AI com Python - Pacote NLTK
Neste capítulo, aprenderemos como começar a usar o Pacote do Natural Language Toolkit.
Pré-requisito
Se quisermos construir aplicativos com processamento de Linguagem Natural, a mudança de contexto torna isso mais difícil. O fator de contexto influencia como a máquina entende uma frase particular. Portanto, precisamos desenvolver aplicativos de linguagem natural usando abordagens de aprendizado de máquina para que a máquina também possa entender a maneira como um ser humano pode entender o contexto.
Para construir tais aplicativos, usaremos o pacote Python chamado NLTK (Natural Language Toolkit Package).
Importando NLTK
Precisamos instalar o NLTK antes de usá-lo. Ele pode ser instalado com a ajuda do seguinte comando -
pip install nltkPara construir um pacote conda para NLTK, use o seguinte comando -
conda install -c anaconda nltkAgora, depois de instalar o pacote NLTK, precisamos importá-lo por meio do prompt de comando do python. Podemos importá-lo escrevendo o seguinte comando no prompt de comando do Python -
>>> import nltkBaixando dados do NLTK
Agora, após importar o NLTK, precisamos baixar os dados necessários. Isso pode ser feito com a ajuda do seguinte comando no prompt de comando do Python -
>>> nltk.download()Instalando outros pacotes necessários
Para construir aplicativos de processamento de linguagem natural usando NLTK, precisamos instalar os pacotes necessários. Os pacotes são os seguintes -
gensim
É uma biblioteca de modelagem semântica robusta, útil para muitos aplicativos. Podemos instalá-lo executando o seguinte comando -
pip install gensimpadronizar
É usado para fazer gensimpacote funcionar corretamente. Podemos instalá-lo executando o seguinte comando
pip install patternConceito de tokenização, stemming e lematização
Nesta seção, entenderemos o que é tokenização, lematização e lematização.
Tokenização
Pode ser definido como o processo de quebrar o texto fornecido, ou seja, a sequência de caracteres em unidades menores chamadas tokens. Os tokens podem ser palavras, números ou sinais de pontuação. Também é chamado de segmentação de palavras. A seguir está um exemplo simples de tokenização -
Input - Manga, banana, abacaxi e maçã são frutas.
Output -

O processo de quebrar o texto fornecido pode ser feito com a ajuda de localizar os limites das palavras. O final de uma palavra e o início de uma nova palavra são chamados de limites de palavras. O sistema de escrita e a estrutura tipográfica das palavras influenciam os limites.
No módulo Python NLTK, temos diferentes pacotes relacionados à tokenização que podemos usar para dividir o texto em tokens de acordo com nossos requisitos. Alguns dos pacotes são os seguintes -
pacote sent_tokenize
Como o nome sugere, este pacote dividirá o texto de entrada em sentenças. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.tokenize import sent_tokenizepacote word_tokenize
Este pacote divide o texto de entrada em palavras. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.tokenize import word_tokenizePacote WordPunctTokenizer
Este pacote divide o texto de entrada em palavras, bem como os sinais de pontuação. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.tokenize import WordPuncttokenizerStemming
Ao trabalhar com palavras, encontramos muitas variações por motivos gramaticais. O conceito de variações aqui significa que temos que lidar com diferentes formas das mesmas palavras, comodemocracy, democratic, e democratization. É muito necessário que as máquinas entendam que essas diferentes palavras têm a mesma forma básica. Desta forma, seria útil extrair as formas básicas das palavras enquanto analisamos o texto.
Podemos conseguir isso parando. Dessa forma, podemos dizer que stemming é o processo heurístico de extrair as formas básicas das palavras cortando as pontas das palavras.
No módulo Python NLTK, temos diferentes pacotes relacionados a lematização. Esses pacotes podem ser usados para obter as formas básicas da palavra. Esses pacotes usam algoritmos. Alguns dos pacotes são os seguintes -
Pacote PorterStemmer
Este pacote Python usa o algoritmo de Porter para extrair o formulário básico. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.stem.porter import PorterStemmerPor exemplo, se dermos a palavra ‘writing’ como entrada para este lematizador, obteremos a palavra ‘write’ após a retirada.
Pacote LancasterStemmer
Este pacote Python usará o algoritmo de Lancaster para extrair o formulário básico. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.stem.lancaster import LancasterStemmerPor exemplo, se dermos a palavra ‘writing’ como entrada para este lematizador, obteremos a palavra ‘write’ após a retirada.
Pacote SnowballStemmer
Este pacote Python usará o algoritmo da bola de neve para extrair o formulário básico. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.stem.snowball import SnowballStemmerPor exemplo, se dermos a palavra ‘writing’ como entrada para este lematizador, obteremos a palavra ‘write’ após a retirada.
Todos esses algoritmos têm diferentes níveis de rigidez. Se compararmos esses três lematizadores, então os lematizadores Porter são os menos estritos e Lancaster é o mais estrito. A haste de bola de neve é boa para usar em termos de velocidade e rigidez.
Lemmatização
Também podemos extrair a forma básica das palavras por lematização. Ele basicamente faz essa tarefa com o uso de um vocabulário e análise morfológica de palavras, normalmente com o objetivo de remover apenas as desinências flexionais. Este tipo de forma básica de qualquer palavra é chamado lema.
A principal diferença entre lematização e lematização é o uso de vocabulário e análise morfológica das palavras. Outra diferença é que a raiz mais comumente reduz palavras derivacionalmente relacionadas, enquanto a lematização comumente reduz as diferentes formas flexionais de um lema. Por exemplo, se fornecermos a palavra saw como a palavra de entrada, o radical pode retornar a palavra 's', mas a lematização tentaria retornar a palavra see ou saw dependendo se o uso do token era um verbo ou um substantivo.
No módulo Python NLTK, temos o seguinte pacote relacionado ao processo de lematização que podemos usar para obter as formas básicas de palavras -
Pacote WordNetLemmatizer
Este pacote Python irá extrair a forma básica da palavra dependendo se ela é usada como substantivo ou verbo. Podemos importar este pacote com a ajuda do seguinte código Python -
from nltk.stem import WordNetLemmatizerChunking: Dividindo Dados em Chunks
É um dos processos importantes no processamento de linguagem natural. A principal tarefa do agrupamento é identificar as classes gramaticais e frases curtas, como substantivos. Já estudamos o processo de tokenização, a criação de tokens. A fragmentação é basicamente a rotulação desses tokens. Em outras palavras, o chunking nos mostrará a estrutura da frase.
Na seção a seguir, aprenderemos sobre os diferentes tipos de Chunking.
Tipos de chunking
Existem dois tipos de agrupamento. Os tipos são os seguintes -
Chunking up
Nesse processo de fragmentação, o objeto, as coisas etc. passam a ser mais gerais e a linguagem fica mais abstrata. Existem mais chances de acordo. Nesse processo, diminuímos o zoom. Por exemplo, se agruparmos a questão “para que propósito os carros são”? Podemos obter a resposta “transporte”.
Chunking down
Nesse processo de fragmentação, o objeto, as coisas etc. passam a ser mais específicos e a linguagem fica mais penetrada. A estrutura mais profunda seria examinada em fragmentação. Nesse processo, aumentamos o zoom. Por exemplo, se analisarmos a questão “Fale especificamente sobre um carro”? Obteremos informações menores sobre o carro.
Example
Neste exemplo, faremos chunking de substantivos, uma categoria de chunking que encontrará os chunks de sintagmas nominais na frase, usando o módulo NLTK em Python -
Follow these steps in python for implementing noun phrase chunking −
Step 1- Nesta etapa, precisamos definir a gramática para chunking. Consistiria nas regras que devemos seguir.
Step 2- Nesta etapa, precisamos criar um analisador de chunk. Ele analisaria a gramática e forneceria a saída.
Step 3 - Nesta última etapa, a saída é produzida em formato de árvore.
Vamos importar o pacote NLTK necessário da seguinte maneira -
import nltkAgora, precisamos definir a frase. Aqui, DT significa o determinante, VBP significa o verbo, JJ significa o adjetivo, IN significa a preposição e NN significa o substantivo.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]Agora, precisamos dar a gramática. Aqui, daremos a gramática na forma de expressão regular.
grammar = "NP:{<DT>?<JJ>*<NN>}"Precisamos definir um analisador que irá analisar a gramática.
parser_chunking = nltk.RegexpParser(grammar)O analisador analisa a frase da seguinte maneira -
parser_chunking.parse(sentence)Em seguida, precisamos obter a saída. A saída é gerada na variável simples chamadaoutput_chunk.
Output_chunk = parser_chunking.parse(sentence)Após a execução do código a seguir, podemos desenhar nossa saída na forma de uma árvore.
output.draw()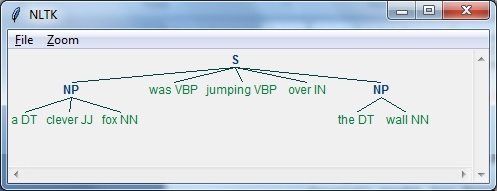
Modelo do saco de palavras (BoW)
Bag of Word (BoW), um modelo em processamento de linguagem natural, é basicamente usado para extrair os recursos do texto para que o texto possa ser usado na modelagem tanto quanto em algoritmos de aprendizado de máquina.
Agora surge a questão de por que precisamos extrair os recursos do texto. É porque os algoritmos de aprendizado de máquina não podem trabalhar com dados brutos e precisam de dados numéricos para que possam extrair informações significativas deles. A conversão de dados de texto em dados numéricos é chamada de extração de recurso ou codificação de recurso.
Como funciona
Esta é uma abordagem muito simples para extrair os recursos do texto. Suponha que temos um documento de texto e desejamos convertê-lo em dados numéricos ou, digamos, deseja extrair os recursos dele, então, primeiro de tudo, este modelo extrai um vocabulário de todas as palavras no documento. Então, usando uma matriz de termos de documento, ele construirá um modelo. Dessa forma, BoW representa o documento apenas como um pacote de palavras. Qualquer informação sobre a ordem ou estrutura das palavras no documento é descartada.
Conceito de matriz de termos de documento
O algoritmo BoW constrói um modelo usando a matriz de termos do documento. Como o nome sugere, a matriz de termos do documento é a matriz de várias contagens de palavras que ocorrem no documento. Com a ajuda desta matriz, o documento de texto pode ser representado como uma combinação ponderada de várias palavras. Definindo o limite e escolhendo as palavras que são mais significativas, podemos construir um histograma de todas as palavras nos documentos que podem ser usadas como um vetor de recurso. A seguir está um exemplo para entender o conceito de matriz de termos de documento -
Example
Suponha que temos as seguintes duas sentenças -
Sentence 1 - Estamos usando o modelo Saco de Palavras.
Sentence 2 - O modelo Bag of Words é usado para extrair os recursos.
Agora, considerando essas duas frases, temos as seguintes 13 palavras distintas -
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
Agora, precisamos construir um histograma para cada frase usando a contagem de palavras em cada frase -
Sentence 1 - [1,1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 - [0,0,0,1,1,1,1,1,1,1,1,1,1,1]
Desta forma, temos os vetores de características que foram extraídos. Cada vetor de característica tem 13 dimensões porque temos 13 palavras distintas.
Conceito de Estatística
O conceito das estatísticas é denominado TermFrequency-Inverse Document Frequency (tf-idf). Cada palavra é importante no documento. As estatísticas nos ajudam a entender a importância de cada palavra.
Frequência do termo (tf)
É a medida da frequência com que cada palavra aparece em um documento. Ele pode ser obtido dividindo a contagem de cada palavra pelo número total de palavras em um determinado documento.
Frequência inversa do documento (idf)
É a medida de quão única é uma palavra para este documento em um determinado conjunto de documentos. Para calcular o idf e formular um vetor de características distintas, precisamos reduzir os pesos de palavras que ocorrem comumente, como o e pesar as palavras raras.
Construindo um modelo de saco de palavras em NLTK
Nesta seção, definiremos uma coleção de strings usando CountVectorizer para criar vetores a partir dessas frases.
Deixe-nos importar o pacote necessário -
from sklearn.feature_extraction.text import CountVectorizerAgora defina o conjunto de frases.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)O programa acima gera a saída conforme mostrado abaixo. Isso mostra que temos 13 palavras distintas nas duas frases acima -
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}Esses são os vetores de recursos (texto para formato numérico) que podem ser usados para aprendizado de máquina.
Resolvendo problemas
Nesta seção, resolveremos alguns problemas relacionados.
Predição de categoria
Em um conjunto de documentos, não apenas as palavras, mas a categoria das palavras também são importantes; em qual categoria de texto uma determinada palavra se enquadra. Por exemplo, queremos prever se uma determinada frase pertence à categoria e-mail, notícias, esportes, computador, etc. No exemplo a seguir, vamos usar tf-idf para formular um vetor de recurso para encontrar a categoria de documentos. Usaremos os dados de 20 conjuntos de dados de grupos de notícias do sklearn.
Precisamos importar os pacotes necessários -
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerDefina o mapa da categoria. Estamos usando cinco categorias diferentes: Religião, Automóveis, Esportes, Eletrônica e Espaço.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}Crie o conjunto de treinamento -
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)Construa um vetorizador de contagem e extraia as contagens de termos -
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)O transformador tf-idf é criado da seguinte maneira -
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)Agora, defina os dados de teste -
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]Os dados acima nos ajudarão a treinar um classificador Multinomial Naive Bayes -
classifier = MultinomialNB().fit(train_tfidf, training_data.target)Transforme os dados de entrada usando o vetorizador de contagem -
input_tc = vectorizer_count.transform(input_data)Agora, vamos transformar os dados vetorizados usando o transformador tfidf -
input_tfidf = tfidf.transform(input_tc)Vamos prever as categorias de saída -
predictions = classifier.predict(input_tfidf)A saída é gerada da seguinte forma -
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])O preditor de categoria gera a seguinte saída -
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: ElectronicsLocalizador de gênero
Nessa definição do problema, um classificador seria treinado para encontrar o gênero (masculino ou feminino) fornecendo os nomes. Precisamos usar uma heurística para construir um vetor de recursos e treinar o classificador. Estaremos usando os dados rotulados do pacote scikit-learn. A seguir está o código Python para construir um localizador de gênero -
Deixe-nos importar os pacotes necessários -
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import namesAgora precisamos extrair as últimas N letras da palavra de entrada. Essas letras funcionarão como recursos -
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':Crie os dados de treinamento usando nomes rotulados (masculinos e femininos) disponíveis em NLTK -
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)Agora, os dados de teste serão criados da seguinte forma -
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']Defina o número de amostras usadas para treinar e testar com o seguinte código
train_sample = int(0.8 * len(data))Agora, precisamos iterar em diferentes comprimentos para que a precisão possa ser comparada -
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)A precisão do classificador pode ser calculada da seguinte forma -
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')Agora, podemos prever a saída -
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))O programa acima irá gerar a seguinte saída -
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> femaleNa saída acima, podemos ver que a precisão no número máximo de letras finais é dois e está diminuindo conforme o número de letras finais aumenta.
Modelagem de Tópico: Identificando Padrões em Dados de Texto
Sabemos que geralmente os documentos são agrupados em tópicos. Às vezes, precisamos identificar os padrões em um texto que correspondem a um tópico específico. A técnica para fazer isso é chamada de modelagem de tópicos. Em outras palavras, podemos dizer que a modelagem de tópicos é uma técnica para descobrir temas abstratos ou estruturas ocultas em um determinado conjunto de documentos.
Podemos usar a técnica de modelagem de tópicos nos seguintes cenários -
Classificação de Texto
Com a ajuda da modelagem de tópicos, a classificação pode ser melhorada porque agrupa palavras semelhantes em vez de usar cada palavra separadamente como um recurso.
Sistemas de Recomendação
Com a ajuda da modelagem de tópicos, podemos construir os sistemas de recomendação usando medidas de similaridade.
Algoritmos para modelagem de tópicos
A modelagem de tópicos pode ser implementada usando algoritmos. Os algoritmos são os seguintes -
Alocação Latent Dirichlet (LDA)
Este algoritmo é o mais popular para modelagem de tópicos. Ele usa os modelos gráficos probabilísticos para implementar a modelagem de tópicos. Precisamos importar o pacote gensim em Python para usar o slgorithm LDA.
Análise Semântica Latente (LDA) ou Indexação Semântica Latente (LSI)
Este algoritmo é baseado na Álgebra Linear. Basicamente, ele usa o conceito de SVD (Singular Value Decomposition) na matriz de termos do documento.
Fatoração de matriz não negativa (NMF)
Também é baseado na Álgebra Linear.
Todos os algoritmos mencionados acima para modelagem de tópicos teriam o number of topics como um parâmetro, Document-Word Matrix como uma entrada e WTM (Word Topic Matrix) E TDM (Topic Document Matrix) como saída.