PyBrain-테스트 네트워크
이 장에서는 데이터를 훈련시키고 훈련 된 데이터의 오류를 테스트 할 몇 가지 예를 살펴 보겠습니다.
우리는 트레이너를 사용할 것입니다.
BackpropTrainer
BackpropTrainer는 (시간을 통해) 오류를 역 전파하여 감독 된 또는 ClassificationDataSet 데이터 세트 (잠재적으로 순차적)에 따라 모듈의 매개 변수를 훈련하는 트레이너입니다.
TrainUntilConvergence
수렴 될 때까지 데이터 세트에서 모듈을 훈련시키는 데 사용됩니다.
신경망을 만들 때 주어진 훈련 데이터를 기반으로 훈련을 받게되는데, 이제 네트워크가 제대로 훈련되었는지 여부는 해당 네트워크에서 테스트 된 테스트 데이터의 예측에 따라 달라집니다.
신경망을 구축하고 훈련 오류, 테스트 오류 및 유효성 검사 오류를 예측하는 작업 예제를 단계별로 살펴 보겠습니다.
네트워크 테스트
다음은 네트워크 테스트를 위해 따라야 할 단계입니다.
- 필요한 PyBrain 및 기타 패키지 가져 오기
- ClassificationDataSet 만들기
- 데이터 세트를 테스트 데이터로 25 %, 훈련 된 데이터로 75 % 분할
- 테스트 데이터 및 훈련 된 데이터를 다시 ClassificationDataSet으로 변환
- 신경망 만들기
- 네트워크 훈련
- 오류 및 유효성 검사 데이터 시각화
- 테스트 데이터 오류 비율
Step 1
필요한 PyBrain 및 기타 패키지 가져 오기.
필요한 패키지는 아래와 같이 가져옵니다.
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravelStep 2
다음 단계는 ClassificationDataSet을 만드는 것입니다.
데이터 세트의 경우 아래 표시된대로 sklearn 데이터 세트의 데이터 세트를 사용합니다.
아래 링크에서 sklearn의 load_digits 데이터 세트를 참조하십시오-
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
# we are having inputs are 64 dim array and since the digits are from 0-9 the
classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasetsStep 3
데이터 세트를 테스트 데이터로 25 %, 훈련 된 데이터로 75 % 분할-
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)따라서 여기에서는 0.25 값을 가진 splitWithProportion ()이라는 데이터 세트에 대한 메소드를 사용했습니다. 데이터 세트를 테스트 데이터로 25 %, 훈련 데이터로 75 %로 분할합니다.
Step 4
Testdata 및 Trained 데이터를 다시 ClassificationDataSet으로 변환합니다.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()데이터 세트에서 splitWithProportion () 메서드를 사용하면 데이터 세트가 감독 된 데이터 세트로 변환되므로 위 단계에서와 같이 데이터 세트를 다시 분류 데이터 세트로 변환합니다.
Step 5
다음 단계는 신경망을 만드는 것입니다.
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)훈련 데이터에서 입력과 출력이 사용되는 네트워크를 만들고 있습니다.
Step 6
네트워크 훈련
이제 중요한 부분은 아래와 같이 데이터 세트에서 네트워크를 훈련시키는 것입니다.
trainer = BackpropTrainer(net, dataset=training_data,
momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)BackpropTrainer () 메서드를 사용하고 생성 된 네트워크에서 데이터 세트를 사용하고 있습니다.
Step 7
다음 단계는 데이터의 오류 및 유효성 검사를 시각화하는 것입니다.
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()10의 epoch 동안 수렴 할 훈련 데이터에 trainUntilConvergence라는 메서드를 사용할 것입니다. 다음과 같이 플로팅 한 훈련 오류와 검증 오류를 반환합니다. 파란색 선은 훈련 오류를 나타내고 빨간색 선은 유효성 검사 오류를 나타냅니다.
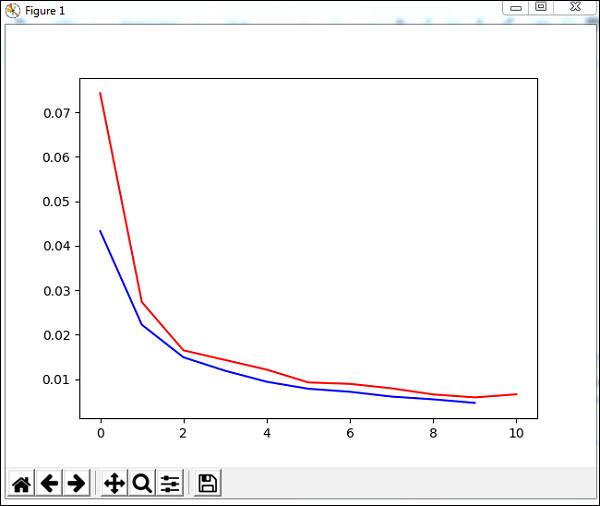
위 코드를 실행하는 동안 수신 된 총 오류는 다음과 같습니다.
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')오류는 0.04에서 시작하고 이후 각 에포크에 대해 감소합니다. 즉, 네트워크가 훈련되고 각 에포크에 대해 향상됩니다.
Step 8
테스트 데이터 오류 비율
아래와 같이 percentError 메서드를 사용하여 백분율 오류를 확인할 수 있습니다.
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))Percent Error on testData − 3.34075723830735
우리는 오류 비율, 즉 3.34 %를 얻고 있는데, 이는 신경망이 97 % 정확하다는 것을 의미합니다.
아래는 전체 코드입니다-
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))