AVRO-퀵 가이드
네트워크 또는 영구 저장소를 통해 데이터를 전송하려면 데이터를 직렬화해야합니다. 이전serialization APIs Java 및 Hadoop에서 제공하는 특수 유틸리티 인 Avro, 스키마 기반 직렬화 기술.
이 자습서에서는 Avro를 사용하여 데이터를 직렬화 및 역 직렬화하는 방법을 설명합니다. Avro는 다양한 프로그래밍 언어에 대한 라이브러리를 제공합니다. 이 튜토리얼에서는 Java 라이브러리를 사용하는 예제를 보여줍니다.
Avro는 무엇입니까?
Apache Avro는 언어 중립적 인 데이터 직렬화 시스템입니다. Hadoop의 아버지 인 Doug Cutting이 개발했습니다. Hadoop 쓰기 가능 클래스는 언어 이식성이 부족하기 때문에 Avro는 여러 언어로 처리 할 수있는 데이터 형식을 처리하므로 매우 유용합니다. Avro는 Hadoop에서 데이터를 직렬화하는 데 선호되는 도구입니다.
Avro에는 스키마 기반 시스템이 있습니다. 언어 독립적 스키마는 읽기 및 쓰기 작업과 연결됩니다. Avro는 기본 제공 스키마가있는 데이터를 직렬화합니다. Avro는 데이터를 모든 애플리케이션에서 역 직렬화 할 수있는 압축 이진 형식으로 직렬화합니다.
Avro는 JSON 형식을 사용하여 데이터 구조를 선언합니다. 현재 Java, C, C ++, C #, Python 및 Ruby와 같은 언어를 지원합니다.
Avro 스키마
Avro는 schema. 스키마에 대한 사전 지식없이 모든 데이터를 작성할 수 있습니다. 빠르게 직렬화되고 결과로 직렬화 된 데이터의 크기가 더 작습니다. 스키마는 추가 처리를 위해 파일에 Avro 데이터와 함께 저장됩니다.
RPC에서 클라이언트와 서버는 연결 중에 스키마를 교환합니다. 이 교환은 동일한 이름의 필드, 누락 된 필드, 추가 필드 등 간의 통신에 도움이됩니다.
Avro 스키마는 JSON 라이브러리가있는 언어로 구현을 단순화하는 JSON으로 정의됩니다.
Avro와 마찬가지로 Hadoop에는 다음과 같은 다른 직렬화 메커니즘이 있습니다. Sequence Files, Protocol Buffers, 과 Thrift.
Thrift 및 프로토콜 버퍼와의 비교
Thrift 과 Protocol BuffersAvro와 함께 가장 유능한 라이브러리입니다. Avro는 다음과 같은 점에서 이러한 프레임 워크와 다릅니다.
Avro는 요구 사항에 따라 동적 및 정적 유형을 모두 지원합니다. 프로토콜 버퍼 및 Thrift는 IDL (인터페이스 정의 언어)을 사용하여 스키마와 유형을 지정합니다. 이러한 IDL은 직렬화 및 역 직렬화를위한 코드를 생성하는 데 사용됩니다.
Avro는 Hadoop 에코 시스템에 구축되었습니다. Thrift 및 프로토콜 버퍼는 Hadoop 에코 시스템에 구축되지 않습니다.
Thrift 및 Protocol Buffer와 달리 Avro의 스키마 정의는 JSON 형식이며 독점 IDL에는 없습니다.
| 특성 | Avro | 중고품 및 프로토콜 버퍼 |
|---|---|---|
| 동적 스키마 | 예 | 아니 |
| Hadoop에 내장 | 예 | 아니 |
| JSON의 스키마 | 예 | 아니 |
| 컴파일 할 필요가 없습니다. | 예 | 아니 |
| ID를 선언 할 필요가 없습니다. | 예 | 아니 |
| 최첨단 | 예 | 아니 |
Avro의 특징
다음은 Avro의 눈에 띄는 기능 중 일부입니다.
Avro는 language-neutral 데이터 직렬화 시스템.
다양한 언어 (현재 C, C ++, C #, Java, Python 및 Ruby)로 처리 할 수 있습니다.
Avro는 이진 구조화 형식을 생성합니다. compressible 과 splittable. 따라서 Hadoop MapReduce 작업에 대한 입력으로 효율적으로 사용할 수 있습니다.
Avro는 rich data structures. 예를 들어 배열, 열거 유형 및 하위 레코드가 포함 된 레코드를 만들 수 있습니다. 이러한 데이터 유형은 모든 언어로 생성 할 수 있고 Hadoop에서 처리 할 수 있으며 결과를 제 3의 언어로 제공 할 수 있습니다.
Avro schemas 정의 JSON, 이미 JSON 라이브러리가있는 언어로 구현을 용이하게합니다.
Avro 는 메타 데이터 섹션의 스키마와 함께 데이터를 저장하는 Avro Data File 이라는 자체 설명 파일을 생성합니다 .
Avro는 RPC (원격 프로 시저 호출)에서도 사용됩니다. RPC 동안 클라이언트와 서버는 연결 핸드 셰이크에서 스키마를 교환합니다.
Avro의 일반 작업
Avro를 사용하려면 주어진 워크 플로우를 따라야합니다.
Step 1− 스키마를 생성합니다. 여기에서 데이터에 따라 Avro 스키마를 설계해야합니다.
Step 2− 프로그램으로 스키마를 읽어보십시오. 두 가지 방법으로 수행됩니다.
By Generating a Class Corresponding to Schema− Avro를 사용하여 스키마를 컴파일합니다. 그러면 스키마에 해당하는 클래스 파일이 생성됩니다.
By Using Parsers Library − 파서 라이브러리를 사용하여 스키마를 직접 읽을 수 있습니다.
Step 3 − Avro에 제공되는 직렬화 API를 사용하여 데이터를 직렬화합니다. package org.apache.avro.specific.
Step 4 − Avro에 제공되는 역 직렬화 API를 사용하여 데이터를 역 직렬화합니다. package org.apache.avro.specific.
데이터는 두 가지 목표에 대해 직렬화됩니다.
영구 저장 소용
네트워크를 통해 데이터를 전송하려면
직렬화 란 무엇입니까?
직렬화는 데이터 구조 또는 개체 상태를 이진 또는 텍스트 형식으로 변환하여 네트워크를 통해 데이터를 전송하거나 일부 영구 저장소에 저장하는 프로세스입니다. 데이터가 네트워크를 통해 전송되거나 영구 저장소에서 검색되면 다시 직렬화 해제해야합니다. 직렬화는 다음과 같이 불립니다.marshalling 역 직렬화는 다음과 같이 불립니다. unmarshalling.
자바 직렬화
Java는 다음과 같은 메커니즘을 제공합니다. object serialization 여기서 객체는 객체의 데이터와 객체의 유형 및 객체에 저장된 데이터 유형에 대한 정보를 포함하는 바이트 시퀀스로 나타낼 수 있습니다.
직렬화 된 객체가 파일에 기록 된 후 파일에서 읽고 직렬화 해제 할 수 있습니다. 즉, 개체와 데이터를 나타내는 형식 정보와 바이트를 사용하여 메모리에서 개체를 다시 만들 수 있습니다.
ObjectInputStream 과 ObjectOutputStream 클래스는 Java에서 각각 객체를 직렬화 및 역 직렬화하는 데 사용됩니다.
Hadoop의 직렬화
일반적으로 Hadoop과 같은 분산 시스템에서 직렬화 개념은 Interprocess Communication 과 Persistent Storage.
프로세스 간 통신
네트워크에 연결된 노드 간의 프로세스 간 통신을 설정하기 위해 RPC 기술이 사용되었습니다.
RPC는 내부 직렬화를 사용하여 메시지를 네트워크를 통해 원격 노드로 보내기 전에 이진 형식으로 변환했습니다. 다른 쪽 끝에서 원격 시스템은 바이너리 스트림을 원래 메시지로 역 직렬화합니다.
RPC 직렬화 형식은 다음과 같아야합니다.
Compact − 데이터 센터에서 가장 부족한 리소스 인 네트워크 대역폭을 최대한 활용합니다.
Fast − 분산 시스템에서는 노드 간의 통신이 중요하므로 직렬화 및 역 직렬화 프로세스가 빨라야하며 오버 헤드가 줄어 듭니다.
Extensible − 프로토콜은 새로운 요구 사항을 충족하기 위해 시간이 지남에 따라 변경되므로 클라이언트와 서버에 대해 제어 된 방식으로 프로토콜을 발전시키는 것이 간단해야합니다.
Interoperable − 메시지 형식은 다른 언어로 작성된 노드를 지원해야합니다.
영구 저장소
Persistent Storage는 전원 공급이 중단 되어도 데이터가 손실되지 않는 디지털 저장 시설입니다. 파일, 폴더, 데이터베이스는 영구 저장소의 예입니다.
쓰기 가능한 인터페이스
이것은 직렬화 및 역 직렬화를위한 방법을 제공하는 Hadoop의 인터페이스입니다. 다음 표는 방법을 설명합니다-
| S. 아니. | 방법 및 설명 |
|---|---|
| 1 | void readFields(DataInput in) 이 메서드는 지정된 개체의 필드를 deserialize하는 데 사용됩니다. |
| 2 | void write(DataOutput out) 이 메서드는 지정된 개체의 필드를 직렬화하는 데 사용됩니다. |
쓰기 가능한 비교 가능한 인터페이스
그것은 조합입니다 Writable 과 Comparable인터페이스. 이 인터페이스는Writable Hadoop의 인터페이스와 Comparable자바의 인터페이스. 따라서 데이터 직렬화, 역 직렬화 및 비교 방법을 제공합니다.
| S. 아니. | 방법 및 설명 |
|---|---|
| 1 | int compareTo(class obj) 이 메소드는 현재 객체를 주어진 객체 obj와 비교합니다. |
이러한 클래스 외에도 Hadoop은 WritableComparable 인터페이스를 구현하는 여러 래퍼 클래스를 지원합니다. 각 클래스는 Java 기본 유형을 래핑합니다. Hadoop 직렬화의 클래스 계층은 다음과 같습니다.
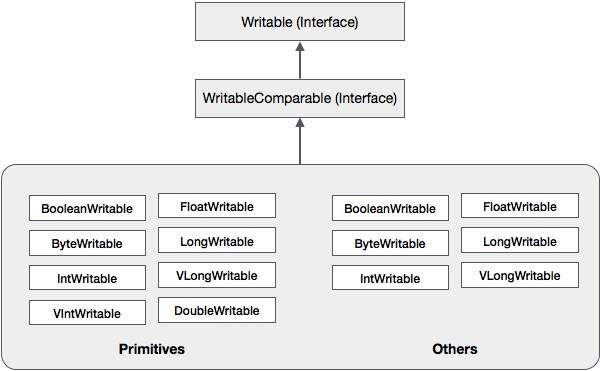
이러한 클래스는 Hadoop에서 다양한 유형의 데이터를 직렬화하는 데 유용합니다. 예를 들어,IntWritable수업. 이 클래스가 Hadoop에서 데이터를 직렬화 및 역 직렬화하는 데 어떻게 사용되는지 살펴 보겠습니다.
IntWritable 클래스
이 클래스는 Writable, Comparable, 과 WritableComparable인터페이스. 정수 데이터 유형을 감 쌉니다. 이 클래스는 정수 유형의 데이터를 직렬화 및 역 직렬화하는 데 사용되는 메서드를 제공합니다.
생성자
| S. 아니. | 요약 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
행동 양식
| S. 아니. | 요약 |
|---|---|
| 1 | int get() 이 방법을 사용하면 현재 개체에있는 정수 값을 가져올 수 있습니다. |
| 2 | void readFields(DataInput in) 이 메서드는 주어진 데이터를 역 직렬화하는 데 사용됩니다. DataInput 목적. |
| 삼 | void set(int value) 이 방법은 현재의 값을 설정하는 데 사용됩니다 IntWritable 목적. |
| 4 | void write(DataOutput out) 이 메소드는 현재 객체의 데이터를 주어진 DataOutput 목적. |
Hadoop에서 데이터 직렬화
정수 유형의 데이터를 직렬화하는 절차는 아래에서 설명합니다.
인스턴스화 IntWritable 정수 값을 래핑하여 클래스.
인스턴스화 ByteArrayOutputStream 수업.
인스턴스화 DataOutputStream 클래스 및 객체 전달 ByteArrayOutputStream 그것에 수업.
다음을 사용하여 IntWritable 개체의 정수 값을 직렬화합니다. write()방법. 이 메서드에는 DataOutputStream 클래스의 개체가 필요합니다.
직렬화 된 데이터는 매개 변수로 전달되는 바이트 배열 객체에 저장됩니다. DataOutputStream인스턴스화시 클래스. 객체의 데이터를 바이트 배열로 변환합니다.
예
다음 예제는 Hadoop에서 정수 유형의 데이터를 직렬화하는 방법을 보여줍니다.
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Hadoop에서 데이터 역 직렬화
정수형 데이터를 역 직렬화하는 절차는 아래에서 설명합니다.
인스턴스화 IntWritable 정수 값을 래핑하여 클래스.
인스턴스화 ByteArrayOutputStream 수업.
인스턴스화 DataOutputStream 클래스 및 객체 전달 ByteArrayOutputStream 그것에 수업.
개체의 데이터를 역 직렬화합니다. DataInputStream 사용 readFields() IntWritable 클래스의 메서드입니다.
역 직렬화 된 데이터는 IntWritable 클래스의 개체에 저장됩니다. 다음을 사용하여이 데이터를 검색 할 수 있습니다.get() 이 클래스의 메서드.
예
다음 예제는 Hadoop에서 정수 유형의 데이터를 역 직렬화하는 방법을 보여줍니다.
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Java 직렬화에 비해 Hadoop의 장점
Hadoop의 쓰기 가능 기반 직렬화는 쓰기 가능한 객체를 재사용하여 객체 생성 오버 헤드를 줄일 수 있습니다. 이는 Java의 기본 직렬화 프레임 워크에서는 불가능합니다.
Hadoop 직렬화의 단점
Hadoop 데이터를 직렬화하려면 두 가지 방법이 있습니다.
당신은 사용할 수 있습니다 Writable Hadoop의 기본 라이브러리에서 제공하는 클래스.
당신은 또한 사용할 수 있습니다 Sequence Files 바이너리 형식으로 데이터를 저장합니다.
이 두 메커니즘의 주요 단점은 Writables 과 SequenceFiles Java API 만 있으며 다른 언어로 쓰거나 읽을 수 없습니다.
따라서 위의 두 가지 메커니즘으로 Hadoop에서 생성 된 파일은 다른 제 3 언어에서 읽을 수 없으므로 Hadoop을 제한된 상자로 만듭니다. 이 단점을 해결하기 위해 Doug Cutting은Avro, 그것은 language independent data structure.
Apache 소프트웨어 기반은 Avro에 다양한 릴리스를 제공합니다. Apache 미러에서 필요한 릴리스를 다운로드 할 수 있습니다. Avro와 함께 작동하도록 환경을 설정하는 방법을 살펴 보겠습니다.
Avro 다운로드
Apache Avro를 다운로드하려면 다음을 진행하십시오.
Apache.org 웹 페이지를 엽니 다 . 아래와 같이 Apache Avro 홈페이지가 표시됩니다.
프로젝트 → 릴리스를 클릭하십시오. 릴리스 목록이 표시됩니다.
다운로드 링크로 연결되는 최신 릴리스를 선택하십시오.
mirror.nexcess 는 아래와 같이 Avro가 지원하는 다양한 언어의 모든 라이브러리 목록을 찾을 수있는 링크 중 하나입니다.

제공된 언어에 대한 라이브러리를 선택하고 다운로드 할 수 있습니다. 이 튜토리얼에서는 Java를 사용합니다. 따라서 jar 파일을 다운로드하십시오.avro-1.7.7.jar 과 avro-tools-1.7.7.jar.
Eclipse와 Avro
Eclipse 환경에서 Avro를 사용하려면 아래 단계를 따라야합니다.
Step 1. 일식을 엽니 다.
Step 2. 프로젝트를 만듭니다.
Step 3.프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다. 바로 가기 메뉴가 나타납니다.
Step 4. 클릭 Build Path. 다른 바로 가기 메뉴로 이동합니다.
Step 5. 클릭 Configure Build Path... 아래와 같이 프로젝트의 속성 창을 볼 수 있습니다.

Step 6. 라이브러리 탭에서 ADD EXternal JARs... 단추.
Step 7. jar 파일 선택 avro-1.77.jar 다운로드했습니다.
Step 8. 클릭 OK.
Maven과 Avro
Maven을 사용하여 Avro 라이브러리를 프로젝트로 가져올 수도 있습니다. 아래에 Avro 용 pom.xml 파일이 있습니다.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>클래스 경로 설정
Linux 환경에서 Avro를 사용하려면 다음 jar 파일을 다운로드하십시오.
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- og4j-core-2.0.beta9.jar.
이러한 파일을 폴더에 복사하고 클래스 경로를./bashrc 아래와 같이 파일.
#class path for Avro
export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
스키마 기반 직렬화 유틸리티 인 Avro는 스키마를 입력으로 받아들입니다. 다양한 스키마를 사용할 수 있지만 Avro는 스키마 정의에 대한 자체 표준을 따릅니다. 이 스키마는 다음 세부 정보를 설명합니다-
- 파일 유형 (기본적으로 기록)
- 기록 위치
- 기록의 이름
- 해당 데이터 유형이있는 레코드의 필드
이러한 스키마를 사용하면 더 적은 공간을 사용하여 직렬화 된 값을 이진 형식으로 저장할 수 있습니다. 이러한 값은 메타 데이터없이 저장됩니다.
Avro 스키마 생성
Avro 스키마는 경량 텍스트 기반 데이터 교환 형식 인 JSON (JavaScript Object Notation) 문서 형식으로 생성됩니다. 다음 방법 중 하나로 생성됩니다.
- JSON 문자열
- JSON 객체
- JSON 배열
Example − 다음 예제는 이름 공간 Tutorialspoint 아래에 이름이 Employee이고 필드 이름과 나이가있는 문서를 정의하는 스키마를 보여줍니다.
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}이 예에서는 각 레코드에 대해 4 개의 필드가 있음을 알 수 있습니다.
type −이 필드는 필드라는 필드 아래뿐만 아니라 문서 아래에도 있습니다.
문서의 경우 여러 필드가 있으므로 일반적으로 레코드 인 문서의 유형을 표시합니다.
필드 인 경우 유형은 데이터 유형을 설명합니다.
namespace −이 필드는 객체가있는 네임 스페이스의 이름을 설명합니다.
name −이 필드는 필드라는 필드 아래뿐만 아니라 문서 아래에도 있습니다.
문서의 경우 스키마 이름을 설명합니다. 네임 스페이스와 함께이 스키마 이름은 저장소 내에서 스키마를 고유하게 식별합니다 (Namespace.schema name). 위의 예에서 스키마의 전체 이름은 Tutorialspoint.Employee입니다.
필드의 경우 필드의 이름을 설명합니다.
Avro의 원시 데이터 유형
Avro 스키마에는 기본 데이터 유형과 복잡한 데이터 유형이 있습니다. 다음 표는primitive data types of Avro −
| 데이터 형식 | 기술 |
|---|---|
| 없는 | Null은 값이없는 유형입니다. |
| int | 32 비트 부호있는 정수. |
| 긴 | 64 비트 부호있는 정수. |
| 흙손 | 단 정밀도 (32 비트) IEEE 754 부동 소수점 숫자. |
| 더블 | 배정 밀도 (64 비트) IEEE 754 부동 소수점 숫자. |
| 바이트 | 8 비트 부호없는 바이트 시퀀스. |
| 끈 | 유니 코드 문자 시퀀스. |
Avro의 복잡한 데이터 유형
원시 데이터 유형과 함께 Avro는 레코드, 열거 형, 배열, 맵, 공용체 및 고정이라는 6 개의 복잡한 데이터 유형을 제공합니다.
기록
Avro의 레코드 데이터 유형은 여러 속성의 모음입니다. 다음 속성을 지원합니다-
name −이 필드의 값은 레코드의 이름을 보유합니다.
namespace −이 필드의 값은 객체가 저장된 네임 스페이스의 이름을 보유합니다.
type −이 속성의 값은 문서 유형 (레코드) 또는 스키마에있는 필드의 데이터 유형을 보유합니다.
fields −이 필드에는 스키마에있는 모든 필드의 목록이있는 JSON 배열이 있으며, 각 필드에는 이름과 유형 속성이 있습니다.
Example
다음은 레코드의 예입니다.
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}열거 형
열거는 컬렉션의 항목 목록이며, Avro 열거는 다음 속성을 지원합니다.
name −이 필드의 값은 열거의 이름을 포함합니다.
namespace −이 필드의 값은 열거의 이름을 규정하는 문자열을 포함합니다.
symbols −이 필드의 값은 열거 형의 기호를 이름 배열로 유지합니다.
Example
다음은 열거의 예입니다.
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}배열
이 데이터 유형은 단일 속성 항목이있는 배열 필드를 정의합니다. 이 항목 속성은 배열의 항목 유형을 지정합니다.
Example
{ " type " : " array ", " items " : " int " }지도
지도 데이터 유형은 키-값 쌍의 배열이며 데이터를 키-값 쌍으로 구성합니다. Avro지도의 키는 문자열이어야합니다. 맵의 값은 맵 컨텐츠의 데이터 유형을 보유합니다.
Example
{"type" : "map", "values" : "int"}연합
통합 데이터 유형은 필드에 하나 이상의 데이터 유형이있을 때마다 사용됩니다. JSON 배열로 표시됩니다. 예를 들어 필드가 int 또는 null 일 수있는 경우 공용체는 [ "int", "null"]로 표시됩니다.
Example
다음은 공용체를 사용하는 예제 문서입니다.
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}결정된
이 데이터 유형은 이진 데이터를 저장하는 데 사용할 수있는 고정 크기 필드를 선언하는 데 사용됩니다. 속성으로 필드 이름과 데이터가 있습니다. Name은 필드의 이름을 보유하고 size는 필드의 크기를 보유합니다.
Example
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}이전 장에서 Avro의 입력 유형, 즉 Avro 스키마에 대해 설명했습니다. 이 장에서는 Avro 스키마의 직렬화 및 역 직렬화에 사용되는 클래스와 메서드를 설명합니다.
SpecificDatumWriter 클래스
이 클래스는 패키지에 속합니다. org.apache.avro.specific. 그것은DatumWriter Java 객체를 메모리 내 직렬 형식으로 변환하는 인터페이스.
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
방법
| S. 아니. | 기술 |
|---|---|
| 1 | SpecificData getSpecificData() 이 라이터가 사용하는 SpecificData 구현을 리턴합니다. |
SpecificDatumReader 클래스
이 클래스는 패키지에 속합니다. org.apache.avro.specific. 그것은DatumReader 스키마의 데이터를 읽고 메모리 내 데이터 표현을 결정하는 인터페이스입니다. SpecificDatumReader 생성 된 Java 클래스를 지원하는 클래스입니다.
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | SpecificDatumReader(Schema schema) 작성자와 독자의 스키마가 동일한 위치를 구성하십시오. |
행동 양식
| S. 아니. | 기술 |
|---|---|
| 1 | SpecificData getSpecificData() 포함 된 SpecificData를 반환합니다. |
| 2 | void setSchema(Schema actual) 이 메소드는 작성자의 스키마를 설정하는 데 사용됩니다. |
DataFileWriter
인스턴스화 DataFileWrite ...에 대한 emp수업. 이 클래스는 파일의 스키마와 함께 스키마를 준수하는 데이터의 시퀀스 직렬화 된 레코드를 작성합니다.
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
행동 양식
| S. 아니 | 기술 |
|---|---|
| 1 | void append(D datum) 파일에 데이텀을 추가합니다. |
| 2 | DataFileWriter<D> appendTo(File file) 이 방법은 기존 파일에 추가하는 작성기를 여는 데 사용됩니다. |
데이터 파일 리더
이 클래스는 다음으로 작성된 파일에 대한 임의 액세스를 제공합니다. DataFileWriter. 클래스를 상속합니다.DataFileStream.
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
행동 양식
| S. 아니. | 기술 |
|---|---|
| 1 | next() 파일에서 다음 데이텀을 읽습니다. |
| 2 | Boolean hasNext() 이 파일에 더 많은 항목이 남아 있으면 true를 반환합니다. |
Schema.parser 클래스
이 클래스는 JSON 형식 스키마의 파서입니다. 스키마를 구문 분석하는 메서드가 포함되어 있습니다. 그것은에 속한다org.apache.avro 꾸러미.
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | Schema.Parser() |
행동 양식
| S. 아니. | 기술 |
|---|---|
| 1 | parse (File file) 제공된 스키마를 구문 분석합니다. file. |
| 2 | parse (InputStream in) 제공된 스키마를 구문 분석합니다. InputStream. |
| 삼 | parse (String s) 제공된 스키마를 구문 분석합니다. String. |
GenricRecord 인터페이스
이 인터페이스는 이름과 색인으로 필드에 액세스하는 방법을 제공합니다.
행동 양식
| S. 아니. | 기술 |
|---|---|
| 1 | Object get(String key) 주어진 필드의 값을 반환합니다. |
| 2 | void put(String key, Object v) 이름이 주어진 필드의 값을 설정합니다. |
GenericData.Record 클래스
건설자
| S. 아니. | 기술 |
|---|---|
| 1 | GenericData.Record(Schema schema) |
행동 양식
| S. 아니. | 기술 |
|---|---|
| 1 | Object get(String key) 주어진 이름의 필드 값을 반환합니다. |
| 2 | Schema getSchema() 이 인스턴스의 스키마를 반환합니다. |
| 삼 | void put(int i, Object v) 스키마에서의 위치가 주어진 필드의 값을 설정합니다. |
| 4 | void put(String key, Object value) 이름이 주어진 필드의 값을 설정합니다. |
스키마에 해당하는 클래스를 생성하거나 파서 라이브러리를 사용하여 Avro 스키마를 프로그램으로 읽을 수 있습니다. 이 장에서는 스키마를 읽는 방법에 대해 설명합니다.by generating a class 과 Serializing Avr을 사용하는 데이터.

클래스를 생성하여 직렬화
Avro를 사용하여 데이터를 직렬화하려면 다음 단계를 따르십시오.
Avro 스키마를 작성합니다.
Avro 유틸리티를 사용하여 스키마를 컴파일합니다. 해당 스키마에 해당하는 Java 코드를 얻습니다.
스키마를 데이터로 채 웁니다.
Avro 라이브러리를 사용하여 직렬화하십시오.
스키마 정의
다음과 같은 세부 사항을 가진 스키마를 원한다고 가정합니다.
| Field | 이름 | 신분증 | 나이 | 봉급 | 주소 |
| type | 끈 | int | int | int | 끈 |
아래와 같이 Avro 스키마를 생성합니다.
다른 이름으로 저장 emp.avsc.
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}스키마 컴파일
Avro 스키마를 생성 한 후 Avro 도구를 사용하여 생성 된 스키마를 컴파일해야합니다. avro-tools-1.7.7.jar 도구가 들어있는 항아리입니다.
Avro 스키마를 컴파일하는 구문
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>홈 폴더에서 터미널을 엽니 다.
아래와 같이 Avro와 함께 작동 할 새 디렉토리를 만듭니다.
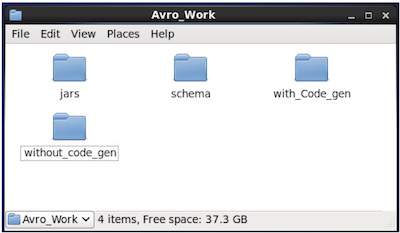
$ mkdir Avro_Work새로 생성 된 디렉토리에 세 개의 하위 디렉토리를 생성합니다.
첫 번째 이름 schema, 스키마를 배치합니다.
두 번째 이름 with_code_gen, 생성 된 코드를 배치합니다.
세 번째 이름 jars, jar 파일을 배치합니다.
$ mkdir schema $ mkdir with_code_gen
$ mkdir jars다음 스크린 샷은 Avro_work 모든 디렉토리를 생성 한 후 폴더는 다음과 같아야합니다.
지금 /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar avro-tools-1.7.7.jar 파일을 다운로드 한 디렉토리의 경로입니다.
/home/Hadoop/Avro_work/schema/ 스키마 파일 emp.avsc가 저장된 디렉토리의 경로입니다.
/home/Hadoop/Avro_work/with_code_gen 생성 된 클래스 파일을 저장할 디렉토리입니다.
이제 아래와 같이 스키마를 컴파일하십시오.
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen컴파일 후 스키마의 네임 스페이스에 따른 패키지가 대상 디렉토리에 생성됩니다. 이 패키지 내에 스키마 이름이있는 Java 소스 코드가 생성됩니다. 이 생성 된 소스 코드는 애플리케이션에서 직접 사용할 수있는 주어진 스키마의 Java 코드입니다.
예를 들어,이 인스턴스에서 이름이 지정된 패키지 / 폴더 tutorialspoint com (네임 스페이스가 tutorialspoint.com이기 때문에)이라는 다른 폴더가 포함 된 폴더가 생성되고 그 안에서 생성 된 파일을 관찰 할 수 있습니다. emp.java. 다음 스냅 샷은emp.java −

이 클래스는 스키마에 따라 데이터를 생성하는 데 유용합니다.
생성 된 클래스에는-
- 기본 생성자 및 스키마의 모든 변수를 허용하는 매개 변수화 된 생성자.
- 스키마의 모든 변수에 대한 setter 및 getter 메서드.
- 스키마를 반환하는 Get () 메서드.
- 빌더 방법.
데이터 생성 및 직렬화
먼저이 프로젝트에서 사용 된 생성 된 Java 파일을 현재 디렉토리에 복사하거나 해당 위치에서 가져옵니다.
이제 새 Java 파일을 작성하고 생성 된 파일에서 클래스를 인스턴스화 할 수 있습니다 (emp)을 클릭하여 직원 데이터를 스키마에 추가합니다.
apache Avro를 사용하여 스키마에 따라 데이터를 생성하는 절차를 살펴 보겠습니다.
1 단계
생성 된 인스턴스화 emp 수업.
emp e1=new emp( );2 단계
setter 메서드를 사용하여 첫 번째 직원의 데이터를 삽입합니다. 예를 들어 Omar라는 직원의 세부 정보를 만들었습니다.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);마찬가지로 setter 메서드를 사용하여 모든 직원 세부 정보를 입력합니다.
3 단계
개체 만들기 DatumWriter 인터페이스를 사용하여 SpecificDatumWriter수업. 이것은 Java 객체를 메모리 내 직렬화 된 형식으로 변환합니다. 다음 예제는 인스턴스화합니다.SpecificDatumWriter 클래스 객체 emp 수업.
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);4 단계
인스턴스화 DataFileWriter ...에 대한 emp수업. 이 클래스는 스키마 자체와 함께 스키마를 준수하는 데이터의 시퀀스 직렬화 된 레코드를 파일에 씁니다. 이 수업에는DatumWriter 생성자에 대한 매개 변수로 객체.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);5 단계
다음을 사용하여 지정된 스키마와 일치하는 데이터를 저장할 새 파일을 엽니 다. create()방법. 이 방법에는 스키마와 데이터가 저장 될 파일의 경로가 매개 변수로 필요합니다.
다음 예에서 스키마는 getSchema() 방법, 데이터 파일은 경로에 저장됩니다- /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));6 단계
다음을 사용하여 생성 된 모든 레코드를 파일에 추가합니다. append() 아래와 같이 방법-
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);예 – 클래스를 생성하여 직렬화
다음 전체 프로그램은 Apache Avro를 사용하여 데이터를 파일로 직렬화하는 방법을 보여줍니다.
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}생성 된 코드가있는 디렉토리를 탐색하십시오. 이 경우home/Hadoop/Avro_work/with_code_gen.
In Terminal −
$ cd home/Hadoop/Avro_work/with_code_gen/In GUI −
이제 위의 프로그램을 복사하여 이름이 지정된 파일에 저장하십시오. Serialize.java
아래와 같이 컴파일하고 실행하십시오-
$ javac Serialize.java
$ java Serialize산출
data successfully serialized프로그램에 주어진 경로를 확인하면 아래와 같이 생성 된 직렬화 파일을 찾을 수 있습니다.
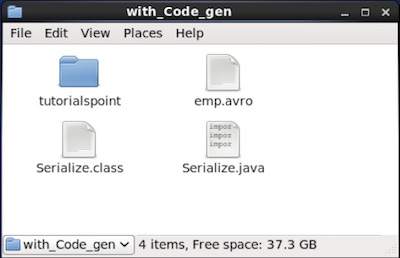
앞에서 설명한 것처럼 스키마에 해당하는 클래스를 생성하거나 파서 라이브러리를 사용하여 Avro 스키마를 프로그램으로 읽을 수 있습니다. 이 장에서는 스키마를 읽는 방법에 대해 설명합니다.by generating a class 과 Deserialize Avro를 사용하여 데이터.
클래스 생성을 통한 역 직렬화
직렬화 된 데이터는 파일에 저장됩니다. emp.avro. Avro를 사용하여 역 직렬화하고 읽을 수 있습니다.

파일에서 직렬화 된 데이터를 역 직렬화하려면 아래 제공된 절차를 따르십시오.
1 단계
개체 만들기 DatumReader 인터페이스 사용 SpecificDatumReader 수업.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);2 단계
인스턴스화 DataFileReader ...에 대한 emp수업. 이 클래스는 파일에서 직렬화 된 데이터를 읽습니다. 그것은Dataumeader 객체 및 직렬화 된 데이터가있는 파일의 경로를 생성자에 대한 매개 변수로 사용합니다.
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);3 단계
다음 방법을 사용하여 역 직렬화 된 데이터를 인쇄합니다. DataFileReader.
그만큼 hasNext() Reader에 요소가있는 경우 메서드는 부울을 반환합니다.
그만큼 next() 의 방법 DataFileReader 판독기에 데이터를 반환합니다.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}예 – 클래스 생성을 통한 역 직렬화
다음 전체 프로그램은 Avro를 사용하여 파일의 데이터를 역 직렬화하는 방법을 보여줍니다.
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}생성 된 코드가있는 디렉토리를 찾습니다. 이 경우home/Hadoop/Avro_work/with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/이제 위의 프로그램을 복사하여 이름이 지정된 파일에 저장하십시오. DeSerialize.java. 아래와 같이 컴파일하고 실행하십시오-
$ javac Deserialize.java $ java Deserialize산출
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}스키마에 해당하는 클래스를 생성하거나 파서 라이브러리를 사용하여 Avro 스키마를 프로그램으로 읽을 수 있습니다. Avro에서 데이터는 항상 해당 스키마와 함께 저장됩니다. 따라서 코드 생성없이 항상 스키마를 읽을 수 있습니다.
이 장에서는 스키마를 읽는 방법에 대해 설명합니다. by using parsers library 그리고 serialize Avro를 사용하여 데이터.

파서 라이브러리를 사용한 직렬화
데이터를 직렬화하려면 스키마를 읽고 스키마에 따라 데이터를 생성 한 다음 Avro API를 사용하여 스키마를 직렬화해야합니다. 다음 절차는 코드를 생성하지 않고 데이터를 직렬화합니다-
1 단계
먼저 파일에서 스키마를 읽으십시오. 이렇게하려면Schema.Parser수업. 이 클래스는 다양한 형식으로 스키마를 구문 분석하는 메서드를 제공합니다.
인스턴스화 Schema.Parser 스키마가 저장된 파일 경로를 전달하여 클래스.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));2 단계
개체 만들기 GenericRecord 인터페이스, 인스턴스화 GenericData.Record아래와 같이 클래스. 위에서 만든 스키마 개체를 생성자에 전달합니다.
GenericRecord e1 = new GenericData.Record(schema);3 단계
다음을 사용하여 스키마에 값을 삽입합니다. put() 의 방법 GenericData 수업.
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");4 단계
개체 만들기 DatumWriter 인터페이스를 사용하여 SpecificDatumWriter수업. Java 개체를 메모리 내 직렬 형식으로 변환합니다. 다음 예제는 인스턴스화합니다.SpecificDatumWriter 클래스 객체 emp 클래스-
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);5 단계
인스턴스화 DataFileWriter ...에 대한 emp수업. 이 클래스는 스키마 자체와 함께 스키마를 준수하는 데이터의 직렬화 된 레코드를 파일에 씁니다. 이 수업에는DatumWriter 생성자에 대한 매개 변수로 객체.
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);6 단계
다음을 사용하여 지정된 스키마와 일치하는 데이터를 저장할 새 파일을 엽니 다. create()방법. 이 방법에는 스키마와 데이터가 저장 될 파일의 경로가 매개 변수로 필요합니다.
아래 주어진 예에서 스키마는 getSchema() 메소드와 데이터 파일이 경로에 저장됩니다.
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));7 단계
다음을 사용하여 생성 된 모든 레코드를 파일에 추가합니다. append( ) 방법은 아래와 같습니다.
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);예 – 파서를 사용한 직렬화
다음 완전한 프로그램은 파서를 사용하여 데이터를 직렬화하는 방법을 보여줍니다-
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}생성 된 코드가있는 디렉토리를 찾습니다. 이 경우home/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/
이제 위의 프로그램을 복사하여 이름이 지정된 파일에 저장하십시오. Serialize.java. 아래와 같이 컴파일하고 실행하십시오-
$ javac Serialize.java
$ java Serialize산출
data successfully serialized프로그램에 주어진 경로를 확인하면 아래와 같이 생성 된 직렬화 파일을 찾을 수 있습니다.
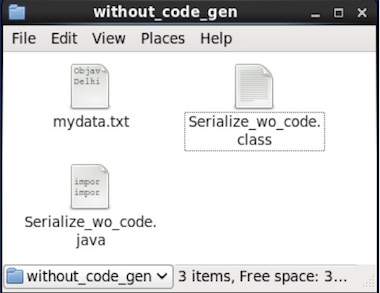
앞서 언급했듯이 스키마에 해당하는 클래스를 생성하거나 파서 라이브러리를 사용하여 Avro 스키마를 프로그램으로 읽을 수 있습니다. Avro에서 데이터는 항상 해당 스키마와 함께 저장됩니다. 따라서 코드 생성없이 항상 직렬화 된 항목을 읽을 수 있습니다.
이 장에서는 스키마를 읽는 방법에 대해 설명합니다. using parsers library 과 Deserializing Avro를 사용하여 데이터.
파서 라이브러리를 사용한 역 직렬화
직렬화 된 데이터는 파일에 저장됩니다. mydata.txt. Avro를 사용하여 역 직렬화하고 읽을 수 있습니다.
파일에서 직렬화 된 데이터를 역 직렬화하려면 아래 제공된 절차를 따르십시오.
1 단계
먼저 파일에서 스키마를 읽으십시오. 이렇게하려면Schema.Parser수업. 이 클래스는 다양한 형식으로 스키마를 구문 분석하는 메서드를 제공합니다.
인스턴스화 Schema.Parser 스키마가 저장된 파일 경로를 전달하여 클래스.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));2 단계
개체 만들기 DatumReader 인터페이스 사용 SpecificDatumReader 수업.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);3 단계
인스턴스화 DataFileReader수업. 이 클래스는 파일에서 직렬화 된 데이터를 읽습니다. 그것은DatumReader 객체 및 직렬화 된 데이터가있는 파일의 경로를 생성자에 대한 매개 변수로 제공합니다.
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);4 단계
다음 방법을 사용하여 역 직렬화 된 데이터를 인쇄합니다. DataFileReader.
그만큼 hasNext() Reader에 요소가있는 경우 메서드는 부울을 반환합니다.
그만큼 next() 의 방법 DataFileReader 판독기에 데이터를 반환합니다.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}예 – 파서 라이브러리를 사용한 역 직렬화
다음 전체 프로그램은 Parsers 라이브러리를 사용하여 직렬화 된 데이터를 역 직렬화하는 방법을 보여줍니다.
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}생성 된 코드가있는 디렉토리를 찾습니다. 이 경우에는home/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/이제 위의 프로그램을 복사하여 이름이 지정된 파일에 저장하십시오. DeSerialize.java. 아래와 같이 컴파일하고 실행하십시오-
$ javac Deserialize.java $ java Deserialize산출
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}