Guia rápido de C ++
C ++ é uma linguagem de programação de forma livre, tipada estaticamente, compilada, de uso geral, que diferencia maiúsculas de minúsculas e oferece suporte à programação procedural, orientada a objetos e genérica.
C ++ é considerado um middle-level linguagem, pois compreende uma combinação de recursos de linguagem de alto e baixo nível.
C ++ foi desenvolvido por Bjarne Stroustrup a partir de 1979 no Bell Labs em Murray Hill, New Jersey, como um aprimoramento da linguagem C e originalmente denominado C com Classes, mas posteriormente foi renomeado C ++ em 1983.
C ++ é um superconjunto de C, e virtualmente qualquer programa C válido é um programa C ++ válido.
Note - Diz-se que uma linguagem de programação usa tipagem estática quando a verificação de tipo é realizada durante o tempo de compilação, em oposição ao tempo de execução.
Programação Orientada a Objetos
C ++ oferece suporte total à programação orientada a objetos, incluindo os quatro pilares do desenvolvimento orientado a objetos -
- Encapsulation
- Ocultação de dados
- Inheritance
- Polymorphism
Bibliotecas Padrão
C ++ padrão consiste em três partes importantes -
A linguagem central fornece todos os blocos de construção, incluindo variáveis, tipos de dados e literais, etc.
A C ++ Standard Library oferece um rico conjunto de funções de manipulação de arquivos, strings, etc.
A Standard Template Library (STL) oferece um rico conjunto de métodos de manipulação de estruturas de dados, etc.
O padrão ANSI
O padrão ANSI é uma tentativa de garantir que C ++ seja portátil; aquele código que você escreve para o compilador da Microsoft compilará sem erros, usando um compilador em um Mac, UNIX, uma caixa do Windows ou um Alpha.
O padrão ANSI está estável há algum tempo e todos os principais fabricantes de compiladores C ++ oferecem suporte ao padrão ANSI.
Aprendendo C ++
O mais importante ao aprender C ++ é focar nos conceitos.
O objetivo de aprender uma linguagem de programação é se tornar um programador melhor; isto é, para se tornar mais eficaz no projeto e implementação de novos sistemas e na manutenção dos antigos.
C ++ oferece suporte a uma variedade de estilos de programação. Você pode escrever no estilo de Fortran, C, Smalltalk, etc., em qualquer idioma. Cada estilo pode atingir seus objetivos com eficácia, mantendo a eficiência do tempo de execução e do espaço.
Uso de C ++
C ++ é usado por centenas de milhares de programadores em essencialmente todos os domínios de aplicativo.
C ++ está sendo muito usado para escrever drivers de dispositivos e outros softwares que dependem da manipulação direta de hardware sob restrições de tempo real.
C ++ é amplamente usado para ensino e pesquisa porque é limpo o suficiente para o ensino bem-sucedido de conceitos básicos.
Qualquer pessoa que tenha usado um Apple Macintosh ou um PC com Windows usou indiretamente C ++ porque as interfaces de usuário primárias desses sistemas são escritas em C ++.
Configuração de ambiente local
Se você ainda deseja configurar seu ambiente para C ++, você precisa ter os dois softwares a seguir em seu computador.
Editor de texto
Isso será usado para digitar seu programa. Exemplos de poucos editores incluem o bloco de notas do Windows, o comando Editar do sistema operacional, Brief, Epsilon, EMACS e vim ou vi.
O nome e a versão do editor de texto podem variar em diferentes sistemas operacionais. Por exemplo, o Bloco de notas será usado no Windows e o vim ou vi pode ser usado no Windows e também no Linux ou UNIX.
Os arquivos que você cria com seu editor são chamados de arquivos de origem e, para C ++, normalmente são nomeados com a extensão .cpp, .cp ou .c.
Um editor de texto deve estar disponível para iniciar sua programação C ++.
Compilador C ++
Este é um compilador C ++ real, que será usado para compilar seu código-fonte no programa executável final.
A maioria dos compiladores C ++ não se importa com qual extensão você dá ao seu código-fonte, mas se você não especificar o contrário, muitos usarão .cpp por padrão.
O compilador mais usado e disponível gratuitamente é o compilador GNU C / C ++, caso contrário, você pode ter compiladores da HP ou Solaris se tiver os respectivos sistemas operacionais.
Instalando o compilador GNU C / C ++
Instalação UNIX / Linux
Se você estiver usando Linux or UNIX em seguida, verifique se o GCC está instalado em seu sistema, digitando o seguinte comando na linha de comando -
$ g++ -vSe você instalou o GCC, ele deve imprimir uma mensagem como a seguinte -
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix=/usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Se o GCC não estiver instalado, você terá que instalá-lo usando as instruções detalhadas disponíveis em https://gcc.gnu.org/install/
Instalação do Mac OS X
Se você usa Mac OS X, a maneira mais fácil de obter o GCC é baixar o ambiente de desenvolvimento Xcode do site da Apple e seguir as instruções simples de instalação.
O Xcode está disponível atualmente em developer.apple.com/technologies/tools/ .
Instalação Windows
Para instalar o GCC no Windows, você precisa instalar o MinGW. Para instalar o MinGW, vá para a página inicial do MinGW, www.mingw.org , e siga o link para a página de download do MinGW. Baixe a versão mais recente do programa de instalação do MinGW, que deve se chamar MinGW- <versão> .exe.
Ao instalar o MinGW, no mínimo, você deve instalar gcc-core, gcc-g ++, binutils e o tempo de execução do MinGW, mas você pode desejar instalar mais.
Adicione o subdiretório bin da instalação do MinGW ao seu PATH variável de ambiente para que você possa especificar essas ferramentas na linha de comando por seus nomes simples.
Quando a instalação for concluída, você poderá executar gcc, g ++, ar, ranlib, dlltool e várias outras ferramentas GNU a partir da linha de comando do Windows.
Quando consideramos um programa C ++, ele pode ser definido como uma coleção de objetos que se comunicam por meio da chamada dos métodos uns dos outros. Vamos agora dar uma olhada rápida no que significam uma classe, objeto, métodos e variáveis instantâneas.
Object- Os objetos têm estados e comportamentos. Exemplo: Um cão tem estados - cor, nome, raça e também comportamentos - abanando, latindo, comendo. Um objeto é uma instância de uma classe.
Class - Uma classe pode ser definida como um template / blueprint que descreve os comportamentos / estados que o objeto de seu tipo suporta.
Methods- Um método é basicamente um comportamento. Uma classe pode conter muitos métodos. É nos métodos onde as lógicas são escritas, os dados são manipulados e todas as ações são executadas.
Instance Variables- Cada objeto tem seu conjunto único de variáveis de instância. O estado de um objeto é criado pelos valores atribuídos a essas variáveis de instância.
Estrutura do programa C ++
Vejamos um código simples que imprimiria as palavras Hello World .
#include <iostream>
using namespace std;
// main() is where program execution begins.
int main() {
cout << "Hello World"; // prints Hello World
return 0;
}Vejamos as várias partes do programa acima -
A linguagem C ++ define vários cabeçalhos, que contêm informações que são necessárias ou úteis para seu programa. Para este programa, o cabeçalho<iostream> é preciso.
A linha using namespace std;diz ao compilador para usar o namespace std. Os namespaces são uma adição relativamente recente ao C ++.
A próxima linha '// main() is where program execution begins.'é um comentário de uma única linha disponível em C ++. Comentários de linha única começam com // e terminam no final da linha.
A linha int main() é a função principal onde a execução do programa começa.
A próxima linha cout << "Hello World"; faz com que a mensagem "Hello World" seja exibida na tela.
A próxima linha return 0; termina a função main () e faz com que ela retorne o valor 0 para o processo de chamada.
Compilar e executar programa C ++
Vejamos como salvar o arquivo, compilar e executar o programa. Siga os passos abaixo -
Abra um editor de texto e adicione o código como acima.
Salve o arquivo como: hello.cpp
Abra um prompt de comando e vá para o diretório onde você salvou o arquivo.
Digite 'g ++ hello.cpp' e pressione Enter para compilar seu código. Se não houver erros em seu código, o prompt de comando o levará para a próxima linha e gerará um arquivo executável.out.
Agora, digite 'a.out' para executar seu programa.
Você poderá ver 'Hello World' impresso na janela.
$ g++ hello.cpp
$ ./a.out
Hello WorldCertifique-se de que g ++ esteja em seu caminho e que você o esteja executando no diretório que contém o arquivo hello.cpp.
Você pode compilar programas C / C ++ usando makefile. Para mais detalhes, você pode verificar nosso 'Tutorial de Makefile' .
Ponto e vírgula e blocos em C ++
Em C ++, o ponto-e-vírgula é um terminador de instrução. Ou seja, cada declaração individual deve terminar com um ponto e vírgula. Indica o fim de uma entidade lógica.
Por exemplo, a seguir estão três declarações diferentes -
x = y;
y = y + 1;
add(x, y);Um bloco é um conjunto de instruções conectadas logicamente que são cercadas por chaves de abertura e fechamento. Por exemplo -
{
cout << "Hello World"; // prints Hello World
return 0;
}C ++ não reconhece o final da linha como um terminador. Por esse motivo, não importa onde você coloca uma declaração em uma linha. Por exemplo -
x = y;
y = y + 1;
add(x, y);é o mesmo que
x = y; y = y + 1; add(x, y);Identificadores C ++
Um identificador C ++ é um nome usado para identificar uma variável, função, classe, módulo ou qualquer outro item definido pelo usuário. Um identificador começa com uma letra de A a Z ou a a z ou um sublinhado (_) seguido por zero ou mais letras, sublinhados e dígitos (0 a 9).
C ++ não permite caracteres de pontuação como @, $ e% nos identificadores. C ++ é uma linguagem de programação que diferencia maiúsculas de minúsculas. Portanto,Manpower e manpower são dois identificadores diferentes em C ++.
Aqui estão alguns exemplos de identificadores aceitáveis -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValPalavras-chave C ++
A lista a seguir mostra as palavras reservadas em C ++. Essas palavras reservadas não podem ser usadas como constantes ou variáveis ou quaisquer outros nomes de identificador.
| asm | outro | Novo | esta |
| auto | enum | operador | lançar |
| bool | explícito | privado | verdadeiro |
| pausa | exportar | protegido | experimentar |
| caso | externo | público | typedef |
| pegar | falso | registro | typeid |
| Caracteres | flutuador | reinterpret_cast | Digite o nome |
| classe | para | Retorna | União |
| const | amigo | baixo | não assinado |
| const_cast | vamos para | assinado | usando |
| continuar | E se | tamanho de | virtual |
| padrão | na linha | estático | vazio |
| excluir | int | static_cast | volátil |
| Faz | grandes | estrutura | wchar_t |
| em dobro | mutável | interruptor | enquanto |
| dynamic_cast | namespace | modelo |
Trígrafos
Alguns caracteres têm uma representação alternativa, chamada de sequência trigraph. Um trígrafo é uma sequência de três caracteres que representa um único caractere e a sequência sempre começa com dois pontos de interrogação.
Os trígrafos são expandidos em qualquer lugar em que apareçam, inclusive em literais de string e literais de caractere, em comentários e em diretivas de pré-processador.
A seguir estão as sequências trígrafo usadas com mais frequência -
| Trigraph | Substituição |
|---|---|
| ?? = | # |
| ?? / | \ |
| ?? ' | ^ |
| ?? ( | [ |
| ??) | ] |
| ??! | | |
| ?? < | { |
| ??> | } |
| ?? - | ~ |
Todos os compiladores não oferecem suporte a trigraphs e não são recomendados para uso devido à sua natureza confusa.
Espaço em branco em C ++
Uma linha contendo apenas espaços em branco, possivelmente com um comentário, é conhecida como uma linha em branco e o compilador C ++ a ignora totalmente.
Espaço em branco é o termo usado em C ++ para descrever espaços em branco, tabulações, caracteres de nova linha e comentários. O espaço em branco separa uma parte de uma instrução de outra e permite que o compilador identifique onde um elemento em uma instrução, como int, termina e o próximo elemento começa.
Declaração 1
int age;Na instrução acima, deve haver pelo menos um caractere de espaço em branco (geralmente um espaço) entre int e age para que o compilador seja capaz de distingui-los.
Declaração 2
fruit = apples + oranges; // Get the total fruitNa afirmação 2 acima, nenhum caractere de espaço em branco é necessário entre fruta e = ou entre = e maçãs, embora você seja livre para incluir alguns se desejar para fins de legibilidade.
Os comentários do programa são declarações explicativas que você pode incluir no código C ++. Esses comentários ajudam qualquer pessoa a ler o código-fonte. Todas as linguagens de programação permitem alguma forma de comentários.
C ++ oferece suporte a comentários de uma e de várias linhas. Todos os caracteres disponíveis dentro de qualquer comentário são ignorados pelo compilador C ++.
Os comentários em C ++ começam com / * e terminam com * /. Por exemplo -
/* This is a comment */
/* C++ comments can also
* span multiple lines
*/Um comentário também pode começar com //, estendendo-se até o final da linha. Por exemplo -
#include <iostream>
using namespace std;
main() {
cout << "Hello World"; // prints Hello World
return 0;
}Quando o código acima for compilado, ele irá ignorar // prints Hello World e o executável final produzirá o seguinte resultado -
Hello WorldDentro de um / * e * / comentário, // os caracteres não têm nenhum significado especial. Dentro de um // comentário, / * e * / não têm nenhum significado especial. Assim, você pode "aninhar" um tipo de comentário em outro tipo. Por exemplo -
/* Comment out printing of Hello World:
cout << "Hello World"; // prints Hello World
*/Ao escrever um programa em qualquer idioma, você precisa usar várias variáveis para armazenar várias informações. As variáveis nada mais são do que locais de memória reservados para armazenar valores. Isso significa que, ao criar uma variável, você reserva algum espaço na memória.
Você pode querer armazenar informações de vários tipos de dados como caractere, caractere largo, inteiro, ponto flutuante, ponto flutuante duplo, booleano etc. Com base no tipo de dados de uma variável, o sistema operacional aloca memória e decide o que pode ser armazenado no memória reservada.
Tipos primitivos integrados
C ++ oferece ao programador uma rica variedade de tipos de dados integrados e definidos pelo usuário. A tabela a seguir lista sete tipos de dados básicos C ++ -
| Tipo | Palavra-chave |
|---|---|
| boleano | bool |
| Personagem | Caracteres |
| Inteiro | int |
| Ponto flutuante | flutuador |
| Ponto flutuante duplo | em dobro |
| Sem valor | vazio |
| Caráter amplo | wchar_t |
Vários dos tipos básicos podem ser modificados usando um ou mais desses modificadores de tipo -
- signed
- unsigned
- short
- long
A tabela a seguir mostra o tipo de variável, quanta memória é necessária para armazenar o valor na memória, e qual é o valor máximo e mínimo que pode ser armazenado neste tipo de variável.
| Tipo | Largura de bit típica | Alcance Típico |
|---|---|---|
| Caracteres | 1 byte | -127 a 127 ou 0 a 255 |
| caracter não identifcado | 1 byte | 0 a 255 |
| char assinado | 1 byte | -127 a 127 |
| int | 4 bytes | -2147483648 a 2147483647 |
| int não assinado | 4 bytes | 0 a 4294967295 |
| int assinado | 4 bytes | -2147483648 a 2147483647 |
| curto int | 2 bytes | -32768 a 32767 |
| int curto sem sinal | 2 bytes | 0 a 65.535 |
| int curto assinado | 2 bytes | -32768 a 32767 |
| longo int | 8 bytes | -2.147.483.648 a 2.147.483.647 |
| assinado longo int | 8 bytes | mesmo que long int |
| int longo sem sinal | 8 bytes | 0 a 4.294.967.295 |
| longo longo int | 8 bytes | - (2 ^ 63) a (2 ^ 63) -1 |
| sem sinal longo longo int | 8 bytes | 0 a 18.446.744.073.709.551.615 |
| flutuador | 4 bytes | |
| em dobro | 8 bytes | |
| longo duplo | 12 bytes | |
| wchar_t | 2 ou 4 bytes | 1 personagem largo |
O tamanho das variáveis pode ser diferente daqueles mostrados na tabela acima, dependendo do compilador e do computador que você está usando.
A seguir está o exemplo, que produzirá o tamanho correto de vários tipos de dados em seu computador.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}Este exemplo usa endl, que insere um caractere de nova linha após cada linha e o operador << está sendo usado para passar vários valores para a tela. Também estamos usandosizeof() operador para obter o tamanho de vários tipos de dados.
Quando o código acima é compilado e executado, ele produz o seguinte resultado, que pode variar de máquina para máquina -
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4Declarações de typedef
Você pode criar um novo nome para um tipo existente usando typedef. A seguir está a sintaxe simples para definir um novo tipo usando typedef -
typedef type newname;Por exemplo, o seguinte diz ao compilador que pés é outro nome para int -
typedef int feet;Agora, a seguinte declaração é perfeitamente legal e cria uma variável inteira chamada distância -
feet distance;Tipos Enumerados
Um tipo enumerado declara um nome de tipo opcional e um conjunto de zero ou mais identificadores que podem ser usados como valores do tipo. Cada enumerador é uma constante cujo tipo é a enumeração.
A criação de uma enumeração requer o uso da palavra-chave enum. A forma geral de um tipo de enumeração é -
enum enum-name { list of names } var-list;Aqui, o enum-name é o nome do tipo de enumeração. A lista de nomes é separada por vírgulas.
Por exemplo, o código a seguir define uma enumeração de cores chamada cores e a variável c do tipo color. Finalmente, c recebe o valor "azul".
enum color { red, green, blue } c;
c = blue;Por padrão, o valor do primeiro nome é 0, o segundo nome tem o valor 1 e o terceiro tem o valor 2 e assim por diante. Mas você pode dar um nome, um valor específico adicionando um inicializador. Por exemplo, na seguinte enumeração,green terá o valor 5.
enum color { red, green = 5, blue };Aqui, blue terá um valor de 6 porque cada nome será um maior do que o que o precede.
Uma variável nos fornece armazenamento nomeado que nossos programas podem manipular. Cada variável em C ++ possui um tipo específico, que determina o tamanho e o layout da memória da variável; a faixa de valores que podem ser armazenados nessa memória; e o conjunto de operações que podem ser aplicadas à variável.
O nome de uma variável pode ser composto de letras, dígitos e o caractere de sublinhado. Deve começar com uma letra ou um sublinhado. Letras maiúsculas e minúsculas são diferentes porque C ++ diferencia maiúsculas de minúsculas -
Existem os seguintes tipos básicos de variáveis em C ++, conforme explicado no último capítulo -
| Sr. Não | Tipo e descrição |
|---|---|
| 1 | bool Armazena o valor verdadeiro ou falso. |
| 2 | char Normalmente, um único octeto (um byte). Este é um tipo inteiro. |
| 3 | int O tamanho mais natural do inteiro para a máquina. |
| 4 | float Um valor de ponto flutuante de precisão única. |
| 5 | double Um valor de ponto flutuante de precisão dupla. |
| 6 | void Representa a ausência de tipo. |
| 7 | wchar_t Um tipo de caractere amplo. |
C ++ também permite definir vários outros tipos de variáveis, que abordaremos em capítulos subsequentes, como Enumeration, Pointer, Array, Reference, Data structures, e Classes.
A seção a seguir cobrirá como definir, declarar e usar vários tipos de variáveis.
Definição de variável em C ++
Uma definição de variável informa ao compilador onde e quanto armazenamento criar para a variável. Uma definição de variável especifica um tipo de dados e contém uma lista de uma ou mais variáveis desse tipo como segue -
type variable_list;Aqui, type deve ser um tipo de dados C ++ válido, incluindo char, w_char, int, float, double, bool ou qualquer objeto definido pelo usuário, etc., e variable_listpode consistir em um ou mais nomes de identificadores separados por vírgulas. Algumas declarações válidas são mostradas aqui -
int i, j, k;
char c, ch;
float f, salary;
double d;A linha int i, j, k;ambos declaram e definem as variáveis i, j e k; que instrui o compilador a criar variáveis chamadas i, j e k do tipo int.
As variáveis podem ser inicializadas (atribuídas a um valor inicial) em sua declaração. O inicializador consiste em um sinal de igual seguido por uma expressão constante da seguinte maneira -
type variable_name = value;Alguns exemplos são -
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Para definição sem um inicializador: variáveis com duração de armazenamento estático são inicializadas implicitamente com NULL (todos os bytes têm o valor 0); o valor inicial de todas as outras variáveis é indefinido.
Declaração de variável em C ++
Uma declaração de variável fornece garantia ao compilador de que existe uma variável com o tipo e nome fornecidos para que o compilador prossiga para a compilação posterior sem precisar de detalhes completos sobre a variável. Uma declaração de variável tem seu significado apenas no momento da compilação, o compilador precisa da definição real da variável no momento da vinculação do programa.
Uma declaração de variável é útil quando você está usando vários arquivos e define sua variável em um dos arquivos que estarão disponíveis no momento da vinculação do programa. Você vai usarexternpalavra-chave para declarar uma variável em qualquer lugar. Embora você possa declarar uma variável várias vezes em seu programa C ++, ela pode ser definida apenas uma vez em um arquivo, função ou bloco de código.
Exemplo
Tente o seguinte exemplo onde uma variável foi declarada no topo, mas foi definida dentro da função principal -
#include <iostream>
using namespace std;
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
// Variable definition:
int a, b;
int c;
float f;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c << endl ;
f = 70.0/3.0;
cout << f << endl ;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
30
23.3333O mesmo conceito se aplica à declaração de função, onde você fornece um nome de função no momento de sua declaração e sua definição real pode ser fornecida em qualquer outro lugar. Por exemplo -
// function declaration
int func();
int main() {
// function call
int i = func();
}
// function definition
int func() {
return 0;
}Lvalues e Rvalues
Existem dois tipos de expressões em C ++ -
lvalue- As expressões que se referem a um local da memória são chamadas de expressão "lvalue". Um lvalue pode aparecer como o lado esquerdo ou direito de uma atribuição.
rvalue- O termo rvalue se refere a um valor de dados que é armazenado em algum endereço da memória. Um rvalue é uma expressão que não pode ter um valor atribuído a ela, o que significa que um rvalue pode aparecer no lado direito, mas não no lado esquerdo de uma atribuição.
As variáveis são lvalues e, portanto, podem aparecer no lado esquerdo de uma atribuição. Literais numéricos são rvalues e, portanto, não podem ser atribuídos e não podem aparecer no lado esquerdo. A seguir está uma declaração válida -
int g = 20;Mas o seguinte não é uma declaração válida e geraria um erro em tempo de compilação -
10 = 20;Um escopo é uma região do programa e, de modo geral, existem três lugares, onde as variáveis podem ser declaradas -
Dentro de uma função ou bloco que é chamado de variáveis locais,
Na definição de parâmetros de função, que são chamados de parâmetros formais.
Fora de todas as funções que são chamadas de variáveis globais.
Aprenderemos o que é uma função e seu parâmetro nos capítulos subsequentes. Aqui, vamos explicar o que são variáveis locais e globais.
Variáveis Locais
Variáveis declaradas dentro de uma função ou bloco são variáveis locais. Eles podem ser usados apenas por instruções que estão dentro dessa função ou bloco de código. Variáveis locais não são conhecidas por funções fora das suas. A seguir está o exemplo usando variáveis locais -
#include <iostream>
using namespace std;
int main () {
// Local variable declaration:
int a, b;
int c;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}Variáveis globais
Variáveis globais são definidas fora de todas as funções, geralmente no topo do programa. As variáveis globais manterão seu valor ao longo da vida útil de seu programa.
Uma variável global pode ser acessada por qualquer função. Ou seja, uma variável global está disponível para uso em todo o programa após sua declaração. A seguir está o exemplo usando variáveis globais e locais -
#include <iostream>
using namespace std;
// Global variable declaration:
int g;
int main () {
// Local variable declaration:
int a, b;
// actual initialization
a = 10;
b = 20;
g = a + b;
cout << g;
return 0;
}Um programa pode ter o mesmo nome para variáveis locais e globais, mas o valor da variável local dentro de uma função terá preferência. Por exemplo -
#include <iostream>
using namespace std;
// Global variable declaration:
int g = 20;
int main () {
// Local variable declaration:
int g = 10;
cout << g;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
10Inicializando Variáveis Locais e Globais
Quando uma variável local é definida, ela não é inicializada pelo sistema, você deve inicializá-la você mesmo. Variáveis globais são inicializadas automaticamente pelo sistema quando você as define da seguinte maneira -
| Tipo de dados | Inicializador |
|---|---|
| int | 0 |
| Caracteres | '\ 0' |
| flutuador | 0 |
| em dobro | 0 |
| ponteiro | NULO |
É uma boa prática de programação inicializar variáveis corretamente, caso contrário, às vezes o programa produziria resultados inesperados.
Constantes referem-se a valores fixos que o programa não pode alterar e são chamados literals.
As constantes podem ser de qualquer um dos tipos de dados básicos e podem ser divididas em numerais inteiros, numerais de ponto flutuante, caracteres, strings e valores booleanos.
Novamente, as constantes são tratadas como variáveis regulares, exceto que seus valores não podem ser modificados após sua definição.
Literais inteiros
Um literal inteiro pode ser uma constante decimal, octal ou hexadecimal. Um prefixo especifica a base ou raiz: 0x ou 0X para hexadecimal, 0 para octal e nada para decimal.
Um literal inteiro também pode ter um sufixo que é uma combinação de U e L, para sem sinal e longo, respectivamente. O sufixo pode ser maiúsculo ou minúsculo e pode estar em qualquer ordem.
Aqui estão alguns exemplos de literais inteiros -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixA seguir estão outros exemplos de vários tipos de literais inteiros -
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned longLiterais de ponto flutuante
Um literal de ponto flutuante possui uma parte inteira, um ponto decimal, uma parte fracionária e uma parte expoente. Você pode representar literais de ponto flutuante na forma decimal ou exponencial.
Ao representar usando a forma decimal, você deve incluir a vírgula decimal, o expoente ou ambos e, ao representar usando a forma exponencial, você deve incluir a parte inteira, a parte fracionária ou ambas. O expoente assinado é introduzido por e ou E.
Aqui estão alguns exemplos de literais de ponto flutuante -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fractionLiterais booleanos
Existem dois literais booleanos e eles fazem parte das palavras-chave C ++ padrão -
Um valor de true representando verdadeiro.
Um valor de false representando falso.
Você não deve considerar o valor de verdadeiro igual a 1 e o valor de falso igual a 0.
Literais de caracteres
Literais de caracteres são colocados entre aspas simples. Se o literal começar com L (apenas maiúsculas), é um literal de caractere largo (por exemplo, L'x ') e deve ser armazenado emwchar_ttipo de variável. Caso contrário, é um literal de caractere estreito (por exemplo, 'x') e pode ser armazenado em uma variável simples dechar tipo.
Um literal de caractere pode ser um caractere simples (por exemplo, 'x'), uma seqüência de escape (por exemplo, '\ t') ou um caractere universal (por exemplo, '\ u02C0').
Existem certos caracteres em C ++ quando eles são precedidos por uma barra invertida, eles têm um significado especial e são usados para representar como nova linha (\ n) ou tabulação (\ t). Aqui, você tem uma lista de alguns desses códigos de sequência de escape -
| Sequência de fuga | Significado |
|---|---|
| \\ | \ personagem |
| \ ' | ' personagem |
| \ " | " personagem |
| \? | ? personagem |
| \uma | Alerta ou sino |
| \ b | Backspace |
| \ f | Feed de formulário |
| \ n | Nova linha |
| \ r | Retorno de carruagem |
| \ t | Aba horizontal |
| \ v | Aba vertical |
| \ ooo | Número octal de um a três dígitos |
| \ xhh. . . | Número hexadecimal de um ou mais dígitos |
A seguir está o exemplo para mostrar alguns caracteres da sequência de escape -
#include <iostream>
using namespace std;
int main() {
cout << "Hello\tWorld\n\n";
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello WorldLiterais de string
Literais de string são colocados entre aspas duplas. Uma string contém caracteres semelhantes aos literais de caracteres: caracteres simples, sequências de escape e caracteres universais.
Você pode quebrar uma linha longa em várias linhas usando literais de string e separá-los usando espaços em branco.
Aqui estão alguns exemplos de literais de string. Todas as três formas são strings idênticas.
"hello, dear"
"hello, \
dear"
"hello, " "d" "ear"Definindo Constantes
Existem duas maneiras simples em C ++ de definir constantes -
Usando #define pré-processador.
Usando const palavra-chave.
O pré-processador #define
A seguir está o formulário para usar o pré-processador #define para definir uma constante -
#define identifier valueO exemplo a seguir explica em detalhes -
#include <iostream>
using namespace std;
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
50A palavra-chave const
Você pode usar const prefixo para declarar constantes com um tipo específico da seguinte forma -
const type variable = value;O exemplo a seguir explica em detalhes -
#include <iostream>
using namespace std;
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
50Observe que é uma boa prática de programação definir constantes em MAIÚSCULAS.
C ++ permite o char, int, e doubletipos de dados para ter modificadores precedendo-os. Um modificador é usado para alterar o significado do tipo base para que ele se ajuste mais precisamente às necessidades de várias situações.
Os modificadores de tipo de dados estão listados aqui -
- signed
- unsigned
- long
- short
Os modificadores signed, unsigned, long, e shortpode ser aplicado a tipos de base inteiros. Além do que, além do mais,signed e unsigned pode ser aplicado a char, e long pode ser aplicado ao dobro.
Os modificadores signed e unsigned também pode ser usado como prefixo para long ou shortmodificadores. Por exemplo,unsigned long int.
C ++ permite uma notação abreviada para declarar unsigned, short, ou longinteiros. Você pode simplesmente usar a palavraunsigned, short, ou long, sem int. Implica automaticamenteint. Por exemplo, as duas instruções a seguir declaram variáveis inteiras sem sinal.
unsigned x;
unsigned int y;Para entender a diferença entre a maneira como os modificadores de inteiros assinados e não assinados são interpretados pelo C ++, você deve executar o seguinte programa curto -
#include <iostream>
using namespace std;
/* This program shows the difference between
* signed and unsigned integers.
*/
int main() {
short int i; // a signed short integer
short unsigned int j; // an unsigned short integer
j = 50000;
i = j;
cout << i << " " << j;
return 0;
}Quando este programa é executado, o seguinte é o resultado -
-15536 50000O resultado acima é porque o padrão de bits que representa 50.000 como um inteiro curto sem sinal é interpretado como -15.536 por um curto.
Qualificadores de tipo em C ++
Os qualificadores de tipo fornecem informações adicionais sobre as variáveis que precedem.
| Sr. Não | Qualificador e Significado |
|---|---|
| 1 | const Objetos do tipo const não pode ser alterado pelo seu programa durante a execução. |
| 2 | volatile O modificador volatile diz ao compilador que o valor de uma variável pode ser alterado de maneiras não especificadas explicitamente pelo programa. |
| 3 | restrict Um ponteiro qualificado por restricté inicialmente o único meio pelo qual o objeto para o qual ele aponta pode ser acessado. Apenas C99 adiciona um novo qualificador de tipo chamado restrito. |
Uma classe de armazenamento define o escopo (visibilidade) e o tempo de vida de variáveis e / ou funções dentro de um Programa C ++. Esses especificadores precedem o tipo que eles modificam. Existem as seguintes classes de armazenamento, que podem ser usadas em um programa C ++
- auto
- register
- static
- extern
- mutable
A classe de armazenamento auto
o auto classe de armazenamento é a classe de armazenamento padrão para todas as variáveis locais.
{
int mount;
auto int month;
}O exemplo acima define duas variáveis com a mesma classe de armazenamento, auto só pode ser usado dentro de funções, ou seja, variáveis locais.
A classe de armazenamento registrada
o registerA classe de armazenamento é usada para definir variáveis locais que devem ser armazenadas em um registro ao invés de RAM. Isso significa que a variável tem um tamanho máximo igual ao tamanho do registro (normalmente uma palavra) e não pode ter o operador unário '&' aplicado a ela (pois não tem uma localização na memória).
{
register int miles;
}O registro deve ser usado apenas para variáveis que requerem acesso rápido, como contadores. Também deve ser notado que definir 'registro' não significa que a variável será armazenada em um registro. Isso significa que PODE ser armazenado em um registro dependendo do hardware e das restrições de implementação.
A classe de armazenamento estática
o staticA classe de armazenamento instrui o compilador a manter uma variável local existente durante o tempo de vida do programa, em vez de criá-la e destruí-la toda vez que ela entrar e sair do escopo. Portanto, tornar as variáveis locais estáticas permite que eles mantenham seus valores entre as chamadas de função.
O modificador estático também pode ser aplicado a variáveis globais. Quando isso é feito, o escopo dessa variável fica restrito ao arquivo no qual ela foi declarada.
Em C ++, quando estático é usado em um membro de dados de classe, ele faz com que apenas uma cópia desse membro seja compartilhada por todos os objetos de sua classe.
#include <iostream>
// Function declaration
void func(void);
static int count = 10; /* Global variable */
main() {
while(count--) {
func();
}
return 0;
}
// Function definition
void func( void ) {
static int i = 5; // local static variable
i++;
std::cout << "i is " << i ;
std::cout << " and count is " << count << std::endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
i is 6 and count is 9
i is 7 and count is 8
i is 8 and count is 7
i is 9 and count is 6
i is 10 and count is 5
i is 11 and count is 4
i is 12 and count is 3
i is 13 and count is 2
i is 14 and count is 1
i is 15 and count is 0A classe de armazenamento externa
o externA classe de armazenamento é usada para fornecer uma referência de uma variável global que é visível para TODOS os arquivos de programa. Quando você usa 'extern', a variável não pode ser inicializada, pois tudo o que ela faz é apontar o nome da variável para um local de armazenamento que foi definido anteriormente.
Quando você tem vários arquivos e define uma variável ou função global, que será usada em outros arquivos também, extern será usado em outro arquivo para dar referência à variável ou função definida. Apenas para entender, extern é usado para declarar uma variável global ou função em outro arquivo.
O modificador externo é mais comumente usado quando há dois ou mais arquivos compartilhando as mesmas variáveis globais ou funções conforme explicado abaixo.
Primeiro arquivo: main.cpp
#include <iostream>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}Segundo arquivo: support.cpp
#include <iostream>
extern int count;
void write_extern(void) {
std::cout << "Count is " << count << std::endl;
}Aqui, a palavra-chave extern está sendo usada para declarar a contagem em outro arquivo. Agora compile esses dois arquivos da seguinte maneira -
$g++ main.cpp support.cpp -o writeIsso vai produzir write programa executável, tente executar write e verifique o resultado da seguinte forma -
$./write
5A classe de armazenamento mutável
o mutableespecificador se aplica apenas a objetos de classe, que são discutidos posteriormente neste tutorial. Ele permite que um membro de um objeto substitua a função de membro const. Ou seja, um membro mutável pode ser modificado por uma função de membro const.
Um operador é um símbolo que informa ao compilador para executar manipulações matemáticas ou lógicas específicas. C ++ é rico em operadores integrados e fornece os seguintes tipos de operadores -
- Operadores aritméticos
- Operadores Relacionais
- Operadores lógicos
- Operadores bit a bit
- Operadores de atribuição
- Operadores diversos
Este capítulo examinará os operadores aritméticos, relacionais, lógicos, de atribuição de bits e outros, um por um.
Operadores aritméticos
Existem seguintes operadores aritméticos suportados pela linguagem C ++ -
Suponha que a variável A tenha 10 e a variável B tenha 20, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| + | Adiciona dois operandos | A + B dará 30 |
| - | Subtrai o segundo operando do primeiro | A - B dará -10 |
| * | Multiplica ambos os operandos | A * B dará 200 |
| / | Divide numerador por de-numerador | B / A dará 2 |
| % | Operador de Módulo e o restante após uma divisão inteira | B% A dará 0 |
| ++ | Operador de incremento , aumenta o valor inteiro em um | A ++ dará 11 |
| - | Operador de decremento , diminui o valor inteiro em um | A-- dará 9 |
Operadores Relacionais
Existem os seguintes operadores relacionais suportados pela linguagem C ++
Suponha que a variável A tenha 10 e a variável B tenha 20, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| == | Verifica se os valores dos dois operandos são iguais ou não, se sim a condição torna-se verdadeira. | (A == B) não é verdade. |
| ! = | Verifica se os valores de dois operandos são iguais ou não, se os valores não são iguais, a condição se torna verdadeira. | (A! = B) é verdade. |
| > | Verifica se o valor do operando esquerdo é maior que o valor do operando direito, se sim então a condição torna-se verdadeira. | (A> B) não é verdade. |
| < | Verifica se o valor do operando esquerdo é menor que o valor do operando direito; se sim, a condição torna-se verdadeira. | (A <B) é verdade. |
| > = | Verifica se o valor do operando esquerdo é maior ou igual ao valor do operando direito, se sim a condição torna-se verdadeira. | (A> = B) não é verdade. |
| <= | Verifica se o valor do operando esquerdo é menor ou igual ao valor do operando direito; em caso afirmativo, a condição torna-se verdadeira. | (A <= B) é verdadeiro. |
Operadores lógicos
Existem os seguintes operadores lógicos suportados pela linguagem C ++.
Suponha que a variável A tenha 1 e a variável B tenha 0, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| && | Operador lógico chamado AND. Se ambos os operandos forem diferentes de zero, a condição se torna verdadeira. | (A && B) é falso. |
| || | Operador lógico ou chamado. Se qualquer um dos dois operandos for diferente de zero, a condição se torna verdadeira. | (A || B) é verdade. |
| ! | Operador lógico chamado NOT. Use para reverter o estado lógico de seu operando. Se uma condição for verdadeira, o operador lógico NOT tornará falsa. | ! (A && B) é verdade. |
Operadores bit a bit
O operador bit a bit funciona em bits e executa a operação bit a bit. As tabelas de verdade para &, | e ^ são as seguintes -
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Suponha que A = 60; e B = 13; agora em formato binário serão os seguintes -
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Os operadores bit a bit suportados pela linguagem C ++ estão listados na tabela a seguir. Suponha que a variável A tenha 60 e a variável B tenha 13, então -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| E | O operador Binário AND copia um bit para o resultado se ele existir em ambos os operandos. | (A e B) dará 12, que é 0000 1100 |
| | | O operador binário OR copia um bit se ele existir em qualquer operando. | (A | B) dará 61, que é 0011 1101 |
| ^ | O operador binário XOR copia o bit se estiver definido em um operando, mas não em ambos. | (A ^ B) dará 49, que é 0011 0001 |
| ~ | O operador de complemento binários é unário e tem o efeito de 'inverter' bits. | (~ A) dará -61 que é 1100 0011 na forma de complemento de 2 devido a um número binário com sinal. |
| << | Operador binário de deslocamento à esquerda. O valor dos operandos à esquerda é movido para a esquerda pelo número de bits especificado pelo operando à direita. | Um << 2 dará 240, que é 1111 0000 |
| >> | Operador binário de deslocamento à direita. O valor dos operandos à esquerda é movido para a direita pelo número de bits especificado pelo operando à direita. | Um >> 2 dará 15, que é 0000 1111 |
Operadores de atribuição
Existem seguintes operadores de atribuição suportados pela linguagem C ++ -
Mostrar exemplos
| Operador | Descrição | Exemplo |
|---|---|---|
| = | Operador de atribuição simples, atribui valores de operandos do lado direito para operando do lado esquerdo. | C = A + B irá atribuir o valor de A + B em C |
| + = | Adicionar operador de atribuição AND, adiciona o operando direito ao operando esquerdo e atribui o resultado ao operando esquerdo. | C + = A é equivalente a C = C + A |
| - = | Subtrai o operador de atribuição AND, ele subtrai o operando direito do operando esquerdo e atribui o resultado ao operando esquerdo. | C - = A é equivalente a C = C - A |
| * = | Operador de atribuição Multiply AND, multiplica o operando direito pelo operando esquerdo e atribui o resultado ao operando esquerdo. | C * = A é equivalente a C = C * A |
| / = | Operador de atribuição Dividir AND, divide o operando esquerdo com o operando direito e atribui o resultado ao operando esquerdo. | C / = A é equivalente a C = C / A |
| % = | Módulo E operador de atribuição. Leva o módulo usando dois operandos e atribui o resultado ao operando esquerdo. | C% = A é equivalente a C = C% A |
| << = | Deslocamento à esquerda E operador de atribuição. | C << = 2 é igual a C = C << 2 |
| >> = | Deslocamento à direita E operador de atribuição. | C >> = 2 é igual a C = C >> 2 |
| & = | Operador de atribuição AND bit a bit. | C & = 2 é igual a C = C & 2 |
| ^ = | OR exclusivo bit a bit e operador de atribuição. | C ^ = 2 é igual a C = C ^ 2 |
| | = | OR inclusivo bit a bit e operador de atribuição. | C | = 2 é igual a C = C | 2 |
Operadores diversos
A tabela a seguir lista alguns outros operadores compatíveis com C ++.
| Sr. Não | Operador e descrição |
|---|---|
| 1 | sizeof operador sizeof retorna o tamanho de uma variável. Por exemplo, sizeof (a), onde 'a' é um número inteiro e retornará 4. |
| 2 | Condition ? X : Y Operador condicional (?) . Se a Condição for verdadeira, ela retornará o valor de X, caso contrário, retornará o valor de Y. |
| 3 | , O operador vírgula faz com que uma sequência de operações seja executada. O valor de toda a expressão de vírgula é o valor da última expressão da lista separada por vírgulas. |
| 4 | . (dot) and -> (arrow) Operadores membro são usados para fazer referência a membros individuais de classes, estruturas e uniões. |
| 5 | Cast Os operadores de conversão convertem um tipo de dados em outro. Por exemplo, int (2.2000) retornaria 2. |
| 6 | & Operador de ponteiro e retorna o endereço de uma variável. Por exemplo, & a; fornecerá o endereço real da variável. |
| 7 | * Operador de ponteiro * é um ponteiro para uma variável. Por exemplo * var; irá apontar para uma variável var. |
Precedência de operadores em C ++
A precedência do operador determina o agrupamento de termos em uma expressão. Isso afeta como uma expressão é avaliada. Certos operadores têm precedência mais alta do que outros; por exemplo, o operador de multiplicação tem precedência mais alta do que o operador de adição -
Por exemplo x = 7 + 3 * 2; aqui, x é atribuído a 13, não 20, porque o operador * tem precedência mais alta do que +, portanto, primeiro é multiplicado por 3 * 2 e, em seguida, é adicionado a 7.
Aqui, os operadores com a precedência mais alta aparecem na parte superior da tabela, aqueles com a mais baixa aparecem na parte inferior. Em uma expressão, os operadores de precedência superior serão avaliados primeiro.
Mostrar exemplos
| Categoria | Operador | Associatividade |
|---|---|---|
| Postfix | () [] ->. ++ - - | Da esquerda para direita |
| Unário | + -! ~ ++ - - (tipo) * & sizeof | Direita para esquerda |
| Multiplicativo | * /% | Da esquerda para direita |
| Aditivo | + - | Da esquerda para direita |
| Mudança | << >> | Da esquerda para direita |
| Relacional | <<=>> = | Da esquerda para direita |
| Igualdade | ==! = | Da esquerda para direita |
| E bit a bit | E | Da esquerda para direita |
| XOR bit a bit | ^ | Da esquerda para direita |
| OR bit a bit | | | Da esquerda para direita |
| E lógico | && | Da esquerda para direita |
| OR lógico | || | Da esquerda para direita |
| Condicional | ?: | Direita para esquerda |
| Tarefa | = + = - = * = / =% = >> = << = & = ^ = | = | Direita para esquerda |
| Vírgula | , | Da esquerda para direita |
Pode haver uma situação em que você precise executar um bloco de código várias vezes. Em geral, as instruções são executadas sequencialmente: a primeira instrução em uma função é executada primeiro, seguida pela segunda e assim por diante.
As linguagens de programação fornecem várias estruturas de controle que permitem caminhos de execução mais complicados.
Uma instrução de loop nos permite executar uma instrução ou grupo de instruções várias vezes e, a seguir, é a forma geral de uma instrução de loop na maioria das linguagens de programação -
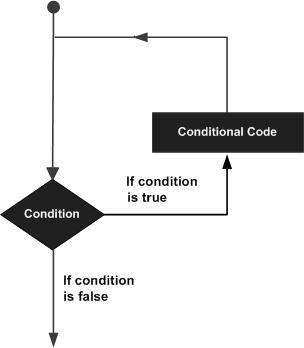
A linguagem de programação C ++ fornece os seguintes tipos de loops para lidar com os requisitos de loop.
| Sr. Não | Tipo de Loop e Descrição |
|---|---|
| 1 | loop while Repete uma declaração ou grupo de declarações enquanto uma determinada condição for verdadeira. Ele testa a condição antes de executar o corpo do loop. |
| 2 | para loop Execute uma sequência de instruções várias vezes e abrevia o código que gerencia a variável de loop. |
| 3 | fazer ... loop while Como uma instrução 'while', exceto que testa a condição no final do corpo do loop. |
| 4 | loops aninhados Você pode usar um ou mais loops dentro de qualquer outro loop 'while', 'for' ou 'do..while'. |
Declarações de controle de loop
As instruções de controle de loop alteram a execução de sua sequência normal. Quando a execução deixa um escopo, todos os objetos automáticos que foram criados nesse escopo são destruídos.
C ++ oferece suporte às seguintes instruções de controle.
| Sr. Não | Declaração de controle e descrição |
|---|---|
| 1 | declaração de quebra Termina o loop ou switch instrução e transfere a execução para a instrução imediatamente após o loop ou switch. |
| 2 | continuar declaração Faz com que o loop pule o restante de seu corpo e teste novamente sua condição imediatamente antes de reiterar. |
| 3 | declaração goto Transfere o controle para a instrução rotulada. Embora não seja aconselhável usar a instrução goto em seu programa. |
The Infinite Loop
Um loop se torna um loop infinito se uma condição nunca se torna falsa. oforloop é tradicionalmente usado para esse propósito. Como nenhuma das três expressões que formam o loop 'for' é necessária, você pode fazer um loop infinito deixando a expressão condicional vazia.
#include <iostream>
using namespace std;
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}Quando a expressão condicional está ausente, ela é considerada verdadeira. Você pode ter uma expressão de inicialização e incremento, mas os programadores C ++ mais comumente usam a construção 'for (;;)' para significar um loop infinito.
NOTE - Você pode encerrar um loop infinito pressionando as teclas Ctrl + C.
As estruturas de tomada de decisão requerem que o programador especifique uma ou mais condições a serem avaliadas ou testadas pelo programa, junto com uma instrução ou instruções a serem executadas se a condição for determinada como verdadeira e, opcionalmente, outras instruções a serem executadas se a condição está determinado a ser falso.
A seguir está a forma geral de uma estrutura típica de tomada de decisão encontrada na maioria das linguagens de programação -
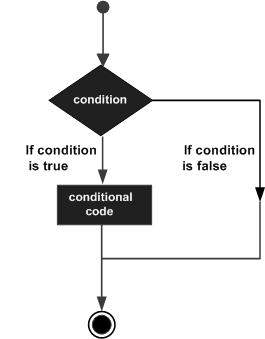
A linguagem de programação C ++ fornece os seguintes tipos de declarações de tomada de decisão.
| Sr. Não | Declaração e descrição |
|---|---|
| 1 | declaração if Uma declaração 'if' consiste em uma expressão booleana seguida por uma ou mais declarações. |
| 2 | declaração if ... else Uma instrução 'if' pode ser seguida por uma instrução 'else' opcional, que é executada quando a expressão booleana é falsa. |
| 3 | declaração switch Uma instrução 'switch' permite que uma variável seja testada quanto à igualdade em relação a uma lista de valores. |
| 4 | declarações if aninhadas Você pode usar uma instrução 'if' ou 'else if' dentro de outra instrução 'if' ou 'else if'. |
| 5 | instruções switch aninhadas Você pode usar uma instrução 'switch' dentro de outra (s) instrução (ões) 'switch'. |
O ? : Operador
Cobrimos o operador condicional “? : ” No capítulo anterior, que pode ser usado para substituirif...elseafirmações. Tem a seguinte forma geral -
Exp1 ? Exp2 : Exp3;Exp1, Exp2 e Exp3 são expressões. Observe o uso e a localização do cólon.
O valor de um '?' expressão é determinada assim: Exp1 é avaliada. Se for verdadeiro, então Exp2 é avaliado e se torna o valor de '?' expressão. Se Exp1 for falso, então Exp3 é avaliado e seu valor se torna o valor da expressão.
Uma função é um grupo de instruções que, juntas, executam uma tarefa. Cada programa C ++ tem pelo menos uma função, que émain(), e todos os programas mais triviais podem definir funções adicionais.
Você pode dividir seu código em funções separadas. Como você divide seu código entre diferentes funções é com você, mas logicamente a divisão geralmente é tal que cada função executa uma tarefa específica.
Uma função declarationinforma ao compilador o nome, o tipo de retorno e os parâmetros de uma função. Uma funçãodefinition fornece o corpo real da função.
A biblioteca padrão C ++ fornece várias funções integradas que seu programa pode chamar. Por exemplo, funçãostrcat() para concatenar duas strings, função memcpy() para copiar um local de memória para outro local e muitas outras funções.
Uma função é conhecida por vários nomes, como um método ou uma sub-rotina ou um procedimento, etc.
Definindo uma função
A forma geral de uma definição de função C ++ é a seguinte -
return_type function_name( parameter list ) {
body of the function
}Uma definição de função C ++ consiste em um cabeçalho de função e um corpo de função. Aqui estão todas as partes de uma função -
Return Type- Uma função pode retornar um valor. oreturn_typeé o tipo de dados do valor que a função retorna. Algumas funções realizam as operações desejadas sem retornar um valor. Neste caso, o return_type é a palavra-chavevoid.
Function Name- Este é o nome real da função. O nome da função e a lista de parâmetros juntos constituem a assinatura da função.
Parameters- Um parâmetro é como um espaço reservado. Quando uma função é chamada, você passa um valor para o parâmetro. Esse valor é conhecido como parâmetro ou argumento real. A lista de parâmetros se refere ao tipo, ordem e número dos parâmetros de uma função. Os parâmetros são opcionais; ou seja, uma função pode não conter parâmetros.
Function Body - O corpo da função contém uma coleção de instruções que definem o que a função faz.
Exemplo
A seguir está o código-fonte para uma função chamada max(). Esta função recebe dois parâmetros num1 e num2 e retorna o maior de ambos -
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Declarações de função
Uma função declarationinforma ao compilador sobre o nome de uma função e como chamá-la. O corpo real da função pode ser definido separadamente.
Uma declaração de função tem as seguintes partes -
return_type function_name( parameter list );Para a função max () definida acima, a seguir está a declaração da função -
int max(int num1, int num2);Os nomes dos parâmetros não são importantes na declaração da função, apenas seu tipo é necessário, portanto, a seguir também está uma declaração válida -
int max(int, int);A declaração da função é necessária quando você define uma função em um arquivo de origem e chama essa função em outro arquivo. Nesse caso, você deve declarar a função na parte superior do arquivo que está chamando a função.
Chamando uma função
Ao criar uma função C ++, você dá uma definição do que a função deve fazer. Para usar uma função, você terá que chamar ou invocar essa função.
Quando um programa chama uma função, o controle do programa é transferido para a função chamada. Uma função chamada executa uma tarefa definida e quando sua instrução de retorno é executada ou quando sua chave de fechamento de finalização de função é alcançada, ela retorna o controle do programa ao programa principal.
Para chamar uma função, você simplesmente precisa passar os parâmetros necessários junto com o nome da função e, se a função retornar um valor, você pode armazenar o valor retornado. Por exemplo -
#include <iostream>
using namespace std;
// function declaration
int max(int num1, int num2);
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int ret;
// calling a function to get max value.
ret = max(a, b);
cout << "Max value is : " << ret << endl;
return 0;
}
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Eu mantive a função max () junto com a função main () e compilei o código-fonte. Durante a execução do executável final, ele produziria o seguinte resultado -
Max value is : 200Argumentos de função
Se uma função deve usar argumentos, ela deve declarar variáveis que aceitam os valores dos argumentos. Essas variáveis são chamadas deformal parameters da função.
Os parâmetros formais se comportam como outras variáveis locais dentro da função e são criados na entrada na função e destruídos na saída.
Ao chamar uma função, existem duas maneiras de os argumentos serem passados para uma função -
| Sr. Não | Tipo e descrição da chamada |
|---|---|
| 1 | Chamada por valor Este método copia o valor real de um argumento para o parâmetro formal da função. Nesse caso, as alterações feitas no parâmetro dentro da função não têm efeito no argumento. |
| 2 | Chamada por Pointer Este método copia o endereço de um argumento no parâmetro formal. Dentro da função, o endereço é usado para acessar o argumento real usado na chamada. Isso significa que as alterações feitas no parâmetro afetam o argumento. |
| 3 | Chamada por Referência Este método copia a referência de um argumento para o parâmetro formal. Dentro da função, a referência é usada para acessar o argumento real usado na chamada. Isso significa que as alterações feitas no parâmetro afetam o argumento. |
Por padrão, C ++ usa call by valuepara passar argumentos. Em geral, isso significa que o código dentro de uma função não pode alterar os argumentos usados para chamar a função e o exemplo mencionado acima ao chamar a função max () usando o mesmo método.
Valores padrão para parâmetros
Ao definir uma função, você pode especificar um valor padrão para cada um dos últimos parâmetros. Este valor será usado se o argumento correspondente for deixado em branco ao chamar a função.
Isso é feito usando o operador de atribuição e atribuindo valores para os argumentos na definição da função. Se um valor para aquele parâmetro não for passado quando a função for chamada, o valor padrão fornecido será usado, mas se um valor for especificado, esse valor padrão será ignorado e o valor passado será usado em seu lugar. Considere o seguinte exemplo -
#include <iostream>
using namespace std;
int sum(int a, int b = 20) {
int result;
result = a + b;
return (result);
}
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int result;
// calling a function to add the values.
result = sum(a, b);
cout << "Total value is :" << result << endl;
// calling a function again as follows.
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total value is :300
Total value is :120Normalmente, quando trabalhamos com Numbers, usamos tipos de dados primitivos como int, short, long, float e double, etc. Os tipos de dados numéricos, seus valores possíveis e intervalos de números foram explicados ao discutir os Tipos de Dados C ++.
Definindo Números em C ++
Você já definiu números em vários exemplos dados nos capítulos anteriores. Aqui está outro exemplo consolidado para definir vários tipos de números em C ++ -
#include <iostream>
using namespace std;
int main () {
// number definition:
short s;
int i;
long l;
float f;
double d;
// number assignments;
s = 10;
i = 1000;
l = 1000000;
f = 230.47;
d = 30949.374;
// number printing;
cout << "short s :" << s << endl;
cout << "int i :" << i << endl;
cout << "long l :" << l << endl;
cout << "float f :" << f << endl;
cout << "double d :" << d << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
short s :10
int i :1000
long l :1000000
float f :230.47
double d :30949.4Operações matemáticas em C ++
Além das várias funções que você pode criar, C ++ também inclui algumas funções úteis que você pode usar. Essas funções estão disponíveis em bibliotecas C e C ++ padrão e chamadasbuilt-infunções. Essas são funções que podem ser incluídas em seu programa e depois usadas.
C ++ possui um rico conjunto de operações matemáticas, que podem ser realizadas em vários números. A tabela a seguir lista algumas funções matemáticas internas úteis disponíveis em C ++.
Para utilizar essas funções, você precisa incluir o arquivo de cabeçalho matemático <cmath>.
| Sr. Não | Função e objetivo |
|---|---|
| 1 | double cos(double); Esta função pega um ângulo (como um duplo) e retorna o cosseno. |
| 2 | double sin(double); Esta função pega um ângulo (como um duplo) e retorna o seno. |
| 3 | double tan(double); Esta função pega um ângulo (como um duplo) e retorna a tangente. |
| 4 | double log(double); Esta função recebe um número e retorna o log natural desse número. |
| 5 | double pow(double, double); O primeiro é um número que você deseja aumentar e o segundo é o poder que você deseja elevar t |
| 6 | double hypot(double, double); Se você passar para esta função o comprimento de dois lados de um triângulo retângulo, ela retornará o comprimento da hipotenusa. |
| 7 | double sqrt(double); Você passa um número para essa função e ela dá a raiz quadrada. |
| 8 | int abs(int); Esta função retorna o valor absoluto de um inteiro que é passado para ela. |
| 9 | double fabs(double); Esta função retorna o valor absoluto de qualquer número decimal passado a ela. |
| 10 | double floor(double); Encontra o número inteiro menor ou igual ao argumento passado para ele. |
A seguir está um exemplo simples para mostrar algumas das operações matemáticas -
#include <iostream>
#include <cmath>
using namespace std;
int main () {
// number definition:
short s = 10;
int i = -1000;
long l = 100000;
float f = 230.47;
double d = 200.374;
// mathematical operations;
cout << "sin(d) :" << sin(d) << endl;
cout << "abs(i) :" << abs(i) << endl;
cout << "floor(d) :" << floor(d) << endl;
cout << "sqrt(f) :" << sqrt(f) << endl;
cout << "pow( d, 2) :" << pow(d, 2) << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
sign(d) :-0.634939
abs(i) :1000
floor(d) :200
sqrt(f) :15.1812
pow( d, 2 ) :40149.7Números Aleatórios em C ++
Existem muitos casos em que você deseja gerar um número aleatório. Na verdade, existem duas funções que você precisa saber sobre a geração de números aleatórios. O primeiro érand(), esta função retornará apenas um número pseudoaleatório. A maneira de corrigir isso é ligar primeiro para osrand() função.
A seguir está um exemplo simples para gerar alguns números aleatórios. Este exemplo faz uso detime() função para obter o número de segundos na hora do sistema, para semear aleatoriamente a função rand () -
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
int main () {
int i,j;
// set the seed
srand( (unsigned)time( NULL ) );
/* generate 10 random numbers. */
for( i = 0; i < 10; i++ ) {
// generate actual random number
j = rand();
cout <<" Random Number : " << j << endl;
}
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Random Number : 1748144778
Random Number : 630873888
Random Number : 2134540646
Random Number : 219404170
Random Number : 902129458
Random Number : 920445370
Random Number : 1319072661
Random Number : 257938873
Random Number : 1256201101
Random Number : 580322989C ++ fornece uma estrutura de dados, the array, que armazena uma coleção sequencial de tamanho fixo de elementos do mesmo tipo. Uma matriz é usada para armazenar uma coleção de dados, mas geralmente é mais útil pensar em uma matriz como uma coleção de variáveis do mesmo tipo.
Em vez de declarar variáveis individuais, como número0, número1, ... e número99, você declara uma variável de matriz, como números e usa números [0], números [1] e ..., números [99] para representar variáveis individuais. Um elemento específico em uma matriz é acessado por um índice.
Todos os arrays consistem em locais de memória contíguos. O endereço mais baixo corresponde ao primeiro elemento e o endereço mais alto ao último elemento.
Declaração de matrizes
Para declarar uma matriz em C ++, o programador especifica o tipo dos elementos e o número de elementos exigidos por uma matriz da seguinte maneira -
type arrayName [ arraySize ];Isso é chamado de matriz de dimensão única. oarraySize deve ser uma constante inteira maior que zero e typepode ser qualquer tipo de dados C ++ válido. Por exemplo, para declarar uma matriz de 10 elementos chamada balance do tipo double, use esta instrução -
double balance[10];Inicializando matrizes
Você pode inicializar os elementos da matriz C ++ um por um ou usando uma única instrução da seguinte maneira -
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};O número de valores entre colchetes {} não pode ser maior do que o número de elementos que declaramos para a matriz entre colchetes []. A seguir está um exemplo para atribuir um único elemento da matriz -
Se você omitir o tamanho do array, um array grande o suficiente para conter a inicialização é criado. Portanto, se você escrever -
double balance[] = {1000.0, 2.0, 3.4, 17.0, 50.0};Você criará exatamente a mesma matriz que fez no exemplo anterior.
balance[4] = 50.0;O acima cessionários instrução número elemento 5 th na matriz um valor de 50,0. O array com o 4º índice será o 5º , ou seja, o último elemento, pois todos os arrays têm 0 como índice do primeiro elemento, também chamado de índice base. A seguir está a representação pictórica da mesma matriz que discutimos acima -

Acessando Elementos de Matriz
Um elemento é acessado indexando o nome da matriz. Isso é feito colocando o índice do elemento entre colchetes após o nome da matriz. Por exemplo -
double salary = balance[9];A declaração acima levará 10 th elemento da matriz e atribuir o valor a variável salário. A seguir está um exemplo, que usará todos os três conceitos acima mencionados viz. declaração, atribuição e acesso a matrizes -
#include <iostream>
using namespace std;
#include <iomanip>
using std::setw;
int main () {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
cout << "Element" << setw( 13 ) << "Value" << endl;
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
cout << setw( 7 )<< j << setw( 13 ) << n[ j ] << endl;
}
return 0;
}Este programa usa setw()função para formatar a saída. Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Matrizes em C ++
Os arrays são importantes para C ++ e precisam de muito mais detalhes. Seguem alguns conceitos importantes, que devem ser claros para um programador C ++ -
| Sr. Não | Conceito e descrição |
|---|---|
| 1 | Matrizes multidimensionais C ++ oferece suporte a matrizes multidimensionais. A forma mais simples da matriz multidimensional é a matriz bidimensional. |
| 2 | Ponteiro para uma matriz Você pode gerar um ponteiro para o primeiro elemento de uma matriz simplesmente especificando o nome da matriz, sem nenhum índice. |
| 3 | Passando matrizes para funções Você pode passar para a função um ponteiro para uma matriz, especificando o nome da matriz sem um índice. |
| 4 | Retorna array de funções C ++ permite que uma função retorne um array. |
C ++ fornece os seguintes dois tipos de representações de string -
- A sequência de caracteres do estilo C.
- O tipo de classe de string introduzido com C ++ padrão.
A string de caracteres C-Style
A cadeia de caracteres do estilo C originou-se na linguagem C e continua a ser compatível com C ++. Esta string é na verdade uma matriz unidimensional de caracteres que é terminada por umnullcaractere '\ 0'. Assim, uma string terminada em nulo contém os caracteres que compõem a string seguida por umnull.
A seguinte declaração e inicialização criam uma string que consiste na palavra "Hello". Para manter o caractere nulo no final do array, o tamanho do array de caracteres que contém a string é um a mais do que o número de caracteres na palavra "Hello".
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};Se você seguir a regra de inicialização de array, poderá escrever a instrução acima da seguinte maneira -
char greeting[] = "Hello";A seguir está a apresentação da memória da string definida acima em C / C ++ -

Na verdade, você não coloca o caractere nulo no final de uma constante de string. O compilador C ++ coloca automaticamente o '\ 0' no final da string ao inicializar o array. Vamos tentar imprimir a string mencionada acima -
#include <iostream>
using namespace std;
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
cout << "Greeting message: ";
cout << greeting << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Greeting message: HelloC ++ suporta uma ampla gama de funções que manipulam strings terminadas em nulos -
| Sr. Não | Função e objetivo |
|---|---|
| 1 | strcpy(s1, s2); Copia a string s2 para a string s1. |
| 2 | strcat(s1, s2); Concatena a string s2 no final da string s1. |
| 3 | strlen(s1); Retorna o comprimento da string s1. |
| 4 | strcmp(s1, s2); Retorna 0 se s1 e s2 forem iguais; menor que 0 se s1 <s2; maior que 0 se s1> s2. |
| 5 | strchr(s1, ch); Retorna um ponteiro para a primeira ocorrência do caractere ch na string s1. |
| 6 | strstr(s1, s2); Retorna um ponteiro para a primeira ocorrência da string s2 na string s1. |
O exemplo a seguir usa algumas das funções mencionadas acima -
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[10] = "Hello";
char str2[10] = "World";
char str3[10];
int len ;
// copy str1 into str3
strcpy( str3, str1);
cout << "strcpy( str3, str1) : " << str3 << endl;
// concatenates str1 and str2
strcat( str1, str2);
cout << "strcat( str1, str2): " << str1 << endl;
// total lenghth of str1 after concatenation
len = strlen(str1);
cout << "strlen(str1) : " << len << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
strcpy( str3, str1) : Hello
strcat( str1, str2): HelloWorld
strlen(str1) : 10A classe String em C ++
A biblioteca C ++ padrão fornece um stringtipo de classe que suporta todas as operações mencionadas acima, além de muito mais funcionalidade. Vamos verificar o seguinte exemplo -
#include <iostream>
#include <string>
using namespace std;
int main () {
string str1 = "Hello";
string str2 = "World";
string str3;
int len ;
// copy str1 into str3
str3 = str1;
cout << "str3 : " << str3 << endl;
// concatenates str1 and str2
str3 = str1 + str2;
cout << "str1 + str2 : " << str3 << endl;
// total length of str3 after concatenation
len = str3.size();
cout << "str3.size() : " << len << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
str3 : Hello
str1 + str2 : HelloWorld
str3.size() : 10Os ponteiros C ++ são fáceis e divertidos de aprender. Algumas tarefas C ++ são realizadas mais facilmente com ponteiros, e outras tarefas C ++, como alocação de memória dinâmica, não podem ser realizadas sem eles.
Como você sabe, cada variável é um local da memória e cada local da memória tem seu endereço definido, que pode ser acessado usando o operador E comercial (&) que denota um endereço na memória. Considere o seguinte, que imprimirá o endereço das variáveis definidas -
#include <iostream>
using namespace std;
int main () {
int var1;
char var2[10];
cout << "Address of var1 variable: ";
cout << &var1 << endl;
cout << "Address of var2 variable: ";
cout << &var2 << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Address of var1 variable: 0xbfebd5c0
Address of var2 variable: 0xbfebd5b6O que são ponteiros?
UMA pointeré uma variável cujo valor é o endereço de outra variável. Como qualquer variável ou constante, você deve declarar um ponteiro antes de trabalhar com ele. A forma geral de uma declaração de variável de ponteiro é -
type *var-name;Aqui, typeé o tipo base do ponteiro; deve ser um tipo C ++ válido evar-nameé o nome da variável de ponteiro. O asterisco que você usou para declarar um ponteiro é o mesmo asterisco que você usa para a multiplicação. No entanto, nesta declaração, o asterisco está sendo usado para designar uma variável como um ponteiro. A seguir estão as declarações de ponteiro válidas -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterO tipo de dados real do valor de todos os ponteiros, seja inteiro, flutuante, caractere ou outro, é o mesmo, um número hexadecimal longo que representa um endereço de memória. A única diferença entre ponteiros de diferentes tipos de dados é o tipo de dados da variável ou constante para a qual o ponteiro aponta.
Usando ponteiros em C ++
Existem algumas operações importantes, que faremos com os ponteiros com muita freqüência. (a) Definimos uma variável de ponteiro. (b) Atribuir o endereço de uma variável a um ponteiro. (c)Finalmente acesse o valor no endereço disponível na variável de ponteiro. Isso é feito usando o operador unário * que retorna o valor da variável localizada no endereço especificado por seu operando. O exemplo a seguir faz uso dessas operações -
#include <iostream>
using namespace std;
int main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
cout << "Value of var variable: ";
cout << var << endl;
// print the address stored in ip pointer variable
cout << "Address stored in ip variable: ";
cout << ip << endl;
// access the value at the address available in pointer
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz um resultado como o seguinte -
Value of var variable: 20
Address stored in ip variable: 0xbfc601ac
Value of *ip variable: 20Ponteiros em C ++
Os ponteiros têm muitos conceitos fáceis e são muito importantes para a programação C ++. Seguem alguns conceitos de ponteiro importantes que devem ser claros para um programador C ++ -
| Sr. Não | Conceito e descrição |
|---|---|
| 1 | Ponteiros nulos C ++ oferece suporte a ponteiro nulo, que é uma constante com valor zero definido em várias bibliotecas padrão. |
| 2 | Pointer Arithmetic Existem quatro operadores aritméticos que podem ser usados em ponteiros: ++, -, +, - |
| 3 | Ponteiros vs matrizes Existe uma relação estreita entre ponteiros e matrizes. |
| 4 | Array of Pointers Você pode definir matrizes para conter uma série de ponteiros. |
| 5 | Ponteiro para Ponteiro C ++ permite que você tenha um ponteiro sobre um ponteiro e assim por diante. |
| 6 | Passando ponteiros para funções Passar um argumento por referência ou por endereço permite que o argumento passado seja alterado na função de chamada pela função chamada. |
| 7 | Return Pointer from Functions C ++ permite que uma função retorne um ponteiro para uma variável local, variável estática e memória alocada dinamicamente. |
Uma variável de referência é um alias, ou seja, outro nome para uma variável já existente. Depois que uma referência é inicializada com uma variável, o nome da variável ou o nome da referência pode ser usado para se referir à variável.
Referências vs ponteiros
As referências são frequentemente confundidas com ponteiros, mas as três principais diferenças entre referências e ponteiros são -
Você não pode ter referências NULL. Você sempre deve ser capaz de presumir que uma referência está conectada a um armazenamento legítimo.
Depois que uma referência é inicializada para um objeto, ela não pode ser alterada para se referir a outro objeto. Os ponteiros podem ser apontados para outro objeto a qualquer momento.
Uma referência deve ser inicializada ao ser criada. Os ponteiros podem ser inicializados a qualquer momento.
Criação de referências em C ++
Pense no nome de uma variável como um rótulo anexado à localização da variável na memória. Você pode então pensar em uma referência como um segundo rótulo anexado a esse local de memória. Portanto, você pode acessar o conteúdo da variável por meio do nome da variável original ou da referência. Por exemplo, suponha que temos o seguinte exemplo -
int i = 17;Podemos declarar variáveis de referência para i da seguinte maneira.
int& r = i;Leia o & nestas declarações como reference. Thus, read the first declaration as "r is an integer reference initialized to i" and read the second declaration as "s is a double reference initialized to d.". Following example makes use of references on int and double −
#include <iostream>
using namespace std;
int main () {
// declare simple variables
int i;
double d;
// declare reference variables
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
}When the above code is compiled together and executed, it produces the following result −
Value of i : 5
Value of i reference : 5
Value of d : 11.7
Value of d reference : 11.7References are usually used for function argument lists and function return values. So following are two important subjects related to C++ references which should be clear to a C++ programmer −
| Sr.No | Concept & Description |
|---|---|
| 1 | References as Parameters C++ supports passing references as function parameter more safely than parameters. |
| 2 | Reference as Return Value You can return reference from a C++ function like any other data type. |
The C++ standard library does not provide a proper date type. C++ inherits the structs and functions for date and time manipulation from C. To access date and time related functions and structures, you would need to include <ctime> header file in your C++ program.
There are four time-related types: clock_t, time_t, size_t, and tm. The types - clock_t, size_t and time_t are capable of representing the system time and date as some sort of integer.
The structure type tm holds the date and time in the form of a C structure having the following elements −
struct tm {
int tm_sec; // seconds of minutes from 0 to 61
int tm_min; // minutes of hour from 0 to 59
int tm_hour; // hours of day from 0 to 24
int tm_mday; // day of month from 1 to 31
int tm_mon; // month of year from 0 to 11
int tm_year; // year since 1900
int tm_wday; // days since sunday
int tm_yday; // days since January 1st
int tm_isdst; // hours of daylight savings time
}Following are the important functions, which we use while working with date and time in C or C++. All these functions are part of standard C and C++ library and you can check their detail using reference to C++ standard library given below.
| Sr.No | Function & Purpose |
|---|---|
| 1 | time_t time(time_t *time); This returns the current calendar time of the system in number of seconds elapsed since January 1, 1970. If the system has no time, .1 is returned. |
| 2 | char *ctime(const time_t *time); This returns a pointer to a string of the form day month year hours:minutes:seconds year\n\0. |
| 3 | struct tm *localtime(const time_t *time); This returns a pointer to the tm structure representing local time. |
| 4 | clock_t clock(void); This returns a value that approximates the amount of time the calling program has been running. A value of .1 is returned if the time is not available. |
| 5 | char * asctime ( const struct tm * time ); This returns a pointer to a string that contains the information stored in the structure pointed to by time converted into the form: day month date hours:minutes:seconds year\n\0 |
| 6 | struct tm *gmtime(const time_t *time); This returns a pointer to the time in the form of a tm structure. The time is represented in Coordinated Universal Time (UTC), which is essentially Greenwich Mean Time (GMT). |
| 7 | time_t mktime(struct tm *time); This returns the calendar-time equivalent of the time found in the structure pointed to by time. |
| 8 | double difftime ( time_t time2, time_t time1 ); This function calculates the difference in seconds between time1 and time2. |
| 9 | size_t strftime(); This function can be used to format date and time in a specific format. |
Current Date and Time
Suppose you want to retrieve the current system date and time, either as a local time or as a Coordinated Universal Time (UTC). Following is the example to achieve the same −
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
// convert now to string form
char* dt = ctime(&now);
cout << "The local date and time is: " << dt << endl;
// convert now to tm struct for UTC
tm *gmtm = gmtime(&now);
dt = asctime(gmtm);
cout << "The UTC date and time is:"<< dt << endl;
}When the above code is compiled and executed, it produces the following result −
The local date and time is: Sat Jan 8 20:07:41 2011
The UTC date and time is:Sun Jan 9 03:07:41 2011Format Time using struct tm
The tm structure is very important while working with date and time in either C or C++. This structure holds the date and time in the form of a C structure as mentioned above. Most of the time related functions makes use of tm structure. Following is an example which makes use of various date and time related functions and tm structure −
While using structure in this chapter, I'm making an assumption that you have basic understanding on C structure and how to access structure members using arrow -> operator.
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
cout << "Number of sec since January 1,1970 is:: " << now << endl;
tm *ltm = localtime(&now);
// print various components of tm structure.
cout << "Year:" << 1900 + ltm->tm_year<<endl;
cout << "Month: "<< 1 + ltm->tm_mon<< endl;
cout << "Day: "<< ltm->tm_mday << endl;
cout << "Time: "<< 5+ltm->tm_hour << ":";
cout << 30+ltm->tm_min << ":";
cout << ltm->tm_sec << endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Number of sec since January 1,1970 is:: 1588485717
Year:2020
Month: 5
Day: 3
Time: 11:31:57As bibliotecas padrão C ++ fornecem um amplo conjunto de recursos de entrada / saída que veremos nos capítulos subsequentes. Este capítulo discutirá as operações de E / S muito básicas e mais comuns necessárias para a programação C ++.
E / S C ++ ocorre em fluxos, que são sequências de bytes. Se os bytes fluem de um dispositivo como um teclado, uma unidade de disco ou uma conexão de rede, etc. para a memória principal, isso é chamadoinput operation e se os bytes fluem da memória principal para um dispositivo como uma tela de exibição, uma impressora, uma unidade de disco ou uma conexão de rede, etc., isso é chamado output operation.
Arquivos de cabeçalho da biblioteca de E / S
Existem os seguintes arquivos de cabeçalho importantes para programas C ++ -
| Sr. Não | Arquivo de cabeçalho e função e descrição |
|---|---|
| 1 | <iostream> Este arquivo define o cin, cout, cerr e clog objetos, que correspondem ao fluxo de entrada padrão, o fluxo de saída padrão, o fluxo de erro padrão sem buffer e o fluxo de erro padrão em buffer, respectivamente. |
| 2 | <iomanip> Este arquivo declara serviços úteis para realizar I / O formatado com os chamados manipuladores de fluxo parametrizados, como setw e setprecision. |
| 3 | <fstream> Este arquivo declara serviços para processamento de arquivo controlado pelo usuário. Discutiremos sobre isso em detalhes no capítulo relacionado a Arquivo e Fluxo. |
O fluxo de saída padrão (cout)
O objeto predefinido cout é uma instância de ostreamclasse. Diz-se que o objeto cout está "conectado" ao dispositivo de saída padrão, que geralmente é a tela de exibição. ocout é usado em conjunto com o operador de inserção de fluxo, que é escrito como <<, que são dois sinais a menos, conforme mostrado no exemplo a seguir.
#include <iostream>
using namespace std;
int main() {
char str[] = "Hello C++";
cout << "Value of str is : " << str << endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Value of str is : Hello C++O compilador C ++ também determina o tipo de dados da variável a ser produzida e seleciona o operador de inserção de fluxo apropriado para exibir o valor. O operador << está sobrecarregado para gerar itens de dados de tipos internos inteiros, flutuantes, duplos, strings e valores de ponteiro.
O operador de inserção << pode ser usado mais de uma vez em uma única instrução, conforme mostrado acima e endl é usado para adicionar uma nova linha no final da linha.
O fluxo de entrada padrão (cin)
O objeto predefinido cin é uma instância de istreamclasse. Diz-se que o objeto cin está conectado ao dispositivo de entrada padrão, que geralmente é o teclado. ocin é usado em conjunto com o operador de extração de fluxo, que é escrito como >>, que são dois sinais maiores que, conforme mostrado no exemplo a seguir.
#include <iostream>
using namespace std;
int main() {
char name[50];
cout << "Please enter your name: ";
cin >> name;
cout << "Your name is: " << name << endl;
}Quando o código acima for compilado e executado, ele solicitará que você insira um nome. Você insere um valor e pressiona Enter para ver o seguinte resultado -
Please enter your name: cplusplus
Your name is: cplusplusO compilador C ++ também determina o tipo de dados do valor inserido e seleciona o operador de extração de fluxo apropriado para extrair o valor e armazená-lo nas variáveis fornecidas.
O operador de extração de fluxo >> pode ser usado mais de uma vez em uma única instrução. Para solicitar mais de um dado, você pode usar o seguinte -
cin >> name >> age;Isso será equivalente às duas declarações a seguir -
cin >> name;
cin >> age;O fluxo de erro padrão (cerr)
O objeto predefinido cerr é uma instância de ostreamclasse. Diz-se que o objeto cerr está conectado ao dispositivo de erro padrão, que também é uma tela de exibição, mas o objetocerr não é armazenado em buffer e cada inserção de fluxo em cerr faz com que sua saída apareça imediatamente.
o cerr também é usado em conjunto com o operador de inserção de fluxo, conforme mostrado no exemplo a seguir.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
cerr << "Error message : " << str << endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Error message : Unable to read....O fluxo de registro padrão (entupir)
O objeto predefinido clog é uma instância de ostreamclasse. Diz-se que o objeto de obstrução está anexado ao dispositivo de erro padrão, que também é uma tela de exibição, mas o objetoclogestá em buffer. Isso significa que cada inserção entupida pode fazer com que sua saída seja mantida em um buffer até que o buffer seja preenchido ou até que o buffer seja esvaziado.
o clog também é usado em conjunto com o operador de inserção de fluxo, conforme mostrado no exemplo a seguir.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
clog << "Error message : " << str << endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Error message : Unable to read....Você não seria capaz de ver nenhuma diferença em cout, cerr e clog com esses pequenos exemplos, mas ao escrever e executar programas grandes a diferença se torna óbvia. Portanto, é uma boa prática exibir mensagens de erro usando cerr stream e, ao exibir outras mensagens de log, deve-se usar o clog.
Os arrays C / C ++ permitem definir variáveis que combinam vários itens de dados do mesmo tipo, mas structure é outro tipo de dados definido pelo usuário que permite combinar itens de dados de diferentes tipos.
As estruturas são usadas para representar um registro, suponha que você deseja manter o controle de seus livros em uma biblioteca. Você pode querer rastrear os seguintes atributos sobre cada livro -
- Title
- Author
- Subject
- ID do livro
Definindo uma Estrutura
Para definir uma estrutura, você deve usar a instrução struct. A instrução struct define um novo tipo de dados, com mais de um membro, para seu programa. O formato da instrução de estrutura é este -
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];o structure tagé opcional e cada definição de membro é uma definição de variável normal, como int i; ou flutuar f; ou qualquer outra definição de variável válida. No final da definição da estrutura, antes do ponto e vírgula final, você pode especificar uma ou mais variáveis de estrutura, mas é opcional. Esta é a maneira como você declararia a estrutura do livro -
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;Acessando membros da estrutura
Para acessar qualquer membro de uma estrutura, usamos o member access operator (.). O operador de acesso de membro é codificado como um período entre o nome da variável de estrutura e o membro da estrutura que desejamos acessar. Você usariastructpalavra-chave para definir variáveis do tipo de estrutura. A seguir está o exemplo para explicar o uso da estrutura -
#include <iostream>
#include <cstring>
using namespace std;
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
cout << "Book 1 title : " << Book1.title <<endl;
cout << "Book 1 author : " << Book1.author <<endl;
cout << "Book 1 subject : " << Book1.subject <<endl;
cout << "Book 1 id : " << Book1.book_id <<endl;
// Print Book2 info
cout << "Book 2 title : " << Book2.title <<endl;
cout << "Book 2 author : " << Book2.author <<endl;
cout << "Book 2 subject : " << Book2.subject <<endl;
cout << "Book 2 id : " << Book2.book_id <<endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book 1 title : Learn C++ Programming
Book 1 author : Chand Miyan
Book 1 subject : C++ Programming
Book 1 id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Yakit Singha
Book 2 subject : Telecom
Book 2 id : 6495700Estruturas como argumentos de função
Você pode passar uma estrutura como um argumento de função de maneira muito semelhante à que passa qualquer outra variável ou ponteiro. Você acessaria as variáveis de estrutura da mesma forma que acessou no exemplo acima -
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
printBook( Book1 );
// Print Book2 info
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
cout << "Book title : " << book.title <<endl;
cout << "Book author : " << book.author <<endl;
cout << "Book subject : " << book.subject <<endl;
cout << "Book id : " << book.book_id <<endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700Indicadores para estruturas
Você pode definir ponteiros para estruturas de maneira muito semelhante à medida que define ponteiros para qualquer outra variável da seguinte maneira -
struct Books *struct_pointer;Agora, você pode armazenar o endereço de uma variável de estrutura na variável de ponteiro definida acima. Para encontrar o endereço de uma variável de estrutura, coloque o operador & antes do nome da estrutura da seguinte maneira -
struct_pointer = &Book1;Para acessar os membros de uma estrutura usando um ponteiro para essa estrutura, você deve usar o operador -> da seguinte maneira -
struct_pointer->title;Vamos reescrever o exemplo acima usando o ponteiro de estrutura, espero que seja fácil para você entender o conceito -
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books *book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// Book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// Book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info, passing address of structure
printBook( &Book1 );
// Print Book1 info, passing address of structure
printBook( &Book2 );
return 0;
}
// This function accept pointer to structure as parameter.
void printBook( struct Books *book ) {
cout << "Book title : " << book->title <<endl;
cout << "Book author : " << book->author <<endl;
cout << "Book subject : " << book->subject <<endl;
cout << "Book id : " << book->book_id <<endl;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700A palavra-chave typedef
Existe uma maneira mais fácil de definir structs ou você pode "alias" os tipos que você cria. Por exemplo -
typedef struct {
char title[50];
char author[50];
char subject[100];
int book_id;
} Books;Agora, você pode usar Books diretamente para definir variáveis do tipo Books sem usar a palavra-chave struct. A seguir está o exemplo -
Books Book1, Book2;Você pode usar typedef palavra-chave para não-estruturas, bem como as seguintes -
typedef long int *pint32;
pint32 x, y, z;x, y e z são todos indicadores para ints longos.
O principal objetivo da programação C ++ é adicionar orientação a objetos à linguagem de programação C e as classes são o recurso central do C ++ que oferece suporte à programação orientada a objetos e são freqüentemente chamados de tipos definidos pelo usuário.
Uma classe é usada para especificar a forma de um objeto e combina representação de dados e métodos para manipular esses dados em um pacote organizado. Os dados e funções dentro de uma classe são chamados de membros da classe.
Definições de classe C ++
Ao definir uma classe, você define um blueprint para um tipo de dados. Na verdade, isso não define nenhum dado, mas define o que o nome da classe significa, ou seja, em que consistirá um objeto da classe e quais operações podem ser realizadas em tal objeto.
Uma definição de classe começa com a palavra-chave classseguido pelo nome da classe; e o corpo da classe, delimitado por um par de chaves. Uma definição de classe deve ser seguida por um ponto e vírgula ou uma lista de declarações. Por exemplo, definimos o tipo de dados Box usando a palavra-chaveclass como segue -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};A palavra-chave publicdetermina os atributos de acesso dos membros da classe que o segue. Um membro público pode ser acessado de fora da classe em qualquer lugar dentro do escopo do objeto de classe. Você também pode especificar os membros de uma classe comoprivate ou protected que discutiremos em uma subseção.
Definir objetos C ++
Uma classe fornece os projetos para objetos, portanto, basicamente, um objeto é criado a partir de uma classe. Declaramos objetos de uma classe exatamente com o mesmo tipo de declaração com que declaramos variáveis de tipos básicos. As seguintes declarações declaram dois objetos da classe Box -
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxAmbos os objetos Box1 e Box2 terão sua própria cópia dos membros de dados.
Acessando os Membros de Dados
Os membros de dados públicos de objetos de uma classe podem ser acessados usando o operador de acesso direto ao membro (.). Vamos tentar o seguinte exemplo para deixar as coisas claras -
#include <iostream>
using namespace std;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Volume of Box1 : 210
Volume of Box2 : 1560É importante observar que membros privados e protegidos não podem ser acessados diretamente usando o operador de acesso direto ao membro (.). Aprenderemos como membros privados e protegidos podem ser acessados.
Classes e objetos em detalhes
Até agora, você teve uma ideia muito básica sobre classes e objetos C ++. Existem outros conceitos interessantes relacionados a classes e objetos C ++ que discutiremos em várias subseções listadas abaixo -
| Sr. Não | Conceito e descrição |
|---|---|
| 1 | Funções de membro de classe Uma função de membro de uma classe é uma função que tem sua definição ou seu protótipo dentro da definição de classe como qualquer outra variável. |
| 2 | Modificadores de acesso de classe Um membro da classe pode ser definido como público, privado ou protegido. Por padrão, os membros seriam considerados privados. |
| 3 | Construtor e Destruidor Um construtor de classe é uma função especial em uma classe que é chamada quando um novo objeto da classe é criado. Um destruidor também é uma função especial que é chamada quando o objeto criado é excluído. |
| 4 | Copiar construtor O construtor de cópia é um construtor que cria um objeto inicializando-o com um objeto da mesma classe, que foi criado anteriormente. |
| 5 | Funções de amigo UMA friend função é permitido o acesso total a membros privados e protegidos de uma classe. |
| 6 | Funções Inline Com uma função embutida, o compilador tenta expandir o código no corpo da função no lugar de uma chamada para a função. |
| 7 | este ponteiro Cada objeto tem um ponteiro especial this que aponta para o próprio objeto. |
| 8 | Ponteiro para classes C ++ Um ponteiro para uma classe é feito exatamente da mesma maneira que um ponteiro para uma estrutura. Na verdade, uma classe é apenas uma estrutura com funções. |
| 9 | Membros estáticos de uma classe Os membros de dados e membros de função de uma classe podem ser declarados como estáticos. |
Um dos conceitos mais importantes na programação orientada a objetos é o de herança. A herança nos permite definir uma classe em termos de outra classe, o que torna mais fácil criar e manter um aplicativo. Isso também fornece uma oportunidade de reutilizar a funcionalidade do código e tempo de implementação rápido.
Ao criar uma classe, em vez de escrever membros de dados e funções de membro completamente novos, o programador pode designar que a nova classe deve herdar os membros de uma classe existente. Esta classe existente é chamada debase classe, e a nova classe é chamada de derived classe.
A ideia de herança implementa o is arelação. Por exemplo, mamífero IS-A animal, cão IS-A mamífero, portanto cão IS-A animal também e assim por diante.
Classes de base e derivadas
Uma classe pode ser derivada de mais de uma classe, o que significa que pode herdar dados e funções de várias classes base. Para definir uma classe derivada, usamos uma lista de derivação de classe para especificar a (s) classe (s) base. Uma lista de derivação de classe nomeia uma ou mais classes base e tem a forma -
class derived-class: access-specifier base-classOnde o especificador de acesso é um dos public, protected, ou private, e classe base é o nome de uma classe definida anteriormente. Se o especificador de acesso não for usado, ele será privado por padrão.
Considere uma classe base Shape e sua classe derivada Rectangle como segue -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 35Controle de acesso e herança
Uma classe derivada pode acessar todos os membros não privados de sua classe base. Portanto, os membros da classe base que não devem ser acessíveis às funções de membro das classes derivadas devem ser declarados privados na classe base.
Podemos resumir os diferentes tipos de acesso de acordo com - quem pode acessá-los da seguinte maneira -
| Acesso | público | protegido | privado |
|---|---|---|---|
| Mesma classe | sim | sim | sim |
| Classes derivadas | sim | sim | não |
| Aulas externas | sim | não | não |
Uma classe derivada herda todos os métodos da classe base com as seguintes exceções -
- Construtores, destruidores e construtores de cópia da classe base.
- Operadores sobrecarregados da classe base.
- As funções de amigo da classe base.
Tipo de Herança
Ao derivar uma classe de uma classe base, a classe base pode ser herdada por meio de public, protected ou privateherança. O tipo de herança é especificado pelo especificador de acesso conforme explicado acima.
Dificilmente usamos protected ou private herança, mas publicherança é comumente usada. Ao usar diferentes tipos de herança, as seguintes regras são aplicadas -
Public Inheritance - Ao derivar uma classe de um public classe base, public membros da classe base se tornam public membros da classe derivada e protected membros da classe base se tornam protectedmembros da classe derivada. De uma classe baseprivate membros nunca são acessíveis diretamente de uma classe derivada, mas podem ser acessados por meio de chamadas para o public e protected membros da classe base.
Protected Inheritance - Ao derivar de um protected classe base, public e protected membros da classe base se tornam protected membros da classe derivada.
Private Inheritance - Ao derivar de um private classe base, public e protected membros da classe base se tornam private membros da classe derivada.
Herança Múltipla
Uma classe C ++ pode herdar membros de mais de uma classe e aqui está a sintaxe estendida -
class derived-class: access baseA, access baseB....Onde o acesso é um de public, protected, ou privatee seriam fornecidos para cada classe base e serão separados por vírgula, conforme mostrado acima. Vamos tentar o seguinte exemplo -
#include <iostream>
using namespace std;
// Base class Shape
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost {
public:
int getCost(int area) {
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total area: 35
Total paint cost: $2450C ++ permite que você especifique mais de uma definição para um function nome ou um operator no mesmo escopo, que é chamado function overloading e operator overloading respectivamente.
Uma declaração sobrecarregada é uma declaração que é declarada com o mesmo nome de uma declaração anteriormente declarada no mesmo escopo, exceto que ambas as declarações têm argumentos diferentes e definições (implementação) obviamente diferentes.
Quando você liga para um sobrecarregado function ou operator, o compilador determina a definição mais apropriada a ser usada, comparando os tipos de argumento que você usou para chamar a função ou operador com os tipos de parâmetro especificados nas definições. O processo de seleção da função ou operador sobrecarregado mais apropriado é chamadooverload resolution.
Sobrecarga de função em C ++
Você pode ter várias definições para o mesmo nome de função no mesmo escopo. A definição da função deve diferir uma da outra pelos tipos e / ou número de argumentos na lista de argumentos. Você não pode sobrecarregar as declarações de função que diferem apenas pelo tipo de retorno.
A seguir está o exemplo onde a mesma função print() está sendo usado para imprimir diferentes tipos de dados -
#include <iostream>
using namespace std;
class printData {
public:
void print(int i) {
cout << "Printing int: " << i << endl;
}
void print(double f) {
cout << "Printing float: " << f << endl;
}
void print(char* c) {
cout << "Printing character: " << c << endl;
}
};
int main(void) {
printData pd;
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello C++");
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Printing int: 5
Printing float: 500.263
Printing character: Hello C++Sobrecarga de operadores em C ++
Você pode redefinir ou sobrecarregar a maioria dos operadores integrados disponíveis em C ++. Assim, um programador também pode usar operadores com tipos definidos pelo usuário.
Operadores sobrecarregados são funções com nomes especiais: a palavra-chave "operador" seguida pelo símbolo do operador que está sendo definido. Como qualquer outra função, um operador sobrecarregado tem um tipo de retorno e uma lista de parâmetros.
Box operator+(const Box&);declara o operador de adição que pode ser usado para adddois objetos Box e retorna o objeto Box final. A maioria dos operadores sobrecarregados pode ser definida como funções não-membro comuns ou como funções-membro de classe. No caso de definirmos a função acima como uma função não membro de uma classe, teríamos que passar dois argumentos para cada operando da seguinte forma -
Box operator+(const Box&, const Box&);A seguir está o exemplo para mostrar o conceito de operador sobre carregamento usando uma função de membro. Aqui, um objeto é passado como um argumento cujas propriedades serão acessadas usando este objeto, o objeto que irá chamar este operador pode ser acessado usandothis operador conforme explicado abaixo -
#include <iostream>
using namespace std;
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
// Overload + operator to add two Box objects.
Box operator+(const Box& b) {
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Box Box3; // Declare Box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// box 2 specification
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// volume of box 1
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// Add two object as follows:
Box3 = Box1 + Box2;
// volume of box 3
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Operadores Sobrecarregáveis / Não-sobrecarregáveis
A seguir está a lista de operadores que podem estar sobrecarregados -
| + | - | * | / | % | ^ |
| E | | | ~ | ! | , | = |
| < | > | <= | > = | ++ | - |
| << | >> | == | ! = | && | || |
| + = | - = | / = | % = | ^ = | & = |
| | = | * = | << = | >> = | [] | () |
| -> | -> * | Novo | Novo [] | excluir | delete [] |
A seguir está a lista de operadores, que não podem ser sobrecarregados -
| :: | . * | . | ?: |
Exemplos de sobrecarga do operador
Aqui estão vários exemplos de sobrecarga de operador para ajudá-lo a entender o conceito.
| Sr. Não | Operadores e exemplo |
|---|---|
| 1 | Sobrecarga de operadores unários |
| 2 | Sobrecarga de operadores binários |
| 3 | Sobrecarga de operadores relacionais |
| 4 | Sobrecarga de operadores de entrada / saída |
| 5 | ++ e - Sobrecarga de operadores |
| 6 | Sobrecarga de operadores de atribuição |
| 7 | Função chamada () Sobrecarga do operador |
| 8 | Subscripting [] Sobrecarga de operador |
| 9 | Operador de acesso de membro de classe -> Sobrecarga |
A palavra polymorphismsignifica ter muitas formas. Normalmente, o polimorfismo ocorre quando há uma hierarquia de classes e elas estão relacionadas por herança.
O polimorfismo C ++ significa que uma chamada para uma função de membro fará com que uma função diferente seja executada, dependendo do tipo de objeto que invoca a função.
Considere o exemplo a seguir, onde uma classe base foi derivada por outras duas classes -
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0){
width = a;
height = b;
}
int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape {
public:
Rectangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape {
public:
Triangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main() {
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Parent class area :
Parent class area :O motivo da saída incorreta é que a chamada da função area () está sendo definida uma vez pelo compilador como a versão definida na classe base. Isso é chamadostatic resolution da chamada de função, ou static linkage- a chamada de função é corrigida antes de o programa ser executado. Isso também é chamado às vezesearly binding porque a função area () é definida durante a compilação do programa.
Mas agora, vamos fazer uma pequena modificação em nosso programa e preceder a declaração de area () na classe Shape com a palavra-chave virtual para que se pareça com isto -
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};Após esta pequena modificação, quando o código de exemplo anterior é compilado e executado, ele produz o seguinte resultado -
Rectangle class area
Triangle class areaDesta vez, o compilador examina o conteúdo do ponteiro em vez de seu tipo. Conseqüentemente, como os endereços dos objetos das classes tri e rec são armazenados no formato *, a função area () respectiva é chamada.
Como você pode ver, cada uma das classes filhas possui uma implementação separada para a função area (). É assimpolymorphismé geralmente usado. Você tem classes diferentes com uma função de mesmo nome e até os mesmos parâmetros, mas com implementações diferentes.
Função Virtual
UMA virtual function é uma função em uma classe base que é declarada usando a palavra-chave virtual. Definir em uma classe base uma função virtual, com outra versão em uma classe derivada, sinaliza ao compilador que não queremos ligação estática para esta função.
O que queremos é que a seleção da função a ser chamada em qualquer ponto do programa seja baseada no tipo de objeto para o qual é chamada. Este tipo de operação é conhecido comodynamic linkage, ou late binding.
Funções virtuais puras
É possível que você queira incluir uma função virtual em uma classe base para que ela possa ser redefinida em uma classe derivada para se adequar aos objetos dessa classe, mas que não haja uma definição significativa que você possa dar para a função na classe base .
Podemos alterar a área de função virtual () na classe base para o seguinte -
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};O = 0 diz ao compilador que a função não tem corpo e a função virtual acima será chamada pure virtual function.
A abstração de dados refere-se a fornecer apenas informações essenciais para o mundo exterior e ocultar seus detalhes de fundo, ou seja, representar as informações necessárias no programa sem apresentar os detalhes.
A abstração de dados é uma técnica de programação (e design) que depende da separação da interface e da implementação.
Vamos dar um exemplo da vida real de uma TV, que você pode ligar e desligar, mudar de canal, ajustar o volume e adicionar componentes externos, como alto-falantes, videocassetes e DVD players, MAS você não sabe seus detalhes internos, que ou seja, você não sabe como ele recebe sinais pelo ar ou por cabo, como os traduz e, finalmente, os exibe na tela.
Assim, podemos dizer que uma televisão separa claramente sua implementação interna de sua interface externa e você pode brincar com suas interfaces como o botão liga / desliga, o trocador de canal e o controle de volume sem ter nenhum conhecimento de seus componentes internos.
Em C ++, as classes fornecem um ótimo nível de data abstraction. Eles fornecem métodos públicos suficientes para o mundo externo brincar com a funcionalidade do objeto e manipular os dados do objeto, ou seja, afirmar sem realmente saber como a classe foi implementada internamente.
Por exemplo, seu programa pode fazer uma chamada para o sort()função sem saber qual algoritmo a função realmente usa para classificar os valores fornecidos. Na verdade, a implementação subjacente da funcionalidade de classificação pode mudar entre as versões da biblioteca e, enquanto a interface permanecer a mesma, sua chamada de função ainda funcionará.
Em C ++, usamos classespara definir nossos próprios tipos de dados abstratos (ADT). Você pode usar ocout objeto de aula ostream para transmitir dados para a saída padrão como este -
#include <iostream>
using namespace std;
int main() {
cout << "Hello C++" <<endl;
return 0;
}Aqui, você não precisa entender como coutexibe o texto na tela do usuário. Você só precisa saber a interface pública e a implementação subjacente de 'cout' pode ser alterada.
Os rótulos de acesso impõem abstração
Em C ++, usamos rótulos de acesso para definir a interface abstrata para a classe. Uma classe pode conter zero ou mais rótulos de acesso -
Os membros definidos com um rótulo público são acessíveis a todas as partes do programa. A visão de abstração de dados de um tipo é definida por seus membros públicos.
Os membros definidos com um rótulo privado não são acessíveis ao código que usa a classe. As seções privadas ocultam a implementação do código que usa o tipo.
Não há restrições sobre a frequência com que um rótulo de acesso pode aparecer. Cada rótulo de acesso especifica o nível de acesso das definições de membro seguintes. O nível de acesso especificado permanece em vigor até que o próximo rótulo de acesso seja encontrado ou a chave direita de fechamento do corpo da classe seja vista.
Benefícios da abstração de dados
A abstração de dados oferece duas vantagens importantes -
As partes internas da classe são protegidas contra erros inadvertidos no nível do usuário, que podem corromper o estado do objeto.
A implementação da classe pode evoluir com o tempo em resposta aos requisitos de mudança ou relatórios de bug sem exigir mudança no código de nível de usuário.
Definindo membros de dados apenas na seção privada da classe, o autor da classe está livre para fazer alterações nos dados. Se a implementação mudar, apenas o código da classe precisará ser examinado para ver o que pode afetar a mudança. Se os dados forem públicos, qualquer função que acesse diretamente os membros de dados da representação antiga pode ser quebrada.
Exemplo de abstração de dados
Qualquer programa C ++ onde você implementa uma classe com membros públicos e privados é um exemplo de abstração de dados. Considere o seguinte exemplo -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total 60Acima da classe soma os números e retorna a soma. Os membros públicos -addNum e getTotalsão as interfaces para o mundo exterior e um usuário precisa conhecê-las para usar a classe. O membro privadototal é algo que o usuário não precisa saber, mas é necessário para que a classe funcione corretamente.
Estratégia de Projeto
A abstração separa o código em interface e implementação. Portanto, ao projetar seu componente, você deve manter a interface independente da implementação para que, se alterar a implementação subjacente, a interface permaneça intacta.
Nesse caso, quaisquer programas que estejam usando essas interfaces, eles não seriam afetados e precisariam apenas de uma recompilação com a implementação mais recente.
Todos os programas C ++ são compostos dos seguintes dois elementos fundamentais -
Program statements (code) - Esta é a parte de um programa que executa ações e são chamadas de funções.
Program data - Os dados são as informações do programa que são afetadas pelas funções do programa.
Encapsulamento é um conceito de Programação Orientada a Objetos que une os dados e as funções que os manipulam e que os mantém protegidos contra interferências externas e uso indevido. O encapsulamento de dados levou ao importante conceito OOP dedata hiding.
Data encapsulation é um mecanismo de agrupar os dados e as funções que os usam e data abstraction é um mecanismo de expor apenas as interfaces e ocultar os detalhes de implementação do usuário.
C ++ suporta as propriedades de encapsulamento e ocultação de dados por meio da criação de tipos definidos pelo usuário, chamados classes. Já estudamos que uma classe pode conterprivate, protected e publicmembros. Por padrão, todos os itens definidos em uma classe são privados. Por exemplo -
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};As variáveis comprimento, largura e altura são private. Isso significa que eles podem ser acessados apenas por outros membros da classe Box, e não por qualquer outra parte de seu programa. Esta é uma forma de o encapsulamento ser alcançado.
Para fazer partes de uma classe public (ou seja, acessível a outras partes do seu programa), você deve declará-los após o publicpalavra-chave. Todas as variáveis ou funções definidas após o especificador público são acessíveis por todas as outras funções em seu programa.
Tornar uma classe amiga de outra expõe os detalhes de implementação e reduz o encapsulamento. O ideal é manter o máximo possível de detalhes de cada classe ocultos de todas as outras classes.
Exemplo de encapsulamento de dados
Qualquer programa C ++ em que você implementa uma classe com membros públicos e privados é um exemplo de encapsulamento e abstração de dados. Considere o seguinte exemplo -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total 60Acima da classe soma os números e retorna a soma. Os membros públicosaddNum e getTotal são as interfaces para o mundo exterior e um usuário precisa conhecê-las para usar a classe. O membro privadototal é algo que está escondido do mundo exterior, mas é necessário para que a classe funcione corretamente.
Estratégia de Projeto
A maioria de nós aprendeu a tornar os alunos privados por padrão, a menos que realmente precisemos expô-los. Isso é bomencapsulation.
Isso é aplicado com mais frequência aos membros de dados, mas se aplica igualmente a todos os membros, incluindo funções virtuais.
Uma interface descreve o comportamento ou os recursos de uma classe C ++ sem se comprometer com uma implementação específica dessa classe.
As interfaces C ++ são implementadas usando abstract classes e essas classes abstratas não devem ser confundidas com abstração de dados, que é um conceito de manter os detalhes de implementação separados dos dados associados.
Uma classe se torna abstrata, declarando pelo menos uma de suas funções como pure virtualfunção. Uma função virtual pura é especificada colocando "= 0" em sua declaração da seguinte forma -
class Box {
public:
// pure virtual function
virtual double getVolume() = 0;
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};O propósito de um abstract class(frequentemente referido como ABC) é fornecer uma classe base apropriada da qual outras classes podem herdar. Classes abstratas não podem ser usadas para instanciar objetos e servem apenas como uminterface. A tentativa de instanciar um objeto de uma classe abstrata causa um erro de compilação.
Assim, se uma subclasse de um ABC precisa ser instanciada, ela deve implementar cada uma das funções virtuais, o que significa que suporta a interface declarada pelo ABC. A falha em substituir uma função virtual pura em uma classe derivada e, em seguida, tentar instanciar objetos dessa classe é um erro de compilação.
As classes que podem ser usadas para instanciar objetos são chamadas concrete classes.
Exemplo de classe abstrata
Considere o exemplo a seguir onde a classe pai fornece uma interface para a classe base para implementar uma função chamada getArea() -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
// pure virtual function providing interface framework.
virtual int getArea() = 0;
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived classes
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
class Triangle: public Shape {
public:
int getArea() {
return (width * height)/2;
}
};
int main(void) {
Rectangle Rect;
Triangle Tri;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total Rectangle area: " << Rect.getArea() << endl;
Tri.setWidth(5);
Tri.setHeight(7);
// Print the area of the object.
cout << "Total Triangle area: " << Tri.getArea() << endl;
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Total Rectangle area: 35
Total Triangle area: 17Você pode ver como uma classe abstrata definiu uma interface em termos de getArea () e duas outras classes implementaram a mesma função, mas com algoritmos diferentes para calcular a área específica da forma.
Estratégia de Projeto
Um sistema orientado a objetos pode usar uma classe base abstrata para fornecer uma interface comum e padronizada apropriada para todos os aplicativos externos. Então, por meio da herança dessa classe base abstrata, classes derivadas são formadas que operam de forma semelhante.
Os recursos (ou seja, as funções públicas) oferecidos pelos aplicativos externos são fornecidos como funções virtuais puras na classe base abstrata. As implementações dessas funções virtuais puras são fornecidas nas classes derivadas que correspondem aos tipos específicos do aplicativo.
Essa arquitetura também permite que novos aplicativos sejam adicionados a um sistema facilmente, mesmo após o sistema ter sido definido.
Até agora, temos usado o iostream biblioteca padrão, que fornece cin e cout métodos para leitura da entrada padrão e gravação na saída padrão, respectivamente.
Este tutorial irá ensiná-lo a ler e escrever a partir de um arquivo. Isso requer outra biblioteca C ++ padrão chamadafstream, que define três novos tipos de dados -
| Sr. Não | Tipo de dados e descrição |
|---|---|
| 1 | ofstream Este tipo de dados representa o fluxo do arquivo de saída e é usado para criar arquivos e gravar informações em arquivos. |
| 2 | ifstream Este tipo de dados representa o fluxo do arquivo de entrada e é usado para ler informações dos arquivos. |
| 3 | fstream Esse tipo de dados representa o fluxo de arquivos em geral e tem os recursos ofstream e ifstream, o que significa que pode criar arquivos, gravar informações em arquivos e ler informações de arquivos. |
Para executar o processamento de arquivos em C ++, os arquivos de cabeçalho <iostream> e <fstream> devem ser incluídos em seu arquivo de origem C ++.
Abrindo um arquivo
Um arquivo deve ser aberto antes que você possa ler ou gravar nele. Ouofstream ou fstreamobjeto pode ser usado para abrir um arquivo para gravação. E o objeto ifstream é usado para abrir um arquivo apenas para leitura.
A seguir está a sintaxe padrão para a função open (), que é membro dos objetos fstream, ifstream e ofstream.
void open(const char *filename, ios::openmode mode);Aqui, o primeiro argumento especifica o nome e a localização do arquivo a ser aberto e o segundo argumento do open() a função de membro define o modo em que o arquivo deve ser aberto.
| Sr. Não | Sinalizador e descrição do modo |
|---|---|
| 1 | ios::app Modo anexo. Todas as saídas desse arquivo devem ser anexadas ao final. |
| 2 | ios::ate Abra um arquivo para saída e mova o controle de leitura / gravação para o final do arquivo. |
| 3 | ios::in Abra um arquivo para leitura. |
| 4 | ios::out Abra um arquivo para gravação. |
| 5 | ios::trunc Se o arquivo já existir, seu conteúdo será truncado antes de abrir o arquivo. |
Você pode combinar dois ou mais desses valores por ORjuntando-os. Por exemplo, se você deseja abrir um arquivo no modo de gravação e deseja truncá-lo caso já exista, a seguinte será a sintaxe -
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );De maneira semelhante, você pode abrir um arquivo para leitura e gravação da seguinte maneira -
fstream afile;
afile.open("file.dat", ios::out | ios::in );Fechando um Arquivo
Quando um programa C ++ termina, ele automaticamente libera todos os fluxos, libera toda a memória alocada e fecha todos os arquivos abertos. Mas é sempre uma boa prática que um programador feche todos os arquivos abertos antes de encerrar o programa.
A seguir está a sintaxe padrão para a função close (), que é membro dos objetos fstream, ifstream e ofstream.
void close();Gravando em um Arquivo
Ao fazer programação C ++, você grava informações em um arquivo de seu programa usando o operador de inserção de fluxo (<<) da mesma forma que usa esse operador para enviar informações para a tela. A única diferença é que você usa umofstream ou fstream objeto em vez do cout objeto.
Lendo de um arquivo
Você lê informações de um arquivo em seu programa usando o operador de extração de fluxo (>>) da mesma forma que usa esse operador para inserir informações do teclado. A única diferença é que você usa umifstream ou fstream objeto em vez do cin objeto.
Ler e escrever exemplo
A seguir está o programa C ++ que abre um arquivo no modo de leitura e gravação. Depois de gravar as informações inseridas pelo usuário em um arquivo denominado afile.dat, o programa lê as informações do arquivo e as exibe na tela -
#include <fstream>
#include <iostream>
using namespace std;
int main () {
char data[100];
// open a file in write mode.
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// write inputted data into the file.
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// again write inputted data into the file.
outfile << data << endl;
// close the opened file.
outfile.close();
// open a file in read mode.
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// write the data at the screen.
cout << data << endl;
// again read the data from the file and display it.
infile >> data;
cout << data << endl;
// close the opened file.
infile.close();
return 0;
}Quando o código acima é compilado e executado, ele produz a seguinte entrada e saída de amostra -
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9Os exemplos acima usam funções adicionais do objeto cin, como a função getline () para ler a linha de fora e a função ignore () para ignorar os caracteres extras deixados pela instrução de leitura anterior.
Indicadores de posição de arquivo
Ambos istream e ostreamfornece funções de membro para reposicionar o ponteiro de posição do arquivo. Essas funções de membro sãoseekg ("buscar obter") para istream e seekp ("buscar colocar") para ostream.
O argumento para seekg e seekp normalmente é um inteiro longo. Um segundo argumento pode ser especificado para indicar a direção da busca. A direção de busca pode serios::beg (o padrão) para posicionamento em relação ao início de um fluxo, ios::cur para posicionamento em relação à posição atual em um fluxo ou ios::end para posicionamento em relação ao final de um fluxo.
O ponteiro de posição do arquivo é um valor inteiro que especifica a localização no arquivo como um número de bytes a partir da localização inicial do arquivo. Alguns exemplos de posicionamento do ponteiro de posição do arquivo "get" são -
// position to the nth byte of fileObject (assumes ios::beg)
fileObject.seekg( n );
// position n bytes forward in fileObject
fileObject.seekg( n, ios::cur );
// position n bytes back from end of fileObject
fileObject.seekg( n, ios::end );
// position at end of fileObject
fileObject.seekg( 0, ios::end );Uma exceção é um problema que surge durante a execução de um programa. Uma exceção C ++ é uma resposta a uma circunstância excepcional que surge durante a execução de um programa, como uma tentativa de divisão por zero.
As exceções fornecem uma maneira de transferir o controle de uma parte de um programa para outra. O tratamento de exceções C ++ é baseado em três palavras-chave:try, catch, e throw.
throw- Um programa lança uma exceção quando um problema aparece. Isso é feito usando umthrow palavra-chave.
catch- Um programa captura uma exceção com um manipulador de exceção no local de um programa onde você deseja manipular o problema. ocatch palavra-chave indica a captura de uma exceção.
try - A tryblock identifica um bloco de código para o qual determinadas exceções serão ativadas. É seguido por um ou mais blocos de captura.
Assumindo que um bloco levantará uma exceção, um método captura uma exceção usando uma combinação de try e catchpalavras-chave. Um bloco try / catch é colocado em torno do código que pode gerar uma exceção. O código dentro de um bloco try / catch é referido como código protegido, e a sintaxe para usar try / catch da seguinte forma -
try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}Você pode listar vários catch declarações para capturar diferentes tipos de exceções no caso de seu try block levanta mais de uma exceção em diferentes situações.
Lançamento de exceções
As exceções podem ser lançadas em qualquer lugar dentro de um bloco de código usando throwdeclaração. O operando da instrução throw determina um tipo para a exceção e pode ser qualquer expressão e o tipo do resultado da expressão determina o tipo de exceção lançada.
A seguir está um exemplo de lançamento de uma exceção quando ocorre a divisão por zero -
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}Captura de exceções
o catch bloco seguindo o trybloco captura qualquer exceção. Você pode especificar o tipo de exceção que deseja capturar e isso é determinado pela declaração de exceção que aparece entre parênteses após a palavra-chave catch.
try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}O código acima irá capturar uma exceção de ExceptionNametipo. Se você quiser especificar que um bloco catch deve lidar com qualquer tipo de exceção que é lançada em um bloco try, você deve colocar reticências, ..., entre os parênteses envolvendo a declaração de exceção da seguinte maneira -
try {
// protected code
} catch(...) {
// code to handle any exception
}A seguir está um exemplo, que lança uma exceção de divisão por zero e capturamos no bloco catch.
#include <iostream>
using namespace std;
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
int main () {
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
} catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}Porque estamos levantando uma exceção do tipo const char*, portanto, ao capturar essa exceção, temos que usar const char * no bloco catch. Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Division by zero condition!Exceções padrão C ++
C ++ fornece uma lista de exceções padrão definidas em <exception>que podemos usar em nossos programas. Eles são organizados em uma hierarquia de classes pai-filho mostrada abaixo -
Aqui está uma pequena descrição de cada exceção mencionada na hierarquia acima -
| Sr. Não | Exceção e descrição |
|---|---|
| 1 | std::exception Uma exceção e classe pai de todas as exceções padrão do C ++. |
| 2 | std::bad_alloc Isso pode ser jogado por new. |
| 3 | std::bad_cast Isso pode ser jogado por dynamic_cast. |
| 4 | std::bad_exception Este é um dispositivo útil para lidar com exceções inesperadas em um programa C ++. |
| 5 | std::bad_typeid Isso pode ser jogado por typeid. |
| 6 | std::logic_error Uma exceção que teoricamente pode ser detectada pela leitura do código. |
| 7 | std::domain_error Esta é uma exceção lançada quando um domínio matematicamente inválido é usado. |
| 8 | std::invalid_argument Isso é lançado devido a argumentos inválidos. |
| 9 | std::length_error Isso é lançado quando uma string std :: muito grande é criada. |
| 10 | std::out_of_range Isso pode ser lançado pelo método 'at', por exemplo um std :: vector e std :: bitset <> :: operator [] (). |
| 11 | std::runtime_error Uma exceção que teoricamente não pode ser detectada pela leitura do código. |
| 12 | std::overflow_error Isso é lançado se ocorrer um estouro matemático. |
| 13 | std::range_error Isso ocorre quando você tenta armazenar um valor que está fora do intervalo. |
| 14 | std::underflow_error Isso é lançado se ocorrer um underflow matemático. |
Definir novas exceções
Você pode definir suas próprias exceções herdando e substituindo exceptionfuncionalidade da classe. A seguir está o exemplo, que mostra como você pode usar a classe std :: exception para implementar sua própria exceção de maneira padrão -
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception {
const char * what () const throw () {
return "C++ Exception";
}
};
int main() {
try {
throw MyException();
} catch(MyException& e) {
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}Isso produziria o seguinte resultado -
MyException caught
C++ ExceptionAqui, what()é um método público fornecido pela classe de exceção e foi substituído por todas as classes de exceção filho. Isso retorna a causa de uma exceção.
Um bom entendimento de como a memória dinâmica realmente funciona em C ++ é essencial para se tornar um bom programador de C ++. A memória em seu programa C ++ é dividida em duas partes -
The stack - Todas as variáveis declaradas dentro da função ocuparão memória da pilha.
The heap - Esta é a memória não utilizada do programa e pode ser usada para alocar a memória dinamicamente quando o programa é executado.
Muitas vezes, você não sabe com antecedência quanta memória precisará para armazenar informações específicas em uma variável definida e o tamanho da memória necessária pode ser determinado em tempo de execução.
Você pode alocar memória em tempo de execução dentro do heap para a variável de um determinado tipo usando um operador especial em C ++ que retorna o endereço do espaço alocado. Este operador é chamadonew operador.
Se você não precisa mais de memória alocada dinamicamente, pode usar delete operador, que desaloca a memória anteriormente alocada pelo novo operador.
novo e excluir operadores
Há a seguinte sintaxe genérica para usar new operador para alocar memória dinamicamente para qualquer tipo de dados.
new data-type;Aqui, data-typepode ser qualquer tipo de dados embutido, incluindo uma matriz, ou quaisquer tipos de dados definidos pelo usuário, incluindo classe ou estrutura. Vamos começar com os tipos de dados integrados. Por exemplo, podemos definir um ponteiro para digitar double e então solicitar que a memória seja alocada em tempo de execução. Podemos fazer isso usando onew operador com as seguintes declarações -
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variableA memória pode não ter sido alocada com sucesso, se o armazenamento gratuito tiver sido usado. Portanto, é uma boa prática verificar se o novo operador está retornando um ponteiro NULL e tomar as medidas adequadas conforme abaixo -
double* pvalue = NULL;
if( !(pvalue = new double )) {
cout << "Error: out of memory." <<endl;
exit(1);
}o malloc()função de C, ainda existe em C ++, mas é recomendado evitar o uso da função malloc (). A principal vantagem de new sobre malloc () é que new não apenas aloca memória, ele constrói objetos que são o propósito principal do C ++.
A qualquer momento, quando você sentir que uma variável que foi alocada dinamicamente não é mais necessária, você pode liberar a memória que ela ocupa no armazenamento gratuito com o operador 'delete' da seguinte forma -
delete pvalue; // Release memory pointed to by pvalueVamos colocar os conceitos acima e formar o seguinte exemplo para mostrar como funcionam 'novo' e 'deletar' -
#include <iostream>
using namespace std;
int main () {
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
*pvalue = 29494.99; // Store value at allocated address
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // free up the memory.
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Value of pvalue : 29495Alocação de memória dinâmica para matrizes
Considere que você deseja alocar memória para um array de caracteres, ou seja, string de 20 caracteres. Usando a mesma sintaxe que usamos acima, podemos alocar memória dinamicamente como mostrado abaixo.
char* pvalue = NULL; // Pointer initialized with null
pvalue = new char[20]; // Request memory for the variablePara remover a matriz que acabamos de criar, a instrução ficaria assim -
delete [] pvalue; // Delete array pointed to by pvalueSeguindo a sintaxe genérica semelhante de novo operador, você pode alocar para uma matriz multidimensional da seguinte maneira -
double** pvalue = NULL; // Pointer initialized with null
pvalue = new double [3][4]; // Allocate memory for a 3x4 arrayNo entanto, a sintaxe para liberar a memória para a matriz multidimensional ainda permanecerá a mesma acima -
delete [] pvalue; // Delete array pointed to by pvalueAlocação de memória dinâmica para objetos
Os objetos não são diferentes dos tipos de dados simples. Por exemplo, considere o código a seguir, onde vamos usar uma matriz de objetos para esclarecer o conceito -
#include <iostream>
using namespace std;
class Box {
public:
Box() {
cout << "Constructor called!" <<endl;
}
~Box() {
cout << "Destructor called!" <<endl;
}
};
int main() {
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}Se você alocasse um array de quatro objetos Box, o construtor Simple seria chamado quatro vezes e, da mesma forma, ao excluir esses objetos, o destructor também seria chamado o mesmo número de vezes.
Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Constructor called!
Constructor called!
Constructor called!
Constructor called!
Destructor called!
Destructor called!
Destructor called!
Destructor called!Considere uma situação em que temos duas pessoas com o mesmo nome, Zara, na mesma classe. Sempre que precisamos diferenciá-los definitivamente, teríamos que usar algumas informações adicionais junto com seus nomes, como a área, se moram em área diferente ou o nome da mãe ou do pai, etc.
A mesma situação pode surgir em seus aplicativos C ++. Por exemplo, você pode estar escrevendo algum código que tem uma função chamada xyz () e há outra biblioteca disponível que também tem a mesma função xyz (). Agora, o compilador não tem como saber a qual versão da função xyz () você está se referindo em seu código.
UMA namespaceé projetado para superar esta dificuldade e é usado como informação adicional para diferenciar funções semelhantes, classes, variáveis etc. com o mesmo nome disponíveis em diferentes bibliotecas. Usando o namespace, você pode definir o contexto no qual os nomes são definidos. Em essência, um namespace define um escopo.
Definindo um Namespace
Uma definição de namespace começa com a palavra-chave namespace seguido pelo nome do namespace da seguinte forma -
namespace namespace_name {
// code declarations
}Para chamar a versão habilitada para namespace de qualquer função ou variável, acrescente (: :) o nome do namespace da seguinte forma -
name::code; // code could be variable or function.Vejamos como o espaço de nomes abrange as entidades, incluindo variáveis e funções -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
int main () {
// Calls function from first name space.
first_space::func();
// Calls function from second name space.
second_space::func();
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Inside first_space
Inside second_spaceA diretiva using
Você também pode evitar prefixar namespaces com o using namespacediretiva. Esta diretiva informa ao compilador que o código subsequente está fazendo uso de nomes no namespace especificado. O namespace é, portanto, implícito para o seguinte código -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main () {
// This calls function from first name space.
func();
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Inside first_spaceA diretiva 'using' também pode ser usada para se referir a um item específico dentro de um namespace. Por exemplo, se a única parte do namespace std que você pretende usar for cout, você pode se referir a ele da seguinte maneira -
using std::cout;O código subsequente pode referir-se a cout sem incluir o namespace, mas outros itens no std o namespace ainda precisará ser explícito da seguinte forma -
#include <iostream>
using std::cout;
int main () {
cout << "std::endl is used with std!" << std::endl;
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
std::endl is used with std!Nomes introduzidos em um usinga diretiva obedece às regras de escopo normais. O nome é visível do ponto dousingdirectiva até ao fim do âmbito em que a directiva se encontra. Entidades com o mesmo nome definido em um escopo externo são ocultadas.
Namespaces descontíguos
Um namespace pode ser definido em várias partes e, portanto, um namespace é composto da soma de suas partes definidas separadamente. As partes separadas de um namespace podem ser distribuídas por vários arquivos.
Portanto, se uma parte do namespace requer um nome definido em outro arquivo, esse nome ainda deve ser declarado. Escrever uma definição de namespace a seguir define um novo namespace ou adiciona novos elementos a um existente -
namespace namespace_name {
// code declarations
}Namespaces aninhados
Os namespaces podem ser aninhados onde você pode definir um namespace dentro de outro namespace da seguinte maneira -
namespace namespace_name1 {
// code declarations
namespace namespace_name2 {
// code declarations
}
}Você pode acessar membros do namespace aninhado usando operadores de resolução da seguinte maneira -
// to access members of namespace_name2
using namespace namespace_name1::namespace_name2;
// to access members of namespace:name1
using namespace namespace_name1;Nas instruções acima, se você estiver usando namespace_name1, ele tornará elementos de namespace_name2 disponíveis no escopo da seguinte forma -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main () {
// This calls function from second name space.
func();
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Inside second_spaceOs modelos são a base da programação genérica, que envolve escrever código de uma maneira independente de qualquer tipo específico.
Um modelo é um projeto ou fórmula para criar uma classe ou função genérica. Os recipientes de biblioteca como iteradores e algoritmos são exemplos de programação genérica e foram desenvolvidos usando o conceito de modelo.
Há uma única definição para cada contêiner, como vector, mas podemos definir muitos tipos diferentes de vetores, por exemplo, vector <int> ou vector <string>.
Você pode usar modelos para definir funções, bem como classes, vamos ver como eles funcionam -
Template de Função
A forma geral de uma definição de função de modelo é mostrada aqui -
template <class type> ret-type func-name(parameter list) {
// body of function
}Aqui, tipo é um nome de espaço reservado para um tipo de dados usado pela função. Este nome pode ser usado na definição da função.
A seguir está o exemplo de um modelo de função que retorna o máximo de dois valores -
#include <iostream>
#include <string>
using namespace std;
template <typename T>
inline T const& Max (T const& a, T const& b) {
return a < b ? b:a;
}
int main () {
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): WorldModelo de classe
Assim como podemos definir modelos de função, também podemos definir modelos de classe. A forma geral de uma declaração de classe genérica é mostrada aqui -
template <class type> class class-name {
.
.
.
}Aqui, typeé o nome do tipo de espaço reservado, que será especificado quando uma classe for instanciada. Você pode definir mais de um tipo de dados genérico usando uma lista separada por vírgulas.
A seguir está o exemplo para definir a classe Stack <> e implementar métodos genéricos para enviar e retirar os elementos da pilha -
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T>
class Stack {
private:
vector<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return true if empty.
return elems.empty();
}
};
template <class T>
void Stack<T>::push (T const& elem) {
// append copy of passed element
elems.push_back(elem);
}
template <class T>
void Stack<T>::pop () {
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// remove last element
elems.pop_back();
}
template <class T>
T Stack<T>::top () const {
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// return copy of last element
return elems.back();
}
int main() {
try {
Stack<int> intStack; // stack of ints
Stack<string> stringStack; // stack of strings
// manipulate int stack
intStack.push(7);
cout << intStack.top() <<endl;
// manipulate string stack
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
} catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
7
hello
Exception: Stack<>::pop(): empty stackOs pré-processadores são as diretivas, que fornecem instruções ao compilador para pré-processar as informações antes do início da compilação real.
Todas as diretivas do pré-processador começam com # e apenas os caracteres de espaço em branco podem aparecer antes de uma diretiva do pré-processador em uma linha. As diretivas do pré-processador não são instruções C ++, portanto, não terminam em ponto-e-vírgula (;).
Você já viu um #includeem todos os exemplos. Esta macro é usada para incluir um arquivo de cabeçalho no arquivo de origem.
Existem várias diretivas de pré-processador suportadas por C ++ como #include, #define, #if, #else, #line, etc. Vamos ver as diretivas importantes -
O pré-processador #define
A diretiva do pré-processador #define cria constantes simbólicas. A constante simbólica é chamada demacro e a forma geral da diretiva é -
#define macro-name replacement-textQuando esta linha aparece em um arquivo, todas as ocorrências subsequentes de macro nesse arquivo serão substituídas por texto de substituição antes que o programa seja compilado. Por exemplo -
#include <iostream>
using namespace std;
#define PI 3.14159
int main () {
cout << "Value of PI :" << PI << endl;
return 0;
}Agora, vamos fazer o pré-processamento deste código para ver o resultado assumindo que temos o arquivo de código-fonte. Portanto, vamos compilá-lo com a opção -E e redirecionar o resultado para test.p. Agora, se você verificar test.p, ele terá muitas informações e, na parte inferior, você encontrará o valor substituído da seguinte forma -
$gcc -E test.cpp > test.p
...
int main () {
cout << "Value of PI :" << 3.14159 << endl;
return 0;
}Macros semelhantes a funções
Você pode usar #define para definir uma macro que terá o seguinte argumento -
#include <iostream>
using namespace std;
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
cout <<"The minimum is " << MIN(i, j) << endl;
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
The minimum is 30Compilação Condicional
Existem várias diretivas, que podem ser usadas para compilar partes seletivas do código-fonte do seu programa. Este processo é chamado de compilação condicional.
A construção do pré-processador condicional é muito parecida com a estrutura de seleção 'if'. Considere o seguinte código de pré-processador -
#ifndef NULL
#define NULL 0
#endifVocê pode compilar um programa para fins de depuração. Você também pode ativar ou desativar a depuração usando uma única macro da seguinte maneira -
#ifdef DEBUG
cerr <<"Variable x = " << x << endl;
#endifIsso faz com que o cerrdeclaração a ser compilada no programa se a constante simbólica DEBUG foi definida antes da diretiva #ifdef DEBUG. Você pode usar a instrução #if 0 para comentar uma parte do programa da seguinte maneira -
#if 0
code prevented from compiling
#endifVamos tentar o seguinte exemplo -
#include <iostream>
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* This is commented part */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
The minimum is 30
Trace: Inside main function
Trace: Coming out of main functionOs operadores # e ##
Os operadores de pré-processador # e ## estão disponíveis em C ++ e ANSI / ISO C. O operador # faz com que um token de substituição de texto seja convertido em uma string entre aspas.
Considere a seguinte definição de macro -
#include <iostream>
using namespace std;
#define MKSTR( x ) #x
int main () {
cout << MKSTR(HELLO C++) << endl;
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
HELLO C++Vamos ver como funcionou. É simples entender que o pré-processador C ++ vira a linha -
cout << MKSTR(HELLO C++) << endl;A linha acima será transformada na seguinte linha -
cout << "HELLO C++" << endl;O operador ## é usado para concatenar dois tokens. Aqui está um exemplo -
#define CONCAT( x, y ) x ## yQuando CONCAT aparece no programa, seus argumentos são concatenados e usados para substituir a macro. Por exemplo, CONCAT (HELLO, C ++) é substituído por "HELLO C ++" no programa da seguinte maneira.
#include <iostream>
using namespace std;
#define concat(a, b) a ## b
int main() {
int xy = 100;
cout << concat(x, y);
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
100Vamos ver como funcionou. É simples entender que o pré-processador C ++ transforma -
cout << concat(x, y);A linha acima será transformada na seguinte linha -
cout << xy;Macros C ++ Predefinidas
C ++ fornece uma série de macros predefinidas mencionadas abaixo -
| Sr. Não | Macro e descrição |
|---|---|
| 1 | __LINE__ Ele contém o número da linha atual do programa quando ele está sendo compilado. |
| 2 | __FILE__ Ele contém o nome do arquivo atual do programa quando ele está sendo compilado. |
| 3 | __DATE__ Ele contém uma string no formato mês / dia / ano que é a data da tradução do arquivo de origem em código-objeto. |
| 4 | __TIME__ Ele contém uma string no formato hora: minuto: segundo que é a hora em que o programa foi compilado. |
Vamos ver um exemplo para todas as macros acima -
#include <iostream>
using namespace std;
int main () {
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}Se compilarmos e executarmos o código acima, isso produzirá o seguinte resultado -
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48Os sinais são as interrupções entregues a um processo pelo sistema operacional que podem encerrar um programa prematuramente. Você pode gerar interrupções pressionando Ctrl + C em um sistema UNIX, LINUX, Mac OS X ou Windows.
Existem sinais que não podem ser captados pelo programa, mas há uma lista de sinais a seguir que você pode capturar em seu programa e pode executar as ações apropriadas com base no sinal. Esses sinais são definidos no arquivo de cabeçalho C ++ <csignal>.
| Sr. Não | Sinal e descrição |
|---|---|
| 1 | SIGABRT Encerramento anormal do programa, como uma chamada para abort. |
| 2 | SIGFPE Uma operação aritmética errada, como uma divisão por zero ou uma operação que resulta em estouro. |
| 3 | SIGILL Detecção de uma instrução ilegal. |
| 4 | SIGINT Recebimento de um sinal de atenção interativo. |
| 5 | SIGSEGV Um acesso inválido ao armazenamento. |
| 6 | SIGTERM Uma solicitação de encerramento enviada ao programa. |
A função signal ()
A biblioteca de tratamento de sinais C ++ fornece funções signalpara capturar eventos inesperados. A seguir está a sintaxe da função signal () -
void (*signal (int sig, void (*func)(int)))(int);Mantendo a simplicidade, esta função recebe dois argumentos: o primeiro argumento como um inteiro que representa o número do sinal e o segundo argumento como um ponteiro para a função de tratamento do sinal.
Vamos escrever um programa C ++ simples onde capturaremos o sinal SIGINT usando a função signal (). Qualquer sinal que você deseja capturar em seu programa, você deve registrar esse sinal usandosignalfunção e associá-la a um manipulador de sinal. Examine o seguinte exemplo -
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(1) {
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Going to sleep....
Going to sleep....
Going to sleep....Agora, pressione Ctrl + C para interromper o programa e você verá que seu programa irá capturar o sinal e sairá imprimindo algo como segue -
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.A função raise ()
Você pode gerar sinais por função raise(), que recebe um número de sinal inteiro como argumento e tem a seguinte sintaxe.
int raise (signal sig);Aqui, sigé o número do sinal para enviar qualquer um dos sinais: SIGINT, SIGABRT, SIGFPE, SIGILL, SIGSEGV, SIGTERM, SIGHUP. A seguir está o exemplo em que levantamos um sinal internamente usando a função raise () como segue -
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
int i = 0;
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(++i) {
cout << "Going to sleep...." << endl;
if( i == 3 ) {
raise( SIGINT);
}
sleep(1);
}
return 0;
}Quando o código acima é compilado e executado, ele produz o seguinte resultado e sairia automaticamente -
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.Multithreading é uma forma especializada de multitarefa e multitarefa é o recurso que permite ao computador executar dois ou mais programas simultaneamente. Em geral, existem dois tipos de multitarefa: baseada em processo e baseada em thread.
A multitarefa baseada em processo lida com a execução simultânea de programas. A multitarefa baseada em thread lida com a execução simultânea de partes do mesmo programa.
Um programa multithread contém duas ou mais partes que podem ser executadas simultaneamente. Cada parte desse programa é chamada de thread e cada thread define um caminho de execução separado.
C ++ não contém nenhum suporte embutido para aplicativos multithread. Em vez disso, ele depende inteiramente do sistema operacional para fornecer esse recurso.
Este tutorial assume que você está trabalhando no sistema operacional Linux e que iremos escrever um programa C ++ multi-threaded usando POSIX. POSIX Threads ou Pthreads fornece API que está disponível em muitos sistemas POSIX do tipo Unix, como FreeBSD, NetBSD, GNU / Linux, Mac OS X e Solaris.
Criando Threads
A seguinte rotina é usada para criar um thread POSIX -
#include <pthread.h>
pthread_create (thread, attr, start_routine, arg)Aqui, pthread_createcria um novo thread e o torna executável. Esta rotina pode ser chamada qualquer número de vezes de qualquer lugar dentro do seu código. Aqui está a descrição dos parâmetros -
| Sr. Não | Parâmetro e Descrição |
|---|---|
| 1 | thread Um identificador opaco e exclusivo para o novo encadeamento retornado pela sub-rotina. |
| 2 | attr Um objeto de atributo opaco que pode ser usado para definir atributos de thread. Você pode especificar um objeto de atributos de thread ou NULL para os valores padrão. |
| 3 | start_routine A rotina C ++ que o encadeamento executará depois de criado. |
| 4 | arg Um único argumento que pode ser passado para start_routine. Deve ser passado por referência como um lançamento de ponteiro do tipo void. NULL pode ser usado se nenhum argumento for passado. |
O número máximo de threads que podem ser criados por um processo depende da implementação. Depois de criados, os threads são pares e podem criar outros threads. Não há hierarquia implícita ou dependência entre threads.
Encerrando Threads
Há a seguinte rotina que usamos para encerrar um thread POSIX -
#include <pthread.h>
pthread_exit (status)Aqui pthread_exité usado para sair explicitamente de um thread. Normalmente, a rotina pthread_exit () é chamada depois que uma thread concluiu seu trabalho e não precisa mais existir.
Se main () terminar antes das threads que criou, e sair com pthread_exit (), as outras threads continuarão em execução. Caso contrário, eles serão encerrados automaticamente quando main () terminar.
Example
Este código de exemplo simples cria 5 threads com a rotina pthread_create (). Cada tópico imprime um "Hello World!" mensagem, e então termina com uma chamada para pthread_exit ().
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid) {
long tid;
tid = (long)threadid;
cout << "Hello World! Thread ID, " << tid << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)i);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Compile o seguinte programa usando a biblioteca -lpthread da seguinte forma -
$gcc test.cpp -lpthreadAgora, execute seu programa que dá a seguinte saída -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Hello World! Thread ID, 0
Hello World! Thread ID, 1
Hello World! Thread ID, 2
Hello World! Thread ID, 3
Hello World! Thread ID, 4Passando Argumentos para Threads
Este exemplo mostra como passar vários argumentos por meio de uma estrutura. Você pode passar qualquer tipo de dados em um retorno de chamada de thread porque ele aponta para void conforme explicado no exemplo a seguir -
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
struct thread_data {
int thread_id;
char *message;
};
void *PrintHello(void *threadarg) {
struct thread_data *my_data;
my_data = (struct thread_data *) threadarg;
cout << "Thread ID : " << my_data->thread_id ;
cout << " Message : " << my_data->message << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
struct thread_data td[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout <<"main() : creating thread, " << i << endl;
td[i].thread_id = i;
td[i].message = "This is message";
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)&td[i]);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Thread ID : 3 Message : This is message
Thread ID : 2 Message : This is message
Thread ID : 0 Message : This is message
Thread ID : 1 Message : This is message
Thread ID : 4 Message : This is messageUnindo e desanexando tópicos
Seguem-se duas rotinas que podemos usar para juntar ou separar threads -
pthread_join (threadid, status)
pthread_detach (threadid)A sub-rotina pthread_join () bloqueia o thread de chamada até que o thread 'threadid' especificado termine. Quando um encadeamento é criado, um de seus atributos define se ele pode ser juntado ou separado. Somente threads que são criados como uníveis podem ser unidos. Se um encadeamento for criado como separado, ele nunca poderá ser unido.
Este exemplo demonstra como aguardar a conclusão do thread usando a rotina de junção Pthread.
#include <iostream>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5
void *wait(void *t) {
int i;
long tid;
tid = (long)t;
sleep(1);
cout << "Sleeping in thread " << endl;
cout << "Thread with id : " << tid << " ...exiting " << endl;
pthread_exit(NULL);
}
int main () {
int rc;
int i;
pthread_t threads[NUM_THREADS];
pthread_attr_t attr;
void *status;
// Initialize and set thread joinable
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], &attr, wait, (void *)i );
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
// free attribute and wait for the other threads
pthread_attr_destroy(&attr);
for( i = 0; i < NUM_THREADS; i++ ) {
rc = pthread_join(threads[i], &status);
if (rc) {
cout << "Error:unable to join," << rc << endl;
exit(-1);
}
cout << "Main: completed thread id :" << i ;
cout << " exiting with status :" << status << endl;
}
cout << "Main: program exiting." << endl;
pthread_exit(NULL);
}Quando o código acima é compilado e executado, ele produz o seguinte resultado -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Sleeping in thread
Thread with id : 0 .... exiting
Sleeping in thread
Thread with id : 1 .... exiting
Sleeping in thread
Thread with id : 2 .... exiting
Sleeping in thread
Thread with id : 3 .... exiting
Sleeping in thread
Thread with id : 4 .... exiting
Main: completed thread id :0 exiting with status :0
Main: completed thread id :1 exiting with status :0
Main: completed thread id :2 exiting with status :0
Main: completed thread id :3 exiting with status :0
Main: completed thread id :4 exiting with status :0
Main: program exiting.O que é CGI?
A Common Gateway Interface, ou CGI, é um conjunto de padrões que definem como as informações são trocadas entre o servidor da web e um script personalizado.
As especificações CGI são atualmente mantidas pela NCSA e a NCSA define CGI como segue -
A Common Gateway Interface, ou CGI, é um padrão para programas de gateway externo fazerem interface com servidores de informações, como servidores HTTP.
A versão atual é CGI / 1.1 e CGI / 1.2 está em andamento.
Navegação na web
Para entender o conceito de CGI, vamos ver o que acontece quando clicamos em um hiperlink para navegar em uma determinada página da web ou URL.
Seu navegador entra em contato com o servidor da web HTTP e exige a URL, ou seja nome do arquivo.
O servidor da Web analisará a URL e procurará o nome do arquivo. Se ele encontrar o arquivo solicitado, o servidor web enviará esse arquivo de volta ao navegador, caso contrário, enviará uma mensagem de erro indicando que você solicitou um arquivo errado.
O navegador da Web obtém a resposta do servidor da Web e exibe o arquivo recebido ou a mensagem de erro com base na resposta recebida.
Porém, é possível configurar o servidor HTTP de forma que sempre que um arquivo em um determinado diretório for solicitado, esse arquivo não seja devolvido; em vez disso, ele é executado como um programa e a saída produzida a partir do programa é enviada de volta ao seu navegador para exibição.
A Common Gateway Interface (CGI) é um protocolo padrão para permitir que aplicativos (chamados de programas CGI ou scripts CGI) interajam com servidores Web e clientes. Esses programas CGI podem ser escritos em Python, PERL, Shell, C ou C ++ etc.
Diagrama de Arquitetura CGI
O seguinte programa simples mostra uma arquitetura simples de CGI -
Configuração do servidor web
Antes de prosseguir com a Programação CGI, certifique-se de que seu servidor da Web suporta CGI e está configurado para lidar com programas CGI. Todos os programas CGI a serem executados pelo servidor HTTP são mantidos em um diretório pré-configurado. Este diretório é denominado diretório CGI e por convenção é denominado / var / www / cgi-bin. Por convenção, os arquivos CGI terão extensão de.cgi, embora sejam executáveis C ++.
Por padrão, o Apache Web Server é configurado para executar programas CGI em / var / www / cgi-bin. Se você deseja especificar qualquer outro diretório para executar seus scripts CGI, você pode modificar a seção a seguir no arquivo httpd.conf -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>Aqui, presumo que você tenha o servidor da Web instalado e funcionando com êxito e seja capaz de executar qualquer outro programa CGI como Perl ou Shell, etc.
Primeiro Programa CGI
Considere o seguinte conteúdo do Programa C ++ -
#include <iostream>
using namespace std;
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Hello World - First CGI Program</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<h2>Hello World! This is my first CGI program</h2>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Compile o código acima e nomeie o executável como cplusplus.cgi. Este arquivo está sendo mantido no diretório / var / www / cgi-bin e possui o seguinte conteúdo. Antes de executar seu programa CGI, certifique-se de alterar o modo de arquivo usandochmod 755 cplusplus.cgi Comando do UNIX para tornar o arquivo executável.
Meu primeiro programa CGI
O programa C ++ acima é um programa simples que grava sua saída no arquivo STDOUT, ou seja, na tela. Há um recurso importante e extra disponível que é a impressão de primeira linhaContent-type:text/html\r\n\r\n. Essa linha é enviada de volta ao navegador e especifica o tipo de conteúdo a ser exibido na tela do navegador. Agora você deve ter entendido o conceito básico de CGI e pode escrever muitos programas CGI complicados usando Python. Um programa C ++ CGI pode interagir com qualquer outro sistema externo, como RDBMS, para trocar informações.
Cabeçalho HTTP
A linha Content-type:text/html\r\n\r\né uma parte do cabeçalho HTTP, que é enviado ao navegador para entender o conteúdo. Todo o cabeçalho HTTP estará no seguinte formato -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\nExistem alguns outros cabeçalhos HTTP importantes, que você usará com freqüência em sua programação CGI.
| Sr. Não | Cabeçalho e Descrição |
|---|---|
| 1 | Content-type: Uma string MIME que define o formato do arquivo que está sendo retornado. O exemplo é Content-type: text / html. |
| 2 | Expires: Date A data em que a informação se torna inválida. Isso deve ser usado pelo navegador para decidir quando uma página precisa ser atualizada. Uma string de data válida deve estar no formato 01 de janeiro de 1998 12:00:00 GMT. |
| 3 | Location: URL O URL que deve ser retornado em vez do URL solicitado. Você pode usar este campo para redirecionar uma solicitação para qualquer arquivo. |
| 4 | Last-modified: Date A data da última modificação do recurso. |
| 5 | Content-length: N O comprimento, em bytes, dos dados que estão sendo retornados. O navegador usa esse valor para relatar o tempo estimado de download de um arquivo. |
| 6 | Set-Cookie: String Defina o cookie passado pela string . |
Variáveis de ambiente CGI
Todo o programa CGI terá acesso às seguintes variáveis de ambiente. Essas variáveis desempenham um papel importante ao escrever qualquer programa CGI.
| Sr. Não | Nome e descrição da variável |
|---|---|
| 1 | CONTENT_TYPE O tipo de dados do conteúdo, usado quando o cliente está enviando conteúdo anexado ao servidor. Por exemplo, upload de arquivo etc. |
| 2 | CONTENT_LENGTH O comprimento das informações da consulta que estão disponíveis apenas para solicitações POST. |
| 3 | HTTP_COOKIE Retorna os cookies definidos na forma de par chave e valor. |
| 4 | HTTP_USER_AGENT O campo de cabeçalho de solicitação do Agente do Usuário contém informações sobre o agente do usuário que originou a solicitação. É o nome do navegador da web. |
| 5 | PATH_INFO O caminho para o script CGI. |
| 6 | QUERY_STRING As informações codificadas por URL que são enviadas com a solicitação do método GET. |
| 7 | REMOTE_ADDR O endereço IP do host remoto que está fazendo a solicitação. Isso pode ser útil para registro ou autenticação. |
| 8 | REMOTE_HOST O nome totalmente qualificado do host que está fazendo a solicitação. Se esta informação não estiver disponível, REMOTE_ADDR pode ser usado para obter o endereço de IR. |
| 9 | REQUEST_METHOD O método usado para fazer a solicitação. Os métodos mais comuns são GET e POST. |
| 10 | SCRIPT_FILENAME O caminho completo para o script CGI. |
| 11 | SCRIPT_NAME O nome do script CGI. |
| 12 | SERVER_NAME O nome do host ou endereço IP do servidor. |
| 13 | SERVER_SOFTWARE O nome e a versão do software que o servidor está executando. |
Aqui está um pequeno programa CGI para listar todas as variáveis CGI.
#include <iostream>
#include <stdlib.h>
using namespace std;
const string ENV[ 24 ] = {
"COMSPEC", "DOCUMENT_ROOT", "GATEWAY_INTERFACE",
"HTTP_ACCEPT", "HTTP_ACCEPT_ENCODING",
"HTTP_ACCEPT_LANGUAGE", "HTTP_CONNECTION",
"HTTP_HOST", "HTTP_USER_AGENT", "PATH",
"QUERY_STRING", "REMOTE_ADDR", "REMOTE_PORT",
"REQUEST_METHOD", "REQUEST_URI", "SCRIPT_FILENAME",
"SCRIPT_NAME", "SERVER_ADDR", "SERVER_ADMIN",
"SERVER_NAME","SERVER_PORT","SERVER_PROTOCOL",
"SERVER_SIGNATURE","SERVER_SOFTWARE" };
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>CGI Environment Variables</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
for ( int i = 0; i < 24; i++ ) {
cout << "<tr><td>" << ENV[ i ] << "</td><td>";
// attempt to retrieve value of environment variable
char *value = getenv( ENV[ i ].c_str() );
if ( value != 0 ) {
cout << value;
} else {
cout << "Environment variable does not exist.";
}
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Biblioteca C ++ CGI
Para exemplos reais, você precisaria fazer muitas operações por seu programa CGI. Existe uma biblioteca CGI escrita para o programa C ++ que você pode baixar em ftp://ftp.gnu.org/gnu/cgicc/ e siga as etapas para instalar a biblioteca -
$tar xzf cgicc-X.X.X.tar.gz
$cd cgicc-X.X.X/ $./configure --prefix=/usr
$make $make installVocê pode verificar a documentação relacionada disponível em 'C ++ CGI Lib Documentation .
Métodos GET e POST
Você deve ter se deparado com muitas situações em que precisa passar algumas informações de seu navegador para o servidor da web e, finalmente, para o seu programa CGI. Na maioria das vezes, o navegador usa dois métodos para passar essas informações ao servidor da web. Esses métodos são o Método GET e o Método POST.
Passando informações usando o método GET
O método GET envia as informações codificadas do usuário anexadas à solicitação de página. A página e as informações codificadas são separadas por? personagem da seguinte forma -
http://www.test.com/cgi-bin/cpp.cgi?key1=value1&key2=value2O método GET é o método padrão para passar informações do navegador para o servidor da web e produz uma longa string que aparece na caixa Location: do seu navegador. Nunca use o método GET se você tiver uma senha ou outras informações confidenciais para passar para o servidor. O método GET tem limitação de tamanho e você pode passar até 1024 caracteres em uma string de solicitação.
Ao usar o método GET, as informações são passadas usando o cabeçalho http QUERY_STRING e estarão acessíveis em seu Programa CGI através da variável de ambiente QUERY_STRING.
Você pode passar informações simplesmente concatenando pares de chave e valor junto com qualquer URL ou pode usar tags HTML <FORM> para passar informações usando o método GET.
Exemplo de URL simples: Método Get
Aqui está uma URL simples que passará dois valores para o programa hello_get.py usando o método GET.
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIAbaixo está um programa para gerar cpp_get.cgiPrograma CGI para lidar com a entrada fornecida pelo navegador da web. Vamos usar a biblioteca C ++ CGI que torna muito fácil acessar as informações passadas -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Using GET and POST Methods</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("first_name");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "First name: " << **fi << endl;
} else {
cout << "No text entered for first name" << endl;
}
cout << "<br/>\n";
fi = formData.getElement("last_name");
if( !fi->isEmpty() &&fi != (*formData).end()) {
cout << "Last name: " << **fi << endl;
} else {
cout << "No text entered for last name" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Agora, compile o programa acima da seguinte maneira -
$g++ -o cpp_get.cgi cpp_get.cpp -lcgiccGere cpp_get.cgi e coloque-o em seu diretório CGI e tente acessar usando o seguinte link -
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIIsso geraria o seguinte resultado -
First name: ZARA
Last name: ALIExemplo de FORM Simples: Método GET
Aqui está um exemplo simples que passa dois valores usando HTML FORM e o botão de envio. Vamos usar o mesmo script CGI cpp_get.cgi para lidar com esta entrada.
<form action = "/cgi-bin/cpp_get.cgi" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Aqui está o resultado real do formulário acima. Você insere o nome e o sobrenome e, em seguida, clica no botão enviar para ver o resultado.
Passando informações usando o método POST
Um método geralmente mais confiável de passar informações para um programa CGI é o método POST. Isso empacota as informações exatamente da mesma maneira que os métodos GET, mas em vez de enviá-las como uma string de texto após um? no URL, ele o envia como uma mensagem separada. Esta mensagem chega ao script CGI na forma de entrada padrão.
O mesmo programa cpp_get.cgi manipulará o método POST também. Tomemos o mesmo exemplo acima, que passa dois valores usando HTML FORM e botão de envio, mas desta vez com o método POST da seguinte maneira -
<form action = "/cgi-bin/cpp_get.cgi" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Aqui está o resultado real do formulário acima. Você insere o nome e o sobrenome e, em seguida, clica no botão enviar para ver o resultado.
Passando os dados da caixa de seleção para o programa CGI
As caixas de seleção são usadas quando mais de uma opção deve ser selecionada.
Aqui está um exemplo de código HTML para um formulário com duas caixas de seleção -
<form action = "/cgi-bin/cpp_checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>O resultado deste código é o seguinte formato -
Abaixo está o programa C ++, que irá gerar o script cpp_checkbox.cgi para lidar com a entrada fornecida pelo navegador da web através do botão da caixa de seleção.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
bool maths_flag, physics_flag;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Checkbox Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
maths_flag = formData.queryCheckbox("maths");
if( maths_flag ) {
cout << "Maths Flag: ON " << endl;
} else {
cout << "Maths Flag: OFF " << endl;
}
cout << "<br/>\n";
physics_flag = formData.queryCheckbox("physics");
if( physics_flag ) {
cout << "Physics Flag: ON " << endl;
} else {
cout << "Physics Flag: OFF " << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Passando Dados do Botão de Rádio para o Programa CGI
Os botões de rádio são usados quando apenas uma opção deve ser selecionada.
Aqui está um exemplo de código HTML para um formulário com dois botões de opção -
<form action = "/cgi-bin/cpp_radiobutton.cgi" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" checked = "checked"/> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>O resultado deste código é o seguinte formato -
Abaixo está o programa C ++, que irá gerar o script cpp_radiobutton.cgi para lidar com a entrada fornecida pelo navegador da web por meio de botões de rádio.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Radio Button Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("subject");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Radio box selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Passando dados da área de texto para o programa CGI
O elemento TEXTAREA é usado quando o texto de várias linhas deve ser passado para o programa CGI.
Aqui está um exemplo de código HTML para um formulário com uma caixa TEXTAREA -
<form action = "/cgi-bin/cpp_textarea.cgi" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>O resultado deste código é o seguinte formato -
Abaixo está o programa C ++, que irá gerar o script cpp_textarea.cgi para lidar com a entrada fornecida pelo navegador da web através da área de texto.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Text Area Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("textcontent");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Text Content: " << **fi << endl;
} else {
cout << "No text entered" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Passando dados da caixa suspensa para o programa CGI
A caixa suspensa é usada quando temos muitas opções disponíveis, mas apenas uma ou duas serão selecionadas.
Aqui está um exemplo de código HTML para um formulário com uma caixa suspensa -
<form action = "/cgi-bin/cpp_dropdown.cgi" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>O resultado deste código é o seguinte formato -
Abaixo está o programa C ++, que irá gerar o script cpp_dropdown.cgi para lidar com a entrada fornecida pelo navegador da web por meio da caixa suspensa.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Drop Down Box Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("dropdown");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Value Selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Usando Cookies em CGI
O protocolo HTTP é um protocolo sem estado. Mas, para um site comercial, é necessário manter as informações da sessão entre as diferentes páginas. Por exemplo, o registro de um usuário termina após completar muitas páginas. Mas como manter as informações da sessão do usuário em todas as páginas da web.
Em muitas situações, o uso de cookies é o método mais eficiente de lembrar e rastrear preferências, compras, comissões e outras informações necessárias para uma melhor experiência do visitante ou estatísticas do site.
Como funciona
Seu servidor envia alguns dados para o navegador do visitante na forma de um cookie. O navegador pode aceitar o cookie. Em caso afirmativo, ele é armazenado como um registro de texto simples no disco rígido do visitante. Agora, quando o visitante chega a outra página do seu site, o cookie fica disponível para recuperação. Uma vez recuperado, seu servidor sabe / lembra o que foi armazenado.
Cookies são um registro de dados de texto simples de 5 campos de comprimento variável -
Expires- Mostra a data em que o cookie irá expirar. Se estiver em branco, o cookie irá expirar quando o visitante sair do navegador.
Domain - Mostra o nome de domínio do seu site.
Path- Mostra o caminho para o diretório ou página da web que definiu o cookie. Isso pode ficar em branco se você quiser recuperar o cookie de qualquer diretório ou página.
Secure- Se este campo contiver a palavra "seguro", o cookie só poderá ser recuperado com um servidor seguro. Se este campo estiver em branco, não existe tal restrição.
Name = Value - Os cookies são definidos e recuperados na forma de pares de chave e valor.
Configurando Cookies
É muito fácil enviar cookies para o navegador. Esses cookies serão enviados juntamente com o cabeçalho HTTP antes do preenchimento do tipo de conteúdo. Presumindo que você deseja definir a ID do usuário e a senha como cookies. Portanto, a configuração dos cookies será feita da seguinte maneira
#include <iostream>
using namespace std;
int main () {
cout << "Set-Cookie:UserID = XYZ;\r\n";
cout << "Set-Cookie:Password = XYZ123;\r\n";
cout << "Set-Cookie:Domain = www.tutorialspoint.com;\r\n";
cout << "Set-Cookie:Path = /perl;\n";
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "Setting cookies" << endl;
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}A partir deste exemplo, você deve ter entendido como definir cookies. Nós usamosSet-Cookie Cabeçalho HTTP para definir cookies.
Aqui, é opcional definir atributos de cookies como Expires, Domain e Path. É notável que os cookies são definidos antes de enviar a linha mágica"Content-type:text/html\r\n\r\n.
Compile o programa acima para produzir setcookies.cgi e tente definir cookies usando o seguinte link. Irá definir quatro cookies no seu computador -
/cgi-bin/setcookies.cgi
Recuperando Cookies
É fácil recuperar todos os cookies definidos. Os cookies são armazenados na variável de ambiente CGI HTTP_COOKIE e terão a seguinte forma.
key1 = value1; key2 = value2; key3 = value3....Aqui está um exemplo de como recuperar cookies.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
const_cookie_iterator cci;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
// get environment variables
const CgiEnvironment& env = cgi.getEnvironment();
for( cci = env.getCookieList().begin();
cci != env.getCookieList().end();
++cci ) {
cout << "<tr><td>" << cci->getName() << "</td><td>";
cout << cci->getValue();
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Agora, compile o programa acima para produzir getcookies.cgi e tente obter uma lista de todos os cookies disponíveis em seu computador -
/cgi-bin/getcookies.cgi
Isso produzirá uma lista de todos os quatro cookies definidos na seção anterior e todos os outros cookies definidos em seu computador -
UserID XYZ
Password XYZ123
Domain www.tutorialspoint.com
Path /perlExemplo de upload de arquivo
Para fazer upload de um arquivo, o formulário HTML deve ter o atributo enctype definido como multipart/form-data. A tag de entrada com o tipo de arquivo criará um botão "Navegar".
<html>
<body>
<form enctype = "multipart/form-data" action = "/cgi-bin/cpp_uploadfile.cgi"
method = "post">
<p>File: <input type = "file" name = "userfile" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>O resultado deste código é o seguinte formato -
Note- O exemplo acima foi desabilitado intencionalmente para impedir que as pessoas enviem arquivos em nosso servidor. Mas você pode tentar o código acima com seu servidor.
Aqui está o roteiro cpp_uploadfile.cpp para lidar com o upload de arquivos -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>File Upload in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
// get list of files to be uploaded
const_file_iterator file = cgi.getFile("userfile");
if(file != cgi.getFiles().end()) {
// send data type at cout.
cout << HTTPContentHeader(file->getDataType());
// write content at cout.
file->writeToStream(cout);
}
cout << "<File uploaded successfully>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}O exemplo acima é para escrever conteúdo em cout stream, mas você pode abrir seu stream de arquivo e salvar o conteúdo do arquivo carregado em um arquivo no local desejado.
Espero que você tenha gostado deste tutorial. Em caso afirmativo, envie-nos seus comentários.