Krótki przewodnik po Pythonie
Python to interpretowany, interaktywny i zorientowany obiektowo język skryptowy wysokiego poziomu. Python został zaprojektowany tak, aby był bardzo czytelny. Często używa angielskich słów kluczowych, podczas gdy inne języki używają interpunkcji i ma mniej konstrukcji składniowych niż inne języki.
Python is Interpreted- Python jest przetwarzany w czasie wykonywania przez interpreter. Nie musisz kompilować programu przed jego wykonaniem. Jest to podobne do PERL i PHP.
Python is Interactive - Możesz faktycznie usiąść przy zachęcie Pythona i bezpośrednio komunikować się z interpreterem, aby pisać programy.
Python is Object-Oriented - Python obsługuje styl zorientowany obiektowo lub technikę programowania, która hermetyzuje kod w obiektach.
Python is a Beginner's Language - Python jest świetnym językiem dla początkujących programistów i wspiera rozwój szerokiej gamy aplikacji, od prostego przetwarzania tekstu, przez przeglądarki WWW, po gry.
Historia Pythona
Python został opracowany przez Guido van Rossuma na przełomie lat osiemdziesiątych i dziewięćdziesiątych w holenderskim National Research Institute for Mathematics and Computer Science.
Python wywodzi się z wielu innych języków, w tym z powłoki ABC, Modula-3, C, C ++, Algol-68, SmallTalk i Unix oraz innych języków skryptowych.
Python jest chroniony prawami autorskimi. Podobnie jak Perl, kod źródłowy Pythona jest teraz dostępny na licencji GNU General Public License (GPL).
Python jest obecnie obsługiwany przez główny zespół programistów w instytucie, chociaż Guido van Rossum nadal odgrywa kluczową rolę w kierowaniu jego postępami.
Funkcje Pythona
Funkcje Pythona obejmują -
Easy-to-learn- Python ma kilka słów kluczowych, prostą strukturę i jasno określoną składnię. Pozwala to uczniowi szybko przyswoić język.
Easy-to-read - Kod Pythona jest wyraźniej zdefiniowany i bardziej widoczny dla oczu.
Easy-to-maintain - Kod źródłowy Pythona jest dość łatwy w utrzymaniu.
A broad standard library - Większość biblioteki Pythona jest bardzo przenośna i kompatybilna z różnymi platformami w systemach UNIX, Windows i Macintosh.
Interactive Mode - Python obsługuje tryb interaktywny, który umożliwia interaktywne testowanie i debugowanie fragmentów kodu.
Portable - Python może działać na wielu różnych platformach sprzętowych i ma ten sam interfejs na wszystkich platformach.
Extendable- Możesz dodać moduły niskiego poziomu do interpretera Pythona. Moduły te umożliwiają programistom dodawanie lub dostosowywanie ich narzędzi, aby były bardziej wydajne.
Databases - Python zapewnia interfejsy do wszystkich głównych komercyjnych baz danych.
GUI Programming - Python obsługuje aplikacje GUI, które można tworzyć i przenosić do wielu wywołań systemowych, bibliotek i systemów Windows, takich jak Windows MFC, Macintosh i system X Window w systemie Unix.
Scalable - Python zapewnia lepszą strukturę i obsługę dużych programów niż skrypty powłoki.
Oprócz wyżej wymienionych funkcji, Python ma dużą listę dobrych funkcji, kilka z nich jest wymienionych poniżej -
Obsługuje funkcjonalne i strukturalne metody programowania, a także OOP.
Może być używany jako język skryptowy lub może być skompilowany do kodu bajtowego do tworzenia dużych aplikacji.
Zapewnia dynamiczne typy danych bardzo wysokiego poziomu i obsługuje dynamiczne sprawdzanie typów.
Obsługuje automatyczne zbieranie śmieci.
Można go łatwo zintegrować z C, C ++, COM, ActiveX, CORBA i Java.
Python jest dostępny na wielu różnych platformach, w tym Linux i Mac OS X. Przyjrzyjmy się, jak skonfigurować nasze środowisko Python.
Konfiguracja środowiska lokalnego
Otwórz okno terminala i wpisz „python”, aby dowiedzieć się, czy jest już zainstalowany i która wersja jest zainstalowana.
- Unix (Solaris, Linux, FreeBSD, AIX, HP / UX, SunOS, IRIX itp.)
- Win 9x / NT / 2000
- Macintosh (Intel, PPC, 68K)
- OS/2
- DOS (wiele wersji)
- PalmOS
- Telefony komórkowe Nokia
- Windows CE
- Acorn / RISC OS
- BeOS
- Amiga
- VMS/OpenVMS
- QNX
- VxWorks
- Psion
- Python został również przeniesiony na maszyny wirtualne Java i .NET
Pobieranie Pythona
Najbardziej aktualny i aktualny kod źródłowy, pliki binarne, dokumentacja, aktualności itp. Są dostępne na oficjalnej stronie Pythona https://www.python.org/
Możesz pobrać dokumentację Pythona z https://www.python.org/doc/. Dokumentacja jest dostępna w formatach HTML, PDF i PostScript.
Instalowanie Pythona
Dystrybucja Pythona jest dostępna na wiele różnych platform. Musisz pobrać tylko kod binarny odpowiedni dla Twojej platformy i zainstalować Pythona.
Jeśli kod binarny dla Twojej platformy nie jest dostępny, potrzebujesz kompilatora C do ręcznej kompilacji kodu źródłowego. Kompilowanie kodu źródłowego zapewnia większą elastyczność pod względem wyboru funkcji wymaganych w instalacji.
Oto krótki przegląd instalacji Pythona na różnych platformach -
Instalacja w systemach Unix i Linux
Oto proste kroki instalacji Pythona na komputerze z systemem Unix / Linux.
Otwórz przeglądarkę internetową i przejdź do https://www.python.org/downloads/.
Kliknij łącze, aby pobrać spakowany kod źródłowy dostępny dla systemów Unix / Linux.
Pobierz i rozpakuj pliki.
Edycja pliku modułów / ustawień , jeśli chcesz dostosować niektóre opcje.
uruchom skrypt ./configure
make
dokonać instalacji
Spowoduje to zainstalowanie Pythona w standardowej lokalizacji / usr / local / bin i jego bibliotek w / usr / local / lib / pythonXX, gdzie XX to wersja Pythona.
Instalacja systemu Windows
Oto kroki instalacji Pythona na komputerze z systemem Windows.
Otwórz przeglądarkę internetową i przejdź do https://www.python.org/downloads/.
Kliknij łącze do pliku instalatora Windows python-XYZ.msi , gdzie XYZ to wersja, którą musisz zainstalować.
Aby użyć tego instalatora python-XYZ.msi , system Windows musi obsługiwać Microsoft Installer 2.0. Zapisz plik instalatora na komputerze lokalnym, a następnie uruchom go, aby sprawdzić, czy Twój komputer obsługuje MSI.
Uruchom pobrany plik. Spowoduje to wyświetlenie kreatora instalacji języka Python, który jest naprawdę łatwy w użyciu. Po prostu zaakceptuj ustawienia domyślne, poczekaj, aż instalacja zostanie zakończona i gotowe.
Instalacja na komputerze Macintosh
Najnowsze komputery Mac są dostarczane z zainstalowanym Pythonem, ale może on być nieaktualny przez kilka lat. Widziećhttp://www.python.org/download/mac/aby uzyskać instrukcje dotyczące pobierania aktualnej wersji wraz z dodatkowymi narzędziami do obsługi programowania na komputerze Mac. W przypadku starszych systemów Mac OS wcześniejszych niż Mac OS X 10.3 (wydany w 2003 r.) Dostępny jest MacPython.
Zajmuje się nim Jack Jansen i możesz mieć pełny dostęp do całej dokumentacji na jego stronie internetowej - http://www.cwi.nl/~jack/macpython.html. Możesz znaleźć pełne szczegóły dotyczące instalacji systemu Mac OS.
Konfigurowanie PATH
Programy i inne pliki wykonywalne mogą znajdować się w wielu katalogach, więc systemy operacyjne zapewniają ścieżkę wyszukiwania zawierającą listę katalogów przeszukiwanych przez system operacyjny w poszukiwaniu plików wykonywalnych.
Ścieżka jest przechowywana w zmiennej środowiskowej, która jest nazwanym ciągiem obsługiwanym przez system operacyjny. Ta zmienna zawiera informacje dostępne dla powłoki poleceń i innych programów.
Plik path zmienna nosi nazwę PATH w systemie Unix lub Path w systemie Windows (w systemie Unix rozróżniana jest wielkość liter; Windows nie).
W systemie Mac OS instalator obsługuje szczegóły ścieżki. Aby wywołać interpreter języka Python z dowolnego katalogu, musisz dodać katalog Python do swojej ścieżki.
Ustawianie ścieżki w Unix / Linux
Aby dodać katalog Pythona do ścieżki dla określonej sesji w systemie Unix -
In the csh shell - wpisz setenv PATH "$ PATH: / usr / local / bin / python" i naciśnij Enter.
In the bash shell (Linux) - wpisz export PATH = "$ PATH: / usr / local / bin / python" i naciśnij Enter.
In the sh or ksh shell - wpisz PATH = "$ PATH: / usr / local / bin / python" i naciśnij Enter.
Note - / usr / local / bin / python to ścieżka do katalogu Pythona
Ustawianie ścieżki w systemie Windows
Aby dodać katalog Python do ścieżki dla określonej sesji w systemie Windows -
At the command prompt - wpisz path% path%; C: \ Python i naciśnij Enter.
Note - C: \ Python to ścieżka do katalogu Pythona
Zmienne środowiskowe Pythona
Oto ważne zmienne środowiskowe, które można rozpoznać w Pythonie -
| Sr.No. | Zmienna i opis |
|---|---|
| 1 | PYTHONPATH Pełni rolę podobną do PATH. Ta zmienna informuje interpreter języka Python, gdzie ma znajdować się pliki modułów zaimportowane do programu. Powinien zawierać katalog biblioteki źródłowej Pythona i katalogi zawierające kod źródłowy Pythona. PYTHONPATH jest czasami wstępnie ustawiana przez instalator Pythona. |
| 2 | PYTHONSTARTUP Zawiera ścieżkę do pliku inicjalizacyjnego zawierającego kod źródłowy Pythona. Jest wykonywany za każdym razem, gdy uruchamiasz tłumacza. Nazywa się .pythonrc.py w systemie Unix i zawiera polecenia, które ładują narzędzia lub modyfikują PYTHONPATH. |
| 3 | PYTHONCASEOK Jest używany w systemie Windows do poinstruowania Pythona, aby znalazł pierwsze dopasowanie bez uwzględniania wielkości liter w instrukcji importu. Ustaw tę zmienną na dowolną wartość, aby ją aktywować. |
| 4 | PYTHONHOME Jest to alternatywna ścieżka wyszukiwania modułu. Zwykle jest osadzony w katalogach PYTHONSTARTUP lub PYTHONPATH, aby ułatwić przełączanie bibliotek modułów. |
Uruchamianie Pythona
Istnieją trzy różne sposoby uruchomienia Pythona -
Interaktywny tłumacz
Możesz uruchomić Pythona z systemu Unix, DOS lub dowolnego innego systemu, który udostępnia interpreter wiersza poleceń lub okno powłoki.
Wchodzić python wiersz poleceń.
Rozpocznij kodowanie od razu w interaktywnym tłumaczu.
$python # Unix/Linux
or
python% # Unix/Linux
or
C:> python # Windows/DOSOto lista wszystkich dostępnych opcji wiersza poleceń -
| Sr.No. | Opcja i opis |
|---|---|
| 1 | -d Zapewnia wyjście debugowania. |
| 2 | -O Generuje zoptymalizowany kod bajtowy (w wyniku czego powstają pliki .pyo). |
| 3 | -S Nie uruchamiaj witryny importu w celu wyszukania ścieżek Pythona podczas uruchamiania. |
| 4 | -v szczegółowe dane wyjściowe (szczegółowe śledzenie instrukcji importu). |
| 5 | -X wyłącz wbudowane wyjątki oparte na klasach (użyj po prostu ciągów znaków); przestarzałe począwszy od wersji 1.6. |
| 6 | -c cmd uruchom skrypt Pythona wysłany jako ciąg cmd |
| 7 | file uruchom skrypt Pythona z podanego pliku |
Skrypt z wiersza poleceń
Skrypt Pythona można wykonać w wierszu poleceń, wywołując interpreter w aplikacji, jak w poniższym przykładzie -
$python script.py # Unix/Linux
or
python% script.py # Unix/Linux
or
C: >python script.py # Windows/DOSNote - Upewnij się, że tryb uprawnień do plików umożliwia wykonanie.
Zintegrowane środowisko programistyczne
Możesz również uruchomić język Python ze środowiska graficznego interfejsu użytkownika (GUI), jeśli masz aplikację GUI w systemie, która obsługuje język Python.
Unix - IDLE jest pierwszym IDE Uniksa dla Pythona.
Windows - PythonWin jest pierwszym interfejsem Windows dla Pythona i jest IDE z GUI.
Macintosh - Wersja Pythona dla komputerów Macintosh wraz z IDLE IDE jest dostępna z głównej strony internetowej, do pobrania jako pliki MacBinary lub BinHex'd.
Jeśli nie możesz poprawnie skonfigurować środowiska, możesz skorzystać z pomocy administratora systemu. Upewnij się, że środowisko Python jest poprawnie skonfigurowane i działa idealnie.
Note - Wszystkie przykłady podane w kolejnych rozdziałach są wykonywane w wersji Python 2.4.3 dostępnej w wersji Linuksa CentOS.
Stworzyliśmy już środowisko programowania Python online, abyś mógł wykonywać wszystkie dostępne przykłady online w tym samym czasie, gdy uczysz się teorii. Zapraszam do modyfikowania dowolnego przykładu i wykonywania go online.
Język Python ma wiele podobieństw do Perl, C i Java. Istnieją jednak pewne wyraźne różnice między językami.
Pierwszy program w Pythonie
Wykonujmy programy w różnych trybach programowania.
Programowanie w trybie interaktywnym
Wywołanie interpretera bez przekazywania pliku skryptu jako parametru powoduje wyświetlenie następującego monitu -
$ python
Python 2.4.3 (#1, Nov 11 2010, 13:34:43)
[GCC 4.1.2 20080704 (Red Hat 4.1.2-48)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>Wpisz następujący tekst w wierszu polecenia Pythona i naciśnij klawisz Enter -
>>> print "Hello, Python!"Jeśli używasz nowej wersji Pythona, musisz użyć instrukcji print z nawiasami, jak w print ("Hello, Python!");. Jednak w wersji 2.4.3 języka Python daje to następujący wynik -
Hello, Python!Programowanie w trybie skryptowym
Wywołanie interpretera z parametrem skryptu rozpoczyna wykonywanie skryptu i trwa do jego zakończenia. Po zakończeniu skryptu interpreter nie jest już aktywny.
Napiszmy w skrypcie prosty program w języku Python. Pliki Python mają rozszerzenie.py. Wpisz następujący kod źródłowy w pliku test.py -
print "Hello, Python!"Zakładamy, że masz ustawiony interpreter Pythona w zmiennej PATH. Teraz spróbuj uruchomić ten program w następujący sposób -
$ python test.pyDaje to następujący wynik -
Hello, Python!Wypróbujmy inny sposób wykonania skryptu w Pythonie. Oto zmodyfikowany plik test.py -
#!/usr/bin/python
print "Hello, Python!"Zakładamy, że masz dostępny interpreter Pythona w katalogu / usr / bin. Teraz spróbuj uruchomić ten program w następujący sposób -
$ chmod +x test.py # This is to make file executable
$./test.pyDaje to następujący wynik -
Hello, Python!Identyfikatory Pythona
Identyfikator Pythona to nazwa używana do identyfikacji zmiennej, funkcji, klasy, modułu lub innego obiektu. Identyfikator zaczyna się od litery od A do Z lub od a do z lub znaku podkreślenia (_), po którym następuje zero lub więcej liter, znaków podkreślenia i cyfr (od 0 do 9).
Python nie zezwala na znaki interpunkcyjne, takie jak @, $ i% w identyfikatorach. Python to język programowania uwzględniający wielkość liter. A zatem,Manpower i manpower to dwa różne identyfikatory w Pythonie.
Oto konwencje nazewnictwa identyfikatorów Pythona -
Nazwy klas rozpoczynają się od dużej litery. Wszystkie inne identyfikatory zaczynają się od małej litery.
Rozpoczęcie identyfikatora pojedynczym początkowym podkreśleniem wskazuje, że identyfikator jest prywatny.
Rozpoczynanie identyfikatora od dwóch wiodących znaków podkreślenia wskazuje na silnie prywatny identyfikator.
Jeśli identyfikator kończy się również dwoma końcowymi podkreśleniami, jest to nazwa specjalna zdefiniowana w języku.
Zastrzeżone słowa
Poniższa lista przedstawia słowa kluczowe języka Python. Są to słowa zastrzeżone i nie można ich używać jako stałych lub zmiennych ani żadnych innych nazw identyfikatorów. Wszystkie słowa kluczowe Pythona zawierają tylko małe litery.
| i | exec | nie |
| zapewniać | Wreszcie | lub |
| przerwa | dla | przechodzić |
| klasa | od | wydrukować |
| kontyntynuj | światowy | podnieść |
| pok | gdyby | powrót |
| del | import | próbować |
| elif | w | podczas |
| jeszcze | jest | z |
| z wyjątkiem | lambda | wydajność |
Linie i wcięcia
Python nie udostępnia nawiasów klamrowych wskazujących bloki kodu dla definicji klas i funkcji lub sterowania przepływem. Bloki kodu są oznaczone wcięciami linii, które są sztywno wymuszane.
Liczba spacji w wcięciach jest zmienna, ale wszystkie instrukcje w bloku muszą mieć wcięcie tej samej wielkości. Na przykład -
if True:
print "True"
else:
print "False"Jednak następujący blok generuje błąd -
if True:
print "Answer"
print "True"
else:
print "Answer"
print "False"Tak więc w Pythonie wszystkie ciągłe linie wcięte z taką samą liczbą spacji utworzyłyby blok. Poniższy przykład zawiera różne bloki instrukcji -
Note- Nie próbuj zrozumieć logiki w tym momencie. Po prostu upewnij się, że rozumiesz różne bloki, nawet jeśli nie mają nawiasów klamrowych.
#!/usr/bin/python
import sys
try:
# open file stream
file = open(file_name, "w")
except IOError:
print "There was an error writing to", file_name
sys.exit()
print "Enter '", file_finish,
print "' When finished"
while file_text != file_finish:
file_text = raw_input("Enter text: ")
if file_text == file_finish:
# close the file
file.close
break
file.write(file_text)
file.write("\n")
file.close()
file_name = raw_input("Enter filename: ")
if len(file_name) == 0:
print "Next time please enter something"
sys.exit()
try:
file = open(file_name, "r")
except IOError:
print "There was an error reading file"
sys.exit()
file_text = file.read()
file.close()
print file_textWyciągi wielowierszowe
Instrukcje w Pythonie zwykle kończą się nową linią. Python zezwala jednak na użycie znaku kontynuacji wiersza (\) do oznaczenia, że linia powinna być kontynuowana. Na przykład -
total = item_one + \
item_two + \
item_threeInstrukcje zawarte w nawiasach [], {} lub () nie muszą używać znaku kontynuacji wiersza. Na przykład -
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']Cytat w Pythonie
Python akceptuje pojedyncze ('), podwójne (") i potrójne (' '' lub" "") cudzysłowy w celu oznaczenia literałów łańcuchowych, o ile ten sam typ cudzysłowu zaczyna i kończy ciąg.
Potrójne cudzysłowy są używane do łączenia ciągu w wiele linii. Na przykład wszystkie poniższe są legalne -
word = 'word'
sentence = "This is a sentence."
paragraph = """This is a paragraph. It is
made up of multiple lines and sentences."""Komentarze w Pythonie
Znak skrótu (#), który nie znajduje się wewnątrz literału ciągu, rozpoczyna komentarz. Wszystkie znaki po # i do końca fizycznej linii są częścią komentarza i interpreter Pythona ignoruje je.
#!/usr/bin/python
# First comment
print "Hello, Python!" # second commentDaje to następujący wynik -
Hello, Python!Możesz wpisać komentarz w tym samym wierszu po instrukcji lub wyrażeniu -
name = "Madisetti" # This is again commentMożesz skomentować wiele linii w następujący sposób -
# This is a comment.
# This is a comment, too.
# This is a comment, too.
# I said that already.Korzystanie z pustych linii
Linia zawierająca tylko białe znaki, prawdopodobnie z komentarzem, jest nazywana pustą linią i Python całkowicie ją ignoruje.
W sesji interaktywnego interpretera należy wprowadzić pusty wiersz fizyczny, aby zakończyć instrukcję wielowierszową.
Czekam na użytkownika
W następnym wierszu programu wyświetlany jest monit, oświadczenie „Naciśnij klawisz Enter, aby wyjść” i czeka, aż użytkownik wykona akcję -
#!/usr/bin/python
raw_input("\n\nPress the enter key to exit.")Tutaj "\ n \ n" służy do tworzenia dwóch nowych linii przed wyświetleniem aktualnej linii. Gdy użytkownik naciśnie klawisz, program się kończy. To fajna sztuczka, aby pozostawić otwarte okno konsoli, dopóki użytkownik nie skończy z aplikacją.
Wiele instrukcji w jednym wierszu
Średnik (;) zezwala na umieszczanie wielu instrukcji w jednym wierszu, pod warunkiem, że żadna z instrukcji nie rozpoczyna nowego bloku kodu. Oto przykładowy wycinek ze średnikiem -
import sys; x = 'foo'; sys.stdout.write(x + '\n')Wiele grup instrukcji jako zestawów
Wywoływana jest grupa pojedynczych instrukcji, które tworzą pojedynczy blok kodu suitesw Pythonie. Instrukcje złożone lub złożone, takie jak if, while, def i class wymagają wiersza nagłówka i zestawu.
Linie nagłówka rozpoczynają instrukcję (słowem kluczowym) i kończą się dwukropkiem (:), a po nich następuje jedna lub więcej linii tworzących zestaw. Na przykład -
if expression :
suite
elif expression :
suite
else :
suiteArgumenty wiersza poleceń
Można uruchomić wiele programów, aby uzyskać podstawowe informacje o tym, jak powinny być uruchamiane. Python umożliwia Ci to za pomocą -h -
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]Możesz także zaprogramować swój skrypt w taki sposób, aby akceptował różne opcje. Argumenty wiersza poleceń to temat zaawansowany i powinien zostać przestudiowany nieco później, po zapoznaniu się z pozostałymi koncepcjami języka Python.
Zmienne to nic innego jak zarezerwowane miejsca w pamięci do przechowywania wartości. Oznacza to, że kiedy tworzysz zmienną, rezerwujesz trochę miejsca w pamięci.
Na podstawie typu danych zmiennej interpreter przydziela pamięć i decyduje, co może być przechowywane w zarezerwowanej pamięci. Dlatego przypisując różne typy danych do zmiennych, można przechowywać w tych zmiennych liczby całkowite, dziesiętne lub znaki.
Przypisywanie wartości do zmiennych
Zmienne Pythona nie wymagają jawnej deklaracji, aby zarezerwować miejsce w pamięci. Deklaracja jest wykonywana automatycznie po przypisaniu wartości do zmiennej. Znak równości (=) służy do przypisywania wartości zmiennym.
Operand po lewej stronie operatora = to nazwa zmiennej, a operand po prawej stronie operatora = to wartość przechowywana w zmiennej. Na przykład -
#!/usr/bin/python
counter = 100 # An integer assignment
miles = 1000.0 # A floating point
name = "John" # A string
print counter
print miles
print nameW tym przypadku 100, 1000,0 i „John” to wartości przypisane odpowiednio do zmiennych licznika , mil i nazw . Daje to następujący wynik -
100
1000.0
JohnPrzydział wielokrotny
Python umożliwia jednoczesne przypisanie jednej wartości do kilku zmiennych. Na przykład -
a = b = c = 1Tutaj tworzony jest obiekt typu integer z wartością 1, a wszystkie trzy zmienne są przypisywane do tej samej lokalizacji pamięci. Możesz także przypisać wiele obiektów do wielu zmiennych. Na przykład -
a,b,c = 1,2,"john"Tutaj dwa obiekty typu integer o wartościach 1 i 2 są przypisane odpowiednio do zmiennych a i b, a jeden obiekt typu string o wartości „john” jest przypisany do zmiennej c.
Standardowe typy danych
Dane przechowywane w pamięci mogą być różnego rodzaju. Na przykład wiek osoby jest przechowywany jako wartość liczbowa, a jej adres jako znaki alfanumeryczne. Python ma różne standardowe typy danych, które są używane do definiowania możliwych na nich operacji i metod przechowywania dla każdego z nich.
Python ma pięć standardowych typów danych -
- Numbers
- String
- List
- Tuple
- Dictionary
Liczby w Pythonie
Typy danych liczbowych przechowują wartości liczbowe. Obiekty liczbowe są tworzone, gdy przypisujesz im wartość. Na przykład -
var1 = 1
var2 = 10Możesz również usunąć odwołanie do obiektu liczbowego, używając instrukcji del. Składnia instrukcji del to -
del var1[,var2[,var3[....,varN]]]]Za pomocą instrukcji del można usunąć pojedynczy obiekt lub wiele obiektów. Na przykład -
del var
del var_a, var_bPython obsługuje cztery różne typy liczbowe -
- int (liczby całkowite ze znakiem)
- długie (długie liczby całkowite, mogą być również reprezentowane ósemkowo i szesnastkowo)
- float (zmiennoprzecinkowe wartości rzeczywiste)
- zespolone (liczby zespolone)
Przykłady
Oto kilka przykładów liczb -
| int | długo | pływak | złożony |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21,9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32,3 + e18 | .876j |
| -0490 | 535633629843L | -90. | -,6545 + 0J |
| -0x260 | -052318172735L | -32,54e100 | 3e + 26J |
| 0x69 | -4721885298529L | 70,2-E12 | 4.53e-7j |
Python pozwala na użycie małej litery l z long, ale zaleca się używanie tylko dużej litery L, aby uniknąć pomyłki z liczbą 1. Python wyświetla długie liczby całkowite z dużą literą L.
Liczba zespolona składa się z uporządkowanej pary rzeczywistych liczb zmiennoprzecinkowych oznaczonych przez x + yj, gdzie x i y to liczby rzeczywiste, a j jest jednostką urojoną.
Ciągi Pythona
Ciągi znaków w Pythonie są identyfikowane jako ciągły zestaw znaków przedstawionych w cudzysłowie. Python pozwala na stosowanie par pojedynczych lub podwójnych cudzysłowów. Podzbiory łańcuchów można pobrać za pomocą operatora wycinka ([] i [:]) z indeksami zaczynającymi się od 0 na początku łańcucha i zaczynającymi się od -1 na końcu.
Znak plus (+) to operator konkatenacji ciągów, a gwiazdka (*) to operator powtórzenia. Na przykład -
#!/usr/bin/python
str = 'Hello World!'
print str # Prints complete string
print str[0] # Prints first character of the string
print str[2:5] # Prints characters starting from 3rd to 5th
print str[2:] # Prints string starting from 3rd character
print str * 2 # Prints string two times
print str + "TEST" # Prints concatenated stringTo da następujący wynik -
Hello World!
H
llo
llo World!
Hello World!Hello World!
Hello World!TESTListy w Pythonie
Listy są najbardziej wszechstronnymi ze złożonych typów danych Pythona. Lista zawiera elementy oddzielone przecinkami i zawarte w nawiasach kwadratowych ([]). Do pewnego stopnia listy są podobne do tablic w C. Jedna różnica między nimi polega na tym, że wszystkie elementy należące do listy mogą mieć różne typy danych.
Dostęp do wartości przechowywanych na liście można uzyskać za pomocą operatora wycinka ([] i [:]) z indeksami zaczynającymi się od 0 na początku listy i prowadzącymi do końca -1. Znak plus (+) to operator konkatenacji listy, a gwiazdka (*) to operator powtórzenia. Na przykład -
#!/usr/bin/python
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tinylist = [123, 'john']
print list # Prints complete list
print list[0] # Prints first element of the list
print list[1:3] # Prints elements starting from 2nd till 3rd
print list[2:] # Prints elements starting from 3rd element
print tinylist * 2 # Prints list two times
print list + tinylist # Prints concatenated listsDaje to następujący wynik -
['abcd', 786, 2.23, 'john', 70.2]
abcd
[786, 2.23]
[2.23, 'john', 70.2]
[123, 'john', 123, 'john']
['abcd', 786, 2.23, 'john', 70.2, 123, 'john']Krotki Pythona
Krotka to inny typ danych sekwencji, który jest podobny do listy. Krotka składa się z szeregu wartości oddzielonych przecinkami. Jednak w przeciwieństwie do list krotki są umieszczone w nawiasach.
Główne różnice między listami a krotkami to: Listy są ujęte w nawiasy kwadratowe ([]), a ich elementy i rozmiar można zmieniać, natomiast krotki są zawarte w nawiasach (()) i nie można ich aktualizować. Krotki można traktować jakoread-onlylisty. Na przykład -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
tinytuple = (123, 'john')
print tuple # Prints the complete tuple
print tuple[0] # Prints first element of the tuple
print tuple[1:3] # Prints elements of the tuple starting from 2nd till 3rd
print tuple[2:] # Prints elements of the tuple starting from 3rd element
print tinytuple * 2 # Prints the contents of the tuple twice
print tuple + tinytuple # Prints concatenated tuplesDaje to następujący wynik -
('abcd', 786, 2.23, 'john', 70.2)
abcd
(786, 2.23)
(2.23, 'john', 70.2)
(123, 'john', 123, 'john')
('abcd', 786, 2.23, 'john', 70.2, 123, 'john')Poniższy kod jest nieprawidłowy w przypadku krotki, ponieważ próbowaliśmy zaktualizować krotkę, co jest niedozwolone. Podobny przypadek jest możliwy w przypadku list -
#!/usr/bin/python
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 )
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ]
tuple[2] = 1000 # Invalid syntax with tuple
list[2] = 1000 # Valid syntax with listSłownik Pythona
Słowniki Pythona są rodzajem tablic mieszających. Działają jak tablice asocjacyjne lub skróty występujące w Perlu i składają się z par klucz-wartość. Klucz słownika może być prawie dowolnego typu w Pythonie, ale zwykle są to liczby lub łańcuchy. Z drugiej strony wartościami mogą być dowolne obiekty w Pythonie.
Słowniki są ujęte w nawiasy klamrowe ({}), a wartości mogą być przypisywane i otwierane za pomocą nawiasów kwadratowych ([]). Na przykład -
#!/usr/bin/python
dict = {}
dict['one'] = "This is one"
dict[2] = "This is two"
tinydict = {'name': 'john','code':6734, 'dept': 'sales'}
print dict['one'] # Prints value for 'one' key
print dict[2] # Prints value for 2 key
print tinydict # Prints complete dictionary
print tinydict.keys() # Prints all the keys
print tinydict.values() # Prints all the valuesDaje to następujący wynik -
This is one
This is two
{'dept': 'sales', 'code': 6734, 'name': 'john'}
['dept', 'code', 'name']
['sales', 6734, 'john']Słowniki nie mają pojęcia porządku między elementami. Nieprawidłowe jest stwierdzenie, że elementy są „niesprawne”; są po prostu nieuporządkowane.
Konwersja typu danych
Czasami może być konieczne wykonanie konwersji między typami wbudowanymi. Aby dokonać konwersji między typami, po prostu użyj nazwy typu jako funkcji.
Istnieje kilka wbudowanych funkcji do przeprowadzania konwersji z jednego typu danych na inny. Te funkcje zwracają nowy obiekt reprezentujący przekonwertowaną wartość.
| Sr.No. | Opis funkcji |
|---|---|
| 1 | int(x [,base]) Konwertuje x na liczbę całkowitą. base określa podstawę, jeśli x jest łańcuchem. |
| 2 | long(x [,base] ) Konwertuje x na długą liczbę całkowitą. base określa podstawę, jeśli x jest łańcuchem. |
| 3 | float(x) Konwertuje x na liczbę zmiennoprzecinkową. |
| 4 | complex(real [,imag]) Tworzy liczbę zespoloną. |
| 5 | str(x) Konwertuje obiekt x na reprezentację w postaci ciągu. |
| 6 | repr(x) Konwertuje obiekt x na ciąg wyrażenia. |
| 7 | eval(str) Oblicza ciąg i zwraca obiekt. |
| 8 | tuple(s) Konwertuje s na krotkę. |
| 9 | list(s) Konwertuje s na listę. |
| 10 | set(s) Konwertuje s na zbiór. |
| 11 | dict(d) Tworzy słownik. d musi być sekwencją krotek (klucz, wartość). |
| 12 | frozenset(s) Konwertuje s na zamrożony zestaw. |
| 13 | chr(x) Konwertuje liczbę całkowitą na znak. |
| 14 | unichr(x) Konwertuje liczbę całkowitą na znak Unicode. |
| 15 | ord(x) Konwertuje pojedynczy znak na jego wartość całkowitą. |
| 16 | hex(x) Konwertuje liczbę całkowitą na ciąg szesnastkowy. |
| 17 | oct(x) Konwertuje liczbę całkowitą na ciąg ósemkowy. |
Operatory to konstrukcje, które mogą manipulować wartością operandów.
Rozważmy wyrażenie 4 + 5 = 9. Tutaj 4 i 5 nazywane są operandami, a + nazywane jest operatorem.
Typy operatorów
Język Python obsługuje następujące typy operatorów.
- Operatory arytmetyczne
- Operatory porównania (relacyjne)
- Operatory przypisania
- Operatory logiczne
- Operatory bitowe
- Operatorzy członkostwa
- Operatory tożsamości
Przyjrzyjmy się kolejno wszystkim operatorom.
Operatory arytmetyczne w Pythonie
Załóżmy, że zmienna a zawiera 10, a zmienna b 20, a następnie -
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| + Dodatek | Dodaje wartości po obu stronach operatora. | a + b = 30 |
| - Odejmowanie | Odejmuje operand po prawej stronie od operandu po lewej stronie. | a - b = -10 |
| * Mnożenie | Mnoży wartości po obu stronach operatora | a * b = 200 |
| / Podział | Dzieli operand lewej ręki przez operand prawej ręki | b / a = 2 |
| % Modułu | Dzieli operand po lewej stronie przez operand po prawej stronie i zwraca resztę | b% a = 0 |
| ** Wykładnik | Wykonuje obliczenia wykładnicze (potęgowe) na operatorach | a ** b = 10 do potęgi 20 |
| // | Podział piętra - dzielenie argumentów, których wynikiem jest iloraz, w którym usuwane są cyfry po przecinku. Ale jeśli jeden z operandów jest ujemny, wynik jest zmienny, tj. Zaokrąglony od zera (w kierunku ujemnej nieskończoności) - | 9 // 2 = 4 i 9,0 // 2,0 = 4,0, -11 // 3 = -4, -11,0 // 3 = -4,0 |
Operatory porównania w Pythonie
Te operatory porównują wartości po obu stronach i decydują o relacji między nimi. Nazywa się je również operatorami relacyjnymi.
Załóżmy, że zmienna a zawiera 10, a zmienna b 20, a następnie -
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| == | Jeśli wartości dwóch operandów są równe, warunek staje się prawdziwy. | (a == b) nie jest prawdą. |
| ! = | Jeśli wartości dwóch operandów nie są równe, warunek staje się prawdziwy. | (a! = b) jest prawdą. |
| <> | Jeśli wartości dwóch operandów nie są równe, warunek staje się prawdziwy. | (a <> b) jest prawdą. Jest to podobne do operatora! =. |
| > | Jeśli wartość lewego operandu jest większa niż wartość prawego operandu, warunek staje się prawdziwy. | (a> b) nie jest prawdą. |
| < | Jeśli wartość lewego operandu jest mniejsza niż wartość prawego operandu, warunek staje się prawdziwy. | (a <b) jest prawdą. |
| > = | Jeśli wartość lewego operandu jest większa lub równa wartości prawego operandu, warunek staje się prawdziwy. | (a> = b) nie jest prawdą. |
| <= | Jeśli wartość lewego operandu jest mniejsza lub równa wartości prawego operandu, warunek staje się prawdziwy. | (a <= b) jest prawdą. |
Operatory przypisania w Pythonie
Załóżmy, że zmienna a zawiera 10, a zmienna b 20, a następnie -
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| = | Przypisuje wartości z operandów po prawej stronie do operandów po lewej stronie | c = a + b przypisuje wartość a + b do c |
| + = Dodaj I | Dodaje prawy operand do lewego operandu i przypisuje wynik do lewego operandu | c + = a jest równoważne c = c + a |
| - = Odejmij AND | Odejmuje prawy operand od lewego operandu i przypisuje wynik lewemu operandowi | c - = a jest równoważne c = c - a |
| * = Pomnóż AND | Mnoży prawy operand z lewym operandem i przypisuje wynik do lewego operandu | c * = a jest równoważne c = c * a |
| / = Dzielenie AND | Dzieli lewy operand z prawym operandem i przypisuje wynik lewemu operandowi | c / = a jest równoważne c = c / a |
| % = Moduł AND | Pobiera moduł używając dwóch operandów i przypisuje wynik do lewego operandu | c% = a jest równoważne c = c% a |
| ** = wykładnik AND | Wykonuje obliczenia wykładnicze (potęgowe) na operatorach i przypisuje wartość do lewego operandu | c ** = a jest równoważne c = c ** a |
| // = Podział piętra | Dokonuje podziału na operatorów i przypisuje wartość do lewego operandu | c // = a jest równoważne c = c // a |
Operatory bitowe Pythona
Operator bitowy działa na bitach i wykonuje operacje bit po bicie. Załóżmy, że a = 60; i b = 13; Teraz w formacie binarnym ich wartości będą wynosić odpowiednio 0011 1100 i 0000 1101. Poniższa tabela zawiera listę operatorów bitowych obsługiwanych przez język Python z przykładem każdego z nich, używamy powyższych dwóch zmiennych (a i b) jako operandów -
a = 0011 1100
b = 0000 1101
-----------------
a & b = 0000 1100
a | b = 0011 1101
a ^ b = 0011 0001
~ a = 1100 0011
Istnieją następujące operatory bitowe obsługiwane przez język Python
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| & Binarne AND | Operator kopiuje trochę do wyniku, jeśli istnieje w obu operandach | (a i b) (oznacza 0000 1100) |
| | Binarny OR | Kopiuje trochę, jeśli istnieje w którymkolwiek operandzie. | (a | b) = 61 (oznacza 0011 1101) |
| ^ Binarny XOR | Kopiuje bit, jeśli jest ustawiony w jednym operandzie, ale nie w obu. | (a ^ b) = 49 (oznacza 0011 0001) |
| ~ Uzupełnienie binarne | Jest jednoargumentowy i powoduje „przerzucanie” bitów. | (~ a) = -61 (oznacza 1100 0011 w postaci uzupełnienia do 2 ze względu na liczbę binarną ze znakiem. |
| << Binarne przesunięcie w lewo | Wartość lewych operandów jest przesuwana w lewo o liczbę bitów określoną przez prawy operand. | a << 2 = 240 (oznacza 1111 0000) |
| >> Binarny prawy Shift | Wartość lewego operandu jest przesuwana w prawo o liczbę bitów określoną przez prawy operand. | a >> 2 = 15 (oznacza 0000 1111) |
Operatory logiczne Pythona
Istnieją następujące operatory logiczne obsługiwane przez język Python. Załóżmy, że zmienna a zawiera 10, a zmienna b 20
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| i logiczne AND | Jeśli oba operandy są prawdziwe, warunek staje się prawdziwy. | (a i b) jest prawdą. |
| lub logiczne LUB | Jeśli którykolwiek z dwóch operandów jest niezerowy, warunek staje się prawdziwy. | (a lub b) jest prawdą. |
| nie logiczne NIE | Służy do odwracania stanu logicznego argumentu. | Nie (a i b) jest fałszem. |
Operatory członkostwa w Pythonie
Operatory członkostwa w Pythonie sprawdzają członkostwo w sekwencji, takiej jak łańcuchy, listy lub krotki. Istnieją dwa operatory członkostwa, jak wyjaśniono poniżej -
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| w | Zwraca wartość true, jeśli znajdzie zmienną w określonej kolejności lub false w przeciwnym razie. | x in y, tutaj w wynikach 1, jeśli x jest członkiem ciągu y. |
| nie w | Zwraca wartość true, jeśli nie znajdzie zmiennej w określonej kolejności lub false w przeciwnym razie. | x nie w y, tutaj nie w wynikach w 1, jeśli x nie jest członkiem ciągu y. |
Operatory tożsamości w Pythonie
Operatory tożsamości porównują lokalizacje pamięci dwóch obiektów. Istnieją dwa operatory tożsamości opisane poniżej -
[ Pokaż przykład ]
| Operator | Opis | Przykład |
|---|---|---|
| jest | Zwraca wartość true, jeśli zmienne po obu stronach operatora wskazują na ten sam obiekt, aw przeciwnym razie - false. | x jest y, tutaj is daje w wyniku 1, jeśli id (x) jest równe id (y). |
| nie jest | Zwraca wartość false, jeśli zmienne po obu stronach operatora wskazują ten sam obiekt, aw przeciwnym razie - true. | x nie jest y, tutaj is not daje 1, jeśli id (x) nie jest równe id (y). |
Pierwszeństwo operatorów Pythona
W poniższej tabeli wymieniono wszystkie operatory od najwyższego do najniższego priorytetu.
[ Pokaż przykład ]
| Sr.No. | Operator i opis |
|---|---|
| 1 | ** Potęgowanie (podniesienie do potęgi) |
| 2 | ~ + - Dopełnienie, jednoargumentowy plus i minus (nazwy metod dla ostatnich dwóch to + @ i - @) |
| 3 | * / % // Mnożenie, dzielenie, dzielenie modulo i piętro |
| 4 | + - Dodawanie i odejmowanie |
| 5 | >> << Przesunięcie bitowe w prawo iw lewo |
| 6 | & Bitowe „AND” |
| 7 | ^ | Wyłączne bitowo „OR” i zwykłe „OR” |
| 8 | <= < > >= Operatory porównania |
| 9 | <> == != Operatory równości |
| 10 | = %= /= //= -= += *= **= Operatory przypisania |
| 11 | is is not Operatory tożsamości |
| 12 | in not in Operatorzy członkostwa |
| 13 | not or and Operatory logiczne |
Podejmowanie decyzji to przewidywanie warunków występujących podczas realizacji programu i określanie podjętych działań zgodnie z warunkami.
Struktury decyzyjne oceniają wiele wyrażeń, które dają wynik PRAWDA lub FAŁSZ. Musisz określić, które działanie należy podjąć i które instrukcje wykonać, jeśli wynik ma wartość TRUE lub FALSE, w przeciwnym razie.
Poniżej przedstawiono ogólną formę typowej struktury podejmowania decyzji występującej w większości języków programowania -
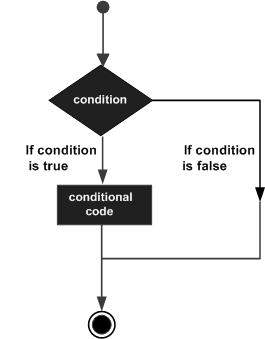
Język programowania Python zakłada dowolne pliki non-zero i non-null wartości jako PRAWDA, a jeśli tak jest zero lub null, wtedy przyjmuje się wartość FAŁSZ.
Język programowania Python udostępnia następujące typy instrukcji decyzyjnych. Kliknij poniższe łącza, aby sprawdzić ich szczegóły.
| Sr.No. | Oświadczenie i opis |
|---|---|
| 1 | jeśli oświadczenia Na if statement składa się z wyrażenia logicznego, po którym następuje co najmniej jedna instrukcja. |
| 2 | if ... else oświadczenia Na if statement może następować opcjonalnie else statement, który jest wykonywany, gdy wyrażenie boolowskie ma wartość FALSE. |
| 3 | zagnieżdżone instrukcje if Możesz użyć jednego if lub else if oświadczenie wewnątrz innego if lub else if sprawozdania). |
Przyjrzyjmy się pokrótce każdej decyzji -
Pakiety z pojedynczym wyciągiem
Jeśli zestaw if klauzula składa się tylko z jednego wiersza, może znajdować się w tym samym wierszu, co instrukcja nagłówka.
Oto przykład pliku one-line if klauzula -
#!/usr/bin/python
var = 100
if ( var == 100 ) : print "Value of expression is 100"
print "Good bye!"Wykonanie powyższego kodu daje następujący wynik -
Value of expression is 100
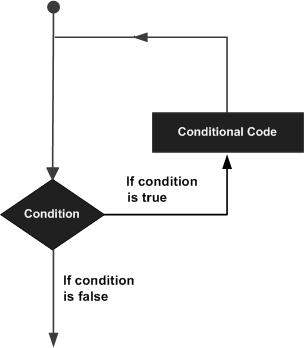
Good bye!Ogólnie instrukcje są wykonywane sekwencyjnie: pierwsza instrukcja funkcji jest wykonywana jako pierwsza, po niej następuje druga i tak dalej. Może zaistnieć sytuacja, w której trzeba będzie kilkakrotnie wykonać blok kodu.
Języki programowania zapewniają różne struktury kontrolne, które pozwalają na bardziej skomplikowane ścieżki wykonywania.
Instrukcja pętli umożliwia wielokrotne wykonanie instrukcji lub grupy instrukcji. Poniższy diagram ilustruje instrukcję pętli -
Język programowania Python zapewnia następujące typy pętli do obsługi wymagań pętli.
| Sr.No. | Typ i opis pętli |
|---|---|
| 1 | pętla while Powtarza instrukcję lub grupę instrukcji, gdy dany warunek ma wartość TRUE. Testuje warunek przed wykonaniem treści pętli. |
| 2 | dla pętli Wykonuje sekwencję instrukcji wiele razy i skraca kod zarządzający zmienną pętli. |
| 3 | pętle zagnieżdżone Możesz użyć jednej lub więcej pętli wewnątrz dowolnej innej pętli while, for lub do..while. |
Instrukcje sterowania pętlą
Instrukcje sterujące pętlą zmieniają wykonanie z jego normalnej sekwencji. Gdy wykonanie opuszcza zakres, wszystkie automatyczne obiekty utworzone w tym zakresie są niszczone.
Python obsługuje następujące instrukcje sterujące. Kliknij poniższe łącza, aby sprawdzić ich szczegóły.
Przyjrzyjmy się pokrótce instrukcjom sterującym pętli
| Sr.No. | Oświadczenie i opis kontroli |
|---|---|
| 1 | instrukcja break Kończy instrukcję pętli i przenosi wykonanie do instrukcji bezpośrednio po pętli. |
| 2 | kontynuuj oświadczenie Powoduje, że pętla pomija pozostałą część swojego ciała i natychmiast ponownie testuje swój stan przed ponownym powtórzeniem. |
| 3 | instrukcja pass Instrukcja pass w Pythonie jest używana, gdy instrukcja jest wymagana składniowo, ale nie chcesz, aby żadne polecenie ani kod były wykonywane. |
Typy danych liczbowych przechowują wartości liczbowe. Są to niezmienne typy danych, co oznacza, że zmiana wartości liczbowego typu danych powoduje powstanie nowo przydzielonego obiektu.
Obiekty liczbowe są tworzone, gdy przypisujesz im wartość. Na przykład -
var1 = 1
var2 = 10Możesz również usunąć odwołanie do obiektu liczbowego przy użyciu rozszerzenia delkomunikat. Składnia instrukcji del to -
del var1[,var2[,var3[....,varN]]]]Możesz usunąć pojedynczy obiekt lub wiele obiektów przy użyciu rozszerzenia delkomunikat. Na przykład -
del var
del var_a, var_bPython obsługuje cztery różne typy liczbowe -
int (signed integers) - Często nazywane są po prostu liczbami całkowitymi lub całkowitymi, są dodatnimi lub ujemnymi liczbami całkowitymi bez kropki dziesiętnej.
long (long integers ) - Nazywane również długimi, są liczbami całkowitymi o nieograniczonej wielkości, zapisanymi jako liczby całkowite, po których następuje duża lub mała litera L.
float (floating point real values)- Nazywane także liczbami zmiennoprzecinkowymi, reprezentują liczby rzeczywiste i są zapisywane z kropką dziesiętną dzielącą część całkowitą i ułamkową. Pływaki mogą być również w notacji naukowej, gdzie E lub e wskazują potęgę 10 (2,5e2 = 2,5 x 10 2 = 250).
complex (complex numbers)- mają postać a + bJ, gdzie a i b są liczbami zmiennoprzecinkowymi, a J (lub j) reprezentuje pierwiastek kwadratowy z -1 (który jest liczbą urojoną). Część rzeczywistą liczby to a, a częścią urojoną jest b. Liczby zespolone nie są zbytnio używane w programowaniu w Pythonie.
Przykłady
Oto kilka przykładów liczb
| int | długo | pływak | złożony |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21,9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEL | 32,3 + e18 | .876j |
| -0490 | 535633629843L | -90. | -,6545 + 0J |
| -0x260 | -052318172735L | -32,54e100 | 3e + 26J |
| 0x69 | -4721885298529L | 70,2-E12 | 4.53e-7j |
Python pozwala na użycie małej litery L z długą, ale zaleca się używanie tylko dużej litery L, aby uniknąć pomyłki z liczbą 1. Python wyświetla długie liczby całkowite z dużą literą L.
Liczba zespolona składa się z uporządkowanej pary rzeczywistych liczb zmiennoprzecinkowych oznaczonych przez a + bj, gdzie a jest częścią rzeczywistą, a b jest częścią urojoną liczby zespolonej.
Konwersja typu liczb
Python wewnętrznie konwertuje liczby w wyrażeniu zawierającym typy mieszane do wspólnego typu w celu oceny. Ale czasami trzeba jawnie przekształcić liczbę z jednego typu na inny, aby spełnić wymagania operatora lub parametru funkcji.
Rodzaj int(x) aby przekonwertować x na zwykłą liczbę całkowitą.
Rodzaj long(x) aby przekonwertować x na długą liczbę całkowitą.
Rodzaj float(x) aby przekonwertować x na liczbę zmiennoprzecinkową.
Rodzaj complex(x) przekonwertować x na liczbę zespoloną z częścią rzeczywistą x i częścią urojoną zero.
Rodzaj complex(x, y)przekonwertować x i y na liczbę zespoloną z częścią rzeczywistą x i częścią urojoną y. x i y to wyrażenia numeryczne
Funkcje matematyczne
Python zawiera następujące funkcje, które wykonują obliczenia matematyczne.
| Sr.No. | Funkcja i zwroty (opis) |
|---|---|
| 1 | abs (x) Wartość bezwzględna x: (dodatnia) odległość między x a zerem. |
| 2 | sufit (x) Pułap x: najmniejsza liczba całkowita nie mniejsza niż x |
| 3 | cmp (x, y) -1 jeśli x <y, 0 jeśli x == y lub 1 jeśli x> y |
| 4 | exp (x) Wykładniczy z x: e x |
| 5 | fabs (x) Wartość bezwzględna x. |
| 6 | piętro (x) Podłoga x: największa liczba całkowita nie większa niż x |
| 7 | log (x) Logarytm naturalny x dla x> 0 |
| 8 | log10 (x) Logarytm dziesiętny z x dla x> 0. |
| 9 | max (x1, x2, ...) Największy z jego argumentów: wartość najbliższa dodatniej nieskończoności |
| 10 | min (x1, x2, ...) Najmniejszy z jego argumentów: wartość najbliższa ujemnej nieskończoności |
| 11 | modf (x) Ułamkowe i całkowite części x w krotce składającej się z dwóch elementów. Obie części mają ten sam znak co x. Część całkowita jest zwracana jako liczba zmiennoprzecinkowa. |
| 12 | pow (x, y) Wartość x ** y. |
| 13 | round (x [, n]) xzaokrąglone do n cyfr od przecinka. Python zaokrągla od zera jako rozstrzygający remis: runda (0,5) to 1,0, a runda (-0,5) to -1,0. |
| 14 | sqrt (x) Pierwiastek kwadratowy z x dla x> 0 |
Funkcje liczb losowych
Liczby losowe są używane w grach, symulacjach, testach, zabezpieczeniach i aplikacjach do ochrony prywatności. Python zawiera następujące powszechnie używane funkcje.
| Sr.No. | Opis funkcji |
|---|---|
| 1 | wybór (kolejność) Losowy element z listy, krotki lub ciągu. |
| 2 | randrange ([start,] stop [, krok]) Losowo wybrany element z zakresu (start, stop, step) |
| 3 | losowy() Losowy zmiennoprzecinkowy r, taki że 0 jest mniejsze lub równe r i r jest mniejsze niż 1 |
| 4 | ziarno ([x]) Ustawia całkowitą wartość początkową używaną podczas generowania liczb losowych. Wywołaj tę funkcję przed wywołaniem jakiejkolwiek innej losowej funkcji modułu. Zwraca brak. |
| 5 | shuffle (lst) Losuje pozycje listy w miejscu. Zwraca brak. |
| 6 | jednolity (x, y) Losowy zmiennoprzecinkowy r, taki, że x jest mniejsze lub równe r i r jest mniejsze niż y |
Funkcje trygonometryczne
Python zawiera następujące funkcje, które wykonują obliczenia trygonometryczne.
| Sr.No. | Opis funkcji |
|---|---|
| 1 | acos (x) Zwraca arcus cosinus z x w radianach. |
| 2 | asin (x) Zwraca arcus sinus z x w radianach. |
| 3 | atan (x) Zwróć styczną łuku dla x w radianach. |
| 4 | atan2 (y, x) Zwraca atan (y / x) w radianach. |
| 5 | cos (x) Zwróć cosinus x radianów. |
| 6 | hypot (x, y) Zwróć normę euklidesową, sqrt (x * x + y * y). |
| 7 | sin (x) Zwraca sinus z x radianów. |
| 8 | opalenizna (x) Zwraca tangens x radianów. |
| 9 | stopnie (x) Konwertuje kąt x z radianów na stopnie. |
| 10 | radiany (x) Konwertuje kąt x ze stopni na radiany. |
Stałe matematyczne
Moduł definiuje również dwie stałe matematyczne -
| Sr.No. | Stałe i opis |
|---|---|
| 1 | pi Matematyczna stała pi. |
| 2 | e Stała matematyczna e. |
Ciągi znaków należą do najpopularniejszych typów w Pythonie. Możemy je tworzyć po prostu umieszczając znaki w cudzysłowach. Python traktuje pojedyncze cudzysłowy tak samo, jak podwójne cudzysłowy. Tworzenie ciągów jest tak proste, jak przypisanie wartości do zmiennej. Na przykład -
var1 = 'Hello World!'
var2 = "Python Programming"Dostęp do wartości w ciągach
Python nie obsługuje typów znaków; są one traktowane jako ciągi o długości jeden, dlatego też są traktowane jako podciąg.
Aby uzyskać dostęp do podciągów, użyj nawiasów kwadratowych do cięcia wraz z indeksem lub indeksami, aby uzyskać podciąg. Na przykład -
#!/usr/bin/python
var1 = 'Hello World!'
var2 = "Python Programming"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]Wykonanie powyższego kodu daje następujący wynik -
var1[0]: H
var2[1:5]: ythoAktualizowanie ciągów
Możesz „zaktualizować” istniejący ciąg poprzez (ponowne) przypisanie zmiennej do innego ciągu. Nowa wartość może być powiązana z jej poprzednią wartością lub zupełnie innym ciągiem. Na przykład -
#!/usr/bin/python
var1 = 'Hello World!'
print "Updated String :- ", var1[:6] + 'Python'Wykonanie powyższego kodu daje następujący wynik -
Updated String :- Hello PythonZnaki ucieczki
Poniższa tabela zawiera listę znaków zmiany znaczenia lub znaków niedrukowalnych, które można przedstawić za pomocą notacji z ukośnikiem odwrotnym.
Znak ucieczki jest interpretowany; w ciągach pojedynczych i podwójnych cudzysłowów.
| Notacja z ukośnikiem odwrotnym | Znak szesnastkowy | Opis |
|---|---|---|
| \za | 0x07 | Dzwonek lub alert |
| \b | 0x08 | Backspace |
| \ cx | Control + x | |
| \ Cx | Control + x | |
| \mi | 0x1b | Ucieczka |
| \fa | 0x0c | Formfeed |
| \ M- \ Cx | Meta-Control-x | |
| \ n | 0x0a | Nowa linia |
| \ nnn | Notacja ósemkowa, gdzie n mieści się w zakresie 0,7 | |
| \ r | 0x0d | Powrót karetki |
| \ s | 0x20 | Przestrzeń |
| \ t | 0x09 | Patka |
| \ v | 0x0b | Zakładka pionowa |
| \ x | Postać x | |
| \ xnn | Zapis szesnastkowy, gdzie n mieści się w zakresie 0,9, af lub AF |
Operatory specjalne łańcuchów
Załóż zmienną łańcuchową a zawiera „Hello” i zmienną b zawiera „Python”, a następnie -
| Operator | Opis | Przykład |
|---|---|---|
| + | Konkatenacja - dodaje wartości po obu stronach operatora | a + b da HelloPython |
| * | Powtórzenie - tworzy nowe ciągi, łącząc wiele kopii tego samego ciągu | a * 2 da -HelloHello |
| [] | Slice - podaje znak z podanego indeksu | a [1] da e |
| [:] | Fragment zakresu - podaje znaki z podanego zakresu | a [1: 4] da łokieć |
| w | Członkostwo - zwraca wartość true, jeśli znak istnieje w podanym ciągu | H w a da 1 |
| nie w | Członkostwo - zwraca wartość true, jeśli znak nie istnieje w podanym ciągu | M nie da 1 |
| r / R | Surowy ciąg - pomija rzeczywiste znaczenie znaków ucieczki. Składnia nieprzetworzonych łańcuchów jest dokładnie taka sama, jak w przypadku zwykłych ciągów, z wyjątkiem surowego operatora łańcucha, litery „r”, która poprzedza cudzysłowy. Litera „r” może być małą (r) lub wielką (R) i musi zostać umieszczona bezpośrednio przed pierwszym cudzysłowem. | print r '\ n' drukuje \ n i drukuje R '\ n'prints \ n |
| % | Format - wykonuje formatowanie ciągów | Zobacz w następnej sekcji |
Operator formatowania łańcucha
Jedną z najfajniejszych funkcji Pythona jest operator formatu ciągu znaków%. Ten operator jest unikalny dla łańcuchów i stanowi pakiet funkcji z rodziny printf () języka C. Oto prosty przykład -
#!/usr/bin/python
print "My name is %s and weight is %d kg!" % ('Zara', 21)Wykonanie powyższego kodu daje następujący wynik -
My name is Zara and weight is 21 kg!Oto lista pełnego zestawu symboli, których można używać wraz z% -
| Symbol formatu | Konwersja |
|---|---|
| %do | postać |
| % s | konwersja ciągów przez str () przed formatowaniem |
| %ja | liczba całkowita dziesiętna ze znakiem |
| %re | liczba całkowita dziesiętna ze znakiem |
| % u | liczba całkowita dziesiętna bez znaku |
| % o | ósemkowa liczba całkowita |
| % x | liczba szesnastkowa całkowita (małe litery) |
| % X | liczba szesnastkowa całkowita (wielkie litery) |
| %mi | notacja wykładnicza (z małą literą „e”) |
| %MI | notacja wykładnicza (z WIELKĄ LITERĄ „E”) |
| %fa | zmiennoprzecinkowa liczba rzeczywista |
| %sol | krótszy z% f i% e |
| %SOL | krótszy z% f i% E |
Inne obsługiwane symbole i funkcje są wymienione w poniższej tabeli -
| Symbol | Funkcjonalność |
|---|---|
| * | argument określa szerokość lub precyzję |
| - | lewe uzasadnienie |
| + | wyświetlić znak |
| <sp> | pozostaw puste miejsce przed liczbą dodatnią |
| # | dodaj wiodące zero ósemkowe („0”) lub wiodące szesnastkowe „0x” lub „0X”, w zależności od tego, czy użyto „x” czy „X”. |
| 0 | wypełnij od lewej zerami (zamiast spacji) |
| % | „%%” pozostawia pojedynczy literał „%” |
| (var) | mapowanie zmiennej (argumenty słownikowe) |
| mn | m to minimalna całkowita szerokość, an to liczba cyfr do wyświetlenia po przecinku (jeśli ma to zastosowanie). |
Potrójne cytaty
Potrójne cudzysłowy w Pythonie przychodzą na ratunek, pozwalając ciągom na rozciąganie wielu wierszy, w tym dosłowne znaki NEWLINE, TAB i inne znaki specjalne.
Składnia potrójnych cudzysłowów składa się z trzech następujących po sobie single or double cytaty.
#!/usr/bin/python
para_str = """this is a long string that is made up of
several lines and non-printable characters such as
TAB ( \t ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [ \n ], or just a NEWLINE within
the variable assignment will also show up.
"""
print para_strWykonanie powyższego kodu daje następujący wynik. Zwróć uwagę, jak każdy pojedynczy znak specjalny został przekonwertowany do postaci drukowanej, aż do ostatniego znaku NEWLINE na końcu ciągu między „w górę”. i zamykające potrójne cudzysłowy. Zwróć też uwagę, że znaki NEWLINE występują albo z jawnym powrotem karetki na końcu wiersza, albo z jego kodem ucieczki (\ n) -
this is a long string that is made up of
several lines and non-printable characters such as
TAB ( ) and they will show up that way when displayed.
NEWLINEs within the string, whether explicitly given like
this within the brackets [
], or just a NEWLINE within
the variable assignment will also show up.Surowe łańcuchy w ogóle nie traktują ukośnika odwrotnego jako znaku specjalnego. Każdy znak, który umieścisz w nieprzetworzonym łańcuchu, pozostaje taki, jaki został napisany -
#!/usr/bin/python
print 'C:\\nowhere'Wykonanie powyższego kodu daje następujący wynik -
C:\nowhereSkorzystajmy teraz z surowego łańcucha. Włożylibyśmy wyrazr'expression' w następujący sposób -
#!/usr/bin/python
print r'C:\\nowhere'Wykonanie powyższego kodu daje następujący wynik -
C:\\nowhereCiąg Unicode
Normalne ciągi znaków w Pythonie są przechowywane wewnętrznie jako 8-bitowe ASCII, podczas gdy ciągi znaków Unicode są przechowywane jako 16-bitowe Unicode. Pozwala to na bardziej zróżnicowany zestaw znaków, w tym znaki specjalne z większości języków na świecie. Ograniczę moje traktowanie ciągów Unicode do następujących -
#!/usr/bin/python
print u'Hello, world!'Wykonanie powyższego kodu daje następujący wynik -
Hello, world!Jak widać, łańcuchy Unicode używają przedrostka u, tak jak ciągi nieprzetworzone używają przedrostka r.
Wbudowane metody łańcuchowe
Python zawiera następujące wbudowane metody do manipulowania ciągami znaków -
| Sr.No. | Metody z opisem |
|---|---|
| 1 | skapitalizować() Zamienia pierwszą literę ciągu na wielką literę |
| 2 | środek (szerokość, znak wypełnienia) Zwraca łańcuch wypełniony spacjami z oryginalnym ciągiem wyśrodkowanym do łącznej szerokości kolumn. |
| 3 | count (str, beg = 0, end = len (string)) Oblicza, ile razy str występuje w ciągu lub w podłańcuchu ciągu, jeśli podano początkowy indeks początkowy i końcowy koniec indeksu. |
| 4 | dekodować (kodowanie = „UTF-8”, błędy = „ścisłe”) Dekoduje ciąg przy użyciu kodeka zarejestrowanego do kodowania. encoding domyślnie na domyślne kodowanie ciągów. |
| 5 | encode (kodowanie = „UTF-8”, błędy = „ścisłe”) Zwraca zakodowaną wersję ciągu znaków; w przypadku błędu domyślnie powoduje zgłoszenie błędu ValueError, chyba że dla błędu podano „ignoruj” lub „zamień”. |
| 6 | endwith (sufiks, początek = 0, koniec = len (ciąg)) Określa, czy łańcuch lub podłańcuch łańcucha (jeśli podano początek indeksu początek i koniec indeksu koniec) kończy się sufiksem; zwraca wartość true, jeśli tak, i false, jeśli jest inaczej |
| 7 | expandtabs (tabsize = 8) Rozwija tabulatory w łańcuchu do wielu spacji; domyślnie 8 spacji na tabulator, jeśli nie podano rozmiaru tabulacji. |
| 8 | find (str, beg = 0 end = len (string)) Określić, czy str występuje w łańcuchu lub w podłańcuchu łańcucha, jeśli podano indeks początkowy początek i koniec indeksu, zwraca indeks, jeśli zostanie znaleziony, a -1 w przeciwnym razie. |
| 9 | index (str, beg = 0, end = len (string)) To samo co find (), ale zgłasza wyjątek, jeśli nie znaleziono ciągu. |
| 10 | isalnum () Zwraca wartość true, jeśli łańcuch ma co najmniej 1 znak, a wszystkie znaki są alfanumeryczne, aw przeciwnym razie - fałsz. |
| 11 | isalpha () Zwraca wartość true, jeśli łańcuch ma co najmniej 1 znak, a wszystkie znaki są alfabetyczne, aw przeciwnym razie - fałsz. |
| 12 | isdigit () Zwraca wartość true, jeśli ciąg zawiera tylko cyfry, lub false, jeśli jest inaczej. |
| 13 | islower () Zwraca wartość true, jeśli łańcuch ma co najmniej 1 znak wielkości liter, a wszystkie znaki pisane są małymi literami, aw przeciwnym razie - fałsz. |
| 14 | isnumeric () Zwraca wartość true, jeśli ciąg znaków Unicode zawiera tylko znaki numeryczne, lub false, jeśli jest inaczej. |
| 15 | isspace () Zwraca wartość true, jeśli ciąg zawiera tylko białe znaki, lub false, jeśli jest inaczej. |
| 16 | istitle () Zwraca wartość „prawda”, jeśli ciąg znaków zawiera poprawnie „tytuł”, a fałsz, jeśli jest inaczej. |
| 17 | isupper () Zwraca wartość true, jeśli łańcuch ma co najmniej jeden znak wielkości liter, a wszystkie znaki wielkości liter są duże, aw przeciwnym razie - fałsz. |
| 18 | dołącz (kolejność) Łączy (łączy) ciągi reprezentujące elementy w sekwencji sekwencyjnej w ciąg z ciągiem separującym. |
| 19 | len (ciąg) Zwraca długość ciągu |
| 20 | ljust (width [, fillchar]) Zwraca ciąg uzupełniony spacjami z oryginalnym ciągiem wyrównanym do lewej do łącznej szerokości kolumn. |
| 21 | niższy() Konwertuje wszystkie wielkie litery w ciągu na małe litery. |
| 22 | lstrip () Usuwa wszystkie wiodące spacje w ciągu. |
| 23 | maketrans () Zwraca tabelę tłumaczeń do użycia w funkcji tłumaczenia. |
| 24 | max (str) Zwraca maksymalny znak alfabetyczny z ciągu str. |
| 25 | min (str) Zwraca min znak alfabetyczny z ciągu str. |
| 26 | zastąp (stary, nowy [, maks.]) Zastępuje wszystkie wystąpienia starego w łańcuchu nowymi lub co najwyżej max wystąpieniami, jeśli podano max. |
| 27 | rfind (str, beg = 0, end = len (string)) To samo, co find (), ale przeszukuje wstecz w ciągu. |
| 28 | rindex (str, beg = 0, end = len (string)) To samo co index (), ale przeszukuje wstecz w ciągu. |
| 29 | rjust (width, [, fillchar]) Zwraca ciąg uzupełniony spacjami z oryginalnym ciągiem wyrównanym do prawej do łącznej szerokości kolumn. |
| 30 | rstrip () Usuwa wszystkie końcowe spacje ciągu. |
| 31 | split (str = "", num = string.count (str)) Dzieli łańcuch zgodnie z separatorem (spacja, jeśli nie podano) i zwraca listę podciągów; podziel na co najwyżej num podciągów, jeśli podano. |
| 32 | splitlines (num = string.count ('\ n')) Dzieli ciąg na wszystkich (lub w liczbie) NEWLINEs i zwraca listę wszystkich wierszy z usuniętymi NEWLINEs. |
| 33 | beginwith (str, beg = 0, end = len (string)) Określa, czy łańcuch lub podłańcuch łańcucha (jeśli podano początkowy indeks początkowy i końcowy indeks końcowy) zaczyna się od podłańcucha str; zwraca wartość true, jeśli tak, i false, jeśli jest inaczej |
| 34 | strip ([znaki]) Wykonuje na łańcuchu zarówno lstrip (), jak i rstrip (). |
| 35 | swapcase () Odwraca wielkość liter dla wszystkich liter w ciągu. |
| 36 | tytuł() Zwraca wersję ciągu oznaczoną „tytułem”, czyli wszystkie słowa zaczynają się od wielkich liter, a pozostałe są małymi literami. |
| 37 | przetłumacz (tabela, deletechars = "") Tłumaczy ciąg zgodnie z tabelą translacji str (256 znaków), usuwając te z łańcucha del. |
| 38 | górny() Konwertuje małe litery w ciągu na duże. |
| 39 | zfill (szerokość) Zwraca oryginalny łańcuch z odstępami zerowymi do całkowitej liczby znaków szerokości; przeznaczona dla liczb, zfill () zachowuje każdy podany znak (pomniejszony o jedno zero). |
| 40 | isdecimal () Zwraca wartość true, jeśli ciąg znaków Unicode zawiera tylko znaki dziesiętne, lub false, jeśli jest inaczej. |
Najbardziej podstawową strukturą danych w Pythonie jest sequence. Każdy element sekwencji ma przypisany numer - jego pozycję lub indeks. Pierwszy indeks to zero, drugi to jeden i tak dalej.
Python ma sześć wbudowanych typów sekwencji, ale najczęściej są to listy i krotki, które zobaczylibyśmy w tym samouczku.
Są pewne rzeczy, które możesz zrobić ze wszystkimi typami sekwencji. Te operacje obejmują indeksowanie, wycinanie, dodawanie, mnożenie i sprawdzanie członkostwa. Ponadto Python ma wbudowane funkcje do znajdowania długości sekwencji oraz znajdowania jej największych i najmniejszych elementów.
Listy w Pythonie
Lista jest najbardziej wszechstronnym typem danych dostępnym w Pythonie, który można zapisać jako listę wartości oddzielonych przecinkami (elementów) w nawiasach kwadratowych. Ważną rzeczą dotyczącą listy jest to, że pozycje na liście nie muszą być tego samego typu.
Tworzenie listy jest tak proste, jak umieszczanie różnych wartości oddzielonych przecinkami w nawiasach kwadratowych. Na przykład -
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"]Podobnie jak w przypadku indeksów łańcuchowych, indeksy list zaczynają się od 0, a listy można kroić, łączyć i tak dalej.
Dostęp do wartości w listach
Aby uzyskać dostęp do wartości na listach, użyj nawiasów kwadratowych do wycinania wraz z indeksem lub indeksami, aby uzyskać wartość dostępną w tym indeksie. Na przykład -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5, 6, 7 ];
print "list1[0]: ", list1[0]
print "list2[1:5]: ", list2[1:5]Wykonanie powyższego kodu daje następujący wynik -
list1[0]: physics
list2[1:5]: [2, 3, 4, 5]Aktualizowanie list
Możesz aktualizować jeden lub wiele elementów list, podając wycinek po lewej stronie operatora przypisania, a możesz dodawać elementy do listy za pomocą metody append (). Na przykład -
#!/usr/bin/python
list = ['physics', 'chemistry', 1997, 2000];
print "Value available at index 2 : "
print list[2]
list[2] = 2001;
print "New value available at index 2 : "
print list[2]Note - metoda append () została omówiona w następnej sekcji.
Wykonanie powyższego kodu daje następujący wynik -
Value available at index 2 :
1997
New value available at index 2 :
2001Usuń elementy listy
Aby usunąć element listy, możesz użyć instrukcji del, jeśli wiesz dokładnie, które elementy usuwasz, lub metody remove (), jeśli nie wiesz. Na przykład -
#!/usr/bin/python
list1 = ['physics', 'chemistry', 1997, 2000];
print list1
del list1[2];
print "After deleting value at index 2 : "
print list1Wykonanie powyższego kodu daje następujący wynik -
['physics', 'chemistry', 1997, 2000]
After deleting value at index 2 :
['physics', 'chemistry', 2000]Note - metodę remove () omówiono w dalszej części.
Podstawowe operacje na listach
Listy reagują na operatory + i *, podobnie jak łańcuchy; tutaj również mają na myśli konkatenację i powtórzenie, z wyjątkiem tego, że wynikiem jest nowa lista, a nie ciąg.
W rzeczywistości listy odpowiadają wszystkim ogólnym operacjom na sekwencjach, których używaliśmy na łańcuchach w poprzednim rozdziale.
| Wyrażenie Pythona | Wyniki | Opis |
|---|---|---|
| len ([1, 2, 3]) | 3 | Długość |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | Powiązanie |
| [„Cześć!”] * 4 | [„Cześć!”, „Cześć!”, „Cześć!”, „Cześć!”] | Powtórzenie |
| 3 w [1, 2, 3] | Prawdziwe | Członkostwo |
| for x in [1, 2, 3]: print x, | 1 2 3 | Iteracja |
Indeksowanie, wycinanie i macierze
Ponieważ listy są sekwencjami, indeksowanie i krojenie działają w taki sam sposób w przypadku list, jak w przypadku łańcuchów.
Zakładając następujące dane wejściowe -
L = ['spam', 'Spam', 'SPAM!']| Wyrażenie Pythona | Wyniki | Opis |
|---|---|---|
| L [2] | SPAM! | Przesunięcia zaczynają się od zera |
| L [-2] | spam | Negatywne: policz od prawej |
| L [1:] | [„Spam”, „SPAM!”] | Cięcie na plasterki pobiera sekcje |
Wbudowane funkcje i metody list
Python zawiera następujące funkcje listowe -
| Sr.No. | Funkcja z opisem |
|---|---|
| 1 | cmp (lista1, lista2) Porównuje elementy obu list. |
| 2 | len (lista) Podaje całkowitą długość listy. |
| 3 | max (lista) Zwraca pozycję z listy o maksymalnej wartości. |
| 4 | min (lista) Zwraca pozycję z listy o wartości minimalnej. |
| 5 | list (seq) Konwertuje krotkę na listę. |
Python zawiera następujące metody listowe
| Sr.No. | Metody z opisem |
|---|---|
| 1 | list.append (obj) Dołącza obiekt obj do listy |
| 2 | list.count (obj) Zwraca liczbę, ile razy obj występuje na liście |
| 3 | list.extend (seq) Dołącza zawartość seq do listy |
| 4 | list.index (obj) Zwraca najniższy indeks na liście, który pojawia się obj |
| 5 | list.insert (indeks, obj) Wstawia obiekt obj do listy pod indeksem offsetu |
| 6 | list.pop (obj = list [-1]) Usuwa i zwraca ostatni obiekt lub obiekt z listy |
| 7 | list.remove (obj) Usuwa obiekt obj z listy |
| 8 | list.reverse () Odwraca obiekty listy w miejscu |
| 9 | list.sort ([func]) Sortuje obiekty na liście, jeśli podano, użyj funkcji porównania |
Krotka to niezmienna sekwencja obiektów Pythona. Krotki to sekwencje, podobnie jak listy. Różnice między krotkami a listami są takie, że krotki nie mogą być zmieniane w przeciwieństwie do list i krotki używają nawiasów, podczas gdy listy używają nawiasów kwadratowych.
Tworzenie krotki jest tak proste, jak umieszczanie różnych wartości oddzielonych przecinkami. Opcjonalnie możesz również umieścić te wartości oddzielone przecinkami w nawiasach. Na przykład -
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";Pusta krotka jest zapisywana jako dwa nawiasy zawierające nic -
tup1 = ();Aby napisać krotkę zawierającą pojedynczą wartość, musisz dołączyć przecinek, nawet jeśli jest tylko jedna wartość -
tup1 = (50,);Podobnie jak indeksy łańcuchowe, indeksy krotek zaczynają się od 0 i mogą być dzielone, łączone i tak dalej.
Dostęp do wartości w krotkach
Aby uzyskać dostęp do wartości w krotce, użyj nawiasów kwadratowych do wycinania wraz z indeksem lub indeksami, aby uzyskać wartość dostępną w tym indeksie. Na przykład -
#!/usr/bin/python
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5, 6, 7 );
print "tup1[0]: ", tup1[0];
print "tup2[1:5]: ", tup2[1:5];Wykonanie powyższego kodu daje następujący wynik -
tup1[0]: physics
tup2[1:5]: [2, 3, 4, 5]Aktualizowanie krotek
Krotki są niezmienne, co oznacza, że nie można aktualizować ani zmieniać wartości elementów krotki. Możesz wziąć fragmenty istniejących krotek, aby utworzyć nowe krotki, jak pokazano w poniższym przykładzie -
#!/usr/bin/python
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# Following action is not valid for tuples
# tup1[0] = 100;
# So let's create a new tuple as follows
tup3 = tup1 + tup2;
print tup3;Wykonanie powyższego kodu daje następujący wynik -
(12, 34.56, 'abc', 'xyz')Usuń elementy krotki
Usunięcie pojedynczych elementów krotki nie jest możliwe. Nie ma oczywiście nic złego w składaniu kolejnej krotki z odrzuconymi niepożądanymi elementami.
Aby jawnie usunąć całą krotkę, po prostu użyj delkomunikat. Na przykład -
#!/usr/bin/python
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
print "After deleting tup : ";
print tup;Daje to następujący wynik. Zwróć uwagę na zgłoszony wyjątek, ponieważ podel tup krotka już nie istnieje -
('physics', 'chemistry', 1997, 2000)
After deleting tup :
Traceback (most recent call last):
File "test.py", line 9, in <module>
print tup;
NameError: name 'tup' is not definedPodstawowe operacje na krotkach
Krotki reagują na operatory + i *, podobnie jak łańcuchy; tutaj również mają na myśli konkatenację i powtarzanie, z tym wyjątkiem, że wynikiem jest nowa krotka, a nie ciąg.
W rzeczywistości krotki odpowiadają na wszystkie ogólne operacje sekwencyjne, których użyliśmy na łańcuchach w poprzednim rozdziale -
| Wyrażenie Pythona | Wyniki | Opis |
|---|---|---|
| len ((1, 2, 3)) | 3 | Długość |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | Powiązanie |
| („Cześć!”,) * 4 | („Cześć!”, „Cześć!”, „Cześć!”, „Cześć!”) | Powtórzenie |
| 3 w (1, 2, 3) | Prawdziwe | Członkostwo |
| for x in (1, 2, 3): print x, | 1 2 3 | Iteracja |
Indeksowanie, wycinanie i macierze
Ponieważ krotki są sekwencjami, indeksowanie i krojenie działają w taki sam sposób w przypadku krotek, jak w przypadku łańcuchów. Zakładając następujące dane wejściowe -
L = ('spam', 'Spam', 'SPAM!')
| Wyrażenie Pythona | Wyniki | Opis |
|---|---|---|
| L [2] | 'SPAM!' | Przesunięcia zaczynają się od zera |
| L [-2] | 'Spam' | Negatywne: policz od prawej |
| L [1:] | [„Spam”, „SPAM!”] | Cięcie na plasterki pobiera sekcje |
Brak ograniczników otaczających
Dowolny zestaw wielu obiektów, oddzielonych przecinkami, zapisanych bez identyfikujących symboli, tj. Nawiasy kwadratowe dla list, nawiasy dla krotek itp., Domyślnie krotki, jak wskazano w tych krótkich przykładach -
#!/usr/bin/python
print 'abc', -4.24e93, 18+6.6j, 'xyz';
x, y = 1, 2;
print "Value of x , y : ", x,y;Wykonanie powyższego kodu daje następujący wynik -
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2Wbudowane funkcje krotki
Python zawiera następujące funkcje krotek -
| Sr.No. | Funkcja z opisem |
|---|---|
| 1 | cmp (tuple1, tuple2) Porównuje elementy obu krotek. |
| 2 | len (krotka) Podaje całkowitą długość krotki. |
| 3 | max (krotka) Zwraca element z krotki o maksymalnej wartości. |
| 4 | min (krotka) Zwraca element z krotki o wartości minimalnej. |
| 5 | krotka (kolejność) Konwertuje listę na krotkę. |
Każdy klucz jest oddzielony od swojej wartości dwukropkiem (:), elementy oddzielone przecinkami, a całość ujęta jest w nawiasy klamrowe. Pusty słownik bez żadnych elementów jest zapisywany za pomocą tylko dwóch nawiasów klamrowych, na przykład: {}.
Klucze są unikalne w słowniku, a wartości nie mogą. Wartości słownika mogą być dowolnego typu, ale klucze muszą być niezmiennym typem danych, takim jak łańcuchy, liczby lub krotki.
Dostęp do wartości w słowniku
Aby uzyskać dostęp do elementów słownika, możesz użyć znanych nawiasów kwadratowych wraz z kluczem, aby uzyskać jego wartość. Oto prosty przykład -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Name']: ", dict['Name']
print "dict['Age']: ", dict['Age']Wykonanie powyższego kodu daje następujący wynik -
dict['Name']: Zara
dict['Age']: 7Jeśli spróbujemy uzyskać dostęp do elementu danych za pomocą klucza, który nie jest częścią słownika, otrzymamy następujący błąd -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Alice']: ", dict['Alice']Wykonanie powyższego kodu daje następujący wynik -
dict['Alice']:
Traceback (most recent call last):
File "test.py", line 4, in <module>
print "dict['Alice']: ", dict['Alice'];
KeyError: 'Alice'Aktualizowanie słownika
Możesz zaktualizować słownik, dodając nowy wpis lub parę klucz-wartość, modyfikując istniejący wpis lub usuwając istniejący wpis, jak pokazano poniżej w prostym przykładzie -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']Wykonanie powyższego kodu daje następujący wynik -
dict['Age']: 8
dict['School']: DPS SchoolUsuń elementy słownika
Możesz usunąć poszczególne elementy słownika lub wyczyścić całą zawartość słownika. Możesz także usunąć cały słownik w jednej operacji.
Aby jawnie usunąć cały słownik, po prostu użyj delkomunikat. Oto prosty przykład -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict['Name']; # remove entry with key 'Name'
dict.clear(); # remove all entries in dict
del dict ; # delete entire dictionary
print "dict['Age']: ", dict['Age']
print "dict['School']: ", dict['School']Daje to następujący wynik. Zauważ, że wyjątek jest zgłaszany, ponieważ afterdel dict słownik już nie istnieje -
dict['Age']:
Traceback (most recent call last):
File "test.py", line 8, in <module>
print "dict['Age']: ", dict['Age'];
TypeError: 'type' object is unsubscriptableNote - metoda del () została omówiona w dalszej części.
Właściwości kluczy słownikowych
Wartości słownikowe nie mają ograniczeń. Mogą to być dowolne obiekty Pythona, obiekty standardowe lub obiekty zdefiniowane przez użytkownika. Jednak to samo nie dotyczy kluczy.
Istnieją dwie ważne kwestie, o których należy pamiętać o klawiszach słownika
(a)Niedozwolona jest więcej niż jedna pozycja na klucz. Co oznacza, że nie można zduplikować klucza. W przypadku napotkania zduplikowanych kluczy podczas przypisywania wygrywa ostatnie przypisanie. Na przykład -
#!/usr/bin/python
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}
print "dict['Name']: ", dict['Name']Wykonanie powyższego kodu daje następujący wynik -
dict['Name']: Manni(b)Klucze muszą być niezmienne. Oznacza to, że możesz używać łańcuchów, liczb lub krotek jako kluczy słownika, ale coś takiego jak ['klucz'] jest niedozwolone. Oto prosty przykład -
#!/usr/bin/python
dict = {['Name']: 'Zara', 'Age': 7}
print "dict['Name']: ", dict['Name']Wykonanie powyższego kodu daje następujący wynik -
Traceback (most recent call last):
File "test.py", line 3, in <module>
dict = {['Name']: 'Zara', 'Age': 7};
TypeError: unhashable type: 'list'Wbudowane funkcje i metody słownika
Python zawiera następujące funkcje słownikowe -
| Sr.No. | Funkcja z opisem |
|---|---|
| 1 | cmp (dict1, dict2) Porównuje elementy obu dykt. |
| 2 | len (dict) Podaje całkowitą długość słownika. Byłoby to równe liczbie pozycji w słowniku. |
| 3 | str (dict) Tworzy drukowalną reprezentację słownika w postaci ciągu |
| 4 | typ (zmienna) Zwraca typ przekazanej zmiennej. Jeśli przekazaną zmienną jest słownik, to zwróci typ słownika. |
Python zawiera następujące metody słownikowe -
| Sr.No. | Metody z opisem |
|---|---|
| 1 | dict.clear () Usuwa wszystkie elementy słowniku dict |
| 2 | dict.copy () Zwraca płytkie kopia słowniku dict |
| 3 | dict.fromkeys () Utwórz nowy słownik z kluczami od seq i wartościami ustawionymi na wartość . |
| 4 | dict.get (key, default = None) W przypadku klucza klucz zwraca wartość lub wartość domyślną, jeśli klucza nie ma w słowniku |
| 5 | dict.has_key (klucz) Zwraca prawdziwe jeśli klucz w słowniku dict , false w przeciwnym razie |
| 6 | dict.items () Zwraca listę par krotek dict (klucz, wartość) |
| 7 | dict.keys () Zwraca listę kluczy słownika |
| 8 | dict.setdefault (key, default = None) Podobne do get (), ale ustawi dict [key] = default, jeśli key nie jest jeszcze w dict |
| 9 | dict.update (dict2) Dodaje pary klucz-wartość ze słownika dict2 do funkcji dict |
| 10 | dict.values () Zwraca listę słownika DICT wartości „s |
Program w Pythonie może obsługiwać datę i godzinę na kilka sposobów. Konwertowanie między formatami daty jest częstym obowiązkiem komputerów. Moduły czasu i kalendarza w Pythonie ułatwiają śledzenie dat i godzin.
Co to jest Tick?
Przedziały czasu to liczby zmiennoprzecinkowe w jednostkach sekund. Poszczególne momenty w czasie są wyrażane w sekundach od godziny 00:00:00 1 stycznia 1970 (epoka).
Jest popularny timemoduł dostępny w Pythonie, który udostępnia funkcje do pracy z czasami i do konwersji między reprezentacjami. Funkcja time.time () zwraca bieżący czas systemowy w taktach od godziny 00:00:00 1 stycznia 1970 (epoka).
Przykład
#!/usr/bin/python
import time; # This is required to include time module.
ticks = time.time()
print "Number of ticks since 12:00am, January 1, 1970:", ticksDałoby to następujący wynik -
Number of ticks since 12:00am, January 1, 1970: 7186862.73399Arytmetyka dat jest łatwa do wykonania przy pomocy tików. Jednak dat sprzed epoki nie można przedstawić w tej formie. Daty w dalekiej przyszłości również nie mogą być przedstawiane w ten sposób - punkt odcięcia przypada w 2038 roku dla systemów UNIX i Windows.
Co to jest TimeTuple?
Wiele funkcji czasu w Pythonie traktuje czas jako krotkę 9 liczb, jak pokazano poniżej -
| Indeks | Pole | Wartości |
|---|---|---|
| 0 | 4-cyfrowy rok | 2008 |
| 1 | Miesiąc | Od 1 do 12 |
| 2 | Dzień | Od 1 do 31 |
| 3 | Godzina | Od 0 do 23 |
| 4 | Minuta | Od 0 do 59 |
| 5 | druga | 0 do 61 (60 lub 61 to sekundy przestępne) |
| 6 | Dzień tygodnia | 0 do 6 (0 to poniedziałek) |
| 7 | Dzień roku | 1 do 366 (dzień juliański) |
| 8 | Czas letni | -1, 0, 1, -1 oznacza, że biblioteka określa czas letni |
Powyższa krotka jest równoważna struct_timeStruktura. Ta struktura ma następujące atrybuty -
| Indeks | Atrybuty | Wartości |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | Od 1 do 12 |
| 2 | tm_mday | Od 1 do 31 |
| 3 | tm_hour | Od 0 do 23 |
| 4 | tm_min | Od 0 do 59 |
| 5 | tm_sec | 0 do 61 (60 lub 61 to sekundy przestępne) |
| 6 | tm_wday | 0 do 6 (0 to poniedziałek) |
| 7 | tm_yday | 1 do 366 (dzień juliański) |
| 8 | tm_isdst | -1, 0, 1, -1 oznacza, że biblioteka określa czas letni |
Pobieram aktualny czas
Aby przetłumaczyć moment czasowy z sekund od wartości zmiennoprzecinkowej epoki na krotkę czasową, przekaż wartość zmiennoprzecinkową do funkcji (np. Czasu lokalnego), która zwraca krotkę czasu z poprawnymi wszystkimi dziewięcioma elementami.
#!/usr/bin/python
import time;
localtime = time.localtime(time.time())
print "Local current time :", localtimeDałoby to następujący wynik, który można sformatować w dowolnej innej możliwej do zaprezentowania formie -
Local current time : time.struct_time(tm_year=2013, tm_mon=7,
tm_mday=17, tm_hour=21, tm_min=26, tm_sec=3, tm_wday=2, tm_yday=198, tm_isdst=0)Uzyskiwanie sformatowanego czasu
You can format any time as per your requirement, but simple method to get time in readable format is asctime() −
#!/usr/bin/python
import time;
localtime = time.asctime( time.localtime(time.time()) )
print "Local current time :", localtimeThis would produce the following result −
Local current time : Tue Jan 13 10:17:09 2009Getting calendar for a month
The calendar module gives a wide range of methods to play with yearly and monthly calendars. Here, we print a calendar for a given month ( Jan 2008 ) −
#!/usr/bin/python
import calendar
cal = calendar.month(2008, 1)
print "Here is the calendar:"
print calThis would produce the following result −
Here is the calendar:
January 2008
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31The time Module
There is a popular time module available in Python which provides functions for working with times and for converting between representations. Here is the list of all available methods −
| Sr.No. | Function with Description |
|---|---|
| 1 | time.altzone The offset of the local DST timezone, in seconds west of UTC, if one is defined. This is negative if the local DST timezone is east of UTC (as in Western Europe, including the UK). Only use this if daylight is nonzero. |
| 2 | time.asctime([tupletime]) Accepts a time-tuple and returns a readable 24-character string such as 'Tue Dec 11 18:07:14 2008'. |
| 3 | time.clock( ) Returns the current CPU time as a floating-point number of seconds. To measure computational costs of different approaches, the value of time.clock is more useful than that of time.time(). |
| 4 | time.ctime([secs]) Like asctime(localtime(secs)) and without arguments is like asctime( ) |
| 5 | time.gmtime([secs]) Accepts an instant expressed in seconds since the epoch and returns a time-tuple t with the UTC time. Note : t.tm_isdst is always 0 |
| 6 | time.localtime([secs]) Accepts an instant expressed in seconds since the epoch and returns a time-tuple t with the local time (t.tm_isdst is 0 or 1, depending on whether DST applies to instant secs by local rules). |
| 7 | time.mktime(tupletime) Accepts an instant expressed as a time-tuple in local time and returns a floating-point value with the instant expressed in seconds since the epoch. |
| 8 | time.sleep(secs) Suspends the calling thread for secs seconds. |
| 9 | time.strftime(fmt[,tupletime]) Accepts an instant expressed as a time-tuple in local time and returns a string representing the instant as specified by string fmt. |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') Parses str according to format string fmt and returns the instant in time-tuple format. |
| 11 | time.time( ) Returns the current time instant, a floating-point number of seconds since the epoch. |
| 12 | time.tzset() Resets the time conversion rules used by the library routines. The environment variable TZ specifies how this is done. |
Let us go through the functions briefly −
There are following two important attributes available with time module −
| Sr.No. | Attribute with Description |
|---|---|
| 1 | time.timezone Attribute time.timezone is the offset in seconds of the local time zone (without DST) from UTC (>0 in the Americas; <=0 in most of Europe, Asia, Africa). |
| 2 | time.tzname Attribute time.tzname is a pair of locale-dependent strings, which are the names of the local time zone without and with DST, respectively. |
The calendar Module
The calendar module supplies calendar-related functions, including functions to print a text calendar for a given month or year.
By default, calendar takes Monday as the first day of the week and Sunday as the last one. To change this, call calendar.setfirstweekday() function.
Here is a list of functions available with the calendar module −
| Sr.No. | Function with Description |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) Returns a multiline string with a calendar for year year formatted into three columns separated by c spaces. w is the width in characters of each date; each line has length 21*w+18+2*c. l is the number of lines for each week. |
| 2 | calendar.firstweekday( ) Returns the current setting for the weekday that starts each week. By default, when calendar is first imported, this is 0, meaning Monday. |
| 3 | calendar.isleap(year) Returns True if year is a leap year; otherwise, False. |
| 4 | calendar.leapdays(y1,y2) Returns the total number of leap days in the years within range(y1,y2). |
| 5 | calendar.month(year,month,w=2,l=1) Returns a multiline string with a calendar for month month of year year, one line per week plus two header lines. w is the width in characters of each date; each line has length 7*w+6. l is the number of lines for each week. |
| 6 | calendar.monthcalendar(year,month) Returns a list of lists of ints. Each sublist denotes a week. Days outside month month of year year are set to 0; days within the month are set to their day-of-month, 1 and up. |
| 7 | calendar.monthrange(year,month) Returns two integers. The first one is the code of the weekday for the first day of the month month in year year; the second one is the number of days in the month. Weekday codes are 0 (Monday) to 6 (Sunday); month numbers are 1 to 12. |
| 8 | calendar.prcal(year,w=2,l=1,c=6) Like print calendar.calendar(year,w,l,c). |
| 9 | calendar.prmonth(year,month,w=2,l=1) Like print calendar.month(year,month,w,l). |
| 10 | calendar.setfirstweekday(weekday) Sets the first day of each week to weekday code weekday. Weekday codes are 0 (Monday) to 6 (Sunday). |
| 11 | calendar.timegm(tupletime) The inverse of time.gmtime: accepts a time instant in time-tuple form and returns the same instant as a floating-point number of seconds since the epoch. |
| 12 | calendar.weekday(year,month,day) Returns the weekday code for the given date. Weekday codes are 0 (Monday) to 6 (Sunday); month numbers are 1 (January) to 12 (December). |
Other Modules & Functions
If you are interested, then here you would find a list of other important modules and functions to play with date & time in Python −
The datetime Module
The pytz Module
The dateutil Module
Funkcja to blok zorganizowanego kodu wielokrotnego użytku, który służy do wykonywania jednej, powiązanej czynności. Funkcje zapewniają lepszą modułowość aplikacji i wysoki stopień ponownego wykorzystania kodu.
Jak już wiesz, Python oferuje wiele wbudowanych funkcji, takich jak print () itp., Ale możesz także tworzyć własne funkcje. Te funkcje są nazywane funkcjami zdefiniowanymi przez użytkownika.
Definiowanie funkcji
Możesz zdefiniować funkcje, aby zapewnić wymaganą funkcjonalność. Oto proste zasady definiowania funkcji w Pythonie.
Bloki funkcyjne zaczynają się od słowa kluczowego def po którym następuje nazwa funkcji i nawiasy (()).
Wszelkie parametry wejściowe lub argumenty należy umieścić w tych nawiasach. Możesz także zdefiniować parametry w tych nawiasach.
Pierwsza deklaracja funkcji może być opcjonalnie zestawienie - ciąg dokumentacja funkcji lub docstring .
Blok kodu w każdej funkcji zaczyna się od dwukropka (:) i jest wcięty.
Instrukcja return [wyrażenie] kończy funkcję, opcjonalnie przekazując z powrotem wyrażenie do wywołującego. Instrukcja return bez argumentów jest tym samym, co instrukcja return None.
Składnia
def functionname( parameters ):
"function_docstring"
function_suite
return [expression]Domyślnie parametry zachowują się pozycyjnie i należy je informować w tej samej kolejności, w jakiej zostały zdefiniowane.
Przykład
Poniższa funkcja przyjmuje ciąg jako parametr wejściowy i wyświetla go na standardowym ekranie.
def printme( str ):
"This prints a passed string into this function"
print str
returnWywołanie funkcji
Zdefiniowanie funkcji tylko nadaje jej nazwę, określa parametry, które mają być zawarte w funkcji i strukturyzuje bloki kodu.
Po sfinalizowaniu podstawowej struktury funkcji można ją wykonać, wywołując ją z innej funkcji lub bezpośrednio z zachęty Pythona. Poniżej znajduje się przykład wywołania funkcji printme () -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme("I'm first call to user defined function!")
printme("Again second call to the same function")Wykonanie powyższego kodu daje następujący wynik -
I'm first call to user defined function!
Again second call to the same functionPrzekaż przez odniesienie a wartość
Wszystkie parametry (argumenty) w języku Python są przekazywane przez odniesienie. Oznacza to, że jeśli zmienisz to, do czego odnosi się parametr w funkcji, zmiana ta będzie również odzwierciedlać z powrotem w funkcji wywołującej. Na przykład -
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist.append([1,2,3,4]);
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylistTutaj utrzymujemy odniesienie do przekazanego obiektu i dołączamy wartości w tym samym obiekcie. To dałoby następujący wynik -
Values inside the function: [10, 20, 30, [1, 2, 3, 4]]
Values outside the function: [10, 20, 30, [1, 2, 3, 4]]Jest jeszcze jeden przykład, w którym argument jest przekazywany przez referencję, a referencja jest nadpisywana wewnątrz wywoływanej funkcji.
#!/usr/bin/python
# Function definition is here
def changeme( mylist ):
"This changes a passed list into this function"
mylist = [1,2,3,4]; # This would assig new reference in mylist
print "Values inside the function: ", mylist
return
# Now you can call changeme function
mylist = [10,20,30];
changeme( mylist );
print "Values outside the function: ", mylistParametr mylist jest lokalny dla funkcji changeme. Zmiana mylisty w ramach funkcji nie wpływa na mylistę . Funkcja nic nie robi i ostatecznie dałaby następujący wynik -
Values inside the function: [1, 2, 3, 4]
Values outside the function: [10, 20, 30]Argumenty funkcji
Możesz wywołać funkcję, używając następujących typów argumentów formalnych -
- Wymagane argumenty
- Argumenty słów kluczowych
- Domyślne argumenty
- Argumenty o zmiennej długości
Wymagane argumenty
Wymagane argumenty to argumenty przekazywane do funkcji w prawidłowej kolejności pozycyjnej. Tutaj liczba argumentów w wywołaniu funkcji powinna być dokładnie zgodna z definicją funkcji.
Aby wywołać funkcję printme () , zdecydowanie musisz przekazać jeden argument, w przeciwnym razie spowoduje to następujący błąd składni -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme()Wykonanie powyższego kodu daje następujący wynik -
Traceback (most recent call last):
File "test.py", line 11, in <module>
printme();
TypeError: printme() takes exactly 1 argument (0 given)Argumenty słów kluczowych
Argumenty słów kluczowych są powiązane z wywołaniami funkcji. Gdy używasz argumentów słów kluczowych w wywołaniu funkcji, obiekt wywołujący identyfikuje argumenty za pomocą nazwy parametru.
Pozwala to na pominięcie argumentów lub umieszczenie ich w niewłaściwej kolejności, ponieważ interpreter Pythona jest w stanie użyć podanych słów kluczowych, aby dopasować wartości do parametrów. Możesz także wywoływać słowa kluczowe do funkcji printme () w następujący sposób -
#!/usr/bin/python
# Function definition is here
def printme( str ):
"This prints a passed string into this function"
print str
return;
# Now you can call printme function
printme( str = "My string")Wykonanie powyższego kodu daje następujący wynik -
My stringPoniższy przykład daje bardziej przejrzysty obraz. Zauważ, że kolejność parametrów nie ma znaczenia.
#!/usr/bin/python
# Function definition is here
def printinfo( name, age ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )Wykonanie powyższego kodu daje następujący wynik -
Name: miki
Age 50Domyślne argumenty
Argument domyślny to argument, który przyjmuje wartość domyślną, jeśli wartość nie została podana w wywołaniu funkcji dla tego argumentu. Poniższy przykład daje pomysł na domyślne argumenty, wyświetla domyślny wiek, jeśli nie zostanie przekazany -
#!/usr/bin/python
# Function definition is here
def printinfo( name, age = 35 ):
"This prints a passed info into this function"
print "Name: ", name
print "Age ", age
return;
# Now you can call printinfo function
printinfo( age=50, name="miki" )
printinfo( name="miki" )Wykonanie powyższego kodu daje następujący wynik -
Name: miki
Age 50
Name: miki
Age 35Argumenty o zmiennej długości
Może zaistnieć potrzeba przetworzenia funkcji dla większej liczby argumentów niż określono podczas definiowania funkcji. Argumenty te nazywane są argumentami o zmiennej długości i nie są nazywane w definicji funkcji, w przeciwieństwie do argumentów wymaganych i domyślnych.
Składnia funkcji z argumentami zmiennymi niebędącymi słowami kluczowymi jest następująca -
def functionname([formal_args,] *var_args_tuple ):
"function_docstring"
function_suite
return [expression]Gwiazdka (*) jest umieszczana przed nazwą zmiennej, która zawiera wartości wszystkich argumentów zmiennych niebędących słowami kluczowymi. Ta krotka pozostaje pusta, jeśli podczas wywołania funkcji nie zostaną określone żadne dodatkowe argumenty. Oto prosty przykład -
#!/usr/bin/python
# Function definition is here
def printinfo( arg1, *vartuple ):
"This prints a variable passed arguments"
print "Output is: "
print arg1
for var in vartuple:
print var
return;
# Now you can call printinfo function
printinfo( 10 )
printinfo( 70, 60, 50 )Wykonanie powyższego kodu daje następujący wynik -
Output is:
10
Output is:
70
60
50W anonimowych Funkcje
Funkcje te nazywane są anonimowymi, ponieważ nie są deklarowane w standardowy sposób za pomocą słowa kluczowego def . Możesz użyć słowa kluczowego lambda do tworzenia małych anonimowych funkcji.
Formy lambda mogą przyjmować dowolną liczbę argumentów, ale zwracają tylko jedną wartość w postaci wyrażenia. Nie mogą zawierać poleceń ani wielu wyrażeń.
Funkcja anonimowa nie może być bezpośrednim wywołaniem drukowania, ponieważ lambda wymaga wyrażenia
Funkcje lambda mają własną lokalną przestrzeń nazw i nie mogą uzyskać dostępu do zmiennych innych niż te na ich liście parametrów i te w globalnej przestrzeni nazw.
Chociaż wydaje się, że wyrażenia lambda są jednowierszową wersją funkcji, nie są one równoważne instrukcjom wbudowanym w C lub C ++, których celem jest przekazywanie alokacji stosu funkcji podczas wywołania ze względu na wydajność.
Składnia
Składnia funkcji lambda zawiera tylko jedną instrukcję, która jest następująca -
lambda [arg1 [,arg2,.....argn]]:expressionPoniżej znajduje się przykład pokazujący, jak działa forma funkcji lambda -
#!/usr/bin/python
# Function definition is here
sum = lambda arg1, arg2: arg1 + arg2;
# Now you can call sum as a function
print "Value of total : ", sum( 10, 20 )
print "Value of total : ", sum( 20, 20 )Wykonanie powyższego kodu daje następujący wynik -
Value of total : 30
Value of total : 40Zwrotny komunikat
Instrukcja return [wyrażenie] kończy funkcję, opcjonalnie przekazując z powrotem wyrażenie do wywołującego. Instrukcja return bez argumentów jest tym samym, co instrukcja return None.
Wszystkie powyższe przykłady nie zwracają żadnej wartości. Możesz zwrócić wartość z funkcji w następujący sposób -
#!/usr/bin/python
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2
print "Inside the function : ", total
return total;
# Now you can call sum function
total = sum( 10, 20 );
print "Outside the function : ", totalWykonanie powyższego kodu daje następujący wynik -
Inside the function : 30
Outside the function : 30Zakres zmiennych
Wszystkie zmienne w programie mogą nie być dostępne we wszystkich lokalizacjach w tym programie. To zależy od tego, gdzie zadeklarowałeś zmienną.
Zakres zmiennej określa część programu, w której można uzyskać dostęp do określonego identyfikatora. W Pythonie istnieją dwa podstawowe zakresy zmiennych -
- Zmienne globalne
- Zmienne lokalne
Zmienne globalne a zmienne lokalne
Zmienne zdefiniowane w treści funkcji mają zasięg lokalny, a te zdefiniowane na zewnątrz mają zasięg globalny.
Oznacza to, że dostęp do zmiennych lokalnych można uzyskać tylko wewnątrz funkcji, w której zostały zadeklarowane, podczas gdy do zmiennych globalnych można uzyskać dostęp w całym ciele programu przez wszystkie funkcje. Kiedy wywołujesz funkcję, zmienne zadeklarowane w niej są przenoszone do zakresu. Oto prosty przykład -
#!/usr/bin/python
total = 0; # This is global variable.
# Function definition is here
def sum( arg1, arg2 ):
# Add both the parameters and return them."
total = arg1 + arg2; # Here total is local variable.
print "Inside the function local total : ", total
return total;
# Now you can call sum function
sum( 10, 20 );
print "Outside the function global total : ", totalWykonanie powyższego kodu daje następujący wynik -
Inside the function local total : 30
Outside the function global total : 0Moduł umożliwia logiczne organizowanie kodu w Pythonie. Grupowanie powiązanego kodu w moduł ułatwia jego zrozumienie i użycie. Moduł to obiekt Pythona z dowolnie nazwanymi atrybutami, które można wiązać i odwoływać.
Po prostu moduł to plik składający się z kodu Pythona. Moduł może definiować funkcje, klasy i zmienne. Moduł może również zawierać kod, który można uruchomić.
Przykład
Kod Pythona dla modułu o nazwie aname zwykle znajduje się w pliku o nazwie aname.py . Oto przykład prostego modułu, support.py
def print_func( par ):
print "Hello : ", par
returnImportu komunikat
Możesz użyć dowolnego pliku źródłowego Pythona jako modułu, wykonując instrukcję importu w innym pliku źródłowym Pythona. Importu ma następującą składnię -
import module1[, module2[,... moduleN]Gdy interpreter napotka instrukcję importu, importuje moduł, jeśli jest on obecny na ścieżce wyszukiwania. Ścieżka wyszukiwania to lista katalogów, które interpreter przeszukuje przed zaimportowaniem modułu. Na przykład, aby zaimportować moduł support.py, musisz umieścić następujące polecenie u góry skryptu -
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Zara")Wykonanie powyższego kodu daje następujący wynik -
Hello : ZaraModuł jest ładowany tylko raz, niezależnie od tego, ile razy był importowany. Zapobiega to wielokrotnemu wykonywaniu modułu w przypadku wielu importów.
Od ... import komunikat
Instrukcja from Pythona umożliwia importowanie określonych atrybutów z modułu do bieżącej przestrzeni nazw. Od ... import ma składnię następujące -
from modname import name1[, name2[, ... nameN]]Na przykład, aby zaimportować funkcję fibonacci z modułu fib, użyj następującej instrukcji -
from fib import fibonacciTa instrukcja nie importuje całego modułu fib do bieżącej przestrzeni nazw; po prostu wprowadza element fibonacci z modułu fib do globalnej tablicy symboli modułu importującego.
Z importu ... * komunikat
Możliwe jest również zaimportowanie wszystkich nazw z modułu do bieżącej przestrzeni nazw za pomocą następującej instrukcji importu -
from modname import *Zapewnia to łatwy sposób importowania wszystkich elementów z modułu do bieżącej przestrzeni nazw; jednakże tego stwierdzenia należy używać oszczędnie.
Lokalizowanie modułów
Podczas importowania modułu interpreter języka Python wyszukuje moduł w następujących sekwencjach -
Bieżący katalog.
Jeśli moduł nie zostanie znaleziony, Python przeszukuje następnie każdy katalog w zmiennej powłoki PYTHONPATH.
Jeśli wszystko inne zawiedzie, Python sprawdza domyślną ścieżkę. W systemie UNIX ta domyślna ścieżka to zwykle / usr / local / lib / python /.
Ścieżka wyszukiwania modułu jest przechowywana w systemie modułów sys jako plik sys.pathzmienna. Zmienna sys.path zawiera bieżący katalog, PYTHONPATH i wartość domyślną zależną od instalacji.
PYTHONPATH Variable
PYTHONPATH to zmienna środowiskowa, składająca się z listy katalogów. Składnia zmiennej PYTHONPATH jest taka sama, jak zmiennej powłoki PATH.
Oto typowa PYTHONPATH z systemu Windows -
set PYTHONPATH = c:\python20\lib;A oto typowa PYTHONPATH z systemu UNIX -
set PYTHONPATH = /usr/local/lib/pythonPrzestrzenie nazw i zakresy
Zmienne to nazwy (identyfikatory), które odwzorowują obiekty. Nazw jest słownikiem nazw zmiennych (klawisze) i odpowiadających im obiektów (wartości).
Instrukcja Pythona może uzyskać dostęp do zmiennych w lokalnej przestrzeni nazw oraz w globalnej przestrzeni nazw . Jeśli zmienna lokalna i globalna mają taką samą nazwę, zmienna lokalna przesłania zmienną globalną.
Każda funkcja ma własną lokalną przestrzeń nazw. Metody klasowe podlegają tej samej zasadzie określania zakresu, co zwykłe funkcje.
Python zgaduje, czy zmienne są lokalne czy globalne. Zakłada, że każda zmienna, której przypisano wartość w funkcji, jest lokalna.
Dlatego, aby przypisać wartość zmiennej globalnej w ramach funkcji, należy najpierw użyć instrukcji global.
Instrukcja global VarName mówi Pythonowi, że VarName jest zmienną globalną. Python przestaje przeszukiwać lokalną przestrzeń nazw dla zmiennej.
Na przykład definiujemy zmienną Money w globalnej przestrzeni nazw. W funkcji Money przypisujemy Money wartość, dlatego Python przyjmuje Money jako zmienną lokalną. Jednak uzyskaliśmy dostęp do wartości zmiennej lokalnej Money przed jej ustawieniem, więc wynikiem jest UnboundLocalError. Usunięcie komentarzy z instrukcji globalnej rozwiązuje problem.
#!/usr/bin/python
Money = 2000
def AddMoney():
# Uncomment the following line to fix the code:
# global Money
Money = Money + 1
print Money
AddMoney()
print MoneyFunkcja dir ()
Funkcja wbudowana dir () zwraca posortowaną listę ciągów zawierających nazwy zdefiniowane przez moduł.
Lista zawiera nazwy wszystkich modułów, zmiennych i funkcji, które są zdefiniowane w module. Oto prosty przykład -
#!/usr/bin/python
# Import built-in module math
import math
content = dir(math)
print contentWykonanie powyższego kodu daje następujący wynik -
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']W tym przypadku specjalna zmienna łańcuchowa __name__ to nazwa modułu, a __file__ to nazwa pliku, z którego moduł został załadowany.
Te globalne () i mieszkańców () Funkcje
Funkcje globals () i locals () mogą służyć do zwracania nazw w globalnej i lokalnej przestrzeni nazw w zależności od lokalizacji, z której są wywoływane.
Jeśli locals () zostanie wywołane z wnętrza funkcji, zwróci wszystkie nazwy, do których można uzyskać dostęp lokalnie z tej funkcji.
Jeśli funkcja globals () zostanie wywołana z wnętrza funkcji, zwróci wszystkie nazwy, do których można uzyskać dostęp globalny z tej funkcji.
Typ zwracany przez obie te funkcje to słownik. Dlatego nazwy można wyodrębnić za pomocą funkcji keys ().
Reload () Funkcja
Gdy moduł jest importowany do skryptu, kod znajdujący się w górnej części modułu jest wykonywany tylko raz.
Dlatego jeśli chcesz ponownie wykonać kod najwyższego poziomu w module, możesz użyć funkcji reload () . Funkcja reload () ponownie importuje wcześniej zaimportowany moduł. Składnia funkcji reload () jest następująca -
reload(module_name)Tutaj nazwa_modułu to nazwa modułu, który chcesz przeładować, a nie ciąg znaków zawierający nazwę modułu. Na przykład, aby ponownie załadować moduł hello , wykonaj następujące czynności -
reload(hello)Pakiety w Pythonie
Pakiet jest hierarchiczną strukturą katalogów plików, która definiuje pojedyncze środowisko aplikacji Pythona, które składa się z modułów, podpakietów i podpakietów itd.
Rozważ plik Pots.py dostępny w katalogu Phone . Ten plik zawiera następujący wiersz kodu źródłowego -
#!/usr/bin/python
def Pots():
print "I'm Pots Phone"W podobny sposób mamy kolejne dwa pliki, które mają różne funkcje i mają taką samą nazwę jak powyżej -
Plik Phone / Isdn.py z funkcją Isdn ()
Plik Phone / G3.py z funkcją G3 ()
Teraz utwórz jeszcze jeden plik __init__.py w katalogu telefonu -
- Phone/__init__.py
Aby wszystkie funkcje były dostępne po zaimportowaniu Phone, musisz umieścić wyraźne instrukcje importu w __init__.py w następujący sposób -
from Pots import Pots
from Isdn import Isdn
from G3 import G3Po dodaniu tych wierszy do __init__.py wszystkie te klasy będą dostępne podczas importowania pakietu Phone.
#!/usr/bin/python
# Now import your Phone Package.
import Phone
Phone.Pots()
Phone.Isdn()
Phone.G3()Wykonanie powyższego kodu daje następujący wynik -
I'm Pots Phone
I'm 3G Phone
I'm ISDN PhoneW powyższym przykładzie wzięliśmy przykład pojedynczej funkcji w każdym pliku, ale możesz zachować wiele funkcji w swoich plikach. Możesz także zdefiniować różne klasy Pythona w tych plikach, a następnie możesz tworzyć pakiety z tych klas.
W tym rozdziale omówiono wszystkie podstawowe funkcje we / wy dostępne w Pythonie. Więcej funkcji można znaleźć w standardowej dokumentacji języka Python.
Drukowanie na ekranie
Najprostszym sposobem uzyskania wyniku jest użycie instrukcji print , w której można przekazać zero lub więcej wyrażeń oddzielonych przecinkami. Ta funkcja konwertuje przekazane wyrażenia na ciąg i zapisuje wynik na standardowe wyjście w następujący sposób -
#!/usr/bin/python
print "Python is really a great language,", "isn't it?"Daje to następujący wynik na ekranie standardowym -
Python is really a great language, isn't it?Czytanie danych z klawiatury
Python udostępnia dwie wbudowane funkcje do odczytu wiersza tekstu ze standardowego wejścia, które domyślnie pochodzi z klawiatury. Te funkcje to -
- raw_input
- input
Raw_input Function
Funkcja raw_input ([zachęta]) odczytuje jedną linię ze standardowego wejścia i zwraca ją jako łańcuch (usuwając końcowy znak nowej linii).
#!/usr/bin/python
str = raw_input("Enter your input: ")
print "Received input is : ", strTo monituje o wprowadzenie dowolnego ciągu i wyświetli ten sam ciąg na ekranie. Kiedy wpisałem „Hello Python!”, Jego wyjście wyglądało tak:
Enter your input: Hello Python
Received input is : Hello PythonWejście Function
Funkcja input ([prompt]) jest równoważna funkcji raw_input, z tą różnicą, że zakłada, że dane wejściowe są poprawnym wyrażeniem Pythona i zwraca oszacowany wynik.
#!/usr/bin/python
str = input("Enter your input: ")
print "Received input is : ", strDałoby to następujący wynik w odniesieniu do wprowadzonych danych wejściowych -
Enter your input: [x*5 for x in range(2,10,2)]
Recieved input is : [10, 20, 30, 40]Otwieranie i zamykanie plików
Do tej pory czytałeś i zapisywałeś na standardowe wejście i wyjście. Teraz zobaczymy, jak używać rzeczywistych plików danych.
Python domyślnie udostępnia podstawowe funkcje i metody niezbędne do manipulowania plikami. Większość operacji na plikach można wykonać za pomocą rozszerzeniafile obiekt.
Otwarty Funkcja
Zanim będziesz mógł odczytać lub zapisać plik, musisz go otworzyć za pomocą wbudowanej funkcji open () języka Python . Ta funkcja tworzy plikfile obiekt, który zostałby użyty do wywołania innych powiązanych z nim metod obsługi.
Składnia
file object = open(file_name [, access_mode][, buffering])Oto szczegóły parametrów -
file_name - Argument nazwa_pliku to ciąg znaków zawierający nazwę pliku, do którego chcesz uzyskać dostęp.
access_mode- access_mode określa tryb, w jakim plik ma zostać otwarty, tj. Czytać, zapisywać, dołączać itp. Pełna lista możliwych wartości jest podana poniżej w tabeli. Jest to parametr opcjonalny, a domyślnym trybem dostępu do plików jest odczyt (r).
buffering- Jeśli wartość buforowania jest ustawiona na 0, buforowanie nie jest wykonywane. Jeśli wartość buforowania wynosi 1, buforowanie linii jest wykonywane podczas dostępu do pliku. Jeśli określisz wartość buforowania jako liczbę całkowitą większą niż 1, operacja buforowania zostanie wykonana ze wskazanym rozmiarem buforu. Jeśli wartość ujemna, rozmiar bufora jest domyślnym systemem (zachowanie domyślne).
Oto lista różnych trybów otwierania pliku -
| Sr.No. | Tryby i opis |
|---|---|
| 1 | r Otwiera plik tylko do odczytu. Wskaźnik pliku jest umieszczany na początku pliku. To jest tryb domyślny. |
| 2 | rb Otwiera plik do odczytu tylko w formacie binarnym. Wskaźnik pliku jest umieszczany na początku pliku. To jest tryb domyślny. |
| 3 | r+ Otwiera plik do odczytu i zapisu. Wskaźnik pliku umieszczony na początku pliku. |
| 4 | rb+ Otwiera plik do odczytu i zapisu w formacie binarnym. Wskaźnik pliku umieszczony na początku pliku. |
| 5 | w Otwiera plik tylko do zapisu. Zastępuje plik, jeśli istnieje. Jeśli plik nie istnieje, tworzy nowy plik do zapisu. |
| 6 | wb Otwiera plik do zapisu tylko w formacie binarnym. Zastępuje plik, jeśli istnieje. Jeśli plik nie istnieje, tworzy nowy plik do zapisu. |
| 7 | w+ Otwiera plik do zapisu i odczytu. Zastępuje istniejący plik, jeśli plik istnieje. Jeśli plik nie istnieje, tworzy nowy plik do odczytu i zapisu. |
| 8 | wb+ Otwiera plik do zapisu i odczytu w formacie binarnym. Zastępuje istniejący plik, jeśli plik istnieje. Jeśli plik nie istnieje, tworzy nowy plik do odczytu i zapisu. |
| 9 | a Otwiera plik do dołączenia. Wskaźnik pliku znajduje się na końcu pliku, jeśli plik istnieje. Oznacza to, że plik jest w trybie dołączania. Jeśli plik nie istnieje, tworzy nowy plik do zapisu. |
| 10 | ab Otwiera plik do dołączenia w formacie binarnym. Wskaźnik pliku znajduje się na końcu pliku, jeśli plik istnieje. Oznacza to, że plik jest w trybie dołączania. Jeśli plik nie istnieje, tworzy nowy plik do zapisu. |
| 11 | a+ Otwiera plik do dołączania i odczytu. Wskaźnik pliku znajduje się na końcu pliku, jeśli plik istnieje. Plik otwiera się w trybie dołączania. Jeśli plik nie istnieje, tworzy nowy plik do odczytu i zapisu. |
| 12 | ab+ Otwiera plik do dołączania i odczytu w formacie binarnym. Wskaźnik pliku znajduje się na końcu pliku, jeśli plik istnieje. Plik otwiera się w trybie dołączania. Jeśli plik nie istnieje, tworzy nowy plik do odczytu i zapisu. |
W pliku Atrybuty obiektu
Po otwarciu pliku i utworzeniu jednego obiektu pliku można uzyskać różne informacje związane z tym plikiem.
Oto lista wszystkich atrybutów związanych z obiektem pliku -
| Sr.No. | Atrybut i opis |
|---|---|
| 1 | file.closed Zwraca true, jeśli plik jest zamknięty, false w przeciwnym razie. |
| 2 | file.mode Zwraca tryb dostępu, w którym plik został otwarty. |
| 3 | file.name Zwraca nazwę pliku. |
| 4 | file.softspace Zwraca fałsz, jeśli miejsce jest jawnie wymagane w print, w przeciwnym razie wartość true. |
Przykład
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
print "Closed or not : ", fo.closed
print "Opening mode : ", fo.mode
print "Softspace flag : ", fo.softspaceDaje to następujący wynik -
Name of the file: foo.txt
Closed or not : False
Opening mode : wb
Softspace flag : 0Close () metoda
Metoda close () obiektu plikowego usuwa wszelkie niepisane informacje i zamyka obiekt plik, po czym nie można już pisać.
Python automatycznie zamyka plik, gdy obiekt odniesienia pliku zostanie ponownie przypisany do innego pliku. Dobrą praktyką jest używanie metody close () do zamykania pliku.
Składnia
fileObject.close()Przykład
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
print "Name of the file: ", fo.name
# Close opend file
fo.close()Daje to następujący wynik -
Name of the file: foo.txtCzytanie i pisanie plików
Obiekt file zapewnia zestaw metod dostępu, które ułatwiają nam życie. Zobaczylibyśmy, jak używać metod read () i write () do odczytu i zapisu plików.
Write () Metoda
Metoda write () zapisuje dowolny ciąg znaków do otwartego pliku. Należy zauważyć, że łańcuchy znaków Pythona mogą zawierać dane binarne, a nie tylko tekst.
Metoda write () nie dodaje znaku nowego wiersza („\ n”) na końcu ciągu -
Składnia
fileObject.write(string)Tutaj przekazany parametr to treść, która ma zostać zapisana do otwartego pliku.
Przykład
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opend file
fo.close()Powyższa metoda utworzyłaby plik foo.txt i zapisze określoną zawartość w tym pliku, a na koniec zamknie ten plik. Gdybyś otworzył ten plik, miałby następującą zawartość.
Python is a great language.
Yeah its great!!Read () Metoda
Metoda read () odczytuje ciąg znaków z otwartego pliku. Należy zauważyć, że łańcuchy znaków Pythona mogą zawierać dane binarne. oprócz danych tekstowych.
Składnia
fileObject.read([count])Tutaj przekazywany parametr to liczba bajtów do odczytania z otwartego pliku. Ta metoda zaczyna czytać od początku pliku i jeśli brakuje count , wtedy próbuje odczytać jak najwięcej, być może do końca pliku.
Przykład
Weźmy plik foo.txt , który stworzyliśmy powyżej.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Close opend file
fo.close()Daje to następujący wynik -
Read String is : Python isPlik Pozycje
Metoda tell () informuje o bieżącej pozycji w pliku; innymi słowy, następny odczyt lub zapis nastąpi z taką liczbą bajtów od początku pliku.
Metoda seek (offset [, from]) zmienia bieżącą pozycję pliku. Przesunięcie Argument wskazuje liczbę bajtów, które mają być przeniesione. Z argumentów określa punkt odniesienia, z którego bajty mają zostać przeniesione.
Jeśli from jest ustawiony na 0, oznacza to, że jako punkt odniesienia użyj początku pliku, a 1 oznacza, że jako punkt odniesienia użyj bieżącej pozycji, a jeśli jest ustawiony na 2, to koniec pliku zostanie przyjęty jako punkt odniesienia .
Przykład
Weźmy plik foo.txt , który stworzyliśmy powyżej.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10)
print "Read String is : ", str
# Check current position
position = fo.tell()
print "Current file position : ", position
# Reposition pointer at the beginning once again
position = fo.seek(0, 0);
str = fo.read(10)
print "Again read String is : ", str
# Close opend file
fo.close()Daje to następujący wynik -
Read String is : Python is
Current file position : 10
Again read String is : Python isZmiana nazwy i usuwanie plików
Pyton os Moduł udostępnia metody ułatwiające wykonywanie operacji przetwarzania plików, takich jak zmiana nazwy i usuwanie plików.
Aby użyć tego modułu, musisz go najpierw zaimportować, a następnie możesz wywołać wszelkie powiązane funkcje.
Metoda rename ()
Metoda rename () przyjmuje dwa argumenty, bieżącą nazwę pliku i nową nazwę pliku.
Składnia
os.rename(current_file_name, new_file_name)Przykład
Poniżej znajduje się przykład zmiany nazwy istniejącego pliku test1.txt -
#!/usr/bin/python
import os
# Rename a file from test1.txt to test2.txt
os.rename( "test1.txt", "test2.txt" )Remove () Metoda
Możesz użyć metody remove () , aby usunąć pliki, podając jako argument nazwę pliku do usunięcia.
Składnia
os.remove(file_name)Przykład
Poniżej znajduje się przykład usunięcia istniejącego pliku test2.txt -
#!/usr/bin/python
import os
# Delete file test2.txt
os.remove("text2.txt")Katalogi w Pythonie
Wszystkie pliki są zawarte w różnych katalogach, a Python nie ma problemu z ich obsługą. Plikos moduł ma kilka metod, które pomagają tworzyć, usuwać i zmieniać katalogi.
Mkdir () Metoda
Możesz użyć metody mkdir () plikuosmoduł do tworzenia katalogów w bieżącym katalogu. Musisz podać argument do tej metody, który zawiera nazwę katalogu, który ma zostać utworzony.
Składnia
os.mkdir("newdir")Przykład
Poniżej znajduje się przykład tworzenia testu katalogu w bieżącym katalogu -
#!/usr/bin/python
import os
# Create a directory "test"
os.mkdir("test")Chdir () Metoda
Aby zmienić bieżący katalog, możesz użyć metody chdir () . Metoda chdir () przyjmuje argument, którym jest nazwa katalogu, który ma być katalogiem bieżącym.
Składnia
os.chdir("newdir")Przykład
Poniżej znajduje się przykład przejścia do katalogu „/ home / newdir” -
#!/usr/bin/python
import os
# Changing a directory to "/home/newdir"
os.chdir("/home/newdir")Getcwd () Metoda
Metoda getcwd () wyświetla bieżący katalog roboczy.
Składnia
os.getcwd()Przykład
Poniżej znajduje się przykład, aby podać bieżący katalog -
#!/usr/bin/python
import os
# This would give location of the current directory
os.getcwd()Rmdir () Metoda
Metoda rmdir () usuwa katalog, który jest przekazywany jako argument w metodzie.
Przed usunięciem katalogu należy usunąć całą jego zawartość.
Składnia
os.rmdir('dirname')Przykład
Poniżej znajduje się przykład usuwania katalogu „/ tmp / test”. Wymagane jest podanie w pełni kwalifikowanej nazwy katalogu, w przeciwnym razie szukałby tego katalogu w bieżącym katalogu.
#!/usr/bin/python
import os
# This would remove "/tmp/test" directory.
os.rmdir( "/tmp/test" )Metody związane z plikami i katalogami
Istnieją trzy ważne źródła, które zapewniają szeroką gamę metod narzędziowych do obsługi plików i katalogów w systemach operacyjnych Windows i Unix oraz do manipulowania nimi. Są następujące -
Metody obiektu pliku : Obiekt pliku udostępnia funkcje do manipulowania plikami.
Metody obiektów systemu operacyjnego : Zapewnia metody przetwarzania plików, a także katalogów.
Python zapewnia dwie bardzo ważne funkcje do obsługi wszelkich nieoczekiwanych błędów w programach w języku Python i dodawania do nich funkcji debugowania -
Exception Handling- Będzie to omówione w tym samouczku. Oto lista standardowych wyjątków dostępnych w Pythonie: Standardowe wyjątki .
Assertions- Zostanie to omówione w samouczku Assertions in Python .
Lista standardowych wyjątków -
| Sr.No. | Nazwa i opis wyjątku |
|---|---|
| 1 | Exception Klasa podstawowa dla wszystkich wyjątków |
| 2 | StopIteration Wywoływane, gdy metoda next () iteratora nie wskazuje na żaden obiekt. |
| 3 | SystemExit Wywołane przez funkcję sys.exit (). |
| 4 | StandardError Klasa podstawowa dla wszystkich wbudowanych wyjątków z wyjątkiem StopIteration i SystemExit. |
| 5 | ArithmeticError Klasa podstawowa dla wszystkich błędów występujących w obliczeniach numerycznych. |
| 6 | OverflowError Podnoszone, gdy obliczenie przekracza maksymalny limit dla typu liczbowego. |
| 7 | FloatingPointError Podnoszone, gdy obliczenia zmiennoprzecinkowe nie powiodły się. |
| 8 | ZeroDivisionError Podnoszony, gdy dla wszystkich typów liczbowych ma miejsce dzielenie lub modulo przez zero. |
| 9 | AssertionError Podnoszone w przypadku niepowodzenia instrukcji Assert. |
| 10 | AttributeError Podniesione w przypadku niepowodzenia odniesienia do atrybutu lub przypisania. |
| 11 | EOFError Wywoływane, gdy nie ma danych wejściowych z funkcji raw_input () lub input () i osiągnięto koniec pliku. |
| 12 | ImportError Wywoływane, gdy instrukcja importu nie powiedzie się. |
| 13 | KeyboardInterrupt Wywoływane, gdy użytkownik przerywa wykonywanie programu, zwykle naciskając Ctrl + c. |
| 14 | LookupError Klasa bazowa dla wszystkich błędów wyszukiwania. |
| 15 | IndexError Podnoszone, gdy indeks nie zostanie znaleziony w sekwencji. |
| 16 | KeyError Wywoływane, gdy określony klucz nie zostanie znaleziony w słowniku. |
| 17 | NameError Wywoływane, gdy identyfikator nie zostanie znaleziony w lokalnej lub globalnej przestrzeni nazw. |
| 18 | UnboundLocalError Wywoływane podczas próby uzyskania dostępu do zmiennej lokalnej w funkcji lub metodzie, ale nie została do niej przypisana żadna wartość. |
| 19 | EnvironmentError Klasa podstawowa dla wszystkich wyjątków, które występują poza środowiskiem Pythona. |
| 20 | IOError Wywoływane, gdy operacja wejścia / wyjścia nie powiedzie się, na przykład instrukcja print lub funkcja open () podczas próby otwarcia pliku, który nie istnieje. |
| 21 | IOError Zgłaszane z powodu błędów związanych z systemem operacyjnym. |
| 22 | SyntaxError Wywoływane, gdy występuje błąd w składni Pythona. |
| 23 | IndentationError Wywoływane, gdy wcięcie nie jest poprawnie określone. |
| 24 | SystemError Wywoływane, gdy interpreter napotka wewnętrzny problem, ale po napotkaniu tego błędu interpreter Pythona nie kończy pracy. |
| 25 | SystemExit Wywoływane, gdy interpreter Pythona jest zamykany za pomocą funkcji sys.exit (). Jeśli nie jest obsługiwane w kodzie, powoduje zakończenie pracy interpretera. |
| 26 | TypeError Wywoływane, gdy podjęto próbę wykonania operacji lub funkcji, która jest nieprawidłowa dla określonego typu danych. |
| 27 | ValueError Wywoływane, gdy funkcja wbudowana dla typu danych ma prawidłowy typ argumentów, ale argumenty mają określone nieprawidłowe wartości. |
| 28 | RuntimeError Wywoływane, gdy wygenerowany błąd nie należy do żadnej kategorii. |
| 29 | NotImplementedError Wywoływane, gdy metoda abstrakcyjna, która musi zostać zaimplementowana w klasie dziedziczonej, nie jest faktycznie zaimplementowana. |
Asercje w Pythonie
Asercja to sprawdzenie poczytalności, które możesz włączyć lub wyłączyć po zakończeniu testowania programu.
Najłatwiejszym sposobem myślenia o asercji jest porównanie jej do a raise-if(a dokładniej mówiąc, podnieś, jeśli nie). Wyrażenie jest testowane i jeśli wynik okaże się fałszywy, zgłaszany jest wyjątek.
Asercje są wykonywane przez instrukcję assert, najnowsze słowo kluczowe języka Python, wprowadzone w wersji 1.5.
Programiści często umieszczają potwierdzenia na początku funkcji, aby sprawdzić poprawność danych wejściowych, i po wywołaniu funkcji, aby sprawdzić poprawność danych wyjściowych.
Assert komunikat
Kiedy napotyka instrukcję assert, Python ocenia towarzyszące jej wyrażenie, które, miejmy nadzieję, jest prawdą. Jeśli wyrażenie jest fałszywe, Python zgłasza wyjątek AssertionError .
Składnia assert to -
assert Expression[, Arguments]Jeśli asercja się nie powiedzie, Python używa ArgumentExpression jako argumentu dla AssertionError. Wyjątki AssertionError mogą być przechwytywane i obsługiwane jak każdy inny wyjątek za pomocą instrukcji try-except, ale jeśli nie zostaną obsłużone, zakończą program i utworzą śledzenie.
Przykład
Oto funkcja, która konwertuje temperaturę ze stopni Kelvina na stopnie Fahrenheita. Ponieważ zero stopni Kelvina jest tak zimne, jak to tylko możliwe, funkcja wyskakuje, jeśli zauważy ujemną temperaturę -
#!/usr/bin/python
def KelvinToFahrenheit(Temperature):
assert (Temperature >= 0),"Colder than absolute zero!"
return ((Temperature-273)*1.8)+32
print KelvinToFahrenheit(273)
print int(KelvinToFahrenheit(505.78))
print KelvinToFahrenheit(-5)Wykonanie powyższego kodu daje następujący wynik -
32.0
451
Traceback (most recent call last):
File "test.py", line 9, in <module>
print KelvinToFahrenheit(-5)
File "test.py", line 4, in KelvinToFahrenheit
assert (Temperature >= 0),"Colder than absolute zero!"
AssertionError: Colder than absolute zero!Co to jest wyjątek?
Wyjątkiem jest zdarzenie, które występuje podczas wykonywania programu, które zakłóca normalny przepływ instrukcji programu. Ogólnie rzecz biorąc, kiedy skrypt w Pythonie napotyka sytuację, z którą nie może sobie poradzić, zgłasza wyjątek. Wyjątkiem jest obiekt Pythona, który reprezentuje błąd.
Kiedy skrypt w Pythonie zgłasza wyjątek, musi albo natychmiast obsłużyć wyjątek, w przeciwnym razie kończy działanie i kończy pracę.
Obsługa wyjątku
Jeśli masz podejrzany kod, który może wywołać wyjątek, możesz chronić swój program, umieszczając podejrzany kod w plikutry:blok. Po wykonaniu try: block dołącz plikexcept: instrukcja, po której następuje blok kodu, który rozwiązuje problem tak elegancko, jak to tylko możliwe.
Składnia
Oto prosta składnia try .... z wyjątkiem bloków ... else -
try:
You do your operations here;
......................
except ExceptionI:
If there is ExceptionI, then execute this block.
except ExceptionII:
If there is ExceptionII, then execute this block.
......................
else:
If there is no exception then execute this block.Oto kilka ważnych punktów dotyczących wyżej wymienionej składni -
Pojedyncza instrukcja try może mieć wiele instrukcji oprócz. Jest to przydatne, gdy blok try zawiera instrukcje, które mogą generować różne typy wyjątków.
Możesz również podać ogólną klauzulę except, która obsługuje każdy wyjątek.
Po klauzuli (-ach) else można dołączyć klauzulę else. Kod w bloku else jest wykonywany, jeśli kod w bloku try: nie zgłosi wyjątku.
Blok else to dobre miejsce na kod, który nie potrzebuje ochrony try: block.
Przykład
Ten przykład otwiera plik, zapisuje zawartość w pliku i wychodzi z wdziękiem, ponieważ nie ma żadnego problemu -
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"
fh.close()Daje to następujący wynik -
Written content in the file successfullyPrzykład
Ten przykład próbuje otworzyć plik, w którym nie masz uprawnień do zapisu, więc zgłasza wyjątek -
#!/usr/bin/python
try:
fh = open("testfile", "r")
fh.write("This is my test file for exception handling!!")
except IOError:
print "Error: can\'t find file or read data"
else:
print "Written content in the file successfully"Daje to następujący wynik -
Error: can't find file or read dataWyjątkiem Klauzula bez wyjątków
Możesz również użyć instrukcji except bez wyjątków zdefiniowanych w następujący sposób -
try:
You do your operations here;
......................
except:
If there is any exception, then execute this block.
......................
else:
If there is no exception then execute this block.Ten rodzaj try-exceptinstrukcja przechwytuje wszystkie wyjątki, które występują. Używanie tego rodzaju instrukcji try-except nie jest jednak uważane za dobrą praktykę programistyczną, ponieważ wyłapuje wszystkie wyjątki, ale nie powoduje, że programiści identyfikują główną przyczynę problemu, który może wystąpić.
Wyjątkiem Clause z wielu wyjątków
Możesz również użyć tej samej instrukcji except do obsługi wielu wyjątków w następujący sposób -
try:
You do your operations here;
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
If there is any exception from the given exception list,
then execute this block.
......................
else:
If there is no exception then execute this block.Klauzula próby ostatecznej
Możesz użyć finally: blok wraz z try:blok. Ostatni blok to miejsce, w którym można umieścić dowolny kod, który musi zostać wykonany, niezależnie od tego, czy blok try wywołał wyjątek, czy nie. Składnia instrukcji try-last jest następująca -
try:
You do your operations here;
......................
Due to any exception, this may be skipped.
finally:
This would always be executed.
......................Nie możesz używać klauzuli else razem z klauzulą last.
Przykład
#!/usr/bin/python
try:
fh = open("testfile", "w")
fh.write("This is my test file for exception handling!!")
finally:
print "Error: can\'t find file or read data"Jeśli nie masz uprawnień do otwierania pliku w trybie do zapisu, da to następujący wynik -
Error: can't find file or read dataTen sam przykład można zapisać jaśniej w następujący sposób -
#!/usr/bin/python
try:
fh = open("testfile", "w")
try:
fh.write("This is my test file for exception handling!!")
finally:
print "Going to close the file"
fh.close()
except IOError:
print "Error: can\'t find file or read data"Gdy wyjątek zostanie zgłoszony w bloku try , wykonanie natychmiast przechodzi do ostatniego bloku. Po wszystkie oświadczenia w końcu bloku są wykonywane, wyjątek jest ponownie podniesione i jest obsługiwana w wyjątkiem oświadczenia, jeżeli występuje w następnej warstwy wyższej w try-oprócz oświadczenia.
Argument wyjątku
Wyjątek może mieć argument będący wartością dostarczającą dodatkowych informacji o problemie. Zawartość argumentu różni się w zależności od wyjątku. Przechwytujesz argument wyjątku, podając zmienną w klauzuli except w następujący sposób -
try:
You do your operations here;
......................
except ExceptionType, Argument:
You can print value of Argument here...Jeśli napiszesz kod obsługujący pojedynczy wyjątek, możesz ustawić zmienną po nazwie wyjątku w instrukcji except. W przypadku zalewkowania wielu wyjątków za krotką wyjątku może podążać zmienna.
Ta zmienna otrzymuje wartość wyjątku zawierającego głównie przyczynę wyjątku. Zmienna może otrzymać jedną wartość lub wiele wartości w postaci krotki. Ta krotka zwykle zawiera ciąg błędu, numer błędu i lokalizację błędu.
Przykład
Poniżej znajduje się przykład pojedynczego wyjątku -
#!/usr/bin/python
# Define a function here.
def temp_convert(var):
try:
return int(var)
except ValueError, Argument:
print "The argument does not contain numbers\n", Argument
# Call above function here.
temp_convert("xyz");Daje to następujący wynik -
The argument does not contain numbers
invalid literal for int() with base 10: 'xyz'Podnoszenie wyjątków
Możesz zgłaszać wyjątki na kilka sposobów, używając instrukcji raise. Ogólna składnia dlaraise oświadczenie jest następujące.
Składnia
raise [Exception [, args [, traceback]]]Tutaj Exception jest typem wyjątku (na przykład NameError), a argument jest wartością argumentu wyjątku. Argument jest opcjonalny; jeśli nie zostanie podany, argument wyjątku to Brak.
Ostatni argument, traceback, jest również opcjonalny (i rzadko używany w praktyce), a jeśli jest obecny, jest obiektem śledzenia używanym w wyjątku.
Przykład
Wyjątkiem może być ciąg znaków, klasa lub obiekt. Większość wyjątków wywoływanych przez rdzeń języka Python to klasy z argumentem będącym instancją klasy. Definiowanie nowych wyjątków jest dość łatwe i można to zrobić w następujący sposób -
def functionName( level ):
if level < 1:
raise "Invalid level!", level
# The code below to this would not be executed
# if we raise the exceptionNote:Aby złapać wyjątek, klauzula „oprócz” musi odnosić się do tego samego zgłoszonego wyjątku, albo obiektu klasy, albo prostego ciągu znaków. Na przykład, aby przechwycić powyższy wyjątek, musimy napisać klauzulę except w następujący sposób -
try:
Business Logic here...
except "Invalid level!":
Exception handling here...
else:
Rest of the code here...Wyjątki zdefiniowane przez użytkownika
Python umożliwia również tworzenie własnych wyjątków poprzez wyprowadzanie klas z wbudowanych wyjątków standardowych.
Oto przykład związany z RuntimeError . Tutaj tworzona jest klasa, która jest podklasą z RuntimeError . Jest to przydatne, gdy chcesz wyświetlić bardziej szczegółowe informacje, gdy zostanie przechwycony wyjątek.
W bloku try wyjątek zdefiniowany przez użytkownika jest zgłaszany i przechwytywany w bloku except. Zmienna e służy do tworzenia instancji klasy Networkerror .
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = argPo zdefiniowaniu powyższej klasy możesz zgłosić wyjątek w następujący sposób -
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.argsPython był językiem zorientowanym obiektowo od samego początku. Z tego powodu tworzenie i używanie klas i obiektów jest wręcz łatwe. Ten rozdział pomoże Ci stać się ekspertem w korzystaniu z obsługi programowania obiektowego w języku Python.
Jeśli nie masz żadnego doświadczenia z programowaniem obiektowym (OO), możesz skorzystać z kursu wprowadzającego lub przynajmniej jakiegoś samouczka, aby zrozumieć podstawowe pojęcia.
Jednak tutaj jest małe wprowadzenie do programowania obiektowego (OOP), aby przyspieszyć -
Przegląd terminologii OOP
Class- Prototyp zdefiniowany przez użytkownika dla obiektu, który definiuje zestaw atrybutów charakteryzujących dowolny obiekt klasy. Atrybuty to elementy składowe danych (zmienne klas i zmienne instancji) oraz metody, do których można uzyskać dostęp za pomocą notacji kropkowej.
Class variable- Zmienna wspólna dla wszystkich instancji klasy. Zmienne klasy są zdefiniowane w klasie, ale poza żadną z metod klasy. Zmienne klas nie są używane tak często, jak zmienne instancji.
Data member - Zmienna klasy lub zmienna instancji, która przechowuje dane powiązane z klasą i jej obiektami.
Function overloading- Przypisanie więcej niż jednego zachowania do określonej funkcji. Wykonywana operacja różni się w zależności od typów obiektów lub argumentów.
Instance variable - Zmienna zdefiniowana wewnątrz metody i należąca tylko do aktualnego wystąpienia klasy.
Inheritance - Przeniesienie cech klasy do innych klas, które z niej pochodzą.
Instance- indywidualny przedmiot określonej klasy. Na przykład obiekt obj należący do klasy Circle jest instancją klasy Circle.
Instantiation - Tworzenie instancji klasy.
Method - Specjalny rodzaj funkcji zdefiniowany w definicji klasy.
Object- Unikalne wystąpienie struktury danych zdefiniowanej przez jej klasę. Obiekt zawiera zarówno elementy członkowskie danych (zmienne klas i zmienne instancji), jak i metody.
Operator overloading - Przypisanie więcej niż jednej funkcji do konkretnego operatora.
Tworzenie klas
Instrukcja class tworzy nową definicję klasy. Nazwa klasy następuje bezpośrednio po słowie kluczowym class, po którym następuje dwukropek w następujący sposób -
class ClassName:
'Optional class documentation string'
class_suiteKlasa zawiera ciąg dokumentacji, do którego można uzyskać dostęp poprzez ClassName .__ doc__ .
Zestaw class_suite składa się ze wszystkich instrukcji komponentów definiujących elementy klasy, atrybuty danych i funkcje.
Przykład
Oto przykład prostej klasy w Pythonie -
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salaryZmienna empCount jest zmienną klasową, której wartość jest wspólna dla wszystkich instancji tej klasy. Dostęp do tego można uzyskać jako Employee.empCount z poziomu klasy lub spoza niej.
Pierwsza metoda __init __ () to specjalna metoda, nazywana konstruktorem klasy lub metodą inicjalizacji, którą Python wywołuje podczas tworzenia nowej instancji tej klasy.
Deklarujesz inne metody klas, takie jak zwykłe funkcje, z wyjątkiem tego, że pierwszym argumentem każdej metody jest self . Python dodaje argument self do listy za Ciebie; nie musisz go dołączać podczas wywoływania metod.
Tworzenie obiektów instancji
Aby utworzyć instancje klasy, wywołujesz klasę używając nazwy klasy i przekazujesz wszystkie argumenty , które akceptuje jej metoda __init__ .
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)Dostęp do atrybutów
Dostęp do atrybutów obiektu uzyskuje się za pomocą operatora kropki z obiektem. Dostęp do zmiennej klasy można uzyskać za pomocą nazwy klasy w następujący sposób -
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCountTeraz łącząc wszystkie koncepcje razem -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
"This would create first object of Employee class"
emp1 = Employee("Zara", 2000)
"This would create second object of Employee class"
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCountWykonanie powyższego kodu daje następujący wynik -
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2Możesz dodawać, usuwać lub modyfikować atrybuty klas i obiektów w dowolnym momencie -
emp1.age = 7 # Add an 'age' attribute.
emp1.age = 8 # Modify 'age' attribute.
del emp1.age # Delete 'age' attribute.Zamiast używać zwykłych instrukcji do uzyskiwania dostępu do atrybutów, możesz użyć następujących funkcji -
Plik getattr(obj, name[, default]) - aby uzyskać dostęp do atrybutu obiektu.
Plik hasattr(obj,name) - aby sprawdzić, czy atrybut istnieje, czy nie.
Plik setattr(obj,name,value)- ustawić atrybut. Jeśli atrybut nie istnieje, zostanie utworzony.
Plik delattr(obj, name) - aby usunąć atrybut.
hasattr(emp1, 'age') # Returns true if 'age' attribute exists
getattr(emp1, 'age') # Returns value of 'age' attribute
setattr(emp1, 'age', 8) # Set attribute 'age' at 8
delattr(empl, 'age') # Delete attribute 'age'Wbudowane atrybuty klas
Każda klasa Pythona śledzi wbudowane atrybuty i można uzyskać do nich dostęp za pomocą operatora kropki, jak każdy inny atrybut -
__dict__ - Słownik zawierający przestrzeń nazw klasy.
__doc__ - Łańcuch dokumentacji klasy lub brak, jeśli jest niezdefiniowany.
__name__ - Nazwa klasy.
__module__- Nazwa modułu, w którym zdefiniowana jest klasa. W trybie interaktywnym ten atrybut to „__main__”.
__bases__ - Prawdopodobnie pusta krotka zawierająca klasy bazowe, w kolejności ich występowania na liście klas bazowych.
W przypadku powyższej klasy spróbujmy uzyskać dostęp do wszystkich tych atrybutów -
#!/usr/bin/python
class Employee:
'Common base class for all employees'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
print "Employee.__doc__:", Employee.__doc__
print "Employee.__name__:", Employee.__name__
print "Employee.__module__:", Employee.__module__
print "Employee.__bases__:", Employee.__bases__
print "Employee.__dict__:", Employee.__dict__Wykonanie powyższego kodu daje następujący wynik -
Employee.__doc__: Common base class for all employees
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: ()
Employee.__dict__: {'__module__': '__main__', 'displayCount':
<function displayCount at 0xb7c84994>, 'empCount': 2,
'displayEmployee': <function displayEmployee at 0xb7c8441c>,
'__doc__': 'Common base class for all employees',
'__init__': <function __init__ at 0xb7c846bc>}Niszczenie obiektów (zbieranie śmieci)
Python automatycznie usuwa niepotrzebne obiekty (typy wbudowane lub instancje klas), aby zwolnić miejsce w pamięci. Proces, za pomocą którego Python okresowo odzyskuje bloki pamięci, które nie są już używane, nazywa się Garbage Collection.
Moduł odśmiecania pamięci Pythona działa podczas wykonywania programu i jest wyzwalany, gdy liczba odwołań do obiektu osiągnie zero. Liczba odwołań do obiektu zmienia się wraz ze zmianą liczby aliasów wskazujących na obiekt.
Liczba odwołań do obiektu wzrasta, gdy zostanie mu przypisana nowa nazwa lub zostanie umieszczony w kontenerze (liście, krotce lub słowniku). Liczba odwołań do obiektu zmniejsza się, gdy jest usuwany za pomocą del , jego odwołanie jest ponownie przypisywane lub jego odwołanie wykracza poza zakres. Gdy liczba odwołań do obiektu osiągnie zero, Python zbiera je automatycznie.
a = 40 # Create object <40>
b = a # Increase ref. count of <40>
c = [b] # Increase ref. count of <40>
del a # Decrease ref. count of <40>
b = 100 # Decrease ref. count of <40>
c[0] = -1 # Decrease ref. count of <40>Zwykle nie zauważysz, kiedy garbage collector niszczy osieroconą instancję i odzyskuje jej miejsce. Ale klasa może implementować specjalną metodę __del __ () , zwaną destruktorem, która jest wywoływana, gdy instancja ma zostać zniszczona. Ta metoda może służyć do czyszczenia zasobów innych niż pamięć używanych przez instancję.
Przykład
Ten niszczyciel __del __ () wyświetla nazwę klasy instancji, która ma zostać zniszczona -
#!/usr/bin/python
class Point:
def __init__( self, x=0, y=0):
self.x = x
self.y = y
def __del__(self):
class_name = self.__class__.__name__
print class_name, "destroyed"
pt1 = Point()
pt2 = pt1
pt3 = pt1
print id(pt1), id(pt2), id(pt3) # prints the ids of the obejcts
del pt1
del pt2
del pt3Wykonanie powyższego kodu daje następujący wynik -
3083401324 3083401324 3083401324
Point destroyedNote- Najlepiej byłoby zdefiniować swoje klasy w oddzielnym pliku, a następnie zaimportować je do głównego pliku programu za pomocą instrukcji import .
Dziedziczenie klas
Zamiast zaczynać od zera, możesz utworzyć klasę, wyprowadzając ją z wcześniej istniejącej klasy, wymieniając klasę nadrzędną w nawiasach po nowej nazwie klasy.
Klasa potomna dziedziczy atrybuty swojej klasy nadrzędnej i możesz używać tych atrybutów tak, jakby były zdefiniowane w klasie potomnej. Klasa potomna może również przesłonić składowe danych i metody z rodzica.
Składnia
Klasy pochodne są deklarowane podobnie jak ich klasa nadrzędna; jednakże lista klas bazowych do dziedziczenia jest podana po nazwie klasy -
class SubClassName (ParentClass1[, ParentClass2, ...]):
'Optional class documentation string'
class_suitePrzykład
#!/usr/bin/python
class Parent: # define parent class
parentAttr = 100
def __init__(self):
print "Calling parent constructor"
def parentMethod(self):
print 'Calling parent method'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "Parent attribute :", Parent.parentAttr
class Child(Parent): # define child class
def __init__(self):
print "Calling child constructor"
def childMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.childMethod() # child calls its method
c.parentMethod() # calls parent's method
c.setAttr(200) # again call parent's method
c.getAttr() # again call parent's methodWykonanie powyższego kodu daje następujący wynik -
Calling child constructor
Calling child method
Calling parent method
Parent attribute : 200W podobny sposób możesz kierować klasą z wielu klas nadrzędnych w następujący sposób -
class A: # define your class A
.....
class B: # define your class B
.....
class C(A, B): # subclass of A and B
.....Możesz użyć funkcji issubclass () lub isinstance (), aby sprawdzić relacje dwóch klas i instancji.
Plik issubclass(sub, sup) funkcja boolowska zwraca prawdę, jeśli dana podklasa sub jest rzeczywiście podklasą nadklasy sup.
Plik isinstance(obj, Class)funkcja boolowska zwraca wartość true, jeśli obj jest instancją klasy Class lub instancją podklasy Class
Metody zastępujące
Zawsze możesz zastąpić metody klasy nadrzędnej. Jednym z powodów nadpisywania metod nadrzędnych jest to, że możesz chcieć specjalnej lub innej funkcjonalności w swojej podklasie.
Przykład
#!/usr/bin/python
class Parent: # define parent class
def myMethod(self):
print 'Calling parent method'
class Child(Parent): # define child class
def myMethod(self):
print 'Calling child method'
c = Child() # instance of child
c.myMethod() # child calls overridden methodWykonanie powyższego kodu daje następujący wynik -
Calling child methodPodstawowe metody przeciążania
Poniższa tabela zawiera listę niektórych ogólnych funkcji, które można zastąpić we własnych klasach -
| Sr.No. | Metoda, opis i przykładowa rozmowa |
|---|---|
| 1 | __init__ ( self [,args...] ) Konstruktor (z dowolnymi opcjonalnymi argumentami) Przykładowe wywołanie: obj = className (args) |
| 2 | __del__( self ) Destructor, usuwa obiekt Przykładowe wywołanie: del obj |
| 3 | __repr__( self ) Szacunkowa reprezentacja ciągu Przykładowe wywołanie: repr (obj) |
| 4 | __str__( self ) Reprezentacja ciągu do druku Przykładowe wywołanie: str (obj) |
| 5 | __cmp__ ( self, x ) Porównanie obiektów Przykładowe wywołanie: cmp (obj, x) |
Operatory przeciążenia
Załóżmy, że utworzyłeś klasę Vector do reprezentowania dwuwymiarowych wektorów, co się stanie, gdy użyjesz operatora plus, aby je dodać? Najprawdopodobniej Python będzie na ciebie krzyczał.
Możesz jednak zdefiniować metodę __add__ w swojej klasie, aby wykonywać dodawanie wektorów, a następnie operator plus zachowywałby się zgodnie z oczekiwaniami -
Przykład
#!/usr/bin/python
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2Wykonanie powyższego kodu daje następujący wynik -
Vector(7,8)Ukrywanie danych
Atrybuty obiektu mogą, ale nie muszą być widoczne poza definicją klasy. Musisz nazwać atrybuty przedrostkiem z podwójnym podkreśleniem, a wtedy atrybuty te nie będą bezpośrednio widoczne dla osób z zewnątrz.
Przykład
#!/usr/bin/python
class JustCounter:
__secretCount = 0
def count(self):
self.__secretCount += 1
print self.__secretCount
counter = JustCounter()
counter.count()
counter.count()
print counter.__secretCountWykonanie powyższego kodu daje następujący wynik -
1
2
Traceback (most recent call last):
File "test.py", line 12, in <module>
print counter.__secretCount
AttributeError: JustCounter instance has no attribute '__secretCount'Python chroni tych członków, zmieniając wewnętrznie nazwę, tak aby zawierała nazwę klasy. Możesz uzyskać dostęp do takich atrybutów, jak object._className__attrName . Jeśli chcesz zamienić ostatnią linię następującą linią, to działa dla Ciebie -
.........................
print counter._JustCounter__secretCountWykonanie powyższego kodu daje następujący wynik -
1
2
2Wyrażenie regularne jest specjalnym ciągiem znaków, który pomaga dopasować lub znaleźć inne ciągi lub zestawy strun przy użyciu specjalistycznego składni przechowywanych w strukturze. Wyrażenia regularne są szeroko stosowane w świecie UNIX.
Moduł rezapewnia pełne wsparcie dla wyrażeń regularnych podobnych do Perla w Pythonie. Moduł re zgłasza wyjątek re.error, jeśli wystąpi błąd podczas kompilacji lub używania wyrażenia regularnego.
Omówilibyśmy dwie ważne funkcje, które byłyby używane do obsługi wyrażeń regularnych. Ale najpierw mała rzecz: są różne znaki, które miałyby specjalne znaczenie, gdy są używane w wyrażeniach regularnych. Aby uniknąć nieporozumień podczas korzystania z wyrażeń regularnych, używamy nieprzetworzonych ciągów jakor'expression'.
Mecz Function
Ta funkcja próbuje dopasować wzorzec RE do łańcucha z opcjonalnymi flagami .
Oto składnia tej funkcji -
re.match(pattern, string, flags=0)Oto opis parametrów -
| Sr.No. | Parametr i opis |
|---|---|
| 1 | pattern To jest wyrażenie regularne do dopasowania. |
| 2 | string To jest ciąg, który byłby przeszukiwany w celu dopasowania do wzorca na początku łańcucha. |
| 3 | flags Możesz określić różne flagi za pomocą bitowego OR (|). Są to modyfikatory wymienione w poniższej tabeli. |
Funkcja re.match zwraca plikmatch sprzeciw wobec sukcesu, Nonena niepowodzenie. Używamy grupę (Lb) lub grupy () Funkcjąmatch obiekt, aby uzyskać dopasowane wyrażenie.
| Sr.No. | Dopasuj metodę i opis obiektu |
|---|---|
| 1 | group(num=0) Ta metoda zwraca całe dopasowanie (lub numer określonej podgrupy) |
| 2 | groups() Ta metoda zwraca wszystkie pasujące podgrupy w krotce (puste, jeśli nie było żadnych) |
Przykład
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"Wykonanie powyższego kodu daje następujący wynik -
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarterWyszukiwania Funkcja
Ta funkcja wyszukuje pierwsze wystąpienie wzorca RE w ciągu z opcjonalnymi flagami .
Oto składnia tej funkcji -
re.search(pattern, string, flags=0)Oto opis parametrów -
| Sr.No. | Parametr i opis |
|---|---|
| 1 | pattern To jest wyrażenie regularne do dopasowania. |
| 2 | string To jest ciąg, który byłby przeszukiwany w celu dopasowania wzorca w dowolnym miejscu w ciągu. |
| 3 | flags Możesz określić różne flagi za pomocą bitowego OR (|). Są to modyfikatory wymienione w poniższej tabeli. |
Funkcja re.search zwraca plikmatch sprzeciw wobec sukcesu, nonena niepowodzenie. Używamy grupę (Lb) lub grupy () Funkcjąmatch obiekt, aby uzyskać dopasowane wyrażenie.
| Sr.No. | Dopasuj metody i opis obiektu |
|---|---|
| 1 | group(num=0) Ta metoda zwraca całe dopasowanie (lub numer określonej podgrupy) |
| 2 | groups() Ta metoda zwraca wszystkie pasujące podgrupy w krotce (puste, jeśli nie było żadnych) |
Przykład
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"Wykonanie powyższego kodu daje następujący wynik -
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarterDopasowywanie a wyszukiwanie
Python oferuje dwie różne prymitywne operacje oparte na wyrażeniach regularnych: match sprawdza dopasowanie tylko na początku łańcucha, podczas gdy search sprawdza dopasowanie w dowolnym miejscu łańcucha (domyślnie robi to Perl).
Przykład
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print "search --> searchObj.group() : ", searchObj.group()
else:
print "Nothing found!!"Wykonanie powyższego kodu daje następujący wynik -
No match!!
search --> searchObj.group() : dogsWyszukaj i zamień
Jeden z najważniejszych re metody używające wyrażeń regularnych to sub.
Składnia
re.sub(pattern, repl, string, max=0)Metoda ta zastępuje wszystkie wystąpienia RE wzór w ciąg z repl , zastępując wszystkie wystąpienia chyba max warunkiem. Ta metoda zwraca zmodyfikowany ciąg.
Przykład
#!/usr/bin/python
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", num
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print "Phone Num : ", numWykonanie powyższego kodu daje następujący wynik -
Phone Num : 2004-959-559
Phone Num : 2004959559Modyfikatory wyrażeń regularnych: flagi opcji
Literały wyrażeń regularnych mogą zawierać opcjonalny modyfikator do kontrolowania różnych aspektów dopasowywania. Modyfikatory są określane jako opcjonalna flaga. Możesz podać wiele modyfikatorów za pomocą wyłącznego LUB (|), jak pokazano wcześniej i mogą być reprezentowane przez jeden z nich -
| Sr.No. | Modyfikator i opis |
|---|---|
| 1 | re.I Dopasowuje bez rozróżniania wielkości liter. |
| 2 | re.L Interpretuje słowa zgodnie z aktualnym językiem. Ta interpretacja wpływa na grupę alfabetyczną (\ w i \ W), a także na zachowanie granic słów (\ b i \ B). |
| 3 | re.M Sprawia, że $ pasuje do końca linii (nie tylko do końca ciągu) i sprawia, że ^ dopasowuje początek dowolnego wiersza (nie tylko początek ciągu). |
| 4 | re.S Sprawia, że kropka (kropka) pasuje do dowolnego znaku, w tym do nowej linii. |
| 5 | re.U Interpretuje litery zgodnie z zestawem znaków Unicode. Ta flaga wpływa na zachowanie \ w, \ W, \ b, \ B. |
| 6 | re.X Zezwala na „ładniejszą” składnię wyrażeń regularnych. Ignoruje białe spacje (z wyjątkiem wewnątrz zestawu [] lub gdy jest poprzedzony odwrotnym ukośnikiem) i traktuje bez znaku # jako znacznik komentarza. |
Wzorce wyrażeń regularnych
Z wyjątkiem znaków sterujących, (+ ? . * ^ $ ( ) [ ] { } | \), wszystkie postacie pasują do siebie. Znaku sterującego można zmienić, poprzedzając go ukośnikiem odwrotnym.
Poniższa tabela przedstawia składnię wyrażeń regularnych dostępną w Pythonie -
| Sr.No. | Wzór i opis |
|---|---|
| 1 | ^ Pasuje do początku wiersza. |
| 2 | $ Pasuje do końca linii. |
| 3 | . Dopasowuje dowolny pojedynczy znak z wyjątkiem nowej linii. Użycie opcji m pozwala dopasować również znak nowej linii. |
| 4 | [...] Dopasowuje dowolny pojedynczy znak w nawiasach. |
| 5 | [^...] Dopasowuje dowolny pojedynczy znak nie w nawiasach |
| 6 | re* Dopasowuje 0 lub więcej wystąpień poprzedniego wyrażenia. |
| 7 | re+ Dopasowuje 1 lub więcej wystąpień poprzedniego wyrażenia. |
| 8 | re? Dopasowuje 0 lub 1 wystąpienie poprzedniego wyrażenia. |
| 9 | re{ n} Dopasowuje dokładnie n liczbę wystąpień poprzedniego wyrażenia. |
| 10 | re{ n,} Dopasowuje n lub więcej wystąpień poprzedniego wyrażenia. |
| 11 | re{ n, m} Pasuje do co najmniej n i co najwyżej m wystąpień poprzedniego wyrażenia. |
| 12 | a| b Pasuje do a lub b. |
| 13 | (re) Grupuje wyrażenia regularne i zapamiętuje dopasowany tekst. |
| 14 | (?imx) Tymczasowo włącza opcje i, m lub x w wyrażeniu regularnym. Jeśli podano w nawiasach, dotyczy to tylko tego obszaru. |
| 15 | (?-imx) Tymczasowo wyłącza opcje i, m lub x w wyrażeniu regularnym. Jeśli podano w nawiasach, dotyczy to tylko tego obszaru. |
| 16 | (?: re) Grupuje wyrażenia regularne bez zapamiętywania dopasowanego tekstu. |
| 17 | (?imx: re) Tymczasowo włącza opcje i, m lub x w nawiasach. |
| 18 | (?-imx: re) Tymczasowo wyłącza opcje i, m lub x w nawiasach. |
| 19 | (?#...) Komentarz. |
| 20 | (?= re) Określa położenie za pomocą wzoru. Nie ma zakresu. |
| 21 | (?! re) Określa pozycję za pomocą negacji wzoru. Nie ma zakresu. |
| 22 | (?> re) Dopasowuje niezależny wzorzec bez cofania. |
| 23 | \w Dopasowuje znaki słowne. |
| 24 | \W Dopasowuje znaki inne niż słowa. |
| 25 | \s Pasuje do białych znaków. Odpowiednik [\ t \ n \ r \ f]. |
| 26 | \S Dopasowuje bez białych znaków. |
| 27 | \d Dopasowuje cyfry. Odpowiednik [0-9]. |
| 28 | \D Dopasowuje niecyfry. |
| 29 | \A Dopasowuje początek łańcucha. |
| 30 | \Z Dopasowuje koniec łańcucha. Jeśli istnieje nowa linia, pasuje ona tuż przed nową linią. |
| 31 | \z Dopasowuje koniec łańcucha. |
| 32 | \G Mecze to miejsce, w którym zakończył się ostatni mecz. |
| 33 | \b Dopasowuje granice wyrazów poza nawiasami. Dopasowuje znak Backspace (0x08) wewnątrz nawiasów. |
| 34 | \B Dopasowuje granice bez słów. |
| 35 | \n, \t, etc. Dopasowuje znaki nowej linii, powroty karetki, tabulatory itp. |
| 36 | \1...\9 Pasuje do n-tego zgrupowanego wyrażenia podrzędnego. |
| 37 | \10 Pasuje do n-tego zgrupowanego wyrażenia podrzędnego, jeśli zostało już dopasowane. W przeciwnym razie odnosi się do ósemkowej reprezentacji kodu znaku. |
Przykłady wyrażeń regularnych
Dosłowne znaki
| Sr.No. | Przykład i opis |
|---|---|
| 1 | python Dopasuj „python”. |
Klasy postaci
| Sr.No. | Przykład i opis |
|---|---|
| 1 | [Pp]ython Dopasuj „Python” lub „python” |
| 2 | rub[ye] Dopasuj „ruby” lub „rube” |
| 3 | [aeiou] Dopasuj dowolną małą samogłoskę |
| 4 | [0-9] Dopasuj dowolną cyfrę; tak samo jak [0123456789] |
| 5 | [a-z] Dopasuj dowolną małą literę ASCII |
| 6 | [A-Z] Dopasuj dowolną wielką literę ASCII |
| 7 | [a-zA-Z0-9] Dopasuj dowolne z powyższych |
| 8 | [^aeiou] Dopasuj wszystko inne niż mała samogłoska |
| 9 | [^0-9] Dopasuj wszystko inne niż cyfra |
Specjalne klasy postaci
| Sr.No. | Przykład i opis |
|---|---|
| 1 | . Dopasuj dowolny znak z wyjątkiem nowej linii |
| 2 | \d Dopasuj cyfrę: [0–9] |
| 3 | \D Dopasuj niecyfrę: [^ 0-9] |
| 4 | \s Dopasuj biały znak: [\ t \ r \ n \ f] |
| 5 | \S Dopasuj bez białych znaków: [^ \ t \ r \ n \ f] |
| 6 | \w Dopasuj pojedynczy znak słowa: [A-Za-z0-9_] |
| 7 | \W Dopasuj znak niebędący słowem: [^ A-Za-z0-9_] |
Przypadki powtórzeń
| Sr.No. | Przykład i opis |
|---|---|
| 1 | ruby? Dopasuj „rub” lub „ruby”: y jest opcjonalne |
| 2 | ruby* Dopasuj „rub” plus 0 lub więcej ys |
| 3 | ruby+ Dopasuj „rub” plus 1 lub więcej ys |
| 4 | \d{3} Dopasuj dokładnie 3 cyfry |
| 5 | \d{3,} Dopasuj 3 lub więcej cyfr |
| 6 | \d{3,5} Dopasuj 3, 4 lub 5 cyfr |
Nongreedy powtórzenie
To pasuje do najmniejszej liczby powtórzeń -
| Sr.No. | Przykład i opis |
|---|---|
| 1 | <.*> Chciwe powtórzenie: dopasowuje „<python> perl>” |
| 2 | <.*?> Nongreedy: dopasowuje „<python>” w „<python> perl>” |
Grupowanie z nawiasami
| Sr.No. | Przykład i opis |
|---|---|
| 1 | \D\d+ Brak grupy: + powtarza \ d |
| 2 | (\D\d)+ Zgrupowane: + powtórzenia \ D \ d para |
| 3 | ([Pp]ython(, )?)+ Dopasuj „Python”, „Python, python, python” itp. |
Backreferences
To ponownie pasuje do poprzednio dopasowanej grupy -
| Sr.No. | Przykład i opis |
|---|---|
| 1 | ([Pp])ython&\1ails Dopasuj python & pails lub Python & Pails |
| 2 | (['"])[^\1]*\1 Ciąg w pojedynczym lub podwójnym cudzysłowie. \ 1 pasuje do dopasowanej pierwszej grupy. \ 2 pasuje do dopasowanej 2. grupy itd. |
Alternatywy
| Sr.No. | Przykład i opis |
|---|---|
| 1 | python|perl Dopasuj „python” lub „perl” |
| 2 | rub(y|le)) Dopasuj „rubin” lub „rubel” |
| 3 | Python(!+|\?) „Python”, po którym następuje jeden lub więcej! czy jeden? |
Kotwice
To musi określić pozycję dopasowania.
| Sr.No. | Przykład i opis |
|---|---|
| 1 | ^Python Dopasuj „Python” na początku łańcucha lub linii wewnętrznej |
| 2 | Python$ Dopasuj „Python” na końcu ciągu lub linii |
| 3 | \APython Dopasuj „Python” na początku łańcucha |
| 4 | Python\Z Dopasuj „Python” na końcu łańcucha |
| 5 | \bPython\b Dopasuj „Python” na granicy słowa |
| 6 | \brub\B \ B nie jest granicą słów: dopasuj „rub” w „rube” i „ruby”, ale nie samodzielnie |
| 7 | Python(?=!) Dopasuj „Python”, jeśli następuje po nim wykrzyknik. |
| 8 | Python(?!!) Dopasuj „Python”, jeśli nie następuje po nim wykrzyknik. |
Specjalna składnia z nawiasami
| Sr.No. | Przykład i opis |
|---|---|
| 1 | R(?#comment) Pasuje do „R”. Cała reszta to komentarz |
| 2 | R(?i)uby Podczas dopasowywania „uby” bez rozróżniania wielkości liter |
| 3 | R(?i:uby) Tak samo jak powyżej |
| 4 | rub(?:y|le)) Grupuj tylko bez tworzenia \ 1 odwołania wstecznego |
Common Gateway Interface (CGI) to zestaw standardów definiujących sposób wymiany informacji między serwerem WWW a niestandardowym skryptem. Specyfikacje CGI są obecnie utrzymywane przez NCSA.
Co to jest CGI?
Interfejs Common Gateway Interface (CGI) jest standardem dla zewnętrznych programów bram do łączenia się z serwerami informacyjnymi, takimi jak serwery HTTP.
Obecna wersja to CGI / 1.1, a CGI / 1.2 jest w trakcie opracowywania.
Przeglądanie sieci
Aby zrozumieć koncepcję CGI, zobaczmy, co się dzieje, gdy klikamy hiperłącze w celu przeglądania określonej strony internetowej lub adresu URL.
Twoja przeglądarka kontaktuje się z serwerem HTTP i żąda adresu URL, tj. Nazwy pliku.
Serwer sieci Web analizuje adres URL i szuka nazwy pliku. Jeśli znajdzie ten plik, odeśle go z powrotem do przeglądarki, w przeciwnym razie wysyła komunikat o błędzie wskazujący, że zażądałeś niewłaściwego pliku.
Przeglądarka internetowa pobiera odpowiedź z serwera WWW i wyświetla otrzymany plik lub komunikat o błędzie.
Możliwe jest jednak takie skonfigurowanie serwera HTTP, aby za każdym razem, gdy zażądano pliku w określonym katalogu, plik ten nie był odsyłany; zamiast tego jest wykonywany jako program i cokolwiek ten program wyprowadza, jest wysyłane z powrotem do przeglądarki do wyświetlenia. Ta funkcja nosi nazwę Common Gateway Interface lub CGI, a programy nazywane są skryptami CGI. Te programy CGI mogą być Python Script, PERL Script, Shell Script, C lub C ++ program itp.
Diagram architektury CGI
Obsługa i konfiguracja serwera WWW
Przed przystąpieniem do programowania CGI upewnij się, że serwer WWW obsługuje CGI i jest skonfigurowany do obsługi programów CGI. Wszystkie programy CGI, które mają być wykonywane przez serwer HTTP, są przechowywane we wstępnie skonfigurowanym katalogu. Ten katalog nosi nazwę Katalog CGI i zgodnie z konwencją nosi nazwę / var / www / cgi-bin. Zgodnie z konwencją, pliki CGI mają rozszerzenie.cgi, ale możesz zachować swoje pliki z rozszerzeniem Python .py także.
Domyślnie serwer Linux jest skonfigurowany do uruchamiania tylko skryptów z katalogu cgi-bin w / var / www. Jeśli chcesz określić inny katalog do uruchamiania skryptów CGI, skomentuj następujące wiersze w pliku httpd.conf -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>W tym przypadku zakładamy, że masz poprawnie uruchomiony serwer sieciowy i możesz uruchomić dowolny inny program CGI, taki jak Perl lub Shell itp.
Pierwszy program CGI
Oto prosty link, który jest powiązany ze skryptem CGI o nazwie hello.py . Ten plik jest przechowywany w katalogu / var / www / cgi-bin i ma następującą zawartość. Przed uruchomieniem programu CGI upewnij się, że masz zmianę trybu pliku za pomocąchmod 755 hello.py Polecenie UNIX, aby uczynić plik wykonywalnym.
#!/usr/bin/python
print "Content-type:text/html\r\n\r\n"
print '<html>'
print '<head>'
print '<title>Hello World - First CGI Program</title>'
print '</head>'
print '<body>'
print '<h2>Hello World! This is my first CGI program</h2>'
print '</body>'
print '</html>'Jeśli klikniesz hello.py, to daje następujący wynik -
Witaj świecie! To jest mój pierwszy program CGI |
Ten hello.py skrypt jest prostym skryptem w Pythonie, który zapisuje swoje dane wyjściowe w pliku STDOUT, tj. Screen. Dostępna jest jedna ważna i dodatkowa funkcja, czyli pierwsza linia do wydrukowaniaContent-type:text/html\r\n\r\n. Ta linia jest wysyłana z powrotem do przeglądarki i określa typ zawartości, która ma być wyświetlana na ekranie przeglądarki.
Do tej pory musisz już zrozumieć podstawową koncepcję CGI i możesz pisać wiele skomplikowanych programów CGI w języku Python. Ten skrypt może współdziałać z dowolnym innym systemem zewnętrznym również w celu wymiany informacji, takich jak RDBMS.
Nagłówek HTTP
Linia Content-type:text/html\r\n\r\njest częścią nagłówka HTTP, który jest wysyłany do przeglądarki w celu zrozumienia treści. Cały nagłówek HTTP będzie miał następującą postać -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\nIstnieje kilka innych ważnych nagłówków HTTP, których będziesz często używać w programowaniu CGI.
| Sr.No. | Nagłówek i opis |
|---|---|
| 1 | Content-type: Ciąg MIME określający format zwracanego pliku. Przykład: Typ treści: tekst / html |
| 2 | Expires: Date Data utraty informacji. Jest używany przez przeglądarkę do decydowania, kiedy strona wymaga odświeżenia. Prawidłowy ciąg daty ma format 01 Jan 1998 12:00:00 GMT. |
| 3 | Location: URL Adres URL, który jest zwracany zamiast żądanego adresu URL. Możesz użyć tego pola, aby przekierować żądanie do dowolnego pliku. |
| 4 | Last-modified: Date Data ostatniej modyfikacji zasobu. |
| 5 | Content-length: N Długość zwracanych danych w bajtach. Przeglądarka używa tej wartości do raportowania szacowanego czasu pobierania pliku. |
| 6 | Set-Cookie: String Ustaw plik cookie przekazany przez ciąg |
Zmienne środowiskowe CGI
Wszystkie programy CGI mają dostęp do następujących zmiennych środowiskowych. Te zmienne odgrywają ważną rolę podczas pisania dowolnego programu CGI.
| Sr.No. | Nazwa i opis zmiennej |
|---|---|
| 1 | CONTENT_TYPE Typ danych treści. Używane, gdy klient wysyła załączoną zawartość na serwer. Na przykład przesyłanie plików. |
| 2 | CONTENT_LENGTH Długość informacji o zapytaniu. Jest dostępny tylko dla żądań POST. |
| 3 | HTTP_COOKIE Zwraca ustawione pliki cookie w postaci pary klucz-wartość. |
| 4 | HTTP_USER_AGENT Pole nagłówka żądania agenta użytkownika zawiera informacje o kliencie użytkownika, który wysłał żądanie. Jest to nazwa przeglądarki internetowej. |
| 5 | PATH_INFO Ścieżka do skryptu CGI. |
| 6 | QUERY_STRING Informacje zakodowane w adresie URL, które są wysyłane z żądaniem metody GET. |
| 7 | REMOTE_ADDR Adres IP zdalnego hosta wysyłającego żądanie. Jest to przydatne do logowania lub do uwierzytelniania. |
| 8 | REMOTE_HOST W pełni kwalifikowana nazwa hosta wysyłającego żądanie. Jeśli te informacje nie są dostępne, można użyć REMOTE_ADDR do uzyskania adresu IR. |
| 9 | REQUEST_METHOD Metoda użyta do wysłania żądania. Najpopularniejsze metody to GET i POST. |
| 10 | SCRIPT_FILENAME Pełna ścieżka do skryptu CGI. |
| 11 | SCRIPT_NAME Nazwa skryptu CGI. |
| 12 | SERVER_NAME Nazwa hosta lub adres IP serwera |
| 13 | SERVER_SOFTWARE Nazwa i wersja oprogramowania, na którym działa serwer. |
Oto mały program CGI do wyszczególnienia wszystkich zmiennych CGI. Kliknij to łącze, aby zobaczyć wynik Pobierz środowisko
#!/usr/bin/python
import os
print "Content-type: text/html\r\n\r\n";
print "<font size=+1>Environment</font><\br>";
for param in os.environ.keys():
print "<b>%20s</b>: %s<\br>" % (param, os.environ[param])Metody GET i POST
Musiałeś spotkać się z wieloma sytuacjami, w których musisz przekazać pewne informacje z przeglądarki na serwer WWW, a ostatecznie do programu CGI. Najczęściej przeglądarka używa dwóch metod przekazywania tych informacji do serwera WWW. Te metody to metoda GET i metoda POST.
Przekazywanie informacji metodą GET
Metoda GET wysyła zakodowane informacje o użytkowniku dołączone do żądania strony. Strona i zakodowane informacje są oddzielone znakiem? znak w następujący sposób -
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2Metoda GET jest domyślną metodą przekazywania informacji z przeglądarki do serwera WWW i tworzy długi ciąg, który pojawia się w polu Lokalizacja: przeglądarki. Nigdy nie używaj metody GET, jeśli masz hasło lub inne poufne informacje do przekazania na serwer. Metoda GET ma ograniczenie rozmiaru: w ciągu żądania można wysłać tylko 1024 znaki. Metoda GET wysyła informacje przy użyciu nagłówka QUERY_STRING i będzie dostępna w programie CGI poprzez zmienną środowiskową QUERY_STRING.
Możesz przekazywać informacje, po prostu łącząc pary klucz i wartość wraz z dowolnym adresem URL lub możesz użyć tagów HTML <FORM>, aby przekazać informacje za pomocą metody GET.
Prosty przykład adresu URL: metoda pobierania
Oto prosty adres URL, który przekazuje dwie wartości do programu hello_get.py przy użyciu metody GET.
/cgi-bin/hello_get.py?first_name=ZARA&last_name=ALIPoniżej jest hello_get.pyskrypt do obsługi danych wejściowych podawanych przez przeglądarkę internetową. Będziemy używaćcgi moduł, który bardzo ułatwia dostęp do przekazywanych informacji -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"Dałoby to następujący wynik -
Witam ZARA ALI |
Prosty przykład FORMULARZA: GET Method
W tym przykładzie dwie wartości są przekazywane przy użyciu formularza HTML i przycisku przesyłania. Używamy tego samego skryptu CGI hello_get.py do obsługi tego wejścia.
<form action = "/cgi-bin/hello_get.py" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Oto rzeczywiste dane wyjściowe powyższego formularza. Wpisz Imię i Nazwisko, a następnie kliknij przycisk Prześlij, aby zobaczyć wynik.
Przekazywanie informacji metodą POST
Generalnie bardziej niezawodną metodą przekazywania informacji do programu CGI jest metoda POST. Spowoduje to pakowanie informacji dokładnie w taki sam sposób, jak metody GET, ale zamiast wysyłać je jako ciąg tekstowy po znaku? w adresie URL wysyła go jako oddzielną wiadomość. Ta wiadomość pojawia się w skrypcie CGI w postaci standardowego wejścia.
Poniżej znajduje się ten sam skrypt hello_get.py, który obsługuje metodę GET i POST.
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
first_name = form.getvalue('first_name')
last_name = form.getvalue('last_name')
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Hello - Second CGI Program</title>"
print "</head>"
print "<body>"
print "<h2>Hello %s %s</h2>" % (first_name, last_name)
print "</body>"
print "</html>"Weźmy ponownie ten sam przykład co powyżej, który przekazuje dwie wartości za pomocą HTML FORM i przycisku przesyłania. Używamy tego samego skryptu CGI hello_get.py do obsługi tego wejścia.
<form action = "/cgi-bin/hello_get.py" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Oto rzeczywisty wynik powyższego formularza. Wpisz Imię i Nazwisko, a następnie kliknij przycisk Prześlij, aby zobaczyć wynik.
Przekazywanie danych pola wyboru do programu CGI
Pola wyboru są używane, gdy wymagane jest wybranie więcej niż jednej opcji.
Oto przykładowy kod HTML formularza z dwoma polami wyboru -
<form action = "/cgi-bin/checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się skrypt checkbox.cgi do obsługi danych wejściowych podawanych przez przeglądarkę internetową dla przycisku wyboru.
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('maths'):
math_flag = "ON"
else:
math_flag = "OFF"
if form.getvalue('physics'):
physics_flag = "ON"
else:
physics_flag = "OFF"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Checkbox - Third CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> CheckBox Maths is : %s</h2>" % math_flag
print "<h2> CheckBox Physics is : %s</h2>" % physics_flag
print "</body>"
print "</html>"Przekazywanie danych przycisku radiowego do programu CGI
Przyciski radiowe są używane, gdy wymagana jest tylko jedna opcja.
Oto przykład kodu HTML dla formularza z dwoma przyciskami opcji -
<form action = "/cgi-bin/radiobutton.py" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" /> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się skrypt radiobutton.py do obsługi danych wejściowych podawanych przez przeglądarkę internetową dla przycisku opcji -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('subject'):
subject = form.getvalue('subject')
else:
subject = "Not set"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Radio - Fourth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"Przekazywanie danych obszaru tekstowego do programu CGI
Element TEXTAREA jest używany, gdy tekst wielowierszowy ma zostać przesłany do programu CGI.
Oto przykładowy kod HTML dla formularza z polem TEXTAREA -
<form action = "/cgi-bin/textarea.py" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się skrypt textarea.cgi do obsługi danych wejściowych podawanych przez przeglądarkę internetową -
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>";
print "<title>Text Area - Fifth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Entered Text Content is %s</h2>" % text_content
print "</body>"Przekazywanie danych z rozwijanej skrzynki do programu CGI
Drop Down Box jest używany, gdy mamy wiele dostępnych opcji, ale tylko jedna lub dwie zostaną wybrane.
Oto przykładowy kod HTML dla formularza z jednym rozwijanym oknem -
<form action = "/cgi-bin/dropdown.py" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>Wynikiem tego kodu jest następująca postać -
Poniżej znajduje się skrypt dropdown.py do obsługi danych wejściowych podawanych przez przeglądarkę internetową.
#!/usr/bin/python
# Import modules for CGI handling
import cgi, cgitb
# Create instance of FieldStorage
form = cgi.FieldStorage()
# Get data from fields
if form.getvalue('dropdown'):
subject = form.getvalue('dropdown')
else:
subject = "Not entered"
print "Content-type:text/html\r\n\r\n"
print "<html>"
print "<head>"
print "<title>Dropdown Box - Sixth CGI Program</title>"
print "</head>"
print "<body>"
print "<h2> Selected Subject is %s</h2>" % subject
print "</body>"
print "</html>"Korzystanie z plików cookie w CGI
Protokół HTTP jest protokołem bezstanowym. W przypadku komercyjnej witryny internetowej wymagane jest przechowywanie informacji o sesjach między różnymi stronami. Na przykład jedna rejestracja użytkownika kończy się po wypełnieniu wielu stron. Jak zachować informacje o sesji użytkownika na wszystkich stronach internetowych?
W wielu sytuacjach używanie plików cookie jest najskuteczniejszą metodą zapamiętywania i śledzenia preferencji, zakupów, prowizji i innych informacji wymaganych dla lepszych wrażeń odwiedzających lub statystyk witryny.
Jak to działa?
Twój serwer wysyła pewne dane do przeglądarki odwiedzającego w formie pliku cookie. Przeglądarka może zaakceptować plik cookie. Jeśli tak, jest przechowywany jako zwykły zapis tekstowy na dysku twardym gościa. Teraz, gdy użytkownik przejdzie na inną stronę w Twojej witrynie, plik cookie jest dostępny do pobrania. Po odzyskaniu serwer wie / pamięta, co zostało zapisane.
Pliki cookie to zapis danych w postaci zwykłego tekstu składający się z 5 pól o zmiennej długości -
Expires- data wygaśnięcia pliku cookie. Jeśli jest puste, plik cookie wygaśnie, gdy odwiedzający zamknie przeglądarkę.
Domain - nazwa domeny Twojej witryny.
Path- Ścieżka do katalogu lub strony internetowej, która ustawia plik cookie. To może być puste, jeśli chcesz pobrać plik cookie z dowolnego katalogu lub strony.
Secure- Jeśli to pole zawiera słowo „bezpieczny”, plik cookie można pobrać tylko z bezpiecznego serwera. Jeśli to pole jest puste, takie ograniczenie nie istnieje.
Name=Value - Pliki cookie są ustawiane i pobierane w postaci par klucza i wartości.
Konfiguracja plików cookie
Wysyłanie plików cookie do przeglądarki jest bardzo łatwe. Te pliki cookie są wysyłane wraz z nagłówkiem HTTP przed do pola typu zawartości. Zakładając, że chcesz ustawić identyfikator użytkownika i hasło jako pliki cookie. Ustawienie plików cookie odbywa się w następujący sposób -
#!/usr/bin/python
print "Set-Cookie:UserID = XYZ;\r\n"
print "Set-Cookie:Password = XYZ123;\r\n"
print "Set-Cookie:Expires = Tuesday, 31-Dec-2007 23:12:40 GMT";\r\n"
print "Set-Cookie:Domain = www.tutorialspoint.com;\r\n"
print "Set-Cookie:Path = /perl;\n"
print "Content-type:text/html\r\n\r\n"
...........Rest of the HTML Content....Na podstawie tego przykładu musisz wiedzieć, jak ustawić pliki cookie. UżywamySet-Cookie Nagłówek HTTP do ustawiania plików cookie.
Opcjonalne jest ustawienie atrybutów plików cookie, takich jak Wygasa, Domena i Ścieżka. Warto zauważyć, że pliki cookie są ustawiane przed wysłaniem magicznej linii"Content-type:text/html\r\n\r\n.
Pobieranie plików cookie
Pobranie wszystkich ustawionych plików cookie jest bardzo łatwe. Pliki cookie są przechowywane w zmiennej środowiskowej CGI HTTP_COOKIE i będą miały następującą postać -
key1 = value1;key2 = value2;key3 = value3....Oto przykład pobierania plików cookie.
#!/usr/bin/python
# Import modules for CGI handling
from os import environ
import cgi, cgitb
if environ.has_key('HTTP_COOKIE'):
for cookie in map(strip, split(environ['HTTP_COOKIE'], ';')):
(key, value ) = split(cookie, '=');
if key == "UserID":
user_id = value
if key == "Password":
password = value
print "User ID = %s" % user_id
print "Password = %s" % passwordDaje to następujący wynik dla plików cookie ustawionych przez powyższy skrypt -
User ID = XYZ
Password = XYZ123Przykład przesyłania plików
Aby przesłać plik, formularz HTML musi mieć atrybut enctype ustawiony na multipart/form-data. Znacznik wejściowy z typem pliku tworzy przycisk „Przeglądaj”.
<html>
<body>
<form enctype = "multipart/form-data"
action = "save_file.py" method = "post">
<p>File: <input type = "file" name = "filename" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>Wynikiem tego kodu jest następująca postać -
Powyższy przykład został celowo wyłączony, aby zapisać osoby przesyłające plik na nasz serwer, ale możesz wypróbować powyższy kod na swoim serwerze.
Oto scenariusz save_file.py do obsługi przesyłania plików -
#!/usr/bin/python
import cgi, os
import cgitb; cgitb.enable()
form = cgi.FieldStorage()
# Get filename here.
fileitem = form['filename']
# Test if the file was uploaded
if fileitem.filename:
# strip leading path from file name to avoid
# directory traversal attacks
fn = os.path.basename(fileitem.filename)
open('/tmp/' + fn, 'wb').write(fileitem.file.read())
message = 'The file "' + fn + '" was uploaded successfully'
else:
message = 'No file was uploaded'
print """\
Content-Type: text/html\n
<html>
<body>
<p>%s</p>
</body>
</html>
""" % (message,)Jeśli uruchomisz powyższy skrypt w systemie Unix / Linux, musisz zadbać o zastąpienie separatora plików w następujący sposób, w przeciwnym razie na komputerze z systemem Windows powyżej instrukcja open () powinna działać dobrze.
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))Jak wywołać okno dialogowe „Pobieranie pliku”?
Czasami pożądane jest udostępnienie opcji, w której użytkownik może kliknąć łącze, a zamiast wyświetlania rzeczywistej zawartości wyświetli się okno dialogowe „Pobieranie pliku”. Jest to bardzo łatwe i można to osiągnąć za pomocą nagłówka HTTP. Ten nagłówek HTTP różni się od nagłówka wspomnianego w poprzedniej sekcji.
Na przykład, jeśli chcesz utworzyć plik FileName plik do pobrania z podanego linku, to jego składnia jest następująca -
#!/usr/bin/python
# HTTP Header
print "Content-Type:application/octet-stream; name = \"FileName\"\r\n";
print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n";
# Actual File Content will go here.
fo = open("foo.txt", "rb")
str = fo.read();
print str
# Close opend file
fo.close()Mam nadzieję, że podobał Ci się ten samouczek. Jeśli tak, prześlij mi swoją opinię na adres: Skontaktuj się z nami
Standardem Pythona dla interfejsów baz danych jest Python DB-API. Większość interfejsów baz danych Pythona jest zgodnych z tym standardem.
Możesz wybrać odpowiednią bazę danych dla swojej aplikacji. Python Database API obsługuje szeroką gamę serwerów baz danych, takich jak -
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
Oto lista dostępnych interfejsów baz danych Pythona : Python Database Interfaces and APIs . Musisz pobrać oddzielny moduł DB API dla każdej bazy danych, do której chcesz uzyskać dostęp. Na przykład, jeśli potrzebujesz dostępu do bazy danych Oracle, a także do bazy danych MySQL, musisz pobrać zarówno moduły bazy danych Oracle, jak i MySQL.
DB API zapewnia minimalny standard pracy z bazami danych przy użyciu struktur i składni Pythona, jeśli tylko jest to możliwe. Ten interfejs API obejmuje następujące -
- Importowanie modułu API.
- Uzyskanie połączenia z bazą danych.
- Wydawanie instrukcji SQL i procedur składowanych.
- Zamykanie połączenia
Uczylibyśmy się wszystkich pojęć używając MySQL, więc porozmawiajmy o module MySQLdb.
Co to jest MySQLdb?
MySQLdb to interfejs do łączenia się z serwerem bazy danych MySQL z Pythona. Implementuje Python Database API v2.0 i jest zbudowany na bazie MySQL C API.
Jak zainstalować MySQLdb?
Zanim przejdziesz dalej, upewnij się, że masz zainstalowaną MySQLdb na swoim komputerze. Po prostu wpisz następujące polecenie w swoim skrypcie Pythona i uruchom go -
#!/usr/bin/python
import MySQLdbJeśli daje następujący wynik, oznacza to, że moduł MySQLdb nie jest zainstalowany -
Traceback (most recent call last):
File "test.py", line 3, in <module>
import MySQLdb
ImportError: No module named MySQLdbAby zainstalować moduł MySQLdb, użyj następującego polecenia -
For Ubuntu, use the following command -
$ sudo apt-get install python-pip python-dev libmysqlclient-dev For Fedora, use the following command - $ sudo dnf install python python-devel mysql-devel redhat-rpm-config gcc
For Python command prompt, use the following command -
pip install MySQL-pythonNote - Upewnij się, że masz uprawnienia roota do zainstalowania powyższego modułu.
Połączenie z bazą danych
Przed połączeniem się z bazą danych MySQL upewnij się, że:
Utworzyłeś bazę danych TESTDB.
Utworzyłeś tabelę PRACOWNIK w TESTDB.
Ta tabela zawiera pola FIRST_NAME, LAST_NAME, AGE, SEX i INCOME.
ID użytkownika „testuser” i hasło „test123” są ustawione na dostęp do bazy danych TESTDB.
Moduł Pythona MySQLdb jest poprawnie zainstalowany na Twoim komputerze.
Przeszedłeś przez samouczek MySQL, aby zrozumieć podstawy MySQL.
Przykład
Poniżej znajduje się przykład połączenia z bazą danych MySQL „TESTDB”
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# execute SQL query using execute() method.
cursor.execute("SELECT VERSION()")
# Fetch a single row using fetchone() method.
data = cursor.fetchone()
print "Database version : %s " % data
# disconnect from server
db.close()Podczas uruchamiania tego skryptu generuje on następujący wynik na moim komputerze z systemem Linux.
Database version : 5.0.45Jeśli połączenie zostanie nawiązane ze źródłem danych, obiekt połączenia jest zwracany i zapisywany w db do dalszego użytku, w przeciwnym razie dbjest ustawiona na Brak. Kolejny,db obiekt służy do tworzenia pliku cursorobiekt, który z kolei służy do wykonywania zapytań SQL. Wreszcie, przed wyjściem, zapewnia zamknięcie połączenia z bazą danych i zwolnienie zasobów.
Tworzenie tabeli bazy danych
Po nawiązaniu połączenia z bazą danych jesteśmy gotowi do tworzenia tabel lub rekordów w tabelach bazy danych za pomocą execute metoda utworzonego kursora.
Przykład
Stwórzmy tabelę bazy danych PRACOWNIK -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Drop table if it already exist using execute() method.
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
# Create table as per requirement
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
# disconnect from server
db.close()Operacja INSERT
Jest to wymagane, gdy chcesz utworzyć rekordy w tabeli bazy danych.
Przykład
Poniższy przykład wykonuje instrukcję SQL INSERT , aby utworzyć rekord w tabeli EMPLOYEE -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = """INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()Powyższy przykład można zapisać w następujący sposób, aby dynamicznie tworzyć zapytania SQL -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to INSERT a record into the database.
sql = "INSERT INTO EMPLOYEE(FIRST_NAME, \
LAST_NAME, AGE, SEX, INCOME) \
VALUES ('%s', '%s', '%d', '%c', '%d' )" % \
('Mac', 'Mohan', 20, 'M', 2000)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()Przykład
Kolejny segment kodu to kolejna forma wykonania, w której można bezpośrednio przekazywać parametry -
..................................
user_id = "test123"
password = "password"
con.execute('insert into Login values("%s", "%s")' % \
(user_id, password))
..................................Operacja READ
READ Operacja na dowolnej bazie danych oznacza pobranie przydatnych informacji z bazy danych.
Po nawiązaniu połączenia z bazą danych możesz wykonać zapytanie do tej bazy danych. Możesz użyć jednego z nichfetchone() metoda pobierania pojedynczego rekordu lub fetchall() metoda pobierania wielu wartości z tabeli bazy danych.
fetchone()- Pobiera następny wiersz zestawu wyników zapytania. Zestaw wyników to obiekt, który jest zwracany, gdy obiekt kursora jest używany do zapytania tabeli.
fetchall()- Pobiera wszystkie wiersze w zestawie wyników. Jeśli niektóre wiersze zostały już wyodrębnione z zestawu wyników, pobiera pozostałe wiersze z zestawu wyników.
rowcount - To jest atrybut tylko do odczytu i zwraca liczbę wierszy, na które wpłynęła metoda execute ().
Przykład
Poniższa procedura odpytuje wszystkie rekordy z tabeli PRACOWNIK z wynagrodzeniem powyżej 1000 -
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > '%d'" % (1000)
try:
# Execute the SQL command
cursor.execute(sql)
# Fetch all the rows in a list of lists.
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# Now print fetched result
print "fname=%s,lname=%s,age=%d,sex=%s,income=%d" % \
(fname, lname, age, sex, income )
except:
print "Error: unable to fecth data"
# disconnect from server
db.close()To da następujący wynik -
fname=Mac, lname=Mohan, age=20, sex=M, income=2000Operacja aktualizacji
UPDATE Operacja na dowolnej bazie danych oznacza aktualizację jednego lub więcej rekordów, które są już dostępne w bazie danych.
Poniższa procedura aktualizuje wszystkie rekordy zawierające PŁEĆ jako 'M'. Tutaj zwiększamy WIEK wszystkich samców o jeden rok.
Przykład
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to UPDATE required records
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1
WHERE SEX = '%c'" % ('M')
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()Operacja USUŃ
Operacja DELETE jest wymagana, gdy chcesz usunąć niektóre rekordy z bazy danych. Poniżej znajduje się procedura usuwania wszystkich zapisów od PRACOWNIKA w wieku powyżej 20 lat -
Przykład
#!/usr/bin/python
import MySQLdb
# Open database connection
db = MySQLdb.connect("localhost","testuser","test123","TESTDB" )
# prepare a cursor object using cursor() method
cursor = db.cursor()
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()
# disconnect from server
db.close()Wykonywanie transakcji
Transakcje to mechanizm zapewniający spójność danych. Transakcje mają następujące cztery właściwości -
Atomicity - Albo transakcja zostaje zakończona, albo nic się nie dzieje.
Consistency - Transakcja musi rozpocząć się w stanie zgodnym i pozostawić system w stanie zgodnym.
Isolation - Pośrednie wyniki transakcji nie są widoczne poza bieżącą transakcją.
Durability - Po zatwierdzeniu transakcji efekty są trwałe, nawet po awarii systemu.
Python DB API 2.0 zapewnia dwie metody zatwierdzania lub wycofywania transakcji.
Przykład
Wiesz już, jak realizować transakcje. Oto znowu podobny przykład -
# Prepare SQL query to DELETE required records
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (20)
try:
# Execute the SQL command
cursor.execute(sql)
# Commit your changes in the database
db.commit()
except:
# Rollback in case there is any error
db.rollback()Operacja COMMIT
Commit to operacja, która daje zielony sygnał do bazy danych w celu sfinalizowania zmian, a po tej operacji żadna zmiana nie może zostać cofnięta.
Oto prosty przykład do zadzwonienia commit metoda.
db.commit()Operacja ROLLBACK
Jeśli nie jesteś zadowolony z co najmniej jednej zmiany i chcesz całkowicie cofnąć te zmiany, użyj rollback() metoda.
Oto prosty przykład do zadzwonienia rollback() metoda.
db.rollback()Odłączanie bazy danych
Aby rozłączyć połączenie z bazą danych, użyj metody close ().
db.close()Jeśli połączenie z bazą danych zostanie zamknięte przez użytkownika za pomocą metody close (), wszystkie oczekujące transakcje są wycofywane przez bazę danych. Jednak zamiast polegać na jakichkolwiek szczegółach implementacji DB niższego poziomu, twoja aplikacja będzie lepiej wywoływać jawne zatwierdzanie lub wycofywanie.
Obsługa błędów
Istnieje wiele źródeł błędów. Kilka przykładów to błąd składni w wykonywanej instrukcji SQL, błąd połączenia lub wywołanie metody pobierania dla już anulowanego lub zakończonego uchwytu instrukcji.
Interfejs API bazy danych definiuje liczbę błędów, które muszą występować w każdym module bazy danych. W poniższej tabeli wymieniono te wyjątki.
| Sr.No. | Wyjątek i opis |
|---|---|
| 1 | Warning Używany w przypadku problemów, które nie są śmiertelne. Musi podklasę StandardError. |
| 2 | Error Klasa bazowa dla błędów. Musi podklasę StandardError. |
| 3 | InterfaceError Używany w przypadku błędów w module bazy danych, a nie w samej bazie danych. Musi podklasa Błąd. |
| 4 | DatabaseError Używane w przypadku błędów w bazie danych. Musi podklasa Błąd. |
| 5 | DataError Podklasa DatabaseError, która odnosi się do błędów w danych. |
| 6 | OperationalError Podklasa DatabaseError, która odnosi się do błędów, takich jak utrata połączenia z bazą danych. Te błędy są na ogół poza kontrolą skryptera języka Python. |
| 7 | IntegrityError Podklasa DatabaseError dla sytuacji, które mogą uszkodzić relacyjną integralność, takich jak ograniczenia unikalności lub klucze obce. |
| 8 | InternalError Podklasa DatabaseError, która odnosi się do błędów wewnętrznych modułu bazy danych, takich jak kursor nie jest już aktywny. |
| 9 | ProgrammingError Podklasa DatabaseError, która odnosi się do błędów, takich jak zła nazwa tabeli i inne rzeczy, za które można bezpiecznie obwiniać Ciebie. |
| 10 | NotSupportedError Podklasa DatabaseError, która odnosi się do próby wywołania nieobsługiwanej funkcjonalności. |
Twoje skrypty Pythona powinny obsługiwać te błędy, ale przed użyciem któregokolwiek z powyższych wyjątków upewnij się, że Twoja baza danych MySQLdb obsługuje ten wyjątek. Możesz uzyskać więcej informacji na ich temat, czytając specyfikację DB API 2.0.
Python zapewnia dwa poziomy dostępu do usług sieciowych. Na niskim poziomie można uzyskać dostęp do podstawowej obsługi gniazd w podstawowym systemie operacyjnym, co umożliwia implementację klientów i serwerów zarówno dla protokołów zorientowanych na połączenie, jak i dla protokołów bezpołączeniowych.
Python ma również biblioteki, które zapewniają wyższy poziom dostępu do określonych protokołów sieciowych na poziomie aplikacji, takich jak FTP, HTTP i tak dalej.
W tym rozdziale poznasz najsłynniejszą koncepcję w sieci - programowanie za pomocą gniazd.
Co to są gniazda?
Gniazda to punkty końcowe dwukierunkowego kanału komunikacyjnego. Gniazda mogą komunikować się w ramach procesu, między procesami na tej samej maszynie lub między procesami na różnych kontynentach.
Gniazda mogą być implementowane w wielu różnych typach kanałów: gniazda domeny Unix, TCP, UDP i tak dalej. Gniazdo biblioteka zapewnia specyficzne klasy do obsługi wspólnych transportów, jak również ogólnego interfejsu do obsługi resztę.
Gniazda mają swoje własne słownictwo -
| Sr.No. | Termin i opis |
|---|---|
| 1 | Domain Rodzina protokołów używanych jako mechanizm transportu. Te wartości są stałymi, takimi jak AF_INET, PF_INET, PF_UNIX, PF_X25 i tak dalej. |
| 2 | type Typ komunikacji między dwoma punktami końcowymi, zwykle SOCK_STREAM dla protokołów zorientowanych na połączenie i SOCK_DGRAM dla protokołów bezpołączeniowych. |
| 3 | protocol Zwykle zero, może to być wykorzystane do identyfikacji wariantu protokołu w domenie i typu. |
| 4 | hostname Identyfikator interfejsu sieciowego -
|
| 5 | port Każdy serwer nasłuchuje klientów dzwoniących na co najmniej jednym porcie. Port może być numerem portu Fixnum, ciągiem znaków zawierającym numer portu lub nazwą usługi. |
Gniazdo modułu
Aby utworzyć gniazdo, musisz użyć funkcji socket.socket () dostępnej w module gniazda , która ma ogólną składnię -
s = socket.socket (socket_family, socket_type, protocol=0)Oto opis parametrów -
socket_family - To jest AF_UNIX lub AF_INET, jak wyjaśniono wcześniej.
socket_type - To jest SOCK_STREAM lub SOCK_DGRAM.
protocol - Zwykle jest to pomijane, domyślnie 0.
Gdy masz już obiekt gniazda , możesz użyć wymaganych funkcji do stworzenia programu klienta lub serwera. Poniżej znajduje się lista wymaganych funkcji -
Metody gniazda serwera
| Sr.No. | Metoda i opis |
|---|---|
| 1 | s.bind() Ta metoda wiąże adres (nazwa hosta, para numerów portów) z gniazdem. |
| 2 | s.listen() Ta metoda konfiguruje i uruchamia odbiornik TCP. |
| 3 | s.accept() To pasywnie akceptuje połączenie klienta TCP, czekając na nadejście połączenia (blokowanie). |
Metody gniazda klienta
| Sr.No. | Metoda i opis |
|---|---|
| 1 | s.connect() Ta metoda aktywnie inicjuje połączenie z serwerem TCP. |
Ogólne metody gniazd
| Sr.No. | Metoda i opis |
|---|---|
| 1 | s.recv() Ta metoda odbiera komunikat TCP |
| 2 | s.send() Ta metoda przesyła komunikat TCP |
| 3 | s.recvfrom() Ta metoda odbiera komunikat UDP |
| 4 | s.sendto() Ta metoda przesyła komunikat UDP |
| 5 | s.close() Ta metoda zamyka gniazdo |
| 6 | socket.gethostname() Zwraca nazwę hosta. |
Prosty serwer
Do pisania serwerów internetowych używamy rozszerzenia socketfunkcja dostępna w module gniazda w celu utworzenia obiektu gniazda. Obiekt gniazda jest następnie używany do wywoływania innych funkcji w celu skonfigurowania serwera gniazda.
Teraz zadzwoń bind(hostname, port)funkcję, aby określić port dla usługi na danym hoście.
Następnie wywołaj metodę accept zwróconego obiektu. Ta metoda czeka, aż klient połączy się z określonym portem, a następnie zwraca obiekt połączenia, który reprezentuje połączenie z tym klientem.
#!/usr/bin/python # This is server.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.bind((host, port)) # Bind to the port
s.listen(5) # Now wait for client connection.
while True:
c, addr = s.accept() # Establish connection with client.
print 'Got connection from', addr
c.send('Thank you for connecting')
c.close() # Close the connectionProsty klient
Napiszmy bardzo prosty program kliencki, który otwiera połączenie z podanym portem 12345 i podanym hostem. Utworzenie klienta gniazda za pomocą funkcji modułu gniazda w języku Python jest bardzo proste .
Plik socket.connect(hosname, port )otwiera połączenie TCP z nazwą hosta na porcie . Gdy masz otwarte gniazdo, możesz z niego czytać jak z każdego obiektu IO. Po zakończeniu pamiętaj, aby go zamknąć, tak jak zamknąłbyś plik.
Poniższy kod to bardzo prosty klient, który łączy się z podanym hostem i portem, odczytuje wszystkie dostępne dane z gniazda, a następnie wychodzi -
#!/usr/bin/python # This is client.py file
import socket # Import socket module
s = socket.socket() # Create a socket object
host = socket.gethostname() # Get local machine name
port = 12345 # Reserve a port for your service.
s.connect((host, port))
print s.recv(1024)
s.close() # Close the socket when doneTeraz uruchom ten server.py w tle, a następnie uruchom powyżej client.py, aby zobaczyć wynik.
# Following would start a server in background.
$ python server.py & # Once server is started run client as follows: $ python client.pyDałoby to następujący wynik -
Got connection from ('127.0.0.1', 48437)
Thank you for connectingModuły internetowe Python
Lista niektórych ważnych modułów programowania w sieci / Internecie w języku Python.
| Protokół | Wspólna funkcja | Port No | Moduł Pythona |
|---|---|---|---|
| HTTP | strony internetowe | 80 | httplib, urllib, xmlrpclib |
| NNTP | Wiadomości Usenet | 119 | nntplib |
| FTP | Przesyłanie plików | 20 | ftplib, urllib |
| SMTP | Wysyłać email | 25 | smtplib |
| POP3 | Pobieranie wiadomości e-mail | 110 | poplib |
| IMAP4 | Pobieranie wiadomości e-mail | 143 | imaplib |
| Telnet | Linie poleceń | 23 | telnetlib |
| Suseł | Przesyłanie dokumentów | 70 | gopherlib, urllib |
Sprawdź wszystkie wymienione powyżej biblioteki, aby współpracowały z protokołami FTP, SMTP, POP i IMAP.
Dalsze lektury
To był szybki start z programowaniem w gniazdach. To obszerny temat. Zaleca się przejście przez poniższy link, aby znaleźć więcej szczegółów -
Programowanie gniazd w systemie Unix .
Biblioteka i moduły gniazd Pythona .
Simple Mail Transfer Protocol (SMTP) to protokół, który obsługuje wysyłanie i kierowanie poczty między serwerami pocztowymi.
Python zapewnia smtplib moduł, który definiuje obiekt sesji klienta SMTP, który może być używany do wysyłania poczty do dowolnego komputera internetowego z demonem nasłuchiwania SMTP lub ESMTP.
Oto prosta składnia tworzenia jednego obiektu SMTP, którego można później użyć do wysłania wiadomości e-mail -
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )Oto szczegóły parametrów -
host- To jest host, na którym działa Twój serwer SMTP. Możesz określić adres IP hosta lub nazwę domeny, na przykład tutorialspoint.com. To jest argument opcjonalny.
port- Jeśli podajesz argument hosta , musisz określić port, na którym nasłuchuje serwer SMTP. Zwykle ten port byłby 25.
local_hostname- Jeśli serwer SMTP działa na komputerze lokalnym, możesz od tej opcji określić tylko localhost .
Obiekt SMTP ma metodę instancji o nazwie sendmail, który jest zwykle używany do wysyłania wiadomości. Potrzeba trzech parametrów -
Nadawca - Ciąg z adresem nadawcy.
Te odbiorniki - wykaz ciągów, po jednym dla każdego odbiorcy.
Wiadomość - wiadomość jako ciąg sformatowany jak określono w różnych dokumentach RFC.
Przykład
Oto prosty sposób na wysłanie jednego e-maila za pomocą skryptu Python. Spróbuj raz -
#!/usr/bin/python
import smtplib
sender = '[email protected]'
receivers = ['[email protected]']
message = """From: From Person <[email protected]>
To: To Person <[email protected]>
Subject: SMTP e-mail test
This is a test e-mail message.
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"Tutaj umieściłeś podstawowy e-mail w wiadomości, używając potrójnego cudzysłowu, zwracając uwagę na prawidłowe formatowanie nagłówków. E-mail wymaga rozszerzeniaFrom, To, i Subject nagłówek, oddzielony od treści wiadomości e-mail pustą linią.
Aby wysłać pocztę, użyj smtpObj do połączenia się z serwerem SMTP na komputerze lokalnym, a następnie użyj metody sendmail wraz z wiadomością, adresem nadawcy i adresem docelowym jako parametrami (nawet jeśli adresy od i do znajdują się w e -mail, nie zawsze są one używane do kierowania poczty).
Jeśli nie używasz serwera SMTP na komputerze lokalnym, możesz użyć klienta smtplib do komunikacji ze zdalnym serwerem SMTP. O ile nie korzystasz z usługi poczty internetowej (takiej jak Hotmail lub Yahoo! Mail), Twój dostawca poczty e-mail musi podać Ci dane serwera poczty wychodzącej, które możesz podać w następujący sposób -
smtplib.SMTP('mail.your-domain.com', 25)Wysyłanie e-maila w formacie HTML za pomocą Pythona
Kiedy wysyłasz wiadomość tekstową za pomocą Pythona, cała zawartość jest traktowana jako zwykły tekst. Nawet jeśli umieścisz tagi HTML w wiadomości tekstowej, jest ona wyświetlana jako zwykły tekst, a tagi HTML nie będą sformatowane zgodnie ze składnią HTML. Ale Python zapewnia opcję wysyłania wiadomości HTML jako rzeczywistej wiadomości HTML.
Wysyłając wiadomość e-mail, możesz określić wersję Mime, typ zawartości i zestaw znaków, aby wysłać wiadomość e-mail w formacie HTML.
Przykład
Poniżej znajduje się przykład wysyłania treści HTML jako wiadomości e-mail. Spróbuj raz -
#!/usr/bin/python
import smtplib
message = """From: From Person <[email protected]>
To: To Person <[email protected]>
MIME-Version: 1.0
Content-type: text/html
Subject: SMTP HTML e-mail test
This is an e-mail message to be sent in HTML format
<b>This is HTML message.</b>
<h1>This is headline.</h1>
"""
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message)
print "Successfully sent email"
except SMTPException:
print "Error: unable to send email"Wysyłanie załączników jako e-mail
Aby wysłać wiadomość e-mail o mieszanej zawartości, należy ustawić Content-type nagłówek do multipart/mixed. Następnie w ramach można określić sekcje tekstu i załącznikówboundaries.
Granicę rozpoczynają dwa łączniki, po których następuje niepowtarzalny numer, który nie może pojawić się w części wiadomości e-mail. Ostateczna granica oznaczająca ostatnią sekcję wiadomości e-mail musi również kończyć się dwoma łącznikami.
Załączone pliki powinny być zakodowane z rozszerzeniem pack("m") funkcja ma kodowanie base64 przed transmisją.
Przykład
Poniżej znajduje się przykład, który wysyła plik /tmp/test.txtjako załącznik. Spróbuj raz -
#!/usr/bin/python
import smtplib
import base64
filename = "/tmp/test.txt"
# Read a file and encode it into base64 format
fo = open(filename, "rb")
filecontent = fo.read()
encodedcontent = base64.b64encode(filecontent) # base64
sender = '[email protected]'
reciever = '[email protected]'
marker = "AUNIQUEMARKER"
body ="""
This is a test email to send an attachement.
"""
# Define the main headers.
part1 = """From: From Person <[email protected]>
To: To Person <[email protected]>
Subject: Sending Attachement
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary=%s
--%s
""" % (marker, marker)
# Define the message action
part2 = """Content-Type: text/plain
Content-Transfer-Encoding:8bit
%s
--%s
""" % (body,marker)
# Define the attachment section
part3 = """Content-Type: multipart/mixed; name=\"%s\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename=%s
%s
--%s--
""" %(filename, filename, encodedcontent, marker)
message = part1 + part2 + part3
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, reciever, message)
print "Successfully sent email"
except Exception:
print "Error: unable to send email"Uruchomienie kilku wątków jest podobne do równoczesnego uruchamiania kilku różnych programów, ale ma następujące zalety -
Wiele wątków w procesie współdzieli tę samą przestrzeń danych z głównym wątkiem i dlatego może łatwiej udostępniać informacje lub komunikować się ze sobą, niż gdyby były oddzielnymi procesami.
Wątki czasami nazywane są procesami lekkimi i nie wymagają dużego narzutu pamięci; są tańsze niż procesy.
Wątek ma początek, sekwencję wykonania i zakończenie. Posiada wskaźnik instrukcji, który śledzi, gdzie w kontekście jest aktualnie uruchomiona.
Może być uprzedzony (przerwany)
Można go tymczasowo zawiesić (znanego również jako spanie), podczas gdy inne wątki są uruchomione - nazywa się to ustępowaniem.
Rozpoczęcie nowego wątku
Aby odrodzić kolejny wątek, musisz wywołać następującą metodę dostępną w module wątków -
thread.start_new_thread ( function, args[, kwargs] )To wywołanie metody umożliwia szybki i wydajny sposób tworzenia nowych wątków w systemie Linux i Windows.
Wywołanie metody wraca natychmiast, a wątek potomny uruchamia się i wywołuje funkcję z przekazaną listą argumentów . Kiedy funkcja zwraca, wątek zostaje zakończony.
Tutaj argumenty to krotka argumentów; użyj pustej krotki, aby wywołać funkcję bez przekazywania żadnych argumentów. kwargs to opcjonalny słownik argumentów słów kluczowych.
Przykład
#!/usr/bin/python
import thread
import time
# Define a function for the thread
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print "%s: %s" % ( threadName, time.ctime(time.time()) )
# Create two threads as follows
try:
thread.start_new_thread( print_time, ("Thread-1", 2, ) )
thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print "Error: unable to start thread"
while 1:
passWykonanie powyższego kodu daje następujący wynik -
Thread-1: Thu Jan 22 15:42:17 2009
Thread-1: Thu Jan 22 15:42:19 2009
Thread-2: Thu Jan 22 15:42:19 2009
Thread-1: Thu Jan 22 15:42:21 2009
Thread-2: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:23 2009
Thread-1: Thu Jan 22 15:42:25 2009
Thread-2: Thu Jan 22 15:42:27 2009
Thread-2: Thu Jan 22 15:42:31 2009
Thread-2: Thu Jan 22 15:42:35 2009Chociaż jest bardzo skuteczny w przypadku wątków niskiego poziomu, ale moduł wątków jest bardzo ograniczony w porównaniu z nowszym modułem wątków.
Threading Moduł
Nowszy moduł obsługi wątków zawarty w Pythonie 2.4 zapewnia znacznie wydajniejszą obsługę wątków na wysokim poziomie niż moduł wątków omówiony w poprzedniej sekcji.
Gwintowania Moduł udostępnia wszystkie te metody z gwintem modułu i zapewnia dodatkowe metody -
threading.activeCount() - Zwraca liczbę aktywnych obiektów wątku.
threading.currentThread() - Zwraca liczbę obiektów wątku w kontrolce wątku wywołującego.
threading.enumerate() - Zwraca listę wszystkich aktualnie aktywnych obiektów wątku.
Oprócz metod moduł wątkowości ma klasę Thread, która implementuje wątkowanie. Metody udostępniane przez klasę Thread są następujące -
run() - Metoda run () jest punktem wejścia dla wątku.
start() - Metoda start () uruchamia wątek przez wywołanie metody run.
join([time]) - Join () czeka na zakończenie wątków.
isAlive() - Metoda isAlive () sprawdza, czy wątek nadal jest wykonywany.
getName() - Metoda getName () zwraca nazwę wątku.
setName() - Metoda setName () ustawia nazwę wątku.
Tworzenie wątku za pomocą modułu Threading
Aby zaimplementować nowy wątek za pomocą modułu Threading, musisz wykonać następujące czynności -
Zdefiniuj nową podklasę klasy Thread .
Zastąp metodę __init __ (self [, args]) , aby dodać dodatkowe argumenty.
Następnie nadpisz metodę run (self [, args]), aby zaimplementować, co wątek powinien zrobić po uruchomieniu.
Po utworzeniu nowej podklasy Thread możesz utworzyć jej instancję, a następnie rozpocząć nowy wątek, wywołując metodę start () , która z kolei wywołuje metodę run () .
Przykład
#!/usr/bin/python
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
print_time(self.name, self.counter, 5)
print "Exiting " + self.name
def print_time(threadName, counter, delay):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
print "Exiting Main Thread"Wykonanie powyższego kodu daje następujący wynik -
Starting Thread-1
Starting Thread-2
Exiting Main Thread
Thread-1: Thu Mar 21 09:10:03 2013
Thread-1: Thu Mar 21 09:10:04 2013
Thread-2: Thu Mar 21 09:10:04 2013
Thread-1: Thu Mar 21 09:10:05 2013
Thread-1: Thu Mar 21 09:10:06 2013
Thread-2: Thu Mar 21 09:10:06 2013
Thread-1: Thu Mar 21 09:10:07 2013
Exiting Thread-1
Thread-2: Thu Mar 21 09:10:08 2013
Thread-2: Thu Mar 21 09:10:10 2013
Thread-2: Thu Mar 21 09:10:12 2013
Exiting Thread-2Synchronizacja wątków
Moduł obsługi wątków dostarczany z Pythonem zawiera prosty w implementacji mechanizm blokujący, który umożliwia synchronizację wątków. Nowa blokada jest tworzona przez wywołanie metody Lock () , która zwraca nową blokadę.
Metoda pozyskiwania (blokowania) nowego obiektu blokady służy do wymuszania synchronicznego działania wątków. Opcjonalny parametr blokowania umożliwia kontrolowanie, czy wątek oczekuje na uzyskanie blokady.
Jeśli blokowanie jest ustawione na 0, wątek zwraca natychmiast wartość 0, jeśli nie można uzyskać blokady, oraz 1, jeśli blokada została uzyskana. Jeśli blokowanie jest ustawione na 1, wątek blokuje się i czeka na zwolnienie blokady.
Metoda release () nowego obiektu blokady służy do zwolnienia blokady, gdy nie jest już potrzebna.
Przykład
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"Wykonanie powyższego kodu daje następujący wynik -
Starting Thread-1
Starting Thread-2
Thread-1: Thu Mar 21 09:11:28 2013
Thread-1: Thu Mar 21 09:11:29 2013
Thread-1: Thu Mar 21 09:11:30 2013
Thread-2: Thu Mar 21 09:11:32 2013
Thread-2: Thu Mar 21 09:11:34 2013
Thread-2: Thu Mar 21 09:11:36 2013
Exiting Main ThreadWielowątkowa kolejka priorytetowa
Queue Moduł pozwala na tworzenie nowego obiektu kolejki, która może pomieścić szereg specyficzny elementów. Istnieją następujące metody kontrolowania kolejki -
get() - Funkcja get () usuwa i zwraca element z kolejki.
put() - Put dodaje element do kolejki.
qsize() - Funkcja qsize () zwraca liczbę elementów, które aktualnie znajdują się w kolejce.
empty()- Empty () zwraca True, jeśli kolejka jest pusta; w przeciwnym razie False.
full()- full () zwraca True, jeśli kolejka jest pełna; w przeciwnym razie False.
Przykład
#!/usr/bin/python
import Queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print "Starting " + self.name
process_data(self.name, self.q)
print "Exiting " + self.name
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print "%s processing %s" % (threadName, data)
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = Queue.Queue(10)
threads = []
threadID = 1
# Create new threads
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# Fill the queue
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# Wait for queue to empty
while not workQueue.empty():
pass
# Notify threads it's time to exit
exitFlag = 1
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"Wykonanie powyższego kodu daje następujący wynik -
Starting Thread-1
Starting Thread-2
Starting Thread-3
Thread-1 processing One
Thread-2 processing Two
Thread-3 processing Three
Thread-1 processing Four
Thread-2 processing Five
Exiting Thread-3
Exiting Thread-1
Exiting Thread-2
Exiting Main ThreadXML to przenośny język open source, który umożliwia programistom tworzenie aplikacji, które mogą być odczytywane przez inne aplikacje, niezależnie od systemu operacyjnego i / lub języka programowania.
Co to jest XML?
Extensible Markup Language (XML) jest językiem znaczników, podobnie jak HTML czy SGML. Jest to zalecane przez konsorcjum World Wide Web i dostępne jako otwarty standard.
XML jest niezwykle przydatny do śledzenia małych i średnich ilości danych bez konieczności korzystania z sieci szkieletowej opartej na języku SQL.
Architektury i API parsera XML
Biblioteka standardowa Pythona zapewnia minimalny, ale przydatny zestaw interfejsów do pracy z XML.
Dwa najbardziej podstawowe i szeroko stosowane interfejsy API do danych XML to interfejsy SAX i DOM.
Simple API for XML (SAX)- Tutaj rejestrujesz wywołania zwrotne dla interesujących zdarzeń, a następnie pozwalasz parserowi przejść przez dokument. Jest to przydatne, gdy dokumenty są duże lub masz ograniczenia pamięci, analizuje plik podczas odczytywania go z dysku, a cały plik nigdy nie jest przechowywany w pamięci.
Document Object Model (DOM) API - To jest zalecenie konsorcjum World Wide Web Consortium, w którym cały plik jest wczytywany do pamięci i przechowywany w formie hierarchicznej (opartej na drzewie), aby przedstawić wszystkie cechy dokumentu XML.
Oczywiście SAX nie może przetwarzać informacji tak szybko, jak DOM podczas pracy z dużymi plikami. Z drugiej strony, używanie wyłącznie DOM może naprawdę zabić twoje zasoby, zwłaszcza jeśli jest używane na wielu małych plikach.
SAX jest tylko do odczytu, podczas gdy DOM umożliwia zmiany w pliku XML. Ponieważ te dwa różne interfejsy API dosłownie się uzupełniają, nie ma powodu, dla którego nie można używać ich obu w dużych projektach.
We wszystkich naszych przykładach kodu XML jako danych wejściowych użyjmy prostego pliku XML movies.xml -
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>Parsowanie XML za pomocą API SAX
SAX to standardowy interfejs do analizowania XML sterowanego zdarzeniami. Parsowanie XML za pomocą SAX zazwyczaj wymaga utworzenia własnego ContentHandler'a przez podklasę xml.sax.ContentHandler.
Twój ContentHandler obsługuje określone tagi i atrybuty Twojego smaku (ów) XML. Obiekt ContentHandler udostępnia metody do obsługi różnych zdarzeń analizy. Jego parser będący właścicielem wywołuje metody ContentHandler podczas analizowania pliku XML.
Metody startDocument i endDocument są wywoływane na początku i na końcu pliku XML. Znaki metody (tekst) są przekazywane jako dane znakowe pliku XML za pośrednictwem tekstu parametru.
ContentHandler jest wywoływana na początku i na końcu każdego elementu. Jeśli parser nie jest w trybie przestrzeni nazw, wywoływane są metody startElement (tag, atrybuty) i endElement (tag) ; w przeciwnym razie wywoływane są odpowiednie metody startElementNS i endElementNS . W tym przypadku tag to znacznik elementu, a atrybuty to obiekt Attributes.
Oto inne ważne metody, które należy zrozumieć przed kontynuowaniem -
Make_parser Metoda
Poniższa metoda tworzy nowy obiekt parsera i zwraca go. Utworzony obiekt parsera będzie pierwszego typu analizatora składni znalezionego przez system.
xml.sax.make_parser( [parser_list] )Oto szczegóły parametrów -
parser_list - Opcjonalny argument składający się z listy parserów do użycia, z których wszystkie muszą implementować metodę make_parser.
Parse Metoda
Poniższa metoda tworzy parser SAX i używa go do parsowania dokumentu.
xml.sax.parse( xmlfile, contenthandler[, errorhandler])Oto szczegóły parametrów -
xmlfile - To jest nazwa pliku XML do odczytu.
contenthandler - To musi być obiekt ContentHandler.
errorhandler - Jeśli określono, errorhandler musi być obiektem SAX ErrorHandler.
ParseString Metoda
Jest jeszcze jedna metoda tworzenia parsera SAX i analizowania podanego XML string.
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])Oto szczegóły parametrów -
xmlstring - To jest nazwa ciągu XML do odczytu.
contenthandler - To musi być obiekt ContentHandler.
errorhandler - Jeśli określono, errorhandler musi być obiektem SAX ErrorHandler.
Przykład
#!/usr/bin/python
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# Call when an element starts
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print "*****Movie*****"
title = attributes["title"]
print "Title:", title
# Call when an elements ends
def endElement(self, tag):
if self.CurrentData == "type":
print "Type:", self.type
elif self.CurrentData == "format":
print "Format:", self.format
elif self.CurrentData == "year":
print "Year:", self.year
elif self.CurrentData == "rating":
print "Rating:", self.rating
elif self.CurrentData == "stars":
print "Stars:", self.stars
elif self.CurrentData == "description":
print "Description:", self.description
self.CurrentData = ""
# Call when a character is read
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# create an XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# override the default ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")Dałoby to następujący wynik -
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredomAby uzyskać szczegółowe informacje na temat dokumentacji API SAX, zapoznaj się ze standardowymi interfejsami API Python SAX .
Przetwarzanie XML za pomocą interfejsów API DOM
Document Object Model („DOM”) to wielojęzyczny interfejs API firmy World Wide Web Consortium (W3C) do uzyskiwania dostępu do dokumentów XML i ich modyfikowania.
DOM jest niezwykle przydatny w aplikacjach o dostępie swobodnym. SAX pozwala na podgląd tylko jednego bitu dokumentu na raz. Jeśli patrzysz na jeden element SAX, nie masz dostępu do innego.
Oto najprostszy sposób na szybkie załadowanie dokumentu XML i utworzenie obiektu minidom przy użyciu modułu xml.dom. Obiekt minidom zapewnia prostą metodę parsera, która szybko tworzy drzewo DOM z pliku XML.
Przykładowa fraza wywołuje funkcję parse (file [, parser]) obiektu minidom w celu przeanalizowania pliku XML wyznaczonego przez plik do obiektu drzewa DOM.
#!/usr/bin/python
from xml.dom.minidom import parse
import xml.dom.minidom
# Open XML document using minidom parser
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print "Root element : %s" % collection.getAttribute("shelf")
# Get all the movies in the collection
movies = collection.getElementsByTagName("movie")
# Print detail of each movie.
for movie in movies:
print "*****Movie*****"
if movie.hasAttribute("title"):
print "Title: %s" % movie.getAttribute("title")
type = movie.getElementsByTagName('type')[0]
print "Type: %s" % type.childNodes[0].data
format = movie.getElementsByTagName('format')[0]
print "Format: %s" % format.childNodes[0].data
rating = movie.getElementsByTagName('rating')[0]
print "Rating: %s" % rating.childNodes[0].data
description = movie.getElementsByTagName('description')[0]
print "Description: %s" % description.childNodes[0].dataDałoby to następujący wynik -
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredomAby uzyskać szczegółowe informacje na temat dokumentacji DOM API, zapoznaj się ze standardowymi interfejsami API języka Python DOM .
Python zapewnia różne opcje tworzenia graficznych interfejsów użytkownika (GUI). Najważniejsze są wymienione poniżej.
Tkinter- Tkinter to interfejs Pythona do zestawu narzędzi Tk GUI dostarczanego z Pythonem. Szukalibyśmy tej opcji w tym rozdziale.
wxPython - To jest interfejs Pythona typu open source dla wxWindows http://wxpython.org.
JPython - JPython to port Pythona dla Javy, który zapewnia skryptom Pythona bezproblemowy dostęp do bibliotek klas Java na komputerze lokalnym http://www.jython.org.
Dostępnych jest wiele innych interfejsów, które można znaleźć w sieci.
Programowanie Tkinter
Tkinter to standardowa biblioteka GUI dla Pythona. Python w połączeniu z Tkinter zapewnia szybki i łatwy sposób tworzenia aplikacji GUI. Tkinter zapewnia potężny, zorientowany obiektowo interfejs do zestawu narzędzi Tk GUI.
Tworzenie aplikacji GUI za pomocą Tkinter jest łatwym zadaniem. Wszystko, co musisz zrobić, to wykonać następujące kroki -
Zaimportuj moduł Tkinter .
Utwórz główne okno aplikacji GUI.
Dodaj jeden lub więcej z wyżej wymienionych widżetów do aplikacji GUI.
Wprowadź główną pętlę zdarzeń, aby podjąć działanie przeciwko każdemu zdarzeniu wyzwalanemu przez użytkownika.
Przykład
#!/usr/bin/python
import Tkinter
top = Tkinter.Tk()
# Code to add widgets will go here...
top.mainloop()Spowoduje to utworzenie następującego okna -
Tkinter Widgets
Tkinter zapewnia różne elementy sterujące, takie jak przyciski, etykiety i pola tekstowe używane w aplikacji GUI. Te elementy sterujące są powszechnie nazywane widżetami.
Obecnie w Tkinter jest dostępnych 15 typów widżetów. Przedstawiamy te widgety, a także krótki opis w poniższej tabeli -
| Sr.No. | Operator i opis |
|---|---|
| 1 | Przycisk Widżet Przycisk służy do wyświetlania przycisków w aplikacji. |
| 2 | Brezentowy Widżet Canvas służy do rysowania w aplikacji kształtów, takich jak linie, owale, wielokąty i prostokąty. |
| 3 | Checkbutton Widget Przycisk wyboru służy do wyświetlania wielu opcji jako pól wyboru. Użytkownik może jednocześnie wybrać wiele opcji. |
| 4 | Wejście Widget Wejście służy do wyświetlania jednowierszowego pola tekstowego służącego do akceptowania wartości od użytkownika. |
| 5 | Rama Widżet Ramka służy jako widget kontenera do organizowania innych widgetów. |
| 6 | Etykieta Widżet Etykieta służy do zapewniania jednowierszowego podpisu dla innych widżetów. Może również zawierać obrazy. |
| 7 | Skrzynka na listy Widżet Listbox służy do udostępniania użytkownikowi listy opcji. |
| 8 | Przycisk MENU Widżet Menubutton służy do wyświetlania menu w aplikacji. |
| 9 | Menu Widget Menu służy do dostarczania użytkownikowi różnych poleceń. Te polecenia są zawarte w Menubutton. |
| 10 | Wiadomość Widget Wiadomość służy do wyświetlania wielowierszowych pól tekstowych służących do akceptowania wartości od użytkownika. |
| 11 | Przycisk radiowy Widget Radiobutton służy do wyświetlania wielu opcji jako przycisków radiowych. Użytkownik może wybrać tylko jedną opcję naraz. |
| 12 | Skala Widżet Skala służy do udostępniania widgetu suwaka. |
| 13 | Pasek przewijania Widżet Pasek przewijania służy do dodawania możliwości przewijania do różnych widżetów, takich jak pola list. |
| 14 | Tekst Widżet Tekst służy do wyświetlania tekstu w wielu wierszach. |
| 15 | Najwyższy poziom Widżet najwyższego poziomu służy do udostępniania osobnego kontenera okna. |
| 16 | Spinbox Widżet Spinbox jest wariantem standardowego widżetu Tkinter Entry, za pomocą którego można wybierać spośród ustalonej liczby wartości. |
| 17 | PanedWindow PanedWindow to widget kontenera, który może zawierać dowolną liczbę paneli, ułożonych poziomo lub pionowo. |
| 18 | LabelFrame Labelframe to prosty widget kontenera. Jego głównym celem jest działanie jako przekładka lub kontener dla złożonych układów okien. |
| 19 | tkMessageBox Ten moduł jest używany do wyświetlania okienek wiadomości w twoich aplikacjach. |
Przeanalizujmy szczegółowo te widżety -
Atrybuty standardowe
Przyjrzyjmy się, jak określono niektóre z ich wspólnych atrybutów, takich jak rozmiary, kolory i czcionki.
Dimensions
Colors
Fonts
Anchors
Style reliefowe
Bitmaps
Cursors
Przeanalizujmy je pokrótce -
Zarządzanie geometrią
Wszystkie widżety Tkinter mają dostęp do określonych metod zarządzania geometrią, których celem jest organizowanie widżetów w obszarze nadrzędnym widżetów. Tkinter ujawnia następujące klasy menedżerów geometrii: opakowanie, siatka i miejsce.
Paczka () Metoda - Menadżer geometria organizuje widżety w blokach przed umieszczeniem ich w widgecie macierzystej.
Siatka () Metoda - Menadżer geometria organizuje widgetów w tabeli jak struktury w widgecie macierzystej.
Miejsce () Metoda - Menadżer geometria organizuje widgetów poprzez umieszczenie ich w pozycji określonej w widgecie macierzystej.
Przeanalizujmy pokrótce metody zarządzania geometrią -
Każdy kod napisany przy użyciu dowolnego języka skompilowanego, takiego jak C, C ++ lub Java, można zintegrować lub zaimportować do innego skryptu Pythona. Ten kod jest traktowany jako „rozszerzenie”.
Moduł rozszerzający Python to nic innego jak zwykła biblioteka C. Na komputerach uniksowych biblioteki te zwykle kończą się na.so(dla wspólnego obiektu). Na komputerach z systemem Windows zazwyczaj widzisz.dll (dla biblioteki połączonej dynamicznie).
Wymagania wstępne dotyczące pisania rozszerzeń
Aby rozpocząć pisanie rozszerzenia, będziesz potrzebować plików nagłówkowych Pythona.
Na komputerach z systemem Unix zwykle wymaga to zainstalowania pakietu dla programisty, takiego jak python2.5-dev .
Użytkownicy systemu Windows otrzymują te nagłówki jako część pakietu, gdy używają binarnego instalatora języka Python.
Ponadto zakłada się, że masz dobrą znajomość C lub C ++, aby napisać dowolne rozszerzenie języka Python przy użyciu programowania w C.
Najpierw spójrz na rozszerzenie Pythona
Aby po raz pierwszy przyjrzeć się modułowi rozszerzenia Python, musisz zgrupować swój kod na cztery części -
Plik nagłówkowy Python.h .
Funkcje C, które chcesz ujawnić jako interfejs z Twojego modułu.
Tabela odwzorowująca nazwy twoich funkcji, tak jak programiści Pythona widzą je na funkcje C wewnątrz modułu rozszerzenia.
Funkcja inicjalizacji.
Plik nagłówkowy Python.h
Musisz dołączyć plik nagłówkowy Python.h do pliku źródłowego C, który daje dostęp do wewnętrznego interfejsu API Pythona używanego do podłączenia modułu do interpretera.
Upewnij się, że dołączasz Python.h przed innymi nagłówkami, których możesz potrzebować. Musisz przestrzegać dołączeń z funkcjami, które chcesz wywołać z Pythona.
Funkcje C.
Podpisy implementacji funkcji w języku C zawsze przyjmują jedną z trzech następujących form -
static PyObject *MyFunction( PyObject *self, PyObject *args );
static PyObject *MyFunctionWithKeywords(PyObject *self,
PyObject *args,
PyObject *kw);
static PyObject *MyFunctionWithNoArgs( PyObject *self );Każda z poprzednich deklaracji zwraca obiekt w języku Python. Nie ma czegoś takiego jak funkcja void w Pythonie, jak w C. Jeśli nie chcesz, aby twoje funkcje zwracały wartość, zwróć odpowiednik funkcji w CNonewartość. Nagłówki Pythona definiują makro Py_RETURN_NONE, które robi to za nas.
Nazwy twoich funkcji C mogą być dowolne, ponieważ nigdy nie są widoczne poza modułem rozszerzającym. Są zdefiniowane jako funkcja statyczna .
Twoje funkcje C zwykle są nazywane przez połączenie razem modułu Pythona i nazw funkcji, jak pokazano tutaj -
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}To jest funkcja Pythona o nazwie func wewnątrz modułu modułu . Będziesz umieszczać wskaźniki do funkcji C w tabeli metod modułu, który zwykle pojawia się jako następny w kodzie źródłowym.
Tabela mapowania metod
Ta tabela metod jest prostą tablicą struktur PyMethodDef. Ta struktura wygląda mniej więcej tak -
struct PyMethodDef {
char *ml_name;
PyCFunction ml_meth;
int ml_flags;
char *ml_doc;
};Oto opis członków tej struktury -
ml_name - To jest nazwa funkcji, jaką prezentuje interpreter języka Python, gdy jest używana w programach w języku Python.
ml_meth - Musi to być adres funkcji, która ma jeden z podpisów opisanych w poprzedniej sekcji.
ml_flags - To mówi interpreterowi, którego z trzech podpisów używa ml_meth.
Ta flaga zwykle ma wartość METH_VARARGS.
Ta flaga może być OR 'bitowa OR' za pomocą METH_KEYWORDS, jeśli chcesz dopuścić argumenty słów kluczowych do swojej funkcji.
Może to również mieć wartość METH_NOARGS, która wskazuje, że nie chcesz akceptować żadnych argumentów.
ml_doc - To jest dokumentacja funkcji, która może mieć wartość NULL, jeśli nie masz ochoty go pisać.
Ta tabela musi być zakończona wartownikiem składającym się z wartości NULL i 0 dla odpowiednich członków.
Przykład
Dla wyżej zdefiniowanej funkcji mamy następującą tabelę mapowania metod -
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};Funkcja inicjalizacji
Ostatnią częścią modułu rozszerzającego jest funkcja inicjalizacji. Ta funkcja jest wywoływana przez interpreter języka Python podczas ładowania modułu. Wymagane jest nazwanie funkcjiinitModule, gdzie Module to nazwa modułu.
Funkcja inicjalizacji musi zostać wyeksportowana z biblioteki, którą będziesz budować. Nagłówki Pythona definiują PyMODINIT_FUNC, aby zawierał odpowiednie inkantacje, które mają się wydarzyć dla określonego środowiska, w którym kompilujemy. Wystarczy, że użyjesz go podczas definiowania funkcji.
Twoja funkcja inicjalizacji C ma ogólnie następującą ogólną strukturę -
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}Oto opis funkcji Py_InitModule3 -
func - To jest funkcja do wyeksportowania.
module_methods - To jest nazwa tabeli odwzorowań zdefiniowana powyżej.
docstring - To jest komentarz, który chcesz umieścić w swoim rozszerzeniu.
Połączenie tego wszystkiego wygląda następująco -
#include <Python.h>
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Do your stuff here. */
Py_RETURN_NONE;
}
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ NULL, NULL, 0, NULL }
};
PyMODINIT_FUNC initModule() {
Py_InitModule3(func, module_methods, "docstring...");
}Przykład
Prosty przykład wykorzystujący wszystkie powyższe koncepcje -
#include <Python.h>
static PyObject* helloworld(PyObject* self) {
return Py_BuildValue("s", "Hello, Python extensions!!");
}
static char helloworld_docs[] =
"helloworld( ): Any message you want to put here!!\n";
static PyMethodDef helloworld_funcs[] = {
{"helloworld", (PyCFunction)helloworld,
METH_NOARGS, helloworld_docs},
{NULL}
};
void inithelloworld(void) {
Py_InitModule3("helloworld", helloworld_funcs,
"Extension module example!");
}Tutaj funkcja Py_BuildValue służy do budowania wartości Pythona. Zapisz powyższy kod w pliku hello.c. Zobaczylibyśmy, jak skompilować i zainstalować ten moduł, aby był wywoływany ze skryptu Pythona.
Tworzenie i instalowanie rozszerzeń
Distutils opakowanie sprawia, że bardzo łatwo rozprowadzać modułów Python, zarówno czystych modułów Pythona i rozszerzeń, w sposób standardowy. Moduły są rozprowadzane w formie źródłowej oraz budowane i instalowane za pomocą skryptu instalacyjnego, zwykle nazywanego setup.py, jak poniżej.
Dla powyższego modułu musisz przygotować następujący skrypt setup.py -
from distutils.core import setup, Extension
setup(name='helloworld', version='1.0', \
ext_modules=[Extension('helloworld', ['hello.c'])])Teraz użyj następującego polecenia, które wykonałoby wszystkie potrzebne kroki kompilacji i łączenia, z odpowiednimi poleceniami i flagami kompilatora i konsolidatora, i kopiuje wynikową bibliotekę dynamiczną do odpowiedniego katalogu -
$ python setup.py installW systemach uniksowych najprawdopodobniej będziesz musiał uruchomić to polecenie jako root, aby mieć uprawnienia do zapisu w katalogu pakietów witryn. Zwykle nie stanowi to problemu w systemie Windows.
Importowanie rozszerzeń
Po zainstalowaniu rozszerzenia będziesz mógł zaimportować i wywołać to rozszerzenie w swoim skrypcie Pythona w następujący sposób -
#!/usr/bin/python
import helloworld
print helloworld.helloworld()Dałoby to następujący wynik -
Hello, Python extensions!!Przekazywanie parametrów funkcji
Ponieważ najprawdopodobniej będziesz chciał zdefiniować funkcje, które akceptują argumenty, możesz użyć jednego z innych podpisów dla swoich funkcji C. Na przykład następująca funkcja, która przyjmuje pewną liczbę parametrów, byłaby zdefiniowana w ten sposób -
static PyObject *module_func(PyObject *self, PyObject *args) {
/* Parse args and do something interesting here. */
Py_RETURN_NONE;
}Tablica metod zawierająca wpis dla nowej funkcji wyglądałaby następująco -
static PyMethodDef module_methods[] = {
{ "func", (PyCFunction)module_func, METH_NOARGS, NULL },
{ "func", module_func, METH_VARARGS, NULL },
{ NULL, NULL, 0, NULL }
};Możesz użyć funkcji API PyArg_ParseTuple, aby wyodrębnić argumenty z jednego wskaźnika PyObject przekazanego do funkcji C.
Pierwszym argumentem PyArg_ParseTuple jest argument args. To jest obiekt, który będziesz analizować . Drugi argument to łańcuch formatu opisujący argumenty w oczekiwanej postaci. Każdy argument jest reprezentowany przez jeden lub więcej znaków w ciągu formatu w następujący sposób.
static PyObject *module_func(PyObject *self, PyObject *args) {
int i;
double d;
char *s;
if (!PyArg_ParseTuple(args, "ids", &i, &d, &s)) {
return NULL;
}
/* Do something interesting here. */
Py_RETURN_NONE;
}Skompilowanie nowej wersji modułu i zaimportowanie go umożliwia wywołanie nowej funkcji z dowolną liczbą argumentów dowolnego typu -
module.func(1, s="three", d=2.0)
module.func(i=1, d=2.0, s="three")
module.func(s="three", d=2.0, i=1)Prawdopodobnie możesz wymyślić jeszcze więcej odmian.
PyArg_ParseTuple Function
Oto standardowy podpis dla PyArg_ParseTuple funkcja -
int PyArg_ParseTuple(PyObject* tuple,char* format,...)Ta funkcja zwraca 0 dla błędów i wartość różną od 0 dla sukcesu. krotka to PyObject *, który był drugim argumentem funkcji C. Tutaj format jest łańcuchem w C, który opisuje obowiązkowe i opcjonalne argumenty.
Oto lista kodów formatów dla PyArg_ParseTuple funkcja -
| Kod | Typ C. | Znaczenie |
|---|---|---|
| do | zwęglać | Ciąg znaków Pythona o długości 1 staje się znakiem C. |
| re | podwójnie | Python float staje się double C. |
| fa | pływak | Python float zmienia się w float w C. |
| ja | int | Int Python staje się int C. |
| l | długo | Int Python staje się długi w C. |
| L | długo, długo | Int Python staje się długi w C. |
| O | PyObject * | Pobiera pożyczone odwołanie do argumentu języka Python o wartości innej niż NULL. |
| s | zwęglać* | Ciąg Pythona bez osadzonych wartości null w znaku C *. |
| s # | char * + int | Dowolny ciąg znaków Pythona na adres i długość w języku C. |
| t # | char * + int | Bufor jednosegmentowy tylko do odczytu na adres C i długość. |
| u | Py_UNICODE * | Python Unicode bez osadzonych wartości null do C. |
| ty # | Py_UNICODE * + int | Dowolny adres i długość w standardzie Python Unicode C. |
| w # | char * + int | Odczyt / zapis buforu pojedynczego segmentu na adres i długość w C. |
| z | zwęglać* | Podobnie jak s, akceptuje także None (ustawia C char * na NULL). |
| z # | char * + int | Podobnie jak s #, akceptuje także None (ustawia C char * na NULL). |
| (...) | zgodnie z ... | Sekwencja Pythona jest traktowana jako jeden argument na element. |
| | | Następujące argumenty są opcjonalne. | |
| : | Formatuj koniec, po którym następuje nazwa funkcji dla komunikatów o błędach. | |
| ; | Koniec formatu, po którym następuje cały tekst komunikatu o błędzie. |
Zwracane wartości
Py_BuildValue przyjmuje ciąg formatu, podobnie jak PyArg_ParseTuple . Zamiast przekazywać adresy budowanych wartości, przekazujesz wartości rzeczywiste. Oto przykład pokazujący, jak zaimplementować funkcję dodawania -
static PyObject *foo_add(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("i", a + b);
}Tak by to wyglądało, gdyby zostało zaimplementowane w Pythonie -
def add(a, b):
return (a + b)Możesz zwrócić dwie wartości ze swojej funkcji w następujący sposób, byłoby to określone za pomocą listy w Pythonie.
static PyObject *foo_add_subtract(PyObject *self, PyObject *args) {
int a;
int b;
if (!PyArg_ParseTuple(args, "ii", &a, &b)) {
return NULL;
}
return Py_BuildValue("ii", a + b, a - b);
}Tak by to wyglądało, gdyby zostało zaimplementowane w Pythonie -
def add_subtract(a, b):
return (a + b, a - b)Py_BuildValue Function
Oto standardowy podpis dla Py_BuildValue funkcja -
PyObject* Py_BuildValue(char* format,...)Tutaj format to napis w C, który opisuje obiekt Pythona do zbudowania. Następujące argumenty Py_BuildValue są wartościami w języku C, na podstawie których budowany jest wynik. Wynik PyObject * jest nowym odniesieniem.
Poniższa tabela zawiera listę często używanych ciągów kodu, z których zero lub więcej jest łączonych w format ciągu.
| Kod | Typ C. | Znaczenie |
|---|---|---|
| do | zwęglać | AC char staje się ciągiem znaków Pythona o długości 1. |
| re | podwójnie | AC double staje się pływakiem Pythona. |
| fa | pływak | AC float zmienia się w Python float. |
| ja | int | AC int staje się intem Pythona. |
| l | długo | AC long staje się intem Pythona. |
| N | PyObject * | Przekazuje obiekt Pythona i kradnie odniesienie. |
| O | PyObject * | Przekazuje obiekt w języku Python i ZWALNIA go jak zwykle. |
| O & | konwertuj + anuluj * | Arbitralna konwersja |
| s | zwęglać* | Znak * zakończony znakiem C 0 na łańcuch w języku Python lub NULL na brak. |
| s # | char * + int | C char * i długość do łańcucha Pythona lub NULL do None. |
| u | Py_UNICODE * | C-wide, zakończony znakiem null ciąg do Python Unicode lub NULL do None. |
| ty # | Py_UNICODE * + int | C-szeroki ciąg i długość do Python Unicode lub NULL do None. |
| w # | char * + int | Odczyt / zapis buforu pojedynczego segmentu na adres i długość w C. |
| z | zwęglać* | Podobnie jak s, akceptuje także None (ustawia C char * na NULL). |
| z # | char * + int | Podobnie jak s #, akceptuje także None (ustawia C char * na NULL). |
| (...) | zgodnie z ... | Tworzy krotkę Pythona z wartości w C. |
| […] | zgodnie z ... | Tworzy listę Pythona z wartości C. |
| {...} | zgodnie z ... | Tworzy słownik Pythona z wartości C, naprzemiennych kluczy i wartości. |
Kod {...} buduje słowniki z parzystej liczby wartości C, na przemian kluczy i wartości. Na przykład Py_BuildValue ("{issi}", 23, "zig", "zag", 42) zwraca słownik, taki jak Python's {23: 'zig', 'zag': 42}.