Talend - rozproszony system plików Hadoop
W tym rozdziale dowiemy się szczegółowo, jak Talend współpracuje z rozproszonym systemem plików Hadoop.
Ustawienia i wymagania wstępne
Zanim przejdziemy do Talend z HDFS, powinniśmy poznać ustawienia i wymagania wstępne, które należy spełnić w tym celu.
Tutaj uruchamiamy Cloudera quickstart 5.10 VM na wirtualnym pudełku. W tej maszynie wirtualnej musi być używana sieć tylko hosta.
Adres IP sieci tylko hosta: 192.168.56.101

Musisz mieć również tego samego hosta działającego w menedżerze Cloudera.

Teraz w systemie Windows przejdź do c: \ Windows \ System32 \ Drivers \ etc \ hosts i edytuj ten plik za pomocą Notatnika, jak pokazano poniżej.

Podobnie na maszynie wirtualnej Cloudera quickstart edytuj plik / etc / hosts, jak pokazano poniżej.
sudo gedit /etc/hosts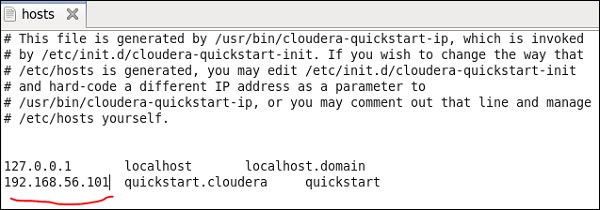
Konfigurowanie połączenia Hadoop
W panelu repozytorium przejdź do Metadane. Kliknij prawym przyciskiem myszy Hadoop Cluster i utwórz nowy klaster. Podaj nazwę, cel i opis tego połączenia klastra Hadoop.
Kliknij Następny.

Wybierz dystrybucję jako cloudera i wybierz wersję, której używasz. Wybierz opcję pobierania konfiguracji i kliknij Dalej.

Wprowadź poświadczenia menedżera (URI z portem, nazwą użytkownika, hasłem), jak pokazano poniżej, i kliknij Połącz. Jeśli szczegóły są poprawne, otrzymasz Cloudera QuickStart pod wykrytymi klastrami.
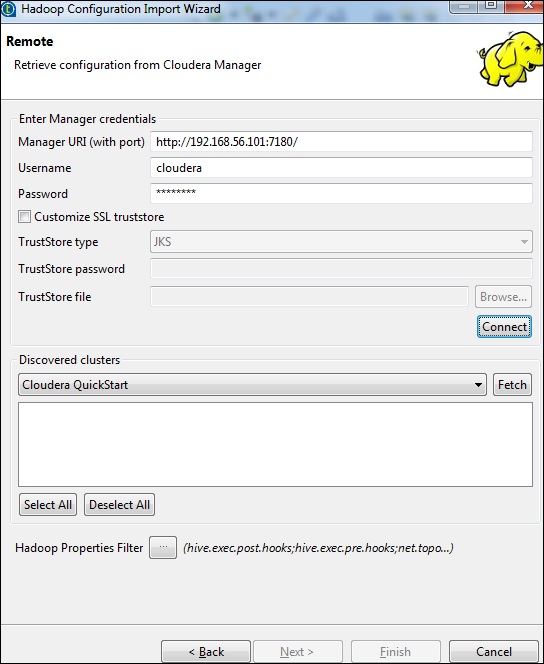
Kliknij Pobierz. Spowoduje to pobranie wszystkich połączeń i konfiguracji dla HDFS, YARN, HBASE, HIVE.
Wybierz Wszystko i kliknij Zakończ.

Pamiętaj, że wszystkie parametry połączenia zostaną automatycznie wypełnione. W nazwie użytkownika wpisz cloudera i kliknij Zakończ.

Dzięki temu udało Ci się połączyć z klastrem Hadoop.

Łączenie z HDFS
W tym zadaniu wymienimy wszystkie katalogi i pliki, które są obecne na HDFS.
Najpierw utworzymy zadanie, a następnie dodamy do niego komponenty HDFS. Kliknij prawym przyciskiem myszy projekt pracy i utwórz nową pracę - hadoopjob.
Teraz dodaj 2 komponenty z palety - tHDFSConnection i tHDFSList. Kliknij prawym przyciskiem myszy tHDFSConnection i połącz te 2 komponenty za pomocą wyzwalacza „OnSubJobOk”.
Teraz skonfiguruj oba komponenty talend hdfs.

W tHDFSConnection wybierz Repozytorium jako Typ właściwości i wybierz utworzony wcześniej klaster Hadoop Cloudera. Automatycznie wypełni wszystkie niezbędne szczegóły wymagane dla tego komponentu.

W tHDFSList wybierz „Użyj istniejącego połączenia” iz listy komponentów wybierz skonfigurowane połączenie tHDFS.
Podaj ścieżkę domową HDFS w katalogu HDFS i kliknij przycisk przeglądania po prawej stronie.

Jeśli poprawnie nawiązałeś połączenie z wyżej wymienionymi konfiguracjami, pojawi się okno pokazane poniżej. Wyświetli listę wszystkich katalogów i plików obecnych w domu HDFS.

Możesz to zweryfikować, sprawdzając swój HDFS w Cloudera.

Czytanie pliku z HDFS
W tej sekcji wyjaśnimy, jak czytać plik z HDFS w Talend. Możesz w tym celu utworzyć nowe stanowisko pracy, jednak tutaj korzystamy z już istniejącego.
Przeciągnij i upuść 3 komponenty - tHDFSConnection, tHDFSInput i tLogRow z palety do okna projektanta.
Kliknij prawym przyciskiem myszy tHDFSConnection i podłącz komponent tHDFSInput za pomocą wyzwalacza „OnSubJobOk”.
Kliknij prawym przyciskiem myszy tHDFSInput i przeciągnij główne łącze do tLogRow.

Zauważ, że tHDFSConnection będzie miał podobną konfigurację jak wcześniej. W tHDFSInput wybierz „Użyj istniejącego połączenia” iz listy komponentów wybierz tHDFSConnection.
W polu Nazwa pliku podaj ścieżkę HDFS do pliku, który chcesz odczytać. Tutaj czytamy prosty plik tekstowy, więc nasz typ pliku to Plik tekstowy. Podobnie, w zależności od danych wejściowych, wypełnij separator wierszy, separator pól i szczegóły nagłówka, jak wspomniano poniżej. Na koniec kliknij przycisk Edytuj schemat.

Ponieważ nasz plik zawiera tylko zwykły tekst, dodajemy tylko jedną kolumnę typu String. Teraz kliknij OK.
Note - Jeśli dane wejściowe mają wiele kolumn różnych typów, należy odpowiednio wspomnieć o schemacie.

W składniku tLogRow kliknij Synchronizuj kolumny w schemacie edycji.
Wybierz tryb, w którym chcesz wydrukować wydruk.

Na koniec kliknij Uruchom, aby wykonać zadanie.
Po pomyślnym odczytaniu pliku HDFS możesz zobaczyć następujące dane wyjściowe.

Zapisywanie pliku do HDFS
Zobaczmy, jak napisać plik z HDFS w Talend. Przeciągnij i upuść 3 komponenty - tHDFSConnection, tFileInputDelimited i tHDFSOutput z palety do okna projektanta.
Kliknij prawym przyciskiem myszy tHDFSConnection i połącz komponent tFileInputDelimited za pomocą wyzwalacza „OnSubJobOk”.
Kliknij prawym przyciskiem myszy tFileInputDelimited i przeciągnij główny link do tHDFSOutput.

Zauważ, że tHDFSConnection będzie miał podobną konfigurację jak wcześniej.
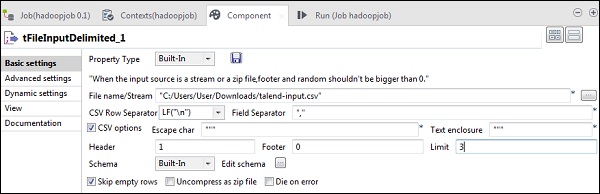
Teraz w tFileInputDelimited podaj ścieżkę do pliku wejściowego w opcji Nazwa pliku / Strumień. Tutaj używamy pliku csv jako danych wejściowych, stąd separator pól to „,”.
Wybierz nagłówek, stopkę, limit zgodnie z plikiem wejściowym. Zauważ, że tutaj nasz nagłówek to 1, ponieważ 1 wiersz zawiera nazwy kolumn, a limit to 3, ponieważ piszemy tylko pierwsze 3 wiersze do HDFS.
Teraz kliknij edytuj schemat.
Teraz, zgodnie z naszym plikiem wejściowym, zdefiniuj schemat. Nasz plik wejściowy ma 3 kolumny, jak wspomniano poniżej.

W składniku tHDFSOutput kliknij synchronizuj kolumny. Następnie wybierz tHDFSConnection w Użyj istniejącego połączenia. Ponadto w polu Nazwa pliku podaj ścieżkę HDFS, w której chcesz zapisać plik.
Zwróć uwagę, że typem pliku będzie plik tekstowy, Akcja to „Utwórz”, separatorem wierszy będzie „\ n”, a separatorem pól będzie „;”

Na koniec kliknij Uruchom, aby wykonać zadanie. Po pomyślnym wykonaniu zadania sprawdź, czy plik znajduje się na HDFS.

Uruchom następujące polecenie hdfs ze ścieżką wyjściową, o której wspomniałeś w zadaniu.
hdfs dfs -cat /input/talendwriteJeśli pomyślnie zapisujesz na HDFS, zobaczysz następujące dane wyjściowe.
