PyBrain-강화 학습 모듈
강화 학습 (RL)은 기계 학습에서 중요한 부분입니다. 강화 학습은 에이전트가 환경의 입력을 기반으로 행동을 학습하게합니다.
Reinforcement 중 서로 상호 작용하는 구성 요소는 다음과 같습니다.
- Environment
- Agent
- Task
- Experiment
강화 학습의 레이아웃은 다음과 같습니다.
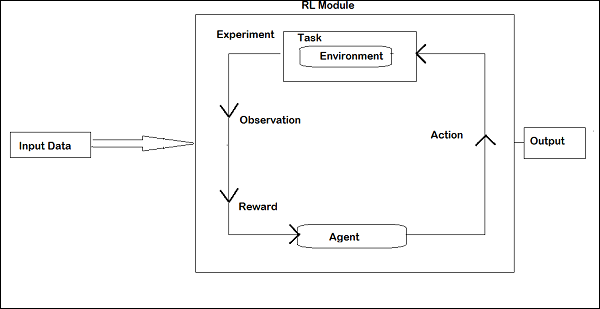
RL에서 에이전트는 반복에서 환경과 대화합니다. 각 반복에서 에이전트는 보상이있는 관찰을받습니다. 그런 다음 작업을 선택하고 환경으로 보냅니다. 각 반복의 환경은 새로운 상태로 이동하고 매번받은 보상이 저장됩니다.
RL 에이전트의 목표는 가능한 많은 보상을 수집하는 것입니다. 반복 사이에서 에이전트의 성능은 좋은 방식으로 행동하는 에이전트의 성능과 비교되며 성능의 차이는 보상 또는 실패를 초래합니다. RL은 기본적으로 로봇 제어, 엘리베이터, 통신, 게임 등과 같은 문제 해결 작업에 사용됩니다.
Pybrain에서 RL을 사용하는 방법을 살펴 보겠습니다.
우리는 미로 작업을 할 것입니다 environment1은 벽이고 0은 자유 필드 인 2 차원 numpy 배열을 사용하여 표현됩니다. 에이전트의 책임은 자유 필드 위로 이동하여 목표 지점을 찾는 것입니다.
다음은 미로 환경 작업의 단계별 흐름입니다.
1 단계
아래 코드로 필요한 패키지를 가져옵니다.
from scipy import *
import sys, time
import matplotlib.pyplot as pylab # for visualization we are using mathplotlib
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task2 단계
아래 코드를 사용하여 미로 환경 만들기-
# create the maze with walls as 1 and 0 is a free field
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7)) # create the environment, the first parameter is the
maze array and second one is the goal field tuple3 단계
다음 단계는 에이전트를 만드는 것입니다.
에이전트는 RL에서 중요한 역할을합니다. getAction () 및 integrationObservation () 메서드를 사용하여 미로 환경과 상호 작용합니다.
에이전트에는 컨트롤러 (상태를 작업에 매핑)와 학습자가 있습니다.
PyBrain의 컨트롤러는 입력이 상태이고이를 액션으로 변환하는 모듈과 같습니다.
controller = ActionValueTable(81, 4)
controller.initialize(1.)그만큼 ActionValueTable2 개의 입력, 즉 상태 및 작업의 수가 필요합니다. 표준 미로 환경에는 북쪽, 남쪽, 동쪽, 서쪽의 4 가지 동작이 있습니다.
이제 학습자를 만듭니다. 에이전트와 함께 사용할 학습자를 위해 SARSA () 학습 알고리즘을 사용할 것입니다.
learner = SARSA()
agent = LearningAgent(controller, learner)4 단계
이 단계는 환경에 에이전트를 추가하는 것입니다.
에이전트를 환경에 연결하려면 태스크라는 특수 구성 요소가 필요합니다. 의 역할task 환경에서 목표를 찾고 에이전트가 행동에 대한 보상을받는 방법을 찾는 것입니다.
환경에는 자체 작업이 있습니다. 우리가 사용한 Maze 환경에는 MDPMazeTask 작업이 있습니다. MDP는“markov decision process”즉, 에이전트는 미로에서 자신의 위치를 알고 있습니다. 환경은 작업의 매개 변수가됩니다.
task = MDPMazeTask(env)5 단계
에이전트를 환경에 추가 한 후 다음 단계는 실험을 만드는 것입니다.
이제 작업과 에이전트가 서로 협력 할 수 있도록 실험을 만들어야합니다.
experiment = Experiment(task, agent)이제 아래와 같이 실험을 1000 번 실행합니다.
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()다음 코드가 실행되면 에이전트와 작업 사이에 환경이 100 번 실행됩니다.
experiment.doInteractions(100)각 반복 후에 에이전트에게 전달되어야하는 정보와 보상을 결정하는 작업에 새로운 상태를 반환합니다. for 루프 내에서 에이전트를 학습하고 재설정 한 후 새 테이블을 플로팅 할 것입니다.
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(table.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")다음은 전체 코드입니다.
예
maze.py
from scipy import *
import sys, time
import matplotlib.pyplot as pylab
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
# create maze array
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
# create task
task = MDPMazeTask(env)
#controller in PyBrain is like a module, for which the input is states and
convert them into actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# create agent with controller and learner - using SARSA()
learner = SARSA()
# create agent
agent = LearningAgent(controller, learner)
# create experiment
experiment = Experiment(task, agent)
# prepare plotting
pylab.gray()
pylab.ion()
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")산출
python maze.py
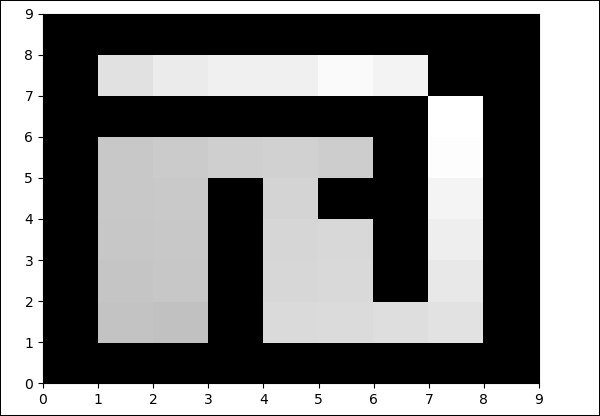
자유 필드의 색상은 반복 할 때마다 변경됩니다.