Python Forensics - Szybki przewodnik
Python to język programowania ogólnego przeznaczenia z łatwym, czytelnym kodem, który może być łatwo zrozumiały zarówno dla profesjonalnych programistów, jak i początkujących programistów. Python składa się z wielu przydatnych bibliotek, których można używać w dowolnej strukturze stosu. Wiele laboratoriów korzysta z języka Python do budowania podstawowych modeli prognozowania i przeprowadzania eksperymentów. Pomaga również kontrolować krytyczne systemy operacyjne.
Python ma wbudowane funkcje wspierające cyfrowe dochodzenia i chroniące integralność dowodów podczas dochodzenia. W tym samouczku wyjaśnimy podstawowe koncepcje stosowania Pythona w kryminalistyce cyfrowej lub obliczeniowej.
Co to jest Computational Forensics?
Computational Forensics to nowa dziedzina badań. Zajmuje się rozwiązywaniem problemów kryminalistycznych metodami cyfrowymi. Wykorzystuje informatykę do badania dowodów cyfrowych.
Computation Forensics obejmuje szeroki zakres tematów, w których badane są przedmioty, substancje i procesy, głównie w oparciu o dowody wzorcowe, takie jak ślady narzędzi, odciski palców, odciski butów, dokumenty itp., A także wzorce fizjologiczne i behawioralne, DNA i dowody cyfrowe w miejsce zbrodni.
Poniższy diagram przedstawia szeroki zakres tematów objętych Computational Forensics.

Obliczeniowa kryminalistyka jest implementowana za pomocą niektórych algorytmów. Algorytmy te są wykorzystywane do przetwarzania sygnałów i obrazów, wizji komputerowej i grafiki. Obejmuje również eksplorację danych, uczenie maszynowe i robotykę.
Informatyka śledcza obejmuje różnorodne metody cyfrowe. Najlepszym rozwiązaniem ułatwiającym stosowanie wszystkich metod cyfrowych w kryminalistyce jest użycie języka programowania ogólnego przeznaczenia, takiego jak Python.
Ponieważ potrzebujemy Pythona do wszystkich czynności związanych z kryminalistyką obliczeniową, przejdźmy krok po kroku i zrozummy, jak go zainstalować.
Step 1 - Idź do https://www.python.org/downloads/ i pobierz pliki instalacyjne Pythona zgodnie z systemem operacyjnym, który masz w swoim systemie.

Step 2 - Po pobraniu pakietu / instalatora kliknij plik exe, aby rozpocząć proces instalacji.

Po zakończeniu instalacji zobaczysz następujący ekran.
Step 3 - Następnym krokiem jest ustawienie zmiennych środowiskowych Pythona w systemie.
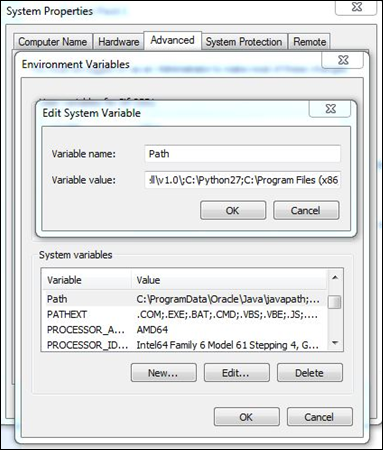
Step 4 - Po ustawieniu zmiennych środowiskowych wpisz polecenie „python” w wierszu polecenia, aby sprawdzić, czy instalacja przebiegła pomyślnie, czy nie.
Jeśli instalacja się powiodła, na konsoli pojawi się następujący wynik.

Kody napisane w Pythonie wyglądają dość podobnie do kodów napisanych w innych konwencjonalnych językach programowania, takich jak C czy Pascal. Mówi się również, że składnia Pythona jest w dużej mierze zapożyczona z C. Obejmuje to wiele słów kluczowych Pythona, które są podobne do języka C.
Python zawiera instrukcje warunkowe i zapętlone, których można użyć do dokładnego wyodrębnienia danych na potrzeby medycyny sądowej. Zapewnia kontrolę przepływuif/else, whilei na wysokim poziomie for instrukcja, która zapętla każdy „iterowalny” obiekt.
if a < b:
max = b
else:
max = aGłównym obszarem, w którym Python różni się od innych języków programowania, jest użycie dynamic typing. Używa nazw zmiennych, które odnoszą się do obiektów. Te zmienne nie muszą być deklarowane.
Typy danych
Python zawiera zestaw wbudowanych typów danych, takich jak łańcuchy znaków, wartości logiczne, liczby itp. Istnieją również typy niezmienne, czyli wartości, których nie można zmienić podczas wykonywania.
Python ma również wbudowane złożone typy danych, które obejmują tuples które są niezmiennymi tablicami, lists, i dictionariesktóre są tabelami skrótów. Wszystkie są wykorzystywane w kryminalistyce cyfrowej do przechowywania wartości podczas gromadzenia dowodów.
Moduły i pakiety innych firm
Python obsługuje grupy modułów i / lub pakietów, które są również nazywane third-party modules (powiązany kod zgrupowany w jednym pliku źródłowym) używany do organizowania programów.
Python zawiera obszerną bibliotekę standardową, co jest jednym z głównych powodów jego popularności w informatyce śledczej.
Cykl życia kodu w Pythonie
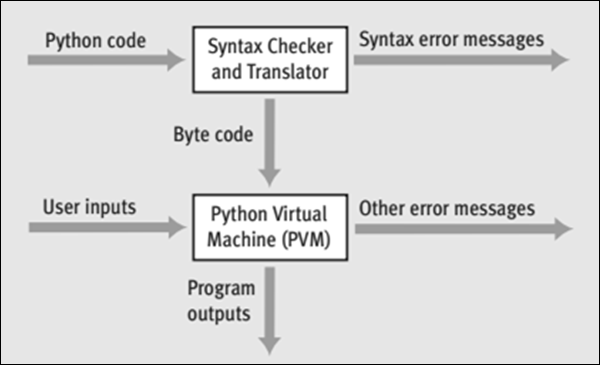
Na początku, gdy wykonujesz kod w Pythonie, interpreter sprawdza kod pod kątem błędów składniowych. Jeśli interpreter wykryje jakiekolwiek błędy składniowe, zostaną one natychmiast wyświetlone jako komunikaty o błędach.
Jeśli nie ma błędów składniowych, kod jest kompilowany w celu utworzenia pliku bytecode i wysłane do PVM (Python Virtual Machine).
Moduł PVM sprawdza kod bajtowy pod kątem błędów w czasie wykonywania lub błędów logicznych. W przypadku znalezienia przez PVM jakichkolwiek błędów wykonawczych, są one natychmiast zgłaszane jako komunikaty o błędach.
Jeśli kod bajtowy jest wolny od błędów, kod jest przetwarzany i otrzymujesz wynik.
Na poniższej ilustracji przedstawiono graficznie, w jaki sposób kod Pythona jest najpierw interpretowany w celu utworzenia kodu bajtowego oraz w jaki sposób kod bajtowy jest przetwarzany przez moduł PVM w celu wygenerowania danych wyjściowych.
Aby utworzyć aplikację zgodnie z wytycznymi kryminalistycznymi, ważne jest zrozumienie i przestrzeganie konwencji i wzorców nazewnictwa.
Konwencje nazewnictwa
Podczas tworzenia aplikacji śledczych w języku Python zasady i konwencje, których należy przestrzegać, opisano w poniższej tabeli.
| Stałe | Wielkie litery z separacją podkreślenia | WYSOKA TEMPERATURA |
| Nazwa zmiennej lokalnej | Małe litery z wyboistymi literami (podkreślenia są opcjonalne) | obecna temperatura |
| Nazwa zmiennej globalnej | Prefiks gl małe litery z wyboistymi literami (podkreślenia są opcjonalne) | gl_maximumRecordedTemperature |
| Nazwa funkcji | Wielkie litery z wypukłymi literami (opcjonalnie podkreślenia) z aktywnym głosem | ConvertFarenheitToCentigrade (...) |
| Nazwa obiektu | Przedrostek ob_ małe litery z wyboistymi literami | ob_myTempRecorder |
| Moduł | Podkreślenie, a po nim małe litery z wyboistymi literami | _tempRecorder |
| Nazwy klas | Przedrostki class_, a następnie wyboiste czapki i krótkie | class_TempSystem |
Weźmy scenariusz, aby zrozumieć znaczenie konwencji nazewnictwa w informatyce obliczeniowej. Załóżmy, że mamy algorytm haszujący, który jest zwykle używany do szyfrowania danych. Algorytm jednokierunkowego mieszania przyjmuje dane wejściowe jako strumień danych binarnych; może to być hasło, plik, dane binarne lub dowolne dane cyfrowe. Następnie algorytm haszujący tworzy plikmessage digest (md) w odniesieniu do danych otrzymanych na wejściu.
Praktycznie niemożliwe jest utworzenie nowego wejścia binarnego, które wygeneruje dany skrót wiadomości. Nawet jeden bit binarnych danych wejściowych, jeśli zostanie zmieniony, wygeneruje unikalny komunikat, który różni się od poprzedniego.
Przykład
Spójrz na następujący przykładowy program, który jest zgodny z wyżej wymienionymi konwencjami.
import sys, string, md5 # necessary libraries
print "Please enter your full name"
line = sys.stdin.readline()
line = line.rstrip()
md5_object = md5.new()
md5_object.update(line)
print md5_object.hexdigest() # Prints the output as per the hashing algorithm i.e. md5
exitPowyższy program generuje następujące dane wyjściowe.
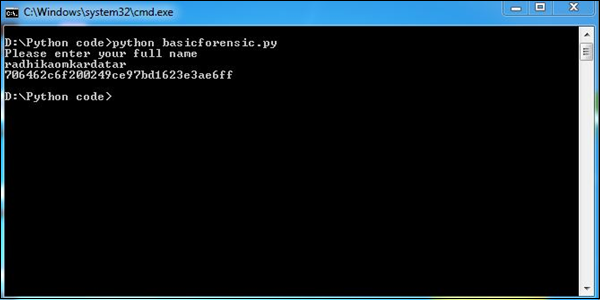
W tym programie skrypt Pythona akceptuje dane wejściowe (Twoje pełne imię i nazwisko) i konwertuje je zgodnie z algorytmem haszowania md5. Szyfruje dane i zabezpiecza informacje, jeśli jest to wymagane. Zgodnie z wytycznymi kryminalistycznymi, nazwy dowodów lub jakiekolwiek inne dowody mogą być zabezpieczone w tym wzorze.
ZA hash functionjest definiowana jako funkcja, która odwzorowuje dużą ilość danych na stałą wartość o określonej długości. Ta funkcja zapewnia, że te same dane wejściowe skutkują tym samym wyjściem, które jest faktycznie zdefiniowane jako suma skrótu. Suma hash zawiera cechę z określonymi informacjami.
Przywrócenie tej funkcji jest praktycznie niemożliwe. W związku z tym każdy atak strony trzeciej, taki jak atak brutalnej siły, jest praktycznie niemożliwy. Również ten rodzaj algorytmu jest nazywanyone-way cryptographic algorithm.
Idealna kryptograficzna funkcja skrótu ma cztery główne właściwości -
- Obliczenie wartości skrótu dla dowolnego wejścia musi być łatwe.
- Wygenerowanie oryginalnych danych wejściowych z jego skrótu musi być niewykonalne.
- Modyfikacja danych wejściowych bez zmiany skrótu musi być niewykonalna.
- Znalezienie dwóch różnych danych wejściowych z tym samym hashem musi być niewykonalne.
Przykład
Rozważmy następujący przykład, który pomaga w dopasowywaniu haseł przy użyciu znaków w formacie szesnastkowym.
import uuid
import hashlib
def hash_password(password):
# userid is used to generate a random number
salt = uuid.uuid4().hex #salt is stored in hexadecimal value
return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ':' + salt
def check_password(hashed_password, user_password):
# hexdigest is used as an algorithm for storing passwords
password, salt = hashed_password.split(':')
return password == hashlib.sha256(salt.encode()
+ user_password.encode()).hexdigest()
new_pass = raw_input('Please enter required password ')
hashed_password = hash_password(new_pass)
print('The string to store in the db is: ' + hashed_password)
old_pass = raw_input('Re-enter new password ')
if check_password(hashed_password, old_pass):
print('Yuppie!! You entered the right password')
else:
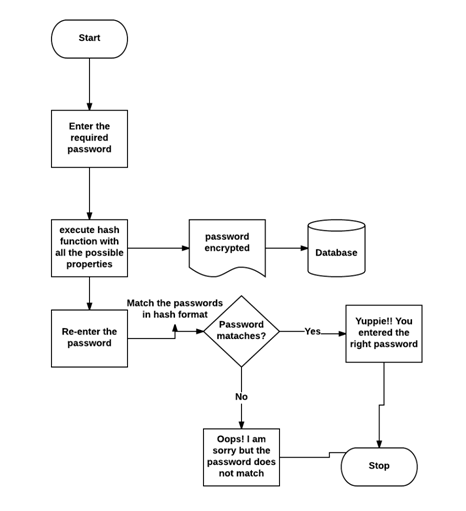
print('Oops! I am sorry but the password does not match')Schemat blokowy
Wyjaśniliśmy logikę tego programu za pomocą następującego schematu blokowego -
Wynik
Nasz kod wygeneruje następujący wynik -
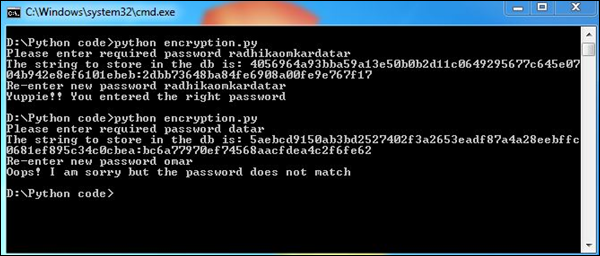
Hasło wprowadzone dwukrotnie jest zgodne z funkcją skrótu. Dzięki temu dwukrotnie wprowadzone hasło jest dokładne, co pomaga w zebraniu przydatnych danych i zapisaniu ich w zaszyfrowanym formacie.
W tym rozdziale dowiemy się, jak złamać dane tekstowe pobrane podczas analizy i dowodów.
Zwykły tekst w kryptografii to zwykły, czytelny tekst, taki jak wiadomość. Z drugiej strony, zaszyfrowany tekst jest wynikiem algorytmu szyfrowania pobranego po wprowadzeniu zwykłego tekstu.
Prosty algorytm, w jaki sposób zamieniamy zwykłą wiadomość tekstową w zaszyfrowany tekst, to szyfr Cezara, wymyślony przez Juliusza Cezara, aby ukryć zwykły tekst przed wrogami. Ten szyfr polega na przesunięciu każdej litery w wiadomości „do przodu” o trzy miejsca w alfabecie.
Poniżej znajduje się ilustracja demonstracyjna.
a → D
b → E.
c → F.
....
w → Z
x → A
y → B
z → C
Przykład
Komunikat wprowadzony podczas uruchamiania skryptu w Pythonie daje wszystkie możliwości znaków, które są używane jako dowód wzorców.
Typy wykorzystywanych dowodów wzorców są następujące:
- Ślady i oznaczenia opon
- Impressions
- Fingerprints
Każde dane biometryczne składa się z danych wektorowych, które musimy złamać, aby zebrać pełne dowody.
Poniższy kod w Pythonie pokazuje, jak można utworzyć zaszyfrowany tekst ze zwykłego tekstu -
import sys
def decrypt(k,cipher):
plaintext = ''
for each in cipher:
p = (ord(each)-k) % 126
if p < 32:
p+=95
plaintext += chr(p)
print plaintext
def main(argv):
if (len(sys.argv) != 1):
sys.exit('Usage: cracking.py')
cipher = raw_input('Enter message: ')
for i in range(1,95,1):
decrypt(i,cipher)
if __name__ == "__main__":
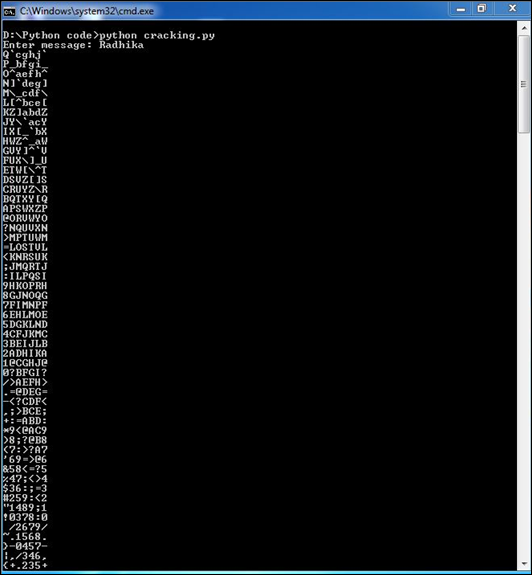
main(sys.argv[1:])Wynik
Teraz sprawdź wyjście tego kodu. Kiedy wprowadzimy prosty tekst „Radhika”, program wygeneruje następujący zaszyfrowany tekst.
Virtualizationto proces emulacji systemów IT, takich jak serwery, stacje robocze, sieci i pamięci masowe. To nic innego jak stworzenie wirtualnej, a nie rzeczywistej wersji dowolnego systemu operacyjnego, serwera, urządzenia magazynującego lub procesów sieciowych.
Główny składnik, który pomaga w emulacji sprzętu wirtualnego, jest zdefiniowany jako plik hyper-visor.
Poniższy rysunek wyjaśnia dwa główne typy stosowanych wirtualizacji systemu.
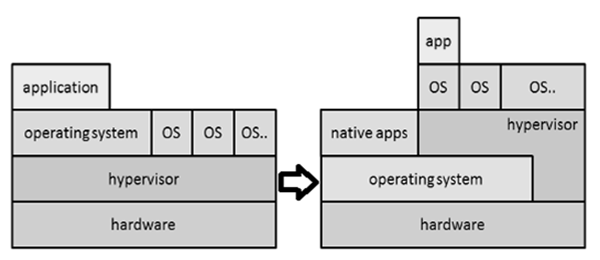
Wirtualizacja jest wykorzystywana w informatyce śledczej na wiele sposobów. Pomaga analitykowi w taki sposób, że stacja robocza może być używana w walidowanym stanie do każdego badania. Odzyskiwanie danych jest możliwe w szczególności poprzez dołączenie obrazu dd dysku jako dysku dodatkowego na maszynie wirtualnej. Ta sama maszyna może być używana jako oprogramowanie do odzyskiwania w celu zebrania dowodów.
Poniższy przykład pomaga w zrozumieniu tworzenia maszyny wirtualnej za pomocą języka programowania Python.
Step 1 - Niech maszyna wirtualna zostanie nazwana „dummy1”.
Każda maszyna wirtualna musi mieć 512 MB pamięci o minimalnej pojemności wyrażonej w bajtach.
vm_memory = 512 * 1024 * 1024Step 2 - Maszyna wirtualna musi być podłączona do domyślnego klastra, który został obliczony.
vm_cluster = api.clusters.get(name = "Default")Step 3 - Maszyna wirtualna musi zostać uruchomiona z wirtualnego dysku twardego.
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])Wszystkie opcje są łączone w obiekt parametrów maszyny wirtualnej przed użyciem metody dodawania kolekcji maszyn wirtualnych do maszyny wirtualnej.
Przykład
Poniżej znajduje się kompletny skrypt Pythona do dodawania maszyny wirtualnej.
from ovirtsdk.api import API #importing API library
from ovirtsdk.xml import params
try: #Api credentials is required for virtual machine
api = API(url = "https://HOST",
username = "Radhika",
password = "a@123",
ca_file = "ca.crt")
vm_name = "dummy1"
vm_memory = 512 * 1024 * 1024 #calculating the memory in bytes
vm_cluster = api.clusters.get(name = "Default")
vm_template = api.templates.get(name = "Blank")
#assigning the parameters to operating system
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])
vm_params = params.VM(name = vm_name,
memory = vm_memory,
cluster = vm_cluster,
template = vm_template
os = vm_os)
try:
api.vms.add(vm = vm_params)
print "Virtual machine '%s' added." % vm_name #output if it is successful.
except Exception as ex:
print "Adding virtual machine '%s' failed: %s" % (vm_name, ex)
api.disconnect()
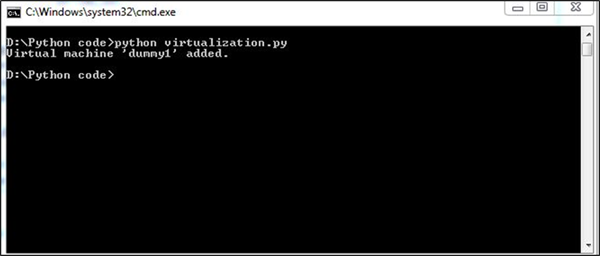
except Exception as ex:
print "Unexpected error: %s" % exWynik
Nasz kod wygeneruje następujący wynik -
Scenariusz współczesnych środowisk sieciowych jest taki, że badanie może być napięte z powodu wielu trudności. Może się tak zdarzyć, niezależnie od tego, czy odpowiadasz na wsparcie w przypadku naruszenia, badasz działania wewnętrzne, przeprowadzasz oceny związane z podatnością lub sprawdzasz zgodność z przepisami.
Koncepcja programowania sieciowego
W programowaniu sieciowym używane są następujące definicje.
Client - Klient jest częścią architektury klient-serwer programowania sieciowego, która działa na komputerze osobistym i stacji roboczej.
Server - Serwer jest częścią architektury klient-serwer, która świadczy usługi innym programom komputerowym na tym samym lub innych komputerach.
WebSockets- WebSockets zapewniają protokół między klientem a serwerem, który działa przez trwałe połączenie TCP. Dzięki temu dwukierunkowe komunikaty mogą być przesyłane między połączeniem gniazda TCP (jednocześnie).
WebSockets to po wielu innych technologiach, które umożliwiają serwerom wysyłanie informacji do klienta. Oprócz uzgadniania nagłówka aktualizacji, WebSockets jest niezależne od protokołu HTTP.

Protokoły te służą do sprawdzania informacji, które są wysyłane lub odbierane przez użytkowników zewnętrznych. Ponieważ szyfrowanie jest jedną z metod stosowanych do zabezpieczania wiadomości, ważne jest również zabezpieczenie kanału, przez który wiadomości zostały przesłane.
Rozważmy następujący program w języku Python, którego używa klient handshaking.
Przykład
# client.py
import socket
# create a socket object
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# connection to hostname on the port.
s.connect((host, port))
# Receive no more than 1024 bytes
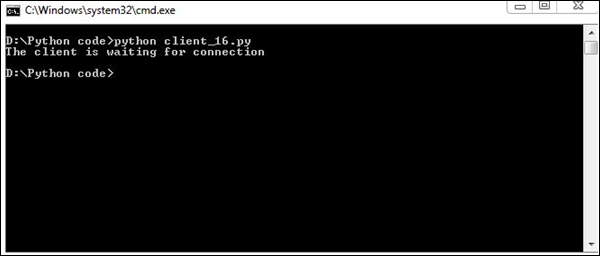
tm = s.recv(1024)
print("The client is waiting for connection")
s.close()Wynik
Wytworzy następujący wynik -
Serwer akceptujący żądanie kanału komunikacyjnego będzie zawierał następujący skrypt.
# server.py
import socket
import time
# create a socket object
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# bind to the port
serversocket.bind((host, port))
# queue up to 5 requests
serversocket.listen(5)
while True:
# establish a connection
clientsocket,addr = serversocket.accept()
print("Got a connection from %s" % str(addr))
currentTime = time.ctime(time.time()) + "\r\n"
clientsocket.send(currentTime.encode('ascii'))
clientsocket.close()Klient i serwer utworzony za pomocą programowania w Pythonie nasłuchują numeru hosta. Początkowo klient wysyła żądanie do serwera w zakresie danych przesłanych w numerze hosta, a serwer akceptuje żądanie i natychmiast wysyła odpowiedź. W ten sposób możemy mieć bezpieczny kanał komunikacji.
Moduły w programach Python pomagają w organizacji kodu. Pomagają w grupowaniu powiązanego kodu w jeden moduł, co ułatwia jego zrozumienie i używanie. Zawiera dowolnie nazwane wartości, których można użyć do powiązania i odniesienia. Krótko mówiąc, moduł to plik składający się z kodu Pythona, który zawiera funkcje, klasy i zmienne.
Kod Pythona dla modułu (pliku) jest zapisywany z .py rozszerzenie, które jest kompilowane w razie potrzeby.
Example
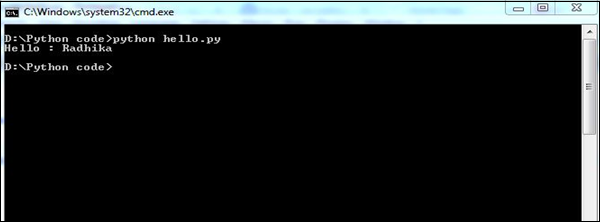
def print_hello_func( par ):
print "Hello : ", par
returnInstrukcja importu
Plik źródłowy Pythona może być używany jako moduł, wykonując plik importinstrukcja importująca inne pakiety lub biblioteki innych firm. Użyta składnia jest następująca -
import module1[, module2[,... moduleN]Gdy interpreter języka Python napotka instrukcję import, importuje określony moduł, który znajduje się w ścieżce wyszukiwania.
Example
Rozważmy następujący przykład.
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Radhika")Wytworzy następujący wynik -
Moduł jest ładowany tylko raz, niezależnie od tego, ile razy był importowany przez kod Pythona.
Od ... oświadczenie importu
Fromatrybut pomaga zaimportować określone atrybuty z modułu do bieżącej przestrzeni nazw. Oto jego składnia.
from modname import name1[, name2[, ... nameN]]Example
Aby zaimportować funkcję fibonacci z modułu fibużyj poniższej instrukcji.
from fib import fibonacciLokalizowanie modułów
Podczas importowania modułu interpreter Pythona wyszukuje następujące sekwencje -
Bieżący katalog.
Jeśli moduł nie istnieje, Python przeszukuje następnie każdy katalog w zmiennej powłoki PYTHONPATH.
Jeśli lokalizacja zmiennej powłoki nie powiedzie się, Python sprawdzi domyślną ścieżkę.
Obliczeniowa kryminalistyka korzysta z modułów Pythona i modułów innych firm, aby uzyskać informacje i łatwiej wyodrębnić dowody. Dalsze rozdziały koncentrują się na implementacji modułów, aby uzyskać niezbędne wyniki.
DShell
Dshellto oparty na Pythonie zestaw narzędzi do analizy kryminalistycznej sieci. Ten zestaw narzędzi został opracowany przez laboratorium badawcze armii amerykańskiej. Ten zestaw narzędzi typu open source został wydany w roku 2014. Głównym celem tego zestawu narzędzi jest ułatwienie prowadzenia dochodzeń kryminalistycznych.
Zestaw narzędzi składa się z dużej liczby dekoderów wymienionych w poniższej tabeli.
| Sr.No. | Nazwa i opis dekodera |
|---|---|
| 1 | dns Służy do wyodrębniania zapytań związanych z DNS |
| 2 | reservedips Identyfikuje rozwiązania problemów z DNS |
| 3 | large-flows Lista przepływów netto |
| 4 | rip-http Służy do wyodrębniania plików z ruchu HTTP |
| 5 | Protocols Służy do identyfikacji niestandardowych protokołów |
Laboratorium armii amerykańskiej utrzymywało repozytorium klonów w GitHub pod następującym linkiem -
https://github.com/USArmyResearchLab/Dshell
Klon składa się ze skryptu install-ubuntu.py () używany do instalacji tego zestawu narzędzi.
Po pomyślnym zakończeniu instalacji automatycznie utworzy pliki wykonywalne i zależności, które będą używane później.
Zależności są następujące -
dependencies = {
"Crypto": "crypto",
"dpkt": "dpkt",
"IPy": "ipy",
"pcap": "pypcap"
}Ten zestaw narzędzi może być używany przeciwko plikom pcap (przechwytywania pakietów), które są zwykle rejestrowane podczas incydentów lub podczas ostrzeżenia. Te pliki pcap są tworzone przez libpcap na platformie Linux lub przez WinPcap na platformie Windows.
Scapy
Scapy to oparte na Pythonie narzędzie służące do analizowania i manipulowania ruchem sieciowym. Poniżej znajduje się link do zestawu narzędzi Scapy -
http://www.secdev.org/projects/scapy/
Ten zestaw narzędzi jest używany do analizy manipulacji pakietami. Jest bardzo zdolny do dekodowania pakietów wielu protokołów i przechwytywania ich. Scapy różni się od zestawu narzędzi Dshell dostarczeniem badaczowi szczegółowego opisu ruchu sieciowego. Te opisy zostały nagrane w czasie rzeczywistym.
Scapy ma możliwość drukowania przy użyciu narzędzi innych firm lub odcisków palców systemu operacyjnego.
Rozważmy następujący przykład.
import scapy, GeoIP #Imports scapy and GeoIP toolkit
from scapy import *
geoIp = GeoIP.new(GeoIP.GEOIP_MEMORY_CACHE) #locates the Geo IP address
def locatePackage(pkg):
src = pkg.getlayer(IP).src #gets source IP address
dst = pkg.getlayer(IP).dst #gets destination IP address
srcCountry = geoIp.country_code_by_addr(src) #gets Country details of source
dstCountry = geoIp.country_code_by_addr(dst) #gets country details of destination
print src+"("+srcCountry+") >> "+dst+"("+dstCountry+")\n"Ten skrypt zawiera szczegółowy opis szczegółów kraju w pakiecie sieciowym, które komunikują się ze sobą.
Powyższy skrypt wygeneruje następujący wynik.
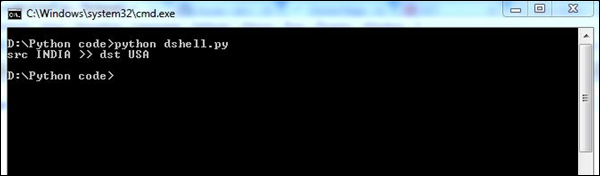
Searchingjest z pewnością jednym z filarów śledztwa kryminalistycznego. W dzisiejszych czasach przeszukiwanie jest tak dobre, jak śledczy, który prowadzi dowody.
Wyszukiwanie słowa kluczowego w wiadomości odgrywa istotną rolę w medycynie sądowej, gdy szukamy dowodów za pomocą słowa kluczowego. Znajomość tego, co ma być przeszukiwane w konkretnym pliku, a także w usuniętych plikach, wymaga zarówno doświadczenia, jak i wiedzy.
Python ma różne wbudowane mechanizmy z obsługą standardowych modułów bibliotecznych searchoperacja. Zasadniczo badacze używają operacji wyszukiwania do znajdowania odpowiedzi na pytania, takie jak „kto”, „co”, „gdzie”, „kiedy” itp.
Przykład
W poniższym przykładzie zadeklarowaliśmy dwa ciągi, a następnie użyliśmy funkcji find, aby sprawdzić, czy pierwszy ciąg zawiera drugi ciąg, czy nie.
# Searching a particular word from a message
str1 = "This is a string example for Computational forensics of gathering evidence!";
str2 = "string";
print str1.find(str2)
print str1.find(str2, 10)
print str1.find(str2, 40)Powyższy skrypt wygeneruje następujący wynik.
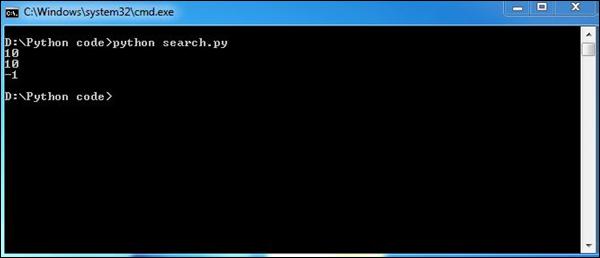
“find”funkcja w Pythonie pomaga w wyszukiwaniu słowa kluczowego w wiadomości lub akapicie. Ma to kluczowe znaczenie przy gromadzeniu odpowiednich dowodów.
Indexingfaktycznie zapewnia badaczowi pełny wgląd w akta i zebranie z nich potencjalnych dowodów. Dowód może znajdować się w pliku, obrazie dysku, migawce pamięci lub śladzie sieci.
Indeksowanie pomaga skrócić czas czasochłonnych zadań, takich jak keyword searching. Badanie kryminalistyczne obejmuje również fazę interaktywnego wyszukiwania, w której indeks jest używany do szybkiej lokalizacji słów kluczowych.
Indeksowanie pomaga również w wyświetlaniu słów kluczowych na posortowanej liście.
Przykład
Poniższy przykład pokazuje, jak możesz używać indexing w Pythonie.
aList = [123, 'sample', 'zara', 'indexing'];
print "Index for sample : ", aList.index('sample')
print "Index for indexing : ", aList.index('indexing')
str1 = "This is sample message for forensic investigation indexing";
str2 = "sample";
print "Index of the character keyword found is "
print str1.index(str2)Powyższy skrypt wygeneruje następujący wynik.
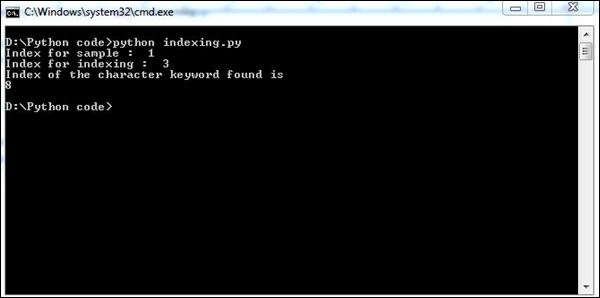
Wydobywanie cennych informacji z dostępnych zasobów jest istotną częścią kryminalistyki cyfrowej. Uzyskanie dostępu do wszystkich dostępnych informacji ma zasadnicze znaczenie dla procesu dochodzenia, ponieważ pomaga w uzyskaniu odpowiednich dowodów.
Zasoby zawierające dane mogą być prostymi strukturami danych, takimi jak bazy danych, lub złożonymi strukturami danych, takimi jak obraz JPEG. Dostęp do prostych struktur danych można uzyskać za pomocą prostych narzędzi komputerowych, podczas gdy wyodrębnianie informacji ze złożonych struktur danych wymaga wyrafinowanych narzędzi programistycznych.
Biblioteka obrazów Python
Python Imaging Library (PIL) dodaje możliwości przetwarzania obrazu do twojego interpretera Pythona. Ta biblioteka obsługuje wiele formatów plików i zapewnia potężne możliwości przetwarzania obrazu i grafiki. Pliki źródłowe PIL można pobrać z:http://www.pythonware.com/products/pil/
Poniższa ilustracja przedstawia pełny schemat blokowy wyodrębniania danych z obrazów (złożonych struktur danych) w PIL.

Przykład
Przyjrzyjmy się teraz przykładowi programowania, aby zrozumieć, jak to naprawdę działa.
Step 1 - Załóżmy, że mamy następujący obraz, z którego musimy wydobyć informacje.

Step 2- Kiedy otworzymy ten obraz za pomocą PIL, najpierw zanotuje niezbędne punkty wymagane do wydobycia dowodów, które obejmują różne wartości pikseli. Oto kod otwierający obraz i zapisujący wartości pikseli -
from PIL import Image
im = Image.open('Capture.jpeg', 'r')
pix_val = list(im.getdata())
pix_val_flat = [x for sets in pix_val for x in sets]
print pix_val_flatStep 3 - Nasz kod wygeneruje następujący wynik po wyodrębnieniu wartości pikseli obrazu.
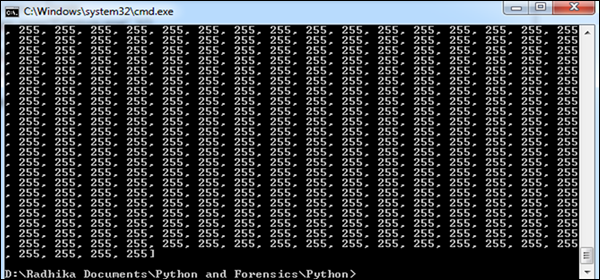
Dostarczone dane wyjściowe reprezentują wartości pikseli kombinacji RGB, co daje lepszy obraz tego, jakie dane są potrzebne do celów dowodowych. Pobrane dane są przedstawiane w postaci tablicy.
Badania kryminalistyczne i analiza standardowego sprzętu komputerowego, takiego jak dyski twarde, rozwinęły się w stabilną dyscyplinę i są śledzone za pomocą technik analizy niestandardowego sprzętu lub przejściowych dowodów.
Chociaż smartfony są coraz częściej wykorzystywane w dochodzeniach cyfrowych, nadal są uważane za niestandardowe.
Analiza kryminalistyczna
Badania kryminalistyczne wyszukują dane, takie jak odebrane połączenia lub wybierane numery ze smartfona. Może zawierać wiadomości tekstowe, zdjęcia lub inne obciążające dowody. Większość smartfonów ma funkcje blokowania ekranu za pomocą haseł lub znaków alfanumerycznych.
Tutaj weźmiemy przykład, aby pokazać, w jaki sposób Python może pomóc złamać hasło blokujące ekran w celu pobrania danych ze smartfona.
Badanie ręczne
Android obsługuje blokadę hasłem za pomocą numeru PIN lub hasła alfanumerycznego. Limit obu haseł musi mieć od 4 do 16 cyfr lub znaków. Hasło smartfona przechowywane jest w systemie Android w specjalnym pliku o nazwiepassword.key w /data/system.
Android przechowuje zasoloną sumę skrótu SHA1 i sumę skrótu MD5 hasła. Te hasła można przetwarzać w następującym kodzie.
public byte[] passwordToHash(String password) {
if (password == null) {
return null;
}
String algo = null;
byte[] hashed = null;
try {
byte[] saltedPassword = (password + getSalt()).getBytes();
byte[] sha1 = MessageDigest.getInstance(algo = "SHA-1").digest(saltedPassword);
byte[] md5 = MessageDigest.getInstance(algo = "MD5").digest(saltedPassword);
hashed = (toHex(sha1) + toHex(md5)).getBytes();
} catch (NoSuchAlgorithmException e) {
Log.w(TAG, "Failed to encode string because of missing algorithm: " + algo);
}
return hashed;
}Nie jest możliwe złamanie hasła za pomocą dictionary attack ponieważ zaszyfrowane hasło jest przechowywane w pliku salt file. Tosaltjest ciągiem szesnastkowym reprezentującym losową liczbę całkowitą 64-bitową. Dostęp dosalt używając Rooted Smartphone lub JTAG Adapter.
Zrootowany smartfon
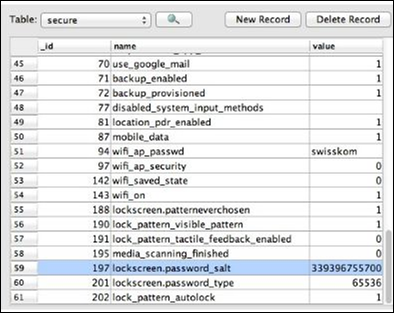
Zrzut pliku /data/system/password.key jest przechowywany w bazie danych SQLite pod rozszerzeniem lockscreen.password_saltklucz. Podsettings.dbhasło jest przechowywane, a wartość jest wyraźnie widoczna na poniższym zrzucie ekranu.
Adapter JTAG
Specjalny sprzęt znany jako adapter JTAG (Joint Test Action Group) może być użyty do uzyskania dostępu do salt. Podobnie, plikRiff-Box lub a JIG-Adapter może być również używany do tej samej funkcji.
Korzystając z informacji uzyskanych z Riff-boxa, możemy znaleźć położenie zaszyfrowanych danych, tj salt. Oto zasady -
Wyszukaj powiązany ciąg „lockscreen.password_salt”.
Bajt reprezentuje rzeczywistą szerokość soli, która jest jej length.
Jest to długość, której faktycznie poszukuje się, aby uzyskać zapisane hasło / kod PIN smartfonów.
Ten zestaw reguł pomaga w uzyskaniu odpowiednich danych dotyczących soli.
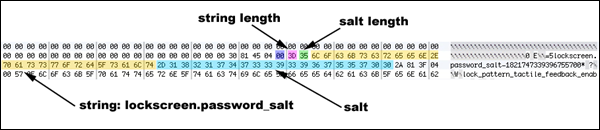
Najpopularniejszym protokołem synchronizacji czasu, który został powszechnie przyjęty jako praktyka, jest protokół Network Time Protocol (NTP).
NTP korzysta z protokołu UDP (User Datagram Protocol), który wykorzystuje minimalny czas do komunikacji pakietów między serwerem a klientem, który chce zsynchronizować się z podanym źródłem czasu.
Funkcje protokołu czasu sieciowego są następujące -
Domyślny port serwera to 123.
Protokół ten składa się z wielu dostępnych serwerów czasu zsynchronizowanych z laboratoriami krajowymi.
Standard protokołu NTP jest zarządzany przez IETF, a proponowanym standardem jest RFC 5905, zatytułowany „Network Time Protocol Version 4: Protocol and Algorithms Specification” [NTP RFC]
Systemy operacyjne, programy i aplikacje używają protokołu NTP do prawidłowej synchronizacji czasu.
W tym rozdziale skupimy się na wykorzystaniu NTP w Pythonie, co jest możliwe z poziomu biblioteki Python ntplib innej firmy. Ta biblioteka skutecznie radzi sobie z podnoszeniem ciężarów, które porównuje wyniki z moim lokalnym zegarem systemowym.
Instalowanie biblioteki NTP
Plik ntplib jest dostępny do pobrania pod adresem https://pypi.python.org/pypi/ntplib/ jak pokazano na poniższym rysunku.
Biblioteka zapewnia prosty interfejs dla serwerów NTP za pomocą metod, które mogą tłumaczyć pola protokołu NTP. Ułatwia to dostęp do innych kluczowych wartości, takich jak sekundy przestępne.

Poniższy program w języku Python pomaga w zrozumieniu użycia protokołu NTP.
import ntplib
import time
NIST = 'nist1-macon.macon.ga.us'
ntp = ntplib.NTPClient()
ntpResponse = ntp.request(NIST)
if (ntpResponse):
now = time.time()
diff = now-ntpResponse.tx_time
print diff;Powyższy program wygeneruje następujący wynik.
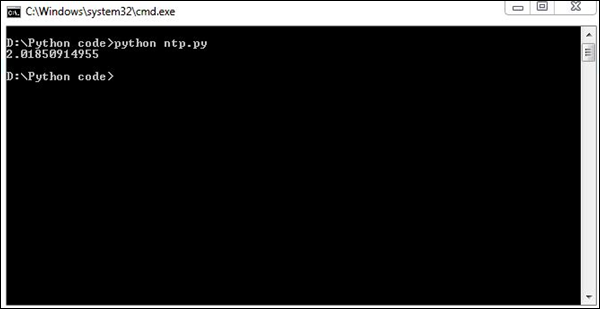
Różnica czasu jest obliczana w powyższym programie. Obliczenia te pomagają w dochodzeniach kryminalistycznych. Uzyskane dane sieciowe różnią się zasadniczo od analizy danych znalezionych na dysku twardym.
Różnica w strefach czasowych lub uzyskanie dokładnych stref czasowych może pomóc w zebraniu dowodów na przechwytywanie wiadomości za pomocą tego protokołu.
Specjalistom medycyny sądowej zwykle trudno jest zastosować rozwiązania cyfrowe do analizy gór cyfrowych dowodów w pospolitych przestępstwach. Większość cyfrowych narzędzi dochodzeniowych jest jednowątkowych i mogą one wykonywać tylko jedno polecenie naraz.
W tym rozdziale skupimy się na możliwościach przetwarzania wieloprocesowego w Pythonie, które mogą odnosić się do typowych wyzwań kryminalistycznych.
Wieloprocesowość
Wieloprocesorowość definiuje się jako zdolność systemu komputerowego do obsługi więcej niż jednego procesu. Systemy operacyjne obsługujące przetwarzanie wieloprocesowe umożliwiają jednoczesne działanie kilku programów.
Istnieją różne typy przetwarzania wieloprocesowego, takie jak symmetric i asymmetric processing. Poniższy diagram odnosi się do symetrycznego systemu przetwarzania wieloprocesowego, który jest zwykle stosowany w dochodzeniach kryminalistycznych.
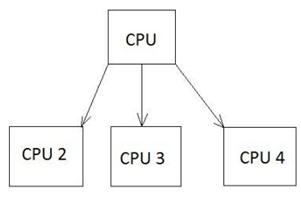
Przykład
Poniższy kod pokazuje, jak różne procesy są wyświetlane wewnętrznie w programowaniu w języku Python.
import random
import multiprocessing
def list_append(count, id, out_list):
#appends the count of number of processes which takes place at a time
for i in range(count):
out_list.append(random.random())
if __name__ == "__main__":
size = 999
procs = 2
# Create a list of jobs and then iterate through
# the number of processes appending each process to
# the job list
jobs = []
for i in range(0, procs):
out_list = list() #list of processes
process1 = multiprocessing.Process(
target = list_append, args = (size, i, out_list))
# appends the list of processes
jobs.append(process)
# Calculate the random number of processes
for j in jobs:
j.start() #initiate the process
# After the processes have finished execution
for j in jobs:
j.join()
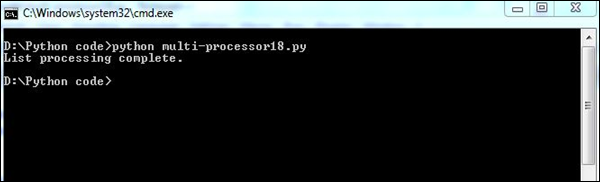
print "List processing complete."Tutaj funkcja list_append() pomaga w wylistowaniu zbioru procesów w systemie.
Wynik
Nasz kod wygeneruje następujący wynik -
W tym rozdziale skupimy się na badaniu ulotnej pamięci za pomocą Volatility, oparty na Pythonie framework do kryminalistyki mający zastosowanie na następujących platformach: Android i Linux.
Ulotna pamięć
Pamięć ulotna to rodzaj pamięci, w której zawartość jest kasowana po wyłączeniu lub przerwaniu zasilania systemu. RAM jest najlepszym przykładem pamięci ulotnej. Oznacza to, że jeśli pracujesz nad dokumentem, który nie został zapisany w pamięci nieulotnej, takiej jak dysk twardy, a komputer stracił zasilanie, wszystkie dane zostaną utracone.
Ogólnie rzecz biorąc, kryminalistyka pamięci ulotnej postępuje według tego samego wzoru, co inne badania kryminalistyczne -
- Wybór celu śledztwa
- Pozyskiwanie danych kryminalistycznych
- Analiza kryminalistyczna
Podstawy volatility plugins które są używane do zbierania plików Android RAM dumpDo analizy. Po zebraniu zrzutu pamięci RAM do analizy ważne jest, aby rozpocząć wyszukiwanie złośliwego oprogramowania w pamięci RAM.
Zasady YARA
YARA to popularne narzędzie, które zapewnia niezawodny język, jest kompatybilne z wyrażeniami regularnymi opartymi na Perlu i służy do sprawdzania podejrzanych plików / katalogów i pasujących łańcuchów.
W tej sekcji użyjemy YARA w oparciu o implementację dopasowania wzorców i połączymy je z zasilaniem sieciowym. Cały proces będzie korzystny dla analizy kryminalistycznej.
Przykład
Rozważmy następujący kod. Ten kod pomaga w wyodrębnieniu kodu.
import operator
import os
import sys
sys.path.insert(0, os.getcwd())
import plyara.interp as interp
# Plyara is a script that lexes and parses a file consisting of one more Yara
# rules into a python dictionary representation.
if __name__ == '__main__':
file_to_analyze = sys.argv[1]
rulesDict = interp.parseString(open(file_to_analyze).read())
authors = {}
imps = {}
meta_keys = {}
max_strings = []
max_string_len = 0
tags = {}
rule_count = 0
for rule in rulesDict:
rule_count += 1
# Imports
if 'imports' in rule:
for imp in rule['imports']:
imp = imp.replace('"','')
if imp in imps:
imps[imp] += 1
else:
imps[imp] = 1
# Tags
if 'tags' in rule:
for tag in rule['tags']:
if tag in tags:
tags[tag] += 1
else:
tags[tag] = 1
# Metadata
if 'metadata' in rule:
for key in rule['metadata']:
if key in meta_keys:
meta_keys[key] += 1
else:
meta_keys[key] = 1
if key in ['Author', 'author']:
if rule['metadata'][key] in authors:
authors[rule['metadata'][key]] += 1
else:
authors[rule['metadata'][key]] = 1
#Strings
if 'strings' in rule:
for strr in rule['strings']:
if len(strr['value']) > max_string_len:
max_string_len = len(strr['value'])
max_strings = [(rule['rule_name'], strr['name'], strr['value'])]
elif len(strr['value']) == max_string_len:
max_strings.append((rule['rule_name'], strr['key'], strr['value']))
print("\nThe number of rules implemented" + str(rule_count))
ordered_meta_keys = sorted(meta_keys.items(), key = operator.itemgetter(1),
reverse = True)
ordered_authors = sorted(authors.items(), key = operator.itemgetter(1),
reverse = True)
ordered_imps = sorted(imps.items(), key = operator.itemgetter(1), reverse = True)
ordered_tags = sorted(tags.items(), key = operator.itemgetter(1), reverse = True)Powyższy kod wygeneruje następujące dane wyjściowe.
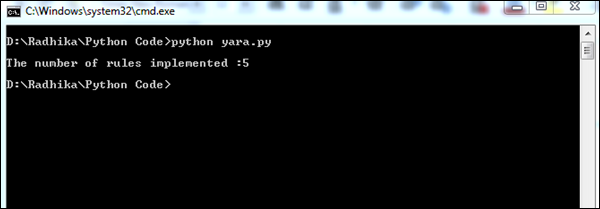
Liczba zaimplementowanych reguł YARA pomaga w uzyskaniu lepszego obrazu podejrzanych plików. Pośrednio lista podejrzanych plików pomaga w zebraniu odpowiednich informacji dla medycyny sądowej.
Poniżej znajduje się kod źródłowy w github: https://github.com/radhikascs/Python_yara
Głównym problemem dochodzeń cyfrowych jest zabezpieczenie ważnych dowodów lub danych za pomocą szyfrowania lub innego formatu. Podstawowym przykładem jest przechowywanie haseł. W związku z tym konieczne jest zrozumienie wykorzystania systemu operacyjnego Linux do implementacji kryminalistyki cyfrowej w celu zabezpieczenia tych cennych danych.
Informacje dla wszystkich użytkowników lokalnych są przeważnie przechowywane w następujących dwóch plikach -
- /etc/passwd
- etc/shadow
Pierwsza jest obowiązkowa, w której przechowuje się wszystkie hasła. Drugi plik jest opcjonalny i przechowuje informacje o użytkownikach lokalnych, w tym zaszyfrowane hasła.
Pojawiają się problemy związane z kwestią bezpieczeństwa przechowywania informacji o haśle w pliku, który może być odczytany przez każdego użytkownika. Dlatego zaszyfrowane hasła są przechowywane w plikach/etc/passwd, gdzie treść jest zastępowana specjalną wartością "x”.
Należy wyszukać odpowiednie skróty /etc/shadow. Ustawienia w/etc/passwd może zastąpić szczegóły w /etc/shadow.
Oba pliki tekstowe w systemie Linux zawierają po jednym wpisie w każdym wierszu, a wpis składa się z wielu pól oddzielonych dwukropkami.
Format /etc/passwd wygląda następująco -
| Sr.No. | Nazwa i opis pola |
|---|---|
| 1 | Username To pole zawiera atrybuty formatu czytelnego dla człowieka |
| 2 | Password hash Składa się z hasła w postaci zakodowanej zgodnie z funkcją kryptograficzną Posix |
Jeśli hasło skrótu zostanie zapisane jako empty, wówczas odpowiedni użytkownik nie będzie wymagał podania hasła, aby zalogować się do systemu. Jeśli to pole zawiera wartość, której nie może wygenerować algorytm wyznaczania wartości skrótu, na przykład wykrzyknik, użytkownik nie może zalogować się przy użyciu hasła.
Użytkownik z zablokowanym hasłem może nadal logować się przy użyciu innych mechanizmów uwierzytelniania, na przykład kluczy SSH. Jak wspomniano wcześniej, specjalna wartość „x”oznacza, że skrót hasła musi znajdować się w pliku shadow.
Plik password hash obejmuje następujące -
Encrypted salt - The encrypted salt pomaga w utrzymywaniu blokad ekranu, pinezek i haseł.
Numerical user ID- To pole oznacza identyfikator użytkownika. Jądro Linuksa przypisuje ten identyfikator użytkownika do systemu.
Numerical group ID - To pole odnosi się do podstawowej grupy użytkowników.
Home directory - Nowe procesy są uruchamiane z odniesieniem do tego katalogu.
Command shell - To opcjonalne pole wskazuje domyślną powłokę, która ma zostać uruchomiona po pomyślnym zalogowaniu się do systemu.
Kryminalistyka cyfrowa obejmuje zbieranie informacji, które są istotne dla śledzenia dowodów. Dlatego identyfikatory użytkowników są przydatne w utrzymywaniu rekordów.
Korzystając z Pythona, wszystkie te informacje mogą być automatycznie analizowane pod kątem wskaźników analizy, rekonstruując ostatnią aktywność systemu. Śledzenie jest proste i łatwe dzięki implementacji powłoki Linux.
Programowanie w Pythonie w systemie Linux
Przykład
import sys
import hashlib
import getpass
def main(argv):
print '\nUser & Password Storage Program in Linux for forensic detection v.01\n'
if raw_input('The file ' + sys.argv[1] + ' will be erased or overwrite if
it exists .\nDo you wish to continue (Y/n): ') not in ('Y','y') :
sys.exit('\nChanges were not recorded\n')
user_name = raw_input('Please Enter a User Name: ')
password = hashlib.sha224(getpass.getpass('Please Enter a Password:')).hexdigest()
# Passwords which are hashed
try:
file_conn = open(sys.argv[1],'w')
file_conn.write(user_name + '\n')
file_conn.write(password + '\n')
file_conn.close()
except:
sys.exit('There was a problem writing the passwords to file!')
if __name__ == "__main__":
main(sys.argv[1:])Wynik
Hasło jest przechowywane w formacie szesnastkowym w pass_db.txtjak pokazano na poniższym zrzucie ekranu. Pliki tekstowe są zapisywane do dalszego wykorzystania w informatyce śledczej.
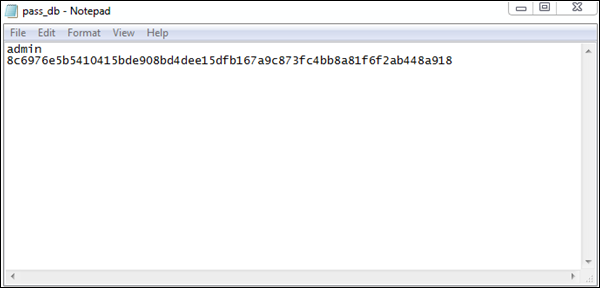
Wskaźniki naruszenia bezpieczeństwa (IOC) definiuje się jako „fragmenty danych kryminalistycznych, które obejmują dane znalezione we wpisach dziennika systemowego lub plikach, które identyfikują potencjalnie złośliwą aktywność w systemie lub sieci”.
Dzięki monitorowaniu pod kątem IOC organizacje mogą wykrywać ataki i działać szybko, aby zapobiegać takim naruszeniom lub ograniczać szkody, zatrzymując ataki na wcześniejszych etapach.
Istnieje kilka przypadków użycia, które umożliwiają przeszukiwanie artefaktów kryminalistycznych, takich jak -
- Szukam konkretnego pliku przez MD5
- Poszukiwanie konkretnej jednostki, która faktycznie jest zapisana w pamięci
- Określony wpis lub zestaw wpisów, który jest przechowywany w rejestrze systemu Windows
Połączenie wszystkich powyższych elementów zapewnia lepsze wyniki w wyszukiwaniu artefaktów. Jak wspomniano powyżej, rejestr systemu Windows stanowi doskonałą platformę do generowania i utrzymywania IOC, co bezpośrednio pomaga w obliczeniach kryminalistycznych.
Metodologia
Poszukaj lokalizacji w systemie plików, a na razie w rejestrze systemu Windows.
Poszukaj zestawu artefaktów, które zostały zaprojektowane przez narzędzia kryminalistyczne.
Poszukaj oznak wszelkich niekorzystnych działań.
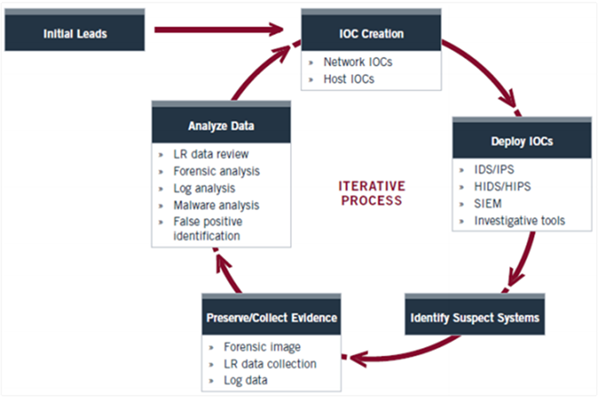
Badawczy cykl życia
Śledczy cykl życia jest zgodny z IOC i wyszukuje określone wpisy w rejestrze.
Stage 1: Initial Evidence- Dowody naruszenia bezpieczeństwa wykryto na hoście lub w sieci. Respondenci zbadają i zidentyfikują dokładne rozwiązanie, które jest konkretnym wskaźnikiem kryminalistycznym.
Stage 2: Create IOCs for Host & Network- Na podstawie zebranych danych tworzony jest IOC, co jest łatwo możliwe dzięki rejestrowi Windows. Elastyczność OpenIOC daje nieograniczoną liczbę permutacji sposobu, w jaki można stworzyć wskaźnik.
Stage 3: Deploy IOCs in the Enterprise - Po utworzeniu określonego IOC badacz wdroży te technologie za pomocą API w rejestrach systemu Windows.
Stage 4: Identification of Suspects- Rozmieszczenie IOC pomaga w normalnej identyfikacji podejrzanych. Zidentyfikowane zostaną nawet dodatkowe systemy.
Stage 5: Collect and Analyze Evidence - Dowody przeciwko podejrzanym są gromadzone i odpowiednio analizowane.
Stage 6: Refine & Create New IOCs - Zespół dochodzeniowy może tworzyć nowe IOC na podstawie ich dowodów i danych znalezionych w przedsiębiorstwie oraz dodatkowej inteligencji, a także nadal udoskonalać ich cykl.
Poniższa ilustracja przedstawia etapy badawczego cyklu życia -
Cloud computingmożna zdefiniować jako zbiór usług hostowanych dostarczanych użytkownikom przez Internet. Umożliwia organizacjom wykorzystanie, a nawet obliczenie zasobu, w tym maszyn wirtualnych (VM), magazynu lub aplikacji jako narzędzia.
Jedną z najważniejszych zalet budowania aplikacji w języku programowania Python jest to, że obejmuje możliwość wdrażania aplikacji praktycznie na dowolnej platformie, w tym cloudtakże. Oznacza to, że Python można uruchomić na serwerach w chmurze, a także można go uruchomić na poręcznych urządzeniach, takich jak komputer stacjonarny, tablet lub smartfon.
Jedną z ciekawych perspektyw jest stworzenie bazy chmurowej wraz z generacją Rainbow tables. Pomaga w integracji jedno- i wieloprocesorowych wersji aplikacji, co wymaga pewnych rozważań.
Pi Cloud
Pi Cloud to platforma przetwarzania w chmurze, która integruje język programowania Python z mocą obliczeniową Amazon Web Services.
Rzućmy okiem na przykład implementacji chmur Pi z rainbow tables.
Tęczowe stoły
ZA rainbow table jest zdefiniowana jako lista wszystkich możliwych permutacji zaszyfrowanych haseł w postaci zwykłego tekstu, specyficznych dla danego algorytmu wyznaczania wartości skrótu.
Tęczowe tabele są zgodne ze standardowym wzorcem, który tworzy listę zaszyfrowanych haseł.
Plik tekstowy służy do generowania haseł, które zawierają znaki lub zwykły tekst haseł do zaszyfrowania.
Plik jest używany przez chmurę Pi, która wywołuje główną funkcję do zapisania.
Dane wyjściowe zaszyfrowanych haseł są również przechowywane w pliku tekstowym.
Algorytm ten może być również używany do zapisywania haseł w bazie danych i przechowywania kopii zapasowych w systemie chmurowym.
Poniższy program wbudowany tworzy listę zaszyfrowanych haseł w pliku tekstowym.
Przykład
import os
import random
import hashlib
import string
import enchant #Rainbow tables with enchant
import cloud #importing pi-cloud
def randomword(length):
return ''.join(random.choice(string.lowercase) for i in range(length))
print('Author- Radhika Subramanian')
def mainroutine():
engdict = enchant.Dict("en_US")
fileb = open("password.txt","a+")
# Capture the values from the text file named password
while True:
randomword0 = randomword(6)
if engdict.check(randomword0) == True:
randomkey0 = randomword0+str(random.randint(0,99))
elif engdict.check(randomword0) == False:
englist = engdict.suggest(randomword0)
if len(englist) > 0:
randomkey0 = englist[0]+str(random.randint(0,99))
else:
randomkey0 = randomword0+str(random.randint(0,99))
randomword3 = randomword(5)
if engdict.check(randomword3) == True:
randomkey3 = randomword3+str(random.randint(0,99))
elif engdict.check(randomword3) == False:
englist = engdict.suggest(randomword3)
if len(englist) > 0:
randomkey3 = englist[0]+str(random.randint(0,99))
else:
randomkey3 = randomword3+str(random.randint(0,99))
if 'randomkey0' and 'randomkey3' and 'randomkey1' in locals():
whasher0 = hashlib.new("md5")
whasher0.update(randomkey0)
whasher3 = hashlib.new("md5")
whasher3.update(randomkey3)
whasher1 = hashlib.new("md5")
whasher1.update(randomkey1)
print(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
print(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
print(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
fileb.write(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
fileb.write(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
fileb.write(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
jid = cloud.call(randomword) #square(3) evaluated on PiCloud
cloud.result(jid)
print('Value added to cloud')
print('Password added')
mainroutine()Wynik
Ten kod wygeneruje następujące dane wyjściowe -

Hasła są przechowywane w plikach tekstowych, które są widoczne, jak pokazano na poniższym zrzucie ekranu.
