IA com Python - aprendizado não supervisionado: clustering
Algoritmos de aprendizado de máquina não supervisionados não têm nenhum supervisor para fornecer qualquer tipo de orientação. É por isso que estão intimamente alinhados com o que alguns chamam de verdadeira inteligência artificial.
Na aprendizagem não supervisionada, não haveria resposta correta e nenhum professor para a orientação. Algoritmos precisam descobrir o padrão interessante em dados para aprendizagem.
O que é clustering?
Basicamente, é um tipo de método de aprendizagem não supervisionado e uma técnica comum para análise de dados estatísticos usada em muitos campos. O clustering é principalmente uma tarefa de dividir o conjunto de observações em subconjuntos, chamados clusters, de forma que as observações no mesmo cluster sejam semelhantes em um sentido e diferentes das observações em outros clusters. Em palavras simples, podemos dizer que o objetivo principal do agrupamento é agrupar os dados com base na similaridade e dissimilaridade.
Por exemplo, o diagrama a seguir mostra tipos semelhantes de dados em diferentes clusters -
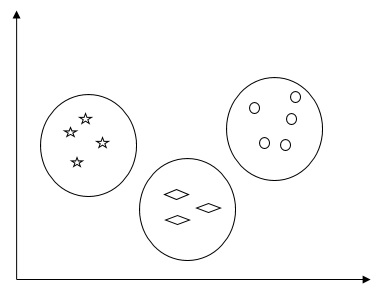
Algoritmos para agrupar os dados
A seguir estão alguns algoritmos comuns para agrupar os dados -
Algoritmo K-Means
O algoritmo de agrupamento K-means é um dos algoritmos bem conhecidos para agrupar os dados. Precisamos assumir que o número de clusters já é conhecido. Isso também é chamado de clustering simples. É um algoritmo de agrupamento iterativo. As etapas fornecidas abaixo precisam ser seguidas para este algoritmo -
Step 1 - Precisamos especificar o número desejado de K subgrupos.
Step 2- Corrija o número de clusters e atribua aleatoriamente cada ponto de dados a um cluster. Ou em outras palavras, precisamos classificar nossos dados com base no número de clusters.
Nesta etapa, os centróides do cluster devem ser calculados.
Como este é um algoritmo iterativo, precisamos atualizar as localizações dos centróides K a cada iteração até encontrarmos os ótimos globais ou em outras palavras, os centróides atingem seus locais ideais.
O código a seguir ajudará na implementação do algoritmo de agrupamento K-means em Python. Vamos usar o módulo Scikit-learn.
Deixe-nos importar os pacotes necessários -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansA linha de código a seguir ajudará na geração do conjunto de dados bidimensional, contendo quatro blobs, usando make_blob de sklearn.dataset pacote.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)Podemos visualizar o conjunto de dados usando o seguinte código -
plt.scatter(X[:, 0], X[:, 1], s = 50);
plt.show()
Aqui, estamos inicializando kmeans para ser o algoritmo KMeans, com o parâmetro necessário de quantos clusters (n_clusters).
kmeans = KMeans(n_clusters = 4)Precisamos treinar o modelo K-means com os dados de entrada.
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis')
centers = kmeans.cluster_centers_O código fornecido a seguir nos ajudará a traçar e visualizar as descobertas da máquina com base em nossos dados, e o ajuste de acordo com o número de clusters que podem ser encontrados.
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5);
plt.show()
Algoritmo de deslocamento médio
É outro algoritmo de agrupamento popular e poderoso usado na aprendizagem não supervisionada. Ele não faz suposições, portanto, é um algoritmo não paramétrico. Também é chamado de agrupamento hierárquico ou análise de agrupamento de deslocamento médio. A seguir estão as etapas básicas deste algoritmo -
Em primeiro lugar, precisamos começar com os pontos de dados atribuídos a um cluster próprio.
Agora, ele calcula os centróides e atualiza a localização de novos centróides.
Ao repetir este processo, aproximamo-nos do pico do cluster, ou seja, em direção à região de maior densidade.
Este algoritmo para no estágio em que os centróides não se movem mais.
Com a ajuda do código a seguir, estamos implementando o algoritmo de agrupamento Mean Shift em Python. Vamos usar o módulo Scikit-learning.
Deixe-nos importar os pacotes necessários -
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")O código a seguir ajudará na geração do conjunto de dados bidimensional, contendo quatro blobs, usando make_blob de sklearn.dataset pacote.
from sklearn.datasets.samples_generator import make_blobsPodemos visualizar o conjunto de dados com o seguinte código
centers = [[2,2],[4,5],[3,10]]
X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1)
plt.scatter(X[:,0],X[:,1])
plt.show()
Agora, precisamos treinar o modelo de cluster de deslocamento médio com os dados de entrada.
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_O código a seguir imprimirá os centros de cluster e o número esperado de cluster de acordo com os dados de entrada -
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2O código fornecido a seguir ajudará a traçar e visualizar as descobertas da máquina com base em nossos dados e a montagem de acordo com o número de clusters que podem ser encontrados.
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(cluster_centers[:,0],cluster_centers[:,1],
marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10)
plt.show()
Medindo o desempenho do clustering
Os dados do mundo real não são organizados naturalmente em vários grupos distintos. Por esse motivo, não é fácil visualizar e fazer inferências. É por isso que precisamos medir o desempenho do cluster, bem como sua qualidade. Isso pode ser feito com a ajuda da análise de silhueta.
Análise de Silhueta
Este método pode ser usado para verificar a qualidade do agrupamento medindo a distância entre os agrupamentos. Basicamente, ele fornece uma maneira de avaliar os parâmetros, como o número de clusters, fornecendo uma pontuação de silhueta. Essa pontuação é uma métrica que mede a proximidade de cada ponto em um cluster dos pontos nos clusters vizinhos.
Análise da pontuação da silhueta
A pontuação tem um intervalo de [-1, 1]. A seguir está a análise dessa pontuação -
Score of +1 - Pontuação próxima de +1 indica que a amostra está longe do agrupamento vizinho.
Score of 0 - A pontuação 0 indica que a amostra está no ou muito perto do limite de decisão entre dois clusters vizinhos.
Score of -1 - A pontuação negativa indica que as amostras foram atribuídas aos clusters errados.
Calculando a pontuação da silhueta
Nesta seção, aprenderemos como calcular a pontuação da silhueta.
A pontuação da silhueta pode ser calculada usando a seguinte fórmula -
$$ pontuação da silhueta = \ frac {\ left (pq \ right)} {max \ left (p, q \ right)} $$
Aqui, é a distância média para os pontos no cluster mais próximo do qual o ponto de dados não faz parte. E, é a distância intra-cluster média para todos os pontos em seu próprio cluster.
Para encontrar o número ideal de clusters, precisamos executar o algoritmo de clusterização novamente, importando o metrics módulo do sklearnpacote. No exemplo a seguir, vamos executar o algoritmo de agrupamento K-means para encontrar o número ideal de clusters -
Importe os pacotes necessários conforme mostrado -
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeansCom a ajuda do código a seguir, geraremos o conjunto de dados bidimensional, contendo quatro blobs, usando make_blob de sklearn.dataset pacote.
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)Inicialize as variáveis conforme mostrado -
scores = []
values = np.arange(2, 10)Precisamos iterar o modelo K-means por meio de todos os valores e também treiná-lo com os dados de entrada.
for num_clusters in values:
kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10)
kmeans.fit(X)Agora, estime a pontuação da silhueta para o modelo de agrupamento atual usando a métrica de distância euclidiana -
score = metrics.silhouette_score(X, kmeans.labels_,
metric = 'euclidean', sample_size = len(X))A linha de código a seguir ajudará a exibir o número de clusters, bem como a pontuação do Silhouette.
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)Você receberá a seguinte saída -
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)Agora, a saída para o número ideal de clusters seria a seguinte -
Optimal number of clusters = 2Encontrar vizinhos mais próximos
Se quisermos construir sistemas de recomendação, como um sistema de recomendação de filmes, precisamos entender o conceito de encontrar os vizinhos mais próximos. É porque o sistema de recomendação utiliza o conceito de vizinhos mais próximos.
o concept of finding nearest neighborspode ser definido como o processo de encontrar o ponto mais próximo ao ponto de entrada do conjunto de dados fornecido. O principal uso deste algoritmo KNN (K-mais próximos vizinhos) é construir sistemas de classificação que classificam um ponto de dados na proximidade do ponto de dados de entrada para várias classes.
O código Python fornecido abaixo ajuda a encontrar os vizinhos K-mais próximos de um determinado conjunto de dados -
Importe os pacotes necessários conforme mostrado abaixo. Aqui, estamos usando oNearestNeighbors módulo do sklearn pacote
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighborsVamos agora definir os dados de entrada -
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])Agora, precisamos definir os vizinhos mais próximos -
k = 3Também precisamos fornecer os dados de teste a partir dos quais os vizinhos mais próximos podem ser encontrados -
test_data = [3.3, 2.9]O código a seguir pode visualizar e plotar os dados de entrada definidos por nós -
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
Agora, precisamos construir o vizinho mais próximo K. O objeto também precisa ser treinado
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X)
distances, indices = knn_model.kneighbors([test_data])Agora, podemos imprimir os K vizinhos mais próximos como segue
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])Podemos visualizar os vizinhos mais próximos junto com o ponto de dados de teste
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
Resultado
K Nearest Neighbors
1 is [ 3.1 2.3]
2 is [ 3.9 3.5]
3 is [ 4.4 2.9]Classificador de vizinhos mais próximos K
Um classificador K-Nearest Neighbours (KNN) é um modelo de classificação que usa o algoritmo de vizinhos mais próximos para classificar um determinado ponto de dados. Implementamos o algoritmo KNN na última seção, agora vamos construir um classificador KNN usando esse algoritmo.
Conceito de classificador KNN
O conceito básico da classificação K-vizinho mais próximo é encontrar um número predefinido, ou seja, o 'k' - das amostras de treinamento mais próximas em distância de uma nova amostra, que deve ser classificada. Novas amostras receberão seu rótulo dos próprios vizinhos. Os classificadores KNN têm uma constante definida pelo usuário fixa para o número de vizinhos que devem ser determinados. Para a distância, a distância euclidiana padrão é a escolha mais comum. O Classificador KNN trabalha diretamente nas amostras aprendidas, em vez de criar as regras de aprendizagem. O algoritmo KNN está entre os mais simples de todos os algoritmos de aprendizado de máquina. Tem sido bem sucedido em um grande número de problemas de classificação e regressão, por exemplo, reconhecimento de caracteres ou análise de imagens.
Example
Estamos construindo um classificador KNN para reconhecer dígitos. Para isso, usaremos o conjunto de dados MNIST. Vamos escrever este código no Notebook Jupyter.
Importe os pacotes necessários conforme mostrado abaixo.
Aqui estamos usando o KNeighborsClassifier módulo do sklearn.neighbors pacote -
from sklearn.datasets import *
import pandas as pd
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as npO código a seguir exibirá a imagem do dígito para verificar qual imagem temos que testar -
def Image_display(i):
plt.imshow(digit['images'][i],cmap = 'Greys_r')
plt.show()Agora, precisamos carregar o conjunto de dados MNIST. Na verdade, há um total de 1797 imagens, mas estamos usando as primeiras 1600 imagens como amostra de treinamento e as 197 restantes seriam mantidas para fins de teste.
digit = load_digits()
digit_d = pd.DataFrame(digit['data'][0:1600])Agora, ao exibir as imagens, podemos ver o resultado da seguinte forma -
Image_display(0)Image_display (0)
A imagem de 0 é exibida da seguinte forma -

Image_display (9)
A imagem de 9 é exibida da seguinte forma -

digit.keys ()
Agora, precisamos criar o conjunto de dados de treinamento e teste e fornecer o conjunto de dados de teste aos classificadores KNN.
train_x = digit['data'][:1600]
train_y = digit['target'][:1600]
KNN = KNeighborsClassifier(20)
KNN.fit(train_x,train_y)A saída a seguir criará o construtor do classificador K vizinho mais próximo -
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2,
weights = 'uniform')Precisamos criar a amostra de teste fornecendo qualquer número arbitrário maior que 1600, que eram as amostras de treinamento.
test = np.array(digit['data'][1725])
test1 = test.reshape(1,-1)
Image_display(1725)Image_display (6)
A imagem de 6 é exibida da seguinte forma -

Agora vamos prever os dados de teste da seguinte forma -
KNN.predict(test1)O código acima irá gerar a seguinte saída -
array([6])Agora, considere o seguinte -
digit['target_names']O código acima irá gerar a seguinte saída -
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])