H2O - Instalacja
H2O można skonfigurować i używać z pięcioma różnymi opcjami wymienionymi poniżej -
Zainstaluj w Pythonie
Zainstaluj w R
Graficzny interfejs użytkownika Flow oparty na sieci Web
Hadoop
Chmura Anaconda
W kolejnych sekcjach zobaczysz instrukcje dotyczące instalacji H2O w oparciu o dostępne opcje. Prawdopodobnie użyjesz jednej z opcji.
Zainstaluj w Pythonie
Aby uruchomić H2O z Pythonem, instalacja wymaga kilku zależności. Zacznijmy więc instalować minimalny zestaw zależności, aby uruchomić H2O.
Instalowanie zależności
Aby zainstalować zależność, wykonaj następujące polecenie pip -
$ pip install requestsOtwórz okno konsoli i wpisz powyższe polecenie, aby zainstalować pakiet żądań. Poniższy zrzut ekranu pokazuje wykonanie powyższego polecenia na naszym komputerze Mac -
Po zainstalowaniu żądań musisz zainstalować trzy kolejne pakiety, jak pokazano poniżej -
$ pip install tabulate
$ pip install "colorama >= 0.3.8"
$ pip install futureNajbardziej aktualna lista zależności jest dostępna na stronie H2O GitHub. W chwili pisania tego tekstu na stronie wymieniono następujące zależności.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Usuwanie starszych wersji
Po zainstalowaniu powyższych zależności należy usunąć wszelkie istniejące instalacje H2O. Aby to zrobić, uruchom następujące polecenie -
$ pip uninstall h2oInstalowanie najnowszej wersji
Teraz zainstalujmy najnowszą wersję H2O za pomocą następującego polecenia -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oPo pomyślnej instalacji na ekranie powinien pojawić się następujący komunikat -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Testowanie instalacji
Aby przetestować instalację, uruchomimy jedną z przykładowych aplikacji dostarczonych w instalacji H2O. Najpierw uruchom wiersz Pythona, wpisując następujące polecenie -
$ Python3Po uruchomieniu interpretera języka Python wpisz następującą instrukcję języka Python w wierszu polecenia języka Python -
>>>import h2oPowyższe polecenie importuje pakiet H2O do twojego programu. Następnie zainicjuj system H2O za pomocą następującego polecenia -
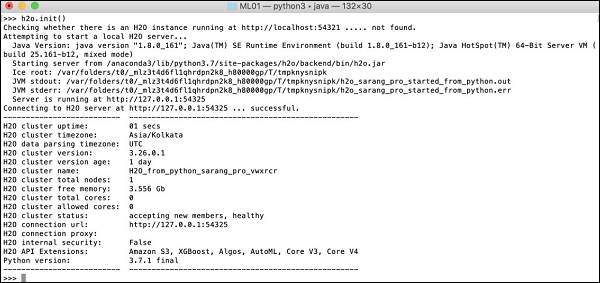
>>>h2o.init()Twój ekran pokaże informacje o klastrze i na tym etapie powinien wyglądać następująco:
Teraz możesz uruchomić przykładowy kod. Wpisz następujące polecenie w wierszu polecenia Pythona i wykonaj je.
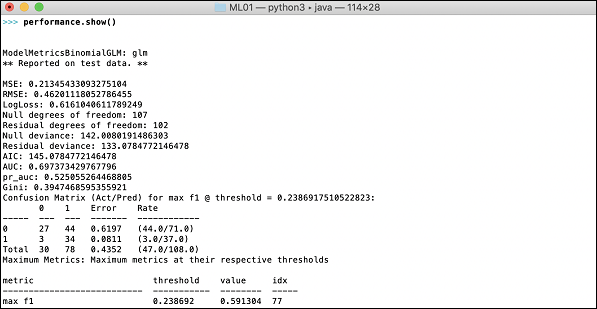
>>>h2o.demo("glm")Demo składa się z notatnika Python z serią poleceń. Po wykonaniu każdego polecenia jego wyjście jest natychmiast wyświetlane na ekranie i zostaniesz poproszony o naciśnięcie klawisza, aby przejść do następnego kroku. Tutaj pokazano częściowy zrzut ekranu dotyczący wykonywania ostatniej instrukcji w notatniku -
Na tym etapie Twoja instalacja Pythona jest zakończona i jesteś gotowy na własne eksperymenty.
Zainstaluj w R
Instalowanie H2O for R jest bardzo podobne do instalowania go w Pythonie, z tym wyjątkiem, że do instalacji używałbyś znaku zachęty R.
Uruchamianie konsoli R.
Uruchom konsolę R, klikając ikonę aplikacji R na swoim komputerze. Ekran konsoli wyglądałby tak, jak pokazano na poniższym zrzucie ekranu -
Twoja instalacja H2O zostanie wykonana w powyższym znaku zachęty R. Jeśli wolisz używać RStudio, wpisz polecenia w oknie podrzędnym konsoli R.
Usuwanie starszych wersji
Na początek usuń starsze wersje za pomocą następującego polecenia w wierszu polecenia -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Pobieranie zależności
Pobierz zależności dla H2O przy użyciu następującego kodu -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}Instalowanie H2O
Zainstaluj H2O, wpisując następujące polecenie w wierszu poleceń R -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))Poniższy zrzut ekranu przedstawia oczekiwane dane wyjściowe -
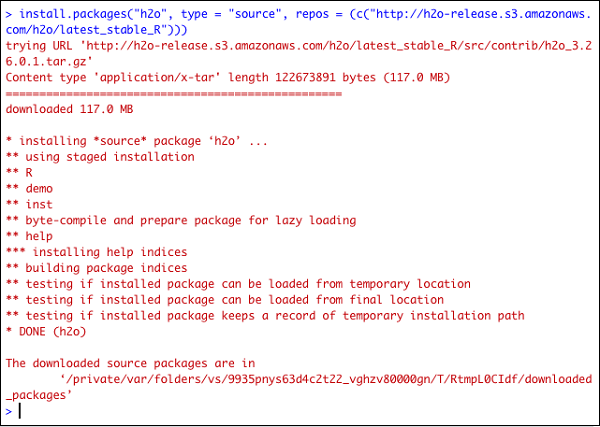
Istnieje inny sposób zainstalowania H2O w R.
Zainstaluj w R z CRAN
Aby zainstalować R z CRAN, użyj następującego polecenia w wierszu polecenia R -
> install.packages("h2o")Zostaniesz poproszony o wybranie lustra -
--- Please select a CRAN mirror for use in this session ---
Na ekranie pojawi się okno dialogowe wyświetlające listę serwerów lustrzanych. Wybierz najbliższą lokalizację lub wybrane lustro.
Testowanie instalacji
W wierszu polecenia R wpisz i uruchom następujący kod -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Wygenerowane dane wyjściowe będą wyglądać tak, jak pokazano na poniższym zrzucie ekranu -
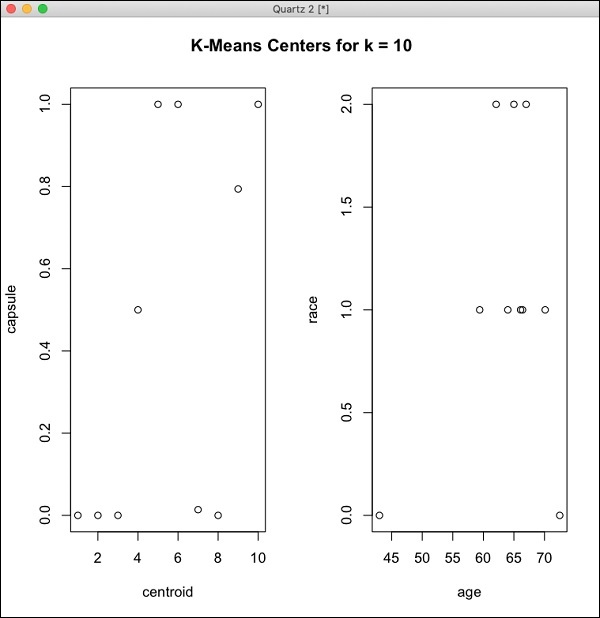
Twoja instalacja H2O w R została zakończona.
Instalowanie Web GUI Flow
Aby zainstalować GUI Flow, pobierz plik instalacyjny z witryny H20. Rozpakuj pobrany plik do preferowanego folderu. Zwróć uwagę na obecność pliku h2o.jar w instalacji. Uruchom ten plik w oknie poleceń za pomocą następującego polecenia -
$ java -jar h2o.jarPo chwili w oknie konsoli pojawi się następujący komunikat.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Aby uruchomić przepływ, otwórz podany adres URL http://localhost:54321w Twojej przeglądarce. Pojawi się następujący ekran -
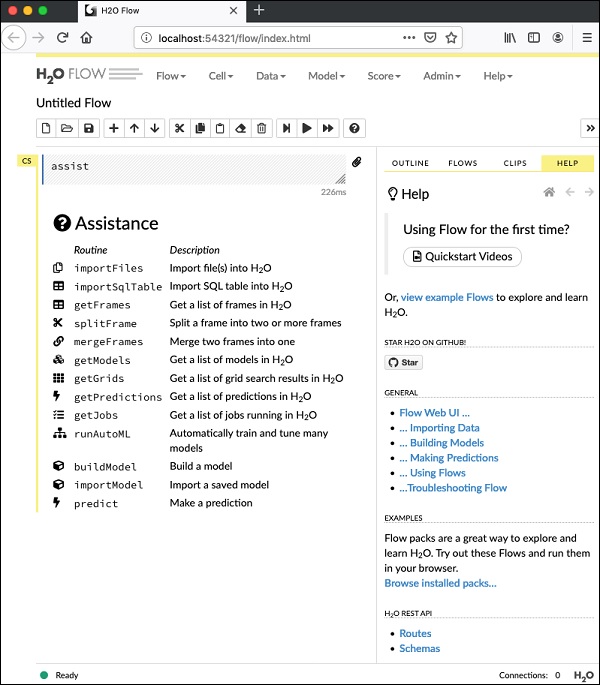
Na tym etapie instalacja Flow jest zakończona.
Zainstaluj w chmurze Hadoop / Anaconda
Jeśli nie jesteś doświadczonym programistą, nie pomyślałbyś o używaniu H2O na Big Data. Wystarczy tutaj powiedzieć, że modele H2O działają sprawnie na ogromnych bazach danych o wielkości kilku terabajtów. Jeśli Twoje dane znajdują się w instalacji Hadoop lub w chmurze, postępuj zgodnie z instrukcjami podanymi w witrynie H2O, aby zainstalować je dla odpowiedniej bazy danych.
Teraz, gdy pomyślnie zainstalowałeś i przetestowałeś H2O na swojej maszynie, jesteś gotowy do prawdziwego rozwoju. Najpierw zobaczymy rozwój z wiersza polecenia. Na kolejnych lekcjach dowiemy się, jak przeprowadzić testowanie modeli w H2O Flow.
Programowanie w wierszu polecenia
Rozważmy teraz użycie H2O do sklasyfikowania roślin na podstawie dobrze znanego zbioru danych tęczówki, który jest swobodnie dostępny do tworzenia aplikacji do uczenia maszynowego.
Uruchom interpreter Pythona, wpisując następujące polecenie w oknie powłoki -
$ Python3Spowoduje to uruchomienie interpretera języka Python. Importuj platformę h2o za pomocą następującego polecenia -
>>> import h2oDo klasyfikacji użyjemy algorytmu Random Forest. Jest to zawarte w pakiecie H2ORandomForestEstimator. Importujemy ten pakiet za pomocą instrukcji import w następujący sposób -
>>> from h2o.estimators import H2ORandomForestEstimatorInicjujemy środowisko H2o, wywołując jego metodę init.
>>> h2o.init()Po pomyślnej inicjalizacji na konsoli powinien zostać wyświetlony następujący komunikat wraz z informacjami o klastrze.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Teraz zaimportujemy dane tęczówki za pomocą metody import_file w H2O.
>>> data = h2o.import_file('iris.csv')Postęp zostanie wyświetlony, jak pokazano na poniższym zrzucie ekranu -

Po załadowaniu pliku do pamięci możesz to sprawdzić, wyświetlając pierwsze 10 wierszy załadowanej tabeli. Używaszhead metoda, aby to zrobić -
>>> data.head()Zobaczysz następujące dane wyjściowe w formacie tabelarycznym.
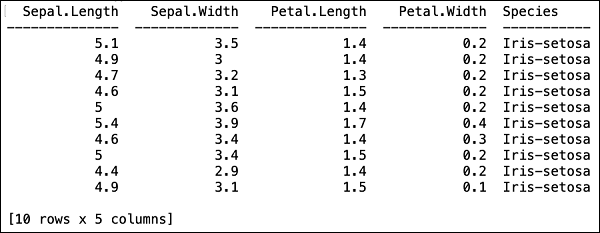
Tabela wyświetla również nazwy kolumn. Użyjemy pierwszych czterech kolumn jako funkcji naszego algorytmu ML, a ostatniej klasy kolumny jako przewidywanego wyniku. Określamy to w wywołaniu naszego algorytmu ML, tworząc najpierw następujące dwie zmienne.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Następnie podzieliliśmy dane na trening i testy, wywołując metodę split_frame.
>>> train, test = data.split_frame(ratios = [0.8])Dane są podzielone w stosunku 80:20. Wykorzystujemy 80% danych do szkolenia, a 20% do testów.
Teraz ładujemy do systemu wbudowany model Random Forest.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)W powyższym wywołaniu ustawiliśmy liczbę drzew na 50, maksymalną głębokość drzewa na 20 i liczbę fałd do weryfikacji krzyżowej na 10. Teraz musimy wytrenować model. Robimy to, wywołując metodę pociągu w następujący sposób -
>>> model.train(x = features, y = output, training_frame = train)Metoda train otrzymuje funkcje i dane wyjściowe, które utworzyliśmy wcześniej, jako pierwsze dwa parametry. Zestaw danych szkoleniowych jest ustawiony na trenowanie, co stanowi 80% naszego pełnego zestawu danych. Podczas treningu zobaczysz postęp, jak pokazano tutaj -
Teraz, gdy proces budowania modelu dobiegł końca, nadszedł czas na przetestowanie modelu. Robimy to, wywołując metodę model_performance na przeszkolonym obiekcie modelu.
>>> performance = model.model_performance(test_data=test)W powyższym wywołaniu metody wysłaliśmy dane testowe jako nasz parametr.
Nadszedł czas, aby zobaczyć wynik, czyli wydajność naszego modelu. Robisz to po prostu drukując wydajność.
>>> print (performance)To da ci następujący wynik -
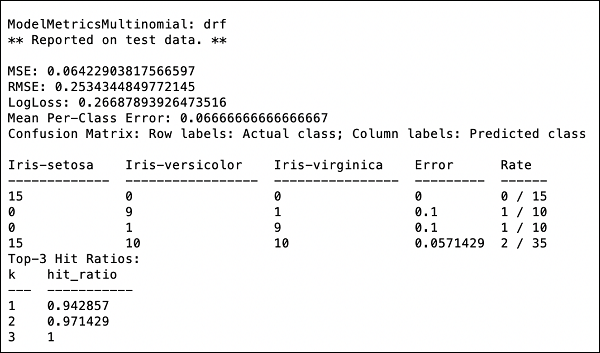
Dane wyjściowe pokazują średni kwadratowy błąd (MSE), średni kwadratowy błąd (RMSE), LogLoss, a nawet macierz konfuzji.
Bieganie w Jupyter
Widzieliśmy wykonanie polecenia, a także zrozumieliśmy cel każdego wiersza kodu. Możesz uruchomić cały kod w środowisku Jupyter, wiersz po wierszu lub cały program na raz. Pełna lista znajduje się tutaj -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Uruchom kod i obserwuj dane wyjściowe. Teraz możesz docenić, jak łatwo jest zastosować i przetestować algorytm Random Forest w swoim zbiorze danych. Siła H20 wykracza daleko poza te możliwości. Co zrobić, jeśli chcesz wypróbować inny model w tym samym zestawie danych, aby sprawdzić, czy możesz uzyskać lepszą wydajność. Jest to wyjaśnione w naszej kolejnej sekcji.
Stosowanie innego algorytmu
Teraz nauczymy się, jak zastosować algorytm zwiększania gradientu do naszego wcześniejszego zbioru danych, aby zobaczyć, jak działa. Na powyższej pełnej liście musisz wprowadzić tylko dwie drobne zmiany, jak zaznaczono w poniższym kodzie -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Uruchom kod, a otrzymasz następujące dane wyjściowe -
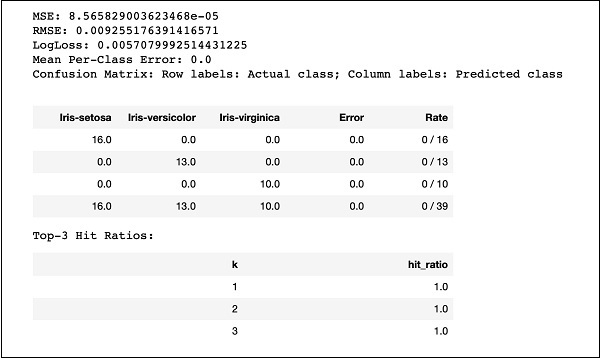
Po prostu porównaj wyniki, takie jak MSE, RMSE, Confusion Matrix itp. Z poprzednimi wynikami i zdecyduj, który z nich zostanie użyty do wdrożenia produkcyjnego. W rzeczywistości możesz zastosować kilka różnych algorytmów, aby wybrać najlepszy, który spełnia Twoje oczekiwania.