Sztuczna inteligencja - krótki przewodnik
Od czasu wynalezienia komputerów lub maszyn ich zdolność do wykonywania różnych zadań rosła wykładniczo. Ludzie rozwinęli moc systemów komputerowych pod względem różnorodnych dziedzin pracy, ich rosnącej szybkości i zmniejszania rozmiaru w stosunku do czasu.
Oddział informatyki zwany sztuczną inteligencją zajmuje się tworzeniem komputerów lub maszyn tak inteligentnych jak ludzie.
Co to jest sztuczna inteligencja?
Według ojca Artificial Intelligence, Johna McCarthy'ego, jest to „Nauka i inżynieria tworzenia inteligentnych maszyn, zwłaszcza inteligentnych programów komputerowych”.
Sztuczna inteligencja to sposób making a computer, a computer-controlled robot, or a software think intelligentlyw podobny sposób myślą inteligentni ludzie.
Sztuczną inteligencję osiąga się poprzez badanie sposobu myślenia ludzkiego mózgu oraz tego, jak ludzie uczą się, decydują i pracują, próbując rozwiązać problem, a następnie wykorzystując wyniki tego badania jako podstawę do tworzenia inteligentnego oprogramowania i systemów.
Filozofia AI
Wykorzystując moc systemów komputerowych, ciekawość człowieka, zastanawia się: „Czy maszyna może myśleć i zachowywać się tak, jak ludzie?”
Tak więc rozwój sztucznej inteligencji rozpoczął się z zamiarem stworzenia podobnej inteligencji w maszynach, które uważamy za wysoko u ludzi.
Cele AI
To Create Expert Systems - Systemy, które wykazują inteligentne zachowanie, uczą się, demonstrują, wyjaśniają i doradzają swoim użytkownikom.
To Implement Human Intelligence in Machines - Tworzenie systemów, które rozumieją, myślą, uczą się i zachowują jak ludzie.
Co wpływa na sztuczną inteligencję?
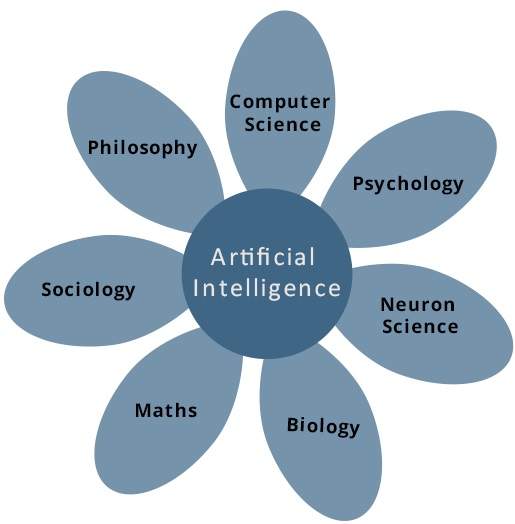
Sztuczna inteligencja to nauka i technologia oparta na takich dyscyplinach jak informatyka, biologia, psychologia, językoznawstwo, matematyka i inżynieria. Głównym celem sztucznej inteligencji jest rozwój funkcji komputerowych związanych z ludzką inteligencją, takich jak rozumowanie, uczenie się i rozwiązywanie problemów.
Z poniższych obszarów jeden lub wiele obszarów może przyczynić się do zbudowania inteligentnego systemu.
Programowanie bez i ze sztuczną inteligencją
Programowanie bez i ze sztuczną inteligencją różni się w następujący sposób -
| Programowanie bez AI | Programowanie z AI |
|---|---|
| Program komputerowy bez AI może odpowiedzieć na specific pytania, które ma rozwiązać. | Program komputerowy z AI może odpowiedzieć na generic pytania, które ma rozwiązać. |
| Modyfikacja programu prowadzi do zmiany jego struktury. | Programy AI mogą wchłonąć nowe modyfikacje, łącząc ze sobą wysoce niezależne fragmenty informacji. Dzięki temu możesz modyfikować nawet drobną informację programu bez naruszania jego struktury. |
| Modyfikacja nie jest szybka i łatwa. Może to niekorzystnie wpłynąć na program. | Szybka i łatwa modyfikacja programu. |
Co to jest technika sztucznej inteligencji?
W prawdziwym świecie ta wiedza ma pewne niepożądane właściwości -
- Jego objętość jest ogromna, wręcz niewyobrażalna.
- Nie jest dobrze zorganizowany ani sformatowany.
- Ciągle się zmienia.
Technika AI to sposób na uporządkowanie i efektywne wykorzystanie wiedzy w taki sposób, aby -
- Powinien być dostrzegalny dla osób, które go dostarczają.
- Powinien być łatwo modyfikowalny, aby poprawić błędy.
- Powinien być przydatny w wielu sytuacjach, chociaż jest niekompletny lub niedokładny.
Techniki AI podnoszą szybkość wykonywania złożonego programu, w który jest wyposażony.
Zastosowania AI
Sztuczna inteligencja dominuje w różnych dziedzinach, takich jak -
Gaming - AI odgrywa kluczową rolę w grach strategicznych, takich jak szachy, poker, kółko i krzyżyk itp., W których maszyna może wymyślić dużą liczbę możliwych pozycji w oparciu o wiedzę heurystyczną.
Natural Language Processing - Możliwa jest interakcja z komputerem, który rozumie naturalny język używany przez ludzi.
Expert Systems- Istnieją aplikacje, które integrują maszynę, oprogramowanie i specjalne informacje w celu przekazania argumentów i porad. Udzielają wyjaśnień i porad użytkownikom.
Vision Systems- Systemy te rozumieją, interpretują i rozumieją wizualne dane wejściowe komputera. Na przykład,
Samolot szpiegowski wykonuje zdjęcia, które służą do uzyskania informacji przestrzennych lub mapy obszarów.
Do diagnozowania pacjenta lekarze wykorzystują system ekspercki klinicznej.
Policja używa oprogramowania komputerowego, które potrafi rozpoznać twarz przestępcy na podstawie przechowywanego portretu wykonanego przez kryminalistę.
Speech Recognition- Niektóre inteligentne systemy są w stanie słyszeć i rozumieć język w kategoriach zdań i ich znaczenia, podczas gdy człowiek do niego mówi. Potrafi obsługiwać różne akcenty, slangowe słowa, hałas w tle, zmiany ludzkiego hałasu spowodowane zimnem itp.
Handwriting Recognition- Oprogramowanie do rozpoznawania pisma odręcznego odczytuje tekst zapisany na papierze za pomocą pióra lub na ekranie za pomocą rysika. Potrafi rozpoznać kształty liter i przekształcić je w edytowalny tekst.
Intelligent Robots- Roboty są w stanie wykonywać zadania powierzone przez człowieka. Posiadają czujniki do wykrywania danych fizycznych z rzeczywistego świata, takich jak światło, ciepło, temperatura, ruch, dźwięk, uderzenia i ciśnienie. Mają wydajne procesory, wiele czujników i ogromną pamięć, aby wykazywać inteligencję. Ponadto potrafią uczyć się na swoich błędach i potrafią dostosować się do nowego środowiska.
Historia AI
Oto historia sztucznej inteligencji w XX wieku -
| Rok | Kamień milowy / innowacja |
|---|---|
| 1923 | Przedstawienie Karela Čapka pod tytułem „Rossum's Universal Robots” (RUR) otwiera się w Londynie, po raz pierwszy użyte zostało słowo „robot” w języku angielskim. |
| 1943 | Założono fundamenty pod sieci neuronowe. |
| 1945 | Isaac Asimov, absolwent Uniwersytetu Columbia, ukuł termin robotyka . |
| 1950 | Alan Turing przedstawił test Turinga do oceny inteligencji i opublikował Computing Machinery and Intelligence. Claude Shannon opublikował szczegółową analizę gry w szachy jako wyszukiwanie. |
| 1956 | John McCarthy ukuł termin sztuczna inteligencja . Demonstracja pierwszego uruchomionego programu AI na Carnegie Mellon University. |
| 1958 | John McCarthy wymyśla język programowania LISP dla sztucznej inteligencji. |
| 1964 | Rozprawa Danny'ego Bobrowa z MIT pokazała, że komputery mogą rozumieć język naturalny na tyle dobrze, aby poprawnie rozwiązywać zadania tekstowe z algebry. |
| 1965 | Joseph Weizenbaum z MIT stworzył ELIZA , interaktywny problem prowadzący dialog w języku angielskim. |
| 1969 | Naukowcy z Stanford Research Institute opracowali Shakey , robota wyposażonego w funkcje lokomocji, percepcji i rozwiązywania problemów. |
| 1973 | Grupa Assembly Robotics z Uniwersytetu w Edynburgu zbudowała Freddy'ego , słynnego szkockiego robota, zdolnego do lokalizowania i składania modeli za pomocą wizji. |
| 1979 | Zbudowano pierwszy autonomiczny pojazd sterowany komputerowo - Stanford Cart. |
| 1985 | Harold Cohen stworzył i zademonstrował program do rysowania, Aaron . |
| 1990 | Duże postępy we wszystkich obszarach sztucznej inteligencji -
|
| 1997 | Program Deep Blue Chess pokonuje ówczesnego mistrza świata, Garry'ego Kasparowa. |
| 2000 | Interaktywne zwierzęta-roboty stają się dostępne w handlu. MIT przedstawia Kismeta , robota z twarzą wyrażającą emocje. Robot Nomad bada odległe regiony Antarktydy i lokalizuje meteoryty. |
Badając sztuczną inteligencję, musisz wiedzieć, czym jest inteligencja. Ten rozdział obejmuje ideę inteligencji, typy i składniki inteligencji.
Co to jest inteligencja?
Zdolność systemu do obliczania, rozumowania, postrzegania relacji i analogii, uczenia się na podstawie doświadczenia, przechowywania i wyszukiwania informacji z pamięci, rozwiązywania problemów, rozumienia złożonych idei, płynnego używania języka naturalnego, klasyfikowania, uogólniania i adaptowania nowych sytuacji.
Rodzaje inteligencji
Jak opisał Howard Gardner, amerykański psycholog rozwojowy, Inteligencja ma wiele aspektów -
| Inteligencja | Opis | Przykład |
|---|---|---|
| Inteligencja językowa | Umiejętność mówienia, rozpoznawania i używania mechanizmów fonologii (dźwięki mowy), składni (gramatyka) i semantyki (znaczenie). | Narratorzy, mówcy |
| Inteligencja muzyczna | Umiejętność tworzenia, komunikowania się i rozumienia znaczeń utworzonych z dźwięku, rozumienie wysokości dźwięku, rytmu. | Muzycy, śpiewacy, kompozytorzy |
| Inteligencja logiczno-matematyczna | Umiejętność używania i rozumienia relacji przy braku działań lub przedmiotów. Zrozumienie złożonych i abstrakcyjnych pomysłów. | Matematycy, naukowcy |
| Inteligencja przestrzenna | Zdolność do postrzegania informacji wizualnych lub przestrzennych, zmieniania ich i odtwarzania obrazów wizualnych bez odniesienia do obiektów, konstruowania obrazów 3D oraz ich przesuwania i obracania. | Czytelnicy map, astronauci, fizycy |
| Inteligencja cielesno-kinestetyczna | Umiejętność wykorzystywania całego ciała lub jego części do rozwiązywania problemów lub tworzenia modnych produktów, kontrolowania drobnych i grubych zdolności motorycznych oraz manipulowania przedmiotami. | Gracze, tancerze |
| Inteligencja interpersonalna | Zdolność do rozróżniania własnych uczuć, intencji i motywacji. | Gautam Buddhha |
| Inteligencja interpersonalna | Umiejętność rozpoznawania i rozróżniania uczuć, przekonań i intencji innych ludzi. | Masowi komunikatorzy, ankieterzy |
Możesz powiedzieć, że maszyna lub system artificially intelligent kiedy jest wyposażony w przynajmniej jedną, a co najwyżej wszystkie inteligencje.
Z czego składa się inteligencja?
Inteligencja jest nieuchwytna. Składa się z -
- Reasoning
- Learning
- Rozwiązywanie problemów
- Perception
- Inteligencja językowa

Przyjrzyjmy się pokrótce wszystkim komponentom -
Reasoning- To zbiór procesów, który pozwala nam zapewnić podstawę do oceny, podejmowania decyzji i przewidywania. Istnieją zasadniczo dwa typy -
| Rozumowanie indukcyjne | Rozumowanie dedukcyjne |
|---|---|
| Prowadzi szczegółowe obserwacje, aby sformułować szerokie, ogólne stwierdzenia. | Rozpoczyna się od ogólnego stwierdzenia i bada możliwości dojścia do konkretnego, logicznego wniosku. |
| Nawet jeśli wszystkie przesłanki w stwierdzeniu są prawdziwe, rozumowanie indukcyjne pozwala na fałszywy wniosek. | Jeśli coś jest prawdą w odniesieniu do jakiejś klasy rzeczy w ogóle, dotyczy to również wszystkich członków tej klasy. |
| Przykład - „Nita jest nauczycielką. Nita jest pilna. Dlatego wszyscy nauczyciele są pilni”. | Przykład - „Wszystkie kobiety w wieku powyżej 60 lat są babciami. Shalini ma 65 lat. Dlatego Shalini jest babcią”. |
Learning- Jest to czynność polegająca na zdobywaniu wiedzy lub umiejętności poprzez naukę, praktykę, uczenie się lub doświadczanie czegoś. Uczenie się zwiększa świadomość badanych osób.
Umiejętność uczenia się posiadają ludzie, niektóre zwierzęta i systemy z obsługą AI. Nauka jest klasyfikowana jako -
Auditory Learning- To nauka przez słuchanie i słyszenie. Na przykład studenci słuchający nagranych wykładów audio.
Episodic Learning- Aby uczyć się poprzez zapamiętywanie sekwencji wydarzeń, których byłeś świadkiem lub którego doświadczyłeś. To jest liniowe i uporządkowane.
Motor Learning- To nauka poprzez precyzyjny ruch mięśni. Na przykład wybieranie przedmiotów, pisanie itp.
Observational Learning- Aby uczyć się, obserwując i naśladując innych. Na przykład dziecko próbuje się uczyć, naśladując swojego rodzica.
Perceptual Learning- To nauka rozpoznawania bodźców, które się wcześniej widziało. Na przykład identyfikowanie i klasyfikowanie obiektów i sytuacji.
Relational Learning- Obejmuje naukę rozróżniania różnych bodźców na podstawie właściwości relacyjnych, a nie właściwości absolutnych. Na przykład dodanie „trochę mniej” soli podczas gotowania ziemniaków, które ostatnio były słone, np. Po ugotowaniu z dodatkiem, powiedzmy łyżki soli.
Spatial Learning - To uczenie się poprzez bodźce wizualne, takie jak obrazy, kolory, mapy itp. Na przykład, osoba może stworzyć mapę drogową w umyśle, zanim faktycznie pójdzie drogą.
Stimulus-Response Learning- Jest to nauka wykonywania określonego zachowania, gdy obecny jest określony bodziec. Na przykład pies podnosi ucho, słysząc dzwonek do drzwi.
Problem Solving - Jest to proces, w którym spostrzega się i próbuje dojść do pożądanego rozwiązania z obecnej sytuacji, wybierając jakąś ścieżkę, którą blokują znane lub nieznane przeszkody.
Rozwiązywanie problemów obejmuje również decision making, który jest procesem wyboru najlepszej, odpowiedniej alternatywy spośród wielu dostępnych alternatyw dla osiągnięcia pożądanego celu.
Perception - Jest to proces pozyskiwania, interpretowania, selekcji i porządkowania informacji sensorycznych.
Percepcja zakłada sensing. U ludzi percepcja jest wspomagana przez narządy zmysłów. W dziedzinie sztucznej inteligencji mechanizm percepcji w znaczący sposób łączy dane zebrane przez czujniki.
Linguistic Intelligence- Jest to umiejętność używania, rozumienia, mówienia i pisania w języku werbalnym i pisanym. Jest to ważne w komunikacji międzyludzkiej.
Różnica między inteligencją ludzką a maszynową
Ludzie postrzegają za pomocą wzorów, podczas gdy maszyny postrzegają za pomocą zestawu reguł i danych.
Ludzie przechowują i przywołują informacje według wzorów, maszyny robią to, wyszukując algorytmy. Na przykład numer 40404040 jest łatwy do zapamiętania, przechowywania i przywoływania, ponieważ jego wzór jest prosty.
Ludzie mogą odgadnąć cały obiekt, nawet jeśli brakuje jakiejś jego części lub jest ona zniekształcona; podczas gdy maszyny nie mogą tego zrobić poprawnie.
Dziedzina sztucznej inteligencji jest ogromna pod względem szerokości i szerokości. Kontynuując, bierzemy pod uwagę szeroko rozpowszechnione i dobrze prosperujące obszary badawcze w dziedzinie sztucznej inteligencji -

Rozpoznawanie mowy i głosu
Te oba terminy są powszechne w robotyce, systemach eksperckich i przetwarzaniu języka naturalnego. Chociaż terminy te są używane zamiennie, ich cele są różne.
| Rozpoznawanie mowy | Rozpoznawanie głosu |
|---|---|
| Rozpoznawanie mowy ma na celu zrozumienie i zrozumienie WHAT zostało powiedziane. | Celem rozpoznawania głosu jest rozpoznawanie WHO mówi. |
| Jest używany do obsługi komputera bez użycia rąk, nawigacji po mapie lub w menu. | Służy do identyfikacji osoby poprzez analizę jej tonu, wysokości głosu, akcentu itp. |
| Maszyna nie wymaga szkolenia w zakresie rozpoznawania mowy, ponieważ nie jest zależna od mówcy. | Ten system rozpoznawania wymaga szkolenia, ponieważ jest zorientowany na osobę. |
| Systemy rozpoznawania mowy niezależne od mówcy są trudne do opracowania. | Systemy rozpoznawania mowy zależne od mówcy są stosunkowo łatwe do opracowania. |
Działanie systemów rozpoznawania mowy i głosu
Treść wprowadzana przez użytkownika wypowiadana przez mikrofon trafia do karty dźwiękowej systemu. Konwerter zamienia sygnał analogowy na równoważny sygnał cyfrowy do przetwarzania mowy. Baza danych służy do porównywania wzorców dźwiękowych w celu rozpoznawania słów. Na koniec do bazy danych przekazywana jest informacja zwrotna.
Ten tekst w języku źródłowym zostaje wprowadzony do silnika tłumaczeń, który przekształca go w tekst w języku docelowym. Obsługiwane są przez interaktywne GUI, dużą bazę słownictwa itp.
Zastosowania obszarów badawczych w prawdziwym życiu
Istnieje wiele aplikacji, w których sztuczna inteligencja służy zwykłym ludziom w ich codziennym życiu -
| Sr.No. | Obszary badawcze | Aplikacja z prawdziwego życia |
|---|---|---|
| 1 | Expert Systems Przykłady - systemy śledzenia lotu, systemy kliniczne. |

|
| 2 | Natural Language Processing Przykłady: funkcja Google Now, rozpoznawanie mowy, automatyczne generowanie głosu. |

|
| 3 | Neural Networks Przykłady - systemy rozpoznawania wzorców, takie jak rozpoznawanie twarzy, rozpoznawanie znaków, rozpoznawanie pisma ręcznego. |

|
| 4 | Robotics Przykłady - roboty przemysłowe do przemieszczania, natryskiwania, malowania, precyzyjnego sprawdzania, wiercenia, czyszczenia, powlekania, rzeźbienia itp. |

|
| 5 | Fuzzy Logic Systems Przykłady - elektronika użytkowa, samochody itp. |

|
Klasyfikacja zadań AI
Dziedzina sztucznej inteligencji jest podzielona na Formal tasks, Mundane tasks, i Expert tasks.

| Domeny zadaniowe sztucznej inteligencji | ||
|---|---|---|
| Pospolite (zwykłe) zadania | Zadania formalne | Zadania eksperckie |
Postrzeganie
|
|
|
Przetwarzanie języka naturalnego
|
Gry
|
Analiza naukowa |
| Zdrowy rozsądek | Weryfikacja | Analiza finansowa |
| Rozumowanie | Dowodzenie twierdzeń | Diagnoza medyczna |
| Planowanie | Kreatywność | |
Robotyka
|
||
Ludzie się uczą mundane (ordinary) tasksod urodzenia. Uczą się poprzez percepcję, mówienie, używanie języka i lokomotyw. Później uczą się zadań formalnych i zadań eksperckich, w tej kolejności.
Dla ludzi przyziemne czynności są najłatwiejsze do nauczenia. To samo uznano za prawdę przed próbą zaimplementowania przyziemnych zadań w maszynach. Wcześniej cała praca AI koncentrowała się w domenie prozaicznych zadań.
Później okazało się, że maszyna wymaga większej wiedzy, złożonej reprezentacji wiedzy i skomplikowanych algorytmów do obsługi przyziemnych zadań. to jest powódwhy AI work is more prospering in the Expert Tasks domain teraz, ponieważ dziedzina zadań eksperckich wymaga wiedzy eksperckiej bez zdrowego rozsądku, która może być łatwiejsza do przedstawienia i obsługi.
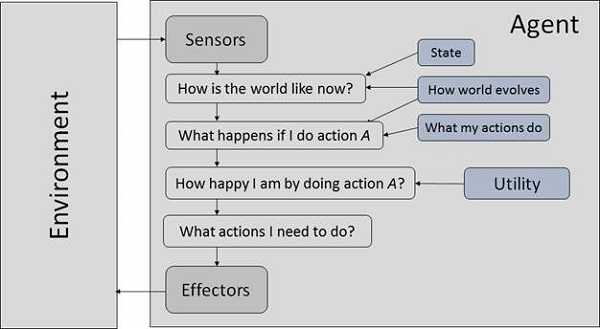
System AI składa się z agenta i jego środowiska. Agenci działają w swoim środowisku. Środowisko może zawierać inne czynniki.
Co to jest agent i środowisko?
Na agent jest wszystkim, przez co może dostrzec swoje otoczenie sensors i działa na to środowisko poprzez effectors.
ZA human agent ma narządy zmysłów, takie jak oczy, uszy, nos, język i skóra, równoległe do czujników i inne narządy, takie jak ręce, nogi, usta, dla efektorów.
ZA robotic agent zastępuje kamery i dalmierze na podczerwień do czujników oraz różne silniki i siłowniki do efektorów.
ZA software agent zakodował ciągi bitów jako swoje programy i akcje.

Terminologia agentów
Performance Measure of Agent - To kryteria, które decydują o sukcesie agenta.
Behavior of Agent - Jest to akcja, którą agent wykonuje po dowolnej sekwencji spostrzeżeń.
Percept - Są to percepcyjne dane wejściowe agenta w danej instancji.
Percept Sequence - To historia wszystkiego, co agent widział do dziś.
Agent Function - Jest to mapa od sekwencji wskazań do działania.
Racjonalność
Racjonalność to nic innego jak status rozsądku, rozsądku i dobrego osądu.
Racjonalność dotyczy oczekiwanych działań i wyników zależnych od tego, co dostrzegł agent. Wykonywanie działań w celu uzyskania użytecznych informacji jest ważną częścią racjonalności.
Co to jest Ideal Rational Agent?
Idealny racjonalny agent to taki, który jest w stanie wykonać oczekiwane działania w celu zmaksymalizowania swojego pomiaru wydajności, na podstawie:
- Sekwencja percepcji
- Wbudowana baza wiedzy
Racjonalność agenta zależy od:
Plik performance measures, które określają stopień sukcesu.
Agenta Percept Sequence do teraz.
Agenta prior knowledge about the environment.
Plik actions które agent może przeprowadzić.
Racjonalny agent zawsze wykonuje właściwe działanie, gdzie właściwe działanie oznacza działanie, które powoduje, że agent osiąga największe sukcesy w danej sekwencji percepcji. Problem rozwiązany przez agenta jest scharakteryzowany przez miernik wydajności, środowisko, siłowniki i czujniki (PEAS).
Struktura inteligentnych agentów
Strukturę agenta można postrzegać jako -
- Agent = Architektura + Program Agent
- Architektura = maszyna, na której działa agent.
- Program agenta = implementacja funkcji agenta.
Proste środki odruchowe
- Wybierają działania tylko na podstawie aktualnego postrzegania.
- Są racjonalne tylko wtedy, gdy właściwa decyzja jest podejmowana tylko na podstawie aktualnych wskazań.
- Ich otoczenie jest całkowicie obserwowalne.
Condition-Action Rule - Jest to reguła, która odwzorowuje stan (warunek) na akcję.

Środki odruchowe oparte na modelu
Korzystają z modelu świata, aby wybrać swoje działania. Utrzymują stan wewnętrzny.
Model - wiedza o tym, „jak rzeczy dzieją się na świecie”.
Internal State - Jest to reprezentacja nieobserwowanych aspektów obecnego stanu w zależności od historii percepcji.
Updating the state requires the information about −
- Jak zmienia się świat.
- Jak działania agenta wpływają na świat.

Agenci na podstawie celów
Wybierają swoje działania, aby osiągnąć cele. Podejście oparte na celach jest bardziej elastyczne niż środek odruchowy, ponieważ wiedza wspierająca decyzję jest wyraźnie modelowana, co pozwala na modyfikacje.
Goal - To opis pożądanych sytuacji.

Agenty oparte na narzędziach
Wybierają działania na podstawie preferencji (użyteczności) dla każdego stanu.
Cele są nieodpowiednie, gdy -
Istnieją sprzeczne cele, z których tylko kilka można osiągnąć.
Cele obarczone są pewną niepewnością co do osiągnięcia i musisz porównać prawdopodobieństwo sukcesu z ważnością celu.
Natura środowisk
Niektóre programy działają w całości w artificial environment ogranicza się do wprowadzania danych z klawiatury, bazy danych, komputerowych systemów plików i wyprowadzania znaków na ekranie.
Z drugiej strony, niektóre agenty oprogramowania (roboty programowe lub softboty) istnieją w bogatych, nieograniczonych domenach softbotów. Symulator ma rozszerzenievery detailed, complex environment. Agent oprogramowania musi wybierać z szerokiej gamy działań w czasie rzeczywistym. Softbot przeznaczony do skanowania preferencji online klienta i pokazywania klientowi interesujących elementów działa wreal jak również artificial środowisko.
Najsławniejszy artificial environment jest Turing Test environment, w którym jeden prawdziwy i inne sztuczne czynniki są testowane na równych zasadach. Jest to bardzo wymagające środowisko, ponieważ agent oprogramowania może działać tak dobrze, jak człowiek.
Test Turinga
Sukces inteligentnego zachowania systemu można zmierzyć za pomocą testu Turinga.
W teście uczestniczą dwie osoby i maszyna do oceny. Jedna z dwóch osób pełni rolę testera. Każdy z nich siedzi w różnych pokojach. Tester nie jest świadomy tego, kto jest maszyną, a kto człowiekiem. Przesłuchuje pytania, wpisując je na maszynie i wysyłając do obu inteligencji, na które otrzymuje odpowiedzi na maszynie.
Ten test ma na celu oszukanie testera. Jeśli tester nie zdoła określić odpowiedzi maszyny na podstawie reakcji człowieka, wówczas mówi się, że maszyna jest inteligentna.
Właściwości środowiska
Środowisko ma wielorakie właściwości -
Discrete / Continuous- Jeśli istnieje ograniczona liczba odrębnych, jasno określonych stanów środowiska, środowisko jest dyskretne (na przykład szachy); w przeciwnym razie jest ciągły (na przykład jazda).
Observable / Partially Observable- jeśli możliwe jest określenie pełnego stanu środowiska w każdym punkcie czasowym na podstawie percepcji, jest on obserwowalny; w przeciwnym razie jest to tylko częściowo widoczne.
Static / Dynamic- Jeśli środowisko nie zmienia się podczas działania agenta, oznacza to, że jest statyczne; w przeciwnym razie jest dynamiczny.
Single agent / Multiple agents - Środowisko może zawierać inne czynniki, które mogą być tego samego lub innego rodzaju co agent.
Accessible / Inaccessible - Jeśli aparat sensoryczny agenta może mieć dostęp do pełnego stanu środowiska, to środowisko jest dostępne dla tego agenta.
Deterministic / Non-deterministic- Jeśli następny stan środowiska jest całkowicie zdeterminowany przez stan aktualny i działania agenta, to środowisko jest deterministyczne; w przeciwnym razie jest niedeterministyczna.
Episodic / Non-episodic- W środowisku epizodycznym każdy epizod składa się z postrzegania przez agenta, a następnie działania. Jakość jego akcji zależy właśnie od samego odcinka. Kolejne odcinki nie zależą od działań w poprzednich odcinkach. Środowiska epizodyczne są znacznie prostsze, ponieważ agent nie musi myśleć z wyprzedzeniem.
Wyszukiwanie to uniwersalna technika rozwiązywania problemów w AI. Istnieje kilka gier dla jednego gracza, takich jak gry kaflowe, Sudoku, krzyżówka itp. Algorytmy wyszukiwania pomagają w wyszukiwaniu określonej pozycji w takich grach.
Problemy z odnajdywaniem ścieżki jednego agenta
Gry takie jak 3X3 z ośmioma kafelkami, 4X4 z piętnastoma kafelkami i 5X5 z dwudziestoma czterema kafelkami są wyzwaniami polegającymi na znajdowaniu ścieżki dla jednego agenta. Składają się z matrycy płytek z pustą płytką. Gracz musi ułożyć płytki, przesuwając je pionowo lub poziomo w puste miejsce w celu osiągnięcia jakiegoś celu.
Inne przykłady problemów ze znajdowaniem ścieżki pojedynczego agenta to Problem komiwojażera, Kostka Rubika i Dowodzenie twierdzeń.
Wyszukaj terminologię
Problem Space- To środowisko, w którym odbywa się poszukiwanie. (Zbiór stanów i zestaw operatorów do zmiany tych stanów)
Problem Instance - To jest stan początkowy + stan celu.
Problem Space Graph- Stanowi problem. Stany są wyświetlane przez węzły, a operatory przez krawędzie.
Depth of a problem - Długość najkrótszej ścieżki lub najkrótszej sekwencji operatorów od stanu początkowego do stanu docelowego.
Space Complexity - Maksymalna liczba węzłów przechowywanych w pamięci.
Time Complexity - Maksymalna liczba tworzonych węzłów.
Admissibility - właściwość algorytmu, który zawsze znajduje optymalne rozwiązanie.
Branching Factor - Średnia liczba węzłów potomnych na wykresie przestrzeni problemu.
Depth - Długość najkrótszej ścieżki od stanu początkowego do stanu docelowego.
Strategie wyszukiwania typu Brute-Force
Są najprostsze, ponieważ nie wymagają żadnej wiedzy dziedzinowej. Działają dobrze z niewielką liczbą możliwych stanów.
Wymagania -
- Opis stanu
- Zestaw prawidłowych operatorów
- Stan początkowy
- Opis stanu celu
Przeszukiwanie wszerz
Rozpoczyna się od węzła głównego, najpierw bada sąsiednie węzły i przesuwa się w kierunku sąsiadów następnego poziomu. Generuje jedno drzewo na raz, aż do znalezienia rozwiązania. Można to zaimplementować za pomocą struktury danych kolejki FIFO. Ta metoda zapewnia najkrótszą ścieżkę do rozwiązania.
Gdyby branching factor(średnia liczba węzłów potomnych dla danego węzła) = b i głębokość = d, a następnie liczba węzłów na poziomie d = b d .
Całkowita liczba węzłów utworzonych w najgorszym przypadku to b + b 2 + b 3 +… + b d .
Disadvantage- Ponieważ każdy poziom węzłów jest zapisywany w celu utworzenia następnego, zajmuje dużo miejsca w pamięci. Wymagana przestrzeń do przechowywania węzłów jest wykładnicza.
Jego złożoność zależy od liczby węzłów. Może sprawdzić zduplikowane węzły.

Przeszukiwanie w głąb
Jest implementowany rekurencyjnie ze strukturą danych stosu LIFO. Tworzy ten sam zestaw węzłów, co metoda Breadth-First, tylko w innej kolejności.
Ponieważ węzły na pojedynczej ścieżce są przechowywane w każdej iteracji od węzła głównego do węzła-liścia, zapotrzebowanie na miejsce do przechowywania węzłów jest liniowe. Przy współczynniku rozgałęzienia b i głębokości m , przestrzeń magazynowa wynosi bm.
Disadvantage- Ten algorytm nie może kończyć się i działać w nieskończoność na jednej ścieżce. Rozwiązaniem tego problemu jest wybranie głębokości odcięcia. Jeśli idealnym punktem odcięcia jest d , a wybrana wartość odcięcia jest mniejsza niż d , to algorytm może się nie powieść. Jeśli wybrana wartość odcięcia jest większa niż d , to czas wykonania wydłuża się.
Jego złożoność zależy od liczby ścieżek. Nie może sprawdzić zduplikowanych węzłów.

Wyszukiwanie dwukierunkowe
Przeszukuje do przodu od stanu początkowego i wstecz od stanu docelowego, aż oba spotkają się, aby zidentyfikować wspólny stan.
Ścieżka ze stanu początkowego jest łączona z odwrotną ścieżką ze stanu docelowego. Każde wyszukiwanie jest wykonywane tylko do połowy całkowitej ścieżki.
Jednolite wyszukiwanie kosztów
Sortowanie odbywa się w rosnącym koszcie ścieżki do węzła. Zawsze rozwija najmniej kosztowny węzeł. Jest to identyczne z wyszukiwaniem według szerokości, jeśli każde przejście ma ten sam koszt.
Bada ścieżki w kolejności rosnących kosztów.
Disadvantage- Może istnieć wiele długich ścieżek o koszcie ≤ C *. Jednolite wyszukiwanie kosztów musi zbadać je wszystkie.
Iteracyjne pogłębianie wyszukiwania w głąb
Wykonuje przeszukiwanie wgłębne do poziomu 1, rozpoczyna od nowa, wykonuje pełne przeszukiwanie w głąb w pierwszej kolejności do poziomu 2 i kontynuuje w taki sposób, aż zostanie znalezione rozwiązanie.
Nigdy nie tworzy węzła, dopóki nie zostaną wygenerowane wszystkie niższe węzły. Oszczędza tylko stos węzłów. Algorytm kończy się, gdy znajdzie rozwiązanie na głębokości d . Liczba węzłów utworzonych na głębokości d wynosi b d, a na głębokości d-1 wynosi b d-1.
Porównanie różnych złożoności algorytmów
Zobaczmy działanie algorytmów opartych na różnych kryteriach -
| Kryterium | Szerokość pierwsza | Najpierw głębokość | Dwukierunkowy | Jednolity koszt | Interaktywne pogłębianie |
|---|---|---|---|---|---|
| Czas | b d | b m | b d / 2 | b d | b d |
| Przestrzeń | b d | b m | b d / 2 | b d | b d |
| Optymalność | tak | Nie | tak | tak | tak |
| Kompletność | tak | Nie | tak | tak | tak |
Świadome (heurystyczne) strategie wyszukiwania
Aby rozwiązać duże problemy z dużą liczbą możliwych stanów, należy dodać wiedzę specyficzną dla problemu, aby zwiększyć wydajność algorytmów wyszukiwania.
Funkcje oceny heurystycznej
Obliczają koszt optymalnej ścieżki między dwoma stanami. Funkcja heurystyczna dla gier z przesuwanymi kafelkami jest obliczana poprzez zliczanie liczby ruchów wykonywanych przez każdą płytkę ze stanu celu i dodanie tej liczby ruchów dla wszystkich płytek.
Czyste wyszukiwanie heurystyczne
Rozwija węzły w kolejności ich wartości heurystycznych. Tworzy dwie listy, zamkniętą listę dla już rozwiniętych węzłów i otwartą listę dla utworzonych, ale nierozwiniętych węzłów.
W każdej iteracji węzeł z minimalną wartością heurystyczną jest rozwijany, wszystkie jego węzły potomne są tworzone i umieszczane na zamkniętej liście. Następnie do węzłów potomnych jest stosowana funkcja heurystyczna i są one umieszczane na liście otwartej zgodnie z ich wartością heurystyczną. Krótsze ścieżki są zapisywane, a dłuższe usuwane.
Wyszukiwanie
Jest to najbardziej znana forma wyszukiwania Best First. Unika rozwijania ścieżek, które już są drogie, ale najpierw rozwija najbardziej obiecujące ścieżki.
f (n) = g (n) + h (n), gdzie
- g (n) koszt (dotychczas) dotarcia do węzła
- h (n) szacowany koszt dotarcia z węzła do celu
- f (n) szacunkowy całkowity koszt ścieżki przez n do celu. Jest realizowany przy użyciu kolejki priorytetów poprzez zwiększenie f (n).
Chciwy Najlepsze pierwsze wyszukiwanie
Rozszerza węzeł, który jest szacowany jako najbliższy celu. Rozwija węzły na podstawie f (n) = h (n). Jest realizowany za pomocą kolejki priorytetów.
Disadvantage- Może utknąć w pętli. To nie jest optymalne.
Lokalne algorytmy wyszukiwania
Rozpoczynają od przyszłego rozwiązania, a następnie przechodzą do rozwiązania sąsiedniego. Mogą zwrócić prawidłowe rozwiązanie, nawet jeśli zostanie przerwane w dowolnym momencie przed zakończeniem.
Wyszukiwanie wspinaczkowe
Jest to algorytm iteracyjny, który rozpoczyna się od dowolnego rozwiązania problemu i próbuje znaleźć lepsze rozwiązanie poprzez stopniową zmianę pojedynczego elementu rozwiązania. Jeśli zmiana daje lepsze rozwiązanie, jako nowe rozwiązanie przyjmuje się stopniową zmianę. Ten proces jest powtarzany, dopóki nie będzie żadnych dalszych ulepszeń.
function Hill-Climbing (problem), zwraca stan będący lokalnym maksimum.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage - Ten algorytm nie jest ani kompletny, ani optymalny.
Wyszukiwanie wiązki lokalnej
W tym algorytmie przechowuje liczbę stanów w dowolnym momencie. Na początku stany te są generowane losowo. Następcy tych k stanów oblicza się za pomocą funkcji celu. Jeśli którykolwiek z tych następców jest maksymalną wartością funkcji celu, algorytm zatrzymuje się.
W przeciwnym razie (początkowe k stanów ik liczba następców stanów = 2k) stanów umieszcza się w puli. Pula jest następnie sortowana numerycznie. Najwyższe k stanów jest wybieranych jako nowe stany początkowe. Ten proces trwa aż do osiągnięcia maksymalnej wartości.
function BeamSearch ( problem, k ), zwraca stan rozwiązania.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
endSymulowanego wyżarzania
Wyżarzanie to proces ogrzewania i chłodzenia metalu w celu zmiany jego wewnętrznej struktury i modyfikacji jego właściwości fizycznych. Gdy metal stygnie, jego nowa struktura zostaje zatarta, a metal zachowuje nowo uzyskane właściwości. W symulowanym procesie wyżarzania utrzymuje się zmienną temperaturę.
Początkowo ustawiamy wysoką temperaturę, a następnie pozwalamy jej powoli „ostygnąć” w miarę postępów algorytmu. Przy wysokiej temperaturze algorytm dopuszcza gorsze rozwiązania o wysokiej częstotliwości.
Początek
- Inicjalizuj k = 0; L = całkowita liczba zmiennych;
- Z i → j, wyszukaj różnicę wydajności Δ.
- Jeśli Δ <= 0 to zaakceptuj else if exp (-Δ / T (k))> random (0,1) to zaakceptuj;
- Powtórz kroki 1 i 2 dla kroków L (k).
- k = k + 1;
Powtarzaj kroki od 1 do 4, aż kryteria zostaną spełnione.
Koniec
Problem komiwojażera
W tym algorytmie celem jest znalezienie taniej wycieczki rozpoczynającej się w mieście, odwiedzającej wszystkie miasta na trasie dokładnie raz i kończącej się w tym samym mieście początkowym.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
Systemy logiki rozmytej (FLS) dają akceptowalne, ale określone dane wyjściowe w odpowiedzi na niepełne, niejednoznaczne, zniekształcone lub niedokładne (rozmyte) dane wejściowe.
Co to jest Fuzzy Logic?
Logika rozmyta (FL) to metoda rozumowania przypominająca rozumowanie ludzkie. Podejście FL naśladuje sposób podejmowania decyzji u ludzi, który obejmuje wszystkie pośrednie możliwości między wartościami cyfrowymi TAK i NIE.
Konwencjonalny blok logiczny, który komputer może zrozumieć, pobiera precyzyjne dane wejściowe i generuje określone wyjście jako PRAWDA lub FAŁSZ, co jest równoważne ludzkiemu TAK lub NIE.
Wynalazca logiki rozmytej, Lotfi Zadeh, zauważył, że w przeciwieństwie do komputerów podejmowanie decyzji przez człowieka obejmuje szereg możliwości od TAK do NIE, takich jak:
| Z PEWNOŚCIĄ TAK |
| MOŻLIWE TAK |
| TRUDNO POWIEDZIEĆ |
| MOŻLIWE NIE |
| NA PEWNO NIE |
Logika rozmyta działa na poziomach możliwości wejścia w celu uzyskania określonego wyjścia.
Realizacja
Może być wdrażany w systemach o różnych rozmiarach i możliwościach, od małych mikrokontrolerów po duże, sieciowe systemy sterowania oparte na stacjach roboczych.
Można go zaimplementować sprzętowo, programowo lub kombinację obu.
Dlaczego Fuzzy Logic?
Logika rozmyta jest przydatna do celów komercyjnych i praktycznych.
- Może sterować maszynami i produktami konsumenckimi.
- Może nie zawierać dokładnego uzasadnienia, ale uzasadnienie do przyjęcia.
- Logika rozmyta pomaga radzić sobie z niepewnością w inżynierii.
Architektura systemów logiki rozmytej
Ma cztery główne części, jak pokazano -
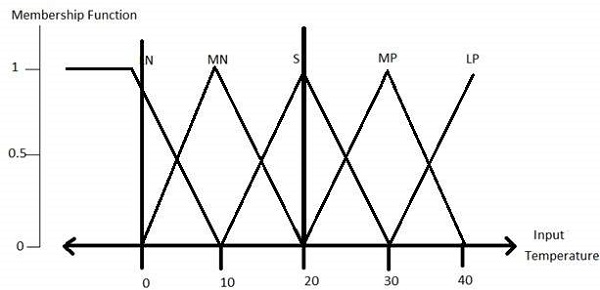
Fuzzification Module- Przekształca dane wejściowe systemu, które są wyraźnymi liczbami, w rozmyte zbiory. Dzieli sygnał wejściowy na pięć etapów, takich jak -
| LP | x jest dużym dodatnim |
| MP | x jest średnio pozytywna |
| S | x jest mały |
| MN | x jest średnio ujemnym |
| LN | x jest dużym ujemnym |
Knowledge Base - Przechowuje reguły IF-THEN dostarczone przez ekspertów.
Inference Engine - Symuluje ludzki proces rozumowania poprzez wnioskowanie rozmyte na podstawie danych wejściowych i reguł IF-THEN.
Defuzzification Module - Przekształca rozmyty zbiór uzyskany przez silnik wnioskowania w wyraźną wartość.

Plik membership functions work on rozmyte zbiory zmiennych.
Członkostwo
Funkcje członkostwa umożliwiają kwantyfikację terminu językowego i graficzną reprezentację rozmytego zbioru. ZAmembership functiondla rozmytego zbioru A we wszechświecie dyskursu X definiuje się jako μ A : X → [0,1].
Tutaj każdy element X jest mapowany na wartość z zakresu od 0 do 1. Nazywa sięmembership value lub degree of membership. To ilościowo stopień przynależności elementu w X do zbiorów rozmytych A .
- Oś x reprezentuje wszechświat dyskursu.
- Oś y reprezentuje stopnie członkostwa w przedziale [0, 1].
Może istnieć wiele funkcji członkostwa mających zastosowanie do fuzzify wartości liczbowej. Proste funkcje członkostwa są używane, ponieważ użycie złożonych funkcji nie zwiększa precyzji wyników.
Wszystkie funkcje członkostwa dla LP, MP, S, MN, i LN pokazano poniżej -

Trójkątne kształty funkcji przynależności są najczęściej spotykane wśród różnych innych kształtów funkcji przynależności, takich jak trapezoid, singleton i Gaussian.
Tutaj sygnał wejściowy do 5-poziomowego fuzzifier zmienia się od -10 woltów do +10 woltów. W związku z tym zmienia się również odpowiedni wynik.
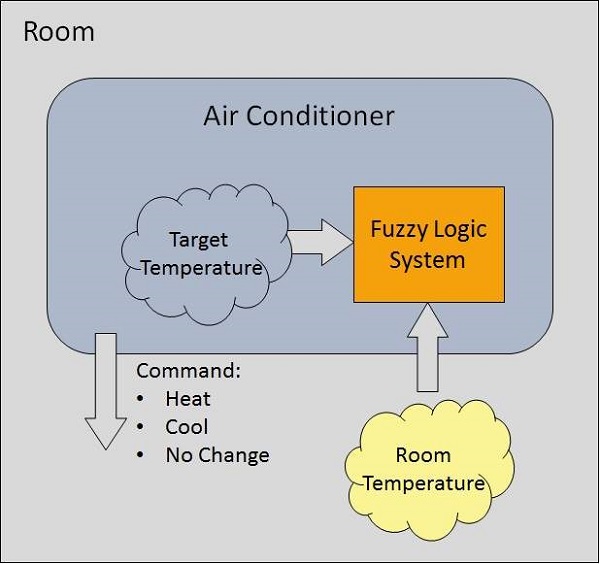
Przykład systemu Fuzzy Logic
Rozważmy system klimatyzacji z 5-poziomowym systemem logiki rozmytej. Ten system reguluje temperaturę klimatyzatora, porównując temperaturę w pomieszczeniu i docelową wartość temperatury.
Algorytm
- Zdefiniuj zmienne językowe i terminy (początek)
- Skonstruuj dla nich funkcje członkostwa. (początek)
- Zbuduj bazę wiedzy o regułach (początek)
- Konwertuj wyraźne dane na rozmyte zestawy danych za pomocą funkcji członkostwa. (fuzzyfikacja)
- Oceń reguły w podstawie reguł. (Silnik wnioskowania)
- Połącz wyniki z każdej reguły. (Silnik wnioskowania)
- Konwertuj dane wyjściowe na wartości nierozmyte. (defuzyfikacja)
Rozwój
Step 1 − Define linguistic variables and terms
Zmienne językowe to zmienne wejściowe i wyjściowe w postaci prostych słów lub zdań. W przypadku temperatury pokojowej termin „zimno”, „ciepło”, „gorąco” itp. To terminy językowe.
Temperatura (t) = {bardzo zimno, zimno, ciepło, bardzo ciepło, gorąco}
Każdy element tego zestawu jest terminem językowym i może obejmować pewną część ogólnych wartości temperatury.
Step 2 − Construct membership functions for them
Funkcje przynależności zmiennej temperatury są pokazane -
Step3 − Construct knowledge base rules
Utwórz macierz między wartościami temperatury pokojowej a docelowymi wartościami temperatury, które ma zapewnić system klimatyzacji.
| Temperatura pokojowa. /Cel | Bardzo zimno | Zimno | Ciepły | Gorąco | Bardzo gorący |
|---|---|---|---|---|---|
| Bardzo zimno | Bez zmiany | Ciepło | Ciepło | Ciepło | Ciepło |
| Zimno | Fajne | Bez zmiany | Ciepło | Ciepło | Ciepło |
| Ciepły | Fajne | Fajne | Bez zmiany | Ciepło | Ciepło |
| Gorąco | Fajne | Fajne | Fajne | Bez zmiany | Ciepło |
| Bardzo gorący | Fajne | Fajne | Fajne | Fajne | Bez zmiany |
Zbuduj zestaw reguł w bazie wiedzy w postaci struktur IF-THEN-ELSE.
| Sr. No. | Stan: schorzenie | Akcja |
|---|---|---|
| 1 | JEŻELI temperatura = (Zimno LUB Bardzo_Zimno) ORAZ docelowa = Ciepło TO | Ciepło |
| 2 | JEŻELI temperatura = (gorąca LUB bardzo_ gorąca) ORAZ docelowa = ciepła WTEDY | Fajne |
| 3 | JEŻELI (temperatura = Ciepło) ORAZ (docelowa = Ciepła) WTEDY | Bez zmiany |
Step 4 − Obtain fuzzy value
Operacje na zbiorach rozmytych wykonują ocenę reguł. Operacje używane dla OR i AND to odpowiednio Max i Min. Połącz wszystkie wyniki oceny, aby uzyskać ostateczny wynik. Ten wynik jest rozmytą wartością.
Step 5 − Perform defuzzification
Defuzzyfikacja jest następnie wykonywana zgodnie z funkcją przynależności do zmiennej wyjściowej.

Obszary zastosowań Fuzzy Logic
Kluczowe obszary zastosowań logiki rozmytej są następujące:
Automotive Systems
- Automatyczne skrzynie biegów
- Sterowanie na cztery koła
- Kontrola otoczenia pojazdu
Consumer Electronic Goods
- Systemy Hi-Fi
- Photocopiers
- Kamery fotograficzne i wideo
- Television
Domestic Goods
- Kuchenka mikrofalowa
- Refrigerators
- Toasters
- Odkurzacze
- Pralki
Environment Control
- Klimatyzatory / suszarki / grzejniki
- Humidifiers
Zalety FLS
Pojęcia matematyczne w ramach rozumowania rozmytego są bardzo proste.
Możesz zmodyfikować FLS, po prostu dodając lub usuwając reguły ze względu na elastyczność logiki rozmytej.
Systemy logiki rozmytej mogą przyjmować nieprecyzyjne, zniekształcone i zaszumione informacje wejściowe.
Pliki FLS są łatwe do skonstruowania i zrozumienia.
Logika rozmyta jest rozwiązaniem złożonych problemów we wszystkich dziedzinach życia, w tym w medycynie, ponieważ przypomina ludzkie rozumowanie i podejmowanie decyzji.
Wady FLS
- Nie ma systematycznego podejścia do projektowania systemów rozmytych.
- Są zrozumiałe tylko wtedy, gdy są proste.
- Nadają się do problemów, które nie wymagają dużej dokładności.
Przetwarzanie języka naturalnego (NLP) odnosi się do metody AI komunikacji z inteligentnymi systemami przy użyciu języka naturalnego, takiego jak angielski.
Przetwarzanie języka naturalnego jest wymagane, gdy chcesz, aby inteligentny system, taki jak robot, działał zgodnie z twoimi instrukcjami, gdy chcesz usłyszeć decyzję od klinicznego systemu eksperckiego opartego na dialogu itp.
Dziedzina NLP obejmuje tworzenie komputerów do wykonywania użytecznych zadań przy użyciu języków naturalnych, którymi posługują się ludzie. Wejście i wyjście systemu NLP może być -
- Speech
- Tekst pisany
Składniki NLP
Jak podano, istnieją dwa składniki NLP -
Rozumienie języka naturalnego (NLU)
Zrozumienie obejmuje następujące zadania -
- Odwzorowanie danych wejściowych w języku naturalnym na przydatne reprezentacje.
- Analiza różnych aspektów języka.
Generowanie języka naturalnego (NLG)
Jest to proces tworzenia znaczących fraz i zdań w formie języka naturalnego z jakiejś wewnętrznej reprezentacji.
Obejmuje -
Text planning - Obejmuje pobieranie odpowiednich treści z bazy wiedzy.
Sentence planning - Obejmuje wybieranie potrzebnych słów, tworzenie znaczących fraz, nadawanie tonowi zdania.
Text Realization - To odwzorowanie planu zdań na strukturę zdań.
NLU jest trudniejsze niż NLG.
Trudności w NLU
NL ma niezwykle bogatą formę i strukturę.
To jest bardzo niejednoznaczne. Mogą istnieć różne poziomy niejednoznaczności -
Lexical ambiguity - Jest na bardzo prymitywnym poziomie, takim jak poziom słów.
Na przykład, traktując słowo „tablica” jako rzeczownik lub czasownik?
Syntax Level ambiguity - Zdanie można analizować na różne sposoby.
Na przykład: „Podniósł chrząszcza z czerwoną czapką”. - Czy użył czapki do podniesienia chrząszcza, czy podniósł chrząszcza, który miał czerwoną czapkę?
Referential ambiguity- Odnoszenie się do czegoś za pomocą zaimków. Na przykład Rima udał się do Gauri. Powiedziała: „Jestem zmęczona”. - Dokładnie kto jest zmęczony?
Jedno wejście może oznaczać różne znaczenia.
Wiele danych wejściowych może oznaczać to samo.
Terminologia NLP
Phonology - To nauka o systematycznym organizowaniu dźwięku.
Morphology - Jest to studium konstrukcji słów z prymitywnych jednostek znaczeniowych.
Morpheme - To prymitywna jednostka znaczeniowa w języku.
Syntax- Odnosi się do układania słów w zdanie. Obejmuje również określenie strukturalnej roli słów w zdaniu i frazach.
Semantics - Dotyczy znaczenia słów i łączenia słów w sensowne zwroty i zdania.
Pragmatics - Dotyczy używania i rozumienia zdań w różnych sytuacjach oraz wpływu na interpretację zdania.
Discourse - Dotyczy tego, jak bezpośrednio poprzedzające zdanie może wpłynąć na interpretację następnego zdania.
World Knowledge - Obejmuje ogólną wiedzę o świecie.
Kroki w NLP
Istnieje pięć ogólnych kroków -
Lexical Analysis- Polega na identyfikacji i analizie struktury słów. Leksykon języka oznacza zbiór słów i zwrotów w języku. Analiza leksykalna polega na podzieleniu całego fragmentu tekstu na akapity, zdania i słowa.
Syntactic Analysis (Parsing)- Obejmuje analizę słów w zdaniu pod kątem gramatyki i układanie słów w sposób, który pokazuje związek między słowami. Zdanie typu „Szkoła idzie do chłopca” jest odrzucane przez angielski analizator składniowy.

Semantic Analysis- Rysuje dokładne znaczenie lub znaczenie słownika z tekstu. Tekst jest sprawdzany pod kątem znaczenia. Odbywa się to poprzez mapowanie struktur składniowych i obiektów w domenie zadań. Analizator semantyczny pomija zdania typu „gorące lody”.
Discourse Integration- Znaczenie każdego zdania zależy od znaczenia zdania tuż przed nim. Ponadto powoduje to również znaczenie następującego bezpośrednio po nim zdania.
Pragmatic Analysis- W tym czasie to, co zostało powiedziane, zostaje ponownie zinterpretowane na podstawie tego, co w rzeczywistości oznaczało. Obejmuje wyprowadzenie tych aspektów języka, które wymagają znajomości świata rzeczywistego.
Implementacyjne aspekty analizy syntaktycznej
Istnieje wiele algorytmów opracowanych przez naukowców do analizy składniowej, ale rozważamy tylko następujące proste metody:
- Gramatyka bezkontekstowa
- Parser odgórny
Zobaczmy je szczegółowo -
Gramatyka bezkontekstowa
To gramatyka składa się z reguł z pojedynczym symbolem po lewej stronie reguł przepisywania. Stwórzmy gramatykę, aby przeanalizować zdanie -
„Ptak dziobie ziarna”
Articles (DET)- a | an | the
Nouns- ptak | ptaki | ziarno | ziarna
Noun Phrase (NP)- Artykuł + Rzeczownik | Przedimek + Przymiotnik + Rzeczownik
= DET N | DET ADJ N
Verbs- dziobaki | dziobanie | dziobał
Verb Phrase (VP)- NP V | V NP
Adjectives (ADJ)- piękny | mały | ćwierkanie
Drzewo parsowania dzieli zdanie na ustrukturyzowane części, dzięki czemu komputer może je łatwo zrozumieć i przetworzyć. Aby algorytm analizy składni mógł skonstruować to drzewo parsowania, należy skonstruować zestaw reguł przepisywania, które opisują, które struktury drzewa są legalne.
Reguły te mówią, że pewien symbol może być rozszerzony w drzewie przez sekwencję innych symboli. Zgodnie z regułą logiki pierwszego rzędu, jeśli istnieją dwa ciągi znaków Rzeczownik Fraza (NP) i Fraza czasownika (VP), to ciąg złożony z NP, po którym następuje VP, jest zdaniem. Zasady przepisywania tego zdania są następujące:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | the
ADJ → piękny | przysiadła
N → ptak | ptaki | ziarno | ziarna
V → dziobać | pecks | dziobanie
Drzewo parsowania można utworzyć, jak pokazano -

Rozważmy teraz powyższe zasady przepisywania. Ponieważ V można zastąpić zarówno „dziobaniem”, jak i „dziobaniem”, zdania takie jak „ptak dziobią ziarna” mogą być błędnie dozwolone. tj. błąd zgodności podmiotu z orzeczeniem jest uznawany za poprawny.
Merit - Najprostszy styl gramatyczny, stąd szeroko stosowany.
Demerits −
Nie są zbyt precyzyjne. Na przykład „Ziarna dziobią ptaka” jest poprawne składniowo według parsera, ale nawet jeśli nie ma to sensu, parser traktuje je jako poprawne zdanie.
Aby uzyskać wysoką precyzję, należy przygotować wiele zestawów gramatycznych. Może to wymagać zupełnie innych zestawów reguł analizowania odmian w liczbie pojedynczej i mnogiej, zdań biernych itp., Co może prowadzić do stworzenia ogromnego zestawu reguł, którymi nie można zarządzać.
Parser odgórny
Tutaj parser zaczyna od symbolu S i próbuje przepisać go na sekwencję symboli końcowych, która pasuje do klas słów w zdaniu wejściowym, aż składa się w całości z symboli terminala.
Są one następnie sprawdzane ze zdaniem wejściowym, aby sprawdzić, czy pasuje. Jeśli nie, proces jest rozpoczynany od nowa z innym zestawem reguł. Powtarza się to do momentu znalezienia określonej reguły opisującej strukturę zdania.
Merit - Jest prosty do wdrożenia.
Demerits −
- Jest to nieefektywne, ponieważ proces wyszukiwania musi zostać powtórzony, jeśli wystąpi błąd.
- Niska prędkość pracy.
Systemy ekspertowe (ES) to jedna z czołowych dziedzin badawczych SI. Został wprowadzony przez naukowców z Wydziału Informatyki Uniwersytetu Stanforda.
Co to są systemy eksperckie?
Systemy ekspertowe to aplikacje komputerowe opracowane w celu rozwiązywania złożonych problemów w określonej dziedzinie, na poziomie niezwykłej ludzkiej inteligencji i wiedzy.
Charakterystyka systemów ekspertowych
- Wysoka wydajność
- Understandable
- Reliable
- Bardzo czuły
Możliwości systemów ekspertowych
Systemy eksperckie są w stanie -
- Advising
- Instruowanie i wspomaganie człowieka w podejmowaniu decyzji
- Demonstrating
- Uzyskanie rozwiązania
- Diagnosing
- Explaining
- Interpretacja danych wejściowych
- Przewidywanie wyników
- Uzasadnienie wniosku
- Sugerowanie alternatywnych rozwiązań problemu
Nie są w stanie -
- Zastępowanie ludzkich decydentów
- Posiadanie ludzkich możliwości
- Tworzenie dokładnych wyników dla niewystarczającej bazy wiedzy
- Udoskonalanie własnej wiedzy
Komponenty systemów ekspertowych
Składniki ES obejmują -
- Baza wiedzy
- Silnik wnioskowania
- Interfejs użytkownika
Zobaczmy je krótko po kolei -

Baza wiedzy
Zawiera wiedzę dziedzinową i wysokiej jakości.
Do przejawiania inteligencji potrzebna jest wiedza. Powodzenie każdego scenariusza narażenia zależy w dużej mierze od zgromadzenia bardzo dokładnej i precyzyjnej wiedzy.
Co to jest wiedza?
Dane to zbiór faktów. Informacje są zorganizowane jako dane i fakty dotyczące domeny zadań.Data, information, i past experience połączone razem określane są jako wiedza.
Składniki bazy wiedzy
Baza wiedzy ES jest magazynem wiedzy zarówno faktycznej, jak i heurystycznej.
Factual Knowledge - Jest to informacja powszechnie akceptowana przez inżynierów wiedzy i naukowców w dziedzinie zadań.
Heuristic Knowledge - Chodzi o praktykę, dokładny osąd, zdolność oceny i zgadywanie.
Reprezentacja wiedzy
Jest to metoda służąca do porządkowania i formalizowania wiedzy w bazie wiedzy. Ma postać reguł IF-TO-INNE.
Zdobywanie wiedzy
Sukces każdego systemu eksperckiego zależy w dużej mierze od jakości, kompletności i dokładności informacji przechowywanych w bazie wiedzy.
Baza wiedzy jest tworzona przez odczyty różnych ekspertów, naukowców i Knowledge Engineers. Inżynier wiedzy to osoba o cechach empatii, szybkiej nauki i umiejętności analizy przypadków.
Uzyskuje informacje od eksperta przedmiotowego poprzez nagrywanie, przeprowadzanie wywiadów, obserwowanie go w pracy, itp. Następnie kategoryzuje i porządkuje informacje w sensowny sposób w postaci reguł IF-THEN-INSE do wykorzystania przez maszynę interferencyjną. Inżynier wiedzy monitoruje również rozwój ES.
Silnik wnioskowania
Zastosowanie wydajnych procedur i reguł przez mechanizm wnioskowania jest niezbędne do odliczenia prawidłowego, bezbłędnego rozwiązania.
W przypadku ES opartego na wiedzy mechanizm wnioskowania pozyskuje wiedzę z bazy wiedzy i manipuluje nią, aby dojść do określonego rozwiązania.
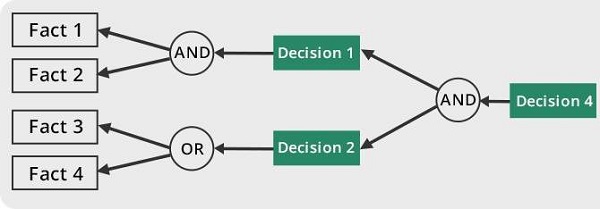
W przypadku ES opartego na regułach, to -
Powtarza stosowanie reguł do faktów uzyskanych z wcześniejszego zastosowania reguły.
W razie potrzeby dodaje nową wiedzę do bazy wiedzy.
Rozwiązuje konflikt reguł, gdy do konkretnego przypadku ma zastosowanie wiele reguł.
Aby zaproponować rozwiązanie, mechanizm wnioskowania wykorzystuje następujące strategie -
- Łańcuch do przodu
- Łańcuch wsteczny
Łańcuch do przodu
To strategia systemu eksperckiego, która ma odpowiedzieć na pytanie, “What can happen next?”
W tym przypadku mechanizm wnioskowania śledzi łańcuch warunków i wyprowadzeń i ostatecznie wydedukuje wynik. Bierze pod uwagę wszystkie fakty i zasady oraz sortuje je przed znalezieniem rozwiązania.
Ta strategia służy do pracy nad wnioskiem, wynikiem lub efektem. Na przykład prognozowanie statusu rynku akcji jako skutku zmian stóp procentowych.

Łańcuch wsteczny
Dzięki tej strategii system ekspercki znajduje odpowiedź na pytanie, “Why this happened?”
Na podstawie tego, co już się wydarzyło, mechanizm wnioskowania próbuje dowiedzieć się, jakie warunki mogły wystąpić w przeszłości dla tego wyniku. Ta strategia jest stosowana w celu znalezienia przyczyny lub przyczyny. Na przykład diagnoza raka krwi u ludzi.
Interfejs użytkownika
Interfejs użytkownika zapewnia interakcję między użytkownikiem scenariusza narażenia a samym schematem. Jest to generalnie przetwarzanie języka naturalnego, z którego może korzystać użytkownik dobrze zorientowany w dziedzinie zadań. Użytkownik scenariusza narażenia niekoniecznie musi być ekspertem w dziedzinie sztucznej inteligencji.
Wyjaśnia, w jaki sposób ES doszedł do konkretnego zalecenia. Wyjaśnienie może pojawić się w następujących formach -
- Język naturalny wyświetlany na ekranie.
- Narracje werbalne w języku naturalnym.
- Lista numerów reguł wyświetlanych na ekranie.
Interfejs użytkownika ułatwia śledzenie wiarygodności odliczeń.
Wymagania wydajnego interfejsu użytkownika ES
Powinien pomóc użytkownikom w osiągnięciu ich celów w możliwie najkrótszy sposób.
Powinien być zaprojektowany tak, aby działał zgodnie z istniejącymi lub pożądanymi praktykami pracy użytkownika.
Jego technologia powinna być dostosowana do wymagań użytkownika; nie na odwrót.
Powinien efektywnie wykorzystywać dane wejściowe użytkownika.
Ograniczenia systemów eksperckich
Żadna technologia nie oferuje łatwego i kompletnego rozwiązania. Duże systemy są kosztowne, wymagają znacznego czasu rozwoju i zasobów komputerowych. ES mają swoje ograniczenia, które obejmują:
- Ograniczenia technologii
- Trudne zdobywanie wiedzy
- ES są trudne do utrzymania
- Wysokie koszty rozwoju
Zastosowania systemu ekspertowego
Poniższa tabela pokazuje, gdzie można zastosować ES.
| Podanie | Opis |
|---|---|
| Domena projektowa | Konstrukcja obiektywu aparatu, konstrukcja samochodu. |
| Domena medyczna | Diagnosis Systems, aby wydedukować przyczynę choroby na podstawie obserwowanych danych, przeprowadzać operacje medyczne na ludziach. |
| Systemy monitorowania | Ciągłe porównywanie danych z obserwowanym systemem lub z zalecanymi zachowaniami, takimi jak monitorowanie wycieków w długim rurociągu naftowym. |
| Systemy sterowania procesami | Sterowanie procesem fizycznym na podstawie monitoringu. |
| Domena wiedzy | Wyszukiwanie usterek w pojazdach, komputerach. |
| Finanse / handel | Wykrywanie możliwych oszustw, podejrzanych transakcji, obrotu giełdowego, planowania linii lotniczych, planowania ładunków. |
Technologia systemu eksperckiego
Dostępnych jest kilka poziomów technologii ES. Technologie systemów eksperckich obejmują -
Expert System Development Environment- Środowisko programistyczne ES obejmuje sprzęt i narzędzia. Oni są -
Stacje robocze, minikomputery, komputery mainframe.
Symboliczne języki programowania wysokiego poziomu, takie jak LISt Pprogramowanie (LISP) i PROgramatyka pl LOGique (PROLOG).
Duże bazy danych.
Tools - W znacznym stopniu zmniejszają wysiłek i koszty związane z opracowaniem systemu ekspertowego.
Potężne edytory i narzędzia do debugowania z wieloma oknami.
Zapewniają szybkie prototypowanie
Mają wbudowane definicje modelu, reprezentacji wiedzy i projektowania wnioskowania.
Shells- Powłoka to nic innego jak system ekspercki bez bazy wiedzy. Powłoka zapewnia programistom zdobywanie wiedzy, mechanizm wnioskowania, interfejs użytkownika i funkcję wyjaśniania. Na przykład kilka pocisków podano poniżej -
Java Expert System Shell (JESS), która zapewnia w pełni rozwinięte API Java do tworzenia systemu ekspertowego.
Vidwan , powłoka opracowana w Narodowym Centrum Technologii Oprogramowania w Bombaju w 1993 roku. Umożliwia kodowanie wiedzy w postaci reguł IF-THEN.
Rozwój systemów ekspertowych: ogólne kroki
Proces tworzenia ES jest iteracyjny. Kroki w tworzeniu scenariusza narażenia obejmują -
Zidentyfikuj problematyczną domenę
- Problem musi być odpowiedni dla systemu eksperckiego, aby go rozwiązać.
- Znajdź ekspertów w dziedzinie zadań dla projektu ES.
- Ustal opłacalność systemu.
Zaprojektuj System
Zidentyfikuj technologię ES
Znać i ustalić stopień integracji z innymi systemami i bazami danych.
Zrozum, w jaki sposób koncepcje mogą najlepiej reprezentować wiedzę domeny.
Opracuj prototyp
Z bazy wiedzy: inżynier wiedzy pracuje w celu -
- Zdobądź wiedzę domenową od eksperta.
- Przedstaw to w postaci reguł Jeśli-TO-INNE.
Przetestuj i udoskonal prototyp
Inżynier wiedzy wykorzystuje przykładowe przypadki, aby przetestować prototyp pod kątem jakichkolwiek niedociągnięć w działaniu.
Użytkownicy końcowi testują prototypy ES.
Opracuj i uzupełnij ES
Przetestuj i zapewnij interakcję scenariusza narażenia ze wszystkimi elementami jego środowiska, w tym użytkownikami końcowymi, bazami danych i innymi systemami informacyjnymi.
Dobrze udokumentuj projekt ES.
Poinstruuj użytkownika, jak korzystać z ES.
Utrzymaj system
Aktualizuj bazę wiedzy, regularnie ją przeglądając i aktualizując.
Zapewnij nowe interfejsy z innymi systemami informacyjnymi w miarę ich rozwoju.
Zalety systemów ekspertowych
Availability - Są łatwo dostępne dzięki masowej produkcji oprogramowania.
Less Production Cost- Koszt produkcji jest rozsądny. To sprawia, że są niedrogie.
Speed- Oferują dużą prędkość. Zmniejszają ilość pracy, jaką osoba wkłada.
Less Error Rate - Poziom błędów jest niski w porównaniu z błędami ludzkimi.
Reducing Risk - Mogą pracować w środowisku niebezpiecznym dla ludzi.
Steady response - Pracują stabilnie, bez ruchu, napięcia i zmęczenia.
Robotyka to dziedzina sztucznej inteligencji zajmująca się badaniem tworzenia inteligentnych i wydajnych robotów.
Co to są roboty?
Roboty to sztuczni agenci działający w rzeczywistym środowisku.
Cel
Celem robotów jest manipulowanie obiektami poprzez postrzeganie, wybieranie, przemieszczanie, modyfikowanie fizycznych właściwości obiektu, niszczenie go lub wywoływanie efektu, w ten sposób uwalniając siłę roboczą od wykonywania powtarzalnych funkcji bez znudzenia, rozproszenia lub wyczerpania.
Co to jest robotyka?
Robotyka to dziedzina sztucznej inteligencji, która składa się z elektrotechniki, inżynierii mechanicznej i informatyki do projektowania, konstruowania i stosowania robotów.
Aspekty robotyki
Roboty mają mechanical construction, forma lub kształt przeznaczony do wykonania określonego zadania.
Oni mają electrical components które zasilają i sterują maszyną.
Zawierają pewien poziom computer program to określa co, kiedy i jak robot coś robi.
Różnica w systemie robota i innym programie AI
Oto różnica między tymi dwoma -
| Programy AI | Roboty |
|---|---|
| Zwykle działają w światach stymulowanych komputerowo. | Działają w prawdziwym świecie fizycznym |
| Dane wejściowe do programu AI są w postaci symboli i reguł. | Sygnał wejściowy do robotów to sygnał analogowy w postaci fali mowy lub obrazów |
| Potrzebują komputerów ogólnego przeznaczenia do działania. | Potrzebują specjalnego sprzętu z czujnikami i efektorami. |
Robot Locomotion
Lokomocja to mechanizm umożliwiający robotowi poruszanie się w swoim otoczeniu. Istnieją różne typy lokomocji -
- Legged
- Wheeled
- Połączenie lokomocji na nogach i na kołach
- Śledzony poślizg / poślizg
Lokomocja na nogach
Ten rodzaj lokomocji zużywa więcej energii podczas demonstrowania stępu, skoku, kłusa, podskoku, wznoszenia lub schodzenia itp.
Wykonanie ruchu wymaga większej liczby silników. Nadaje się zarówno do nierównego, jak i gładkiego terenu, gdzie nieregularna lub zbyt gładka powierzchnia powoduje, że zużywa więcej energii na lokomocję kołową. Jest to trochę trudne do wdrożenia ze względu na problemy ze stabilnością.
Jest dostępny z jedną, dwiema, czterema i sześcioma nogami. Jeśli robot ma wiele nóg, koordynacja nóg jest niezbędna do poruszania się.
Całkowita liczba możliwych gaits (okresowa sekwencja zdarzeń podnoszenia i zwolnienia dla każdej z wszystkich odnóg), którą robot może podróżować, zależy od liczby jego nóg.
Jeśli robot ma k nóg, to liczba możliwych zdarzeń N = (2k-1) !.
W przypadku robota dwunożnego (k = 2) liczba możliwych zdarzeń wynosi N = (2k-1)! = (2 * 2-1)! = 3! = 6.
Stąd istnieje sześć możliwych różnych wydarzeń -
- Podnoszenie lewej nogi
- Uwalnianie lewej nogi
- Podnoszenie prawej nogi
- Uwalnianie prawej nogi
- Unoszenie obu nóg razem
- Rozluźnienie obu nóg razem
W przypadku k = 6 odnóg jest 39916800 możliwych zdarzeń. Stąd złożoność robotów jest wprost proporcjonalna do liczby nóg.

Lokomocja na kołach
Do wykonania ruchu potrzeba mniejszej liczby silników. Jest mało łatwy do wdrożenia, ponieważ w przypadku większej liczby kół występuje mniej problemów ze stabilnością. Jest energooszczędny w porównaniu do lokomocji na nogach.
Standard wheel - Obraca się wokół osi koła i wokół kontaktu
Castor wheel - Obraca się wokół osi koła i przesuniętego przegubu skrętnego.
Swedish 45o and Swedish 90o wheels - Omni-koło, obraca się wokół punktu styku, wokół osi koła i wokół rolek.
Ball or spherical wheel - Koło wielokierunkowe, technicznie trudne do wykonania.

Lokomocja poślizgowa / ślizgowa
W tym typie pojazdy poruszają się po gąsienicach jak w czołgu. Robot jest sterowany poprzez przesuwanie gąsienic z różnymi prędkościami w tym samym lub przeciwnym kierunku. Zapewnia stabilność dzięki dużej powierzchni styku toru z podłożem.

Komponenty robota
Roboty są zbudowane z następującymi -
Power Supply - Roboty są zasilane bateriami, energią słoneczną, hydraulicznymi lub pneumatycznymi źródłami energii.
Actuators - Zamieniają energię w ruch.
Electric motors (AC/DC) - Są wymagane do ruchu obrotowego.
Pneumatic Air Muscles - Kurczą się prawie 40%, gdy zassane jest do nich powietrze.
Muscle Wires - Kurczą się o 5%, gdy przepływa przez nie prąd elektryczny.
Piezo Motors and Ultrasonic Motors - Najlepsze do robotów przemysłowych.
Sensors- Dostarczają wiedzy w czasie rzeczywistym o środowisku zadań. Roboty są wyposażone w czujniki wizyjne do obliczania głębokości w środowisku. Dotykowy czujnik imituje mechaniczne właściwości receptorów dotyku ludzkich palców.
Wizja komputerowa
Jest to technologia sztucznej inteligencji, dzięki której roboty mogą widzieć. Wizja komputerowa odgrywa istotną rolę w dziedzinach bezpieczeństwa, ochrony, zdrowia, dostępu i rozrywki.
Wizja komputerowa automatycznie wyodrębnia, analizuje i pojmuje przydatne informacje z pojedynczego obrazu lub szeregu obrazów. Proces ten obejmuje opracowanie algorytmów umożliwiających automatyczne rozumienie wizualne.
Sprzęt komputerowego systemu wizyjnego
Obejmuje to -
- Zasilacz
- Urządzenie do pozyskiwania obrazu, takie jak kamera
- Procesor
- Oprogramowanie
- Urządzenie wyświetlające do monitorowania systemu
- Akcesoria, takie jak stojaki na kamery, kable i złącza
Zadania widzenia komputerowego
OCR - W dziedzinie komputerów, optyczny czytnik znaków, oprogramowanie do konwersji zeskanowanych dokumentów do edytowalnego tekstu, które jest dołączone do skanera.
Face Detection- Wiele najnowocześniejszych aparatów jest wyposażonych w tę funkcję, która pozwala odczytać twarz i zrobić zdjęcie z idealnym wyrazem twarzy. Służy do umożliwienia użytkownikowi dostępu do oprogramowania po poprawnym dopasowaniu.
Object Recognition - Są instalowane w supermarketach, kamerach, samochodach z wyższej półki, takich jak BMW, GM i Volvo.
Estimating Position - Jest to szacowanie położenia obiektu względem aparatu, jak w przypadku guza w organizmie człowieka.
Domeny aplikacji widzenia komputerowego
- Agriculture
- Autonomiczne pojazdy
- Biometrics
- Rozpoznawanie postaci
- Kryminalistyka, bezpieczeństwo i nadzór
- Kontrola jakości przemysłowej
- Rozpoznawanie twarzy
- Analiza gestów
- Geoscience
- Zdjęcia medyczne
- Monitorowanie zanieczyszczeń
- Kontrola procesu
- Teledetekcja
- Robotics
- Transport
Zastosowania robotyki
Robotyka odegrała kluczową rolę w różnych dziedzinach, takich jak:
Industries - Roboty służą do przenoszenia materiału, cięcia, spawania, malowania, wiercenia, polerowania itp.
Military- Autonomiczne roboty mogą podczas wojny dotrzeć do niedostępnych i niebezpiecznych stref. Robot o imieniu Daksh , opracowany przez Defense Research and Development Organization (DRDO), służy do bezpiecznego niszczenia obiektów zagrażających życiu.
Medicine - Roboty są w stanie przeprowadzać jednocześnie setki testów klinicznych, rehabilitować osoby trwale niepełnosprawne i wykonywać złożone operacje, takie jak guzy mózgu.
Exploration - Roboty alpinistami używanymi do eksploracji kosmosu, podwodne drony używane do eksploracji oceanów to tylko kilka z nich.
Entertainment - Inżynierowie Disneya stworzyli setki robotów do kręcenia filmów.
Kolejny obszar badań w dziedzinie sztucznej inteligencji, sieci neuronowe, jest inspirowany naturalną siecią neuronową ludzkiego układu nerwowego.
Co to są sztuczne sieci neuronowe (SSN)?
Wynalazca pierwszego neurokomputera, dr Robert Hecht-Nielsen, definiuje sieć neuronową jako -
„... system komputerowy składający się z szeregu prostych, silnie połączonych ze sobą elementów przetwarzających, które przetwarzają informacje poprzez ich dynamiczną odpowiedź stanu na zewnętrzne wejścia”.
Podstawowa struktura SSN
Idea SSN opiera się na przekonaniu, że działanie ludzkiego mózgu poprzez tworzenie odpowiednich połączeń można naśladować za pomocą krzemu i przewodów jako żywych neurons i dendrites.
Ludzki mózg składa się z 86 miliardów komórek nerwowych tzw neurons. Są połączone z innymi tysiącami komórek za pomocą Axons.Bodźce ze środowiska zewnętrznego lub bodźce z narządów zmysłów są akceptowane przez dendryty. Wejścia te wytwarzają impulsy elektryczne, które szybko przemieszczają się przez sieć neuronową. Neuron może następnie wysłać wiadomość do innego neuronu w celu rozwiązania problemu lub nie przesyła go dalej.

SSN składają się z wielu nodes, które imitują biologiczne neuronsludzkiego mózgu. Neurony są połączone linkami i oddziałują na siebie. Węzły mogą pobierać dane wejściowe i wykonywać proste operacje na danych. Wynik tych operacji jest przekazywany do innych neuronów. Dane wyjściowe w każdym węźle nazywane są jegoactivation lub node value.
Każdy link jest powiązany z weight.SSN są zdolne do uczenia się, co odbywa się poprzez zmianę wartości wagi. Poniższa ilustracja przedstawia prostą SSN -

Rodzaje sztucznych sieci neuronowych
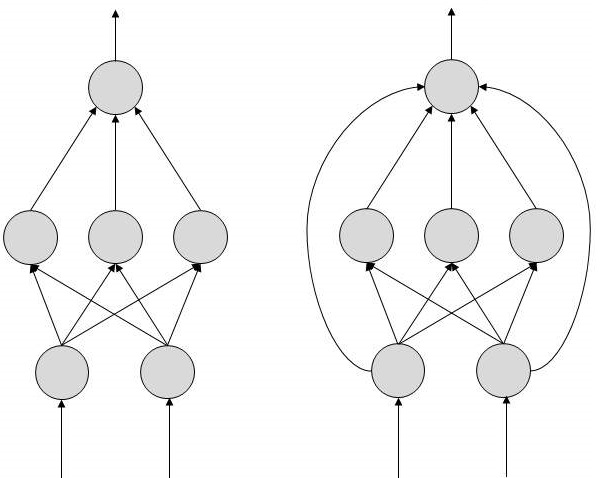
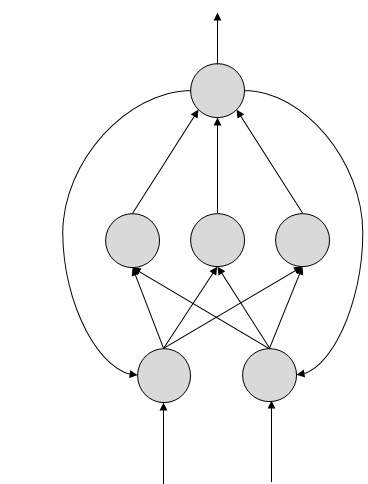
Istnieją dwie topologie sztucznych sieci neuronowych - FeedForward i Feedback.
FeedForward ANN
W tej sieci SSN przepływ informacji jest jednokierunkowy. Jednostka wysyła informacje do innej jednostki, od której nie otrzymuje żadnych informacji. Nie ma pętli informacji zwrotnych. Są używane do generowania / rozpoznawania / klasyfikacji wzorców. Mają stałe wejścia i wyjścia.
FeedBack ANN
Tutaj dozwolone są pętle opinii. Są używane w pamięciach adresowalnych treści.
Działanie SSN
Na przedstawionych diagramach topologii każda strzałka przedstawia połączenie między dwoma neuronami i wskazuje ścieżkę przepływu informacji. Każde połączenie ma wagę, liczbę całkowitą, która kontroluje sygnał między dwoma neuronami.
Jeśli sieć generuje „dobre lub pożądane” wyjście, nie ma potrzeby dostosowywania wag. Jeśli jednak sieć generuje „słabe lub niepożądane” wyjście lub błąd, wówczas system zmienia wagi w celu poprawy późniejszych wyników.
Uczenie maszynowe w sieciach ANN
SSN są zdolne do uczenia się i wymagają przeszkolenia. Istnieje kilka strategii uczenia się -
Supervised Learning- Dotyczy nauczyciela, który jest uczonym niż sama SSN. Na przykład nauczyciel podaje przykładowe dane, na które nauczyciel zna już odpowiedzi.
Na przykład rozpoznawanie wzorców. SSN wymyśla domysły podczas rozpoznawania. Następnie nauczyciel dostarcza odpowiedzi do SSN. Następnie sieć porównuje zgadnięte odpowiedzi z „poprawnymi” odpowiedziami nauczyciela i wprowadza poprawki na podstawie błędów.
Unsupervised Learning- Jest wymagany, gdy nie ma przykładowego zestawu danych ze znanymi odpowiedziami. Na przykład wyszukiwanie ukrytego wzoru. W tym przypadku grupowanie, czyli dzielenie zbioru elementów na grupy według nieznanego wzorca, odbywa się na podstawie istniejących istniejących zbiorów danych.
Reinforcement Learning- Ta strategia opiera się na obserwacji. SSN podejmuje decyzję, obserwując swoje otoczenie. Jeśli obserwacja jest negatywna, sieć dostosowuje swoje wagi, aby następnym razem móc podjąć inną wymaganą decyzję.
Algorytm propagacji wstecznej
Jest to algorytm uczenia lub uczenia. Uczy się na przykładzie. Jeśli podasz algorytmowi przykład tego, co chcesz, aby sieć zrobiła, zmienia on wagi sieci tak, aby po zakończeniu szkolenia mogła wygenerować pożądane dane wyjściowe dla określonego wejścia.
Wstecz Sieci propagacyjne są idealne do prostych zadań rozpoznawania wzorców i mapowania.
Sieci Bayesa (BN)
Są to struktury graficzne używane do reprezentowania relacji probabilistycznej między zestawem zmiennych losowych. Nazywa się również sieci bayesowskieBelief Networks lub Bayes Nets. Powód BN dotyczący niepewnej domeny.
W tych sieciach każdy węzeł reprezentuje zmienną losową z określonymi propozycjami. Na przykład w dziedzinie diagnostyki medycznej węzeł Rak reprezentuje twierdzenie, że pacjent ma raka.
Krawędzie łączące węzły reprezentują zależności probabilistyczne między tymi zmiennymi losowymi. Jeżeli z dwóch węzłów jeden wpływa na drugi, to muszą być bezpośrednio połączone w kierunkach efektu. Siła związku między zmiennymi jest określana ilościowo przez prawdopodobieństwo związane z każdym węzłem.
Istnieje jedyne ograniczenie dotyczące łuków w BN, że nie można powrócić do węzła po prostu wykonując skierowane łuki. Stąd BN nazywane są skierowanymi grafami acyklicznymi (DAG).
BN mogą jednocześnie obsługiwać zmienne wielowartościowe. Zmienne BN składają się z dwóch wymiarów -
- Zakres przyimków
- Prawdopodobieństwo przypisane do każdego z przyimków.
Rozważmy zbiór skończony X = {X 1 , X 2 ,…, X n } dyskretnych zmiennych losowych, gdzie każda zmienna X i może przyjmować wartości ze zbioru skończonego, oznaczonego przez Val (X i ). Jeśli istnieje bezpośrednie łącze od zmiennej X i do zmiennej X j , to zmienna X i będzie rodzicem zmiennej X j pokazującej bezpośrednie zależności między zmiennymi.
Struktura BN jest idealna do łączenia wcześniejszej wiedzy i obserwowanych danych. BN można wykorzystać do poznania związków przyczynowych i zrozumienia różnych dziedzin problemowych oraz do przewidywania przyszłych wydarzeń, nawet w przypadku braku danych.
Budowanie sieci bayesowskiej
Inżynier wiedzy może zbudować sieć bayesowską. Istnieje wiele kroków, które inżynier wiedzy musi wykonać podczas jego tworzenia.
Example problem- Rak płuc. Pacjent cierpiał na duszność. Odwiedza lekarza, podejrzewając, że ma raka płuc. Lekarz wie, że poza rakiem płuc istnieje wiele innych możliwych chorób, na które może chorować pacjent, takich jak gruźlica i zapalenie oskrzeli.
Gather Relevant Information of Problem
- Czy pacjent jest palaczem? Jeśli tak, to wysokie ryzyko raka i zapalenia oskrzeli.
- Czy pacjent jest narażony na zanieczyszczenie powietrza? Jeśli tak, jakiego rodzaju zanieczyszczenie powietrza?
- Wykonanie pozytywnego prześwietlenia rentgenowskiego wskazuje na gruźlicę lub raka płuc.
Identify Interesting Variables
Inżynier wiedzy próbuje odpowiedzieć na pytania -
- Które węzły reprezentować?
- Jakie wartości mogą przyjąć? W jakim mogą być stanie?
Na razie rozważmy węzły z tylko wartościami dyskretnymi. Zmienna musi na raz przyjmować dokładnie jedną z tych wartości.
Common types of discrete nodes are -
Boolean nodes - Reprezentują zdania, przyjmując wartości binarne PRAWDA (T) i FAŁSZ (F).
Ordered values- Zanieczyszczenie węzła może reprezentować i przyjmować wartości od {niskie, średnie, wysokie} opisujące stopień narażenia pacjenta na zanieczyszczenie.
Integral values- Węzeł o nazwie Wiek może reprezentować wiek pacjenta z możliwymi wartościami od 1 do 120. Nawet na tym wczesnym etapie dokonuje się wyborów dotyczących modelowania.
Możliwe węzły i wartości na przykładzie raka płuca -
| Nazwa węzła | Rodzaj | Wartość | Tworzenie węzłów |
|---|---|---|---|
| Zanieczyszczenie | Dwójkowy | {NISKI, WYSOKI, ŚREDNI} |

|
| Palący | Boolean | {TRUE, FASLE} | |
| Rak płuc | Boolean | {TRUE, FASLE} | |
| Rentgen | Dwójkowy | {Pozytywny Negatywny} |
Create Arcs between Nodes
Topologia sieci powinna uwzględniać jakościowe relacje między zmiennymi.
Na przykład, co powoduje, że pacjent ma raka płuc? - Zanieczyszczenie i palenie. Następnie dodaj łuki z węzła Zanieczyszczenia i Węzła Palacza do węzła Rak płuc.
Podobnie, jeśli pacjent ma raka płuc, wynik RTG będzie dodatni. Następnie dodaj łuki z węzła raka płuc do węzła RTG.

Specify Topology
Tradycyjnie BN są rozmieszczone tak, aby łuki były skierowane od góry do dołu. Zestaw węzłów macierzystych węzła X jest podawany przez Rodzice (X).
Lung Cancer węzeł ma dwoje rodziców (przyczyny lub przyczyn): Zanieczyszczenie i palący , natomiast węzeł palący jestancestorwęzła RTG . Podobnie, RTG jest dzieckiem (konsekwencją lub skutkami) węzła raka płuca isuccessorwęzłów Palacz i zanieczyszczenia.
Conditional Probabilities
Teraz określ ilościowo relacje między połączonymi węzłami: odbywa się to poprzez określenie warunkowego rozkładu prawdopodobieństwa dla każdego węzła. Ponieważ rozważane są tutaj tylko zmienne dyskretne, ma to postaćConditional Probability Table (CPT).
Najpierw dla każdego węzła musimy przyjrzeć się wszystkim możliwym kombinacjom wartości tych węzłów nadrzędnych. Każda taka kombinacja nazywana jestinstantiationzestawu macierzystego. Dla każdej odrębnej instancji wartości węzła nadrzędnego musimy określić prawdopodobieństwo, jakie przyjmie dziecko.
Na przykład rodzicami węzła Lung-Cancer są Zanieczyszczenia i Palenie. Przyjmują możliwe wartości = {(H, T), (H, F), (L, T), (L, F)}. CPT określa prawdopodobieństwo raka dla każdego z tych przypadków odpowiednio <0,05, 0,02, 0,03, 0,001>.
Każdy węzeł będzie miał prawdopodobieństwo warunkowe powiązane w następujący sposób -

Zastosowania sieci neuronowych
Potrafią wykonywać zadania łatwe dla człowieka, ale trudne dla maszyny -
Aerospace - Samoloty z autopilotem, wykrywanie usterek samolotu.
Automotive - Samochodowe systemy naprowadzania.
Military - Orientacja i sterowanie bronią, śledzenie celu, dyskryminacja obiektów, rozpoznawanie twarzy, identyfikacja sygnału / obrazu.
Electronics - Przewidywanie sekwencji kodu, układ chipów IC, analiza awarii chipów, wizja maszynowa, synteza głosu.
Financial - Wycena nieruchomości, doradca kredytowy, weryfikacja kredytów hipotecznych, rating obligacji korporacyjnych, program handlu portfelowego, analiza finansowa przedsiębiorstw, prognozowanie wartości waluty, czytniki dokumentów, osoby oceniające wnioski kredytowe.
Industrial - Kontrola procesu produkcyjnego, projektowanie i analiza produktu, systemy kontroli jakości, analiza jakości spawania, przewidywanie jakości papieru, analiza projektu produktu chemicznego, modelowanie dynamiczne systemów procesów chemicznych, analiza konserwacji maszyn, składanie ofert, planowanie i zarządzanie.
Medical - Analiza komórek nowotworowych, analiza EEG i EKG, projektowanie protez, optymalizacja czasu przeszczepu.
Speech - Rozpoznawanie mowy, klasyfikacja mowy, konwersja tekstu na mowę.
Telecommunications - Kompresja obrazu i danych, automatyczne usługi informacyjne, tłumaczenie języka mówionego w czasie rzeczywistym.
Transportation - Diagnostyka układu hamulcowego ciężarówki, planowanie pojazdów, systemy wyznaczania tras.
Software - Rozpoznawanie wzorców w rozpoznawaniu twarzy, optycznym rozpoznawaniu znaków itp.
Time Series Prediction - SSN są wykorzystywane do prognozowania zapasów i klęsk żywiołowych.
Signal Processing - Sieci neuronowe można wyszkolić do przetwarzania sygnału audio i odpowiedniego filtrowania go w aparatach słuchowych.
Control - SSN są często używane do podejmowania decyzji dotyczących kierowania pojazdami fizycznymi.
Anomaly Detection - Ponieważ SSN są ekspertami w rozpoznawaniu wzorców, można je również wytrenować, aby generowały wynik, gdy wydarzy się coś niezwykłego, co nie pasuje do wzorca.
AI rozwija się z niesamowitą szybkością, czasami wydaje się magiczna. Wśród badaczy i programistów panuje opinia, że sztuczna inteligencja może rozwinąć się tak niezwykle silna, że ludziom trudno będzie ją kontrolować.
Ludzie rozwinęli systemy sztucznej inteligencji, wprowadzając do nich każdą możliwą inteligencję, jaką mogli, dla której sami ludzie wydają się teraz zagrożeni.
Zagrożenie prywatności
Program AI, który rozpoznaje mowę i rozumie język naturalny, jest teoretycznie zdolny do zrozumienia każdej rozmowy w wiadomościach e-mail i telefonach.
Zagrożenie godności ludzkiej
Systemy AI zaczęły już zastępować ludzi w kilku branżach. Nie powinno zastępować ludzi w sektorach, w których zajmują godne stanowiska związane z etyką, takich jak pielęgniarka, chirurg, sędzia, policjant itp.
Zagrożenie dla bezpieczeństwa
Samodoskonalące się systemy SI mogą stać się tak potężne od ludzi, że powstrzymanie ich przed osiągnięciem celów może być bardzo trudne, co może prowadzić do niezamierzonych konsekwencji.
Oto lista często używanych terminów w dziedzinie sztucznej inteligencji -
| Sr.No | Termin i znaczenie |
|---|---|
| 1 | Agent Agenci to systemy lub programy zdolne do autonomicznego, celowego i rozumowania ukierunkowanego na jeden lub więcej celów. Nazywani są również asystentami, brokerami, botami, robotami, inteligentnymi agentami i agentami oprogramowania. |
| 2 | Autonomous Robot Robot wolny od zewnętrznej kontroli lub wpływów i zdolny do samodzielnego sterowania. |
| 3 | Backward Chaining Strategia pracy wstecz dla przyczyny / przyczyny problemu. |
| 4 | Blackboard Jest to pamięć wewnętrzna komputera, która służy do komunikacji pomiędzy współpracującymi systemami ekspertowymi. |
| 5 | Environment Jest to część świata rzeczywistego lub obliczeniowego, w której znajduje się agent. |
| 6 | Forward Chaining Strategia pracy naprzód w celu zakończenia / rozwiązania problemu. |
| 7 | Heuristics Jest to wiedza oparta na próbach i błędach, ocenach i eksperymentach. |
| 8 | Knowledge Engineering Pozyskiwanie wiedzy od ekspertów ludzkich i innych zasobów. |
| 9 | Percepts Jest to format, w jakim agent uzyskuje informacje o środowisku. |
| 10 | Pruning Zignorowanie niepotrzebnych i nieistotnych rozważań w systemach SI. |
| 11 | Rule Jest to format reprezentacji bazy wiedzy w systemie ekspertowym. Ma postać IF-TO-INNY. |
| 12 | Shell Powłoka to oprogramowanie, które pomaga w projektowaniu silnika wnioskowania, bazy wiedzy i interfejsu użytkownika systemu ekspertowego. |
| 13 | Task Jest to cel, do którego dąży agent. |
| 14 | Turing Test Test opracowany przez Allana Turinga w celu sprawdzenia inteligencji maszyny w porównaniu z ludzką inteligencją. |