Algorytm równoległy - modele
Model algorytmu równoległego jest tworzony poprzez rozważenie strategii podziału danych i metody przetwarzania oraz zastosowanie odpowiedniej strategii w celu ograniczenia interakcji. W tym rozdziale omówimy następujące równoległe modele algorytmów -
- Model równoległy danych
- Model wykresu zadań
- Model puli pracy
- Model Master slave
- Producent konsumenta lub model potoku
- Model hybrydowy
Dane równoległe
W modelu równoległym do danych zadania są przypisane do procesów, a każde zadanie wykonuje podobne operacje na innych danych. Data parallelism jest konsekwencją pojedynczej operacji wykonywanej na wielu elementach danych.
Model równoległy do danych można zastosować w przypadku współdzielonych przestrzeni adresowych i paradygmatów przekazywania wiadomości. W modelu równoległym do danych, narzuty związane z interakcjami można zmniejszyć, wybierając lokalizację zachowującą dekompozycję, stosując zoptymalizowane procedury interakcji zbiorowej lub nakładając się na siebie obliczenia i interakcje.
Podstawową cechą problemów z modelami równoległymi do danych jest to, że intensywność równoległości danych rośnie wraz z rozmiarem problemu, co z kolei umożliwia wykorzystanie większej liczby procesów do rozwiązania większych problemów.
Example - Gęste mnożenie macierzy.

Model wykresu zadań
W modelu wykresu zadań równoległość jest wyrażana przez a task graph. Wykres zadań może być trywialny lub nietrywialny. W tym modelu korelacje między zadaniami są wykorzystywane do promowania lokalności lub minimalizowania kosztów interakcji. Model ten jest wymuszany do rozwiązywania problemów, w których ilość danych związanych z zadaniami jest ogromna w porównaniu z liczbą obliczeń z nimi związanych. Zadania są przydzielane w celu poprawy kosztów przenoszenia danych między zadaniami.
Examples - Równoległe szybkie sortowanie, rzadka faktoryzacja macierzy i równoległe algorytmy wyprowadzone metodą dziel i rządź.
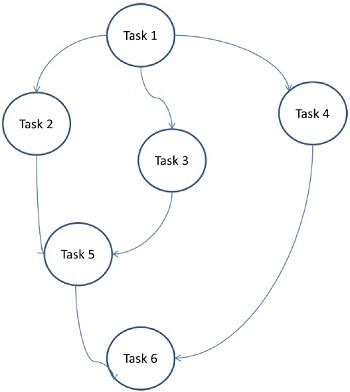
Tutaj problemy są podzielone na atomowe zadania i realizowane w postaci wykresu. Każde zadanie jest niezależną jednostką zadania, która ma zależności od jednego lub więcej zadań poprzedzających. Po zakończeniu zadania dane wyjściowe poprzedniego zadania są przekazywane do zadania zależnego. Zadanie z poprzednikiem rozpoczyna wykonywanie dopiero po ukończeniu całego poprzednika. Końcowy wynik wykresu jest otrzymywany po zakończeniu ostatniego zadania zależnego (Zadanie 6 na powyższym rysunku).
Model puli pracy
W modelu puli pracy zadania są dynamicznie przypisywane do procesów równoważenia obciążenia. Dlatego każdy proces może potencjalnie wykonać dowolne zadanie. Ten model jest używany, gdy ilość danych związanych z zadaniami jest stosunkowo mniejsza niż obliczenia związane z zadaniami.
Nie ma pożądanego wstępnego przypisywania zadań do procesów. Przydzielanie zadań jest scentralizowane lub zdecentralizowane. Wskaźniki do zadań są zapisywane na fizycznie udostępnianej liście, w kolejce priorytetowej lub w tabeli skrótów lub drzewie albo mogą być zapisane w fizycznie rozproszonej strukturze danych.
Zadanie może być dostępne na początku lub może być generowane dynamicznie. Jeśli zadanie jest generowane dynamicznie i odbywa się zdecentralizowane przydzielanie zadań, wymagany jest algorytm wykrywania zakończenia, aby wszystkie procesy mogły faktycznie wykryć zakończenie całego programu i przestać szukać kolejnych zadań.
Example - Równoległe wyszukiwanie drzew

Model Master-Slave
W modelu master-slave jeden lub więcej procesów nadrzędnych generuje zadanie i przydziela je do procesów podrzędnych. Zadania można przydzielić z wyprzedzeniem, jeżeli:
- kapitan może oszacować wielkość zadań, lub
- losowe przypisanie może wykonać zadowalające zadanie równoważenia obciążenia lub
- niewolnikom w różnym czasie przydzielane są mniejsze zadania.
Ten model jest ogólnie równie odpowiedni dla shared-address-space lub message-passing paradigms, ponieważ interakcja przebiega naturalnie na dwa sposoby.
W niektórych przypadkach może być konieczne wykonanie zadania etapami, a zadanie w każdej fazie musi zostać ukończone, zanim będzie można wygenerować zadanie w kolejnych fazach. Model master-slave można uogólnić nahierarchical lub multi-level master-slave model w którym mistrz najwyższego poziomu przekazuje dużą część zadań do mistrza drugiego poziomu, który dalej dzieli zadania między swoich niewolników i może samodzielnie wykonać część zadania.
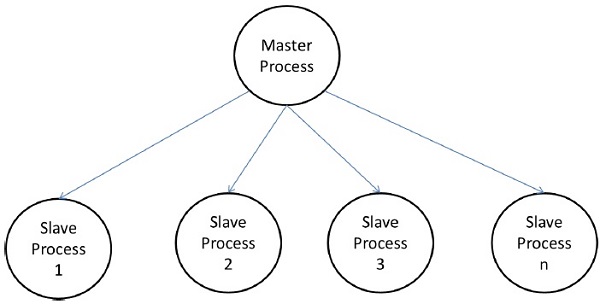
Środki ostrożności przy korzystaniu z modelu master-slave
Należy zadbać o to, aby kapitan nie stał się punktem zatoru. Może się tak zdarzyć, jeśli zadania są zbyt małe lub pracownicy są stosunkowo szybcy.
Zadania powinny być tak dobrane, aby koszt wykonania zadania przeważał nad kosztem komunikacji i kosztem synchronizacji.
Interakcja asynchroniczna może pomóc w nakładaniu się interakcji i obliczeń związanych z generowaniem pracy przez mistrza.
Model rurociągu
Jest również znany jako producer-consumer model. W tym przypadku zestaw danych jest przekazywany przez szereg procesów, z których każdy wykonuje na nim jakieś zadanie. Tutaj pojawienie się nowych danych powoduje wykonanie nowego zadania przez proces w kolejce. Procesy mogą tworzyć kolejkę w postaci liniowych lub wielowymiarowych tablic, drzew lub ogólnych wykresów z cyklami lub bez.
Ten model to łańcuch producentów i konsumentów. Każdy proces w kolejce można traktować jako konsumenta sekwencji elementów danych dla procesu poprzedzającego go w kolejce oraz jako producenta danych dla procesu następującego po nim w kolejce. Kolejka nie musi być łańcuchem liniowym; może to być wykres skierowany. Najpopularniejszą techniką minimalizacji interakcji stosowaną w tym modelu jest nakładanie się interakcji z obliczeniami.
Example - Równoległy algorytm faktoryzacji LU.

Modele hybrydowe
Model algorytmu hybrydowego jest wymagany, gdy do rozwiązania problemu może być potrzebny więcej niż jeden model.
Model hybrydowy może składać się z wielu modeli stosowanych hierarchicznie lub z wielu modeli stosowanych kolejno do różnych faz równoległego algorytmu.
Example - Równoległe szybkie sortowanie