Montaż - skrócona instrukcja
Co to jest język asemblera?
Każdy komputer osobisty jest wyposażony w mikroprocesor, który zarządza działaniami arytmetycznymi, logicznymi i kontrolnymi komputera.
Każda rodzina procesorów ma własny zestaw instrukcji do obsługi różnych operacji, takich jak pobieranie danych wejściowych z klawiatury, wyświetlanie informacji na ekranie i wykonywanie różnych innych zadań. Ten zestaw instrukcji nazywany jest „instrukcjami języka maszynowego”.
Procesor rozumie tylko instrukcje języka maszynowego, które są ciągami jedynek i zer. Jednak język maszynowy jest zbyt niejasny i skomplikowany, aby można go było używać w tworzeniu oprogramowania. Tak więc język asemblera niskiego poziomu jest przeznaczony dla określonej rodziny procesorów, które reprezentują różne instrukcje w kodzie symbolicznym i bardziej zrozumiałej formie.
Zalety języka asemblera
Zrozumienie języka asemblera uświadamia -
- Jak programy współpracują z systemem operacyjnym, procesorem i systemem BIOS;
- Sposób reprezentacji danych w pamięci i innych urządzeniach zewnętrznych;
- W jaki sposób procesor uzyskuje dostęp i wykonuje instrukcje;
- Jak instrukcje uzyskują dostęp do danych i je przetwarzają;
- W jaki sposób program uzyskuje dostęp do urządzeń zewnętrznych.
Inne zalety używania języka asemblera to -
Wymaga mniej pamięci i czasu wykonywania;
Pozwala w łatwiejszy sposób na złożone zadania specyficzne dla sprzętu;
Nadaje się do prac, w których liczy się czas;
Jest najbardziej odpowiedni do pisania procedur obsługi przerwań i innych programów rezydujących w pamięci.
Podstawowe cechy sprzętu komputerowego
Główny wewnętrzny sprzęt komputera PC składa się z procesora, pamięci i rejestrów. Rejestry to elementy procesora, które przechowują dane i adresy. W celu wykonania programu system kopiuje go z urządzenia zewnętrznego do pamięci wewnętrznej. Procesor wykonuje instrukcje programu.
Podstawową jednostką pamięci komputera jest trochę; może być WŁĄCZONY (1) lub WYŁĄCZONY (0), a grupa 8 powiązanych bitów tworzy bajt na większości nowoczesnych komputerów.
Tak więc bit parzystości jest używany, aby liczba bitów w bajcie była nieparzysta. Jeśli parzystość jest równa, system zakłada, że wystąpił błąd parzystości (choć rzadki), który mógł być spowodowany usterką sprzętową lub zakłóceniem elektrycznym.
Procesor obsługuje następujące rozmiary danych -
- Słowo: 2-bajtowa pozycja danych
- Podwójne słowo: 4-bajtowa (32-bitowa) pozycja danych
- Quadword: 8-bajtowy (64-bitowy) element danych
- Akapit: obszar 16-bajtowy (128-bitowy)
- Kilobajt: 1024 bajty
- Megabajt: 1048576 bajtów
System liczb binarnych
Każdy system liczbowy używa notacji pozycyjnej, tj. Każda pozycja, w której zapisana jest cyfra, ma inną wartość pozycyjną. Każda pozycja jest potęgą podstawy, która wynosi 2 dla systemu liczb binarnych, a te potęgi zaczynają się od 0 i rosną o 1.
W poniższej tabeli przedstawiono wartości pozycyjne 8-bitowej liczby binarnej, w której wszystkie bity są ustawione na ON.
| Wartość bitowa | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Wartość pozycji jako potęga podstawy 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Numer bitu | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Wartość liczby binarnej opiera się na obecności 1 bitów i ich wartości pozycyjnej. Czyli wartość danej liczby binarnej to -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
czyli to samo co 2 8 - 1.
System liczb szesnastkowych
System liczb szesnastkowych używa podstawy 16. Cyfry w tym systemie mieszczą się w zakresie od 0 do 15. Zgodnie z konwencją, litery od A do F są używane do reprezentowania cyfr szesnastkowych odpowiadających wartościom dziesiętnym od 10 do 15.
Liczby szesnastkowe w obliczeniach służą do skrócenia długich reprezentacji binarnych. Zasadniczo system liczb szesnastkowych reprezentuje dane binarne, dzieląc każdy bajt na pół i wyrażając wartość każdego pół-bajtu. Poniższa tabela zawiera odpowiedniki dziesiętne, dwójkowe i szesnastkowe -
| Liczba dziesiętna | Reprezentacja binarna | Reprezentacja szesnastkowa |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | ZA |
| 11 | 1011 | b |
| 12 | 1100 | do |
| 13 | 1101 | re |
| 14 | 1110 | mi |
| 15 | 1111 | fa |
Aby przekonwertować liczbę dwójkową na jej szesnastkowy odpowiednik, podziel ją na grupy po 4 kolejne grupy każda, zaczynając od prawej strony, i zapisz te grupy na odpowiednich cyfrach liczby szesnastkowej.
Example - Liczba binarna 1000 1100 1101 0001 jest odpowiednikiem liczby szesnastkowej - 8CD1
Aby przekonwertować liczbę szesnastkową na dwójkową, po prostu zapisz każdą cyfrę szesnastkową na jej 4-cyfrowy odpowiednik binarny.
Example - Liczba szesnastkowa FAD8 jest odpowiednikiem liczby dwójkowej - 1111 1010 1101 1000
Arytmetyka binarna
Poniższa tabela przedstawia cztery proste zasady dodawania binarnego -
| (ja) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
Reguły (iii) i (iv) pokazują przeniesienie 1-bitu na następną lewą pozycję.
Example
| Dziesiętny | Dwójkowy |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Ujemna wartość binarna jest wyrażana w two's complement notation. Zgodnie z tą zasadą konwersja liczby binarnej na jej wartość ujemną polega na odwróceniu jej wartości bitowych i dodaniu 1 .
Example
| Numer 53 | 00110101 |
| Odwróć bity | 11001010 |
| Dodaj 1 | 0000000 1 |
| Numer -53 | 11001011 |
Aby odjąć jedną wartość od drugiej, przekonwertuj odejmowaną liczbę do formatu uzupełnienia do dwóch i dodaj liczby .
Example
Odejmij 42 od 53
| Numer 53 | 00110101 |
| Numer 42 | 00101010 |
| Odwróć bity 42 | 11010101 |
| Dodaj 1 | 0000000 1 |
| Numer -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
Przepełnienie ostatniego 1 bitu zostanie utracone.
Adresowanie danych w pamięci
Proces, za pomocą którego procesor steruje wykonywaniem instrukcji, nazywany jest fetch-decode-execute cycle albo execution cycle. Składa się z trzech ciągłych kroków -
- Pobieranie instrukcji z pamięci
- Dekodowanie lub identyfikacja instrukcji
- Wykonanie instrukcji
Procesor może jednocześnie uzyskiwać dostęp do jednego lub większej liczby bajtów pamięci. Rozważmy liczbę szesnastkową 0725H. Ta liczba będzie wymagać dwóch bajtów pamięci. Najstarszy bajt lub najbardziej znaczący bajt to 07, a najmniejszy bajt to 25.
Procesor przechowuje dane w odwrotnej kolejności bajtów, tj. Bajt niskiego rzędu jest przechowywany w niskim adresie pamięci, a bajt wyższego rzędu w adresie dużej pamięci. Tak więc, jeśli procesor przeniesie wartość 0725H z rejestru do pamięci, prześle najpierw 25 do niższego adresu pamięci, a 07 do następnego adresu pamięci.
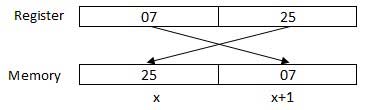
x: adres pamięci
Kiedy procesor pobiera dane numeryczne z pamięci do rejestracji, ponownie odwraca bajty. Istnieją dwa rodzaje adresów pamięci -
Adres bezwzględny - bezpośrednie odniesienie do określonej lokalizacji.
Adres segmentu (lub offset) - adres początkowy segmentu pamięci z wartością offsetu.
Konfiguracja środowiska lokalnego
Język asemblera zależy od zestawu instrukcji i architektury procesora. W tym samouczku skupiamy się na procesorach Intel-32, takich jak Pentium. Aby skorzystać z tego samouczka, będziesz potrzebować -
- IBM PC lub dowolny równoważny kompatybilny komputer
- Kopia systemu operacyjnego Linux
- Kopia programu asemblera NASM
Istnieje wiele dobrych programów asemblera, takich jak -
- Asembler firmy Microsoft (MASM)
- Borland Turbo Assembler (TASM)
- Asembler GNU (GAS)
Użyjemy asemblera NASM, tak jak jest -
- Wolny. Możesz go pobrać z różnych źródeł internetowych.
- Dobrze udokumentowane, a otrzymasz mnóstwo informacji w sieci.
- Może być używany zarówno w systemie Linux, jak i Windows.
Instalowanie NASM
Jeśli wybierzesz "Development Tools" podczas instalacji Linuksa, możesz zainstalować NASM wraz z systemem operacyjnym Linux i nie musisz pobierać i instalować go oddzielnie. Aby sprawdzić, czy masz już zainstalowany NASM, wykonaj następujące czynności -
Otwórz terminal Linux.
Rodzaj whereis nasm i naciśnij ENTER.
Jeśli jest już zainstalowany, pojawi się taka linia, jak nasm: / usr / bin / nasm . W przeciwnym razie zobaczysz po prostu nasm:, wtedy musisz zainstalować NASM.
Aby zainstalować NASM, wykonaj następujące czynności -
Sprawdź witrynę internetową asemblera sieci (NASM), aby uzyskać najnowszą wersję.
Pobierz archiwum źródłowe Linuksa
nasm-X.XX.ta.gz, gdzie w archiwumX.XXznajduje się numer wersji NASM.Rozpakuj archiwum do katalogu, który tworzy podkatalog
nasm-X. XX.cd do
nasm-X.XXi wpisz./configure. Ten skrypt powłoki znajdzie najlepszy kompilator C do użycia i odpowiednio skonfiguruje pliki Makefile.Rodzaj make aby zbudować pliki binarne nasm i ndisasm.
Rodzaj make install zainstalować nasm i ndisasm w / usr / local / bin oraz strony podręcznika.
To powinno zainstalować NASM w twoim systemie. Alternatywnie możesz użyć dystrybucji RPM dla Fedory Linux. Ta wersja jest prostsza w instalacji, wystarczy dwukrotnie kliknąć plik RPM.
Program montażu można podzielić na trzy części -
Plik data Sekcja,
Plik bss sekcja i
Plik text Sekcja.
Dane Sekcja
Plik dataSekcja służy do deklarowania zainicjowanych danych lub stałych. Te dane nie zmieniają się w czasie wykonywania. W tej sekcji można zadeklarować różne wartości stałe, nazwy plików, rozmiar bufora itp.
Składnia deklarowania sekcji danych to -
section.dataBSS Sekcja
Plik bssSekcja służy do deklarowania zmiennych. Składnia deklarowania sekcji bss to -
section.bssTekst sekcja
Plik textSekcja służy do przechowywania aktualnego kodu. Ta sekcja musi zaczynać się od deklaracjiglobal _start, który informuje jądro, gdzie rozpoczyna się wykonywanie programu.
Składnia deklarowania sekcji tekstowej to -
section.text
global _start
_start:Komentarze
Komentarz asemblera zaczyna się od średnika (;). Może zawierać dowolne znaki drukowalne, w tym puste. Może pojawić się samodzielnie w linii, na przykład -
; This program displays a message on screenlub w tym samym wierszu wraz z instrukcją, na przykład -
add eax, ebx ; adds ebx to eaxInstrukcje języka asemblera
Programy w języku asemblerowym składają się z trzech typów instrukcji -
- Wykonywalne instrukcje lub instrukcje,
- Dyrektywy asemblera lub pseudo-operacje i
- Macros.
Plik executable instructions lub po prostu instructionspowiedz procesorowi, co ma robić. Każda instrukcja składa się z plikuoperation code(kod operacji). Każda instrukcja wykonywalna generuje jedną instrukcję języka maszynowego.
Plik assembler directives lub pseudo-opspowiedz asemblerowi o różnych aspektach procesu montażu. Nie są one wykonywalne i nie generują instrukcji języka maszynowego.
Macros są w zasadzie mechanizmem zastępowania tekstu.
Składnia instrukcji języka asemblera
Instrukcje asemblera są wprowadzane po jednej instrukcji w każdym wierszu. Każda instrukcja ma następujący format -
[label] mnemonic [operands] [;comment]Pola w nawiasach kwadratowych są opcjonalne. Instrukcja podstawowa składa się z dwóch części, pierwsza to nazwa instrukcji (lub mnemonik), która ma zostać wykonana, a druga to operandy lub parametry polecenia.
Oto kilka przykładów typowych instrukcji języka asemblera -
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerProgram Hello World w asemblerze
Poniższy kod języka asemblera wyświetla na ekranie ciąg „Hello World” -
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringKiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello, world!Kompilowanie i łączenie programu Assembly w NASM
Upewnij się, że ustawiłeś ścieżkę nasm i ldpliki binarne w zmiennej środowiskowej PATH. Teraz wykonaj następujące kroki, aby skompilować i połączyć powyższy program -
Wpisz powyższy kod za pomocą edytora tekstu i zapisz go jako hello.asm.
Upewnij się, że jesteś w tym samym katalogu, w którym zapisałeś hello.asm.
Aby złożyć program, wpisz nasm -f elf hello.asm
Jeśli wystąpi jakikolwiek błąd, zostaniesz o tym poproszony na tym etapie. W przeciwnym razie plik obiektowy programu o nazwiehello.o zostanie utworzona.
Aby połączyć plik obiektu i utworzyć plik wykonywalny o nazwie hello, wpisz ld -m elf_i386 -s -o hello hello.o
Uruchom program, wpisując ./hello
Jeśli wszystko wykonałeś poprawnie, wyświetli się komunikat „Hello, world!” na ekranie.
Omówiliśmy już trzy sekcje programu montażu. Te sekcje reprezentują również różne segmenty pamięci.
Co ciekawe, jeśli zamienisz słowo kluczowe sekcja na segment, uzyskasz ten sam wynik. Wypróbuj następujący kod -
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringKiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello, world!Segmenty pamięci
Model pamięci segmentowej dzieli pamięć systemową na grupy niezależnych segmentów, do których odwołują się wskaźniki znajdujące się w rejestrach segmentów. Każdy segment zawiera określony typ danych. Jeden segment jest używany do przechowywania kodów instrukcji, inny segment przechowuje elementy danych, a trzeci segment przechowuje stos programu.
W świetle powyższej dyskusji możemy określić różne segmenty pamięci jako -
Data segment - Jest reprezentowany przez .data sekcja i .bss. Sekcja .data służy do zadeklarowania obszaru pamięci, w którym przechowywane są elementy danych programu. Ta sekcja nie może zostać rozszerzona po zadeklarowaniu elementów danych i pozostaje statyczna w całym programie.
Sekcja .bss jest również sekcją pamięci statycznej, która zawiera bufory dla danych, które mają być zadeklarowane później w programie. Ta pamięć buforowa jest zapełniona zerami.
Code segment - Jest reprezentowany przez .textSekcja. To definiuje obszar w pamięci, który przechowuje kody instrukcji. Jest to również obszar stały.
Stack - Ten segment zawiera wartości danych przekazywane do funkcji i procedur w programie.
Operacje procesora obejmują głównie przetwarzanie danych. Te dane mogą być przechowywane w pamięci i stamtąd dostępne. Jednak odczytywanie i przechowywanie danych w pamięci spowalnia procesor, ponieważ wiąże się ze skomplikowanymi procesami wysyłania żądania danych przez magistralę sterującą do jednostki pamięci i pobierania danych tym samym kanałem.
Aby przyspieszyć działanie procesora, procesor zawiera kilka lokalizacji pamięci wewnętrznej, tzw registers.
Rejestry przechowują elementy danych do przetwarzania bez konieczności dostępu do pamięci. Ograniczona liczba rejestrów jest wbudowana w chip procesora.
Rejestry procesorów
W architekturze IA-32 jest dziesięć 32-bitowych i sześć 16-bitowych rejestrów procesora. Rejestry są podzielone na trzy kategorie -
- Rejestry ogólne,
- Rejestry kontrolne i
- Rejestry segmentowe.
Rejestry ogólne są dalej podzielone na następujące grupy -
- Rejestry danych,
- Rejestry wskaźnikowe i
- Rejestry indeksowe.
Rejestry danych
Cztery 32-bitowe rejestry danych są używane do operacji arytmetycznych, logicznych i innych. Te 32-bitowe rejestry mogą być używane na trzy sposoby -
Jako kompletne 32-bitowe rejestry danych: EAX, EBX, ECX, EDX.
Dolne połówki rejestrów 32-bitowych można wykorzystać jako cztery rejestry danych 16-bitowych: AX, BX, CX i DX.
Dolne i wyższe połówki wspomnianych powyżej czterech 16-bitowych rejestrów mogą być użyte jako osiem 8-bitowych rejestrów danych: AH, AL, BH, BL, CH, CL, DH i DL.

Niektóre z tych rejestrów danych mają szczególne zastosowanie w operacjach arytmetycznych.
AX is the primary accumulator; jest używany we wprowadzaniu / wyprowadzaniu i większości instrukcji arytmetycznych. Na przykład, w operacji mnożenia, jeden operand jest przechowywany w rejestrze EAX lub AX lub AL zgodnie z rozmiarem argumentu.
BX is known as the base register, ponieważ może być używany w adresowaniu indeksowanym.
CX is known as the count register, podobnie jak w ECX, rejestry CX przechowują liczbę pętli w operacjach iteracyjnych.
DX is known as the data register. Jest również używany w operacjach wejścia / wyjścia. Jest również używany z rejestrem AX wraz z DX do operacji mnożenia i dzielenia obejmujących duże wartości.
Rejestry wskaźników
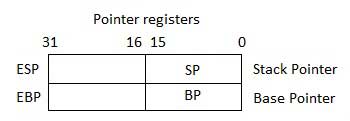
Rejestry wskaźnikowe to 32-bitowe rejestry EIP, ESP i EBP oraz odpowiadające im 16-bitowe prawe części IP, SP i BP. Istnieją trzy kategorie rejestrów wskaźników -
Instruction Pointer (IP)- 16-bitowy rejestr IP przechowuje przesunięty adres następnej instrukcji do wykonania. IP w połączeniu z rejestrem CS (jako CS: IP) podaje pełny adres aktualnej instrukcji w segmencie kodu.
Stack Pointer (SP)- 16-bitowy rejestr SP dostarcza wartość przesunięcia w stosie programu. SP w połączeniu z rejestrem SS (SS: SP) odnosi się do aktualnej pozycji danych lub adresu w stosie programu.
Base Pointer (BP)- 16-bitowy rejestr BP pomaga głównie w odwoływaniu się do zmiennych parametrów przekazywanych do podprogramu. Adres w rejestrze SS jest łączony z przesunięciem w BP, aby uzyskać lokalizację parametru. BP można również łączyć z DI i SI jako rejestrem bazowym do specjalnego adresowania.
Rejestry indeksowe
32-bitowe rejestry indeksowe, ESI i EDI oraz ich 16-bitowe prawostronne części. SI i DI są używane do adresowania indeksowanego, a czasami używane jako dodawanie i odejmowanie. Istnieją dwa zestawy wskaźników indeksu -
Source Index (SI) - Jest używany jako indeks źródłowy dla operacji na łańcuchach.
Destination Index (DI) - Jest używany jako indeks docelowy dla operacji na łańcuchach.

Rejestry kontrolne
32-bitowy rejestr wskaźnika instrukcji i 32-bitowy rejestr flagowy są uważane za rejestry sterujące.
Wiele instrukcji obejmuje porównania i obliczenia matematyczne oraz zmienia stan flag, a niektóre inne instrukcje warunkowe testują wartość tych flag stanu, aby przenieść przepływ sterowania w inne miejsce.
Typowe bity flag to:
Overflow Flag (OF) - Wskazuje przepełnienie wyższego rzędu bitu (skrajny lewy bit) danych po operacji arytmetycznej ze znakiem.
Direction Flag (DF)- Określa lewy lub prawy kierunek przesuwania lub porównywania danych ciągów. Gdy wartość DF wynosi 0, operacja na łańcuchu przyjmuje kierunek od lewej do prawej, a gdy wartość jest ustawiona na 1, operacja na łańcuchu przebiega w kierunku od prawej do lewej.
Interrupt Flag (IF)- Określa, czy zewnętrzne przerwania, takie jak wprowadzanie danych z klawiatury itp., Mają być ignorowane lub przetwarzane. Wyłącza przerwanie zewnętrzne, gdy wartość wynosi 0 i włącza przerwania, gdy jest ustawiona na 1.
Trap Flag (TF)- Umożliwia ustawienie pracy procesora w trybie jednostopniowym. Program DEBUG, którego użyliśmy, ustawia flagę pułapki, abyśmy mogli przejść przez wykonywanie jednej instrukcji na raz.
Sign Flag (SF)- Pokazuje znak wyniku operacji arytmetycznej. Ta flaga jest ustawiana zgodnie ze znakiem elementu danych po operacji arytmetycznej. Znak jest wskazywany przez najwyższy rząd lewego bitu. Wynik dodatni powoduje skasowanie wartości SF na 0, a wynik ujemny na 1.
Zero Flag (ZF)- Wskazuje wynik operacji arytmetycznej lub porównania. Wynik niezerowy czyści flagę zero na 0, a wynik zerowy ustawia ją na 1.
Auxiliary Carry Flag (AF)- Zawiera przeniesienie z bitu 3 do bitu 4 po operacji arytmetycznej; używany do specjalistycznej arytmetyki. AF jest ustawiane, gdy 1-bajtowa operacja arytmetyczna powoduje przeniesienie z bitu 3 do bitu 4.
Parity Flag (PF)- Wskazuje całkowitą liczbę 1-bitów w wyniku otrzymanym z operacji arytmetycznej. Parzysta liczba 1-bitów zeruje flagę parzystości do 0, a nieparzysta liczba 1-bitów ustawia flagę parzystości na 1.
Carry Flag (CF)- Zawiera przeniesienie 0 lub 1 z bitu najwyższego rzędu (najbardziej po lewej) po operacji arytmetycznej. Przechowuje również zawartość ostatniego bitu operacji przesunięcia lub obrotu .
Poniższa tabela przedstawia położenie bitów flag w 16-bitowym rejestrze flag:
| Flaga: | O | re | ja | T | S | Z | ZA | P. | do | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit nie: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Rejestry segmentowe
Segmenty to określone obszary zdefiniowane w programie, które zawierają dane, kod i stos. Istnieją trzy główne segmenty -
Code Segment- Zawiera wszystkie instrukcje do wykonania. 16-bitowy rejestr segmentu kodu lub rejestr CS przechowuje początkowy adres segmentu kodu.
Data Segment- Zawiera dane, stałe i obszary robocze. 16-bitowy rejestr segmentu danych lub rejestr DS przechowuje początkowy adres segmentu danych.
Stack Segment- Zawiera dane i adresy zwrotne procedur lub podprogramów. Jest implementowany jako struktura danych „stosu”. Rejestr segmentu stosu lub rejestr SS przechowuje adres początkowy stosu.
Oprócz rejestrów DS, CS i SS istnieją inne dodatkowe rejestry segmentowe - ES (dodatkowy segment), FS i GS, które zapewniają dodatkowe segmenty do przechowywania danych.
W programowaniu w asemblerze program potrzebuje dostępu do lokalizacji pamięci. Wszystkie lokalizacje pamięci w segmencie odnoszą się do adresu początkowego segmentu. Segment zaczyna się w adresie, który jest równo podzielny przez 16 lub szesnastkowo 10. Tak więc najbardziej prawą cyfrą szesnastkową we wszystkich takich adresach pamięci jest 0, które zwykle nie jest przechowywane w rejestrach segmentów.
Rejestry segmentów przechowują początkowe adresy segmentu. Aby uzyskać dokładną lokalizację danych lub instrukcji w segmencie, wymagana jest wartość przesunięcia (lub przesunięcie). Aby odwołać się do dowolnej lokalizacji pamięci w segmencie, procesor łączy adres segmentu w rejestrze segmentu z wartością przesunięcia lokalizacji.
Przykład
Spójrz na następujący prosty program, aby zrozumieć użycie rejestrów w programowaniu w asemblerze. Ten program wyświetla 9 gwiazdek na ekranie wraz z prostą wiadomością -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Displaying 9 stars
*********Wywołania systemowe to interfejsy API dla interfejsu między przestrzenią użytkownika a przestrzenią jądra. Skorzystaliśmy już z wywołań systemowych. sys_write i sys_exit, odpowiednio do pisania na ekranie i wychodzenia z programu.
Połączenia systemowe Linux
Możesz korzystać z wywołań systemowych Linuksa w programach asemblera. Musisz wykonać następujące kroki, aby używać wywołań systemowych Linux w swoim programie:
- Umieść numer wywołania systemowego w rejestrze EAX.
- Przechowuj argumenty wywołania systemowego w rejestrach EBX, ECX itp.
- Wywołaj odpowiednie przerwanie (80h).
- Wynik jest zwykle zwracany w rejestrze EAX.
Istnieje sześć rejestrów przechowujących argumenty użytego wywołania systemowego. Są to EBX, ECX, EDX, ESI, EDI i EBP. Rejestry te przyjmują kolejne argumenty, zaczynając od rejestru EBX. Jeśli argumentów jest więcej niż sześć, to lokalizacja pamięci pierwszego argumentu jest przechowywana w rejestrze EBX.
Poniższy fragment kodu przedstawia użycie wywołania systemowego sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelPoniższy fragment kodu przedstawia użycie wywołania systemowego sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelWszystkie wywołania systemowe są wymienione w /usr/include/asm/unistd.h , wraz z ich numerami (wartość, którą należy wprowadzić do EAX przed wywołaniem int 80h).
W poniższej tabeli przedstawiono niektóre wywołania systemowe używane w tym samouczku -
| % eax | Nazwa | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | unsigned int | char * | size_t | - | - |
| 4 | sys_write | unsigned int | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | unsigned int | - | - | - | - |
Przykład
Poniższy przykład odczytuje liczbę z klawiatury i wyświetla ją na ekranie -
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hKiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Please enter a number:
1234
You have entered:1234Większość instrukcji języka asemblera wymaga przetwarzania argumentów. Adres argumentu określa lokalizację, w której przechowywane są dane do przetworzenia. Niektóre instrukcje nie wymagają operandu, podczas gdy inne instrukcje mogą wymagać jednego, dwóch lub trzech operandów.
Gdy instrukcja wymaga dwóch operandów, pierwszy argument jest zwykle miejscem docelowym, który zawiera dane w rejestrze lub komórce pamięci, a drugi argument jest źródłem. Źródło zawiera dane do dostarczenia (adresowanie bezpośrednie) lub adres (w rejestrze lub pamięci) danych. Generalnie dane źródłowe pozostają niezmienione po operacji.
Trzy podstawowe tryby adresowania to -
- Zarejestruj adresowanie
- Natychmiastowe adresowanie
- Adresowanie pamięci
Zarejestruj adresowanie
W tym trybie adresowania rejestr zawiera operand. W zależności od instrukcji rejestr może być pierwszym operandem, drugim operandem lub obydwoma.
Na przykład,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersPonieważ przetwarzanie danych między rejestrami nie obejmuje pamięci, zapewnia najszybsze przetwarzanie danych.
Natychmiastowe adresowanie
Bezpośredni operand ma stałą wartość lub wyrażenie. Gdy instrukcja z dwoma argumentami używa adresowania bezpośredniego, pierwszy argument może być rejestrem lub lokalizacją pamięci, a drugi argument jest natychmiastową stałą. Pierwszy operand określa długość danych.
Na przykład,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXBezpośrednie adresowanie pamięci
Gdy operandy są określone w trybie adresowania pamięci, wymagany jest bezpośredni dostęp do pamięci głównej, zwykle do segmentu danych. Ten sposób adresowania skutkuje wolniejszym przetwarzaniem danych. Aby zlokalizować dokładną lokalizację danych w pamięci, potrzebujemy adresu początkowego segmentu, który zwykle znajduje się w rejestrze DS i wartości przesunięcia. Ta wartość przesunięcia jest również nazywanaeffective address.
W trybie adresowania bezpośredniego wartość offsetu jest określana bezpośrednio jako część instrukcji, zwykle wskazywana przez nazwę zmiennej. Asembler oblicza wartość przesunięcia i utrzymuje tabelę symboli, w której przechowywane są wartości przesunięcia wszystkich zmiennych używanych w programie.
W bezpośrednim adresowaniu pamięci jeden z argumentów odnosi się do miejsca w pamięci, a drugi do rejestru.
Na przykład,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerAdresowanie z bezpośrednim przesunięciem
Ten tryb adresowania wykorzystuje operatory arytmetyczne do modyfikacji adresu. Na przykład spójrz na następujące definicje, które definiują tabele danych -
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsNastępujące operacje uzyskują dostęp do danych z tablic w pamięci do rejestrów -
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEPośrednie adresowanie pamięci
Ten tryb adresowania wykorzystuje zdolność komputera do adresowania Segment: Offset . Generalnie do tego celu wykorzystywane są rejestry bazowe EBX, EBP (lub BX, BP) i rejestry indeksowe (DI, SI), zakodowane w nawiasach kwadratowych jako odniesienia do pamięci.
Adresowanie pośrednie jest zwykle używane w przypadku zmiennych zawierających kilka elementów, takich jak tablice. Początkowy adres tablicy jest przechowywany, powiedzmy, w rejestrze EBX.
Poniższy fragment kodu pokazuje, jak uzyskać dostęp do różnych elementów zmiennej.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123Instrukcja MOV
Skorzystaliśmy już z instrukcji MOV, która służy do przenoszenia danych z jednej przestrzeni pamięci do drugiej. Instrukcja MOV przyjmuje dwa operandy.
Składnia
Składnia instrukcji MOV to -
MOV destination, sourceInstrukcja MOV może mieć jedną z następujących pięciu form -
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerNależy pamiętać, że -
- Oba operandy w operacji MOV powinny mieć ten sam rozmiar
- Wartość operandu źródłowego pozostaje niezmieniona
Instrukcja MOV czasami powoduje niejednoznaczność. Na przykład spójrz na stwierdzenia -
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110Nie jest jasne, czy chcesz przenieść równoważnik bajtowy, czy odpowiednik słowa liczby 110. W takich przypadkach rozsądnie jest użyć znaku type specifier.
W poniższej tabeli przedstawiono niektóre typowe specyfikatory typu -
| Specyfikator typu | Adresowane bajty |
|---|---|
| BAJT | 1 |
| SŁOWO | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
Przykład
Poniższy program ilustruje niektóre z omówionych powyżej koncepcji. Przechowuje nazwę „Zara Ali” w sekcji danych pamięci, a następnie programowo zmienia jej wartość na inną nazwę „Nuha Ali” i wyświetla obie nazwy.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Zara Ali Nuha AliNASM zapewnia różne define directivesdo rezerwowania miejsca do przechowywania zmiennych. Dyrektywa define assembler służy do alokacji przestrzeni dyskowej. Można go użyć do zarezerwowania, jak również zainicjowania jednego lub więcej bajtów.
Przydzielanie miejsca na dane dla zainicjowanych danych
Składnia instrukcji alokacji pamięci dla zainicjowanych danych jest następująca:
[variable-name] define-directive initial-value [,initial-value]...Gdzie nazwa-zmiennej to identyfikator każdej przestrzeni dyskowej. Asembler przypisuje wartość przesunięcia dla każdej nazwy zmiennej zdefiniowanej w segmencie danych.
Istnieje pięć podstawowych form zdefiniowanej dyrektywy -
| Dyrektywa | Cel, powód | Przestrzeń magazynowa |
|---|---|---|
| DB | Zdefiniuj bajt | przydziela 1 bajt |
| DW | Zdefiniuj słowo | przydziela 2 bajty |
| DD | Zdefiniuj Doubleword | przydziela 4 bajty |
| DQ | Zdefiniuj Quadword | przydziela 8 bajtów |
| DT | Zdefiniuj dziesięć bajtów | przydziela 10 bajtów |
Poniżej znajduje się kilka przykładów użycia dyrektyw define -
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Należy pamiętać, że -
Każdy bajt znaku jest przechowywany jako jego wartość ASCII w postaci szesnastkowej.
Każda wartość dziesiętna jest automatycznie konwertowana na jej 16-bitowy odpowiednik binarny i zapisywana jako liczba szesnastkowa.
Procesor używa kolejności bajtów little-endian.
Liczby ujemne są konwertowane na reprezentację uzupełnienia do 2.
Krótkie i długie liczby zmiennoprzecinkowe są reprezentowane odpowiednio za pomocą 32 lub 64 bitów.
Poniższy program pokazuje użycie dyrektywy define -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
yPrzydzielanie miejsca na dane niezainicjowane
Dyrektywy rezerwy służą do rezerwowania miejsca na niezainicjowane dane. Dyrektywy rezerwowe przyjmują jeden operand, który określa liczbę jednostek przestrzeni do zarezerwowania. Każda dyrektywa Definicja ma powiązaną dyrektywę dotyczącą rezerw.
Istnieje pięć podstawowych form dyrektywy w sprawie rezerw -
| Dyrektywa | Cel, powód |
|---|---|
| RESB | Zarezerwuj bajt |
| RESW | Zarezerwuj słowo |
| RESD | Zarezerwuj podwójne słowo |
| RESQ | Zarezerwuj Quadword |
| ODPOCZYNEK | Zarezerwuj dziesięć bajtów |
Wiele definicji
W programie można mieć wiele instrukcji definiujących dane. Na przykład -
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HAsembler przydziela ciągłą pamięć dla wielu definicji zmiennych.
Wiele inicjalizacji
Dyrektywa TIMES zezwala na wielokrotne inicjalizacje tej samej wartości. Na przykład tablicę nazwaną markami o rozmiarze 9 można zdefiniować i zainicjować do zera za pomocą następującej instrukcji -
marks TIMES 9 DW 0Dyrektywa TIMES jest przydatna przy definiowaniu tablic i tabel. Poniższy program wyświetla 9 gwiazdek na ekranie -
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
*********Istnieje kilka dyrektyw dostarczonych przez NASM, które definiują stałe. Korzystaliśmy już z dyrektywy EQU w poprzednich rozdziałach. Omówimy w szczególności trzy dyrektywy -
- EQU
- %assign
- %define
Dyrektywa EQU
Plik EQUDyrektywa służy do definiowania stałych. Składnia dyrektywy EQU jest następująca -
CONSTANT_NAME EQU expressionNa przykład,
TOTAL_STUDENTS equ 50Następnie możesz użyć tej stałej wartości w swoim kodzie, na przykład -
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSOperand instrukcji EQU może być wyrażeniem -
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthPowyższy segment kodu zdefiniowałby OBSZAR jako 200.
Przykład
Poniższy przykład ilustruje zastosowanie dyrektywy EQU -
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!Dyrektywa% assign
Plik %assigndyrektywy można używać do definiowania stałych numerycznych, takich jak dyrektywa EQU. Ta dyrektywa pozwala na przedefiniowanie. Na przykład można zdefiniować stałą TOTAL jako -
%assign TOTAL 10W dalszej części kodu możesz przedefiniować go jako -
%assign TOTAL 20W tej dyrektywie rozróżniana jest wielkość liter.
% Definiuje dyrektywę
Plik %defineDyrektywa pozwala na zdefiniowanie stałych numerycznych i łańcuchowych. Ta dyrektywa jest podobna do #define w C. Na przykład można zdefiniować stałą PTR jako -
%define PTR [EBP+4]Powyższy kod zastępuje PTR przez [EBP + 4].
Dyrektywa ta pozwala również na przedefiniowanie i rozróżnia wielkość liter.
Instrukcja INC
Instrukcja INC jest używana do zwiększania operandu o jeden. Działa na pojedynczym operandzie, który może znajdować się w rejestrze lub w pamięci.
Składnia
Instrukcja INC ma następującą składnię -
INC destinationMiejsce docelowe operandu może być 8-bitowym, 16-bitowym lub 32-bitowym operandem.
Przykład
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableInstrukcja DEC
Instrukcja DEC służy do zmniejszania wartości operandu o jeden. Działa na pojedynczym operandzie, który może znajdować się w rejestrze lub w pamięci.
Składnia
Instrukcja DEC ma następującą składnię -
DEC destinationMiejsce docelowe operandu może być 8-bitowym, 16-bitowym lub 32-bitowym operandem.
Przykład
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]Instrukcje ADD i SUB
Instrukcje ADD i SUB są używane do wykonywania prostego dodawania / odejmowania danych binarnych w rozmiarze bajtu, słowa i słowa podwójnego, tj. Do dodawania lub odejmowania odpowiednio 8-bitowych, 16-bitowych lub 32-bitowych argumentów.
Składnia
Instrukcje ADD i SUB mają następującą składnię -
ADD/SUB destination, sourceInstrukcja ADD / SUB może mieć miejsce między -
- Zarejestruj się, aby się zarejestrować
- Pamięć do zarejestrowania
- Zarejestruj się w pamięci
- Zarejestruj się na stałe dane
- Pamięć do stałych danych
Jednak, podobnie jak inne instrukcje, operacje z pamięci do pamięci nie są możliwe przy użyciu instrukcji ADD / SUB. Operacja ADD lub SUB ustawia lub usuwa przepełnienie i flagi przenoszenia.
Przykład
Poniższy przykład poprosi użytkownika o podanie dwóch cyfr, zapisze cyfry odpowiednio w rejestrze EAX i EBX, doda wartości, zapisze wynik w lokalizacji pamięci „ res ” i na koniec wyświetli wynik.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The sum is:
7Instrukcja MUL / IMUL
Istnieją dwie instrukcje dotyczące mnożenia danych binarnych. Instrukcja MUL (Multiply) obsługuje dane bez znaku, a IMUL (Integer Multiply) obsługuje dane ze znakiem. Obie instrukcje mają wpływ na flagę Carry i Overflow.
Składnia
Składnia instrukcji MUL / IMUL jest następująca -
MUL/IMUL multiplierMnożnik w obu przypadkach będzie znajdował się w akumulatorze, w zależności od rozmiaru mnożnika i mnożnika, a wygenerowany iloczyn jest również przechowywany w dwóch rejestrach w zależności od rozmiaru argumentów. Poniższa sekcja wyjaśnia instrukcje MUL w trzech różnych przypadkach -
| Sr.No. | Scenariusze |
|---|---|
| 1 | When two bytes are multiplied − Mnożnik znajduje się w rejestrze AL, a mnożnik jest bajtem w pamięci lub w innym rejestrze. Produkt jest w AX. 8 bitów produktu wysokiego rzędu jest przechowywanych w AH, a 8 bitów niskiego rzędu jest przechowywanych w AL.

|
| 2 | When two one-word values are multiplied − Mnożnik powinien znajdować się w rejestrze AX, a mnożnik to słowo w pamięci lub inny rejestr. Na przykład, dla instrukcji takiej jak MUL DX, musisz zapisać mnożnik w DX, a mnożnik w AX. Otrzymany iloczyn jest podwójnym słowem, które będzie wymagało dwóch rejestrów. Część najwyższego rzędu (skrajna lewa) zostaje zapisana w DX, a część niższego rzędu (skrajna prawa) zostaje zapisana w AX.

|
| 3 | When two doubleword values are multiplied − Kiedy mnoży się dwie wartości podwójnego słowa, mnożnik powinien być w EAX, a mnożnik jest wartością podwójnego słowa przechowywaną w pamięci lub w innym rejestrze. Wygenerowany produkt jest przechowywany w rejestrach EDX: EAX, tj. 32 bity wyższego rzędu są przechowywane w rejestrze EDX, a 32 bity najniższego rzędu są przechowywane w rejestrze EAX.

|
Przykład
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLPrzykład
Poniższy przykład mnoży 3 przez 2 i wyświetla wynik -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The result is:
6Instrukcje DIV / IDIV
Operacja dzielenia generuje dwa elementy - a quotient i a remainder. W przypadku mnożenia przepełnienie nie występuje, ponieważ do przechowywania iloczynu używane są rejestry o podwójnej długości. Jednak w przypadku podziału może wystąpić przelanie. Procesor generuje przerwanie, jeśli wystąpi przepełnienie.
Instrukcja DIV (Divide) jest używana dla danych bez znaku, a IDIV (Integer Divide) jest używana dla danych ze znakiem.
Składnia
Format instrukcji DIV / IDIV -
DIV/IDIV divisorDywidenda jest akumulowana. Obie instrukcje mogą działać z 8-bitowymi, 16-bitowymi lub 32-bitowymi operandami. Operacja wpływa na wszystkie sześć flag stanu. Poniższa sekcja wyjaśnia trzy przypadki dzielenia o różnej wielkości operandu -
| Sr.No. | Scenariusze |
|---|---|
| 1 | When the divisor is 1 byte − Zakłada się, że dywidenda znajduje się w rejestrze AX (16 bitów). Po podzieleniu iloraz trafia do rejestru AL, a reszta do rejestru AH.

|
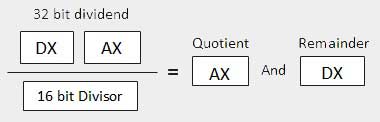
| 2 | When the divisor is 1 word − Zakłada się, że dywidenda ma długość 32 bity i znajduje się w rejestrach DX: AX. 16 bitów wysokiego rzędu jest w DX, a 16 bitów niskiego rzędu w AX. Po podzieleniu, 16-bitowy iloraz trafia do rejestru AX, a 16-bitowa reszta trafia do rejestru DX.
|
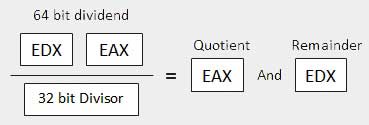
| 3 | When the divisor is doubleword − Zakłada się, że dywidenda ma długość 64 bitów i jest zapisana w rejestrach EDX: EAX. 32 bity najwyższego rzędu są w EDX, a 32 bity najniższego rzędu w EAX. Po podzieleniu 32-bitowy iloraz trafia do rejestru EAX, a 32-bitowa reszta trafia do rejestru EDX.
|
Przykład
Poniższy przykład dzieli 8 przez 2. dividend 8 jest przechowywany w 16-bit AX register i divisor 2 jest przechowywany w 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The result is:
4Zestaw instrukcji procesora zawiera instrukcje AND, OR, XOR, TEST i NOT logikę Boole'a, która testuje, ustawia i czyści bity zgodnie z potrzebami programu.
Format tych instrukcji -
| Sr.No. | Instrukcja | Format |
|---|---|---|
| 1 | I | AND operand1, operand2 |
| 2 | LUB | OR operand1, operand2 |
| 3 | XOR | XOR operand1, operand2 |
| 4 | TEST | TEST operand1, operand2 |
| 5 | NIE | NIE operand1 |
Pierwszy operand we wszystkich przypadkach może znajdować się w rejestrze lub w pamięci. Drugi operand może znajdować się w rejestrze / pamięci lub mieć wartość bezpośrednią (stałą). Jednak operacje wymiany pamięci nie są możliwe. Te instrukcje porównują lub dopasowują bity operandów i ustawiają flagi CF, OF, PF, SF i ZF.
Instrukcja AND
Instrukcja AND jest używana do obsługi wyrażeń logicznych przez wykonywanie operacji bitowej AND. Operacja bitowa AND zwraca 1, jeśli pasujące bity z obu operandów wynoszą 1, w przeciwnym razie zwraca 0. Na przykład -
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001Operacja AND może służyć do kasowania jednego lub więcej bitów. Na przykład, powiedzmy, że rejestr BL zawiera 0011 1010. Jeśli chcesz skasować bity wyższego rzędu do zera, to ORAZ to z 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Weźmy inny przykład. Jeśli chcesz sprawdzić, czy podana liczba jest nieparzysta czy parzysta, prostym testem byłoby sprawdzenie najmniej znaczącego bitu liczby. Jeśli jest to 1, liczba jest nieparzysta, w przeciwnym razie liczba jest parzysta.
Zakładając, że numer jest w rejestrze AL, możemy napisać -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBERPoniższy program ilustruje to -
Przykład
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgKiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Even Number!Zmień wartość w rejestrze ax na nieparzystą cyfrę, na przykład -
mov ax, 9h ; getting 9 in the axProgram wyświetli:
Odd Number!Podobnie, aby wyczyścić cały rejestr, możesz ORAZ to zrobić za pomocą 00H.
Instrukcja OR
Instrukcja OR jest używana do obsługi wyrażeń logicznych przez wykonywanie operacji bitowej OR. Operator bitowy OR zwraca 1, jeśli pasujące bity z jednego lub obu operandów są jednością. Zwraca 0, jeśli oba bity są równe zero.
Na przykład,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111Operacja OR może być używana do ustawiania jednego lub więcej bitów. Na przykład załóżmy, że rejestr AL zawiera 0011 1010, musisz ustawić cztery najmniej znaczące bity, możesz OR na wartość 0000 1111, czyli FH.
OR BL, 0FH ; This sets BL to 0011 1111Przykład
Poniższy przykład ilustruje instrukcję OR. Zapiszmy wartość 5 i 3 odpowiednio w rejestrach AL i BL, a następnie instrukcję,
OR AL, BLpowinien przechowywać 7 w rejestrze AL -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
7Instrukcja XOR
Instrukcja XOR implementuje bitową operację XOR. Operacja XOR ustawia wynikowy bit na 1, wtedy i tylko wtedy, gdy bity argumentów są różne. Jeśli bity z operandów są takie same (oba 0 lub oba 1), wynikowy bit jest zerowany.
Na przykład,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing operand sam ze sobą zmienia operand na 0. Służy do czyszczenia rejestru.
XOR EAX, EAXInstrukcja TEST
Instrukcja TEST działa tak samo jak operacja AND, ale w przeciwieństwie do instrukcji AND nie zmienia pierwszego operandu. Jeśli więc musimy sprawdzić, czy liczba w rejestrze jest parzysta czy nieparzysta, możemy to również zrobić za pomocą instrukcji TEST bez zmiany pierwotnej liczby.
TEST AL, 01H
JZ EVEN_NUMBERInstrukcja NOT
Instrukcja NOT implementuje operację bitową NOT. Operacja NOT odwraca bity w operandzie. Operand może znajdować się w rejestrze lub w pamięci.
Na przykład,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100Warunkowe wykonanie w języku asemblera jest realizowane przez kilka instrukcji pętlowych i rozgałęziających. Te instrukcje mogą zmienić przepływ sterowania w programie. Warunkowe wykonanie jest obserwowane w dwóch scenariuszach -
| Sr.No. | Instrukcje warunkowe |
|---|---|
| 1 | Unconditional jump Jest to realizowane przez instrukcję JMP. Warunkowe wykonanie często wiąże się z przekazaniem kontroli na adres instrukcji, która nie następuje po aktualnie wykonywanej instrukcji. Przeniesienie kontroli może nastąpić do przodu w celu wykonania nowego zestawu instrukcji lub do tyłu w celu ponownego wykonania tych samych kroków. |
| 2 | Conditional jump Jest to wykonywane przez zestaw instrukcji skoku j <warunek> w zależności od warunku. Instrukcje warunkowe przekazują sterowanie przez przerwanie przepływu sekwencyjnego i robią to poprzez zmianę wartości przesunięcia w IP. |
Omówmy instrukcję CMP przed omówieniem instrukcji warunkowych.
Instrukcja CMP
Instrukcja CMP porównuje dwa operandy. Jest zwykle używany w wykonywaniu warunkowym. Ta instrukcja zasadniczo odejmuje jeden operand od drugiego w celu porównania, czy operandy są równe, czy nie. Nie zakłóca operandów celu ani źródła. Jest używany wraz z instrukcją warunkowego skoku do podejmowania decyzji.
Składnia
CMP destination, sourceCMP porównuje dwa numeryczne pola danych. Operand docelowy może znajdować się w rejestrze lub w pamięci. Operand źródłowy może być stałymi (natychmiastowymi) danymi, rejestrem lub pamięcią.
Przykład
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP jest często używany do porównywania, czy wartość licznika osiągnęła liczbę razy, gdy pętla musi zostać uruchomiona. Rozważ następujący typowy stan -
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Bezwarunkowy skok
Jak wspomniano wcześniej, jest to wykonywane przez instrukcję JMP. Warunkowe wykonanie często wiąże się z przekazaniem kontroli na adres instrukcji, która nie następuje po aktualnie wykonywanej instrukcji. Przeniesienie kontroli może nastąpić do przodu w celu wykonania nowego zestawu instrukcji lub do tyłu w celu ponownego wykonania tych samych kroków.
Składnia
Instrukcja JMP zapewnia nazwę etykiety, do której przepływ sterowania jest przesyłany natychmiast. Składnia instrukcji JMP to -
JMP labelPrzykład
Poniższy fragment kodu ilustruje instrukcję JMP -
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsSkok warunkowy
Jeśli jakiś określony warunek jest spełniony w skoku warunkowym, przepływ sterowania jest przekazywany do instrukcji docelowej. W zależności od stanu i danych istnieje wiele warunkowych instrukcji skoku.
Poniżej znajdują się warunkowe instrukcje skoku używane na podpisanych danych używanych do operacji arytmetycznych -
| Instrukcja | Opis | Testowane flagi |
|---|---|---|
| JE / JZ | Jump Equal lub Jump Zero | ZF |
| JNE / JNZ | Skok nie równy lub skok nie zerowy | ZF |
| JG / JNLE | Skacz większy lub nie mniejszy / równy | OF, SF, ZF |
| JGE / JNL | Skacz większy / równy lub nie mniejszy | OF, SF |
| JL / JNGE | Skacz mniej lub skacz nie większy / równy | OF, SF |
| JLE / JNG | Skocz mniej / równo lub skocz nie wyżej | OF, SF, ZF |
Poniżej znajdują się instrukcje warunkowego skoku używane na danych bez znaku używanych do operacji logicznych -
| Instrukcja | Opis | Testowane flagi |
|---|---|---|
| JE / JZ | Jump Equal lub Jump Zero | ZF |
| JNE / JNZ | Skok nie równy lub skok nie zerowy | ZF |
| JA / JNBE | Skocz powyżej lub skocz nie poniżej / równy | CF, ZF |
| JAE / JNB | Skocz powyżej / równo lub nie poniżej | CF |
| JB / JNAE | Skocz poniżej lub skocz nie powyżej / równo | CF |
| JBE / JNA | Skocz poniżej / równo lub skocz nie powyżej | AF, CF |
Poniższe instrukcje warunkowego skoku mają specjalne zastosowania i sprawdzają wartość flag -
| Instrukcja | Opis | Testowane flagi |
|---|---|---|
| JXCZ | Skocz, jeśli CX wynosi zero | Żaden |
| JC | Jump If Carry | CF |
| JNC | Jump If No Carry | CF |
| JO | Skocz, jeśli przepełnienie | Z |
| JNO | Skocz, jeśli nie ma przepełnienia | Z |
| JP / JPE | Skok z parzystością lub Parzysty skok z parzystością | PF |
| JNP / JPO | Skok bez parzystości lub Skok z parzystością Odd | PF |
| JS | Znak skoku (wartość ujemna) | SF |
| JNS | Jump No Sign (wartość dodatnia) | SF |
Składnia zestawu instrukcji J <condition> -
Przykład,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Przykład
Poniższy program wyświetla największą z trzech zmiennych. Zmienne są zmiennymi dwucyfrowymi. Trzy zmienne num1, num2 i num3 mają odpowiednio wartości 47, 22 i 31 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The largest digit is:
47Do implementacji pętli można użyć instrukcji JMP. Na przykład poniższego fragmentu kodu można użyć do wykonania treści pętli 10 razy.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1Zestaw instrukcji procesora zawiera jednak grupę instrukcji pętli do implementacji iteracji. Podstawowa instrukcja LOOP ma następującą składnię -
LOOP labelGdzie etykieta jest etykietą docelową, która identyfikuje instrukcję docelową, tak jak w instrukcjach skoku. Instrukcja LOOP zakłada, żeECX register contains the loop count. Gdy wykonywana jest instrukcja pętli, rejestr ECX jest zmniejszany, a sterowanie przeskakuje do etykiety docelowej, aż wartość rejestru ECX, tj. Licznik osiągnie wartość zero.
Powyższy fragment kodu można zapisać jako -
mov ECX,10
l1:
<loop body>
loop l1Przykład
Poniższy program drukuje cyfry od 1 do 9 na ekranie -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
123456789:Dane liczbowe są zwykle przedstawiane w systemie binarnym. Instrukcje arytmetyczne działają na danych binarnych. Liczby wyświetlane na ekranie lub wprowadzane z klawiatury mają postać ASCII.
Do tej pory przekonwertowaliśmy te dane wejściowe w postaci ASCII na binarne do obliczeń arytmetycznych i przekonwertowaliśmy wynik z powrotem na binarny. Poniższy kod pokazuje to -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The sum is:
7Takie konwersje mają jednak narzut, a programowanie w języku asemblerowym umożliwia przetwarzanie liczb w bardziej efektywny sposób, w postaci binarnej. Liczby dziesiętne można przedstawić w dwóch formach -
- Formularz ASCII
- BCD lub postać dziesiętna w kodzie binarnym
Reprezentacja ASCII
W reprezentacji ASCII liczby dziesiętne są przechowywane jako ciąg znaków ASCII. Na przykład wartość dziesiętna 1234 jest przechowywana jako -
31 32 33 34HGdzie 31H to wartość ASCII dla 1, 32H to wartość ASCII dla 2 i tak dalej. Istnieją cztery instrukcje przetwarzania liczb w reprezentacji ASCII -
AAA - Regulacja ASCII po dodaniu
AAS - Regulacja ASCII po odjęciu
AAM - Regulacja ASCII po pomnożeniu
AAD - Regulacja ASCII przed dzieleniem
Te instrukcje nie pobierają żadnych operandów i zakładają, że wymagany operand znajduje się w rejestrze AL.
Poniższy przykład używa instrukcji AAS, aby zademonstrować koncepcję -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The Result is:
6Reprezentacja BCD
Istnieją dwa rodzaje reprezentacji BCD -
- Rozpakowana reprezentacja BCD
- Zapakowana reprezentacja BCD
W rozpakowanej reprezentacji BCD każdy bajt przechowuje binarny odpowiednik cyfry dziesiętnej. Na przykład liczba 1234 jest przechowywana jako -
01 02 03 04HIstnieją dwie instrukcje dotyczące przetwarzania tych liczb -
AAM - Regulacja ASCII po pomnożeniu
AAD - Regulacja ASCII przed dzieleniem
Cztery instrukcje dopasowania ASCII, AAA, AAS, AAM i AAD, mogą być również używane z rozpakowaną reprezentacją BCD. W spakowanej reprezentacji BCD każda cyfra jest przechowywana w czterech bitach. W bajcie pakowane są dwie cyfry dziesiętne. Na przykład liczba 1234 jest przechowywana jako -
12 34HIstnieją dwie instrukcje dotyczące przetwarzania tych liczb -
DAA - Korekta dziesiętna po dodaniu
DAS - Regulacja dziesiętna po odjęciu
Nie ma obsługi mnożenia i dzielenia w spakowanej reprezentacji BCD.
Przykład
Poniższy program dodaje dwie 5-cyfrowe liczby dziesiętne i wyświetla sumę. Wykorzystuje powyższe koncepcje -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The Sum is:
35801W naszych poprzednich przykładach używaliśmy już ciągów o zmiennej długości. Łańcuchy o zmiennej długości mogą mieć dowolną liczbę znaków. Ogólnie rzecz biorąc, określamy długość ciągu na jeden z dwóch sposobów -
- Jawne przechowywanie długości łańcucha
- Używanie znaku wartowniczego
Możemy jawnie przechowywać długość ciągu, używając symbolu licznika lokalizacji $, który reprezentuje bieżącą wartość licznika lokalizacji. W poniższym przykładzie -
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ wskazuje bajt po ostatnim znaku zmiennej łańcuchowej msg . W związku z tym,$-msgpodaje długość sznurka. Możemy też pisać
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringAlternatywnie można przechowywać ciągi z końcowym znakiem wartownika, aby oddzielić ciąg, zamiast jawnie przechowywać długość ciągu. Znak wartownika powinien być znakiem specjalnym, który nie występuje w ciągu.
Na przykład -
message DB 'I am loving it!', 0Instrukcje dotyczące strun
Każda instrukcja łańcuchowa może wymagać operandu źródłowego, operandu docelowego lub obu. W przypadku segmentów 32-bitowych instrukcje łańcuchowe używają rejestrów ESI i EDI do wskazywania odpowiednio operandów źródłowych i docelowych.
Jednak w przypadku segmentów 16-bitowych rejestry SI i DI są używane do wskazywania odpowiednio źródła i celu.
Istnieje pięć podstawowych instrukcji dotyczących przetwarzania łańcuchów. Oni są -
MOVS - Ta instrukcja przenosi 1 bajt, słowo lub podwójne słowo danych z komórki pamięci do innej.
LODS- Ta instrukcja ładuje się z pamięci. Jeśli operand jest jednobajtowy, jest ładowany do rejestru AL, jeśli operand jest jednym słowem, jest ładowany do rejestru AX, a podwójne słowo jest ładowane do rejestru EAX.
STOS - Ta instrukcja przechowuje dane z rejestru (AL, AX lub EAX) do pamięci.
CMPS- Ta instrukcja porównuje dwa elementy danych w pamięci. Dane mogą mieć rozmiar bajtowy, słowo lub podwójne słowo.
SCAS - Ta instrukcja porównuje zawartość rejestru (AL, AX lub EAX) z zawartością pozycji w pamięci.
Każda z powyższych instrukcji ma wersję zawierającą bajty, słowo i podwójne słowo, a instrukcje łańcuchowe można powtórzyć, używając przedrostka powtórzenia.
Te instrukcje używają pary rejestrów ES: DI i DS: SI, gdzie rejestry DI i SI zawierają ważne adresy przesunięcia, które odnoszą się do bajtów przechowywanych w pamięci. SI jest zwykle skojarzona z DS (segmentem danych), a DI jest zawsze związana z ES (segment dodatkowy).
Rejestry DS: SI (lub ESI) i ES: DI (lub EDI) wskazują odpowiednio operandy źródłowe i docelowe. Zakłada się, że operand źródłowy znajduje się w DS: SI (lub ESI), a operand docelowy w ES: DI (lub EDI) w pamięci.
W przypadku adresów 16-bitowych używane są rejestry SI i DI, a w przypadku adresów 32-bitowych - rejestry ESI i EDI.
Poniższa tabela zawiera różne wersje instrukcji łańcuchowych i zakładaną przestrzeń operandów.
| Podstawowa instrukcja | Operandy w | Operacja na bajtach | Operacja na słowie | Operacja podwójnego słowa |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Prefiksy powtórzeń
Prefiks REP ustawiony przed instrukcją łańcuchową, na przykład REP MOVSB, powoduje powtórzenie instrukcji na podstawie licznika umieszczonego w rejestrze CX. REP wykonuje instrukcję, zmniejsza CX o 1 i sprawdza, czy CX wynosi zero. Powtarza przetwarzanie instrukcji, aż CX będzie wynosić zero.
Flaga kierunku (DF) określa kierunek operacji.
- Użyj CLD (Clear Direction Flag, DF = 0), aby wykonać operację od lewej do prawej.
- Użyj STD (Ustaw flagę kierunku, DF = 1), aby wykonać operację od prawej do lewej.
Prefiks REP ma również następujące odmiany:
REP: To bezwarunkowa powtórka. Powtarza operację, aż wartość CX wynosi zero.
REPE lub REPZ: Jest to warunkowe powtórzenie. Powtarza operację, podczas gdy flaga zero wskazuje równość / zero. Zatrzymuje się, gdy ZF wskazuje, że nie jest równe / zero lub gdy CX wynosi zero.
REPNE lub REPNZ: Jest to również powtórzenie warunkowe. Powtarza operację, podczas gdy flaga zero wskazuje, że nie jest równa / zero. Zatrzymuje się, gdy ZF wskazuje równe / zero lub gdy wartość CX jest zmniejszana do zera.
Omówiliśmy już, że dyrektywy definicji danych do asemblera służą do przydzielania pamięci dla zmiennych. Zmienną można również zainicjować określoną wartością. Zainicjowaną wartość można określić w postaci szesnastkowej, dziesiętnej lub binarnej.
Na przykład, możemy zdefiniować zmienną słowo „miesiące” w jeden z następujących sposobów -
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BDyrektywy definicji danych mogą być również używane do definiowania jednowymiarowej tablicy. Zdefiniujmy jednowymiarową tablicę liczb.
NUMBERS DW 34, 45, 56, 67, 75, 89Powyższa definicja deklaruje tablicę sześciu słów, z których każde jest zainicjowane numerami 34, 45, 56, 67, 75, 89. To alokuje 2x6 = 12 bajtów kolejnej pamięci. Symboliczny adres pierwszej liczby to LICZBY, a adres drugiej liczby to LICZBY + 2 i tak dalej.
Weźmy inny przykład. Możesz zdefiniować tablicę o nazwie spis o rozmiarze 8 i zainicjować wszystkie wartości zerem, ponieważ -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Który można skrócić jako -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0Dyrektywy TIMES można również użyć do wielu inicjalizacji tej samej wartości. Używając TIMES, tablicę INVENTORY można zdefiniować jako:
INVENTORY TIMES 8 DW 0Przykład
Poniższy przykład demonstruje powyższe koncepcje, definiując 3-elementową tablicę x, która przechowuje trzy wartości: 2, 3 i 4. Dodaje wartości do tablicy i wyświetla sumę 9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
9Procedury lub podprogramy są bardzo ważne w języku asemblerowym, ponieważ programy w asemblerze mają zwykle duże rozmiary. Procedury są identyfikowane nazwą. Po tej nazwie opisana jest treść procedury, która wykonuje dobrze zdefiniowaną pracę. Zakończenie procedury sygnalizowane jest zwrotem.
Składnia
Poniżej znajduje się składnia definiująca procedurę -
proc_name:
procedure body
...
retProcedura jest wywoływana z innej funkcji za pomocą instrukcji CALL. Instrukcja CALL powinna mieć jako argument nazwę wywoływanej procedury, jak pokazano poniżej -
CALL proc_nameWywołana procedura zwraca sterowanie do procedury wywołującej przy użyciu instrukcji RET.
Przykład
Napiszmy bardzo prostą procedurę o nazwie sum, która dodaje zmienne zapisane w rejestrze ECX i EDX i zwraca sumę w rejestrze EAX -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The sum is:
9Struktura danych stosów
Stos to macierzowa struktura danych w pamięci, w której dane mogą być przechowywane i usuwane z miejsca zwanego „górą” stosu. Dane, które mają być przechowywane, są „wypychane” do stosu, a dane do pobrania są „wyrzucane” ze stosu. Stos to struktura danych LIFO, tj. Dane zapisane jako pierwsze są pobierane jako ostatnie.
Język asemblera udostępnia dwie instrukcje dotyczące operacji na stosie: PUSH i POP. Te instrukcje mają składnię taką jak -
PUSH operand
POP address/registerPrzestrzeń pamięci zarezerwowana w segmencie stosu jest używana do implementacji stosu. Rejestry SS i ESP (lub SP) są używane do implementacji stosu. Szczyt stosu, który wskazuje na ostatni element danych wstawiony do stosu, jest wskazywany przez rejestr SS: ESP, gdzie rejestr SS wskazuje początek segmentu stosu, a SP (lub ESP) podaje przesunięcie do segment stosu.
Implementacja stosu ma następujące cechy -
Tylko words lub doublewords można zapisać na stosie, a nie bajt.
Stos rośnie w odwrotnym kierunku, tj. W kierunku niższego adresu pamięci
Góra stosu wskazuje na ostatni element włożony do stosu; wskazuje na niższy bajt ostatniego wstawionego słowa.
Jak rozmawialiśmy o przechowywaniu wartości rejestrów w stosie przed użyciem ich do jakiegoś użytku; można to zrobić w następujący sposób -
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXPrzykład
Poniższy program wyświetla cały zestaw znaków ASCII. Główny program wywołuje procedurę o nazwie display , która wyświetla zestaw znaków ASCII.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Procedura rekurencyjna to taka, która sama siebie wywołuje. Istnieją dwa rodzaje rekursji: bezpośrednia i pośrednia. W przypadku rekursji bezpośredniej procedura wywołuje samą siebie, aw przypadku rekursji pośredniej pierwsza procedura wywołuje drugą procedurę, która z kolei wywołuje procedurę pierwszą.
Rekursję można było zaobserwować w wielu algorytmach matematycznych. Na przykład rozważmy przypadek obliczenia silni liczby. Silnia liczby jest określona równaniem -
Fact (n) = n * fact (n-1) for n > 0Na przykład: silnia 5 to 1 x 2 x 3 x 4 x 5 = 5 x silnia 4 i może to być dobry przykład pokazujący procedurę rekurencyjną. Każdy algorytm rekurencyjny musi mieć warunek końcowy, tj. Rekurencyjne wywołanie programu powinno zostać zatrzymane, gdy warunek zostanie spełniony. W przypadku algorytmu silniowego warunek końcowy jest osiągany, gdy n wynosi 0.
Poniższy program pokazuje, jak silnia n jest implementowana w języku asemblera. Aby program był prosty, obliczymy silnię 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Factorial 3 is:
6Pisanie makra to kolejny sposób na zapewnienie modułowego programowania w języku asemblera.
Makro to sekwencja instrukcji przypisanych nazwą i może być używane w dowolnym miejscu programu.
W NASM makra są definiowane za pomocą %macro i %endmacro dyrektyw.
Makro zaczyna się od dyrektywy% macro, a kończy na dyrektywie% endmacro.
Składnia definicji makr -
%macro macro_name number_of_params
<macro body>
%endmacroGdzie number_of_params określa parametry numeryczne, macro_name Określa nazwę makra.
Makro jest wywoływane przy użyciu nazwy makra wraz z niezbędnymi parametrami. Kiedy musisz wielokrotnie użyć sekwencji instrukcji w programie, możesz umieścić te instrukcje w makrze i używać go zamiast pisać instrukcje przez cały czas.
Na przykład bardzo powszechną potrzebą programów jest napisanie ciągu znaków na ekranie. Aby wyświetlić ciąg znaków, potrzebujesz następującej sekwencji instrukcji -
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelW powyższym przykładzie wyświetlania ciągu znaków, rejestry EAX, EBX, ECX i EDX zostały wykorzystane przez wywołanie funkcji INT 80H. Tak więc za każdym razem, gdy chcesz wyświetlić na ekranie, musisz zapisać te rejestry na stosie, wywołać INT 80H, a następnie przywrócić pierwotną wartość rejestrów ze stosu. Przydałoby się więc napisanie dwóch makr do zapisywania i przywracania danych.
Zauważyliśmy, że niektóre instrukcje, takie jak IMUL, IDIV, INT itp., Wymagają przechowywania niektórych informacji w określonych rejestrach, a nawet zwracania wartości w określonych rejestrach. Jeżeli program korzystał już z tych rejestrów do przechowywania ważnych danych, to istniejące dane z tych rejestrów należy zapisać na stosie i odtworzyć po wykonaniu instrukcji.
Przykład
Poniższy przykład pokazuje definiowanie i używanie makr -
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!System traktuje dane wejściowe lub wyjściowe jako strumień bajtów. Istnieją trzy standardowe strumienie plików -
- Wejście standardowe (stdin),
- Standardowe wyjście (stdout) i
- Błąd standardowy (stderr).
Deskryptor pliku
ZA file descriptorto 16-bitowa liczba całkowita przypisana do pliku jako identyfikator pliku. Gdy tworzony jest nowy plik lub otwierany jest istniejący plik, do uzyskania dostępu do pliku używany jest deskryptor pliku.
Deskryptor plików standardowych strumieni plików - stdin, stdout i stderr wynoszą odpowiednio 0, 1 i 2.
Wskaźnik pliku
ZA file pointerokreśla lokalizację kolejnej operacji odczytu / zapisu w pliku w bajtach. Każdy plik jest traktowany jako sekwencja bajtów. Każdy otwarty plik jest powiązany ze wskaźnikiem pliku, który określa przesunięcie w bajtach względem początku pliku. Kiedy plik jest otwierany, wskaźnik pliku jest ustawiany na zero.
Wywołania systemowe obsługi plików
Poniższa tabela pokrótce opisuje wywołania systemowe związane z obsługą plików -
| % eax | Nazwa | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
Kroki wymagane do korzystania z wywołań systemowych są takie same, jak omówiliśmy wcześniej -
- Umieść numer wywołania systemowego w rejestrze EAX.
- Przechowuj argumenty wywołania systemowego w rejestrach EBX, ECX itp.
- Wywołaj odpowiednie przerwanie (80h).
- Wynik jest zwykle zwracany w rejestrze EAX.
Tworzenie i otwieranie pliku
Aby utworzyć i otworzyć plik, wykonaj następujące czynności -
- Umieść wywołanie systemowe sys_creat () numer 8 w rejestrze EAX.
- Umieść nazwę pliku w rejestrze EBX.
- Umieść uprawnienia do plików w rejestrze ECX.
Wywołanie systemowe zwraca deskryptor utworzonego pliku w rejestrze EAX, w przypadku błędu kod błędu znajduje się w rejestrze EAX.
Otwieranie istniejącego pliku
Aby otworzyć istniejący plik, wykonaj następujące czynności -
- Umieść wywołanie systemowe sys_open () numer 5 w rejestrze EAX.
- Umieść nazwę pliku w rejestrze EBX.
- Umieść tryb dostępu do pliku w rejestrze ECX.
- Umieść uprawnienia do plików w rejestrze EDX.
Wywołanie systemowe zwraca deskryptor utworzonego pliku w rejestrze EAX, w przypadku błędu kod błędu znajduje się w rejestrze EAX.
Wśród trybów dostępu do plików najczęściej używane są: tylko do odczytu (0), tylko do zapisu (1) i do odczytu i zapisu (2).
Czytanie z pliku
Aby odczytać z pliku, wykonaj następujące czynności -
Umieść wywołanie systemowe sys_read () numer 3 w rejestrze EAX.
Umieść deskryptor pliku w rejestrze EBX.
Umieść wskaźnik na buforze wejściowym w rejestrze ECX.
Umieść rozmiar bufora, tj. Liczbę bajtów do odczytania, w rejestrze EDX.
Wywołanie systemowe zwraca liczbę bajtów odczytanych w rejestrze EAX, w przypadku błędu kod błędu znajduje się w rejestrze EAX.
Zapisywanie do pliku
Aby zapisać do pliku, wykonaj następujące czynności -
Umieść wywołanie systemowe sys_write () numer 4 w rejestrze EAX.
Umieść deskryptor pliku w rejestrze EBX.
Umieść wskaźnik na buforze wyjściowym w rejestrze ECX.
Umieść rozmiar bufora, tj. Liczbę bajtów do zapisu, w rejestrze EDX.
Wywołanie systemowe zwraca rzeczywistą liczbę bajtów zapisanych w rejestrze EAX, w przypadku błędu kod błędu znajduje się w rejestrze EAX.
Zamykanie pliku
Aby zamknąć plik, wykonaj następujące czynności -
- Umieść wywołanie systemowe sys_close () numer 6 w rejestrze EAX.
- Umieść deskryptor pliku w rejestrze EBX.
W przypadku błędu wywołanie systemowe zwraca kod błędu w rejestrze EAX.
Aktualizacja pliku
Aby zaktualizować plik, wykonaj następujące czynności -
- Umieść wywołanie systemowe sys_lseek () numer 19 w rejestrze EAX.
- Umieść deskryptor pliku w rejestrze EBX.
- Umieść wartość przesunięcia w rejestrze ECX.
- Umieść punkt odniesienia dla przesunięcia w rejestrze EDX.
Punktem odniesienia mogłoby być:
- Początek pliku - wartość 0
- Aktualna pozycja - wartość 1
- Koniec pliku - wartość 2
W przypadku błędu wywołanie systemowe zwraca kod błędu w rejestrze EAX.
Przykład
Poniższy program tworzy i otwiera plik o nazwie myfile.txt i zapisuje tekst „Welcome to Tutorials Point” w tym pliku. Następnie program odczytuje z pliku i zapisuje dane w buforze o nazwie info . Na koniec wyświetla tekst zapisany w info .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Written to file
Welcome to Tutorials PointPlik sys_brk()wywołanie systemowe jest dostarczane przez jądro, aby przydzielić pamięć bez potrzeby jej późniejszego przenoszenia. To wywołanie przydziela pamięć bezpośrednio za obrazem aplikacji w pamięci. Ta funkcja systemu pozwala ustawić najwyższy dostępny adres w sekcji danych.
To wywołanie systemowe przyjmuje jeden parametr, który jest najwyższym adresem pamięci wymaganym do ustawienia. Ta wartość jest przechowywana w rejestrze EBX.
W przypadku jakiegokolwiek błędu sys_brk () zwraca -1 lub sam zwraca ujemny kod błędu. Poniższy przykład ilustruje dynamiczną alokację pamięci.
Przykład
Poniższy program przydziela 16kb pamięci za pomocą funkcji systemowej sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgKiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Allocated 16 kb of memory!