PyBrain-데이터 세트 데이터 가져 오기
이 장에서는 Pybrain 데이터 세트와 함께 작동 할 데이터를 얻는 방법을 배웁니다.
가장 일반적으로 사용되는 데이터 세트는 다음과 같습니다.
- sklearn 사용
- CSV 파일에서
sklearn 사용
sklearn 사용
다음은 sklearn의 데이터 세트 세부 정보가있는 링크입니다.https://scikit-learn.org/stable/datasets/index.html
다음은 sklearn에서 데이터 세트를 사용하는 방법에 대한 몇 가지 예입니다.
예 1 : load_digits ()
from sklearn import datasets
from pybrain.datasets import ClassificationDataSet
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])예제 2 : load_iris ()
from sklearn import datasets
from pybrain.datasets import ClassificationDataSet
digits = datasets.load_iris()
X, y = digits.data, digits.target
ds = ClassificationDataSet(4, 1, nb_classes=3)
for i in range(len(X)):
ds.addSample(X[i], y[i])CSV 파일에서
다음과 같이 csv 파일의 데이터를 사용할 수도 있습니다.
다음은 xor 진리표에 대한 샘플 데이터입니다. datasettest.csv
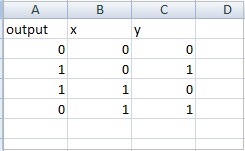
다음은 데이터 세트의 .csv 파일에서 데이터를 읽는 작업 예제입니다.
예
from pybrain.tools.shortcuts import buildNetwork
from pybrain.structure import TanhLayer
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
import pandas as pd
print('Read data...')
df = pd.read_csv('data/datasettest.csv',header=0).head(1000)
data = df.values
train_output = data[:,0]
train_data = data[:,1:]
print(train_output)
print(train_data)
# Create a network with two inputs, three hidden, and one output
nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer)
# Create a dataset that matches network input and output sizes:
_gate = SupervisedDataSet(2, 1)
# Create a dataset to be used for testing.
nortrain = SupervisedDataSet(2, 1)
# Add input and target values to dataset
# Values for NOR truth table
for i in range(0, len(train_output)) :
_gate.addSample(train_data[i], train_output[i])
#Training the network with dataset norgate.
trainer = BackpropTrainer(nn, _gate)
# will run the loop 1000 times to train it.
for epoch in range(1000):
trainer.train()
trainer.testOnData(dataset=_gate, verbose = True)Panda는 예제와 같이 csv 파일에서 데이터를 읽는 데 사용됩니다.
산출
C:\pybrain\pybrain\src>python testcsv.py
Read data...
[0 1 1 0]
[
[0 0]
[0 1]
[1 0]
[1 1]
]
Testing on data:
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000795
('out: ', '[0.997 ]')
('correct:', '[1 ]')
error: 0.00000380
('out: ', '[0.996 ]')
('correct:', '[1 ]')
error: 0.00000826
('out: ', '[0.004 ]')
('correct:', '[0 ]')
error: 0.00000829
('All errors:', [7.94733477723902e-06, 3.798267582566822e-06, 8.260969076585322e
-06, 8.286246525558165e-06])
('Average error:', 7.073204490487332e-06)
('Max error:', 8.286246525558165e-06, 'Median error:', 8.260969076585322e-06)