품사 (POS) 태깅의 기본 사항
POS 태깅이란 무엇입니까?
분류의 일종 인 태깅은 토큰 설명을 자동으로 할당하는 것입니다. 우리는 품사 (명사, 동사, 부사, 형용사, 대명사, 접속사 및 하위 범주), 의미 정보 등의 부분 중 하나를 나타내는 설명 자의 '태그'라고합니다.
반면 품사 (POS) 태깅에 대해 이야기하면 단어 목록 형태의 문장을 튜플 목록으로 변환하는 과정으로 정의 할 수 있습니다. 여기에서 튜플은 (단어, 태그) 형식입니다. 또한 품사 중 하나를 주어진 단어에 할당하는 프로세스를 POS 태깅이라고 부를 수 있습니다.
다음 표는 Penn Treebank 코퍼스에서 가장 자주 사용되는 POS 알림을 나타냅니다.
| Sr. 아니요 | 꼬리표 | 기술 |
|---|---|---|
| 1 | NNP | 고유 명사, 단수 |
| 2 | NNPS | 고유 명사, 복수 |
| 삼 | PDT | 사전 결정자 |
| 4 | POS | 소유 결말 |
| 5 | PRP | 개인 대명사 |
| 6 | PRP $ | 소유 대명사 |
| 7 | RB | 부사 |
| 8 | RBR | 부사, 비교 |
| 9 | RBS | 부사, 최상급 |
| 10 | RP | 입자 |
| 11 | SYM | 기호 (수학적 또는 과학적) |
| 12 | 에 | ...에 |
| 13 | 어 | 감탄사 |
| 14 | VB | 동사, 기본형 |
| 15 | VBD | 동사, 과거형 |
| 16 | VBG | 동사, 동명사 / 현재 분사 |
| 17 | VBN | 동사, 과거 |
| 18 | WP | Wh- 대명사 |
| 19 | WP $ | 소유격 wh- 대명사 |
| 20 | WRB | Wh- 부사 |
| 21 | # | 파운드 기호 |
| 22 | $ | 달러 표시 |
| 23 | . | 문장-최종 구두점 |
| 24 | , | 반점 |
| 25 | : | 콜론, 세미콜론 |
| 26 | ( | 왼쪽 대괄호 문자 |
| 27 | ) | 오른쪽 대괄호 문자 |
| 28 | " | 곧은 큰 따옴표 |
| 29 | ' | 왼쪽 열림 작은 따옴표 |
| 30 | " | 왼쪽 열림 큰 따옴표 |
| 31 | ' | 오른쪽 닫는 작은 따옴표 |
| 32 | " | 오른쪽 열림 큰 따옴표 |
예
파이썬 실험으로 이해합시다.
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))산출
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]왜 POS 태깅인가?
POS 태깅은 다음과 같이 추가 NLP 분석의 전제 조건으로 작동하기 때문에 NLP의 중요한 부분입니다.
- Chunking
- 구문 분석
- 정보 추출
- 기계 번역
- 감정 분석
- 문법 분석 및 단어 의미 명확화
TaggerI-기본 클래스
모든 tagger는 NLTK의 nltk.tag 패키지에 있습니다. 이러한 태거의 기본 클래스는TaggerI, 모든 tagger가이 클래스에서 상속됨을 의미합니다.
Methods − TaggerI 클래스에는 모든 하위 클래스에서 구현해야하는 다음 두 가지 메서드가 있습니다.
tag() method − 이름에서 알 수 있듯이이 메서드는 단어 목록을 입력으로 취하고 태그가 지정된 단어 목록을 출력으로 반환합니다.
evaluate() method −이 방법의 도움으로 태거의 정확성을 평가할 수 있습니다.
POS 태깅의 기준
POS 태깅의 기준 또는 기본 단계는 Default Tagging이는 NLTK의 DefaultTagger 클래스를 사용하여 수행 할 수 있습니다. 기본 태깅은 단순히 모든 토큰에 동일한 POS 태그를 할당합니다. 기본 태깅은 정확도 향상을 측정하기위한 기준을 제공합니다.
DefaultTagger 클래스
기본 태깅은 다음을 사용하여 수행됩니다. DefaultTagging 단일 인수, 즉 적용하려는 태그를받는 클래스입니다.
어떻게 작동합니까?
앞서 말했듯이 모든 태거는 TaggerI수업. 그만큼DefaultTagger 물려받은 SequentialBackoffTagger 의 하위 클래스입니다 TaggerI class. 다음 다이어그램으로 이해하겠습니다.
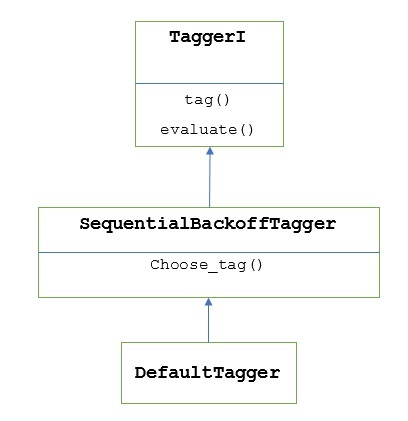
의 일부로서 SeuentialBackoffTagger, DefaultTagger 다음 세 가지 인수를 취하는 choose_tag () 메소드를 구현해야합니다.
- 토큰 목록
- 현재 토큰의 인덱스
- 이전 토큰 목록, 즉 이력
예
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])산출
[('Tutorials', 'NN'), ('Point', 'NN')]이 예에서는 가장 일반적인 단어 유형이기 때문에 명사 태그를 선택했습니다. 게다가,DefaultTagger 가장 일반적인 POS 태그를 선택할 때도 가장 유용합니다.
정확성 평가
그만큼 DefaultTagger태그 사용자의 정확성을 평가하는 기준이기도합니다. 그것이 우리가 그것을 함께 사용할 수있는 이유입니다evaluate()정확도 측정 방법. 그만큼evaluate() 메소드는 태거를 평가하기위한 금색 표준으로 태그가 지정된 토큰 목록을 사용합니다.
다음은 기본 태거를 사용한 예입니다. exptagger의 하위 집합의 정확성을 평가하기 위해 위에서 만든 treebank 말뭉치 태그 문장 −
예
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)산출
0.13198749536374715위의 출력은 NN 모든 태그에 대해 1000 개의 항목에 대해 약 13 %의 정확도 테스트를 달성 할 수 있습니다. treebank 신체.
문장 목록에 태그 달기
한 문장에 태그를 붙이는 대신 NLTK의 TaggerI 수업은 또한 우리에게 tag_sents()방법을 사용하여 문장 목록에 태그를 지정할 수 있습니다. 다음은 두 개의 간단한 문장에 태그를 붙인 예입니다.
예
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])산출
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]위의 예에서는 이전에 만든 기본 태거 인 exptagger.
문장 태그 해제
문장의 태그를 해제 할 수도 있습니다. NLTK는이를 위해 nltk.tag.untag () 메소드를 제공합니다. 태그가있는 문장을 입력으로 받아 태그가없는 단어 목록을 제공합니다. 예를 봅시다-
예
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])산출
['Tutorials', 'Point']