AVRO-직렬화
데이터는 두 가지 목표에 대해 직렬화됩니다.
영구 저장 소용
네트워크를 통해 데이터를 전송하려면
직렬화 란 무엇입니까?
직렬화는 데이터 구조 또는 개체 상태를 이진 또는 텍스트 형식으로 변환하여 네트워크를 통해 데이터를 전송하거나 일부 영구 저장소에 저장하는 프로세스입니다. 데이터가 네트워크를 통해 전송되거나 영구 저장소에서 검색되면 다시 직렬화 해제해야합니다. 직렬화는 다음과 같이 불립니다.marshalling 역 직렬화는 다음과 같이 불립니다. unmarshalling.
자바 직렬화
Java는 다음과 같은 메커니즘을 제공합니다. object serialization 여기서 객체는 객체의 데이터와 객체의 유형 및 객체에 저장된 데이터 유형에 대한 정보를 포함하는 바이트 시퀀스로 나타낼 수 있습니다.
직렬화 된 객체가 파일에 기록 된 후 파일에서 읽고 직렬화 해제 할 수 있습니다. 즉, 개체와 데이터를 나타내는 형식 정보와 바이트를 사용하여 메모리에서 개체를 다시 만들 수 있습니다.
ObjectInputStream 과 ObjectOutputStream 클래스는 Java에서 각각 객체를 직렬화 및 역 직렬화하는 데 사용됩니다.
Hadoop의 직렬화
일반적으로 Hadoop과 같은 분산 시스템에서 직렬화 개념은 Interprocess Communication 과 Persistent Storage.
프로세스 간 통신
네트워크에 연결된 노드 간의 프로세스 간 통신을 설정하기 위해 RPC 기술이 사용되었습니다.
RPC는 내부 직렬화를 사용하여 메시지를 네트워크를 통해 원격 노드로 보내기 전에 이진 형식으로 변환했습니다. 다른 쪽 끝에서 원격 시스템은 바이너리 스트림을 원래 메시지로 역 직렬화합니다.
RPC 직렬화 형식은 다음과 같아야합니다.
Compact − 데이터 센터에서 가장 부족한 리소스 인 네트워크 대역폭을 최대한 활용합니다.
Fast − 분산 시스템에서는 노드 간의 통신이 중요하므로 직렬화 및 역 직렬화 프로세스가 빨라야하며 오버 헤드가 적습니다.
Extensible − 프로토콜은 새로운 요구 사항을 충족하기 위해 시간이 지남에 따라 변경되므로 클라이언트와 서버에 대해 제어 된 방식으로 프로토콜을 발전시키는 것이 간단해야합니다.
Interoperable − 메시지 형식은 다른 언어로 작성된 노드를 지원해야합니다.
영구 저장소
Persistent Storage는 전원 공급이 중단 되어도 데이터가 손실되지 않는 디지털 저장 시설입니다. 파일, 폴더, 데이터베이스는 영구 저장소의 예입니다.
쓰기 가능한 인터페이스
이것은 직렬화 및 역 직렬화를위한 방법을 제공하는 Hadoop의 인터페이스입니다. 다음 표는 방법을 설명합니다-
| S. 아니. | 방법 및 설명 |
|---|---|
| 1 | void readFields(DataInput in) 이 메서드는 지정된 개체의 필드를 deserialize하는 데 사용됩니다. |
| 2 | void write(DataOutput out) 이 메서드는 지정된 개체의 필드를 직렬화하는 데 사용됩니다. |
쓰기 가능한 비교 가능한 인터페이스
그것은 조합입니다 Writable 과 Comparable인터페이스. 이 인터페이스는Writable Hadoop의 인터페이스와 Comparable자바의 인터페이스. 따라서 데이터 직렬화, 역 직렬화 및 비교 방법을 제공합니다.
| S. 아니. | 방법 및 설명 |
|---|---|
| 1 | int compareTo(class obj) 이 메소드는 현재 객체를 주어진 객체 obj와 비교합니다. |
이러한 클래스 외에도 Hadoop은 WritableComparable 인터페이스를 구현하는 여러 래퍼 클래스를 지원합니다. 각 클래스는 Java 기본 유형을 래핑합니다. Hadoop 직렬화의 클래스 계층은 다음과 같습니다.
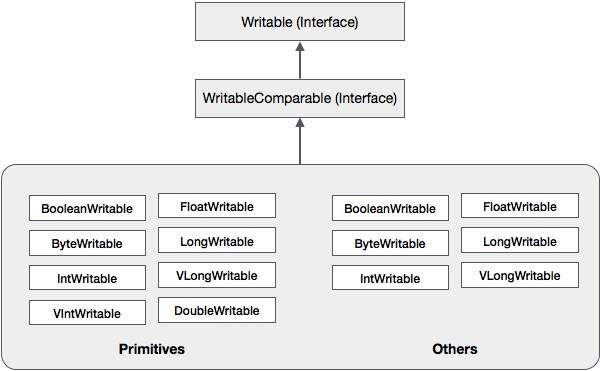
이러한 클래스는 Hadoop에서 다양한 유형의 데이터를 직렬화하는 데 유용합니다. 예를 들어,IntWritable수업. 이 클래스가 Hadoop에서 데이터를 직렬화 및 역 직렬화하는 데 어떻게 사용되는지 살펴 보겠습니다.
IntWritable 클래스
이 클래스는 Writable, Comparable, 과 WritableComparable인터페이스. 정수 데이터 유형을 감 쌉니다. 이 클래스는 정수 유형의 데이터를 직렬화 및 역 직렬화하는 데 사용되는 메서드를 제공합니다.
생성자
| S. 아니. | 요약 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
행동 양식
| S. 아니. | 요약 |
|---|---|
| 1 | int get() 이 방법을 사용하면 현재 개체에있는 정수 값을 가져올 수 있습니다. |
| 2 | void readFields(DataInput in) 이 메서드는 주어진 데이터를 역 직렬화하는 데 사용됩니다. DataInput 목적. |
| 삼 | void set(int value) 이 방법은 현재의 값을 설정하는 데 사용됩니다 IntWritable 목적. |
| 4 | void write(DataOutput out) 이 메소드는 현재 객체의 데이터를 주어진 DataOutput 목적. |
Hadoop에서 데이터 직렬화
정수 유형의 데이터를 직렬화하는 절차는 아래에서 설명합니다.
인스턴스화 IntWritable 정수 값을 래핑하여 클래스.
인스턴스화 ByteArrayOutputStream 수업.
인스턴스화 DataOutputStream 클래스 및 객체 전달 ByteArrayOutputStream 그것에 수업.
다음을 사용하여 IntWritable 개체의 정수 값을 직렬화합니다. write()방법. 이 메서드에는 DataOutputStream 클래스의 개체가 필요합니다.
직렬화 된 데이터는 매개 변수로 전달되는 바이트 배열 객체에 저장됩니다. DataOutputStream인스턴스화시 클래스. 객체의 데이터를 바이트 배열로 변환합니다.
예
다음 예제는 Hadoop에서 정수 유형의 데이터를 직렬화하는 방법을 보여줍니다.
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Hadoop에서 데이터 역 직렬화
정수형 데이터를 역 직렬화하는 절차는 아래에서 설명합니다.
인스턴스화 IntWritable 정수 값을 래핑하여 클래스.
인스턴스화 ByteArrayOutputStream 수업.
인스턴스화 DataOutputStream 클래스 및 객체 전달 ByteArrayOutputStream 그것에 수업.
개체의 데이터를 역 직렬화합니다. DataInputStream 사용 readFields() IntWritable 클래스의 메서드입니다.
역 직렬화 된 데이터는 IntWritable 클래스의 개체에 저장됩니다. 다음을 사용하여이 데이터를 검색 할 수 있습니다.get() 이 클래스의 메서드.
예
다음 예제는 Hadoop에서 정수 유형의 데이터를 역 직렬화하는 방법을 보여줍니다.
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Java 직렬화에 비해 Hadoop의 장점
Hadoop의 쓰기 가능 기반 직렬화는 Java의 기본 직렬화 프레임 워크에서는 불가능한 쓰기 가능 객체를 재사용하여 객체 생성 오버 헤드를 줄일 수 있습니다.
Hadoop 직렬화의 단점
Hadoop 데이터를 직렬화하려면 두 가지 방법이 있습니다.
당신은 사용할 수 있습니다 Writable Hadoop의 기본 라이브러리에서 제공하는 클래스.
당신은 또한 사용할 수 있습니다 Sequence Files 바이너리 형식으로 데이터를 저장합니다.
이 두 메커니즘의 주요 단점은 Writables 과 SequenceFiles Java API 만 있으며 다른 언어로 쓰거나 읽을 수 없습니다.
따라서 위의 두 가지 메커니즘으로 Hadoop에서 생성 된 파일은 다른 제 3 언어로 읽을 수 없으므로 Hadoop을 제한된 상자로 만듭니다. 이 단점을 해결하기 위해 Doug Cutting은Avro, 그것은 language independent data structure.