Natural Language Toolkit-유니 그램 태거
Unigram Tagger는 무엇입니까?
이름에서 알 수 있듯이 유니 그램 태거는 POS (Part-of-Speech) 태그를 결정하는 컨텍스트로 한 단어 만 사용하는 태거입니다. 간단히 말해서 Unigram Tagger는 컨텍스트가 단일 단어 인 Unigram 인 컨텍스트 기반 태거입니다.
어떻게 작동합니까?
NLTK는 UnigramTagger이 목적을 위해. 그러나 그 작업에 깊이 들어가기 전에 다음 다이어그램의 도움으로 계층 구조를 이해합시다.
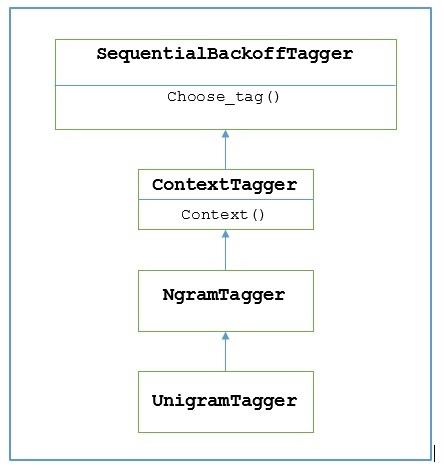
위의 다이어그램에서 UnigramTagger 물려받은 NgramTagger 의 하위 클래스입니다 ContextTagger, 상속 SequentialBackoffTagger.
작업 UnigramTagger 다음 단계의 도움으로 설명됩니다-
우리가 보았 듯이 UnigramTagger 상속 ContextTagger, 그것은 context()방법. 이context() 메소드는 다음과 같은 세 개의 인수를 사용합니다. choose_tag() 방법.
결과 context()method는 모델을 만드는 데 더 많이 사용되는 단어 토큰입니다. 모델이 생성되면 토큰이라는 단어도 최고의 태그를 찾는 데 사용됩니다.
이런 식으로, UnigramTagger 태그가 지정된 문장 목록에서 컨텍스트 모델을 구축합니다.
유니 그램 태거 훈련
NLTK UnigramTagger초기화시 태그 된 문장 목록을 제공하여 학습 할 수 있습니다. 아래 예에서는 treebank 말뭉치의 태그가 지정된 문장을 사용합니다. 우리는 그 말뭉치에서 처음 2500 개의 문장을 사용할 것입니다.
예
먼저 nltk에서 UniframTagger 모듈을 가져옵니다.
from nltk.tag import UnigramTagger다음으로 사용할 말뭉치를 가져옵니다. 여기서 우리는 treebank 말뭉치를 사용하고 있습니다-
from nltk.corpus import treebank이제 훈련 목적으로 문장을 가져 가십시오. 우리는 훈련 목적으로 처음 2500 문장을 취하고 태그를 붙일 것입니다.
train_sentences = treebank.tagged_sents()[:2500]다음으로 훈련 목적으로 사용되는 문장에 UnigramTagger를 적용합니다.
Uni_tagger = UnigramTagger(train_sentences)훈련 목적 즉, 테스트 목적을 위해 2500과 같거나 더 적은 문장을 가져옵니다. 여기서 우리는 테스트 목적으로 처음 1500 개를 사용합니다.
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)산출
0.8942306156033808여기서 POS 태그를 결정하기 위해 단일 단어 조회를 사용하는 태거의 정확도는 약 89 %입니다.
완전한 구현 예
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)산출
0.8942306156033808컨텍스트 모델 재정의
위의 다이어그램에서 UnigramTagger, 우리는 ContextTagger은 자체적으로 학습하는 대신 미리 빌드 된 모델을 사용할 수 있습니다. 이 사전 빌드 된 모델은 단순히 컨텍스트 키를 태그에 매핑하는 Python 사전입니다. 그리고UnigramTagger, 컨텍스트 키는 개별 단어이고 기타 NgramTagger 서브 클래스의 경우 튜플이됩니다.
다른 간단한 모델을 전달하여이 컨텍스트 모델을 재정의 할 수 있습니다. UnigramTagger교육 세트를 통과하는 대신 수업. 아래의 쉬운 예를 통해 이해합시다.
예
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])산출
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]우리 모델에는 'Vinken'이 유일한 컨텍스트 키로 포함되어 있으므로 위의 출력에서이 단어에만 태그가 있고 다른 모든 단어에는 태그로 None이 있음을 확인할 수 있습니다.
최소 주파수 임계 값 설정
주어진 컨텍스트에 대해 가장 가능성이 높은 태그를 결정하려면 ContextTagger클래스는 발생 빈도를 사용합니다. 컨텍스트 단어와 태그가 한 번만 발생하더라도 기본적으로 수행되지만, 다음을 전달하여 최소 빈도 임계 값을 설정할 수 있습니다.cutoff 가치 UnigramTagger수업. 아래 예에서는 UnigramTagger를 학습 한 이전 레시피의 컷오프 값을 전달합니다.
예
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)산출
0.7357651629613641