H2O - Szybki przewodnik
Czy kiedykolwiek poproszono Cię o opracowanie modelu uczenia maszynowego na ogromnej bazie danych? Zazwyczaj klient dostarcza bazę danych i prosi o zrobienie pewnych prognoz, takich jak kto będzie potencjalnym kupującym; czy możliwe jest wczesne wykrycie oszukańczych przypadków, itp. Aby odpowiedzieć na te pytania, Twoim zadaniem byłoby opracowanie algorytmu uczenia maszynowego, który zapewni odpowiedź na zapytanie klienta. Tworzenie algorytmu uczenia maszynowego od podstaw nie jest łatwym zadaniem i po co to robić, skoro na rynku dostępnych jest kilka gotowych do użycia bibliotek uczenia maszynowego.
W dzisiejszych czasach wolisz korzystać z tych bibliotek, zastosować dobrze przetestowany algorytm z tych bibliotek i spojrzeć na jego wydajność. Gdyby wydajność nie mieściła się w akceptowalnych granicach, można spróbować dostroić aktualny algorytm lub wypróbować zupełnie inny.
Podobnie możesz wypróbować wiele algorytmów na tym samym zbiorze danych, a następnie wybrać najlepszy, który w zadowalający sposób spełnia wymagania klienta. Tutaj z pomocą przychodzi H2O. Jest to platforma uczenia maszynowego typu open source z w pełni przetestowanymi implementacjami kilku powszechnie akceptowanych algorytmów ML. Musisz tylko pobrać algorytm z jego ogromnego repozytorium i zastosować go do swojego zbioru danych. Zawiera najczęściej używane algorytmy statystyczne i ML.
Aby wspomnieć o kilku tutaj, obejmuje maszyny ze wzmocnieniem gradientowym (GBM), uogólniony model liniowy (GLM), głębokie uczenie i wiele innych. Nie tylko, że obsługuje również funkcję AutoML, która będzie oceniać wydajność różnych algorytmów w zbiorze danych, zmniejszając w ten sposób wysiłki związane ze znalezieniem najlepiej działającego modelu. H2O jest używany na całym świecie przez ponad 18000 organizacji i dobrze współpracuje z językami R i Python w celu ułatwienia programowania. Jest to platforma w pamięci, która zapewnia doskonałą wydajność.
W tym samouczku najpierw nauczysz się instalować H2O na komputerze z opcjami języka Python i R. Zrozumiemy, jak używać tego w linii poleceń, abyś zrozumiał, jak działa wiersz poleceń. Jeśli jesteś miłośnikiem Pythona, możesz używać Jupytera lub dowolnego innego IDE do tworzenia aplikacji H2O. Jeśli wolisz R, możesz użyć RStudio do programowania.
W tym samouczku rozważymy przykład, aby zrozumieć, jak należy pracować z H2O. Dowiemy się również, jak zmienić algorytm w kodzie programu i porównać jego wydajność z wcześniejszym. H2O zapewnia również narzędzie internetowe do testowania różnych algorytmów w zbiorze danych. Nazywa się to przepływem.
Samouczek wprowadzi Cię w korzystanie z Flow. Równocześnie omówimy wykorzystanie AutoML, które pozwoli zidentyfikować najlepiej działający algorytm w Twoim zbiorze danych. Nie jesteś podekscytowany nauką H2O? Czytaj dalej!
H2O można skonfigurować i używać z pięcioma różnymi opcjami wymienionymi poniżej -
Zainstaluj w Pythonie
Zainstaluj w R
Graficzny interfejs użytkownika Flow oparty na sieci Web
Hadoop
Chmura Anaconda
W kolejnych sekcjach zobaczysz instrukcje dotyczące instalacji H2O w oparciu o dostępne opcje. Prawdopodobnie użyjesz jednej z opcji.
Zainstaluj w Pythonie
Aby uruchomić H2O z Pythonem, instalacja wymaga kilku zależności. Zacznijmy więc instalować minimalny zestaw zależności, aby uruchomić H2O.
Instalowanie zależności
Aby zainstalować zależność, wykonaj następujące polecenie pip -
$ pip install requestsOtwórz okno konsoli i wpisz powyższe polecenie, aby zainstalować pakiet żądań. Poniższy zrzut ekranu pokazuje wykonanie powyższego polecenia na naszym komputerze Mac -
Po zainstalowaniu żądań musisz zainstalować trzy kolejne pakiety, jak pokazano poniżej -
$ pip install tabulate
$ pip install "colorama >= 0.3.8" $ pip install futureNajbardziej aktualna lista zależności jest dostępna na stronie H2O GitHub. W chwili pisania tego tekstu na stronie wymieniono następujące zależności.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Usuwanie starszych wersji
Po zainstalowaniu powyższych zależności należy usunąć wszelkie istniejące instalacje H2O. Aby to zrobić, uruchom następujące polecenie -
$ pip uninstall h2oInstalowanie najnowszej wersji
Teraz zainstalujmy najnowszą wersję H2O za pomocą następującego polecenia -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oPo pomyślnej instalacji na ekranie powinien pojawić się następujący komunikat -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Testowanie instalacji
Aby przetestować instalację, uruchomimy jedną z przykładowych aplikacji dostarczonych w instalacji H2O. Najpierw uruchom wiersz Pythona, wpisując następujące polecenie -
$ Python3Po uruchomieniu interpretera języka Python wpisz następującą instrukcję języka Python w wierszu polecenia języka Python -
>>>import h2oPowyższe polecenie importuje pakiet H2O do twojego programu. Następnie zainicjuj system H2O za pomocą następującego polecenia -
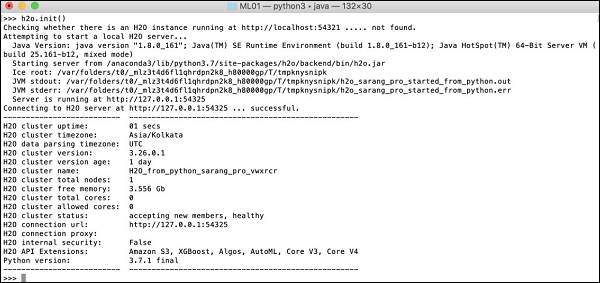
>>>h2o.init()Twój ekran pokaże informacje o klastrze i na tym etapie powinien wyglądać następująco:
Teraz możesz uruchomić przykładowy kod. Wpisz następujące polecenie w wierszu polecenia Pythona i wykonaj je.
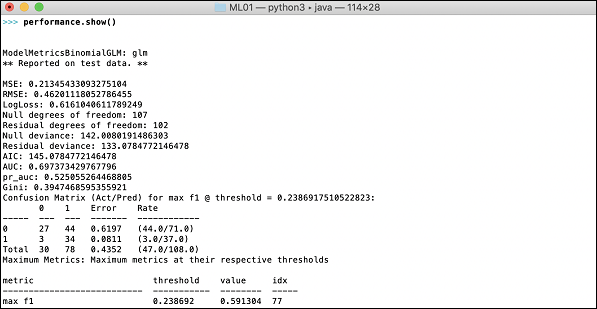
>>>h2o.demo("glm")Demo składa się z notatnika Python z serią poleceń. Po wykonaniu każdego polecenia jego wyjście jest natychmiast wyświetlane na ekranie i zostaniesz poproszony o naciśnięcie klawisza, aby przejść do następnego kroku. Tutaj pokazano częściowy zrzut ekranu dotyczący wykonywania ostatniej instrukcji w notatniku -
Na tym etapie Twoja instalacja Pythona jest zakończona i jesteś gotowy na własne eksperymenty.
Zainstaluj w R
Instalowanie H2O for R jest bardzo podobne do instalowania go w Pythonie, z tym wyjątkiem, że do instalacji używałbyś znaku zachęty R.
Uruchamianie konsoli R.
Uruchom konsolę R, klikając ikonę aplikacji R na swoim komputerze. Ekran konsoli wyglądałby tak, jak pokazano na poniższym zrzucie ekranu -
Twoja instalacja H2O zostanie wykonana w powyższym znaku zachęty R. Jeśli wolisz używać RStudio, wpisz polecenia w oknie podrzędnym konsoli R.
Usuwanie starszych wersji
Na początek usuń starsze wersje za pomocą następującego polecenia w wierszu polecenia -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Pobieranie zależności
Pobierz zależności dla H2O przy użyciu następującego kodu -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}Instalowanie H2O
Zainstaluj H2O, wpisując następujące polecenie w wierszu poleceń R -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))Poniższy zrzut ekranu przedstawia oczekiwane dane wyjściowe -
Istnieje inny sposób zainstalowania H2O w R.
Zainstaluj w R z CRAN
Aby zainstalować R z CRAN, użyj następującego polecenia w wierszu polecenia R -
> install.packages("h2o")Zostaniesz poproszony o wybranie lustra -
--- Please select a CRAN mirror for use in this session ---
Na ekranie pojawi się okno dialogowe wyświetlające listę serwerów lustrzanych. Wybierz najbliższą lokalizację lub wybrane lustro.
Testowanie instalacji
W wierszu polecenia R wpisz i uruchom następujący kod -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Wygenerowane dane wyjściowe będą wyglądać tak, jak pokazano na poniższym zrzucie ekranu -
Twoja instalacja H2O w R została zakończona.
Instalowanie Web GUI Flow
Aby zainstalować GUI Flow, pobierz plik instalacyjny z witryny H20. Rozpakuj pobrany plik do preferowanego folderu. Zwróć uwagę na obecność pliku h2o.jar w instalacji. Uruchom ten plik w oknie poleceń za pomocą następującego polecenia -
$ java -jar h2o.jarPo chwili w oknie konsoli pojawi się następujący komunikat.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Aby uruchomić przepływ, otwórz podany adres URL http://localhost:54321w Twojej przeglądarce. Pojawi się następujący ekran -
Na tym etapie instalacja Flow jest zakończona.
Zainstaluj w chmurze Hadoop / Anaconda
Jeśli nie jesteś doświadczonym programistą, nie pomyślałbyś o używaniu H2O na Big Data. W tym miejscu wystarczy powiedzieć, że modele H2O działają wydajnie na ogromnych bazach danych o wielkości kilku terabajtów. Jeśli Twoje dane znajdują się w instalacji Hadoop lub w chmurze, postępuj zgodnie z instrukcjami podanymi w witrynie H2O, aby zainstalować je w odpowiedniej bazie danych.
Teraz, gdy pomyślnie zainstalowałeś i przetestowałeś H2O na swojej maszynie, jesteś gotowy do prawdziwego rozwoju. Najpierw zobaczymy rozwój z wiersza polecenia. Na kolejnych lekcjach dowiemy się, jak przeprowadzić testowanie modeli w H2O Flow.
Programowanie w wierszu polecenia
Rozważmy teraz użycie H2O do sklasyfikowania roślin z dobrze znanego zbioru danych tęczówki, który jest swobodnie dostępny do tworzenia aplikacji do uczenia maszynowego.
Uruchom interpreter Pythona, wpisując następujące polecenie w oknie powłoki -
$ Python3Spowoduje to uruchomienie interpretera języka Python. Importuj platformę h2o za pomocą następującego polecenia -
>>> import h2oDo klasyfikacji użyjemy algorytmu Random Forest. Jest to zawarte w pakiecie H2ORandomForestEstimator. Importujemy ten pakiet za pomocą instrukcji import w następujący sposób -
>>> from h2o.estimators import H2ORandomForestEstimatorInicjujemy środowisko H2o, wywołując jego metodę init.
>>> h2o.init()Po pomyślnej inicjalizacji na konsoli powinien zostać wyświetlony następujący komunikat wraz z informacjami o klastrze.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Teraz zaimportujemy dane tęczówki za pomocą metody import_file w H2O.
>>> data = h2o.import_file('iris.csv')Postęp zostanie wyświetlony, jak pokazano na poniższym zrzucie ekranu -

Po załadowaniu pliku do pamięci możesz to sprawdzić, wyświetlając pierwsze 10 wierszy załadowanej tabeli. Używaszhead metoda, aby to zrobić -
>>> data.head()Zobaczysz następujące dane wyjściowe w formacie tabelarycznym.
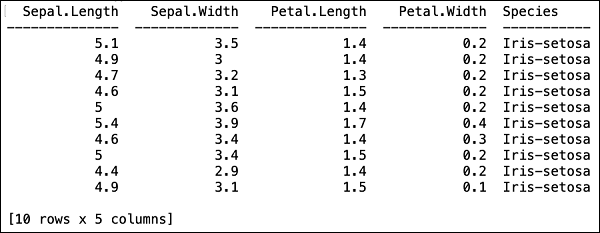
Tabela wyświetla również nazwy kolumn. Użyjemy pierwszych czterech kolumn jako funkcji naszego algorytmu ML, a ostatniej klasy kolumny jako przewidywanego wyniku. Określamy to w wywołaniu naszego algorytmu ML, tworząc najpierw następujące dwie zmienne.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Następnie podzieliliśmy dane na trening i testy, wywołując metodę split_frame.
>>> train, test = data.split_frame(ratios = [0.8])Dane są podzielone w stosunku 80:20. Wykorzystujemy 80% danych do szkolenia, a 20% do testów.
Teraz ładujemy do systemu wbudowany model Random Forest.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)W powyższym wywołaniu ustawiliśmy liczbę drzew na 50, maksymalną głębokość drzewa na 20, a liczbę fałd do weryfikacji krzyżowej na 10. Teraz musimy wytrenować model. Robimy to, wywołując metodę pociągu w następujący sposób -
>>> model.train(x = features, y = output, training_frame = train)Metoda train otrzymuje funkcje i dane wyjściowe, które utworzyliśmy wcześniej, jako pierwsze dwa parametry. Zestaw danych szkoleniowych jest ustawiony na trenowanie, co stanowi 80% naszego pełnego zestawu danych. Podczas treningu zobaczysz postęp, jak pokazano tutaj -
Teraz, gdy proces budowania modelu dobiegł końca, nadszedł czas na przetestowanie modelu. Robimy to, wywołując metodę model_performance na przeszkolonym obiekcie modelu.
>>> performance = model.model_performance(test_data=test)W powyższym wywołaniu metody wysłaliśmy dane testowe jako nasz parametr.
Nadszedł czas, aby zobaczyć wynik, czyli wydajność naszego modelu. Robisz to po prostu drukując wydajność.
>>> print (performance)To da ci następujący wynik -
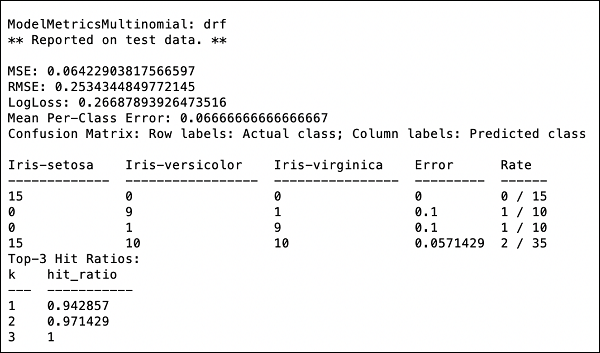
Dane wyjściowe pokazują średni kwadratowy błąd (MSE), średni kwadratowy błąd (RMSE), logLoss, a nawet macierz konfuzji.
Bieganie w Jupyter
Widzieliśmy wykonanie polecenia, a także zrozumieliśmy cel każdego wiersza kodu. Możesz uruchomić cały kod w środowisku Jupyter, wiersz po wierszu lub cały program na raz. Pełna lista znajduje się tutaj -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Uruchom kod i obserwuj dane wyjściowe. Teraz możesz docenić, jak łatwo jest zastosować i przetestować algorytm Random Forest w swoim zbiorze danych. Siła H20 wykracza daleko poza te możliwości. Co zrobić, jeśli chcesz wypróbować inny model w tym samym zestawie danych, aby sprawdzić, czy możesz uzyskać lepszą wydajność. Jest to wyjaśnione w naszej kolejnej sekcji.
Stosowanie innego algorytmu
Teraz nauczymy się, jak zastosować algorytm zwiększania gradientu do naszego wcześniejszego zbioru danych, aby zobaczyć, jak działa. Na powyższej pełnej liście musisz wprowadzić tylko dwie drobne zmiany, jak zaznaczono w poniższym kodzie -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Uruchom kod, a otrzymasz następujące dane wyjściowe -
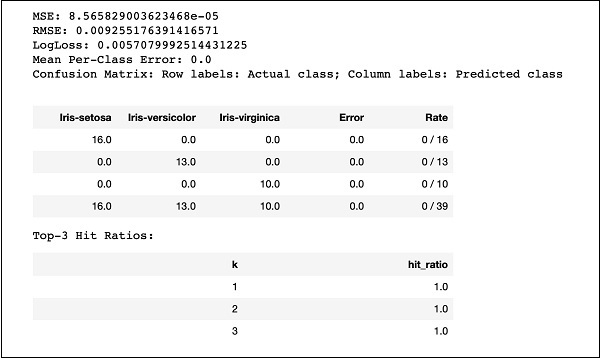
Po prostu porównaj wyniki, takie jak MSE, RMSE, Confusion Matrix itp. Z poprzednimi wynikami i zdecyduj, który z nich zostanie użyty do wdrożenia produkcyjnego. W rzeczywistości możesz zastosować kilka różnych algorytmów, aby wybrać najlepszy, który spełnia Twoje oczekiwania.
Podczas ostatniej lekcji nauczyłeś się tworzyć modele ML oparte na H2O przy użyciu interfejsu wiersza poleceń. H2O Flow spełnia ten sam cel, ale z interfejsem internetowym.
W kolejnych lekcjach pokażę, jak uruchomić H2O Flow i uruchomić przykładową aplikację.
Rozpoczynanie przepływu H2O
Pobrana wcześniej instalacja H2O zawiera plik h2o.jar. Aby uruchomić H2O Flow, najpierw uruchom ten jar z wiersza polecenia -
$ java -jar h2o.jarPo pomyślnym uruchomieniu jar na konsoli pojawi się następujący komunikat -
Open H2O Flow in your web browser: http://192.168.1.10:54321Teraz otwórz wybraną przeglądarkę i wpisz powyższy adres URL. Zobaczysz pulpit sieciowy H2O, jak pokazano tutaj -
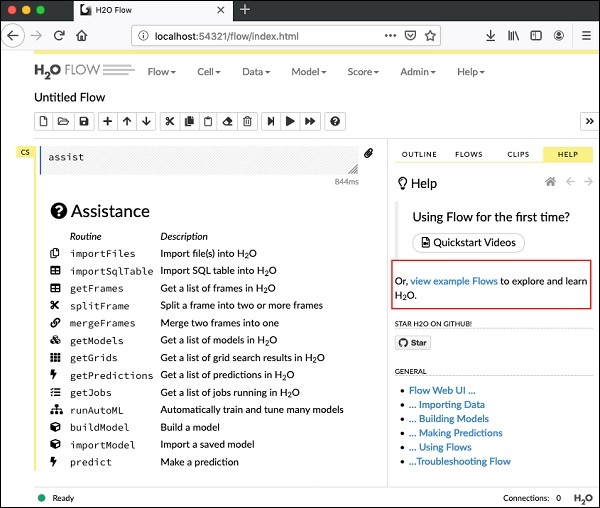
Jest to w zasadzie notatnik podobny do Colaba lub Jupytera. Pokażę Ci, jak załadować i uruchomić przykładową aplikację w tym notebooku, jednocześnie wyjaśniając różne funkcje Flow. Kliknij łącze Wyświetl przykład Przepływy na powyższym ekranie, aby wyświetlić listę podanych przykładów.
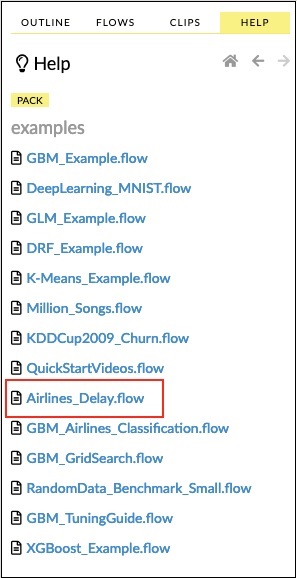
Opiszę przykład przepływu opóźnienia linii lotniczych z próbki.
Kliknij łącze Airlines Delay Flow na liście próbek, jak pokazano na poniższym zrzucie ekranu -
Po potwierdzeniu nowy notatnik zostanie załadowany.
Kasowanie wszystkich wyników
Zanim wyjaśnimy instrukcje kodu w notatniku, wyczyśćmy wszystkie dane wyjściowe, a następnie stopniowo uruchom notebook. Aby wyczyścić wszystkie wyjścia, wybierz następującą opcję menu -
Flow / Clear All Cell ContentsJest to pokazane na poniższym zrzucie ekranu -
Po wyczyszczeniu wszystkich danych wyjściowych uruchomimy każdą komórkę w notebooku indywidualnie i zbadamy jej dane wyjściowe.
Prowadzenie pierwszej celi
Kliknij pierwszą komórkę. Po lewej stronie pojawi się czerwona flaga wskazująca, że komórka została wybrana. Jest to pokazane na poniższym zrzucie ekranu -

Zawartość tej komórki to tylko komentarz do programu napisany w języku MarkDown (MD). Treść opisuje, co robi załadowana aplikacja. Aby uruchomić komórkę, kliknij ikonę Uruchom, jak pokazano na poniższym zrzucie ekranu -

Nie zobaczysz żadnych danych wyjściowych pod komórką, ponieważ w bieżącej komórce nie ma kodu wykonywalnego. Kursor przesuwa się teraz automatycznie do następnej komórki, która jest gotowa do wykonania.
Importowanie danych
Następna komórka zawiera następującą instrukcję Pythona -
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Oświadczenie importuje plik allyears2k.csv z Amazon AWS do systemu. Po uruchomieniu komórki importuje plik i wyświetla następujące dane wyjściowe.
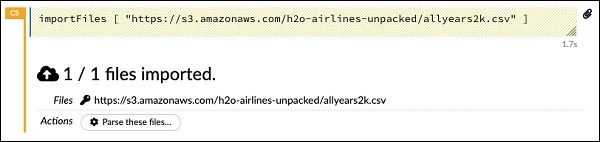
Konfigurowanie parsera danych
Teraz musimy przeanalizować dane i dostosować je do naszego algorytmu ML. Odbywa się to za pomocą następującego polecenia -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]Po wykonaniu powyższej instrukcji pojawi się okno dialogowe konfiguracji. W oknie dialogowym dostępnych jest kilka ustawień analizowania pliku. Jest to pokazane na poniższym zrzucie ekranu -
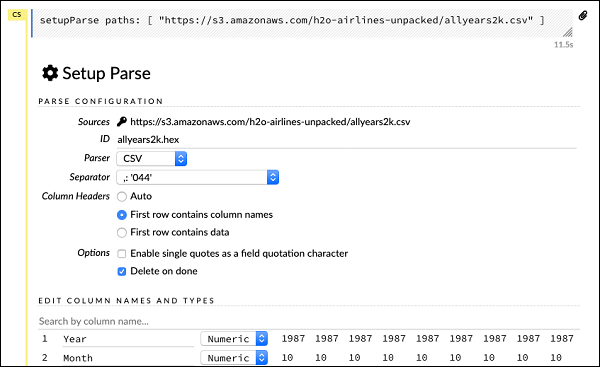
W tym oknie dialogowym możesz wybrać żądany parser z podanej listy rozwijanej i ustawić inne parametry, takie jak separator pól itp.
Analizowanie danych
Następna instrukcja, która faktycznie analizuje plik danych przy użyciu powyższej konfiguracji, jest długa i jest taka, jak pokazano tutaj -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
chunk_size: 4194304Zwróć uwagę, że parametry ustawione w oknie konfiguracji są wymienione w powyższym kodzie. Teraz uruchom tę komórkę. Po chwili parsowanie zostanie zakończone i zobaczysz następujące dane wyjściowe -
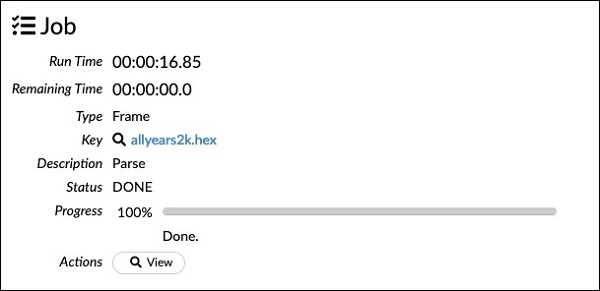
Badanie Dataframe
Po przetworzeniu generuje ramkę danych, którą można zbadać za pomocą następującej instrukcji -
getFrameSummary "allyears2k.hex"Po wykonaniu powyższej instrukcji zobaczysz następujący wynik -
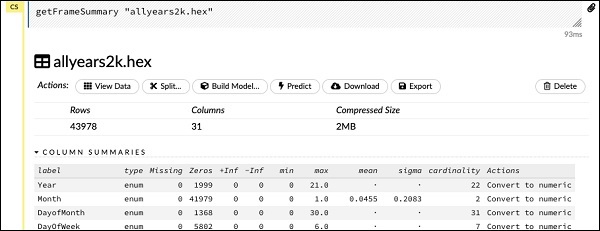
Teraz Twoje dane są gotowe do wprowadzenia do algorytmu uczenia maszynowego.
Następna instrukcja to komentarz do programu, który mówi, że będziemy używać modelu regresji i określa wstępnie ustawione regularyzacje i wartości lambda.
Budowanie modelu
Dalej następuje najważniejsze stwierdzenie, czyli samo zbudowanie modelu. Jest to określone w następującym oświadczeniu -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}Używamy glm, który jest zestawem uogólnionego modelu liniowego z typem rodziny ustawionym na dwumian. Możesz zobaczyć te podkreślone w powyższym oświadczeniu. W naszym przypadku oczekiwany wynik jest binarny i dlatego używamy typu dwumianowego. Możesz samodzielnie zbadać pozostałe parametry; na przykład spójrz na alfa i lambda, które określiliśmy wcześniej. Objaśnienie wszystkich parametrów można znaleźć w dokumentacji modelu GLM.
Teraz uruchom to oświadczenie. Po wykonaniu zostanie wygenerowany następujący wynik -

Z pewnością czas wykonania na twoim komputerze byłby inny. A teraz najciekawsza część tego przykładowego kodu.
Badanie wyników
Po prostu wyprowadzamy model, który zbudowaliśmy, używając następującej instrukcji -
getModel "glm_model"Zwróć uwagę, że glm_model to identyfikator modelu, który określiliśmy jako parametr model_id podczas budowania modelu w poprzedniej instrukcji. Daje nam to ogromne dane wyjściowe zawierające szczegółowe wyniki z kilkoma różnymi parametrami. Częściowe wyniki raportu pokazano na poniższym zrzucie ekranu -
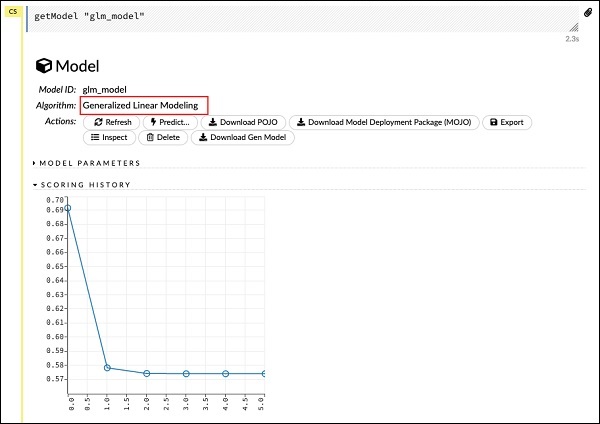
Jak widać w danych wyjściowych, jest to wynik działania algorytmu uogólnionego modelowania liniowego na zbiorze danych.
Tuż nad HISTORIĄ PUNKTÓW, zobaczysz tag MODEL PARAMETERS, rozwiń go, a zobaczysz listę wszystkich parametrów, które są używane podczas budowania modelu. Pokazuje to poniższy zrzut ekranu.
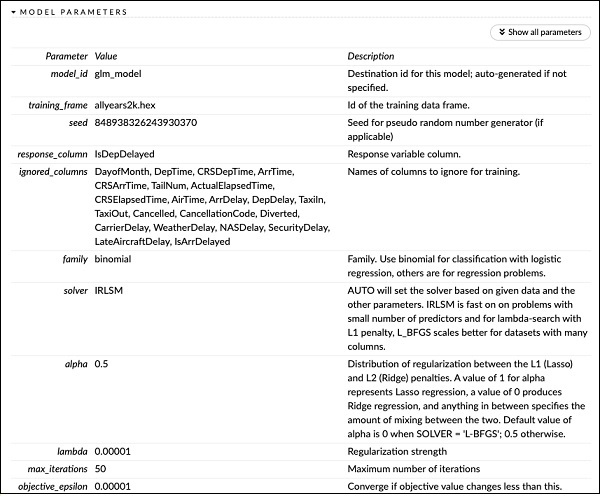
Podobnie każdy znacznik zapewnia szczegółowe dane wyjściowe określonego typu. Rozwiń samodzielnie różne tagi, aby przeanalizować wyniki różnego rodzaju.
Budowanie innego modelu
Następnie zbudujemy model Deep Learning w naszej ramce danych. Następna instrukcja w przykładowym kodzie to tylko komentarz do programu. Poniższa instrukcja jest w rzeczywistości poleceniem budowania modelu. Jest jak pokazano tutaj -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Jak widać w powyższym kodzie, określamy deeplearning do budowy modelu z kilkoma parametrami ustawionymi na odpowiednie wartości, jak określono w dokumentacji modelu deeplearning. Po uruchomieniu tej instrukcji zajmie to więcej czasu niż tworzenie modelu GLM. Po zakończeniu budowania modelu zobaczysz następujące dane wyjściowe, choć z różnymi czasami.

Analiza wyników modelu uczenia głębokiego
Generuje to rodzaj danych wyjściowych, które można zbadać za pomocą poniższej instrukcji, tak jak we wcześniejszym przypadku.
getModel "deeplearning_model"W celu szybkiego odniesienia rozważymy wynik krzywej ROC, jak pokazano poniżej.
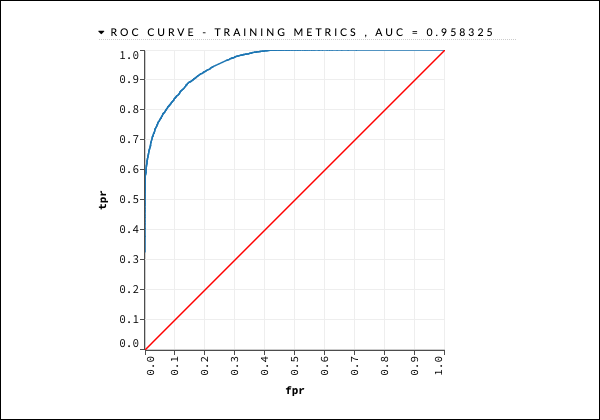
Podobnie jak w poprzednim przypadku, rozwiń różne zakładki i przeanalizuj różne wyniki.
Zapisywanie modelu
Po przestudiowaniu wyników różnych modeli decydujesz się użyć jednego z nich w środowisku produkcyjnym. H20 umożliwia zapisanie tego modelu jako POJO (zwykły stary obiekt Java).
Rozwiń ostatni znacznik PREVIEW POJO w danych wyjściowych, a zobaczysz kod Java dla swojego precyzyjnie dostrojonego modelu. Użyj tego w swoim środowisku produkcyjnym.
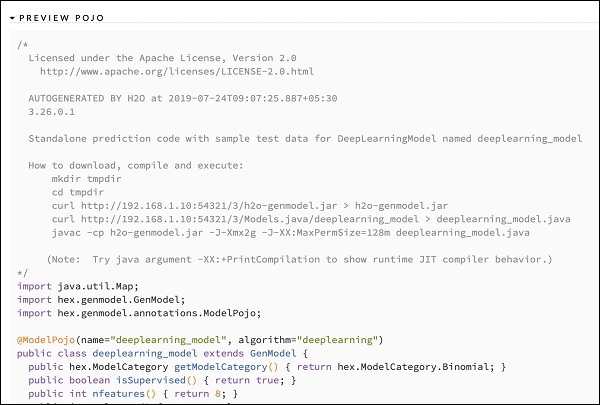
Następnie dowiemy się o bardzo ekscytującej funkcji H2O. Dowiemy się, jak używać AutoML do testowania i oceniania różnych algorytmów na podstawie ich wydajności.
Aby korzystać z AutoML, uruchom nowy notatnik Jupyter i wykonaj poniższe czynności.
Importowanie AutoML
Najpierw zaimportuj pakiet H2O i AutoML do projektu za pomocą następujących dwóch instrukcji -
import h2o
from h2o.automl import H2OAutoMLZainicjuj H2O
Zainicjuj wodę, używając następującej instrukcji -
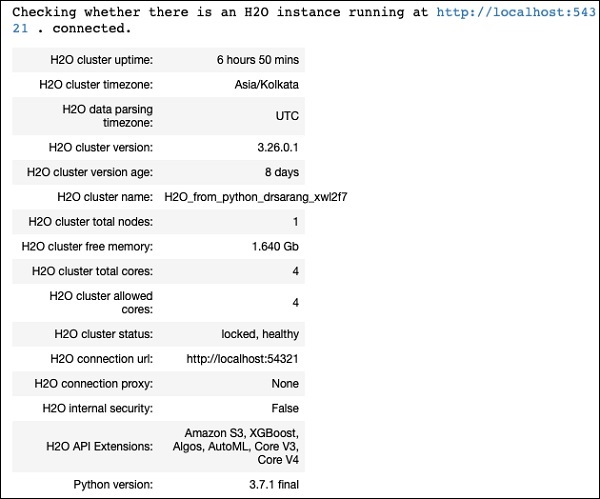
h2o.init()Powinieneś zobaczyć informacje o klastrze na ekranie, jak pokazano na poniższym zrzucie ekranu -
Ładowanie danych
Użyjemy tego samego zbioru danych iris.csv, którego użyłeś wcześniej w tym samouczku. Załaduj dane, używając następującej instrukcji -
data = h2o.import_file('iris.csv')Przygotowywanie zbioru danych
Musimy zdecydować o funkcjach i kolumnach prognoz. Używamy tych samych funkcji i kolumny orzekania, co w naszym wcześniejszym przypadku. Ustaw funkcje i kolumnę wyjściową za pomocą następujących dwóch instrukcji -
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'Podziel dane w stosunku 80:20 na potrzeby treningu i testów -
train, test = data.split_frame(ratios=[0.8])Stosowanie AutoML
Teraz wszyscy jesteśmy gotowi do zastosowania AutoML w naszym zbiorze danych. AutoML będzie działać przez ustalony przez nas czas i dostarczy nam zoptymalizowany model. Skonfigurowaliśmy AutoML za pomocą następującej instrukcji -
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)Pierwszy parametr określa liczbę modeli, które chcemy ocenić i porównać.
Drugi parametr określa czas działania algorytmu.
Teraz wywołujemy metodę pociągu na obiekcie AutoML, jak pokazano tutaj -
aml.train(x = features, y = output, training_frame = train)Określamy x jako tablicę cech, którą utworzyliśmy wcześniej, y jako zmienną wyjściową wskazującą przewidywaną wartość, a ramkę danych jako train zbiór danych.
Uruchom kod, będziesz musiał poczekać 5 minut (ustawiliśmy max_runtime_secs na 300), aż uzyskasz następujący wynik -

Drukowanie tabeli liderów
Po zakończeniu przetwarzania AutoML tworzy ranking wszystkich 30 algorytmów, które ocenił. Aby zobaczyć pierwsze 10 rekordów tabeli wyników, użyj następującego kodu -
lb = aml.leaderboard
lb.head()Po wykonaniu powyższy kod wygeneruje następujące dane wyjściowe -
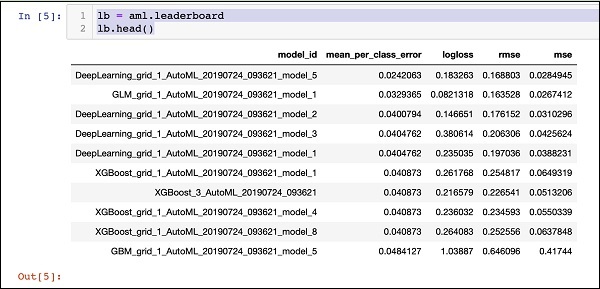
Najwyraźniej algorytm DeepLearning uzyskał maksymalny wynik.
Przewidywanie na podstawie danych testowych
Teraz masz sklasyfikowane modele, możesz zobaczyć wydajność najwyżej ocenianego modelu na swoich danych testowych. Aby to zrobić, uruchom następującą instrukcję kodu -
preds = aml.predict(test)Przetwarzanie będzie trwało przez chwilę, a po jego zakończeniu zobaczysz następujące dane wyjściowe.

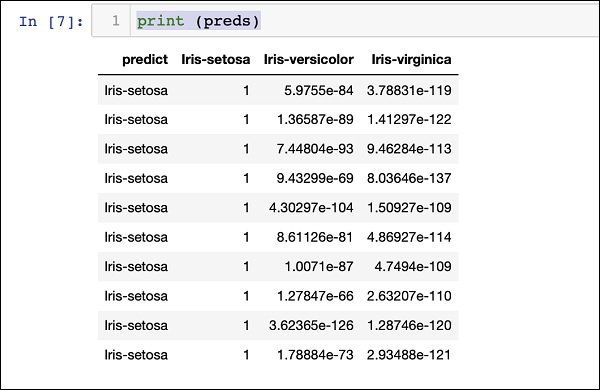
Wynik drukowania
Wydrukuj przewidywany wynik, używając następującej instrukcji -
print (preds)Po wykonaniu powyższej instrukcji zobaczysz następujący wynik -
Drukowanie rankingu dla wszystkich
Jeśli chcesz zobaczyć rangi wszystkich testowanych algorytmów, uruchom następującą instrukcję kodu -
lb.head(rows = lb.nrows)Po wykonaniu powyższej instrukcji zostanie wygenerowany następujący wynik (częściowo pokazany) -
Wniosek
H2O zapewnia łatwą w użyciu platformę open source do stosowania różnych algorytmów ML na danym zbiorze danych. Zapewnia kilka algorytmów statystycznych i ML, w tym głębokie uczenie się. Podczas testowania można dostosować parametry do tych algorytmów. Możesz to zrobić za pomocą wiersza poleceń lub dostarczonego interfejsu internetowego o nazwie Flow. H2O obsługuje także AutoML, które zapewnia ranking wśród kilku algorytmów na podstawie ich wydajności. H2O działa również dobrze na Big Data. Jest to z pewnością dobrodziejstwem dla Data Scientist, aby zastosować różne modele uczenia maszynowego w swoim zbiorze danych i wybrać najlepszy, który spełni ich potrzeby.