AI with Python - Analiza danych szeregów czasowych
Przewidywanie następnego w danej sekwencji wejściowej to kolejna ważna koncepcja w uczeniu maszynowym. Ten rozdział zawiera szczegółowe wyjaśnienie dotyczące analizy danych szeregów czasowych.
Wprowadzenie
Dane szeregów czasowych oznaczają dane, które znajdują się w szeregu określonych przedziałów czasowych. Jeśli chcemy zbudować przewidywanie sekwencji w uczeniu maszynowym, musimy radzić sobie z sekwencyjnymi danymi i czasem. Dane szeregowe to abstrakcja danych sekwencyjnych. Porządkowanie danych jest ważną cechą danych sekwencyjnych.
Podstawowe pojęcia analizy sekwencji lub analizy szeregów czasowych
Analiza sekwencji lub analiza szeregów czasowych polega na przewidywaniu następnej w danej sekwencji wejściowej na podstawie wcześniej zaobserwowanej. Przewidywanie może dotyczyć wszystkiego, co może nastąpić później: symbolu, liczby, pogody na następny dzień, następnego słowa w mowie itp. Analiza sekwencji może być bardzo przydatna w zastosowaniach, takich jak analiza giełdowa, prognozy pogody i rekomendacje produktów.
Example
Rozważ następujący przykład, aby zrozumieć przewidywanie sekwencji. TutajA,B,C,D są podanymi wartościami i musisz je przewidzieć E za pomocą modelu przewidywania sekwencji.

Instalowanie przydatnych pakietów
Do analizy danych szeregów czasowych za pomocą Pythona musimy zainstalować następujące pakiety -
Pandy
Pandas to biblioteka na licencji BSD typu open source, która zapewnia wysoką wydajność, łatwość korzystania ze struktury danych i narzędzia do analizy danych dla Pythona. Możesz zainstalować Pandy za pomocą następującego polecenia -
pip install pandasJeśli używasz Anacondy i chcesz zainstalować przy użyciu conda menedżera pakietów, możesz użyć następującego polecenia -
conda install -c anaconda pandashmmlearn
Jest to biblioteka na licencji BSD typu open source, która składa się z prostych algorytmów i modeli do nauki ukrytych modeli Markowa (HMM) w Pythonie. Możesz go zainstalować za pomocą następującego polecenia -
pip install hmmlearnJeśli używasz Anacondy i chcesz zainstalować przy użyciu conda menedżera pakietów, możesz użyć następującego polecenia -
conda install -c omnia hmmlearnPyStruct
Jest to ustrukturyzowana biblioteka uczenia się i przewidywania. Algorytmy uczące się zaimplementowane w PyStruct mają takie nazwy, jak warunkowe pola losowe (CRF), sieci losowe o maksymalnej marży Markowa (M3N) lub maszyny wektorów nośnych strukturalnych. Możesz go zainstalować za pomocą następującego polecenia -
pip install pystructCVXOPT
Służy do optymalizacji wypukłej w oparciu o język programowania Python. Jest to również bezpłatny pakiet oprogramowania. Możesz go zainstalować za pomocą następującego polecenia -
pip install cvxoptJeśli używasz Anacondy i chcesz zainstalować przy użyciu conda menedżera pakietów, możesz użyć następującego polecenia -
conda install -c anaconda cvdoxtPandy: Obsługa, wycinanie i wyodrębnianie statystyk z danych szeregów czasowych
Pandy to bardzo przydatne narzędzie, jeśli musisz pracować z danymi szeregów czasowych. Z pomocą Pand możesz wykonać następujące czynności -
Utwórz zakres dat przy użyciu rozszerzenia pd.date_range pakiet
Indeksuj pandy z datami przy użyciu rozszerzenia pd.Series pakiet
Wykonaj ponowne próbkowanie za pomocą ts.resample pakiet
Zmień częstotliwość
Przykład
Poniższy przykład przedstawia obsługę i wycinanie danych szeregów czasowych przy użyciu Pandas. Zwróć uwagę, że tutaj używamy danych dotyczących miesięcznej oscylacji arktycznej, które można pobrać ze strony Month.ao.index.b50.current.ascii i przekonwertować na format tekstowy do naszego użytku.
Obsługa danych szeregów czasowych
W celu obsługi danych szeregów czasowych należy wykonać następujące czynności -
Pierwszy krok polega na zaimportowaniu następujących pakietów -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdNastępnie zdefiniuj funkcję, która odczyta dane z pliku wejściowego, jak pokazano w kodzie podanym poniżej -
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)Teraz przekonwertuj te dane na szeregi czasowe. W tym celu utwórz zakres dat naszych szeregów czasowych. W tym przykładzie zachowujemy jeden miesiąc jako częstotliwość danych. W naszym pliku znajdują się dane od stycznia 1950 roku.
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')W tym kroku tworzymy dane szeregów czasowych za pomocą Pandas Series, jak pokazano poniżej -
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':Wprowadź ścieżkę do pliku wejściowego, jak pokazano tutaj -
input_file = "/Users/admin/AO.txt"Teraz przekonwertuj kolumnę do formatu timeeries, jak pokazano tutaj -
timeseries = read_data(input_file)Na koniec wykreśl i zwizualizuj dane, używając przedstawionych poleceń -
plt.figure()
timeseries.plot()
plt.show()Będziesz obserwować działki, jak pokazano na poniższych obrazach -


Wycinanie danych szeregów czasowych
Wycinanie obejmuje pobieranie tylko części danych szeregów czasowych. W ramach przykładu wycinamy dane tylko od 1980 do 1990 roku. Zwróć uwagę na następujący kod, który wykonuje to zadanie -
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()Po uruchomieniu kodu do wycinania danych szeregów czasowych można zaobserwować następujący wykres, jak pokazano na poniższym obrazku -

Wyodrębnianie statystyki z danych szeregów czasowych
Będziesz musiał wyciągnąć pewne statystyki z podanych danych, w przypadkach, gdy będziesz musiał wyciągnąć jakiś ważny wniosek. Średnia, wariancja, korelacja, wartość maksymalna i wartość minimalna to tylko niektóre z takich statystyk. Możesz użyć następującego kodu, jeśli chcesz wyodrębnić takie statystyki z danych danych szeregu czasowego -
Oznaczać
Możesz użyć mean() funkcja, do znalezienia średniej, jak pokazano tutaj -
timeseries.mean()Następnie wynik, który zaobserwujesz dla omawianego przykładu, to:
-0.11143128165238671Maksymalny
Możesz użyć max() funkcja, aby znaleźć maksimum, jak pokazano tutaj -
timeseries.max()Następnie wynik, który zaobserwujesz dla omawianego przykładu, to:
3.4952999999999999Minimum
Możesz użyć funkcji min (), aby znaleźć minimum, jak pokazano tutaj -
timeseries.min()Następnie wynik, który zaobserwujesz dla omawianego przykładu, to:
-4.2656999999999998Wszystko na raz
Jeśli chcesz obliczyć wszystkie statystyki naraz, możesz użyć rozszerzenia describe() funkcja, jak pokazano tutaj -
timeseries.describe()Następnie wynik, który zaobserwujesz dla omawianego przykładu, to:
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64Ponowne pobieranie próbek
Możesz ponownie próbkować dane z inną częstotliwością czasową. Dwa parametry ponownego pobierania próbek to -
- Okres czasu
- Method
Ponowne pobieranie próbek ze średnią ()
Możesz użyć następującego kodu do ponownego próbkowania danych za pomocą metody mean (), która jest metodą domyślną -
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()Następnie możesz obserwować następujący wykres jako wynik ponownego próbkowania przy użyciu metody mean () -

Ponowne pobieranie próbek z medianą ()
Możesz użyć następującego kodu, aby ponownie próbkować dane przy użyciu median()metoda -
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()Następnie możesz zobaczyć poniższy wykres jako wynik ponownego próbkowania z medianą () -

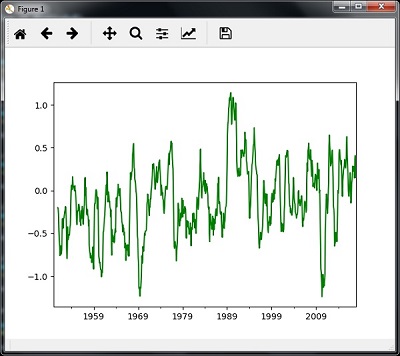
Rolling Mean
Możesz użyć następującego kodu do obliczenia średniej kroczącej (ruchomej) -
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()Następnie możesz obserwować następujący wykres jako wynik średniej kroczącej (ruchomej) -
Analiza danych sekwencyjnych według ukrytego modelu Markowa (HMM)
HMM to model statystyczny, który jest szeroko stosowany do danych mających ciągłość i rozszerzalność, takich jak analiza giełdowych szeregów czasowych, kontrola stanu zdrowia i rozpoznawanie mowy. W tej sekcji szczegółowo omówiono analizę danych sekwencyjnych przy użyciu ukrytego modelu Markowa (HMM).
Ukryty model Markowa (HMM)
HMM to model stochastyczny, który jest zbudowany na koncepcji łańcucha Markowa opartego na założeniu, że prawdopodobieństwo przyszłych statystyk zależy tylko od aktualnego stanu procesu, a nie od stanu, który go poprzedzał. Na przykład rzucając monetą nie możemy powiedzieć, że wynikiem piątego rzutu będzie głowa. Dzieje się tak, ponieważ moneta nie ma żadnej pamięci, a następny wynik nie zależy od poprzedniego wyniku.
Matematycznie HMM składa się z następujących zmiennych -
Stany (S)
Jest to zbiór ukrytych lub utajonych stanów obecnych w HMM. Jest oznaczony przez S.
Symbole wyjściowe (O)
Jest to zbiór możliwych symboli wyjściowych obecnych w HMM. Jest oznaczony przez O.
Macierz prawdopodobieństwa przejścia stanów (A)
Jest to prawdopodobieństwo przejścia z jednego stanu do każdego innego. Jest oznaczony przez A.
Macierz prawdopodobieństwa emisji z obserwacji (B)
Jest to prawdopodobieństwo wyemitowania / zaobserwowania symbolu w określonym stanie. Jest oznaczony przez B.
Macierz wcześniejszego prawdopodobieństwa (Π)
Jest to prawdopodobieństwo startu w określonym stanie z różnych stanów układu. Jest oznaczony przez Π.
Stąd HMM można zdefiniować jako = (S,O,A,B,),
gdzie,
- S = {s1,s2,…,sN} jest zbiorem N możliwych stanów,
- O = {o1,o2,…,oM} to zbiór M możliwych symboli obserwacji,
- A jest NN macierz prawdopodobieństwa przejścia stanów (TPM),
- B jest NM macierz obserwacji lub prawdopodobieństwa emisji (EPM),
- π jest N-wymiarowym wektorem rozkładu prawdopodobieństwa stanu początkowego.
Przykład: Analiza danych giełdowych
W tym przykładzie będziemy analizować dane giełdowe krok po kroku, aby dowiedzieć się, jak HMM działa z danymi sekwencyjnymi lub szeregami czasowymi. Zwróć uwagę, że implementujemy ten przykład w Pythonie.
Zaimportuj niezbędne pakiety, jak pokazano poniżej -
import datetime
import warningsTeraz użyj danych giełdowych z pliku matpotlib.finance pakiet, jak pokazano tutaj -
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMMZaładuj dane od daty rozpoczęcia i daty zakończenia, tj. Między dwiema określonymi datami, jak pokazano tutaj -
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)W tym kroku będziemy codziennie wyodrębniać kwotowania zamykające. W tym celu użyj następującego polecenia -
closing_quotes = np.array([quote[2] for quote in quotes])Teraz wyodrębnimy wolumen akcji będących w obrocie każdego dnia. W tym celu użyj następującego polecenia -
volumes = np.array([quote[5] for quote in quotes])[1:]W tym miejscu weź procentową różnicę cen akcji zamknięcia, używając kodu pokazanego poniżej -
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])Na tym etapie utwórz i wytrenuj Gaussa HMM. W tym celu użyj następującego kodu -
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)Teraz wygeneruj dane za pomocą modelu HMM, używając pokazanych poleceń -
num_samples = 300
samples, _ = hmm.sample(num_samples)Wreszcie, na tym etapie wykreślamy i wizualizujemy procentową różnicę i wolumen akcji będących w obrocie jako dane wyjściowe w formie wykresu.
Użyj poniższego kodu, aby wykreślić i zwizualizować różnice procentowe -
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')Użyj poniższego kodu, aby wykreślić i wizualizować wolumen akcji będących w obrocie -
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()