Programowanie D - Szybki przewodnik
Język programowania D jest zorientowanym obiektowo językiem programowania systemów z wieloma paradygmatami, opracowanym przez Waltera Brighta z Digital Mars. Jego rozwój rozpoczął się w 1999 r., A po raz pierwszy został wydany w 2001 r. Główna wersja D (1.0) została wydana w 2007 r. Obecnie mamy wersję D2 D2.
D to język, którego składnia jest w stylu C i używa statycznego pisania. Istnieje wiele funkcji C i C ++ w D, ale są też pewne funkcje z tego języka, które nie są zawarte w części D. Niektóre z godnych uwagi dodatków do D obejmują:
- Testów jednostkowych
- Prawdziwe moduły
- Zbieranie śmieci
- Tablice pierwszej klasy
- Wolne i otwarte
- Tablice asocjacyjne
- Tablice dynamiczne
- Klasy wewnętrzne
- Closures
- Funkcje anonimowe
- Leniwa ocena
- Closures
Wiele paradygmatów
D jest językiem programowania o wielu paradygmatach. Wiele paradygmatów obejmuje:
- Imperative
- Zorientowany obiektowo
- Programowanie meta
- Functional
- Concurrent
Przykład
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Nauka D
Najważniejszą rzeczą do zrobienia podczas nauki D jest skupienie się na pojęciach i nie zagubienie się w technicznych szczegółach języka.
Celem nauki języka programowania jest stać się lepszym programistą; to znaczy bardziej efektywnie projektować i wdrażać nowe systemy oraz konserwować stare.
Zakres D.
Programowanie w języku D ma kilka interesujących funkcji, a oficjalna witryna programistyczna w języku D twierdzi, że D jest wygodna, wydajna i wydajna. Programowanie w języku D dodaje wiele funkcji do podstawowego języka, który dostarczył język C w postaci bibliotek standardowych, takich jak zmienna wielkość tablicy i funkcja ciągów. D to doskonały drugi język dla średnio zaawansowanych i zaawansowanych programistów. D lepiej radzi sobie z pamięcią i wskaźnikami, które często powodują problemy w C ++.
Programowanie D jest przeznaczone głównie na nowe programy, które konwertują istniejące programy. Zapewnia wbudowane testowanie i weryfikację, co jest idealnym rozwiązaniem dla dużego nowego projektu, który zostanie napisany z milionami linii kodu przez duże zespoły.
Konfiguracja środowiska lokalnego dla D
Jeśli nadal chcesz skonfigurować swoje środowisko dla języka programowania D, potrzebujesz następujących dwóch programów dostępnych na swoim komputerze: (a) Edytor tekstu, (b) Kompilator D.
Edytor tekstu do programowania D.
Będzie to użyte do wpisania twojego programu. Przykłady kilku edytorów obejmują Notatnik Windows, polecenie edycji systemu operacyjnego, Brief, Epsilon, EMACS i vim lub vi.
Nazwa i wersja edytora tekstu mogą się różnić w różnych systemach operacyjnych. Na przykład Notatnik będzie używany w systemie Windows, a vim lub vi może być używany w systemie Windows, a także w systemie Linux lub UNIX.
Pliki utworzone za pomocą edytora nazywane są plikami źródłowymi i zawierają kod źródłowy programu. Pliki źródłowe programów D mają rozszerzenie „.d”.
Przed rozpoczęciem programowania upewnij się, że masz jeden edytor tekstu i masz wystarczające doświadczenie, aby napisać program komputerowy, zapisać go w pliku, zbudować i ostatecznie wykonać.
Kompilator D.
Większość obecnych implementacji D kompiluje się bezpośrednio do kodu maszynowego w celu wydajnego wykonania.
Mamy dostępnych wiele kompilatorów D, w tym następujące.
DMD - Kompilator Digital Mars D jest oficjalnym kompilatorem D autorstwa Waltera Brighta.
GDC - Front-end dla zaplecza GCC, zbudowany przy użyciu otwartego kodu źródłowego kompilatora DMD.
LDC - Kompilator oparty na frontonie DMD, który używa LLVM jako zaplecza kompilatora.
Powyższe różne kompilatory można pobrać z D Downloads
Będziemy używać wersji D 2 i nie zalecamy pobierania D1.
Mamy następujący program helloWorld.d. Użyjemy tego jako pierwszego programu, który uruchomimy na wybranej przez Ciebie platformie.
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Widzimy następujący wynik.
$ hello worldInstalacja D w systemie Windows
Pobierz instalator systemu Windows .
Uruchom pobrany plik wykonywalny, aby zainstalować D, co można zrobić, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Teraz możemy zbudować i uruchomić plik reklamy, powiedz helloWorld.d, przełączając się do folderu zawierającego plik za pomocą dysku CD, a następnie wykonując następujące czynności -
C:\DProgramming> DMD helloWorld.d
C:\DProgramming> helloWorldWidzimy następujący wynik.
hello worldC: \ DProgramming to folder, którego używam do zapisywania moich próbek. Możesz zmienić go na folder, w którym zapisałeś D. programy.
Instalacja D na Ubuntu / Debian
Pobierz instalator Debiana .
Uruchom pobrany plik wykonywalny, aby zainstalować D, co można zrobić, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Teraz możemy zbudować i uruchomić plik reklamy, powiedz helloWorld.d, przełączając się do folderu zawierającego plik za pomocą dysku CD, a następnie wykonując następujące czynności -
$ dmd helloWorld.d
$ ./helloWorldWidzimy następujący wynik.
$ hello worldInstalacja D na Mac OS X
Pobierz instalator dla komputerów Mac .
Uruchom pobrany plik wykonywalny, aby zainstalować D, co można zrobić, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Teraz możemy zbudować i uruchomić plik reklamy, powiedz helloWorld.d, przełączając się do folderu zawierającego plik za pomocą dysku CD, a następnie wykonując następujące czynności -
$ dmd helloWorld.d $ ./helloWorldWidzimy następujący wynik.
$ hello worldInstalacja D w Fedorze
Pobierz instalator Fedory .
Uruchom pobrany plik wykonywalny, aby zainstalować D, co można zrobić, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Teraz możemy zbudować i uruchomić plik reklamy, powiedz helloWorld.d, przełączając się do folderu zawierającego plik za pomocą dysku CD, a następnie wykonując następujące czynności -
$ dmd helloWorld.d
$ ./helloWorldWidzimy następujący wynik.
$ hello worldInstalacja D na OpenSUSE
Pobierz instalator OpenSUSE .
Uruchom pobrany plik wykonywalny, aby zainstalować D, co można zrobić, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Teraz możemy zbudować i uruchomić plik reklamy, powiedz helloWorld.d, przełączając się do folderu zawierającego plik za pomocą dysku CD, a następnie wykonując następujące czynności -
$ dmd helloWorld.d $ ./helloWorldWidzimy następujący wynik.
$ hello worldD IDE
W większości przypadków mamy wsparcie IDE dla D w postaci wtyczek. To zawiera,
Wtyczka Visual D to wtyczka do Visual Studio 2005-13
DDT to wtyczka eclipse, która zapewnia uzupełnianie kodu i debugowanie za pomocą GDB.
Uzupełnianie kodu Mono-D , refaktoryzacja z obsługą dmd / ldc / gdc. Było częścią GSoC 2012.
Code Blocks to wieloplatformowe środowisko IDE, które obsługuje tworzenie projektów D, wyróżnianie i debugowanie.
D jest dość prosty do nauczenia i zacznijmy tworzyć nasz pierwszy program D!
Pierwszy program D.
Napiszmy prosty program w D. Wszystkie pliki D będą miały rozszerzenie .d. Więc umieść następujący kod źródłowy w pliku test.d.
import std.stdio;
/* My first program in D */
void main(string[] args) {
writeln("test!");
}Zakładając, że środowisko D jest poprawnie skonfigurowane, uruchommy programowanie przy użyciu -
$ dmd test.d
$ ./testWidzimy następujący wynik.
testPrzyjrzyjmy się teraz podstawowej strukturze programu w języku D, aby ułatwić zrozumienie podstawowych elementów składowych języka programowania D.
Import w D
Biblioteki, które są zbiorem części programu wielokrotnego użytku, mogą być udostępniane naszemu projektowi za pomocą importu. Tutaj importujemy standardową bibliotekę io, która zapewnia podstawowe operacje we / wy. writeln, który jest używany w powyższym programie, jest funkcją w bibliotece standardowej D. Służy do drukowania linii tekstu. Zawartość biblioteki w D jest pogrupowana w moduły w oparciu o typy zadań, które zamierzają wykonywać. Jedynym modułem używanym przez ten program jest std.stdio, który obsługuje wprowadzanie i wyprowadzanie danych.
Główna funkcja
Główną funkcją jest uruchomienie programu i określa kolejność wykonywania oraz sposób wykonywania innych sekcji programu.
Żetony w D
Program AD składa się z różnych tokenów, a token jest słowem kluczowym, identyfikatorem, stałą, literałem ciągu lub symbolem. Na przykład następująca instrukcja D składa się z czterech tokenów -
writeln("test!");Poszczególne żetony to -
writeln (
"test!"
)
;Komentarze
Komentarze są jak tekst pomocniczy w programie D i są ignorowane przez kompilator. Komentarz wielowierszowy zaczyna się od / * i kończy znakami * /, jak pokazano poniżej -
/* My first program in D */Pojedynczy komentarz jest zapisywany przy użyciu // na początku komentarza.
// my first program in DIdentyfikatory
Identyfikator AD to nazwa używana do identyfikacji zmiennej, funkcji lub dowolnego innego elementu zdefiniowanego przez użytkownika. Identyfikator zaczyna się od litery od A do Z lub od a do z lub podkreślenia _, po którym następuje zero lub więcej liter, znaków podkreślenia i cyfr (od 0 do 9).
D nie zezwala na znaki interpunkcyjne, takie jak @, $ i% w identyfikatorach. D jestcase sensitivejęzyk programowania. Zatem siła robocza i siła robocza to dwa różne identyfikatory w D. Oto kilka przykładów dopuszczalnych identyfikatorów -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValSłowa kluczowe
Poniższa lista przedstawia kilka zastrzeżonych słów w D. Te zarezerwowane słowa nie mogą być używane jako stałe lub zmienne ani żadne inne nazwy identyfikatorów.
| abstrakcyjny | Alias | wyrównać | jako M |
| zapewniać | automatyczny | ciało | bool |
| bajt | walizka | odlew | łapać |
| zwęglać | klasa | konst | kontyntynuj |
| dchar | odpluskwić | domyślna | delegat |
| przestarzałe | zrobić | podwójnie | jeszcze |
| enum | eksport | zewnętrzny | fałszywy |
| finał | Wreszcie | pływak | dla |
| dla każdego | funkcjonować | iść do | gdyby |
| import | w | inout | int |
| berło | niezmienny | jest | długo |
| makro | mixin | moduł | Nowy |
| zero | na zewnątrz | nadpisanie | pakiet |
| pragma | prywatny | chroniony | publiczny |
| real | ref | powrót | zakres |
| krótki | statyczny | struct | Wspaniały |
| przełącznik | zsynchronizowane | szablon | to |
| rzucać | prawdziwe | próbować | typid |
| typ | ubyte | uint | ulong |
| unia | unittest | ushort | wersja |
| unieważnić | wchar | podczas | z |
Spacja w D
Linia zawierająca tylko białe spacje, prawdopodobnie z komentarzem, jest nazywana pustą linią i kompilator D całkowicie ją ignoruje.
Białe znaki to termin używany w języku D do opisania spacji, tabulatorów, znaków nowej linii i komentarzy. Biała spacja oddziela jedną część instrukcji od drugiej i umożliwia interpreterowi określenie, gdzie kończy się jeden element instrukcji, na przykład int, a zaczyna następny. Dlatego w poniższym oświadczeniu -
local ageAby tłumacz mógł je rozróżnić, musi istnieć co najmniej jeden znak odstępu (zwykle spacja) między określeniem lokalnym a wiekiem. Z drugiej strony w poniższym oświadczeniu
int fruit = apples + oranges //get the total fruitsPomiędzy owocami a = lub między = a jabłkami nie są potrzebne żadne spacje, chociaż możesz je dodać, jeśli chcesz, aby były czytelne.
Zmienna to nic innego jak nazwa nadana obszarowi pamięci, którym nasze programy mogą manipulować. Każda zmienna w D ma określony typ, który określa rozmiar i układ pamięci zmiennej; zakres wartości, które mogą być przechowywane w tej pamięci; oraz zestaw operacji, które można zastosować do zmiennej.
Nazwa zmiennej może składać się z liter, cyfr i znaku podkreślenia. Musi zaczynać się od litery lub podkreślenia. Wielkie i małe litery są różne, ponieważ w D jest rozróżniana wielkość liter. W oparciu o podstawowe typy wyjaśnione w poprzednim rozdziale, będą następujące podstawowe typy zmiennych -
| Sr.No. | Typ i opis |
|---|---|
| 1 | char Zwykle pojedynczy oktet (jeden bajt). To jest typ całkowity. |
| 2 | int Najbardziej naturalny rozmiar liczby całkowitej dla maszyny. |
| 3 | float Wartość zmiennoprzecinkowa o pojedynczej precyzji. |
| 4 | double Wartość zmiennoprzecinkowa podwójnej precyzji. |
| 5 | void Reprezentuje brak typu. |
Język programowania D pozwala również na definiowanie różnych innych typów zmiennych, takich jak Enumeration, Pointer, Array, Structure, Union itp., Które omówimy w kolejnych rozdziałach. W tym rozdziale przyjrzyjmy się tylko podstawowym typom zmiennych.
Definicja zmiennej w D
Definicja zmiennej informuje kompilator, gdzie i ile miejsca ma utworzyć dla zmiennej. Definicja zmiennej określa typ danych i zawiera listę co najmniej jednej zmiennej tego typu w następujący sposób -
type variable_list;Tutaj, type musi być prawidłowym typem danych D, w tym char, wchar, int, float, double, bool lub dowolny obiekt zdefiniowany przez użytkownika itp. oraz variable_listmoże składać się z jednej lub więcej nazw identyfikatorów oddzielonych przecinkami. Tutaj pokazano kilka ważnych deklaracji -
int i, j, k;
char c, ch;
float f, salary;
double d;Linia int i, j, k;zarówno deklaruje, jak i definiuje zmienne i, j oraz k; co instruuje kompilator, aby utworzył zmienne o nazwach i, j i k typu int.
Zmienne można zainicjować (przypisać wartość początkową) w ich deklaracji. Inicjator składa się ze znaku równości, po którym następuje stałe wyrażenie w następujący sposób -
type variable_name = value;Przykłady
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Gdy zmienna jest zadeklarowana w D, zawsze jest ustawiona na swój „domyślny inicjator”, do którego można uzyskać dostęp ręcznie jako T.init gdzie T jest typem (np. int.init). Domyślnym inicjatorem dla typów całkowitych jest 0, dla wartości logicznych false, a dla liczb zmiennoprzecinkowych NaN.
Deklaracja zmiennej w D
Deklaracja zmiennej zapewnia kompilatorowi, że istnieje jedna zmienna o podanym typie i nazwie, dzięki czemu kompilator przechodzi do dalszej kompilacji bez konieczności posiadania pełnych szczegółów na temat zmiennej. Deklaracja zmiennej ma swoje znaczenie tylko w momencie kompilacji, kompilator potrzebuje rzeczywistej deklaracji zmiennej w momencie linkowania programu.
Przykład
Wypróbuj poniższy przykład, w którym zmienne zostały zadeklarowane na początku programu, ale są zdefiniowane i zainicjowane wewnątrz funkcji głównej -
import std.stdio;
int a = 10, b = 10;
int c;
float f;
int main () {
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333Lwów i Rwartości w D
Istnieją dwa rodzaje wyrażeń w D -
lvalue - Wyrażenie, które jest lwartością, może pojawić się po lewej lub prawej stronie przypisania.
rvalue - Wyrażenie, które jest wartością r, może pojawić się po prawej, ale nie po lewej stronie przypisania.
Zmienne to lvalues, więc mogą pojawiać się po lewej stronie przydziału. Literały numeryczne są wartościami r, więc nie można ich przypisywać i nie mogą pojawiać się po lewej stronie. Poniższe oświadczenie jest ważne -
int g = 20;Ale poniższa instrukcja nie jest prawidłową instrukcją i spowodowałaby błąd w czasie kompilacji -
10 = 20;W języku programowania D typy danych odnoszą się do rozbudowanego systemu używanego do deklarowania zmiennych lub funkcji różnych typów. Typ zmiennej określa, ile miejsca zajmuje ona w pamięci i jak jest interpretowany zapisany wzór bitowy.
Typy w D można podzielić w następujący sposób -
| Sr.No. | Rodzaje i opis |
|---|---|
| 1 | Basic Types Są to typy arytmetyczne i składają się z trzech typów: (a) liczba całkowita, (b) zmiennoprzecinkowa i (c) znak. |
| 2 | Enumerated types Są znowu typami arytmetycznymi. Służą do definiowania zmiennych, którym można przypisać tylko określone dyskretne wartości całkowite w całym programie. |
| 3 | The type void Specyfikator typu void wskazuje, że żadna wartość nie jest dostępna. |
| 4 | Derived types Obejmują one (a) typy wskaźników, (b) typy tablic, (c) typy struktur, (d) typy sum, oraz (e) typy funkcji. |
Typy tablic i typy struktur są nazywane zbiorczo typami zagregowanymi. Typ funkcji określa typ wartości zwracanej przez funkcję. W następnej sekcji zobaczymy podstawowe typy, podczas gdy inne typy zostaną omówione w kolejnych rozdziałach.
Typy całkowite
Poniższa tabela zawiera listę standardowych typów liczb całkowitych wraz z ich rozmiarami i zakresami wartości -
| Rodzaj | Rozmiar pamięci | Zakres wartości |
|---|---|---|
| bool | 1 bajt | fałszywe lub prawdziwe |
| bajt | 1 bajt | -128 do 127 |
| ubyte | 1 bajt | Od 0 do 255 |
| int | 4 bajty | -2 147 483 648 do 2 147 483 647 |
| uint | 4 bajty | Od 0 do 4 294 967 295 |
| krótki | 2 bajty | -32 768 do 32767 |
| ushort | 2 bajty | 0 do 65 535 |
| długo | 8 bajtów | -9223372036854775808 do 9223372036854775807 |
| ulong | 8 bajtów | 0 do 18446744073709551615 |
Aby uzyskać dokładny rozmiar typu lub zmiennej, możesz użyć rozszerzenia sizeofoperator. Wyrażenie type. (Sizeof) zwraca rozmiar pamięci obiektu lub typ w bajtach. Poniższy przykład pobiera rozmiar typu int na dowolnym komputerze -
import std.stdio;
int main() {
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}Kiedy kompilujesz i wykonujesz powyższy program, daje on następujący wynik -
Length in bytes: 8Typy zmiennoprzecinkowe
W poniższej tabeli wymieniono standardowe typy zmiennoprzecinkowe z rozmiarami pamięci, zakresami wartości i ich przeznaczeniem -
| Rodzaj | Rozmiar pamięci | Zakres wartości | Cel, powód |
|---|---|---|---|
| pływak | 4 bajty | Od 1.17549e-38 do 3.40282e + 38 | 6 miejsc po przecinku |
| podwójnie | 8 bajtów | 2.22507e-308 do 1.79769e + 308 | 15 miejsc po przecinku |
| real | 10 bajtów | Od 3.3621e-4932 do 1.18973e + 4932 | największy typ zmiennoprzecinkowy obsługiwany przez sprzęt lub podwójny; cokolwiek jest większe |
| ifloat | 4 bajty | Od 1.17549e-38i do 3.40282e + 38i | wartość urojona typu float |
| idouble | 8 bajtów | 2.22507e-308i do 1.79769e + 308i | urojony typ wartości double |
| realne | 10 bajtów | Od 3.3621e-4932 do 1.18973e + 4932 | urojony typ wartości rzeczywistej |
| cfloat | 8 bajtów | 1.17549e-38 + 1.17549e-38i do 3.40282e + 38 + 3.40282e + 38i | liczba zespolona składająca się z dwóch liczb zmiennoprzecinkowych |
| cdouble | 16 bajtów | 2.22507e-308 + 2.22507e-308i do 1.79769e + 308 + 1.79769e + 308i | liczba zespolona złożona z dwóch podwójnych |
| creal | 20 bajtów | 3.3621e-4932 + 3.3621e-4932i do 1.18973e + 4932 + 1.18973e + 4932i | typ liczb zespolonych złożony z dwóch liczb rzeczywistych |
Poniższy przykład wypisuje miejsce zajmowane przez typ zmiennoprzecinkowy i jego wartości zakresu -
import std.stdio;
int main() {
writeln("Length in bytes: ", float.sizeof);
return 0;
}Kiedy kompilujesz i uruchamiasz powyższy program, daje on następujący wynik w systemie Linux -
Length in bytes: 4Typy postaci
W poniższej tabeli wymieniono standardowe typy znaków wraz z rozmiarami pamięci i jej przeznaczeniem.
| Rodzaj | Rozmiar pamięci | Cel, powód |
|---|---|---|
| zwęglać | 1 bajt | Jednostka kodu UTF-8 |
| wchar | 2 bajty | Jednostka kodu UTF-16 |
| dchar | 4 bajty | Jednostka kodu UTF-32 i punkt kodowy Unicode |
Poniższy przykład drukuje miejsce do przechowywania zajmowane przez typ char.
import std.stdio;
int main() {
writeln("Length in bytes: ", char.sizeof);
return 0;
}Kiedy kompilujesz i wykonujesz powyższy program, daje on następujący wynik -
Length in bytes: 1The void Type
Typ void określa, że żadna wartość nie jest dostępna. Jest używany w dwóch sytuacjach -
| Sr.No. | Rodzaje i opis |
|---|---|
| 1 | Function returns as void Istnieją różne funkcje w D, które nie zwracają wartości lub można powiedzieć, że zwracają void. Funkcja bez zwracanej wartości ma zwracany typ void. Na przykład,void exit (int status); |
| 2 | Function arguments as void W D są różne funkcje, które nie akceptują żadnego parametru. Funkcja bez parametru może zostać uznana za nieważną. Na przykład,int rand(void); |
Typ pustki może nie być dla Ciebie w tym momencie zrozumiały, więc przejdźmy dalej i omówimy te koncepcje w kolejnych rozdziałach.
Wyliczenie służy do definiowania nazwanych wartości stałych. Typ wyliczeniowy jest deklarowany przy użyciuenum słowo kluczowe.
Enum Składnia
Najprostsza forma definicji wyliczenia jest następująca -
enum enum_name {
enumeration list
}Gdzie,
Enum_name określa nazwę typu wyliczenie.
Lista wyliczeń to lista identyfikatorów oddzielonych przecinkami.
Każdy z symboli na liście wyliczeń oznacza wartość całkowitą, o jeden większą niż symbol, który ją poprzedza. Domyślnie wartość pierwszego symbolu wyliczenia wynosi 0. Na przykład -
enum Days { sun, mon, tue, wed, thu, fri, sat };Przykład
Poniższy przykład demonstruje użycie zmiennej wyliczeniowej -
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Current Day: 1
Friday : 5W powyższym programie możemy zobaczyć, jak można użyć wyliczenia. Początkowo tworzymy zmienną o nazwie day z naszych dni wyliczeniowych zdefiniowanych przez użytkownika. Następnie ustawiamy go na mon za pomocą operatora kropki. Musimy użyć metody writefln, aby wydrukować wartość mon, która została zapisana. Musisz również określić typ. Jest to liczba całkowita, dlatego do drukowania używamy% d.
Nazwane właściwości wyliczeń
Powyższy przykład używa nazwy Dni do wyliczenia i nosi nazwę nazwanych wyliczeń. Te nazwane wyliczenia mają następujące właściwości -
Init - Inicjuje pierwszą wartość w wyliczeniu.
min - Zwraca najmniejszą wartość wyliczenia.
max - Zwraca największą wartość wyliczenia.
sizeof - Zwraca rozmiar magazynu do wyliczenia.
Zmodyfikujmy poprzedni przykład, aby skorzystać z właściwości.
import std.stdio;
// Initialized sun with value 1
enum Days { sun = 1, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Min : 1
Max : 7
Size of: 4Anonimowy wyliczenie
Wyliczenie bez nazwy nazywa się anonimowym wyliczeniem. Przykład dlaanonymous enum podano poniżej.
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Sunday : 0
Monday : 1Anonimowe wyliczenia działają prawie tak samo jak nazwane wyliczenia, ale nie mają właściwości max, min i sizeof.
Wyliczenie ze składnią typu podstawowego
Poniżej przedstawiono składnię wyliczenia z typem podstawowym.
enum :baseType {
enumeration list
}Niektóre typy podstawowe obejmują long, int i string. Przykład użycia długich jest pokazany poniżej.
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args) {
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
A : hello
B : worldWięcej funkcji
Wyliczenie w D zapewnia funkcje, takie jak inicjowanie wielu wartości w wyliczeniu z wieloma typami. Przykład jest pokazany poniżej.
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args) {
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
A : 1.200000
B : 2.200000
C : 3
D : 4Wywoływane są stałe wartości, które są wpisywane w programie jako część kodu źródłowego literals.
Literały mogą mieć dowolny z podstawowych typów danych i można je podzielić na liczby całkowite, liczby zmiennoprzecinkowe, znaki, ciągi znaków i wartości logiczne.
Ponownie, literały są traktowane tak jak zwykłe zmienne, z tym wyjątkiem, że ich wartości nie mogą być modyfikowane po ich definicji.
Literały całkowite
Literał liczby całkowitej może mieć następujące typy:
Decimal używa normalnej reprezentacji liczb, przy czym pierwsza cyfra nie może być 0, ponieważ ta cyfra jest zarezerwowana dla wskazania systemu ósemkowego.
Octal używa 0 jako prefiksu do numeru.
Binary używa 0b lub 0B jako prefiksu.
Hexadecimal używa 0x lub 0X jako prefiksu.
Literał liczby całkowitej może również mieć sufiks będący kombinacją U i L, odpowiednio dla unsigned i long. Sufiks może być pisany wielką lub małą literą i może mieć dowolną kolejność.
Gdy nie używasz sufiksu, kompilator sam wybiera między int, uint, long i ulong na podstawie wielkości wartości.
Oto kilka przykładów literałów całkowitych -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixPoniżej znajdują się inne przykłady różnych typów literałów całkowitych -
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binaryLiterały zmiennoprzecinkowe
Literały zmiennoprzecinkowe można określić albo w systemie dziesiętnym, jak w 1.568, albo w systemie szesnastkowym, jak w 0x91.bc.
W systemie dziesiętnym wykładnik można przedstawić przez dodanie litery e lub E, a następnie liczby. Na przykład 2,3e4 oznacza „2,3 razy 10 do potęgi 4”. Znak „+” można podać przed wartością wykładnika, ale nie ma to żadnego skutku. Na przykład 2.3e4 i 2.3e + 4 są takie same.
Znak „-” dodany przed wartością wykładnika zmienia znaczenie dzielenia przez 10 na potęgę „”. Na przykład 2,3e-2 oznacza „2,3 podzielone przez 10 do potęgi 2”.
W systemie szesnastkowym wartość zaczyna się od 0x lub 0X. Wykładnik jest określony przez p lub P zamiast e lub E. Wykładnik nie oznacza „10 do potęgi”, ale „2 do potęgi”. Na przykład P4 w 0xabc.defP4 oznacza „abc.de razy 2 do potęgi 4”.
Oto kilka przykładów literałów zmiennoprzecinkowych -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.Domyślnie typ literału zmiennoprzecinkowego to double. F i F oznaczają zmiennoprzecinkę, a specyfikator L oznacza wartość rzeczywistą.
Literały logiczne
Istnieją dwa literały Boolean i są one częścią standardowych słów kluczowych D -
Wartość true reprezentujące prawdę.
Wartość false reprezentujące fałsz.
Nie powinieneś brać pod uwagę wartości true równej 1 i wartości fałszu równej 0.
Literały postaci
Literały znakowe są ujęte w pojedyncze cudzysłowy.
Literał znakowy może być zwykłym znakiem (np. „X”), sekwencją ucieczki (np. „\ T”), znakiem ASCII (np. „\ X21”), znakiem Unicode (np. „\ U011e”) lub jako znak nazwany (np. „\ ©”, „\ ♥”, „\ €”).
Istnieją pewne znaki w D, gdy są poprzedzone odwrotnym ukośnikiem, będą miały specjalne znaczenie i są używane do reprezentowania jak nowa linia (\ n) lub tabulator (\ t). Tutaj masz listę niektórych takich kodów sekwencji ucieczki -
| Sekwencja ewakuacyjna | Znaczenie |
|---|---|
| \\ | \ postać |
| \ ' | ' postać |
| \ " | " postać |
| \? | ? postać |
| \za | Alert lub dzwonek |
| \b | Backspace |
| \fa | Form feed |
| \ n | Nowa linia |
| \ r | Powrót karetki |
| \ t | Zakładka pozioma |
| \ v | Zakładka pionowa |
Poniższy przykład przedstawia kilka znaków sekwencji ucieczki -
import std.stdio;
int main(string[] args) {
writefln("Hello\tWorld%c\n",'\x21');
writefln("Have a good day%c",'\x21');
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello World!
Have a good day!Literały strunowe
Literały łańcuchowe są ujęte w podwójne cudzysłowy. Ciąg zawiera znaki podobne do literałów znakowych: zwykłe znaki, sekwencje ucieczki i znaki uniwersalne.
Możesz podzielić długi wiersz na wiele wierszy za pomocą literałów łańcuchowych i oddzielić je odstępami.
Oto kilka przykładów literałów tekstowych -
import std.stdio;
int main(string[] args) {
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'\x21');
auto str = q{int value = 20; ++value;};
writeln(str);
}W powyższym przykładzie można znaleźć użycie q "MY_DELIMITER MY_DELIMITER" do reprezentowania znaków wieloliniowych. Możesz również zobaczyć q {}, aby reprezentować samą instrukcję języka D.
Operator to symbol, który mówi kompilatorowi, aby wykonał określone operacje matematyczne lub logiczne. Język D jest bogaty we wbudowane operatory i zapewnia następujące typy operatorów -
- Operatory arytmetyczne
- Operatorzy relacyjni
- Operatory logiczne
- Operatory bitowe
- Operatory przypisania
- Różne operatory
W tym rozdziale opisano po kolei operatory arytmetyczne, relacyjne, logiczne, bitowe, przypisania i inne.
Operatory arytmetyczne
W poniższej tabeli przedstawiono wszystkie operatory arytmetyczne obsługiwane przez język D. Przyjmij zmiennąA posiada 10 i zmienną B mieści wtedy 20 -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| + | Dodaje dwa operandy. | A + B daje 30 |
| - | Odejmuje drugi operand od pierwszego. | A - B daje -10 |
| * | Mnoży oba operandy. | A * B daje 200 |
| / | Dzieli licznik przez mianownik. | B / A daje 2 |
| % | Zwraca resztę z dzielenia liczb całkowitych. | B% A daje 0 |
| ++ | Operator inkrementacji zwiększa wartość całkowitą o jeden. | A ++ daje 11 |
| - | Operator zmniejszania wartości zmniejsza wartość całkowitą o jeden. | A - daje 9 |
Operatorzy relacyjni
Poniższa tabela przedstawia wszystkie operatory relacyjne obsługiwane przez język D. Przyjmij zmiennąA posiada 10 i zmienną B mieści 20, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| == | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli tak, warunek staje się prawdziwy. | (A == B) nie jest prawdą. |
| ! = | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli wartości nie są równe, warunek staje się prawdziwy. | (A! = B) jest prawdą. |
| > | Sprawdza, czy wartość lewego operandu jest większa niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A> B) nie jest prawdą. |
| < | Sprawdza, czy wartość lewego operandu jest mniejsza niż wartość prawego operandu. Jeśli tak, warunek staje się prawdziwy. | (A <B) jest prawdą. |
| > = | Sprawdza, czy wartość lewego operandu jest większa lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A> = B) nie jest prawdą. |
| <= | Sprawdza, czy wartość lewego operandu jest mniejsza lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. | (A <= B) jest prawdą. |
Operatory logiczne
W poniższej tabeli przedstawiono wszystkie operatory logiczne obsługiwane przez język D. Przyjmij zmiennąA zawiera 1 i zmienną B posiada 0, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| && | Nazywa się to operatorem logicznym AND. Jeśli oba operandy są niezerowe, warunek staje się prawdziwy. | (A && B) jest fałszem. |
| || | Nazywa się to operatorem logicznym OR. Jeśli którykolwiek z dwóch operandów jest niezerowy, warunek staje się prawdziwy. | (A || B) jest prawdą. |
| ! | Nazywa się to operatorem logicznym NOT. Służy do odwracania stanu logicznego operandu. Jeśli warunek jest spełniony, operator logiczny NOT spowoduje fałsz. | ! (A && B) jest prawdą. |
Operatory bitowe
Operatory bitowe działają na bitach i wykonują operacje bit po bicie. Tabele prawdy dla &, | i ^ są następujące -
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Załóżmy, że A = 60; i B = 13. W formacie binarnym będą one następujące -
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
W poniższej tabeli wymieniono operatory bitowe obsługiwane przez język D. Załóżmy, że zmienna A zawiera 60, a zmienna B 13, a następnie -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| & | Operator binarny AND kopiuje trochę do wyniku, jeśli istnieje w obu operandach. | (A i B) da 12, oznacza 0000 1100. |
| | | Operator binarny OR kopiuje bit, jeśli istnieje w którymkolwiek operandzie. | (A | B) daje 61. Oznacza 0011 1101. |
| ^ | Binarny operator XOR kopiuje bit, jeśli jest ustawiony w jednym operandzie, ale nie w obu. | (A ^ B) daje 49. Oznacza 0011 0001 |
| ~ | Operator dopełniacza binarnego jest jednoargumentowy i powoduje „odwracanie” bitów. | (~ A) daje -61. Oznacza 1100 0011 w postaci dopełnienia 2. |
| << | Binarny operator przesunięcia w lewo. Wartość lewych operandów jest przesuwana w lewo o liczbę bitów określoną przez prawy operand. | A << 2 daje 240. Oznacza 1111 0000 |
| >> | Binarny operator przesunięcia w prawo. Wartość lewego operandu jest przesuwana w prawo o liczbę bitów określoną przez prawy operand. | A >> 2 daje 15. Środki 0000 1111. |
Operatory przypisania
Następujące operatory przypisania są obsługiwane przez język D -
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| = | Jest to prosty operator przypisania. Przypisuje wartości z operandów po prawej stronie do operandów po lewej stronie | C = A + B przypisuje wartość A + B do C. |
| + = | Jest to operator dodawania AND przypisania. Dodaje prawy operand do lewego operandu i przypisuje wynik do lewego operandu | C + = A jest równoważne C = C + A |
| - = | Jest to operator odejmowania AND przypisania. Odejmuje prawy operand od lewego operandu i przypisuje wynik lewemu operandowi. | C - = A jest równoważne C = C - A |
| * = | Jest operatorem mnożenia AND przypisania. Mnoży prawy operand z lewym operandem i przypisuje wynik lewemu operandowi. | C * = A jest równoważne C = C * A |
| / = | Jest operatorem dzielenia AND przypisania. Dzieli lewy operand z prawym operandem i przypisuje wynik lewemu operandowi. | C / = A jest równoważne C = C / A |
| % = | Jest to operator przypisania modułu AND. Pobiera moduł używając dwóch operandów i przypisuje wynik do lewego operandu. | C% = A jest równoważne C = C% A |
| << = | Jest to lewy operator przypisania AND. | C << = 2 to to samo, co C = C << 2 |
| >> = | Jest to operator przypisania w prawo ORAZ. | C >> = 2 to to samo, co C = C >> 2 |
| & = | Jest to operator przypisania bitowego AND. | C & = 2 to to samo, co C = C & 2 |
| ^ = | Jest to bitowe OR i operator przypisania. | C ^ = 2 to to samo, co C = C ^ 2 |
| | = | Jest bitowym operatorem OR i przypisaniem | C | = 2 to to samo, co C = C | 2 |
Operatory różne - Sizeof i Ternary
Istnieje kilka innych ważnych operatorów, w tym sizeof i ? : obsługiwane przez język D.
Pokaż przykłady
| Operator | Opis | Przykład |
|---|---|---|
| rozmiar() | Zwraca rozmiar zmiennej. | sizeof (a), gdzie a jest liczbą całkowitą, zwraca 4. |
| & | Zwraca adres zmiennej. | &za; podaje rzeczywisty adres zmiennej. |
| * | Wskaźnik do zmiennej. | *za; daje wskaźnik do zmiennej. |
| ? : | Wyrażenie warunkowe | Jeśli warunek jest prawdziwy, to wartość X: w przeciwnym razie wartość Y. |
Pierwszeństwo operatorów w D.
Pierwszeństwo operatorów określa grupowanie terminów w wyrażeniu. Ma to wpływ na sposób oceny wyrażenia. Niektóre operatory mają pierwszeństwo przed innymi.
Na przykład operator mnożenia ma wyższy priorytet niż operator dodawania.
Rozważmy wyrażenie
x = 7 + 3 * 2.
Tutaj x ma przypisane 13, a nie 20. Prostą przyczyną jest to, że operator * ma wyższy priorytet niż +, stąd 3 * 2 jest obliczane jako pierwsze, a następnie wynik jest dodawany do 7.
Tutaj operatory o najwyższym priorytecie pojawiają się na górze tabeli, a operatory o najniższym priorytecie - na dole. W wyrażeniu najpierw są oceniane operatory o wyższym priorytecie.
Pokaż przykłady
| Kategoria | Operator | Łączność |
|---|---|---|
| Przyrostek | () [] ->. ++ - - | Z lewej na prawą |
| Jednoargumentowe | + -! ~ ++ - - (typ) * & sizeof | Od prawej do lewej |
| Mnożny | * /% | Z lewej na prawą |
| Przyłączeniowy | + - | Z lewej na prawą |
| Zmiana | << >> | Z lewej na prawą |
| Relacyjny | <<=>> = | Z lewej na prawą |
| Równość | ==! = | Z lewej na prawą |
| Bitowe AND | & | Z lewej na prawą |
| Bitowe XOR | ^ | Z lewej na prawą |
| Bitowe OR | | | Z lewej na prawą |
| Logiczne AND | && | Z lewej na prawą |
| Logiczne LUB | || | Z lewej na prawą |
| Warunkowy | ?: | Od prawej do lewej |
| Zadanie | = + = - = * = / =% = >> = << = & = ^ = | = | Od prawej do lewej |
| Przecinek | , | Z lewej na prawą |
Może zaistnieć sytuacja, gdy trzeba będzie kilkakrotnie wykonać blok kodu. Ogólnie instrukcje są wykonywane sekwencyjnie: pierwsza instrukcja funkcji jest wykonywana jako pierwsza, po niej następuje druga i tak dalej.
Języki programowania zapewniają różne struktury kontrolne, które pozwalają na bardziej skomplikowane ścieżki wykonywania.
Instrukcja pętli wykonuje instrukcję lub grupę instrukcji wiele razy. Następująca ogólna forma instrukcji pętli jest najczęściej używana w językach programowania -

Język programowania D zapewnia następujące typy pętli do obsługi wymagań dotyczących pętli. Kliknij poniższe łącza, aby sprawdzić ich szczegóły.
| Sr.No. | Typ i opis pętli |
|---|---|
| 1 | pętla while Powtarza stwierdzenie lub grupę instrukcji, gdy dany warunek jest prawdziwy. Testuje warunek przed wykonaniem treści pętli. |
| 2 | dla pętli Wykonuje sekwencję instrukcji wiele razy i skraca kod zarządzający zmienną pętli. |
| 3 | zrobić ... pętla while Podobnie jak instrukcja while, z tą różnicą, że testuje warunek na końcu treści pętli. |
| 4 | pętle zagnieżdżone Możesz użyć jednej lub więcej pętli wewnątrz dowolnej innej pętli while, for lub do..while. |
Instrukcje sterowania pętlą
Instrukcje sterujące pętlą zmieniają wykonanie z jego normalnej sekwencji. Gdy wykonanie opuszcza zakres, wszystkie automatyczne obiekty utworzone w tym zakresie są niszczone.
D obsługuje następujące instrukcje sterujące -
| Sr.No. | Oświadczenie i opis kontroli |
|---|---|
| 1 | instrukcja break Kończy pętlę lub instrukcję switch i przenosi wykonanie do instrukcji bezpośrednio po pętli lub przełączniku. |
| 2 | kontynuuj oświadczenie Powoduje, że pętla pomija pozostałą część swojego ciała i natychmiast ponownie testuje swój stan przed ponownym powtórzeniem. |
Nieskończona pętla
Pętla staje się nieskończoną pętlą, jeśli warunek nigdy nie staje się fałszywy. Plikforpętla jest tradycyjnie używana do tego celu. Ponieważ żadne z trzech wyrażeń tworzących pętlę for nie jest wymagane, można utworzyć nieskończoną pętlę, pozostawiając puste wyrażenie warunkowe.
import std.stdio;
int main () {
for( ; ; ) {
writefln("This loop will run forever.");
}
return 0;
}W przypadku braku wyrażenia warunkowego przyjmuje się, że jest ono prawdziwe. Możesz mieć wyrażenie inicjujące i inkrementujące, ale programiści D częściej używają konstrukcji for (;;) do oznaczenia nieskończonej pętli.
NOTE - Możesz zakończyć nieskończoną pętlę, naciskając klawisze Ctrl + C.
Struktury decyzyjne zawierają warunek do oceny oraz dwa zestawy instrukcji do wykonania. Jeden zestaw instrukcji jest wykonywany, jeśli warunek jest prawdziwy, a inny zestaw instrukcji jest wykonywany, jeśli warunek jest fałszywy.
Poniżej przedstawiono ogólną formę typowej struktury podejmowania decyzji występującej w większości języków programowania -
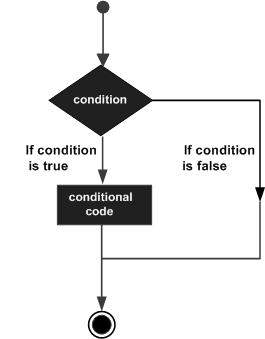
Język programowania D zakłada dowolne non-zero i non-null wartości jako truei jeśli tak jest zero lub null, to przyjmuje się, że false wartość.
Język programowania D zapewnia następujące typy instrukcji decyzyjnych.
| Sr.No. | Oświadczenie i opis |
|---|---|
| 1 | jeśli oświadczenie Na if statement składa się z wyrażenia logicznego, po którym następuje co najmniej jedna instrukcja. |
| 2 | if ... else oświadczenie Na if statement może następować opcjonalnie else statement, która jest wykonywana, gdy wyrażenie logiczne ma wartość false. |
| 3 | zagnieżdżone instrukcje if Możesz użyć jednego if lub else if oświadczenie wewnątrz innego if lub else if sprawozdania). |
| 4 | instrukcja przełączania ZA switch Instrukcja umożliwia testowanie zmiennej pod kątem równości względem listy wartości. |
| 5 | zagnieżdżone instrukcje przełączające Możesz użyć jednego switch oświadczenie wewnątrz innego switch sprawozdania). |
The? : Operator w D
Omówiliśmy conditional operator ? : w poprzednim rozdziale, które można zastąpić if...elsesprawozdania. Ma następującą ogólną formę
Exp1 ? Exp2 : Exp3;Gdzie Exp1, Exp2 i Exp3 to wyrażenia. Zwróć uwagę na użycie i położenie okrężnicy.
Wartość? wyrażenie jest określane w następujący sposób -
Oceniany jest Exp1. Jeśli to prawda, to Exp2 jest obliczane i staje się wartością całości? wyrażenie.
Jeśli Exp1 ma wartość false, to Exp3 jest oceniane, a jego wartość staje się wartością wyrażenia.
W tym rozdziale opisano funkcje używane w programowaniu D.
Definicja funkcji w D
Podstawowa definicja funkcji składa się z nagłówka funkcji i treści funkcji.
Składnia
return_type function_name( parameter list ) {
body of the function
}Oto wszystkie części funkcji -
Return Type- Funkcja może zwrócić wartość. Plikreturn_typejest typem danych wartości zwracanej przez funkcję. Niektóre funkcje wykonują żądane operacje bez zwracania wartości. W tym przypadku return_type jest słowem kluczowymvoid.
Function Name- To jest rzeczywista nazwa funkcji. Nazwa funkcji i lista parametrów razem tworzą podpis funkcji.
Parameters- Parametr działa jak symbol zastępczy. Gdy funkcja jest wywoływana, przekazujesz wartość do parametru. Ta wartość jest określana jako rzeczywisty parametr lub argument. Lista parametrów odnosi się do typu, kolejności i liczby parametrów funkcji. Parametry są opcjonalne; to znaczy funkcja może nie zawierać żadnych parametrów.
Function Body - Treść funkcji zawiera zbiór instrukcji, które definiują, co robi funkcja.
Wywołanie funkcji
Możesz wywołać funkcję w następujący sposób -
function_name(parameter_values)Typy funkcji w D
Programowanie D obsługuje szeroki zakres funkcji i są one wymienione poniżej.
- Czyste funkcje
- Funkcje Nothrow
- Funkcje ref
- Funkcje automatyczne
- Funkcje wariadyczne
- Funkcje Inout
- Funkcje właściwości
Różne funkcje opisano poniżej.
Czyste funkcje
Czyste funkcje to funkcje, które nie mogą uzyskać dostępu do globalnego lub statycznego, zmiennego stanu, poza swoimi argumentami. Może to umożliwić optymalizacje oparte na fakcie, że czysta funkcja gwarantuje, że nie zmutuje niczego, co nie zostanie do niej przekazane, aw przypadkach, gdy kompilator może zagwarantować, że czysta funkcja nie może zmienić swoich argumentów, może zapewnić pełną, funkcjonalną czystość, że jest gwarancją, że funkcja zawsze zwróci ten sam wynik dla tych samych argumentów).
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s) {
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main() {
writeln("Value returned from pure function : ",purefunc(x,null,null));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Value returned from pure function : 30Funkcje Nothrow
Funkcje Nothrow nie zgłaszają żadnych wyjątków pochodzących z klasy Exception. Funkcje nothrow są kowariantne z funkcjami rzucającymi.
Nothrow gwarantuje, że funkcja nie emituje żadnego wyjątku.
import std.stdio;
int add(int a, int b) nothrow {
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
} catch (Exception error) { // catches all exceptions
}
return result;
}
void main() {
writeln("Added value is ", add(10,20));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
adding
Added value is 30Funkcje ref
Funkcje ref pozwalają funkcjom zwracać się przez odniesienie. Jest to analogiczne do parametrów funkcji ref.
import std.stdio;
ref int greater(ref int first, ref int second) {
return (first > second) ? first : second;
}
void main() {
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
a: 1, b: 12Funkcje automatyczne
Funkcje automatyczne mogą zwracać wartość dowolnego typu. Nie ma ograniczeń dotyczących zwracanego typu. Prosty przykład funkcji auto typu jest podany poniżej.
import std.stdio;
auto add(int first, double second) {
double result = first + second;
return result;
}
void main() {
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
add(a,b) = 3.5Funkcje wariadyczne
Funkcje variadiac to te funkcje, w których liczba parametrów funkcji jest określana w czasie wykonywania. W C istnieje ograniczenie związane z posiadaniem co najmniej jednego parametru. Ale w programowaniu D nie ma takiego ograniczenia. Poniżej przedstawiono prosty przykład.
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++) {
write(_arguments[i]);
if (_arguments[i] == typeid(int)) {
int j = va_arg!(int)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(long)) {
long j = va_arg!(long)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(double)) {
double d = va_arg!(double)(_argptr);
writefln("\t%g", d);
}
}
}
void main() {
printargs(1, 2, 3L, 4.5);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
int 2
long 3
double 4.5Funkcje Inout
Inout może być używany zarówno dla parametrów, jak i typów zwracanych funkcji. Jest jak szablon dla zmiennych, stałych i niezmiennych. Atrybut zmienności jest wywnioskowany z parametru. Oznacza, że inout przenosi wydedukowany atrybut zmienności do typu zwracanego. Prosty przykład pokazujący, jak zmienia się zmienność, pokazano poniżej.
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase) {
return '"' ~ phrase ~ '"';
}
void main() {
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
char[] "test a"
const(char)[] "test b"
string "test c"Funkcje właściwości
Właściwości pozwalają na używanie funkcji składowych, takich jak zmienne składowe. Używa słowa kluczowego @property. Właściwości są połączone z pokrewną funkcją, która zwraca wartości na podstawie wymagań. Poniżej przedstawiono prosty przykład właściwości.
import std.stdio;
struct Rectangle {
double width;
double height;
double area() const @property {
return width*height;
}
void area(double newArea) @property {
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main() {
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The area is 200
Value set!
Modified width is 30Znaki są budulcem strun. Każdy symbol systemu pisma nazywany jest znakiem: litery alfabetu, cyfry, znaki interpunkcyjne, spacja itp. Myląco, same elementy składowe znaków nazywane są również znakami.
Wartość całkowita małej litery a wynosi 97, a wartość całkowita cyfry 1 to 49. Wartości te zostały przypisane jedynie przez konwencje podczas projektowania tabeli ASCII.
W poniższej tabeli wymieniono standardowe typy znaków, ich rozmiary i przeznaczenie.
Znaki są reprezentowane przez typ char, który może zawierać tylko 256 różnych wartości. Jeśli znasz typ char z innych języków, być może już wiesz, że nie jest on wystarczająco duży, aby obsługiwać symbole wielu systemów pisma.
| Rodzaj | Rozmiar pamięci | Cel, powód |
|---|---|---|
| zwęglać | 1 bajt | Jednostka kodu UTF-8 |
| wchar | 2 bajty | Jednostka kodu UTF-16 |
| dchar | 4 bajty | Jednostka kodu UTF-32 i punkt kodowy Unicode |
Niektóre przydatne funkcje znaków są wymienione poniżej -
isLower - Określa, czy jest to mała litera?
isUpper - Określa, czy jest to duża litera?
isAlpha - Określa, czy znak alfanumeryczny Unicode (zazwyczaj jest to litera lub cyfra)?
isWhite - Określa, czy jest to biały znak?
toLower - Tworzy małe litery podanego znaku.
toUpper - Tworzy wielką literę podanego znaku.
import std.stdio;
import std.uni;
void main() {
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('\n'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: ICzytanie znaków w D.
Możemy czytać znaki za pomocą readf, jak pokazano poniżej.
readf(" %s", &letter);Ponieważ programowanie D obsługuje Unicode, aby odczytać znaki Unicode, musimy przeczytać dwa razy i dwa razy napisać, aby uzyskać oczekiwany wynik. To nie działa w kompilatorze online. Przykład pokazano poniżej.
import std.stdio;
void main() {
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ", firstCode, secondCode);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Please enter a letter: ğ
The letter that has been read: ğD zapewnia następujące dwa typy reprezentacji ciągów -
- Tablica znaków
- Ciąg języka podstawowego
Tablica znaków
Tablicę znaków możemy przedstawić w jednej z dwóch form, jak pokazano poniżej. Pierwsza forma podaje rozmiar bezpośrednio, a druga korzysta z metody dup, która tworzy zapisywalną kopię ciągu „Dzień dobry”.
char[9] greeting1 = "Hello all";
char[] greeting2 = "Good morning".dup;Przykład
Oto prosty przykład wykorzystujący powyższe proste tablice znaków.
import std.stdio;
void main(string[] args) {
char[9] greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
Hello all
Good morningCiąg języka podstawowego
Ciągi znaków są wbudowane w rdzeń języka D. Ciągi te współdziałają z tablicą znaków pokazaną powyżej. Poniższy przykład przedstawia prostą reprezentację ciągu.
string greeting1 = "Hello all";Przykład
import std.stdio;
void main(string[] args) {
string greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3 = greeting1;
writefln("%s",greeting3);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
Hello all
Good morning
Hello allKonkatenacja ciągów
W przypadku konkatenacji ciągów znaków w programowaniu D używany jest symbol tyldy (~).
Przykład
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
char[] greeting2 = "morning".dup;
char[] greeting3 = greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4 = "morning";
string greeting5 = greeting1~" "~greeting4;
writefln("%s",greeting5);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
Good morning
Good morningDługość sznurka
Długość łańcucha w bajtach można pobrać za pomocą funkcji długości.
Przykład
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Length of string greeting1 is 4
Length of string greeting2 is 7Porównanie ciągów
Porównanie ciągów jest dość łatwe w programowaniu w D. Do porównań ciągów można używać operatorów ==, <i>.
Przykład
import std.stdio;
void main() {
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3) {
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2) {
writeln("'", s1, "' comes before '", s2, "'.");
} else {
writeln("'", s2, "' comes before '", s1, "'.");
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
s2: World and S3: World are the same!
'Hello' comes before 'World'.Zastępowanie ciągów
Możemy zamienić łańcuchy za pomocą string [].
Przykład
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje wynik w następujący sposób -
hello sampleMetody indeksowania
Metody indeksu dotyczące lokalizacji podciągu w ciągu, w tym indexOf i lastIndexOf, zostały wyjaśnione w poniższym przykładzie.
Przykład
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
indexOf.of llo in hello is 2
hello World
lastIndexOf of O in hello is 7Obsługa spraw
Poniższy przykład przedstawia metody używane do zmiany obserwacji.
Przykład
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello worldOgraniczające znaki
W poniższym przykładzie przedstawiono znaki spoczynkowe w łańcuchach.
Przykład
import std.stdio;
import std.string;
void main() {
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello WorldJęzyk programowania D zapewnia strukturę danych o nazwie arrays, który przechowuje sekwencyjną kolekcję elementów tego samego typu o stałym rozmiarze. Tablica służy do przechowywania kolekcji danych. Często bardziej przydatne jest myślenie o tablicy jako o zbiorze zmiennych tego samego typu.
Zamiast deklarować pojedyncze zmienne, takie jak liczba0, liczba1, ... i liczba99, deklarujesz jedną zmienną tablicową, taką jak liczby, i używasz liczb [0], liczb [1] i ..., liczb [99] do reprezentowania indywidualne zmienne. Dostęp do określonego elementu w tablicy uzyskuje się za pomocą indeksu.
Wszystkie tablice składają się z ciągłych lokalizacji pamięci. Najniższy adres odpowiada pierwszemu elementowi, a najwyższy adres ostatniemu elementowi.
Deklarowanie tablic
Aby zadeklarować tablicę w języku programowania D, programista określa typ elementów i liczbę elementów wymaganych przez tablicę w następujący sposób -
type arrayName [ arraySize ];Nazywa się to tablicą jednowymiarową. ArraySize musi być liczbą całkowitą większą od zera stała i typ może być dowolny poprawny typ danych języka programowania D. Na przykład, aby zadeklarować 10-elementową tablicę o nazwie balance typu double, użyj tej instrukcji -
double balance[10];Inicjowanie tablic
Elementy tablicy języka programowania D można inicjować pojedynczo lub za pomocą pojedynczej instrukcji w następujący sposób
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];Liczba wartości w nawiasach kwadratowych [] po prawej stronie nie może być większa niż liczba elementów zadeklarowanych w tablicy w nawiasach kwadratowych []. Poniższy przykład przypisuje pojedynczy element tablicy -
Jeśli pominiesz rozmiar tablicy, zostanie utworzona tablica wystarczająco duża, aby pomieścić inicjalizację. Dlatego jeśli piszesz
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];następnie utworzysz dokładnie taką samą tablicę, jak w poprzednim przykładzie.
balance[4] = 50.0;Powyższa instrukcja przypisuje elementowi numerowi 5. w tablicy wartość 50,0. Tablica z czwartym indeksem będzie piątym, czyli ostatnim elementem, ponieważ wszystkie tablice mają 0 jako indeks pierwszego elementu, który jest również nazywany indeksem bazowym. Poniższe przedstawienie graficzne przedstawia tę samą tablicę, którą omówiliśmy powyżej -

Dostęp do elementów tablicy
Dostęp do elementu uzyskuje się poprzez indeksowanie nazwy tablicy. Odbywa się to poprzez umieszczenie indeksu elementu w nawiasach kwadratowych po nazwie tablicy. Na przykład -
double salary = balance[9];Powyższe stwierdzenie ma 10 th elementu z tablicy i przypisuje się wartość zmiennej wynagrodzenia . Poniższy przykład implementuje deklarację, przypisanie i dostęp do tablic -
import std.stdio;
void main() {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element \t Value");
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
writeln(j," \t ",n[j]);
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Tablice statyczne a tablice dynamiczne
Jeśli długość tablicy jest określona podczas pisania programu, tablica ta jest tablicą statyczną. Gdy długość może się zmienić podczas wykonywania programu, tablica ta jest tablicą dynamiczną.
Definiowanie tablic dynamicznych jest prostsze niż definiowanie tablic o stałej długości, ponieważ pominięcie długości powoduje utworzenie tablicy dynamicznej -
int[] dynamicArray;Właściwości tablicy
Oto właściwości tablic -
| Sr.No. | Właściwość i opis |
|---|---|
| 1 | .init Tablica statyczna zwraca literał tablicowy, w którym każdy element literału jest właściwością .init typu elementu tablicy. |
| 2 | .sizeof Tablica statyczna zwraca długość tablicy pomnożoną przez liczbę bajtów na element tablicy, podczas gdy tablice dynamiczne zwracają rozmiar odwołania do tablicy dynamicznej, który wynosi 8 w kompilacjach 32-bitowych i 16 w kompilacjach 64-bitowych. |
| 3 | .length Tablica statyczna zwraca liczbę elementów w tablicy, podczas gdy tablice dynamiczne są używane do pobierania / ustawiania liczby elementów w tablicy. Długość jest typu size_t. |
| 4 | .ptr Zwraca wskaźnik do pierwszego elementu tablicy. |
| 5 | .dup Utwórz tablicę dynamiczną o tym samym rozmiarze i skopiuj do niej zawartość tablicy. |
| 6 | .idup Utwórz tablicę dynamiczną o tym samym rozmiarze i skopiuj do niej zawartość tablicy. Kopia jest wpisywana jako niezmienna. |
| 7 | .reverse Odwraca kolejność elementów w tablicy. Zwraca tablicę. |
| 8 | .sort Sortuje w kolejności elementów w tablicy. Zwraca tablicę. |
Przykład
Poniższy przykład wyjaśnia różne właściwości tablicy -
import std.stdio;
void main() {
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Pointer:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Pointer:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]Tablice wielowymiarowe w D
Programowanie D umożliwia tworzenie tablic wielowymiarowych. Oto ogólna forma wielowymiarowej deklaracji tablicy -
type name[size1][size2]...[sizeN];Przykład
Poniższa deklaracja tworzy trójwymiarową 5. 10. 4 tablica liczb całkowitych -
int threedim[5][10][4];Tablice dwuwymiarowe w D
Najprostszą formą tablicy wielowymiarowej jest tablica dwuwymiarowa. Dwuwymiarowa tablica to w istocie lista tablic jednowymiarowych. Aby zadeklarować dwuwymiarową tablicę liczb całkowitych o rozmiarze [x, y], należy napisać składnię w następujący sposób -
type arrayName [ x ][ y ];Gdzie type może być dowolnym poprawnym typem danych programowania D i arrayName będzie prawidłowym identyfikatorem programowania D.
Gdzie typ może być dowolnym prawidłowym typem danych programowania D, a arrayName jest prawidłowym identyfikatorem programowania D.
Dwuwymiarową tablicę można traktować jako tabelę, która ma x liczbę wierszy i y liczbę kolumn. Dwuwymiarowa tablicaa zawierający trzy wiersze i cztery kolumny można wyświetlić jak poniżej -
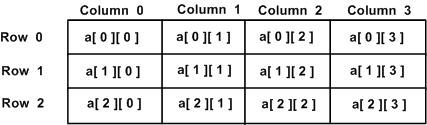
Zatem każdy element w tablicy a jest identyfikowany przez element jako a[ i ][ j ], gdzie a to nazwa tablicy, a i i j to indeksy, które jednoznacznie identyfikują każdy element w.
Inicjowanie tablic dwuwymiarowych
Tablice wielowymiarowe można zainicjować, określając wartości w nawiasach kwadratowych dla każdego wiersza. Poniższa tablica ma 3 wiersze, a każdy wiersz ma 4 kolumny.
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];Zagnieżdżone nawiasy klamrowe, które wskazują zamierzony wiersz, są opcjonalne. Następująca inicjalizacja jest równoważna z poprzednim przykładem -
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];Dostęp do dwuwymiarowych elementów tablicy
Dostęp do elementu w dwuwymiarowej tablicy uzyskuje się za pomocą indeksów, czyli indeksu wiersza i kolumny tablicy. Na przykład
int val = a[2][3];Powyższa instrukcja przyjmuje czwarty element z trzeciego wiersza tablicy. Możesz to zweryfikować w powyższym digramie.
import std.stdio;
void main () {
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) {
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8Typowe operacje na tablicach w D
Oto różne operacje wykonywane na tablicach -
Wycinanie szyku
Często używamy części tablicy, a dzielenie tablicy jest często bardzo pomocne. Poniżej przedstawiono prosty przykład podziału na tablice.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
[2, 3.4]Kopiowanie w tablicy
Używamy również kopiowania tablicy. Poniżej przedstawiono prosty przykład kopiowania macierzy.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]Ustawienie tablicy
Poniżej przedstawiono prosty przykład ustawienia wartości w tablicy.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Array a:[5, 5, 5, 5, 5]Konkatenacja tablic
Poniżej przedstawiono prosty przykład konkatenacji dwóch tablic.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]Tablice asocjacyjne mają indeks, który niekoniecznie jest liczbą całkowitą i może być rzadko wypełniany. Indeks tablicy asocjacyjnej nazywa sięKey, a jego typ nazywa się KeyType.
Tablice asocjacyjne są deklarowane przez umieszczenie KeyType w [] deklaracji tablicy. Poniżej przedstawiono prosty przykład tablicy asocjacyjnej.
import std.stdio;
void main () {
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
3
Tuts
["test":"Tuts"]
[]Inicjalizacja tablicy asocjacyjnej
Poniżej przedstawiono prostą inicjalizację tablicy asocjacyjnej.
import std.stdio;
void main () {
int[string] days =
[ "Monday" : 0,
"Tuesday" : 1,
"Wednesday" : 2,
"Thursday" : 3,
"Friday" : 4,
"Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
1Właściwości tablicy asocjacyjnej
Oto właściwości tablicy asocjacyjnej -
| Sr.No. | Właściwość i opis |
|---|---|
| 1 | .sizeof Zwraca rozmiar odwołania do tablicy asocjacyjnej; jest to 4 w kompilacjach 32-bitowych i 8 w kompilacjach 64-bitowych. |
| 2 | .length Zwraca liczbę wartości w tablicy asocjacyjnej. W przeciwieństwie do tablic dynamicznych jest tylko do odczytu. |
| 3 | .dup Utwórz nową tablicę asocjacyjną o tym samym rozmiarze i skopiuj do niej zawartość tablicy asocjacyjnej. |
| 4 | .keys Zwraca tablicę dynamiczną, której elementami są klucze w tablicy asocjacyjnej. |
| 5 | .values Zwraca tablicę dynamiczną, której elementami są wartości w tablicy asocjacyjnej. |
| 6 | .rehash Reorganizuje tablicę asocjacyjną w miejscu, aby wyszukiwania były bardziej wydajne. rehash jest skuteczny, gdy na przykład program wczytuje tablicę symboli i wymaga teraz szybkiego wyszukiwania w niej. Zwraca odniesienie do zreorganizowanej tablicy. |
| 7 | .byKey() Zwraca delegata odpowiedniego do użycia jako Aggregate do ForeachStatement, który będzie iterował po kluczach tablicy asocjacyjnej. |
| 8 | .byValue() Zwraca delegata odpowiedniego do użycia jako Aggregate do ForeachStatement, który będzie iterował po wartościach tablicy asocjacyjnej. |
| 9 | .get(Key key, lazy Value defVal) Wyszukuje klucz; jeśli istnieje, zwraca odpowiednią wartość else oblicza i zwraca wartość defVal. |
| 10 | .remove(Key key) Usuwa obiekt dla klucza. |
Przykład
Przykład użycia powyższych właściwości pokazano poniżej.
import std.stdio;
void main () {
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
sizeof: 8
length: 2
dup: ["test":3, "test2":20]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]Wskaźniki programowania D są łatwe i przyjemne do nauczenia. Niektóre zadania programowania D są łatwiejsze do wykonania za pomocą wskaźników, a inne zadania programowania D, takie jak dynamiczna alokacja pamięci, nie mogą być wykonywane bez nich. Poniżej przedstawiono prosty wskaźnik.
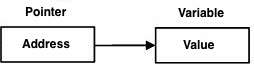
Zamiast bezpośrednio wskazywać na zmienną, wskaźnik wskazuje adres zmiennej. Jak wiadomo, każda zmienna jest miejscem w pamięci, a każda lokalizacja pamięci ma zdefiniowany adres, do którego można uzyskać dostęp za pomocą operatora ampersand (&), który oznacza adres w pamięci. Rozważmy następujący, który wypisuje adres zdefiniowanych zmiennych -
import std.stdio;
void main () {
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930Co to są wskaźniki?
ZA pointerjest zmienną, której wartością jest adres innej zmiennej. Jak w przypadku każdej zmiennej lub stałej, przed rozpoczęciem pracy należy zadeklarować wskaźnik. Ogólną postacią deklaracji zmiennej wskaźnikowej jest -
type *var-name;Tutaj, typejest typem bazowym wskaźnika; musi to być prawidłowy typ programowania ivar-namejest nazwą zmiennej wskaźnika. Gwiazdka użyta do zadeklarowania wskaźnika to ta sama gwiazdka, której używasz do mnożenia. Jednak; w tej instrukcji gwiazdka jest używana do oznaczenia zmiennej jako wskaźnika. Poniżej znajduje się prawidłowa deklaracja wskaźnika -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterRzeczywisty typ danych wartości wszystkich wskaźników, niezależnie od tego, czy są to liczby całkowite, zmiennoprzecinkowe, znakowe, czy inne, jest taki sam, długa liczba szesnastkowa, która reprezentuje adres pamięci. Jedyną różnicą między wskaźnikami różnych typów danych jest typ danych zmiennej lub stałej, na którą wskazuje wskaźnik.
Używanie wskaźników w programowaniu D.
Jest kilka ważnych operacji, gdy używamy wskaźników bardzo często.
definiujemy zmienne wskaźnikowe
przypisać adres zmiennej do wskaźnika
na koniec uzyskaj dostęp do wartości pod adresem dostępnym w zmiennej wskaźnika.
Odbywa się to za pomocą jednoargumentowego operatora *która zwraca wartość zmiennej znajdującej się pod adresem określonym przez jej operand. Poniższy przykład wykorzystuje te operacje -
import std.stdio;
void main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20Puste wskaźniki
Zawsze dobrze jest przypisać wskaźnik NULL do zmiennej wskaźnikowej, na wypadek gdybyś nie posiadał dokładnego adresu do przypisania. Odbywa się to w momencie deklaracji zmiennej. Wskaźnik, któremu przypisano wartość null, nazywa się anull wskaźnik.
Wskaźnik zerowy jest stałą o wartości zero zdefiniowaną w kilku standardowych bibliotekach, w tym w iostream. Rozważ następujący program -
import std.stdio;
void main () {
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The value of ptr is nullW większości systemów operacyjnych programy nie mają dostępu do pamięci pod adresem 0, ponieważ pamięć ta jest zarezerwowana przez system operacyjny. Jednak; adres pamięci 0 ma szczególne znaczenie; sygnalizuje, że wskaźnik nie ma wskazywać dostępnego miejsca w pamięci.
Zgodnie z konwencją, jeśli wskaźnik zawiera wartość null (zero), zakłada się, że nie wskazuje niczego. Aby sprawdzić pusty wskaźnik, możesz użyć instrukcji if w następujący sposób -
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is nullTak więc, jeśli wszystkie nieużywane wskaźniki mają wartość null i unikasz używania wskaźnika pustego, możesz uniknąć przypadkowego niewłaściwego użycia niezainicjowanego wskaźnika. Często niezainicjalizowane zmienne przechowują pewne niepotrzebne wartości i debugowanie programu staje się trudne.
Arytmetyka wskaźników
Istnieją cztery operatory arytmetyczne, których można używać na wskaźnikach: ++, -, + i -
Aby zrozumieć arytmetykę wskaźników, rozważmy wskaźnik o nazwie całkowitej ptr, co wskazuje na adres 1000. Zakładając 32-bitowe liczby całkowite, wykonajmy na wskaźniku następującą operację arytmatyczną -
ptr++a później ptrwskaże lokalizację 1004, ponieważ za każdym razem, gdy ptr jest zwiększane, wskazuje na następną liczbę całkowitą. Ta operacja przeniesie wskaźnik do następnej lokalizacji pamięci bez wpływu na rzeczywistą wartość w tej lokalizacji.
Gdyby ptr wskazuje na znak o adresie 1000, to powyższa operacja wskazuje na lokalizację 1001, ponieważ następny znak będzie dostępny pod 1001.
Zwiększanie wskaźnika
Preferujemy użycie wskaźnika w naszym programie zamiast tablicy, ponieważ wskaźnik zmiennej może być zwiększany, w przeciwieństwie do nazwy tablicy, której nie można zwiększać, ponieważ jest wskaźnikiem stałym. Poniższy program zwiększa wskaźnik zmiennej, aby uzyskać dostęp do każdego kolejnego elementu tablicy -
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200Wskaźniki a tablica
Wskaźniki i tablice są silnie powiązane. Jednak wskaźniki i tablice nie są całkowicie zamienne. Na przykład rozważmy następujący program -
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}W powyższym programie możesz zobaczyć var.ptr [2], aby ustawić drugi element i ptr [0], który jest używany do ustawienia elementu zerowego. Operator inkrementacji może być używany z ptr, ale nie z var.
Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290Wskaźnik do wskaźnika
Wskaźnik do wskaźnika jest formą wielokrotnego pośrednictwa lub łańcuchem wskaźników. Zwykle wskaźnik zawiera adres zmiennej. Kiedy definiujemy wskaźnik do wskaźnika, pierwszy wskaźnik zawiera adres drugiego wskaźnika, który wskazuje lokalizację zawierającą rzeczywistą wartość, jak pokazano poniżej.

Zmienna będąca wskaźnikiem do wskaźnika musi być zadeklarowana jako taka. Odbywa się to poprzez umieszczenie dodatkowej gwiazdki przed jego nazwą. Na przykład, poniżej przedstawiono składnię deklarowania wskaźnika do wskaźnika typu int -
int **var;Gdy wartość docelowa jest pośrednio wskazywana przez wskaźnik do wskaźnika, dostęp do tej wartości wymaga dwukrotnego zastosowania operatora gwiazdki, jak pokazano poniżej w przykładzie -
import std.stdio;
const int MAX = 3;
void main () {
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000Przekazywanie wskaźnika do funkcji
D umożliwia przekazanie wskaźnika do funkcji. Aby to zrobić, po prostu deklaruje parametr funkcji jako typ wskaźnika.
Poniższy prosty przykład przekazuje wskaźnik do funkcji.
import std.stdio;
void main () {
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size) {
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum/size;
return avg;
}Kiedy powyższy kod jest kompilowany i wykonywany razem, daje następujący wynik -
Average is :214.4Zwróć wskaźnik z funkcji
Rozważmy następującą funkcję, która zwraca 10 liczb za pomocą wskaźnika, czyli adres pierwszego elementu tablicy.
import std.stdio;
void main () {
int *p = getNumber();
for ( int i = 0; i < 10; i++ ) {
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( ) {
static int r [10];
for (int i = 0; i < 10; ++i) {
r[i] = i;
}
return &r[0];
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9Wskaźnik do tablicy
Nazwa tablicy jest stałym wskaźnikiem do pierwszego elementu tablicy. Dlatego w deklaracji -
double balance[50];balancejest wskaźnikiem do & balance [0], który jest adresem pierwszego elementu tablicy balance. W ten sposób przypisuje się następujący fragment programup adres pierwszego elementu balance -
double *p;
double balance[10];
p = balance;Dozwolone jest używanie nazw tablic jako stałych wskaźników i na odwrót. Dlatego * (balance + 4) jest legalnym sposobem dostępu do danych w bilansie [4].
Po zapisaniu adresu pierwszego elementu w p, możesz uzyskać dostęp do elementów tablicy za pomocą * p, * (p + 1), * (p + 2) i tak dalej. Poniższy przykład pokazuje wszystkie koncepcje omówione powyżej -
import std.stdio;
void main () {
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using pointer " );
for ( int i = 0; i < 5; i++ ) {
writeln( "*(p + ", i, ") : ", *(p + i));
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Array values using pointer
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50Krotki służą do łączenia wielu wartości w jeden obiekt. Krotki zawierają sekwencję elementów. Elementami mogą być typy, wyrażenia lub aliasy. Liczba i elementy krotki są ustalane w czasie kompilacji i nie można ich zmienić w czasie wykonywania.
Krotki mają cechy zarówno struktur, jak i tablic. Elementy krotki mogą być różnych typów, takich jak struktury. Dostęp do elementów można uzyskać poprzez indeksowanie, podobnie jak tablice. Są zaimplementowane jako funkcja biblioteki przez szablon Tuple z modułu std.typecons. Tuple korzysta z TypeTuple z modułu std.typetuple dla niektórych swoich operacji.
Tuple Using tuple ()
Krotki można konstruować za pomocą funkcji tuple (). Dostęp do elementów członkowskich krotki uzyskuje się za pomocą wartości indeksu. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
import std.typecons;
void main() {
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Tuple!(int, string)(1, "Tuts")
1
TutsKrotka przy użyciu szablonu krotki
Krotka może być również skonstruowana bezpośrednio przez szablon krotki zamiast funkcji tuple (). Typ i nazwa każdego elementu członkowskiego są określane jako dwa kolejne parametry szablonu. Dostęp do członków można uzyskać za pomocą właściwości, gdy są tworzone przy użyciu szablonów.
import std.stdio;
import std.typecons;
void main() {
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value TutsRozszerzanie parametrów właściwości i funkcji
Składowe krotki można rozszerzyć za pomocą właściwości .expand lub przez wycinanie. Ta rozszerzona / podzielona na plasterki wartość może być przekazana jako lista argumentów funkcji. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(int a, float b, char c) {
writeln("method 2 ",a,"\t",b,"\t",c);
}
void main() {
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 rTypeTuple
TypeTuple jest zdefiniowany w module std.typetuple. Lista wartości i typów oddzielonych przecinkami. Poniżej podano prosty przykład użycia TypeTuple. TypeTuple służy do tworzenia listy argumentów, listy szablonów i listy literałów tablicowych.
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
method 1 5 my string 3.3 r
5 6Plik structure jest kolejnym typem danych zdefiniowanym przez użytkownika dostępnym w programowaniu D, który umożliwia łączenie elementów danych różnego rodzaju.
Struktury służą do reprezentowania rekordu. Załóżmy, że chcesz śledzić swoje książki w bibliotece. Możesz chcieć śledzić następujące atrybuty dotyczące każdej książki -
- Title
- Author
- Subject
- Identyfikator książki
Definiowanie struktury
Aby zdefiniować strukturę, musisz użyć structkomunikat. Instrukcja struct definiuje nowy typ danych z więcej niż jednym składnikiem programu. Format instrukcji struct jest następujący -
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];Plik structure tagjest opcjonalna, a każda definicja elementu jest zwykłą definicją zmiennej, na przykład int i; lub float f; lub jakąkolwiek inną prawidłową definicję zmiennej. Na końcu definicji struktury przed średnikiem można określić jedną lub więcej zmiennych strukturalnych, które są opcjonalne. Oto sposób, w jaki można zadeklarować strukturę Książek -
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};Dostęp do członków struktury
Aby uzyskać dostęp do dowolnego elementu członkowskiego struktury, użyj rozszerzenia member access operator (.). Operator dostępu do elementu jest zakodowany jako okres między nazwą zmiennej strukturalnej a elementem struktury, do którego chcemy uzyskać dostęp. Użyłbyśstructsłowo kluczowe do definiowania zmiennych typu konstrukcji. Poniższy przykład wyjaśnia użycie struktury -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : D Programming
Book 2 author : Raj
Book 2 subject : D Programming Tutorial
Book 2 book_id : 6495700Struktury jako argumenty funkcji
Możesz przekazać strukturę jako argument funkcji w bardzo podobny sposób, jak przekazujesz dowolną inną zmienną lub wskaźnik. Dostęp do zmiennych strukturalnych uzyskasz w podobny sposób, jak w powyższym przykładzie -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495700Inicjalizacja struktur
Struktury mogą być inicjalizowane w dwóch formach, jedna przy użyciu construtor, a druga przy użyciu formatu {}. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("D Programming".dup,
"D Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001Członkowie statyczni
Zmienne statyczne są inicjowane tylko raz. Na przykład, aby mieć unikalne identyfikatory książek, możemy ustawić identyfikator book_id jako statyczny i zwiększyć identyfikator książki. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003ZA unionto specjalny typ danych dostępny w D, który umożliwia przechowywanie różnych typów danych w tej samej lokalizacji pamięci. Możesz zdefiniować unię z wieloma członkami, ale tylko jeden członek może zawierać wartość w danym momencie. Związki zapewniają efektywny sposób używania tej samej lokalizacji pamięci do wielu celów.
Definiowanie unii w D.
Aby zdefiniować sumę, musisz użyć instrukcji union w bardzo podobny sposób, jak podczas definiowania struktury. Instrukcja union definiuje nowy typ danych z więcej niż jednym składnikiem programu. Format oświadczenia związku jest następujący -
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];Plik union tagjest opcjonalna, a każda definicja elementu jest zwykłą definicją zmiennej, na przykład int i; lub float f; lub jakąkolwiek inną prawidłową definicję zmiennej. Na końcu definicji unii, przed ostatnim średnikiem, można określić jedną lub więcej zmiennych sumujących, ale jest to opcjonalne. Oto sposób zdefiniowania typu unii o nazwie Dane, który ma trzech członkówi, f, i str -
union Data {
int i;
float f;
char str[20];
} data;Zmienna Datatype może przechowywać liczbę całkowitą, liczbę zmiennoprzecinkową lub ciąg znaków. Oznacza to, że jedna zmienna (ta sama lokalizacja pamięci) może służyć do przechowywania wielu typów danych. W ramach unii można używać dowolnych wbudowanych lub zdefiniowanych przez użytkownika typów danych w zależności od wymagań.
Pamięć zajmowana przez związek będzie wystarczająco duża, aby pomieścić największego członka związku. Na przykład w powyższym przykładzie Typ danych zajmie 20 bajtów pamięci, ponieważ jest to maksymalna przestrzeń, jaką może zajmować ciąg znaków. Poniższy przykład wyświetla całkowity rozmiar pamięci zajmowanej przez powyższą sumę -
import std.stdio;
union Data {
int i;
float f;
char str[20];
};
int main( ) {
Data data;
writeln( "Memory size occupied by data : ", data.sizeof);
return 0;
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Memory size occupied by data : 20Dostęp do członków związku
Aby uzyskać dostęp do dowolnego członka związku, używamy rozszerzenia member access operator (.). Operator dostępu do członka jest zakodowany jako kropka między nazwą zmiennej unii a członkiem związku, do którego chcemy uzyskać dostęp. Aby zdefiniować zmienne typu union, należy użyć słowa kluczowego union.
Przykład
Poniższy przykład wyjaśnia użycie union -
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
data.i = 10;
data.f = 220.5;
data.str = "D Programming".dup;
writeln( "size of : ", data.sizeof);
writeln( "data.i : ", data.i);
writeln( "data.f : ", data.f);
writeln( "data.str : ", data.str);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
size of : 16
data.i : 1917853764
data.f : 4.12236e+30
data.str : D ProgrammingTutaj możesz zobaczyć, że wartości i i f członkowie związku ulegli uszkodzeniu, ponieważ ostateczna wartość przypisana do zmiennej zajęła miejsce w pamięci i jest to powód, dla którego wartość str członek jest bardzo dobrze drukowany.
Teraz spójrzmy jeszcze raz na ten sam przykład, w którym będziemy używać jednej zmiennej naraz, co jest głównym celem posiadania unii -
Zmodyfikowany przykład
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
writeln( "size of : ", data.sizeof);
data.i = 10;
writeln( "data.i : ", data.i);
data.f = 220.5;
writeln( "data.f : ", data.f);
data.str = "D Programming".dup;
writeln( "data.str : ", data.str);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
size of : 16
data.i : 10
data.f : 220.5
data.str : D ProgrammingTutaj wszyscy członkowie są bardzo dobrze drukowani, ponieważ jeden członek jest używany na raz.
Zakresy są abstrakcją dostępu do elementów. Ta abstrakcja umożliwia stosowanie dużej liczby algorytmów w wielu typach kontenerów. Zakresy kładą nacisk na sposób uzyskiwania dostępu do elementów kontenera, w przeciwieństwie do sposobu implementacji kontenerów. Zakresy to bardzo prosta koncepcja oparta na tym, czy typ definiuje określone zestawy funkcji składowych.
Zakresy są integralną częścią wycinków D. D są implementacjami najpotężniejszego zakresu RandomAccessRange, aw Phobos jest wiele funkcji zasięgu. Wiele algorytmów Phobos zwraca tymczasowe obiekty zasięgu. Na przykład filter () wybiera elementy, które są większe niż 10 w poniższym kodzie, w rzeczywistości zwraca obiekt zakresu, a nie tablicę.
Zakresy liczbowe
Zakresy liczb są dość powszechnie używane, a te zakresy liczb są typu int. Poniżej przedstawiono kilka przykładów zakresów liczb -
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];Zakresy Phobosa
Zakresy związane ze strukturami i interfejsami klas to zakresy fobos. Phobos jest oficjalną biblioteką wykonawczą i standardową dostarczaną wraz z kompilatorem języka D.
Istnieją różne rodzaje zakresów, które obejmują -
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
InputRange
Najprostszym zakresem jest zakres wejściowy. Inne zakresy stawiają więcej wymagań niż zakres, na którym są oparte. Istnieją trzy funkcje, których wymaga InputRange -
empty- Określa, czy zakres jest pusty; musi zwrócić prawdę, gdy zakres jest uważany za pusty; w przeciwnym razie fałsz.
front - Zapewnia dostęp do elementu na początku zakresu.
popFront() - Skraca zasięg od początku usuwając pierwszy element.
Przykład
import std.stdio;
import std.string;
struct Student {
string name;
int number;
string toString() const {
return format("%s(%s)", name, number);
}
}
struct School {
Student[] students;
}
struct StudentRange {
Student[] students;
this(School school) {
this.students = school.students;
}
@property bool empty() const {
return students.length == 0;
}
@property ref Student front() {
return students[0];
}
void popFront() {
students = students[1 .. $];
}
}
void main() {
auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]);
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]ForwardRange
ForwardRange dodatkowo wymaga części składowej składowej składowania z pozostałych trzech funkcji InputRange i zwraca kopię zakresu po wywołaniu funkcji składowania.
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%s: %s", title, range.take(5));
}
void main() {
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]Dwukierunkowy zakres
Funkcja BidirectionalRange dodatkowo zapewnia dwie funkcje składowe w stosunku do funkcji składowych ForwardRange. Funkcja tyłu, podobnie jak przód, zapewnia dostęp do ostatniego elementu asortymentu. Funkcja popBack jest podobna do funkcji popFront i usuwa ostatni element z zakresu.
Przykład
import std.array;
import std.stdio;
import std.string;
struct Reversed {
int[] range;
this(int[] range) {
this.range = range;
}
@property bool empty() const {
return range.empty;
}
@property int front() const {
return range.back; // reverse
}
@property int back() const {
return range.front; // reverse
}
void popFront() {
range.popBack();
}
void popBack() {
range.popFront();
}
}
void main() {
writeln(Reversed([ 1, 2, 3]));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
[3, 2, 1]Nieskończony RandomAccessRange
opIndex () jest dodatkowo wymagana w porównaniu z ForwardRange. Ponadto wartość pustej funkcji, która ma być znana w czasie kompilacji, jako fałsz. Prosty przykład wyjaśniono za pomocą zakresu kwadratów pokazano poniżej.
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main() {
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]Finite RandomAccessRange
opIndex () i length są dodatkowo wymagane w porównaniu z zakresem dwukierunkowym. Jest to wyjaśnione za pomocą szczegółowego przykładu, w którym użyto wcześniej wykorzystanego przykładu szeregów Fibonacciego i zakresu kwadratów. Ten przykład działa dobrze na normalnym kompilatorze D, ale nie działa na kompilatorze online.
Przykład
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together {
const(int)[][] slices;
this(const(int)[][] slices ...) {
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront() {
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack() {
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const {
return slices.empty;
}
@property int front() const {
return slices.front.front;
}
void popFront() {
slices.front.popFront();
clearFront();
}
@property Together save() const {
return Together(slices.dup);
}
@property int back() const {
return slices.back.back;
}
void popBack() {
slices.back.popBack();
clearBack();
}
@property size_t length() const {
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const {
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)", originalIndex, this.length));
}
}
void main() {
auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]OutputRange
OutputRange reprezentuje przesyłane strumieniowo dane wyjściowe elementu, podobne do wysyłania znaków na standardowe wyjście. OutputRange wymaga obsługi operacji put (zakres, element). put () to funkcja zdefiniowana w module std.range. Określa możliwości zakresu i elementu w czasie kompilacji i używa najbardziej odpowiedniej metody do użycia w celu wyprowadzenia elementów. Poniżej przedstawiono prosty przykład.
import std.algorithm;
import std.stdio;
struct MultiFile {
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...) {
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element) {
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main() {
auto output = MultiFile("\n", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
[1, 2, 3]
["red", "blue", "green"]Alias, zgodnie z nazwą, zapewnia alternatywną nazwę dla istniejących nazw. Poniżej przedstawiono składnię aliasów.
alias new_name = existing_name;Poniżej znajduje się starsza składnia, na wypadek gdybyś odwołał się do przykładów starszego formatu. Zdecydowanie odradza się korzystanie z tego.
alias existing_name new_name;Istnieje również inna składnia, która jest używana z wyrażeniem i jest podana poniżej, w której możemy bezpośrednio użyć nazwy aliasu zamiast wyrażenia.
alias expression alias_name ;Jak być może wiesz, typedef dodaje możliwość tworzenia nowych typów. Alias może wykonywać pracę typedef, a nawet więcej. Poniżej przedstawiono prosty przykład użycia aliasu, który wykorzystuje nagłówek std.conv, który zapewnia możliwość konwersji typu.
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main() {
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Test10W powyższym przykładzie zamiast używać to! String (a), przypisaliśmy go do aliasu toString, dzięki czemu jest wygodniejszy i łatwiejszy do zrozumienia.
Alias dla krotki
Spójrzmy na inny przykład, w którym możemy ustawić nazwę aliasu krotki.
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
method1(5, 6L);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
5 6W powyższym przykładzie krotka typu jest przypisana do zmiennej aliasu i upraszcza definicję metody i dostęp do zmiennych. Ten rodzaj dostępu jest jeszcze bardziej przydatny, gdy próbujemy ponownie użyć krotek tego typu.
Alias dla typów danych
Wiele razy możemy zdefiniować wspólne typy danych, które muszą być używane w całej aplikacji. Kiedy wielu programistów koduje aplikację, może się zdarzyć, że jedna osoba używa int, inna double i tak dalej. Aby uniknąć takich konfliktów, często używamy typów dla typów danych. Poniżej przedstawiono prosty przykład.
Przykład
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main() {
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
10TestStringAlias dla zmiennych klas
Często istnieje wymóg, w którym musimy uzyskać dostęp do zmiennych składowych nadklasy w podklasie, można to zrobić za pomocą aliasu, prawdopodobnie pod inną nazwą.
Jeśli nie masz doświadczenia z koncepcją klas i dziedziczenia, zapoznaj się z samouczkiem dotyczącym klas i dziedziczenia, zanim zaczniesz od tej sekcji.
Przykład
Poniżej przedstawiono prosty przykład.
import std.stdio;
class Shape {
int area;
}
class Square : Shape {
string name() const @property {
return "Square";
}
alias Shape.area squareArea;
}
void main() {
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Square
42Alias This
Alias zapewnia możliwość automatycznej konwersji typów typów zdefiniowanych przez użytkownika. Składnia jest pokazana poniżej, gdzie alias słów kluczowych jest zapisany po obu stronach zmiennej składowej lub funkcji składowej.
alias member_variable_or_member_function this;Przykład
Przykład jest pokazany poniżej, aby pokazać moc aliasu this.
import std.stdio;
struct Rectangle {
long length;
long breadth;
double value() const @property {
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height) {
return rectangle * height;
}
void main() {
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}W powyższym przykładzie widać, że prostokąt struct jest konwertowany na podwójną wartość za pomocą aliasu tej metody.
Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
30Miksy to struktury, które umożliwiają mieszanie wygenerowanego kodu z kodem źródłowym. Mieszanki mogą być następujących typów -
- Mixy strunowe
- Mieszanki szablonów
- Mieszane przestrzenie nazw
Mixy strunowe
D ma możliwość wstawiania kodu jako łańcucha, o ile ten ciąg jest znany w czasie kompilacji. Składnia kombinacji ciągów jest pokazana poniżej -
mixin (compile_time_generated_string)Przykład
Poniżej przedstawiono prosty przykład miksów stringów.
import std.stdio;
void main() {
mixin(`writeln("Hello World!");`);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Hello World!Oto kolejny przykład, w którym możemy przekazać ciąg w czasie kompilacji, aby miksery mogły używać funkcji do ponownego wykorzystania kodu. Jest to pokazane poniżej.
import std.stdio;
string print(string s) {
return `writeln("` ~ s ~ `");`;
}
void main() {
mixin (print("str1"));
mixin (print("str2"));
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
str1
str2Mieszanki szablonów
Szablony D definiują typowe wzorce kodu, aby kompilator generował rzeczywiste wystąpienia z tego wzorca. Szablony mogą generować funkcje, struktury, związki, klasy, interfejsy i każdy inny legalny kod D. Składnia kombinacji szablonów jest pokazana poniżej.
mixin a_template!(template_parameters)Prosty przykład mieszania ciągów jest pokazany poniżej, gdzie tworzymy szablon z klasą Departament i mikserem tworzącym instancję szablonu, a tym samym udostępniając funkcje setName i printNames dla struktury college.
Przykład
import std.stdio;
template Department(T, size_t count) {
T[count] names;
void setName(size_t index, T name) {
names[index] = name;
}
void printNames() {
writeln("The names");
foreach (i, name; names) {
writeln(i," : ", name);
}
}
}
struct College {
mixin Department!(string, 2);
}
void main() {
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The names
0 : name1
1 : name2Pomieszane przestrzenie nazw
Przestrzenie nazw w domenie są używane, aby uniknąć niejednoznaczności w szablonach. Na przykład mogą istnieć dwie zmienne, jedna zdefiniowana jawnie w main, a druga wmieszana. Gdy nazwa wmieszana jest taka sama jak nazwa w otaczającym zakresie, wówczas nazwa znajdująca się w otaczającym zakresie zostanie używany. Ten przykład jest pokazany poniżej.
Przykład
import std.stdio;
template Person() {
string name;
void print() {
writeln(name);
}
}
void main() {
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
name 1
name 2Moduły są elementami składowymi D. Opierają się na prostej koncepcji. Każdy plik źródłowy jest modułem. W związku z tym pojedyncze pliki, w których piszemy programy, są pojedynczymi modułami. Domyślnie nazwa modułu jest taka sama, jak nazwa pliku bez rozszerzenia .d.
W przypadku jawnego określenia nazwa modułu jest definiowana przez słowo kluczowe module, które musi występować jako pierwsza linia nie będąca komentarzem w pliku źródłowym. Na przykład załóżmy, że nazwa pliku źródłowego to „pracownik.d”. Następnie nazwa modułu jest określana za pomocą słowa kluczowego modułu, po którym następuje pracownik . Jest tak, jak pokazano poniżej.
module employee;
class Employee {
// Class definition goes here.
}Linia modułu jest opcjonalna. Jeśli nie jest określony, jest taki sam jak nazwa pliku bez rozszerzenia .d.
Nazwy plików i modułów
D obsługuje Unicode w kodzie źródłowym i nazwach modułów. Jednak obsługa Unicode w systemach plików jest różna. Na przykład, chociaż większość systemów plików Linuksa obsługuje Unicode, nazwy plików w systemach plików Windows mogą nie rozróżniać małych i dużych liter. Ponadto większość systemów plików ogranicza liczbę znaków, których można używać w nazwach plików i katalogów. Ze względu na przenośność zalecam używanie w nazwach plików tylko małych liter ASCII. Na przykład „pracownik.d” będzie odpowiednią nazwą pliku dla klasy o nazwie pracownik.
W związku z tym nazwa modułu składałaby się również z liter ASCII -
module employee; // Module name consisting of ASCII letters
class eëmployëë { }Pakiety D.
Połączenie powiązanych modułów nazywane jest pakietem. Pakiety D to również prosta koncepcja: pliki źródłowe, które znajdują się w tym samym katalogu, są traktowane jako należące do tego samego pakietu. Nazwa katalogu staje się nazwą pakietu, którą należy również podać jako pierwszą część nazw modułów.
Na przykład, jeśli „pracownik.d” i „biuro.d” znajdują się w katalogu „firma”, to określenie nazwy katalogu wraz z nazwą modułu spowoduje, że będą one częścią tego samego pakietu -
module company.employee;
class Employee { }Podobnie dla modułu biurowego -
module company.office;
class Office { }Ponieważ nazwy pakietów odpowiadają nazwom katalogów, nazwy pakietów modułów, które są głębsze niż jeden poziom katalogu, muszą odzwierciedlać tę hierarchię. Na przykład, jeśli katalog „firma” zawiera katalog „oddział”, nazwa modułu w tym katalogu będzie również zawierać oddział.
module company.branch.employee;Korzystanie z modułów w programach
Słowo kluczowe import, którego używaliśmy do tej pory w prawie każdym programie, służy do wprowadzenia modułu do aktualnego modułu -
import std.stdio;Nazwa modułu może również zawierać nazwę pakietu. Na przykład std. część powyżej wskazuje, że stdio to moduł, który jest częścią pakietu std.
Lokalizacje modułów
Kompilator znajduje pliki modułów, konwertując nazwy pakietów i modułów bezpośrednio na nazwy katalogów i plików.
Na przykład dwa moduły pracownik i biuro będą znajdować się odpowiednio jako „firma / pracownik.d” i „zwierzę / biuro.d” (lub „firma \ pracownik.d” i „firma \ biuro.d”, w zależności od system plików) dla firma.pracownik i firma.biuro.
Długie i krótkie nazwy modułów
Nazwy używane w programie można przeliterować wraz z nazwami modułów i pakietów, jak pokazano poniżej.
import company.employee;
auto employee0 = Employee();
auto employee1 = company.employee.Employee();Długie nazwy zwykle nie są potrzebne, ale czasami występują konflikty nazw. Na przykład, odwołując się do nazwy, która pojawia się w więcej niż jednym module, kompilator nie może zdecydować, o którą z nich chodzi. Poniższy program podaje długie nazwy, aby rozróżnić dwie oddzielne struktury pracowników, które są zdefiniowane w dwóch oddzielnych modułach: firma i uczelnia. .
Pierwszy moduł pracownika w folderze firmowym jest następujący.
module company.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("Company Employee: ",str);
}
}Drugi moduł dla pracowników w folderze college jest następujący.
module college.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("College Employee: ",str);
}
}Główny moduł hello.d powinien zostać zapisany w folderze zawierającym foldery uczelni i firm. Jest to następujące.
import company.employee;
import college.employee;
import std.stdio;
void main() {
auto myemployee1 = new company.employee.Employee();
myemployee1.str = "emp1";
myemployee1.print();
auto myemployee2 = new college.employee.Employee();
myemployee2.str = "emp2";
myemployee2.print();
}Słowo kluczowe import nie jest wystarczające, aby moduły stały się częściami programu. Po prostu udostępnia funkcje modułu wewnątrz bieżącego modułu. Tyle potrzeba tylko do skompilowania kodu.
Aby można było zbudować powyższy program, w wierszu kompilacji należy również określić „firma / pracownik.d” i „uczelnia / pracownik.d”.
Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx
$ ./hello.amx
Company Employee: emp1
College Employee: emp2Szablony są podstawą programowania ogólnego, które obejmuje pisanie kodu w sposób niezależny od określonego typu.
Szablon jest planem lub formułą służącą do tworzenia ogólnej klasy lub funkcji.
Szablony to funkcja, która pozwala opisywać kod jako wzorzec, aby kompilator automatycznie generował kod programu. Części kodu źródłowego można pozostawić kompilatorowi do wypełnienia, dopóki ta część nie zostanie faktycznie wykorzystana w programie. Kompilator uzupełnia brakujące części.
Szablon funkcji
Definiowanie funkcji jako szablonu pozostawia jeden lub więcej typów, których używa, jako nieokreślonych, aby kompilator mógł je później wywnioskować. Typy, które mają pozostać nieokreślone, są definiowane na liście parametrów szablonu, która znajduje się między nazwą funkcji a listą parametrów funkcji. Z tego powodu szablony funkcji mają dwie listy parametrów -
- lista parametrów szablonu
- lista parametrów funkcji
import std.stdio;
void print(T)(T value) {
writefln("%s", value);
}
void main() {
print(42);
print(1.2);
print("test");
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
42
1.2
testSzablon funkcji z wieloma parametrami typu
Może istnieć wiele typów parametrów. Przedstawiono je w poniższym przykładzie.
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2) {
writefln(" %s %s", value1, value2);
}
void main() {
print(42, "Test");
print(1.2, 33);
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
42 Test
1.2 33Szablony klas
Tak jak możemy definiować szablony funkcji, możemy również definiować szablony klas. Poniższy przykład definiuje klasę Stack i implementuje metody ogólne do wypychania i zdejmowania elementów ze stosu.
import std.stdio;
import std.string;
class Stack(T) {
private:
T[] elements;
public:
void push(T element) {
elements ~= element;
}
void pop() {
--elements.length;
}
T top() const @property {
return elements[$ - 1];
}
size_t length() const @property {
return elements.length;
}
}
void main() {
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Test2
2
Test1
1Często używamy zmiennych, które są mutowalne, ale może się zdarzyć, że zmienność nie jest wymagana. W takich przypadkach można użyć niezmiennych zmiennych. Poniżej podano kilka przykładów, w których można użyć niezmiennej zmiennej.
W przypadku stałych matematycznych, takich jak pi, które nigdy się nie zmieniają.
W przypadku tablic, w których chcemy zachować wartości i nie jest to wymaganie mutacji.
Niezmienność pozwala zrozumieć, czy zmienne są niezmienne, czy zmienne, gwarantując, że pewne operacje nie zmieniają pewnych zmiennych. Zmniejsza również ryzyko wystąpienia niektórych typów błędów programu. Pojęcie niezmienności D jest reprezentowane przez const i niezmienne słowa kluczowe. Chociaż same te dwa słowa mają bliskie znaczenie, ich obowiązki w programach są różne i czasami są niezgodne.
Pojęcie niezmienności D jest reprezentowane przez const i niezmienne słowa kluczowe. Chociaż same te dwa słowa mają bliskie znaczenie, ich obowiązki w programach są różne i czasami są niezgodne.
Typy niezmiennych zmiennych w D
Istnieją trzy typy zmiennych definiujących, których nigdy nie można modyfikować.
- stałe wyliczeniowe
- niezmienne zmienne
- zmienne const
enum Stałe w D
Stałe wyliczeniowe umożliwiają powiązanie wartości stałych ze znaczącymi nazwami. Poniżej przedstawiono prosty przykład.
Przykład
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main() {
Day day;
day = Day.Sunday;
if (day == Day.Sunday) {
writeln("The day is Sunday");
}
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
The day is SundayNiezmienne zmienne w D
Niezmienne zmienne można określić podczas wykonywania programu. Po prostu kieruje kompilatorem, aby po inicjalizacji stał się niezmienny. Poniżej przedstawiono prosty przykład.
Przykład
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
immutable(int)4
immutable(int)100W powyższym przykładzie widać, jak można przenieść typ danych do innej zmiennej i użyć stringof podczas drukowania.
Zmienne Const w D.
Zmiennych const nie można modyfikować podobnie do niezmiennych. niezmienne zmienne mogą być przekazywane do funkcji jako ich niezmienne parametry, dlatego zaleca się używanie niezmiennych zamiast stałych. Ten sam przykład użyty wcześniej został zmodyfikowany dla const, jak pokazano poniżej.
Przykład
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Jeśli skompilujemy i uruchomimy powyższy kod, otrzymamy następujący wynik -
const(int)7
const(int)100Niezmienne parametry w D
const usuwa informacje o tym, czy oryginalna zmienna jest modyfikowalna, czy niezmienna, a zatem użycie niezmiennej powoduje przekazanie jej do innych funkcji z zachowanym typem oryginalnym. Poniżej przedstawiono prosty przykład.
Przykład
import std.stdio;
void print(immutable int[] array) {
foreach (i, element; array) {
writefln("%s: %s", i, element);
}
}
void main() {
immutable int[] array = [ 1, 2 ];
print(array);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
0: 1
1: 2Pliki są reprezentowane przez pliku struktury modułu std.stdio. Plik reprezentuje sekwencję bajtów, nie ma znaczenia, czy jest to plik tekstowy czy binarny.
Język programowania D zapewnia dostęp do funkcji wysokiego poziomu, a także wywołań niskiego poziomu (poziom systemu operacyjnego) do obsługi plików na urządzeniach magazynujących.
Otwieranie plików w D
Standardowe strumienie wejściowe i wyjściowe stdin i stdout są już otwarte, gdy programy są uruchamiane. Są gotowe do użycia. Z drugiej strony, pliki należy najpierw otworzyć, określając nazwę pliku i wymagane prawa dostępu.
File file = File(filepath, "mode");Tutaj, filename to literał łańcuchowy, którego używasz do nazwania pliku i uzyskania dostępu mode może mieć jedną z następujących wartości -
| Sr.No. | Tryb i opis |
|---|---|
| 1 | r Otwiera istniejący plik tekstowy do odczytu. |
| 2 | w Otwiera plik tekstowy do zapisu, jeśli nie istnieje, tworzony jest nowy plik. Tutaj twój program zacznie zapisywać zawartość od początku pliku. |
| 3 | a Otwiera plik tekstowy do zapisu w trybie dołączania, jeśli nie istnieje, tworzony jest nowy plik. Tutaj Twój program rozpocznie dołączanie zawartości do istniejącej zawartości pliku. |
| 4 | r+ Otwiera plik tekstowy do odczytu i zapisu obu. |
| 5 | w+ Otwiera plik tekstowy do odczytu i zapisu obu. Najpierw skraca plik do zerowej długości, jeśli istnieje, w przeciwnym razie tworzy plik, jeśli nie istnieje. |
| 6 | a+ Otwiera plik tekstowy do odczytu i zapisu obu. Tworzy plik, jeśli nie istnieje. Czytanie rozpocznie się od początku, ale tekst można tylko dołączyć. |
Zamknięcie pliku w D
Aby zamknąć plik, użyj funkcji file.close (), gdzie plik przechowuje odniesienie do pliku. Prototypem tej funkcji jest -
file.close();Każdy plik, który został otwarty przez program, musi zostać zamknięty, gdy program zakończy korzystanie z tego pliku. W większości przypadków pliki nie muszą być jawnie zamykane; są one automatycznie zamykane po zakończeniu obiektów File.
Pisanie pliku w D
file.writeln służy do zapisu w otwartym pliku.
file.writeln("hello");import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}Kiedy powyższy kod jest kompilowany i wykonywany, tworzy nowy plik test.txt w katalogu, w którym został uruchomiony (w katalogu roboczym programu).
Czytanie pliku w D
Poniższa metoda odczytuje pojedynczy wiersz z pliku -
string s = file.readln();Pełny przykład odczytu i zapisu przedstawiono poniżej.
import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
helloOto kolejny przykład odczytu pliku do końca pliku.
import std.stdio;
import std.string;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof()) {
string line = chomp(file.readln());
writeln("line -", line);
}
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
line -hello
line -world
line -W powyższym przykładzie możesz zobaczyć pustą trzecią linię, ponieważ writeln przenosi ją do następnej linii po wykonaniu.
Współbieżność powoduje, że program działa jednocześnie w wielu wątkach. Przykładem programu współbieżnego jest serwer WWW odpowiadający wielu klientom w tym samym czasie. Współbieżność jest łatwa przy przekazywaniu wiadomości, ale bardzo trudna do napisania, jeśli opiera się na udostępnianiu danych.
Dane przekazywane między wątkami nazywane są wiadomościami. Wiadomości mogą składać się z dowolnego typu i dowolnej liczby zmiennych. Każdy wątek ma identyfikator, który służy do określania odbiorców wiadomości. Każdy wątek, który rozpoczyna inny wątek, jest nazywany właścicielem nowego wątku.
Inicjowanie wątków w D
Funkcja spawn () przyjmuje wskaźnik jako parametr i rozpoczyna nowy wątek z tej funkcji. Wszelkie operacje wykonywane przez tę funkcję, w tym inne funkcje, które może wywołać, zostaną wykonane w nowym wątku. Właściciel i pracownik rozpoczynają wykonywanie oddzielnie, tak jakby byli niezależnymi programami.
Przykład
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a) {
foreach (i; 0 .. 4) {
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main() {
foreach (i; 1 .. 4) {
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(≈worker, i * 5);
}
writeln("main is done.");
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18Identyfikatory wątków w D
ThisTid zmienna ogólnie dostępne na poziomie modułu jest zawsze ID bieżącego wątku. Możesz również otrzymać threadId, gdy zostanie wywołana spawn. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
import std.concurrency;
void printTid(string tag) {
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker() {
printTid("Worker");
}
void main() {
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)Przekazywanie wiadomości w D
Funkcja send () wysyła wiadomości, a funkcja otrzymaszOnly () czeka na wiadomość określonego typu. Istnieją inne funkcje o nazwach PrioritySend (), Receive () i ReceiveTimeout (), które zostaną wyjaśnione później.
Właściciel w następującym programie wysyła swojemu pracownikowi wiadomość typu int i czeka na wiadomość od pracownika typu double. Wątki wysyłają wiadomości tam iz powrotem, dopóki właściciel nie wyśle negatywnej int. Przykład jest pokazany poniżej.
Przykład
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
int value = 0;
while (value >= 0) {
value = receiveOnly!int();
auto result = to!double(value) * 5; tid.send(result);
}
}
void main() {
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45Przekazywanie wiadomości z czekaniem w D
Poniżej przedstawiono prosty przykład z komunikatem przekazywanym wraz z czekaniem.
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main() {
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received) {
received = receiveTimeout(dur!("msecs")( 100 ), (string message) {
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: helloWyjątkiem jest problem, który pojawia się podczas wykonywania programu. Wyjątek AD jest odpowiedzią na wyjątkowe okoliczności, które pojawiają się podczas działania programu, na przykład próba podzielenia przez zero.
Wyjątki umożliwiają przekazanie kontroli z jednej części programu do drugiej. Obsługa wyjątków D jest oparta na trzech słowach kluczowychtry, catch, i throw.
throw- Program zgłasza wyjątek, gdy pojawia się problem. Odbywa się to za pomocą plikuthrow słowo kluczowe.
catch- Program przechwytuje wyjątek z obsługą wyjątków w miejscu programu, w którym chcesz obsłużyć problem. Plikcatch słowo kluczowe wskazuje na przechwycenie wyjątku.
try - A tryblok identyfikuje blok kodu, dla którego zostały aktywowane określone wyjątki. Po nim następuje jeden lub więcej bloków catch.
Zakładając, że blok zgłosi wyjątek, metoda przechwytuje wyjątek przy użyciu kombinacji try i catchsłowa kluczowe. Blok try / catch jest umieszczany wokół kodu, który może generować wyjątek. Kod w bloku try / catch jest nazywany kodem chronionym, a składnia użycia try / catch wygląda następująco -
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}Możesz wymienić wiele catch instrukcje, aby wychwycić różne typy wyjątków w przypadku, gdy plik try block wywołuje więcej niż jeden wyjątek w różnych sytuacjach.
Rzucanie wyjątków w D.
Wyjątki można zgłaszać w dowolnym miejscu w bloku kodu przy użyciu throwsprawozdania. Operand instrukcji throw określa typ wyjątku i może być dowolnym wyrażeniem, a typ wyniku wyrażenia określa typ zgłoszonego wyjątku.
Poniższy przykład zgłasza wyjątek, gdy występuje warunek dzielenia przez zero -
Przykład
double division(int a, int b) {
if( b == 0 ) {
throw new Exception("Division by zero condition!");
}
return (a/b);
}Łapanie wyjątków w D.
Plik catch blok następujący po tryblok wyłapuje każdy wyjątek. Możesz określić typ wyjątku, który chcesz przechwycić, i jest to określone przez deklarację wyjątku, która pojawia się w nawiasach po słowie kluczowym catch.
try {
// protected code
}
catch( ExceptionName e ) {
// code to handle ExceptionName exception
}Powyższy kod łapie wyjątek od ExceptionNamerodzaj. Jeśli chcesz określić, że blok catch powinien obsługiwać każdy typ wyjątku, który jest zgłaszany w bloku try, musisz umieścić wielokropek, ..., między nawiasami otaczającymi deklarację wyjątku w następujący sposób -
try {
// protected code
}
catch(...) {
// code to handle any exception
}Poniższy przykład zgłasza wyjątek dzielenia przez zero. Został złapany w blokadę.
import std.stdio;
import std.string;
string division(int a, int b) {
string result = "";
try {
if( b == 0 ) {
throw new Exception("Cannot divide by zero!");
} else {
result = format("%s",a/b);
}
} catch (Exception e) {
result = e.msg;
}
return result;
}
void main () {
int x = 50;
int y = 0;
writeln(division(x, y));
y = 10;
writeln(division(x, y));
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
Cannot divide by zero!
5Programowanie kontraktowe w programowaniu D koncentruje się na zapewnieniu prostego i zrozumiałego sposobu obsługi błędów. Programowanie kontraktowe w D jest realizowane za pomocą trzech typów bloków kodu -
- blok ciała
- w bloku
- się blok
Body Block w D.
Blok ciała zawiera rzeczywisty kod funkcjonalności wykonania. Bloki wejściowe i wyjściowe są opcjonalne, natomiast blokada ciała jest obowiązkowa. Poniżej przedstawiono prostą składnię.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}W bloku dla warunków wstępnych w D
W bloku jest dla prostych warunków wstępnych, które weryfikują, czy parametry wejściowe są akceptowalne i mieszczą się w zakresie, który może być obsługiwany przez kod. Zaletą bloku in jest to, że wszystkie warunki wejścia mogą być przechowywane razem i oddzielone od rzeczywistej treści funkcji. Poniżej przedstawiono prosty warunek wstępny weryfikacji hasła dla jego minimalnej długości.
import std.stdio;
import std.string;
bool isValid(string password)
in {
assert(password.length>=5);
}
body {
// other conditions
return true;
}
void main() {
writeln(isValid("password"));
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
trueNasze bloki dla warunków pocztowych w D
Blok out dba o wartości zwracane przez funkcję. Sprawdza, czy zwracana wartość mieści się w oczekiwanym zakresie. Poniżej pokazano prosty przykład zawierający zarówno wejście, jak i wyjście, który konwertuje miesiące, rok na połączoną dziesiętną formę wieku.
import std.stdio;
import std.string;
double getAge(double months,double years)
in {
assert(months >= 0);
assert(months <= 12);
}
out (result) {
assert(result>=years);
}
body {
return years + months/12;
}
void main () {
writeln(getAge(10,12));
}Gdy powyższy kod jest kompilowany i wykonywany, odczytuje plik utworzony w poprzedniej sekcji i generuje następujący wynik -
12.8333Kompilacja warunkowa to proces wyboru kodu do skompilowania, a który nie, podobnie jak w przypadku #if / #else / #endif w C i C ++. Każda instrukcja, która nie została wkompilowana, nadal musi być poprawna składniowo.
Kompilacja warunkowa obejmuje sprawdzanie warunków, które można ocenić w czasie kompilacji. Instrukcje warunkowe środowiska wykonawczego, takie jak if, for, while nie są funkcjami kompilacji warunkowej. Następujące funkcje D są przeznaczone do kompilacji warunkowej -
- debug
- version
- statyczne, jeśli
Instrukcja debugowania w D
Debug jest przydatna w trakcie rozwoju programu. Wyrażenia i instrukcje oznaczone jako debugowane są kompilowane do programu tylko wtedy, gdy jest włączony przełącznik kompilatora -debug.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}Klauzula else jest opcjonalna. Zarówno pojedyncze wyrażenie, jak i powyższy blok kodu są kompilowane tylko wtedy, gdy jest włączony przełącznik kompilatora -debug.
Zamiast całkowicie usuwać wiersze można zamiast tego oznaczyć je jako debugujące.
debug writefln("%s debug only statement", value);Takie wiersze są dołączane do programu tylko wtedy, gdy jest włączony przełącznik kompilatora -debug.
dmd test.d -oftest -w -debugInstrukcja Debug (tag) w D
Poleceniom debug można nadać nazwy (znaczniki), które mają być włączane do programu w sposób selektywny.
debug(mytag) writefln("%s not found", value);Takie wiersze są dołączane do programu tylko wtedy, gdy jest włączony przełącznik kompilatora -debug.
dmd test.d -oftest -w -debug = mytagBloki debugowania mogą również zawierać znaczniki.
debug(mytag) {
//
}Jednocześnie można włączyć więcej niż jeden tag debugowania.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2Instrukcja Debug (level) w D
Czasami bardziej przydatne jest powiązanie instrukcji debugowania według poziomów liczbowych. Zwiększenie poziomów może dostarczyć bardziej szczegółowych informacji.
import std.stdio;
void myFunction() {
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main() {
myFunction();
}Zostałyby skompilowane wyrażenia debugowania i bloki, które są mniejsze lub równe podanemu poziomowi.
$ dmd test.d -oftest -w -debug = 1 $ ./test
debug1Wersja (znacznik) i Wersja (poziom) Instrukcje w D
Wersja jest podobna do debugowania i jest używana w ten sam sposób. Klauzula else jest opcjonalna. Chociaż wersja działa zasadniczo tak samo jak debugowanie, posiadanie oddzielnych słów kluczowych pomaga rozróżnić ich niepowiązane zastosowania. Podobnie jak w przypadku debugowania, można włączyć więcej niż jedną wersję.
import std.stdio;
void myFunction() {
version(1) writeln("version1");
version(2) writeln("version2");
}
void main() {
myFunction();
}Zostałyby skompilowane wyrażenia debugowania i bloki, które są mniejsze lub równe podanemu poziomowi.
$ dmd test.d -oftest -w -version = 1 $ ./test
version1Statyczne, jeśli
Statyczny if jest odpowiednikiem czasu kompilacji instrukcji if. Podobnie jak instrukcja if, static if przyjmuje wyrażenie logiczne i oblicza je. W przeciwieństwie do instrukcji if, statyczne if nie dotyczy przepływu wykonywania; raczej określa, czy fragment kodu powinien być zawarty w programie, czy nie.
Wyrażenie if nie jest powiązane z operatorem is, który widzieliśmy wcześniej, zarówno pod względem składniowym, jak i semantycznym. Jest oceniany w czasie kompilacji. Daje wartość int, 0 lub 1; w zależności od wyrażenia podanego w nawiasach. Chociaż wyrażenie, które przyjmuje, nie jest wyrażeniem logicznym, samo wyrażenie is jest używane jako wyrażenie logiczne czasu kompilacji. Jest to szczególnie przydatne w statycznych, jeśli są uwarunkowane i szablonowe.
import std.stdio;
enum Days {
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate) {
static if (is (T == class)) {
writeln("This is a class type");
} else static if (is (T == enum)) {
writeln("This is an enum type");
}
}
void main() {
Days day;
myFunction(day);
}Kiedy kompilujemy i uruchamiamy, otrzymamy następujące dane wyjściowe.
This is an enum typeKlasy są centralną cechą programowania D, która obsługuje programowanie obiektowe i są często nazywane typami zdefiniowanymi przez użytkownika.
Klasa służy do określania formy obiektu i łączy reprezentację danych i metody manipulowania tymi danymi w jeden zgrabny pakiet. Dane i funkcje w klasie nazywane są członkami klasy.
Definicje klasy D.
Definiując klasę, definiujesz plan dla typu danych. W rzeczywistości nie definiuje to żadnych danych, ale określa, co oznacza nazwa klasy, czyli z czego będzie się składał obiekt tej klasy i jakie operacje można wykonać na takim obiekcie.
Definicja klasy zaczyna się od słowa kluczowego classpo którym następuje nazwa klasy; i treść klasy, ujęta w nawiasy klamrowe. Po definicji klasy należy umieścić średnik lub listę deklaracji. Na przykład zdefiniowaliśmy typ danych Box za pomocą słowa kluczowegoclass w następujący sposób -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}Słowo kluczowe publicokreśla atrybuty dostępu członków klasy, która po nim następuje. Dostęp do publicznego członka można uzyskać spoza klasy w dowolnym miejscu w zakresie obiektu klasy. Możesz również określić członków klasy jakoprivate lub protected które omówimy w podrozdziale.
Definiowanie obiektów D.
Klasa zapewnia plany obiektów, więc zasadniczo obiekt jest tworzony z klasy. Deklarujesz obiekty klasy z dokładnie takim samym rodzajem deklaracji, jak deklarujesz zmienne typu podstawowego. Poniższe instrukcje deklarują dwa obiekty klasy Box -
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxOba obiekty Box1 i Box2 mają własne kopie członków danych.
Dostęp do członków danych
Dostęp do publicznych członków danych obiektów klasy można uzyskać za pomocą operatora bezpośredniego dostępu do elementu członkowskiego (.). Wypróbujmy następujący przykład, aby wyjaśnić sprawę -
import std.stdio;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main() {
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Volume of Box1 : 210
Volume of Box2 : 1560Należy zauważyć, że nie można uzyskać bezpośredniego dostępu do członków prywatnych i chronionych za pomocą operatora bezpośredniego dostępu do członków (.). Wkrótce dowiesz się, jak można uzyskać dostęp do prywatnych i chronionych członków.
Klasy i obiekty w D
Jak dotąd masz bardzo podstawowe pojęcie o klasach D i obiektach. Istnieją dalsze interesujące koncepcje związane z klasami D i obiektami, które omówimy w różnych podsekcjach wymienionych poniżej -
| Sr.No. | Koncepcja i opis |
|---|---|
| 1 | Funkcje składowe klasy Funkcja składowa klasy to funkcja, która ma swoją definicję lub swój prototyp w definicji klasy, jak każda inna zmienna. |
| 2 | Modyfikatory dostępu do klas Członka klasy można zdefiniować jako publiczny, prywatny lub chroniony. Domyślnie członkowie zostaną uznani za prywatnych. |
| 3 | Konstruktor i destruktor Konstruktor klasy to specjalna funkcja w klasie, która jest wywoływana, gdy tworzony jest nowy obiekt tej klasy. Destruktor to także specjalna funkcja, która jest wywoływana po usunięciu utworzonego obiektu. |
| 4 | Wskaźnik this w D Każdy obiekt ma specjalny wskaźnik this co wskazuje na sam obiekt. |
| 5 | Wskaźnik do klas D. Wskaźnik do klasy jest wykonywany dokładnie w taki sam sposób, jak wskaźnik do struktury. W rzeczywistości klasa jest po prostu strukturą zawierającą funkcje. |
| 6 | Statyczne składowe klasy Zarówno elementy członkowskie danych, jak i elementy członkowskie funkcji klasy można zadeklarować jako statyczne. |
Dziedziczenie jest jedną z najważniejszych koncepcji programowania obiektowego. Dziedziczenie pozwala zdefiniować klasę pod względem innej klasy, co ułatwia tworzenie i utrzymywanie aplikacji. Daje to również możliwość ponownego wykorzystania funkcjonalności kodu i szybkiego czasu implementacji.
Tworząc klasę, zamiast pisać zupełnie nowe składowe danych i funkcje składowe, programista może wyznaczyć, że nowa klasa powinna dziedziczyć składowe istniejącej klasy. Ta istniejąca klasa nosi nazwębase class, a nowa klasa jest nazywana derived klasa.
Idea dziedziczenia implementuje relację. Na przykład, ssak IS-A zwierzę, pies IS-A ssak, stąd też pies IS-A zwierzę i tak dalej.
Klasy bazowe i klasy pochodne w D
Klasa może pochodzić z więcej niż jednej klasy, co oznacza, że może dziedziczyć dane i funkcje z wielu klas bazowych. Aby zdefiniować klasę pochodną, używamy listy pochodnych klas, aby określić klasy bazowe. Lista pochodnych klas zawiera nazwę jednej lub więcej klas bazowych i ma postać -
class derived-class: base-classRozważ klasę bazową Shape i jej klasa pochodna Rectangle w następujący sposób -
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 35Kontrola dostępu i dziedziczenie
Klasa pochodna może uzyskać dostęp do wszystkich nieprywatnych elementów członkowskich swojej klasy bazowej. W związku z tym elementy członkowskie klasy bazowej, które nie powinny być dostępne dla funkcji składowych klas pochodnych, powinny być zadeklarowane jako prywatne w klasie bazowej.
Klasa pochodna dziedziczy wszystkie metody klasy bazowej z następującymi wyjątkami -
- Konstruktory, destruktory i konstruktory kopiujące klasy bazowej.
- Przeciążone operatory klasy bazowej.
Dziedziczenie wielopoziomowe
Dziedziczenie może być wielopoziomowe i pokazano to w poniższym przykładzie.
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
class Square: Rectangle {
this(int side) {
this.setWidth(side);
this.setHeight(side);
}
}
void main() {
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 169D pozwala określić więcej niż jedną definicję pliku function imię lub nazwisko operator w tym samym zakresie, który jest nazywany function overloading i operator overloading odpowiednio.
Deklaracja przeciążona to deklaracja, która została zadeklarowana z taką samą nazwą jak poprzednia deklaracja w tym samym zakresie, z tym wyjątkiem, że obie deklaracje mają różne argumenty i oczywiście inną definicję (implementację).
Kiedy dzwonisz do przeciążonego pliku function lub operator, kompilator określa najbardziej odpowiednią definicję do użycia, porównując typy argumentów użyte do wywołania funkcji lub operatora z typami parametrów określonymi w definicjach. Wywoływany jest proces wyboru najbardziej odpowiedniej przeciążonej funkcji lub operatoraoverload resolution..
Przeciążanie funkcji
Możesz mieć wiele definicji dla tej samej nazwy funkcji w tym samym zakresie. Definicja funkcji musi różnić się od siebie typami i / lub liczbą argumentów na liście argumentów. Nie można przeciążać deklaracji funkcji, które różnią się tylko zwracanym typem.
Przykład
Poniższy przykład używa tej samej funkcji print() wydrukować różne typy danych -
import std.stdio;
import std.string;
class printData {
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main() {
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Printing int: 5
Printing float: 500.263
Printing string: Hello DPrzeciążanie operatorów
Możesz przedefiniować lub przeciążać większość wbudowanych operatorów dostępnych w D. W ten sposób programista może również używać operatorów z typami zdefiniowanymi przez użytkownika.
Operatory mogą być przeciążane za pomocą string op, po którym następuje Add, Sub i tak dalej na podstawie operatora, który jest przeciążany. Możemy przeciążać operatora +, aby dodać dwa pola, jak pokazano poniżej.
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}Poniższy przykład przedstawia koncepcję przeciążania operatora przy użyciu funkcji składowej. W tym przypadku obiekt jest przekazywany jako argument, którego właściwości są dostępne za pomocą tego obiektu. Dostęp do obiektu, który wywołuje tego operatora, można uzyskać za pomocąthis operator, jak wyjaśniono poniżej -
import std.stdio;
class Box {
public:
double getVolume() {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( ) {
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Typy przeciążania operatorów
Zasadniczo istnieją trzy typy przeciążania operatorów, wymienione poniżej.
| Sr.No. | Typy przeciążenia |
|---|---|
| 1 | Przeciążanie operatorów jednoargumentowych |
| 2 | Przeciążanie operatorów binarnych |
| 3 | Przeciążanie operatorów porównania |
Wszystkie programy D składają się z następujących dwóch podstawowych elementów -
Program statements (code) - To jest część programu, która wykonuje czynności i nazywa się je funkcjami.
Program data - Jest to informacja o programie, na który mają wpływ funkcje programu.
Hermetyzacja to koncepcja programowania zorientowanego obiektowo, która wiąże dane i funkcje, które manipulują danymi, i która chroni zarówno przed zewnętrznymi zakłóceniami, jak i niewłaściwym wykorzystaniem. Hermetyzacja danych doprowadziła do powstania ważnej koncepcji OOPdata hiding.
Data encapsulation jest mechanizmem łączenia danych i funkcji, które z nich korzystają oraz data abstraction to mechanizm ujawniania tylko interfejsów i ukrywania szczegółów implementacji przed użytkownikiem.
D obsługuje właściwości hermetyzacji i ukrywania danych poprzez tworzenie typów zdefiniowanych przez użytkownika, tzw classes. Sprawdziliśmy już, że klasa może zawieraćprivate, chronione i publicczłonków. Domyślnie wszystkie elementy zdefiniowane w klasie są prywatne. Na przykład -
class Box {
public:
double getVolume() {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Zmienne długość, szerokość i wysokość to private. Oznacza to, że dostęp do nich mają tylko inni członkowie klasy Box, a nie inna część programu. Jest to jeden ze sposobów osiągnięcia hermetyzacji.
Tworzyć części klasy public (tj. dostępne dla innych części twojego programu), musisz zadeklarować je po publicsłowo kluczowe. Wszystkie zmienne lub funkcje zdefiniowane po publicznym specyfikatorze są dostępne dla wszystkich innych funkcji w programie.
Zaprzyjaźnienie jednej klasy z inną ujawnia szczegóły implementacji i zmniejsza hermetyzację. Idealnie jest, aby jak najwięcej szczegółów każdej klasy było ukryte przed wszystkimi innymi klasami.
Hermetyzacja danych w D
Każdy program D, w którym zaimplementowano klasę z publicznymi i prywatnymi elementami członkowskimi, jest przykładem enkapsulacji i abstrakcji danych. Rozważmy następujący przykład -
Przykład
import std.stdio;
class Adder {
public:
// constructor
this(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
}
void main( ) {
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total 60Powyższa klasa dodaje liczby do siebie i zwraca sumę. Członkowie publiczniaddNum i getTotalto interfejsy do świata zewnętrznego i użytkownik musi je znać, aby używać tej klasy. Suma członka prywatnego to coś, co jest ukryte przed światem zewnętrznym, ale jest potrzebne do prawidłowego działania klasy.
Strategia projektowania klas w D
Większość z nas nauczyła się poprzez gorzkie doświadczenie, aby domyślnie uczynić członków klasy prywatnymi, chyba że naprawdę musimy ich ujawniać. To jest po prostu dobreencapsulation.
Mądrość ta jest najczęściej stosowana do członków danych, ale dotyczy w równym stopniu wszystkich członków, w tym funkcji wirtualnych.
Interfejs to sposób na zmuszenie klas, które po nim dziedziczą, do implementacji pewnych funkcji lub zmiennych. Funkcje nie mogą być implementowane w interfejsie, ponieważ są zawsze implementowane w klasach dziedziczących po interfejsie.
Interfejs jest tworzony za pomocą słowa kluczowego interface zamiast słowa kluczowego class, mimo że są one pod wieloma względami podobne. Jeśli chcesz dziedziczyć z interfejsu, a klasa dziedziczy już z innej klasy, musisz oddzielić nazwę klasy od nazwy interfejsu przecinkiem.
Spójrzmy na prosty przykład, który wyjaśnia użycie interfejsu.
Przykład
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 35Interfejs z funkcjami końcowymi i statycznymi w D
Interfejs może mieć ostateczną i statyczną metodę, dla której definicje powinny być zawarte w samym interfejsie. Te funkcje nie mogą zostać zastąpione przez klasę pochodną. Poniżej przedstawiono prosty przykład.
Przykład
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1() {
writeln("This is a static method");
}
final void myfunction2() {
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}Kiedy powyższy kod jest kompilowany i wykonywany, daje następujący wynik -
Total area: 35
This is a static method
This is a final methodAbstrakcja odnosi się do zdolności do tworzenia abstrakcyjnych klas w OOP. Klasa abstrakcyjna to taka, której nie można utworzyć. Wszystkie inne funkcje klasy nadal istnieją, a jej pola, metody i konstruktory są dostępne w ten sam sposób. Po prostu nie możesz utworzyć instancji klasy abstrakcyjnej.
Jeśli klasa jest abstrakcyjna i nie można jej utworzyć instancji, nie ma ona większego zastosowania, chyba że jest podklasą. Tak zazwyczaj powstają klasy abstrakcyjne na etapie projektowania. Klasa nadrzędna zawiera typową funkcjonalność kolekcji klas potomnych, ale sama klasa nadrzędna jest zbyt abstrakcyjna, aby mogła być używana samodzielnie.
Korzystanie z klasy abstrakcyjnej w D
Użyj abstractsłowo kluczowe, aby zadeklarować abstrakcję klasy. Słowo kluczowe pojawia się w deklaracji klasy gdzieś przed słowem kluczowym class. Poniżej przedstawiono przykład sposobu dziedziczenia i używania klasy abstrakcyjnej.
Przykład
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person {
int empID;
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}Kiedy kompilujemy i uruchamiamy powyższy program, otrzymamy następujące dane wyjściowe.
Emp1
37Funkcje abstrakcyjne
Podobnie jak funkcje, klasy mogą być również abstrakcyjne. Implementacja takiej funkcji nie jest podana w jej klasie, ale powinna być zapewniona w klasie, która dziedziczy klasę z funkcją abstrakcyjną. Powyższy przykład został zaktualizowany o funkcję abstrakcyjną.
Przykład
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person {
int empID;
override void print() {
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}Kiedy kompilujemy i uruchamiamy powyższy program, otrzymamy następujące dane wyjściowe.
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 37