Weka-데이터로드
이 장에서는 데이터를 전처리하는 데 사용하는 첫 번째 탭부터 시작합니다. 이는 모델 구축을 위해 데이터에 적용하는 모든 알고리즘에 공통적이며 WEKA의 모든 후속 작업에 대한 공통 단계입니다.
기계 학습 알고리즘이 허용 가능한 정확도를 제공하려면 먼저 데이터를 정리해야합니다. 이는 필드에서 수집 된 원시 데이터에 null 값, 관련없는 열 등이 포함될 수 있기 때문입니다.
이 장에서는 원시 데이터를 사전 처리하고 향후 사용을 위해 깨끗하고 의미있는 데이터 세트를 만드는 방법을 배웁니다.
먼저 WEKA 탐색기에 데이터 파일을로드하는 방법을 배웁니다. 데이터는 다음 소스에서로드 할 수 있습니다.
- 로컬 파일 시스템
- Web
- Database
이 장에서는 데이터를로드하는 세 가지 옵션을 모두 자세히 살펴 봅니다.
로컬 파일 시스템에서 데이터로드
이전 강의에서 학습 한 Machine Learning 탭 바로 아래에 다음 세 개의 버튼이 있습니다.
- 파일 열기 ...
- URL 열기 ...
- DB 열기 ...
클릭 Open file... 버튼. 다음 화면과 같이 디렉토리 탐색기 창이 열립니다.
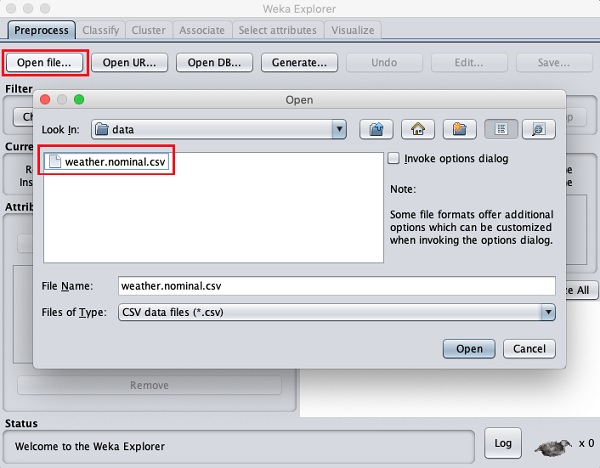
이제 데이터 파일이 저장된 폴더로 이동하십시오. WEKA 설치에는 실험 할 수있는 많은 샘플 데이터베이스가 제공됩니다. 이들은data WEKA 설치 폴더.
학습 목적으로이 폴더에서 데이터 파일을 선택하십시오. 파일의 내용은 WEKA 환경에서로드됩니다. 이로드 된 데이터를 검사하고 처리하는 방법을 곧 배울 것입니다. 그 전에 웹에서 데이터 파일을로드하는 방법을 살펴 보겠습니다.
웹에서 데이터로드
클릭하면 Open URL ... 버튼을 누르면 다음과 같은 창이 나타납니다.
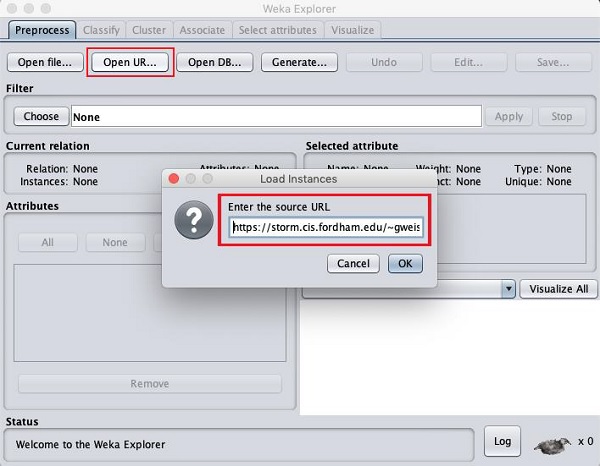
공개 URL에서 파일을 엽니 다. 팝업 상자에 다음 URL을 입력합니다.
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
데이터가 저장되는 다른 URL을 지정할 수 있습니다. 그만큼Explorer 원격 사이트의 데이터를 해당 환경으로로드합니다.
DB에서 데이터로드
클릭하면 Open DB ... 버튼을 누르면 다음과 같은 창이 나타납니다.
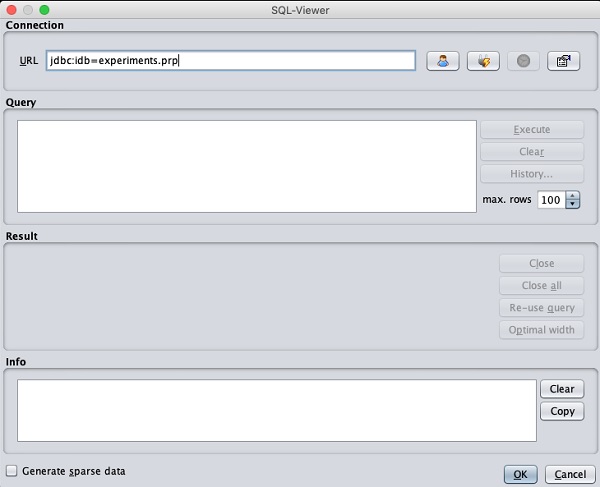
데이터베이스에 연결 문자열을 설정하고, 데이터 선택을위한 쿼리를 설정하고, 쿼리를 처리하고 WEKA에서 선택한 레코드를로드합니다.