Weka-클러스터링
클러스터링 알고리즘은 전체 데이터 세트에서 유사한 인스턴스 그룹을 찾습니다. WEKA는 EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans 등과 같은 여러 클러스터링 알고리즘을 지원합니다. WEKA 기능을 완전히 활용하려면 이러한 알고리즘을 완전히 이해해야합니다.
분류의 경우와 마찬가지로 WEKA를 사용하면 감지 된 클러스터를 그래픽으로 시각화 할 수 있습니다. 클러스터링을 설명하기 위해 제공된 홍채 데이터베이스를 사용합니다. 데이터 세트에는 각각 50 개 인스턴스의 세 가지 클래스가 포함됩니다. 각 클래스는 붓꽃의 유형을 나타냅니다.
데이터로드
WEKA 탐색기에서 Preprocess탭. 클릭Open file ... 옵션을 선택하고 iris.arff파일 선택 대화 상자에서 파일. 데이터를로드하면 다음과 같은 화면이 나타납니다.
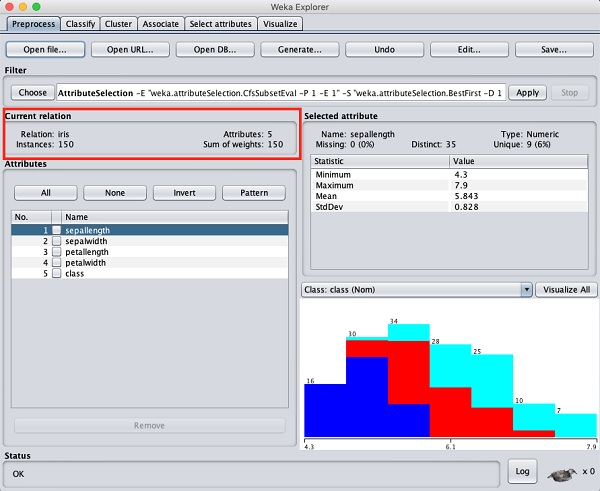
150 개의 인스턴스와 5 개의 속성이 있음을 알 수 있습니다. 속성 이름은 다음과 같이 나열됩니다.sepallength, sepalwidth, petallength, petalwidth 과 class. 처음 4 개의 속성은 숫자 유형이고 클래스는 3 개의 고유 값이있는 명목 유형입니다. 데이터베이스의 기능을 이해하려면 각 속성을 조사하십시오. 이 데이터에 대해 사전 처리를하지 않고 곧바로 모델 구축을 진행합니다.
클러스터링
클릭 Cluster로드 된 데이터에 클러스터링 알고리즘을 적용하려면 Tab 키를 누릅니다. 클릭Choose단추. 다음 화면이 표시됩니다-

이제 선택 EM클러스터링 알고리즘으로. 에서Cluster mode 하위 창에서 Classes to clusters evaluation 아래 스크린 샷에 표시된 옵션-

클릭 Start버튼을 눌러 데이터를 처리합니다. 잠시 후 결과가 화면에 표시됩니다.
다음으로 결과를 살펴 보겠습니다.
출력 검토
데이터 처리의 출력은 아래 화면에 표시됩니다.
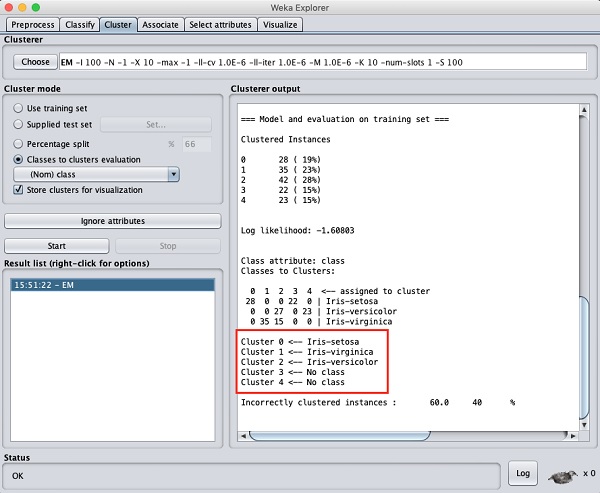
출력 화면에서 다음을 관찰 할 수 있습니다.
데이터베이스에서 5 개의 클러스터 된 인스턴스가 감지되었습니다.
그만큼 Cluster 0 세토 사, Cluster 1 virginica를 나타냅니다. Cluster 2 마지막 두 클러스터에는 연결된 클래스가없는 반면, versicolor를 나타냅니다.
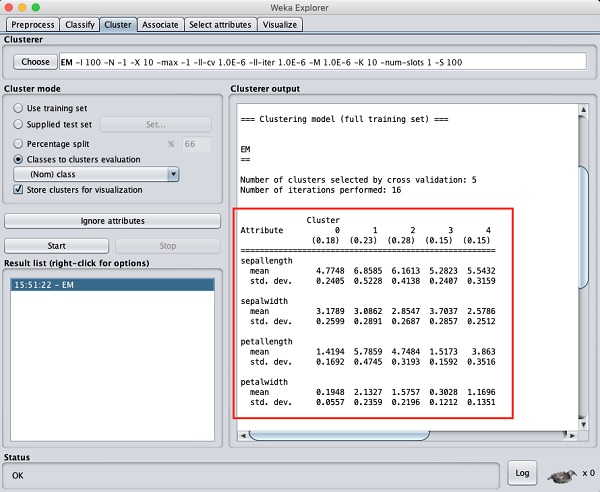
출력 창을 위로 스크롤하면 감지 된 다양한 클러스터의 각 속성에 대한 평균 및 표준 편차를 제공하는 일부 통계도 표시됩니다. 이것은 아래 주어진 스크린 샷에 표시됩니다-
다음으로 클러스터의 시각적 표현을 살펴 보겠습니다.
클러스터 시각화
클러스터를 시각화하려면 EM 결과 Result list. 다음 옵션이 표시됩니다.
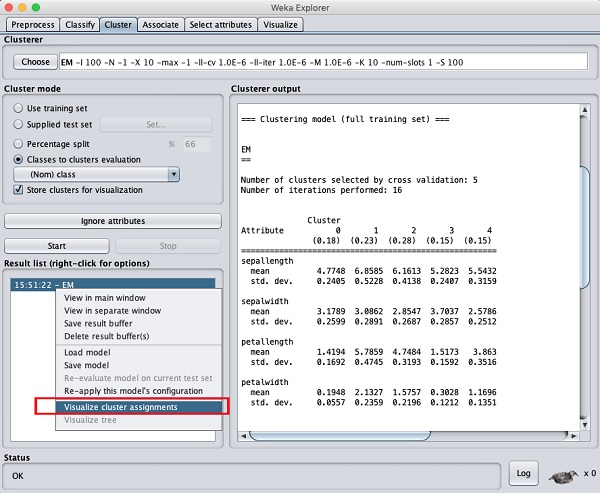
고르다 Visualize cluster assignments. 다음 출력이 표시됩니다.
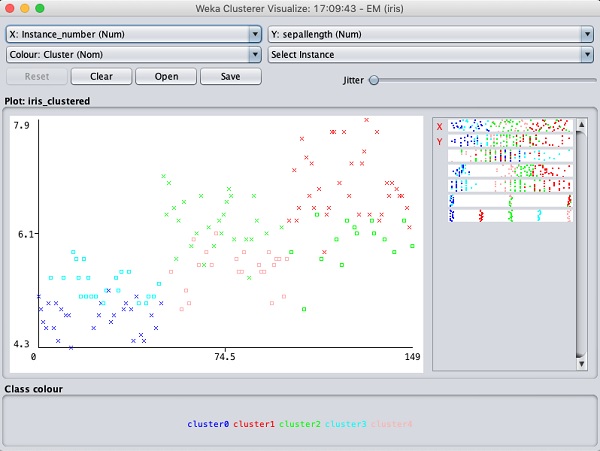
분류의 경우와 마찬가지로 올바르게 식별 된 인스턴스와 잘못 식별 된 인스턴스의 차이를 알 수 있습니다. 결과를 분석하기 위해 X 및 Y 축을 변경하여 놀 수 있습니다. 분류의 경우처럼 지 터링을 사용하여 올바르게 식별 된 인스턴스의 농도를 알아낼 수 있습니다. 시각화 플롯의 작업은 분류의 경우 연구 한 작업과 유사합니다.
계층 적 클러스터 러 적용
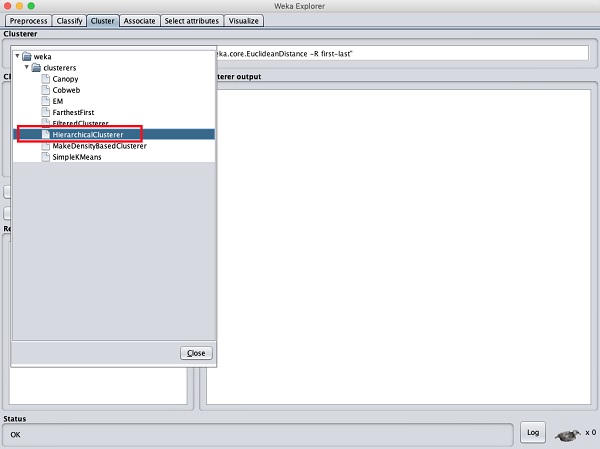
WEKA의 힘을 입증하기 위해 이제 다른 클러스터링 알고리즘의 응용 프로그램을 살펴 보겠습니다. WEKA 탐색기에서HierarchicalClusterer 아래 스크린 샷과 같이 ML 알고리즘으로
선택 Cluster mode 선택 Classes to cluster evaluation을 클릭하고 Start단추. 다음 출력이 표시됩니다.
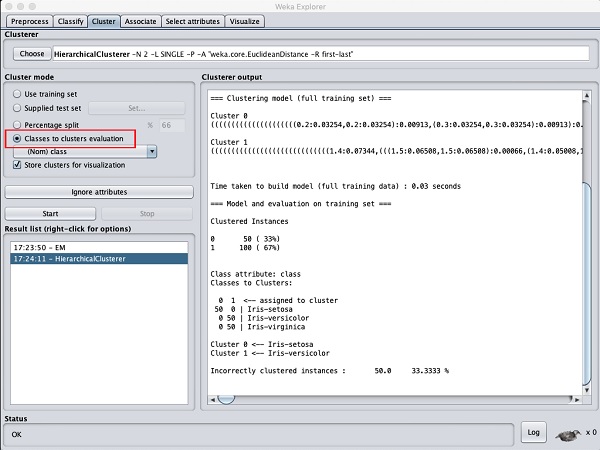
에 유의하십시오 Result list, 두 가지 결과가 나열됩니다. 첫 번째는 EM 결과이고 두 번째는 현재 계층 구조입니다. 마찬가지로 동일한 데이터 세트에 여러 ML 알고리즘을 적용하고 결과를 빠르게 비교할 수 있습니다.
이 알고리즘에 의해 생성 된 트리를 살펴보면 다음과 같은 출력을 볼 수 있습니다.
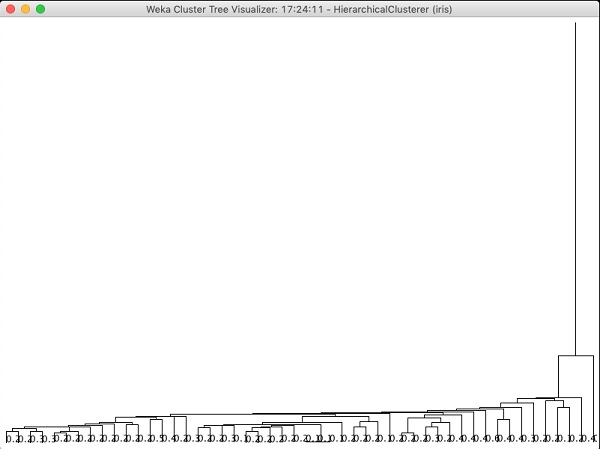
다음 장에서는 Associate ML 알고리즘 유형.