Apache Tajo-SQL 문
이전 장에서 Tajo에서 테이블을 만드는 방법을 이해했습니다. 이 장에서는 Tajo의 SQL 문에 대해 설명합니다.
테이블 문 만들기
테이블 생성으로 이동하기 전에 다음과 같이 Tajo 설치 디렉토리 경로에“students.csv”텍스트 파일을 생성합니다.
students.csv
| 신분증 | 이름 | 주소 | 나이 | 점수 |
|---|---|---|---|---|
| 1 | 아담 | 23 뉴 스트리트 | 21 | 90 |
| 2 | 아밋 | 12 올드 스트리트 | 13 | 95 |
| 3 | 단발 | 10 크로스 스트리트 | 12 | 80 |
| 4 | 데이비드 | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 가든 스트리트 | 13 | 50 |
| 6 | Ganga | 25 노스 스트리트 | 12 | 55 |
| 7 | 잭 | 2 파크 스트리트 | 12 | 60 |
| 8 | Leena | 24 사우스 스트리트 | 12 | 70 |
| 9 | 메리 | 5 웨스트 스트리트 | 12 | 75 |
| 10 | 베드로 | 16 파크 애비뉴 | 12 | 95 |
파일이 생성되면 터미널로 이동하여 Tajo 서버와 쉘을 하나씩 시작합니다.
데이터베이스 생성
다음 명령을 사용하여 새 데이터베이스를 만듭니다-
질문
default> create database sampledb;
OK현재 생성 된 "sampledb"데이터베이스에 연결합니다.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.그런 다음 "sampledb"에 다음과 같이 테이블을 만듭니다.
질문
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;결과
위의 쿼리는 다음 결과를 생성합니다.
OK여기에서 외부 테이블이 생성됩니다. 이제 파일 위치를 입력하기 만하면됩니다. hdfs에서 테이블을 할당해야하는 경우 파일 대신 hdfs를 사용하십시오.
다음으로 “students.csv”파일에는 쉼표로 구분 된 값이 있습니다. 그만큼text.delimiter 필드에는 ','가 지정됩니다.
이제 "sampledb"에서 "mytable"을 성공적으로 만들었습니다.
테이블 표시
Tajo에서 테이블을 표시하려면 다음 쿼리를 사용하십시오.
질문
sampledb> \d
mytable
sampledb> \d mytable결과
위의 쿼리는 다음 결과를 생성합니다.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4목록 테이블
테이블의 모든 레코드를 가져 오려면 다음 쿼리를 입력하십시오.
질문
sampledb> select * from mytable;결과
위의 쿼리는 다음 결과를 생성합니다.

테이블 문 삽입
Tajo는 다음 구문을 사용하여 테이블에 레코드를 삽입합니다.
통사론
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo의 삽입 문은 다음과 유사합니다. INSERT INTO SELECT SQL 문.
질문
기존 테이블의 테이블 데이터를 덮어 쓰는 테이블을 만들어 보겠습니다.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \d결과
위의 쿼리는 다음 결과를 생성합니다.
mytable
test레코드 삽입
"test"테이블에 레코드를 삽입하려면 다음 쿼리를 입력합니다.
질문
sampledb> insert overwrite into test select * from mytable;결과
위의 쿼리는 다음 결과를 생성합니다.
Progress: 100%, response time: 0.518 sec여기서 "mytable"레코드는 "test"테이블을 덮어 씁니다. "test"테이블을 생성하지 않으려면 쿼리 삽입에 대한 대체 옵션에서 언급 한대로 물리적 경로 위치를 즉시 할당합니다.
레코드 가져 오기
다음 쿼리를 사용하여 "테스트"테이블의 모든 레코드를 나열합니다.
질문
sampledb> select * from test;결과
위의 쿼리는 다음 결과를 생성합니다.

이 문은 기존 테이블의 열을 추가, 제거 또는 수정하는 데 사용됩니다.
테이블의 이름을 바꾸려면 다음 구문을 사용하십시오-
Alter table table1 RENAME TO table2;질문
sampledb> alter table test rename to students;결과
위의 쿼리는 다음 결과를 생성합니다.
OK변경된 테이블 이름을 확인하려면 다음 쿼리를 사용하십시오.
sampledb> \d
mytable
students이제 "test"테이블이 "students"테이블로 변경되었습니다.
열 추가
“학생”테이블에 새 열을 삽입하려면 다음 구문을 입력하십시오.
Alter table <table_name> ADD COLUMN <column_name> <data_type>질문
sampledb> alter table students add column grade text;결과
위의 쿼리는 다음 결과를 생성합니다.
OK속성 설정
이 속성은 테이블의 속성을 변경하는 데 사용됩니다.
질문
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OK여기에서 압축 유형 및 코덱 속성이 할당됩니다.
텍스트 구분 기호 속성을 변경하려면 다음을 사용하십시오.
질문
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OK결과
위의 쿼리는 다음 결과를 생성합니다.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXT위의 결과는 "SET"속성을 사용하여 테이블의 속성이 변경되었음을 보여줍니다.
Select 문
SELECT 문은 데이터베이스에서 데이터를 선택하는 데 사용됩니다.
Select 문의 구문은 다음과 같습니다.
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Where 절
Where 절은 테이블에서 레코드를 필터링하는 데 사용됩니다.
질문
sampledb> select * from mytable where id > 5;결과
위의 쿼리는 다음 결과를 생성합니다.
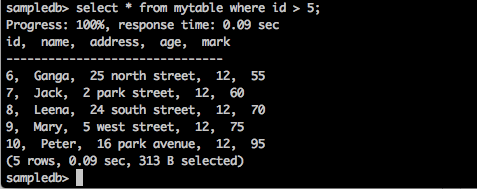
쿼리는 ID가 5보다 큰 학생의 레코드를 반환합니다.
질문
sampledb> select * from mytable where name = ‘Peter’;결과
위의 쿼리는 다음 결과를 생성합니다.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12결과는 Peter의 레코드 만 필터링합니다.
고유 조항
테이블 열에 중복 값이 포함될 수 있습니다. DISTINCT 키워드는 고유 한 (다른) 값만 반환하는 데 사용할 수 있습니다.
통사론
SELECT DISTINCT column1,column2 FROM table_name;질문
sampledb> select distinct age from mytable;결과
위의 쿼리는 다음 결과를 생성합니다.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12이 쿼리는 mytable.
조항 별 그룹화
GROUP BY 절은 SELECT 문과 함께 사용되어 동일한 데이터를 그룹으로 배열합니다.
통사론
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;질문
select age,sum(mark) as sumofmarks from mytable group by age;결과
위의 쿼리는 다음 결과를 생성합니다.
age, sumofmarks
-------------------------------
13, 145
12, 610여기에서 "mytable"열에는 12 세와 13 세라는 두 가지 유형의 연령이 있습니다. 이제 쿼리는 연령별로 레코드를 그룹화하고 해당 학생 연령에 대한 점수 합계를 생성합니다.
조항 있음
HAVING 절을 사용하면 최종 결과에 나타나는 그룹 결과를 필터링하는 조건을 지정할 수 있습니다. WHERE 절은 선택한 열에 조건을 배치하는 반면 HAVING 절은 GROUP BY 절에 의해 생성 된 그룹에 조건을 배치합니다.
통사론
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]질문
sampledb> select age from mytable group by age having sum(mark) > 200;결과
위의 쿼리는 다음 결과를 생성합니다.
age
-------------------------------
12쿼리는 나이별로 레코드를 그룹화하고 조건 결과 sum (mark)> 200 일 때 나이를 반환합니다.
조항 별 주문
ORDER BY 절은 하나 이상의 열을 기준으로 데이터를 오름차순 또는 내림차순으로 정렬하는 데 사용됩니다. Tajo 데이터베이스는 기본적으로 쿼리 결과를 오름차순으로 정렬합니다.
통사론
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];질문
sampledb> select * from mytable where mark > 60 order by name desc;결과
위의 쿼리는 다음 결과를 생성합니다.

쿼리는 점수가 60보다 큰 학생의 이름을 내림차순으로 반환합니다.
인덱스 문 생성
CREATE INDEX 문은 테이블에 인덱스를 만드는 데 사용됩니다. 인덱스는 데이터를 빠르게 검색하는 데 사용됩니다. 현재 버전은 HDFS에 저장된 일반 TEXT 형식에 대해서만 인덱스를 지원합니다.
통사론
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }질문
create index student_index on mytable(id);결과
위의 쿼리는 다음 결과를 생성합니다.
id
———————————————열에 할당 된 인덱스를 보려면 다음 쿼리를 입력하십시오.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )여기서는 Tajo에서 기본적으로 TWO_LEVEL_BIN_TREE 메서드가 사용됩니다.
Drop Table 문
Drop Table 문은 데이터베이스에서 테이블을 삭제하는 데 사용됩니다.
통사론
drop table table name;질문
sampledb> drop table mytable;테이블이 테이블에서 삭제되었는지 확인하려면 다음 쿼리를 입력하십시오.
sampledb> \d mytable;결과
위의 쿼리는 다음 결과를 생성합니다.
ERROR: relation 'mytable' does not exist사용 가능한 Tajo 테이블을 나열하기 위해“\ d”명령을 사용하여 쿼리를 확인할 수도 있습니다.