Apache Solr - na Hadoop
Solr może być używany razem z Hadoop. Ponieważ Hadoop obsługuje dużą ilość danych, Solr pomaga nam znaleźć potrzebne informacje z tak dużego źródła. W tej sekcji wyjaśnij, jak możesz zainstalować Hadoop w swoim systemie.
Pobieranie Hadoop
Poniżej podano kroki, które należy wykonać, aby pobrać Hadoop na swój system.
Step 1- Przejdź do strony głównej Hadoop. Możesz skorzystać z linku - www.hadoop.apache.org/ . Kliknij w linkReleases, jak podkreślono na poniższym zrzucie ekranu.
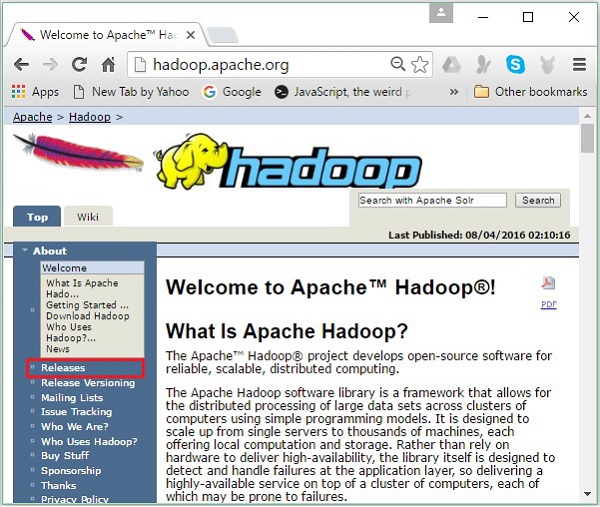
Przekieruje Cię do Apache Hadoop Releases strona zawierająca łącza do serwerów lustrzanych plików źródłowych i binarnych różnych wersji Hadoop w następujący sposób -
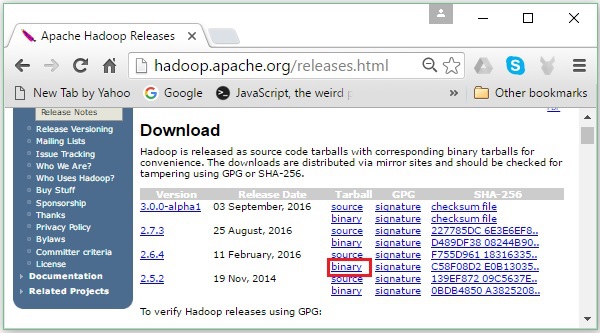
Step 2 - Wybierz najnowszą wersję Hadoop (w naszym poradniku jest to 2.6.4) i kliknij jej binary link. Zabierze Cię to do strony, na której dostępne są serwery lustrzane binarnego Hadoop. Kliknij jeden z tych serwerów lustrzanych, aby pobrać Hadoop.
Pobierz Hadoop z wiersza polecenia
Otwórz terminal Linux i zaloguj się jako superużytkownik.
$ su
password:Przejdź do katalogu, w którym chcesz zainstalować Hadoop, i zapisz tam plik, korzystając z linku skopiowanego wcześniej, jak pokazano w poniższym bloku kodu.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzPo pobraniu Hadoop wyodrębnij go za pomocą następujących poleceń.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstalowanie Hadoop
Wykonaj poniższe czynności, aby zainstalować Hadoop w trybie pseudo-rozproszonym.
Krok 1: Konfigurowanie Hadoop
Możesz ustawić zmienne środowiskowe Hadoop, dołączając następujące polecenia do ~/.bashrc plik.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMENastępnie zastosuj wszystkie zmiany w aktualnie działającym systemie.
$ source ~/.bashrcKrok 2: Konfiguracja Hadoop
Wszystkie pliki konfiguracyjne Hadoop można znaleźć w lokalizacji „$ HADOOP_HOME / etc / hadoop”. Wymagane jest wprowadzenie zmian w tych plikach konfiguracyjnych zgodnie z infrastrukturą Hadoop.
$ cd $HADOOP_HOME/etc/hadoopAby tworzyć programy Hadoop w Javie, musisz zresetować zmienne środowiskowe Java w hadoop-env.sh plik, zastępując JAVA_HOME wartość z położeniem Java w systemie.
export JAVA_HOME = /usr/local/jdk1.7.0_71Poniżej znajduje się lista plików, które musisz edytować, aby skonfigurować Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
Plik core-site.xml plik zawiera informacje, takie jak numer portu używany dla wystąpienia Hadoop, pamięć przydzielona dla systemu plików, limit pamięci do przechowywania danych i rozmiar buforów do odczytu / zapisu.
Otwórz plik core-site.xml i dodaj następujące właściwości wewnątrz tagów <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Plik hdfs-site.xml plik zawiera informacje takie jak wartość danych replikacji, namenode ścieżka i datanodeścieżki lokalnych systemów plików. To miejsce, w którym chcesz przechowywać infrastrukturę Hadoop.
Załóżmy następujące dane.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOtwórz ten plik i dodaj następujące właściwości wewnątrz znaczników <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - W powyższym pliku wszystkie wartości właściwości są zdefiniowane przez użytkownika i można wprowadzać zmiany zgodnie z infrastrukturą Hadoop.
yarn-site.xml
Ten plik służy do konfigurowania przędzy w Hadoop. Otwórz plik yarn-site.xml i dodaj następujące właściwości między tagami <configuration>, </configuration> w tym pliku.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ten plik jest używany do określenia, której platformy MapReduce używamy. Domyślnie Hadoop zawiera szablon yarn-site.xml. Przede wszystkim należy skopiować plik zmapred-site,xml.template do mapred-site.xml plik za pomocą następującego polecenia.
$ cp mapred-site.xml.template mapred-site.xmlotwarty mapred-site.xml file i dodaj następujące właściwości wewnątrz tagów <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Weryfikacja instalacji Hadoop
Poniższe kroki służą do weryfikacji instalacji Hadoop.
Krok 1: Konfiguracja nazwy węzła
Skonfiguruj namenode za pomocą polecenia „hdfs namenode –format” w następujący sposób.
$ cd ~
$ hdfs namenode -formatOczekiwany wynik jest następujący.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Krok 2: weryfikacja plików dfs Hadoop
Następujące polecenie służy do uruchamiania systemu plików dfs Hadoop. Wykonanie tego polecenia spowoduje uruchomienie systemu plików Hadoop.
$ start-dfs.shOczekiwany wynik jest następujący -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Krok 3: Weryfikacja skryptu przędzy
Następujące polecenie służy do uruchamiania skryptu Yarn. Wykonanie tego polecenia spowoduje uruchomienie demonów Yarn.
$ start-yarn.shOczekiwany wynik w następujący sposób -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outKrok 4: Dostęp do Hadoop w przeglądarce
Domyślny numer portu dostępu do Hadoop to 50070. Użyj następującego adresu URL, aby pobrać usługi Hadoop w przeglądarce.
http://localhost:50070/
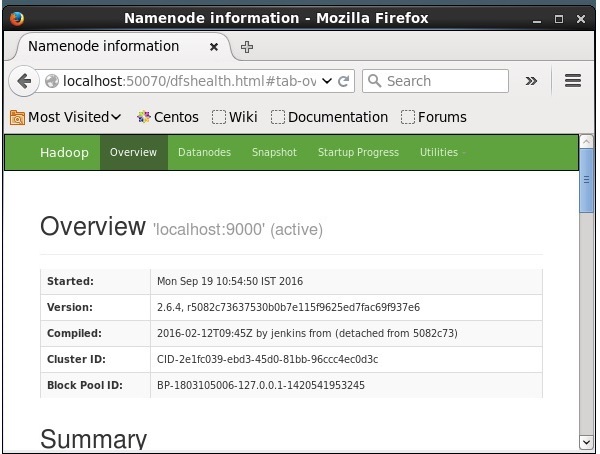
Instalowanie Solr na Hadoop
Wykonaj poniższe czynności, aby pobrać i zainstalować Solr.
Krok 1
Otwórz stronę główną Apache Solr, klikając poniższy link - https://lucene.apache.org/solr/
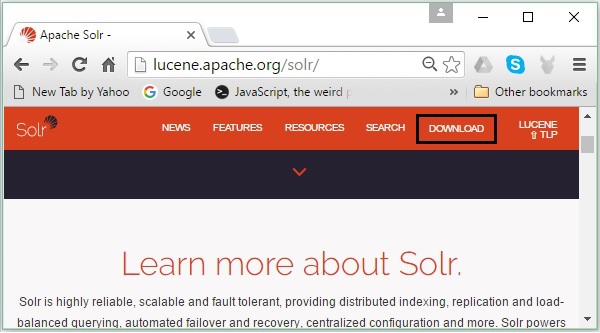
Krok 2
Kliknij download button(zaznaczone na powyższym zrzucie ekranu). Po kliknięciu zostaniesz przekierowany na stronę, na której masz różne mirrory Apache Solr. Wybierz serwer lustrzany i kliknij go, co spowoduje przekierowanie do strony, na której możesz pobrać pliki źródłowe i binarne Apache Solr, jak pokazano na poniższym zrzucie ekranu.
Krok 3
Po kliknięciu folder o nazwie Solr-6.2.0.tqzzostanie pobrany w folderze pobierania systemu. Wypakuj zawartość pobranego folderu.
Krok 4
Utwórz folder o nazwie Solr w katalogu głównym Hadoop i przenieś do niego zawartość wyodrębnionego folderu, jak pokazano poniżej.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Weryfikacja
Przejrzyj bin folder of Solr Home directory and verify the installation using the version option, as shown in the following code block.
$ cd bin/
$ ./Solr version
6.2.0Setting home and path
Open the .bashrc file using the following command −
[Hadoop@localhost ~]$ source ~/.bashrcNow set the home and path directories for Apache Solr as follows −
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Open the terminal and execute the following command −
[Hadoop@localhost Solr]$ source ~/.bashrcNow, you can execute the commands of Solr from any directory.