Weka-탐색기 시작
이 장에서는 탐색기가 빅 데이터 작업을 위해 제공하는 다양한 기능을 살펴 보겠습니다.
클릭하면 Explorer 버튼 Applications 선택기를 선택하면 다음 화면이 열립니다.
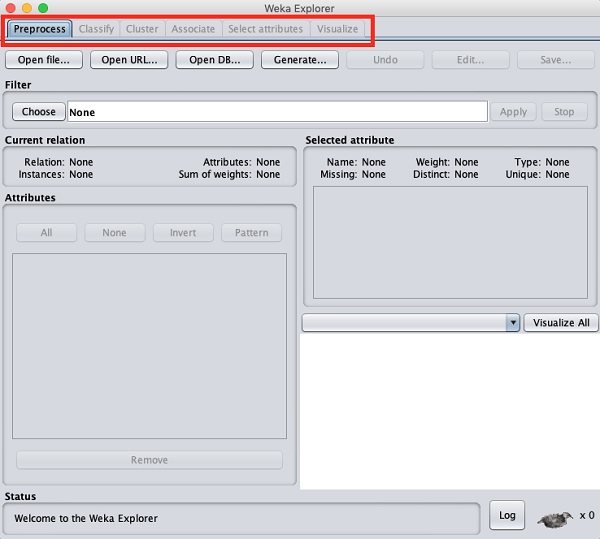
상단에는 여기에 나열된 여러 탭이 표시됩니다.
- Preprocess
- Classify
- Cluster
- Associate
- 속성 선택
- Visualize
이 탭 아래에는 미리 구현 된 몇 가지 기계 학습 알고리즘이 있습니다. 이제 각각에 대해 자세히 살펴 보겠습니다.
전처리 탭
처음에는 탐색기를 열 때 Preprocess탭이 활성화됩니다. 기계 학습의 첫 번째 단계는 데이터를 사전 처리하는 것입니다. 따라서Preprocess 옵션을 선택하면 데이터 파일을 선택하고 처리하여 다양한 기계 학습 알고리즘을 적용하는 데 적합합니다.
분류 탭
그만큼 Classify탭은 데이터 분류를위한 여러 기계 학습 알고리즘을 제공합니다. 몇 가지를 나열하기 위해 선형 회귀, 로지스틱 회귀, 지원 벡터 머신, 의사 결정 트리, RandomTree, RandomForest, NaiveBayes 등과 같은 알고리즘을 적용 할 수 있습니다. 이 목록은 매우 포괄적이며 감독 및 비지도 기계 학습 알고리즘을 모두 제공합니다.
클러스터 탭
아래의 Cluster 탭에는 SimpleKMeans, FilteredClusterer, HierarchicalClusterer 등과 같은 여러 클러스터링 알고리즘이 제공됩니다.
연결 탭
아래의 Associate 탭에서 Apriori, FilteredAssociator 및 FPGrowth를 찾을 수 있습니다.
속성 탭 선택
Select Attributes ClassifierSubsetEval, PrinicipalComponents 등과 같은 여러 알고리즘을 기반으로 기능을 선택할 수 있습니다.
시각화 탭
마지막으로 Visualize 옵션을 사용하면 분석을 위해 처리 된 데이터를 시각화 할 수 있습니다.
아시다시피 WEKA는 기계 학습 애플리케이션을 테스트하고 구축하기 위해 즉시 사용할 수있는 몇 가지 알고리즘을 제공합니다. WEKA를 효과적으로 사용하려면 이러한 알고리즘, 작동 방식, 어떤 상황에서 어떤 알고리즘을 선택할지, 처리 된 출력에서 무엇을 찾아야하는지 등에 대한 건전한 지식이 있어야합니다. 간단히 말해, 앱을 빌드하는 데 WEKA를 효과적으로 사용하려면 머신 러닝의 견고한 기반이 있어야합니다.
다음 장에서는 탐색기의 각 탭에 대해 자세히 알아 봅니다.