IMS DB - indeksowanie wtórne
Indeksowanie wtórne jest używane, gdy chcemy uzyskać dostęp do bazy danych bez użycia pełnego połączonego klucza lub gdy nie chcemy używać pól podstawowych sekwencji.
Segment wskaźnika indeksu
DL / I przechowuje wskaźnik do segmentów indeksowanej bazy danych w oddzielnej bazie danych. Segment wskaźnika indeksu jest jedynym typem indeksu dodatkowego. Składa się z dwóch części -
- Element prefiksu
- Element danych
Element prefiksu
Część będąca prefiksem segmentu wskaźnika indeksu zawiera wskaźnik do segmentu docelowego indeksu. Segment docelowy indeksu to segment, do którego można uzyskać dostęp za pomocą indeksu dodatkowego.
Element danych
Element danych zawiera wartość klucza z segmentu w indeksowanej bazie danych, na podstawie której zbudowany jest indeks. Jest to również znane jako segment źródłowy indeksu.
Oto kluczowe punkty, na które należy zwrócić uwagę na temat indeksowania pomocniczego -
Segment źródłowy indeksu i docelowy segment źródłowy nie muszą być takie same.
Kiedy ustawiamy indeks pomocniczy, jest on automatycznie utrzymywany przez DL / I.
DBA definiuje wiele indeksów pomocniczych zgodnie z wieloma ścieżkami dostępu. Te indeksy pomocnicze są przechowywane w oddzielnej bazie danych indeksów.
Nie powinniśmy tworzyć więcej indeksów pomocniczych, ponieważ nakładają one dodatkowe obciążenie przetwarzania na DL / I.
Dodatkowe klucze
Punkty do zapamiętania -
Pole w segmencie źródłowym indeksu, na którym jest zbudowany indeks pomocniczy, jest nazywane kluczem pomocniczym.
Dowolne pole może służyć jako klucz dodatkowy. Nie musi to być pole sekwencji segmentów.
Klucze pomocnicze mogą być dowolną kombinacją pojedynczych pól w segmencie źródłowym indeksu.
Dodatkowe wartości klucza nie muszą być unikalne.
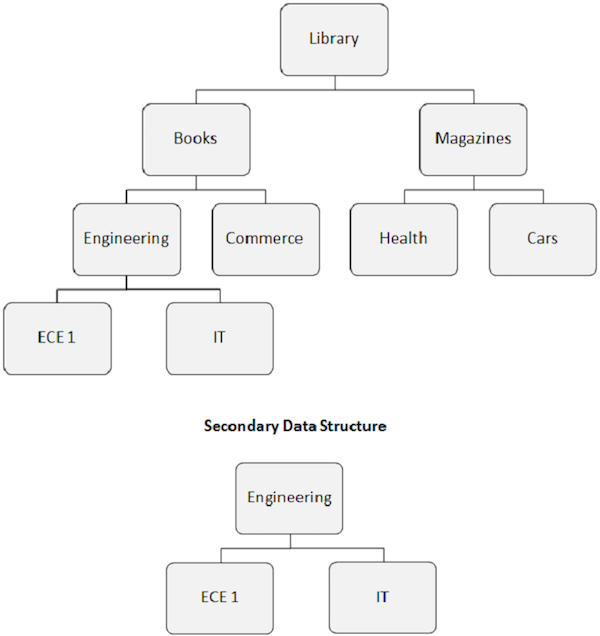
Wtórne struktury danych
Punkty do zapamiętania -
Kiedy tworzymy indeks pomocniczy, pozorna hierarchiczna struktura bazy danych również ulega zmianie.
Segment docelowy indeksu staje się pozornym segmentem głównym. Jak pokazano na poniższej ilustracji, segment Inżynieria staje się segmentem głównym, nawet jeśli nie jest to segment główny.
Zmiana struktury bazy danych spowodowana indeksem pomocniczym jest nazywana drugorzędną strukturą danych.
Wtórne struktury danych nie powodują żadnych zmian w głównej fizycznej strukturze bazy danych znajdującej się na dysku. Jest to tylko sposób na zmianę struktury bazy danych przed programem użytkowym.
Niezależny operator AND
Punkty do zapamiętania -
Gdy operator AND (* lub &) jest używany z indeksami pomocniczymi, jest znany jako operator zależny AND.
Niezależne AND (#) pozwala nam określić kwalifikacje, które byłyby niemożliwe w przypadku zależnego AND.
Ten operator może być używany tylko w przypadku indeksów pomocniczych, w których segment źródłowy indeksu jest zależny od segmentu docelowego indeksu.
Możemy zakodować SSA z niezależnym AND, aby określić, że wystąpienie segmentu docelowego zostanie przetworzone na podstawie pól w dwóch lub więcej zależnych segmentach źródłowych.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Rzadkie sekwencjonowanie
Punkty do zapamiętania -
Rzadkie sekwencjonowanie jest również znane jako rzadkie indeksowanie. Możemy usunąć niektóre segmenty źródłowe indeksu z indeksu przy użyciu rzadkiego sekwencjonowania z pomocniczą bazą danych indeksów.
Rzadkie sekwencjonowanie służy do poprawy wydajności. Jeśli niektóre wystąpienia segmentu źródłowego indeksu nie są używane, możemy to usunąć.
DL / I używa wartości tłumienia lub procedury tłumienia, lub obu, do określenia, czy segment powinien być indeksowany.
Jeśli wartość pola sekwencji w segmencie źródłowym indeksu jest zgodna z wartością pomijania, nie jest ustanawiana żadna relacja indeksu.
Procedura pomijania to program napisany przez użytkownika, który ocenia segment i określa, czy powinien on być indeksowany, czy nie.
Kiedy używane jest rzadkie indeksowanie, jego funkcje są obsługiwane przez DL / I. Nie musimy robić tego specjalnie w programie aplikacyjnym.
Wymagania DBDGEN
Jak omówiono we wcześniejszych modułach, DBDGEN służy do tworzenia DBD. Kiedy tworzymy indeksy pomocnicze, zaangażowane są dwie bazy danych. DBA musi utworzyć dwa DBD przy użyciu dwóch DBDGEN do tworzenia relacji między indeksowaną bazą danych a dodatkową indeksowaną bazą danych.
Wymagania PSBGEN
Po utworzeniu dodatkowego indeksu dla bazy danych administrator musi utworzyć nadawcy usług publicznych. PSBGEN dla programu określa prawidłową sekwencję przetwarzania dla bazy danych w parametrze PROCSEQ makra PSB. W przypadku parametru PROCSEQ DBA koduje nazwę DBD dla pomocniczej bazy danych indeksów.