Python Forensics - przegląd języka Python
Kody napisane w Pythonie wyglądają dość podobnie do kodów napisanych w innych konwencjonalnych językach programowania, takich jak C czy Pascal. Mówi się również, że składnia Pythona jest mocno zapożyczona z C. Obejmuje to wiele słów kluczowych Pythona, które są podobne do języka C.
Python zawiera instrukcje warunkowe i zapętlone, których można użyć do dokładnego wyodrębnienia danych na potrzeby medycyny sądowej. Zapewnia kontrolę przepływuif/else, whilei na wysokim poziomie for instrukcja, która zapętla każdy „iterowalny” obiekt.
if a < b:
max = b
else:
max = aGłównym obszarem, w którym Python różni się od innych języków programowania, jest użycie dynamic typing. Używa nazw zmiennych, które odnoszą się do obiektów. Te zmienne nie muszą być deklarowane.
Typy danych
Python zawiera zestaw wbudowanych typów danych, takich jak łańcuchy znaków, wartości logiczne, liczby itp. Istnieją również typy niezmienne, czyli wartości, których nie można zmienić podczas wykonywania.
Python ma również wbudowane złożone typy danych, które obejmują tuples które są niezmiennymi tablicami, lists, i dictionariesktóre są tabelami skrótów. Wszystkie są używane w kryminalistyce cyfrowej do przechowywania wartości podczas gromadzenia dowodów.
Moduły i pakiety innych firm
Python obsługuje grupy modułów i / lub pakietów, które są również nazywane third-party modules (powiązany kod zgrupowany w jednym pliku źródłowym) używany do organizowania programów.
Python zawiera obszerną bibliotekę standardową, co jest jednym z głównych powodów jego popularności w informatyce śledczej.
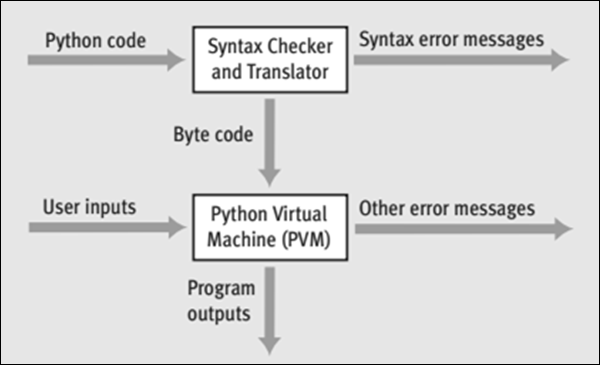
Cykl życia kodu w Pythonie
Na początku, kiedy wykonujesz kod w Pythonie, interpreter sprawdza kod pod kątem błędów składniowych. Jeśli interpreter wykryje jakiekolwiek błędy składniowe, zostaną one natychmiast wyświetlone jako komunikaty o błędach.
Jeśli nie ma błędów składniowych, kod jest kompilowany w celu utworzenia pliku bytecode i wysłane do PVM (Python Virtual Machine).
Moduł PVM sprawdza kod bajtowy pod kątem błędów w czasie wykonywania lub błędów logicznych. W przypadku, gdy PVM wykryje jakiekolwiek błędy uruchomieniowe, zostaną one natychmiast zgłoszone jako komunikaty o błędach.
Jeśli kod bajtowy jest wolny od błędów, kod jest przetwarzany i otrzymujesz wynik.
Na poniższej ilustracji przedstawiono graficznie, w jaki sposób kod Pythona jest najpierw interpretowany w celu utworzenia kodu bajtowego oraz w jaki sposób kod bajtowy jest przetwarzany przez moduł PVM w celu wygenerowania danych wyjściowych.