Rozproszony DBMS - środowiska baz danych
W tej części samouczka przeanalizujemy różne aspekty pomocne w projektowaniu środowisk rozproszonych baz danych. Ten rozdział rozpoczyna się od typów rozproszonych baz danych. Rozproszone bazy danych można podzielić na jednorodne i niejednorodne bazy danych posiadające dalsze podziały. Następna sekcja tego rozdziału omawia rozproszone architektury, a mianowicie klient-serwer, każdy z każdym i multi-DBMS. Na koniec przedstawiono różne alternatywy projektowe, takie jak replikacja i fragmentacja.
Typy rozproszonych baz danych
Rozproszone bazy danych można ogólnie podzielić na jednorodne i heterogeniczne rozproszone środowiska baz danych, z których każde ma dalsze podziały, jak pokazano na poniższej ilustracji.

Jednorodne rozproszone bazy danych
W jednorodnej, rozproszonej bazie danych wszystkie witryny używają identycznego DBMS i systemów operacyjnych. Jego właściwości to -
Witryny używają bardzo podobnego oprogramowania.
Witryny używają identycznego DBMS lub DBMS od tego samego dostawcy.
Każda witryna zna wszystkie inne witryny i współpracuje z innymi witrynami w celu przetwarzania żądań użytkowników.
Dostęp do bazy danych uzyskuje się za pośrednictwem jednego interfejsu, tak jakby była to pojedyncza baza danych.
Typy jednorodnej rozproszonej bazy danych
Istnieją dwa typy jednorodnej rozproszonej bazy danych -
Autonomous- Każda baza danych jest niezależna i funkcjonuje samodzielnie. Są one zintegrowane z aplikacją sterującą i wykorzystują przekazywanie komunikatów do udostępniania aktualizacji danych.
Non-autonomous - Dane są dystrybuowane w jednorodnych węzłach, a centralny lub nadrzędny system DBMS koordynuje aktualizacje danych w lokalizacjach.
Heterogeniczne rozproszone bazy danych
W heterogenicznej rozproszonej bazie danych różne witryny mają różne systemy operacyjne, produkty DBMS i modele danych. Jego właściwości to -
Różne witryny używają odmiennych schematów i oprogramowania.
System może składać się z różnych systemów DBMS, takich jak relacyjne, sieciowe, hierarchiczne lub obiektowe.
Przetwarzanie zapytań jest złożone z powodu różnych schematów.
Przetwarzanie transakcji jest skomplikowane ze względu na różne oprogramowanie.
Witryna może nie wiedzieć o innych witrynach, dlatego współpraca przy przetwarzaniu żądań użytkowników jest ograniczona.
Typy heterogenicznych rozproszonych baz danych
Federated - Heterogeniczne systemy baz danych są z natury niezależne i zintegrowane razem, dzięki czemu działają jako jeden system baz danych.
Un-federated - Systemy baz danych wykorzystują centralny moduł koordynujący, za pośrednictwem którego uzyskuje się dostęp do baz danych.
Rozproszone architektury DBMS
Architektury DDBMS są generalnie opracowywane w zależności od trzech parametrów -
Distribution - Określa fizyczną dystrybucję danych w różnych lokalizacjach.
Autonomy - Wskazuje podział kontroli nad systemem baz danych i stopień, w jakim każdy składowy DBMS może działać niezależnie.
Heterogeneity - Odnosi się do jednolitości lub odmienności modeli danych, komponentów systemu i baz danych.
Modele architektoniczne
Niektóre z typowych modeli architektonicznych to -
- Architektura klient - serwer dla DDBMS
- Architektura peer-to-peer dla DDBMS
- Architektura Multi - DBMS
Architektura klient - serwer dla DDBMS
Jest to architektura dwupoziomowa, w której funkcjonalność jest podzielona na serwery i klientów. Funkcje serwera obejmują przede wszystkim zarządzanie danymi, przetwarzanie zapytań, optymalizację i zarządzanie transakcjami. Funkcje klienta obejmują głównie interfejs użytkownika. Mają jednak pewne funkcje, takie jak sprawdzanie spójności i zarządzanie transakcjami.
Dwie różne architektury klient-serwer to -
- Jeden serwer, wielu klientów
- Multiple Server Multiple Client (pokazany na poniższym diagramie)

Architektura peer-to-peer dla DDBMS
W tych systemach każdy peer działa zarówno jako klient, jak i serwer w celu przekazywania usług bazy danych. Rówieśnicy dzielą się swoimi zasobami z innymi rówieśnikami i koordynują swoje działania.
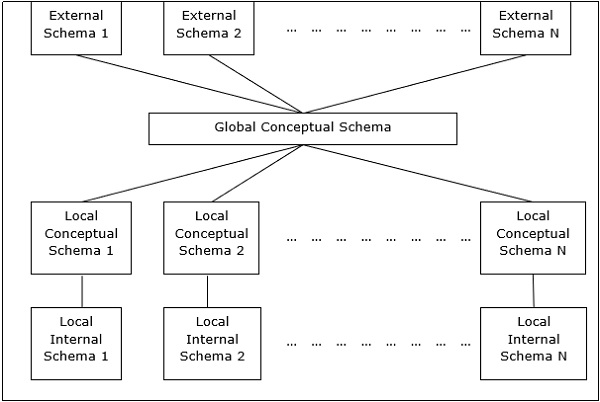
Ta architektura ma ogólnie cztery poziomy schematów -
Global Conceptual Schema - Przedstawia globalny logiczny widok danych.
Local Conceptual Schema - Przedstawia logiczną organizację danych w każdym miejscu.
Local Internal Schema - Przedstawia fizyczną organizację danych w każdej lokalizacji.
External Schema - Przedstawia widok danych użytkownika.
Architektury Multi - DBMS
Jest to zintegrowany system baz danych utworzony przez zbiór dwóch lub więcej autonomicznych systemów baz danych.
Multi-DBMS można wyrazić za pomocą sześciu poziomów schematów -
Multi-database View Level - Przedstawia wiele widoków użytkowników składających się z podzbiorów zintegrowanej rozproszonej bazy danych.
Multi-database Conceptual Level - Przedstawia zintegrowaną wiele baz danych, która zawiera globalne logiczne definicje struktur wielu baz danych.
Multi-database Internal Level - Przedstawia dystrybucję danych w różnych lokalizacjach i mapowanie wielu baz danych do lokalnych danych.
Local database View Level - Przedstawia publiczny widok danych lokalnych.
Local database Conceptual Level - Przedstawia lokalną organizację danych w każdym miejscu.
Local database Internal Level - Przedstawia fizyczną organizację danych w każdej lokalizacji.
Istnieją dwie alternatywy projektowe dla wielu DBMS -
- Model z poziomem koncepcyjnym obejmującym wiele baz danych.
- Model bez poziomu koncepcyjnego obejmującego wiele baz danych.


Alternatywy projektowe
Alternatywy projektu dystrybucji dla tabel w DDBMS są następujące -
- Brak replikacji i fragmentacji
- W pełni zreplikowane
- Częściowo zreplikowane
- Fragmented
- Mixed
Brak replikacji i fragmentacji
W tej alternatywnej konstrukcji różne tabele są umieszczane w różnych miejscach. Dane są umieszczane tak, aby znajdowały się blisko miejsca, w którym są najczęściej używane. Jest najbardziej odpowiedni dla systemów baz danych, w których odsetek zapytań potrzebnych do połączenia informacji w tabelach umieszczonych w różnych witrynach jest niski. Jeśli zostanie przyjęta odpowiednia strategia dystrybucji, ta alternatywa projektowa pomaga zmniejszyć koszty komunikacji podczas przetwarzania danych.
W pełni zreplikowane
W tym alternatywnym projekcie w każdej lokacji przechowywana jest jedna kopia wszystkich tabel bazy danych. Ponieważ każda witryna ma swoją własną kopię całej bazy danych, zapytania są bardzo szybkie i wymagają znikomych kosztów komunikacji. Wręcz przeciwnie, ogromna nadmiarowość danych wymaga ogromnych kosztów podczas operacji aktualizacji. Dlatego jest to odpowiednie dla systemów, w których wymagana jest obsługa dużej liczby zapytań, podczas gdy liczba aktualizacji baz danych jest niska.
Częściowo zreplikowane
Kopie tabel lub części tabel są przechowywane w różnych witrynach. Dystrybucja tabel odbywa się zgodnie z częstotliwością dostępu. Uwzględnia to fakt, że częstotliwość uzyskiwania dostępu do tabel różni się znacznie w zależności od lokalizacji. Liczba kopii tabel (lub ich części) zależy od częstotliwości wykonywania zapytań dostępu oraz od witryny, która je generuje.
Fragmentowane
W tym projekcie tabela jest podzielona na dwie lub więcej części zwanych fragmentami lub partycjami, a każdy fragment może być przechowywany w różnych miejscach. Uwzględnia to fakt, że rzadko zdarza się, że wszystkie dane przechowywane w tabeli są wymagane w danej witrynie. Ponadto fragmentacja zwiększa równoległość i zapewnia lepsze odzyskiwanie po awarii. Tutaj jest tylko jedna kopia każdego fragmentu w systemie, czyli brak zbędnych danych.
Trzy techniki fragmentacji to -
- Fragmentacja pionowa
- Pozioma fragmentacja
- Fragmentacja hybrydowa
Dystrybucja mieszana
Jest to połączenie fragmentacji i częściowych replikacji. Tutaj tabele są początkowo pofragmentowane w dowolnej formie (poziomej lub pionowej), a następnie te fragmenty są częściowo replikowane w różnych miejscach zgodnie z częstotliwością uzyskiwania dostępu do fragmentów.