다중 프로세서 및 다중 컴퓨터
이 장에서는 다중 프로세서 및 다중 컴퓨터에 대해 설명합니다.
다중 프로세서 시스템 상호 연결
병렬 처리는 입출력 및 주변 장치, 멀티 프로세서 및 공유 메모리 간의 빠른 통신을 위해 효율적인 시스템 상호 연결을 사용해야합니다.
계층 적 버스 시스템
계층 적 버스 시스템은 컴퓨터의 다양한 시스템과 하위 시스템 / 구성 요소를 연결하는 버스의 계층 구조로 구성됩니다. 각 버스는 여러 신호, 제어 및 전력선으로 구성됩니다. 로컬 버스, 백플레인 버스 및 I / O 버스와 같은 다른 버스는 서로 다른 상호 연결 기능을 수행하는 데 사용됩니다.
로컬 버스는 인쇄 회로 기판에 구현 된 버스입니다. 백플레인 버스는 기능 보드를 연결하는 데 많은 커넥터가 사용되는 인쇄 회로입니다. 입력 / 출력 장치를 컴퓨터 시스템에 연결하는 버스를 I / O 버스라고합니다.
크로스바 스위치 및 멀티 포트 메모리
스위칭 네트워크는 입력과 출력 사이에 동적 상호 연결을 제공합니다. 중소 규모 시스템은 대부분 크로스바 네트워크를 사용합니다. 지연 시간 증가 문제를 해결할 수 있다면 다단계 네트워크를 더 큰 시스템으로 확장 할 수 있습니다.
크로스바 스위치와 멀티 포트 메모리 구성은 모두 단일 단계 네트워크입니다. 단일 단계 네트워크는 구축 비용이 더 저렴하지만 특정 연결을 설정하려면 여러 패스가 필요할 수 있습니다. 다단계 네트워크에는 여러 단계의 스위치 박스가 있습니다. 이러한 네트워크는 모든 입력을 모든 출력에 연결할 수 있어야합니다.
다단계 및 결합 네트워크
다단계 네트워크 또는 다단계 상호 연결 네트워크는 주로 네트워크 한쪽 끝의 처리 요소와 다른 쪽 끝의 메모리 요소로 구성되며 스위칭 요소로 연결된 고속 컴퓨터 네트워크의 한 종류입니다.
이러한 네트워크는 더 큰 다중 프로세서 시스템을 구축하는 데 적용됩니다. 여기에는 Omega Network, Butterfly Network 등이 포함됩니다.
다중 컴퓨터
다중 컴퓨터는 분산 메모리 MIMD 아키텍처입니다. 다음 다이어그램은 다중 컴퓨터의 개념적 모델을 보여줍니다.
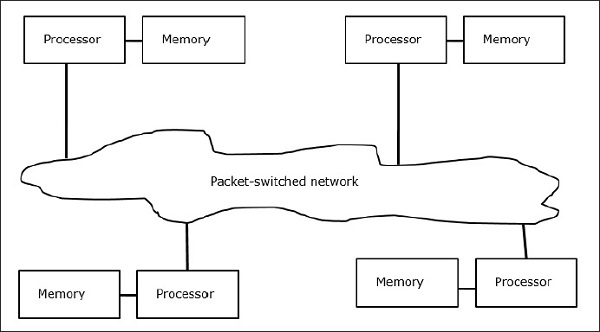
다중 컴퓨터는 데이터를 교환하기 위해 패킷 교환 방법을 적용하는 메시지 전달 기계입니다. 여기에서 각 프로세서에는 개인 메모리가 있지만 프로세서가 자체 로컬 메모리에만 액세스 할 수 있으므로 전역 주소 공간이 없습니다. 따라서 통신은 투명하지 않습니다. 여기서 프로그래머는 통신 기본 요소를 코드에 명시 적으로 넣어야합니다.
전역 적으로 액세스 할 수있는 메모리가 없다는 것은 다중 컴퓨터의 단점입니다. 이것은 다음 두 가지 방식을 사용하여 해결할 수 있습니다.
- 가상 공유 메모리 (VSM)
- 공유 가상 메모리 (SVM)
이러한 체계에서 응용 프로그램 프로그래머는 전역 적으로 주소 지정이 가능한 큰 공유 메모리를 가정합니다. 필요한 경우 응용 프로그램에서 만든 메모리 참조는 메시지 전달 패러다임으로 변환됩니다.
가상 공유 메모리 (VSM)
VSM은 하드웨어 구현입니다. 따라서 운영 체제의 가상 메모리 시스템은 VSM 위에 투명하게 구현됩니다. 따라서 운영 체제는 공유 메모리가있는 시스템에서 실행되고 있다고 생각합니다.
공유 가상 메모리 (SVM)
SVM은 프로세서의 MMU (Memory Management Unit)에서 하드웨어를 지원하는 운영 체제 수준의 소프트웨어 구현입니다. 여기서 공유 단위는 운영 체제 메모리 페이지입니다.
프로세서가 특정 메모리 위치를 지정하면 MMU는 메모리 액세스와 관련된 메모리 페이지가 로컬 메모리에 있는지 여부를 결정합니다. 페이지가 메모리에 없으면 일반 컴퓨터 시스템에서는 운영 체제에 의해 디스크에서 스왑됩니다. 그러나 SVM에서 운영 체제는 특정 페이지를 소유 한 원격 노드에서 페이지를 가져옵니다.
3 세대 멀티 컴퓨터
이 섹션에서는 3 세대 다중 컴퓨터에 대해 설명합니다.
과거의 디자인 선택
프로세서 기술을 선택하는 동안 다중 컴퓨터 설계자는 저비용 중형 프로세서를 빌딩 블록으로 선택합니다. 대부분의 병렬 컴퓨터는 표준 기성 마이크로 프로세서로 구축됩니다. 확장 성을 제한하는 공유 메모리를 사용하지 않고 다중 컴퓨터에 분산 메모리를 선택했습니다. 각 프로세서에는 자체 로컬 메모리 장치가 있습니다.
상호 연결 방식의 경우 다중 컴퓨터에는 주소 스위칭 네트워크가 아닌 메시지 전달, 지점 간 직접 네트워크가 있습니다. 제어 전략을 위해 다중 컴퓨터 설계자는 비동기 MIMD, MPMD 및 SMPD 작업을 선택합니다. Caltech의 Cosmic Cube (Seitz, 1983)는 1 세대 다중 컴퓨터 중 첫 번째입니다.
현재와 미래의 개발
차세대 컴퓨터는 전 세계적으로 공유되는 가상 메모리를 사용하는 중간 크기에서 미세 입자로 진화했습니다. 2 세대 다중 컴퓨터는 현재 여전히 사용되고 있습니다. 그러나 i386, i860 등과 같은 더 나은 프로세서를 사용하여 2 세대 컴퓨터가 많이 개발되었습니다.
3 세대 컴퓨터는 VLSI 구현 노드가 사용되는 차세대 컴퓨터입니다. 각 노드는 단일 칩에 통합 된 14-MIPS 프로세서, 20-Mbytes / s 라우팅 채널 및 16KB RAM을 가질 수 있습니다.
Intel Paragon 시스템
이전에는 모든 기능이 호스트에 주어 졌기 때문에 하이퍼 큐브 다중 컴퓨터를 만드는 데 동종 노드가 사용되었습니다. 따라서 이것은 I / O 대역폭을 제한했습니다. 따라서 대규모 문제를 효율적으로 또는 높은 처리량으로 해결하기 위해 이러한 컴퓨터를 사용할 수 없었습니다. Intel Paragon System은 이러한 어려움을 극복하도록 설계되었습니다. 네트워크 환경에서 다중 사용자 액세스가 가능한 애플리케이션 서버로 다중 컴퓨터를 전환했습니다.
메시지 전달 메커니즘
다중 컴퓨터 네트워크의 메시지 전달 메커니즘에는 특별한 하드웨어 및 소프트웨어 지원이 필요합니다. 이 섹션에서는 몇 가지 체계에 대해 설명합니다.
메시지 라우팅 체계
저장 및 전달 라우팅 체계를 사용하는 다중 컴퓨터에서 패킷은 정보 전송의 가장 작은 단위입니다. 웜홀 라우팅 네트워크에서 패킷은 플릿으로 더 나뉩니다. 패킷 길이는 라우팅 체계와 네트워크 구현에 의해 결정되는 반면 플리트 길이는 네트워크 크기의 영향을받습니다.
에 Store and forward routing, 패킷은 정보 전송의 기본 단위입니다. 이 경우 각 노드는 패킷 버퍼를 사용합니다. 패킷은 일련의 중간 노드를 통해 소스 노드에서 대상 노드로 전송됩니다. 지연 시간은 소스와 대상 사이의 거리에 정비례합니다.
에 wormhole routing, 소스 노드에서 대상 노드로의 전송은 일련의 라우터를 통해 이루어집니다. 동일한 패킷의 모든 플릿은 파이프 라인 방식으로 분리 할 수없는 시퀀스로 전송됩니다. 이 경우 헤더 플리트 만이 패킷이 어디로 가는지 알고 있습니다.
교착 상태 및 가상 채널
가상 채널은 두 노드 간의 논리적 링크입니다. 소스 노드와 리시버 노드의 플리트 버퍼와 그 사이의 물리적 채널로 구성됩니다. 한 쌍에 물리적 채널이 할당되면 하나의 소스 버퍼가 하나의 수신기 버퍼와 쌍을 이루어 가상 채널을 형성합니다.
모든 채널이 메시지에 의해 점유되고주기의 어느 채널도 해제되지 않으면 교착 상태가 발생합니다. 이를 방지하려면 교착 상태 방지 계획을 따라야합니다.