캐시 일관성 및 동기화
이 장에서는 다중 캐시 불일치 문제에 대처하기위한 캐시 일관성 프로토콜에 대해 설명합니다.
캐시 일관성 문제
다중 프로세서 시스템에서 데이터 불일치는 인접한 레벨 사이에서 또는 동일한 레벨의 메모리 계층 내에서 발생할 수 있습니다. 예를 들어 캐시와 주 메모리에 동일한 개체의 일관성없는 복사본이있을 수 있습니다.
여러 프로세서가 병렬로 작동하고 독립적으로 여러 캐시가 동일한 메모리 블록의 서로 다른 복사본을 가질 수 있으므로 cache coherence problem. Cache coherence schemes 캐시 된 각 데이터 블록에 대해 균일 한 상태를 유지하여이 문제를 방지 할 수 있습니다.
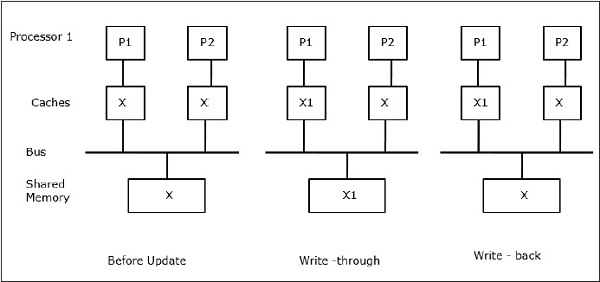
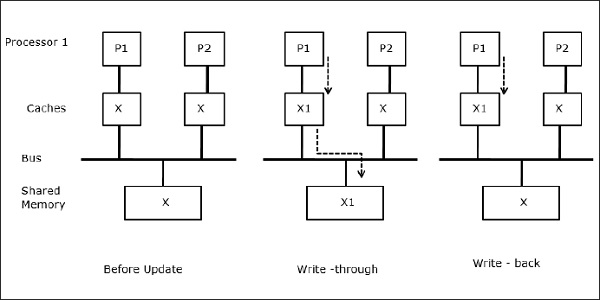
X를 두 개의 프로세서 P1과 P2가 참조하는 공유 데이터의 요소라고합시다. 처음에는 X의 세 복사본이 일치합니다. 프로세서 P1이 새 데이터 X1을 캐시에 쓰는 경우write-through policy, 동일한 사본이 공유 메모리에 즉시 기록됩니다. 이 경우 캐시 메모리와 주 메모리간에 불일치가 발생합니다. 때write-back policy 사용되는 경우 캐시의 수정 된 데이터가 교체되거나 무효화 될 때 주 메모리가 업데이트됩니다.
일반적으로 불일치 문제에는 세 가지 원인이 있습니다.
- 쓰기 가능한 데이터 공유
- 프로세스 마이그레이션
- I / O 활동
스누피 버스 프로토콜
스누피 프로토콜은 버스 기반 메모리 시스템을 통해 캐시 메모리와 공유 메모리 간의 데이터 일관성을 달성합니다. Write-invalidate 과 write-update 정책은 캐시 일관성을 유지하는 데 사용됩니다.
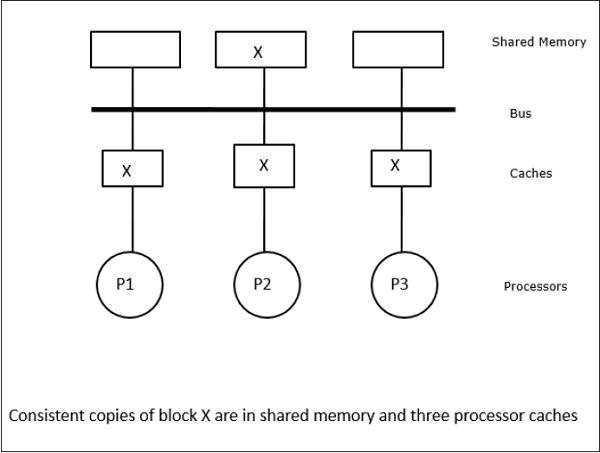
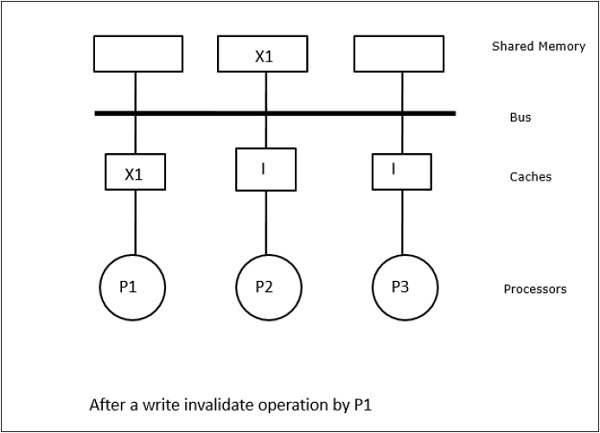
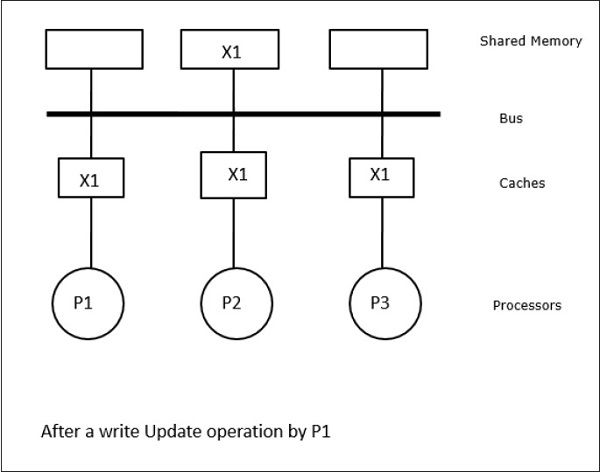
이 경우 로컬 캐시 메모리와 공유 메모리에 데이터 요소 'X'의 일관된 복사본이있는 3 개의 프로세서 P1, P2 및 P3이 있습니다 (그림 -a). 프로세서 P1은 다음을 사용하여 캐시 메모리에 X1을 씁니다.write-invalidate protocol. 따라서 다른 모든 사본은 버스를 통해 무효화됩니다. 'I'로 표시됩니다 (그림 -b). 무효화 된 블록은 다음과 같이 알려져 있습니다.dirty즉, 사용해서는 안됩니다. 그만큼write-update protocol버스를 통해 모든 캐시 사본을 업데이트합니다. 사용하여write back cache, 메모리 사본도 업데이트됩니다 (그림 -c).
캐시 이벤트 및 작업
메모리 액세스 및 무효화 명령 실행시 다음 이벤트 및 작업이 발생합니다.
Read-miss− 프로세서가 블록을 읽으려고하는데 캐시에 없으면 read-miss가 발생합니다. 이것은bus-read조작. 더티 복사본이 없으면 일관된 복사본이있는 주 메모리가 요청하는 캐시 메모리에 복사본을 제공합니다. 원격 캐시 메모리에 더티 복사본이 있으면 해당 캐시는 주 메모리를 제한하고 요청하는 캐시 메모리로 복사본을 보냅니다. 두 경우 모두 캐시 사본은 읽기 실패 후 유효한 상태가됩니다.
Write-hit − 사본이 더럽거나 reserved상태, 쓰기는 로컬로 수행되고 새 상태는 더티입니다. 새 상태가 유효하면 write-invalidate 명령이 모든 캐시에 브로드 캐스트되어 복사본이 무효화됩니다. 공유 메모리가 쓰일 때 결과 상태는 첫 번째 쓰기 후에 예약됩니다.
Write-miss− 프로세서가 로컬 캐시 메모리에 쓰기에 실패하면 복사본은 주 메모리 또는 더티 블록이있는 원격 캐시 메모리에서 가져와야합니다. 이것은read-invalidate모든 캐시 복사본을 무효화합니다. 그런 다음 로컬 복사본이 더티 상태로 업데이트됩니다.
Read-hit − Read-hit은 항상 상태 전환을 일으키거나 무효화를 위해 스누피 버스를 사용하지 않고 로컬 캐시 메모리에서 수행됩니다.
Block replacement− 복사본이 더러워지면 블록 교체 방식으로 메인 메모리에 다시 기록됩니다. 그러나 복사본이 유효하거나 예약되었거나 유효하지 않은 상태이면 교체가 수행되지 않습니다.
디렉터리 기반 프로토콜
수백 개의 프로세서가있는 대형 멀티 프로세서를 구축하기 위해 다단계 네트워크를 사용함으로써 스누피 캐시 프로토콜을 네트워크 기능에 맞게 수정해야합니다. 브로드 캐스팅은 다단계 네트워크에서 수행하는 데 매우 비용이 많이 들기 때문에 일관성 명령은 블록 사본을 보관하는 캐시에만 전송됩니다. 이것이 네트워크에 연결된 멀티 프로세서를위한 디렉토리 기반 프로토콜을 개발 한 이유입니다.
디렉토리 기반 프로토콜 시스템에서 공유 할 데이터는 캐시 간의 일관성을 유지하는 공통 디렉토리에 배치됩니다. 여기서 디렉토리는 프로세서가 기본 메모리에서 캐시 메모리로 항목을로드 할 권한을 요청하는 필터 역할을합니다. 항목이 변경되면 디렉토리는 항목을 업데이트하거나 해당 항목이있는 다른 캐시를 무효화합니다.
하드웨어 동기화 메커니즘
동기화는 데이터 제어 대신 동일하거나 다른 프로세서에있는 통신 프로세스간에 정보가 교환되는 특수한 형태의 통신입니다.
다중 프로세서 시스템은 하드웨어 메커니즘을 사용하여 저수준 동기화 작업을 구현합니다. 대부분의 다중 프로세서에는 일부 동기화 기본 요소를 구현하기 위해 메모리 읽기, 쓰기 또는 읽기-수정-쓰기 작업과 같은 원자 적 작업을 부과하는 하드웨어 메커니즘이 있습니다. 원자 메모리 작업 외에 일부 프로세서 간 인터럽트도 동기화 목적으로 사용됩니다.
공유 메모리 시스템의 캐시 일관성
프로세서에 로컬 캐시 메모리가 포함 된 경우 캐시 일관성 유지는 다중 프로세서 시스템에서 문제가됩니다. 이 시스템에서는 서로 다른 캐시 간의 데이터 불일치가 쉽게 발생합니다.
주요 관심 분야는-
- 쓰기 가능한 데이터 공유
- 프로세스 마이그레이션
- I / O 활동
쓰기 가능한 데이터 공유
두 프로세서 (P1 및 P2)의 로컬 캐시에 동일한 데이터 요소 (X)가 있고 하나의 프로세스 (P1)가 데이터 요소 (X)에 기록하는 경우 캐시가 P1의 write-through 로컬 캐시이므로 주 메모리는 다음과 같습니다. 또한 업데이트되었습니다. 이제 P2가 데이터 요소 (X)를 읽으려고 할 때 P2 캐시의 데이터 요소가 오래 되었기 때문에 X를 찾지 못합니다.
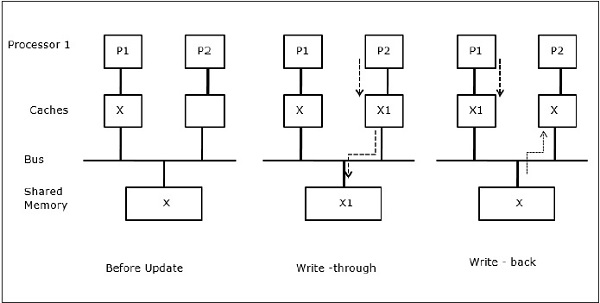
프로세스 마이그레이션
첫 번째 단계에서 P1의 캐시에는 데이터 요소 X가있는 반면 P2에는 아무것도 없습니다. P2의 프로세스는 먼저 X에 쓴 다음 P1로 마이그레이션합니다. 이제 프로세스는 데이터 요소 X 읽기를 시작하지만 프로세서 P1에 오래된 데이터가 있으므로 프로세스는 읽을 수 없습니다. 따라서 P1의 프로세스는 데이터 요소 X에 기록한 다음 P2로 마이그레이션합니다. 마이그레이션 후 P2의 프로세스는 데이터 요소 X를 읽기 시작하지만 주 메모리에서 오래된 버전의 X를 찾습니다.
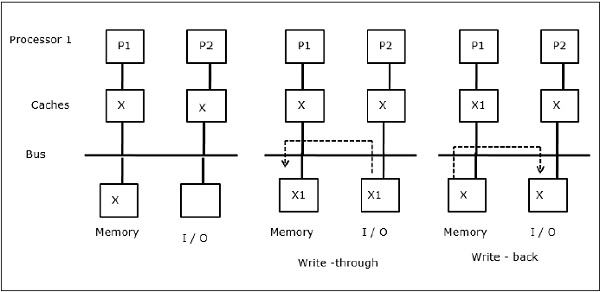
I / O 활동
그림에 표시된 것처럼 I / O 장치는 2 프로세서 멀티 프로세서 아키텍처에서 버스에 추가됩니다. 처음에는 두 캐시 모두 데이터 요소 X를 포함합니다. I / O 장치가 새 요소 X를 수신하면 새 요소를 주 메모리에 직접 저장합니다. 이제 P1 또는 P2 (P1 가정)가 요소 X를 읽으려고 할 때 오래된 사본을 얻습니다. 따라서 P1은 요소 X에 씁니다. 이제 I / O 장치가 X를 전송하려고하면 오래된 복사본을 얻습니다.
UMA (Uniform Memory Access)
UMA (Uniform Memory Access) 아키텍처는 공유 메모리가 시스템의 모든 프로세서에 대해 동일 함을 의미합니다. 일반적으로 (파일) 서버에 사용되는 UMA 시스템의 인기있는 클래스는 소위 SMP (Symmetric Multiprocessor)입니다. SMP에서 메모리, 디스크, 기타 I / O 장치 등과 같은 모든 시스템 리소스는 프로세서가 균일 한 방식으로 액세스 할 수 있습니다.
NUMA (Non-Uniform Memory Access)
NUMA 아키텍처에는 확장 가능한 메시지 전달 네트워크에 연결된 내부 간접 / 공유 네트워크가있는 여러 SMP 클러스터가 있습니다. 따라서 NUMA 아키텍처는 논리적으로 공유되는 물리적으로 분산 된 메모리 아키텍처입니다.
NUMA 시스템에서 프로세서의 캐시 컨트롤러는 메모리 참조가 SMP 메모리에 대해 로컬인지 원격인지를 결정합니다. 원격 메모리 액세스 수를 줄이기 위해 NUMA 아키텍처는 일반적으로 원격 데이터를 캐시 할 수있는 캐싱 프로세서를 적용합니다. 그러나 캐시가 관련되면 캐시 일관성을 유지해야합니다. 따라서 이러한 시스템을 CC-NUMA (Cache Coherent NUMA)라고도합니다.
캐시 전용 메모리 아키텍처 (COMA)
COMA 머신은 NUMA 머신과 유사하지만 COMA 머신의 주 메모리가 직접 매핑되거나 집합 연관 캐시로 작동한다는 유일한 차이점이 있습니다. 데이터 블록은 주소에 따라 DRAM 캐시의 위치로 해시됩니다. 원격으로 가져온 데이터는 실제로 로컬 메인 메모리에 저장됩니다. 또한 데이터 블록에는 고정 된 홈 위치가 없으므로 시스템 전체에서 자유롭게 이동할 수 있습니다.
COMA 아키텍처는 대부분 계층 적 메시지 전달 네트워크를 가지고 있습니다. 이러한 트리의 스위치에는 하위 트리와 같은 데이터 요소가있는 디렉토리가 포함됩니다. 데이터에는 집 위치가 없으므로 명시 적으로 검색해야합니다. 즉, 원격 액세스에는 필요한 데이터에 대한 디렉토리를 검색하려면 트리의 스위치를 따라 순회해야합니다. 따라서 네트워크의 스위치가 동일한 데이터에 대해 하위 트리에서 여러 요청을 수신하면이를 스위치의 상위로 전송되는 단일 요청으로 결합합니다. 요청 된 데이터가 반환되면 스위치는 하위 트리 아래로 여러 복사본을 보냅니다.
COMA 대 CC-NUMA
다음은 COMA와 CC-NUMA의 차이점입니다.
COMA는 OS 없이도 데이터 마이그레이션 및 복제를 투명하게 지원하기 때문에 CC-NUMA보다 유연성이 더 높습니다.
COMA 머신은 비표준 메모리 관리 하드웨어가 필요하고 일관성 프로토콜을 구현하기가 더 어렵 기 때문에 구축 비용이 많이 들고 복잡합니다.
COMA의 원격 액세스는 데이터를 찾기 위해 트리 네트워크를 통과해야하기 때문에 CC-NUMA의 원격 액세스보다 종종 느립니다.