Legalność skrobania sieci
Dzięki Pythonowi możemy zeskrobać dowolną witrynę lub poszczególne elementy strony internetowej, ale czy masz pojęcie, czy jest to legalne, czy nie? Przed skrobaniem jakiejkolwiek strony internetowej musimy wiedzieć o legalności skrobania sieci. W tym rozdziale wyjaśnione zostaną pojęcia związane z legalnością skrobania sieci.
Wprowadzenie
Ogólnie rzecz biorąc, jeśli zamierzasz wykorzystać zeskrobane dane do użytku osobistego, może nie być żadnego problemu. Ale jeśli zamierzasz ponownie opublikować te dane, to przed zrobieniem tego samego powinieneś poprosić właściciela o pobranie lub poszukać informacji na temat zasad, a także danych, które zamierzasz zeskrobać.
Badania wymagane przed skrobaniem
Jeśli kierujesz stronę internetową do pobierania z niej danych, musimy zrozumieć jej skalę i strukturę. Oto niektóre pliki, które musimy przeanalizować przed rozpoczęciem skrobania sieci.
Analiza pliku robots.txt
W rzeczywistości większość wydawców pozwala programistom w pewnym zakresie indeksować ich witryny internetowe. Innymi słowy, wydawcy chcą, aby indeksowane były określone fragmenty witryn. Aby to zdefiniować, strony internetowe muszą określić pewne reguły określające, które części mogą być indeksowane, a które nie. Takie reguły są zdefiniowane w pliku o nazwierobots.txt.
robots.txtto czytelny dla człowieka plik używany do identyfikowania części witryny, które roboty indeksujące mogą, a które nie mogą zeskrobać. Nie ma standardowego formatu pliku robots.txt, a wydawcy strony mogą wprowadzać modyfikacje zgodnie ze swoimi potrzebami. Możemy sprawdzić plik robots.txt dla konkretnej witryny, podając ukośnik i robots.txt po adresie URL tej witryny. Na przykład, jeśli chcemy sprawdzić go pod kątem Google.com, musimy wpisaćhttps://www.google.com/robots.txt a otrzymamy coś takiego -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..Oto niektóre z najczęstszych reguł zdefiniowanych w pliku robots.txt witryny -
User-agent: BadCrawler
Disallow: /Powyższa reguła oznacza, że plik robots.txt pyta robota indeksującego o BadCrawler klient użytkownika nie indeksuje swojej witryny.
User-agent: *
Crawl-delay: 5
Disallow: /trapPowyższa reguła oznacza, że plik robots.txt opóźnia robota indeksującego o 5 sekund między żądaniami pobrania dla wszystkich klientów użytkownika, aby uniknąć przeciążenia serwera. Plik/traplink spróbuje zablokować złośliwe roboty indeksujące, które korzystają z niedozwolonych linków. Istnieje wiele innych reguł, które wydawca witryny może zdefiniować zgodnie z ich wymaganiami. Niektóre z nich są omówione tutaj -
Analizowanie plików map witryn
Co powinieneś zrobić, jeśli chcesz przeszukać witrynę w celu uzyskania aktualnych informacji? Przeszukasz każdą stronę internetową w celu uzyskania zaktualizowanych informacji, ale zwiększy to ruch na serwerze tej konkretnej witryny. Dlatego strony internetowe udostępniają pliki map witryn, które pomagają robotom indeksującym w lokalizowaniu aktualizowanych treści bez konieczności indeksowania każdej strony internetowej. Standard mapy witryny jest zdefiniowany pod adresemhttp://www.sitemaps.org/protocol.html.
Zawartość pliku mapy witryny
Poniżej znajduje się zawartość pliku mapy witryny https://www.microsoft.com/robots.txt który jest wykryty w pliku robot.txt -
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xmlPowyższa treść pokazuje, że mapa witryny zawiera listę adresów URL w witrynie, a ponadto pozwala webmasterowi określić dodatkowe informacje, takie jak data ostatniej aktualizacji, zmiana treści, ważność adresu URL w stosunku do innych itp. O każdym adresie URL.
Jaki jest rozmiar witryny internetowej?
Czy rozmiar witryny internetowej, tj. Liczba jej stron internetowych, wpływa na sposób, w jaki się indeksujemy? Z pewnością tak. Ponieważ jeśli mamy mniej stron internetowych do zindeksowania, to wydajność nie byłaby poważnym problemem, ale załóżmy, że jeśli nasza witryna ma miliony stron internetowych, na przykład Microsoft.com, pobieranie każdej strony sekwencyjnej zajmie kilka miesięcy i wtedy wydajność byłaby poważnym problemem.
Sprawdzanie rozmiaru witryny
Sprawdzając rozmiar wyniku robota Google, możemy oszacować rozmiar witryny. Nasz wynik można filtrować za pomocą słowa kluczowegositepodczas wyszukiwania w Google. Na przykład oszacowanie rozmiaruhttps://authoraditiagarwal.com/ podano poniżej -
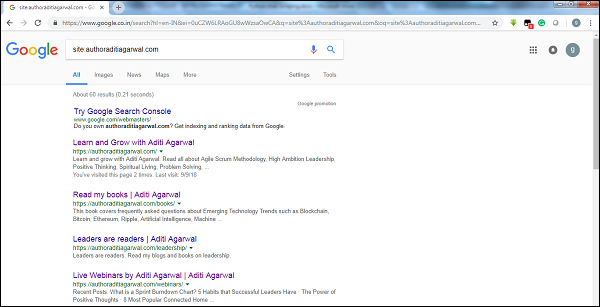
Możesz zobaczyć około 60 wyników, co oznacza, że nie jest to duża witryna, a indeksowanie nie doprowadziłoby do problemu z wydajnością.
Z jakiej technologii korzysta strona internetowa?
Kolejnym ważnym pytaniem jest to, czy technologia używana przez witrynę wpływa na sposób, w jaki się indeksujemy? Tak, to wpływa. Ale jak możemy sprawdzić, z jakiej technologii korzysta strona internetowa? Istnieje biblioteka Pythona o nazwiebuiltwith za pomocą których możemy dowiedzieć się, z jakiej technologii korzysta serwis.
Przykład
W tym przykładzie sprawdzimy technologię używaną przez serwis https://authoraditiagarwal.com przy pomocy biblioteki Python builtwith. Ale przed użyciem tej biblioteki musimy zainstalować ją w następujący sposób -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3Teraz, podążając za prostą linią kodów, możemy sprawdzić technologię używaną przez daną witrynę -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}Kto jest właścicielem strony internetowej?
Właściciel witryny ma również znaczenie, ponieważ jeśli znany jest z blokowania robotów indeksujących, to muszą one być ostrożne podczas pobierania danych ze strony. Istnieje protokół o nazwieWhois za pomocą których możemy dowiedzieć się o właścicielu serwisu.
Przykład
W tym przykładzie zamierzamy sprawdzić, czy właściciel witryny internetowej mówi microsoft.com z pomocą Whois. Ale przed użyciem tej biblioteki musimy zainstalować ją w następujący sposób -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0Teraz, podążając za prostą linią kodów, możemy sprawdzić technologię używaną przez daną witrynę -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
],
}