Talend - Zmniejsz mapę
W poprzednim rozdziale widzieliśmy, jak Talend współpracuje z Big Data. W tym rozdziale wyjaśnimy, jak używać mapy Reduce z Talendem.
Tworzenie zadania Talend MapReduce
Nauczmy się, jak uruchomić zadanie MapReduce na Talend. Tutaj uruchomimy przykład liczby słów MapReduce.
W tym celu kliknij prawym przyciskiem myszy Job Design i utwórz nowe zadanie - MapreduceJob. Podaj szczegóły zadania i kliknij Zakończ.
Dodawanie komponentów do zadania MapReduce
Aby dodać komponenty do zadania MapReduce, przeciągnij i upuść pięć komponentów Talend - tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput z palety do okna projektanta. Kliknij prawym przyciskiem myszy tHDFSInput i utwórz główne łącze do tNormalize.
Kliknij prawym przyciskiem myszy tNormalizuj i utwórz główne łącze do tAggregateRow. Następnie kliknij prawym przyciskiem myszy tAggregateRow i utwórz główne łącze do tMap. Teraz kliknij prawym przyciskiem myszy tMap i utwórz główne łącze do tHDFSOutput.
Konfiguracja komponentów i przekształceń
W tHDFSInput wybierz dystrybucję cloudera i jej wersję. Zwróć uwagę, że identyfikator URI Namenode powinien mieć postać „hdfs: //quickstart.cloudera: 8020”, a nazwa użytkownika - „cloudera”. W opcji nazwy pliku podaj ścieżkę pliku wejściowego do zadania MapReduce. Upewnij się, że ten plik wejściowy jest obecny w HDFS.
Teraz wybierz typ pliku, separator wierszy, separator plików i nagłówek zgodnie z plikiem wejściowym.
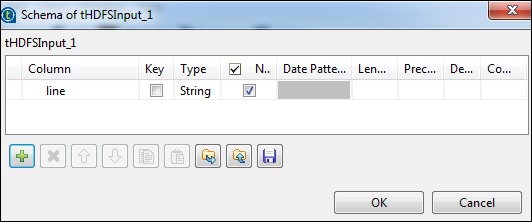
Kliknij edytuj schemat i dodaj pole „linia” jako typ ciągu.
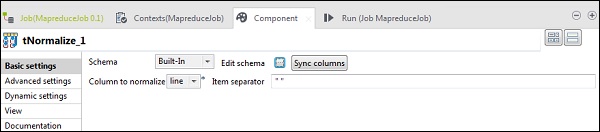
W tNomalize kolumną do normalizacji będzie linia, a separatorem pozycji będzie spacja -> „”. Teraz kliknij edytuj schemat. tNormalize będzie miał line column, a tAggregateRow będzie miał 2 kolumny word i wordcount, jak pokazano poniżej.
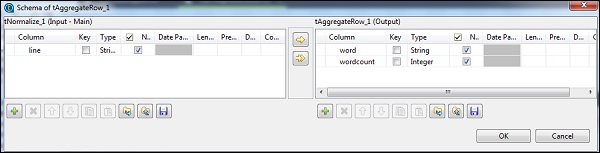
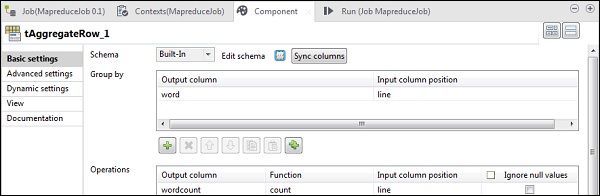
W tAggregateRow, wstaw słowo jako kolumnę wyjściową w opcji Grupuj według. W operacjach umieść wordcount jako kolumnę wyjściową, funkcję jako liczbę i pozycję kolumny wejściowej jako wiersz.
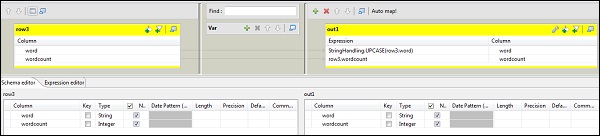
Teraz kliknij dwukrotnie komponent tMap, aby wejść do edytora map i zmapować wejście z wymaganym wyjściem. W tym przykładzie słowo jest odwzorowywane na słowo, a liczba słów jest odwzorowywane za pomocą liczby słów. W kolumnie wyrażeń kliknij […], aby wejść do konstruktora wyrażeń.
Teraz wybierz StringHandling z listy kategorii i funkcji UPCASE. Edytuj wyrażenie na „StringHandling.UPCASE (row3.word)” i kliknij OK. Zachowaj row3.wordcount w kolumnie wyrażenia odpowiadającej wordcount, jak pokazano poniżej.
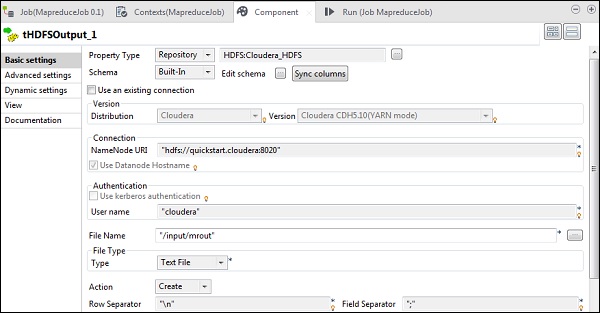
W tHDFSOutput połącz się z klastrem Hadoop, który utworzyliśmy na podstawie typu właściwości jako repozytorium. Zwróć uwagę, że pola zostaną automatycznie wypełnione. W polu Nazwa pliku podaj ścieżkę wyjściową, w której chcesz przechowywać dane wyjściowe. Zachowaj Akcję, separator wierszy i separator pól, jak pokazano poniżej.
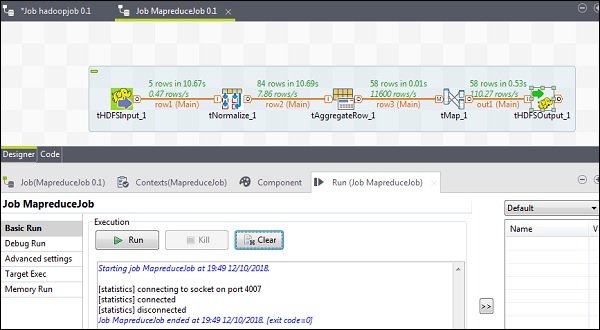
Wykonywanie zadania MapReduce
Po pomyślnym zakończeniu konfiguracji kliknij Uruchom i wykonaj zadanie MapReduce.
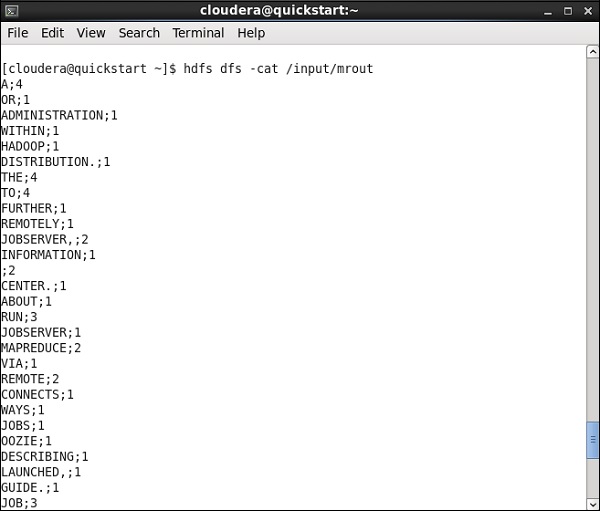
Przejdź do ścieżki HDFS i sprawdź dane wyjściowe. Zauważ, że wszystkie słowa będą pisane wielkimi literami wraz z ich liczbą.