Głębokie sieci neuronowe
Głęboka sieć neuronowa (DNN) to sieć SSN z wieloma ukrytymi warstwami między warstwą wejściową i wyjściową. Podobnie jak płytkie SSN, DNN mogą modelować złożone zależności nieliniowe.
Głównym celem sieci neuronowej jest otrzymywanie zestawu danych wejściowych, wykonywanie na nich stopniowo złożonych obliczeń i dostarczanie danych wyjściowych do rozwiązywania rzeczywistych problemów, takich jak klasyfikacja. Ograniczamy się do przekazywania naprzód sieci neuronowych.
Mamy wejście, wyjście i przepływ danych sekwencyjnych w głębokiej sieci.
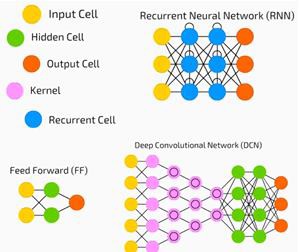
Sieci neuronowe są szeroko stosowane w nadzorowanym uczeniu się i problemach uczenia się ze wzmocnieniem. Sieci te są oparte na zestawie warstw połączonych ze sobą.
W uczeniu głębokim liczba ukrytych warstw, głównie nieliniowych, może być duża; powiedzmy około 1000 warstw.
Modele DL dają znacznie lepsze wyniki niż zwykłe sieci ML.
Najczęściej używamy metody gradientu do optymalizacji sieci i minimalizacji funkcji strat.
Możemy użyć Imagenet, repozytorium milionów obrazów cyfrowych do klasyfikowania zbioru danych w kategorie, takie jak koty i psy. Sieci DL są coraz częściej wykorzystywane do dynamicznych obrazów oprócz statycznych oraz do analizy szeregów czasowych i tekstu.
Szkolenie zbiorów danych stanowi ważną część modeli uczenia głębokiego. Ponadto Backpropagation jest głównym algorytmem w uczeniu modeli DL.
DL zajmuje się uczeniem dużych sieci neuronowych ze złożonymi przekształceniami wejściowymi i wyjściowymi.
Jednym z przykładów DL jest odwzorowanie zdjęcia na nazwisko osoby (osób) na zdjęciu, tak jak to robią w sieciach społecznościowych, i opisanie zdjęcia frazą to kolejne niedawne zastosowanie DL.
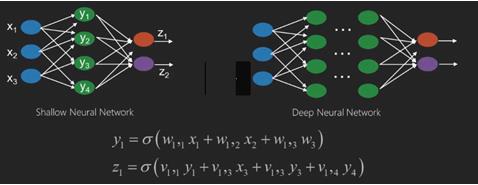
Sieci neuronowe to funkcje, które mają dane wejściowe, takie jak x1, x2, x3…, które są przekształcane na sygnały wyjściowe, takie jak z1, z2, z3 itd. W dwóch (płytkich sieciach) lub kilku operacjach pośrednich zwanych również warstwami (sieci głębokie).
Wagi i odchylenia zmieniają się z warstwy na warstwę. „w” i „v” to wagi lub synapsy warstw sieci neuronowych.
Najlepszym przykładem zastosowania uczenia głębokiego jest problem uczenia nadzorowanego, w którym mamy duży zestaw danych wejściowych z pożądanym zestawem wyników.
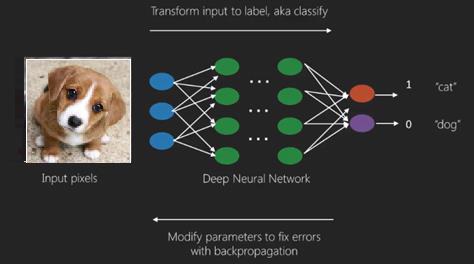
Tutaj stosujemy algorytm wstecznej propagacji, aby uzyskać prawidłowe przewidywanie wyjściowe.
Najbardziej podstawowym zestawem danych głębokiego uczenia się jest MNIST, zbiór danych składający się z odręcznych cyfr.
Możemy głęboko wyszkolić konwolucyjną sieć neuronową za pomocą Keras, aby klasyfikować obrazy odręcznych cyfr z tego zestawu danych.
Odpalenie lub aktywacja klasyfikatora sieci neuronowej daje wynik. Na przykład, aby sklasyfikować pacjentów jako chorych i zdrowych, bierzemy pod uwagę takie parametry, jak wzrost, waga i temperatura ciała, ciśnienie krwi itp.
Wysoki wynik oznacza, że pacjent jest chory, a niski wynik oznacza, że jest zdrowy.
Każdy węzeł w warstwie wyjściowej i warstwie ukrytej ma własne klasyfikatory. Warstwa wejściowa pobiera dane wejściowe i przekazuje swoje wyniki do następnej warstwy ukrytej w celu dalszej aktywacji, a ta trwa do momentu osiągnięcia wyniku.
Nazywa się to postępem od wejścia do wyjścia od lewej do prawej w kierunku do przodu forward propagation.
Ścieżka przypisania kredytu (CAP) w sieci neuronowej to seria transformacji począwszy od wejścia do wyjścia. CAP opracowują prawdopodobne związki przyczynowe między wejściem a wyjściem.
Głębokość CAP dla danej sieci neuronowej ze sprzężeniem zwrotnym lub głębokość CAP to liczba warstw ukrytych plus jedna, gdy uwzględniona jest warstwa wyjściowa. W przypadku powtarzających się sieci neuronowych, w których sygnał może przechodzić przez warstwę kilka razy, głębokość CAP może być potencjalnie nieograniczona.
Sieci głębokie i płytkie
Nie ma wyraźnego progu głębokości, który oddziela płytkie uczenie się od uczenia głębokiego; ale większość z nich jest zgodna, że w przypadku uczenia głębokiego, które ma wiele warstw nieliniowych, CAP musi być większe niż dwa.
Podstawowym węzłem w sieci neuronowej jest percepcja naśladująca neuron w biologicznej sieci neuronowej. Następnie mamy wielowarstwową Percepcję lub MLP. Każdy zestaw danych wejściowych jest modyfikowany przez zestaw wag i odchyleń; każda krawędź ma unikalną wagę, a każdy węzeł ma unikalne odchylenie.
Przepowiednia accuracy sieci neuronowej zależy od jej weights and biases.
Proces poprawiania dokładności sieci neuronowej to tzw training. Wynik z przedniej sieci podpór jest porównywany z wartością, o której wiadomo, że jest poprawna.
Plik cost function or the loss function jest różnicą między wygenerowaną wartością wyjściową a rzeczywistą wydajnością.
Celem szkolenia jest maksymalne zmniejszenie kosztu szkolenia w milionach przykładów szkoleniowych. Aby to zrobić, sieć dostosowuje wagi i odchylenia, aż prognoza pasuje do właściwych wyników.
Po odpowiednim przeszkoleniu sieć neuronowa może za każdym razem dokonywać dokładnych prognoz.
Kiedy wzorzec staje się skomplikowany i chcesz, aby Twój komputer je rozpoznał, musisz sięgnąć po sieci neuronowe. W tak złożonych scenariuszach wzorców sieć neuronowa przewyższa wszystkie inne konkurencyjne algorytmy.
Istnieją teraz procesory graficzne, które mogą trenować je szybciej niż kiedykolwiek wcześniej. Głębokie sieci neuronowe już teraz rewolucjonizują dziedzinę sztucznej inteligencji
Komputery okazały się dobre w wykonywaniu powtarzalnych obliczeń i wykonywaniu szczegółowych instrukcji, ale nie były tak dobre w rozpoznawaniu złożonych wzorców.
Jeśli istnieje problem z rozpoznawaniem prostych wzorców, maszyna wektorów nośnych (svm) lub klasyfikator regresji logistycznej mogą wykonać zadanie dobrze, ale wraz ze wzrostem złożoności wzorców nie ma innego wyjścia, jak tylko sięgnąć po głębokie sieci neuronowe.
Dlatego w przypadku złożonych wzorów, takich jak ludzka twarz, płytkie sieci neuronowe zawodzą i nie mają innego wyjścia, jak tylko sięgnąć po głębokie sieci neuronowe z większą liczbą warstw. Sieci głębokie są w stanie wykonać swoją pracę, rozkładając złożone wzory na prostsze. Na przykład ludzka twarz; Sieć adeep użyłaby krawędzi do wykrycia części takich jak usta, nos, oczy, uszy i tak dalej, a następnie ponownie połączyłaby je ze sobą, aby utworzyć ludzką twarz
Dokładność prawidłowych przewidywań stała się tak dokładna, że ostatnio podczas konkursu Google Pattern Recognition Challenge głęboka sieć uderzyła człowieka.
Idea sieci warstwowych perceptronów istnieje już od jakiegoś czasu; na tym obszarze głębokie sieci naśladują ludzki mózg. Ale jedną wadą jest to, że trenowanie ich zajmuje dużo czasu, co jest ograniczeniem sprzętowym
Jednak ostatnie wysokowydajne procesory graficzne były w stanie trenować tak głębokie sieci w czasie krótszym niż tydzień; podczas gdy szybkie procesory cpus mogłyby zająć tygodnie lub miesiące, aby zrobić to samo.
Wybór głębokiej sieci
Jak wybrać głęboką siatkę? Musimy zdecydować, czy budujemy klasyfikator, czy też próbujemy znaleźć wzorce w danych i czy będziemy korzystać z uczenia się bez nadzoru. Aby wyodrębnić wzorce z zestawu nieoznaczonych danych, używamy ograniczonej maszyny Boltzman lub kodera automatycznego.
Wybierając głęboką siatkę, weź pod uwagę następujące punkty -
Do przetwarzania tekstu, analizy sentymentów, analizowania i rozpoznawania jednostek nazw używamy sieci rekurencyjnej lub rekurencyjnej sieci tensorowej lub RNTN;
W przypadku każdego modelu językowego, który działa na poziomie znaków, używamy sieci rekurencyjnej.
Do rozpoznawania obrazu używamy sieci głębokich przekonań DBN lub sieci konwolucyjnej.
Do rozpoznawania obiektów używamy RNTN lub sieci konwolucyjnej.
Do rozpoznawania mowy używamy sieci cyklicznej.
Ogólnie rzecz biorąc, sieci głębokich przekonań i wielowarstwowe perceptrony z rektyfikowanymi jednostkami liniowymi lub RELU są dobrym wyborem do klasyfikacji.
W przypadku analizy szeregów czasowych zawsze zaleca się stosowanie sieci okresowej.
Sieci neuronowe istnieją od ponad 50 lat; ale dopiero teraz zyskały na znaczeniu. Powodem jest to, że są trudne do wyszkolenia; kiedy próbujemy je wytrenować metodą zwaną propagacją wsteczną, napotykamy na problem zwany zanikaniem lub eksplodującym gradientem. Kiedy to się dzieje, trening zajmuje więcej czasu, a dokładność zajmuje mało miejsca. Podczas uczenia zestawu danych stale obliczamy funkcję kosztu, która jest różnicą między przewidywanymi wynikami a rzeczywistymi wynikami z zestawu oznaczonych danych treningowych. Funkcja kosztu jest następnie minimalizowana poprzez dostosowywanie wag i wartości odchyleń aż do najniższej wartości jest uzyskiwane. W procesie uczenia stosuje się gradient, czyli szybkość, z jaką zmienia się koszt w odniesieniu do zmiany wagi lub wartości odchylenia.
Ograniczone sieci Boltzman lub autokodery - RBN
W 2006 roku dokonano przełomu w rozwiązaniu problemu zanikających gradientów. Geoff Hinton opracował nowatorską strategię, która doprowadziła do rozwojuRestricted Boltzman Machine - RBM, płytka dwuwarstwowa siatka.
Pierwsza warstwa to visible warstwa, a druga warstwa to hiddenwarstwa. Każdy węzeł w warstwie widocznej jest połączony z każdym węzłem w warstwie ukrytej. Sieć jest znana jako ograniczona, ponieważ żadne dwie warstwy w tej samej warstwie nie mogą współużytkować połączenia.
Autokodery to sieci, które kodują dane wejściowe jako wektory. Tworzą ukrytą lub skompresowaną reprezentację surowych danych. Wektory są przydatne w redukcji wymiarowości; wektor kompresuje surowe dane do mniejszej liczby niezbędnych wymiarów. Autoenkodery są sparowane z dekoderami, co umożliwia rekonstrukcję danych wejściowych na podstawie ich ukrytej reprezentacji.
RBM to matematyczny odpowiednik tłumacza dwukierunkowego. Przejście do przodu pobiera dane wejściowe i przekształca je na zestaw liczb, który koduje dane wejściowe. W międzyczasie przejście do tyłu przyjmuje ten zestaw liczb i przekłada je z powrotem na zrekonstruowane dane wejściowe. Dobrze wyszkolona siatka zapewnia tylną podpórkę z dużą dokładnością.
W każdym z etapów wagi i odchylenia odgrywają kluczową rolę; pomagają RBM w dekodowaniu współzależności między danymi wejściowymi oraz w decydowaniu, które dane wejściowe są niezbędne do wykrywania wzorców. Poprzez przejścia do przodu i do tyłu RBM jest uczony, aby ponownie konstruować dane wejściowe z różnymi wagami i odchyleniami, aż dane wejściowe i konstrukcja tam są jak najbliższe. Interesującym aspektem RBM jest to, że dane nie muszą być etykietowane. Okazuje się, że jest to bardzo ważne w przypadku zestawów danych ze świata rzeczywistego, takich jak zdjęcia, filmy, głosy i dane z czujników, z których wszystkie są zwykle nieoznaczone. Zamiast ręcznie oznaczać dane przez ludzi, RBM automatycznie sortuje dane; poprzez odpowiednie dostosowanie wag i odchyleń, KMS jest w stanie wyodrębnić ważne cechy i zrekonstruować dane wejściowe. RBM jest częścią rodziny sieci neuronowych z ekstrakcją cech, które są przeznaczone do rozpoznawania nieodłącznych wzorców w danych. Są one również nazywane auto-koderami, ponieważ muszą kodować własną strukturę.

Sieci głębokich przekonań - DBN
Sieci głębokich przekonań (DBN) powstają poprzez połączenie KMS i wprowadzenie sprytnej metody szkolenia. Mamy nowy model, który ostatecznie rozwiązuje problem zanikającego gradientu. Geoff Hinton wynalazł KMS, a także sieci głębokiego przekonania jako alternatywę dla propagacji wstecznej.
DBN ma podobną strukturę do MLP (wielowarstwowy perceptron), ale bardzo różni się pod względem treningu. to szkolenie umożliwia DBN osiąganie lepszych wyników niż ich płytkie odpowiedniki
DBN można wizualizować jako stos KMS, gdzie ukryta warstwa jednego KMS jest widoczną warstwą KMS znajdującą się nad nią. Pierwszy KMS jest przeszkolony, aby jak najdokładniej odtworzyć jego dane wejściowe.
Ukryta warstwa pierwszego KMS jest traktowana jako widoczna warstwa drugiego KMS, a druga KMS jest trenowana przy użyciu danych wyjściowych z pierwszego KMS. Ten proces jest powtarzany, aż każda warstwa w sieci zostanie przeszkolona.
W DBN każdy RBM uczy się całego wejścia. DBN działa globalnie, dostrajając kolejno cały sygnał wejściowy, ponieważ model powoli poprawia się, tak jak obiektyw aparatu powoli skupia obraz. Stos RBM przewyższa pojedynczy KMS, ponieważ wielowarstwowy perceptron MLP przewyższa pojedynczy perceptron.
Na tym etapie systemy KMS wykryły nieodłączne wzorce w danych, ale bez nazw ani etykiet. Aby zakończyć szkolenie DBN, musimy wprowadzić etykiety do wzorów i dostroić sieć z uczeniem nadzorowanym.
Potrzebujemy bardzo małego zestawu oznaczonych próbek, aby cechy i wzory można było skojarzyć z nazwą. Ten niewielki zestaw danych jest używany do uczenia. Ten zestaw oznaczonych danych może być bardzo mały w porównaniu z oryginalnym zestawem danych.
Wagi i odchylenia są nieznacznie zmienione, co powoduje niewielką zmianę w postrzeganiu wzorców przez sieć i często niewielki wzrost całkowitej dokładności.
Szkolenie można również ukończyć w rozsądnym czasie, używając procesorów graficznych dających bardzo dokładne wyniki w porównaniu z płytkimi sieciami, a także widzimy rozwiązanie problemu znikającego gradientu.
Generative Adversarial Networks - GAN
Generatywne sieci przeciwstawne to głębokie sieci neuronowe składające się z dwóch sieci ustawionych jedna przeciwko drugiej, stąd nazwa „kontradyktoryjność”.
GAN zostały przedstawione w artykule opublikowanym przez naukowców z Uniwersytetu w Montrealu w 2014 roku. Yann LeCun, ekspert AI Facebooka, odnosząc się do GAN, nazwał szkolenie adwersarzy „najciekawszym pomysłem ostatnich 10 lat w ML”.
Potencjał sieci GAN jest ogromny, ponieważ skanowanie sieci uczy się naśladować dowolną dystrybucję danych. GAN można nauczyć tworzenia równoległych światów uderzająco podobnych do naszych w dowolnej dziedzinie: obrazów, muzyki, mowy, prozy. Są w pewnym sensie twórcami robotów, a ich dorobek jest imponujący.
W GAN, jedna sieć neuronowa, zwana generatorem, generuje nowe instancje danych, podczas gdy druga, dyskryminator, ocenia je pod kątem autentyczności.
Powiedzmy, że próbujemy wygenerować odręczne liczby, takie jak te, które znajdują się w zbiorze danych MNIST, który pochodzi ze świata rzeczywistego. Praca dyskryminatora, gdy zostanie pokazana instancja z prawdziwego zbioru danych MNIST, polega na rozpoznaniu ich jako autentycznych.
Rozważ teraz następujące kroki GAN -
Sieć generatora pobiera dane wejściowe w postaci liczb losowych i zwraca obraz.
Ten wygenerowany obraz jest podawany jako dane wejściowe do sieci dyskryminatora wraz ze strumieniem obrazów pobranych z rzeczywistego zbioru danych.
Dyskryminator przyjmuje zarówno rzeczywiste, jak i fałszywe obrazy i zwraca prawdopodobieństwa, liczbę od 0 do 1, gdzie 1 oznacza prognozę autentyczności, a 0 oznacza fałszywy.
Masz więc podwójną pętlę sprzężenia zwrotnego -
Dyskryminator jest w pętli sprzężenia zwrotnego z podstawową prawdą obrazów, które znamy.
Generator jest w pętli sprzężenia zwrotnego z dyskryminatorem.
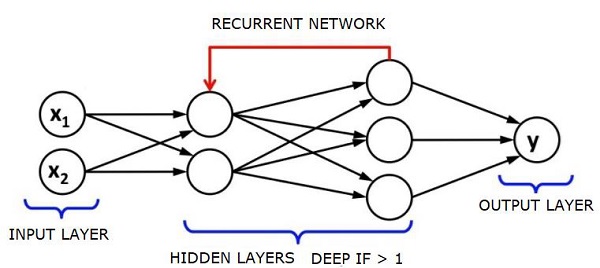
Powtarzające się sieci neuronowe - RNN
RNNSare sieci neuronowe, w których dane mogą przepływać w dowolnym kierunku. Sieci te są używane do zastosowań, takich jak modelowanie języka lub przetwarzanie języka naturalnego (NLP).
Podstawową koncepcją leżącą u podstaw sieci RNN jest wykorzystanie informacji sekwencyjnej. W normalnej sieci neuronowej zakłada się, że wszystkie wejścia i wyjścia są od siebie niezależne. Jeśli chcemy przewidzieć następne słowo w zdaniu, musimy wiedzieć, jakie słowa pojawiły się przed nim.
RNN nazywane są cyklicznymi, ponieważ powtarzają to samo zadanie dla każdego elementu sekwencji, a dane wyjściowe są oparte na poprzednich obliczeniach. Można zatem powiedzieć, że RNN mają „pamięć”, która przechwytuje informacje o tym, co zostało wcześniej obliczone. Teoretycznie RNN mogą wykorzystywać informacje w bardzo długich sekwencjach, ale w rzeczywistości mogą spojrzeć wstecz tylko na kilka kroków.
Sieci pamięci długoterminowej (LSTM) są najczęściej używanymi sieciami RNN.
Razem z konwolucyjnymi sieciami neuronowymi, RNN zostały wykorzystane jako część modelu do generowania opisów obrazów bez etykiet. To niesamowite, jak dobrze to działa.
Konwolucyjne głębokie sieci neuronowe - CNN
Jeśli zwiększymy liczbę warstw w sieci neuronowej, aby ją pogłębić, zwiększy to złożoność sieci i pozwoli nam modelować funkcje, które są bardziej skomplikowane. Jednak liczba wag i odchyleń będzie rosła wykładniczo. W rzeczywistości poznanie tak trudnych problemów może stać się niemożliwe dla normalnych sieci neuronowych. Prowadzi to do rozwiązania, konwolucyjnych sieci neuronowych.
CNN są szeroko stosowane w wizji komputerowej; znalazły również zastosowanie w modelowaniu akustycznym do automatycznego rozpoznawania mowy.
Ideą konwolucyjnych sieci neuronowych jest idea „ruchomego filtra”, który przechodzi przez obraz. Ten ruchomy filtr lub splot dotyczy pewnego sąsiedztwa węzłów, które na przykład mogą być pikselami, gdzie zastosowany filtr to 0,5 x wartość węzła -
Znany badacz Yann LeCun był pionierem konwolucyjnych sieci neuronowych. Facebook jako oprogramowanie do rozpoznawania twarzy korzysta z tych sieci. CNN to rozwiązanie dla projektów wizyjnych. Sieć konwolucyjna składa się z wielu warstw. W wyzwaniu Imagenet maszyna była w stanie pokonać człowieka w rozpoznawaniu obiektów w 2015 roku.
Krótko mówiąc, konwolucyjne sieci neuronowe (CNN) to wielowarstwowe sieci neuronowe. Warstwy mają czasem do 17 lub więcej i zakładają, że danymi wejściowymi są obrazy.
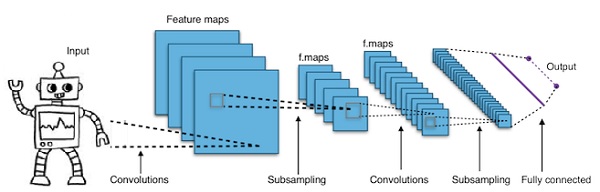
CNN drastycznie zmniejszają liczbę parametrów, które należy dostroić. Tak więc sieci CNN wydajnie radzą sobie z wysoką wymiarowością surowych obrazów.