Natural Language Toolkit-소개
자연어 처리 (NLP) 란 무엇입니까?
인간이 말하고, 읽고, 쓸 수있는 도움으로 의사 소통하는 방법은 언어입니다. 즉, 우리 인간은 자연어로 생각하고, 계획하고, 결정을 내릴 수 있습니다. 여기서 큰 질문은 인공 지능, 기계 학습 및 딥 러닝 시대에 인간이 컴퓨터 / 기계와 자연 언어로 의사 소통 할 수 있다는 것입니다. 컴퓨터에는 구조화 된 데이터가 필요하기 때문에 NLP 응용 프로그램을 개발하는 것은 우리에게 큰 도전입니다. 반면에 인간의 음성은 구조화되지 않고 종종 모호합니다.
자연어는 컴퓨터 과학, 특히 AI의 하위 분야로, 컴퓨터 / 기계가 인간의 언어를 이해, 처리 및 조작 할 수 있도록합니다. 간단히 말해서 NLP는 힌디어, 영어, 프랑스어, 네덜란드어 등과 같은 인간의 자연어에서 의미를 분석, 이해 및 도출하는 기계의 방법입니다.
어떻게 작동합니까?
NLP의 작업에 깊이 들어가기 전에 인간이 언어를 사용하는 방법을 이해해야합니다. 매일 우리 인간은 수백, 수천 개의 단어를 사용하고 다른 인간은 그것을 해석하고 그에 따라 대답합니다. 인간을위한 단순한 의사 소통이지 않습니까? 그러나 우리는 단어가 그보다 훨씬 더 깊이 있다는 것을 알고 있으며 항상 우리가 말하는 것과 말하는 방식에서 컨텍스트를 도출합니다. 그렇기 때문에 NLP는 음성 변조에 초점을 맞추기보다 상황에 맞는 패턴을 사용한다고 말할 수 있습니다.
예를 들어 이해합시다.
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.인간은 어떤 단어가 무엇을 의미하는지 어떻게 압니까? 이 질문에 대한 답은 우리가 경험을 통해 배우는 것입니다. 그러나 기계 / 컴퓨터는 어떻게 똑같이 학습합니까?
다음과 같은 쉬운 단계로 이해합시다.
먼저 기계가 경험을 통해 배울 수 있도록 충분한 데이터를 기계에 공급해야합니다.
그런 다음 기계는 이전에 공급 한 데이터와 주변 데이터에서 딥 러닝 알고리즘을 사용하여 단어 벡터를 생성합니다.
그런 다음 이러한 단어 벡터에 대해 간단한 대수 연산을 수행함으로써 기계는 인간으로서 답을 제공 할 수 있습니다.
NLP의 구성 요소
다음 다이어그램은 자연어 처리 (NLP)의 구성 요소를 나타냅니다.
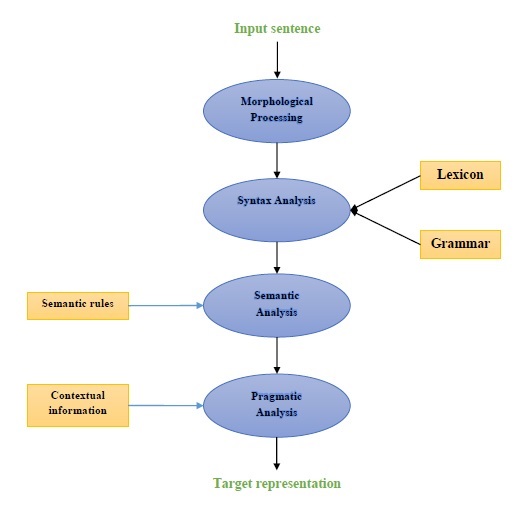
형태 학적 처리
형태 학적 처리는 NLP의 첫 번째 구성 요소입니다. 여기에는 언어 입력 청크를 단락, 문장 및 단어에 해당하는 토큰 세트로 나누는 것이 포함됩니다. 예를 들어, 다음과 같은 단어“everyday” 다음과 같이 두 개의 하위 단어 토큰으로 나눌 수 있습니다. “every-day”.
구문 분석
두 번째 구성 요소 인 구문 분석은 NLP의 가장 중요한 구성 요소 중 하나입니다. 이 구성 요소의 목적은 다음과 같습니다.
문장의 형식이 올바른지 확인합니다.
다른 단어 간의 구문 관계를 보여주는 구조로 나누는 것입니다.
예 : 같은 문장 “The school goes to the student” 구문 분석기에서 거부됩니다.
의미 분석
Semantic Analysis는 텍스트의 의미를 확인하는 데 사용되는 NLP의 세 번째 구성 요소입니다. 그것은 정확한 의미를 그리는 것을 포함하거나 텍스트에서 사전 적 의미를 말할 수 있습니다. 예 : "뜨거운 아이스크림입니다."와 같은 문장. 의미 분석기에 의해 폐기됩니다.
실용적인 분석
실용적 분석은 NLP의 네 번째 구성 요소입니다. 여기에는 각 컨텍스트에 존재하는 실제 객체 또는 이벤트를 이전 구성 요소, 즉 의미 분석에서 얻은 객체 참조와 맞추는 것이 포함됩니다. 예 : 같은 문장“Put the fruits in the basket on the table” 두 가지 의미 해석을 가질 수 있으므로 실용적인 분석기는이 두 가지 가능성 중에서 선택합니다.
NLP 애플리케이션의 예
신기술 인 NLP는 오늘날 우리가 보았던 다양한 형태의 AI를 파생합니다. 현재와 미래의 점점 더 인지도가 높아지는 애플리케이션의 경우, 인간과 기계 간의 원활한 대화 형 인터페이스를 만드는 데 NLP를 사용하는 것이 계속 최우선 순위가 될 것입니다. 다음은 NLP의 매우 유용한 응용 프로그램 중 일부입니다.
기계 번역
기계 번역 (MT)은 자연어 처리의 가장 중요한 응용 프로그램 중 하나입니다. MT는 기본적으로 하나의 소스 언어 또는 텍스트를 다른 언어로 번역하는 프로세스입니다. 기계 번역 시스템은 이중 언어 또는 다국어가 될 수 있습니다.
스팸 퇴치
원하지 않는 이메일이 엄청나게 증가함에 따라 스팸 필터는이 문제에 대한 첫 번째 방어선이기 때문에 중요해졌습니다. 위양성 및 위음성 문제를 주요 이슈로 고려하여 NLP의 기능을 활용하여 스팸 필터링 시스템을 개발할 수 있습니다.
N- 그램 모델링, 단어 형태소 분석 및 베이지안 분류는 스팸 필터링에 사용할 수있는 기존 NLP 모델 중 일부입니다.
정보 검색 및 웹 검색
Google, Yahoo, Bing, WolframAlpha 등과 같은 대부분의 검색 엔진은 기계 번역 (MT) 기술을 NLP 딥 러닝 모델을 기반으로합니다. 이러한 딥 러닝 모델은 알고리즘이 웹 페이지의 텍스트를 읽고 의미를 해석하고 다른 언어로 번역 할 수 있도록합니다.
자동 텍스트 요약
자동 텍스트 요약은 긴 텍스트 문서를 짧고 정확하게 요약하는 기술입니다. 따라서 더 짧은 시간에 관련 정보를 얻는 데 도움이됩니다. 이 디지털 시대에 우리는 인터넷을 통해 멈추지 않을 정보의 홍수 때문에 자동 텍스트 요약이 절실히 필요합니다. NLP와 그 기능은 자동 텍스트 요약을 개발하는 데 중요한 역할을합니다.
문법 교정
맞춤법 교정 및 문법 교정은 Microsoft Word와 같은 워드 프로세서 소프트웨어의 매우 유용한 기능입니다. 이러한 목적으로 자연어 처리 (NLP)가 널리 사용됩니다.
질문 답변
자연어 처리 (NLP)의 또 다른 주요 응용 프로그램 인 질문 응답은 사용자가 게시 한 질문에 자연어로 자동 응답하는 시스템 구축에 중점을 둡니다.
감정 분석
감정 분석은 자연어 처리 (NLP)의 다른 중요한 응용 분야 중 하나입니다. 이름에서 알 수 있듯이 감정 분석은 다음과 같은 용도로 사용됩니다.
여러 게시물 사이의 감정을 파악하고
감정이 명시 적으로 표현되지 않은 감정을 식별합니다.
Amazon, ebay 등과 같은 온라인 전자 상거래 회사는 감정 분석을 사용하여 온라인에서 고객의 의견과 감정을 식별하고 있습니다. 고객이 제품과 서비스에 대해 어떻게 생각하는지 이해하는 데 도움이됩니다.
음성 엔진
Siri, Google Voice, Alexa와 같은 음성 엔진은 자연어로 통신 할 수 있도록 NLP를 기반으로합니다.
NLP 구현
위에서 언급 한 애플리케이션을 구축하기 위해서는 언어를 효율적으로 처리 할 수있는 언어 및 도구에 대한 이해도가 높은 특정 기술이 필요합니다. 이를 위해 다양한 오픈 소스 도구를 사용할 수 있습니다. 그들 중 일부는 오픈 소스이고 다른 일부는 자체 NLP 애플리케이션을 구축하기 위해 조직에서 개발합니다. 다음은 일부 NLP 도구 목록입니다.
자연어 도구 키트 (NLTK)
Mallet
GATE
NLP 열기
UIMA
Genism
Stanford 툴킷
이러한 도구의 대부분은 Java로 작성되었습니다.
자연어 도구 키트 (NLTK)
위에서 언급 한 NLP 도구 중 NLTK는 개념에 대한 사용 용이성과 설명 측면에서 매우 높은 점수를 받았습니다. Python의 학습 곡선은 매우 빠르며 NLTK는 Python으로 작성되어 있으므로 NLTK에도 매우 좋은 학습 키트가 있습니다. NLTK는 토큰 화, 형태소 분석, Lemmatization, 구두점, 문자 수 및 단어 수와 같은 대부분의 작업을 통합했습니다. 매우 우아하고 작업하기 쉽습니다.