AI with Python - Unsupervised Learning: Clustering
Nienadzorowane algorytmy uczenia maszynowego nie mają żadnego nadzorcy, który mógłby zapewnić jakiekolwiek wskazówki. Dlatego są ściśle powiązane z tym, co niektórzy nazywają prawdziwą sztuczną inteligencją.
W uczeniu się bez nadzoru nie byłoby poprawnej odpowiedzi ani nauczyciela, który udziela wskazówek. Algorytmy muszą odkryć interesujący wzorzec w danych do nauki.
Co to jest klastrowanie?
Zasadniczo jest to rodzaj metody uczenia się bez nadzoru i powszechna technika statystycznej analizy danych wykorzystywana w wielu dziedzinach. Grupowanie to głównie zadanie polegające na podzieleniu zbioru obserwacji na podzbiory, zwane skupieniami, w taki sposób, aby obserwacje w tym samym skupieniu były w pewnym sensie podobne i niepodobne do obserwacji w innych skupieniach. W prostych słowach można powiedzieć, że głównym celem tworzenia klastrów jest grupowanie danych na podstawie podobieństwa i odmienności.
Na przykład poniższy diagram przedstawia podobny rodzaj danych w różnych klastrach -
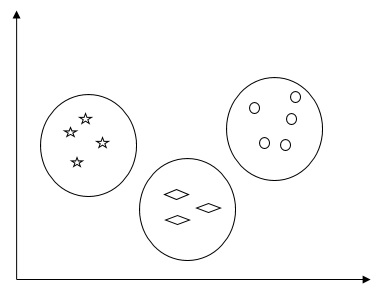
Algorytmy grupowania danych
Poniżej znajduje się kilka typowych algorytmów do grupowania danych -
Algorytm K-średnich
Algorytm grupowania metodą K-średnich jest jednym z dobrze znanych algorytmów grupowania danych. Musimy założyć, że liczba klastrów jest już znana. Nazywa się to również grupowaniem płaskim. Jest to iteracyjny algorytm klastrowania. W przypadku tego algorytmu należy postępować zgodnie z poniższymi krokami -
Step 1 - Musimy określić żądaną liczbę K podgrup.
Step 2- Ustal liczbę klastrów i losowo przypisz każdy punkt danych do klastra. Innymi słowy, musimy klasyfikować nasze dane na podstawie liczby klastrów.
Na tym etapie należy obliczyć centroidy klastrów.
Ponieważ jest to algorytm iteracyjny, musimy aktualizować lokalizacje centroidów K z każdą iteracją, aż znajdziemy optymalne globalne, czyli innymi słowy, centroidy osiągną swoje optymalne lokalizacje.
Poniższy kod pomoże w implementacji algorytmu klastrowania K-średnich w Pythonie. Będziemy używać modułu Scikit-learning.
Zaimportujmy niezbędne pakiety -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansPoniższy wiersz kodu pomoże w wygenerowaniu dwuwymiarowego zestawu danych zawierającego cztery obiekty blob przy użyciu make_blob z sklearn.dataset pakiet.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)Możemy zwizualizować zbiór danych za pomocą następującego kodu -
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
Tutaj inicjalizujemy kmeans, aby był algorytmem KMeans, z wymaganym parametrem liczby klastrów (n_clusters).
kmeans = KMeans(n_clusters = 4)Musimy wytrenować model K-średnich z danymi wejściowymi.
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_Kod podany poniżej pomoże nam wykreślić i zwizualizować wyniki maszyny w oparciu o nasze dane oraz dopasowanie zgodnie z liczbą klastrów, które mają zostać znalezione.
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
Algorytm zmiany średniej
Jest to kolejny popularny i potężny algorytm klastrowania używany w uczeniu się bez nadzoru. Nie przyjmuje żadnych założeń, dlatego jest algorytmem nieparametrycznym. Nazywa się to również grupowaniem hierarchicznym lub analizą skupień średnich przesunięć. Poniżej przedstawiono podstawowe kroki tego algorytmu -
Przede wszystkim musimy zacząć od punktów danych przypisanych do własnego klastra.
Teraz oblicza centroidy i aktualizuje położenie nowych centroid.
Powtarzając ten proces przybliżamy wierzchołek klastra, czyli w kierunku regionu o większej gęstości.
Ten algorytm zatrzymuje się na etapie, w którym centroidy już się nie poruszają.
Za pomocą poniższego kodu wdrażamy algorytm klastrowania Mean Shift w Pythonie. Będziemy używać modułu Scikit-learning.
Zaimportujmy niezbędne pakiety -
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")Poniższy kod pomoże w wygenerowaniu dwuwymiarowego zestawu danych zawierającego cztery obiekty blob przy użyciu make_blob z sklearn.dataset pakiet.
from sklearn.datasets.samples_generator import make_blobsMożemy zwizualizować zbiór danych za pomocą następującego kodu
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
Teraz musimy wyszkolić model klastra zmiany średniej z danymi wejściowymi.
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_Poniższy kod wydrukuje centra klastrów i oczekiwaną liczbę klastrów zgodnie z danymi wejściowymi -
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2Kod podany poniżej pomoże wykreślić i zwizualizować wyniki maszyny w oparciu o nasze dane oraz dopasowanie zgodnie z liczbą klastrów, które mają zostać znalezione.
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
Pomiar wydajności klastrowania
Dane ze świata rzeczywistego nie są w naturalny sposób zorganizowane w wiele odrębnych klastrów. Z tego powodu nie jest łatwo wizualizować i wyciągać wnioski. Dlatego musimy mierzyć wydajność klastrowania, a także jego jakość. Można to zrobić za pomocą analizy sylwetki.
Analiza sylwetki
Tej metody można użyć do sprawdzenia jakości klastrowania poprzez pomiar odległości między klastrami. Zasadniczo zapewnia sposób oceny parametrów, takich jak liczba klastrów, poprzez ocenę sylwetki. Ten wynik jest miernikiem, który mierzy, jak blisko każdego punktu w jednym klastrze jest do punktów w sąsiednich klastrach.
Analiza oceny sylwetki
Wynik ma zakres [-1, 1]. Poniżej znajduje się analiza tego wyniku -
Score of +1 - Wynik bliski +1 wskazuje, że próbka jest daleko od sąsiedniego klastra.
Score of 0 - Wynik 0 wskazuje, że próbka znajduje się na granicy decyzyjnej między dwoma sąsiadującymi klastrami lub bardzo blisko niej.
Score of -1 - Wynik ujemny wskazuje, że próbki zostały przypisane do niewłaściwych klastrów.
Obliczanie wyniku sylwetki
W tej sekcji dowiemy się, jak obliczyć wynik sylwetki.
Ocenę sylwetki można obliczyć za pomocą następującego wzoru -
$$ sylwetka score = \ frac {\ left (pq \ right)} {max \ left (p, q \ right)} $$
Tutaj jest to średnia odległość do punktów w najbliższej klastrze, której punkt danych nie jest częścią. I jest średnią odległością wewnątrz klastra do wszystkich punktów w jej własnym klastrze.
Aby znaleźć optymalną liczbę klastrów, musimy ponownie uruchomić algorytm grupowania, importując plik metrics moduł z sklearnpakiet. W poniższym przykładzie uruchomimy algorytm grupowania K-średnich, aby znaleźć optymalną liczbę klastrów -
Zaimportuj niezbędne pakiety, jak pokazano -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansZa pomocą poniższego kodu wygenerujemy dwuwymiarowy zestaw danych zawierający cztery obiekty blob przy użyciu make_blob z sklearn.dataset pakiet.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)Zainicjuj zmienne, jak pokazano -
scores = []
values = np.arange(2, 10)Musimy iterować model K-średnich przez wszystkie wartości, a także musimy przeszkolić go z danymi wejściowymi.
for num_clusters in values:
kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10)
kmeans.fit(X)Teraz oszacuj wynik sylwetki dla bieżącego modelu skupień za pomocą metryki odległości euklidesowej -
score = metrics.silhouette_score(X, kmeans.labels_,
metric = 'euclidean', sample_size = len(X))Poniższy wiersz kodu pomoże w wyświetleniu liczby klastrów, a także wyniku Silhouette.
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)Otrzymasz następujący wynik -
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)Teraz wynik dla optymalnej liczby klastrów byłby następujący:
Optimal number of clusters = 2Znajdowanie najbliższych sąsiadów
Jeśli chcemy budować systemy rekomendujące, takie jak system rekomendujący filmy, musimy zrozumieć koncepcję znajdowania najbliższych sąsiadów. Dzieje się tak, ponieważ system rekomendujący wykorzystuje koncepcję najbliższych sąsiadów.
Plik concept of finding nearest neighborsmożna zdefiniować jako proces znajdowania punktu znajdującego się najbliżej punktu wejściowego z danego zbioru danych. Głównym zastosowaniem tego algorytmu KNN) K-najbliższych sąsiadów jest tworzenie systemów klasyfikacyjnych, które klasyfikują punkt danych na podstawie bliskości punktu danych wejściowych do różnych klas.
Podany poniżej kod Pythona pomaga w znalezieniu K-najbliższych sąsiadów danego zbioru danych -
Zaimportuj niezbędne pakiety, jak pokazano poniżej. Tutaj używamyNearestNeighbors moduł z sklearn pakiet
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighborsZdefiniujmy teraz dane wejściowe -
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])Teraz musimy zdefiniować najbliższych sąsiadów -
k = 3Musimy również podać dane testowe, z których można znaleźć najbliższych sąsiadów -
test_data = [3.3, 2.9]Poniższy kod może wizualizować i rysować zdefiniowane przez nas dane wejściowe -
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
Teraz musimy zbudować najbliższego sąsiada K. Obiekt również wymaga przeszkolenia
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X)
distances, indices = knn_model.kneighbors([test_data])Teraz możemy wydrukować K najbliższych sąsiadów w następujący sposób
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])Możemy wizualizować najbliższych sąsiadów wraz z testowym punktem danych
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
Wynik
K Nearest Neighbors
1 is [ 3.1 2.3]
2 is [ 3.9 3.5]
3 is [ 4.4 2.9]Klasyfikator najbliższych sąsiadów K
Klasyfikator K-Nearest Neighbors (KNN) to model klasyfikacji, który wykorzystuje algorytm najbliższych sąsiadów do sklasyfikowania danego punktu danych. Zaimplementowaliśmy algorytm KNN w ostatniej sekcji, teraz zamierzamy zbudować klasyfikator KNN za pomocą tego algorytmu.
Koncepcja klasyfikatora KNN
Podstawową koncepcją klasyfikacji K-najbliższego sąsiada jest znalezienie z góry określonej liczby, tj. „K” - próbek szkoleniowych znajdujących się najbliżej nowej próbki, która musi zostać sklasyfikowana. Nowe próbki otrzymają etykiety od samych sąsiadów. Klasyfikatory KNN mają stałą, zdefiniowaną przez użytkownika, określającą liczbę sąsiadów, którą należy określić. Jeśli chodzi o odległość, najczęściej wybierana jest standardowa odległość euklidesowa. Klasyfikator KNN działa bezpośrednio na wyuczonych próbkach, zamiast tworzyć reguły uczenia się. Algorytm KNN jest jednym z najprostszych algorytmów uczenia maszynowego. Odniósł sukces w wielu problemach klasyfikacji i regresji, na przykład w rozpoznawaniu znaków lub analizie obrazu.
Example
Budujemy klasyfikator KNN do rozpoznawania cyfr. W tym celu użyjemy zbioru danych MNIST. Napiszemy ten kod w Notatniku Jupyter.
Zaimportuj niezbędne pakiety, jak pokazano poniżej.
Tutaj używamy KNeighborsClassifier moduł z sklearn.neighbors pakiet -
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as npPoniższy kod wyświetli obraz cyfry, aby zweryfikować, jaki obraz musimy przetestować -
def Image_display(i):
plt.imshow(digit['images'][i],cmap = 'Greys_r')
plt.show()Teraz musimy załadować zestaw danych MNIST. W rzeczywistości istnieje łącznie 1797 obrazów, ale używamy pierwszych 1600 obrazów jako próbki treningowej, a pozostałe 197 pozostanie do celów testowych.
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])Teraz, wyświetlając obrazy, możemy zobaczyć dane wyjściowe w następujący sposób -
Image_display(0)Image_display (0)
Obraz 0 jest wyświetlany w następujący sposób -

Obraz_display (9)
Obraz 9 jest wyświetlany w następujący sposób -

digit.keys ()
Teraz musimy utworzyć zbiór danych uczących i testujących oraz dostarczyć zestaw danych testowych do klasyfikatorów KNN.
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x,train_y)Poniższe dane wyjściowe utworzą konstruktora klasyfikatora najbliższych sąsiadów K -
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')Musimy utworzyć próbkę testową, podając dowolną liczbę większą niż 1600, która była próbkami szkoleniowymi.
test = np.array(digit['data'][1725])
test1 = test.reshape(1,-1)
Image_display(1725)Image_display (6)
Obraz 6 jest wyświetlany w następujący sposób -

Teraz będziemy przewidywać dane testowe w następujący sposób -
KNN.predict(test1)Powyższy kod wygeneruje następujące dane wyjściowe -
array([6])Teraz rozważ następujące -
digit['target_names']Powyższy kod wygeneruje następujące dane wyjściowe -
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])