Python Web Scraping - radzenie sobie z tekstem
W poprzednim rozdziale widzieliśmy, jak postępować z filmami wideo i obrazami, które uzyskujemy w ramach treści do pobierania z sieci. W tym rozdziale zajmiemy się analizą tekstu przy użyciu biblioteki Python i dowiemy się o tym szczegółowo.
Wprowadzenie
Analizę tekstu można przeprowadzić w programie, korzystając z biblioteki Python o nazwie Natural Language Tool Kit (NLTK). Zanim przejdziemy do koncepcji NLTK, zrozummy związek między analizą tekstu a skrobaniem sieci.
Analiza słów w tekście może doprowadzić nas do ustalenia, które słowa są ważne, które są nietypowe, jak słowa są grupowane. Ta analiza ułatwia zadanie skrobania sieci.
Pierwsze kroki z NLTK
Zestaw narzędzi języka naturalnego (NLTK) to zbiór bibliotek Pythona, które zostały zaprojektowane specjalnie do identyfikowania i oznaczania części mowy występujących w tekście języka naturalnego, takiego jak angielski.
Instalowanie NLTK
Możesz użyć następującego polecenia, aby zainstalować NLTK w Pythonie -
pip install nltkJeśli używasz programu Anaconda, pakiet conda dla NLTK można zbudować za pomocą następującego polecenia -
conda install -c anaconda nltkPobieranie danych NLTK
Po zainstalowaniu NLTK musimy pobrać gotowe repozytoria tekstu. Ale przed pobraniem repozytoriów predefiniowanych tekstów musimy zaimportować NLTK za pomocąimport polecenie w następujący sposób -
mport nltkTeraz za pomocą następującego polecenia można pobrać dane NLTK -
nltk.download()Instalacja wszystkich dostępnych pakietów NLTK zajmie trochę czasu, ale zawsze zaleca się zainstalowanie wszystkich pakietów.
Instalowanie innych niezbędnych pakietów
Potrzebujemy również innych pakietów Pythona, takich jak gensim i pattern do przeprowadzania analizy tekstu, a także budowania aplikacji przetwarzających język naturalny przy użyciu NLTK.
gensim- Solidna biblioteka do modelowania semantycznego, przydatna w wielu aplikacjach. Można go zainstalować za pomocą następującego polecenia -
pip install gensimpattern - Robiłem gensimpakiet działa poprawnie. Można go zainstalować za pomocą następującego polecenia -
pip install patternTokenizacja
Proces dzielenia danego tekstu na mniejsze jednostki zwane tokenami nazywa się tokenizacją. Tymi żetonami mogą być słowa, cyfry lub znaki interpunkcyjne. Nazywa się to równieżword segmentation.
Przykład

Moduł NLTK udostępnia różne pakiety do tokenizacji. Możemy używać tych pakietów zgodnie z naszymi wymaganiami. Niektóre pakiety są opisane tutaj -
sent_tokenize package- Ten pakiet podzieli tekst wejściowy na zdania. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.tokenize import sent_tokenizeword_tokenize package- Ten pakiet podzieli tekst wejściowy na słowa. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Ten pakiet podzieli tekst wejściowy oraz znaki interpunkcyjne na słowa. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.tokenize import WordPuncttokenizerPrzybitka
W każdym języku istnieją różne formy słów. Język zawiera wiele odmian ze względów gramatycznych. Na przykład rozważ słowademocracy, democratic, i democratization. W przypadku uczenia maszynowego, jak również w przypadku projektów polegających na skrobaniu stron internetowych, ważne jest, aby maszyny zrozumiały, że te różne słowa mają tę samą formę podstawową. Stąd można powiedzieć, że przy analizie tekstu przydatne może być wyodrębnienie form bazowych słów.
Można to osiągnąć przez zapychanie, które można zdefiniować jako heurystyczny proces wyodrębniania podstawowych form słów przez odcinanie końców słów.
Moduł NLTK zapewnia różne pakiety do wyprowadzania. Możemy używać tych pakietów zgodnie z naszymi wymaganiami. Niektóre z tych pakietów są opisane tutaj -
PorterStemmer package- Algorytm Portera jest używany przez ten pakiet bazujący w Pythonie do wyodrębnienia formy podstawowej. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.stem.porter import PorterStemmerNa przykład po podaniu słowa ‘writing’ jako dane wejściowe do tego stempla, wyjściem będzie słowo ‘write’ po wyhodowaniu.
LancasterStemmer package- Algorytm Lancaster jest używany przez ten pakiet bazujący w Pythonie do wyodrębnienia formy podstawowej. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.stem.lancaster import LancasterStemmerNa przykład po podaniu słowa ‘writing’ jako wejście do tego stempla, wyjście byłoby słowem ‘writ’ po wyhodowaniu.
SnowballStemmer package- Algorytm Snowballa jest używany przez ten pakiet bazujący w Pythonie do wyodrębnienia formy podstawowej. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.stem.snowball import SnowballStemmerNa przykład po podaniu słowa „pisanie” jako danych wejściowych do tego stempla, wynikiem będzie słowo „napisz” po wbudowaniu.
Lemmatyzacja
Innym sposobem wyodrębnienia podstawowej formy słów jest lematyzacja, zwykle mająca na celu usunięcie końcówek fleksyjnych za pomocą słownictwa i analizy morfologicznej. Podstawową formą dowolnego słowa po lematyzacji jest lemat.
Moduł NLTK udostępnia następujące pakiety do lematyzacji -
WordNetLemmatizer package- Wyodrębni podstawową formę słowa w zależności od tego, czy jest używane jako rzeczownik jako czasownik. Możesz użyć następującego polecenia, aby zaimportować ten pakiet -
from nltk.stem import WordNetLemmatizerKruszenie
Chunking, czyli dzielenie danych na małe fragmenty, jest jednym z ważnych procesów w przetwarzaniu języka naturalnego w celu identyfikacji części mowy i krótkich fraz, takich jak frazy rzeczownikowe. Chunking polega na etykietowaniu tokenów. Możemy uzyskać strukturę zdania za pomocą procesu fragmentacji.
Przykład
W tym przykładzie zamierzamy zaimplementować fragmentację typu rzeczownik-fraza przy użyciu modułu NLTK Python. NP chunking to kategoria dzielenia się na fragmenty, w której znajdują się fragmenty wyrażeń rzeczownikowych w zdaniu.
Kroki wdrażania fragmentacji wyrażeń rzeczownikowych
Aby zaimplementować fragmentację wyrażeń rzeczownikowych, musimy postępować zgodnie z poniższymi krokami -
Krok 1 - Definicja gramatyki fragmentów
W pierwszym kroku zdefiniujemy gramatykę fragmentów. Składałby się z zasad, których musimy przestrzegać.
Krok 2 - Tworzenie parsera fragmentów
Teraz utworzymy parser fragmentów. To przeanalizowałoby gramatykę i dałoby wynik.
Krok 3 - Wynik
W tym ostatnim kroku dane wyjściowe zostaną utworzone w formacie drzewa.
Najpierw musimy zaimportować pakiet NLTK w następujący sposób -
import nltkNastępnie musimy zdefiniować zdanie. Tutaj DT: wyznacznik, VBP: czasownik, JJ: przymiotnik, IN: przyimek i NN: rzeczownik.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Następnie podajemy gramatykę w postaci wyrażenia regularnego.
grammar = "NP:{<DT>?<JJ>*<NN>}"Teraz następny wiersz kodu zdefiniuje parser do analizowania gramatyki.
parser_chunking = nltk.RegexpParser(grammar)Teraz parser przeanalizuje zdanie.
parser_chunking.parse(sentence)Następnie podajemy nasze wyjście w zmiennej.
Output = parser_chunking.parse(sentence)Za pomocą poniższego kodu możemy narysować nasze dane wyjściowe w postaci drzewa, jak pokazano poniżej.
output.draw()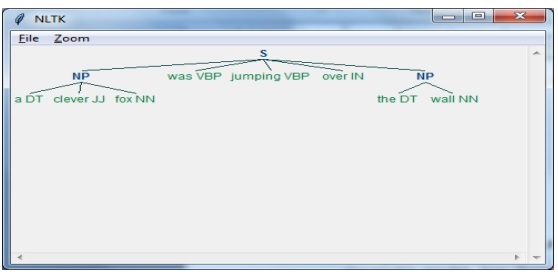
Model worka słów (BoW) Wyodrębnianie i przekształcanie tekstu w postać liczbową
Bag of Word (BoW), przydatny model w przetwarzaniu języka naturalnego, jest zasadniczo używany do wyodrębniania cech z tekstu. Po wyodrębnieniu funkcji z tekstu można go użyć w modelowaniu w algorytmach uczenia maszynowego, ponieważ surowych danych nie można używać w aplikacjach ML.
Działanie modelu BoW
Początkowo model wyodrębnia słownik ze wszystkich słów w dokumencie. Później, używając macierzy terminów dokumentu, zbudowałoby model. W ten sposób model BoW przedstawia dokument jako zbiór samych słów, a kolejność lub struktura jest odrzucana.
Przykład
Załóżmy, że mamy następujące dwa zdania -
Sentence1 - To jest przykład modelu Bag of Words.
Sentence2 - Możemy wyodrębnić funkcje za pomocą modelu Bag of Words.
Teraz, biorąc pod uwagę te dwa zdania, mamy następujących 14 różnych słów:
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Tworzenie modelu worka słów w NLTK
Przyjrzyjmy się poniższemu skryptowi w Pythonie, który zbuduje model BoW w NLTK.
Najpierw zaimportuj następujący pakiet -
from sklearn.feature_extraction.text import CountVectorizerNastępnie zdefiniuj zestaw zdań -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Wynik
Pokazuje, że mamy 14 różnych słów w powyższych dwóch zdaniach -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Modelowanie tematów: identyfikowanie wzorców w danych tekstowych
Ogólnie dokumenty są pogrupowane według tematów, a modelowanie tematyczne jest techniką identyfikowania wzorców w tekście, które odnoszą się do określonego tematu. Innymi słowy, modelowanie tematyczne służy do odkrywania abstrakcyjnych motywów lub ukrytej struktury w danym zestawie dokumentów.
Modelowania tematów można używać w następujących scenariuszach -
Klasyfikacja tekstu
Klasyfikację można ulepszyć za pomocą modelowania tematycznego, ponieważ grupuje ono podobne słowa, zamiast używać każdego słowa oddzielnie jako cechy.
Systemy rekomendujące
Możemy budować systemy rekomendujące, używając miar podobieństwa.
Algorytmy modelowania tematycznego
Możemy zaimplementować modelowanie tematyczne za pomocą następujących algorytmów -
Latent Dirichlet Allocation(LDA) - Jest to jeden z najpopularniejszych algorytmów wykorzystujący probabilistyczne modele graficzne do implementacji modelowania tematycznego.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - Opiera się na algebrze liniowej i wykorzystuje koncepcję SVD (rozkład wartości osobliwych) na macierzy terminów dokumentu.
Non-Negative Matrix Factorization (NMF) - Opiera się również na algebrze liniowej, podobnie jak LDA.
Powyższe algorytmy miałyby następujące elementy -
- Liczba tematów: parametr
- Macierz dokument-słowo: wejście
- WTM (Word Topic Matrix) i TDM (Topic Document Matrix): Wyjście