ggplot2 - Szybki przewodnik
ggplot2 to pakiet R zaprojektowany specjalnie do wizualizacji danych i zapewniający najlepszą eksploracyjną analizę danych. Zapewnia piękne, bezproblemowe działki, które dbają o najdrobniejsze szczegóły, takie jak legendy rysowania i ich przedstawianie. Wykresy można tworzyć iteracyjnie i edytować później. Ten pakiet został zaprojektowany do pracy w sposób warstwowy, zaczynając od warstwy przedstawiającej surowe dane zebrane podczas eksploracyjnej analizy danych za pomocą R, a następnie dodając warstwy adnotacji i podsumowań statystycznych.
Nawet najbardziej doświadczeni użytkownicy języka R potrzebują pomocy przy tworzeniu eleganckiej grafiki. Ta biblioteka jest fenomenalnym narzędziem do tworzenia grafiki w języku R, ale nawet po wielu latach niemal codziennego użytkowania nadal musimy odwoływać się do naszego ściągawki.
Ten pakiet działa w ramach głębokiej gramatyki zwanej „Gramatyka grafiki”, która składa się z zestawu niezależnych komponentów, które można tworzyć na wiele sposobów. „Gramatyka grafiki” to jedyny powód, dla którego ggplot2 jest bardzo potężny, ponieważ programista R nie jest ograniczony do zestawu wstępnie określonej grafiki, która jest używana w innych pakietach. Gramatyka zawiera prosty zestaw podstawowych reguł i zasad.
W 2005 roku Wilkinson stworzył, a raczej zapoczątkował koncepcję gramatyki grafiki, aby opisać głębokie cechy, które są zawarte między wszystkimi grafikami statystycznymi. Koncentruje się na podstawowej warstwie, która obejmuje adaptację funkcji osadzonych w R.
Związek między „Grammar of Graphics” a R.
Informuje użytkownika lub programistę, że grafika statystyczna jest używana do mapowania danych do atrybutów estetycznych, takich jak kolor, kształt, rozmiar odnośnych obiektów geometrycznych, takich jak punkty, linie i paski. Wykres może również zawierać różne transformacje statystyczne danych, które są rysowane na wspomnianym układzie współrzędnych. Zawiera również funkcję zwaną „Faceting”, która jest zwykle używana do tworzenia tego samego wykresu dla różnych podzbiorów wspomnianego zbioru danych. R zawiera różne wbudowane zestawy danych. Połączenie tych niezależnych komponentów w całości składa się z określonej grafiki.
Skoncentrujmy się teraz na różnych typach wykresów, które można stworzyć w odniesieniu do gramatyki -
Dane
Jeśli użytkownik chce zwizualizować podany zestaw odwzorowań estetycznych, który opisuje, w jaki sposób wymagane zmienne w danych są mapowane razem w celu utworzenia mapowanych atrybutów estetycznych.
Warstwy
Składa się z elementów geometrycznych i wymaganej transformacji statystycznej. Warstwy obejmują obiekty geometryczne, geomy dla krótkich danych, które w rzeczywistości przedstawiają wykres za pomocą punktów, linii, wielokątów i wielu innych. Najlepszą demonstracją jest binowanie i zliczanie obserwacji w celu utworzenia określonego histogramu podsumowującego zależność 2D określonego modelu liniowego.
Waga
Skale służą do mapowania wartości w przestrzeni danych, która jest używana do tworzenia wartości, niezależnie od tego, czy jest to kolor, rozmiar i kształt. Pomaga narysować legendę lub osie potrzebne do odwrócenia odwrotnego odwzorowania umożliwiającego odczytanie oryginalnych wartości danych ze wspomnianego wykresu.
System współrzędnych
Opisuje, w jaki sposób współrzędne danych są odwzorowywane razem na wspomnianą płaszczyznę grafiki. Dostarcza również informacji o osiach i liniach siatki, które są potrzebne do odczytania wykresu. Zwykle jest używany jako kartezjański układ współrzędnych, który obejmuje współrzędne biegunowe i odwzorowania map.
Faceting
Obejmuje specyfikację, jak podzielić dane na wymagane podzbiory i wyświetlić podzbiory jako wielokrotności danych. Nazywa się to również procesem kondycjonowania lub siatkowania.
Motyw
Kontroluje szczegóły wyświetlania, takie jak rozmiar czcionki i właściwości koloru tła. Aby stworzyć atrakcyjną działkę, zawsze lepiej wziąć pod uwagę referencje.
Teraz równie ważne jest omówienie ograniczeń lub funkcji, których gramatyka nie zapewnia -
Brakuje sugestii, którą grafikę należy zastosować lub którą użytkownik jest zainteresowany.
Nie opisuje interaktywności, zawiera jedynie opis grafiki statycznej. Do tworzenia dynamicznej grafiki należy zastosować inne alternatywne rozwiązanie.
Prosty wykres utworzony za pomocą ggplot2 jest wymieniony poniżej -

Pakiety R mają różne możliwości, takie jak analizowanie informacji statystycznych lub uzyskiwanie dogłębnych badań danych geoprzestrzennych lub proste tworzenie podstawowych raportów.
Pakiety R można zdefiniować jako funkcje języka R, dane i skompilowany kod w dobrze zdefiniowanym formacie. Folder lub katalog, w którym przechowywane są pakiety, nazywany jest biblioteką.

Jak widać na powyższym rysunku, libPaths () jest funkcją, która wyświetla bibliotekę, która się znajduje, a biblioteka funkcji pokazuje pakiety, które są zapisane w bibliotece.
R zawiera wiele funkcji, które manipulują pakietami. Skoncentrujemy się na trzech głównych funkcjach, które są głównie używane, są to:
- Instalowanie pakietu
- Ładowanie paczki
- Poznanie pakietu
Składnia z funkcją instalowania pakietu w R to -
Install.packages(“<package-name>”)Poniżej przedstawiono prostą demonstrację instalacji pakietu. Weź pod uwagę, że musimy zainstalować pakiet „ggplot2”, który jest biblioteką wizualizacji danych, używana jest następująca składnia -
Install.packages(“ggplot2”)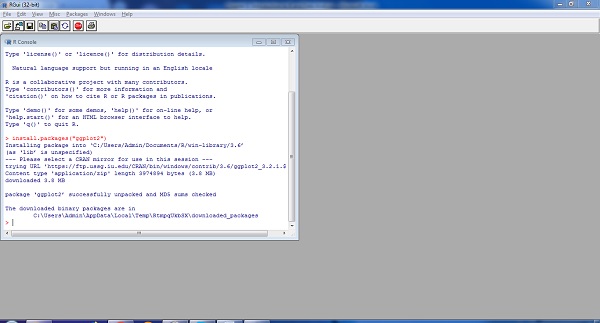
Aby załadować konkretny pakiet, musimy postępować zgodnie z poniższą składnią -
Library(<package-name>)To samo dotyczy ggplot2, jak wspomniano poniżej -
library(“ggplot2”)Wynik jest przedstawiony na migawce poniżej -

Aby zrozumieć potrzebę wymaganego pakietu i podstawowych funkcji, R udostępnia funkcję pomocy, która zawiera wszystkie szczegóły instalowanego pakietu.
Pełna składnia jest wymieniona poniżej -
help(ggplot2)
W tym rozdziale skupimy się na tworzeniu prostej fabuły za pomocą ggplot2. Wykonamy następujące kroki, aby utworzyć domyślny wykres w R.
Włączenie biblioteki i zbioru danych do obszaru roboczego
Dołącz bibliotekę w R. Ładowanie pakietu, który jest potrzebny. Teraz skupimy się na pakiecie ggplot2.
# Load ggplot2
library(ggplot2)Zaimplementujemy zbiór danych o nazwie „Iris”. Zbiór danych zawiera 3 klasy po 50 instancji każda, gdzie każda klasa odnosi się do rodzaju rośliny tęczówki. Jedną klasę można oddzielić liniowo od dwóch pozostałych; te ostatnie NIE dają się od siebie liniowo oddzielić.
# Read in dataset
data(iris)Lista atrybutów zawartych w zbiorze danych jest podana poniżej -

Używanie atrybutów do przykładowego wykresu
Wykreślenie wykresu zbioru danych tęczówki za pomocą ggplot2 w prostszy sposób wymaga następującej składni -
# Plot
IrisPlot <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species))
+ geom_point()
print(IrisPlot)Pierwszy parametr pobiera zestaw danych jako dane wejściowe, drugi parametr wspomina o legendzie i atrybutach, które należy wykreślić w bazie danych. W tym przykładzie używamy legendy Gatunki. Geom_point () implikuje rozproszony wykres, który zostanie szczegółowo omówiony w późniejszym rozdziale.
Wygenerowane dane wyjściowe są wymienione poniżej -
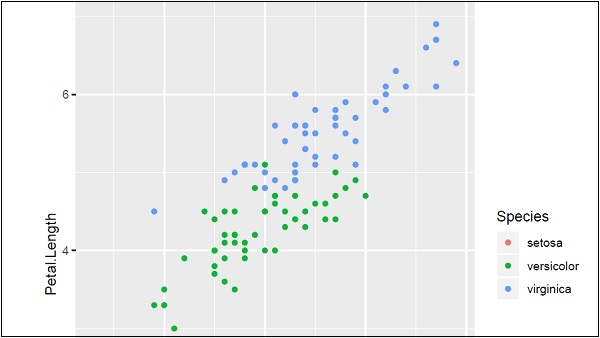
Tutaj możemy zmodyfikować tytuł, etykietę x i etykietę y, co oznacza etykiety osi x i osi y w systematycznym formacie, jak podano poniżej -
print(IrisPlot + labs(y="Petal length (cm)", x = "Sepal length (cm)")
+ ggtitle("Petal and sepal length of iris"))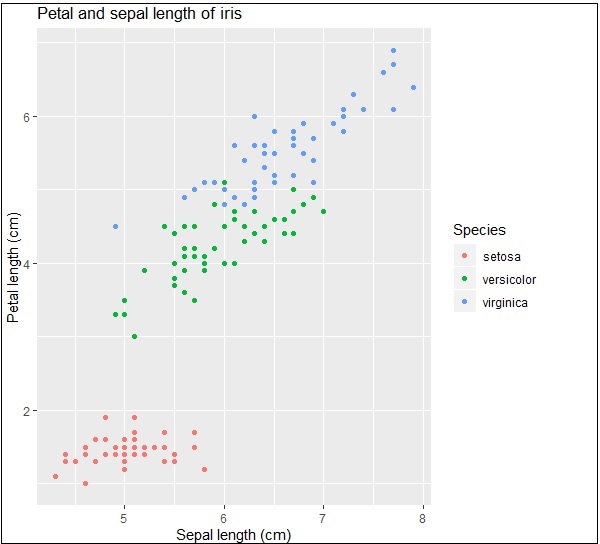
Kiedy mówimy o osiach na wykresach, chodzi o osie X i Y, które są reprezentowane w dwuwymiarowy sposób. W tym rozdziale skupimy się na dwóch zestawach danych „Wzrost roślin” i „Irys”, które są powszechnie używane przez analityków danych.
Implementacja osi w zbiorze danych Iris
Wykonamy następujące kroki, aby pracować na osiach x i y przy użyciu pakietu ggplot2 R.
W celu uzyskania funkcjonalności pakietu zawsze ważne jest, aby załadować bibliotekę.
# Load ggplot
library(ggplot2)
# Read in dataset
data(iris)Tworzenie punktów wykresu
Jak omówiono w poprzednim rozdziale, utworzymy wykres z punktami. Innymi słowy, definiuje się go jako wykres rozproszony.
# Plot
p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point()
p
Teraz zrozumiemy funkcjonalność aes, która wspomina o strukturze mapowania „ggplot2”. Odwzorowania estetyczne opisują strukturę zmiennych potrzebną do kreślenia oraz dane, którymi należy zarządzać w formacie poszczególnych warstw.
Dane wyjściowe podano poniżej -
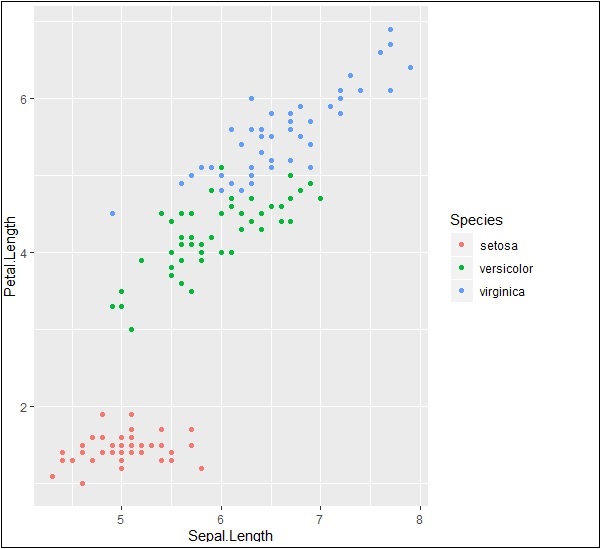
Zaznacz i zaznacz znaki
Narysuj znaczniki z wymienionymi współrzędnymi osi x i y, jak wspomniano poniżej. Obejmuje dodawanie tekstu, powtarzanie tekstu, podkreślanie określonego obszaru i dodawanie segmentu w następujący sposób -
# add text
p + annotate("text", x = 6, y = 5, label = "text")
# add repeat
p + annotate("text", x = 4:6, y = 5:7, label = "text")
# highlight an area
p + annotate("rect", xmin = 5, xmax = 7, ymin = 4, ymax = 6, alpha = .5)
# segment
p + annotate("segment", x = 5, xend = 7, y = 4, yend = 5, colour = "black")Dane wyjściowe wygenerowane do dodania tekstu podano poniżej -

Powtórzenie określonego tekstu z wymienionymi współrzędnymi generuje następujący wynik. Tekst jest generowany przy użyciu współrzędnych x od 4 do 6 i współrzędnych y od 5 do 7 -
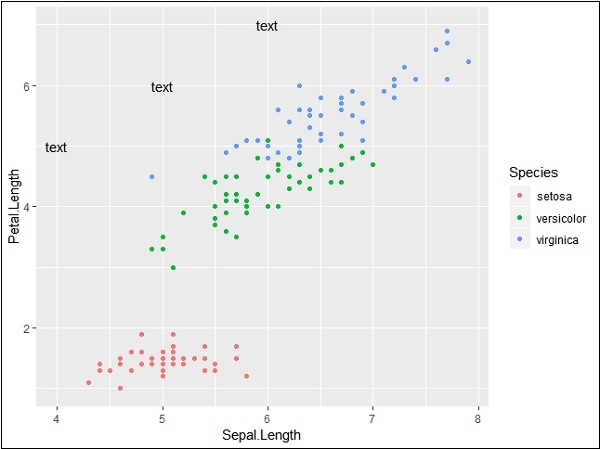
Segmentację i wyróżnienie produkcji poszczególnych obszarów podano poniżej -

Zestaw danych PlantGrowth
Skoncentrujmy się teraz na pracy z innym zbiorem danych o nazwie „Wzrost roślin”, a krok, który jest potrzebny, podano poniżej.
Zadzwoń do biblioteki i sprawdź atrybuty „Plantgrowth”. Ten zestaw danych zawiera wyniki eksperymentu mającego na celu porównanie plonów (mierzonych wagą suszonych roślin) uzyskanych w kontroli i w dwóch różnych warunkach traktowania.
> PlantGrowth
weight group
1 4.17 ctrl
2 5.58 ctrl
3 5.18 ctrl
4 6.11 ctrl
5 4.50 ctrl
6 4.61 ctrl
7 5.17 ctrl
8 4.53 ctrl
9 5.33 ctrl
10 5.14 ctrl
11 4.81 trt1
12 4.17 trt1
13 4.41 trt1
14 3.59 trt1
15 5.87 trt1
16 3.83 trt1
17 6.03 trt1Dodawanie atrybutów z osiami
Spróbuj wykreślić prosty wykres z wymaganymi osiami X i Y wykresu, jak wspomniano poniżej -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) +
+ geom_point()
> bpWygenerowane dane wyjściowe podano poniżej -

Na koniec możemy przesuwać osie x i y zgodnie z naszymi wymaganiami z podstawową funkcją, jak wspomniano poniżej -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) +
+ geom_point()
> bp
Zasadniczo możemy użyć wielu właściwości z odwzorowaniami estetycznymi, aby pracować z osiami przy użyciu ggplot2.
Topory i legendy są wspólnie nazywane przewodnikami. Pozwalają nam odczytać obserwacje z wykresu i odwzorować je z powrotem w odniesieniu do oryginalnych wartości. Klucze legendy i etykiety znaczników są określane przez podział na skalę. Legendy i osie są tworzone automatycznie na podstawie odpowiednich skal i geometrii, które są potrzebne do kreślenia.
Następujące kroki zostaną wdrożone, aby zrozumieć działanie legend w ggplot2 -
Włączenie pakietu i zbioru danych do obszaru roboczego
Utwórzmy ten sam wykres, aby skupić się na legendzie wykresu wygenerowanego za pomocą ggplot2 -
> # Load ggplot
> library(ggplot2)
>
> # Read in dataset
> data(iris)
>
> # Plot
> p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point()
> p
Jeśli obserwujesz fabułę, legendy są tworzone w lewym rogu większości, jak wspomniano poniżej -

Tutaj legenda obejmuje różne typy gatunków z danego zbioru danych.
Zmiana atrybutów legend
Możemy usunąć legendę za pomocą właściwości „legend.position” i uzyskać odpowiedni wynik -
> # Remove Legend
> p + theme(legend.position="none")
Możemy również ukryć tytuł legendy za pomocą właściwości „element_blank ()”, jak podano poniżej -
> # Hide the legend title
> p + theme(legend.title=element_blank())Możemy również użyć pozycji legendy w razie potrzeby. Ta właściwość służy do generowania dokładnej reprezentacji wykresu.
> #Change the legend position
> p + theme(legend.position="top")
>
> p + theme(legend.position="bottom")Top representation
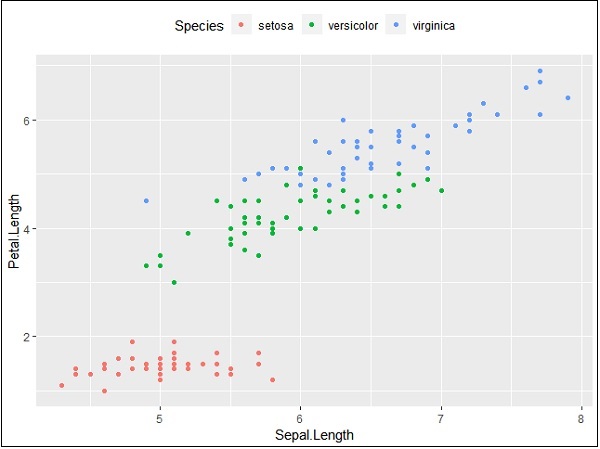
Bottom representation

Zmiana stylu czcionki w legendach
Możemy zmienić styl i typ czcionki tytułu oraz inne atrybuty legendy, jak wspomniano poniżej -
> #Change the legend title and text font styles
> # legend title
> p + theme(legend.title = element_text(colour = "blue", size = 10, + face = "bold"))
> # legend labels
> p + theme(legend.text = element_text(colour = "red", size = 8, + face = "bold"))Wygenerowane dane wyjściowe podano poniżej -
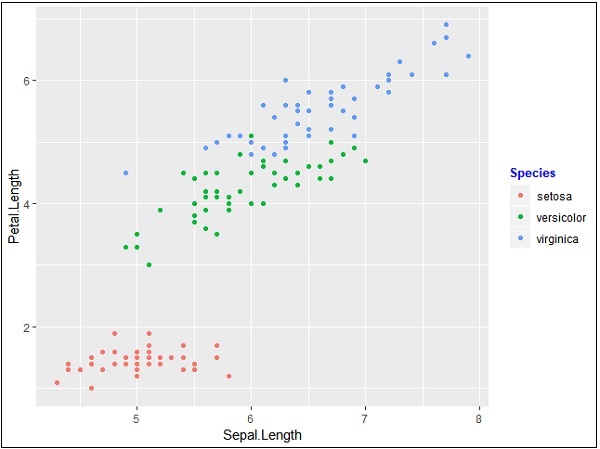

Nadchodzące rozdziały skupią się na różnych typach wykresów z różnymi właściwościami tła, takimi jak kolor, motywy i znaczenie każdego z nich z punktu widzenia nauki o danych.
Wykresy punktowe są podobne do wykresów liniowych, które są zwykle używane do kreślenia. Wykresy punktowe pokazują, jak bardzo jedna zmienna jest powiązana z inną. Zależność między zmiennymi nazywana jest korelacją, która jest zwykle używana w metodach statystycznych. Będziemy używać tego samego zbioru danych o nazwie „Iris”, który zawiera wiele różnic między każdą zmienną. Jest to słynny zbiór danych, który podaje pomiary w centymetrach zmiennych długości i szerokości działek oraz długości i szerokości płatków dla 50 kwiatów z każdego z 3 gatunków tęczówki. Gatunki te nazywane są Iris setosa, versicolor i virginica.
Tworzenie podstawowego wykresu punktowego
Poniższe kroki dotyczą tworzenia wykresów punktowych za pomocą pakietu „ggplot2” -
Aby utworzyć podstawowy wykres punktowy, wykonuje się następujące polecenie -
> # Basic Scatter Plot
> ggplot(iris, aes(Sepal.Length, Petal.Length)) +
+ geom_point()
Dodawanie atrybutów
Możemy zmienić kształt punktów za pomocą właściwości o nazwie shape w funkcji geom_point ().
> # Change the shape of points
> ggplot(iris, aes(Sepal.Length, Petal.Length)) +
+ geom_point(shape=1)
Możemy dodać kolor do punktów, które są dodawane na wymaganych wykresach rozrzutu.
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1)
W tym przykładzie stworzyliśmy kolory według gatunków wymienionych w legendach. Te trzy gatunki wyróżniają się wyjątkowo na wspomnianej działce.
Teraz skupimy się na ustaleniu relacji między zmiennymi.
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm)geom_smooth funkcja wspomaga wzór nakładania się i tworzenie wzorca wymaganych zmiennych.
Metoda atrybutów „lm” wspomina o linii regresji, którą należy opracować.
> # Add a regression line
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm)
Możemy również dodać linię regresji bez zacienionego obszaru ufności z poniższą składnią -
># Add a regression line but no shaded confidence region
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm, se=FALSE)
Obszary zacienione reprezentują elementy inne niż regiony zaufania.
Wykresy jittera
Wykresy fluktuacji zawierają efekty specjalne, za pomocą których można przedstawić wykresy rozproszone. Jitter to nic innego jak losowa wartość przypisywana kropkom w celu ich oddzielenia, jak wspomniano poniżej -
> ggplot(mpg, aes(cyl, hwy)) +
+ geom_point() +
+ geom_jitter(aes(colour = class))
Wykresy słupkowe przedstawiają dane jakościowe w sposób prostokątny. Słupki można kreślić w pionie i poziomie. Wysokości lub długości są proporcjonalne do wartości przedstawionych na wykresach. Osie X i Y wykresów słupkowych określają kategorię, która jest zawarta w określonym zestawie danych.
Histogram to wykres słupkowy, który przedstawia surowe dane z wyraźnym obrazem rozkładu wspomnianego zestawu danych.
W tym rozdziale skupimy się na tworzeniu wykresów słupkowych i histogramów za pomocą ggplot2.
Zrozumienie zbioru danych MPG
Rozumiemy zbiór danych, który będzie używany. Zestaw danych MPG zawiera podzbiór danych dotyczących zużycia paliwa, które EPA udostępnia w poniższym linku -
http://fueleconomy.gov
Składa się z modeli, które co roku były wypuszczane w latach 1999-2008. Zostało to wykorzystane jako wskaźnik popularności samochodu.
Następujące polecenie jest wykonywane w celu zrozumienia listy atrybutów wymaganych dla zestawu danych.
> library(ggplot2)Pakiet dołączający to ggplot2.
Następujący obiekt jest zamaskowany _by_ .GlobalEnv -
mpgKomunikaty ostrzegawcze
- pakiet arules został zbudowany pod R w wersji 3.5.1
- pakiet tuneR został zbudowany pod R w wersji 3.5.3
- pakiet ggplot2 został zbudowany pod R w wersji 3.5.3

Tworzenie wykresu liczby słupków
Wykres liczby słupków można utworzyć za pomocą poniższego wykresu -
> # A bar count plot
> p <- ggplot(mpg, aes(x=factor(cyl)))+
+ geom_bar(stat="count")
> p
geom_bar () to funkcja używana do tworzenia wykresów słupkowych. Przyjmuje atrybut wartości statystycznej o nazwie count.
Histogram
Wykres liczby histogramów można utworzyć za pomocą poniższego wykresu -
> # A historgram count plot
> ggplot(data=mpg, aes(x=hwy)) +
+ geom_histogram( col="red",
+ fill="green",
+ alpha = .2,
+ binwidth = 5)geom_histogram () zawiera wszystkie niezbędne atrybuty do tworzenia histogramu. Tutaj przyjmuje atrybut hwy z odpowiednią liczbą. Kolor jest pobierany zgodnie z wymaganiami.

Skumulowany wykres słupkowy
Ogólne wykresy wykresów słupkowych i histogramu można utworzyć jak poniżej -
> p <- ggplot(mpg, aes(class))
> p + geom_bar()
> p + geom_bar()
Ten wykres obejmuje wszystkie kategorie zdefiniowane na wykresach słupkowych z odpowiednią klasą. Ten wykres nazywa się wykresem skumulowanym.
Wykres kołowy jest traktowany jako okrągły wykres statystyczny, który jest podzielony na wycinki w celu zilustrowania proporcji liczbowych. Na wspomnianym wykresie kołowym długość łuku każdego wycinka jest proporcjonalna do ilości, którą reprezentuje. Długość łuku przedstawia kąt wykresu kołowego. Całkowite stopnie wykresu kołowego to 360 stopni. Wykres półkole lub półkole zawiera 180 stopni.
Tworzenie wykresów kołowych
Załaduj pakiet we wspomnianym obszarze roboczym, jak pokazano poniżej -
> # Load modules
> library(ggplot2)
>
> # Source: Frequency table
> df <- as.data.frame(table(mpg$class))
> colnames(df) <- c("class", "freq")
Przykładowy wykres można utworzyć za pomocą następującego polecenia -
> pie <- ggplot(df, aes(x = "", y=freq, fill = factor(class))) +
+ geom_bar(width = 1, stat = "identity") +
+ theme(axis.line = element_blank(),
+ plot.title = element_text(hjust=0.5)) +
+ labs(fill="class",
+ x=NULL,
+ y=NULL,
+ title="Pie Chart of class",
+ caption="Source: mpg")
> pieJeśli obserwujesz dane wyjściowe, diagram nie jest tworzony w sposób cykliczny, jak wspomniano poniżej -
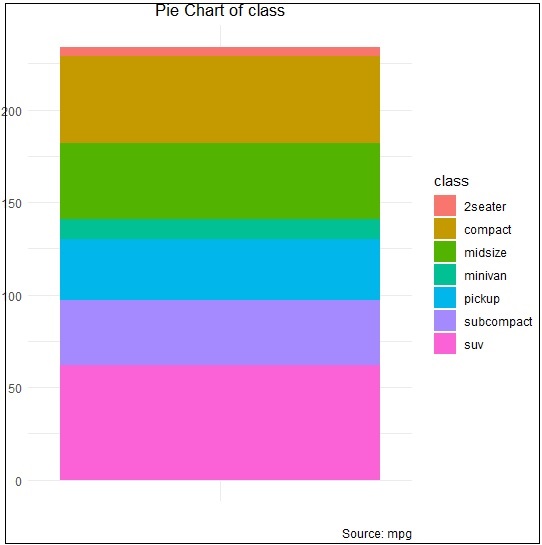
Tworzenie współrzędnych
Wykonajmy następujące polecenie, aby utworzyć wymagany wykres kołowy w następujący sposób -
> pie + coord_polar(theta = "y", start=0)
W tym rozdziale omówimy wykresy krańcowe.
Zrozumienie wątków krańcowych
Wykresy krańcowe służą do oceny zależności między dwiema zmiennymi i zbadania ich rozkładów. Kiedy mówimy o tworzeniu wykresów marginalnych, są one niczym innym jak wykresami punktowymi, które mają histogramy, wykresy pudełkowe lub wykresy punktowe na marginesach odpowiednich osi x i y.
Poniższe kroki zostaną wykorzystane do stworzenia wykresu marginalnego za pomocą R przy użyciu pakietu „ggExtra”. Ten pakiet ma na celu ulepszenie funkcji pakietu „ggplot2” i zawiera różne funkcje do tworzenia udanych wykresów marginalnych.
Krok 1
Zainstaluj pakiet „ggExtra” za pomocą następującego polecenia, aby pomyślnie wykonać (jeśli pakiet nie jest zainstalowany w Twoim systemie).
> install.packages("ggExtra")Krok 2
Uwzględnij wymagane biblioteki w obszarze roboczym, aby utworzyć wykresy krańcowe.
> library(ggplot2)
> library(ggExtra)Krok 3
Czytanie wymaganego zbioru danych „mpg”, którego używaliśmy w poprzednich rozdziałach.
> data(mpg)
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
>Krok 4
Teraz stwórzmy prosty wykres przy użyciu „ggplot2”, który pomoże nam zrozumieć koncepcję wykresów marginalnych.
> #Plot
> g <- ggplot(mpg, aes(cty, hwy)) +
+ geom_count() +
+ geom_smooth(method="lm", se=F)
> g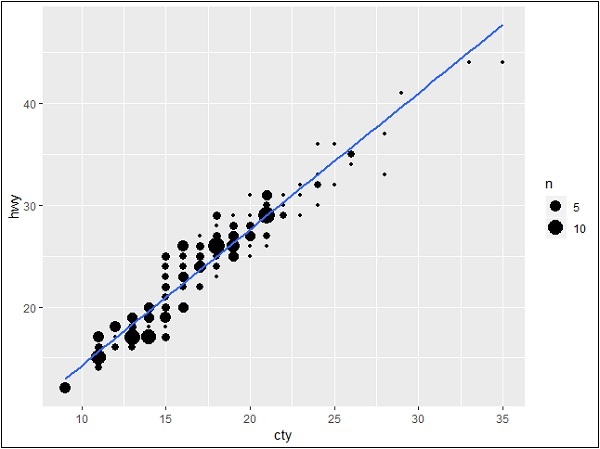
Związek między zmiennymi
Teraz stwórzmy wykresy krańcowe za pomocą funkcji ggMarginal, która pomaga wygenerować związek między dwoma atrybutami „hwy” i „cty”.
> ggMarginal(g, type = "histogram", fill="transparent")
> ggMarginal(g, type = "boxplot", fill="transparent")Dane wyjściowe dla wykresów krańcowych histogramu są wymienione poniżej -

Dane wyjściowe dla wykresów brzeżnych skrzynkowych są wymienione poniżej -

Wykresy bąbelkowe to nic innego jak wykresy bąbelkowe, które są w zasadzie wykresem punktowym z trzecią zmienną numeryczną używaną do określania rozmiaru koła. W tym rozdziale skupimy się na tworzeniu wykresów z liczbą słupków i zliczeń histogramów, które są uważane za replikę wykresów bąbelkowych.
Poniższe kroki służą do tworzenia wykresów bąbelkowych i wykresów zliczania ze wspomnianym pakietem -
Zrozumienie zbioru danych
Załaduj odpowiedni pakiet i wymagany zestaw danych, aby utworzyć wykresy bąbelkowe i wykresy zliczeniowe.
> # Load ggplot
> library(ggplot2)
>
> # Read in dataset
> data(mpg)
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~Wykres liczby słupków można utworzyć za pomocą następującego polecenia -
> # A bar count plot
> p <- ggplot(mpg, aes(x=factor(cyl)))+
+ geom_bar(stat="count")
> p
Analiza z histogramami
Wykres liczby histogramów można utworzyć za pomocą następującego polecenia -
> # A historgram count plot
> ggplot(data=mpg, aes(x=hwy)) +
+ geom_histogram( col="red",
+ fill="green",
+ alpha = .2,
+ binwidth = 5)
Wykresy bąbelkowe
Stwórzmy teraz najbardziej podstawowy wykres bąbelkowy z wymaganymi atrybutami zwiększania wymiarów punktów wymienionych na wykresie rozproszonym.
ggplot(mpg, aes(x=cty, y=hwy, size = pop)) +geom_point(alpha=0.7)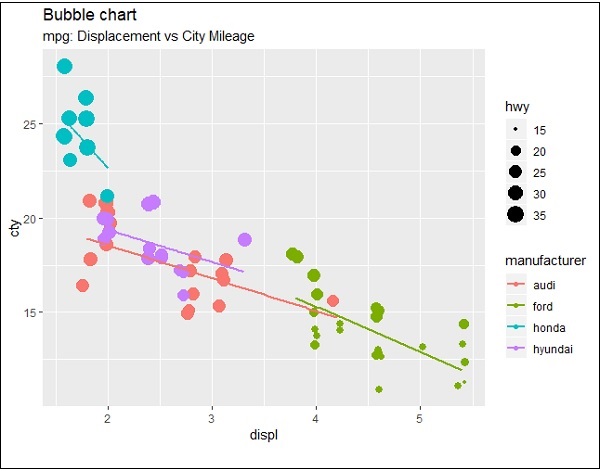
Fabuła opisuje charakter producentów, co jest zawarte w formacie legendy. Przedstawione wartości obejmują różne wymiary atrybutu „hwy”.
W poprzednich rozdziałach przyjrzeliśmy się różnym typom wykresów, które można tworzyć za pomocą pakietu „ggplot2”. Skoncentrujemy się teraz na odmianach takich samych, jak rozbieżne wykresy słupkowe, wykresy typu lizak i wiele innych. Na początek zaczniemy od tworzenia rozbieżnych wykresów słupkowych, a kroki, które należy wykonać, opisano poniżej -
Zrozumienie zbioru danych
Załaduj wymagany pakiet i utwórz nową kolumnę o nazwie „nazwa samochodu” w zestawie danych mpg.
#Load ggplot
> library(ggplot2)
> # create new column for car names
> mtcars$`car name` <- rownames(mtcars)
> # compute normalized mpg
> mtcars$mpg_z <- round((mtcars$mpg - mean(mtcars$mpg))/sd(mtcars$mpg), 2)
> # above / below avg flag
> mtcars$mpg_type <- ifelse(mtcars$mpg_z < 0, "below", "above")
> # sort
> mtcars <- mtcars[order(mtcars$mpg_z), ]Powyższe obliczenia obejmują utworzenie nowej kolumny dla nazw samochodów, obliczenie znormalizowanego zestawu danych za pomocą funkcji round. Możemy również użyć flagi powyżej i poniżej avg, aby uzyskać wartości funkcji „type”. Później sortujemy wartości, aby utworzyć wymagany zbiór danych.
Otrzymane dane wyjściowe są następujące -

Zamień wartości na czynniki, aby zachować posortowaną kolejność na określonym wykresie, jak wspomniano poniżej -
> # convert to factor to retain sorted order in plot.
> mtcars$`car name` <- factor(mtcars$`car name`, levels = mtcars$`car name`)Uzyskane dane wyjściowe są wymienione poniżej -

Rozbieżny wykres słupkowy
Teraz utwórz rozbieżny wykres słupkowy ze wspomnianymi atrybutami, które są traktowane jako wymagane współrzędne.
> # Diverging Barcharts
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_bar(stat='identity', aes(fill=mpg_type), width=.5) +
+ scale_fill_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ labs(subtitle="Normalised mileage from 'mtcars'",
+ title= "Diverging Bars") +
+ coord_flip()Note - Rozbieżne znaki słupkowe dla niektórych elementów wymiaru wskazujące w górę lub w dół w odniesieniu do wymienionych wartości.
Wynik rozbieżnego wykresu słupkowego jest wymieniony poniżej, gdzie używamy funkcji geom_bar do tworzenia wykresu słupkowego -

Rozbieżny wykres Lollipop
Utwórz rozbieżny wykres typu lollipop z takimi samymi atrybutami i współrzędnymi, ze zmianą tylko funkcji, która ma być używana, tj. Geom_segment (), która pomaga w tworzeniu wykresów typu lizak.
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', fill="black", size=6) +
+ geom_segment(aes(y = 0,
+ x = `car name`,
+ yend = mpg_z,
+ xend = `car name`),
+ color = "black") +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Lollipop Chart",
+ subtitle="Normalized mileage from 'mtcars': Lollipop") +
+ ylim(-2.5, 2.5) +
+ coord_flip()
Rozbieżny wykres punktowy
Utwórz rozbieżny wykres punktowy w podobny sposób, gdzie kropki reprezentują punkty na rozproszonych wykresach w większym wymiarze.
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', aes(col=mpg_type), size=6) +
+ scale_color_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Dot Plot",
+ subtitle="Normalized mileage from 'mtcars': Dotplot") +
+ ylim(-2.5, 2.5) +
+ coord_flip()
Tutaj legendy przedstawiają wartości „Powyżej średniej” i „Poniżej średniej” w różnych kolorach - zielonym i czerwonym. Wykres punktowy przekazuje informacje statyczne. Zasady są takie same, jak w przypadku wykresu słupkowego z rozbieżnością, z tym że używany jest tylko punkt.
W tym rozdziale skupimy się na używaniu niestandardowego motywu, który służy do zmiany wyglądu i stylu obszaru roboczego. Użyjemy pakietu „ggthemes”, aby zrozumieć koncepcję zarządzania motywami w przestrzeni roboczej R.
Zaimplementujmy następujące kroki, aby użyć wymaganego motywu w ramach wspomnianego zbioru danych.
GGTHEMES
Zainstaluj pakiet „ggthemes” z wymaganym pakietem w obszarze roboczym R.
> install.packages("ggthemes")
> Library(ggthemes)
Zaimplementuj nowy motyw, aby wygenerować legendy producentów z rokiem produkcji i przemieszczeniem.
> library(ggthemes)
> ggplot(mpg, aes(year, displ, color=factor(manufacturer)))+
+ geom_point()+ggtitle("This plot looks a lot different from the default")+
+ theme_economist()+scale_colour_economist()
Można zauważyć, że domyślny rozmiar tekstu zaznaczenia, legend i innych elementów jest niewielki przy poprzednim zarządzaniu motywami. Zmiana rozmiaru wszystkich elementów tekstu na raz jest niezwykle łatwa. Można to zrobić, tworząc motyw niestandardowy, który możemy zaobserwować w poniższym kroku, że rozmiary wszystkich elementów są względne (rel ()) w stosunku do base_size.
> theme_set(theme_gray(base_size = 30))
> ggplot(mpg, aes(x=year, y=class))+geom_point(color="red")
Wielopanelowe wykresy oznaczają tworzenie wielu wykresów razem na jednym wykresie. Użyjemy funkcji par (), aby umieścić wiele wykresów na jednym wykresie, przekazując parametry graficzne mfrow i mfcol.
Tutaj użyjemy zestawu danych „AirQuality” do realizacji wykresów wielopanelowych. Najpierw zrozummy zbiór danych, aby przyjrzeć się tworzeniu wykresów wielopanelowych. Ten zestaw danych zawiera odpowiedzi z wieloczujnikowego urządzenia gazowego rozmieszczonego na polu we włoskim mieście. Średnie odpowiedzi godzinowe są rejestrowane wraz z referencjami stężeń gazów z certyfikowanego analizatora.
Wgląd w funkcję par ()
Zapoznaj się z funkcją par (), aby utworzyć wymiar wymaganych wykresów wielopanelowych.
> par(mfrow=c(1,2))
> # set the plotting area into a 1*2 arrayTworzy to pusty wykres o wymiarach 1 * 2.

Teraz utwórz wykres słupkowy i kołowy wspomnianego zestawu danych za pomocą następującego polecenia. To samo zjawisko można osiągnąć za pomocą parametru graficznego mfcol.
Tworzenie wykresów wielopanelowych
Jedyna różnica między nimi polega na tym, że mfrow wypełnia wiersz regionu podplotu, podczas gdy mfcol wypełnia go kolumnami.
> Temperature <- airquality$Temp
> Ozone <- airquality$Ozone
> par(mfrow=c(2,2))
> hist(Temperature)
> boxplot(Temperature, horizontal=TRUE)
> hist(Ozone)
> boxplot(Ozone, horizontal=TRUE)
Wykresy pudełkowe i wykresy słupkowe są tworzone w jednym oknie, zasadniczo tworząc wykresy wielopanelowe.
Ten sam wykres ze zmianą wymiarów w funkcji par wyglądałby następująco -
par(mfcol = c(2, 2))
W tym rozdziale skupimy się na tworzeniu wielu działek, które można później wykorzystać do tworzenia wykresów trójwymiarowych. Lista działek, które zostaną pokryte obejmuje:
- Wykres gęstości
- Wykres pudełkowy
- Wykres punktowy
- Fabuła skrzypiec
Będziemy używać zbioru danych „mpg”, tak jak w poprzednich rozdziałach. Ten zestaw danych zawiera dane dotyczące zużycia paliwa z lat 1999 i 2008 dla 38 popularnych modeli samochodów. Zestaw danych jest dostarczany z pakietem ggplot2. Ważne jest, aby wykonać poniższy krok, aby utworzyć różne rodzaje działek.
> # Load Modules
> library(ggplot2)
>
> # Dataset
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~Wykres gęstości
Wykres gęstości jest graficzną reprezentacją rozkładu dowolnej zmiennej numerycznej we wspomnianym zbiorze danych. Wykorzystuje oszacowanie gęstości jądra, aby pokazać funkcję gęstości prawdopodobieństwa zmiennej.
Pakiet „ggplot2” zawiera funkcję o nazwie geom_density () do tworzenia wykresu gęstości.
Wykonamy następujące polecenie, aby utworzyć wykres gęstości -
> p −- ggplot(mpg, aes(cty)) +
+ geom_density(aes(fill=factor(cyl)), alpha=0.8)
> pZ utworzonej poniżej działki możemy obserwować różne zagęszczenia -
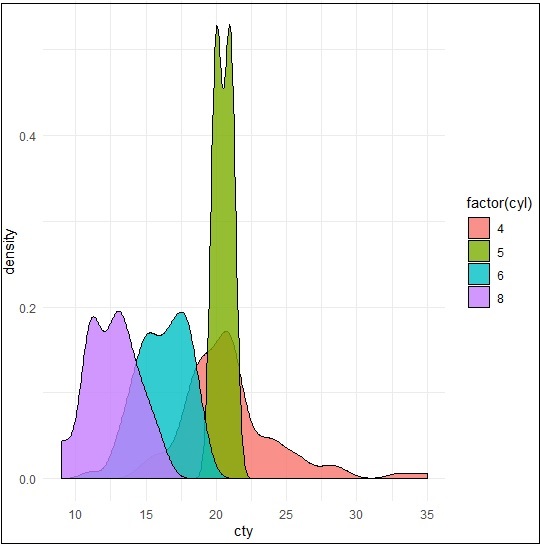
Możemy stworzyć fabułę, zmieniając nazwy osi X i Y, co zapewnia lepszą przejrzystość dzięki włączeniu tytułu i legend z różnymi kombinacjami kolorów.
> p + labs(title="Density plot",
+ subtitle="City Mileage Grouped by Number of cylinders",
+ caption="Source: mpg",
+ x="City Mileage",
+ fill="# Cylinders")
Wykres pudełkowy
Wykres pudełkowy, nazywany również wykresem pudełkowym i wąsami, reprezentuje pięciocyfrowe podsumowanie danych. Pięć podsumowań liczb obejmuje wartości takie jak minimum, pierwszy kwartyl, mediana, trzeci kwartyl i maksimum. Pionowa linia przechodząca przez środkową część wykresu pudełkowego jest uważana za „medianę”.
Możemy utworzyć wykres pudełkowy za pomocą następującego polecenia -
> p <- ggplot(mpg, aes(class, cty)) +
+ geom_boxplot(varwidth=T, fill="blue")
> p + labs(title="A Box plot Example",
+ subtitle="Mileage by Class",
+ caption="MPG Dataset",
+ x="Class",
+ y="Mileage")
>pTutaj tworzymy wykres pudełkowy z uwzględnieniem atrybutów klasy i cty.

Wykres punktowy
Wykresy punktowe są podobne do wykresów rozproszonych, ale różnią się tylko wymiarami. W tej sekcji dodamy wykres kropkowy do istniejącego wykresu pudełkowego, aby uzyskać lepszy obraz i przejrzystość.
Wykres pudełkowy można utworzyć za pomocą następującego polecenia -
> p <- ggplot(mpg, aes(manufacturer, cty)) +
+ geom_boxplot() +
+ theme(axis.text.x = element_text(angle=65, vjust=0.6))
> p
Wykres kropkowy jest tworzony, jak wspomniano poniżej -
> p + geom_dotplot(binaxis='y',
+ stackdir='center',
+ dotsize = .5
+ )
Fabuła skrzypiec
Fabuła skrzypiec jest również tworzona w podobny sposób, z jedyną zmianą struktury skrzypiec zamiast pudełka. Wynik jest wyraźnie wymieniony poniżej -
> p <- ggplot(mpg, aes(class, cty))
>
> p + geom_violin()
Istnieją sposoby na zmianę całego wyglądu działki za pomocą jednej funkcji, jak wspomniano poniżej. Ale jeśli chcesz po prostu zmienić kolor tła panelu, możesz użyć następującego -
Wdrażanie tła panelu
Możemy zmienić kolor tła za pomocą następującego polecenia, które pomaga w zmianie panelu (panel.background) -
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(panel.background = element_rect(fill = 'grey75'))Zmiana koloru jest wyraźnie przedstawiona na poniższym obrazku -

Wdrażanie Panel.grid.major
Możemy zmienić linie siatki za pomocą właściwości „panel.grid.major”, jak wspomniano w poniższym poleceniu -
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(panel.background = element_rect(fill = 'grey75'),
+ panel.grid.major = element_line(colour = "orange", size=2),
+ panel.grid.minor = element_line(colour = "blue"))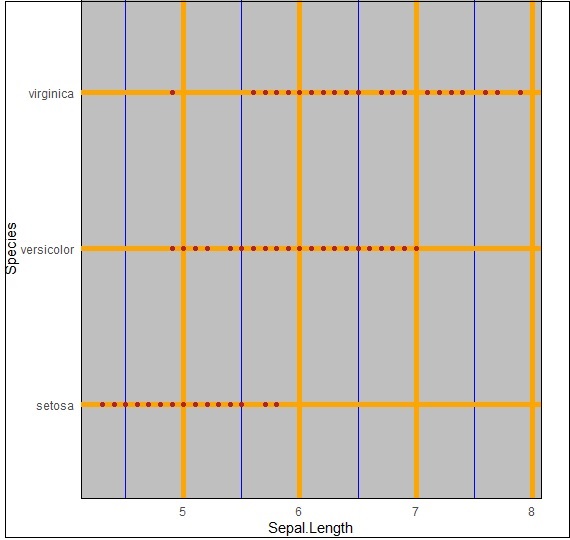
Możemy nawet zmienić tło wykresu, zwłaszcza wyłączając panel za pomocą właściwości „plot.background”, jak wspomniano poniżej -
ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(plot.background = element_rect(fill = 'pink'))
Szereg czasowy to wykres graficzny, który przedstawia serię punktów danych w określonej kolejności czasowej. Szereg czasowy to sekwencja utworzona z sekwencji w kolejnych równych odstępach czasu. Szeregi czasowe można traktować jako dane dyskretne. Zbiór danych, którego będziemy używać w tym rozdziale, to zbiór danych „ekonomicznych”, który zawiera wszystkie szczegóły szeregu czasowego dla gospodarki amerykańskiej.
Ramka danych zawiera następujące atrybuty wymienione poniżej -
| Data | Miesiąc zbierania danych |
| Psavert | Stopa oszczędności osobistych |
| Szt | Spożycie osobiste |
| Bezrobotny | Liczba bezrobotnych w tysiącach |
| Niewzruszony | Mediana czasu trwania bezrobocia |
| Muzyka pop | Całkowita liczba ludności w tysiącach |
Załaduj wymagane pakiety i ustaw domyślną kompozycję, aby utworzyć serię czasową.
> library(ggplot2)
> theme_set(theme_minimal())
> # Demo dataset
> head(economics)
# A tibble: 6 x 6
date pce pop psavert uempmed unemploy
<date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1967-07-01 507. 198712 12.6 4.5 2944
2 1967-08-01 510. 198911 12.6 4.7 2945
3 1967-09-01 516. 199113 11.9 4.6 2958
4 1967-10-01 512. 199311 12.9 4.9 3143
5 1967-11-01 517. 199498 12.8 4.7 3066
6 1967-12-01 525. 199657 11.8 4.8 3018Utwórz podstawowe wykresy liniowe, które utworzą strukturę szeregów czasowych.
> # Basic line plot
> ggplot(data = economics, aes(x = date, y = pop))+
+ geom_line(color = "#00AFBB", size = 2)
Możemy wykreślić podzbiór danych za pomocą następującego polecenia -
> # Plot a subset of the data
> ss <- subset(economics, date > as.Date("2006-1-1"))
> ggplot(data = ss, aes(x = date, y = pop)) +
+ geom_line(color = "#FC4E07", size = 2)
Tworzenie szeregów czasowych
Tutaj wykreślimy zmienne psavert i nieempmed według dat. Tutaj musimy zmienić kształt danych za pomocą pakietu tidyr. Można to osiągnąć, zwijając wartości psavert i uempmed w tej samej kolumnie (nowa kolumna). Funkcja R: zbieraj () [tidyr]. Następnym krokiem jest utworzenie zmiennej grupującej, której poziomy = psavert i uempmed.
> library(tidyr)
> library(dplyr)
Attaching package: ‘dplyr’
The following object is masked from ‘package:ggplot2’: vars
The following objects are masked from ‘package:stats’: filter, lag
The following objects are masked from ‘package:base’: intersect, setdiff, setequal, union
> df <- economics %>%
+ select(date, psavert, uempmed) %>%
+ gather(key = "variable", value = "value", -date)
> head(df, 3)
# A tibble: 3 x 3
date variable value
<date> <chr> <dbl>
1 1967-07-01 psavert 12.6
2 1967-08-01 psavert 12.6
3 1967-09-01 psavert 11.9Utwórz wieloliniowe wykresy za pomocą następującego polecenia, aby przyjrzeć się relacji między „psavert” i „unempmed” -
> ggplot(df, aes(x = date, y = value)) +
+ geom_line(aes(color = variable), size = 1) +
+ scale_color_manual(values = c("#00AFBB", "#E7B800")) +
+ theme_minimal()