Gensim-퀵 가이드
이 장은 Gensim의 사용 및 장점과 함께 Gensim의 역사와 기능을 이해하는 데 도움이 될 것입니다.
Gensim은 무엇입니까?
Gensim = “Generate Similar”비지도 주제 모델링에 사용되는 인기있는 오픈 소스 자연어 처리 (NLP) 라이브러리입니다. 그것은 다음과 같은 다양한 복잡한 작업을 수행하기 위해 최고의 학술 모델과 현대 통계 기계 학습을 사용합니다.
- 문서 또는 단어 벡터 작성
- Corpora
- 주제 식별 수행
- 문서 비교 수행 (의미 상 유사한 문서 검색)
- 의미 구조에 대한 일반 텍스트 문서 분석
위의 복잡한 작업을 수행하는 것 외에도 Python 및 Cython으로 구현 된 Gensim은 데이터 스트리밍 및 증분 온라인 알고리즘을 사용하여 대규모 텍스트 컬렉션을 처리하도록 설계되었습니다. 따라서 메모리 내 처리만을 대상으로하는 기계 학습 소프트웨어 패키지와 다릅니다.
역사
2008 년 Gensim은 체코 디지털 수학을위한 다양한 Python 스크립트 모음으로 시작했습니다. 거기에서 특정 기사와 가장 유사한 기사의 짧은 목록을 생성하는 역할을했습니다. 그러나 2009 년에 RARE Technologies Ltd.는 최초 릴리스를 출시했습니다. 그런 다음 2019 년 7 월 말에 안정적인 릴리스 (3.8.0)를 얻었습니다.
다양한 기능
다음은 Gensim이 제공하는 기능 중 일부입니다-
확장 성
Gensim은 증분 온라인 교육 알고리즘을 사용하여 대규모 웹 규모 말뭉치를 쉽게 처리 할 수 있습니다. 전체 입력 코퍼스가 한 번에 RAM (Random Access Memory)에 완전히 상주 할 필요가 없기 때문에 본질적으로 확장 가능합니다. 즉, 모든 알고리즘은 말뭉치 크기와 관련하여 메모리에 독립적입니다.
건장한
Gensim은 본질적으로 견고하며 다양한 사람과 조직에서 4 년 이상 다양한 시스템에서 사용되었습니다. 우리는 우리 자신의 입력 말뭉치 또는 데이터 스트림을 쉽게 연결할 수 있습니다. 다른 벡터 공간 알고리즘으로 확장하는 것도 매우 쉽습니다.
플랫폼 불가지론
Python이 순수 Python이기 때문에 Gensim은 Python 및 Numpy를 지원하는 모든 플랫폼 (Windows, Mac OS, Linux 등)에서 실행되므로 매우 다양한 언어입니다.
효율적인 멀티 코어 구현
머신 클러스터에서 처리 및 검색 속도를 높이기 위해 Gensim은 다음과 같은 다양한 인기 알고리즘의 효율적인 멀티 코어 구현을 제공합니다. Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), Random Projections (RP), Hierarchical Dirichlet Process (HDP).
오픈 소스 및 풍부한 커뮤니티 지원
Gensim은 OSI 승인 GNU LGPL 라이선스에 따라 라이선스가 부여되어 개인용 및 상업용으로 모두 무료로 사용할 수 있습니다. Gensim에서 만든 모든 수정은 차례로 오픈 소스이며 풍부한 커뮤니티 지원도 제공합니다.
Gensim의 용도
Gensim은 수천 개가 넘는 상업 및 학술 응용 프로그램에서 사용되고 인용되었습니다. 다양한 연구 논문과 학생 논문에서도 인용됩니다. 그것은 다음의 스트리밍 병렬 구현을 포함합니다-
fastText
fastText는 단어 임베딩에 신경망을 사용하며, 단어 임베딩 및 텍스트 분류 학습을위한 라이브러리입니다. 페이스 북의 AI Research (FAIR) 연구소에서 만든 것입니다. 기본적으로이 모델을 사용하면 단어에 대한 벡터 표현을 얻기위한 감독 또는 비지도 알고리즘을 만들 수 있습니다.
Word2vec
워드 임베딩을 생성하는 데 사용되는 Word2vec은 얕은 2 층 신경망 모델 그룹입니다. 모델은 기본적으로 단어의 언어 적 맥락을 재구성하도록 훈련되었습니다.
LSA (잠재 의미 분석)
문서 세트와 포함 된 용어 간의 관계를 분석 할 수있는 NLP (Natural Language Processing)의 기술입니다. 문서 및 용어와 관련된 일련의 개념을 생성하여 수행됩니다.
LDA (잠재 디리클레 할당)
관찰되지 않은 그룹이 일련의 관찰을 설명 할 수있는 NLP의 기술입니다. 이 관찰되지 않은 그룹은 데이터의 일부가 유사한 이유를 설명합니다. 그 이유는 생성 적 통계 모델입니다.
tf-idf (용어 빈도-역 문서 빈도)
정보 검색의 숫자 통계 인 tf-idf는 말뭉치의 문서에서 단어가 얼마나 중요한지를 반영합니다. 검색 엔진에서 사용자 쿼리에 따라 문서의 관련성을 평가하고 순위를 매기는 데 자주 사용됩니다. 텍스트 요약 및 분류에서 불용어 필터링에도 사용할 수 있습니다.
이들 모두는 다음 섹션에서 자세히 설명합니다.
장점
Gensim은 토픽 모델링을 수행하는 NLP 패키지입니다. Gensim의 중요한 장점은 다음과 같습니다.
주제 모델링 및 단어 임베딩 기능을 다음과 같은 다른 패키지에 사용할 수 있습니다. ‘scikit-learn’ 과 ‘R’,하지만 Gensim이 토픽 모델 및 단어 임베딩을 구축하기 위해 제공하는 기능은 비교할 수 없습니다. 또한 텍스트 처리를위한보다 편리한 기능을 제공합니다.
Gensim의 또 다른 가장 중요한 장점은 전체 파일을 메모리에로드하지 않고도 대용량 텍스트 파일을 처리 할 수 있다는 것입니다.
Gensim은 감독되지 않은 모델을 사용하기 때문에 값 비싼 주석이나 문서에 손으로 태그를 지정할 필요가 없습니다.
이 장에서는 Gensim 설치를위한 전제 조건, 핵심 종속성 및 현재 버전에 대한 정보에 대해 설명합니다.
전제 조건
Gensim을 설치하려면 컴퓨터에 Python이 설치되어 있어야합니다. www.python.org/downloads/ 링크로 이동하여 Windows 및 Linux / Unix와 같은 OS의 최신 버전을 선택할 수 있습니다 . Python에 대한 기본 자습서는 www.tutorialspoint.com/python3/index.htm 링크를 참조하십시오 . Gensim은 Linux, Windows 및 Mac OS X에서 지원됩니다.
코드 종속성
Gensim은 다음을 지원하는 모든 플랫폼에서 실행되어야합니다. Python 2.7 or 3.5+ 과 NumPy. 실제로 다음 소프트웨어에 따라 다릅니다.
파이썬
Gensim은 Python 버전 2.7, 3.5, 3.6 및 3.7에서 테스트되었습니다.
Numpy
아시다시피 NumPy는 Python을 사용한 과학 컴퓨팅을위한 패키지입니다. 또한 일반 데이터의 효율적인 다차원 컨테이너로 사용할 수도 있습니다. Gensim은 번호 처리를 위해 NumPy 패키지에 의존합니다. Python에 대한 기본 자습서는 www.tutorialspoint.com/numpy/index.htm 링크를 참조하십시오 .
smart_open
Python 2 및 Python 3 라이브러리 인 smart_open은 매우 큰 파일을 효율적으로 스트리밍하는 데 사용됩니다. S3, HDFS, WebHDFS, HTTP, HTTPS, SFTP 또는 로컬 파일 시스템과 같은 스토리지에서 스트리밍을 지원합니다. Gensim은smart_open 원격 저장소의 파일과 압축 파일을 투명하게 여는 Python 라이브러리입니다.
현재 버전
Gensim의 현재 버전은 3.8.0 2019 년 7 월에 출시되었습니다.
터미널을 사용하여 설치
Gensim을 설치하는 가장 간단한 방법 중 하나는 터미널에서 다음 명령을 실행하는 것입니다.
pip install --upgrade gensimConda 환경을 사용하여 설치
Gensim을 다운로드하는 다른 방법은 다음을 사용하는 것입니다. conda환경. 다음 명령을 실행하십시오.conda 터미널-
conda install –c conda-forge gensim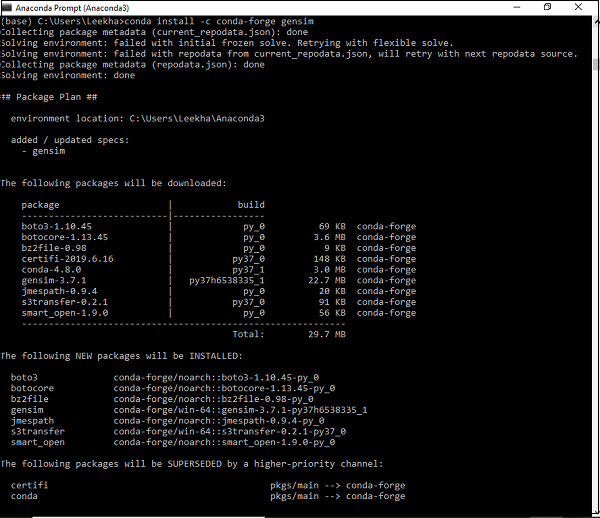
소스 패키지를 사용하여 설치
소스 패키지를 다운로드하고 압축을 푼 경우 다음 명령을 실행해야합니다.
python setup.py test
python setup.py install여기서는 문서와 말뭉치에 중점을 둔 Gensim의 핵심 개념에 대해 배웁니다.
Gensim의 핵심 개념
다음은 Gensim을 이해하고 사용하는 데 필요한 핵심 개념과 용어입니다.
Document − Z 일부 텍스트를 의미합니다.
Corpus − 문서 모음을 의미합니다.
Vector − 문서의 수학적 표현을 벡터라고합니다.
Model − 한 표현에서 다른 표현으로 벡터를 변환하는 데 사용되는 알고리즘을 나타냅니다.
문서 란?
논의한 바와 같이 일부 텍스트를 참조합니다. 자세히 살펴보면 다음과 같이 알려진 텍스트 시퀀스 유형의 객체입니다.‘str’ 예를 들어 Gensim에서 문서는 다음과 같이 될 수 있습니다.
- 140 자 짧은 트윗
- 단일 단락, 즉 기사 또는 연구 논문 초록
- 뉴스 기사
- Book
- Novel
- Theses
텍스트 시퀀스
텍스트 시퀀스 유형은 일반적으로 다음과 같이 알려져 있습니다. ‘str’ 파이썬 3에서 우리가 알고 있듯이, 파이썬에서 텍스트 데이터는 문자열 또는 더 구체적으로 ‘str’사물. 문자열은 기본적으로 유니 코드 코드 포인트의 변경 불가능한 시퀀스이며 다음과 같은 방법으로 작성할 수 있습니다.
Single quotes − 예 : ‘Hi! How are you?’. 또한 큰 따옴표를 포함 할 수 있습니다. 예를 들면‘Hi! “How” are you?’
Double quotes − 예 : "Hi! How are you?". 작은 따옴표도 포함 할 수 있습니다. 예를 들면"Hi! 'How' are you?"
Triple quotes − 다음과 같이 세 개의 작은 따옴표를 가질 수 있습니다. '''Hi! How are you?'''. 또는 다음과 같은 세 개의 큰 따옴표,"""Hi! 'How' are you?"""
모든 공백은 문자열 리터럴에 포함됩니다.
예
다음은 Gensim 문서의 예입니다-
Document = “Tutorialspoint.com is the biggest online tutorials library and it’s all free also”코퍼스는 무엇입니까?
말뭉치는 자연스러운 의사 소통 환경에서 생성 된 크고 구조화 된 기계 판독 가능 텍스트 세트로 정의 될 수 있습니다. Gensim에서는 문서 객체 모음을 말뭉치라고합니다. 말뭉치의 복수는corpora.
Gensim에서 코퍼스의 역할
Gensim의 코퍼스는 다음 두 가지 역할을합니다.
모델 훈련을위한 입력으로 사용
Gensim에서 말뭉치가 수행하는 첫 번째이자 중요한 역할은 모델 훈련을위한 입력입니다. 모델의 내부 매개 변수를 초기화하기 위해 학습 중에 모델은 학습 코퍼스에서 몇 가지 공통 주제와 주제를 찾습니다. 위에서 논의한 바와 같이 Gensim은 감독되지 않은 모델에 초점을 맞추므로 어떤 종류의 인간 개입도 필요하지 않습니다.
주제 추출기로 사용
모델이 학습되면 새 문서에서 주제를 추출하는 데 사용할 수 있습니다. 여기에서 새 문서는 교육 단계에서 사용되지 않는 문서입니다.
예
코퍼스에는 특정인의 모든 트윗, 신문의 모든 기사 목록 또는 특정 주제에 대한 모든 연구 논문 등이 포함될 수 있습니다.
코퍼스 수집
다음은 5 개의 문서를 포함하는 작은 말뭉치의 예입니다. 여기에서 모든 문서는 단일 문장으로 구성된 문자열입니다.
t_corpus = [
"A survey of user opinion of computer system response time",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
]코퍼스 수집 전처리
말뭉치를 수집 한 후에는 말뭉치를 단순하게 유지하기 위해 몇 가지 전처리 단계를 수행해야합니다. 'the'와 같이 일반적으로 사용되는 영어 단어를 간단히 제거 할 수 있습니다. 말뭉치에서 한 번만 나오는 단어를 제거 할 수도 있습니다.
예를 들어, 다음 Python 스크립트는 각 문서를 소문자로 나누고 공백으로 나누고 불용어를 필터링하는 데 사용됩니다.
예
import pprint
t_corpus = [
"A survey of user opinion of computer system response time",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus]
pprint.pprint(processed_corpus)
]산출
[['survey', 'user', 'opinion', 'computer', 'system', 'response', 'time'],
['relation', 'user', 'perceived', 'response', 'time', 'error', 'measurement'],
['generation', 'random', 'binary', 'unordered', 'trees'],
['intersection', 'graph', 'paths', 'trees'],
['graph', 'minors', 'iv', 'widths', 'trees', 'well', 'quasi', 'ordering']]효과적인 전처리
Gensim은 또한 말뭉치의보다 효과적인 전처리 기능을 제공합니다. 이러한 종류의 전처리에서는 문서를 소문자 토큰 목록으로 변환 할 수 있습니다. 너무 짧거나 너무 긴 토큰도 무시할 수 있습니다. 이러한 기능은gensim.utils.simple_preprocess(doc, deacc=False, min_len=2, max_len=15).
gensim.utils.simple_preprocess() fucntion
Gensim은 문서를 소문자 토큰 목록으로 변환하고 너무 짧거나 너무 긴 토큰을 무시하는이 기능을 제공합니다. 다음과 같은 매개 변수가 있습니다.
doc (str)
전처리를 적용해야하는 입력 문서를 의미합니다.
deacc (bool, 선택 사항)
이 매개 변수는 토큰에서 악센트 표시를 제거하는 데 사용됩니다. 그것은 사용합니다deaccent() 이것을하기 위해.
min_len (int, 선택 사항)
이 매개 변수의 도움으로 토큰의 최소 길이를 설정할 수 있습니다. 정의 된 길이보다 짧은 토큰은 폐기됩니다.
max_len (int, 선택 사항)
이 매개 변수의 도움으로 토큰의 최대 길이를 설정할 수 있습니다. 정의 된 길이보다 긴 토큰은 폐기됩니다.
이 함수의 출력은 입력 문서에서 추출 된 토큰입니다.
여기서는 벡터와 모델에 중점을두고 Gensim의 핵심 개념에 대해 배웁니다.
벡터 란?
우리 말뭉치의 잠재 구조를 추론하려면 어떻게해야합니까? 이를 위해 우리는 동일한 것을 수학적으로 조작 할 수있는 방식으로 문서를 표현해야합니다. 인기있는 표현 유형 중 하나는 말뭉치의 모든 문서를 특징 벡터로 표현하는 것입니다. 그래서 벡터는 문서를 수학적으로 편리하게 표현한 것이라고 말할 수 있습니다.
예를 들어, 위에서 사용한 코퍼스의 단일 기능을 QA 쌍으로 표현해 보겠습니다.
Q − 단어는 몇 번입니까? Hello 문서에 표시됩니까?
A − 제로 (0).
Q − 문서에 몇 개의 단락이 있습니까?
A − 두 (2)
질문은 일반적으로 정수 ID로 표시되므로이 문서의 표현은 (1, 0.0), (2, 2.0)과 같은 일련의 쌍입니다. 이러한 벡터 표현은dense벡터. 왜dense, 위의 모든 질문에 대한 명시적인 답변으로 구성되어 있기 때문입니다.
모든 질문을 미리 알고 있다면 표현은 (0, 2)와 같이 간단 할 수 있습니다. 이러한 일련의 답변 (물론 질문이 미리 알려진 경우)은vector 우리 문서를 위해.
또 다른 인기있는 표현은 bag-of-word (BoW)모델. 이 접근 방식에서 각 문서는 기본적으로 사전에있는 모든 단어의 빈도 수를 포함하는 벡터로 표현됩니다.
예를 들어, [ 'Hello', 'How', 'are', 'you']라는 단어가 포함 된 사전이 있다고 가정합니다. 문자열 "How are you how"로 구성된 문서는 벡터 [0, 2, 1, 1]로 표현됩니다. 여기에서 벡터의 항목은 "Hello", "How", "are"및 "you"의 발생 순서입니다.
벡터 대 문서
위의 벡터 설명에서 문서와 벡터의 구분을 거의 알 수 있습니다. 하지만 더 명확하게하기 위해document 텍스트이고 vector텍스트를 수학적으로 편리하게 표현한 것입니다. 불행히도 때때로 많은 사람들이 이러한 용어를 같은 의미로 사용합니다.
예를 들어, 임의의 문서 A가있는 경우 "문서 A에 해당하는 벡터"대신 "벡터 A"또는 "문서 A"라고 말합니다. 이것은 큰 모호성을 가져옵니다. 여기서 주목해야 할 한 가지 더 중요한 점은 두 개의 서로 다른 문서가 동일한 벡터 표현을 가질 수 있다는 것입니다.
말뭉치를 벡터 목록으로 변환
말뭉치를 벡터 목록으로 변환하는 구현 예를 취하기 전에 말뭉치의 각 단어를 고유 한 정수 ID와 연결해야합니다. 이를 위해 위 장에서 가져온 예제를 확장 할 것입니다.
예
from gensim import corpora
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)산출
Dictionary(25 unique tokens: ['computer', 'opinion', 'response', 'survey', 'system']...)우리 말뭉치에 25 개의 서로 다른 토큰이 있음을 보여줍니다. gensim.corpora.Dictionary.
구현 예
사전을 사용하여 토큰 화 된 문서를 다음과 같이 5 가지 식 벡터로 변환 할 수 있습니다.
pprint.pprint(dictionary.token2id)산출
{
'binary': 11,
'computer': 0,
'error': 7,
'generation': 12,
'graph': 16,
'intersection': 17,
'iv': 19,
'measurement': 8,
'minors': 20,
'opinion': 1,
'ordering': 21,
'paths': 18,
'perceived': 9,
'quasi': 22,
'random': 13,
'relation': 10,
'response': 2,
'survey': 3,
'system': 4,
'time': 5,
'trees': 14,
'unordered': 15,
'user': 6,
'well': 23,
'widths': 24
}마찬가지로 문서에 대한 bag-of-word 표현을 다음과 같이 만들 수 있습니다.
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)산출
[
[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1)],
[(2, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1)],
[(11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[(14, 1), (16, 1), (17, 1), (18, 1)],
[(14, 1), (16, 1), (19, 1), (20, 1), (21, 1), (22, 1), (23, 1), (24, 1)]
]모델이란?
말뭉치를 벡터화하면 다음은 무엇입니까? 이제 모델을 사용하여 변환 할 수 있습니다. 모델은 한 문서 표현을 다른 문서 표현으로 변환하는 데 사용되는 알고리즘을 참조 할 수 있습니다.
앞서 논의했듯이 Gensim에서 문서는 벡터로 표시되므로 두 벡터 공간 간의 변환으로 모델링 할 수 있습니다. 모델이 이러한 변환의 세부 사항을 학습하는 훈련 단계가 항상 있습니다. 모델은 훈련 단계에서 훈련 코퍼스를 읽습니다.
모델 초기화
초기화합시다 tf-idf모델. 이 모델은 벡터를 BoW (Bag of Words) 표현에서 코퍼스의 모든 단어의 상대적 희귀도에 따라 빈도 수에 가중치를 부여하는 다른 벡터 공간으로 변환합니다.
구현 예
다음 예제에서 우리는 초기화 할 것입니다 tf-idf모델. 말뭉치에서 학습 한 다음 "trees graph"문자열을 변환합니다.
예
from gensim import models
tfidf = models.TfidfModel(BoW_corpus)
words = "trees graph".lower().split()
print(tfidf[dictionary.doc2bow(words)])산출
[(3, 0.4869354917707381), (4, 0.8734379353188121)]이제 모델을 생성하면 tfidf를 통해 전체 말뭉치를 변환하고 색인을 생성하고 말뭉치의 각 문서에 대해 쿼리 문서 (쿼리 문서 '트리 시스템'제공)의 유사성을 쿼리 할 수 있습니다.
예
from gensim import similarities
index = similarities.SparseMatrixSimilarity(tfidf[BoW_corpus],num_features=5)
query_document = 'trees system'.split()
query_bow = dictionary.doc2bow(query_document)
simils = index[tfidf[query_bow]]
print(list(enumerate(simils)))산출
[(0, 0.0), (1, 0.0), (2, 1.0), (3, 0.4869355), (4, 0.4869355)]위의 결과에서 문서 4와 문서 5의 유사성 점수는 약 49 %입니다.
또한 다음과 같이 가독성을 높이기 위해이 출력을 정렬 할 수도 있습니다.
예
for doc_number, score in sorted(enumerate(sims), key=lambda x: x[1], reverse=True):
print(doc_number, score)산출
2 1.0
3 0.4869355
4 0.4869355
0 0.0
1 0.0벡터와 모델에 대해 논의한 지난 장에서 사전에 대한 아이디어를 얻었습니다. 여기서 우리는Dictionary 개체를 좀 더 자세히 설명합니다.
사전이란 무엇입니까?
사전의 개념에 깊이 들어가기 전에 몇 가지 간단한 NLP 개념을 이해합시다.
Token − 토큰은 '단어'를 의미합니다.
Document − 문서는 문장 또는 단락을 의미합니다.
Corpus − 문서 모음을 단어 모음 (BoW)이라고합니다.
모든 문서에서 말뭉치는 항상 각 단어의 토큰 ID와 문서의 빈도 수를 포함합니다.
Gensim의 사전 개념으로 이동하겠습니다. 텍스트 문서 작업을 위해 Gensim은 단어, 즉 토큰을 고유 ID로 변환해야합니다. 이를 달성하기 위해 우리에게Dictionary object, 각 단어를 고유 한 정수 ID에 매핑합니다. 입력 텍스트를 단어 목록으로 변환 한 다음corpora.Dictionary() 목적.
사전 필요
이제 딕셔너리 객체가 실제로 필요한 것은 무엇이며 어디에서 사용할 수 있는지에 대한 질문이 생깁니다. Gensim에서 사전 객체는 주제 모델링 및 기타 모델에 대한 입력으로 추가로 사용되는 단어 모음 (BoW) 코퍼스를 만드는 데 사용됩니다.
텍스트 입력 형식
입력 텍스트에는 세 가지 형식이 있습니다. Gensim에 제공 할 수 있습니다.
Python의 기본 목록 객체 (로 알려진 str 파이썬 3)
단일 텍스트 파일로 (작거나 큰 파일 일 수 있음)
여러 텍스트 파일
Gensim을 사용하여 사전 생성
논의 된 바와 같이 Gensim에서 사전에는 고유 한 정수 ID에 대한 모든 단어 (일명 토큰)의 매핑이 포함되어 있습니다. 하나 이상의 텍스트 파일 (여러 줄의 텍스트를 포함하는 텍스트 파일)에서 문장 목록에서 사전을 만들 수 있습니다. 자, 먼저 문장 목록을 사용하여 사전을 만들어 보겠습니다.
문장 목록에서
다음 예에서는 문장 목록에서 사전을 만듭니다. 문장 목록이 있거나 여러 문장을 말할 수있는 경우 모든 문장을 단어 목록으로 변환해야하며 이해력은이를 수행하는 매우 일반적인 방법 중 하나입니다.
구현 예
먼저 다음과 같이 필요하고 필요한 패키지를 가져옵니다.
import gensim
from gensim import corpora
from pprint import pprint다음으로, 문장 / 문서 목록에서 이해 목록을 만들어 사전을 만드는 데 사용합니다.
doc = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain."
]다음으로 문장을 단어로 분할해야합니다. 이를 토큰 화라고합니다.
text_tokens = [[text for text in doc.split()] for doc in doc]이제 다음 스크립트의 도움으로 사전을 만들 수 있습니다.
dict_LoS = corpora.Dictionary(text_tokens)이제 딕셔너리에있는 토큰의 수와 같은 더 많은 정보를 얻자-
print(dict_LoS)산출
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)다음과 같이 고유 한 정수 매핑에 대한 단어를 볼 수도 있습니다.
print(dict_LoS.token2id)산출
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19, 'learning': 20,
'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}완전한 구현 예
import gensim
from gensim import corpora
from pprint import pprint
doc = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain."
]
text_tokens = [[text for text in doc.split()] for doc in doc]
dict_LoS = corpora.Dictionary(text_tokens)
print(dict_LoS.token2id)단일 텍스트 파일에서
다음 예에서는 단일 텍스트 파일에서 사전을 생성합니다. 비슷한 방식으로 하나 이상의 텍스트 파일 (예 : 파일 디렉토리)에서 사전을 만들 수도 있습니다.
이를 위해 이전 예제에서 사용 된 문서를 텍스트 파일에 저장했습니다. doc.txt. Gensim은 파일을 한 줄씩 읽고 다음을 사용하여 한 번에 한 줄씩 처리합니다.simple_preprocess. 이런 식으로 전체 파일을 한 번에 메모리에로드 할 필요가 없습니다.
구현 예
먼저 다음과 같이 필요하고 필요한 패키지를 가져옵니다.
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os다음 코드 줄은 doc.txt라는 단일 텍스트 파일을 사용하여 gensim 사전을 만듭니다.
dict_STF = corpora.Dictionary(
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
)이제 딕셔너리에있는 토큰의 수와 같은 더 많은 정보를 얻자-
print(dict_STF)산출
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)다음과 같이 고유 한 정수 매핑에 대한 단어를 볼 수도 있습니다.
print(dict_STF.token2id)산출
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}완전한 구현 예
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os
dict_STF = corpora.Dictionary(
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
)
dict_STF = corpora.Dictionary(text_tokens)
print(dict_STF.token2id)여러 텍스트 파일에서
이제 여러 파일, 즉 동일한 디렉토리에 저장된 둘 이상의 텍스트 파일에서 사전을 만들어 보겠습니다. 이 예에서는 세 개의 다른 텍스트 파일을 만들었습니다.first.txt, second.txt 과 third.txt텍스트 파일 (doc.txt)의 세 줄을 포함하며 이전 예제에서 사용했습니다. 이 세 개의 텍스트 파일은 모두ABC.
구현 예
이를 구현하려면 디렉터리 (ABC)의 세 텍스트 파일 (First, Second, Third.txt)을 모두 반복하고 처리 된 단어 토큰 목록을 생성 할 수있는 메서드로 클래스를 정의해야합니다.
명명 된 클래스를 정의합시다. Read_files __라는 메서드가 있습니다.iteration__ () 다음과 같이-
class Read_files(object):
def __init__(self, directoryname):
elf.directoryname = directoryname
def __iter__(self):
for fname in os.listdir(self.directoryname):
for line in open(os.path.join(self.directoryname, fname), encoding='latin'):
yield simple_preprocess(line)다음으로 다음과 같이 디렉토리의 경로를 제공해야합니다.
path = "ABC"#provide the path as per your computer system where you saved the directory.
다음 단계는 이전 예제에서했던 것과 유사합니다. 다음 코드 줄은 세 개의 텍스트 파일이있는 디렉토리를 사용하여 Gensim 디렉토리를 만듭니다.
dict_MUL = corpora.Dictionary(Read_files(path))산출
Dictionary(27 unique tokens: ['CNTK', 'Computational', 'Network', 'Toolkit', 'as']...)이제 다음과 같이 고유 한 정수 매핑에 대한 단어도 볼 수 있습니다.
print(dict_MUL.token2id)산출
{
'CNTK': 0, 'Computational': 1, 'Network': 2, 'Toolkit': 3, 'as': 4,
'formerly': 5, 'known': 6, 'a': 7, 'commercial-grade': 8, 'easy-to-use': 9,
'free': 10, 'is': 11, 'open-source': 12, 'toolkit': 13, 'algorithms': 14,
'brain.': 15, 'deep': 16, 'enable': 17, 'human': 18, 'learn': 19,
'learning': 20, 'like': 21, 'that': 22, 'the': 23, 'to': 24, 'train': 25, 'us': 26
}Gensim 사전 저장 및로드
Gensim은 자체 네이티브 지원 save() 사전을 디스크에 저장하는 방법 및 load() 디스크에서 사전을 다시로드하는 방법입니다.
예를 들어, 다음 스크립트를 사용하여 사전을 저장할 수 있습니다.
Gensim.corpora.dictionary.save(filename)#provide the path where you want to save the dictionary.
마찬가지로 load () 메서드를 사용하여 저장된 사전을로드 할 수 있습니다. 다음 스크립트는 이것을 할 수 있습니다-
Gensim.corpora.dictionary.load(filename)#provide the path where you have saved the dictionary.
우리는 문서 목록과 텍스트 파일에서 사전을 생성하는 방법을 이해했습니다. 이제이 섹션에서는 BoW (bag-of-words) 말뭉치를 생성합니다. Gensim과 함께 작업하기 위해서는 우리가 익숙해 져야하는 가장 중요한 개체 중 하나입니다. 기본적으로 각 문서에서 단어 id와 빈도를 포함하는 말뭉치입니다.
BoW Corpus 생성
논의 된 바와 같이 Gensim에서 말뭉치는 모든 문서에서 단어 id와 빈도를 포함합니다. 간단한 문서 목록과 텍스트 파일에서 BoW 코퍼스를 만들 수 있습니다. 우리가해야 할 일은 토큰 화 된 단어 목록을 이름이 지정된 객체에 전달하는 것입니다.Dictionary.doc2bow(). 따라서 먼저 간단한 문서 목록을 사용하여 BoW 코퍼스를 생성 해 보겠습니다.
간단한 문장 목록에서
다음 예에서는 세 개의 문장이 포함 된 간단한 목록에서 BoW 말뭉치를 생성합니다.
먼저 다음과 같이 필요한 모든 패키지를 가져와야합니다.
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess이제 문장이 포함 된 목록을 제공하십시오. 목록에는 세 문장이 있습니다.
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]다음으로 다음과 같이 문장의 토큰 화를 수행하십시오.
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]개체 만들기 corpora.Dictionary() 다음과 같이-
dictionary = corpora.Dictionary()이제이 토큰 화 된 문장을 dictionary.doc2bow() object다음과 같이-
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]마침내 Bag of word corpus를 인쇄 할 수 있습니다 −
print(BoW_corpus)산출
[
[(0, 1), (1, 1), (2, 1), (3, 1)],
[(2, 1), (3, 1), (4, 2)], [(0, 2), (3, 3), (5, 2), (6, 1), (7, 2), (8, 1)]
]위의 출력은 id = 0 인 단어가 첫 번째 문서에 한 번 나타나는 것을 보여줍니다 (출력에 (0,1)이 있기 때문에).
위의 출력은 인간이 읽을 수 없습니다. 이 ID를 단어로 변환 할 수도 있지만이를 위해서는 다음과 같이 변환을 수행하기 위해 사전이 필요합니다.
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus]
print(id_words)산출
[
[('are', 1), ('hello', 1), ('how', 1), ('you', 1)],
[('how', 1), ('you', 1), ('do', 2)],
[('are', 2), ('you', 3), ('doing', 2), ('hey', 1), ('what', 2), ('yes', 1)]
]이제 위의 출력은 어떻게 든 사람이 읽을 수 있습니다.
완전한 구현 예
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
print(BoW_corpus)
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus]
print(id_words)텍스트 파일에서
다음 예에서는 텍스트 파일에서 BoW 코퍼스를 생성합니다. 이를 위해 이전 예제에서 사용 된 문서를 텍스트 파일에 저장했습니다.doc.txt..
Gensim은 파일을 한 줄씩 읽고 다음을 사용하여 한 번에 한 줄씩 처리합니다. simple_preprocess. 이런 식으로 전체 파일을 한 번에 메모리에로드 할 필요가 없습니다.
구현 예
먼저 다음과 같이 필요하고 필요한 패키지를 가져옵니다.
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os다음으로, 다음 코드 줄은 doc.txt에서 문서를 읽고 토큰 화합니다.
doc_tokenized = [
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
]
dictionary = corpora.Dictionary()이제 토큰 화 된 단어를 dictionary.doc2bow() 개체 (이전 예에서와 같이)
BoW_corpus = [
dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized
]
print(BoW_corpus)산출
[
[(9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[
(15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1),
(22, 1), (23, 1), (24, 1)
],
[
(23, 2), (25, 1), (26, 1), (27, 1), (28, 1), (29, 1),
(30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 1), (36, 1)
],
[(3, 1), (18, 1), (37, 1), (38, 1), (39, 1), (40, 1), (41, 1), (42, 1), (43, 1)],
[
(18, 1), (27, 1), (31, 2), (32, 1), (38, 1), (41, 1), (43, 1),
(44, 1), (45, 1), (46, 1), (47, 1), (48, 1), (49, 1), (50, 1), (51, 1), (52, 1)
]
]그만큼 doc.txt 파일에는 다음 내용이 있습니다-
이전에 Computational Network Toolkit으로 알려진 CNTK는 인간의 두뇌처럼 학습 할 수 있도록 딥 러닝 알고리즘을 훈련 할 수있는 사용하기 쉬운 무료 오픈 소스 상용 등급 툴킷입니다.
tutorialspoint.com에서 무료 자습서를 찾을 수 있으며 AI 딥 러닝 머신 러닝과 같은 기술에 대한 최고의 기술 자습서를 무료로 제공합니다.
완전한 구현 예
import gensim
from gensim import corpora
from pprint import pprint
from gensim.utils import simple_preprocess
from smart_open import smart_open
import os
doc_tokenized = [
simple_preprocess(line, deacc =True) for line in open(‘doc.txt’, encoding=’utf-8’)
]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
print(BoW_corpus)Gensim Corpus 저장 및로드
다음 스크립트의 도움으로 말뭉치를 저장할 수 있습니다.
corpora.MmCorpus.serialize(‘/Users/Desktop/BoW_corpus.mm’, bow_corpus)#provide the path and the name of the corpus. The name of corpus is BoW_corpus and we saved it in Matrix Market format.
마찬가지로 다음 스크립트를 사용하여 저장된 말뭉치를로드 할 수 있습니다.
corpus_load = corpora.MmCorpus(‘/Users/Desktop/BoW_corpus.mm’)
for line in corpus_load:
print(line)이 장은 Gensim의 다양한 변형에 대해 배우는 데 도움이 될 것입니다. 변형 문서를 이해하는 것으로 시작하겠습니다.
문서 변형
문서 변환은 문서를 수학적으로 조작 할 수있는 방식으로 문서를 표현하는 것을 의미합니다. 말뭉치의 잠재 구조를 추론하는 것 외에도 문서 변환은 다음과 같은 목표를 달성합니다.
단어 사이의 관계를 발견합니다.
그것은 말뭉치의 숨겨진 구조를 드러냅니다.
문서를 새롭고 더 의미있는 방식으로 설명합니다.
문서의 표현을보다 간결하게 만듭니다.
새로운 표현이 더 적은 자원을 소비하므로 효율성이 향상됩니다.
새로운 표현에서 한계 데이터 추세가 무시되기 때문에 효율성이 향상됩니다.
새 문서 표현에서도 노이즈가 줄어 듭니다.
한 벡터 공간 표현에서 다른 벡터 공간 표현으로 문서를 변환하는 구현 단계를 살펴 보겠습니다.
구현 단계
문서를 변환하려면 다음 단계를 따라야합니다.
1 단계 : 코퍼스 만들기
첫 번째이자 기본 단계는 문서에서 말뭉치를 만드는 것입니다. 이전 예제에서 이미 말뭉치를 만들었습니다. 몇 가지 향상된 기능으로 다른 하나를 만들어 보겠습니다 (일반적인 단어와 한 번만 나타나는 단어 제거)-
import gensim
import pprint
from collections import defaultdict
from gensim import corpora이제 말뭉치를 만들기위한 문서를 제공합니다.
t_corpus = [ "이전에는 Computational Network Toolkit으로 알려진 CNTK", "사용하기 쉬운 무료 오픈 소스 상용 등급 툴킷입니다.", "인간의 두뇌처럼 학습 할 수 있도록 딥 러닝 알고리즘을 훈련시킬 수 있습니다.", " tutorialspoint.com에서 무료 자습서를 찾을 수 있습니다. ","Tutorialspoint.com은 AI 딥 러닝 머신 러닝과 같은 기술에 대한 최고의 기술 자습서도 무료로 제공합니다. "]
다음으로 우리는 토큰 화를해야하고 그와 함께 일반적인 단어도 제거 할 것입니다.
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[
word for word in document.lower().split() if word not in stoplist
]
for document in t_corpus
]다음 스크립트는 표시되는 단어 만 제거합니다.
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)산출
[
['toolkit'],
['free', 'toolkit'],
['deep', 'learning', 'like'],
['free', 'on', 'tutorialspoint.com'],
['tutorialspoint.com', 'on', 'like', 'deep', 'learning', 'learning', 'free']
]이제 그것을 corpora.dictionary() 우리 말뭉치에서 고유 한 객체를 얻기위한 객체-
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)산출
Dictionary(7 unique tokens: ['toolkit', 'free', 'deep', 'learning', 'like']...)다음으로, 다음 코드 줄은 우리 코퍼스에 대한 Bag of Word 모델을 생성합니다.
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)산출
[
[(0, 1)],
[(0, 1), (1, 1)],
[(2, 1), (3, 1), (4, 1)],
[(1, 1), (5, 1), (6, 1)],
[(1, 1), (2, 1), (3, 2), (4, 1), (5, 1), (6, 1)]
]2 단계 : 변환 생성
변환은 몇 가지 표준 Python 객체입니다. 훈련 된 말뭉치를 사용하여 이러한 변환, 즉 Python 객체를 초기화 할 수 있습니다. 여기서 우리는tf-idf 훈련 된 말뭉치의 변형을 만드는 모델, 즉 BoW_corpus.
먼저 gensim에서 모델 패키지를 가져와야합니다.
from gensim import models이제 다음과 같이 모델을 초기화해야합니다.
tfidf = models.TfidfModel(BoW_corpus)3 단계 : 벡터 변환
이제이 마지막 단계에서 벡터는 이전 표현에서 새 표현으로 변환됩니다. 위 단계에서 tfidf 모델을 초기화 했으므로 tfidf는 이제 읽기 전용 개체로 처리됩니다. 여기서이 tfidf 객체를 사용하여 벡터를 단어 표현 (이전 표현)에서 Tfidf 실수 값 가중치 (새 표현)로 변환합니다.
doc_BoW = [(1,1),(3,1)]
print(tfidf[doc_BoW]산출
[(1, 0.4869354917707381), (3, 0.8734379353188121)]우리는 말뭉치의 두 값에 변환을 적용했지만 다음과 같이 전체 말뭉치에 적용 할 수도 있습니다.
corpus_tfidf = tfidf[BoW_corpus]
for doc in corpus_tfidf:
print(doc)산출
[(0, 1.0)]
[(0, 0.8734379353188121), (1, 0.4869354917707381)]
[(2, 0.5773502691896257), (3, 0.5773502691896257), (4, 0.5773502691896257)]
[(1, 0.3667400603126873), (5, 0.657838022678017), (6, 0.657838022678017)]
[
(1, 0.19338287240886842), (2, 0.34687949360312714), (3, 0.6937589872062543),
(4, 0.34687949360312714), (5, 0.34687949360312714), (6, 0.34687949360312714)
]완전한 구현 예
import gensim
import pprint
from collections import defaultdict
from gensim import corpora
t_corpus = [
"CNTK formerly known as Computational Network Toolkit",
"is a free easy-to-use open-source commercial-grade toolkit",
"that enable us to train deep learning algorithms to learn like the human brain.",
"You can find its free tutorial on tutorialspoint.com",
"Tutorialspoint.com also provide best technical tutorials on
technologies like AI deep learning machine learning for free"
]
stoplist = set('for a of the and to in'.split(' '))
processed_corpus = [
[word for word in document.lower().split() if word not in stoplist]
for document in t_corpus
]
frequency = defaultdict(int)
for text in processed_corpus:
for token in text:
frequency[token] += 1
processed_corpus = [
[token for token in text if frequency[token] > 1]
for text in processed_corpus
]
pprint.pprint(processed_corpus)
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)
BoW_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
pprint.pprint(BoW_corpus)
from gensim import models
tfidf = models.TfidfModel(BoW_corpus)
doc_BoW = [(1,1),(3,1)]
print(tfidf[doc_BoW])
corpus_tfidf = tfidf[BoW_corpus]
for doc in corpus_tfidf:
print(doc)Gensim의 다양한 변환
Gensim을 사용하여 다양한 인기 변환, 즉 벡터 공간 모델 알고리즘을 구현할 수 있습니다. 그들 중 일부는 다음과 같습니다-
Tf-Idf (용어 주파수-역 문서 주파수)
초기화 중에이 tf-idf 모델 알고리즘은 정수 값 (예 : Bag-of-Words 모델)을 갖는 학습 코퍼스를 예상합니다. 그런 다음 변환 할 때 벡터 표현을 가져와 다른 벡터 표현을 반환합니다.
출력 벡터는 동일한 차원을 갖지만 희귀 기능의 값 (훈련 시점)이 증가합니다. 기본적으로 정수 값 벡터를 실수 벡터로 변환합니다. 다음은 Tf-idf 변환의 구문입니다-
Model=models.TfidfModel(corpus, normalize=True)LSI (Latent Semantic Indexing)
LSI 모델 알고리즘은 정수 값 벡터 모델 (예 : Bag-of-Words 모델) 또는 Tf-Idf 가중치 공간에서 잠복 공간으로 문서를 변환 할 수 있습니다. 출력 벡터는 더 낮은 차원입니다. 다음은 LSI 변환의 구문입니다-
Model=models.LsiModel(tfidf_corpus, id2word=dictionary, num_topics=300)LDA (Latent Dirichlet Allocation)
LDA 모델 알고리즘은 Bag-of-Words 모델 공간에서 토픽 공간으로 문서를 변환하는 또 다른 알고리즘입니다. 출력 벡터는 더 낮은 차원입니다. 다음은 LSI 변환의 구문입니다-
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)무작위 투영 (RP)
매우 효율적인 접근 방식 인 RP는 벡터 공간의 차원을 줄이는 것을 목표로합니다. 이 접근 방식은 기본적으로 문서 간의 Tf-Idf 거리에 가깝습니다. 이것은 약간의 무작위성을 던져서 수행합니다.
Model=models.RpModel(tfidf_corpus, num_topics=500)계층 적 디리클레 프로세스 (HDP)
HDP는 Gensim에 새로 추가 된 비모수 베이지안 방법입니다. 우리는 그것을 사용하는 동안주의를 기울여야합니다.
Model=models.HdpModel(corpus, id2word=dictionary여기에서는 Gensim의 도움으로 TF-IDF (Term Frequency-Inverse Document Frequency) 매트릭스를 만드는 방법에 대해 알아 봅니다.
TF-IDF 란 무엇입니까?
백 오브 워드 (bag-of-words) 모델이기도 한 Term Frequency-Inverse Document Frequency 모델입니다. 토큰에 가중치를 부여하기 때문에 일반 말뭉치와 다릅니다. 즉, 문서에서 자주 나타나는 단어입니다. 초기화 중에이 tf-idf 모델 알고리즘은 정수 값 (예 : Bag-of-Words 모델)을 갖는 학습 코퍼스를 예상합니다.
그런 다음 변환시 벡터 표현을 취하고 다른 벡터 표현을 반환합니다. 출력 벡터는 동일한 차원을 갖지만 희귀 기능의 값 (훈련 시점)이 증가합니다. 기본적으로 정수 값 벡터를 실수 벡터로 변환합니다.
계산 방법
TF-IDF 모델은 다음 두 가지 간단한 단계를 통해 tfidf를 계산합니다.
1 단계 : 로컬 및 글로벌 구성 요소 곱하기
이 첫 번째 단계에서 모델은 TF (Term Frequency)와 같은 로컬 구성 요소를 IDF (Inverse Document Frequency)와 같은 전역 구성 요소와 곱합니다.
2 단계 : 결과 정규화
곱셈이 끝나면 다음 단계에서 TFIDF 모델은 결과를 단위 길이로 정규화합니다.
위의 두 단계의 결과로 문서 전체에서 자주 발생하는 단어의 가중치가 낮아집니다.
TF-IDF 가중치를 얻는 방법?
여기에서는 TF-IDF 가중치를 얻는 방법을보기위한 예제를 구현할 것입니다. 기본적으로 TF-IDF 가중치를 얻으려면 먼저 말뭉치를 훈련 한 다음 해당 말뭉치를 tfidf 모델 내에서 적용해야합니다.
코퍼스 훈련
위에서 말했듯이 TF-IDF를 얻으려면 먼저 말뭉치를 훈련해야합니다. 먼저 다음과 같이 필요한 모든 패키지를 가져와야합니다.
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess이제 문장이 포함 된 목록을 제공하십시오. 목록에는 세 문장이 있습니다.
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]다음으로 다음과 같이 문장의 토큰 화를 수행하십시오.
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]개체 만들기 corpora.Dictionary() 다음과 같이-
dictionary = corpora.Dictionary()이제이 토큰 화 된 문장을 dictionary.doc2bow() 다음과 같이 개체-
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]다음으로, 우리는 문서에서 단어 id와 그 빈도를 얻을 것입니다.
for doc in BoW_corpus:
print([[dictionary[id], freq] for id, freq in doc])산출
[['are', 1], ['hello', 1], ['how', 1], ['you', 1]]
[['how', 1], ['you', 1], ['do', 2]]
[['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]]이런 식으로 우리는 말뭉치 (Bag-of-Word 말뭉치)를 훈련 시켰습니다.
다음으로이 훈련 된 말뭉치를 tfidf 모델 내에 적용해야합니다. models.TfidfModel().
먼저 numpay 패키지 가져 오기-
import numpy as np이제 훈련 된 말뭉치 (BoW_corpus)를 대괄호 안에 적용합니다. models.TfidfModel()
tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc')다음으로, 우리는 tfidf 모델링 된 말뭉치에서 단어 id와 그 빈도를 얻을 것입니다.
for doc in tfidf[BoW_corpus]:
print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])산출
[['are', 0.33], ['hello', 0.89], ['how', 0.33]]
[['how', 0.18], ['do', 0.98]]
[['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]]
[['are', 1], ['hello', 1], ['how', 1], ['you', 1]]
[['how', 1], ['you', 1], ['do', 2]]
[['are', 2], ['you', 3], ['doing', 2], ['hey', 1], ['what', 2], ['yes', 1]]
[['are', 0.33], ['hello', 0.89], ['how', 0.33]]
[['how', 0.18], ['do', 0.98]]
[['are', 0.23], ['doing', 0.62], ['hey', 0.31], ['what', 0.62], ['yes', 0.31]]위의 출력에서 문서의 단어 빈도 차이를 볼 수 있습니다.
완전한 구현 예
import gensim
import pprint
from gensim import corpora
from gensim.utils import simple_preprocess
doc_list = [
"Hello, how are you?", "How do you do?",
"Hey what are you doing? yes you What are you doing?"
]
doc_tokenized = [simple_preprocess(doc) for doc in doc_list]
dictionary = corpora.Dictionary()
BoW_corpus = [dictionary.doc2bow(doc, allow_update=True) for doc in doc_tokenized]
for doc in BoW_corpus:
print([[dictionary[id], freq] for id, freq in doc])
import numpy as np
tfidf = models.TfidfModel(BoW_corpus, smartirs='ntc')
for doc in tfidf[BoW_corpus]:
print([[dictionary[id], np.around(freq,decomal=2)] for id, freq in doc])단어 무게의 차이
위에서 설명한 것처럼 문서에서 더 자주 나오는 단어는 더 작은 가중치를 갖게됩니다. 위의 두 출력에서 단어 가중치의 차이를 이해합시다. 단어‘are’두 개의 문서에서 발생하고 가중치를 낮췄습니다. 마찬가지로 단어‘you’ 모든 문서에 나타나고 모두 제거됩니다.
이 장에서는 Gensim과 관련된 주제 모델링을 다룹니다.
데이터에 주석을 달고 문장 구조를 이해하는 가장 좋은 방법 중 하나는 전산 언어 알고리즘을 사용하는 것입니다. 의심 할 여지없이 이러한 계산 언어 알고리즘의 도움으로 데이터에 대한 세부 정보를 이해할 수 있지만
우리 말뭉치에서 어떤 단어가 다른 단어보다 더 자주 나타나는지 알 수 있습니까?
데이터를 그룹화 할 수 있습니까?
데이터의 기본 주제가 될 수 있습니까?
우리는 토픽 모델링의 도움으로이 모든 것을 달성 할 수 있습니다. 이제 주제 모델의 개념에 대해 자세히 살펴 보겠습니다.
주제 모델이란 무엇입니까?
주제 모델은 텍스트의 주제에 대한 정보를 포함하는 확률 모델로 정의 될 수 있습니다. 그러나 여기서 다음과 같은 두 가지 중요한 질문이 발생합니다.
먼저, what exactly a topic is?
이름에서 알 수 있듯이 주제는 텍스트에 표현 된 기본 아이디어 또는 주제입니다. 예를 들어, 다음을 포함하는 말뭉치newspaper articles 관련 주제가있을 것입니다 finance, weather, politics, sports, various states news 등등.
둘째, what is the importance of topic models in text processing?
아시다시피 텍스트의 유사성을 식별하기 위해 단어를 사용하여 정보 검색 및 검색 기술을 수행 할 수 있습니다. 그러나 주제 모델의 도움으로 이제는 단어가 아닌 주제를 사용하여 텍스트 파일을 검색하고 정렬 할 수 있습니다.
이런 의미에서 우리는 주제가 단어의 확률 적 분포라고 말할 수 있습니다. 그렇기 때문에 주제 모델을 사용하여 문서를 주제의 확률 적 분포로 설명 할 수 있습니다.
주제 모델의 목표
위에서 논의한 바와 같이 주제 모델링의 초점은 기본 아이디어와 주제에 있습니다. 주요 목표는 다음과 같습니다.
주제 모델은 텍스트 요약에 사용할 수 있습니다.
문서를 구성하는 데 사용할 수 있습니다. 예를 들어, 주제 모델링을 사용하여 뉴스 기사를 구성 / 상호 연결된 섹션으로 그룹화 할 수 있습니다.cricket.
검색 결과를 향상시킬 수 있습니다. 어떻게? 검색 쿼리의 경우 주제 모델을 사용하여 서로 다른 키워드가 혼합 된 문서를 표시 할 수 있지만 거의 동일한 아이디어입니다.
추천 개념은 마케팅에 매우 유용합니다. 다양한 온라인 쇼핑 웹 사이트, 뉴스 웹 사이트 등에서 사용됩니다. 주제 모델은 무엇을 구입할지, 다음에 읽을 내용 등을 추천하는 데 도움이됩니다. 목록에서 공통 주제가있는 자료를 찾아서 수행합니다.
Gensim의 주제 모델링 알고리즘
의심 할 여지없이 Gensim은 가장 인기있는 토픽 모델링 툴킷입니다. 무료 가용성과 Python으로 인해 더 인기가 있습니다. 이 섹션에서는 가장 인기있는 토픽 모델링 알고리즘에 대해 설명합니다. 여기서는 Gensim이 우리를 위해 아주 잘 추상화하기 때문에 '어떻게'보다는 '무엇'에 초점을 맞출 것입니다.
잠재 디리클레 할당 (LDA)
잠재 디리클레 할당 (LDA)은 현재 토픽 모델링에 사용되는 가장 일반적이고 인기있는 기술입니다. Facebook 연구원들이 2013 년에 발표 한 연구 논문에서 사용한 것입니다. David Blei, Andrew Ng, Michael Jordan이 2003 년에 처음 제안했습니다. 그들은 단순히 제목이 붙은 논문에서 LDA를 제안했습니다.Latent Dirichlet allocation.
LDA의 특징
그 특성을 통해이 멋진 기술에 대해 더 많이 알자-
Probabilistic topic modeling technique
LDA는 확률 론적 주제 모델링 기법입니다. 위에서 논의했듯이 주제 모델링에서 상호 관련된 문서 모음 (학술 논문, 신문 기사, Facebook 게시물, 트윗, 이메일 등이 될 수 있음)에는 각 문서에 몇 가지 주제 조합이 포함되어 있다고 가정합니다. .
확률 론적 주제 모델링의 주요 목표는 상호 관련된 문서 모음을위한 숨겨진 주제 구조를 발견하는 것입니다. 다음 세 가지가 일반적으로 주제 구조에 포함됩니다.
Topics
문서 간 주제의 통계적 분포
주제를 구성하는 문서의 단어
Work in an unsupervised way
LDA는 감독되지 않는 방식으로 작동합니다. LDA는 숨겨진 주제 구조를 발견하기 위해 조건부 확률을 사용하기 때문입니다. 주제가 상호 관련된 문서 모음 전체에 고르지 않게 분포되어 있다고 가정합니다.
Very easy to create it in Gensim
Gensim에서 LDA 모델을 만드는 것은 매우 쉽습니다. 말뭉치, 사전 매핑 및 모델에서 사용하려는 주제 수를 지정하기 만하면됩니다.
Model=models.LdaModel(corpus, id2word=dictionary, num_topics=100)May face computationally intractable problem
가능한 모든 주제 구조의 확률을 계산하는 것은 LDA가 직면 한 계산상의 문제입니다. 가능한 모든 주제 구조에서 관찰 된 모든 단어의 확률을 계산해야하기 때문에 어렵습니다. 주제와 단어가 많은 경우 LDA는 계산적으로 다루기 힘든 문제에 직면 할 수 있습니다.
LSI (Latent Semantic Indexing)
Gensim에서 처음 구현 된 주제 모델링 알고리즘은 Latent Dirichlet Allocation (LDA) 이다 Latent Semantic Indexing (LSI). 그것은 또한 불린다Latent Semantic Analysis (LSA).
1988 년 Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landaur, Karen Lochbaum, Lynn Streeter가 특허를 받았습니다. 이 섹션에서는 LSI 모델을 설정합니다. LDA 모델 설정과 동일한 방법으로 수행 할 수 있습니다. LSI 모델을 가져와야합니다.gensim.models.
LSI의 역할
실제로 LSI는 특히 분산 의미론에서 기술 NLP입니다. 문서 세트와 이러한 문서에 포함 된 용어 간의 관계를 분석합니다. 작동에 대해 이야기하면 큰 텍스트에서 문서 당 단어 수를 포함하는 행렬을 구성합니다.
일단 구성되면 행 수를 줄이기 위해 LSI 모델은 SVD (singular value decomposition)라는 수학적 기술을 사용합니다. 행 수를 줄이는 것과 함께 열 간의 유사성 구조도 유지합니다. 행렬에서 행은 고유 한 단어를 나타내고 열은 각 문서를 나타냅니다. 분포 가설에 따라 작동합니다. 즉, 의미가 가까운 단어가 같은 종류의 텍스트에서 발생한다고 가정합니다.
Model=models.LsiModel(corpus, id2word=dictionary, num_topics=100)계층 적 디리클레 프로세스 (HDP)
LDA 및 LSI와 같은 주제 모델은 손으로 분석 할 수없는 대용량 텍스트 아카이브를 요약하고 구성하는 데 도움이됩니다. LDA 및 LSI 외에도 Gensim의 또 다른 강력한 주제 모델은 HDP (Hierarchical Dirichlet Process)입니다. 기본적으로 그룹화 된 데이터의 감독되지 않은 분석을위한 혼합 멤버십 모델입니다. LDA (유한 대응)와 달리 HDP는 데이터에서 주제 수를 유추합니다.
Model=models.HdpModel(corpus, id2word=dictionary이 장은 Gensim에서 LDA (Latent Dirichlet assignment) 토픽 모델을 생성하는 방법을 배우는 데 도움이됩니다.
NLP (자연어 처리)의 주요 응용 프로그램 중 하나에서 대량 텍스트에서 주제에 대한 정보를 자동으로 추출합니다. 많은 양의 텍스트는 호텔 리뷰, 트윗, Facebook 게시물, 다른 소셜 미디어 채널의 피드, 영화 리뷰, 뉴스 기사, 사용자 피드백, 이메일 등의 피드가 될 수 있습니다.
이 디지털 시대에 사람 / 고객이 무엇에 대해 이야기하고 있는지, 그들의 의견과 문제를 이해하는 것은 기업, 정치 캠페인 및 관리자에게 매우 가치가있을 수 있습니다. 그러나 그렇게 많은 양의 텍스트를 수동으로 읽은 다음 주제에서 정보를 추출 할 수 있습니까?
아니, 그렇지 않습니다. 이처럼 방대한 양의 텍스트 문서를 읽고 여기에서 논의 된 필수 정보 / 주제를 자동으로 추출 할 수있는 자동 알고리즘이 필요합니다.
LDA의 역할
주제 모델링에 대한 LDA의 접근 방식은 문서의 텍스트를 특정 주제로 분류하는 것입니다. Dirichlet 분포로 모델링 된 LDA는-
- 문서 모델 별 주제 및
- 주제 모델 당 단어
LDA 토픽 모델 알고리즘을 제공 한 후 토픽-키워드 배포의 좋은 구성을 얻기 위해 다시 정렬합니다.
- 문서 내의 주제 분포 및
- 주제 내 키워드 분포
처리하는 동안 LDA의 일부 가정은 다음과 같습니다.
- 모든 문서는 주제의 다중 명목 분포로 모델링됩니다.
- 모든 주제는 단어의 다중 명목 분포로 모델링됩니다.
- LDA는 각 텍스트 청크에 관련 단어가 포함되어 있다고 가정하기 때문에 올바른 데이터 코퍼스를 선택해야합니다.
- LDA는 또한 문서가 주제의 혼합으로 생성되었다고 가정합니다.
Gensim으로 구현
여기서는 LDA (Latent Dirichlet Allocation)를 사용하여 데이터 세트에서 자연스럽게 논의되는 주제를 추출합니다.
데이터 세트로드
우리가 사용할 데이터 셋은 ’20 Newsgroups’뉴스 보고서의 다양한 섹션에서 수천 개의 뉴스 기사가 있습니다. 아래에서 사용할 수 있습니다.Sklearn데이터 세트. 다음 Python 스크립트의 도움으로 쉽게 다운로드 할 수 있습니다.
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')다음 스크립트의 도움으로 샘플 뉴스를 살펴 보겠습니다.
newsgroups_train.data[:4]["From: [email protected] (where's my thing)\nSubject:
WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization:
University of Maryland, College Park\nLines:
15\n\n I was wondering if anyone out there could enlighten me on this car
I saw\nthe other day. It was a 2-door sports car, looked to be from the
late 60s/\nearly 70s. It was called a Bricklin. The doors were really small.
In addition,\nthe front bumper was separate from the rest of the body.
This is \nall I know. If anyone can tellme a model name,
engine specs, years\nof production, where this car is made, history, or
whatever info you\nhave on this funky looking car, please e-mail.\n\nThanks,
\n- IL\n ---- brought to you by your neighborhood Lerxst ----\n\n\n\n\n",
"From: [email protected] (Guy Kuo)\nSubject: SI Clock Poll - Final
Call\nSummary: Final call for SI clock reports\nKeywords:
SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization:
University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA
fair number of brave souls who upgraded their SI clock oscillator have\nshared their
experiences for this poll. Please send a brief message detailing\nyour experiences with
the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat
sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies
are especially requested.\n\nI will be summarizing in the next two days, so please add
to the network\nknowledge base if you have done the clock upgrade and haven't answered
this\npoll. Thanks.\n\nGuy Kuo <;[email protected]>\n",
'From: [email protected] (Thomas E Willis)\nSubject:
PB questions...\nOrganization: Purdue University Engineering
Computer Network\nDistribution: usa\nLines: 36\n\nwell folks,
my mac plus finally gave up the ghost this weekend after\nstarting
life as a 512k way back in 1985. sooo, i\'m in the market for
a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking
into picking up a powerbook 160 or maybe 180 and have a bunch\nof
questions that (hopefully) somebody can answer:\n\n* does anybody
know any dirt on when the next round of powerbook\nintroductions
are expected? i\'d heard the 185c was supposed to make an\nappearence
"this summer" but haven\'t heard anymore on it - and since i\ndon\'t
have access to macleak, i was wondering if anybody out there had\nmore
info...\n\n* has anybody heard rumors about price drops to the powerbook
line like the\nones the duo\'s just went through recently?\n\n* what\'s
the impression of the display on the 180? i could probably swing\na 180
if i got the 80Mb disk rather than the 120, but i don\'t really have\na
feel for how much "better" the display is (yea, it looks great in the\nstore,
but is that all "wow" or is it really that good?). could i solicit\nsome
opinions of people who use the 160 and 180 day-to-day on if its
worth\ntaking the disk size and money hit to get the active display?
(i realize\nthis is a real subjective question, but i\'ve only played around
with the\nmachines in a computer store breifly and figured the opinions
of somebody\nwho actually uses the machine daily might prove helpful).\n\n*
how well does hellcats perform? ;)\n\nthanks a bunch in advance for any info -
if you could email, i\'ll post a\nsummary (news reading time is at a premium
with finals just around the\ncorner... :
( )\n--\nTom Willis \\ [email protected] \\ Purdue Electrical
Engineering\n---------------------------------------------------------------------------\
n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n',
'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization:
Harris Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host:
amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert
J.C. Kyanko ([email protected]) wrote:\n >[email protected] writes in article
<[email protected] >:\n> > Anyone know about the
Weitek P9000 graphics chip?\n > As far as the low-level stuff goes, it looks
pretty nice. It\'s got this\n> quadrilateral fill command that requires just
the four points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get
some information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris
Corporation\[email protected]\t\t\tComputer Systems Division\n"The only
thing that really scares me is a person with no sense of humor.
"\n\t\t\t\t\t\t-- Jonathan Winters\n']전제 조건
NLTK의 불용어와 Scapy의 영어 모델이 필요합니다. 둘 다 다음과 같이 다운로드 할 수 있습니다-
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])필요한 패키지 가져 오기
LDA 모델을 구축하려면 다음과 같은 패키지를 가져와야합니다.
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt불용어 준비
이제 불용어를 가져 와서 사용해야합니다.
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])텍스트 정리
이제 Gensim의 도움으로 simple_preprocess()각 문장을 단어 목록으로 토큰 화해야합니다. 구두점과 불필요한 문자도 제거해야합니다. 이를 위해 다음과 같은 이름의 함수를 생성합니다.sent_to_words() −
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))Bigram 및 Trigram 모델 구축
아시다시피, bigram은 문서에서 자주 발생하는 두 단어이고 trigram은 문서에서 자주 발생하는 세 단어입니다. Gensim의 도움으로Phrases 모델, 우리는 이것을 할 수 있습니다-
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)불용어 필터링
다음으로 불용어를 필터링해야합니다. 이와 함께, 우리는 또한 bigrams, trigrams 및 lemmatisation을위한 함수를 만들 것입니다.
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out주제 모델을위한 사전 및 코퍼스 구축
이제 사전과 말뭉치를 구축해야합니다. 이전 예제에서도 수행했습니다.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]LDA 주제 모델 구축
우리는 이미 LDA 모델을 훈련하는 데 필요한 모든 것을 구현했습니다. 이제 LDA 토픽 모델을 구축 할 때입니다. 구현 예의 경우 다음 코드 줄을 사용하여 수행 할 수 있습니다.
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus, id2word=id2word, num_topics=20, random_state=100,
update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True
)구현 예
LDA 토픽 모델을 구축하기위한 전체 구현 예제를 보겠습니다.
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import pyLDAvis
import pyLDAvis.gensim
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
[trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(data_words_bigrams, allowed_postags=[
'NOUN', 'ADJ', 'VERB', 'ADV'
])
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus, id2word=id2word, num_topics=20, random_state=100,
update_every=1, chunksize=100, passes=10, alpha='auto', per_word_topics=True
)이제 위에서 만든 LDA 모델을 사용하여 주제를 가져오고 Model Perplexity를 계산할 수 있습니다.
이 장에서는 LDA (Latent Dirichlet Allocation) 주제 모델을 사용하는 방법을 이해합니다.
LDA 모델에서 주제보기
위에서 만든 LDA 모델 (lda_model)을 사용하여 문서의 주제를 볼 수 있습니다. 다음 스크립트의 도움으로 할 수 있습니다-
pprint(lda_model.print_topics())
doc_lda = lda_model[corpus]산출
[
(0,
'0.036*"go" + 0.027*"get" + 0.021*"time" + 0.017*"back" + 0.015*"good" + '
'0.014*"much" + 0.014*"be" + 0.013*"car" + 0.013*"well" + 0.013*"year"'),
(1,
'0.078*"screen" + 0.067*"video" + 0.052*"character" + 0.046*"normal" + '
'0.045*"mouse" + 0.034*"manager" + 0.034*"disease" + 0.031*"processor" + '
'0.028*"excuse" + 0.028*"choice"'),
(2,
'0.776*"ax" + 0.079*"_" + 0.011*"boy" + 0.008*"ticket" + 0.006*"red" + '
'0.004*"conservative" + 0.004*"cult" + 0.004*"amazing" + 0.003*"runner" + '
'0.003*"roughly"'),
(3,
'0.086*"season" + 0.078*"fan" + 0.072*"reality" + 0.065*"trade" + '
'0.045*"concept" + 0.040*"pen" + 0.028*"blow" + 0.025*"improve" + '
'0.025*"cap" + 0.021*"penguin"'),
(4,
'0.027*"group" + 0.023*"issue" + 0.016*"case" + 0.016*"cause" + '
'0.014*"state" + 0.012*"whole" + 0.012*"support" + 0.011*"government" + '
'0.010*"year" + 0.010*"rate"'),
(5,
'0.133*"evidence" + 0.047*"believe" + 0.044*"religion" + 0.042*"belief" + '
'0.041*"sense" + 0.041*"discussion" + 0.034*"atheist" + 0.030*"conclusion" +
'
'0.029*"explain" + 0.029*"claim"'),
(6,
'0.083*"space" + 0.059*"science" + 0.031*"launch" + 0.030*"earth" + '
'0.026*"route" + 0.024*"orbit" + 0.024*"scientific" + 0.021*"mission" + '
'0.018*"plane" + 0.017*"satellite"'),
(7,
'0.065*"file" + 0.064*"program" + 0.048*"card" + 0.041*"window" + '
'0.038*"driver" + 0.037*"software" + 0.034*"run" + 0.029*"machine" + '
'0.029*"entry" + 0.028*"version"'),
(8,
'0.078*"publish" + 0.059*"mount" + 0.050*"turkish" + 0.043*"armenian" + '
'0.027*"western" + 0.026*"russian" + 0.025*"locate" + 0.024*"proceed" + '
'0.024*"electrical" + 0.022*"terrorism"'),
(9,
'0.023*"people" + 0.023*"child" + 0.021*"kill" + 0.020*"man" + 0.019*"death" '
'+ 0.015*"die" + 0.015*"live" + 0.014*"attack" + 0.013*"age" + '
'0.011*"church"'),
(10,
'0.092*"cpu" + 0.085*"black" + 0.071*"controller" + 0.039*"white" + '
'0.028*"water" + 0.027*"cold" + 0.025*"solid" + 0.024*"cool" + 0.024*"heat" '
'+ 0.023*"nuclear"'),
(11,
'0.071*"monitor" + 0.044*"box" + 0.042*"option" + 0.041*"generate" + '
'0.038*"vote" + 0.032*"battery" + 0.029*"wave" + 0.026*"tradition" + '
'0.026*"fairly" + 0.025*"task"'),
(12,
'0.048*"send" + 0.045*"mail" + 0.036*"list" + 0.033*"include" + '
'0.032*"price" + 0.031*"address" + 0.027*"email" + 0.026*"receive" + '
'0.024*"book" + 0.024*"sell"'),
(13,
'0.515*"drive" + 0.052*"laboratory" + 0.042*"blind" + 0.020*"investment" + '
'0.011*"creature" + 0.010*"loop" + 0.005*"dialog" + 0.000*"slave" + '
'0.000*"jumper" + 0.000*"sector"'),
(14,
'0.153*"patient" + 0.066*"treatment" + 0.062*"printer" + 0.059*"doctor" + '
'0.036*"medical" + 0.031*"energy" + 0.029*"study" + 0.029*"probe" + '
'0.024*"mph" + 0.020*"physician"'),
(15,
'0.068*"law" + 0.055*"gun" + 0.039*"government" + 0.036*"right" + '
'0.029*"state" + 0.026*"drug" + 0.022*"crime" + 0.019*"person" + '
'0.019*"citizen" + 0.019*"weapon"'),
(16,
'0.107*"team" + 0.102*"game" + 0.078*"play" + 0.055*"win" + 0.052*"player" + '
'0.051*"year" + 0.030*"score" + 0.025*"goal" + 0.023*"wing" + 0.023*"run"'),
(17,
'0.031*"say" + 0.026*"think" + 0.022*"people" + 0.020*"make" + 0.017*"see" + '
'0.016*"know" + 0.013*"come" + 0.013*"even" + 0.013*"thing" + 0.013*"give"'),
(18,
'0.039*"system" + 0.034*"use" + 0.023*"key" + 0.016*"bit" + 0.016*"also" + '
'0.015*"information" + 0.014*"source" + 0.013*"chip" + 0.013*"available" + '
'0.010*"provide"'),
(19,
'0.085*"line" + 0.073*"write" + 0.053*"article" + 0.046*"organization" + '
'0.034*"host" + 0.023*"be" + 0.023*"know" + 0.017*"thank" + 0.016*"want" + '
'0.014*"help"')
]컴퓨팅 모델 난이도
위에서 만든 LDA 모델 (lda_model)은 모델의 난이도, 즉 모델이 얼마나 좋은지를 계산하는 데 사용할 수 있습니다. 점수가 낮을수록 모델이 더 좋아집니다. 다음 스크립트의 도움으로 할 수 있습니다-
print('\nPerplexity: ', lda_model.log_perplexity(corpus))산출
Perplexity: -12.338664984332151일관성 점수 계산
LDA 모델 (lda_model)위에서 생성 한 것은 모델의 일관성 점수, 즉 주제에있는 단어의 쌍별 단어 유사성 점수의 평균 / 중앙값을 계산하는 데 사용할 수 있습니다. 다음 스크립트의 도움으로 할 수 있습니다-
coherence_model_lda = CoherenceModel(
model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v'
)
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)산출
Coherence Score: 0.510264381411751주제-키워드 시각화
LDA 모델 (lda_model)위에서 만든 내용을 사용하여 생성 된 주제 및 관련 키워드를 검토 할 수 있습니다. 다음을 사용하여 시각화 할 수 있습니다.pyLDAvis다음과 같이 패키지-
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
vis산출
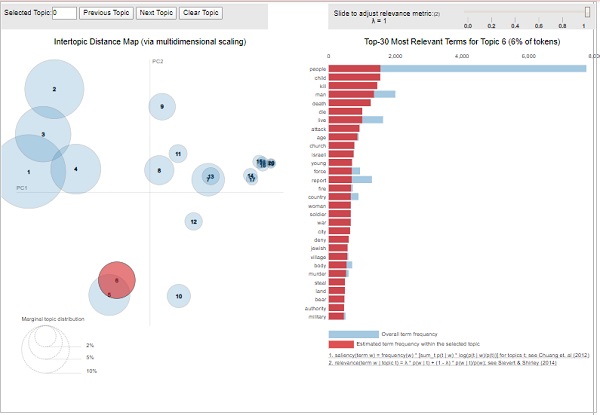
위의 출력에서 왼쪽의 거품은 주제를 나타내고 거품이 클수록 해당 주제가 더 널리 퍼집니다. 주제 모델에 차트 전체에 겹치지 않는 큰 거품이 흩어져 있으면 주제 모델이 좋습니다.
이 장에서는 LDA (Latent Dirichlet Allocation) 말렛 모델이 무엇이며 Gensim에서이를 생성하는 방법에 대해 설명합니다.
이전 섹션에서 우리는 LDA 모델을 구현하고 20Newsgroup 데이터 세트의 문서에서 주제를 가져 왔습니다. 그것은 Gensim의 LDA 알고리즘의 내장 버전이었습니다. 더 나은 품질의 주제를 제공하는 Gensim의 Mallet 버전도 있습니다. 여기서는 이미 구현 한 이전 예제에 Mallet의 LDA를 적용 할 것입니다.
LDA 말렛 모델이란?
오픈 소스 툴킷 인 Mallet은 Andrew McCullum이 작성했습니다. 기본적으로 NLP, 문서 분류, 클러스터링, 주제 모델링 및 기타 많은 기계 학습 응용 프로그램에서 텍스트로 사용되는 Java 기반 패키지입니다. LDA 및 계층 적 LDA의 효율적인 샘플링 기반 구현을 포함하는 Mallet Topic Modeling 툴킷을 제공합니다.
Mallet2.0은 Java 토픽 모델링 툴킷 인 MALLET의 현재 릴리스입니다. Gensim for LDA와 함께 사용하기 전에 시스템에 mallet-2.0.8.zip 패키지를 다운로드하고 압축을 풀어야합니다. 설치하고 압축을 푼 후에는 환경 변수 % MALLET_HOME %을 MALLET 디렉토리를 가리키는 지점으로 수동 또는 우리가 제공 할 코드로 설정하고, 다음에 Mallet으로 LDA를 구현합니다.
Gensim 래퍼
Python은 LDA (Latent Dirichlet Allocation)를위한 Gensim 래퍼를 제공합니다. 해당 래퍼의 구문은 다음과 같습니다.gensim.models.wrappers.LdaMallet. MALLET의 축소 된 깁스 샘플링 인이 모듈을 사용하면 학습 코퍼스에서 LDA 모델을 추정하고 보이지 않는 새 문서에 대한 주제 배포를 추론 할 수 있습니다.
구현 예
이전에 구축 된 LDA 모델에서 LDA Mallet을 사용하고 Coherence 점수를 계산하여 성능 차이를 확인할 것입니다.
Mallet 파일 경로 제공
이전 예제에서 구축 한 말뚝에 Mallet LDA 모델을 적용하기 전에 환경 변수를 업데이트하고 Mallet 파일의 경로도 제공해야합니다. 다음 코드를 사용하여 수행 할 수 있습니다.
import os
from gensim.models.wrappers import LdaMallet
os.environ.update({'MALLET_HOME':r'C:/mallet-2.0.8/'})
#You should update this path as per the path of Mallet directory on your system.
mallet_path = r'C:/mallet-2.0.8/bin/mallet'
#You should update this path as per the path of Mallet directory on your system.Mallet 파일의 경로를 제공했으면 이제 말뭉치에서 사용할 수 있습니다. 다음의 도움으로 수행 할 수 있습니다.ldamallet.show_topics() 다음과 같이 기능-
ldamallet = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=20, id2word=id2word
)
pprint(ldamallet.show_topics(formatted=False))산출
[
(4,
[('gun', 0.024546225966016102),
('law', 0.02181426826996709),
('state', 0.017633545129043606),
('people', 0.017612848479831116),
('case', 0.011341763768445888),
('crime', 0.010596684396796159),
('weapon', 0.00985160502514643),
('person', 0.008671896020034356),
('firearm', 0.00838214293105946),
('police', 0.008257963035784506)]),
(9,
[('make', 0.02147966482730431),
('people', 0.021377478029838543),
('work', 0.018557122419783363),
('money', 0.016676885346413244),
('year', 0.015982015123646026),
('job', 0.012221540976905783),
('pay', 0.010239117106069897),
('time', 0.008910688739014919),
('school', 0.0079092581238504),
('support', 0.007357449417535254)]),
(14,
[('power', 0.018428398507941996),
('line', 0.013784244460364121),
('high', 0.01183271164249895),
('work', 0.011560979224821522),
('ground', 0.010770484918850819),
('current', 0.010745781971789235),
('wire', 0.008399002000938712),
('low', 0.008053160742076529),
('water', 0.006966231071366814),
('run', 0.006892122230182061)]),
(0,
[('people', 0.025218349201353372),
('kill', 0.01500904870564167),
('child', 0.013612400660948935),
('armenian', 0.010307655991816822),
('woman', 0.010287984892595798),
('start', 0.01003226060272248),
('day', 0.00967818081674404),
('happen', 0.009383114328428673),
('leave', 0.009383114328428673),
('fire', 0.009009363443229208)]),
(1,
[('file', 0.030686386604212003),
('program', 0.02227713642901929),
('window', 0.01945561169918489),
('set', 0.015914874783314277),
('line', 0.013831003577619592),
('display', 0.013794120901412606),
('application', 0.012576992586582082),
('entry', 0.009275993066056873),
('change', 0.00872275292295209),
('color', 0.008612104894331132)]),
(12,
[('line', 0.07153810971508515),
('buy', 0.02975597944523662),
('organization', 0.026877236406682988),
('host', 0.025451316957679788),
('price', 0.025182275552207485),
('sell', 0.02461728860071565),
('mail', 0.02192687454599263),
('good', 0.018967419085797303),
('sale', 0.017998870026097017),
('send', 0.013694207538540181)]),
(11,
[('thing', 0.04901329901329901),
('good', 0.0376018876018876),
('make', 0.03393393393393394),
('time', 0.03326898326898327),
('bad', 0.02664092664092664),
('happen', 0.017696267696267698),
('hear', 0.015615615615615615),
('problem', 0.015465465465465466),
('back', 0.015143715143715144),
('lot', 0.01495066495066495)]),
(18,
[('space', 0.020626317374284855),
('launch', 0.00965716006366413),
('system', 0.008560244332602057),
('project', 0.008173097603991913),
('time', 0.008108573149223556),
('cost', 0.007764442723792318),
('year', 0.0076784101174345075),
('earth', 0.007484836753129436),
('base', 0.0067535595990880545),
('large', 0.006689035144319697)]),
(5,
[('government', 0.01918437232469453),
('people', 0.01461203206475212),
('state', 0.011207097828624796),
('country', 0.010214802708381975),
('israeli', 0.010039691804809714),
('war', 0.009436532025838587),
('force', 0.00858043427504086),
('attack', 0.008424780138532182),
('land', 0.0076659662230523775),
('world', 0.0075103120865437)]),
(2,
[('car', 0.041091194044470564),
('bike', 0.015598981291017729),
('ride', 0.011019688510138114),
('drive', 0.010627877363110981),
('engine', 0.009403467528651191),
('speed', 0.008081104907434616),
('turn', 0.007738270153785875),
('back', 0.007738270153785875),
('front', 0.007468899990204721),
('big', 0.007370947203447938)])
]성능 평가
이제 다음과 같이 일관성 점수를 계산하여 성능을 평가할 수도 있습니다.
ldamallet = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=20, id2word=id2word
)
pprint(ldamallet.show_topics(formatted=False))산출
Coherence Score: 0.5842762900901401이 장에서는 Gensim의 문서와 LDA 모델에 대해 설명합니다.
LDA에 대한 최적의 주제 수 찾기
다양한 토픽 가치를 가진 많은 LDA 모델을 만들어 LDA를위한 최적의 토픽 수를 찾을 수 있습니다. 이러한 LDA 중에서 일관성 값이 가장 높은 것을 선택할 수 있습니다.
다음 함수 이름 coherence_values_computation()여러 LDA 모델을 훈련시킵니다. 또한 모델과 해당 일관성 점수를 제공합니다.
def coherence_values_computation(dictionary, corpus, texts, limit, start=2, step=3):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet(
mallet_path, corpus=corpus, num_topics=num_topics, id2word=id2word
)
model_list.append(model)
coherencemodel = CoherenceModel(
model=model, texts=texts, dictionary=dictionary, coherence='c_v'
)
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values이제 다음 코드의 도움으로 그래프의 도움으로 표시 할 수있는 최적의 항목 수를 얻을 수 있습니다.
model_list, coherence_values = coherence_values_computation (
dictionary=id2word, corpus=corpus, texts=data_lemmatized,
start=1, limit=50, step=8
)
limit=50; start=1; step=8;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()산출
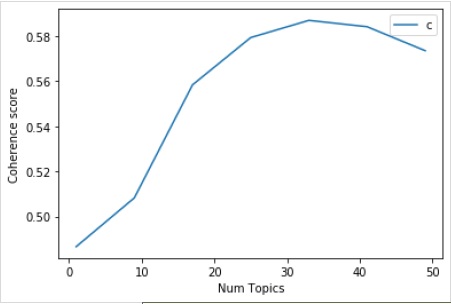
다음으로 다음과 같이 다양한 주제에 대한 일관성 값을 인쇄 할 수도 있습니다.
for m, cv in zip(x, coherence_values):
print("Num Topics =", m, " is having Coherence Value of", round(cv, 4))산출
Num Topics = 1 is having Coherence Value of 0.4866
Num Topics = 9 is having Coherence Value of 0.5083
Num Topics = 17 is having Coherence Value of 0.5584
Num Topics = 25 is having Coherence Value of 0.5793
Num Topics = 33 is having Coherence Value of 0.587
Num Topics = 41 is having Coherence Value of 0.5842
Num Topics = 49 is having Coherence Value of 0.5735이제 어떤 모델을 선택해야할까요? 좋은 관행 중 하나는 모델을 선택하는 것입니다. 이는 아첨하기 전에 가장 높은 일관성 값을 제공하는 것입니다. 그래서 우리는 위 목록에서 4 위인 25 개의 주제를 가진 모델을 선택할 것입니다.
optimal_model = model_list[3]
model_topics = optimal_model.show_topics(formatted=False)
pprint(optimal_model.print_topics(num_words=10))
[
(0,
'0.018*"power" + 0.011*"high" + 0.010*"ground" + 0.009*"current" + '
'0.008*"low" + 0.008*"wire" + 0.007*"water" + 0.007*"work" + 0.007*"design" '
'+ 0.007*"light"'),
(1,
'0.036*"game" + 0.029*"team" + 0.029*"year" + 0.028*"play" + 0.020*"player" '
'+ 0.019*"win" + 0.018*"good" + 0.013*"season" + 0.012*"run" + 0.011*"hit"'),
(2,
'0.020*"image" + 0.019*"information" + 0.017*"include" + 0.017*"mail" + '
'0.016*"send" + 0.015*"list" + 0.013*"post" + 0.012*"address" + '
'0.012*"internet" + 0.012*"system"'),
(3,
'0.986*"ax" + 0.002*"_" + 0.001*"tm" + 0.000*"part" + 0.000*"biz" + '
'0.000*"mb" + 0.000*"mbs" + 0.000*"pne" + 0.000*"end" + 0.000*"di"'),
(4,
'0.020*"make" + 0.014*"work" + 0.013*"money" + 0.013*"year" + 0.012*"people" '
'+ 0.011*"job" + 0.010*"group" + 0.009*"government" + 0.008*"support" + '
'0.008*"question"'),
(5,
'0.011*"study" + 0.011*"drug" + 0.009*"science" + 0.008*"food" + '
'0.008*"problem" + 0.008*"result" + 0.008*"effect" + 0.007*"doctor" + '
'0.007*"research" + 0.007*"patient"'),
(6,
'0.024*"gun" + 0.024*"law" + 0.019*"state" + 0.015*"case" + 0.013*"people" + '
'0.010*"crime" + 0.010*"weapon" + 0.010*"person" + 0.008*"firearm" + '
'0.008*"police"'),
(7,
'0.012*"word" + 0.011*"question" + 0.011*"exist" + 0.011*"true" + '
'0.010*"religion" + 0.010*"claim" + 0.008*"argument" + 0.008*"truth" + '
'0.008*"life" + 0.008*"faith"'),
(8,
'0.077*"time" + 0.029*"day" + 0.029*"call" + 0.025*"back" + 0.021*"work" + '
'0.019*"long" + 0.015*"end" + 0.015*"give" + 0.014*"year" + 0.014*"week"'),
(9,
'0.048*"thing" + 0.041*"make" + 0.038*"good" + 0.037*"people" + '
'0.028*"write" + 0.019*"bad" + 0.019*"point" + 0.018*"read" + 0.018*"post" + '
'0.016*"idea"'),
(10,
'0.022*"book" + 0.020*"_" + 0.013*"man" + 0.012*"people" + 0.011*"write" + '
'0.011*"find" + 0.010*"history" + 0.010*"armenian" + 0.009*"turkish" + '
'0.009*"number"'),
(11,
'0.064*"line" + 0.030*"buy" + 0.028*"organization" + 0.025*"price" + '
'0.025*"sell" + 0.023*"good" + 0.021*"host" + 0.018*"sale" + 0.017*"mail" + '
'0.016*"cost"'),
(12,
'0.041*"car" + 0.015*"bike" + 0.011*"ride" + 0.010*"engine" + 0.009*"drive" '
'+ 0.008*"side" + 0.008*"article" + 0.007*"turn" + 0.007*"front" + '
'0.007*"speed"'),
(13,
'0.018*"people" + 0.011*"attack" + 0.011*"state" + 0.011*"israeli" + '
'0.010*"war" + 0.010*"country" + 0.010*"government" + 0.009*"live" + '
'0.009*"give" + 0.009*"land"'),
(14,
'0.037*"file" + 0.026*"line" + 0.021*"read" + 0.019*"follow" + '
'0.018*"number" + 0.015*"program" + 0.014*"write" + 0.012*"entry" + '
'0.012*"give" + 0.011*"check"'),
(15,
'0.196*"write" + 0.172*"line" + 0.165*"article" + 0.117*"organization" + '
'0.086*"host" + 0.030*"reply" + 0.010*"university" + 0.008*"hear" + '
'0.007*"post" + 0.007*"news"'),
(16,
'0.021*"people" + 0.014*"happen" + 0.014*"child" + 0.012*"kill" + '
'0.011*"start" + 0.011*"live" + 0.010*"fire" + 0.010*"leave" + 0.009*"hear" '
'+ 0.009*"home"'),
(17,
'0.038*"key" + 0.018*"system" + 0.015*"space" + 0.015*"technology" + '
'0.014*"encryption" + 0.010*"chip" + 0.010*"bit" + 0.009*"launch" + '
'0.009*"public" + 0.009*"government"'),
(18,
'0.035*"drive" + 0.031*"system" + 0.027*"problem" + 0.027*"card" + '
'0.020*"driver" + 0.017*"bit" + 0.017*"work" + 0.016*"disk" + '
'0.014*"monitor" + 0.014*"machine"'),
(19,
'0.031*"window" + 0.020*"run" + 0.018*"color" + 0.018*"program" + '
'0.017*"application" + 0.016*"display" + 0.015*"set" + 0.015*"version" + '
'0.012*"screen" + 0.012*"problem"')
]문장에서 지배적 인 주제 찾기
문장에서 지배적 인 주제를 찾는 것은 주제 모델링의 가장 유용한 실용적인 응용 프로그램 중 하나입니다. 주어진 문서의 주제를 결정합니다. 여기에서 특정 문서에서 가장 높은 비율을 차지하는 주제 번호를 찾을 수 있습니다. 테이블의 정보를 집계하기 위해 다음과 같은 이름의 함수를 생성합니다.dominant_topics() −
def dominant_topics(ldamodel=lda_model, corpus=corpus, texts=data):
sent_topics_df = pd.DataFrame()다음으로 모든 문서의 주요 주제를 살펴 보겠습니다.
for i, row in enumerate(ldamodel[corpus]):
row = sorted(row, key=lambda x: (x[1]), reverse=True)다음으로 모든 문서에 대한 지배적 인 주제, 퍼크 기여 및 키워드를 얻을 것입니다.
for j, (topic_num, prop_topic) in enumerate(row):
if j == 0: # => dominant topic
wp = ldamodel.show_topic(topic_num)
topic_keywords = ", ".join([word for word, prop in wp])
sent_topics_df = sent_topics_df.append(
pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True
)
else:
break
sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']다음 코드를 사용하여 출력 끝에 원본 텍스트를 추가합니다.
contents = pd.Series(texts)
sent_topics_df = pd.concat([sent_topics_df, contents], axis=1)
return(sent_topics_df)
df_topic_sents_keywords = dominant_topics(
ldamodel=optimal_model, corpus=corpus, texts=data
)이제 다음과 같이 문장에서 주제의 형식을 지정하십시오.
df_dominant_topic = df_topic_sents_keywords.reset_index()
df_dominant_topic.columns = [
'Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text'
]마지막으로 다음과 같이 지배적 인 주제를 보여줄 수 있습니다.
df_dominant_topic.head(15)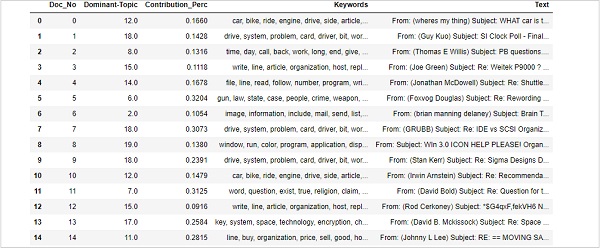
가장 대표적인 문서 찾기
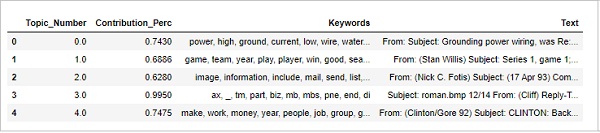
주제에 대해 더 많이 이해하기 위해 주어진 주제가 가장 많이 기여한 문서를 찾을 수도 있습니다. 특정 문서를 읽음으로써 그 주제를 추론 할 수 있습니다.
sent_topics_sorteddf_mallet = pd.DataFrame()
sent_topics_outdf_grpd = df_topic_sents_keywords.groupby('Dominant_Topic')
for i, grp in sent_topics_outdf_grpd:
sent_topics_sorteddf_mallet = pd.concat([sent_topics_sorteddf_mallet,
grp.sort_values(['Perc_Contribution'], ascending=[0]).head(1)], axis=0)
sent_topics_sorteddf_mallet.reset_index(drop=True, inplace=True)
sent_topics_sorteddf_mallet.columns = [
'Topic_Number', "Contribution_Perc", "Keywords", "Text"
]
sent_topics_sorteddf_mallet.head()산출
주제의 양 및 분포
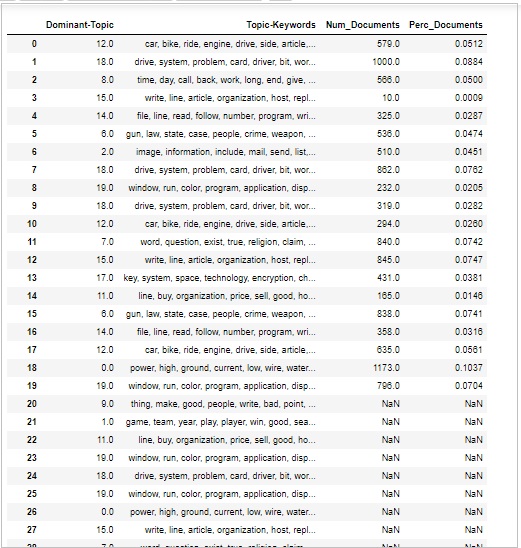
때때로 우리는 또한 문서에서 주제가 얼마나 광범위하게 논의되는지 판단하고 싶습니다. 이를 위해서는 문서 전반에 걸친 주제의 양과 분포를 이해해야합니다.
먼저 다음과 같이 모든 주제에 대한 문서 수를 계산하십시오.
topic_counts = df_topic_sents_keywords['Dominant_Topic'].value_counts()다음으로 다음과 같이 모든 주제에 대한 문서 비율을 계산합니다.
topic_contribution = round(topic_counts/topic_counts.sum(), 4)이제 다음과 같이 주제 번호 및 키워드를 찾으십시오-
topic_num_keywords = df_topic_sents_keywords[['Dominant_Topic', 'Topic_Keywords']]이제 다음과 같이 컬럼 현명한 연결-
df_dominant_topics = pd.concat(
[topic_num_keywords, topic_counts, topic_contribution], axis=1
)다음으로 열 이름을 다음과 같이 변경합니다.
df_dominant_topics.columns = [
'Dominant-Topic', 'Topic-Keywords', 'Num_Documents', 'Perc_Documents'
]
df_dominant_topics산출
이 장에서는 Gensim과 관련하여 LSI (Latent Semantic Indexing) 및 HDP (Hierarchical Dirichlet Process) 주제 모델을 만드는 방법을 다룹니다.
Gensim에서 LDA (Latent Dirichlet Allocation)로 처음 구현 된 주제 모델링 알고리즘은 다음과 같습니다. Latent Semantic Indexing (LSI). 그것은 또한 불린다Latent Semantic Analysis (LSA). 1988 년 Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landaur, Karen Lochbaum, Lynn Streeter가 특허를 받았습니다.
이 섹션에서는 LSI 모델을 설정합니다. LDA 모델 설정과 동일한 방법으로 수행 할 수 있습니다. LSI 모델을 가져와야합니다.gensim.models.
LSI의 역할
실제로 LSI는 특히 분산 의미론에서 기술 NLP입니다. 문서 세트와 이러한 문서에 포함 된 용어 간의 관계를 분석합니다. 작동에 대해 이야기하면 큰 텍스트에서 문서 당 단어 수를 포함하는 행렬을 구성합니다.
일단 구성되면 행 수를 줄이기 위해 LSI 모델은 SVD (singular value decomposition)라는 수학적 기술을 사용합니다. 행 수를 줄이는 것과 함께 열 간의 유사성 구조도 유지합니다.
행렬에서 행은 고유 한 단어를 나타내고 열은 각 문서를 나타냅니다. 분포 가설에 따라 작동합니다. 즉, 의미가 가까운 단어가 같은 종류의 텍스트에서 발생한다고 가정합니다.
Gensim으로 구현
여기서는 LSI (Latent Semantic Indexing)를 사용하여 데이터 세트에서 자연스럽게 논의 된 주제를 추출합니다.
데이터 세트로드
우리가 사용할 데이터 셋은 ’20 Newsgroups’뉴스 보고서의 다양한 섹션에서 수천 개의 뉴스 기사가 있습니다. 아래에서 사용할 수 있습니다.Sklearn데이터 세트. 다음 Python 스크립트의 도움으로 쉽게 다운로드 할 수 있습니다.
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')다음 스크립트의 도움으로 샘플 뉴스를 살펴 보겠습니다.
newsgroups_train.data[:4]
["From: [email protected] (where's my thing)\nSubject:
WHAT car is this!?\nNntp-Posting-Host: rac3.wam.umd.edu\nOrganization:
University of Maryland, College Park\nLines: 15\n\n
I was wondering if anyone out there could enlighten me on this car
I saw\nthe other day. It was a 2-door sports car,
looked to be from the late 60s/\nearly 70s. It was called a Bricklin.
The doors were really small. In addition,\nthe front bumper was separate from
the rest of the body. This is \nall I know. If anyone can tellme a model name,
engine specs, years\nof production, where this car is made, history, or
whatever info you\nhave on this funky looking car,
please e-mail.\n\nThanks,\n- IL\n ---- brought to you by your neighborhood
Lerxst ----\n\n\n\n\n",
"From: [email protected] (Guy Kuo)\nSubject:
SI Clock Poll - Final Call\nSummary: Final call for SI clock reports\nKeywords:
SI,acceleration,clock,upgrade\nArticle-I.D.: shelley.1qvfo9INNc3s\nOrganization:
University of Washington\nLines: 11\nNNTP-Posting-Host: carson.u.washington.edu\n\nA
fair number of brave souls who upgraded their SI clock oscillator have\nshared their
experiences for this poll. Please send a brief message detailing\nyour experiences with
the procedure. Top speed attained, CPU rated speed,\nadd on cards and adapters, heat
sinks, hour of usage per day, floppy disk\nfunctionality with 800 and 1.4 m floppies
are especially requested.\n\nI will be summarizing in the next two days, so please add
to the network\nknowledge base if you have done the clock upgrade and haven't answered
this\npoll. Thanks.\n\nGuy Kuo <[email protected]>\n",
'From: [email protected] (Thomas E Willis)\nSubject:
PB questions...\nOrganization: Purdue University Engineering Computer
Network\nDistribution: usa\nLines: 36\n\nwell folks, my mac plus finally gave up the
ghost this weekend after\nstarting life as a 512k way back in 1985. sooo, i\'m in the
market for a\nnew machine a bit sooner than i intended to be...\n\ni\'m looking into
picking up a powerbook 160 or maybe 180 and have a bunch\nof questions that (hopefully)
somebody can answer:\n\n* does anybody know any dirt on when the next round of
powerbook\nintroductions are expected? i\'d heard the 185c was supposed to make
an\nappearence "this summer" but haven\'t heard anymore on it - and since i\ndon\'t
have access to macleak, i was wondering if anybody out there had\nmore info...\n\n* has
anybody heard rumors about price drops to the powerbook line like the\nones the duo\'s
just went through recently?\n\n* what\'s the impression of the display on the 180? i
could probably swing\na 180 if i got the 80Mb disk rather than the 120, but i don\'t
really have\na feel for how much "better" the display is (yea, it looks great in
the\nstore, but is that all "wow" or is it really that good?). could i solicit\nsome
opinions of people who use the 160 and 180 day-to-day on if its worth\ntaking the disk
size and money hit to get the active display? (i realize\nthis is a real subjective
question, but i\'ve only played around with the\nmachines in a computer store breifly
and figured the opinions of somebody\nwho actually uses the machine daily might prove
helpful).\n\n* how well does hellcats perform? ;)\n\nthanks a bunch in advance for any
info - if you could email, i\'ll post a\nsummary (news reading time is at a premium
with finals just around the\ncorner... :( )\n--\nTom Willis \\ [email protected]
\\ Purdue Electrical
Engineering\n---------------------------------------------------------------------------\
n"Convictions are more dangerous enemies of truth than lies." - F. W.\nNietzsche\n',
'From: jgreen@amber (Joe Green)\nSubject: Re: Weitek P9000 ?\nOrganization: Harris
Computer Systems Division\nLines: 14\nDistribution: world\nNNTP-Posting-Host:
amber.ssd.csd.harris.com\nX-Newsreader: TIN [version 1.1 PL9]\n\nRobert J.C. Kyanko
([email protected]) wrote:\n > [email protected] writes in article <
[email protected]>:\n> > Anyone know about the Weitek P9000
graphics chip?\n > As far as the low-level stuff goes, it looks pretty nice. It\'s
got this\n > quadrilateral fill command that requires just the four
points.\n\nDo you have Weitek\'s address/phone number? I\'d like to get some
information\nabout this chip.\n\n--\nJoe Green\t\t\t\tHarris
Corporation\[email protected]\t\t\tComputer Systems Division\n"The only thing that
really scares me is a person with no sense of humor."\n\t\t\t\t\t\t-- Jonathan
Winters\n']전제 조건
NLTK의 불용어와 Scapy의 영어 모델이 필요합니다. 둘 다 다음과 같이 다운로드 할 수 있습니다-
import nltk;
nltk.download('stopwords')
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])필요한 패키지 가져 오기
LSI 모델을 구축하려면 다음과 같은 패키지를 가져와야합니다.
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import matplotlib.pyplot as plt불용어 준비
이제 불용어를 가져 와서 사용해야합니다.
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])텍스트 정리
이제 Gensim의 도움으로 simple_preprocess()각 문장을 단어 목록으로 토큰 화해야합니다. 구두점과 불필요한 문자도 제거해야합니다. 이를 위해 다음과 같은 이름의 함수를 생성합니다.sent_to_words() −
def sent_to_words(sentences):
for sentence in sentences:
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
data_words = list(sent_to_words(data))Bigram 및 Trigram 모델 구축
우리가 알고 있듯이 bigram은 문서에서 자주 발생하는 두 단어이고 trigram은 문서에서 자주 발생하는 세 단어입니다. Gensim의 Phrases 모델의 도움으로 우리는 이것을 할 수 있습니다.
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)불용어 필터링
다음으로 불용어를 필터링해야합니다. 이와 함께, 우리는 또한 bigrams, trigrams 및 lemmatisation을위한 함수를 만들 것입니다.
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out주제 모델을위한 사전 및 코퍼스 구축
이제 사전과 말뭉치를 구축해야합니다. 이전 예제에서도 수행했습니다.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]LSI 주제 모델 구축
우리는 이미 LSI 모델을 교육하는 데 필요한 모든 것을 구현했습니다. 이제 LSI 토픽 모델을 구축 할 때입니다. 구현 예의 경우 다음 코드 줄을 사용하여 수행 할 수 있습니다.
lsi_model = gensim.models.lsimodel.LsiModel(
corpus=corpus, id2word=id2word, num_topics=20,chunksize=100
)구현 예
LDA 토픽 모델을 구축하기위한 전체 구현 예제를 보겠습니다.
import re
import numpy as np
import pandas as pd
from pprint import pprint
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
import spacy
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
from sklearn.datasets import fetch_20newsgroups
newsgroups_train = fetch_20newsgroups(subset='train')
data = newsgroups_train.data
data = [re.sub('\S*@\S*\s?', '', sent) for sent in data]
data = [re.sub('\s+', ' ', sent) for sent in data]
data = [re.sub("\'", "", sent) for sent in data]
print(data_words[:4]) #it will print the data after prepared for stopwords
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100)
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
data_words_nostops = remove_stopwords(data_words)
data_words_bigrams = make_bigrams(data_words_nostops)
nlp = spacy.load('en_core_web_md', disable=['parser', 'ner'])
data_lemmatized = lemmatization(
data_words_bigrams, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']
)
print(data_lemmatized[:4]) #it will print the lemmatized data.
id2word = corpora.Dictionary(data_lemmatized)
texts = data_lemmatized
corpus = [id2word.doc2bow(text) for text in texts]
print(corpus[:4]) #it will print the corpus we created above.
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:4]]
#it will print the words with their frequencies.
lsi_model = gensim.models.lsimodel.LsiModel(
corpus=corpus, id2word=id2word, num_topics=20,chunksize=100
)이제 위에서 만든 LSI 모델을 사용하여 주제를 가져올 수 있습니다.
LSI 모델에서 주제보기
LSI 모델 (lsi_model)위에서 만든 문서를 사용하여 문서의 주제를 볼 수 있습니다. 다음 스크립트의 도움으로 할 수 있습니다-
pprint(lsi_model.print_topics())
doc_lsi = lsi_model[corpus]산출
[
(0,
'1.000*"ax" + 0.001*"_" + 0.000*"tm" + 0.000*"part" + 0.000*"pne" + '
'0.000*"biz" + 0.000*"mbs" + 0.000*"end" + 0.000*"fax" + 0.000*"mb"'),
(1,
'0.239*"say" + 0.222*"file" + 0.189*"go" + 0.171*"know" + 0.169*"people" + '
'0.147*"make" + 0.140*"use" + 0.135*"also" + 0.133*"see" + 0.123*"think"')
]계층 적 디리클레 프로세스 (HPD)
LDA 및 LSI와 같은 주제 모델은 손으로 분석 할 수없는 대용량 텍스트 아카이브를 요약하고 구성하는 데 도움이됩니다. LDA 및 LSI 외에도 Gensim의 또 다른 강력한 주제 모델은 HDP (Hierarchical Dirichlet Process)입니다. 기본적으로 그룹화 된 데이터의 감독되지 않은 분석을위한 혼합 멤버십 모델입니다. LDA (유한 대응)와 달리 HDP는 데이터에서 주제 수를 유추합니다.
Gensim으로 구현
Gensim에서 HDP를 구현하려면 gensim.models.HdpModel에서 가져올 수있는 HDP 주제 모델을 학습해야합니다. 여기에서도 20Newsgroup 데이터에 HDP 주제 모델을 구현할 것이며 단계도 동일합니다.
말뭉치와 사전 (위의 LSI 및 LDA 모델에 대한 예제에서 생성됨)의 경우 다음과 같이 HdpModel을 가져올 수 있습니다.
Hdp_model = gensim.models.hdpmodel.HdpModel(corpus=corpus, id2word=id2word)LSI 모델에서 주제보기
HDP 모델 (Hdp_model)문서에서 주제를 보는 데 사용할 수 있습니다. 다음 스크립트의 도움으로 할 수 있습니다-
pprint(Hdp_model.print_topics())산출
[
(0,
'0.009*line + 0.009*write + 0.006*say + 0.006*article + 0.006*know + '
'0.006*people + 0.005*make + 0.005*go + 0.005*think + 0.005*be'),
(1,
'0.016*line + 0.011*write + 0.008*article + 0.008*organization + 0.006*know '
'+ 0.006*host + 0.006*be + 0.005*get + 0.005*use + 0.005*say'),
(2,
'0.810*ax + 0.001*_ + 0.000*tm + 0.000*part + 0.000*mb + 0.000*pne + '
'0.000*biz + 0.000*end + 0.000*wwiz + 0.000*fax'),
(3,
'0.015*line + 0.008*write + 0.007*organization + 0.006*host + 0.006*know + '
'0.006*article + 0.005*use + 0.005*thank + 0.004*get + 0.004*problem'),
(4,
'0.004*line + 0.003*write + 0.002*believe + 0.002*think + 0.002*article + '
'0.002*belief + 0.002*say + 0.002*see + 0.002*look + 0.002*organization'),
(5,
'0.005*line + 0.003*write + 0.003*organization + 0.002*article + 0.002*time '
'+ 0.002*host + 0.002*get + 0.002*look + 0.002*say + 0.001*number'),
(6,
'0.003*line + 0.002*say + 0.002*write + 0.002*go + 0.002*gun + 0.002*get + '
'0.002*organization + 0.002*bill + 0.002*article + 0.002*state'),
(7,
'0.003*line + 0.002*write + 0.002*article + 0.002*organization + 0.001*none '
'+ 0.001*know + 0.001*say + 0.001*people + 0.001*host + 0.001*new'),
(8,
'0.004*line + 0.002*write + 0.002*get + 0.002*team + 0.002*organization + '
'0.002*go + 0.002*think + 0.002*know + 0.002*article + 0.001*well'),
(9,
'0.004*line + 0.002*organization + 0.002*write + 0.001*be + 0.001*host + '
'0.001*article + 0.001*thank + 0.001*use + 0.001*work + 0.001*run'),
(10,
'0.002*line + 0.001*game + 0.001*write + 0.001*get + 0.001*know + '
'0.001*thing + 0.001*think + 0.001*article + 0.001*help + 0.001*turn'),
(11,
'0.002*line + 0.001*write + 0.001*game + 0.001*organization + 0.001*say + '
'0.001*host + 0.001*give + 0.001*run + 0.001*article + 0.001*get'),
(12,
'0.002*line + 0.001*write + 0.001*know + 0.001*time + 0.001*article + '
'0.001*get + 0.001*think + 0.001*organization + 0.001*scope + 0.001*make'),
(13,
'0.002*line + 0.002*write + 0.001*article + 0.001*organization + 0.001*make '
'+ 0.001*know + 0.001*see + 0.001*get + 0.001*host + 0.001*really'),
(14,
'0.002*write + 0.002*line + 0.002*know + 0.001*think + 0.001*say + '
'0.001*article + 0.001*argument + 0.001*even + 0.001*card + 0.001*be'),
(15,
'0.001*article + 0.001*line + 0.001*make + 0.001*write + 0.001*know + '
'0.001*say + 0.001*exist + 0.001*get + 0.001*purpose + 0.001*organization'),
(16,
'0.002*line + 0.001*write + 0.001*article + 0.001*insurance + 0.001*go + '
'0.001*be + 0.001*host + 0.001*say + 0.001*organization + 0.001*part'),
(17,
'0.001*line + 0.001*get + 0.001*hit + 0.001*go + 0.001*write + 0.001*say + '
'0.001*know + 0.001*drug + 0.001*see + 0.001*need'),
(18,
'0.002*option + 0.001*line + 0.001*flight + 0.001*power + 0.001*software + '
'0.001*write + 0.001*add + 0.001*people + 0.001*organization + 0.001*module'),
(19,
'0.001*shuttle + 0.001*line + 0.001*roll + 0.001*attitude + 0.001*maneuver + '
'0.001*mission + 0.001*also + 0.001*orbit + 0.001*produce + 0.001*frequency')
]이 장은 Gensim에서 단어 임베딩 개발을 이해하는 데 도움이 될 것입니다.
단어 및 문서를 표현하는 접근 방식 인 단어 임베딩은 동일한 의미를 가진 단어가 비슷한 표현을 갖는 텍스트에 대한 조밀 한 벡터 표현입니다. 다음은 단어 임베딩의 몇 가지 특성입니다.
사전 정의 된 벡터 공간에서 개별 단어를 실수 벡터로 표현하는 기술 클래스입니다.
이 기술은 모든 단어가 하나의 벡터에 매핑되고 벡터 값이 NN (신경망)과 동일한 방식으로 학습되기 때문에 DL (딥 러닝) 분야에 집중되는 경우가 많습니다.
단어 임베딩 기술의 주요 접근 방식은 모든 단어에 대한 조밀 한 분산 표현입니다.
다른 단어 포함 방법 / 알고리즘
위에서 설명한 것처럼 단어 임베딩 방법 / 알고리즘은 텍스트 코퍼스에서 실수 값 벡터 표현을 학습합니다. 이 학습 프로세스는 문서 분류와 같은 작업에서 NN 모델과 함께 사용할 수 있거나 문서 통계와 같은 비지도 프로세스입니다. 여기서 우리는 텍스트에서 단어 임베딩을 배우는 데 사용할 수있는 두 가지 방법 / 알고리즘에 대해 논의 할 것입니다.
Google의 Word2Vec
Tomas Mikolov 등이 개발 한 Word2Vec. al. 2013 년 Google에서는 텍스트 말뭉치에서 임베딩 된 단어를 효율적으로 학습하기위한 통계적 방법입니다. 실제로 NN 기반의 단어 임베딩 학습을보다 효율적으로 만들기위한 응답으로 개발되었습니다. 그것은 단어 임베딩의 사실상의 표준이되었습니다.
Word2Vec에 의한 단어 임베딩에는 학습 된 벡터 분석과 단어 표현에 대한 벡터 수학 탐구가 포함됩니다. 다음은 Word2Vec 방법의 일부로 사용할 수있는 두 가지 학습 방법입니다.
- CBoW (Continuous Bag of Words) 모델
- 연속 스킵 그램 모델
GloVe by Standford
GloVe (단어 표현을위한 글로벌 벡터)는 Word2Vec 메서드의 확장입니다. Pennington et al.에 의해 개발되었습니다. 스탠포드에서. GloVe 알고리즘은 두 가지가 혼합되어 있습니다.
- LSA (Latent Semantic Analysis)와 같은 매트릭스 분해 기술의 글로벌 통계
- Word2Vec의 로컬 컨텍스트 기반 학습.
창을 사용하여 로컬 컨텍스트를 정의하는 대신 작동에 대해 이야기하면 GloVe는 전체 텍스트 코퍼스에 대한 통계를 사용하여 명시적인 단어 동시 발생 행렬을 구성합니다.
Word2Vec 임베딩 개발
여기에서는 Gensim을 사용하여 Word2Vec 임베딩을 개발합니다. Word2Vec 모델로 작업하기 위해 Gensim은Word2Vec 가져올 수있는 클래스 models.word2vec. 구현을 위해 word2vec에는 전체 Amazon 리뷰 코퍼스와 같은 많은 텍스트가 필요합니다. 그러나 여기서 우리는 작은 메모리 텍스트에이 원칙을 적용 할 것입니다.
구현 예
먼저 다음과 같이 gensim.models에서 Word2Vec 클래스를 가져와야합니다.
from gensim.models import Word2Vec다음으로 훈련 데이터를 정의해야합니다. 큰 텍스트 파일을 사용하는 대신이 원칙을 구현하기 위해 몇 가지 문장을 사용하고 있습니다.
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]훈련 데이터가 제공되면 모델을 훈련해야합니다. 다음과 같이 할 수 있습니다-
model = Word2Vec(sentences, min_count=1)모델을 다음과 같이 요약 할 수 있습니다.
print(model)어휘를 다음과 같이 요약 할 수 있습니다.
words = list(model.wv.vocab)
print(words)다음으로 한 단어에 대한 벡터에 액세스 해 보겠습니다. 우리는 '튜토리얼'이라는 단어를 위해 그것을하고 있습니다.
print(model['tutorial'])다음으로 모델을 저장해야합니다.
model.save('model.bin')다음으로 모델을로드해야합니다.
new_model = Word2Vec.load('model.bin')마지막으로 저장된 모델을 다음과 같이 인쇄합니다.
print(new_model)완전한 구현 예
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)산출
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)워드 임베딩 시각화
시각화로 임베딩이라는 단어를 탐색 할 수도 있습니다. 고전적인 프로젝션 방법 (예 : PCA)을 사용하여 고차원 워드 벡터를 2D 플롯으로 줄임으로써 수행 할 수 있습니다. 축소되면 그래프에 그릴 수 있습니다.
PCA를 사용하여 단어 벡터 플로팅
먼저 다음과 같이 훈련 된 모델에서 모든 벡터를 검색해야합니다.
Z = model[model.wv.vocab]다음으로, 다음과 같이 PCA 클래스를 사용하여 단어 벡터의 2-D PCA 모델을 만들어야합니다.
pca = PCA(n_components=2)
result = pca.fit_transform(Z)이제 다음과 같이 matplotlib를 사용하여 결과 투영을 플로팅 할 수 있습니다.
Pyplot.scatter(result[:,0],result[:,1])또한 단어 자체로 그래프의 점에 주석을 달 수 있습니다. 다음과 같이 matplotlib를 사용하여 결과 투영을 플롯합니다.
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))완전한 구현 예
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()산출
Word2Vec 모델과 반대되는 Doc2Vec 모델은 집합 적으로 단일 단위로 취해진 단어 그룹의 벡터화 된 표현을 만드는 데 사용됩니다. 문장에있는 단어의 단순한 평균만을 제공하는 것은 아닙니다.
Doc2Vec을 사용하여 문서 벡터 만들기
여기서 Doc2Vec을 사용하여 문서 벡터를 생성하려면 다음에서 다운로드 할 수있는 text8 데이터 세트를 사용합니다. gensim.downloader.
데이터 세트 다운로드
다음 명령을 사용하여 text8 데이터 세트를 다운로드 할 수 있습니다.
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]text8 데이터 세트를 다운로드하는 데 시간이 걸립니다.
Doc2Vec 훈련
모델을 학습 시키려면 다음을 사용하여 생성 할 수있는 태그가 지정된 문서가 필요합니다. models.doc2vec.TaggedDcument() 다음과 같이-
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))훈련 된 데이터 세트를 다음과 같이 인쇄 할 수 있습니다.
print(data_for_training [:1])산출
[TaggedDocument(words=['anarchism', 'originated', 'as', 'a', 'term', 'of',
'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals',
'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution',
'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution',
'whilst', 'the', 'term', 'is', 'still', 'used', 'in', 'a', 'pejorative',
'way', 'to', 'describe', 'any', 'act', 'that', 'used', 'violent',
'means', 'to', 'destroy',
'the', 'organization', 'of', 'society', 'it', 'has', 'also', 'been'
, 'taken', 'up', 'as', 'a', 'positive', 'label', 'by', 'self', 'defined',
'anarchists', 'the', 'word', 'anarchism', 'is', 'derived', 'from', 'the',
'greek', 'without', 'archons', 'ruler', 'chief', 'king', 'anarchism',
'as', 'a', 'political', 'philosophy', 'is', 'the', 'belief', 'that',
'rulers', 'are', 'unnecessary', 'and', 'should', 'be', 'abolished',
'although', 'there', 'are', 'differing', 'interpretations', 'of',
'what', 'this', 'means', 'anarchism', 'also', 'refers', 'to',
'related', 'social', 'movements', 'that', 'advocate', 'the',
'elimination', 'of', 'authoritarian', 'institutions', 'particularly',
'the', 'state', 'the', 'word', 'anarchy', 'as', 'most', 'anarchists',
'use', 'it', 'does', 'not', 'imply', 'chaos', 'nihilism', 'or', 'anomie',
'but', 'rather', 'a', 'harmonious', 'anti', 'authoritarian', 'society',
'in', 'place', 'of', 'what', 'are', 'regarded', 'as', 'authoritarian',
'political', 'structures', 'and', 'coercive', 'economic', 'institutions',
'anarchists', 'advocate', 'social', 'relations', 'based', 'upon', 'voluntary',
'association', 'of', 'autonomous', 'individuals', 'mutual', 'aid', 'and',
'self', 'governance', 'while', 'anarchism', 'is', 'most', 'easily', 'defined',
'by', 'what', 'it', 'is', 'against', 'anarchists', 'also', 'offer',
'positive', 'visions', 'of', 'what', 'they', 'believe', 'to', 'be', 'a',
'truly', 'free', 'society', 'however', 'ideas', 'about', 'how', 'an', 'anarchist',
'society', 'might', 'work', 'vary', 'considerably', 'especially', 'with',
'respect', 'to', 'economics', 'there', 'is', 'also', 'disagreement', 'about',
'how', 'a', 'free', 'society', 'might', 'be', 'brought', 'about', 'origins',
'and', 'predecessors', 'kropotkin', 'and', 'others', 'argue', 'that', 'before',
'recorded', 'history', 'human', 'society', 'was', 'organized', 'on', 'anarchist',
'principles', 'most', 'anthropologists', 'follow', 'kropotkin', 'and', 'engels',
'in', 'believing', 'that', 'hunter', 'gatherer', 'bands', 'were', 'egalitarian',
'and', 'lacked', 'division', 'of', 'labour', 'accumulated', 'wealth', 'or', 'decreed',
'law', 'and', 'had', 'equal', 'access', 'to', 'resources', 'william', 'godwin',
'anarchists', 'including', 'the', 'the', 'anarchy', 'organisation', 'and', 'rothbard',
'find', 'anarchist', 'attitudes', 'in', 'taoism', 'from', 'ancient', 'china',
'kropotkin', 'found', 'similar', 'ideas', 'in', 'stoic', 'zeno', 'of', 'citium',
'according', 'to', 'kropotkin', 'zeno', 'repudiated', 'the', 'omnipotence', 'of',
'the', 'state', 'its', 'intervention', 'and', 'regimentation', 'and', 'proclaimed',
'the', 'sovereignty', 'of', 'the', 'moral', 'law', 'of', 'the', 'individual', 'the',
'anabaptists', 'of', 'one', 'six', 'th', 'century', 'europe', 'are', 'sometimes',
'considered', 'to', 'be', 'religious', 'forerunners', 'of', 'modern', 'anarchism',
'bertrand', 'russell', 'in', 'his', 'history', 'of', 'western', 'philosophy',
'writes', 'that', 'the', 'anabaptists', 'repudiated', 'all', 'law', 'since',
'they', 'held', 'that', 'the', 'good', 'man', 'will', 'be', 'guided', 'at',
'every', 'moment', 'by', 'the', 'holy', 'spirit', 'from', 'this', 'premise',
'they', 'arrive', 'at', 'communism', 'the', 'diggers', 'or', 'true', 'levellers',
'were', 'an', 'early', 'communistic', 'movement',
(truncated…)모델 초기화
훈련을 마치면 이제 모델을 초기화해야합니다. 다음과 같이 할 수 있습니다-
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)이제 다음과 같이 어휘를 구축하십시오.
model.build_vocab(data_for_training)이제 다음과 같이 Doc2Vec 모델을 학습 해 보겠습니다.
model.train(data_for_training, total_examples=model.corpus_count, epochs=model.epochs)출력 분석
마지막으로 다음과 같이 model.infer_vector ()를 사용하여 출력을 분석 할 수 있습니다.
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))완전한 구현 예
import gensim
import gensim.downloader as api
dataset = api.load("text8")
data = [d for d in dataset]
def tagged_document(list_of_list_of_words):
for i, list_of_words in enumerate(list_of_list_of_words):
yield gensim.models.doc2vec.TaggedDocument(list_of_words, [i])
data_for_training = list(tagged_document(data))
print(data_for_training[:1])
model = gensim.models.doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
model.build_vocab(data_training)
model.train(data_training, total_examples=model.corpus_count, epochs=model.epochs)
print(model.infer_vector(['violent', 'means', 'to', 'destroy', 'the','organization']))산출
[
-0.2556166 0.4829361 0.17081228 0.10879577 0.12525807 0.10077011
-0.21383236 0.19294572 0.11864349 -0.03227958 -0.02207291 -0.7108424
0.07165232 0.24221905 -0.2924459 -0.03543589 0.21840079 -0.1274817
0.05455418 -0.28968817 -0.29146606 0.32885507 0.14689675 -0.06913587
-0.35173815 0.09340707 -0.3803535 -0.04030455 -0.10004586 0.22192696
0.2384828 -0.29779273 0.19236489 -0.25727913 0.09140676 0.01265439
0.08077634 -0.06902497 -0.07175519 -0.22583418 -0.21653089 0.00347822
-0.34096122 -0.06176808 0.22885063 -0.37295452 -0.08222228 -0.03148199
-0.06487323 0.11387568
]