Apache Solr - szybki przewodnik
Solr to platforma wyszukiwania typu open source, która służy do tworzenia search applications. Został zbudowany na szczycieLucene(wyszukiwarka pełnotekstowa). Solr jest gotowy dla przedsiębiorstw, szybki i wysoce skalowalny. Aplikacje zbudowane w Solr są zaawansowane i zapewniają wysoką wydajność.
To było Yonik Seelyktóry stworzył Solr w 2004 roku w celu dodania możliwości wyszukiwania do firmowej strony CNET Networks. W styczniu 2006 został utworzony jako projekt open source w ramach Apache Software Foundation. Jego najnowsza wersja, Solr 6.0, została wydana w 2016 roku z obsługą wykonywania równoległych zapytań SQL.
Solr może być używany razem z Hadoop. Ponieważ Hadoop obsługuje dużą ilość danych, Solr pomaga nam znaleźć potrzebne informacje z tak dużego źródła. Nie tylko wyszukiwanie, Solr może być również używany do celów przechowywania. Podobnie jak inne bazy danych NoSQL, jest to pliknon-relational data storage i processing technology.
Krótko mówiąc, Solr to skalowalny, gotowy do wdrożenia silnik wyszukiwania / przechowywania zoptymalizowany pod kątem przeszukiwania dużych ilości danych tekstowych.
Funkcje Apache Solr
Solr to opakowanie wokół Java API Lucene. Dlatego korzystając z Solr, możesz wykorzystać wszystkie funkcje Lucene. Przyjrzyjmy się niektórym z najważniejszych cech Solr -
Restful APIs- Do komunikacji z Solr nie jest wymagana znajomość programowania w języku Java. Zamiast tego możesz korzystać z usług uspokajających, aby się z nim komunikować. Wprowadzamy dokumenty w Solr w formatach plików takich jak XML, JSON i .CSV i uzyskujemy wyniki w tych samych formatach plików.
Full text search - Solr zapewnia wszystkie możliwości potrzebne do wyszukiwania pełnotekstowego, takie jak tokeny, frazy, sprawdzanie pisowni, symbole wieloznaczne i autouzupełnianie.
Enterprise ready - W zależności od potrzeb organizacji, Solr można wdrożyć w dowolnych systemach (dużych lub małych), takich jak samodzielne, rozproszone, w chmurze itp.
Flexible and Extensible - Rozszerzając klasy Java i odpowiednio je konfigurując, możemy łatwo dostosowywać komponenty Solr.
NoSQL database - Solr może być również używany jako baza danych NOSQL typu big data, w której możemy rozprowadzać zadania wyszukiwania wzdłuż klastra.
Admin Interface - Solr zapewnia łatwy w obsłudze, przyjazny dla użytkownika, oparty na funkcjach interfejs użytkownika, za pomocą którego możemy wykonywać wszystkie możliwe zadania, takie jak zarządzanie dziennikami, dodawanie, usuwanie, aktualizowanie i wyszukiwanie dokumentów.
Highly Scalable - Korzystając z Solr z Hadoopem, możemy skalować jego pojemność poprzez dodawanie replik.
Text-Centric and Sorted by Relevance - Solr jest najczęściej używany do wyszukiwania dokumentów tekstowych, a wyniki są dostarczane zgodnie z trafnością zapytania użytkownika w kolejności.
W przeciwieństwie do Lucene, nie musisz mieć umiejętności programowania w Javie podczas pracy z Apache Solr. Zapewnia wspaniałą usługę gotową do wdrożenia, umożliwiającą tworzenie pola wyszukiwania z funkcją autouzupełniania, której Lucene nie zapewnia. Korzystając z Solr, możemy skalować, dystrybuować i zarządzać indeksami dla aplikacji na dużą skalę (Big Data).
Lucene w wyszukiwarkach
Lucene to prosta, ale potężna biblioteka wyszukiwania oparta na języku Java. Można go używać w dowolnej aplikacji w celu dodania możliwości wyszukiwania. Lucene to skalowalna i wydajna biblioteka służąca do indeksowania i wyszukiwania praktycznie każdego rodzaju tekstu. Biblioteka Lucene zapewnia podstawowe operacje wymagane przez każdą aplikację wyszukującą, taką jakIndexing i Searching.
Jeśli mamy portal internetowy z ogromną ilością danych, to najprawdopodobniej będziemy potrzebować wyszukiwarki w naszym portalu, aby wydobyć odpowiednie informacje z ogromnej puli danych. Lucene działa jako serce każdej aplikacji wyszukującej i zapewnia podstawowe operacje związane z indeksowaniem i wyszukiwaniem.
Wyszukiwarka odnosi się do ogromnej bazy danych zasobów internetowych, takich jak strony internetowe, grupy dyskusyjne, programy, obrazy itp. Pomaga zlokalizować informacje w sieci WWW.
Użytkownicy mogą wyszukiwać informacje, przesyłając zapytania do wyszukiwarki w postaci słów kluczowych lub fraz. Wyszukiwarka przeszukuje następnie swoją bazę danych i zwraca użytkownikowi odpowiednie linki.
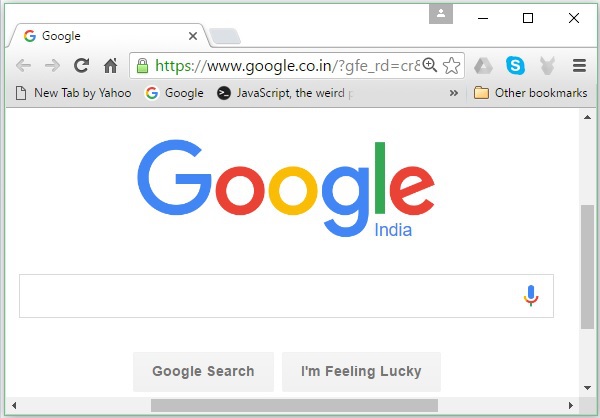
Komponenty wyszukiwarek
Ogólnie rzecz biorąc, istnieją trzy podstawowe elementy wyszukiwarki wymienione poniżej -
Web Crawler - Przeszukiwacze sieci są również znane jako spiders lub bots. Jest to komponent oprogramowania, który przeszukuje sieć w celu zebrania informacji.
Database- Wszystkie informacje w sieci są przechowywane w bazach danych. Zawierają ogromną ilość zasobów sieciowych.
Search Interfaces- Ten komponent jest interfejsem między użytkownikiem a bazą danych. Pomaga użytkownikowi przeszukiwać bazę danych.
Jak działają wyszukiwarki?
Do wykonania niektórych lub wszystkich poniższych operacji wymagana jest dowolna aplikacja wyszukująca.
| Krok | Tytuł | Opis |
|---|---|---|
1 |
Zdobądź surową zawartość |
Pierwszym krokiem każdej aplikacji wyszukującej jest zebranie docelowej treści, na której ma zostać przeprowadzone wyszukiwanie. |
2 |
Zbuduj dokument |
Następnym krokiem jest zbudowanie dokumentu (ów) z surowej treści, którą aplikacja wyszukująca może łatwo zrozumieć i zinterpretować. |
3 |
Przeanalizuj dokument |
Przed rozpoczęciem indeksowania dokument ma zostać przeanalizowany. |
4 |
Indeksowanie dokumentu |
Po zbudowaniu i przeanalizowaniu dokumentów następnym krokiem jest ich indeksowanie, aby można było pobrać ten dokument na podstawie określonych kluczy, a nie całej zawartości dokumentu. Indeksowanie jest podobne do indeksów, które mamy na końcu książki, w których typowe słowa są wyświetlane wraz z numerami stron, dzięki czemu można je szybko prześledzić, zamiast przeszukiwać całą książkę. |
5 |
Interfejs użytkownika do wyszukiwania |
Gdy baza indeksów jest już gotowa, aplikacja może wykonywać operacje wyszukiwania. Aby pomóc użytkownikowi w wyszukiwaniu, aplikacja musi zapewniać interfejs użytkownika, w którym użytkownik może wprowadzać tekst i inicjować proces wyszukiwania |
6 |
Utwórz zapytanie |
Gdy użytkownik zgłosi żądanie wyszukania tekstu, aplikacja powinna przygotować obiekt zapytania wykorzystujący ten tekst, który następnie może zostać wykorzystany do odpytania bazy danych indeksu w celu uzyskania odpowiednich informacji. |
7 |
Wyszukiwana fraza |
Przy użyciu obiektu zapytania sprawdzana jest baza danych indeksu w celu uzyskania odpowiednich szczegółów i dokumentów treści. |
8 |
Wyniki renderowania |
Po otrzymaniu wymaganego wyniku aplikacja powinna zdecydować, jak wyświetlić wyniki użytkownikowi za pomocą interfejsu użytkownika. |
Spójrz na poniższą ilustrację. Przedstawia ogólny obraz funkcjonowania wyszukiwarek.
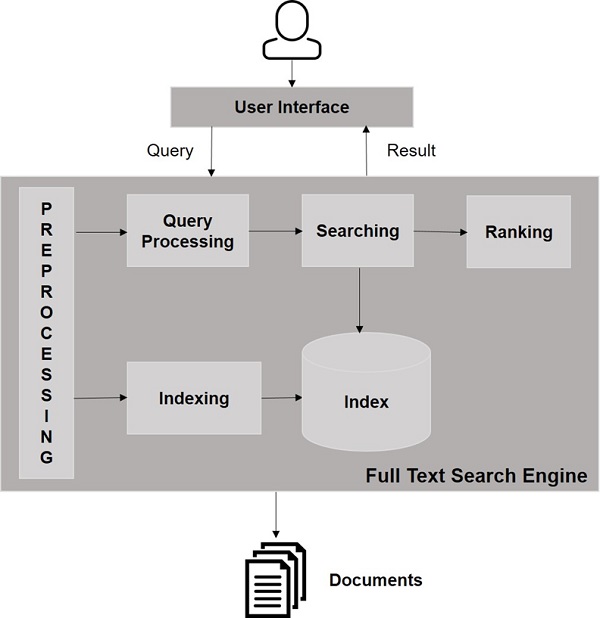
Oprócz tych podstawowych operacji aplikacje wyszukujące mogą również udostępniać interfejs administratora i użytkownika, pomagając administratorom kontrolować poziom wyszukiwania w oparciu o profile użytkowników. Analiza wyników wyszukiwania to kolejny ważny i zaawansowany aspekt każdej aplikacji wyszukującej.
W tym rozdziale omówimy, jak skonfigurować Solr w środowisku Windows. Aby zainstalować Solr w systemie Windows, należy postępować zgodnie z instrukcjami podanymi poniżej -
Odwiedź stronę główną Apache Solr i kliknij przycisk pobierania.
Wybierz jeden z serwerów lustrzanych, aby uzyskać indeks Apache Solr. Stamtąd pobierz plik o nazwieSolr-6.2.0.zip.
Przenieś plik z downloads folder do wymaganego katalogu i rozpakuj go.
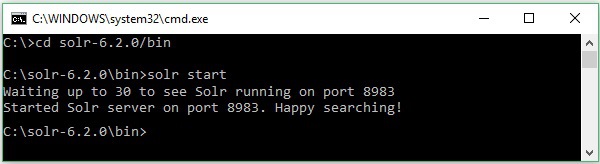
Załóżmy, że pobrałeś Solr fie i rozpakowałeś go na dysk C. W takim przypadku możesz uruchomić Solr, jak pokazano na poniższym zrzucie ekranu.
Aby zweryfikować instalację, użyj następującego adresu URL w przeglądarce.
http://localhost:8983/
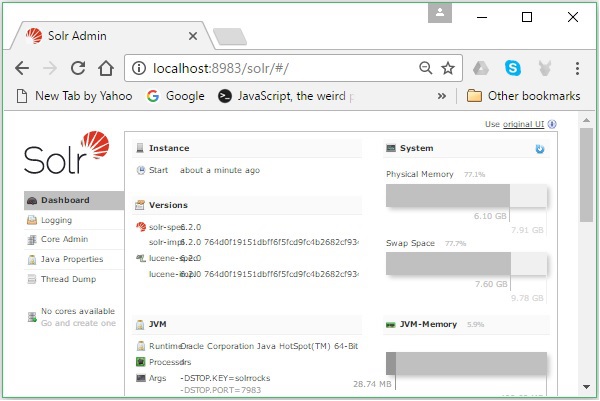
Jeśli proces instalacji powiedzie się, zobaczysz pulpit nawigacyjny interfejsu użytkownika Apache Solr, jak pokazano poniżej.
Ustawianie środowiska Java
Możemy również komunikować się z Apache Solr za pomocą bibliotek Java; ale zanim uzyskasz dostęp do Solr za pomocą Java API, musisz ustawić ścieżkę klas dla tych bibliotek.
Ustawianie ścieżki klas
Ustaw classpath do bibliotek Solr w .bashrcplik. otwarty.bashrc w dowolnym z edytorów, jak pokazano poniżej.
$ gedit ~/.bashrcUstaw ścieżkę klas dla bibliotek Solr (lib folder w HBase), jak pokazano poniżej.
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*Ma to zapobiec wystąpieniu wyjątku „nie znaleziono klasy” podczas uzyskiwania dostępu do bazy danych HBase przy użyciu interfejsu API języka Java.
Solr może być używany razem z Hadoop. Ponieważ Hadoop obsługuje dużą ilość danych, Solr pomaga nam znaleźć potrzebne informacje z tak dużego źródła. W tej sekcji wyjaśnij, jak możesz zainstalować Hadoop w swoim systemie.
Pobieranie Hadoop
Poniżej podano kroki, które należy wykonać, aby pobrać Hadoop na swój system.
Step 1- Przejdź do strony głównej Hadoop. Możesz skorzystać z linku - www.hadoop.apache.org/ . Kliknij w linkReleases, jak podkreślono na poniższym zrzucie ekranu.
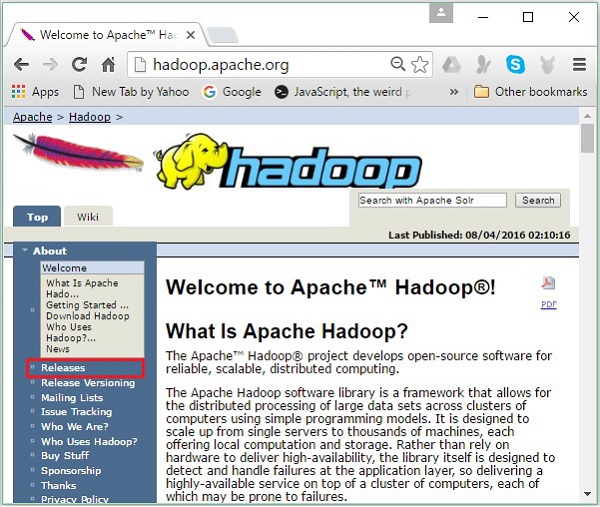
Przekieruje Cię do Apache Hadoop Releases strona zawierająca łącza do serwerów lustrzanych plików źródłowych i binarnych różnych wersji Hadoop w następujący sposób -
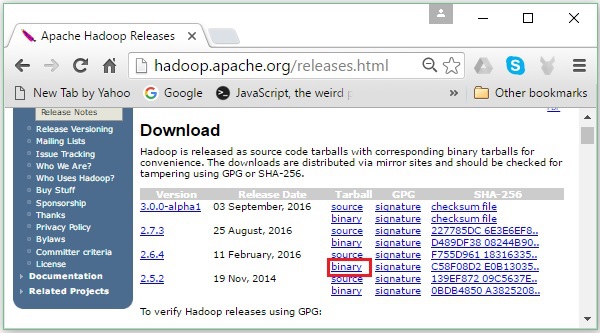
Step 2 - Wybierz najnowszą wersję Hadoop (w naszym poradniku jest to 2.6.4) i kliknij jej binary link. Przeniesie Cię do strony, na której dostępne są serwery lustrzane binarnego Hadoop. Kliknij jeden z tych serwerów lustrzanych, aby pobrać Hadoop.
Pobierz Hadoop z wiersza polecenia
Otwórz terminal Linux i zaloguj się jako superużytkownik.
$ su
password:Przejdź do katalogu, w którym chcesz zainstalować Hadoop, i zapisz tam plik, korzystając z linku skopiowanego wcześniej, jak pokazano w poniższym bloku kodu.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzPo pobraniu Hadoop wyodrębnij go za pomocą następujących poleceń.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstalowanie Hadoop
Wykonaj poniższe czynności, aby zainstalować Hadoop w trybie pseudo-rozproszonym.
Krok 1: Konfigurowanie Hadoop
Możesz ustawić zmienne środowiskowe Hadoop, dołączając następujące polecenia do ~/.bashrc plik.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL = $HADOOP_HOMENastępnie zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 2: Konfiguracja Hadoop
Wszystkie pliki konfiguracyjne Hadoop można znaleźć w lokalizacji „$ HADOOP_HOME / etc / hadoop”. Wymagane jest wprowadzenie zmian w tych plikach konfiguracyjnych zgodnie z infrastrukturą Hadoop.
$ cd $HADOOP_HOME/etc/hadoopAby tworzyć programy Hadoop w Javie, musisz zresetować zmienne środowiskowe Java w hadoop-env.sh plik, zastępując JAVA_HOME wartość z położeniem Java w systemie.
export JAVA_HOME = /usr/local/jdk1.7.0_71Poniżej znajduje się lista plików, które musisz edytować, aby skonfigurować Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
Plik core-site.xml plik zawiera informacje, takie jak numer portu używany dla wystąpienia Hadoop, pamięć przydzielona dla systemu plików, limit pamięci do przechowywania danych i rozmiar buforów do odczytu / zapisu.
Otwórz plik core-site.xml i dodaj następujące właściwości wewnątrz tagów <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Plik hdfs-site.xml plik zawiera informacje takie jak wartość danych replikacji, namenode ścieżka i datanodeścieżki lokalnych systemów plików. To miejsce, w którym chcesz przechowywać infrastrukturę Hadoop.
Przyjmijmy następujące dane.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOtwórz ten plik i dodaj następujące właściwości wewnątrz znaczników <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - W powyższym pliku wszystkie wartości właściwości są zdefiniowane przez użytkownika i można wprowadzać zmiany zgodnie z infrastrukturą Hadoop.
yarn-site.xml
Ten plik służy do konfigurowania przędzy w Hadoop. Otwórz plik yarn-site.xml i dodaj następujące właściwości między tagami <configuration>, </configuration> w tym pliku.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ten plik jest używany do określenia, której platformy MapReduce używamy. Domyślnie Hadoop zawiera szablon yarn-site.xml. Przede wszystkim należy skopiować plik zmapred-site,xml.template do mapred-site.xml plik za pomocą następującego polecenia.
$ cp mapred-site.xml.template mapred-site.xmlotwarty mapred-site.xml file i dodaj następujące właściwości wewnątrz tagów <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Weryfikacja instalacji Hadoop
Poniższe kroki służą do weryfikacji instalacji Hadoop.
Krok 1: Konfiguracja nazwy węzła
Skonfiguruj namenode za pomocą polecenia „hdfs namenode –format” w następujący sposób.
$ cd ~
$ hdfs namenode -formatOczekiwany wynik jest następujący.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Krok 2: weryfikacja plików dfs Hadoop
Następujące polecenie służy do uruchamiania systemu plików dfs Hadoop. Wykonanie tego polecenia spowoduje uruchomienie systemu plików Hadoop.
$ start-dfs.shOczekiwany wynik jest następujący -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Krok 3: Weryfikacja skryptu przędzy
Następujące polecenie służy do uruchamiania skryptu Yarn. Wykonanie tego polecenia spowoduje uruchomienie demonów Yarn.
$ start-yarn.shOczekiwany wynik w następujący sposób -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outKrok 4: Dostęp do Hadoop w przeglądarce
Domyślny numer portu dostępu do Hadoop to 50070. Użyj następującego adresu URL, aby pobrać usługi Hadoop w przeglądarce.
http://localhost:50070/
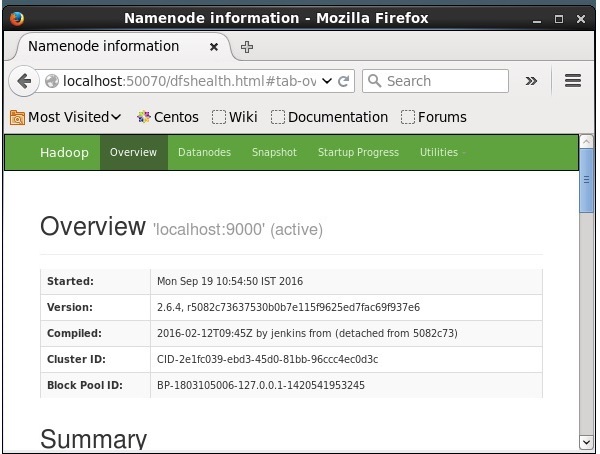
Instalowanie Solr na Hadoop
Wykonaj poniższe czynności, aby pobrać i zainstalować Solr.
Krok 1
Otwórz stronę główną Apache Solr, klikając poniższy link - https://lucene.apache.org/solr/
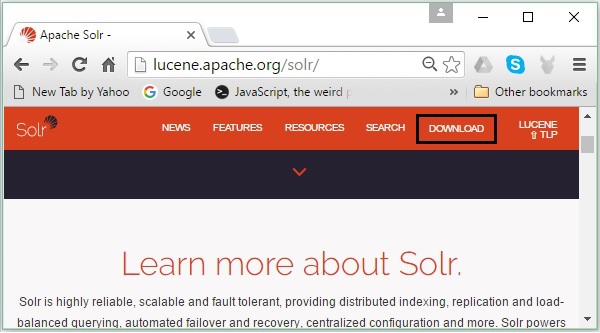
Krok 2
Kliknij download button(zaznaczone na powyższym zrzucie ekranu). Po kliknięciu zostaniesz przekierowany na stronę, na której masz różne mirrory Apache Solr. Wybierz serwer lustrzany i kliknij go, co spowoduje przekierowanie do strony, na której możesz pobrać pliki źródłowe i binarne Apache Solr, jak pokazano na poniższym zrzucie ekranu.
Krok 3
Po kliknięciu folder o nazwie Solr-6.2.0.tqzzostanie pobrany w folderze pobierania systemu. Wypakuj zawartość pobranego folderu.
Krok 4
Utwórz folder o nazwie Solr w katalogu głównym Hadoop i przenieś do niego zawartość wyodrębnionego folderu, jak pokazano poniżej.
$ mkdir Solr
$ cd Downloads $ mv Solr-6.2.0 /home/Hadoop/Weryfikacja
Przejrzyj bin w katalogu Solr Home i zweryfikuj instalację przy użyciu pliku version opcja, jak pokazano w poniższym bloku kodu.
$ cd bin/ $ ./Solr version
6.2.0Ustawienie domu i ścieżki
Otworzyć .bashrc plik za pomocą następującego polecenia -
[Hadoop@localhost ~]$ source ~/.bashrcTeraz ustaw katalogi główne i ścieżki dla Apache Solr w następujący sposób -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Otwórz terminal i wykonaj następujące polecenie -
[Hadoop@localhost Solr]$ source ~/.bashrcTeraz możesz wykonywać polecenia Solr z dowolnego katalogu.
W tym rozdziale omówimy architekturę Apache Solr. Poniższa ilustracja przedstawia schemat blokowy architektury Apache Solr.
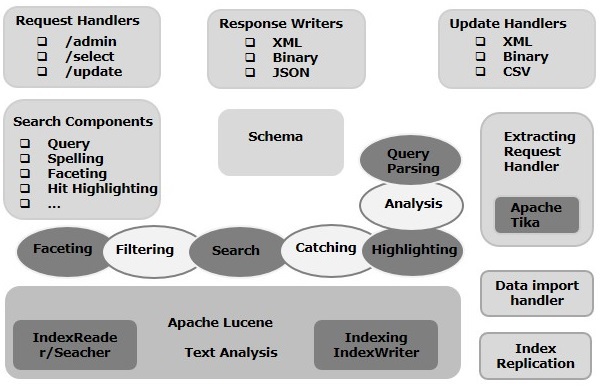
Architektura Solr ─ Bloki konstrukcyjne
Poniżej znajdują się główne bloki budulcowe (komponenty) Apache Solr -
Request Handler- Żądania, które wysyłamy do Apache Solr, są przetwarzane przez te programy obsługi żądań. Żądania mogą być żądaniami zapytań lub żądaniami aktualizacji indeksu. Na podstawie naszych wymagań musimy wybrać osobę obsługującą żądania. Aby przekazać żądanie do Solr, generalnie mapujemy program obsługi do określonego punktu końcowego URI i określone żądanie będzie przez niego obsługiwane.
Search Component- Komponent wyszukiwania to typ (funkcja) wyszukiwania dostępna w Apache Solr. Może to być sprawdzanie pisowni, zapytania, faceting, wyróżnianie trafień itp. Te komponenty wyszukiwania są rejestrowane jakosearch handlers. W module obsługi wyszukiwania można zarejestrować wiele składników.
Query Parser- Parser zapytań Apache Solr analizuje zapytania, które przekazujemy do Solr i weryfikuje zapytania pod kątem błędów składniowych. Po przeanalizowaniu zapytań tłumaczy je na format zrozumiały dla Lucene.
Response Writer- Moduł zapisujący odpowiedzi w Apache Solr to komponent, który generuje sformatowane dane wyjściowe dla zapytań użytkowników. Solr obsługuje formaty odpowiedzi, takie jak XML, JSON, CSV itp. Mamy różnych autorów odpowiedzi dla każdego typu odpowiedzi.
Analyzer/tokenizer- Lucene rozpoznaje dane w postaci tokenów. Apache Solr analizuje zawartość, dzieli ją na tokeny i przekazuje te tokeny Lucene. Analizator w Apache Solr bada tekst pól i generuje strumień tokenów. Tokenizer dzieli strumień tokenów przygotowany przez analizator na tokeny.
Update Request Processor - Za każdym razem, gdy wysyłamy żądanie aktualizacji do Apache Solr, żądanie jest uruchamiane przez zestaw wtyczek (podpis, logowanie, indeksowanie), zwanych łącznie update request processor. Ten procesor jest odpowiedzialny za modyfikacje, takie jak upuszczenie pola, dodanie pola itp.
W tym rozdziale postaramy się zrozumieć prawdziwe znaczenie niektórych terminów, które są często używane podczas pracy nad Solr.
Terminologia ogólna
Poniżej znajduje się lista ogólnych terminów używanych we wszystkich typach konfiguracji Solr -
Instance - Tak jak tomcat instance lub a jetty instancetermin ten odnosi się do serwera aplikacji, który działa wewnątrz maszyny JVM. Katalog domowy Solr zawiera odniesienia do każdej z tych instancji Solr, w których jeden lub więcej rdzeni można skonfigurować do działania w każdej instancji.
Core - Podczas uruchamiania wielu indeksów w aplikacji można mieć wiele rdzeni w każdej instancji zamiast wielu instancji z jednym rdzeniem.
Home - Termin $ SOLR_HOME odnosi się do katalogu domowego, który zawiera wszystkie informacje dotyczące rdzeni i ich indeksów, konfiguracji i zależności.
Shard - W środowiskach rozproszonych dane są partycjonowane między wieloma instancjami Solr, gdzie każdy fragment danych można nazwać Shard. Zawiera podzbiór całego indeksu.
Terminologia SolrCloud
We wcześniejszym rozdziale omówiliśmy, jak zainstalować Apache Solr w trybie samodzielnym. Zauważ, że możemy również zainstalować Solr w trybie rozproszonym (środowisko chmurowe), w którym Solr jest zainstalowany we wzorcu master-slave. W trybie rozproszonym indeks jest tworzony na serwerze głównym i replikowany na co najmniej jednym serwerze podrzędnym.
Kluczowe terminy związane z Solr Cloud są następujące -
Node - W chmurze Solr każda pojedyncza instancja Solr jest traktowana jako plik node.
Cluster - Wszystkie węzły środowiska razem tworzą plik cluster.
Collection - Klaster ma indeks logiczny, który jest znany jako collection.
Shard - Fragment to część kolekcji, która ma co najmniej jedną replikę indeksu.
Replica - W Solr Core kopia fragmentu działająca w węźle jest znana jako plik replica.
Leader - Jest to również replika sharda, która rozsyła żądania chmury Solr do pozostałych replik.
Zookeeper - Jest to projekt Apache, który Solr Cloud wykorzystuje do scentralizowanej konfiguracji i koordynacji, do zarządzania klastrem i do wyboru lidera.
Pliki konfiguracyjne
Główne pliki konfiguracyjne w Apache Solr są następujące -
Solr.xml- Jest to plik w katalogu $ SOLR_HOME zawierający informacje związane z Solr Cloud. Aby załadować rdzenie, Solr odwołuje się do tego pliku, co pomaga w ich identyfikacji.
Solrconfig.xml - Ten plik zawiera definicje i specyficzne dla rdzenia konfiguracje związane z obsługą żądań i formatowaniem odpowiedzi, wraz z indeksowaniem, konfigurowaniem, zarządzaniem pamięcią i dokonywaniem zatwierdzeń.
Schema.xml - Ten plik zawiera cały schemat wraz z polami i typami pól.
Core.properties- Ten plik zawiera konfiguracje specyficzne dla rdzenia. Jest określonycore discovery, ponieważ zawiera nazwę rdzenia i ścieżkę katalogu danych. Może być używany w dowolnym katalogu, który będzie wtedy traktowany jako plikcore directory.
Uruchamianie Solr
Po zainstalowaniu Solr przejdź do bin folder w katalogu domowym Solr i uruchom Solr za pomocą następującego polecenia.
[Hadoop@localhost ~]$ cd [Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/ [Hadoop@localhost bin]$ ./Solr startTo polecenie uruchamia Solr w tle, nasłuchując na porcie 8983, wyświetlając następujący komunikat.
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!Uruchamianie Solr na pierwszym planie
Jeśli zaczniesz Solr używając startpolecenie, Solr uruchomi się w tle. Zamiast tego możesz uruchomić Solr na pierwszym planie za pomocą–f option.
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_coreUruchamianie Solr na innym porcie
Za pomocą –p option z start polecenie, możemy uruchomić Solr na innym porcie, jak pokazano na poniższym bloku kodu.
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!Zatrzymanie Solr
Możesz zatrzymać Solr za pomocą stop Komenda.
$ ./Solr stopTo polecenie zatrzymuje Solr, wyświetlając komunikat, jak pokazano poniżej.
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.Restartowanie Solr
Plik restartkomenda Solr zatrzymuje Solr na 5 sekund i uruchamia go ponownie. Możesz zrestartować Solr za pomocą następującego polecenia -
./Solr restartTo polecenie uruchamia ponownie Solr, wyświetlając następujący komunikat -
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!Solr ─ help Command
Plik help Polecenie Solr może służyć do sprawdzenia użycia znaku zachęty Solr i jego opcji.
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpSolr ─ status Command
To statusPolecenie Solr może służyć do wyszukiwania i znajdowania uruchomionych instancji Solr na twoim komputerze. Może dostarczyć informacji o instancji Solr, takich jak jej wersja, użycie pamięci itp.
Możesz sprawdzić stan instancji Solr za pomocą polecenia status w następujący sposób -
[Hadoop@localhost bin]$ ./Solr statusPo wykonaniu powyższego polecenia wyświetla stan Solr w następujący sposób -
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}Solr Admin
Po uruchomieniu Apache Solr możesz odwiedzić stronę główną Solr web interface używając następującego adresu URL.
Localhost:8983/Solr/Interfejs Solr Admin wygląda następująco -
Solr Core to działająca instancja indeksu Lucene, która zawiera wszystkie pliki konfiguracyjne Solr wymagane do korzystania z niego. Musimy stworzyć Solr Core, aby wykonywać operacje takie jak indeksowanie i analizowanie.
Aplikacja Solr może zawierać jeden lub wiele rdzeni. W razie potrzeby dwa rdzenie w aplikacji Solr mogą się ze sobą komunikować.
Tworzenie rdzenia
Po zainstalowaniu i uruchomieniu Solr możesz połączyć się z klientem (interfejsem WWW) Solr.
Jak pokazano na poniższym zrzucie ekranu, początkowo w Apache Solr nie ma rdzeni. Teraz zobaczymy, jak stworzyć rdzeń w Solr.
Korzystanie z polecenia tworzenia
Jednym ze sposobów tworzenia rdzenia jest utworzenie pliku schema-less core używając create polecenie, jak pokazano poniżej -
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleTutaj próbujemy stworzyć rdzeń o nazwie Solr_samplew Apache Solr. To polecenie tworzy rdzeń wyświetlający następujący komunikat.
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}W Solr możesz stworzyć wiele rdzeni. Po lewej stronie panelu administracyjnego Solr możesz zobaczyć plikcore selector gdzie możesz wybrać nowo utworzony rdzeń, jak pokazano na poniższym zrzucie ekranu.
Za pomocą polecenia create_core
Alternatywnie możesz utworzyć rdzeń przy użyciu create_coreKomenda. To polecenie ma następujące opcje -
| -do core_name | Nazwa rdzenia, który chciałeś utworzyć |
| -p port_name | Port, w którym chcesz utworzyć rdzeń |
| -re conf_dir | Katalog konfiguracji portu |
Zobaczmy, jak możesz użyć create_coreKomenda. Tutaj postaramy się stworzyć rdzeń o nazwiemy_core.
[Hadoop@localhost bin]$ ./Solr create_core -c my_corePodczas wykonywania powyższego polecenia tworzy rdzeń wyświetlający następujący komunikat -
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}Usuwanie rdzenia
Możesz usunąć rdzeń za pomocą deletedowództwo Apache Solr. Załóżmy, że mamy rdzeń o nazwiemy_core w Solr, jak pokazano na poniższym zrzucie ekranu.
Możesz usunąć ten rdzeń za pomocą delete polecenie, przekazując nazwę rdzenia do tego polecenia w następujący sposób -
[Hadoop@localhost bin]$ ./Solr delete -c my_corePo wykonaniu powyższego polecenia określony rdzeń zostanie usunięty, wyświetlając następujący komunikat.
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
}Możesz otworzyć interfejs sieciowy Solr, aby sprawdzić, czy rdzeń został usunięty, czy nie.
Ogólnie, indexingto układ dokumentów lub (innych podmiotów) systematycznie. Indeksowanie umożliwia użytkownikom zlokalizowanie informacji w dokumencie.
Indeksowanie zbiera, analizuje i przechowuje dokumenty.
Indeksowanie ma na celu zwiększenie szybkości i wydajności zapytania wyszukiwania podczas znajdowania wymaganego dokumentu.
Indeksowanie w Apache Solr
W Apache Solr możemy indeksować (dodawać, usuwać, modyfikować) różne formaty dokumentów takie jak xml, csv, pdf itp. Dane do indeksu Solr możemy dodawać na kilka sposobów.
W tym rozdziale omówimy indeksowanie -
- Korzystanie z interfejsu internetowego Solr.
- Korzystanie z dowolnego interfejsu API klienta, takiego jak Java, Python itp.
- Używając post tool.
W tym rozdziale omówimy, jak dodać dane do indeksu Apache Solr za pomocą różnych interfejsów (wiersz poleceń, interfejs WWW i API klienta Java)
Dodawanie dokumentów za pomocą polecenia Post
Solr ma post polecenie w jego bin/informator. Za pomocą tego polecenia możesz indeksować różne formaty plików, takie jak JSON, XML, CSV w Apache Solr.
Przejrzyj bin katalogu Apache Solr i wykonaj plik –h option polecenia post, jak pokazano w poniższym bloku kodu.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hWykonując powyższe polecenie, otrzymasz listę opcji pliku post command, jak pokazano niżej.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Przykład
Załóżmy, że mamy plik o nazwie sample.csv z następującą zawartością (w bin informator).
| legitymacja studencka | Imię | Nazwisko | Telefon | Miasto |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Kalkuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Powyższy zestaw danych zawiera dane osobowe, takie jak identyfikator ucznia, imię, nazwisko, telefon i miasto. Plik CSV zbioru danych przedstawiono poniżej. Tutaj musisz zauważyć, że musisz wspomnieć o schemacie, dokumentując jego pierwszą linię.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiMożesz zindeksować te dane pod rdzeniem o nazwie sample_Solr używając post polecenie w następujący sposób -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvPo wykonaniu powyższego polecenia, dany dokument jest indeksowany pod określonym rdzeniem, generując następujący wynik.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Odwiedź stronę główną interfejsu użytkownika Solr, używając następującego adresu URL -
http://localhost:8983/
Wybierz rdzeń Solr_sample. Domyślną obsługą żądań jest/selecta zapytanie brzmi „:”. Nie wprowadzając żadnych modyfikacji, kliknij plikExecuteQuery przycisk u dołu strony.
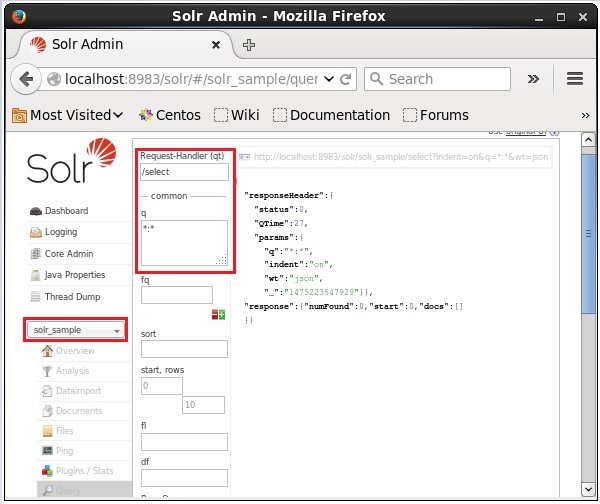
Podczas wykonywania zapytania można obserwować zawartość zindeksowanego dokumentu CSV w formacie JSON (domyślnie), jak pokazano na poniższym zrzucie ekranu.
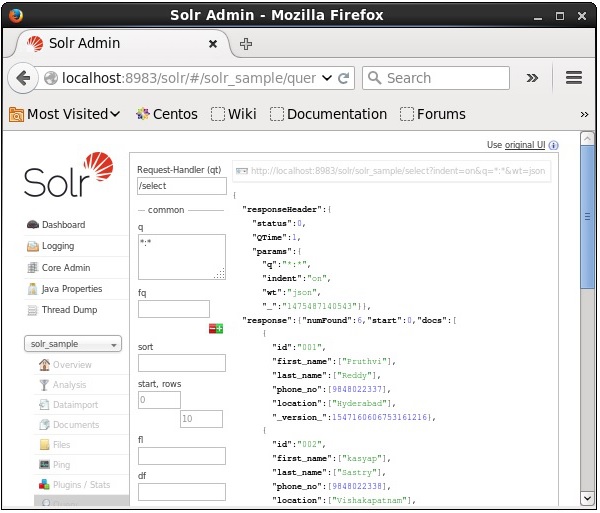
Note - W ten sam sposób możesz indeksować inne formaty plików, takie jak JSON, XML, CSV itp.
Dodawanie dokumentów za pomocą interfejsu internetowego Solr
Możesz także indeksować dokumenty za pomocą interfejsu internetowego dostarczonego przez Solr. Zobaczmy, jak zindeksować następujący dokument JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Krok 1
Otwórz interfejs sieciowy Solr, używając następującego adresu URL -
http://localhost:8983/
Step 2
Wybierz rdzeń Solr_sample. Domyślnie wartości pól Request Handler, Common Within, Overwrite i Boost to odpowiednio / update, 1000, true i 1.0, jak pokazano na poniższym zrzucie ekranu.
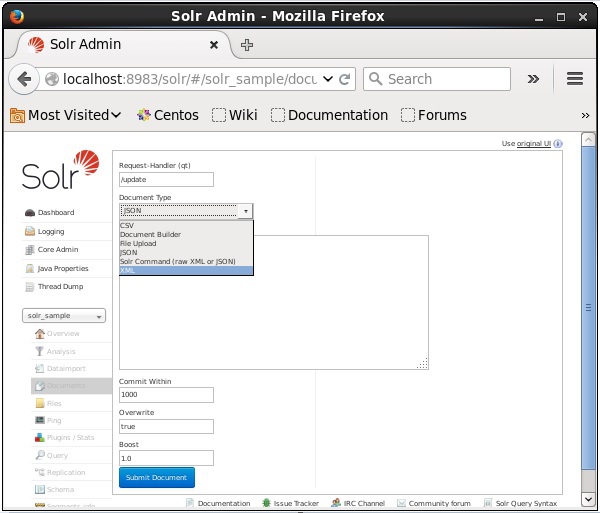
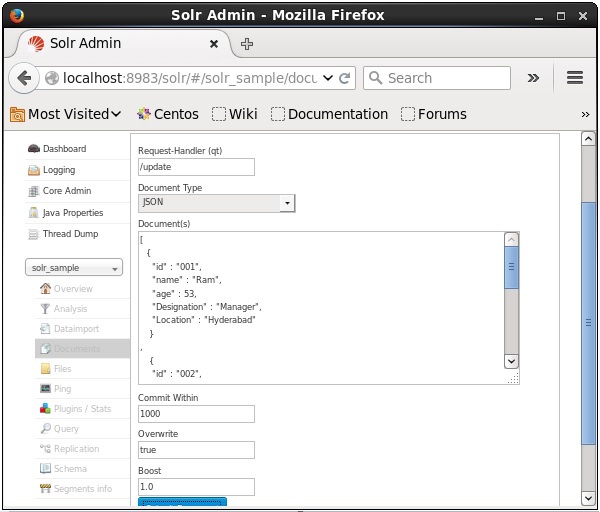
Teraz wybierz żądany format dokumentu z JSON, CSV, XML itp. Wpisz dokument, który ma być indeksowany w polu tekstowym i kliknij Submit Document przycisk, jak pokazano na poniższym zrzucie ekranu.
Dodawanie dokumentów za pomocą Java Client API
Poniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
Documents addedW poprzednim rozdziale wyjaśniliśmy, jak dodawać dane do Solr, które są w formatach JSON i .CSV. W tym rozdziale pokażemy, jak dodać dane do indeksu Apache Solr przy użyciu formatu dokumentu XML.
Przykładowe dane
Załóżmy, że musimy dodać następujące dane do indeksu Solr przy użyciu formatu pliku XML.
| legitymacja studencka | Imię | Nazwisko | Telefon | Miasto |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Kalkuta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Dodawanie dokumentów za pomocą XML
Aby dodać powyższe dane do indeksu Solr, musimy przygotować dokument XML, jak pokazano poniżej. Zapisz ten dokument w pliku o nazwiesample.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>Jak można zauważyć, plik XML napisany w celu dodania danych do indeksu zawiera trzy ważne tagi, a mianowicie <add> </add>, <doc> </doc> i <field> </ field>.
add- To jest główny znacznik służący do dodawania dokumentów do indeksu. Zawiera jeden lub więcej dokumentów, które mają zostać dodane.
doc- Dodawane przez nas dokumenty powinny być opakowane w znaczniki <doc> </doc>. Ten dokument zawiera dane w postaci pól.
field - Znacznik pola zawiera nazwę i wartość pól dokumentu.
Po przygotowaniu dokumentu możesz dodać ten dokument do indeksu przy użyciu dowolnego ze środków omówionych w poprzednim rozdziale.
Załóżmy, że plik XML istnieje w bin katalogu Solr i ma być zindeksowany w rdzeniu o nazwie my_core, następnie możesz dodać go do indeksu Solr za pomocą post narzędzie w następujący sposób -
[Hadoop@localhost bin]$ ./post -c my_core sample.xmlPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.201Weryfikacja
Odwiedź stronę główną interfejsu internetowego Apache Solr i wybierz rdzeń my_core. Spróbuj pobrać wszystkie dokumenty, przekazując zapytanie „:” w polu tekstowymqi wykonaj zapytanie. Podczas wykonywania można zauważyć, że żądane dane są dodawane do indeksu Solr.
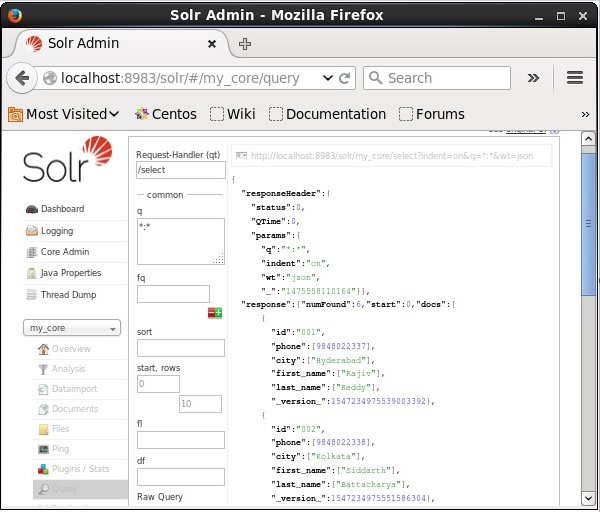
Aktualizacja dokumentu za pomocą XML
Poniżej znajduje się plik XML używany do aktualizacji pola w istniejącym dokumencie. Zapisz to w pliku o nazwieupdate.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>Jak widać, plik XML napisany w celu aktualizacji danych jest taki sam, jak ten, którego używamy do dodawania dokumentów. Ale jedyną różnicą jest to, że używamyupdate atrybut pola.
W naszym przykładzie użyjemy powyższego dokumentu i spróbujemy zaktualizować pola dokumentu o id 001.
Załóżmy, że dokument XML istnieje w binkatalog Solr. Ponieważ aktualizujemy indeks, który istnieje w rdzeniu o nazwiemy_core, możesz zaktualizować za pomocą post narzędzie w następujący sposób -
[Hadoop@localhost bin]$ ./post -c my_core update.xmlPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159Weryfikacja
Odwiedź stronę główną interfejsu internetowego Apache Solr i wybierz rdzeń jako my_core. Spróbuj pobrać wszystkie dokumenty, przekazując zapytanie „:” w polu tekstowymqi wykonaj zapytanie. Podczas wykonywania można zauważyć, że dokument jest aktualizowany.
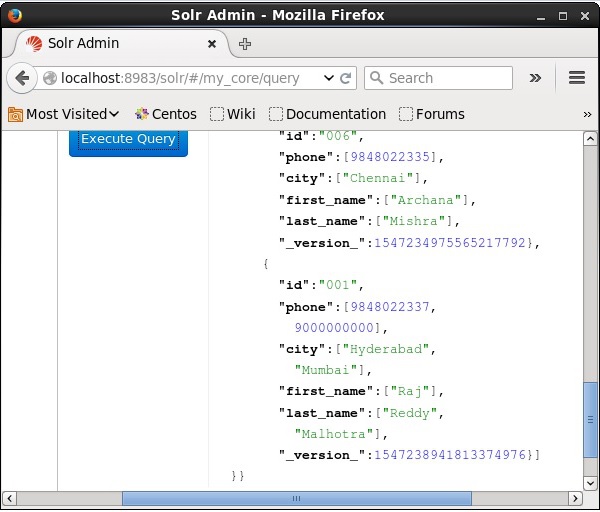
Aktualizacja dokumentu za pomocą języka Java (interfejs API klienta)
Poniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocumentPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
Documents updatedUsuwanie dokumentu
Aby usunąć dokumenty z indeksu Apache Solr, musimy podać identyfikatory dokumentów do usunięcia między tagami <delete> </delete>.
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>Tutaj ten kod XML służy do usuwania dokumentów z identyfikatorami 003 i 005. Zapisz ten kod w pliku o nazwiedelete.xml.
Jeśli chcesz usunąć dokumenty z indeksu, który należy do rdzenia o nazwie my_core, możesz opublikować delete.xml plik przy użyciu rozszerzenia post narzędzie, jak pokazano poniżej.
[Hadoop@localhost bin]$ ./post -c my_core delete.xmlPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179Weryfikacja
Odwiedź stronę główną interfejsu internetowego Apache Solr i wybierz rdzeń jako my_core. Spróbuj pobrać wszystkie dokumenty, przekazując zapytanie „:” w polu tekstowymqi wykonaj zapytanie. Podczas wykonywania można zauważyć, że określone dokumenty są usuwane.
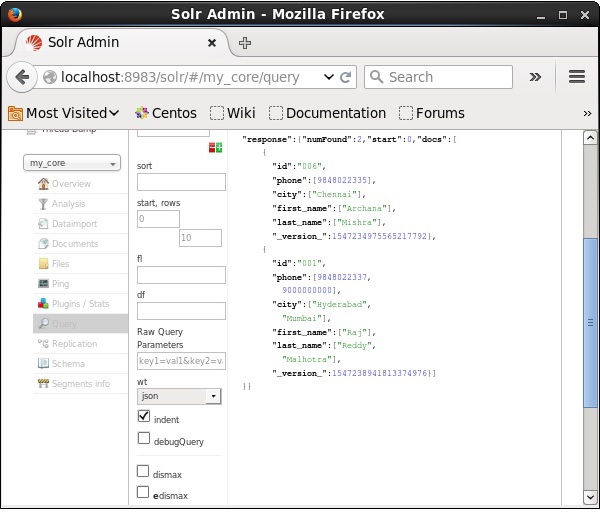
Usuwanie pola
Czasami musimy usunąć dokumenty na podstawie innych pól niż ID. Na przykład może być konieczne usunięcie dokumentów, w których znajduje się miasto Chennai.
W takich przypadkach musisz określić nazwę i wartość pola w parze tagów <query> </query>.
<delete>
<query>city:Chennai</query>
</delete>Zapisz to jako delete_field.xml i wykonaj operację usuwania na rdzeniu o nazwie my_core używając post narzędzie Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xmlWykonując powyższe polecenie, generuje następujące dane wyjściowe.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.084Weryfikacja
Odwiedź stronę główną interfejsu internetowego Apache Solr i wybierz rdzeń jako my_core. Spróbuj pobrać wszystkie dokumenty, przekazując zapytanie „:” w polu tekstowymqi wykonaj zapytanie. Podczas wykonywania można zauważyć, że dokumenty zawierające określoną parę wartości pola są usuwane.
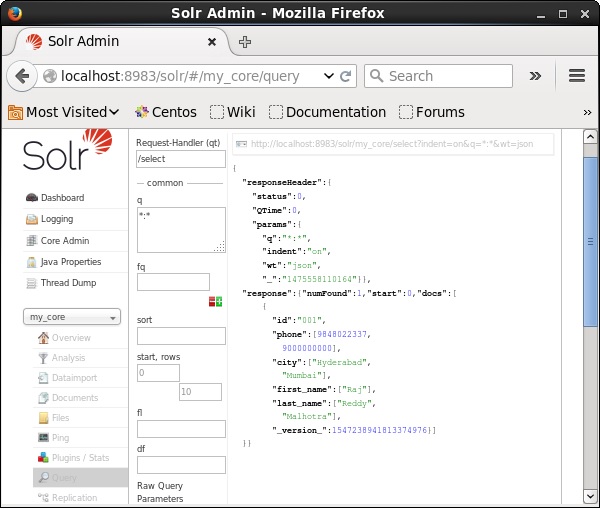
Usuwanie wszystkich dokumentów
Podobnie jak w przypadku usuwania określonego pola, jeśli chcesz usunąć wszystkie dokumenty z indeksu, wystarczy przekazać symbol „:” między tagami <query> </ query>, jak pokazano poniżej.
<delete>
<query>*:*</query>
</delete>Zapisz to jako delete_all.xml i wykonaj operację usuwania na rdzeniu o nazwie my_core używając post narzędzie Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xmlWykonując powyższe polecenie, generuje następujące dane wyjściowe.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.138Weryfikacja
Odwiedź stronę główną interfejsu internetowego Apache Solr i wybierz rdzeń jako my_core. Spróbuj pobrać wszystkie dokumenty, przekazując zapytanie „:” w polu tekstowymqi wykonaj zapytanie. Podczas wykonywania można zauważyć, że dokumenty zawierające określoną parę wartości pola są usuwane.
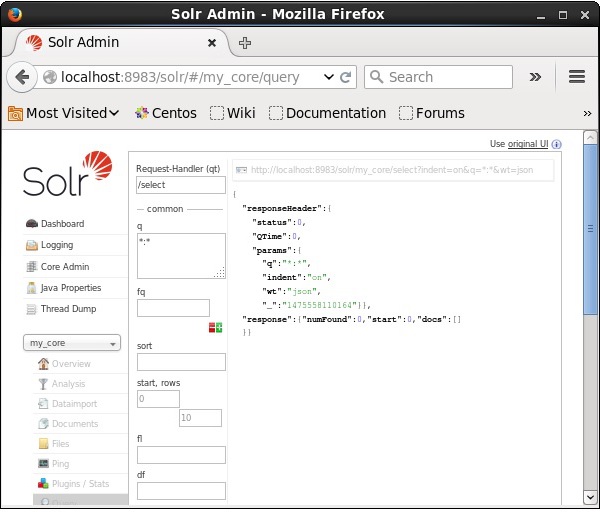
Usuwanie wszystkich dokumentów za pomocą Java (Client API)
Poniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac DeletingAllDocuments [Hadoop@localhost bin]$ java DeletingAllDocumentsPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
Documents deletedW tym rozdziale omówimy sposób pobierania danych za pomocą Java Client API. Załóżmy, że mamy dokument .csv o nazwiesample.csv z następującą treścią.
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,KhannaMożesz zindeksować te dane pod rdzeniem o nazwie sample_Solr używając post Komenda.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvPoniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieRetrievingData.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingDataPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}Oprócz przechowywania danych Apache Solr zapewnia również możliwość odpytywania ich w razie potrzeby. Solr udostępnia określone parametry, za pomocą których możemy odpytywać przechowywane w nim dane.
W poniższej tabeli wymieniliśmy różne parametry zapytań dostępne w Apache Solr.
| Parametr | Opis |
|---|---|
| q | Jest to główny parametr zapytania Apache Solr, dokumenty są oceniane na podstawie podobieństwa do terminów w tym parametrze. |
| fq | Ten parametr reprezentuje zapytanie filtrujące Apache Solr i ogranicza zestaw wyników do dokumentów pasujących do tego filtru. |
| początek | Parametr start reprezentuje przesunięcia początkowe dla strony, w wyniku której domyślną wartością tego parametru jest 0. |
| wydziwianie | Ten parametr reprezentuje liczbę dokumentów, które mają zostać pobrane na stronę. Domyślna wartość tego parametru to 10. |
| sortować | Ten parametr określa listę pól oddzielonych przecinkami, na podstawie których mają być sortowane wyniki zapytania. |
| fl | Ten parametr określa listę pól do zwrócenia dla każdego dokumentu w zestawie wyników. |
| wt | Ten parametr reprezentuje typ modułu zapisującego odpowiedź, który chcieliśmy wyświetlić wynik. |
Możesz zobaczyć wszystkie te parametry jako opcje zapytania Apache Solr. Odwiedź stronę główną Apache Solr. W lewej części strony kliknij opcję Zapytanie. Tutaj możesz zobaczyć pola parametrów zapytania.
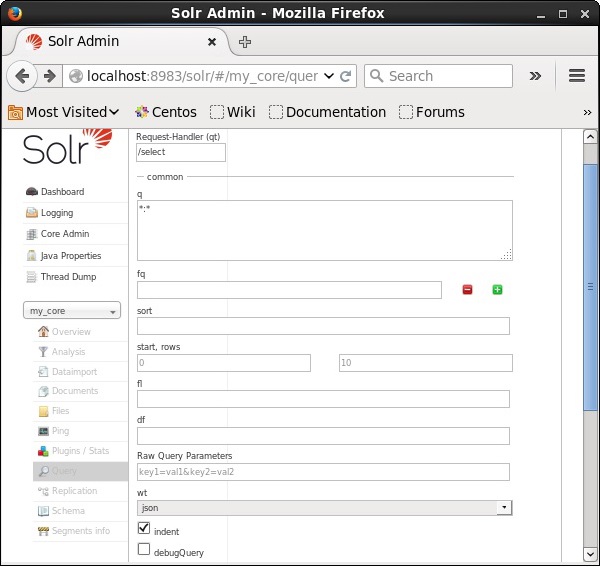
Pobieranie rekordów
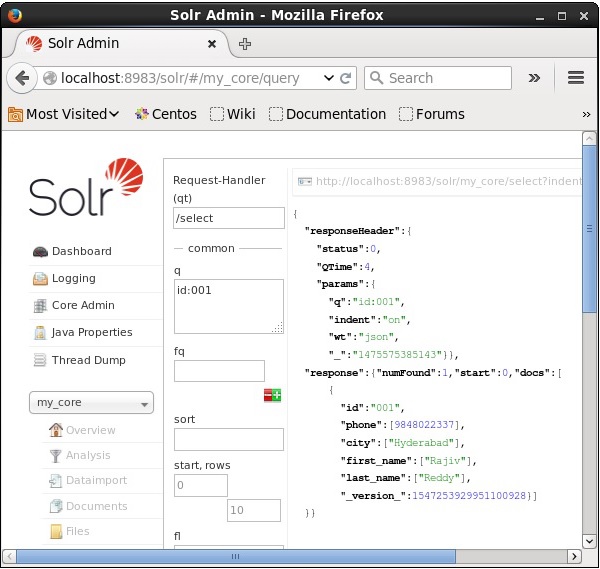
Załóżmy, że mamy 3 rekordy w rdzeniu o nazwie my_core. Aby pobrać konkretny rekord z wybranego rdzenia, musisz przekazać pary nazw i wartości pól określonego dokumentu. Na przykład, jeśli chcesz pobrać rekord z wartością polaid, musisz przekazać parę nazwa-wartość pola jako - Id:001 jako wartość parametru q i wykonaj zapytanie.
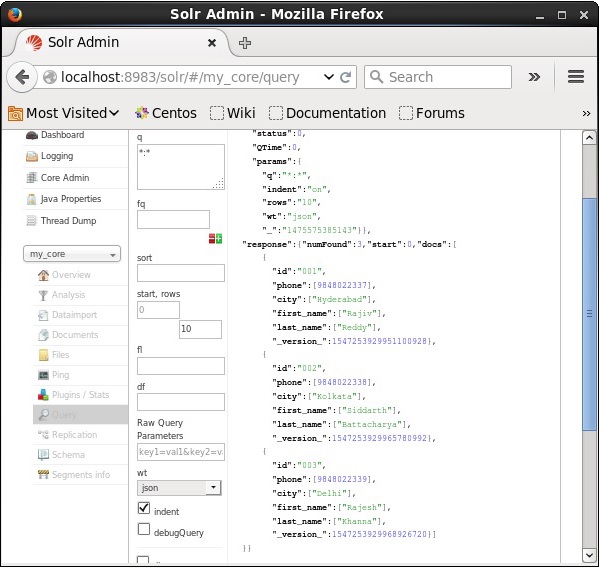
W ten sam sposób możesz pobrać wszystkie rekordy z indeksu, przekazując *: * jako wartość do parametru q, jak pokazano na poniższym zrzucie ekranu.
Pobieranie z drugiego rekordu
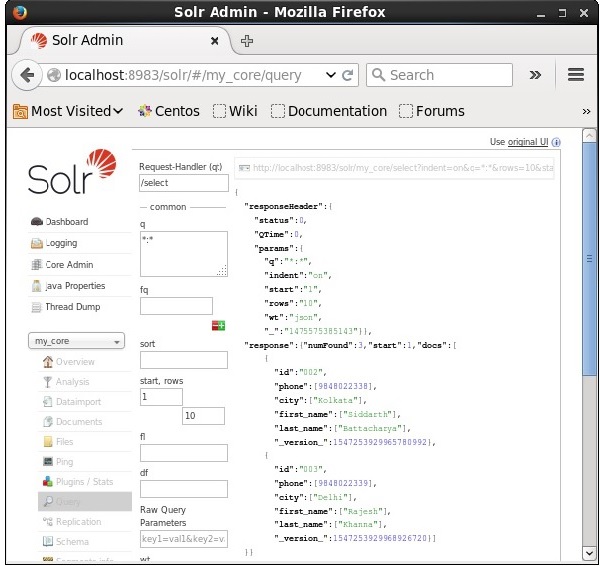
Możemy pobrać rekordy z drugiego rekordu, przekazując 2 jako wartość do parametru start, jak pokazano na poniższym zrzucie ekranu.
Ograniczenie liczby rekordów
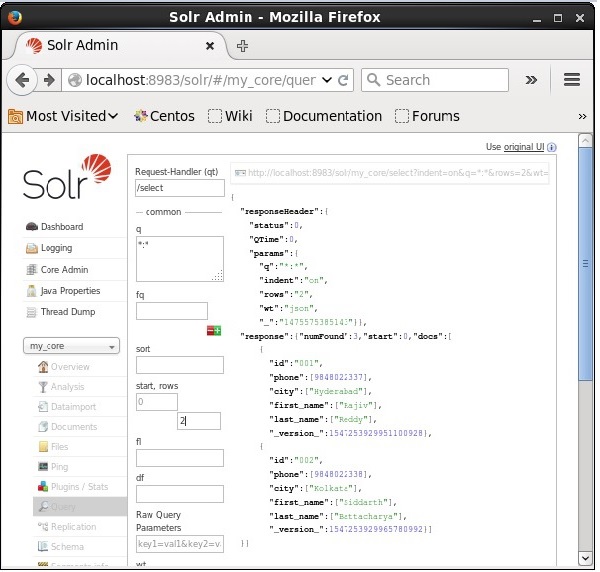
Możesz ograniczyć liczbę rekordów, określając wartość w rowsparametr. Na przykład, możemy ograniczyć całkowitą liczbę rekordów w wyniku zapytania do 2, przekazując wartość 2 do parametrurows, jak pokazano na poniższym zrzucie ekranu.
Typ autora odpowiedzi
Możesz uzyskać odpowiedź w wymaganym typie dokumentu, wybierając jedną z podanych wartości parametru wt.
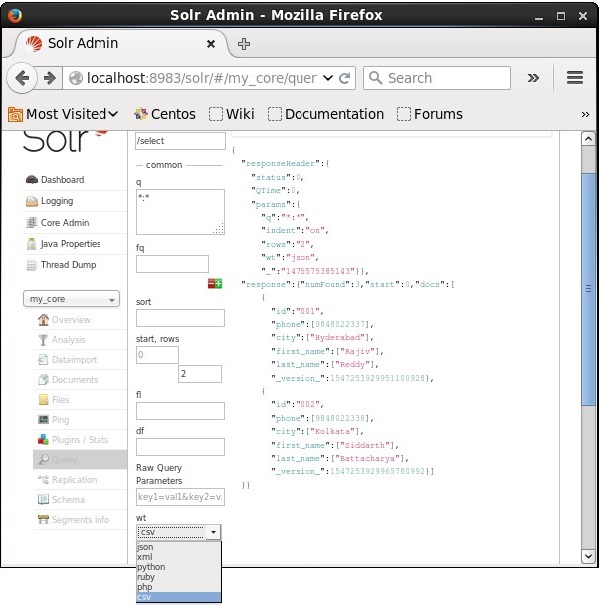
W powyższym przypadku wybraliśmy .csv format, aby uzyskać odpowiedź.
Lista pól
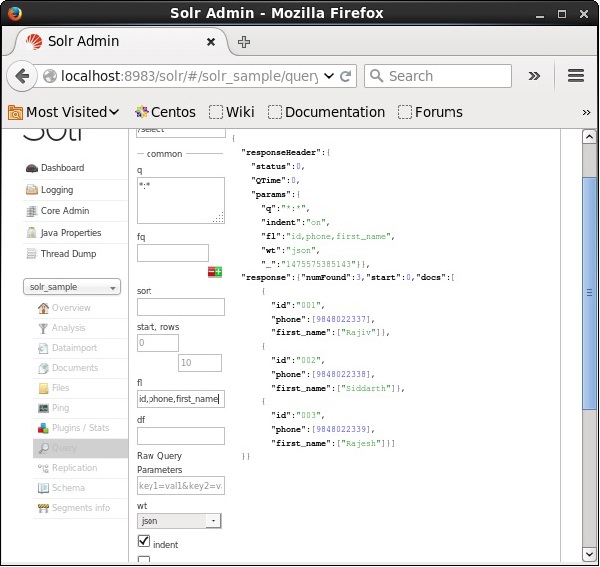
Jeśli chcemy mieć określone pola w wynikowych dokumentach, musimy przekazać listę wymaganych pól, oddzielonych przecinkami, jako wartość do właściwości fl.
W poniższym przykładzie próbujemy pobrać pola - id, phone, i first_name.
Faceting w Apache Solr odnosi się do klasyfikacji wyników wyszukiwania na różne kategorie. W tym rozdziale omówimy typy facetingu dostępne w Apache Solr -
Query faceting - Zwraca liczbę dokumentów w bieżących wynikach wyszukiwania, które również pasują do podanego zapytania.
Date faceting - Zwraca liczbę dokumentów mieszczących się w określonych zakresach dat.
Polecenia facetingu są dodawane do każdego normalnego zapytania Solr, a liczniki facetingu są zwracane w tej samej odpowiedzi na zapytanie.
Przykład zapytania Faceting
Korzystanie z pola faceting, możemy pobrać liczby dla wszystkich terminów lub tylko najważniejszych terminów w danym polu.
Jako przykład rozważmy następujące kwestie books.csv plik zawierający dane o różnych książkach.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyPrześlijmy ten plik do Apache Solr przy użyciu rozszerzenia post narzędzie.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvPo wykonaniu powyższego polecenia wszystkie dokumenty wymienione w podanym .csv plik zostanie przesłany do Apache Solr.
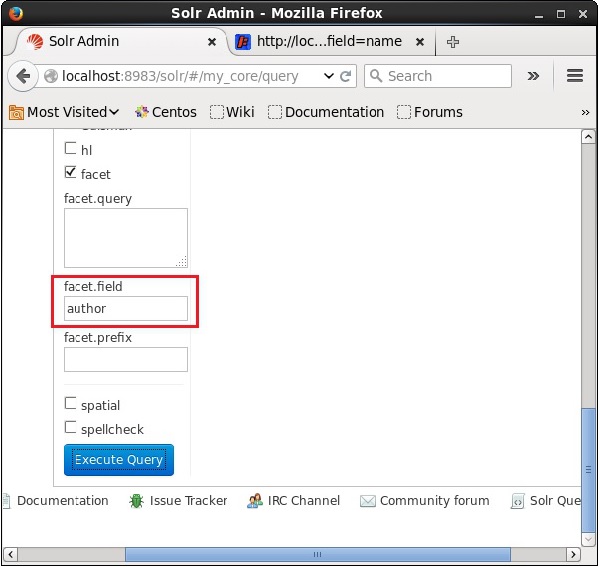
Wykonajmy teraz fasetowe zapytanie na polu author z 0 wierszami w kolekcji / rdzeniu my_core.
Otwórz interfejs WWW Apache Solr i zaznacz pole wyboru po lewej stronie strony facet, jak pokazano na poniższym zrzucie ekranu.
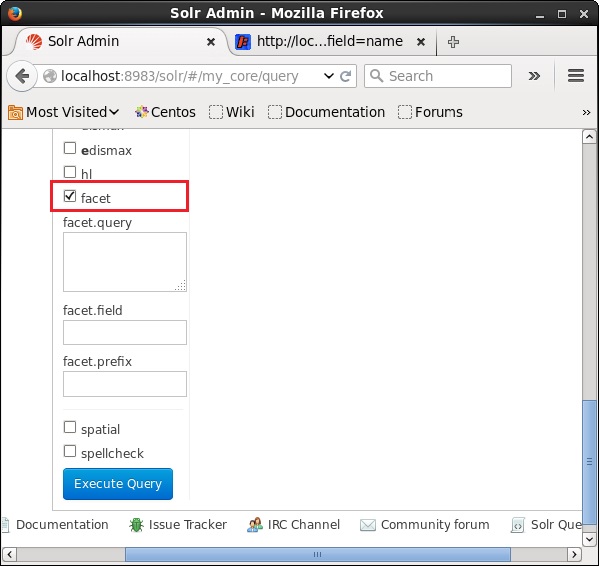
Po zaznaczeniu tego pola wyboru będziesz mieć trzy dodatkowe pola tekstowe na przekazanie parametrów wyszukiwania aspektowego. Teraz jako parametry zapytania przekaż następujące wartości.
q = *:*, rows = 0, facet.field = authorNa koniec wykonaj zapytanie, klikając plik Execute Query przycisk.
Podczas wykonywania da następujący wynik.
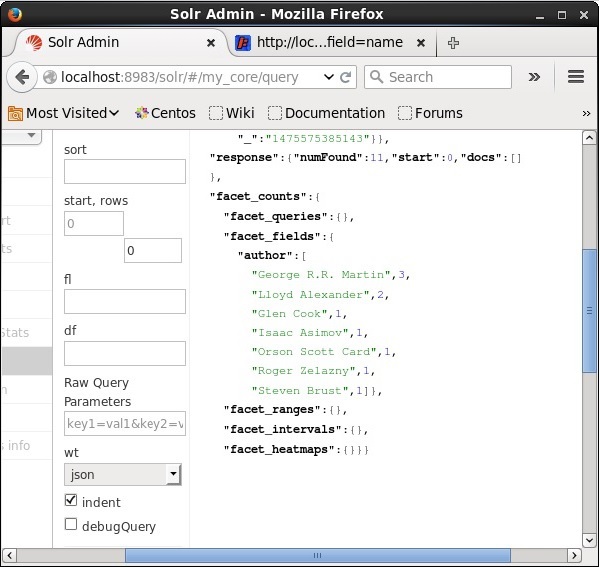
Kategoryzuje dokumenty w indeksie na podstawie autora i określa liczbę książek wniesionych przez każdego autora.
Faceting przy użyciu Java Client API
Poniżej znajduje się program Java do dodawania dokumentów do indeksu Apache Solr. Zapisz ten kod w pliku o nazwieHitHighlighting.java.
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}Skompiluj powyższy kod, wykonując następujące polecenia w terminalu -
[Hadoop@localhost bin]$ javac HitHighlighting [Hadoop@localhost bin]$ java HitHighlightingPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe.
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]