 모든 행을 유지합니다.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음 결과를 생성합니다.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105여기서 Right Outer Join은 customer_order (right) 테이블의 empid 행과 customers 테이블의 행과 일치하는 이름 열을 반환합니다.
전체 외부 결합
완전 외부 조인은 왼쪽 및 오른쪽 테이블의 모든 행을 유지합니다.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
위의 쿼리는 다음 결과를 생성합니다.

쿼리는 customers 및 customer_order 테이블 모두에서 일치하는 행과 일치하지 않는 행을 모두 반환합니다.
교차 결합
두 개 이상의 조인 된 테이블에서 레코드 집합의 데카르트 곱을 반환합니다.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
위의 쿼리는 다음 결과를 생성합니다.
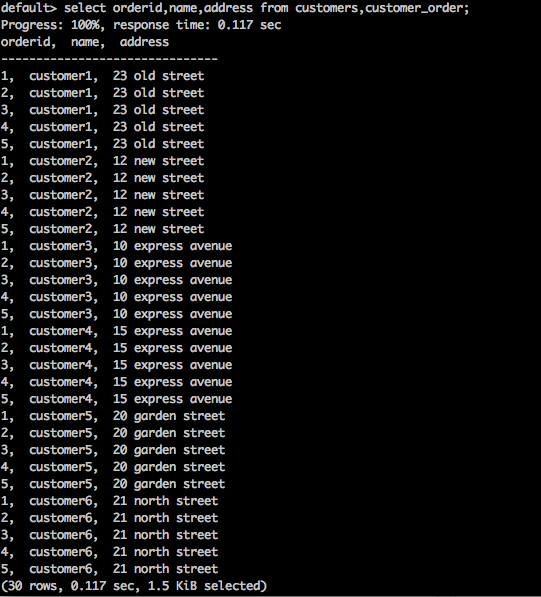
위 쿼리는 테이블의 카티 전 곱을 반환합니다.
자연 조인
Natural Join은 비교 연산자를 사용하지 않습니다. 데카르트 곱이하는 방식을 연결하지 않습니다. 두 관계 사이에 하나 이상의 공통 속성이있는 경우에만 자연 조인을 수행 할 수 있습니다.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
위의 쿼리는 다음 결과를 생성합니다.

여기에는 두 테이블 사이에 존재하는 하나의 공통 열 ID가 있습니다. 공통 열을 사용하여Natural Join 두 테이블을 조인합니다.
셀프 조인
SQL SELF JOIN은 테이블이 두 테이블 인 것처럼 테이블을 자신에 조인하는 데 사용되어 SQL 문에서 하나 이상의 테이블 이름을 일시적으로 변경합니다.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
위의 쿼리는 다음 결과를 생성합니다.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6쿼리는 고객 테이블을 자신에 조인합니다.