IA com Python - análise de dados de série temporal
Prever o próximo em uma determinada sequência de entrada é outro conceito importante no aprendizado de máquina. Este capítulo fornece uma explicação detalhada sobre a análise de dados de série temporal.
Introdução
Dados de série temporal significam os dados que estão em uma série de intervalos de tempo específicos. Se quisermos construir predição de sequência no aprendizado de máquina, temos que lidar com tempo e dados sequenciais. Os dados da série são um resumo dos dados sequenciais. A ordenação de dados é um recurso importante dos dados sequenciais.
Conceito básico de análise de sequência ou análise de série temporal
A análise de sequência ou análise de série de tempo serve para prever o próximo em uma determinada sequência de entrada com base no observado anteriormente. A previsão pode ser de qualquer coisa que venha a seguir: um símbolo, um número, clima no dia seguinte, próximo termo na fala etc. A análise de sequência pode ser muito útil em aplicações como análise de mercado de ações, previsão do tempo e recomendações de produtos.
Example
Considere o exemplo a seguir para entender a previsão de sequência. AquiA,B,C,D são os valores dados e você deve prever o valor E usando um modelo de predição de sequência.

Instalando Pacotes Úteis
Para análise de dados de série temporal usando Python, precisamos instalar os seguintes pacotes -
Pandas
Pandas é uma biblioteca de código aberto com licença BSD que fornece alto desempenho, facilidade de uso de estrutura de dados e ferramentas de análise de dados para Python. Você pode instalar o Pandas com a ajuda do seguinte comando -
pip install pandasSe você estiver usando o Anaconda e quiser instalar usando o conda gerenciador de pacotes, então você pode usar o seguinte comando -
conda install -c anaconda pandashmmlearn
É uma biblioteca licenciada por BSD de código aberto que consiste em algoritmos e modelos simples para aprender Modelos de Markov Ocultos (HMM) em Python. Você pode instalá-lo com a ajuda do seguinte comando -
pip install hmmlearnSe você estiver usando o Anaconda e quiser instalar usando o conda gerenciador de pacotes, então você pode usar o seguinte comando -
conda install -c omnia hmmlearnPyStruct
É uma biblioteca estruturada de aprendizagem e previsão. Os algoritmos de aprendizagem implementados em PyStruct têm nomes como campos aleatórios condicionais (CRF), Redes Aleatórias de Markov de Margem Máxima (M3N) ou máquinas de vetores de suporte estrutural. Você pode instalá-lo com a ajuda do seguinte comando -
pip install pystructCVXOPT
É usado para otimização convexa com base na linguagem de programação Python. Também é um pacote de software livre. Você pode instalá-lo com a ajuda do seguinte comando -
pip install cvxoptSe você estiver usando o Anaconda e quiser instalar usando o conda gerenciador de pacotes, então você pode usar o seguinte comando -
conda install -c anaconda cvdoxtPandas: manipulação, divisão e extração de estatísticas de dados de série temporal
O Pandas é uma ferramenta muito útil se você tiver que trabalhar com dados de séries temporais. Com a ajuda do Pandas, você pode realizar o seguinte -
Crie um intervalo de datas usando o pd.date_range pacote
Indexar pandas com datas usando o pd.Series pacote
Realize uma nova amostragem usando o ts.resample pacote
Mudar a frequência
Exemplo
O exemplo a seguir mostra como manipular e dividir os dados da série temporal usando o Pandas. Observe que aqui estamos usando os dados de Oscilação Ártica Mensal, que podem ser baixados de mensal.ao.index.b50.current.ascii e podem ser convertidos para o formato de texto para nosso uso.
Tratamento de dados de série temporal
Para lidar com dados de série temporal, você terá que executar as seguintes etapas -
A primeira etapa envolve a importação dos seguintes pacotes -
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdEm seguida, defina uma função que irá ler os dados do arquivo de entrada, conforme mostrado no código fornecido abaixo -
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)Agora, converta esses dados em séries temporais. Para isso, crie o intervalo de datas de nossa série temporal. Neste exemplo, mantemos um mês como frequência de dados. Nosso arquivo contém os dados que começam em janeiro de 1950.
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')Nesta etapa, criamos os dados da série temporal com a ajuda da Série Pandas, conforme mostrado abaixo -
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':Insira o caminho do arquivo de entrada conforme mostrado aqui -
input_file = "/Users/admin/AO.txt"Agora, converta a coluna para o formato de série temporal, conforme mostrado aqui -
timeseries = read_data(input_file)Finalmente, plote e visualize os dados, usando os comandos mostrados -
plt.figure()
timeseries.plot()
plt.show()Você observará os gráficos conforme mostrado nas imagens a seguir -


Fatiar dados de série temporal
O fatiamento envolve a recuperação de apenas uma parte dos dados da série temporal. Como parte do exemplo, estamos dividindo os dados apenas de 1980 a 1990. Observe o código a seguir que executa esta tarefa -
timeseries['1980':'1990'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00>
plt.show()Ao executar o código para dividir os dados da série temporal, você pode observar o gráfico a seguir, conforme mostrado na imagem aqui -

Extração de estatística de dados de série temporal
Você terá que extrair algumas estatísticas de um dado dado, nos casos em que você precisa tirar alguma conclusão importante. Média, variância, correlação, valor máximo e valor mínimo são algumas dessas estatísticas. Você pode usar o código a seguir se quiser extrair essas estatísticas de dados de uma determinada série temporal -
Significar
Você pode usar o mean() função, para encontrar a média, conforme mostrado aqui -
timeseries.mean()Então, a saída que você observará para o exemplo discutido é -
-0.11143128165238671Máximo
Você pode usar o max() função, para encontrar o máximo, conforme mostrado aqui -
timeseries.max()Então, a saída que você observará para o exemplo discutido é -
3.4952999999999999Mínimo
Você pode usar a função min (), para encontrar o mínimo, conforme mostrado aqui -
timeseries.min()Então, a saída que você observará para o exemplo discutido é -
-4.2656999999999998Obtendo tudo de uma vez
Se quiser calcular todas as estatísticas de uma vez, você pode usar o describe() função conforme mostrado aqui -
timeseries.describe()Então, a saída que você observará para o exemplo discutido é -
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64Reamostragem
Você pode reamostrar os dados para uma frequência de tempo diferente. Os dois parâmetros para realizar a reamostragem são -
- Período de tempo
- Method
Reamostragem com média ()
Você pode usar o seguinte código para reamostrar os dados com o método mean (), que é o método padrão -
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()Então, você pode observar o gráfico a seguir como a saída da reamostragem usando mean () -

Reamostragem com mediana ()
Você pode usar o seguinte código para reamostrar os dados usando o median()método -
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()Então, você pode observar o seguinte gráfico como a saída da nova amostragem com mediana () -

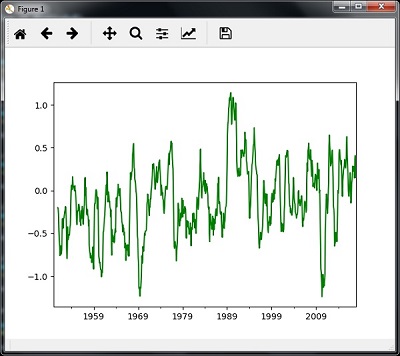
Média móvel
Você pode usar o seguinte código para calcular a média móvel (móvel) -
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()Então, você pode observar o seguinte gráfico como a saída da média móvel (móvel) -
Analisando dados sequenciais por modelo de Markov oculto (HMM)
HMM é um modelo estatístico amplamente utilizado para dados com continuação e extensibilidade, como análise de mercado de ações de séries temporais, exame de saúde e reconhecimento de fala. Esta seção trata detalhadamente da análise de dados sequenciais usando o modelo Hidden Markov (HMM).
Modelo de Markov Oculto (HMM)
HMM é um modelo estocástico que se baseia no conceito de cadeia de Markov com base na suposição de que a probabilidade de estatísticas futuras depende apenas do estado atual do processo, e não de qualquer estado que o precedeu. Por exemplo, ao jogar uma moeda, não podemos dizer que o resultado do quinto lance será uma cara. Isso ocorre porque uma moeda não tem memória e o próximo resultado não depende do resultado anterior.
Matematicamente, o HMM consiste nas seguintes variáveis -
Estados (S)
É um conjunto de estados ocultos ou latentes presentes em um HMM. É denotado por S.
Símbolos de saída (O)
É um conjunto de possíveis símbolos de saída presentes em um HMM. É denotado por O.
Matriz de probabilidade de transição de estado (A)
É a probabilidade de fazer a transição de um estado para cada um dos outros estados. É denotado por A.
Matriz de probabilidade de emissão de observação (B)
É a probabilidade de emitir / observar um símbolo em um determinado estado. É denotado por B.
Matriz de probabilidade anterior (Π)
É a probabilidade de iniciar em um determinado estado a partir de vários estados do sistema. É denotado por Π.
Portanto, um HMM pode ser definido como = (S,O,A,B,),
Onde,
- S = {s1,s2,…,sN} é um conjunto de N estados possíveis,
- O = {o1,o2,…,oM} é um conjunto de M possíveis símbolos de observação,
- A é um NN Matriz de Probabilidade de Transição (TPM),
- B é um NM observação ou Matriz de Probabilidade de Emissão (EPM),
- π é um vetor de distribuição de probabilidade de estado inicial N dimensional.
Exemplo: análise de dados do mercado de ações
Neste exemplo, vamos analisar os dados do mercado de ações, passo a passo, para ter uma ideia de como o HMM funciona com dados sequenciais ou séries temporais. Observe que estamos implementando este exemplo em Python.
Importe os pacotes necessários conforme mostrado abaixo -
import datetime
import warningsAgora, use os dados do mercado de ações do matpotlib.finance pacote, conforme mostrado aqui -
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMMCarregue os dados de uma data de início e de término, ou seja, entre duas datas específicas, conforme mostrado aqui -
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)Nesta etapa, extrairemos as cotações de fechamento todos os dias. Para isso, use o seguinte comando -
closing_quotes = np.array([quote[2] for quote in quotes])Agora, vamos extrair o volume de ações negociadas a cada dia. Para isso, use o seguinte comando -
volumes = np.array([quote[5] for quote in quotes])[1:]Aqui, pegue a diferença percentual dos preços de fechamento das ações, usando o código mostrado abaixo -
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])Nesta etapa, crie e treine o HMM gaussiano. Para isso, use o seguinte código -
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)Agora, gere dados usando o modelo HMM, usando os comandos mostrados -
num_samples = 300
samples, _ = hmm.sample(num_samples)Por fim, nesta etapa, traçamos e visualizamos a diferença percentual e o volume de ações negociadas como produto na forma de gráfico.
Use o seguinte código para traçar e visualizar as porcentagens de diferença -
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')Use o seguinte código para traçar e visualizar o volume de ações negociadas -
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()