Optymalizacja zapytań w systemach rozproszonych
W tym rozdziale omówiono optymalizację zapytań w systemie rozproszonych baz danych.
Architektura rozproszonego przetwarzania zapytań
W systemie rozproszonych baz danych przetwarzanie zapytania obejmuje optymalizację zarówno na poziomie globalnym, jak i lokalnym. Zapytanie trafia do systemu bazy danych na kliencie lub w ośrodku kontrolnym. Tutaj użytkownik jest weryfikowany, zapytanie jest sprawdzane, tłumaczone i optymalizowane na poziomie globalnym.
Architekturę można przedstawić jako -
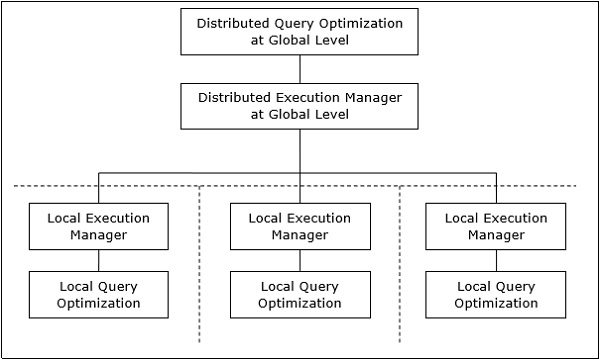
Mapowanie zapytań globalnych do zapytań lokalnych
Proces mapowania zapytań globalnych do lokalnych można zrealizować w następujący sposób -
Tabele wymagane w zapytaniu globalnym zawierają fragmenty rozmieszczone w wielu witrynach. Lokalne bazy danych zawierają informacje tylko o danych lokalnych. Witryna kontrolująca korzysta z globalnego słownika danych do zbierania informacji o dystrybucji i rekonstruuje widok globalny z fragmentów.
Jeśli nie ma replikacji, globalny optymalizator uruchamia lokalne zapytania w lokacjach, w których przechowywane są fragmenty. W przypadku replikacji globalny optymalizator wybiera lokację na podstawie kosztu komunikacji, obciążenia i szybkości serwera.
Globalny optymalizator generuje rozproszony plan wykonania, dzięki czemu między lokacjami następuje najmniejszy transfer danych. Plan określa lokalizację fragmentów, kolejność wykonywania kroków zapytania oraz procesy związane z przesyłaniem wyników pośrednich.
Lokalne zapytania są optymalizowane przez lokalne serwery baz danych. Na koniec, lokalne wyniki zapytania są łączone razem poprzez operację sumowania w przypadku fragmentów poziomych i operację łączenia dla fragmentów pionowych.
Na przykład, weźmy pod uwagę, że następujący schemat projektu jest podzielony poziomo według miasta, a miasta to New Delhi, Kalkuta i Hyderabad.
PROJEKT
| PId | Miasto | Departament | Status |
Załóżmy, że istnieje zapytanie w celu pobrania szczegółów wszystkich projektów, których stan to „W toku”.
Globalne zapytanie to & inus;
$$ \ sigma_ {status} = {\ small "w toku"} ^ {(PROJEKT)} $$
Zapytanie na serwerze New Delhi będzie -
$$ \ sigma_ {status} = {\ small "w toku"} ^ {({NewD} _- {PROJECT})} $$
Zapytanie na serwerze Kalkuty będzie -
$$ \ sigma_ {status} = {\ small "w toku"} ^ {({Kol} _- {PROJEKT})} $$
Zapytanie na serwerze Hyderabad będzie -
$$ \ sigma_ {status} = {\ small "w toku"} ^ {({Hyd} _- {PROJEKT})} $$
Aby uzyskać ogólny wynik, musimy połączyć wyniki trzech zapytań w następujący sposób -
$ \ sigma_ {status} = {\ small "w toku"} ^ {({NewD} _- {PROJECT})} \ cup \ sigma_ {status} = {\ small "w toku"} ^ {({kol} _- {PROJEKT})} \ cup \ sigma_ {status} = {\ small "w toku"} ^ {({Hyd} _- {PROJECT})} $
Optymalizacja zapytań rozproszonych
Optymalizacja zapytań rozproszonych wymaga oceny dużej liczby drzew zapytań, z których każde daje wymagane wyniki zapytania. Wynika to przede wszystkim z obecności dużej ilości zreplikowanych i pofragmentowanych danych. Dlatego celem jest znalezienie optymalnego rozwiązania zamiast najlepszego.
Główne problemy związane z optymalizacją zapytań rozproszonych to:
- Optymalne wykorzystanie zasobów w systemie rozproszonym.
- Handel zapytaniami.
- Zmniejszenie przestrzeni rozwiązania zapytania.
Optymalne wykorzystanie zasobów w systemie rozproszonym
System rozproszony ma kilka serwerów baz danych w różnych lokacjach, które wykonują operacje dotyczące zapytania. Poniżej przedstawiono podejścia do optymalnego wykorzystania zasobów -
Operation Shipping- W przypadku wysyłki operacyjnej operacja jest wykonywana w miejscu przechowywania danych, a nie w siedzibie klienta. Wyniki są następnie przesyłane do witryny klienta. Jest to odpowiednie dla operacji, w których argumenty są dostępne w tej samej witrynie. Przykład: operacje Select i Project.
Data Shipping- W przypadku przesyłania danych fragmenty danych są przesyłane na serwer bazy danych, na którym wykonywane są operacje. Jest to używane w operacjach, w których operandy są rozprowadzane w różnych miejscach. Jest to również odpowiednie w systemach, w których koszty komunikacji są niskie, a lokalne procesory są znacznie wolniejsze niż serwer klienta.
Hybrid Shipping- Jest to połączenie przesyłania danych i operacji. Tutaj fragmenty danych są przesyłane do szybkich procesorów, na których przebiega operacja. Wyniki są następnie wysyłane do witryny klienta.

Query Trading
W algorytmie handlu zapytaniami dla systemów rozproszonych baz danych, witryna kontrolująca / kliencka dla zapytań rozproszonych nazywana jest kupującym, a strony, w których wykonywane są zapytania lokalne, nazywane są sprzedawcami. Kupujący formułuje szereg alternatyw wyboru sprzedawców i rekonstruowania globalnych wyników. Celem kupującego jest osiągnięcie optymalnego kosztu.
Algorytm rozpoczyna się od przypisania przez kupującego zapytań podrzędnych do witryn sprzedawcy. Plan optymalny jest tworzony z lokalnych zoptymalizowanych planów zapytań zaproponowanych przez sprzedawców w połączeniu z kosztem komunikacji w celu odtworzenia wyniku końcowego. Po sformułowaniu globalnego planu optymalnego zapytanie jest wykonywane.
Zmniejszenie przestrzeni rozwiązania zapytania
Optymalne rozwiązanie zazwyczaj obejmuje redukcję miejsca na rozwiązanie, tak aby zmniejszyć koszt zapytań i transferu danych. Można to osiągnąć za pomocą zestawu reguł heurystycznych, podobnie jak heurystyki w systemach scentralizowanych.
Oto niektóre zasady -
Wykonaj operacje wyboru i projekcji tak wcześnie, jak to możliwe. Zmniejsza to przepływ danych w sieci komunikacyjnej.
Uprość operacje na fragmentach poziomych, eliminując warunki selekcji, które nie są istotne dla konkretnego obszaru.
W przypadku operacji łączenia i łączenia składających się z fragmentów znajdujących się w wielu lokalizacjach, prześlij pofragmentowane dane do miejsca, w którym znajduje się większość danych, i wykonaj tam operację.
Użyj operacji sprzężenia połowicznego, aby zakwalifikować krotki, które mają zostać połączone. Zmniejsza to ilość przesyłanych danych, co z kolei zmniejsza koszty komunikacji.
Scal wspólne liście i poddrzewa w rozproszonym drzewie zapytań.