IMS DB - Przetwarzanie DL / I
IMS DB przechowuje dane na różnych poziomach. Dane są pobierane i wstawiane przez wywołanie DL / I z aplikacji. Szczegółowo omówimy rozmowy DL / I w kolejnych rozdziałach. Dane mogą być przetwarzane na dwa sposoby -
- Przetwarzanie sekwencyjne
- Przetwarzanie losowe
Przetwarzanie sekwencyjne
Gdy segmenty są pobierane sekwencyjnie z bazy danych, DL / I postępuje zgodnie z predefiniowanym wzorcem. Rozumiemy sekwencyjne przetwarzanie IMS DB.
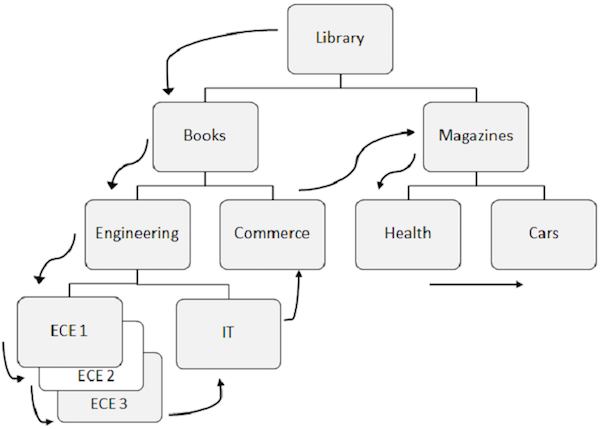
Poniżej wymieniono punkty, na które należy zwrócić uwagę na temat przetwarzania sekwencyjnego -
Predefiniowany wzorzec dostępu do danych w DL / I znajduje się najpierw w dół hierarchii, a następnie od lewej do prawej.
Segment główny jest pobierany jako pierwszy, następnie DL / I przechodzi do pierwszego lewego dziecka i schodzi do najniższego poziomu. Na najniższym poziomie pobiera wszystkie wystąpienia segmentów bliźniaczych. Następnie przechodzi do prawego segmentu.
Aby lepiej zrozumieć, spójrz na strzałki na powyższym rysunku, które pokazują przepływ dostępu do segmentów. Biblioteka jest segmentem głównym, a przepływ zaczyna się od tego miejsca i przechodzi do samochodów, aby uzyskać dostęp do pojedynczego rekordu. Ten sam proces jest powtarzany dla wszystkich wystąpień, aby uzyskać wszystkie rekordy danych.
Podczas uzyskiwania dostępu do danych program używa rozszerzenia position w bazie danych, która pomaga pobierać i wstawiać segmenty.
Przetwarzanie losowe
Przetwarzanie losowe jest również nazywane bezpośrednim przetwarzaniem danych w IMS DB. Weźmy przykład, aby zrozumieć przetwarzanie losowe w IMS DB -
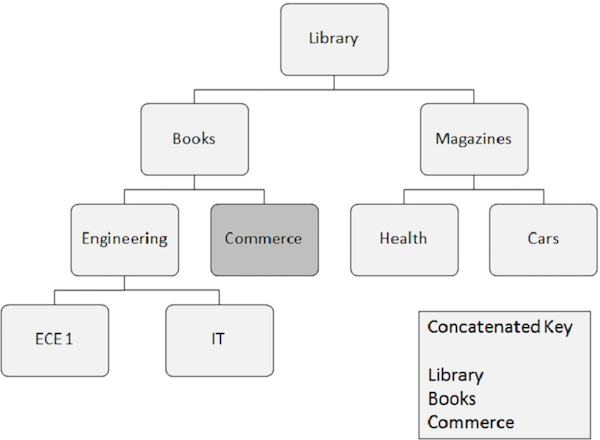
Poniżej wymienione są punkty, na które należy zwrócić uwagę na temat losowego przetwarzania -
Wystąpienie segmentu, które należy pobrać losowo, wymaga kluczowych pól wszystkich segmentów, od których zależy. Te kluczowe pola są dostarczane przez aplikację.
Połączony klucz całkowicie identyfikuje ścieżkę od segmentu głównego do segmentu, który chcesz pobrać.
Załóżmy, że chcesz pobrać wystąpienie segmentu Handel, a następnie musisz podać połączone wartości pól kluczowych segmentów, od których zależy, takich jak Biblioteka, Książki i Handel.
Przetwarzanie losowe jest szybsze niż przetwarzanie sekwencyjne. W warunkach rzeczywistych aplikacje łączą ze sobą metody przetwarzania sekwencyjnego i losowego, aby osiągnąć najlepsze wyniki.
Kluczowe pole
Punkty do zapamiętania -
Pole klucza jest również nazywane polem sekwencji.
Pole klucza znajduje się w segmencie i jest używane do pobrania wystąpienia segmentu.
Pole klucza zarządza wystąpieniem segmentu w kolejności rosnącej.
W każdym segmencie tylko jedno pole może służyć jako pole klucza lub pole sekwencji.
Pole wyszukiwania
Jak wspomniano, tylko jedno pole może być używane jako pole kluczowe. Jeśli chcesz wyszukać zawartość innych pól segmentu, które nie są polami kluczowymi, pole, które jest używane do pobierania danych, jest znane jako pole wyszukiwania.