Rozproszony DBMS - Szybki przewodnik
Do prawidłowego funkcjonowania każdej organizacji potrzebna jest dobrze utrzymana baza danych. W niedawnej przeszłości bazy danych miały charakter scentralizowany. Jednak wraz ze wzrostem globalizacji organizacje są zróżnicowane na całym świecie. Mogą zdecydować się na dystrybucję danych na lokalnych serwerach zamiast do centralnej bazy danych. W ten sposób powstała koncepcjaDistributed Databases.
Ten rozdział zawiera przegląd baz danych i systemów zarządzania bazami danych (DBMS). Baza danych to uporządkowany zbiór powiązanych danych. DBMS to pakiet oprogramowania do pracy z bazą danych. Szczegółowe omówienie DBMS jest dostępne w naszym samouczku o nazwie „Naucz się DBMS”. W tym rozdziale dokonamy przeglądu głównych koncepcji, aby badanie DDBMS było łatwe. Omówione trzy tematy to schematy baz danych, typy baz danych i operacje na bazach danych.
System zarządzania bazą danych i bazą danych
ZA databaseto uporządkowany zbiór powiązanych danych, który został utworzony w określonym celu. Baza danych może być zorganizowana jako zbiór wielu tabel, gdzie tabela reprezentuje rzeczywisty element lub jednostkę. Każda tabela ma kilka różnych pól, które reprezentują charakterystyczne cechy jednostki.
Na przykład baza danych firmy może zawierać tabele projektów, pracowników, działów, produktów i zapisów finansowych. Pola w tabeli Employee mogą mieć postać Name, Company_Id, Date_of_Joining i tak dalej.
ZA database management systemto zbiór programów umożliwiających tworzenie i utrzymywanie bazy danych. DBMS jest dostępny jako pakiet oprogramowania, który ułatwia definiowanie, konstruowanie, manipulowanie i udostępnianie danych w bazie danych. Definicja bazy danych obejmuje opis struktury bazy danych. Budowa bazy danych polega na faktycznym przechowywaniu danych na dowolnym nośniku. Manipulacja odnosi się do pobierania informacji z bazy danych, aktualizowania bazy danych i generowania raportów. Udostępnianie danych ułatwia dostęp do danych różnym użytkownikom lub programom.
Przykłady obszarów zastosowań DBMS
- Automatyczne maszyny kasowe
- System rezerwacji pociągów
- System zarządzania pracownikami
- System informacji o uczniach
Przykłady pakietów DBMS
- MySQL
- Oracle
- SQL Server
- dBASE
- FoxPro
- PostgreSQL itp.
Schematy baz danych
Schemat bazy danych to opis bazy danych określony podczas projektowania bazy danych i podlegający rzadkim zmianom. Określa organizację danych, relacje między nimi oraz związane z nimi ograniczenia.
Bazy danych są często reprezentowane przez three-schema architecture lub ANSISPARC architecture. Celem tej architektury jest oddzielenie aplikacji użytkownika od fizycznej bazy danych. Trzy poziomy to -
Internal Level having Internal Schema - Opisuje strukturę fizyczną, szczegóły dotyczące pamięci wewnętrznej i ścieżki dostępu do bazy danych.
Conceptual Level having Conceptual Schema- Opisuje strukturę całej bazy danych, ukrywając szczegóły fizycznego przechowywania danych. Ilustruje to jednostki, atrybuty z ich typami danych i ograniczeniami, operacje użytkownika i relacje.
External or View Level having External Schemas or Views - Opisuje część bazy danych odnoszącą się do konkretnego użytkownika lub grupy użytkowników, ukrywając resztę bazy danych.
Rodzaje DBMS
Istnieją cztery typy DBMS.
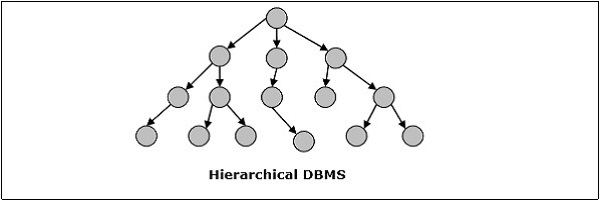
Hierarchiczny DBMS
W hierarchicznym DBMS relacje między danymi w bazie danych są ustanawiane w taki sposób, że jeden element danych istnieje jako podrzędny względem innego. Elementy danych mają relacje rodzic-dziecko i są modelowane przy użyciu „drzewiastej” struktury danych. Są bardzo szybkie i proste.
Sieć DBMS
Sieciowy DBMS w takim, w którym relacje między danymi w bazie danych są typu wiele-do-wielu w postaci sieci. Struktura jest ogólnie skomplikowana z powodu istnienia wielu relacji wiele do wielu. Sieć DBMS jest modelowana za pomocą „grafowej” struktury danych.

Relacyjny DBMS
W relacyjnych bazach danych baza danych jest reprezentowana w postaci relacji. Każda relacja modeluje jednostkę i jest reprezentowana jako tabela wartości. W relacji lub tabeli wiersz nazywany jest krotką i oznacza pojedynczy rekord. Kolumna nazywana jest polem lub atrybutem i oznacza charakterystyczną właściwość jednostki. RDBMS to najpopularniejszy system zarządzania bazami danych.
Na przykład - Relacja studencka -

DBMS zorientowany obiektowo
DBMS zorientowany obiektowo wywodzi się z modelu paradygmatu programowania obiektowego. Są pomocne w reprezentowaniu zarówno spójnych danych przechowywanych w bazach danych, jak i danych przejściowych, jakie można znaleźć w wykonywanych programach. Używają małych elementów wielokrotnego użytku zwanych obiektami. Każdy obiekt zawiera część danych i zestaw operacji, które działają na danych. Obiekt i jego atrybuty są dostępne za pośrednictwem wskaźników, a nie są przechowywane w relacyjnych modelach tabel.
Na przykład - Uproszczona obiektowa baza danych kont bankowych -

Rozproszony DBMS
Rozproszona baza danych to zestaw połączonych ze sobą baz danych, które są rozproszone w sieci komputerowej lub Internecie. Rozproszony system zarządzania bazami danych (DDBMS) zarządza rozproszoną bazą danych i zapewnia mechanizmy zapewniające przejrzystość baz danych dla użytkowników. W tych systemach dane są celowo dystrybuowane między wieloma węzłami, aby wszystkie zasoby obliczeniowe organizacji mogły być optymalnie wykorzystane.
Operacje na DBMS
Cztery podstawowe operacje na bazie danych to tworzenie, pobieranie, aktualizowanie i usuwanie.
CREATE strukturę bazy danych i zapełnij ją danymi - Tworzenie relacji z bazą danych obejmuje określenie struktur danych, typów danych i ograniczeń danych, które mają być przechowywane.
Example - Polecenie SQL do tworzenia tabeli uczniów -
CREATE TABLE STUDENT (
ROLL INTEGER PRIMARY KEY,
NAME VARCHAR2(25),
YEAR INTEGER,
STREAM VARCHAR2(10)
);Po zdefiniowaniu formatu danych rzeczywiste dane są przechowywane zgodnie z formatem na jakimś nośniku pamięci.
Example Polecenie SQL do wstawienia pojedynczej krotki do tabeli uczniów -
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM)
VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');RETRIEVEinformacje z bazy danych - pobieranie informacji zazwyczaj obejmuje wybranie podzbioru tabeli lub wyświetlenie danych z tabeli po wykonaniu niektórych obliczeń. Odbywa się to poprzez zapytanie o tabelę.
Example - Aby pobrać nazwiska wszystkich studentów strumienia informatyki, należy wykonać następujące zapytanie SQL -
SELECT NAME FROM STUDENT
WHERE STREAM = 'COMPUTER SCIENCE';UPDATE informacje przechowywane i modyfikuj strukturę bazy danych - aktualizacja tabeli obejmuje zmianę starych wartości w istniejących wierszach tabeli na nowe wartości.
Example - Polecenie SQL do zmiany strumienia z elektroniki na elektronikę i komunikację -
UPDATE STUDENT
SET STREAM = 'ELECTRONICS AND COMMUNICATIONS'
WHERE STREAM = 'ELECTRONICS';Modyfikacja bazy danych oznacza zmianę struktury tabeli. Jednak modyfikacja tabeli podlega szeregowi ograniczeń.
Example - Aby dodać nowe pole lub kolumnę, powiedz adres do tabeli Ucznia, używamy następującego polecenia SQL -
ALTER TABLE STUDENT
ADD ( ADDRESS VARCHAR2(50) );DELETE informacje przechowywane lub usuwaj tabelę jako całość - usunięcie określonych informacji wiąże się z usunięciem wybranych wierszy z tabeli, które spełniają określone warunki.
Example- Aby usunąć wszystkich uczniów, którzy obecnie omdlają na czwartym roku, używamy polecenia SQL -
DELETE FROM STUDENT
WHERE YEAR = 4;Alternatywnie całą tabelę można usunąć z bazy danych.
Example - Aby całkowicie usunąć tabelę uczniów, użytym poleceniem SQL jest -
DROP TABLE STUDENT;W tym rozdziale przedstawiono koncepcję DDBMS. W rozproszonej bazie danych istnieje wiele baz danych, które mogą być rozmieszczone geograficznie na całym świecie. Rozproszony DBMS zarządza rozproszoną bazą danych w taki sposób, że jest ona widoczna dla użytkowników jako jedna baza danych. W dalszej części rozdziału przejdziemy do analizy czynników, które prowadzą do powstania rozproszonych baz danych, ich zalet i wad.
ZA distributed database to zbiór wielu połączonych ze sobą baz danych, które są fizycznie rozmieszczone w różnych lokalizacjach, które komunikują się za pośrednictwem sieci komputerowej.
funkcje
Bazy danych w kolekcji są ze sobą powiązane logicznie. Często reprezentują jedną logiczną bazę danych.
Dane są fizycznie przechowywane w wielu witrynach. Dane w każdej witrynie mogą być zarządzane przez DBMS niezależnie od innych witryn.
Procesory w witrynach są połączone za pośrednictwem sieci. Nie mają konfiguracji wieloprocesorowej.
Rozproszona baza danych nie jest luźno połączonym systemem plików.
Rozproszona baza danych obejmuje przetwarzanie transakcji, ale nie jest synonimem systemu przetwarzania transakcji.
Rozproszony system zarządzania bazą danych
Rozproszony system zarządzania bazą danych (DDBMS) to scentralizowany system oprogramowania, który zarządza rozproszoną bazą danych w taki sposób, jakby wszystkie były przechowywane w jednym miejscu.
funkcje
Służy do tworzenia, pobierania, aktualizowania i usuwania rozproszonych baz danych.
Okresowo synchronizuje bazę danych i zapewnia mechanizmy dostępu, dzięki którym dystrybucja staje się przejrzysta dla użytkowników.
Zapewnia powszechną aktualizację danych modyfikowanych w dowolnej witrynie.
Jest używany w obszarach zastosowań, w których duże ilości danych są przetwarzane i używane przez wielu użytkowników jednocześnie.
Jest przeznaczony dla heterogenicznych platform bazodanowych.
Zachowuje poufność i integralność danych w bazach danych.
Czynniki zachęcające do DDBMS
Poniższe czynniki zachęcają do przejścia na DDBMS -
Distributed Nature of Organizational Units- Większość organizacji w obecnych czasach jest podzielona na wiele jednostek, które są fizycznie rozmieszczone na całym świecie. Każda jednostka wymaga własnego zestawu danych lokalnych. W ten sposób ogólna baza danych organizacji zostaje rozproszona.
Need for Sharing of Data- Wiele jednostek organizacyjnych często musi komunikować się ze sobą oraz udostępniać swoje dane i zasoby. Wymaga to wspólnych lub zreplikowanych baz danych, których należy używać w sposób zsynchronizowany.
Support for Both OLTP and OLAP- Przetwarzanie transakcji online (OLTP) i przetwarzanie analityczne online (OLAP) działają na zróżnicowanych systemach, które mogą mieć wspólne dane. Rozproszone systemy baz danych wspomagają oba te procesy, dostarczając zsynchronizowane dane.
Database Recovery- Jedną z powszechnych technik stosowanych w DDBMS jest replikacja danych w różnych witrynach. Replikacja danych automatycznie pomaga w odzyskiwaniu danych, jeśli baza danych w dowolnej witrynie jest uszkodzona. Użytkownicy mogą uzyskać dostęp do danych z innych witryn, podczas gdy uszkodzona witryna jest odtwarzana. Dlatego awaria bazy danych może stać się prawie niezauważalna dla użytkowników.
Support for Multiple Application Software- Większość organizacji korzysta z różnorodnych aplikacji, z których każde obsługuje określone bazy danych. DDBMS zapewnia jednolitą funkcjonalność do wykorzystywania tych samych danych na różnych platformach.
Zalety rozproszonych baz danych
Poniżej przedstawiono zalety rozproszonych baz danych w porównaniu ze scentralizowanymi bazami danych.
Modular Development- Jeśli system wymaga rozbudowy o nowe lokalizacje lub nowe jednostki, w scentralizowanych systemach bazodanowych, działanie wymaga znacznego wysiłku i zakłócenia dotychczasowego funkcjonowania. Jednak w rozproszonych bazach danych praca wymaga po prostu dodania nowych komputerów i danych lokalnych do nowej witryny, a na koniec podłączenia ich do systemu rozproszonego, bez przerywania bieżących funkcji.
More Reliable- W przypadku awarii baz danych cały system scentralizowanych baz danych zostaje zatrzymany. Jednak w systemach rozproszonych, gdy składnik ulegnie awarii, działanie systemu może nadal przebiegać z obniżoną wydajnością. Dlatego DDBMS jest bardziej niezawodny.
Better Response- Jeśli dane są dystrybuowane w efektywny sposób, żądania użytkowników mogą być zaspokajane z samych danych lokalnych, co zapewnia szybszą odpowiedź. Z drugiej strony w systemach scentralizowanych wszystkie zapytania muszą przechodzić przez komputer centralny w celu przetworzenia, co zwiększa czas odpowiedzi.
Lower Communication Cost- W rozproszonych systemach baz danych, jeśli dane są zlokalizowane lokalnie, gdzie są najczęściej używane, wówczas koszty komunikacji związane z manipulacją danymi można zminimalizować. Nie jest to wykonalne w systemach scentralizowanych.
Wady rozproszonych baz danych
Poniżej przedstawiono niektóre przeciwności związane z rozproszonymi bazami danych.
Need for complex and expensive software - DDBMS wymaga złożonego i często kosztownego oprogramowania zapewniającego przejrzystość danych i koordynację w różnych lokalizacjach.
Processing overhead - Nawet proste operacje mogą wymagać dużej liczby komunikatów i dodatkowych obliczeń, aby zapewnić jednolitość danych w różnych lokalizacjach.
Data integrity - Konieczność aktualizacji danych w wielu witrynach stwarza problemy z integralnością danych.
Overheads for improper data distribution- Reakcja na zapytania w dużej mierze zależy od właściwej dystrybucji danych. Niewłaściwa dystrybucja danych często prowadzi do bardzo powolnej odpowiedzi na żądania użytkowników.
W tej części samouczka przeanalizujemy różne aspekty pomocne w projektowaniu środowisk rozproszonych baz danych. Ten rozdział rozpoczyna się od typów rozproszonych baz danych. Rozproszone bazy danych można podzielić na jednorodne i niejednorodne bazy danych posiadające dalsze podziały. Następna sekcja tego rozdziału omawia rozproszone architektury, a mianowicie klient-serwer, każdy z każdym i multi-DBMS. Na koniec przedstawiono różne alternatywy projektowe, takie jak replikacja i fragmentacja.
Typy rozproszonych baz danych
Rozproszone bazy danych można ogólnie podzielić na jednorodne i heterogeniczne rozproszone środowiska baz danych, z których każdy ma dalsze podziały, jak pokazano na poniższej ilustracji.

Jednorodne rozproszone bazy danych
W jednorodnej rozproszonej bazie danych wszystkie witryny używają identycznego DBMS i systemów operacyjnych. Jego właściwości to -
Witryny używają bardzo podobnego oprogramowania.
Witryny używają identycznego DBMS lub DBMS od tego samego dostawcy.
Każda witryna zna wszystkie inne witryny i współpracuje z innymi witrynami w celu przetwarzania żądań użytkowników.
Dostęp do bazy danych uzyskuje się za pośrednictwem jednego interfejsu, tak jakby była to pojedyncza baza danych.
Typy jednorodnej rozproszonej bazy danych
Istnieją dwa typy jednorodnej rozproszonej bazy danych -
Autonomous- Każda baza danych jest niezależna i funkcjonuje samodzielnie. Są one zintegrowane z aplikacją sterującą i wykorzystują przekazywanie komunikatów do udostępniania aktualizacji danych.
Non-autonomous - Dane są rozprowadzane w jednorodnych węzłach, a centralny lub nadrzędny system DBMS koordynuje aktualizacje danych w lokalizacjach.
Heterogeniczne rozproszone bazy danych
W heterogenicznej rozproszonej bazie danych różne witryny mają różne systemy operacyjne, produkty DBMS i modele danych. Jego właściwości to -
Różne witryny używają odmiennych schematów i oprogramowania.
System może składać się z różnych systemów DBMS, takich jak relacyjne, sieciowe, hierarchiczne lub obiektowe.
Przetwarzanie zapytań jest skomplikowane ze względu na odmienne schematy.
Przetwarzanie transakcji jest skomplikowane ze względu na różne oprogramowanie.
Witryna może nie wiedzieć o innych witrynach, dlatego współpraca przy przetwarzaniu żądań użytkowników jest ograniczona.
Typy heterogenicznych rozproszonych baz danych
Federated - Heterogeniczne systemy baz danych są z natury niezależne i zintegrowane razem, dzięki czemu działają jako jeden system baz danych.
Un-federated - Systemy baz danych wykorzystują centralny moduł koordynujący, za pośrednictwem którego uzyskuje się dostęp do baz danych.
Rozproszone architektury DBMS
Architektury DDBMS są generalnie opracowywane w zależności od trzech parametrów -
Distribution - Określa fizyczną dystrybucję danych w różnych lokalizacjach.
Autonomy - Wskazuje podział kontroli nad systemem baz danych i stopień, w jakim każdy składowy DBMS może działać niezależnie.
Heterogeneity - Odnosi się do jednolitości lub odmienności modeli danych, komponentów systemu i baz danych.
Modele architektoniczne
Niektóre z typowych modeli architektonicznych to -
- Architektura klient - serwer dla DDBMS
- Architektura peer-to-peer dla DDBMS
- Architektura Multi - DBMS
Architektura klient - serwer dla DDBMS
Jest to architektura dwupoziomowa, w której funkcjonalność jest podzielona na serwery i klientów. Funkcje serwera obejmują przede wszystkim zarządzanie danymi, przetwarzanie zapytań, optymalizację i zarządzanie transakcjami. Funkcje klienta obejmują głównie interfejs użytkownika. Mają jednak pewne funkcje, takie jak sprawdzanie spójności i zarządzanie transakcjami.
Dwie różne architektury klient-serwer to -
- Jeden serwer, wielu klientów
- Multiple Server Multiple Client (pokazany na poniższym diagramie)

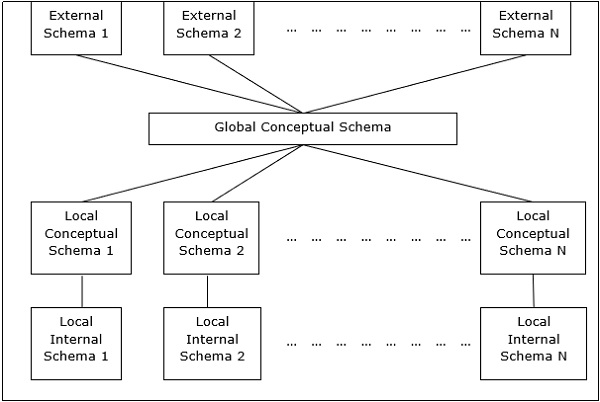
Architektura peer-to-peer dla DDBMS
W tych systemach każdy peer działa zarówno jako klient, jak i serwer w celu przekazywania usług bazy danych. Rówieśnicy dzielą się swoimi zasobami z innymi rówieśnikami i koordynują swoje działania.
Ta architektura ma ogólnie cztery poziomy schematów -
Global Conceptual Schema - Przedstawia globalny logiczny widok danych.
Local Conceptual Schema - Przedstawia logiczną organizację danych w każdym miejscu.
Local Internal Schema - Przedstawia fizyczną organizację danych w każdej lokalizacji.
External Schema - Przedstawia widok danych użytkownika.
Architektury Multi - DBMS
Jest to zintegrowany system baz danych utworzony przez zbiór dwóch lub więcej autonomicznych systemów baz danych.
Multi-DBMS można wyrazić za pomocą sześciu poziomów schematów -
Multi-database View Level - Przedstawia wiele widoków użytkownika składających się z podzbiorów zintegrowanej rozproszonej bazy danych.
Multi-database Conceptual Level - Przedstawia zintegrowaną wiele baz danych, która zawiera globalne logiczne definicje struktur wielu baz danych.
Multi-database Internal Level - Przedstawia dystrybucję danych w różnych lokalizacjach i mapowanie wielu baz danych do lokalnych danych.
Local database View Level - Przedstawia publiczny widok danych lokalnych.
Local database Conceptual Level - Przedstawia lokalną organizację danych w każdym miejscu.
Local database Internal Level - Przedstawia fizyczną organizację danych w każdej lokalizacji.
Istnieją dwie alternatywy projektowe dla wielu DBMS -
- Model z poziomem koncepcyjnym obejmującym wiele baz danych.
- Model bez poziomu koncepcyjnego obejmującego wiele baz danych.


Alternatywy projektowe
Alternatywy projektu dystrybucji dla tabel w DDBMS są następujące -
- Brak replikacji i fragmentacji
- W pełni zreplikowane
- Częściowo zreplikowane
- Fragmented
- Mixed
Brak replikacji i fragmentacji
W tej alternatywnej konstrukcji różne tabele są umieszczane w różnych miejscach. Dane są umieszczane tak, aby znajdowały się blisko miejsca, w którym są najczęściej używane. Jest najbardziej odpowiedni dla systemów baz danych, w których odsetek zapytań potrzebnych do połączenia informacji w tabelach umieszczonych w różnych miejscach jest niski. Jeśli zostanie przyjęta odpowiednia strategia dystrybucji, ta alternatywa projektowa pomaga zmniejszyć koszty komunikacji podczas przetwarzania danych.
W pełni zreplikowane
W tym alternatywnym projekcie w każdej lokacji przechowywana jest jedna kopia wszystkich tabel bazy danych. Ponieważ każda witryna ma własną kopię całej bazy danych, zapytania są bardzo szybkie i wymagają niewielkich kosztów komunikacji. Wręcz przeciwnie, ogromna nadmiarowość danych wymaga ogromnych kosztów podczas operacji aktualizacji. Dlatego jest to odpowiednie dla systemów, w których wymagana jest obsługa dużej liczby zapytań, podczas gdy liczba aktualizacji bazy danych jest niewielka.
Częściowo zreplikowane
Kopie tabel lub części tabel są przechowywane w różnych witrynach. Dystrybucja tabel odbywa się zgodnie z częstotliwością dostępu. Uwzględnia to fakt, że częstotliwość uzyskiwania dostępu do tabel różni się znacznie w zależności od witryny. Liczba kopii tabel (lub ich części) zależy od częstotliwości wykonywania zapytań dostępu oraz od witryny, która je generuje.
Fragmentowane
W tym projekcie tabela jest podzielona na dwie lub więcej części zwanych fragmentami lub partycjami, a każdy fragment może być przechowywany w różnych miejscach. Uwzględnia to fakt, że rzadko zdarza się, że wszystkie dane przechowywane w tabeli są wymagane w danej witrynie. Ponadto fragmentacja zwiększa równoległość i zapewnia lepsze odzyskiwanie po awarii. Tutaj jest tylko jedna kopia każdego fragmentu w systemie, czyli brak zbędnych danych.
Trzy techniki fragmentacji to -
- Fragmentacja pionowa
- Pozioma fragmentacja
- Fragmentacja hybrydowa
Dystrybucja mieszana
Jest to połączenie fragmentacji i częściowych replikacji. Tutaj tabele są początkowo pofragmentowane w dowolnej formie (poziomej lub pionowej), a następnie te fragmenty są częściowo replikowane w różnych miejscach zgodnie z częstotliwością uzyskiwania dostępu do fragmentów.
W ostatnim rozdziale przedstawiliśmy różne alternatywy projektowe. W tym rozdziale przeanalizujemy strategie, które pomagają w przyjmowaniu projektów. Strategie można ogólnie podzielić na replikację i fragmentację. Jednak w większości przypadków używana jest kombinacja tych dwóch.
Replikacja danych
Replikacja danych to proces przechowywania oddzielnych kopii bazy danych w co najmniej dwóch lokalizacjach. Jest to popularna technika odporności na uszkodzenia w rozproszonych bazach danych.
Zalety replikacji danych
Reliability - W przypadku awarii dowolnej witryny system bazy danych nadal działa, ponieważ kopia jest dostępna w innej witrynie (witrynach).
Reduction in Network Load- Ponieważ dostępne są lokalne kopie danych, przetwarzanie zapytań może odbywać się przy ograniczonym wykorzystaniu sieci, szczególnie w godzinach największej oglądalności. Aktualizacja danych może odbywać się poza godzinami największej oglądalności.
Quicker Response - Dostępność lokalnych kopii danych zapewnia szybkie przetwarzanie zapytań, a tym samym szybki czas odpowiedzi.
Simpler Transactions- Transakcje wymagają mniejszej liczby łączeń tabel znajdujących się w różnych witrynach i minimalnej koordynacji w całej sieci. W ten sposób stają się prostsze z natury.
Wady replikacji danych
Increased Storage Requirements- Utrzymywanie wielu kopii danych wiąże się ze zwiększonymi kosztami przechowywania. Wymagana przestrzeń dyskowa jest wielokrotnością miejsca wymaganego dla scentralizowanego systemu.
Increased Cost and Complexity of Data Updating- Za każdym razem, gdy element danych jest aktualizowany, aktualizacja musi być odzwierciedlona we wszystkich kopiach danych w różnych lokalizacjach. Wymaga to skomplikowanych technik i protokołów synchronizacji.
Undesirable Application – Database coupling- Jeżeli nie są stosowane złożone mechanizmy aktualizacji, usunięcie niespójności danych wymaga złożonej koordynacji na poziomie aplikacji. Powoduje to niepożądane połączenie aplikacji z bazą danych.
Niektóre powszechnie stosowane techniki replikacji to:
- Replikacja migawek
- Replikacja w czasie prawie rzeczywistym
- Ściągnij replikację
Podział
Fragmentacja to zadanie polegające na podzieleniu tabeli na zestaw mniejszych tabel. Podzbiory tabeli nazywane sąfragments. Fragmentacja może mieć trzy typy: poziomą, pionową i hybrydową (połączenie poziomej i pionowej). Fragmentację poziomą można dalej podzielić na dwie techniki: pierwotną fragmentację poziomą i pochodną fragmentację poziomą.
Fragmentację należy wykonać w taki sposób, aby z fragmentów można było zrekonstruować oryginalny stół. Jest to potrzebne, aby w razie potrzeby można było zrekonstruować oryginalny stół z fragmentów. Ten wymóg nazywa się „rekonstrukcją”.
Zalety fragmentacji
Ponieważ dane są przechowywane blisko miejsca użytkowania, zwiększa się wydajność systemu bazy danych.
Lokalne techniki optymalizacji zapytań są wystarczające dla większości zapytań, ponieważ dane są dostępne lokalnie.
Ponieważ w witrynach nie są dostępne nieistotne dane, można zachować bezpieczeństwo i prywatność systemu bazy danych.
Wady fragmentacji
Gdy wymagane są dane z różnych fragmentów, prędkości dostępu mogą być bardzo wysokie.
W przypadku fragmentacji rekurencyjnych rekonstrukcja będzie wymagała kosztownych technik.
Brak kopii zapasowych danych w różnych witrynach może spowodować, że baza danych będzie nieskuteczna w przypadku awarii witryny.
Fragmentacja pionowa
W przypadku fragmentacji pionowej pola lub kolumny tabeli są grupowane we fragmenty. Aby zachować rekonstrukcję, każdy fragment powinien zawierać pole (pola) klucza podstawowego tabeli. Fragmentacja pionowa może służyć do egzekwowania prywatności danych.
Na przykład, weźmy pod uwagę, że baza danych uniwersytetu przechowuje zapisy wszystkich zarejestrowanych studentów w tabeli Studentów o następującym schemacie.
STUDENT
| Regd_No | Nazwa | Kierunek | Adres | Semestr | Opłaty | Znaki |
Teraz szczegóły opłat są przechowywane w sekcji rachunki. W takim przypadku projektant podzieli bazę danych w następujący sposób -
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;Fragmentacja pozioma
Fragmentacja pozioma grupuje krotki tabeli zgodnie z wartościami jednego lub większej liczby pól. Horyzontalne rozdrobnienie powinno również potwierdzać zasadę rekonstrukcji. Każdy poziomy fragment musi mieć wszystkie kolumny oryginalnej tabeli podstawowej.
Na przykład w schemacie studenta, jeśli dane wszystkich studentów kursu informatyki muszą być utrzymane w Wyższej Szkole Informatyki, projektant podzieli bazę danych w poziomie w następujący sposób -
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";Fragmentacja hybrydowa
W przypadku fragmentacji hybrydowej stosuje się kombinację technik fragmentacji poziomej i pionowej. Jest to najbardziej elastyczna technika fragmentacji, ponieważ generuje fragmenty z minimalną ilością dodatkowych informacji. Jednak rekonstrukcja oryginalnego stołu jest często kosztownym zadaniem.
Fragmentację hybrydy można przeprowadzić na dwa alternatywne sposoby -
Najpierw wygeneruj zestaw fragmentów poziomych; następnie wygeneruj fragmenty pionowe z jednego lub więcej fragmentów poziomych.
Najpierw wygeneruj zestaw pionowych fragmentów; następnie wygeneruj fragmenty poziome z jednego lub więcej fragmentów pionowych.
Przejrzystość dystrybucji jest własnością rozproszonych baz danych, dzięki czemu wewnętrzne szczegóły dystrybucji są ukryte przed użytkownikami. Projektant DDBMS może zdecydować się na fragmentację tabel, replikację fragmentów i przechowywanie ich w różnych miejscach. Ponieważ jednak użytkownicy nie zdają sobie sprawy z tych szczegółów, uważają rozproszoną bazę danych za łatwą w użyciu, jak każda scentralizowana baza danych.
Trzy wymiary przejrzystości dystrybucji to:
- Przejrzystość lokalizacji
- Przejrzystość fragmentacji
- Przejrzystość replikacji
Przejrzystość lokalizacji
Przejrzystość lokalizacji zapewnia, że użytkownik może wykonywać zapytania dotyczące dowolnej tabeli lub fragmentu tabeli, tak jakby były przechowywane lokalnie w witrynie użytkownika. Fakt, że tabela lub jej fragmenty są przechowywane w zdalnym miejscu w systemie rozproszonej bazy danych, powinien być całkowicie nieświadomy dla użytkownika końcowego. Adres odległych stron i mechanizmy dostępu są całkowicie ukryte.
W celu uwzględnienia przejrzystości lokalizacji DDBMS powinno mieć dostęp do aktualnego i dokładnego słownika danych oraz katalogu DDBMS, który zawiera szczegółowe informacje na temat lokalizacji danych.
Przejrzystość fragmentacji
Przejrzystość fragmentacji umożliwia użytkownikom tworzenie zapytań dotyczących dowolnej tabeli, tak jakby była ona niefragmentowana. W ten sposób ukrywa fakt, że tabela, do której pyta użytkownik, jest w rzeczywistości fragmentem lub sumą niektórych fragmentów. Ukrywa też fakt, że fragmenty znajdują się w różnych miejscach.
Jest to nieco podobne do użytkowników widoków SQL, w których użytkownik może nie wiedzieć, że używa widoku tabeli zamiast samej tabeli.
Przejrzystość replikacji
Przejrzystość replikacji zapewnia, że replikacja baz danych jest ukryta przed użytkownikami. Umożliwia użytkownikom tworzenie zapytań dotyczących tabeli tak, jakby istniała tylko jedna kopia tabeli.
Przezroczystość replikacji jest związana z przezroczystością współbieżności i przezroczystością awarii. Za każdym razem, gdy użytkownik aktualizuje element danych, aktualizacja jest odzwierciedlana we wszystkich kopiach tabeli. Jednak ta operacja nie powinna być znana użytkownikowi. To jest przejrzystość współbieżności. Ponadto, w przypadku awarii witryny, użytkownik może nadal przetwarzać swoje zapytania przy użyciu replikowanych kopii bez wiedzy o awarii. To jest przejrzystość porażek.
Połączenie folii
W każdym rozproszonym systemie bazodanowym projektant powinien zapewnić, że wszystkie podane przezroczystości są w znacznym stopniu zachowane. Projektant może zdecydować się na fragmentację tabel, powielenie ich i przechowywanie w różnych miejscach; wszyscy nieświadomi użytkownika końcowego. Jednak pełna przejrzystość dystrybucji jest trudnym zadaniem i wymaga znacznych wysiłków projektowych.
Kontrola baz danych odnosi się do zadania egzekwowania przepisów, aby zapewnić prawidłowe dane autentycznym użytkownikom i aplikacjom bazy danych. Aby poprawne dane były dostępne dla użytkowników, wszystkie dane powinny być zgodne z ograniczeniami integralności zdefiniowanymi w bazie danych. Poza tym dane powinny być chronione przed nieuprawnionymi użytkownikami, aby zachować bezpieczeństwo i prywatność bazy danych. Kontrola bazy danych jest jednym z podstawowych zadań administratora bazy danych (DBA).
Trzy wymiary kontroli bazy danych to:
- Authentication
- Prawa dostępu
- Ograniczenia integralności
Poświadczenie
W systemie rozproszonych baz danych uwierzytelnianie jest procesem, dzięki któremu tylko uprawnieni użytkownicy mogą uzyskać dostęp do zasobów danych.
Uwierzytelnianie można wymusić na dwóch poziomach -
Controlling Access to Client Computer- Na tym poziomie dostęp użytkownika jest ograniczony podczas logowania do komputera klienckiego, który zapewnia interfejs użytkownika do serwera bazy danych. Najpopularniejszą metodą jest kombinacja nazwy użytkownika i hasła. Jednak w przypadku danych o wysokim poziomie bezpieczeństwa można zastosować bardziej wyrafinowane metody, takie jak uwierzytelnianie biometryczne.
Controlling Access to the Database Software- Na tym poziomie oprogramowanie / administrator bazy danych przypisuje użytkownikowi pewne poświadczenia. Użytkownik uzyskuje dostęp do bazy danych przy użyciu tych poświadczeń. Jedną z metod jest utworzenie konta logowania na serwerze bazy danych.
Prawa dostępu
Prawa dostępu użytkownika odnoszą się do uprawnień, które użytkownik ma w odniesieniu do operacji DBMS, takich jak prawa do tworzenia tabeli, usuwania tabeli, dodawania / usuwania / aktualizowania krotek w tabeli lub kwerendy w tabeli.
W środowiskach rozproszonych, ze względu na dużą liczbę tabel i jeszcze większą liczbę użytkowników, nie jest możliwe przypisanie użytkownikom indywidualnych praw dostępu. Tak więc DDBMS definiuje pewne role. Rola to konstrukcja z określonymi uprawnieniami w systemie bazy danych. Po zdefiniowaniu różnych ról poszczególnym użytkownikom przypisuje się jedną z tych ról. Często hierarchia ról jest definiowana zgodnie z hierarchią władzy i odpowiedzialności w organizacji.
Na przykład następujące instrukcje SQL tworzą rolę „Księgowy”, a następnie przypisują tę rolę użytkownikowi „ABC”.
CREATE ROLE ACCOUNTANT;
GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT;
GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT;
GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT;
COMMIT;
GRANT ACCOUNTANT TO ABC;
COMMIT;Kontrola integralności semantycznej
Kontrola integralności semantycznej definiuje i wymusza ograniczenia integralności systemu bazy danych.
Ograniczenia integralności są następujące -
- Ograniczenie integralności typu danych
- Ograniczenie integralności jednostki
- Więzy więzów integralności
Ograniczenie integralności typu danych
Ograniczenie typu danych ogranicza zakres wartości i typ operacji, które można zastosować do pola o określonym typie danych.
Na przykład, weźmy pod uwagę, że tabela „HOSTEL” ma trzy pola - numer hostelu, nazwę hostelu i pojemność. Numer hostelu powinien zaczynać się wielką literą „H” i nie może mieć wartości NULL, a pojemność nie powinna przekraczać 150. Do definicji danych można użyć następującego polecenia SQL -
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) NOT NULL,
H_NAME VARCHAR2(15),
CAPACITY INTEGER,
CHECK ( H_NO LIKE 'H%'),
CHECK ( CAPACITY <= 150)
);Kontrola integralności jednostki
Kontrola integralności jednostki wymusza reguły, dzięki czemu każda krotka może być jednoznacznie zidentyfikowana na podstawie innych krotek. W tym celu definiuje się klucz podstawowy. Klucz podstawowy to zestaw minimalnych pól, które mogą jednoznacznie identyfikować krotkę. Ograniczenie integralności jednostki stwierdza, że żadne dwie krotki w tabeli nie mogą mieć identycznych wartości dla kluczy podstawowych i żadne pole, które jest częścią klucza podstawowego, nie może mieć wartości NULL.
Na przykład w powyższej tabeli hosteli numer hostelu można przypisać jako klucz podstawowy za pomocą następującej instrukcji SQL (ignorując sprawdzanie) -
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) PRIMARY KEY,
H_NAME VARCHAR2(15),
CAPACITY INTEGER
);Wiązanie więzów integralności
Więzienie integralności referencyjnej określa reguły kluczy obcych. Klucz obcy to pole w tabeli danych, które jest kluczem podstawowym powiązanej tabeli. Ograniczenie więzów integralności określa regułę, zgodnie z którą wartość pola klucza obcego powinna albo należeć do wartości klucza podstawowego tabeli, do której istnieje odwołanie, albo być całkowicie NULL.
Na przykład rozważmy stolik studencki, na którym student może zdecydować się na zamieszkanie w hostelu. Aby to uwzględnić, klucz podstawowy tabeli hostelu powinien być zawarty jako klucz obcy w tabeli uczniów. Poniższa instrukcja SQL zawiera to -
CREATE TABLE STUDENT (
S_ROLL INTEGER PRIMARY KEY,
S_NAME VARCHAR2(25) NOT NULL,
S_COURSE VARCHAR2(10),
S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL
);Po umieszczeniu zapytania jest ono najpierw skanowane, analizowane i sprawdzane. Następnie tworzona jest wewnętrzna reprezentacja zapytania, taka jak drzewo zapytań lub wykres zapytań. Następnie opracowywane są alternatywne strategie wykonywania pobierania wyników z tabel bazy danych. Proces wybierania najbardziej odpowiedniej strategii wykonywania zapytań jest nazywany optymalizacją zapytań.
Query Optimization Issues in DDBMS
W DDBMS optymalizacja zapytań jest kluczowym zadaniem. Złożoność jest duża, ponieważ liczba alternatywnych strategii może rosnąć wykładniczo z powodu następujących czynników:
- Obecność wielu fragmentów.
- Dystrybucja fragmentów lub tabel w różnych witrynach.
- Szybkość łączy komunikacyjnych.
- Różnica w lokalnych możliwościach przetwarzania.
Dlatego w systemie rozproszonym często celem jest znalezienie dobrej strategii wykonywania zapytań, a nie najlepszej. Czas wykonania zapytania to suma następujących elementów -
- Czas na przekazywanie zapytań do baz danych.
- Czas na wykonanie lokalnych fragmentów zapytania.
- Czas zebrać dane z różnych witryn.
- Czas na wyświetlenie wyników aplikacji.
Przetwarzanie zapytań
Przetwarzanie zapytań to zestaw wszystkich czynności, począwszy od umieszczenia zapytania, a skończywszy na wyświetleniu wyników zapytania. Kroki są pokazane na poniższym schemacie -

Algebra relacyjna
Algebra relacyjna definiuje podstawowy zestaw operacji modelu relacyjnej bazy danych. Sekwencja operacji algebry relacyjnej tworzy wyrażenie algebry relacyjnej. Wynik tego wyrażenia reprezentuje wynik zapytania do bazy danych.
Podstawowe operacje to -
- Projection
- Selection
- Union
- Intersection
- Minus
- Join
Występ
Operacja rzutowania wyświetla podzbiór pól tabeli. Daje to pionowy podział tabeli.
Syntax in Relational Algebra
$$ \ pi _ {<{AttributeList}>} {(<{Table Name}>)} $$
Na przykład rozważmy następującą bazę danych uczniów -
|
|
||||
| Roll_No | Name | Course | Semester | Gender |
| 2 | Amit Prasad | BCA | 1 | Męski |
| 4 | Varsha Tiwari | BCA | 1 | Płeć żeńska |
| 5 | Asif Ali | MCA | 2 | Męski |
| 6 | Joe Wallace | MCA | 1 | Męski |
| 8 | Shivani Iyengar | BCA | 1 | Płeć żeńska |
Jeśli chcemy wyświetlić nazwiska i kursy wszystkich uczniów, użyjemy następującego wyrażenia algebry relacyjnej -
$$\pi_{Name,Course}{(STUDENT)}$$
Wybór
Operacja wyboru wyświetla podzbiór krotek tabeli, który spełnia określone warunki. Daje to poziomy podział tabeli.
Syntax in Relational Algebra
$$ \ sigma _ {<{Conditions}>} {(<{Table Name}>)} $$
Na przykład w tabeli Student, jeśli chcemy wyświetlić szczegóły wszystkich studentów, którzy wybrali kurs MCA, użyjemy następującego wyrażenia algebry relacyjnej -
$$\sigma_{Course} = {\small "BCA"}^{(STUDENT)}$$
Połączenie operacji projekcji i wyboru
W przypadku większości zapytań potrzebujemy kombinacji operacji rzutowania i wyboru. Istnieją dwa sposoby zapisania tych wyrażeń -
- Korzystanie z sekwencji operacji rzutowania i wyboru.
- Używanie operacji zmiany nazwy do generowania wyników pośrednich.
Na przykład, aby wyświetlić imiona i nazwiska wszystkich studentek kursu BCA -
- Wyrażenie algebry relacyjnej przy użyciu sekwencji rzutowania i operacji wyboru
$$\pi_{Name}(\sigma_{Gender = \small "Female" AND \: Course = \small "BCA"}{(STUDENT)})$$
- Wyrażenie algebry relacyjnej wykorzystujące operację zmiany nazwy do generowania wyników pośrednich
$$FemaleBCAStudent \leftarrow \sigma_{Gender = \small "Female" AND \: Course = \small "BCA"} {(STUDENT)}$$
$$Result \leftarrow \pi_{Name}{(FemaleBCAStudent)}$$
Unia
Jeśli P jest wynikiem operacji, a Q jest wynikiem innej operacji, suma P i Q ($p \cup Q$) jest zbiorem wszystkich krotek, które są w P lub w Q lub w obu bez duplikatów.
Na przykład, aby wyświetlić wszystkich studentów, którzy są w semestrze 1 lub na kursie BCA -
$$Sem1Student \leftarrow \sigma_{Semester = 1}{(STUDENT)}$$
$$BCAStudent \leftarrow \sigma_{Course = \small "BCA"}{(STUDENT)}$$
$$Result \leftarrow Sem1Student \cup BCAStudent$$
Skrzyżowanie
Jeśli P jest wynikiem operacji, a Q jest wynikiem innej operacji, przecięcie P i Q ( $p \cap Q$ ) jest zbiorem wszystkich krotek znajdujących się zarówno w P, jak i Q.
Na przykład, biorąc pod uwagę następujące dwa schematy -
EMPLOYEE
| EmpID | Nazwa | Miasto | Departament | Wynagrodzenie |
PROJECT
| PId | Miasto | Departament | Status |
Aby wyświetlić nazwy wszystkich miast, w których znajduje się projekt, a także mieszka pracownik -
$$CityEmp \leftarrow \pi_{City}{(EMPLOYEE)}$$
$$CityProject \leftarrow \pi_{City}{(PROJECT)}$$
$$Result \leftarrow CityEmp \cap CityProject$$
Minus
Jeśli P jest wynikiem operacji, a Q jest wynikiem innej operacji, P - Q jest zbiorem wszystkich krotek, które są w P, a nie w Q.
Na przykład, aby wyświetlić wszystkie działy, które nie mają trwającego projektu (projekty ze statusem = w toku) -
$$AllDept \leftarrow \pi_{Department}{(EMPLOYEE)}$$
$$ProjectDept \leftarrow \pi_{Department} (\sigma_{Status = \small "ongoing"}{(PROJECT)})$$
$$Result \leftarrow AllDept - ProjectDept$$
Przystąp
Operacja łączenia łączy powiązane krotki z dwóch różnych tabel (wyników zapytań) w jedną tabelę.
Na przykład rozważ dwa schematy, klienta i oddział w bazie danych banku w następujący sposób -
CUSTOMER
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
BRANCH
| BranchID | Nazwa filii | Kod IFSC | Adres |
Aby wyświetlić dane pracownika wraz z danymi oddziału -
$$Result \leftarrow CUSTOMER \bowtie_{Customer.BranchID=Branch.BranchID}{BRANCH}$$
Tłumaczenie zapytań SQL na algebrę relacyjną
Zapytania SQL są tłumaczone na równoważne wyrażenia algebry relacyjnej przed optymalizacją. Zapytanie jest najpierw rozkładane na mniejsze bloki zapytań. Bloki te są tłumaczone na równoważne wyrażenia algebry relacyjnej. Optymalizacja obejmuje optymalizację każdego bloku, a następnie optymalizację zapytania jako całości.
Przykłady
Rozważmy następujące schematy -
PRACOWNIK
| EmpID | Nazwa | Miasto | Departament | Wynagrodzenie |
PROJEKT
| PId | Miasto | Departament | Status |
PRACUJE
| EmpID | PID | godziny |
Przykład 1
Aby wyświetlić szczegóły wszystkich pracowników, którzy zarabiają NIŻEJ niż średnia pensja, piszemy zapytanie SQL -
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;To zapytanie zawiera jedno zagnieżdżone zapytanie podrzędne. Można to więc podzielić na dwa bloki.
Blok wewnętrzny to -
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;Jeśli wynikiem tego zapytania jest AvgSal, to blok zewnętrzny to -
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;Wyrażenie algebry relacyjnej dla bloku wewnętrznego -
$$AvgSal \leftarrow \Im_{AVERAGE(Salary)}{EMPLOYEE}$$
Wyrażenie algebry relacyjnej dla bloku zewnętrznego -
$$ \ sigma_ {Salary <{AvgSal}>} {EMPLOYEE} $$
Przykład 2
Aby wyświetlić identyfikator projektu i status wszystkich projektów pracownika „Arun Kumar”, piszemy zapytanie SQL -
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));To zapytanie zawiera dwa zagnieżdżone zapytania podrzędne. W ten sposób można podzielić na trzy bloki w następujący sposób -
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;(Tutaj ArunEmpID i ArunPID to wyniki zapytań wewnętrznych)
Wyrażenia algebry relacyjnej dla trzech bloków to -
$$ArunEmpID \leftarrow \pi_{EmpID}(\sigma_{Name = \small "Arun Kumar"} {(EMPLOYEE)})$$
$$ArunPID \leftarrow \pi_{PID}(\sigma_{EmpID = \small "ArunEmpID"} {(WORKS)})$$
$$Result \leftarrow \pi_{PID, Status}(\sigma_{PID = \small "ArunPID"} {(PROJECT)})$$
Obliczanie operatorów algebry relacyjnej
Obliczenia operatorów algebry relacyjnej można wykonać na wiele różnych sposobów, a każda alternatywa nosi nazwę access path.
Alternatywa obliczeniowa zależy od trzech głównych czynników -
- Typ operatora
- Dostępna pamięć
- Struktury dyskowe
Czas do wykonania operacji algebry relacyjnej jest sumą -
- Czas przetworzyć krotki.
- Czas pobrać krotki tabeli z dysku do pamięci.
Ponieważ czas przetwarzania krotki jest znacznie krótszy niż czas pobierania krotki z pamięci, szczególnie w systemie rozproszonym, dostęp do dysku jest bardzo często brany pod uwagę jako miara do obliczania kosztu wyrażenia relacyjnego.
Obliczanie selekcji
Obliczenie operacji selekcji zależy od złożoności warunku selekcji i dostępności indeksów atrybutów tabeli.
Poniżej przedstawiono alternatywy obliczeń w zależności od indeksów -
No Index- Jeśli tabela jest nieposortowana i nie ma indeksów, wówczas proces wyboru obejmuje skanowanie wszystkich bloków dyskowych tabeli. Każdy blok jest wprowadzany do pamięci, a każda krotka w bloku jest badana w celu sprawdzenia, czy spełnia warunek wyboru. Jeśli warunek jest spełniony, jest wyświetlany jako dane wyjściowe. Jest to najbardziej kosztowne podejście, ponieważ każda krotka jest wprowadzana do pamięci i każda krotka jest przetwarzana.
B+ Tree Index- Większość systemów baz danych jest zbudowana na indeksie B + Tree. Jeśli warunek wyboru jest oparty na polu, które jest kluczem tego indeksu B + Tree, to ten indeks jest używany do pobierania wyników. Jednak przetwarzanie instrukcji wyboru ze złożonymi warunkami może wiązać się z większą liczbą dostępów do bloków dysku, aw niektórych przypadkach z całkowitym skanowaniem tabeli.
Hash Index- Jeśli używane są indeksy haszujące, a jego pole klucza jest używane w warunku selekcji, pobieranie krotek przy użyciu indeksu skrótu staje się prostym procesem. Indeks skrótu używa funkcji skrótu, aby znaleźć adres zasobnika, w którym przechowywana jest wartość klucza odpowiadająca wartości skrótu. Aby znaleźć wartość klucza w indeksie, wykonywana jest funkcja skrótu i znajduje się adres zasobnika. Przeszukiwane są wartości kluczowe w zasobniku. Jeśli zostanie znalezione dopasowanie, rzeczywista krotka jest pobierana z bloku dysku do pamięci.
Obliczanie połączeń
Kiedy chcemy połączyć dwie tabele, powiedzmy P i Q, każdą krotkę w P należy porównać z każdą krotką w Q, aby sprawdzić, czy warunek łączenia jest spełniony. Jeśli warunek jest spełniony, odpowiednie krotki są łączone, eliminując zduplikowane pola i dołączane do relacji wyniku. W konsekwencji jest to najdroższa operacja.
Typowe podejścia do obliczania sprzężeń to -
Podejście w pętli zagnieżdżonej
Jest to konwencjonalne podejście do łączenia. Można to zilustrować za pomocą następującego pseudokodu (tabele P i Q, z krotkami tuple_p i tuple_q oraz atrybutem łączenia a) -
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-pPodejście sortowania
W tym podejściu dwie tabele są sortowane indywidualnie na podstawie atrybutu łączenia, a następnie sortowane tabele są łączone. Przyjęto zewnętrzne techniki sortowania, ponieważ liczba rekordów jest bardzo duża i nie można ich umieścić w pamięci. Po posortowaniu poszczególnych tabel do pamięci przenoszona jest jedna strona każdej z posortowanych tabel, łączona na podstawie atrybutu łączenia, a połączone krotki są zapisywane.
Podejście z łączeniem mieszanym
Podejście to obejmuje dwie fazy: fazę podziału i fazę sondowania. W fazie partycjonowania tabele P i Q są podzielone na dwa zestawy rozłącznych partycji. Podjęto decyzję o wspólnej funkcji skrótu. Ta funkcja skrótu służy do przypisywania krotek do partycji. W fazie sondowania krotki w partycji P są porównywane z krotkami odpowiedniej partycji Q. Jeśli pasują do siebie, są zapisywane.
Po wyznaczeniu alternatywnych ścieżek dostępu do obliczenia wyrażenia algebry relacyjnej określana jest optymalna ścieżka dostępu. W tym rozdziale zajmiemy się optymalizacją zapytań w systemie scentralizowanym, natomiast w kolejnym rozdziale zajmiemy się optymalizacją zapytań w systemie rozproszonym.
W scentralizowanym systemie przetwarzanie zapytań odbywa się w następującym celu -
Minimalizacja czasu odpowiedzi na zapytanie (czas potrzebny do uzyskania wyników na zapytanie użytkownika).
Maksymalizuj przepustowość systemu (liczba żądań przetwarzanych w określonym czasie).
Zmniejsz ilość pamięci i miejsca wymaganego do przetwarzania.
Zwiększ równoległość.
Analiza kwerendy i tłumaczenie
Początkowo skanowane jest zapytanie SQL. Następnie jest analizowany pod kątem błędów składniowych i poprawności typów danych. Jeśli zapytanie przejdzie ten krok, zostanie rozłożone na mniejsze bloki zapytań. Każdy blok jest następnie tłumaczony na równoważne wyrażenie algebry relacyjnej.
Kroki optymalizacji zapytań
Optymalizacja zapytań obejmuje trzy kroki, a mianowicie generowanie drzewa zapytań, generowanie planu i generowanie kodu planu zapytania.
Step 1 − Query Tree Generation
Drzewo zapytań to struktura danych drzewiastych reprezentująca wyrażenie algebry relacyjnej. Tabele zapytania są reprezentowane jako węzły liści. Operacje algebry relacyjnej są reprezentowane jako węzły wewnętrzne. Rdzeń reprezentuje zapytanie jako całość.
Podczas wykonywania węzeł wewnętrzny jest wykonywany zawsze, gdy dostępne są jego tablice operandów. Węzeł jest następnie zastępowany tabelą wyników. Ten proces jest kontynuowany dla wszystkich węzłów wewnętrznych do momentu wykonania węzła głównego i zastąpienia go tabelą wynikową.
Na przykład rozważmy następujące schematy -
PRACOWNIK
| EmpID | EName | Wynagrodzenie | DeptNo | Data dołączenia |
DEPARTAMENT
| DNo | DName | Lokalizacja |
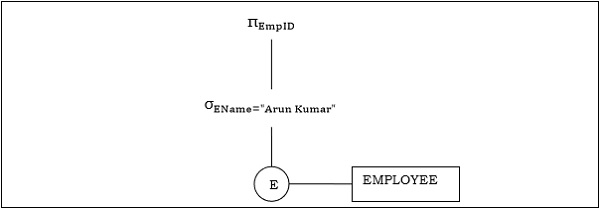
Przykład 1
Rozważmy zapytanie w następujący sposób.
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
Odpowiednie drzewo zapytań będzie -
Przykład 2
Rozważmy inne zapytanie dotyczące sprzężenia.
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
Poniżej znajduje się drzewo zapytań dla powyższego zapytania.

Step 2 − Query Plan Generation
Po wygenerowaniu drzewa zapytań tworzony jest plan zapytań. Plan zapytań to rozszerzone drzewo zapytań, które zawiera ścieżki dostępu do wszystkich operacji w drzewie zapytań. Ścieżki dostępu określają sposób wykonywania operacji relacyjnych w drzewie. Na przykład operacja selekcji może mieć ścieżkę dostępu, która zawiera szczegółowe informacje na temat użycia indeksu drzewa B + do wyboru.
Poza tym plan zapytań określa również, w jaki sposób tabele pośrednie powinny być przekazywane od jednego operatora do drugiego, jak powinny być używane tabele tymczasowe i jak operacje powinny być potokowane / łączone.
Step 3− Code Generation
Generowanie kodu to ostatni krok optymalizacji zapytań. Jest to wykonywalna forma zapytania, której forma zależy od typu podstawowego systemu operacyjnego. Po wygenerowaniu kodu zapytania Execution Manager uruchamia go i generuje wyniki.
Podejścia do optymalizacji zapytań
Wśród podejść do optymalizacji zapytań najczęściej stosuje się wyszukiwanie wyczerpujące i algorytmy oparte na heurystyce.
Wyczerpująca optymalizacja wyszukiwania
W przypadku tych technik dla zapytania początkowo generowane są wszystkie możliwe plany zapytań, a następnie wybierany jest najlepszy plan. Chociaż te techniki zapewniają najlepsze rozwiązanie, mają one wykładniczą złożoność czasową i przestrzenną ze względu na dużą przestrzeń rozwiązań. Na przykład technika programowania dynamicznego.
Optymalizacja oparta na heurystyce
Optymalizacja oparta na heurystyce korzysta z metod optymalizacji opartych na regułach do optymalizacji zapytań. Algorytmy te mają wielomianową złożoność czasową i przestrzenną, która jest mniejsza niż wykładnicza złożoność algorytmów opartych na wyczerpującym wyszukiwaniu. Jednak te algorytmy niekoniecznie zapewniają najlepszy plan zapytań.
Niektóre z typowych reguł heurystycznych to:
Wykonaj operacje wyboru i projektu przed połączeniem. Odbywa się to poprzez przeniesienie operacji wyboru i projektu w dół drzewa zapytań. Zmniejsza to liczbę krotek dostępnych do łączenia.
Najpierw wykonaj najbardziej restrykcyjne operacje wyboru / projektu przed innymi operacjami.
Unikaj operacji obejmujących różne produkty, ponieważ skutkują one bardzo dużymi tabelami pośrednimi.
W tym rozdziale omówiono optymalizację zapytań w systemie rozproszonych baz danych.
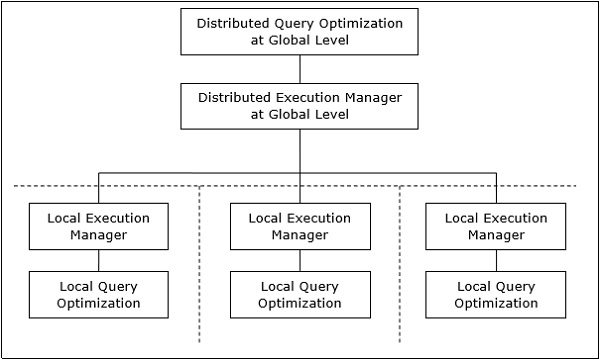
Architektura rozproszonego przetwarzania zapytań
W systemie rozproszonych baz danych przetwarzanie zapytania obejmuje optymalizację zarówno na poziomie globalnym, jak i lokalnym. Zapytanie trafia do systemu bazy danych na kliencie lub w ośrodku kontrolnym. Tutaj użytkownik jest weryfikowany, zapytanie jest sprawdzane, tłumaczone i optymalizowane na poziomie globalnym.
Architekturę można przedstawić jako -
Mapowanie zapytań globalnych do zapytań lokalnych
Proces mapowania zapytań globalnych do lokalnych można zrealizować w następujący sposób -
Tabele wymagane w zapytaniu globalnym zawierają fragmenty rozmieszczone w wielu witrynach. Lokalne bazy danych zawierają informacje tylko o danych lokalnych. Witryna kontrolująca korzysta z globalnego słownika danych do zbierania informacji o dystrybucji i rekonstruuje widok globalny z fragmentów.
Jeśli nie ma replikacji, globalny optymalizator uruchamia lokalne zapytania w lokacjach, w których przechowywane są fragmenty. W przypadku replikacji globalny optymalizator wybiera lokację na podstawie kosztów komunikacji, obciążenia i szybkości serwera.
Globalny optymalizator generuje rozproszony plan wykonania, dzięki czemu między lokacjami następuje najmniejszy transfer danych. Plan określa lokalizację fragmentów, kolejność wykonywania kroków zapytania oraz procesy związane z przesyłaniem wyników pośrednich.
Lokalne zapytania są optymalizowane przez lokalne serwery baz danych. Na koniec, lokalne wyniki zapytania są łączone razem poprzez operację sumowania w przypadku fragmentów poziomych i operację łączenia dla fragmentów pionowych.
Na przykład, weźmy pod uwagę, że następujący schemat projektu jest podzielony poziomo według miasta, a miasta to New Delhi, Kalkuta i Hyderabad.
PROJEKT
| PId | Miasto | Departament | Status |
Załóżmy, że istnieje zapytanie w celu pobrania szczegółów wszystkich projektów, których stan to „W toku”.
Globalne zapytanie to & inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
Zapytanie na serwerze New Delhi będzie -
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
Zapytanie na serwerze Kalkuty będzie -
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
Zapytanie na serwerze Hyderabad będzie -
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
Aby uzyskać ogólny wynik, musimy połączyć wyniki trzech zapytań w następujący sposób -
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
Optymalizacja zapytań rozproszonych
Optymalizacja zapytań rozproszonych wymaga oceny dużej liczby drzew zapytań, z których każde daje wymagane wyniki zapytania. Wynika to przede wszystkim z obecności dużej ilości zreplikowanych i pofragmentowanych danych. Dlatego celem jest znalezienie optymalnego rozwiązania zamiast najlepszego.
Główne problemy związane z optymalizacją zapytań rozproszonych to:
- Optymalne wykorzystanie zasobów w systemie rozproszonym.
- Handel zapytaniami.
- Zmniejszenie przestrzeni rozwiązania zapytania.
Optymalne wykorzystanie zasobów w systemie rozproszonym
System rozproszony ma kilka serwerów baz danych w różnych lokacjach, które wykonują operacje dotyczące zapytania. Poniżej przedstawiono podejścia do optymalnego wykorzystania zasobów -
Operation Shipping- W przypadku wysyłki operacyjnej operacja jest wykonywana w miejscu przechowywania danych, a nie w siedzibie klienta. Wyniki są następnie przesyłane do witryny klienta. Jest to odpowiednie dla operacji, w których argumenty są dostępne w tej samej witrynie. Przykład: operacje Select i Project.
Data Shipping- W przypadku przesyłania danych fragmenty danych są przesyłane na serwer bazy danych, na którym wykonywane są operacje. Jest to używane w operacjach, w których operandy są rozprowadzane w różnych miejscach. Jest to również odpowiednie w systemach, w których koszty komunikacji są niskie, a lokalne procesory są znacznie wolniejsze niż serwer klienta.
Hybrid Shipping- Jest to połączenie przesyłania danych i operacji. Tutaj fragmenty danych są przesyłane do szybkich procesorów, na których przebiega operacja. Wyniki są następnie wysyłane do witryny klienta.

Query Trading
W algorytmie handlu zapytaniami dla systemów rozproszonych baz danych, witryna kontrolująca / kliencka dla zapytań rozproszonych nazywana jest kupującym, a strony, w których wykonywane są zapytania lokalne, nazywane są sprzedawcami. Kupujący formułuje szereg alternatyw wyboru sprzedawców i odtwarzania globalnych wyników. Celem kupującego jest osiągnięcie optymalnego kosztu.
Algorytm rozpoczyna się od przypisania przez kupującego zapytań podrzędnych do witryn sprzedawcy. Plan optymalny jest tworzony z lokalnych zoptymalizowanych planów zapytań zaproponowanych przez sprzedawców w połączeniu z kosztem komunikacji w celu odtworzenia wyniku końcowego. Po sformułowaniu globalnego planu optymalnego zapytanie jest wykonywane.
Zmniejszenie przestrzeni rozwiązania zapytania
Optymalne rozwiązanie zazwyczaj obejmuje redukcję miejsca na rozwiązania, tak aby obniżyć koszt zapytań i transferu danych. Można to osiągnąć za pomocą zestawu reguł heurystycznych, podobnie jak heurystyki w systemach scentralizowanych.
Oto niektóre zasady -
Wykonaj operacje wyboru i projekcji tak wcześnie, jak to możliwe. Zmniejsza to przepływ danych w sieci komunikacyjnej.
Uprość operacje na fragmentach poziomych, eliminując warunki selekcji, które nie są istotne dla konkretnego obszaru.
W przypadku operacji łączenia i łączenia składających się z fragmentów znajdujących się w wielu lokalizacjach, prześlij pofragmentowane dane do miejsca, w którym znajduje się większość danych, i wykonaj tam operację.
Użyj operacji sprzężenia połowicznego, aby kwalifikować krotki, które mają zostać połączone. Zmniejsza to ilość przesyłanych danych, co z kolei zmniejsza koszty komunikacji.
Scal wspólne liście i poddrzewa w rozproszonym drzewie zapytań.
W tym rozdziale omówiono różne aspekty przetwarzania transakcji. Przeanalizujemy również zadania niskiego poziomu zawarte w transakcji, stany transakcji i właściwości transakcji. W ostatniej części przyjrzymy się harmonogramom i możliwości serializacji harmonogramów.
Transakcje
Transakcja to program zawierający zbiór operacji na bazie danych, wykonywanych jako logiczna jednostka przetwarzania danych. Operacje wykonywane w ramach transakcji obejmują jedną lub więcej operacji bazy danych, takich jak wstawianie, usuwanie, aktualizowanie lub pobieranie danych. Jest to atomowy proces, który albo jest całkowicie zakończony, albo nie jest wykonywany wcale. Transakcja obejmująca tylko pobieranie danych bez aktualizacji danych nazywana jest transakcją tylko do odczytu.
Każdą operację wysokiego poziomu można podzielić na szereg zadań lub operacji niskiego poziomu. Na przykład operację aktualizacji danych można podzielić na trzy zadania -
read_item() - odczytuje dane z pamięci do pamięci głównej.
modify_item() - zmień wartość pozycji w pamięci głównej.
write_item() - zapisz zmodyfikowaną wartość z pamięci głównej do pamięci.
Dostęp do bazy danych jest ograniczony do operacji read_item () i write_item (). Podobnie, dla wszystkich transakcji, podstawowe operacje na bazie danych w formularzach do odczytu i zapisu.
Operacje transakcyjne
Operacje niskiego poziomu wykonywane w transakcji to -
begin_transaction - Znacznik określający początek realizacji transakcji.
read_item or write_item - Operacje na bazie danych, które mogą być przeplatane z operacjami pamięci głównej jako część transakcji.
end_transaction - Znacznik określający koniec transakcji.
commit - Sygnał wskazujący, że transakcja została pomyślnie zakończona w całości i nie zostanie cofnięta.
rollback- Sygnał wskazujący, że transakcja się nie powiodła, a zatem wszystkie tymczasowe zmiany w bazie danych są cofane. Zatwierdzonej transakcji nie można cofnąć.
Stany transakcji
Transakcja może przejść przez podzbiór pięciu stanów, aktywnych, częściowo zatwierdzonych, zatwierdzonych, zakończonych niepowodzeniem i przerwanych.
Active- Stan początkowy, w który wchodzi transakcja, to stan aktywny. Transakcja pozostaje w tym stanie podczas wykonywania operacji odczytu, zapisu lub innych operacji.
Partially Committed - Transakcja wchodzi w ten stan po wykonaniu ostatniego zestawienia transakcji.
Committed - Transakcja przechodzi w ten stan po pomyślnym zakończeniu transakcji, a kontrole systemu wydały sygnał zatwierdzenia.
Failed - Transakcja przechodzi ze stanu częściowo zatwierdzonego lub stanu aktywnego do stanu niepowodzenia, gdy okaże się, że normalne wykonanie nie może być kontynuowane lub testy systemu kończą się niepowodzeniem.
Aborted - jest to stan po wycofaniu transakcji po awarii i przywróceniu bazy danych do stanu sprzed rozpoczęcia transakcji.
Poniższy diagram przejścia stanów przedstawia stany w transakcji oraz operacje transakcyjne niskiego poziomu, które powodują zmianę stanów.
Pożądane właściwości transakcji
Każda transakcja musi zachować właściwości ACID, a mianowicie. Atomowość, spójność, izolacja i trwałość.
Atomicity- Ta właściwość stwierdza, że transakcja jest niepodzielną jednostką przetwarzania, to znaczy albo jest wykonywana w całości, albo w ogóle nie jest wykonywana. Żadna częściowa aktualizacja nie powinna istnieć.
Consistency- Transakcja powinna przenieść bazę danych z jednego spójnego stanu do innego spójnego stanu. Nie powinno to niekorzystnie wpływać na żadną pozycję danych w bazie danych.
Isolation- Transakcja powinna być wykonana tak, jakby była jedyną w systemie. Nie powinno być żadnych zakłóceń ze strony innych współbieżnych transakcji, które są jednocześnie uruchomione.
Durability - Jeżeli zatwierdzona transakcja powoduje zmianę, zmiana ta powinna być trwała w bazie danych i nie zostać utracona w przypadku jakiejkolwiek awarii.
Harmonogramy i konflikty
W systemie z wieloma jednoczesnymi transakcjami a scheduleto całkowita kolejność wykonywania operacji. Biorąc pod uwagę harmonogram S zawierający n transakcji, powiedzmy T1, T2, T3 ……… ..Tn; dla każdej transakcji Ti operacje w Ti muszą zostać przeprowadzone zgodnie z harmonogramem S.
Rodzaje harmonogramów
Istnieją dwa rodzaje harmonogramów -
Serial Schedules- W harmonogramie seryjnym w dowolnym momencie aktywna jest tylko jedna transakcja, tj. Nie ma nakładania się transakcji. Przedstawia to poniższy wykres -

Parallel Schedules- W harmonogramach równoległych jednocześnie aktywnych jest więcej niż jedna transakcja, tj. Transakcje zawierają operacje, które nakładają się w czasie. Przedstawia to poniższy wykres -

Konflikty w zestawieniach
W harmonogramie obejmującym wiele transakcji: a conflictwystępuje, gdy dwie aktywne transakcje wykonują niezgodne operacje. Mówi się, że dwie operacje są ze sobą w konflikcie, gdy wszystkie poniższe trzy warunki występują jednocześnie:
Te dwie operacje są częścią różnych transakcji.
Obie operacje mają dostęp do tego samego elementu danych.
Co najmniej jedna z operacji jest operacją write_item (), tj. Próbuje zmodyfikować element danych.
Możliwość serializacji
ZA serializable schedulez transakcji „n” jest harmonogramem równoległym, który jest odpowiednikiem harmonogramu seryjnego zawierającego te same transakcje „n”. Harmonogram z możliwością serializacji zawiera poprawność harmonogramu szeregowego przy jednoczesnym zapewnieniu lepszego wykorzystania procesora przez harmonogram równoległy.
Równoważność harmonogramów
Równoważność dwóch harmonogramów może być następujących typów -
Result equivalence - Dwa harmonogramy dające identyczne wyniki są uważane za równoważne wynikom.
View equivalence - Dwa harmonogramy, które wykonują podobne czynności w podobny sposób, są uważane za równoważne w widoku.
Conflict equivalence - O dwóch harmonogramach mówi się, że są równoważne w konflikcie, jeśli oba zawierają ten sam zestaw transakcji i mają tę samą kolejność sprzecznych par operacji.
Techniki kontroli współbieżności zapewniają, że wiele transakcji jest wykonywanych jednocześnie, zachowując właściwości ACID transakcji i możliwość serializacji w harmonogramach.
W tym rozdziale przeanalizujemy różne podejścia do kontroli współbieżności.
Protokoły kontroli współbieżności oparte na blokowaniu
Protokoły kontroli współbieżności oparte na blokowaniu używają koncepcji blokowania elementów danych. ZAlockjest zmienną powiązaną z elementem danych, która określa, czy operacje odczytu / zapisu mogą być wykonywane na tym elemencie danych. Ogólnie używana jest macierz zgodności blokad, która określa, czy element danych może być zablokowany przez dwie transakcje w tym samym czasie.
Systemy kontroli współbieżności oparte na blokowaniu mogą używać protokołów blokowania jednofazowego lub dwufazowego.
Jednofazowy protokół blokowania
W tej metodzie każda transakcja blokuje przedmiot przed użyciem i zwalnia blokadę, gdy zakończy się jej używanie. Ta metoda blokowania zapewnia maksymalną współbieżność, ale nie zawsze wymusza możliwość serializacji.
Dwufazowy protokół blokowania
W tej metodzie wszystkie operacje blokowania poprzedzają pierwszą operację zwolnienia blokady lub odblokowania. Transakcja składa się z dwóch faz. W pierwszej fazie transakcja uzyskuje tylko wszystkie potrzebne blokady i nie zwalnia żadnej blokady. Nazywa się to rozszerzaniem lubgrowing phase. W drugiej fazie transakcja zwalnia blokady i nie może zażądać żadnych nowych blokad. Nazywa się toshrinking phase.
Każda transakcja, która następuje po protokole blokowania dwufazowego, gwarantuje możliwość serializacji. Jednak takie podejście zapewnia niski paralelizm między dwiema sprzecznymi transakcjami.
Algorytmy kontroli współbieżności znacznika czasu
Algorytmy kontroli współbieżności oparte na sygnaturach czasowych używają sygnatury czasowej transakcji do koordynowania równoczesnego dostępu do elementu danych w celu zapewnienia serializacji. Znacznik czasu to unikalny identyfikator nadawany przez DBMS transakcji, który reprezentuje czas rozpoczęcia transakcji.
Algorytmy te zapewniają, że transakcje są zatwierdzane w kolejności określonej przez ich znaczniki czasu. Starsza transakcja powinna zostać zatwierdzona przed młodszą transakcją, ponieważ starsza transakcja wchodzi do systemu przed młodszą.
Techniki kontroli współbieżności oparte na znacznikach czasowych generują harmonogramy, które można serializować, tak że równoważny harmonogram szeregowy jest uporządkowany według wieku transakcji uczestniczących.
Niektóre z algorytmów kontroli współbieżności opartych na sygnaturach czasowych to:
- Podstawowy algorytm porządkowania znaczników czasu.
- Konserwatywny algorytm porządkowania znaczników czasu.
- Algorytm wielu wersji na podstawie kolejności sygnatur czasowych.
Porządkowanie oparte na sygnaturach czasowych jest zgodne z trzema regułami wymuszającymi serializowalność -
Access Rule- Gdy dwie transakcje próbują uzyskać dostęp do tego samego elementu danych jednocześnie, w przypadku operacji powodujących konflikt priorytet ma starsza transakcja. Powoduje to, że młodsza transakcja czeka, aż starsza transakcja zostanie zatwierdzona jako pierwsza.
Late Transaction Rule- Jeżeli młodsza transakcja zapisała pozycję danych, to starsza transakcja nie może odczytać ani zapisać tej pozycji danych. Ta reguła zapobiega zatwierdzeniu starszej transakcji po zatwierdzeniu młodszej transakcji.
Younger Transaction Rule - Młodsza transakcja może odczytywać lub zapisywać dane, które zostały już zapisane przez starszą transakcję.
Algorytm optymistycznej kontroli współbieżności
W systemach o niskim współczynniku konfliktów zadanie sprawdzania poprawności każdej transakcji pod kątem możliwości serializacji może obniżyć wydajność. W takich przypadkach test możliwości serializacji jest odkładany tuż przed zatwierdzeniem. Ponieważ współczynnik konfliktów jest niski, prawdopodobieństwo przerwania transakcji, których nie można serializować, jest również niskie. Takie podejście nazywa się optymistyczną techniką kontroli współbieżności.
W tym podejściu cykl życia transakcji dzieli się na trzy następujące fazy -
Execution Phase - Transakcja pobiera elementy danych do pamięci i wykonuje na nich operacje.
Validation Phase - Transakcja sprawdza, czy zatwierdzanie zmian w bazie danych przechodzi test serializacji.
Commit Phase - Transakcja zapisuje z powrotem zmodyfikowane dane w pamięci na dysk.
Ten algorytm używa trzech reguł do wymuszenia serializacji w fazie walidacji -
Rule 1- Biorąc pod uwagę dwie transakcje T i i T j , jeśli T i czyta element danych, który zapisuje T j , to faza wykonania T i nie może pokrywać się z fazą zatwierdzania T j . T j może zatwierdzić dopiero po zakończeniu wykonywania T i .
Rule 2- Biorąc pod uwagę dwie transakcje T i i T j , jeśli T i zapisuje element danych, który odczytuje T j , to faza zatwierdzania T i nie może pokrywać się z fazą wykonywania T j . T j może rozpocząć wykonywanie dopiero po zatwierdzeniu T i .
Rule 3- Biorąc pod uwagę dwie transakcje T i i T j , jeśli T i zapisuje element danych, który zapisuje również T j , to faza zatwierdzania T i nie może pokrywać się z fazą zatwierdzania T j . T j może rozpocząć zatwierdzanie dopiero po zatwierdzeniu przez T i .
Kontrola współbieżności w systemach rozproszonych
W tej sekcji zobaczymy, jak powyższe techniki są implementowane w systemie rozproszonych baz danych.
Rozproszony dwufazowy algorytm blokujący
Podstawowa zasada rozproszonego blokowania dwufazowego jest taka sama, jak podstawowy protokół blokowania dwufazowego. Jednak w systemie rozproszonym istnieją witryny wyznaczone jako menedżery blokad. Menedżer blokad kontroluje żądania przejęcia blokady z monitorów transakcji. Aby wymusić koordynację między menedżerami zamków w różnych lokalizacjach, przynajmniej jedna witryna ma uprawnienia do przeglądania wszystkich transakcji i wykrywania konfliktów blokad.
W zależności od liczby witryn, które mogą wykryć konflikty blokad, można podzielić rozproszone dwufazowe podejścia do blokowania:
Centralized two-phase locking- W tym podejściu jedna lokalizacja jest wyznaczona jako zarządca centralnej śluzy. Wszystkie lokalizacje w środowisku znają lokalizację administratora centralnego zamka i uzyskują od niego blokadę podczas transakcji.
Primary copy two-phase locking- W tym podejściu szereg lokalizacji jest wyznaczonych jako centra kontroli śluz. Każda z tych witryn jest odpowiedzialna za zarządzanie określonym zestawem blokad. Wszystkie strony wiedzą, które centrum kontroli zamków jest odpowiedzialne za zarządzanie zamkiem, którego elementu tabeli danych / fragmentu.
Distributed two-phase locking- W tym podejściu istnieje kilka menedżerów blokad, w których każdy menedżer blokad kontroluje blokady elementów danych przechowywanych w jego lokalnej lokalizacji. Lokalizacja menedżera blokad zależy od dystrybucji i replikacji danych.
Rozproszona kontrola współbieżności znacznika czasu
W systemie scentralizowanym znacznik czasu dowolnej transakcji jest określany na podstawie fizycznego odczytu zegara. Jednak w systemie rozproszonym odczyty lokalnego zegara fizycznego / logicznego dowolnej witryny nie mogą być używane jako globalne znaczniki czasu, ponieważ nie są one globalnie unikalne. Tak więc sygnatura czasowa składa się z kombinacji identyfikatora witryny i odczytu zegara tej witryny.
W celu implementacji algorytmów porządkowania znaczników czasu każda witryna ma program planujący, który utrzymuje oddzielną kolejkę dla każdego menedżera transakcji. Podczas transakcji menedżer transakcji wysyła żądanie blokady do harmonogramu witryny. Program planujący umieszcza żądanie w odpowiedniej kolejce w rosnącej kolejności znacznika czasu. Żądania są przetwarzane od początku kolejek w kolejności ich znaczników czasu, tj. Od najstarszych do najstarszych.
Wykresy konfliktów
Inną metodą jest tworzenie wykresów konfliktów. Dla tej transakcji definiowane są klasy. Klasa transakcji zawiera dwa zestawy elementów danych zwane zestawem do odczytu i zestawem do zapisu. Transakcja należy do określonej klasy, jeśli zbiór odczytów transakcji jest podzbiorem zestawu do odczytu klasy, a zbiór zapisu transakcji jest podzbiorem zbioru zapisu klasy. W fazie odczytu każda transakcja wysyła swoje żądania odczytu dla elementów danych w swoim zestawie do odczytu. W fazie zapisu każda transakcja wysyła swoje żądania zapisu.
Dla klas, do których należą aktywne transakcje, tworzony jest wykres konfliktu. Zawiera zestaw krawędzi pionowych, poziomych i ukośnych. Pionowa krawędź łączy dwa węzły w klasie i oznacza konflikty w klasie. Pozioma krawędź łączy dwa węzły w dwóch klasach i oznacza konflikt zapisu i zapisu między różnymi klasami. Ukośna krawędź łączy dwa węzły w dwóch klasach i oznacza konflikt zapisu i odczytu lub odczytu i zapisu między dwiema klasami.
Wykresy konfliktu są analizowane w celu ustalenia, czy dwie transakcje w tej samej klasie lub w dwóch różnych klasach mogą przebiegać równolegle.
Algorytm rozproszonej optymistycznej kontroli współbieżności
Rozproszony optymistyczny algorytm sterowania współbieżnością rozszerza optymistyczny algorytm sterowania współbieżnością. W przypadku tego rozszerzenia obowiązują dwie zasady -
Rule 1- Zgodnie z tą zasadą transakcja musi zostać zweryfikowana lokalnie we wszystkich witrynach podczas jej wykonywania. Jeśli okaże się, że transakcja jest nieważna w jakimkolwiek miejscu, jest przerywana. Lokalna walidacja gwarantuje, że transakcja zachowuje możliwość serializacji w lokacjach, w których została wykonana. Po przejściu lokalnego testu walidacji transakcja jest weryfikowana globalnie.
Rule 2- Zgodnie z tą zasadą, gdy transakcja przejdzie lokalny test walidacji, powinna zostać zweryfikowana globalnie. Globalna walidacja zapewnia, że jeśli dwie sprzeczne transakcje są uruchamiane razem w więcej niż jednej lokalizacji, powinny one zatwierdzać w tej samej względnej kolejności we wszystkich witrynach, które razem obsługują. Może to wymagać, aby transakcja czekała na inną konfliktową transakcję po sprawdzeniu poprawności przed zatwierdzeniem. To wymaganie sprawia, że algorytm jest mniej optymistyczny, ponieważ transakcja może nie być w stanie zatwierdzić, gdy tylko zostanie zweryfikowana w witrynie.
W tym rozdziale omówiono mechanizmy obsługi zakleszczeń w systemach baz danych. Przeanalizujemy mechanizmy obsługi zakleszczeń zarówno w scentralizowanym, jak i rozproszonym systemie baz danych.
Co to są zakleszczenia?
Zakleszczenie to stan systemu bazy danych, w którym występują co najmniej dwie transakcje, gdy każda transakcja oczekuje na element danych, który jest blokowany przez inną transakcję. Zakleszczenie może być wskazywane przez cykl na wykresie oczekiwania na. Jest to wykres skierowany, w którym wierzchołki oznaczają transakcje, a krawędzie oznaczają oczekiwania na elementy danych.
Na przykład w poniższym grafie oczekiwania na transakcję T1 oczekuje element danych X, który jest zablokowany przez T3. T3 czeka na Y, które jest zablokowane przez T2, a T2 czeka na Z, które jest blokowane przez T1. W związku z tym powstaje cykl oczekiwania i żadna z transakcji nie może kontynuować wykonywania.

Obsługa zakleszczenia w systemach scentralizowanych
Istnieją trzy klasyczne podejścia do obsługi impasu, a mianowicie:
- Zapobieganie zakleszczeniom.
- Unikanie impasu.
- Wykrywanie i usuwanie zakleszczeń.
Wszystkie trzy podejścia można zastosować zarówno w scentralizowanym, jak i rozproszonym systemie baz danych.
Zapobieganie zakleszczeniom
Podejście zapobiegające zakleszczeniom nie pozwala żadnej transakcji na uzyskanie blokad, które doprowadzą do zakleszczenia. Konwencja jest taka, że gdy więcej niż jedna transakcja żąda zablokowania tego samego elementu danych, blokada jest przyznawana tylko jednej z nich.
Jedną z najpopularniejszych metod zapobiegania zakleszczeniom jest wstępne przejęcie wszystkich blokad. W tej metodzie transakcja nabywa wszystkie blokady przed rozpoczęciem wykonywania i zachowuje blokady przez cały czas trwania transakcji. Jeśli inna transakcja wymaga któregokolwiek z już nabytych blokad, musi poczekać, aż wszystkie potrzebne blokady będą dostępne. Stosując to podejście, system jest chroniony przed zakleszczeniem, ponieważ żadna z oczekujących transakcji nie posiada żadnej blokady.
Unikanie impasu
Podejście unikania zakleszczeń obsługuje zakleszczenia, zanim one wystąpią. Analizuje transakcje i blokady, aby określić, czy oczekiwanie prowadzi do impasu.
Metodę można pokrótce opisać w następujący sposób. Transakcje rozpoczynają się i żądają elementów danych, które muszą zablokować. Menedżer blokad sprawdza, czy blokada jest dostępna. Jeśli jest dostępny, menedżer blokad przydziela element danych, a transakcja uzyskuje blokadę. Jeśli jednak pozycja jest zablokowana przez inną transakcję w trybie niezgodnym, menedżer blokady uruchamia algorytm w celu sprawdzenia, czy utrzymywanie transakcji w stanie oczekiwania spowoduje zakleszczenie, czy nie. W związku z tym algorytm decyduje, czy transakcja może czekać, czy też jedna z transakcji powinna zostać przerwana.
Do tego celu służą dwa algorytmy wait-die i wound-wait. Załóżmy, że istnieją dwie transakcje, T1 i T2, w których T1 próbuje zablokować pozycję danych, która jest już zablokowana przez T2. Algorytmy są następujące -
Wait-Die- Jeśli T1 jest starszy niż T2, T1 może czekać. W przeciwnym razie, jeśli T1 jest młodszy niż T2, T1 jest przerywany i później uruchamiany ponownie.
Wound-Wait- Jeśli T1 jest starszy niż T2, T2 jest przerywany i później uruchamiany ponownie. W przeciwnym razie, jeśli T1 jest młodszy niż T2, T1 może czekać.
Wykrywanie i usuwanie zakleszczeń
Podejście do wykrywania i usuwania zakleszczeń okresowo uruchamia algorytm wykrywania zakleszczeń i usuwa zakleszczenia w przypadku ich wystąpienia. Nie sprawdza zakleszczenia, gdy transakcja żąda blokady. Gdy transakcja żąda blokady, menedżer blokady sprawdza, czy jest ona dostępna. Jeśli jest dostępny, transakcja może zablokować element danych; w przeciwnym razie transakcja może czekać.
Ponieważ nie ma żadnych środków ostrożności podczas przyznawania żądań blokady, niektóre transakcje mogą być zakleszczone. Aby wykryć zakleszczenia, menedżer blokad okresowo sprawdza, czy wykres oczekiwania ma cykle. Jeśli system jest zakleszczony, menedżer blokad wybiera transakcję ofiary z każdego cyklu. Ofiara zostaje przerwana i wycofana; a następnie uruchomiono ponownie później. Niektóre z metod stosowanych do selekcji ofiar to:
- Wybierz najmłodszą transakcję.
- Wybierz transakcję z najmniejszą liczbą pozycji danych.
- Wybierz transakcję, która wykonała najmniejszą liczbę aktualizacji.
- Wybierz transakcję, która ma najmniejszy koszt ponownego uruchomienia.
- Wybierz transakcję, która jest wspólna dla dwóch lub więcej cykli.
To podejście jest przede wszystkim odpowiednie dla systemów z niską liczbą transakcji i gdzie potrzebna jest szybka odpowiedź na żądania blokady.
Obsługa zakleszczenia w systemach rozproszonych
Przetwarzanie transakcji w rozproszonym systemie baz danych jest również rozproszone, tj. Ta sama transakcja może być przetwarzana w więcej niż jednym miejscu. Dwa główne problemy związane z obsługą zakleszczeń w rozproszonym systemie baz danych, które nie występują w systemie scentralizowanym, totransaction location i transaction control. Po rozwiązaniu tych obaw, zakleszczenia są obsługiwane przez dowolne metody zapobiegania zakleszczeniom, unikania zakleszczeń lub wykrywania i usuwania zakleszczeń.
Lokalizacja transakcji
Transakcje w systemie rozproszonej bazy danych są przetwarzane w wielu witrynach i wykorzystują elementy danych w wielu witrynach. Ilość przetwarzanych danych nie jest równomiernie rozłożona na te witryny. Różny jest również okres przetwarzania. Zatem ta sama transakcja może być aktywna w niektórych witrynach, a nieaktywna w innych. Gdy w witrynie znajdują się dwie sprzeczne transakcje, może się zdarzyć, że jedna z nich jest nieaktywna. Ten stan nie występuje w scentralizowanym systemie. Ten problem nazywa się problemem lokalizacji transakcji.
Ten problem może rozwiązać model Daisy Chain. W tym modelu transakcja przenosi pewne szczegóły podczas przenoszenia z jednej witryny do drugiej. Niektóre szczegóły to lista wymaganych tabel, lista wymaganych witryn, lista odwiedzonych tabel i witryn, lista tabel i witryn, które jeszcze nie zostały odwiedzone oraz lista nabytych blokad z typami. Po zakończeniu transakcji przez zatwierdzenie lub przerwanie, informacje powinny zostać przesłane do wszystkich zainteresowanych stron.
Kontrola transakcji
Kontrola transakcji dotyczy wyznaczania i kontrolowania miejsc wymaganych do przetwarzania transakcji w systemie rozproszonej bazy danych. Istnieje wiele opcji dotyczących wyboru miejsca przetwarzania transakcji i wyznaczania centrum kontroli, na przykład -
- Jeden serwer może zostać wybrany jako centrum kontroli.
- Centrum kontroli może przemieszczać się z jednego serwera na drugi.
- Odpowiedzialność za kontrolowanie może być współdzielona przez kilka serwerów.
Rozproszone zapobieganie zakleszczeniom
Podobnie jak w przypadku scentralizowanego zapobiegania zakleszczeniom, w rozproszonym podejściu do zapobiegania zakleszczeniom transakcja powinna uzyskać wszystkie blokady przed rozpoczęciem wykonywania. Zapobiega to zakleszczeniom.
Witryna, do której dochodzi transakcja, jest wyznaczana jako witryna kontrolna. Witryna kontrolująca wysyła komunikaty do witryn, w których znajdują się elementy danych, w celu ich zablokowania. Następnie czeka na potwierdzenie. Gdy wszystkie witryny potwierdzą, że zablokowały pozycje danych, rozpoczyna się transakcja. Jeśli jakakolwiek witryna lub łącze komunikacyjne ulegnie awarii, transakcja musi poczekać, aż zostaną naprawione.
Chociaż implementacja jest prosta, to podejście ma pewne wady -
Wstępne pozyskanie blokad wymaga długiego czasu na opóźnienia w komunikacji. Zwiększa to czas potrzebny na transakcję.
W przypadku awarii witryny lub łącza transakcja musi długo czekać, aby witryny zostały przywrócone. Tymczasem w uruchomionych witrynach pozycje są zablokowane. Może to uniemożliwić wykonanie innych transakcji.
Jeśli witryna kontrolująca zawiedzie, nie może komunikować się z innymi lokacjami. Witryny te nadal utrzymują zablokowane elementy danych w stanie zablokowanym, co powoduje blokowanie.
Rozproszone unikanie zakleszczenia
Podobnie jak w systemie scentralizowanym, rozproszone unikanie zakleszczenia obsługuje zakleszczenie przed jego wystąpieniem. Ponadto w systemach rozproszonych należy zająć się kwestiami lokalizacji i kontroli transakcji. Ze względu na rozproszony charakter transakcji mogą wystąpić następujące konflikty -
- Konflikt między dwiema transakcjami w tej samej witrynie.
- Konflikt między dwiema transakcjami w różnych witrynach.
W przypadku konfliktu jedna z transakcji może zostać przerwana lub pozwolić na czekanie zgodnie z algorytmami rozproszonego czekania lub rozproszonego oczekiwania na ranę.
Załóżmy, że istnieją dwie transakcje, T1 i T2. T1 dociera do Ośrodka P i próbuje zablokować element danych, który jest już zablokowany przez T2 w tym miejscu. W związku z tym istnieje konflikt w Ośrodku P. Algorytmy są następujące -
Distributed Wound-Die
Jeśli T1 jest starszy niż T2, T1 może czekać. T1 może wznowić wykonywanie po tym, jak ośrodek P otrzyma komunikat, że T2 zatwierdził lub przerwał pomyślnie we wszystkich lokalizacjach.
Jeśli T1 jest młodszy niż T2, T1 jest przerywany. Kontrola współbieżności w lokacji P wysyła komunikat do wszystkich lokacji, w których odwiedził T1, aby przerwać T1. Witryna kontrolująca powiadamia użytkownika o pomyślnym przerwaniu T1 we wszystkich witrynach.
Distributed Wait-Wait
Jeśli T1 jest starszy niż T2, T2 musi zostać przerwane. Jeśli T2 jest aktywny w Ośrodku P, Ośrodek P przerywa i wycofuje T2, a następnie rozgłasza ten komunikat do innych odpowiednich miejsc. Jeśli T2 opuścił ośrodek P, ale jest aktywny w ośrodku Q, ośrodek P rozgłasza, że T2 został przerwany; Ośrodek L następnie przerywa pracę i wycofuje T2 i wysyła ten komunikat do wszystkich lokalizacji.
Jeśli T1 jest młodszy niż T1, T1 może czekać. T1 może wznowić wykonywanie po tym, jak ośrodek P otrzyma komunikat, że T2 zakończył przetwarzanie.
Rozproszone wykrywanie zakleszczeń
Podobnie jak podejście do scentralizowanego wykrywania zakleszczeń, zakleszczenia mogą wystąpić i są usuwane w przypadku wykrycia. System nie przeprowadza żadnych kontroli, gdy transakcja nakłada żądanie blokady. W celu wdrożenia tworzone są globalne wykresy oczekiwania na. Istnienie cyklu na globalnym wykresie oczekiwania na oznacza zakleszczenie. Jednak trudno jest wykryć zakleszczenia, ponieważ transakcja oczekuje na zasoby w sieci.
Alternatywnie algorytmy wykrywania zakleszczenia mogą wykorzystywać zegary. Każda transakcja jest powiązana z licznikiem czasu, który jest ustawiony na okres czasu, w którym transakcja ma się zakończyć. Jeśli transakcja nie zakończy się w tym czasie, licznik czasu wyłączy się, wskazując na możliwy zakleszczenie.
Innym narzędziem służącym do obsługi zakleszczeń jest detektor zakleszczeń. W systemie scentralizowanym istnieje jeden czujnik zakleszczenia. W systemie rozproszonym może istnieć więcej niż jeden detektor zakleszczenia. Detektor zakleszczenia może znaleźć zakleszczenia w kontrolowanych przez siebie miejscach. Istnieją trzy alternatywy dla wykrywania zakleszczeń w systemie rozproszonym, a mianowicie.
Centralized Deadlock Detector - Jedno miejsce jest wyznaczone jako centralny detektor zakleszczenia.
Hierarchical Deadlock Detector - Wiele detektorów zakleszczenia jest ułożonych hierarchicznie.
Distributed Deadlock Detector - Wszystkie witryny uczestniczą w wykrywaniu zakleszczeń i ich usuwaniu.
W tym rozdziale omówiono kontrolę replikacji, która jest wymagana do utrzymania spójnych danych we wszystkich lokacjach. Zbadamy techniki kontroli replikacji i algorytmy wymagane do kontroli replikacji.
Jak wspomniano wcześniej, replicationto technika używana w rozproszonych bazach danych do przechowywania wielu kopii tabeli danych w różnych witrynach. Problem związany z posiadaniem wielu kopii w wielu witrynach wiąże się z obciążeniem związanym z utrzymaniem spójności danych, szczególnie podczas operacji aktualizacji.
Aby zachować wzajemnie spójne dane we wszystkich lokalizacjach, należy zastosować techniki kontroli replikacji. Istnieją dwa podejścia do kontroli replikacji, a mianowicie -
- Synchroniczna kontrola replikacji
- Asynchroniczna kontrola replikacji
Synchroniczna kontrola replikacji
W podejściu replikacji synchronicznej baza danych jest zsynchronizowana, tak aby wszystkie replikacje zawsze miały tę samą wartość. Transakcja żądająca elementu danych będzie miała dostęp do tej samej wartości we wszystkich witrynach. Aby zapewnić tę jednolitość, transakcja, która aktualizuje element danych, jest rozszerzana tak, że dokonuje aktualizacji we wszystkich kopiach elementu danych. Zwykle do tego celu służy protokół zatwierdzania dwufazowego.
Na przykład rozważmy tabelę danych PROJECT (PId, PName, PLocation). Musimy uruchomić transakcję T1, która aktualizuje PLocation do „Mumbai”, jeśli PLocation to „Bombay”. Jeśli nie ma replikacji, operacje w transakcji T1 będą -
Begin T1:
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1;Jeśli tabela danych ma dwie repliki w Ośrodku A i Ośrodku B, T1 musi odrodzić dwa elementy podrzędne T1A i T1B odpowiadające dwóm lokalizacjom. Rozszerzona transakcja T1 będzie -
Begin T1:
Begin T1A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1A;
Begin T2A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T2A;
End T1;Asynchroniczna kontrola replikacji
W podejściu replikacji asynchronicznej repliki nie zawsze zachowują tę samą wartość. Co najmniej jedna replika może przechowywać nieaktualną wartość, a transakcja może wyświetlać różne wartości. Nazywa się proces przywracania wszystkich replik do aktualnej wartościsynchronization.
Popularną metodą synchronizacji jest metoda store and forward. W tej metodzie jedna lokacja jest wyznaczana jako lokacja główna, a pozostałe lokacje są lokacjami dodatkowymi. Lokacja główna zawsze zawiera zaktualizowane wartości. Wszystkie transakcje najpierw trafiają do lokacji głównej. Transakcje te są następnie umieszczane w kolejce do zastosowania w lokacjach dodatkowych. Lokacje dodatkowe są aktualizowane przy użyciu metody wdrażania tylko wtedy, gdy zaplanowano wykonanie transakcji.
Algorytmy kontroli replikacji
Niektóre z algorytmów kontroli replikacji to:
- Algorytm sterowania replikacją typu master-slave.
- Rozproszony algorytm głosowania.
- Algorytm konsensusu większości.
- Algorytm krążącego tokena.
Algorytm sterowania replikacją typu master-slave
Jest jedna witryna główna i witryny podrzędne „N”. Algorytm nadrzędny działa w ośrodku wzorcowym w celu wykrywania konfliktów. Kopia algorytmu slave działa w każdej lokalizacji slave. Ogólny algorytm jest wykonywany w dwóch następujących fazach -
Transaction acceptance/rejection phase- Kiedy transakcja wchodzi do monitora transakcji strony podrzędnej, strona podrzędna wysyła żądanie do strony głównej. Witryna główna sprawdza, czy nie występują konflikty. Jeśli nie ma żadnych konfliktów, master wysyła komunikat „ACK +” do witryny slave, która następnie rozpoczyna fazę składania wniosków transakcyjnych. W przeciwnym razie master wysyła komunikat „ACK-” do slave'a, który następnie odrzuca transakcję.
Transaction application phase- Po wejściu w tę fazę, strona slave, w której została zawarta transakcja, rozsyła żądanie do wszystkich slave'ów o wykonanie transakcji. Po odebraniu żądań peer slave wykonują transakcję i wysyłają „ACK” do żądającego slave'a po jej zakończeniu. Po tym, jak żądający slave otrzyma komunikaty „ACK” od wszystkich swoich peerów, wysyła komunikat „DONE” do strony głównej. Master rozumie, że transakcja została zakończona i usuwa ją z oczekującej kolejki.
Rozproszony algorytm głosowania
Obejmuje to „N” peer-site, z których wszystkie muszą „zatwierdzić” transakcję przed rozpoczęciem jej wykonywania. Poniżej przedstawiono dwie fazy tego algorytmu -
Distributed transaction acceptance phase- Gdy transakcja wchodzi do menedżera transakcji w witrynie, wysyła żądanie transakcji do wszystkich innych witryn. Po otrzymaniu żądania witryna równorzędna rozwiązuje konflikty za pomocą reguł głosowania na podstawie priorytetów. Jeśli wszystkie witryny równorzędne są „OK” z transakcją, witryna żądająca rozpoczyna fazę składania wniosków. Jeśli żadna z witryn równorzędnych nie zatwierdzi transakcji, witryna żądająca odrzuca transakcję.
Distributed transaction application phase- Po wejściu w tę fazę, strona, w której transakcja została zawarta, rozsyła żądanie do wszystkich slave'ów o wykonanie transakcji. Po odebraniu żądań równorzędne slave'y wykonują transakcję i wysyłają wiadomość „ACK” do żądającego slave'a po jej zakończeniu. Po tym, jak żądający slave otrzyma komunikaty „ACK” od wszystkich swoich partnerów, informuje menedżera transakcji, że transakcja została zakończona.
Algorytm konsensusu większości
Jest to odmiana algorytmu głosowania rozproszonego, w którym transakcja może zostać wykonana, gdy większość partnerów „zgadza się” na transakcję. Dzieli się to na trzy fazy -
Voting phase- Gdy transakcja wchodzi do menedżera transakcji w witrynie, wysyła żądanie transakcji do wszystkich innych witryn. Po odebraniu żądania strona równorzędna sprawdza, czy nie występują konflikty, używając reguł głosowania i umieszcza konfliktowe transakcje, jeśli takie istnieją, w kolejce oczekujących. Następnie wysyła komunikat „OK” lub „NIE OK”.
Transaction acceptance/rejection phase- Jeżeli strona żądająca otrzyma większość „OK” transakcji, akceptuje transakcję i rozgłasza „AKCEPTUJ” do wszystkich witryn. W przeciwnym razie emituje komunikat „ODRZUĆ” do wszystkich witryn i odrzuca transakcję.
Transaction application phase- Kiedy strona równorzędna otrzyma komunikat „ODRZUĆ”, usuwa tę transakcję ze swojej listy oczekujących i ponownie rozpatruje wszystkie odroczone transakcje. Gdy strona równorzędna otrzyma komunikat „AKCEPTUJ”, stosuje transakcję i odrzuca wszystkie odroczone transakcje w kolejce oczekującej, które są w konflikcie z tą transakcją. Po zakończeniu wysyła „ACK” do żądającego slave'a.
Algorytm krążących tokenów
W tym podejściu transakcje w systemie są serializowane za pomocą krążącego tokena i odpowiednio wykonywane na każdej replice bazy danych. W ten sposób wszystkie transakcje są akceptowane, tj. Żadna nie jest odrzucana. Ma to dwie fazy -
Transaction serialization phase- W tej fazie wszystkie transakcje są planowane do uruchomienia w kolejności serializacji. Każda transakcja w każdej witrynie ma przypisany unikalny bilet z serii sekwencyjnej, wskazujący kolejność transakcji. Po przypisaniu transakcji bilet jest transmitowany do wszystkich witryn.
Transaction application phase- Gdy witryna otrzymuje transakcję wraz z biletem, umieszcza transakcję do wykonania zgodnie z biletem. Po zakończeniu transakcji ta witryna emituje odpowiedni komunikat. Transakcja kończy się po zakończeniu wykonywania we wszystkich witrynach.
System zarządzania bazą danych jest podatny na wiele awarii. W tym rozdziale przeanalizujemy typy błędów i protokoły zatwierdzania. W systemie rozproszonych baz danych awarie można ogólnie podzielić na miękkie awarie, twarde awarie i awarie sieci.
Miękka awaria
Awaria miękka to rodzaj awarii, która powoduje utratę pamięci ulotnej komputera, a nie pamięci trwałej. Tutaj informacje przechowywane w pamięci nietrwałej, takiej jak pamięć główna, bufory, pamięci podręczne lub rejestry, są tracone. Są również znane jako awaria systemu. Różne rodzaje miękkich awarii są następujące:
- Awaria systemu operacyjnego.
- Awaria głównej pamięci.
- Niepowodzenie transakcji lub aborcja.
- System wygenerował błąd, taki jak przepełnienie liczby całkowitej lub błąd dzielenia przez zero.
- Awaria oprogramowania wspomagającego.
- Brak energii.
Ciężka awaria
Twarda awaria to typ awarii, która powoduje utratę danych w pamięci trwałej lub nieulotnej, takiej jak dysk. Awaria dysku może spowodować uszkodzenie danych w niektórych blokach dyskowych lub uszkodzenie całego dysku. Przyczyny poważnej awarii to:
- Brak energii.
- Usterki w mediach.
- Błąd odczytu i zapisu.
- Uszkodzenie informacji na dysku.
- Awaria głowicy odczytu / zapisu dysku.
Odzyskiwanie po awarii dysku może być krótkie, jeśli w rezerwie znajduje się nowy, sformatowany i gotowy do użycia dysk. W przeciwnym razie czas trwania obejmuje czas potrzebny na uzyskanie zamówienia, zakup dysku i przygotowanie go.
Awaria sieci
Awarie sieci są powszechne w rozproszonych lub sieciowych bazach danych. Obejmuje to błędy wywołane w systemie baz danych ze względu na rozproszony charakter danych i przesyłanie danych w sieci. Przyczyny awarii sieci są następujące -
- Błąd łącza komunikacyjnego.
- Przeciążenie sieci.
- Uszkodzenie informacji podczas przesyłania.
- Błędy witryny.
- Partycjonowanie sieci.
Protokoły zatwierdzania
Każdy system bazy danych powinien gwarantować zachowanie pożądanych właściwości transakcji nawet po awarii. W przypadku niepowodzenia podczas wykonywania transakcji może się zdarzyć, że wszystkie zmiany wprowadzone przez transakcję nie zostaną zatwierdzone. To powoduje, że baza danych jest niespójna. Protokoły zatwierdzania zapobiegają temu scenariuszowi przy użyciu cofania transakcji (wycofywanie) lub ponawiania transakcji (przywracanie).
Punkt zatwierdzenia
Moment, w którym podejmowana jest decyzja o zatwierdzeniu lub przerwaniu transakcji, nazywany jest punktem zatwierdzenia. Poniżej przedstawiono właściwości punktu zatwierdzenia.
Jest to moment, w którym baza danych jest spójna.
W tym momencie modyfikacje wprowadzone przez bazę danych można zobaczyć w innych transakcjach. Wszystkie transakcje mogą mieć spójny widok bazy danych.
W tym momencie wszystkie operacje transakcji zostały pomyślnie wykonane, a ich efekty zostały zapisane w dzienniku transakcji.
W tym momencie transakcję można w razie potrzeby bezpiecznie cofnąć.
W tym momencie transakcja zwalnia wszystkie posiadane przez nią blokady.
Cofnij transakcję
Proces cofania wszystkich zmian wprowadzonych w bazie danych przez transakcję nazywa się cofnięciem transakcji lub wycofaniem transakcji. Jest to najczęściej stosowane w przypadku miękkich awarii.
Ponów transakcję
Proces ponownego zastosowania zmian wprowadzonych do bazy danych przez transakcję nazywa się ponowieniem transakcji lub wycofaniem transakcji. Jest to głównie stosowane do odzyskiwania po poważnej awarii.
Dziennik transakcji
Dziennik transakcji to plik sekwencyjny, który śledzi operacje transakcyjne na elementach bazy danych. Ponieważ dziennik ma charakter sekwencyjny, jest przetwarzany sekwencyjnie od początku lub od końca.
Cele dziennika transakcji -
- Obsługa protokołów zatwierdzania do zatwierdzania lub obsługi transakcji.
- Aby wspomóc odzyskiwanie bazy danych po awarii.
Dziennik transakcji jest zwykle przechowywany na dysku, więc nie ma na niego wpływu miękkie awarie. Ponadto dziennik jest okresowo zapisywany w kopii zapasowej w magazynie archiwalnym, takim jak taśma magnetyczna, aby chronić go również przed awariami dysków.
Listy w dziennikach transakcji
Dziennik transakcji przechowuje pięć typów list w zależności od statusu transakcji. Lista ta pomaga menedżerowi ds. Odzyskiwania w ustaleniu statusu transakcji. Stan i odpowiednie listy są następujące -
Transakcja, która ma rekord rozpoczęcia transakcji i rekord zatwierdzenia transakcji, jest transakcją zatwierdzoną - utrzymywaną na liście zatwierdzeń.
Transakcja, która ma rekord rozpoczęcia transakcji i rekord nieudanej transakcji, ale nie rekord przerwania transakcji, jest transakcją zakończoną niepowodzeniem - utrzymywaną na liście nieudanych transakcji.
Transakcja, która ma rekord rozpoczęcia transakcji i rekord przerwania transakcji, jest transakcją przerwaną - utrzymywaną na liście przerwanych.
Transakcja, która ma rekord rozpoczęcia transakcji i rekord transakcji przed zatwierdzeniem, jest transakcją przed zatwierdzeniem, tj. Transakcją, w której wszystkie operacje zostały wykonane, ale nie zostały zatwierdzone - utrzymywana na liście przed zatwierdzeniem.
Transakcja, która ma rekord rozpoczęcia transakcji, ale nie ma zapisów przed zatwierdzeniem, zatwierdzeniem, przerwaniem lub niepowodzeniem, jest transakcją aktywną - utrzymywaną na liście aktywnej.
Natychmiastowa aktualizacja i odroczona aktualizacja
Natychmiastowa aktualizacja i odroczona aktualizacja to dwie metody obsługi dzienników transakcji.
W immediate updatetryb, kiedy transakcja jest wykonywana, aktualizacje dokonywane przez transakcję są zapisywane bezpośrednio na dysku. Stare wartości i wartości aktualizacji są zapisywane w dzienniku przed zapisaniem w bazie danych na dysku. Po zatwierdzeniu zmiany wprowadzone na dysku stają się trwałe. Podczas wycofywania zmiany wprowadzone przez transakcję w bazie danych są odrzucane, a stare wartości są przywracane do bazy danych ze starych wartości zapisanych w dzienniku.
W deferred updatetryb, gdy transakcja jest wykonywana, aktualizacje wprowadzone do bazy danych przez transakcję są zapisywane w pliku dziennika. Po zatwierdzeniu zmiany w dzienniku są zapisywane na dysku. Podczas wycofywania zmiany w dzienniku są odrzucane i żadne zmiany nie są stosowane w bazie danych.
Aby odzyskać sprawność po awarii bazy danych, systemy zarządzania bazami danych stosują szereg technik zarządzania odtwarzaniem. W tym rozdziale przeanalizujemy różne podejścia do odzyskiwania baz danych.
Typowe strategie odzyskiwania bazy danych to:
W przypadku awarii miękkich, które skutkują niespójnością bazy danych, strategia odzyskiwania obejmuje cofnięcie lub wycofanie transakcji. Jednak czasami można również zastosować ponowienie transakcji, aby przywrócić jej spójny stan.
W przypadku poważnych awarii skutkujących rozległymi uszkodzeniami bazy danych, strategie odzyskiwania obejmują przywrócenie wcześniejszej kopii bazy danych z archiwalnej kopii zapasowej. Bardziej aktualny stan bazy danych uzyskuje się poprzez ponowne wykonanie operacji zatwierdzonych transakcji z dziennika transakcji.
Przywracanie po awarii zasilania
Awaria zasilania powoduje utratę informacji w pamięci nietrwałej. Po przywróceniu zasilania następuje ponowne uruchomienie systemu operacyjnego i systemu zarządzania bazą danych. Menedżer odzyskiwania inicjuje odzyskiwanie z dzienników transakcji.
W przypadku trybu natychmiastowej aktualizacji menedżer odzyskiwania podejmuje następujące działania -
Transakcje, które znajdują się na liście aktywnej i liście zakończonej niepowodzeniem, są cofane i zapisywane na liście przerwanych.
Transakcje znajdujące się na liście przed zatwierdzeniem są ponownie wykonywane.
Żadne działanie nie jest podejmowane dla transakcji na listach zatwierdzania lub przerywania.
W przypadku odroczonej aktualizacji menedżer odzyskiwania podejmuje następujące działania -
Transakcje, które znajdują się na liście aktywnej i liście zakończonej niepowodzeniem, są zapisywane na liście przerwanych. Nie są wymagane żadne operacje cofania, ponieważ zmiany nie zostały jeszcze zapisane na dysku.
Transakcje znajdujące się na liście przed zatwierdzeniem są ponownie wykonywane.
Żadne działanie nie jest podejmowane dla transakcji na listach zatwierdzania lub przerywania.
Odzyskiwanie po awarii dysku
Awaria dysku lub twarda awaria powoduje całkowitą utratę bazy danych. Aby odzyskać dane po tej twardej awarii, przygotowywany jest nowy dysk, następnie przywracany jest system operacyjny, a na koniec odzyskiwana jest baza danych przy użyciu kopii zapasowej bazy danych i dziennika transakcji. Metoda odzyskiwania jest taka sama dla trybów aktualizacji natychmiastowej i odroczonej.
Menedżer odzyskiwania podejmuje następujące działania -
Transakcje na liście zatwierdzeń i liście przed zatwierdzeniem są ponownie wykonywane i zapisywane na liście zatwierdzeń w dzienniku transakcji.
Transakcje na liście aktywnej i liście zakończonej niepowodzeniem są cofane i zapisywane na liście przerwanych w dzienniku transakcji.
Punkty kontrolne
Checkpointjest momentem, w którym rekord jest zapisywany w bazie danych z buforów. W konsekwencji, w przypadku awarii systemu, menedżer odzyskiwania nie musi powtarzać transakcji, które zostały zatwierdzone przed punktem kontrolnym. Okresowe sprawdzanie punktów kontrolnych skraca proces odzyskiwania.
Dwa rodzaje technik punktowania to:
- Spójne punkty kontrolne
- Rozmyte punkty kontrolne
Spójne punkty kontrolne
Spójne punkty kontrolne tworzą spójny obraz bazy danych w punkcie kontrolnym. Podczas odzyskiwania tylko te transakcje, które znajdują się po prawej stronie ostatniego punktu kontrolnego, są cofane lub ponownie wykonywane. Transakcje po lewej stronie ostatniego spójnego punktu kontrolnego są już zatwierdzone i nie muszą być ponownie przetwarzane. Działania podjęte w celu uzyskania punktów kontrolnych to -
- Aktywne transakcje są tymczasowo zawieszone.
- Wszystkie zmiany w buforach pamięci głównej są zapisywane na dysku.
- Rekord „punktu kontrolnego” jest zapisywany w dzienniku transakcji.
- Dziennik transakcji jest zapisywany na dysku.
- Zawieszone transakcje są wznawiane.
Jeśli w kroku 4 dziennik transakcji również zostanie zarchiwizowany, to punkt kontrolny pomaga w odzyskiwaniu po awariach dysków i awariach zasilania, w przeciwnym razie wspomaga odzyskiwanie tylko po awarii zasilania.
Rozmyte punkty kontrolne
W rozmytym punkcie kontrolnym, w momencie punktu kontrolnego, wszystkie aktywne transakcje są zapisywane w dzienniku. W przypadku awarii zasilania menedżer odzyskiwania przetwarza tylko te transakcje, które były aktywne podczas punktu kontrolnego i później. Transakcje, które zostały zatwierdzone przed punktem kontrolnym, są zapisywane na dysku i dlatego nie muszą być ponownie wykonywane.
Przykład punktów kontrolnych
Weźmy pod uwagę, że w systemie czas sprawdzania punktów kontrolnych jest zaznaczony, a czas awarii systemu to błąd. Niech będą cztery transakcje T a , T b , T c i T d takie, że -
T a zatwierdza przed punktem kontrolnym.
T b rozpoczyna się przed punktem kontrolnym i zatwierdza przed awarią systemu.
T c rozpoczyna się po punkcie kontrolnym i zatwierdza przed awarią systemu.
T d rozpoczyna się po punkcie kontrolnym i był aktywny w momencie awarii systemu.
Sytuację przedstawia poniższy diagram -
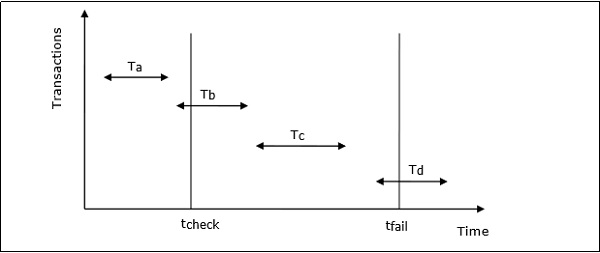
Działania podjęte przez menedżera odzyskiwania to:
- Nic się nie dzieje z T a .
- Ponowienie transakcji jest wykonywane dla T b i T c .
- Cofnięcie transakcji jest wykonywane dla T d .
Odzyskiwanie transakcji przy użyciu Cofnij / Ponów
Odzyskiwanie transakcji ma na celu raczej wyeliminowanie niekorzystnych skutków wadliwych transakcji niż przywrócenie sprawności po awarii. Wadliwe transakcje obejmują wszystkie transakcje, które zmieniły bazę danych w niepożądany stan, oraz transakcje, w których użyto wartości zapisanych przez błędne transakcje.
Odzyskiwanie transakcji w takich przypadkach jest procesem dwuetapowym -
Cofnij wszystkie błędne transakcje i transakcje, na które mogą mieć wpływ błędne transakcje.
REDO wszystkie transakcje, które nie są błędne, ale zostały cofnięte z powodu wadliwych transakcji.
Kroki operacji COFNIJ to -
Jeśli wadliwa transakcja zakończyła INSERT, menedżer odzyskiwania usuwa wstawione elementy danych.
Jeśli wadliwa transakcja wykonała USUNIĘCIE, menedżer odzyskiwania wstawia usunięte elementy danych z dziennika.
Jeśli błędna transakcja wykonała UPDATE, menedżer odzyskiwania eliminuje tę wartość, zapisując w dzienniku wartość sprzed aktualizacji.
Kroki operacji REDO to -
Jeśli transakcja wykonała INSERT, menedżer odzyskiwania generuje wstawkę z dziennika.
Jeśli transakcja zakończyła DELETE, menedżer odzyskiwania generuje usunięcie z dziennika.
Jeśli transakcja zakończyła AKTUALIZACJĘ, menedżer odzyskiwania generuje aktualizację z dziennika.
W systemie lokalnej bazy danych, aby zatwierdzić transakcję, menedżer transakcji musi jedynie przekazać decyzję o zatwierdzeniu menedżerowi odtwarzania. Jednak w systemie rozproszonym menedżer transakcji powinien przekazać decyzję o zatwierdzeniu wszystkim serwerom w różnych lokalizacjach, w których transakcja jest wykonywana, i jednolicie egzekwować tę decyzję. Po zakończeniu przetwarzania w każdej lokacji dochodzi do stanu częściowo zatwierdzonej transakcji i czeka, aż wszystkie inne transakcje osiągną stan częściowo zatwierdzony. Kiedy otrzyma wiadomość, że wszystkie strony są gotowe do zatwierdzenia, zaczyna zatwierdzać. W systemie rozproszonym zatwierdzają albo wszystkie witryny, albo żadna z nich.
Różne protokoły zatwierdzania rozproszonego to -
- Zatwierdzenie jednofazowe
- Zatwierdzenie dwufazowe
- Zatwierdzenie trójfazowe
Rozproszone zatwierdzenie jednofazowe
Rozproszone jednofazowe zatwierdzanie jest najprostszym protokołem zatwierdzania. Rozważmy, że istnieje strona kontrolująca i kilka stron podrzędnych, w których transakcja jest wykonywana. Kroki w zatwierdzaniu rozproszonym to -
Gdy każdy slave zakończy lokalnie swoją transakcję, wysyła komunikat „DONE” do strony kontrolującej.
Slave'y czekają na komunikat „Commit” lub „Abort” ze strony kontrolującej. Ten czas oczekiwania nazywa sięwindow of vulnerability.
Kiedy strona kontrolująca otrzyma komunikat „DONE” od każdego slave'a, podejmuje decyzję o zatwierdzeniu lub przerwaniu. Nazywa się to punktem zatwierdzenia. Następnie wysyła tę wiadomość do wszystkich niewolników.
Po odebraniu tej wiadomości slave zatwierdza lub przerywa, a następnie wysyła wiadomość z potwierdzeniem do strony kontrolującej.
Rozproszone zatwierdzenie dwufazowe
Rozproszone zatwierdzanie dwufazowe zmniejsza podatność protokołów zatwierdzania jednofazowego. Kroki wykonywane w obu fazach są następujące -
Phase 1: Prepare Phase
Gdy każdy slave zakończy lokalnie swoją transakcję, wysyła komunikat „DONE” do strony kontrolującej. Kiedy strona kontrolująca otrzyma komunikat „DONE” od wszystkich slaveów, wysyła komunikat „Prepare” do slaveów.
Niewolnicy głosują nad tym, czy nadal chcą popełnić, czy nie. Jeśli slave chce zatwierdzić, wysyła komunikat „Gotowy”.
Slave, który nie chce zatwierdzić, wysyła komunikat „Niegotowy”. Może się tak zdarzyć, gdy slave ma sprzeczne współbieżne transakcje lub upłynął limit czasu.
Phase 2: Commit/Abort Phase
Po tym, jak strona kontrolująca otrzyma komunikat „Gotowe” od wszystkich niewolników -
Strona kontrolująca wysyła komunikat „Global Commit” do slaveów.
Slave'y realizują transakcję i wysyłają komunikat „Commit ACK” do strony kontrolującej.
Kiedy strona kontrolująca otrzyma komunikat „Commit ACK” od wszystkich slaveów, uznaje transakcję za zatwierdzoną.
Po tym, jak witryna kontrolująca otrzyma pierwszy komunikat „Brak gotowości” od dowolnego urządzenia podrzędnego -
Strona kontrolująca wysyła wiadomość „Global Abort” do slaveów.
Urządzenia slave przerywają transakcję i wysyłają komunikat „Abort ACK” do strony kontrolującej.
Kiedy stacja kontrolująca otrzyma komunikat „Abort ACK” od wszystkich slaveów, uważa transakcję za przerwaną.
Rozproszone zatwierdzenie trójfazowe
Kroki w rozproszonym zatwierdzaniu trójfazowym są następujące -
Phase 1: Prepare Phase
Kroki są takie same, jak w przypadku rozproszonego zatwierdzania dwufazowego.
Phase 2: Prepare to Commit Phase
- Strona kontrolująca wysyła komunikat „Enter Prepared State”.
- Witryny slave głosują w odpowiedzi na „OK”.
Phase 3: Commit / Abort Phase
Kroki są takie same jak w przypadku zatwierdzania dwufazowego, z wyjątkiem tego, że komunikat „Commit ACK” / „Abort ACK” nie jest wymagany.
W tym rozdziale przyjrzymy się zagrożeniom, na jakie napotyka system baz danych, oraz sposobom kontroli. Będziemy również studiować kryptografię jako narzędzie bezpieczeństwa.
Bezpieczeństwo baz danych i zagrożenia
Bezpieczeństwo danych jest nadrzędnym aspektem każdego systemu baz danych. Ma to szczególne znaczenie w systemach rozproszonych ze względu na dużą liczbę użytkowników, pofragmentowane i replikowane dane, wiele lokalizacji i rozproszoną kontrolę.
Zagrożenia w bazie danych
Availability loss - Utrata dostępności dotyczy niedostępności obiektów bazy danych przez uprawnionych użytkowników.
Integrity loss- Utrata integralności występuje, gdy niedopuszczalne operacje są wykonywane na bazie danych przez przypadek lub celowo. Może się to zdarzyć podczas tworzenia, wstawiania, aktualizacji lub usuwania danych. Powoduje to uszkodzenie danych, co prowadzi do błędnych decyzji.
Confidentiality loss- Utrata poufności wynika z nieuprawnionego lub niezamierzonego ujawnienia informacji poufnych. Może to skutkować działaniami niezgodnymi z prawem, zagrożeniami bezpieczeństwa i utratą zaufania publicznego.
Środki kontroli
Środki kontroli można ogólnie podzielić na następujące kategorie -
Access Control- Kontrola dostępu obejmuje mechanizmy bezpieczeństwa w systemie zarządzania bazą danych w celu ochrony przed nieuprawnionym dostępem. Użytkownik może uzyskać dostęp do bazy danych po wyczyszczeniu procesu logowania za pomocą tylko ważnych kont użytkowników. Każde konto użytkownika jest chronione hasłem.
Flow Control- Systemy rozproszone obejmują wiele przepływów danych z jednej lokalizacji do drugiej, a także w obrębie witryny. Kontrola przepływu zapobiega przesyłaniu danych w taki sposób, że mogą uzyskać do nich dostęp nieautoryzowani agenci. Polityka przepływu określa kanały, przez które mogą przepływać informacje. Definiuje także klasy bezpieczeństwa dla danych oraz transakcji.
Data Encryption- Szyfrowanie danych odnosi się do kodowania danych, gdy dane wrażliwe mają być przekazywane kanałami publicznymi. Nawet jeśli nieupoważniony agent uzyska dostęp do danych, nie może ich zrozumieć, ponieważ mają one niezrozumiały format.
Co to jest kryptografia?
Cryptography to nauka o kodowaniu informacji przed wysłaniem przez zawodne ścieżki komunikacyjne, tak aby tylko upoważniony odbiorca mógł je zdekodować i wykorzystać.
Zostaje wywołana zakodowana wiadomość cipher text a oryginalna wiadomość jest nazywana plain text. Proces konwersji zwykłego tekstu na tekst zaszyfrowany przez nadawcę nazywa się kodowaniem lubencryption. Proces konwersji zaszyfrowanego tekstu na zwykły tekst przez odbiorcę nazywa się dekodowaniem lubdecryption.
Całą procedurę komunikacji za pomocą kryptografii można zilustrować na poniższym diagramie -

Konwencjonalne metody szyfrowania
W konwencjonalnej kryptografii szyfrowanie i deszyfrowanie odbywa się przy użyciu tego samego tajnego klucza. W tym przypadku nadawca szyfruje wiadomość algorytmem szyfrującym, używając kopii tajnego klucza. Zaszyfrowana wiadomość jest następnie przesyłana publicznymi kanałami komunikacyjnymi. Po odebraniu zaszyfrowanej wiadomości odbiorca odszyfrowuje ją za pomocą odpowiedniego algorytmu deszyfrującego przy użyciu tego samego tajnego klucza.
Bezpieczeństwo w kryptografii konwencjonalnej zależy od dwóch czynników -
Algorytm dźwięku, który jest znany wszystkim.
Losowo generowany, najlepiej długi, tajny klucz znany tylko nadawcy i odbiorcy.
Najbardziej znanym konwencjonalnym algorytmem kryptograficznym jest Data Encryption Standard lub DES.
Zaletą tej metody jest łatwość zastosowania. Jednak największym problemem konwencjonalnej kryptografii jest współdzielenie tajnego klucza między komunikującymi się stronami. Sposoby wysłania klucza są uciążliwe i bardzo podatne na podsłuchiwanie.
Kryptografia klucza publicznego
W przeciwieństwie do konwencjonalnej kryptografii, kryptografia klucza publicznego wykorzystuje dwa różne klucze, określane jako klucz publiczny i klucz prywatny. Każdy użytkownik generuje parę klucza publicznego i klucza prywatnego. Następnie użytkownik umieszcza klucz publiczny w dostępnym miejscu. Gdy nadawca chce wysłać wiadomość, szyfruje ją za pomocą klucza publicznego odbiorcy. Po otrzymaniu zaszyfrowanej wiadomości odbiorca odszyfrowuje ją za pomocą swojego klucza prywatnego. Ponieważ klucz prywatny nie jest znany nikomu poza odbiorcą, żadna inna osoba, która otrzyma wiadomość, nie może go odszyfrować.
Najpopularniejszymi algorytmami kryptografii klucza publicznego są RSA algorytm i Diffie– Hellmanalgorytm. Ta metoda jest bardzo bezpieczna do wysyłania prywatnych wiadomości. Problem polega jednak na tym, że wymaga wielu obliczeń, przez co okazuje się nieefektywny w przypadku długich komunikatów.
Rozwiązaniem jest użycie kombinacji kryptografii konwencjonalnej i kryptografii klucza publicznego. Tajny klucz jest szyfrowany przy użyciu kryptografii klucza publicznego przed udostępnieniem między komunikującymi się stronami. Następnie wiadomość jest wysyłana przy użyciu konwencjonalnej kryptografii przy pomocy wspólnego tajnego klucza.
Podpisy cyfrowe
Podpis cyfrowy (DS) to technika uwierzytelniania oparta na kryptografii klucza publicznego stosowana w aplikacjach handlu elektronicznego. Przypisuje jednostce unikalny znak w treści jej przesłania. Pomaga to innym w uwierzytelnianiu prawidłowych nadawców wiadomości.
Zazwyczaj podpis cyfrowy użytkownika różni się w zależności od wiadomości, aby zapewnić ochronę przed fałszowaniem. Metoda jest następująca -
Nadawca przyjmuje wiadomość, oblicza skrót wiadomości i podpisuje ją kluczem prywatnym.
Następnie nadawca dołącza podpisane podsumowanie wraz z wiadomością w postaci zwykłego tekstu.
Wiadomość przesyłana jest kanałem komunikacyjnym.
Odbiorca usuwa dołączone podpisane podsumowanie i weryfikuje podsumowanie przy użyciu odpowiedniego klucza publicznego.
Następnie odbiorca pobiera wiadomość w postaci zwykłego tekstu i przepuszcza ją przez ten sam algorytm skrótu wiadomości.
Jeżeli wyniki etapu 4 i 5 są zgodne, wówczas odbiorca wie, że wiadomość jest integralna i autentyczna.
System rozproszony wymaga dodatkowych środków bezpieczeństwa niż system scentralizowany, ponieważ istnieje wielu użytkowników, zróżnicowane dane, wiele lokalizacji i rozproszona kontrola. W tym rozdziale przyjrzymy się różnym aspektom bezpieczeństwa rozproszonych baz danych.
W rozproszonych systemach komunikacyjnych istnieją dwa rodzaje intruzów -
Passive eavesdroppers - Monitorują wiadomości i zdobywają prywatne informacje.
Active attackers - Nie tylko monitorują komunikaty, ale także uszkadzają dane, wprowadzając nowe lub modyfikując istniejące.
Środki bezpieczeństwa obejmują bezpieczeństwo komunikacji, bezpieczeństwo danych i audyt danych.
Bezpieczeństwo komunikacji
W rozproszonej bazie danych odbywa się duża wymiana danych dzięki zróżnicowanej lokalizacji danych, użytkowników i transakcji. Dlatego wymaga bezpiecznej komunikacji między użytkownikami i bazami danych oraz między różnymi środowiskami baz danych.
Bezpieczeństwo komunikacji obejmuje:
Dane nie powinny być uszkodzone podczas przesyłania.
Kanał komunikacyjny powinien być chroniony zarówno przed podsłuchiwaniem biernym, jak i aktywnymi atakującymi.
Aby spełnić powyższe wymagania, należy przyjąć dobrze zdefiniowane algorytmy i protokoły bezpieczeństwa.
Dwie popularne, spójne technologie zapewniające kompleksową bezpieczną komunikację to:
- Secure Socket Layer Protocol lub Transport Layer Security Protocol.
- Wirtualne sieci prywatne (VPN).
Ochrona danych
W systemach rozproszonych konieczne jest podjęcie środków w celu zabezpieczenia danych poza komunikacją. Środki bezpieczeństwa danych to -
Authentication and authorization- Są to środki kontroli dostępu przyjęte w celu zapewnienia, że tylko autentyczni użytkownicy mogą korzystać z bazy danych. Aby zapewnić uwierzytelnianie, używane są certyfikaty cyfrowe. Poza tym logowanie jest ograniczone poprzez kombinację nazwy użytkownika i hasła.
Data encryption - Dwa podejścia do szyfrowania danych w systemach rozproszonych to -
Podejście wewnętrzne do rozproszonej bazy danych: aplikacje użytkownika szyfrują dane, a następnie przechowują zaszyfrowane dane w bazie danych. Aby wykorzystać zapisane dane, aplikacje pobierają zaszyfrowane dane z bazy danych, a następnie je odszyfrowują.
Zewnętrzna do rozproszonej bazy danych: rozproszony system baz danych ma własne możliwości szyfrowania. Aplikacje użytkownika przechowują dane i pobierają je bez zdawania sobie sprawy, że dane są przechowywane w bazie danych w postaci zaszyfrowanej.
Validated input- W ramach tego środka bezpieczeństwa aplikacja użytkownika sprawdza każde wejście, zanim będzie można je wykorzystać do aktualizacji bazy danych. Niezatwierdzone dane wejściowe mogą powodować szeroki zakres exploitów, takich jak przepełnienie bufora, wstrzykiwanie poleceń, wykonywanie skryptów między witrynami i uszkodzenie danych.
Audyt danych
System bezpieczeństwa bazy danych musi wykrywać i monitorować naruszenia bezpieczeństwa, aby ustalić, jakie środki bezpieczeństwa powinien zastosować. Często bardzo trudno jest wykryć naruszenie bezpieczeństwa w momencie wystąpienia zdarzenia. Jedną z metod identyfikacji naruszeń bezpieczeństwa jest zbadanie dzienników inspekcji. Dzienniki audytów zawierają informacje, takie jak -
- Data, godzina i miejsce nieudanych prób dostępu.
- Szczegóły udanych prób dostępu.
- Istotne modyfikacje w systemie baz danych.
- Dostęp do ogromnych ilości danych, szczególnie z baz danych w wielu witrynach.
Wszystkie powyższe informacje dają wgląd w działania w bazie danych. Okresowa analiza dziennika pomaga zidentyfikować każdą nienaturalną aktywność wraz z jej miejscem i czasem wystąpienia. Ten dziennik jest idealnie przechowywany na oddzielnym serwerze, aby był niedostępny dla atakujących.