Apache Solr - indeksowanie danych
Ogólnie, indexingto układ dokumentów lub (innych podmiotów) systematycznie. Indeksowanie umożliwia użytkownikom zlokalizowanie informacji w dokumencie.
Indeksowanie zbiera, analizuje i przechowuje dokumenty.
Indeksowanie ma na celu zwiększenie szybkości i wydajności zapytania wyszukiwania podczas znajdowania wymaganego dokumentu.
Indeksowanie w Apache Solr
W Apache Solr możemy indeksować (dodawać, usuwać, modyfikować) różne formaty dokumentów takie jak xml, csv, pdf itp. Dane do indeksu Solr możemy dodawać na kilka sposobów.
W tym rozdziale omówimy indeksowanie -
- Korzystanie z interfejsu internetowego Solr.
- Korzystanie z dowolnego interfejsu API klienta, takiego jak Java, Python itp.
- Używając post tool.
W tym rozdziale omówimy, jak dodać dane do indeksu Apache Solr za pomocą różnych interfejsów (wiersz poleceń, interfejs WWW i API klienta Java)
Dodawanie dokumentów za pomocą polecenia Post
Solr ma post polecenie w jego bin/informator. Za pomocą tego polecenia możesz indeksować różne formaty plików, takie jak JSON, XML, CSV w Apache Solr.
Przejrzyj bin katalogu Apache Solr i wykonaj plik –h option polecenia post, jak pokazano w poniższym bloku kodu.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hWykonując powyższe polecenie, otrzymasz listę opcji pliku post command, jak pokazano niżej.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Przykład
Załóżmy, że mamy plik o nazwie sample.csv z następującą zawartością (w bin informator).
| legitymacja studencka | Imię | Nazwisko | Telefon | Miasto |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Kalkuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Powyższy zestaw danych zawiera dane osobowe, takie jak identyfikator ucznia, imię, nazwisko, telefon i miasto. Plik CSV zbioru danych przedstawiono poniżej. Tutaj musisz zauważyć, że musisz wspomnieć o schemacie, dokumentując jego pierwszą linię.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiMożesz zindeksować te dane pod rdzeniem o nazwie sample_Solr używając post polecenie w następujący sposób -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvPo wykonaniu powyższego polecenia, dany dokument jest indeksowany pod określonym rdzeniem, generując następujący wynik.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Odwiedź stronę główną interfejsu użytkownika Solr, używając następującego adresu URL -
http://localhost:8983/
Wybierz rdzeń Solr_sample. Domyślną obsługą żądań jest/selecta zapytanie brzmi „:”. Nie wprowadzając żadnych modyfikacji, kliknij plikExecuteQuery przycisk u dołu strony.
Podczas wykonywania zapytania można obserwować zawartość zindeksowanego dokumentu CSV w formacie JSON (domyślnie), jak pokazano na poniższym zrzucie ekranu.
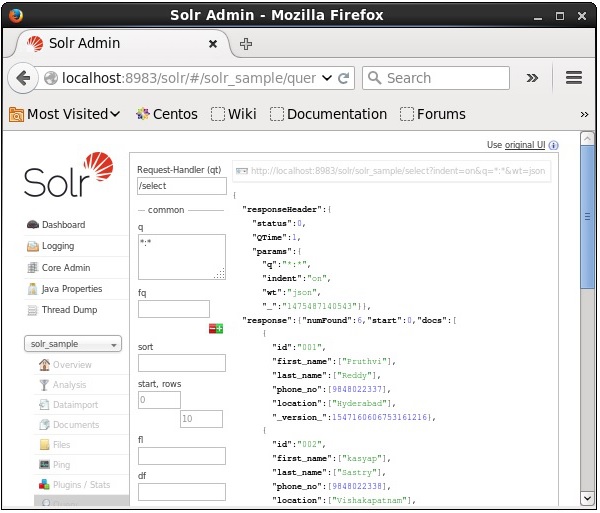
Note - W ten sam sposób możesz indeksować inne formaty plików, takie jak JSON, XML, CSV itp.
Dodawanie dokumentów za pomocą interfejsu internetowego Solr
Możesz także indeksować dokumenty za pomocą interfejsu internetowego dostarczonego przez Solr. Zobaczmy, jak zindeksować następujący dokument JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Krok 1
Otwórz interfejs sieciowy Solr, używając następującego adresu URL -
http://localhost:8983/
Step 2
Wybierz rdzeń Solr_sample. Domyślnie wartości pól Request Handler, Common Within, Overwrite i Boost to odpowiednio / update, 1000, true i 1.0, jak pokazano na poniższym zrzucie ekranu.
Teraz wybierz żądany format dokumentu z JSON, CSV, XML itp. Wpisz dokument, który ma być indeksowany w polu tekstowym i kliknij Submit Document przycisk, jak pokazano na poniższym zrzucie ekranu.
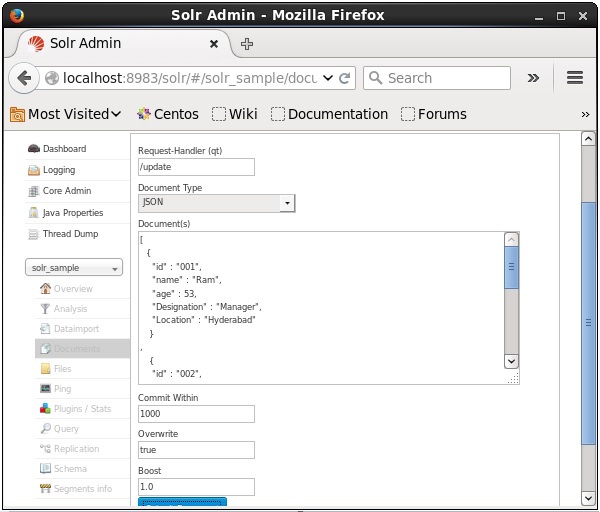
Dodawanie dokumentów za pomocą Java Client API
Poniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
Documents added