IMS DB - Szybki przewodnik
Krótki przegląd
Baza danych to zbiór skorelowanych elementów danych. Te elementy danych są zorganizowane i przechowywane w sposób zapewniający szybki i łatwy dostęp. Baza danych IMS to hierarchiczna baza danych, w której dane są przechowywane na różnych poziomach, a każda jednostka jest zależna od jednostek wyższego poziomu. Poniższy rysunek przedstawia fizyczne elementy systemu aplikacji korzystającego z IMS.
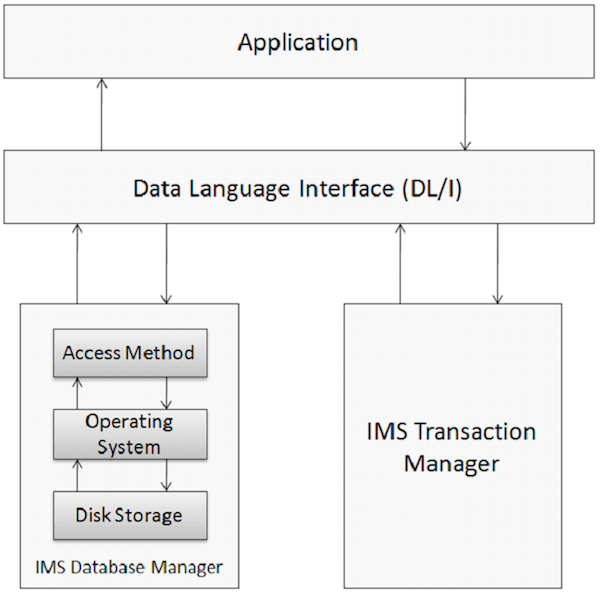
Zarządzania bazami danych
System zarządzania bazą danych to zestaw aplikacji służących do przechowywania, uzyskiwania dostępu i zarządzania danymi w bazie danych. System zarządzania bazą danych IMS zachowuje integralność i umożliwia szybkie odzyskiwanie danych poprzez organizację ich w taki sposób, aby były łatwe do odzyskania. IMS utrzymuje dużą ilość danych korporacyjnych na świecie za pomocą swojego systemu zarządzania bazą danych.
Menedżer transakcji
Zadaniem menedżera transakcji jest zapewnienie platformy komunikacyjnej między bazą danych a aplikacjami. IMS pełni rolę menedżera transakcji. Menedżer transakcji współpracuje z użytkownikiem końcowym w celu przechowywania i pobierania danych z bazy danych. IMS może używać IMS DB lub DB2 jako wewnętrznej bazy danych do przechowywania danych.
DL / I - interfejs języka danych
DL / I składa się z programów użytkowych, które umożliwiają dostęp do danych przechowywanych w bazie danych. IMS DB używa DL / I, który służy jako język interfejsu używany przez programistów do uzyskiwania dostępu do bazy danych w aplikacji. Omówimy to bardziej szczegółowo w kolejnych rozdziałach.
Charakterystyka IMS
Punkty do zapamiętania -
- IMS obsługuje aplikacje z różnych języków, takich jak Java i XML.
- Dostęp do aplikacji i danych IMS można uzyskać na dowolnej platformie.
- Przetwarzanie bazy danych IMS jest bardzo szybkie w porównaniu z DB2.
Ograniczenia IMS
Punkty do zapamiętania -
- Wdrożenie IMS DB jest bardzo złożone.
- Struktura drzewa predefiniowana w systemie IMS ogranicza elastyczność.
- IMS DB jest trudny w zarządzaniu.
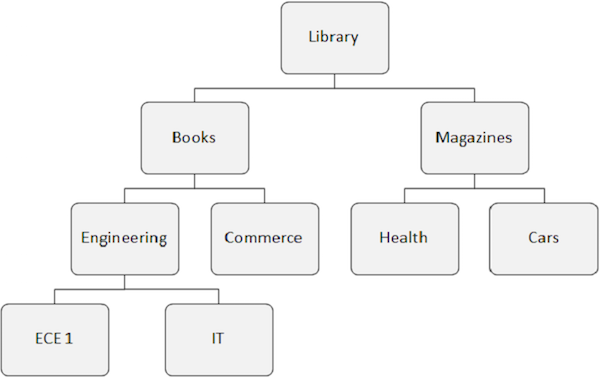
Struktura hierarchiczna
Baza danych IMS to zbiór danych zawierających pliki fizyczne. W hierarchicznej bazie danych najwyższy poziom zawiera ogólne informacje o encji. W miarę przechodzenia od najwyższego do najniższego poziomu w hierarchii otrzymujemy coraz więcej informacji o jednostce.
Każdy poziom w hierarchii zawiera segmenty. W standardowych plikach trudno jest zaimplementować hierarchie, ale DL / I obsługuje hierarchie. Poniższy rysunek przedstawia strukturę IMS DB.
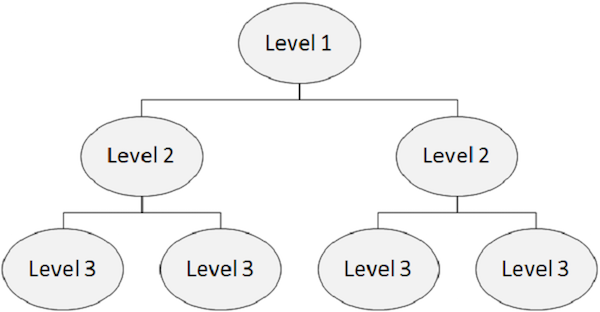
Człon
Punkty do zapamiętania -
Segment jest tworzony przez zgrupowanie razem podobnych danych.
Jest to najmniejsza jednostka informacji, jaką DL / I przekazuje do i z programu użytkowego podczas dowolnej operacji wejścia-wyjścia.
Segment może mieć jedno lub więcej pól danych zgrupowanych razem.
W poniższym przykładzie segment Student ma cztery pola danych.
| Student | |||
|---|---|---|---|
| Liczba rolek | Nazwa | Kierunek | Numer telefonu komórkowego |
Pole
Punkty do zapamiętania -
Pole to pojedynczy fragment danych w segmencie. Na przykład: Roll Number, Name, Course i Mobile Number to pojedyncze pola w segmencie uczniów.
Segment składa się z powiązanych pól służących do gromadzenia informacji o jednostce.
Pola mogą służyć jako klucz do uporządkowania segmentów.
Pola mogą służyć jako kwalifikatory do wyszukiwania informacji o określonym segmencie.
Typ segmentu
Punkty do zapamiętania -
Typ segmentu to kategoria danych w segmencie.
Baza danych DL / I może mieć 255 różnych typów segmentów i 15 poziomów hierarchii.
Na poniższym rysunku przedstawiono trzy segmenty, a mianowicie: Biblioteka, Informacje o książkach i Informacje o studentach.
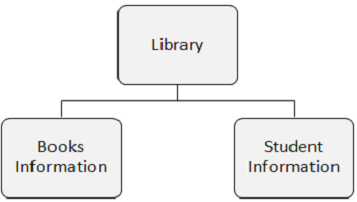
Występowanie segmentu
Punkty do zapamiętania -
Wystąpienie segmentu to pojedynczy segment określonego typu zawierający dane użytkownika. W powyższym przykładzie Informacje o książkach to jeden typ segmentu i może wystąpić dowolna liczba wystąpień, ponieważ mogą przechowywać informacje o dowolnej liczbie książek.
W bazie danych IMS istnieje tylko jedno wystąpienie każdego typu segmentu, ale może istnieć nieograniczona liczba wystąpień każdego typu segmentu.
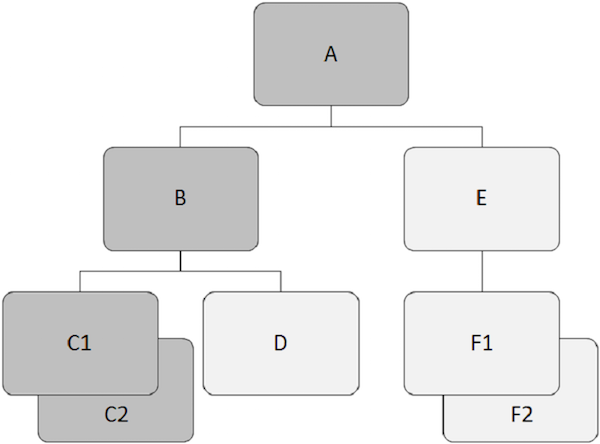
Hierarchiczne bazy danych działają na relacjach między dwoma lub więcej segmentami. Poniższy przykład pokazuje, jak segmenty są ze sobą powiązane w strukturze bazy danych IMS.
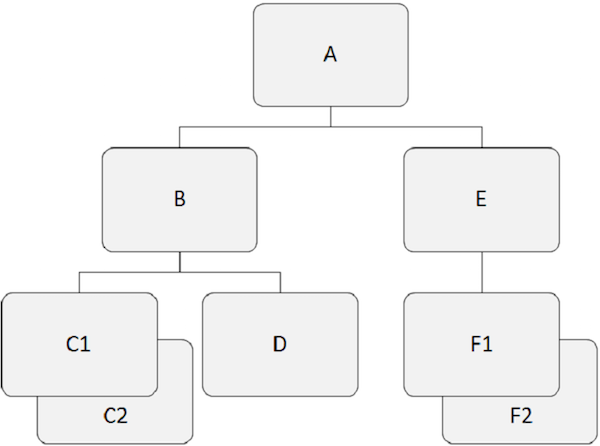
Segment główny
Punkty do zapamiętania -
Segment, który znajduje się na szczycie hierarchii, nazywany jest segmentem głównym.
Segment główny jest jedynym segmentem, przez który dostępne są wszystkie segmenty zależne.
Segment główny jest jedynym segmentem w bazie danych, który nigdy nie jest segmentem podrzędnym.
W strukturze bazy danych IMS może istnieć tylko jeden segment główny.
Na przykład, 'A' jest segmentem głównym w powyższym przykładzie.
Segment nadrzędny
Punkty do zapamiętania -
Segment nadrzędny ma jeden lub więcej segmentów zależnych bezpośrednio pod nim.
Na przykład, 'A', 'B', i 'E' są segmentami nadrzędnymi w powyższym przykładzie.
Segment zależny
Punkty do zapamiętania -
Wszystkie segmenty inne niż segment główny nazywane są segmentami zależnymi.
Zależne segmenty zależą od jednego lub więcej segmentów, aby przedstawić pełne znaczenie.
Na przykład, 'B', 'C1', 'C2', 'D', 'E', 'F1' i 'F2' w naszym przykładzie są segmentami zależnymi.
Segment podrzędny
Punkty do zapamiętania -
Każdy segment posiadający segment bezpośrednio nad nim w hierarchii jest nazywany segmentem podrzędnym.
Każdy segment zależny w strukturze jest segmentem podrzędnym.
Na przykład, 'B', 'C1', 'C2', 'D', 'E', 'F1' i 'F2' są segmentami podrzędnymi.
Bliźniacze segmenty
Punkty do zapamiętania -
Dwa lub więcej wystąpień segmentu określonego typu w ramach jednego segmentu nadrzędnego nazywane są segmentami bliźniaczymi.
Na przykład, 'C1' i 'C2' są bliźniaczymi segmentami, tak samo 'F1' i 'F2' są.
Segment rodzeństwa
Punkty do zapamiętania -
Segmenty rodzeństwa to segmenty różnych typów i tego samego rodzica.
Na przykład, 'B' i 'E' są segmentami rodzeństwa. Podobnie,'C1', 'C2', i 'D' są segmentami rodzeństwa.
Rekord bazy danych
Punkty do zapamiętania -
Każde wystąpienie segmentu głównego oraz wszystkie wystąpienia segmentu podrzędnego tworzą jeden rekord bazy danych.
Każdy rekord bazy danych ma tylko jeden segment główny, ale może mieć dowolną liczbę wystąpień segmentu.
W standardowym przetwarzaniu plików rekord to jednostka danych używana przez aplikację do określonych operacji. W DL / I ta jednostka danych jest znana jako segment. Pojedynczy rekord bazy danych ma wiele wystąpień segmentów.
Ścieżka bazy danych
Punkty do zapamiętania -
Ścieżka to seria segmentów, która zaczyna się od segmentu głównego rekordu bazy danych do dowolnego wystąpienia określonego segmentu.
Ścieżka w strukturze hierarchii nie musi być kompletna do najniższego poziomu. To zależy od tego, ile informacji potrzebujemy na temat podmiotu.
Ścieżka musi być ciągła i nie możemy pominąć poziomów pośrednich w konstrukcji.
Na poniższym rysunku rekordy podrzędne w kolorze ciemnoszarym pokazują ścieżkę rozpoczynającą się od 'A' i przechodzi 'C2'.
IMS DB przechowuje dane na różnych poziomach. Dane są pobierane i wstawiane przez wywołanie DL / I z aplikacji. Szczegółowo omówimy rozmowy DL / I w kolejnych rozdziałach. Dane mogą być przetwarzane na dwa sposoby -
- Przetwarzanie sekwencyjne
- Przetwarzanie losowe
Przetwarzanie sekwencyjne
Gdy segmenty są pobierane sekwencyjnie z bazy danych, DL / I postępuje zgodnie z predefiniowanym wzorcem. Rozumiemy sekwencyjne przetwarzanie IMS DB.
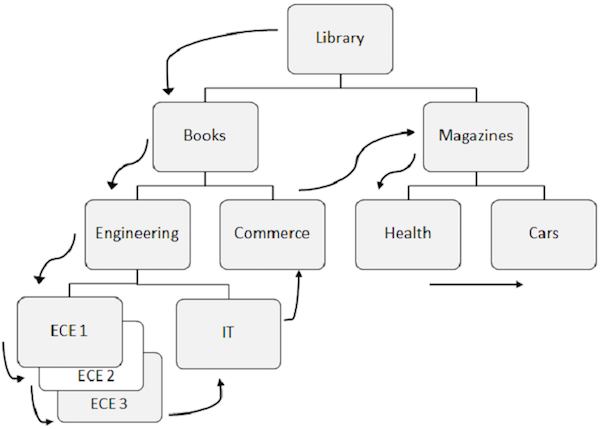
Poniżej wymieniono punkty, na które należy zwrócić uwagę na temat przetwarzania sekwencyjnego -
Predefiniowany wzorzec dostępu do danych w DL / I znajduje się najpierw w dół hierarchii, a następnie od lewej do prawej.
Segment główny jest pobierany jako pierwszy, następnie DL / I przechodzi do pierwszego lewego dziecka i schodzi do najniższego poziomu. Na najniższym poziomie pobiera wszystkie wystąpienia segmentów bliźniaczych. Następnie przechodzi do prawego segmentu.
Aby lepiej zrozumieć, spójrz na strzałki na powyższym rysunku, które pokazują przepływ dostępu do segmentów. Biblioteka jest segmentem głównym, a przepływ zaczyna się od tego miejsca i przechodzi do samochodów, aby uzyskać dostęp do pojedynczego rekordu. Ten sam proces jest powtarzany dla wszystkich wystąpień, aby uzyskać wszystkie rekordy danych.
Podczas uzyskiwania dostępu do danych program używa rozszerzenia position w bazie danych, która pomaga pobierać i wstawiać segmenty.
Przetwarzanie losowe
Losowe przetwarzanie jest również znane jako bezpośrednie przetwarzanie danych w IMS DB. Weźmy przykład, aby zrozumieć przetwarzanie losowe w IMS DB -
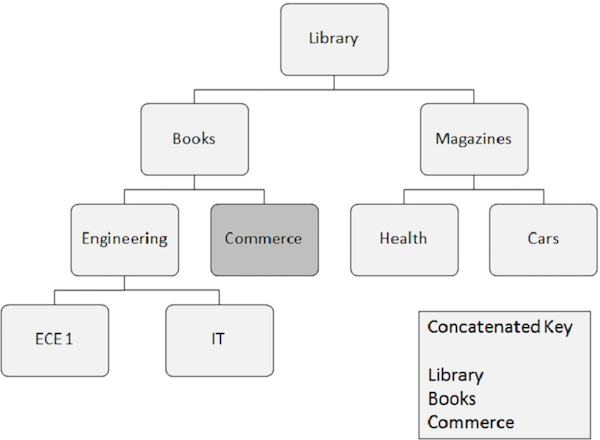
Poniżej wymienione są punkty, na które należy zwrócić uwagę na temat losowego przetwarzania -
Wystąpienie segmentu, które należy pobrać losowo, wymaga pól kluczowych wszystkich segmentów, od których zależy. Te kluczowe pola są dostarczane przez aplikację.
Połączony klucz całkowicie identyfikuje ścieżkę od segmentu głównego do segmentu, który chcesz odzyskać.
Załóżmy, że chcesz pobrać wystąpienie segmentu Handel, a następnie musisz podać połączone wartości pól kluczowych segmentów, od których zależy, takich jak Biblioteka, Książki i Handel.
Przetwarzanie losowe jest szybsze niż przetwarzanie sekwencyjne. W warunkach rzeczywistych aplikacje łączą ze sobą metody przetwarzania sekwencyjnego i losowego, aby osiągnąć najlepsze wyniki.
Kluczowe pole
Punkty do zapamiętania -
Pole klucza jest również nazywane polem sekwencji.
Pole klucza znajduje się w segmencie i jest używane do pobrania wystąpienia segmentu.
Pole klucza zarządza wystąpieniem segmentu w porządku rosnącym.
W każdym segmencie tylko jedno pole może służyć jako pole klucza lub pole sekwencji.
Pole wyszukiwania
Jak wspomniano, tylko jedno pole może być używane jako pole kluczowe. Jeśli chcesz wyszukać zawartość innych pól segmentu, które nie są polami kluczowymi, pole, które jest używane do pobierania danych, jest znane jako pole wyszukiwania.
Bloki sterujące IMS definiują strukturę bazy danych IMS i dostęp do nich programu. Poniższy diagram przedstawia strukturę bloków sterujących IMS.
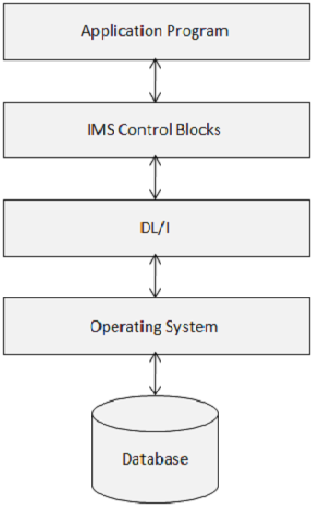
DL / I wykorzystuje następujące trzy typy bloków sterujących -
- Deskryptor bazy danych (DBD)
- Blok specyfikacji programu (PSB)
- Blok kontroli dostępu (ACB)
Deskryptor bazy danych (DBD)
Punkty do zapamiętania -
DBD opisuje pełną fizyczną strukturę bazy danych po zdefiniowaniu wszystkich segmentów.
Podczas instalowania bazy danych DL / I należy utworzyć jedną DBD, ponieważ jest ona wymagana do uzyskania dostępu do bazy danych IMS.
Aplikacje mogą korzystać z różnych widoków DBD. Nazywane są one strukturami danych aplikacji i są określone w bloku specyfikacji programu.
Administrator bazy danych tworzy DBD przez kodowanie DBDGEN instrukcje kontrolne.
DBDGEN
DBDGEN jest generatorem deskryptorów bazy danych. Za tworzenie bloków sterujących odpowiada administrator bazy danych. Wszystkie moduły ładujące są przechowywane w bibliotece IMS. Do tworzenia bloków sterujących używane są makra języka asemblera. Poniżej podano przykładowy kod, który pokazuje, jak utworzyć DBD za pomocą instrukcji sterujących DBDGEN -
PRINT NOGEN
DBD NAME=LIBRARY,ACCESS=HIDAM
DATASET DD1=LIB,DEVICE=3380
SEGM NAME=LIBSEG,PARENT=0,BYTES=10
FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5
FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C
SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9
FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C
DBDGEN
FINISH
ENDRozumiemy terminy użyte w powyższym DBDGEN -
Kiedy wykonujesz powyższe instrukcje sterujące w JCL, tworzy fizyczną strukturę, w której BIBLIOTEKA jest segmentem głównym, a KSIĄŻKI i MAGZINY są jego segmentami potomnymi.
Pierwsza instrukcja makra DBD identyfikuje bazę danych. Tutaj musimy wspomnieć o NAZWIE i DOSTĘPIE, które są używane przez DL / I w celu uzyskania dostępu do tej bazy danych.
Druga instrukcja makra DATASET identyfikuje plik zawierający bazę danych.
Typy segmentów są definiowane za pomocą makropolecenia SEGM. Musimy określić PARENT tego segmentu. Jeśli jest to segment główny, podaj PARENT = 0.
W poniższej tabeli przedstawiono parametry używane w makropoleceniu FIELD -
| S.Nr | Parametr i opis |
|---|---|
| 1 | Name Nazwa pola, zwykle od 1 do 8 znaków |
| 2 | Bytes Długość pola |
| 3 | Start Położenie pola w segmencie |
| 4 | Type Typ danych pola |
| 5 | Type C Typ danych znakowych |
| 6 | Type P Pakowany typ danych dziesiętnych |
| 7 | Type Z Strefowy typ danych dziesiętnych |
| 8 | Type X Szesnastkowy typ danych |
| 9 | Type H Binarny typ danych pół słowa |
| 10 | Type F Typ danych binarnych pełnych słów |
Blok specyfikacji programu (PSB)
Podstawy PSB podano poniżej -
Baza danych ma pojedynczą strukturę fizyczną zdefiniowaną przez DBD, ale aplikacje, które ją przetwarzają, mogą mieć różne widoki bazy danych. Te widoki nazywane są strukturą danych aplikacji i są zdefiniowane w PSB.
Żaden program nie może używać więcej niż jednego PSB w jednym wykonaniu.
Programy użytkowe mają własny PSB i często programy aplikacyjne, które mają podobne wymagania przetwarzania bazy danych, współużytkują PSB.
PSB składa się z jednego lub więcej bloków sterujących zwanych programowymi blokami komunikacyjnymi (PCB). PSB zawiera jedną płytkę PCB dla każdej bazy danych DL / I, do której program aplikacji będzie miał dostęp. Więcej o PCB omówimy w kolejnych modułach.
Aby utworzyć PSB dla programu, należy wykonać PSBGEN.
PSBGEN
PSBGEN jest znany jako Generator bloku specyfikacji programu. Poniższy przykład tworzy PSB przy użyciu PSBGEN -
PRINT NOGEN
PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS
SENSEG NAME=LIBSEG
SENSEG NAME=BOOKSEG,PARENT=LIBSEG
SENSEG NAME=MAGSEG,PARENT=LIBSEG
PSBGEN PSBNAME=LIBPSB,LANG=COBOL
ENDRozumiemy terminy użyte w powyższym DBDGEN -
Pierwsza instrukcja makro to blok komunikacyjny programu (PCB), który opisuje typ bazy danych, nazwę, długość klucza i opcję przetwarzania.
Parametr DBDNAME w makrze PCB określa nazwę DBD. KEYLEN określa długość najdłuższego połączonego klucza. Program może przetwarzać w bazie danych. Parametr PROCOPT określa opcje przetwarzania programu. Na przykład LS oznacza tylko operacje LOAD.
SENSEG jest znany jako czułość na poziomie segmentu. Określa dostęp programu do części bazy danych i jest identyfikowany na poziomie segmentu. Program ma dostęp do wszystkich pól w segmentach, na które jest wrażliwy. Program może mieć również czułość na poziomie pola. W tym miejscu definiujemy nazwę segmentu i nazwę nadrzędną segmentu.
Ostatnia instrukcja makro to PCBGEN. PSBGEN to ostatnia instrukcja mówiąca, że nie ma więcej instrukcji do przetworzenia. PSBNAME definiuje nazwę nadaną wyjściowemu modułowi PSB. Parametr LANG określa język, w którym napisana jest aplikacja, np. COBOL.
Blok kontroli dostępu (ACB)
Poniżej wymienione są punkty, na które należy zwrócić uwagę na temat bloków kontroli dostępu -
Bloki kontroli dostępu dla programu aplikacji łączą deskryptor bazy danych i blok specyfikacji programu w postać wykonywalną.
ACBGEN jest znany jako Generator bloków kontroli dostępu. Służy do generowania wyłączników mocy.
W przypadku programów online musimy wstępnie zbudować ACB. Dlatego narzędzie ACBGEN jest uruchamiane przed wykonaniem programu użytkowego.
W przypadku programów wsadowych, ACB mogą być również generowane w czasie wykonywania.
Aplikacja zawierająca wywołania DL / I nie może być wykonywana bezpośrednio. Zamiast tego do wyzwolenia modułu wsadowego IMS DL / I wymagany jest JCL. Moduł inicjalizacji wsadowej w IMS to DFSRRC00. Program aplikacji i moduł DL / I są wykonywane razem. Poniższy diagram przedstawia strukturę aplikacji, która obejmuje wywołania DL / I w celu uzyskania dostępu do bazy danych.
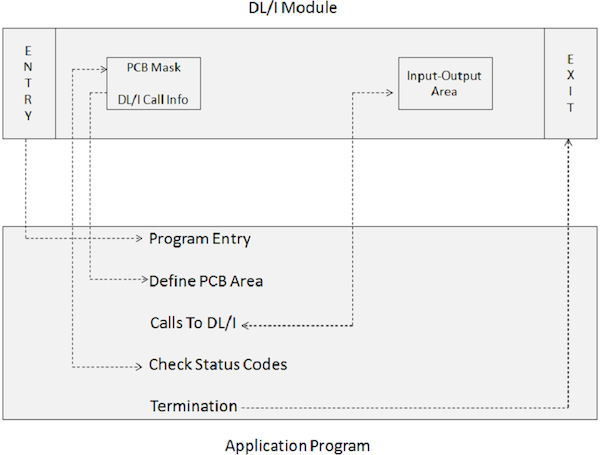
Aplikacja łączy się z modułami IMS DL / I za pośrednictwem następujących elementów programu -
Instrukcja ENTRY określa, że PCB są wykorzystywane przez program.
Maska PCB jest powiązana z informacjami zachowanymi w gotowej płytce drukowanej, która otrzymuje informacje zwrotne z IMS.
Obszar wejścia-wyjścia służy do przekazywania segmentów danych do i z bazy danych IMS.
Wywołania do DL / I określają funkcje przetwarzania, takie jak pobieranie, wstawianie, usuwanie, zastępowanie itp.
Funkcja Sprawdź kody stanu służy do sprawdzania kodu powrotu SQL określonej opcji przetwarzania w celu poinformowania, czy operacja zakończyła się powodzeniem, czy nie.
Instrukcja Terminate służy do zakończenia przetwarzania programu aplikacji, który zawiera DL / I.
Układ segmentów
Do tej pory dowiedzieliśmy się, że IMS składa się z segmentów, które są używane w językach programowania wysokiego poziomu do uzyskiwania dostępu do danych. Rozważ następującą strukturę bazy danych IMS biblioteki, którą widzieliśmy wcześniej, a tutaj widzimy układ jej segmentów w języku COBOL -
01 LIBRARY-SEGMENT.
05 BOOK-ID PIC X(5).
05 ISSUE-DATE PIC X(10).
05 RETURN-DATE PIC X(10).
05 STUDENT-ID PIC A(25).
01 BOOK-SEGMENT.
05 BOOK-ID PIC X(5).
05 BOOK-NAME PIC A(30).
05 AUTHOR PIC A(25).
01 STUDENT-SEGMENT.
05 STUDENT-ID PIC X(5).
05 STUDENT-NAME PIC A(25).
05 DIVISION PIC X(10).Przegląd aplikacji
Struktura aplikacji IMS różni się od struktury aplikacji innej niż IMS. Programu IMS nie można wykonać bezpośrednio; jest raczej zawsze nazywany podprogramem. Program aplikacji IMS składa się z bloków specyfikacji programu, które zapewniają widok bazy danych IMS.
Program aplikacji i PSB połączone z tym programem są ładowane, gdy wykonujemy program aplikacji, który zawiera moduły IMS DL / I. Następnie żądania CALL wyzwalane przez programy aplikacyjne są wykonywane przez moduł IMS.
Usługi IMS
Następujące usługi IMS są używane przez aplikację -
- Dostęp do rekordów bazy danych
- Wydawanie poleceń IMS
- Wystawianie zgłoszeń serwisowych IMS
- Wzywa Checkpoint
- Synchronizuj połączenia
- Wysyłanie lub odbieranie wiadomości z terminali użytkowników online
Zawieramy wywołania DL / I wewnątrz aplikacji COBOL w celu komunikacji z bazą danych IMS. W celu uzyskania dostępu do bazy danych używamy następujących instrukcji DL / I w programie COBOL -
- Oświadczenie wejścia
- Oświadczenie Goback
- Instrukcja Call
Oświadczenie wejścia
Służy do przekazania sterowania z DL / I do programu COBOL. Oto składnia instrukcji wejścia -
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]Powyższe stwierdzenie jest zakodowane w Procedure Divisionprogramu COBOL. Przejdźmy do szczegółów instrukcji wejściowej w programie COBOL -
Moduł inicjalizacji wsadowej uruchamia program aplikacji i jest wykonywany pod jego kontrolą.
DL / I ładuje wymagane bloki i moduły sterujące oraz program aplikacji, a sterowanie jest przekazywane do programu aplikacji.
DLITCBL oznacza DL/I to COBOL. Instrukcja wejścia służy do definiowania punktu wejścia w programie.
Kiedy wywołujemy podprogram w języku COBOL, podawany jest również jego adres. Podobnie, gdy DL / I przekazuje sterowanie do programu aplikacji, dostarcza również adres każdej płytki drukowanej zdefiniowanej w PSB programu.
Wszystkie płytki drukowane używane w aplikacji muszą być zdefiniowane wewnątrz Linkage Section programu COBOL, ponieważ PCB znajduje się poza programem użytkowym.
Definicja PCB wewnątrz sekcji Linkage nosi nazwę PCB Mask.
Relację między maskami PCB a rzeczywistymi PCB w magazynie tworzy się poprzez wyszczególnienie PCB w oświadczeniu wejściowym. Kolejność umieszczania na liście wpisu powinna być taka sama, jak w PSBGEN.
Oświadczenie Goback
Służy do przekazania sterowania z powrotem do programu sterującego IMS. Poniżej znajduje się składnia instrukcji Goback -
GOBACKPoniżej wymienione są podstawowe punkty, na które należy zwrócić uwagę na temat oświadczenia Goback -
GOBACK jest zakodowany na końcu programu użytkowego. Zwraca sterowanie do DL / I z programu.
Nie powinniśmy używać funkcji STOP RUN, ponieważ zwraca sterowanie do systemu operacyjnego. Jeśli użyjemy STOP RUN, DL / I nigdy nie ma szansy wykonać swoich funkcji kończących. Dlatego w aplikacjach DL / I używa się instrukcji Goback.
Przed wydaniem instrukcji Goback wszystkie zbiory danych inne niż DL / I używane w aplikacji COBOL muszą zostać zamknięte, w przeciwnym razie program zakończy się nieprawidłowo.
Instrukcja Call
Instrukcja Call służy do żądania usług DL / I, takich jak wykonywanie określonych operacji w bazie danych IMS. Oto składnia instrukcji call -
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]Powyższa składnia przedstawia parametry, których można użyć w instrukcji call. Omówimy każdy z nich w poniższej tabeli -
| S.No. | Parametr i opis |
|---|---|
| 1 | DLI Function Code Identyfikuje funkcję DL / I do wykonania. Ten argument to nazwa czterech pól znakowych, które opisują operację we / wy. |
| 2 | PCB Mask Definicja PCB w sekcji Linkage nosi nazwę maski PCB. Są używane w instrukcji wejścia. Nie są wymagane żadne instrukcje SELECT, ASSIGN, OPEN ani CLOSE. |
| 3 | Segment I/O Area Nazwa obszaru roboczego wejścia / wyjścia. Jest to obszar programu użytkowego, w którym DL / I umieszcza żądany segment. |
| 4 | Segment Search Arguments Są to parametry opcjonalne w zależności od typu wysłanego wywołania. Służą do wyszukiwania segmentów danych w bazie danych IMS. |
Poniżej podano punkty, na które należy zwrócić uwagę na temat instrukcji Call -
CBLTDLI oznacza COBOL to DL/I. Jest to nazwa modułu interfejsu, który jest łączony z modułem obiektu programu.
Po każdym wywołaniu DL / I DLI zapisuje kod stanu na PCB. Program może użyć tego kodu, aby określić, czy wywołanie zakończyło się powodzeniem, czy niepowodzeniem.
Przykład
Aby lepiej zrozumieć język COBOL, możesz zapoznać się z naszym samouczkiem dotyczącym języka COBOL tutaj . Poniższy przykład przedstawia strukturę programu w języku COBOL, który korzysta z bazy danych IMS i wywołań DL / I. W kolejnych rozdziałach szczegółowo omówimy każdy z parametrów zastosowanych w przykładzie.
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.Funkcja DL / I jest pierwszym parametrem używanym w wywołaniu DL / I. Ta funkcja informuje, która operacja będzie wykonywana na bazie danych IMS przez wywołanie IMS DL / I. Składnia funkcji DL / I jest następująca -
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.Ta składnia reprezentuje następujące kluczowe punkty -
Dla tego parametru możemy podać dowolną czteroznakową nazwę jako pole do przechowywania kodu funkcji.
Parametr funkcji DL / I jest kodowany w sekcji pamięci roboczej programu COBOL.
Aby określić funkcję DL / I, programista musi zakodować jedną z nazw danych poziomu 05, takich jak DLI-GU w wywołaniu DL / I, ponieważ COBOL nie pozwala na kodowanie literałów w instrukcji CALL.
Funkcje DL / I są podzielone na trzy kategorie: funkcje pobierania, aktualizacji i inne. Omówmy szczegółowo każdy z nich.
Uzyskaj funkcje
Funkcje Get są podobne do operacji odczytu obsługiwanej przez dowolny język programowania. Funkcja Get służy do pobierania segmentów z bazy danych IMS DL / I. Następujące funkcje Get są używane w IMS DB -
- Uzyskaj wyjątkowy
- Get Next
- Przejdź dalej w ramach rodzica
- Get Hold Unique
- Get Hold Next
- Get Hold Next w ramach rodzica
Rozważmy następującą strukturę bazy danych IMS, aby zrozumieć wywołania funkcji DL / I -
Uzyskaj wyjątkowy
Kod „GU” jest używany w funkcji Get Unique. Działa podobnie do instrukcji odczytu losowego w języku COBOL. Służy do pobierania wystąpienia określonego segmentu na podstawie wartości pól. Wartości pól można podać za pomocą argumentów wyszukiwania segmentów. Składnia wywołania GU jest następująca -
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Jeśli wykonasz powyższą instrukcję wywołania, podając odpowiednie wartości dla wszystkich parametrów w programie COBOL, możesz pobrać segment w obszarze segmentu I / O z bazy danych. W powyższym przykładzie, jeśli podasz wartości pól Biblioteka, Czasopisma i Zdrowie, otrzymasz żądane wystąpienie segmentu Zdrowie.
Get Next
Kod „GN” jest używany w funkcji Get Next. Działa podobnie do instrukcji read next w języku COBOL. Służy do pobierania wystąpień segmentów w sekwencji. Wstępnie zdefiniowany wzorzec dostępu do wystąpień segmentów danych znajduje się w dół hierarchii, a następnie od lewej do prawej. Składnia wywołania GN jest następująca -
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Jeśli wykonasz powyższą instrukcję wywołania, podając odpowiednie wartości dla wszystkich parametrów w programie COBOL, możesz pobrać wystąpienie segmentu w obszarze we / wy segmentu z bazy danych w kolejności sekwencyjnej. W powyższym przykładzie zaczyna się od uzyskania dostępu do segmentu Biblioteka, następnie do segmentu Książki i tak dalej. Wykonujemy wywołanie GN raz po raz, aż osiągniemy żądane wystąpienie segmentu.
Przejdź dalej w ramach rodzica
Kod „GNP” służy do pobierania następnego w ramach elementu nadrzędnego. Ta funkcja służy do pobierania wystąpień segmentów w kolejności podporządkowanej ustalonemu segmentowi nadrzędnemu. Składnia wywołania PNB jest następująca -
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Unique
Kod „GHU” jest używany do Get Hold Unique. Funkcja Hold określa, że będziemy aktualizować segment po pobraniu. Funkcja Get Hold Unique odpowiada wywołaniu Get Unique. Poniżej podano składnię wywołania GHU -
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Next
Kod „GHN” jest używany do Get Hold Next. Funkcja Hold określa, że będziemy aktualizować segment po pobraniu. Funkcja Get Hold Next odpowiada wywołaniu Get Next. Poniżej podano składnię połączenia GHN -
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]Get Hold Next w ramach rodzica
Kod „GHNP” służy do „Get Hold Next” w ramach funkcji Parent. Funkcja Hold określa, że będziemy aktualizować segment po pobraniu. Funkcja Get Hold Next w ramach funkcji Parent odpowiada funkcji Get Next w ramach połączenia Parent. Poniżej podano składnię połączenia GHNP -
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Funkcje aktualizacji
Funkcje aktualizacji są podobne do operacji ponownego zapisu lub wstawiania w dowolnym innym języku programowania. Funkcje aktualizacji służą do aktualizacji segmentów w bazie danych IMS DL / I. Przed użyciem funkcji aktualizacji musi istnieć pomyślne wywołanie z klauzulą Hold dla wystąpienia segmentu. Następujące funkcje aktualizacji są używane w IMS DB -
- Insert
- Delete
- Replace
Wstawić
Kod „ISRT” jest używany dla funkcji Wstaw. Funkcja ISRT służy do dodawania nowego segmentu do bazy danych. Służy do zmiany istniejącej bazy danych lub załadowania nowej bazy danych. Poniżej podano składnię wywołania ISRT -
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]Usunąć
Do funkcji Usuń używany jest kod „DLET”. Służy do usuwania segmentu z bazy danych IMS DL / I. Poniżej podano składnię wywołania DLET -
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]Zastąpić
Kod „REPL” służy do „Get Hold Next” w ramach elementu Parent. Funkcja Replace służy do zastąpienia segmentu w bazie danych IMS DL / I. Poniżej podano składnię wywołania REPL -
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]Inne funkcje
Następujące inne funkcje są używane w połączeniach IMS DL / I -
- Checkpoint
- Restart
- PCB
Punkt kontrolny
Kod „CHKP” jest używany dla funkcji Checkpoint. Jest używany w funkcjach odzyskiwania IMS. Poniżej podano składnię wywołania CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]Uruchom ponownie
Kod „XRST” jest używany do funkcji Restart. Jest używany w funkcjach ponownego uruchamiania IMS. Poniżej podano składnię wywołania XRST -
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]PCB
Funkcja PCB jest wykorzystywana w programach CICS w bazie danych IMS DL / I. Poniżej podano składnię wywołania PCB -
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]Więcej informacji na temat tych funkcji można znaleźć w rozdziale dotyczącym odzyskiwania.
PCB oznacza blok komunikacji programu. Maska PCB jest drugim parametrem używanym w wywołaniu DL / I. Jest to zadeklarowane w sekcji połączeń. Poniżej podano składnię maski PCB -
01 PCB-NAME.
05 DBD-NAME PIC X(8).
05 SEG-LEVEL PIC XX.
05 STATUS-CODE PIC XX.
05 PROC-OPTIONS PIC X(4).
05 RESERVED-DLI PIC S9(5).
05 SEG-NAME PIC X(8).
05 LENGTH-FB-KEY PIC S9(5).
05 NUMB-SENS-SEGS PIC S9(5).
05 KEY-FB-AREA PIC X(n).Oto kluczowe punkty, na które należy zwrócić uwagę -
Dla każdej bazy danych DL / I utrzymuje obszar pamięci zwany blokiem komunikacji programu. Przechowuje informacje o bazie danych, do których dostęp jest uzyskiwany w aplikacjach.
Instrukcja ENTRY tworzy połączenie między maskami PCB w sekcji Linkage i PCB w PSB programu. Maski PCB używane w wywołaniu DL / I informują, której bazy danych użyć do działania.
Można założyć, że jest to podobne do określania nazwy pliku w instrukcji COBOL READ lub nazwy rekordu w instrukcji zapisu w języku COBOL. Nie są wymagane żadne instrukcje SELECT, ASSIGN, OPEN ani CLOSE.
Po każdym wywołaniu DL / I, DL / I zapisuje kod statusu na PCB, a program może użyć tego kodu do określenia, czy połączenie powiodło się, czy nie.
Nazwa PCB
Punkty do zapamiętania -
Nazwa PCB to nazwa obszaru odnosząca się do całej struktury pól PCB.
Nazwa PCB jest używana w instrukcjach programu.
Nazwa PCB nie jest polem w PCB.
Nazwa DBD
Punkty do zapamiętania -
Nazwa DBD zawiera dane znaku. Ma długość ośmiu bajtów.
Pierwsze pole na PCB to nazwa przetwarzanej bazy danych i podaje nazwę DBD z biblioteki opisów baz danych powiązanych z daną bazą danych.
Poziom segmentu
Punkty do zapamiętania -
Poziom segmentu jest znany jako wskaźnik poziomu hierarchii segmentów. Zawiera dane znakowe i ma długość dwóch bajtów.
Pole poziomu segmentu przechowuje poziom przetworzonego segmentu. Po pomyślnym pobraniu segmentu zapisywany jest tutaj numer poziomu pobranego segmentu.
Pole poziomu segmentu nigdy nie ma wartości większej niż 15, ponieważ jest to maksymalna liczba poziomów dozwolonych w bazie danych DL / I.
Kod statusu
Punkty do zapamiętania -
Pole kodu statusu zawiera dwa bajty danych znakowych.
Kod stanu zawiera kod statusu DL / I.
Spacje są przenoszone do pola kodu stanu, gdy DL / I pomyślnie zakończy przetwarzanie wywołań.
Wartości inne niż spacje wskazują, że wywołanie nie powiodło się.
Kod stanu GB wskazuje koniec pliku, a kod stanu GE wskazuje, że żądany segment nie został znaleziony.
Opcje proc
Punkty do zapamiętania -
Opcje proc są znane jako opcje przetwarzania, które zawierają czteroznakowe pola danych.
Pole Opcja przetwarzania wskazuje, do jakiego rodzaju przetwarzania program jest upoważniony w bazie danych.
Zastrzeżone DL / I
Punkty do zapamiętania -
Zarezerwowany DL / I jest znany jako zarezerwowany obszar IMS. Przechowuje czterobajtowe dane binarne.
IMS wykorzystuje ten obszar do własnego wewnętrznego powiązania związanego z aplikacją.
Nazwa segmentu
Punkty do zapamiętania -
Nazwa SEG jest znana jako obszar informacji zwrotnej o nazwie segmentu. Zawiera 8 bajtów danych znakowych.
Nazwa segmentu jest przechowywana w tym polu po każdym wywołaniu DL / I.
Długość klucza FB
Punkty do zapamiętania -
Długość klawisza FB jest znana jako długość obszaru informacji zwrotnej klawisza. Przechowuje cztery bajty danych binarnych.
To pole służy do zgłaszania długości połączonego klucza segmentu najniższego poziomu przetworzonego podczas poprzedniego wywołania.
Jest używany z kluczowym obszarem informacji zwrotnej.
Liczba segmentów czułości
Punkty do zapamiętania -
Liczba segmentów czułości zawiera czterobajtowe dane binarne.
Określa, na jaki poziom wrażliwy jest program użytkowy. Reprezentuje liczbę segmentów w logicznej strukturze danych.
Kluczowy obszar opinii
Punkty do zapamiętania -
Kluczowy obszar informacji zwrotnych różni się długością w zależności od PCB.
Zawiera najdłuższy możliwy połączony klucz, którego można używać z widokiem bazy danych programu.
Po operacji na bazie danych DL / I zwraca konkatenowany klucz segmentu najniższego poziomu przetwarzanego w tym polu i zwraca długość klucza w obszarze informacji zwrotnej o długości klucza.
SSA oznacza argumenty wyszukiwania segmentów. SSA służy do identyfikacji wystąpienia segmentu, do którego uzyskuje się dostęp. Jest to parametr opcjonalny. W zależności od wymagań możemy dołączyć dowolną liczbę SSA. Istnieją dwa rodzaje SSA -
- Bez zastrzeżeń SSA
- Kwalifikowany SSA
Bez zastrzeżeń SSA
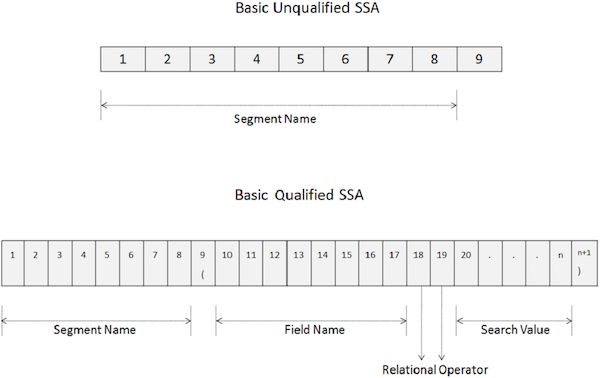
Niekwalifikowany SSA podaje nazwę segmentu używanego w wywołaniu. Poniżej podano składnię niekwalifikowanego SSA -
01 UNQUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X VALUE SPACE.Kluczowe punkty niekwalifikowanych SSA są następujące:
Podstawowy niekwalifikowany SSA ma długość 9 bajtów.
Pierwsze 8 bajtów zawiera nazwę segmentu, który jest używany do przetwarzania.
Ostatni bajt zawsze zawiera spację.
DL / I używa ostatniego bajtu do określenia typu SSA.
Aby uzyskać dostęp do określonego segmentu, przenieś nazwę segmentu w polu NAZWA-SEGMENTU.
Poniższe obrazy przedstawiają struktury niekwalifikowanych i kwalifikowanych SSA -
Kwalifikowany SSA
Kwalifikowany SSA zapewnia typowi segmentu określone wystąpienie segmentu w bazie danych. Poniżej podano składnię kwalifikowanego SSA -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.Kluczowe punkty kwalifikowanego SSA są następujące:
Pierwsze 8 bajtów kwalifikowanego SSA zawiera nazwę segmentu używanego do przetwarzania.
Dziewiąty bajt to lewy nawias '('.
Kolejne 8 bajtów zaczynając od dziesiątej pozycji określa nazwę pola, które chcemy przeszukać.
Po nazwie pola w 18 th i 19 th pozycjach, możemy określić dwa-znakowy kod operatora relacyjnego.
Następnie określamy wartość pola, aw ostatnim bajcie znajduje się prawy nawias „)”.
W poniższej tabeli przedstawiono operatory relacyjne używane w kwalifikowanym SSA.
| Operator relacyjny | Symbol | Opis |
|---|---|---|
| EQ | = | Równy |
| NE | ~ = ˜ | Nie równe |
| GT | > | Lepszy niż |
| GE | > = | Większy bądź równy |
| LT | << | Mniej niż |
| LE | <= | Mniejsze lub równe |
Kody poleceń
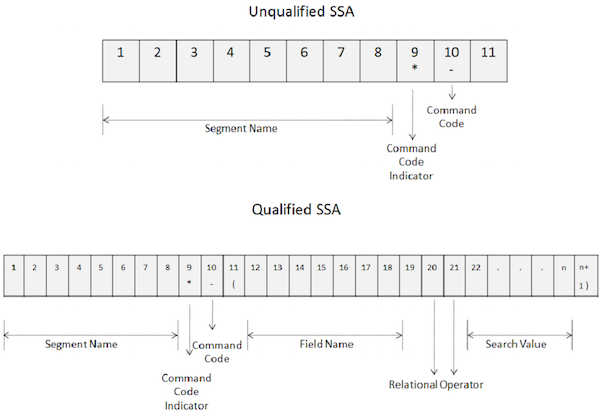
Kody poleceń są używane w celu zwiększenia funkcjonalności wywołań DL / I. Kody poleceń zmniejszają liczbę wywołań DL / I, upraszczając programy. Poprawia również wydajność, ponieważ zmniejsza się liczba połączeń. Poniższy obraz przedstawia, w jaki sposób kody poleceń są używane w niekwalifikowanych i kwalifikowanych SSA -
Kluczowe punkty kodów poleceń są następujące:
Stosują kody polecenia określ gwiazdką w 9 -tego położenia SSA, jak przedstawiono na rysunku powyżej.
Kod polecenia jest zakodowany na dziesiątej pozycji.
Od 10 th pozycja r DL / I wszystkie znaki uważa się kody poleceń, dopóki nie napotka przestrzeń dla niewykwalifikowanego SSA i lewy nawias dla wykwalifikowanego SSA.
Poniższa tabela przedstawia listę kodów poleceń używanych w SSA -
| Kod polecenia | Opis |
|---|---|
| do | Połączony klucz |
| re | Połączenie z trasą |
| fa | Pierwsze wystąpienie |
| L | Ostatnie wystąpienie |
| N | Wywołanie ścieżki Ignoruj |
| P. | Ustaw rodzicielstwo |
| Q | Umieść segment w kolejce |
| U | Utrzymaj pozycję na tym poziomie |
| V | Utrzymaj pozycję na tym i wszystkich powyższych poziomach |
| - | Pusty kod polecenia |
Wiele kwalifikacji
Podstawowe punkty wielu kwalifikacji są następujące:
Wielokrotne kwalifikacje są wymagane, gdy do porównania musimy użyć dwóch lub więcej kwalifikacji lub pól.
Używamy operatorów logicznych, takich jak AND i OR, aby połączyć dwie lub więcej kwalifikacji.
Można użyć wielu kwalifikacji, gdy chcemy przetworzyć segment na podstawie zakresu możliwych wartości dla pojedynczego pola.
Poniżej podano składnię wielu kwalifikacji -
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.MUL-QUAL to krótki termin dla MULtiple QUALIification, w którym możemy podać operatory logiczne, takie jak AND lub OR.
Różne metody pobierania danych używane w wywołaniach IMS DL / I są następujące:
- GU Call
- GN Call
- Korzystanie z kodów poleceń
- Wielokrotne przetwarzanie
Rozważmy następującą strukturę bazy danych IMS, aby zrozumieć wywołania funkcji pobierania danych -
GU Call
Podstawy wywołania GU są następujące -
Wywołanie GU jest znane jako połączenie Get Unique. Służy do losowego przetwarzania.
Jeśli aplikacja nie aktualizuje regularnie bazy danych lub jeśli liczba aktualizacji bazy danych jest mniejsza, używamy przetwarzania losowego.
Wywołanie GU służy do umieszczenia wskaźnika w określonej pozycji w celu dalszego sekwencyjnego wyszukiwania.
Wywołania GU są niezależne od pozycji wskaźnika ustalonej przez poprzednie wywołania.
Przetwarzanie wywołań GU jest oparte na unikalnych polach kluczy dostarczonych w instrukcji wywołania.
Jeśli podamy pole klucza, które nie jest unikalne, DL / I zwraca wystąpienie pierwszego segmentu pola klucza.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSAPowyższy przykład pokazuje, że wysyłamy wywołanie GU, udostępniając pełny zestaw kwalifikowanych SSA. Obejmuje wszystkie kluczowe pola, począwszy od poziomu głównego do wystąpienia segmentu, który chcemy pobrać.
Uwagi dotyczące wywołania GU
Jeśli w wezwaniu nie podamy pełnego zestawu kwalifikowanych SSA, wówczas DL / I działa w następujący sposób -
Kiedy używamy niekwalifikowanego SSA w wywołaniu GU, DL / I uzyskuje dostęp do pierwszego wystąpienia segmentu w bazie danych, które spełnia określone przez Ciebie kryteria.
Kiedy wywołujemy GU bez żadnych SSA, DL / I zwraca pierwsze wystąpienie segmentu głównego w bazie danych.
Jeżeli w zaproszeniu nie wymieniono niektórych SSA na poziomach pośrednich, wówczas DL / I stosuje ustaloną pozycję lub domyślną wartość niekwalifikowanego SSA dla segmentu.
Kody stanu
W poniższej tabeli przedstawiono odpowiednie kody stanu po wywołaniu GU -
| S.Nr | Kod stanu i opis |
|---|---|
| 1 | Spaces Udane połączenie |
| 2 | GE DL / I nie udało się znaleźć segmentu spełniającego kryteria określone w wezwaniu |
GN Call
Podstawy wywołania GN są następujące -
Wywołanie GN jest znane jako wywołanie Get Next. Służy do podstawowego przetwarzania sekwencyjnego.
Początkowa pozycja wskaźnika w bazie danych znajduje się przed segmentem głównym pierwszego rekordu bazy danych.
Pozycja wskaźnika bazy danych znajduje się przed następnym wystąpieniem segmentu w sekwencji, po udanym wywołaniu GN.
Wywołanie GN rozpoczyna się w bazie danych od pozycji ustalonej przez poprzednie wywołanie.
Jeśli wywołanie GN jest niekwalifikowane, zwraca następne wystąpienie segmentu w bazie danych niezależnie od jego typu, w kolejności hierarchicznej.
Jeśli wywołanie GN zawiera SSA, wówczas DL / I pobiera tylko segmenty, które spełniają wymagania wszystkich określonych SSA.
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSAPowyższy przykład pokazuje, że wysyłamy wywołanie GN, podając pozycję początkową do sekwencyjnego odczytu rekordów. Pobiera pierwsze wystąpienie segmentu KSIĄŻKI.
Kody stanu
W poniższej tabeli przedstawiono odpowiednie kody stanu po wywołaniu GN -
| S.Nr | Kod stanu i opis |
|---|---|
| 1 | Spaces Udane połączenie |
| 2 | GE DL / I nie mogłem znaleźć segmentu spełniającego kryteria określone w wezwaniu. |
| 3 | GA Niekwalifikowane wywołanie GN przechodzi o jeden poziom w górę w hierarchii bazy danych, aby pobrać segment. |
| 4 | GB Osiągnięto koniec bazy danych i nie znaleziono segmentu. |
GK Niekwalifikowane wywołanie GN próbuje pobrać segment określonego typu, inny niż ten właśnie pobrany, ale pozostaje na tym samym poziomie hierarchii. |
Kody poleceń
Kody poleceń są używane z wywołaniami w celu pobrania wystąpienia segmentu. Poniżej omówiono różne kody poleceń używane w wywołaniach.
Kod polecenia F.
Punkty do zapamiętania -
Gdy kod polecenia F jest określony w wywołaniu, wywołanie przetwarza pierwsze wystąpienie segmentu.
Kody poleceń F mogą być używane, gdy chcemy przetwarzać sekwencyjnie i mogą być używane z wywołaniami GN i wywołaniami GNP.
Jeśli określimy kod polecenia F z wywołaniem GU, nie ma to żadnego znaczenia, ponieważ wywołania GU domyślnie pobierają wystąpienie pierwszego segmentu.
Kod polecenia L.
Punkty do zapamiętania -
Gdy kod polecenia L jest określony w wywołaniu, wywołanie przetwarza ostatnie wystąpienie segmentu.
Kody poleceń L mogą być używane, gdy chcemy przetwarzać sekwencyjnie i mogą być używane z wywołaniami GN i wywołaniami GNP.
Kod polecenia D.
Punkty do zapamiętania -
Kod polecenia D jest używany do pobierania więcej niż jednego wystąpienia segmentu przy użyciu tylko jednego wywołania.
Zwykle DL / I działa w segmencie najniższego poziomu określonego w SSA, ale w wielu przypadkach potrzebujemy również danych z innych poziomów. W takich przypadkach możemy użyć kodu polecenia D.
Kod polecenia D ułatwia pobieranie całej ścieżki segmentów.
Kod polecenia C.
Punkty do zapamiętania -
Kod polecenia C służy do łączenia kluczy.
Korzystanie z operatorów relacji jest nieco skomplikowane, ponieważ musimy określić nazwę pola, operator relacyjny i wartość wyszukiwania. Zamiast tego możemy użyć kodu polecenia C, aby dostarczyć połączony klucz.
Poniższy przykład pokazuje użycie kodu polecenia C -
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSAKod polecenia P.
Punkty do zapamiętania -
Kiedy wykonujemy wywołanie GU lub GN, DL / I ustala swoje pochodzenie na najniższym poziomie pobieranego segmentu.
Jeśli włączymy kod polecenia P, wówczas DL / I ustanawia swoje pochodzenie na segmencie wyższego poziomu w ścieżce hierarchicznej.
Kod polecenia U.
Punkty do zapamiętania -
Gdy kod polecenia U jest określony w niekwalifikowanym SSA w wywołaniu GN, DL / I ogranicza wyszukiwanie segmentu.
Kod polecenia U jest ignorowany, jeśli jest używany z kwalifikowanym SSA.
Kod polecenia V.
Punkty do zapamiętania -
Kod polecenia V działa podobnie do kodu polecenia U, ale ogranicza wyszukiwanie segmentu na określonym poziomie i na wszystkich poziomach powyżej hierarchii.
Kod polecenia V jest ignorowany, gdy jest używany z kwalifikowanym SSA.
Q Command Code
Punkty do zapamiętania -
Kod polecenia Q jest używany do umieszczania w kolejce lub rezerwowania segmentu do wyłącznego użytku programu aplikacji.
Kod polecenia Q jest używany w środowisku interaktywnym, w którym inny program może dokonać zmiany w segmencie.
Wielokrotne przetwarzanie
Program może mieć wiele pozycji w bazie danych IMS, co jest znane jako przetwarzanie wielokrotne. Wielokrotne przetwarzanie można przeprowadzić na dwa sposoby -
- Wiele PCB
- Wielokrotne pozycjonowanie
Wiele PCB
Dla jednej bazy danych można zdefiniować wiele PCB. Jeśli istnieje wiele płytek drukowanych, program aplikacji może mieć różne widoki. Ta metoda implementacji wielokrotnego przetwarzania jest nieefektywna z powodu narzutów narzuconych przez dodatkowe PCB.
Wielokrotne pozycjonowanie
Program może utrzymywać wiele pozycji w bazie danych za pomocą jednej płytki PCB. Osiąga się to poprzez utrzymanie odrębnej pozycji dla każdej ścieżki hierarchicznej. Wielokrotne pozycjonowanie służy do uzyskiwania dostępu do segmentów dwóch lub więcej typów sekwencyjnie w tym samym czasie.
Różne metody manipulacji danymi używane w wywołaniach IMS DL / I są następujące:
- Połączenie ISRT
- Otrzymuj połączenia zawieszone
- REPL Zadzwoń
- Połączenie DLET
Rozważmy następującą strukturę bazy danych IMS, aby zrozumieć wywołania funkcji manipulacji danymi -
Połączenie ISRT
Punkty do zapamiętania -
Wywołanie ISRT jest znane jako wywołanie wstawiania, które jest używane do dodawania wystąpień segmentów do bazy danych.
Wywołania ISRT służą do ładowania nowej bazy danych.
Wysyłamy wywołanie ISRT, gdy pole opisu segmentu jest ładowane danymi.
Niekwalifikowany lub kwalifikowany SSA musi być określony w wywołaniu, aby DL / I wiedział, gdzie umieścić wystąpienie segmentu.
W rozmowie możemy użyć kombinacji zarówno niekwalifikowanych, jak i kwalifikowanych usług SSA. Dla wszystkich powyższych poziomów można określić kwalifikowany SSA. Rozważmy następujący przykład -
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSAPowyższy przykład pokazuje, że wysyłamy wywołanie ISRT, udostępniając kombinację kwalifikowanych i niekwalifikowanych SSA.
Kiedy nowy segment, który wstawiamy, ma unikalne pole klucza, to jest on dodawany we właściwej pozycji. Jeśli pole klucza nie jest unikalne, jest dodawane zgodnie z regułami zdefiniowanymi przez administratora bazy danych.
Kiedy wywołujemy ISRT bez określania pola kluczowego, wówczas reguła wstawiania mówi, gdzie umieścić segmenty względem istniejących segmentów bliźniaczych. Poniżej podano zasady wstawiania -
First - Jeśli reguła jest pierwsza, nowy segment jest dodawany przed istniejącymi bliźniakami.
Last - Jeśli reguła jest ostatnia, nowy segment jest dodawany po wszystkich istniejących bliźniakach.
Here - Jeśli reguła jest tutaj, jest dodawana w bieżącej pozycji względem istniejących bliźniaków, które mogą być pierwsze, ostatnie lub gdziekolwiek.
Kody stanu
W poniższej tabeli przedstawiono odpowiednie kody stanu po wywołaniu ISRT -
| S.Nr | Kod stanu i opis |
|---|---|
| 1 | Spaces Udane połączenie |
| 2 | GE Stosowanych jest wiele SSA, a DL / I nie może spełnić połączenia z określoną ścieżką. |
| 3 | II Spróbuj dodać wystąpienie segmentu, które jest już obecne w bazie danych. |
| 4 | LB / LC LD / LE Otrzymujemy te kody stanu podczas przetwarzania ładowania. W większości przypadków wskazują one, że segmenty nie są wstawiane w dokładnej kolejności hierarchicznej. |
Odbierz połączenie zawieszone
Punkty do zapamiętania -
Istnieją trzy typy połączeń Get Hold, które określamy w wywołaniu DL / I:
Get Hold Unique (GHU)
Get Hold Next (GHN)
Get Hold Next within Parent (GHNP)
Funkcja Hold określa, że będziemy aktualizować segment po pobraniu. Tak więc przed wywołaniem REPL lub DLET musi zostać wydane połączenie zawieszające z powodzeniem, informujące DL / I o zamiarze aktualizacji bazy danych.
REPL Zadzwoń
Punkty do zapamiętania -
Po pomyślnym odebraniu połączenia zawieszonego wysyłamy wywołanie REPL, aby zaktualizować wystąpienie segmentu.
Nie możemy zmienić długości segmentu za pomocą wywołania REPL.
Nie możemy zmienić wartości pola klucza za pomocą wywołania REPL.
Nie możemy używać kwalifikowanego SSA z wywołaniem REPL. Jeśli określimy kwalifikowany SSA, wywołanie nie powiedzie się.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.Powyższy przykład aktualizuje wystąpienie segmentu IT za pomocą wywołania REPL. Najpierw wysyłamy wywołanie GHU, aby uzyskać wystąpienie segmentu, które chcemy zaktualizować. Następnie wysyłamy wywołanie REPL, aby zaktualizować wartości tego segmentu.
Połączenie DLET
Punkty do zapamiętania -
Wywołanie DLET działa podobnie jak wywołanie REPL.
Po pomyślnym odebraniu połączenia, wysyłamy wywołanie DLET, aby usunąć wystąpienie segmentu.
Nie możemy używać kwalifikowanego SSA z połączeniem DLET. Jeśli określimy kwalifikowany SSA, wywołanie nie powiedzie się.
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.Powyższy przykład usuwa wystąpienie segmentu IT za pomocą wywołania DLET. Najpierw wysyłamy wywołanie GHU, aby uzyskać wystąpienie segmentu, które chcemy usunąć. Następnie wysyłamy wywołanie DLET, aby zaktualizować wartości tego segmentu.
Kody stanu
W poniższej tabeli przedstawiono odpowiednie kody stanu po wywołaniu REPL lub DLET -
| S.Nr | Kod stanu i opis |
|---|---|
| 1 | Spaces Udane połączenie |
| 2 | AJ Kwalifikowany SSA używany w połączeniu REPL lub DLET. |
| 3 | DJ Program wysyła połączenie zastępcze bez poprzedzającego go bezpośrednio połączenia wstrzymanego. |
| 4 | DA Program dokonuje zmiany w polu klucza segmentu przed wywołaniem REPL lub DLET |
Indeksowanie wtórne jest używane, gdy chcemy uzyskać dostęp do bazy danych bez użycia pełnego połączonego klucza lub gdy nie chcemy używać pól podstawowych sekwencji.
Segment wskaźnika indeksu
DL / I przechowuje wskaźnik do segmentów indeksowanej bazy danych w oddzielnej bazie danych. Segment wskaźnika indeksu jest jedynym typem indeksu dodatkowego. Składa się z dwóch części -
- Element przedrostka
- Element danych
Element przedrostka
Część będąca prefiksem segmentu wskaźnika indeksu zawiera wskaźnik do segmentu docelowego indeksu. Segment docelowy indeksu to segment, do którego można uzyskać dostęp za pomocą indeksu dodatkowego.
Element danych
Element danych zawiera wartość klucza z segmentu w indeksowanej bazie danych, na podstawie której zbudowany jest indeks. Jest to również znane jako segment źródłowy indeksu.
Oto kluczowe punkty, na które należy zwrócić uwagę na temat indeksowania pomocniczego -
Segment źródłowy indeksu i docelowy segment źródłowy nie muszą być takie same.
Kiedy ustawiamy indeks pomocniczy, jest on automatycznie utrzymywany przez DL / I.
DBA definiuje wiele indeksów pomocniczych zgodnie z wieloma ścieżkami dostępu. Te indeksy pomocnicze są przechowywane w oddzielnej bazie danych indeksów.
Nie powinniśmy tworzyć więcej indeksów pomocniczych, ponieważ nakładają one dodatkowe obciążenie przetwarzania na DL / I.
Dodatkowe klucze
Punkty do zapamiętania -
Pole w segmencie źródłowym indeksu, na podstawie którego zbudowany jest indeks pomocniczy, jest nazywane kluczem pomocniczym.
Dowolne pole może służyć jako klucz dodatkowy. Nie musi to być pole sekwencji segmentów.
Klucze pomocnicze mogą być dowolną kombinacją pojedynczych pól w segmencie źródłowym indeksu.
Dodatkowe wartości klucza nie muszą być unikalne.
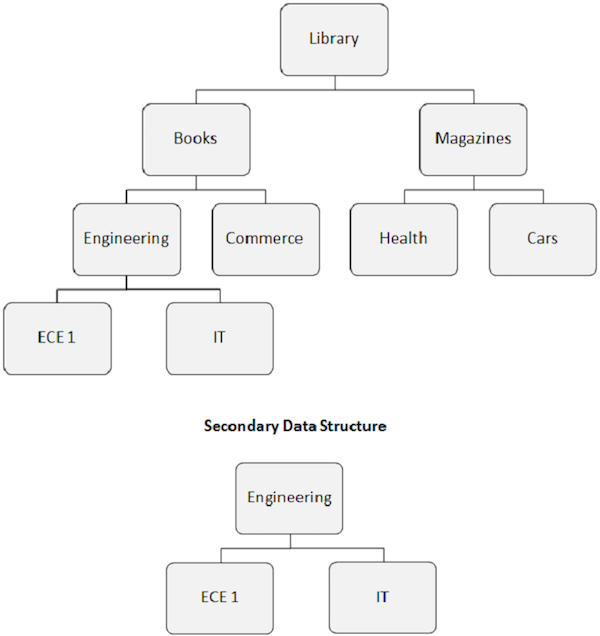
Wtórne struktury danych
Punkty do zapamiętania -
Kiedy tworzymy indeks pomocniczy, pozorna hierarchiczna struktura bazy danych również ulega zmianie.
Segment docelowy indeksu staje się pozornym segmentem głównym. Jak pokazano na poniższej ilustracji, segment Inżynieria staje się segmentem głównym, nawet jeśli nie jest to segment główny.
Zmiana struktury bazy danych spowodowana indeksem pomocniczym jest nazywana drugorzędną strukturą danych.
Wtórne struktury danych nie wprowadzają żadnych zmian w głównej fizycznej strukturze bazy danych znajdującej się na dysku. Jest to tylko sposób na zmianę struktury bazy danych przed programem użytkowym.
Niezależny operator AND
Punkty do zapamiętania -
Gdy operator AND (* lub &) jest używany z indeksami pomocniczymi, jest znany jako operator zależny AND.
Niezależne AND (#) pozwala nam określić kwalifikacje, które byłyby niemożliwe w przypadku zależnego AND.
Ten operator może być używany tylko w przypadku indeksów pomocniczych, w których segment źródłowy indeksu jest zależny od segmentu docelowego indeksu.
Możemy zakodować SSA z niezależnym AND, aby określić, że wystąpienie segmentu docelowego zostanie przetworzone na podstawie pól w dwóch lub więcej zależnych segmentach źródłowych.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.Rzadkie sekwencjonowanie
Punkty do zapamiętania -
Rzadkie sekwencjonowanie jest również znane jako rzadkie indeksowanie. Możemy usunąć niektóre segmenty źródłowe indeksu z indeksu przy użyciu rzadkiego sekwencjonowania z pomocniczą bazą danych indeksów.
Rzadkie sekwencjonowanie służy do poprawy wydajności. Jeśli niektóre wystąpienia segmentu źródłowego indeksu nie są używane, możemy to usunąć.
DL / I używa wartości tłumienia lub procedury tłumienia, lub obu, do określenia, czy segment powinien być indeksowany.
Jeśli wartość pola sekwencji w segmencie źródłowym indeksu jest zgodna z wartością pomijania, nie jest ustanawiana żadna relacja indeksu.
Procedura pomijania to program napisany przez użytkownika, który ocenia segment i określa, czy powinien on być indeksowany, czy nie.
Kiedy używane jest rzadkie indeksowanie, jego funkcje są obsługiwane przez DL / I. Nie musimy robić tego specjalnie w programie użytkowym.
Wymagania DBDGEN
Jak omówiono we wcześniejszych modułach, DBDGEN służy do tworzenia DBD. Podczas tworzenia indeksów pomocniczych zaangażowane są dwie bazy danych. DBA musi utworzyć dwa DBD przy użyciu dwóch DBDGEN do tworzenia relacji między indeksowaną bazą danych a dodatkową indeksowaną bazą danych.
Wymagania PSBGEN
Po utworzeniu dodatkowego indeksu dla bazy danych administrator musi utworzyć nadawcy usług publicznych. PSBGEN dla programu określa prawidłową sekwencję przetwarzania dla bazy danych w parametrze PROCSEQ makra PSB. W przypadku parametru PROCSEQ DBA koduje nazwę DBD dla pomocniczej bazy danych indeksów.
W bazie danych IMS obowiązuje zasada, że każdy typ segmentu może mieć tylko jednego rodzica. Ogranicza to złożoność fizycznej bazy danych. Wiele aplikacji DL / I wymaga złożonej struktury, która umożliwia segmentowi posiadanie dwóch typów segmentów nadrzędnych. Aby przezwyciężyć to ograniczenie, DL / I umożliwia administratorowi DBA implementację relacji logicznych, w których segment może mieć zarówno fizycznych, jak i logicznych rodziców. Możemy tworzyć dodatkowe relacje w ramach jednej fizycznej bazy danych. Nowa struktura danych po zaimplementowaniu relacji logicznej jest nazywana logiczną bazą danych.
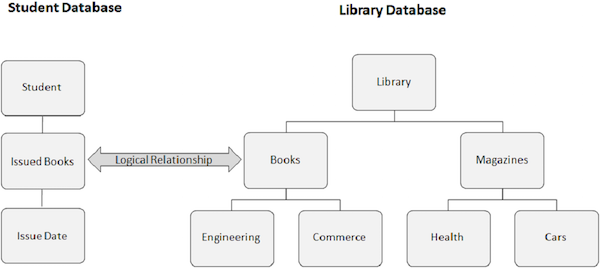
Relacja logiczna
Relacja logiczna ma następujące właściwości -
Relacja logiczna to ścieżka między dwoma segmentami, które są powiązane logicznie, a nie fizycznie.
Zwykle logiczna relacja jest ustanawiana między oddzielnymi bazami danych. Ale możliwe jest istnienie relacji między segmentami jednej konkretnej bazy danych.
Poniższy obraz przedstawia dwie różne bazy danych. Jedna to baza danych Studentów, a druga to baza danych Biblioteki. Tworzymy logiczną relację między segmentem Książki wydane z bazy danych Studentów a segmentem Książki z bazy danych Biblioteki.
Tak wygląda logiczna baza danych podczas tworzenia relacji logicznej -
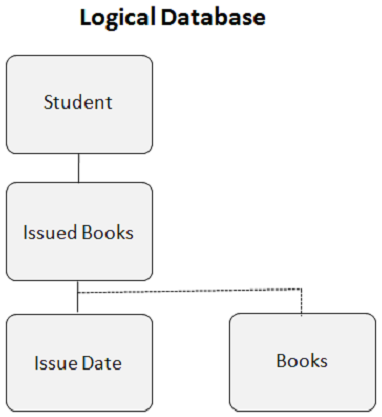
Logiczny segment podrzędny
Logiczny segment potomny jest podstawą relacji logicznej. Jest to fizyczny segment danych, ale w przypadku DL / I wygląda na to, że ma dwoje rodziców. Segment Książki w powyższym przykładzie ma dwa segmenty nadrzędne. Segment wydanych książek jest logicznym elementem nadrzędnym, a segment biblioteki jest fizycznym nadrzędnym. Jedno wystąpienie logicznego segmentu podrzędnego ma tylko jedno wystąpienie logicznego segmentu nadrzędnego, a jedno wystąpienie logicznego segmentu nadrzędnego może mieć wiele wystąpień logicznego segmentu podrzędnego.
Logiczne bliźniaki
Logiczne bliźniaki to wystąpienia typu logicznego segmentu podrzędnego, które są podporządkowane pojedynczemu wystąpieniu typu logicznego segmentu nadrzędnego. DL / I sprawia, że logiczny segment podrzędny wygląda podobnie do rzeczywistego fizycznego segmentu podrzędnego. Jest to również znane jako wirtualny logiczny segment podrzędny.
Rodzaje relacji logicznych
DBA tworzy logiczne relacje między segmentami. Aby zaimplementować relację logiczną, DBA musi określić ją w DBDGEN dla zaangażowanych fizycznych baz danych. Istnieją trzy typy relacji logicznych -
- Unidirectional
- Dwukierunkowy wirtualny
- Dwukierunkowe fizyczne
Jednokierunkowy
Połączenie logiczne przechodzi od logicznego dziecka do logicznego rodzica i nie może być odwrotne.
Dwukierunkowy wirtualny
Umożliwia dostęp w obu kierunkach. Logiczne dziecko w swojej fizycznej strukturze i odpowiadające mu wirtualne logiczne dziecko mogą być postrzegane jako sparowane segmenty.
Dwukierunkowe fizyczne
Dziecko logiczne to fizycznie zmagazynowany podległy zarówno swoim fizycznym, jak i logicznym rodzicom. W aplikacjach wygląda to tak samo, jak dwukierunkowe wirtualne logiczne dziecko.
Zagadnienia dotyczące programowania
Zagadnienia programistyczne dotyczące korzystania z logicznej bazy danych są następujące:
Połączenia DL / I w celu uzyskania dostępu do bazy danych pozostają takie same z logiczną bazą danych.
Blok specyfikacji programu wskazuje strukturę, której używamy w naszych wywołaniach. W niektórych przypadkach nie możemy stwierdzić, że używamy logicznej bazy danych.
Relacje logiczne nadają nowy wymiar programowaniu baz danych.
Podczas pracy z logicznymi bazami danych należy zachować ostrożność, ponieważ dwie bazy danych są ze sobą zintegrowane. Jeśli zmodyfikujesz jedną bazę danych, te same modyfikacje muszą zostać odzwierciedlone w drugiej bazie danych.
Specyfikacje programu powinny wskazywać, jakie przetwarzanie jest dozwolone w bazie danych. Jeśli reguła przetwarzania zostanie naruszona, otrzymasz niepusty kod stanu.
Segment skonsolidowany
Logiczny segment podrzędny zawsze zaczyna się od pełnego, połączonego klucza docelowego elementu nadrzędnego. Jest to znane jako łączony klucz docelowy nadrzędny (DPCK). Musisz zawsze zakodować DPCK na początku obszaru we / wy segmentu dla logicznego elementu potomnego. W logicznej bazie danych połączony segment tworzy połączenie między segmentami zdefiniowanymi w różnych fizycznych bazach danych. Połączony segment składa się z następujących dwóch części -
- Logiczny segment podrzędny
- Docelowy segment nadrzędny
Logiczny segment podrzędny składa się z następujących dwóch części -
- Skonsolidowany klucz nadrzędny miejsca docelowego (DPCK)
- Logiczne dane użytkownika podrzędnego

Kiedy pracujemy z połączonymi segmentami podczas aktualizacji, może być możliwe dodanie lub zmiana danych zarówno w logicznym elemencie podrzędnym, jak i docelowym rodzicu za pomocą jednego wywołania. Zależy to również od reguł określonych przez DBA dla bazy danych. W przypadku wkładki podaj DPCK we właściwej pozycji. W celu zastąpienia lub usunięcia nie zmieniaj DPCK ani danych pola sekwencji w żadnej części połączonego segmentu.
Administrator bazy danych musi zaplanować przywrócenie bazy danych w przypadku awarii systemu. Awarie mogą być różnego rodzaju, takie jak awarie aplikacji, błędy sprzętowe, awarie zasilania itp.
Proste podejście
Oto kilka prostych podejść do odzyskiwania bazy danych:
Wykonuj okresowe kopie zapasowe ważnych zbiorów danych, aby zachować wszystkie transakcje zaksięgowane na tych zbiorach.
Jeśli zbiór danych zostanie uszkodzony w wyniku awarii systemu, problem zostanie rozwiązany poprzez przywrócenie kopii zapasowej. Następnie skumulowane transakcje są ponownie księgowane w kopii zapasowej w celu ich aktualizacji.
Wady prostego podejścia
Wady prostego podejścia do odzyskiwania bazy danych są następujące -
Ponowne zaksięgowanie skumulowanych transakcji zajmuje dużo czasu.
Wszystkie inne aplikacje muszą czekać na wykonanie do zakończenia odzyskiwania.
Odzyskiwanie bazy danych jest dłuższe niż odzyskiwanie plików, jeśli występują relacje między indeksami logicznymi i pomocniczymi.
Nieprawidłowe procedury zakończenia
Program DL / I ulega awarii w sposób inny niż zwykły program, ponieważ program standardowy jest wykonywany bezpośrednio przez system operacyjny, a program DL / I nie. Stosując procedurę nieprawidłowego zakończenia, system zakłóca działanie, tak że przywrócenie może nastąpić po nieprawidłowym zakończeniu (ABEND). Nieprawidłowa procedura zakończenia wykonuje następujące czynności -
- Zamyka wszystkie zbiory danych
- Anuluje wszystkie oczekujące zadania w kolejce
- Tworzy zrzut pamięci, aby znaleźć główną przyczynę ABEND
Ograniczeniem tej procedury jest to, że nie gwarantuje ona, czy używane dane są dokładne, czy nie.
Dziennik DL / I
Kiedy aplikacja działa ABEND, konieczne jest cofnięcie zmian wprowadzonych przez aplikację, poprawienie błędu i ponowne uruchomienie aplikacji. Aby to zrobić, wymagane jest posiadanie dziennika DL / I. Oto kluczowe punkty dotyczące rejestrowania DL / I -
DL / I rejestruje wszystkie zmiany dokonane przez aplikację w pliku zwanym plikiem dziennika.
Kiedy aplikacja zmienia segment, jego obraz przed i po są tworzone przez DL / I.
Te obrazy segmentów mogą służyć do przywracania segmentów w przypadku awarii aplikacji.
DL / I używa techniki zwanej rejestrowaniem z wyprzedzeniem do rejestrowania zmian w bazie danych. W przypadku rejestrowania z zapisem z wyprzedzeniem zmiana bazy danych jest zapisywana w zestawie danych dziennika, zanim zostanie zapisana w rzeczywistym zestawie danych.
Ponieważ dziennik jest zawsze przed bazą danych, narzędzia do odtwarzania mogą określić stan każdej zmiany w bazie danych.
Gdy program wykonuje wywołanie zmiany segmentu bazy danych, DL / I zajmuje się jego częścią rejestrującą.
Odzyskiwanie - do przodu i do tyłu
Dwa podejścia do odzyskiwania bazy danych to:
Forward Recovery - DL / I używa pliku dziennika do przechowywania danych zmian. Skumulowane transakcje są ponownie księgowane przy użyciu tego pliku dziennika.
Backward Recovery- Odzyskiwanie wstecz jest również znane jako odzyskiwanie po wycofaniu. Rekordy dziennika programu są odczytywane wstecz, a ich skutki są odwracane w bazie danych. Po zakończeniu wycofywania bazy danych są w tym samym stanie, w jakim były przed awarią, przy założeniu, że w międzyczasie żadna inna aplikacja nie zmieniła bazy danych.
Punkt kontrolny
Punkt kontrolny to etap, na którym zmiany bazy danych wprowadzone przez aplikację są uważane za kompletne i dokładne. Poniżej wymienione są punkty, na które należy zwrócić uwagę na temat punktu kontrolnego -
Zmiany bazy danych wprowadzone przed ostatnim punktem kontrolnym nie są cofane przez odtwarzanie wstecz.
Zmiany bazy danych zarejestrowane po ostatnim punkcie kontrolnym nie są stosowane do kopii obrazu bazy danych podczas odzyskiwania do przodu.
Korzystając z metody punktu kontrolnego, baza danych jest przywracana do stanu z ostatniego punktu kontrolnego po zakończeniu procesu odzyskiwania.
Domyślnie dla programów wsadowych punkt kontrolny jest początkiem programu.
Punkt kontrolny można ustanowić za pomocą wywołania punktu kontrolnego (CHKP).
Wywołanie punktu kontrolnego powoduje zapisanie rekordu punktu kontrolnego w dzienniku DL / I.
Poniżej pokazano składnię wywołania CHKP -
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-IDIstnieją dwie metody punktów kontrolnych -
Basic Checkpointing - Pozwala programiście na wysyłanie wywołań punktów kontrolnych, których narzędzia odzyskiwania DL / I używają podczas przetwarzania odzyskiwania.
Symbolic Checkpointing- Jest to zaawansowana forma punktów kontrolnych, która jest używana w połączeniu z rozszerzoną funkcją restartu. Symboliczne punkty kontrolne i rozszerzony restart pozwalają programiście aplikacji zakodować programy tak, aby mogły wznowić przetwarzanie w punkcie tuż za punktem kontrolnym.