Talend - szybki przewodnik
Talend to platforma integracji oprogramowania, która zapewnia rozwiązania w zakresie integracji danych, jakości danych, zarządzania danymi, przygotowania danych i dużych zbiorów danych. Zapotrzebowanie na specjalistów ETL ze znajomością Talend jest duże. Ponadto jest to jedyne narzędzie ETL ze wszystkimi wtyczkami, które można łatwo zintegrować z ekosystemem Big Data.
Według firmy Gartner Talend należy do magicznego kwadrantu liderów pod względem narzędzi do integracji danych.
Talend oferuje różne produkty komercyjne wymienione poniżej -
- Jakość danych Talend
- Integracja danych Talend
- Przygotowanie danych Talend
- Chmura Talend
- Talend Big Data
- Platforma Talend MDM (Master Data Management)
- Platforma usług danych Talend
- Menedżer metadanych Talend
- Talend Data Fabric
Talend oferuje również Open Studio, które jest darmowym narzędziem typu open source, szeroko stosowanym do integracji danych i Big Data.
Poniżej przedstawiono wymagania systemowe do pobrania i pracy z Talend Open Studio -
Zalecany system operacyjny
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Wymagania dotyczące pamięci
- Pamięć - co najmniej 4 GB, zalecane 8 GB
- Przestrzeń dyskowa - 30 GB
Poza tym potrzebujesz również działającego klastra Hadoop (najlepiej Cloudera.
Note - Java 8 musi być dostępna z już ustawionymi zmiennymi środowiskowymi.
Aby pobrać Talend Open Studio do integracji dużych zbiorów danych i danych, wykonaj następujące czynności -
Step 1 - Przejdź do strony: https://www.talend.com/products/big-data/big-data-open-studio/i kliknij przycisk pobierania. Jak widać, rozpoczyna się pobieranie pliku TOS_BD_xxxxxxx.zip.
Step 2 - Po zakończeniu pobierania wypakuj zawartość pliku zip, utworzy on folder ze wszystkimi plikami Talend.
Step 3- Otwórz folder Talend i kliknij dwukrotnie plik wykonywalny: TOS_BD-win-x86_64.exe. Zaakceptuj umowę licencyjną użytkownika.
Step 4 - Utwórz nowy projekt i kliknij Zakończ.
Step 5 - Kliknij opcję Zezwól na dostęp, jeśli pojawi się alert zabezpieczeń systemu Windows.
Step 6 - Teraz otworzy się strona powitalna Talend Open Studio.
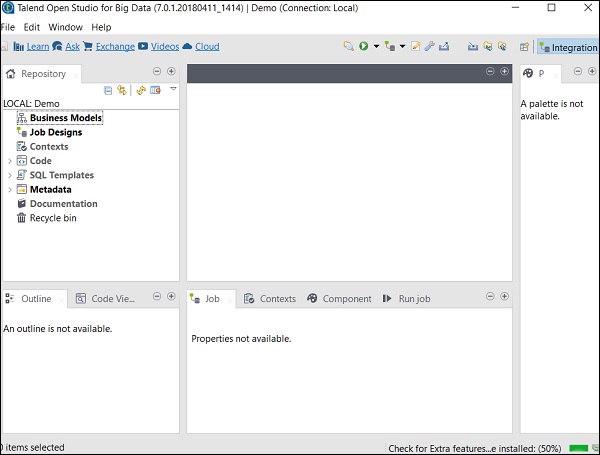
Step 7 - Kliknij przycisk Zakończ, aby zainstalować wymagane biblioteki innych firm.
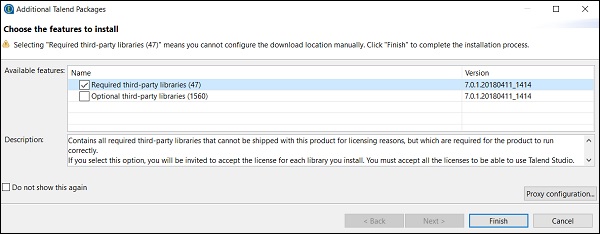
Step 8 - Zaakceptuj warunki i kliknij Zakończ.
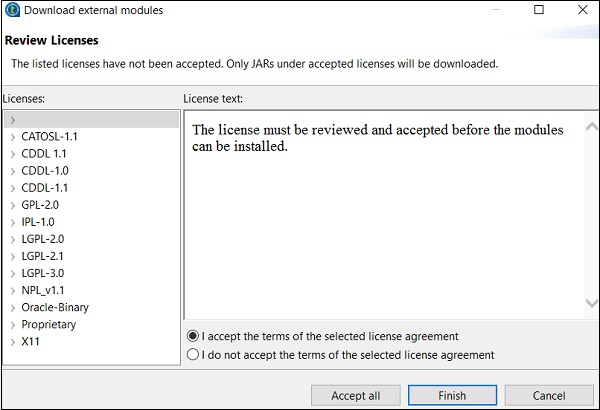
Step 9 - Kliknij Tak.
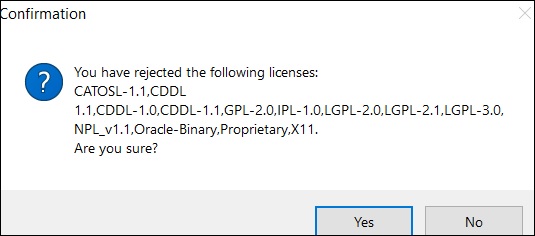
Teraz Twoje Talend Open Studio jest gotowe z niezbędnymi bibliotekami.
Talend Open Studio to darmowe narzędzie ETL typu open source do integracji danych i dużych zbiorów danych. Jest to oparte na Eclipse narzędzie programistyczne i projektant zadań. Wystarczy przeciągnąć i upuścić komponenty i połączyć je, aby tworzyć i uruchamiać zadania ETL lub ETL. Narzędzie automatycznie utworzy kod Java dla zadania i nie musisz pisać ani jednej linii kodu.
Istnieje wiele opcji łączenia się ze źródłami danych, takimi jak RDBMS, Excel, ekosystem SaaS Big Data, a także aplikacjami i technologiami, takimi jak SAP, CRM, Dropbox i wiele innych.
Oto kilka ważnych korzyści, które oferuje Talend Open Studio -
Zapewnia wszystkie funkcje potrzebne do integracji i synchronizacji danych z 900 komponentami, wbudowanymi łącznikami, automatyczną konwersją zadań do kodu Java i nie tylko.
Narzędzie jest całkowicie darmowe, stąd duże oszczędności kosztów.
W ciągu ostatnich 12 lat wiele gigantycznych organizacji przyjęło TOS do integracji danych, co wskazuje na bardzo wysoki współczynnik zaufania do tego narzędzia.
Społeczność Talend zajmująca się integracją danych jest bardzo aktywna.
Talend ciągle dodaje funkcje do tych narzędzi, a dokumentacja jest dobrze zorganizowana i bardzo łatwa do naśladowania.
Większość organizacji pobiera dane z wielu miejsc i przechowuje je oddzielnie. Teraz, jeśli organizacja musi podejmować decyzje, musi pobierać dane z różnych źródeł, przedstawiać je w ujednoliconym widoku, a następnie analizować, aby uzyskać wynik. Ten proces nazywa się integracją danych.
Korzyści
Integracja danych oferuje wiele korzyści opisanych poniżej -
Poprawia współpracę między różnymi zespołami w organizacji próbującymi uzyskać dostęp do danych organizacji.
Oszczędza czas i ułatwia analizę danych, ponieważ dane są skutecznie integrowane.
Zautomatyzowany proces integracji danych synchronizuje dane i ułatwia raportowanie w czasie rzeczywistym i okresowe, które w przeciwnym razie jest czasochłonne, jeśli wykonywane jest ręcznie.
Dane, które są integrowane z kilku źródeł, dojrzewają i ulepszają się z czasem, co ostatecznie pomaga w lepszej jakości danych.
Praca z projektami
W tej sekcji wyjaśnijmy, jak pracować nad projektami Talend -
Tworzenie projektu
Kliknij dwukrotnie plik wykonywalny TOS Big Data, otworzy się okno pokazane poniżej.
Wybierz opcję Utwórz nowy projekt, podaj nazwę projektu i kliknij Utwórz.

Wybierz utworzony projekt i kliknij Zakończ.

Importowanie projektu
Kliknij dwukrotnie plik wykonywalny TOS Big Data, zobaczysz okno, jak pokazano poniżej. Wybierz opcję Importuj projekt demonstracyjny i kliknij Wybierz.

Możesz wybrać jedną z poniższych opcji. Tutaj wybieramy wersje demonstracyjne integracji danych. Teraz kliknij Zakończ.

Teraz podaj nazwę i opis projektu. Kliknij Finish.

Zaimportowany projekt możesz zobaczyć pod listą istniejących projektów.
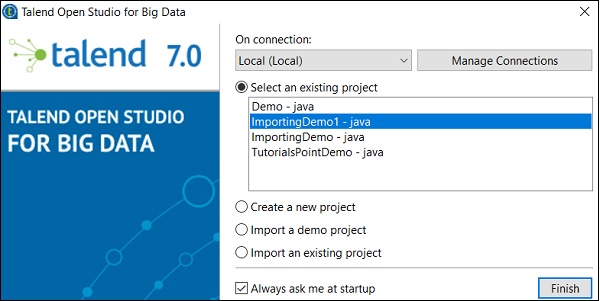
Teraz zrozumiemy, jak zaimportować istniejący projekt Talend.
Wybierz opcję Importuj istniejący projekt i kliknij Wybierz.

Podaj nazwę projektu i wybierz opcję „Wybierz katalog główny”.

Przejrzyj istniejący katalog domowy projektu Talend i kliknij Zakończ.

Twój istniejący projekt Talend zostanie zaimportowany.
Otwieranie projektu
Wybierz projekt z istniejącego projektu i kliknij Zakończ. Otworzy się ten projekt Talend.

Usuwanie projektu
Aby usunąć projekt, kliknij Zarządzaj połączeniami.

Kliknij Usuń istniejące projekty

Wybierz projekt, który chcesz usunąć i kliknij OK.
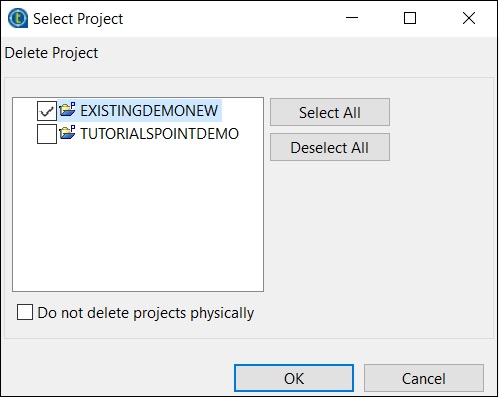
Kliknij ponownie OK.
Eksportowanie projektu
Kliknij opcję Eksportuj projekt.

Wybierz projekt, który chcesz wyeksportować i podaj ścieżkę do miejsca, w którym ma zostać wyeksportowany. Kliknij Zakończ.

Model biznesowy to graficzna reprezentacja projektu integracji danych. Jest to nietechniczne przedstawienie przepływu pracy w firmie.
Dlaczego potrzebujesz modelu biznesowego?
Model biznesowy jest zbudowany tak, aby pokazać wyższemu kierownictwu, co robisz, a także pozwala Twojemu zespołowi zrozumieć, co próbujesz osiągnąć. Projektowanie modelu biznesowego jest uważane za jedną z najlepszych praktyk, które organizacje przyjmują na początku projektu integracji danych. Poza tym, pomagając w obniżeniu kosztów, znajduje i usuwa wąskie gardła w Twoim projekcie. W razie potrzeby model można modyfikować w trakcie i po realizacji projektu.
Tworzenie modelu biznesowego w Talend Open Studio
Otwarte studio Talend zapewnia wiele kształtów i łączników do tworzenia i projektowania modelu biznesowego. Każdy moduł w modelu biznesowym może mieć dołączoną do siebie dokumentację.
Talend Open Studio oferuje następujące kształty i opcje łączników do tworzenia modelu biznesowego -
Decision - Ten kształt służy do umieszczania warunku w modelu.
Action - Ten kształt służy do wyświetlania wszelkich przekształceń, tłumaczeń lub formatowania.
Terminal - Ten kształt pokazuje typ terminala wyjściowego.
Data - Ten kształt jest używany do pokazania typu danych.
Document - Ten kształt służy do wstawiania obiektu dokumentu, który może służyć do wprowadzania / wyprowadzania przetwarzanych danych.
Input - Ten kształt służy do wstawiania obiektu wejściowego, za pomocą którego użytkownik może ręcznie przekazywać dane.
List - Ten kształt zawiera wyodrębnione dane i można go zdefiniować tak, aby zawierał tylko określony rodzaj danych na liście.
Database - Ten kształt służy do przechowywania danych wejściowych / wyjściowych.
Actor - Ten kształt symbolizuje osoby zaangażowane w procesy decyzyjne i techniczne
Ellipse - Wstawia kształt elipsy.
Gear - Ten kształt pokazuje programy ręczne, które należy zastąpić zadaniami Talend.
Wszystkie operacje w Talend są wykonywane przez złącza i komponenty. Talend oferuje ponad 800 złączy i komponentów do wykonywania kilku operacji. Te komponenty są obecne w palecie i istnieje 21 głównych kategorii, do których należą komponenty. Możesz wybrać złącza i po prostu przeciągnąć i upuścić je w panelu projektanta, automatycznie utworzy kod java, który zostanie skompilowany po zapisaniu kodu Talend.
Główne kategorie zawierające komponenty są pokazane poniżej -
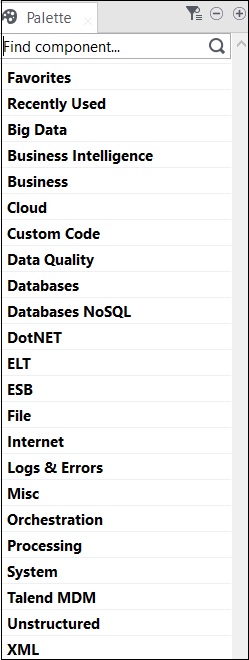
Poniżej znajduje się lista powszechnie używanych konektorów i komponentów do integracji danych w Talend Open Studio -
tMysqlConnection - Łączy się z bazą danych MySQL zdefiniowaną w komponencie.
tMysqlInput - Uruchamia zapytanie do bazy danych w celu odczytania bazy danych i wyodrębnienia pól (tabel, widoków itp.) W zależności od zapytania.
tMysqlOutput - Służy do zapisywania, aktualizowania, modyfikowania danych w bazie danych MySQL.
tFileInputDelimited - Odczytuje rozdzielany plik wiersz po wierszu i dzieli je na osobne pola i przekazuje do następnego składnika.
tFileInputExcel - Odczytuje plik Excela wiersz po wierszu i dzieli je na osobne pola i przekazuje do następnego komponentu.
tFileList - Pobiera wszystkie pliki i katalogi z podanego wzorca maski pliku.
tFileArchive - Kompresuje zestaw plików lub folderów do pliku archiwum zip, gzip lub tar.gz.
tRowGenerator - Zapewnia edytor, w którym można pisać funkcje lub wybierać wyrażenia do generowania przykładowych danych.
tMsgBox - Zwraca okno dialogowe z określonym komunikatem i przyciskiem OK.
tLogRow- Monitoruje przetwarzane dane. Wyświetla dane / dane wyjściowe w konsoli uruchamiania.
tPreJob - Określa zadania podrzędne, które będą uruchamiane przed rozpoczęciem rzeczywistego zadania.
tMap- Działa jako wtyczka w studiu Talend. Pobiera dane z co najmniej jednego źródła, przekształca je, a następnie wysyła przekształcone dane do co najmniej jednego miejsca docelowego.
tJoin - Łączy 2 tabele, wykonując połączenia wewnętrzne i zewnętrzne między przepływem głównym a przepływem wyszukiwania.
tJava - Umożliwia korzystanie ze spersonalizowanego kodu java w programie Talend.
tRunJob - Zarządza złożonymi systemami zadań, uruchamiając jedno zadanie Talend po drugim.
To jest techniczna implementacja / graficzne przedstawienie modelu biznesowego. W tym projekcie jeden lub więcej komponentów jest połączonych ze sobą, aby uruchomić proces integracji danych. Tak więc, kiedy przeciągasz i upuszczasz komponenty w okienku projektu, a następnie łączysz się z łącznikami, projekt zadania przekształca wszystko w kod i tworzy kompletny program do uruchomienia, który tworzy przepływ danych.
Tworzenie pracy
W oknie repozytorium kliknij prawym przyciskiem myszy Projekt pracy i kliknij Utwórz zadanie.
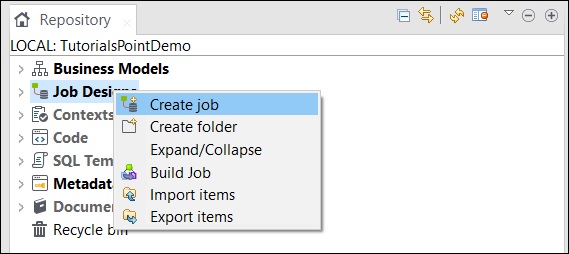
Podaj nazwę, cel i opis zadania i kliknij przycisk Zakończ.
Możesz zobaczyć, że Twoja praca została utworzona w Projektowaniu Pracy.
Teraz wykorzystajmy to zadanie, aby dodać komponenty, podłączyć je i skonfigurować. Tutaj weźmiemy plik Excela jako dane wejściowe i utworzymy plik Excela jako wyjście z tymi samymi danymi.
Dodawanie komponentów do zadania
W palecie jest kilka komponentów do wyboru. Istnieje również opcja wyszukiwania, w której można wpisać nazwę elementu, aby go wybrać.
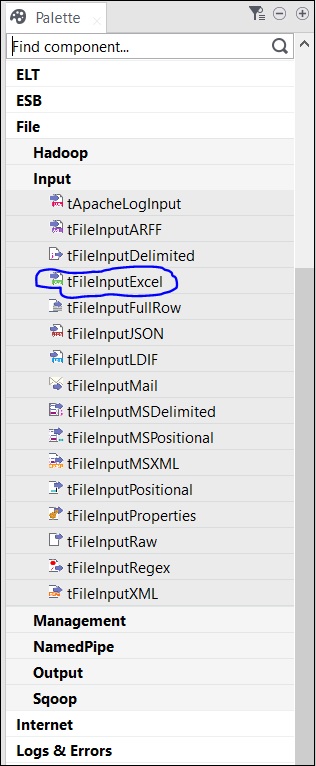
Ponieważ jako dane wejściowe bierzemy plik Excela, przeciągniemy i upuścimy komponent tFileInputExcel z palety do okna Projektanta.

Teraz, jeśli klikniesz w dowolnym miejscu okna projektanta, pojawi się pole wyszukiwania. Znajdź tLogRow i wybierz go, aby przenieść go do okna projektanta.

Na koniec wybierz komponent tFileOutputExcel z palety i przeciągnij i upuść go w oknie projektanta.
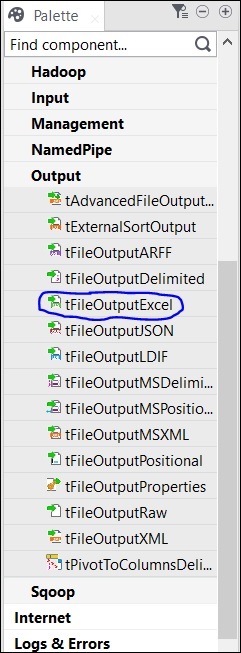
Teraz dodawanie komponentów jest zakończone.
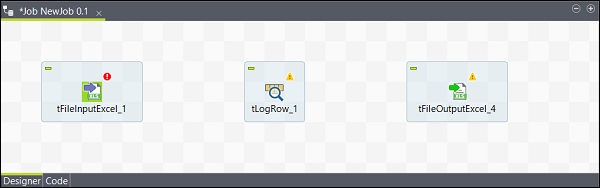
Podłączanie komponentów
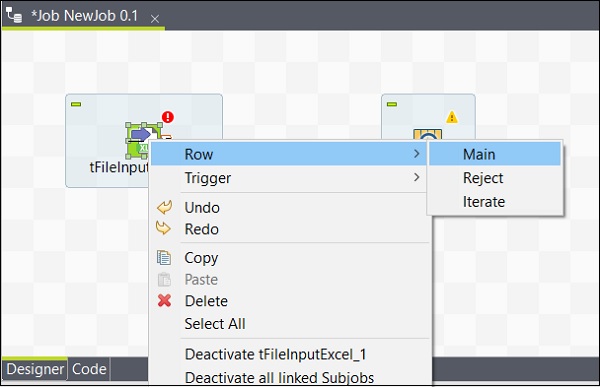
Po dodaniu komponentów należy je połączyć. Kliknij prawym przyciskiem myszy pierwszy komponent tFileInputExcel i narysuj linię główną do tLogRow, jak pokazano poniżej.
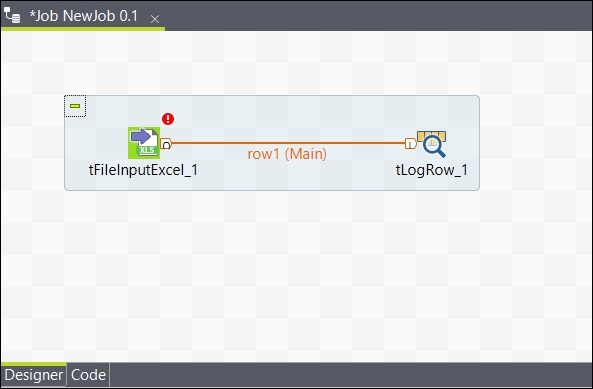
Podobnie, kliknij prawym przyciskiem myszy tLogRow i narysuj linię główną na tFileOutputExcel. Teraz twoje komponenty są połączone.
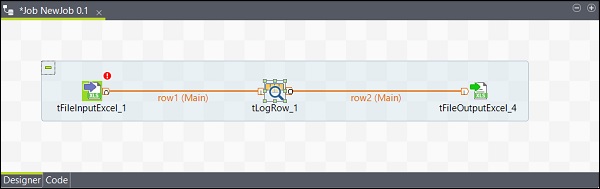
Konfiguracja komponentów
Po dodaniu i podłączeniu komponentów w zadaniu należy je skonfigurować. W tym celu kliknij dwukrotnie pierwszy składnik tFileInputExcel, aby go skonfigurować. Podaj ścieżkę do pliku wejściowego w polu Nazwa pliku / strumień, jak pokazano poniżej.
Jeśli pierwszy wiersz w programie Excel zawiera nazwy kolumn, wpisz 1 w opcji Nagłówek.
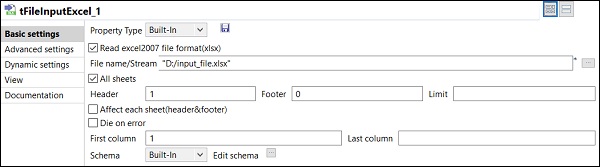
Kliknij Edytuj schemat i dodaj kolumny oraz ich typ zgodnie z wejściowym plikiem Excel. Kliknij OK po dodaniu schematu.
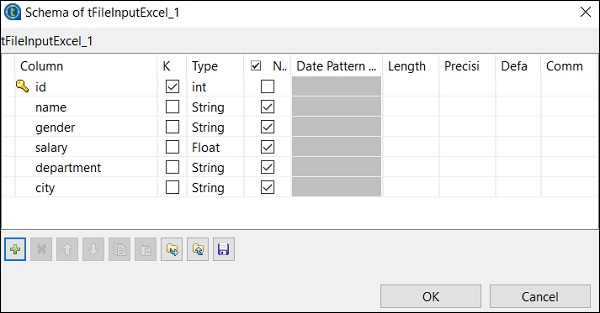
Kliknij Tak.
W komponencie tLogRow kliknij synchronizację kolumn i wybierz tryb, w którym chcesz generować wiersze z wprowadzonych danych. Tutaj wybraliśmy tryb podstawowy z „,” jako separatorem pól.
Na koniec w komponencie tFileOutputExcel podaj ścieżkę z nazwą pliku, w którym chcesz przechowywać
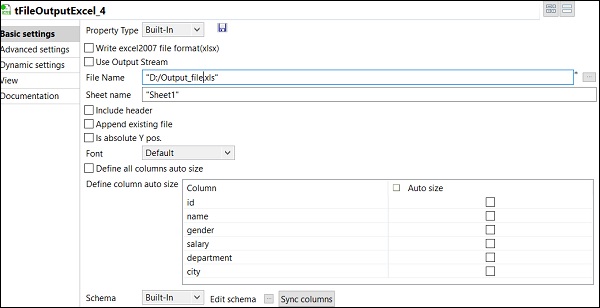
Twój wyjściowy plik Excela z nazwą arkusza. Click on sync columns.
Wykonanie zadania
Gdy skończysz dodawać, podłączać i konfigurować komponenty, jesteś gotowy do wykonania zadania Talend. Kliknij przycisk Uruchom, aby rozpocząć wykonywanie.

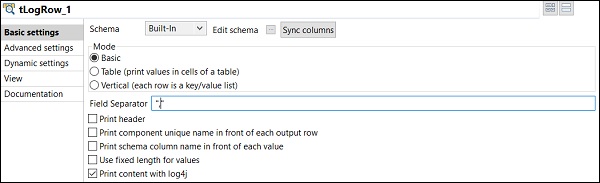
Zobaczysz wynik w trybie podstawowym z separatorem „,”.
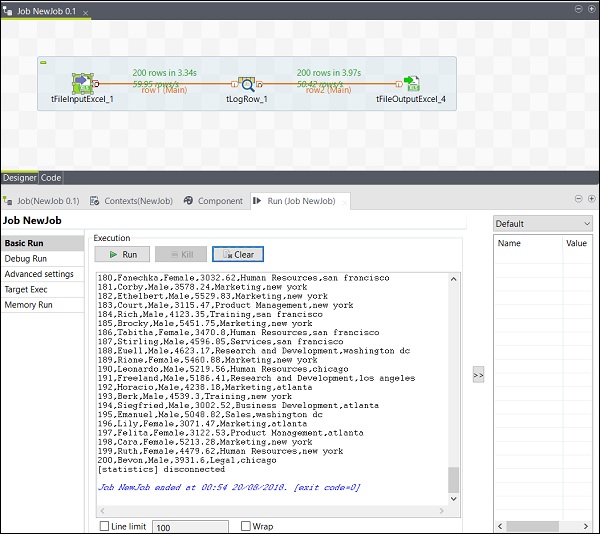
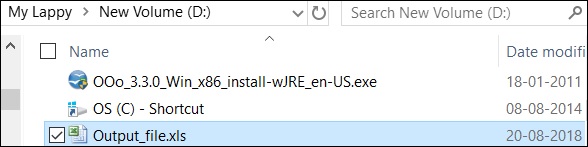
Możesz również zobaczyć, że Twoje dane wyjściowe są zapisywane jako Excel w ścieżce wyjściowej, o której wspomniałeś.
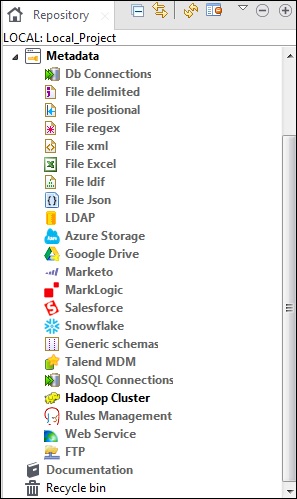
Metadane zasadniczo oznaczają dane o danych. Mówi o tym, co, kiedy, dlaczego, kto, gdzie, jakie i jak dane. W Talend metadane zawierają wszystkie informacje o danych, które są obecne w Talend Studio. Opcja metadanych znajduje się w panelu Repozytorium w Talend Open Studio.
Różne źródła, takie jak połączenia DB, różnego rodzaju pliki, LDAP, Azure, Salesforce, usługi internetowe FTP, klaster Hadoop i wiele innych opcji są dostępne w Metadanych Talend.
Głównym zastosowaniem metadanych w Talend Open Studio jest to, że możesz używać tych źródeł danych w kilku zadaniach, po prostu przeciągając i upuszczając z panelu Metadane w repozytorium.
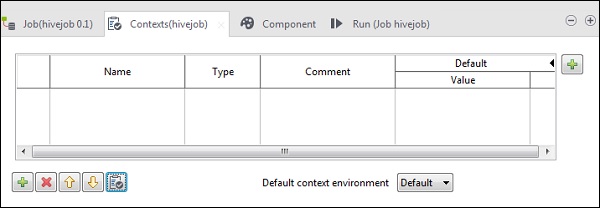
Zmienne kontekstowe to zmienne, które mogą mieć różne wartości w różnych środowiskach. Możesz utworzyć grupę kontekstów, która może zawierać wiele zmiennych kontekstowych. Nie musisz dodawać pojedynczo każdej zmiennej kontekstowej do zadania, możesz po prostu dodać grupę kontekstów do zadania.
Te zmienne są używane do przygotowania produkcji kodu. Za pomocą zmiennych kontekstowych można przenosić kod w środowiskach programistycznych, testowych lub produkcyjnych, będzie działał we wszystkich środowiskach.
W każdym zadaniu możesz przejść do zakładki Konteksty, jak pokazano poniżej i dodać zmienne kontekstowe.
W tym rozdziale przyjrzyjmy się zarządzaniu zadaniami i odpowiadającym im funkcjom zawartym w Talend.
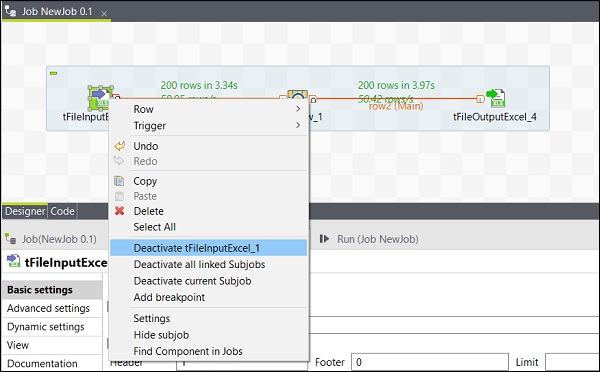
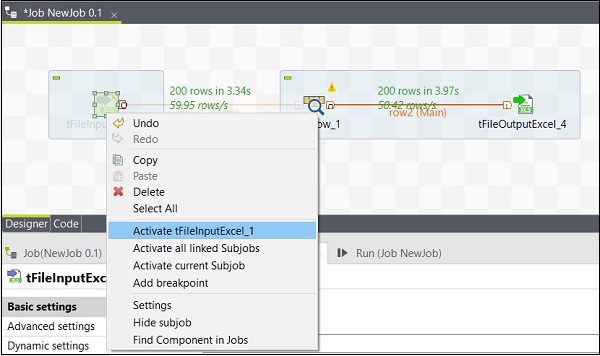
Aktywacja / dezaktywacja komponentu
Aktywacja / dezaktywacja komponentu jest bardzo prosta. Wystarczy wybrać komponent, kliknąć go prawym przyciskiem myszy i wybrać opcję dezaktywacji lub aktywacji tego komponentu.
Importowanie / eksportowanie elementów i prac budowlanych
Aby wyeksportować element z zadania, kliknij prawym przyciskiem myszy zadanie w projektach pracy i kliknij opcję Eksportuj elementy.
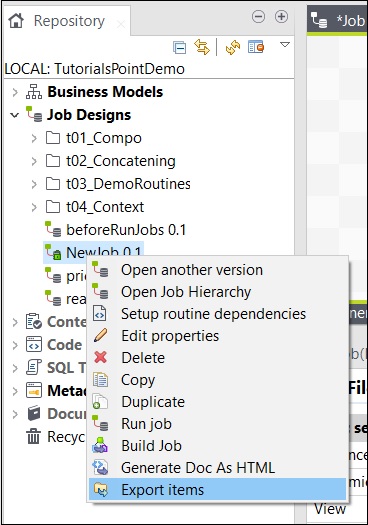
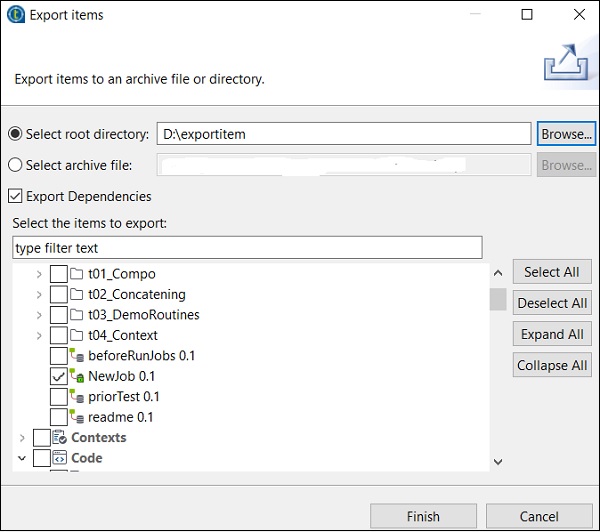
Wprowadź ścieżkę, do której chcesz wyeksportować element, i kliknij Zakończ.
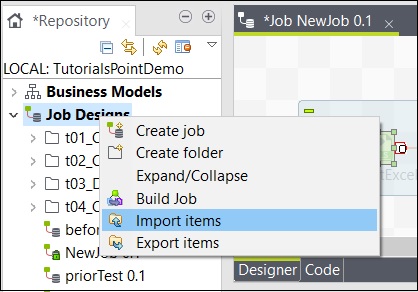
Aby zaimportować element z zadania, kliknij prawym przyciskiem myszy zadanie w projektach pracy i kliknij Importuj elementy.
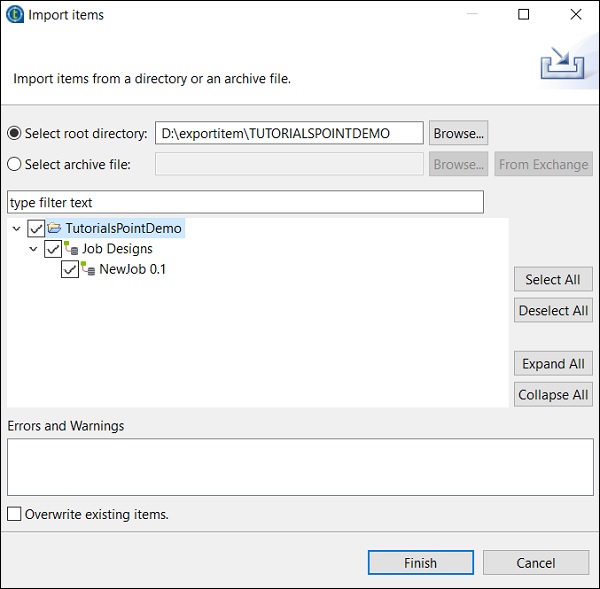
Przeglądaj katalog główny, z którego chcesz zaimportować elementy.
Zaznacz wszystkie pola wyboru i kliknij Zakończ.
W tym rozdziale przyjrzyjmy się, jak radzić sobie z wykonywaniem zadań w Talend.
Aby zbudować pracę, kliknij ją prawym przyciskiem myszy i wybierz opcję Utwórz pracę.
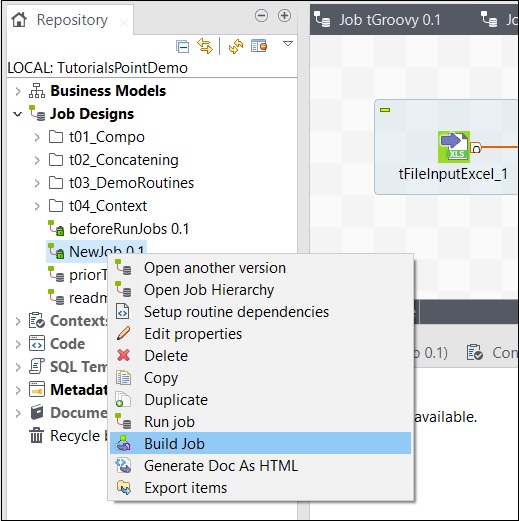
Podaj ścieżkę, w której chcesz zarchiwizować zadanie, wybierz wersję zadania i typ kompilacji, a następnie kliknij przycisk Zakończ.
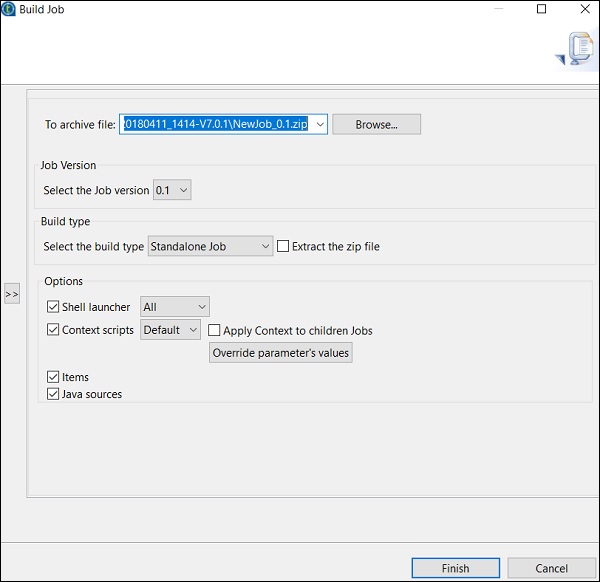
Jak uruchomić zadanie w trybie normalnym
Aby uruchomić zadanie w normalnym węźle, musisz wybrać „Uruchomienie podstawowe” i kliknąć przycisk Uruchom, aby rozpocząć wykonywanie.
Jak uruchomić zadanie w trybie debugowania
Aby uruchomić zadanie w trybie debugowania, dodaj punkt przerwania do składników, które chcesz debugować.
Następnie wybierz i kliknij prawym przyciskiem myszy komponent, kliknij opcję Dodaj punkt przerwania. Zwróć uwagę, że tutaj dodaliśmy punkty przerwania do składników tFileInputExcel i tLogRow. Następnie przejdź do Debug Run i kliknij przycisk Java Debug.
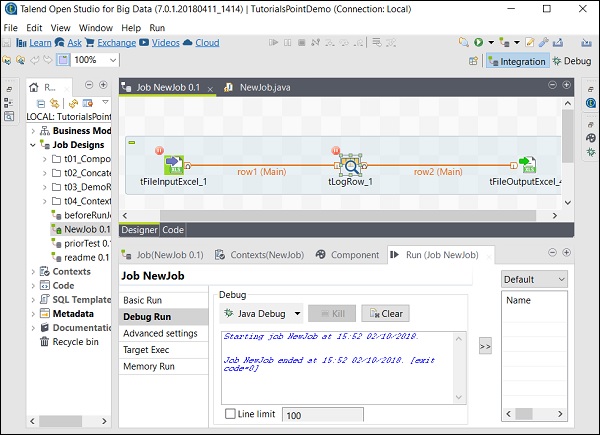
Na poniższym zrzucie ekranu widać, że zadanie zostanie teraz wykonane w trybie debugowania i zgodnie z punktami przerwania, o których wspomnieliśmy.
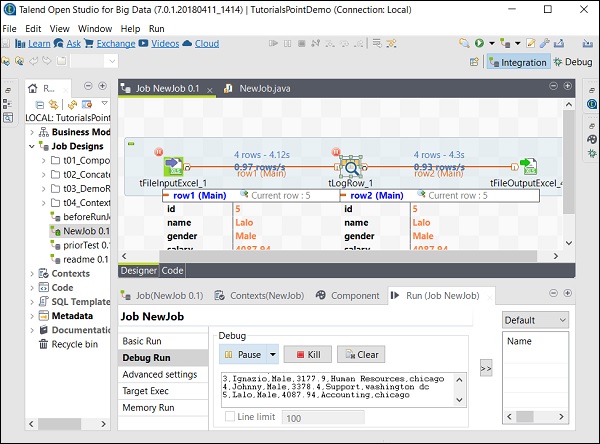
Zaawansowane ustawienia
W ustawieniach zaawansowanych można wybrać Statystyki, Czas wykonania, Zapisz zadanie przed wykonaniem, Wyczyść przed uruchomieniem i ustawienia JVM. Każda z tych opcji ma funkcjonalność opisaną tutaj -
Statistics - Wyświetla wskaźnik wydajności przetwarzania;
Exec Time - Czas potrzebny na wykonanie zadania.
Save Job before Execution - Automatycznie zapisuje zadanie przed rozpoczęciem wykonywania.
Clear before Run - Usuwa wszystko z konsoli wyjściowej.
JVM Settings - Pomaga nam skonfigurować własne argumenty Java.
Hasłem przewodnim Open Studio z Big Data jest „Uprość ETL i ELT dzięki wiodącemu bezpłatnemu narzędziu ETL typu open source do obsługi dużych zbiorów danych”. W tym rozdziale przyjrzyjmy się wykorzystaniu Talend jako narzędzia do przetwarzania danych w środowisku big data.
Wprowadzenie
Talend Open Studio - Big Data to darmowe narzędzie typu open source do bardzo łatwego przetwarzania danych w środowisku Big Data. W Talend Open Studio dostępnych jest wiele komponentów Big Data, które pozwalają tworzyć i uruchamiać zadania Hadoop po prostu przez proste przeciąganie i upuszczanie kilku komponentów Hadoop.
Poza tym nie musimy pisać dużych linii kodów MapReduce; Talend Open Studio Big data pomaga to zrobić z obecnymi w nim komponentami. Automatycznie generuje dla Ciebie kod MapReduce, wystarczy przeciągnąć i upuścić komponenty oraz skonfigurować kilka parametrów.
Daje także możliwość połączenia się z kilkoma dystrybucjami Big Data, takimi jak Cloudera, HortonWorks, MapR, Amazon EMR, a nawet Apache.
Komponenty Talend dla Big Data
Poniżej znajduje się lista kategorii z komponentami do uruchomienia zadania w środowisku Big Data w ramach Big Data -
Lista łączników i komponentów Big Data w Talend Open Studio jest pokazana poniżej -
tHDFSConnection - Służy do łączenia się z HDFS (rozproszony system plików Hadoop).
tHDFSInput - Odczytuje dane z podanej ścieżki hdfs, umieszcza je w schemacie talend, a następnie przekazuje do następnego komponentu w zadaniu.
tHDFSList - Pobiera wszystkie pliki i foldery w podanej ścieżce hdfs.
tHDFSPut - Kopiuje plik / folder z lokalnego systemu plików (zdefiniowanego przez użytkownika) do hdfs pod podaną ścieżką.
tHDFSGet - Kopiuje plik / folder z hdfs do lokalnego systemu plików (zdefiniowanego przez użytkownika) pod podaną ścieżką.
tHDFSDelete - Usuwa plik z HDFS
tHDFSExist - Sprawdza, czy plik jest obecny w HDFS, czy nie.
tHDFSOutput - Zapisuje przepływy danych w HDFS.
tCassandraConnection - Otwiera połączenie z serwerem Cassandra.
tCassandraRow - Uruchamia zapytania CQL (język zapytań Cassandra) w określonej bazie danych.
tHBaseConnection - Otwiera połączenie z bazą danych HBase.
tHBaseInput - odczytuje dane z bazy danych HBase.
tHiveConnection - Otwiera połączenie z bazą danych Hive.
tHiveCreateTable - Tworzy tabelę w bazie danych gałęzi.
tHiveInput - Odczytuje dane z bazy danych ula.
tHiveLoad - Zapisuje dane do tabeli gałęzi lub określonego katalogu.
tHiveRow - uruchamia zapytania HiveQL w określonej bazie danych.
tPigLoad - Ładuje dane wejściowe do strumienia wyjściowego.
tPigMap - Służy do przekształcania i routingu danych w procesie wieprzowym.
tPigJoin - Wykonuje operację łączenia 2 plików w oparciu o klucze łączenia.
tPigCoGroup - Grupuje i agreguje dane pochodzące z wielu wejść.
tPigSort - Sortuje podane dane w oparciu o jeden lub więcej zdefiniowanych kluczy sortowania.
tPigStoreResult - Przechowuje wynik działania świń w określonej przestrzeni magazynowej.
tPigFilterRow - Filtruje określone kolumny, aby podzielić dane na podstawie podanego warunku.
tPigDistinct - usuwa zduplikowane krotki z relacji.
tSqoopImport - Przesyła dane z relacyjnej bazy danych, takiej jak MySQL, Oracle DB do HDFS.
tSqoopExport - Przesyła dane z HDFS do relacyjnej bazy danych, takiej jak MySQL, Oracle DB
W tym rozdziale dowiemy się szczegółowo, jak Talend współpracuje z rozproszonym systemem plików Hadoop.
Ustawienia i wymagania wstępne
Zanim przejdziemy do Talend z HDFS, powinniśmy poznać ustawienia i wymagania wstępne, które należy spełnić w tym celu.
Tutaj uruchamiamy Cloudera quickstart 5.10 VM na wirtualnym pudełku. W tej maszynie wirtualnej musi być używana sieć tylko hosta.
Adres IP sieci tylko hosta: 192.168.56.101

Musisz mieć również tego samego hosta działającego w menedżerze Cloudera.

Teraz w systemie Windows przejdź do c: \ Windows \ System32 \ Drivers \ etc \ hosts i edytuj ten plik za pomocą Notatnika, jak pokazano poniżej.

Podobnie na maszynie wirtualnej Cloudera quickstart edytuj plik / etc / hosts, jak pokazano poniżej.
sudo gedit /etc/hosts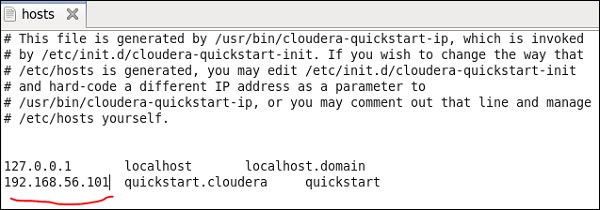
Konfigurowanie połączenia Hadoop
W panelu repozytorium przejdź do Metadane. Kliknij prawym przyciskiem myszy Hadoop Cluster i utwórz nowy klaster. Podaj nazwę, cel i opis tego połączenia klastra Hadoop.
Kliknij Następny.

Wybierz dystrybucję jako cloudera i wybierz wersję, której używasz. Wybierz opcję pobierania konfiguracji i kliknij Dalej.

Wprowadź poświadczenia menedżera (URI z portem, nazwą użytkownika, hasłem), jak pokazano poniżej, i kliknij Połącz. Jeśli szczegóły są poprawne, otrzymasz Cloudera QuickStart pod wykrytymi klastrami.
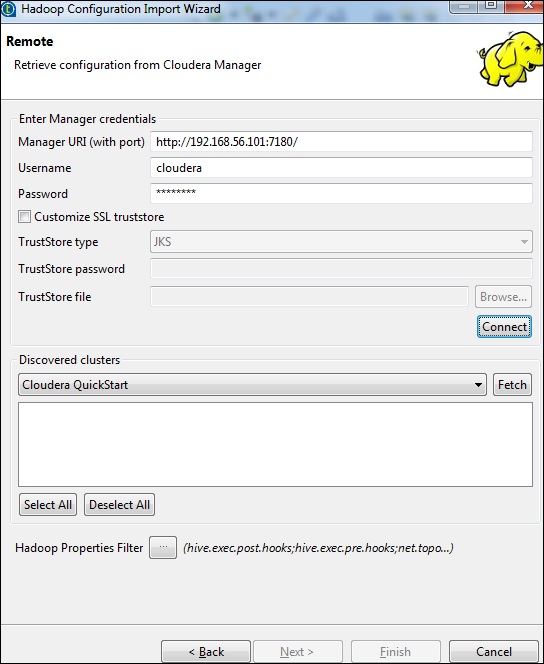
Kliknij Pobierz. Spowoduje to pobranie wszystkich połączeń i konfiguracji dla HDFS, YARN, HBASE, HIVE.
Wybierz Wszystko i kliknij Zakończ.

Pamiętaj, że wszystkie parametry połączenia zostaną automatycznie wypełnione. W nazwie użytkownika wpisz cloudera i kliknij Zakończ.

Dzięki temu udało Ci się połączyć z klastrem Hadoop.

Łączenie z HDFS
W tym zadaniu wymienimy wszystkie katalogi i pliki, które są obecne na HDFS.
Najpierw utworzymy zadanie, a następnie dodamy do niego komponenty HDFS. Kliknij prawym przyciskiem myszy projekt pracy i utwórz nową pracę - hadoopjob.
Teraz dodaj 2 komponenty z palety - tHDFSConnection i tHDFSList. Kliknij prawym przyciskiem myszy tHDFSConnection i połącz te 2 komponenty za pomocą wyzwalacza „OnSubJobOk”.
Teraz skonfiguruj oba komponenty talend hdfs.

W tHDFSConnection wybierz Repozytorium jako Typ właściwości i wybierz utworzony wcześniej klaster Hadoop Cloudera. Automatycznie wypełni wszystkie niezbędne szczegóły wymagane dla tego komponentu.

W tHDFSList wybierz „Użyj istniejącego połączenia” iz listy komponentów wybierz skonfigurowane połączenie tHDFS.
Podaj ścieżkę domową HDFS w katalogu HDFS i kliknij przycisk przeglądania po prawej stronie.

Jeśli poprawnie nawiązałeś połączenie z wyżej wymienionymi konfiguracjami, pojawi się okno pokazane poniżej. Wyświetli listę wszystkich katalogów i plików obecnych w domu HDFS.

Możesz to zweryfikować, sprawdzając swój HDFS w Cloudera.

Czytanie pliku z HDFS
W tej sekcji wyjaśnimy, jak czytać plik z HDFS w Talend. Możesz w tym celu utworzyć nowe stanowisko pracy, jednak tutaj korzystamy z już istniejącego.
Przeciągnij i upuść 3 komponenty - tHDFSConnection, tHDFSInput i tLogRow z palety do okna projektanta.
Kliknij prawym przyciskiem myszy tHDFSConnection i podłącz komponent tHDFSInput za pomocą wyzwalacza „OnSubJobOk”.
Kliknij prawym przyciskiem myszy tHDFSInput i przeciągnij główne łącze do tLogRow.

Zauważ, że tHDFSConnection będzie miał podobną konfigurację jak wcześniej. W tHDFSInput wybierz „Użyj istniejącego połączenia” iz listy komponentów wybierz tHDFSConnection.
W polu Nazwa pliku podaj ścieżkę HDFS do pliku, który chcesz odczytać. Tutaj czytamy prosty plik tekstowy, więc nasz typ pliku to Plik tekstowy. Podobnie, w zależności od danych wejściowych, wypełnij separator wiersza, separator pól i szczegóły nagłówka, jak wspomniano poniżej. Na koniec kliknij przycisk Edytuj schemat.

Ponieważ nasz plik zawiera tylko zwykły tekst, dodajemy tylko jedną kolumnę typu String. Teraz kliknij OK.
Note - Jeśli dane wejściowe mają wiele kolumn różnych typów, należy odpowiednio wspomnieć o schemacie.

W składniku tLogRow kliknij Synchronizuj kolumny w schemacie edycji.
Wybierz tryb, w którym chcesz wydrukować wydruk.

Na koniec kliknij Uruchom, aby wykonać zadanie.
Po pomyślnym odczytaniu pliku HDFS możesz zobaczyć następujące dane wyjściowe.

Zapisywanie pliku do HDFS
Zobaczmy, jak napisać plik z HDFS w Talend. Przeciągnij i upuść 3 komponenty - tHDFSConnection, tFileInputDelimited i tHDFSOutput z palety do okna projektanta.
Kliknij prawym przyciskiem myszy tHDFSConnection i połącz komponent tFileInputDelimited za pomocą wyzwalacza „OnSubJobOk”.
Kliknij prawym przyciskiem myszy tFileInputDelimited i przeciągnij główny link do tHDFSOutput.

Zauważ, że tHDFSConnection będzie miał podobną konfigurację jak wcześniej.
Teraz w tFileInputDelimited podaj ścieżkę do pliku wejściowego w opcji Nazwa pliku / Strumień. Tutaj używamy pliku csv jako danych wejściowych, stąd separator pól to „,”.
Wybierz nagłówek, stopkę, limit zgodnie z plikiem wejściowym. Zauważ, że tutaj nasz nagłówek to 1, ponieważ 1 wiersz zawiera nazwy kolumn, a limit to 3, ponieważ piszemy tylko pierwsze 3 wiersze do HDFS.
Teraz kliknij edytuj schemat.
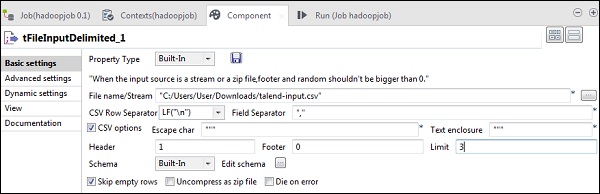
Teraz, zgodnie z naszym plikiem wejściowym, zdefiniuj schemat. Nasz plik wejściowy ma 3 kolumny, jak wspomniano poniżej.

W składniku tHDFSOutput kliknij synchronizuj kolumny. Następnie wybierz tHDFSConnection w Użyj istniejącego połączenia. Ponadto w polu Nazwa pliku podaj ścieżkę HDFS, w której chcesz zapisać plik.
Zwróć uwagę, że typem pliku będzie plik tekstowy, Akcja to „Utwórz”, separatorem wierszy będzie „\ n”, a separatorem pól będzie „;”

Na koniec kliknij Uruchom, aby wykonać zadanie. Po pomyślnym wykonaniu zadania sprawdź, czy plik znajduje się na HDFS.

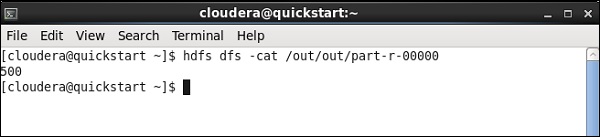
Uruchom następujące polecenie hdfs ze ścieżką wyjściową, o której wspomniałeś w zadaniu.
hdfs dfs -cat /input/talendwriteJeśli pomyślnie zapisujesz na HDFS, zobaczysz następujące dane wyjściowe.

W poprzednim rozdziale widzieliśmy, jak Talend współpracuje z Big Data. W tym rozdziale wyjaśnimy, jak używać mapy Reduce z Talendem.
Tworzenie zadania Talend MapReduce
Nauczmy się, jak uruchomić zadanie MapReduce na Talend. Tutaj uruchomimy przykład liczby słów MapReduce.
W tym celu kliknij prawym przyciskiem myszy Job Design i utwórz nowe zadanie - MapreduceJob. Podaj szczegóły zadania i kliknij Zakończ.
Dodawanie komponentów do zadania MapReduce
Aby dodać komponenty do zadania MapReduce, przeciągnij i upuść pięć komponentów Talend - tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput z palety do okna projektanta. Kliknij prawym przyciskiem myszy tHDFSInput i utwórz główne łącze do tNormalize.
Kliknij prawym przyciskiem myszy tNormalizuj i utwórz główne łącze do tAggregateRow. Następnie kliknij prawym przyciskiem myszy tAggregateRow i utwórz główne łącze do tMap. Teraz kliknij prawym przyciskiem myszy tMap i utwórz główne łącze do tHDFSOutput.
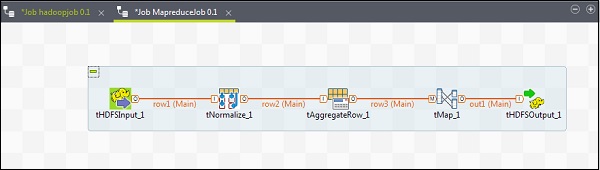
Konfiguracja komponentów i przekształceń
W tHDFSInput wybierz dystrybucję cloudera i jej wersję. Zwróć uwagę, że identyfikator URI Namenode powinien mieć postać „hdfs: //quickstart.cloudera: 8020”, a nazwa użytkownika - „cloudera”. W opcji nazwy pliku podaj ścieżkę pliku wejściowego do zadania MapReduce. Upewnij się, że ten plik wejściowy jest obecny w HDFS.
Teraz wybierz typ pliku, separator wierszy, separator plików i nagłówek zgodnie z plikiem wejściowym.
Kliknij edytuj schemat i dodaj pole „linia” jako typ ciągu.
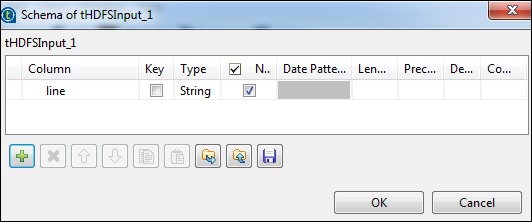
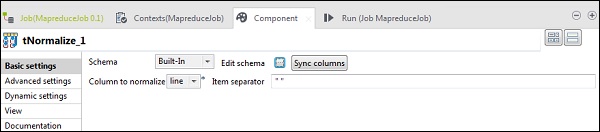
W tNomalize kolumną do normalizacji będzie linia, a separatorem pozycji będzie spacja -> „”. Teraz kliknij edytuj schemat. tNormalize będzie miał line column, a tAggregateRow będzie miał 2 kolumny word i wordcount, jak pokazano poniżej.
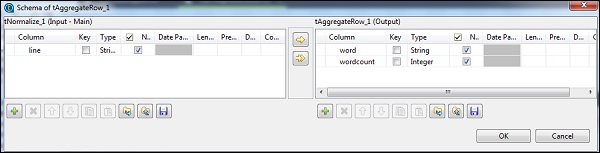
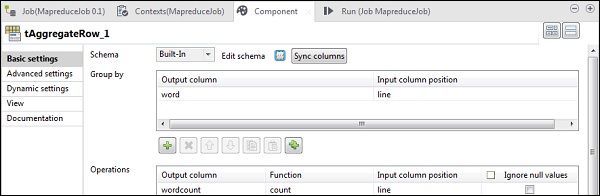
W tAggregateRow, wstaw słowo jako kolumnę wyjściową w opcji Grupuj według. W operacjach umieść wordcount jako kolumnę wyjściową, funkcję jako liczbę i pozycję kolumny wejściowej jako wiersz.
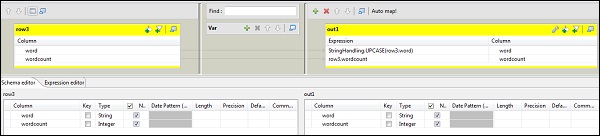
Teraz kliknij dwukrotnie komponent tMap, aby wejść do edytora map i zmapować wejście z wymaganym wyjściem. W tym przykładzie słowo jest odwzorowywane na słowo, a liczba słów jest odwzorowywane za pomocą liczby słów. W kolumnie wyrażeń kliknij […], aby wejść do konstruktora wyrażeń.
Teraz wybierz StringHandling z listy kategorii i funkcji UPCASE. Edytuj wyrażenie na „StringHandling.UPCASE (row3.word)” i kliknij OK. Zachowaj row3.wordcount w kolumnie wyrażenia odpowiadającej wordcount, jak pokazano poniżej.
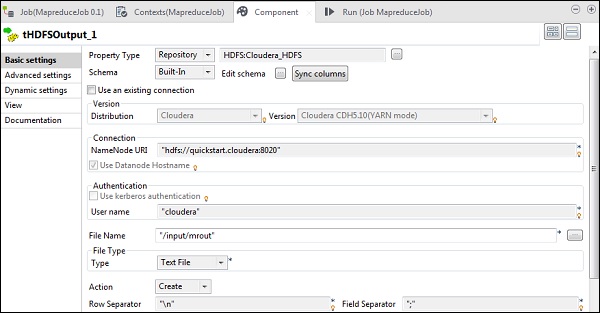
W tHDFSOutput połącz się z klastrem Hadoop, który utworzyliśmy na podstawie typu właściwości jako repozytorium. Zwróć uwagę, że pola zostaną automatycznie wypełnione. W polu Nazwa pliku podaj ścieżkę wyjściową, w której chcesz przechowywać dane wyjściowe. Zachowaj Akcję, separator wierszy i separator pól, jak pokazano poniżej.
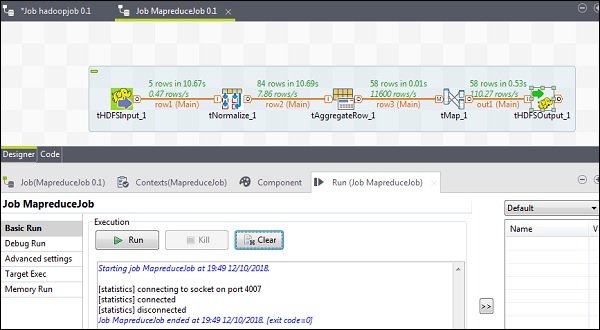
Wykonywanie zadania MapReduce
Po pomyślnym zakończeniu konfiguracji kliknij Uruchom i wykonaj zadanie MapReduce.
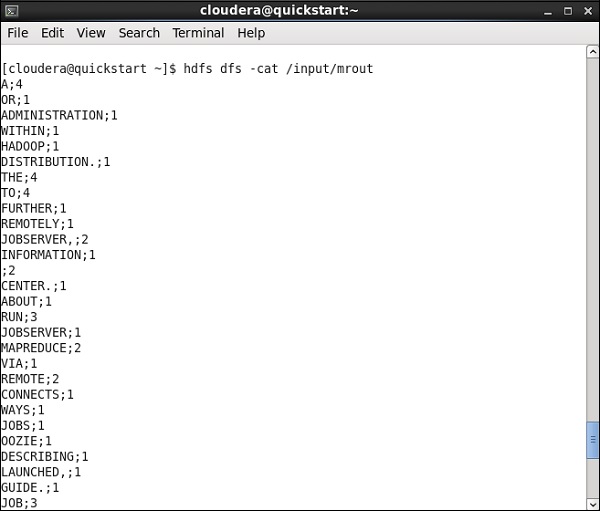
Przejdź do ścieżki HDFS i sprawdź dane wyjściowe. Zauważ, że wszystkie słowa będą pisane wielkimi literami wraz z ich liczbą.
W tym rozdziale nauczmy się, jak pracować ze świnią w Talend.
Tworzenie pracy Talend Pig
W tej sekcji nauczmy się, jak wykonywać pracę Świni w Talend. Tutaj będziemy przetwarzać dane NYSE, aby ustalić średnią wielkość zapasów IBM.
W tym celu kliknij prawym przyciskiem myszy Job Design i utwórz nowe zadanie - pigjob. Podaj szczegóły zadania i kliknij Zakończ.
Dodawanie komponentów do zadania Pig
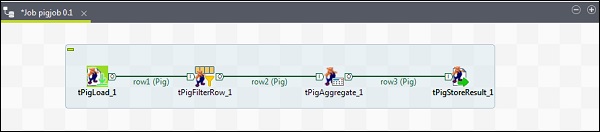
Aby dodać komponenty do zadania Pig, przeciągnij i upuść cztery komponenty Talend: tPigLoad, tPigFilterRow, tPigAggregate, tPigStoreResult, z palety do okna projektanta.
Następnie kliknij prawym przyciskiem myszy tPigLoad i utwórz linię Pig Combine do tPigFilterRow. Następnie kliknij prawym przyciskiem myszy tPigFilterRow i utwórz linię Pig Combine do tPigAggregate. Kliknij prawym przyciskiem myszy tPigAggregate i utwórz linię łączenia Pig do tPigStoreResult.
Konfiguracja komponentów i przekształceń
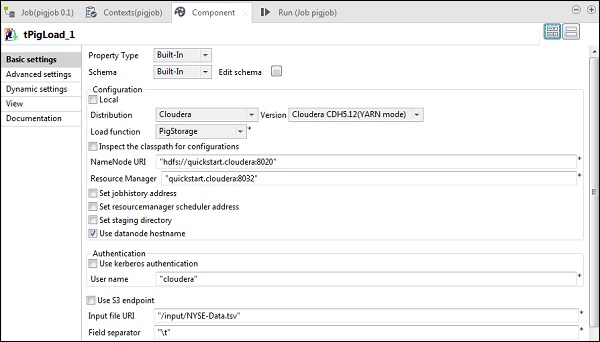
W tPigLoad wspomnij o dystrybucji jako cloudera i wersji cloudera. Zauważ, że identyfikator URI Namenode powinien mieć postać „hdfs: //quickstart.cloudera: 8020”, a Menedżer zasobów - „quickstart.cloudera: 8020”. Ponadto nazwa użytkownika powinna brzmieć „cloudera”.
W URI pliku wejściowego podaj ścieżkę swojego pliku wejściowego NYSE do zadania świń. Zauważ, że ten plik wejściowy powinien być obecny w HDFS.
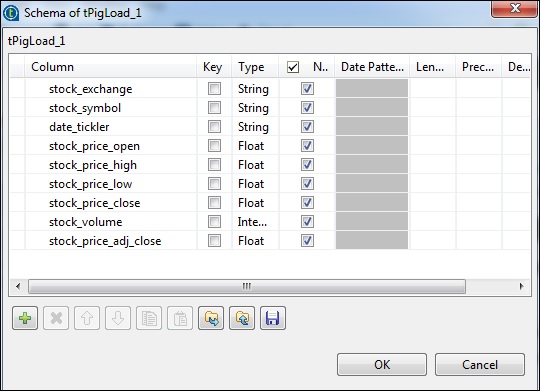
Kliknij edytuj schemat, dodaj kolumny i ich typ, jak pokazano poniżej.
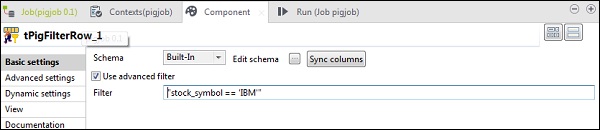
W tPigFilterRow wybierz opcję „Użyj filtru zaawansowanego” i wpisz „stock_symbol = = 'IBM'” w opcji Filtr.
W tAggregateRow kliknij edytuj schemat i dodaj kolumnę avg_stock_volume w danych wyjściowych, jak pokazano poniżej.
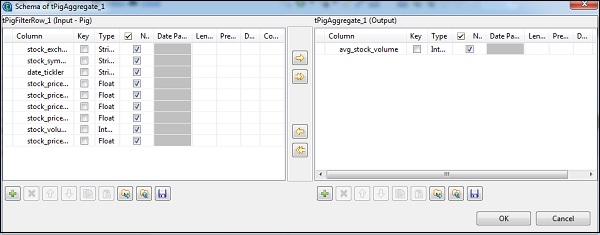
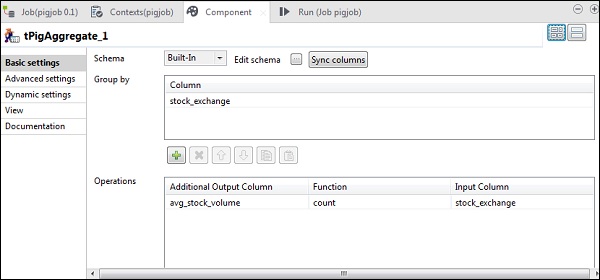
Teraz umieść kolumnę stock_exchange w opcji Grupuj według. Dodaj kolumnę avg_stock_volume w polu Operations z funkcją count i stock_exchange jako kolumną wejściową.
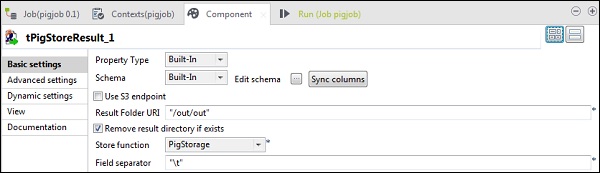
W tPigStoreResult podaj ścieżkę wyjściową w URI folderu wyników, w którym chcesz zapisać wynik zadania Pig. Wybierz funkcję magazynu jako PigStorage i separator pól (nie obowiązkowy) jako „\ t”.
Wykonywanie zadania świni
Teraz kliknij Uruchom, aby wykonać zadanie Świni. (Zignoruj ostrzeżenia)
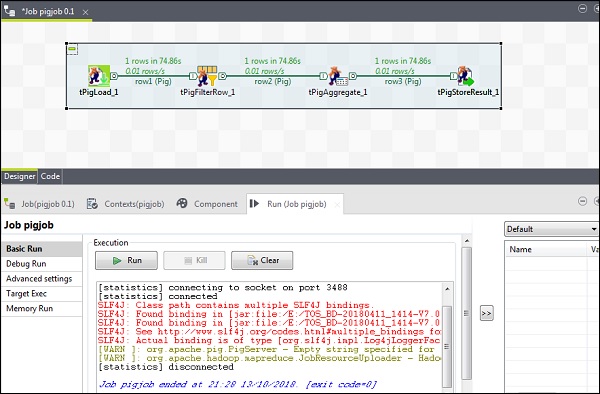
Po zakończeniu zadania przejdź i sprawdź swoje dane wyjściowe na ścieżce HDFS, o której wspomniałeś, aby zapisać wynik zadania świni. Średnia wielkość zapasów IBM wynosi 500.
W tym rozdziale przyjrzyjmy się, jak pracować z zadaniem Hive w programie Talend.
Tworzenie zadania Talend Hive
Na przykład załadujemy dane NYSE do tabeli gałęzi i uruchomimy podstawowe zapytanie gałęzi. Kliknij prawym przyciskiem myszy Job Design i utwórz nową ofertę - hivejob. Podaj szczegóły zadania i kliknij Zakończ.
Dodawanie komponentów do zadania Hive
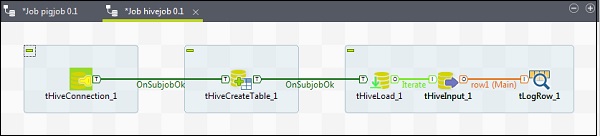
Aby przypisać komponenty do zadania Hive, przeciągnij i upuść pięć najlepszych komponentów - tHiveConnection, tHiveCreateTable, tHiveLoad, tHiveInput i tLogRow z palety do okna projektanta. Następnie kliknij prawym przyciskiem myszy tHiveConnection i utwórz wyzwalacz OnSubjobOk do tHiveCreateTable. Teraz kliknij prawym przyciskiem myszy tHiveCreateTable i utwórz wyzwalacz OnSubjobOk do tHiveLoad. Kliknij prawym przyciskiem myszy tHiveLoad i utwórz wyzwalacz iteracyjny na tHiveInput. Na koniec kliknij prawym przyciskiem myszy tHiveInput i utwórz główną linię do tLogRow.
Konfiguracja komponentów i przekształceń
W tHiveConnection wybierz dystrybucję jako cloudera i jej wersję, której używasz. Należy pamiętać, że tryb połączenia będzie niezależny, a usługą Hive będzie Hive 2. Sprawdź również, czy następujące parametry są odpowiednio ustawione -
- Host: „quickstart.cloudera”
- Port: „10000”
- Baza danych: „domyślna”
- Nazwa użytkownika: „hive”
Pamiętaj, że hasło zostanie uzupełnione automatycznie, nie musisz go edytować. Również inne właściwości Hadoop zostaną wstępnie ustawione i ustawione domyślnie.
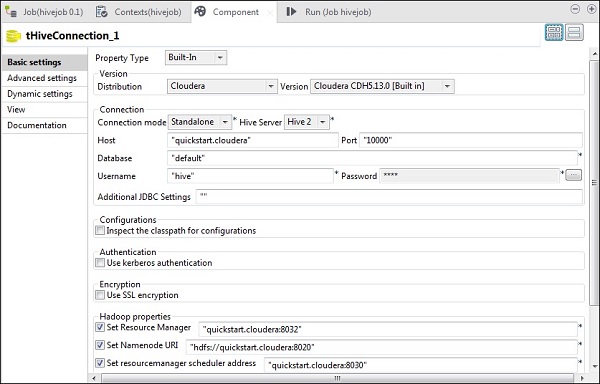
W tHiveCreateTable wybierz opcję Użyj istniejącego połączenia i umieść tHiveConnection na liście składników. Podaj nazwę tabeli, którą chcesz utworzyć w domyślnej bazie danych. Zachowaj pozostałe parametry, jak pokazano poniżej.
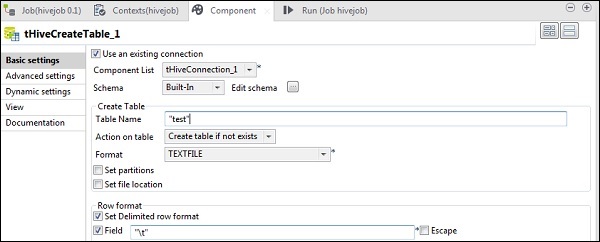
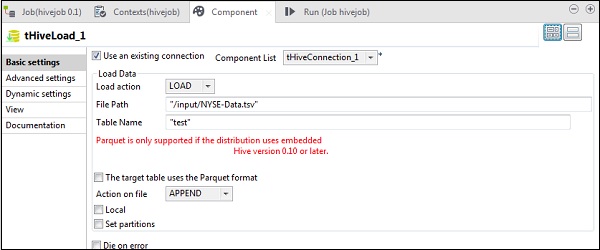
W tHiveLoad, wybierz „Użyj istniejącego połączenia” i umieść tHiveConnection na liście komponentów. Wybierz LOAD w akcji Load. W polu Ścieżka pliku podaj ścieżkę HDFS do pliku wejściowego NYSE. Wspomnij o tabeli w nazwie tabeli, do której chcesz załadować dane wejściowe. Zachowaj pozostałe parametry, jak pokazano poniżej.
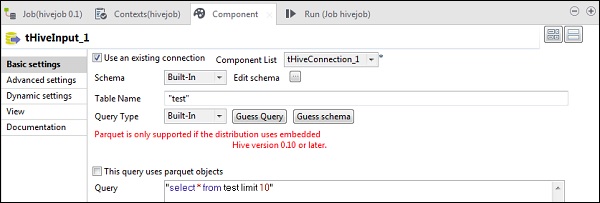
W tHiveInput wybierz opcję Użyj istniejącego połączenia i umieść tHiveConnection na liście składników. Kliknij edytuj schemat, dodaj kolumny i ich typ, jak pokazano na migawce schematu poniżej. Teraz podaj nazwę tabeli, którą utworzyłeś w tHiveCreateTable.
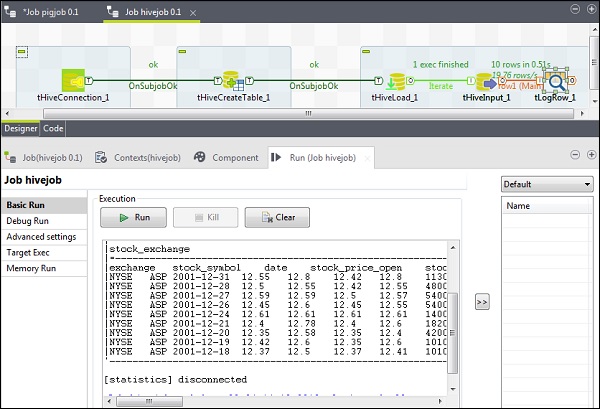
Umieść zapytanie w opcji zapytania, którą chcesz uruchomić w tabeli programu Hive. Tutaj drukujemy wszystkie kolumny pierwszych 10 wierszy w tabeli ula testowego.
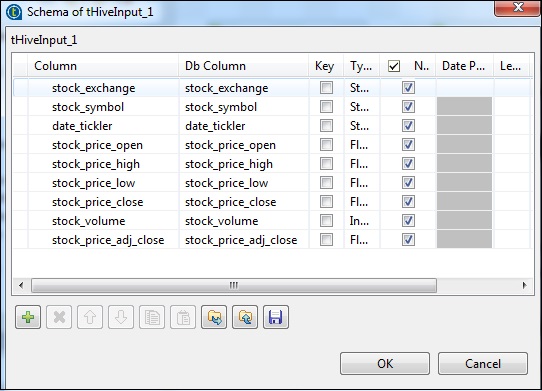
W tLogRow kliknij synchronizuj kolumny i wybierz tryb tabeli, aby wyświetlić dane wyjściowe.
Wykonywanie zadania ula
Kliknij Uruchom, aby rozpocząć wykonywanie. Jeśli wszystkie połączenia i parametry zostały ustawione poprawnie, zobaczysz wynik zapytania, jak pokazano poniżej.